

本文来源 | https://zhuanlan.zhihu.com/p/60458049
导读:如果面试的时候碰到这样一个面试题:ES 在数据量很大的情况下(数十亿级别)如何提高查询效率?
这个问题,其实就是在看你是否用过 ES,其实 ES 性能并没有你想象中那么好的。很多时候数据量大了,特别是有几亿条数据的时候,可能你会懵逼的发现,跑个搜索怎么一下 5~10s。
第一次搜索的时候,是5~10s,后面反而就快了,可能就几百毫秒。
你就很懵,每个用户第一次访问都会比较慢,比较卡么?所以你要是没玩儿过 ES,或者就是自己玩玩儿 Demo,被问到这个问题容易懵逼,显示出你对 ES 确实玩的不怎么样。
说实话,ES 性能优化是没有银弹的,不要期待着随手调一个参数,就可以万能的应对所有性能慢的场景。也许有的场景你换个参数,或者调整一下语法,就可以搞定,但绝对不是所有场景都可以这样。
性能优化的杀手锏:Filesystem Cache
你向 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去。
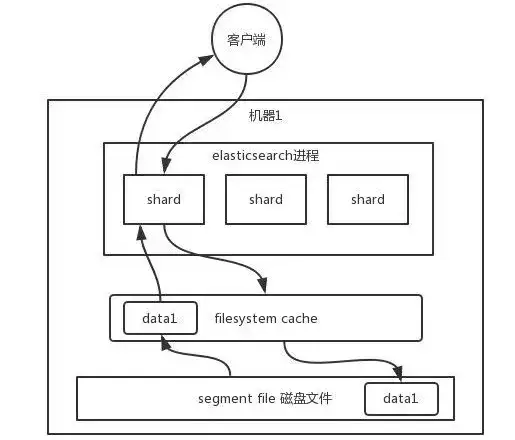
ES 的搜索引擎严重依赖于底层的 Filesystem Cache,如果给 Filesystem Cache 更多的内存,尽量让内存可以容纳所有的 IDX Segment File 索引数据文件,那么你在搜索的时候基本都会走内存且性能会非常高。
性能差距究竟可以有多大?我们之前很多的测试和压测,如果走磁盘一般肯定上秒,搜索性能绝对是秒级别的,1 秒、5 秒、10 秒。但如果走 Filesystem Cache,则是走纯内存的,那么一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等。
这里有个真实的案例:某个公司 ES 节点有 3 台机器,每台机器看起来内存很多(64G),总内存就是 64 * 3 = 192G。
每台机器给 ES JVM Heap 是 32G,那么剩下来留给 Filesystem Cache 的就是每台机器才 32G,总共集群里给 Filesystem Cache 的就是 32 * 3 = 96G 内存。
而此时,整个磁盘上索引数据文件,在 3 台机器上一共占用了 1T 的磁盘容量,ES 数据量是 1T,那么每台机器的数据量是 300G。这样性能好吗?
Filesystem Cache 的内存才 100G,十分之一的数据可以放内存,其它的都在磁盘,然后你执行搜索操作,大部分操作都是走磁盘,性能肯定差。
根据我们自己的生产环境实践经验,最佳的情况下,是仅仅在 ES 中就存少量的数据,就是你要用来搜索的那些索引,如果内存留给 Filesystem Cache 的是 100G,那么你就将索引数据控制在 100G 以内即可。这样,你的数据几乎全部走内存来搜索,性能非常之高,一般可以在1秒以内。
比如,你现在有一行数据:id,name,age .... 30 个字段。但是你现在搜索,只需要根据 id,name,age 三个字段来搜索。如果你傻乎乎往 ES 里写入一行数据所有的字段,就会导致 90% 的数据无法用来搜索。
结果硬是占据了 ES 机器上的 Filesystem Cache 的空间,单条数据的数据量越大,就会导致 Filesystem Cahce 能缓存的数据就越少。
其实,仅仅写入 ES 中要用来检索的少数几个字段就可以了,比如写入 es id,name,age 三个字段。
然后你将其他的字段数据存在 MySQL/HBase 里,我们一般是建议用 ES + HBase 这个架构。
HBase 的特点是适用于海量数据的在线存储,就是对 HBase 可以写入海量数据,但是不要做复杂的搜索,做很简单的一些根据 id 或者范围进行查询的操作就可以了。
从 ES 中根据 name 和 age 去搜索,拿到的结果可能就 20 个 doc id,然后根据 doc id 到 HBase 里去查询每个 doc id 对应的完整的数据,查出来后再返回给前端。
写入 ES 的数据最好小于等于,或者是略微大于 ES 的 Filesystem Cache 的内存容量。你从 ES 检索可能只花费 20ms,然后再根据 ES 返回的 id 去 HBase 里查询,查 20 条数据,可能只耗费 30ms。
可能你原来那么玩儿,1T 数据都放 ES,会每次查询都是 5~10s,现在可能性能就会很高,每次查询就是 50ms。
数据预热
假如你按照上述的方案去做了,ES 集群中每个机器写入的数据量还是超过了 Filesystem Cache 一倍。那么可以做数据预热。拿微博举例,你可以把一些大 V,平时看的人很多的数据,提前在后台搞个系统。
每隔一会儿,去搜索一下热数据,刷到 Filesystem Cache 里去,后面用户实际来看这个热数据的时候,他们就是直接从内存里进行了搜索。又或者是电商,你可以将平时查看最多的一些商品,例如 iPhone 8,热数据提前后台搞个程序,每隔 1 分钟自己主动访问一次,刷到 Filesystem Cache 里去。
对于那些你觉得比较热的、经常会有人访问的数据,最好做一个专门的缓存预热子系统。就是对热数据每隔一段时间,就提前访问一下,让数据进入 Filesystem Cache 里面去。这样下次别人访问的时候,性能一定会好很多。
冷热分离
ES 可以做类似于 MySQL 的水平拆分,即将大量的访问很少、频率很低的数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。
最好将冷数据写入一个索引中,然后热数据写入另外一个索引中,这样可以确保热数据在被预热之后,尽量都让他们留在 Filesystem OS Cache 里。
假设你有 6 台机器,2 个索引,一个放冷数据,一个放热数据,每个索引 3 个 Shard。3 台机器放热数据 Index,另外 3 台机器放冷数据 Index。
那么,你大量的时间是在访问热数据 Index,热数据可能就占总数据量的 10%,此时数据量很少,几乎全都保留在 Filesystem Cache 里面了,就可以确保热数据的访问性能是很高的。
但是对于冷数据而言,是在别的 Index 里的,跟热数据 Index 不在相同的机器上。
如果有人访问冷数据,可能大量数据是在磁盘上的,此时性能差点,就 10% 的人去访问冷数据,90% 的人在访问热数据,也无所谓了。
Document 模型设计
对于 MySQL,我们经常有一些复杂的关联查询。在 ES 里该怎么玩儿,ES 中复杂的关联查询尽量别用,一旦用了性能一般都不太好。
最好是先在 Java 系统里就完成关联,将关联好的数据直接写入 ES 中。搜索的时候,就不需要利用 ES 的搜索语法来完成 Join 之类的关联搜索了。
Document 模型设计是非常重要的,很多操作,不要在搜索的时候才想去执行各种复杂的乱七八糟的操作。
ES 能支持的操作就那么多,不要考虑用 ES 做一些它不好操作的事情。如果真的有那种操作,尽量在 Document 模型设计的时候,写入的时候就完成,另外对于一些太复杂的操作,比如 join/nested/parent-child 搜索都要尽量避免,性能都很差的。
分页性能优化
ES 的分页是较坑的。假如你每页是 10 条数据,你现在要查询第 100 页,实际上是会把每个 Shard 上存储的前 1000 条数据都查到一个协调节点上。
如果你有 5 个 Shard,那么就有 5000 条数据,接着协调节点对这 5000 条数据进行一些合并、处理,再获取到最终第 100 页的 10 条数据。
分布式则要查第 100 页的 10 条数据,不可能从 5 个 Shard中,每个查 2 条数据,最后到协调节点合并成 10 条数据吧?
所以,你必须得从每个 Shard 都查 1000 条数据过来,然后根据你的需求进行排序、筛选等操作,最后再次分页,拿到里面第 100 页的数据。
在翻页的时候,你翻的越深,每个 Shard 返回的数据就越多,而且协调节点处理的时间越长。所以用 ES 做分页的时候,你会发现越翻到后面,就越是慢。
我们之前也是遇到过这个问题,用 ES 做分页,前几页就几十毫秒,翻到 10 页或者几十页的时候,基本上就要 5~10 秒才能查出来一页数据了。
有什么解决方案吗?不允许深度分页(默认深度分页性能很差),跟产品经理提出这个问题。
类似于 App 里的推荐商品不断下拉出来一页一页的;类似于微博中,下拉刷微博,刷出来一页一页的,你可以用 Scroll API,关于如何使用,自行上网搜索。
Scroll 会一次性给你生成所有数据的一个快照,然后每次滑动向后翻页就是通过游标 scroll_id 移动,获取下一页、下一页这样子,性能会比上面说的那种分页性能要高很多,基本上都是毫秒级的。但是,这种只适合于类似微博下拉翻页的,不能随意跳到任何一页的场景。
所以现在很多产品,都是不允许你随意翻页的,App、也有一些网站,做的就是你只能往下拉,一页一页的翻。
初始化时必须指定 Scroll 参数,告诉 ES 要保存此次搜索的上下文多长时间。你需要确保用户不会持续不断翻页翻几个小时,否则可能因为超时而失败。
除了用 Scroll API,你也可以用 search_after 来做。search_after 的思想是使用前一页的结果来帮助检索下一页的数据。显然,这种方式也不允许你随意翻页,你只能一页页往后翻。初始化时,需要使用一个唯一值的字段作为 Sort 字段。
活动推荐
2019年6月21-23日,GIAC全球互联网架构大会将在深圳举办,组委会从互联网架构最热门的Cloud-Native、IoT、人工智能等前沿技术、数据及商业智能、大中台、经典架构、工程文化及管理等领域甄选前沿的有典型代表的技术创新及研发实践的架构案例,邀请了BAT、美团、滴滴等企业技术专家为我们分享最新的技术成果。



相关推荐
基于STM32蓝牙控制小车系统设计(硬件+源代码+论文)
某汽车联合车间工艺布置图.zip
统计学中的因果推断
1:后台登录地址为/admin/login.php,提供便捷的配置入口。 2:默认用户名是admin,密码为password123,首次登录后可。 3:使用方法:上传到虚拟机或服务器并解压,访问首页查看效果, 4:进入后台可编辑3个固定修改链接、添加或删除额外链接、设置底部文字及选择模板。 5:底部文字通过转义处理,不支持HTML,确保输出安全。 6:无论是个人项目还是分享导航,LinkEase都提供简单的解决方案。
blast_furnace_front_on
j
该资源为h5py-3.13.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl,欢迎下载使用哦!
内容概要:本文档是关于数字图像处理课程作业的报告,主要分为两个部分:形态学处理和纹理分析。形态学处理部分涵盖边界提取、孔洞填充和组件标记三个任务,详细描述了每个任务的具体步骤和方法,如通过形态学方法找到白色图案的内部区域并进行边界提取,利用连通分量标记技术进行孔洞填充,以及采用4邻接和8邻接方式对对象进行组件标记。纹理分析部分则介绍了使用Law's方法获取特征向量的过程,包括卷积和能量计算,还展示了如何用K-means算法对像素进行分类,并提出了一些改进措施,如调整窗口大小、优化K值选择等。 适合人群:具有图像处理基础知识的学生或研究人员,特别是正在学习数字图像处理课程的人士。 使用场景及目标:①帮助学生理解形态学处理的基本概念和技术,如边界提取、孔洞填充和组件标记;②指导学生掌握纹理分析的方法,如Law's方法和K-means聚类算法的应用;③通过实例操作提高学生的实践能力和问题解决能力。 阅读建议:此文档为课程作业报告,内容较为具体和技术化,建议读者先了解基本的形态学处理和纹理分析理论,再结合文档中的具体步骤进行实践操作,以便更好地理解和掌握相关知识。
内容概要:本文介绍了如何设置xv6操作系统的学习环境。xv6是MIT创建的一个用于教学的类Unix内核示例。文章首先解释了为什么选择Docker作为虚拟化工具,强调了其轻量级的特点,并指导读者安装Docker。接着详细描述了从克隆GitHub仓库到加载Docker镜像的具体步骤,以及如何使用QEMU模拟器在非RISC-V架构上启动xv6。最后提供了一个简单的练习,要求编写一个名为detective的程序,利用UNIX系统调用来查找特定名称的文件,并通过管道在父子进程间通信。 适合人群:具备一定C语言编程能力和系统编程经验的学生或开发者,尤其是对操作系统原理感兴趣的人士。 使用场景及目标:①学习Docker的安装与配置,理解容器化技术的优势;②掌握xv6内核的基本操作,包括编译和运行;③通过完成detective程序,深入理解进程管理、文件系统遍历和进程间通信等操作系统核心概念。 阅读建议:建议读者按照文档逐步实践,确保每一步都能成功执行。由于部分命令和工具基于Linux平台,推荐在Linux环境下进行操作。此外,在动手之前先阅读xv6参考书籍的第一章,有助于更好地理解和完成练习。
糖化、水罐及CIP工艺流程.rar
activator_rail_on
液压剪式升降平台(step SolidWorks)设计.rar
内容概要:本文详细介绍了HarmonyOS及其Linux内核子集(LOS)。HarmonyOS是华为自主研发的面向全场景的分布式操作系统,旨在打破国外操作系统垄断,推动国产操作系统发展。LOS作为HarmonyOS的重要组成部分,位于内核层,负责管理硬件资源、内存、文件系统和网络等。LOS具有虚拟内存管理、进程隔离、强大的网络支持、高效的文件系统、多线程编程支持和任务调度机制等技术特点。LOS在智能手机、智能家居设备和智能穿戴设备等领域发挥了重要作用,确保了系统的性能、稳定性和低功耗。与Linux原生内核和鸿蒙微内核相比,LOS在功能特性、性能表现和适用场景上有明显优势,并且与鸿蒙微内核协同工作,共同推动HarmonyOS的发展。未来,LOS将在安全性、性能优化和新功能支持等方面取得更大突破,推动HarmonyOS生态的繁荣发展。 适合人群:对操作系统底层技术感兴趣的开发者、科技爱好者以及从事智能设备相关领域的工程师。 使用场景及目标:①深入了解HarmonyOS及其内核子集(LOS)的技术特点和应用场景;②为开发基于HarmonyOS的智能设备提供理论支持和技术参考;③探索LOS在不同智能设备中的优化和应用,推动智能设备的创新和发展。 其他说明:本文不仅介绍了LOS的技术细节,还探讨了其与鸿蒙微内核的区别和协同工作方式,以及对未来发展的展望。这有助于读者全面理解HarmonyOS的内核架构和技术优势,为未来的开发和研究提供指导。
第三章习题作业.docx
为了解决信创环境下不能连网,因此在Kylin Server V10 下编译了openssl最新版本,而且做成了离线安装的脚本,安装步骤如下所示: 1. 解压软件包 [root@daolian ~]# tar -zxvf openssl-3.5.0-202504152120-multiple-Kylin-Server-V10-GFB-arm64.tar.gz 2. 查看目录中内容 [root@daolian nginx]# ls openssl.tar.gz setup.sh 3.安装 [root@daolian openssl]# ./setup.sh OPENSSL 3.5.0 INSTALL Sucesses 4.查看版本号 root@daolian:~# openssl version -a OpenSSL 3.5.0 8 Apr 2025 (Library: OpenSSL 3.5.0 8 Apr 2025) built on: Tue Apr 15 12:43:51 2025 UTC platform: linux-aarch64 options: bn(64,64)
模具-Φ146.6药瓶注塑模设计.zip
该资源为h5py-3.13.0-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl,欢迎下载使用哦!
基于Python的模仿元气骑士的游戏
基于SpringBoot的pc端仿淘宝系统,系统包含三种角色:管理员、用户,商家主要功能如下。 【用户功能】 首页:浏览系统的主要信息。 商城商品:查看商城中的各类商品,包括商品详情和价格。 商城公告:阅读系统发布的相关公告和通知。 官方客服:与系统提供的官方客服进行在线沟通。 购物车:管理已选购商品,包括添加、删除和结算功能。 个人中心:管理个人信息、查看订单记录等。 【管理员功能】 系统首页:查看系统整体概况。 个人中心:管理个人信息。 商家管理:审核和管理注册商家的基本信息。 用户管理:管理系统注册用户的信息。 商品种类管理:管理商城中的商品分类信息。 商城商品管理:监管和管理商城中的商品信息。 系统管理:管理系统的基本设置和运行参数。 订单管理:查看和处理用户的购物订单。 【商家功能】 系统首页:查看商家相关的概况。 个人中心:管理个人商家信息。 商家管理:编辑和管理商家基本信息。 商城商品管理:管理商家发布的商品信息。 订单管理:查看和处理用户购买商家商品的订单。 二、项目技术 编程语言:Java 数据库:MySQL 项目管理工具:Maven 前端技术:Vue 后端技术:SpringBoot 三、运行环境 操作系统:Windows、macOS都可以 JDK版本:JDK1.8以上都可以 开发工具:IDEA、Ecplise、Myecplise都可以 数据库: MySQL5.7以上都可以 Maven:任意版本都可以
基于SpringBoot的集团门户网站,系统包含两种角色:管理员、用户主要功能如下。 【用户功能】 1. **首页:** 浏览集团门户网站的主要信息。 2. **论坛:** 参与用户间的交流和讨论。 3. **集团文化:** 了解和学习集团的文化理念和价值观。 4. **公告通知:** 获取集团发布的重要通知和公告。 5. **集团简介:** 阅读关于集团的简要介绍和发展历程。 6. **核心竞争力:** 掌握集团的核心竞争力和特色。 7. **集团新闻:** 查看集团的最新新闻和活动报道。 8. **个人中心:** 管理个人信息。 【管理员功能】 1. **首页:** 查看集团门户网站的整体概况。 2. **个人中心:** 修改密码、管理个人信息。 3. **管理员管理:** 审核和管理注册管理员用户的信息。 4. **基础数据管理:** 管理网站的基础数据。 5. **论坛管理:** 管理用户间的讨论和交流,包括删除不当内容。 6. **集团文化管理:** 发布、编辑和删除集团文化信息,管理留言和收藏。 7. **公告通知管理:** 发布、编辑和删除公告通知。 8. **单页数据管理:** 管理单页数据的内容和展示。 9. **集团新闻管理:** 发布、编辑和删除集团新闻。 10. **用户管理:** 审核和管理注册用户的信息。 11. **轮播图信息:** 管理网站首页的轮播图。 二、项目技术 编程语言:Java 数据库:MySQL 项目管理工具:Maven 前端技术:Vue 后端技术:SpringBoot 三、运行环境 操作系统:Windows、macOS都可以 JDK版本:JDK1.8以上都可以 开发工具:IDEA、Ecplise、Myecplise都可以 数据库: MySQL5.7以上都可以 Maven:任意版本都可以