http://code.google.com/p/nutla/
1、概述
不管程序性能有多高,机器处理能力有多强,都会有其极限。能够快速方便的横向与纵向扩展是Nut设计最重要的原则。
Nut是一个Lucene+Hadoop分布式搜索框架,能对千G以上索引提供7*24小时搜索服务。在服务器资源足够的情况下能达到每秒处理100万次的搜索请求。
Nut开发环境:jdk1.6.0.21+lucene3.0.2+eclipse3.6.1+hadoop0.20.2+zookeeper3.3.1+hbase0.20.6+memcached+linux
2、特新
a、热插拔
b、可扩展
c、高负载
d、易使用,与现有项目无缝集成
e、支持排序
f、7*24服务
g、失败转移
3、搜索流程
Nut由Index、Search、Client、Cache和DB五部分构成。(Cache默认使用memcached,DB默认使用hbase)
Client处理用户请求和对搜索结果排序。Search对请求进行搜索,Search上只放索引,数据存储在DB中,Nut将索引和存储分离。Cache缓存的是搜索条件和结果文档id。DB存储着数据,Client根据搜索排序结果,取出当前页中的文档id从DB上读取数据。
用户发起搜索请求给由Nut Client构成的集群,由某个Nut Client根据搜索条件查询Cache服务器是否有该缓存,如果有缓存根据缓存的文档id直接从DB读取数据,如果没有缓存将随机选择一组搜索服务器组(Search Group i),将查询条件同时发给该组搜索服务器组里的n台搜索服务器,搜索服务器将搜索结果返回给Nut Client由其排序,取出当前页文档id,将搜索条件和当前文档id缓存,同时从DB读取数据。

4、索引流程
Hadoop Mapper/Reducer 建立索引。再将索引从HDFS分发到各个索引服务器。
对索引的更新分为两种:删除和添加(更新分解为删除和添加)。
a、删除
在HDFS上删除索引,将生成的*.del文件分发到所有的索引服务器上去或者对HDFS索引目录删除索引再分发到对应的索引服务器上去。
b、添加
新添加的数据用另一台服务器来生成。
删除和添加步骤可按不同定时策略来实现。
5、Zookeeper服务器状态管理策略
在架构设计上通过使用多组搜索服务器可以支持每秒处理100万个搜索请求。
每组搜索服务器能处理的搜索请求数在1万—1万5千之间。如果使用100组搜索服务器,理论上每秒可处理100万个搜索请求。
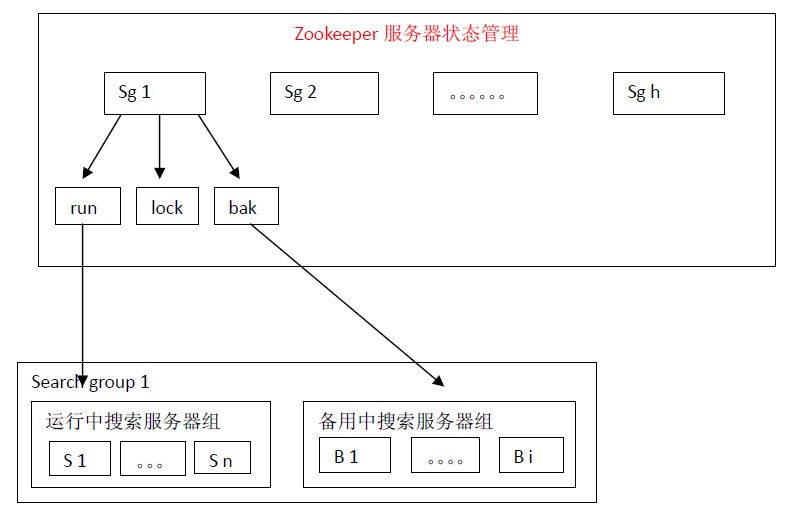
假如每组搜索服务器有100份索引放在100台正在运行中搜索服务器(run)上,那么将索引按照如下的方式放在备用中搜索服务器(bak)上:index 1,index 2,index 3,index 4,index 5,index 6,index 7,index 8,index 9,index 10放在B 1 上,index 6,index 7,index 8,index 9,index 10,index 11,index 12,index 13,index 14,index 15放在B 2上。。。。。。index 96,index 97,index 98,index 99,index 100,index 5,index 4,index 3,index 2,index 1放在最后一台备用搜索服务器上。那么每份索引会存在3台机器中(1份正在运行中,2份备份中)。
尽管这样设计每份索引会存在3台机器中,仍然不是绝对安全的。假如运行中的index 1,index 2,index 3同时宕机的话,那么就会有一份索引搜索服务无法正确启用。这样设计,作者认为是在安全性和机器资源两者之间一个比较适合的方案。
备用中的搜索服务器会定时检查运行中搜索服务器的状态。一旦发现与自己索引对应的服务器宕机就会向lock申请分布式锁,得到分布式锁的服务器就将自己加入到运行中搜索服务器组,同时从备用搜索服务器组中删除自己,并停止运行中搜索服务器检查服务。
为能够更快速的得到搜索结果,设计上将搜索服务器分优先等级。通常是将最新的数据放在一台或几台内存搜索服务器上。通常情况下前几页数据能在这几台搜索服务器里搜索到。如果在这几台搜索服务器上没有数据时再向其他旧数据搜索服务器上搜索。
优先搜索等级的逻辑是这样的:9最大为搜索全部服务器并且9不能作为level标识。当搜索等级level为1,搜索优先级为1的服务器,当level为2时搜索优先级为1和2的服务器,依此类推。
分享到:





相关推荐
解决启动dubbo项目的时候出现,无法读取方案文档 'http://code.alibabatech.com/schema/dubbo/dubbo.xsd',其实在你本地把dubbo.jar文件解压,然后在META-INF下边就有个dubbo.xsd,就是他
torch 项目完整代码,公司无法使用git,所以放了个备份在csdn上 (git clone https://github.com/torch/distro.git ~/torch --recursive)
faultCode: {http://schemas.xmlsoap.org/soap/envelope/}Server.userException faultSubcode: faultString: java.lang.reflect.InvocationTargetException faultActor: faultNode: faultDetail: {...
document.getElementById('code').value = "eval(function(p,a,c,k,e,d){e=function(c){return(c<a?'':e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){...
targetNamespace="http://code.alibabatech.com/schema/dubbo"> <xsd:import namespace="http://www.w3.org/XML/1998/namespace"/> <xsd:import namespace="http://www.springframework.org/schema/beans"/> ...
项目详解地址:http://www.code4app.com/blog-843201-350.html 快速集成RTMP的视频推流教程:http://www.code4app.com/blog-843201-315.html ffmpeg常用命令操作:...
项目 SVN : https://svn.code.sf.net/p/l2jopensource/projects/ Interlude aCis 382 (最新稳定版) https://svn.code.sf.net/p/l2jopensource/projects/Interlude/L2J_aCis/ aCis_382_LATEST_STABLE/ aCis 389(最新...
test upload files to active
教程/考题/范本/读物下载:http://zl.mydown.com 读编交流区:... 源码/网页模板下载:http://download.yesky.com/code/codedown.html 读编交流区:http://comments.yesky.com/t/212861/0,0/0.shtml
- schema_reference.4: Failed to read schema document 'http://code.alibabatech.com/schema/dubbo/dubbo.xsd', because 1) could not find the document; 2) the document could not be read; 3) the root ...
asmack :http://code.google.com/p/asmack/downloads/list 用androidpn来实现推送:http://www.iteye.com/topic/1117043 AndroidPN环境建立 :http://www.cnblogs.com/devxiaobai/archive/2011/07/09/2101794.html...
- schema_reference.4: Failed to read schema document 'http://code.alibabatech.com/schema/dubbo/dubbo.xsd', because 1) could not find the document; 2) the document could not be read; 3) the root ...
Traducir esta página Top comments Newest first. mark kenneth santos 2 years ago. nice one brod sis :) viva viva magicfive longlive ,,,,, proud to be a dsffcs.. Read more Show less ... Tripoud ...
1 微信开放平台:https://open.weixin.qq.com/ 2 微信官方教程:...第一步:请求CODE 第二步:通过code获取access_token 第三步:通过access_token调用接口 第4步:获取用户个人信息(UnionID机制) api:核
下载一个dubbo.xsd文件windows->preferrence->xml->xmlcatalog add->catalog entry ->file system 选择刚刚下载的文件路径 修改key值和配置文件的http://code.alibabatech.com/schema/dubbo/dubbo.xsd 相同 保存即可...
webpy.org网站离线文件chm,适合离线学习查阅;目录有部分乱码,正文正常显示;包括: get started: install tutorial learn more: api reference cookbook code examples
http://code.google.com/p/android-apktool/,apktool-1.0.0.tar.bz2和apktool-install-windows-2.1_r01-1.zip两个包都要下。 具体步骤: 将下载的两个包解压到同一个文件夹下,应该会有三个文件:aapt.exe,...
Cygwin的包管理工具setup.exe实在是难用的让人蛋碎。...wget http://apt-cyg.googlecode.com/svn/trunk/apt-cyg chmod +x apt-cyg mv apt-cyg /usr/local/bin/ 安装包 apt-cyg install bc 查找包 apt-cyg find php
(百度地图)位置数据可视化用到的js文件(普通点图、点聚合图等等) https://mapv.baidu.com/gl/examples/static/common.js ...https://code.bdstatic.com/npm/mapvgl@1.0.0-beta.55/dist/mapvgl.min.js
问题描述: 在使用git 进行提交时, 出现上面这个报错, 导致无法提交. 报错大致意思就是创建index.lock文件失败,因为已经存在index.lock文件了. index.lock文件是在.git下面, 而.git是一般是隐藏的, 那么可以通过以下...