
转载于:http://www.javabloger.com/article/apache-zookeeper-Hadoop.html
口水:Zookeeper是我目前接触过Apache开源系统中比较复杂的一个产品,要搞清楚这个东东里面的运作关系还真不是一时半会可以搞定的事,本人目前只略知皮毛之术。
ZooKeeper 是什么?
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive) 、 小猪(Pig) 的管理员, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等项目中都采用到了 Zookeeper。ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,ZooKeeper是以Fast Paxos算法为基础,实现同步服务,配置维护和命名服务等分布式应用。
ZooKeeper 如何工作?
ZooKeeper是作为分布式应用建立更高层次的同步(synchronization)、配置管理 (configuration maintenance)、群组(groups)以及名称服务(naming)。在编程上,ZooKeeper设计很简单,所使用的数据模型风格很像文件系统的目录树结构,简单来说,有点类似windows中注册表的结构,有名称,有树节点,有Key(键)/Value(值)对的关系,可以看做一个树形结构的数据库,分布在不同的机器上做名称管理。
Zookeeper分为2个部分:服务器端和客户端,客户端只连接到整个ZooKeeper服务的某个服务器上。客户端使用并维护一个TCP连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个TCP连接中断,客户端将尝试连接到另外的ZooKeeper服务器。客户端第一次连接到ZooKeeper服务时,接受这个连接的 ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。
启动Zookeeper服务器集群环境后,多个Zookeeper服务器在工作前会选举出一个Leader,在接下来的工作中这个被选举出来的Leader死了,而剩下的Zookeeper服务器会知道这个Leader死掉了,在活着的Zookeeper集群中会继续选出一个Leader,选举出leader的目的是为了可以在分布式的环境中保证数据的一致性。如图所示:
另外,ZooKeeper 支持watch(观察)的概念。客户端可以在每个znode结点上设置一个观察。如果被观察服务端的znode结点有变更,那么watch就会被触发,这个watch所属的客户端将接收到一个通知包被告知结点已经发生变化。若客户端和所连接的ZooKeeper服务器断开连接时,其他客户端也会收到一个通知,也就说一个Zookeeper服务器端可以对于多个客户端,当然也可以多个Zookeeper服务器端可以对于多个客户端,如图所示:
你还可以通过命令查看出,当前那个Zookeeper服务端的节点是Leader,哪个是Follower,如图所示:
我通过试验观察到 Zookeeper的集群环境最好有3台以上的节点,如果只有2台,那么2台当中不管那台机器down掉,将只会剩下一个leader,那么如果有再有客户端连接上来,将无法工作,并且剩下的leader服务器会不断的抛出异常。内容如下:
Java.net.ConnectException: Connection refused
at sun.nio.ch.Net.connect(Native Method)
at sun.nio.ch.SocketChannelImpl.connect(SocketChannelImpl.java:507)
at java.nio.channels.SocketChannel.open(SocketChannel.java:146)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:347)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:381)
at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:674)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:611)
2010-11-15 00:31:52,031 – INFO [QuorumPeer:/0:0:0:0:0:0:0:0:2181:FastLeaderElection@683] – Notification time out: 12800
并且客户端连接时还会抛出这样的异常,说明连接被拒绝,并且等待一个socket连接新的连接,这里socket新的连接指的是zookeeper中的一个Follower。
org.apache.zookeeper.ClientCnxn$SendThread.startConnect(ClientCnxn.java:1000) Opening socket connection to server 192.168.50.211/192.168.50.211:2181
org.apache.zookeeper.ClientCnxn$SendThread.primeConnection(ClientCnxn.java:908) Socket connection established to 192.168.50.211/192.168.50.211:2181, initiating session
org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1118) Unable to read additional data from server sessionid 0×0, likely server has closed socket, closing socket connection and attempting reconnect
org.apache.zookeeper.ClientCnxn$SendThread.startConnect(ClientCnxn.java:1000) Opening socket connection to server localhost/127.0.0.1:2181
2010-11-15 13:31:56,626 WARN org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1120) Session 0×0 for server null, unexpected error, closing socket connection and attempting reconnect
先写到这里,全面了解Zookeeper不太容易,光看Apache Zookeeper官方的wiki和文档还不能对其有深入的了解,想阅读Zookeeper中的部分源代码。另外,本人目前正在学习和了解ing,欢迎大家与我交流,谢谢。
==================
记得在大约在2006年的时候Google出了Chubby来解决分布一致性的问题(distributed consensus problem),所有集群中的服务器通过Chubby最终选出一个Master Server ,最后这个Master Server来协调工作。简单来说其原理就是:在一个分布式系统中,有一组服务器在运行同样的程序,它们需要确定一个Value,以那个服务器提供的信息为主/为准,当这个服务器经过n/2+1的方式被选出来后,所有的机器上的Process都会被通知到这个服务器就是主服务器 Master服务器,大家以他提供的信息为准。很想知道Google Chubby中的奥妙,可惜人家Google不开源,自家用。
但是在2009年3年以后沉默已久的Yahoo在Apache上推出了类似的产品ZooKeeper,并且在Google原有Chubby的设计思想上做了一些改进,因为ZooKeeper并不是完全遵循Paxos协议,而是基于自身设计并优化的一个2 phase commit的协议,如图所示:
ZooKeeper跟Chubby一样用来存放一些相互协作的信息(Coordination),这些信息比较小一般不会超过1M,在zookeeper中是以一种hierarchical tree的形式来存放,这些具体的Key/Value信息就store在tree node中,如图所示:
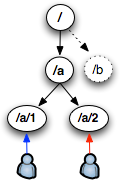
当有事件导致node数据,例如:变更,增加,删除时,Zookeeper就会调用 triggerWatch方法,判断当前的path来是否有对应的监听者(watcher),如果有watcher,会触发其process方法,执行process方法中的业务逻辑,如图所示:
应用实例
ZooKeeper有了上述的这些用途,让我们设想一下,在一个分布式系统中有这这样的一个应用:
2个任务工厂(Task Factory)一主一从,如果从的发现主的死了以后,从的就开始工作,他的工作就是向下面很多台代理(Agent)发送指令,让每台代理(Agent)获得不同的账户进行分布式并行计算,而每台代理(Agent)中将分配很多帐号,如果其中一台代理(Agent)死掉了,那么这台死掉的代理上的账户就不会继续工作了。
上述,出现了3个最主要的问题:
1.Task Factory 主/从一致性的问题
2.Task Factory 主/从心跳如何用简单+稳定 或者2者折中的方式实现。
3.一台代理(Agent)死掉了以后,一部分的账户就无法继续工作,需要通知所有在线的代理(Agent)重新分配一次帐号。
怕文字阐述的不够清楚,画了系统中的Task Factory和Agent的大概系统关系,如图所示:

OK,让我们想想ZooKeeper是不是能帮助我们去解决目前遇到的这3个最主要的问题呢?
解决思路
1. 任务工厂Task Factory都连接到ZooKeeper上,创建节点,设置对这个节点进行监控,监控方法例如:
event= new WatchedEvent(EventType.NodeDeleted, KeeperState.SyncConnected, "/TaskFactory");
这个方法的意思就是只要Task Factory与zookeeper断开连接后,这个节点就会被自动删除。
2.原来主的任务工厂断开了TCP连接,这个被创建的/TaskFactory节点就不存在了,而且另外一个连接在上面的Task Factory可以立刻收到这个事件(Event),知道这个节点不存在了,也就是说主TaskFactory死了。
3.接下来另外一个活着的TaskFactory会再次创建/TaskFactory节点,并且写入自己的ip到znode里面,作为新的标记。
4.此时Agents也会知道主的TaskFactory不工作了,为了防止系统中大量的抛出异常,他们将会先把自己手上的事情做完,然后挂起,等待收到Zookeeper上重新创建一个/TaskFactory节点,收到 EventType.NodeCreated 类型的事件将会继续工作。
5.原来从的TaskFactory 将自己变成一个主TaskFactory,当系统管理员启动原来死掉的主的TaskFactory,世界又恢复平静了。
6.如果一台代理死掉,其他代理他们将会先把自己手上的事情做完,然后挂起,向TaskFactory发送请求,TaskFactory会重新分配(sharding)帐户到每个Agent上了,继续工作。
上述内容,大致如图所示:
口水:
1.以上内容说的还不够好,希望能和有经验的同学们交流一下,说说你们在大规模计算中是如何解决分布式一致性的问题,谢谢
2.大量了很多文章,最后的确是看了Hbase部分和zookeeper的源代码 有了点启发。
http://hbase.apache.org/docs/r0.89.20100726/xref/org/apache/hadoop/hbase/master/ZKMasterAddressWatcher.html
=========================
开场白:
在上一篇关于介绍Zookeeper的文章中有同学给我留言,说到Zookeeper/Hbase/Hadoop三者之间的关系,在此我把三者之间的关系画在一张图上希望能表达的清楚一些。

Zookeeper用来同步Hbase服务状态、监控集群防止单点失效
HDFS是Hadoop中最核心的一部分,用来对Hbase的数据进行存储
1、Zookeeper客户端与服务端的大致结构
服务端
Zookeeper还是属于一个C/S的架构的应用服务,Zookeeper的服务器端分为2种运行模式:单台和集群多台的运行模式,通过conf/zoo.cfg中的配置判定你启用的运行模式,以及在群集模式中数据同步和心跳的频率等等。
Zookeeper集群中的Leader和Follower之间的选举通过Paxos算法来实现的,它是一个基于消息传递的一致性算法,这里讲述了http://zh.wikipedia.org/zh-cn/Paxos算法,传说中Paxos算法是分布式一致性算法中最有效的一种算法。
口水:在源代码中的通讯部分看见了大量采用NIO和concurrent的代码(例如:LinkedBlockingQueue/AtomicLong)。
客户端
ZooKeeper的Client由三个主要模块组成:
Zookeeper
Zookeeper是最主要的类,可以写入一个或者多个Zookeeper的服务器地址,例如:"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002" ,当你new Zookeeper( ….)的时候会有两个线程被创建:SendThread和EventThread,会在Server端创建大量的Session。
WatcherManager
在Zookeeper类中还有一个WatcherManager,用来管理Watcher的,Watcher是ZK的一大特色功能,允许多个Client对一个或多个 ZNode进行监控,当ZNode有变化时能够通知到监控这个ZNode的各个Client,管理了ZK Client绑定的所有Watcher。
ClientCnxn
在Zookeeper类中还包含了对ClientCnxn类的调用,ClientCnxn这个类管理所有对Zookeeper服务器端的网络通讯,服务端和客户端所有交互的数据都要调用这个类,包括给ZK Server发送Request,从ZK Server接受Response,以及从ZK Server接受Watcher Event。
2、服务端运行模式
服务端单机模式
zoo.cfg文件配置参数详解
# 这个时间是被用来做服务器之间或客户端与服务器心跳和最低会话超时时间的基数。
tickTime=2000
# 存储在内存中数据快照的目录。
dataDir=d:/zookeeperdata/1
# 服务器端开启的监听端口,用来接受客户端访问请求的端口。
clientPort=2181
服务端集群模式
配置参数详解
#Zookeeper服务器集群中连接到Leader与Follower 服务器少次心跳时间间隔数,以及最大通讯的超时时间,总时间为 5(initLimit)*2000(tickTime)=10 秒。
initLimit=5
#Leader与Follower间请求/应答时间长度,这里总时间长度就是 2(syncLimit)*2000(tickTime)=4 秒。
syncLimit=2
#server是固定配置,1和2表示这个是第几号服务器,2888:3888表示服务器与集群中的 Leader 服务器的通讯端口。
server.1=192.168.1.1:2888:3888
server.2=192.168.1.2:2888:3888
另外,集群模式下还要在 dataDir 目录下创建一个myid文件,这个文件中写入的内容就是一个数字,这个数字就是和server.x中的x这个数字对应,Zookeeper 启动时会读取这个文件判定自己是谁,myid文件的编码格式是ANSI。



相关推荐
### Zookeeper 入门到精通 #### 一、Zookeeper 概述 ##### 1.1 什么是 Zookeeper? Zookeeper 是一个分布式的协调服务框架,最初由雅虎实验室开发,后来成为 Apache 的顶级项目。它是 Google Chubby 的一种开源...
**Zookeeper系列1:入门** Zookeeper是一款分布式协调服务,由Apache基金会开发,广泛应用于分布式系统中的数据共享、配置管理、命名服务、集群同步等场景。它的设计目标是简化分布式环境下的复杂问题,提供高可用...
**Zookeeper入门练习Demo** Zookeeper是一个分布式协调服务,由Apache Hadoop项目开发,广泛应用于分布式计算、配置管理、命名服务、分布式锁等场景。这个"Zookeeper入门练习Demo"旨在帮助初学者快速掌握Zookeeper...
尚硅谷大数据技术之Zookeeper1是关于Apache Zookeeper入门教程的一部分,旨在介绍Zookeeper的基本概念、特点、数据结构、应用场景以及如何在本地模式下进行安装和操作。Zookeeper是一个开源的分布式协调服务,它在...
《Zookeeper入门到精通》教学视频及文档涵盖了分布式协调服务Zookeeper的核心概念、安装配置、基本操作以及在实际应用中的高级技巧。Zookeeper是Apache Hadoop项目的一个子项目,它为分布式应用程序提供高效且可靠的...
【标题】"dubbo+zookeeper入门资源"涵盖了两个核心概念:Dubbo和Zookeeper,它们在分布式系统中扮演着重要角色。Dubbo是中国阿里巴巴开源的一款高性能、轻量级的Java服务治理框架,它提供了服务注册、服务发现、调用...
Apache ZooKeeper是一个用于分布式系统的协调服务,它可以帮助程序进行数据同步、配置管理等。如果你想要开始使用ZooKeeper,可以参考本资源。
在“ZooKeeper入门简介及配置使用”文档中,你将学习到以下关键知识点: 1. **ZooKeeper的基本概念**:了解ZooKeeper的核心组件,包括服务器节点、客户端、会话、Watcher、ZNode(ZooKeeper的数据节点)等。理解...
Apache Zookeeper AMI 用于创建安装了 Apache Zookeeper 的虚拟机的 AMI。概要此脚本将创建一个 AMI,其中安装了 Apache Zookeeper 和所有必需的初始化脚本。 此脚本生成的 AMI 应该是用于实例化 Zookeeper 服务器...
### Zookeeper入门教程 #### 一、Zookeeper简介 Zookeeper是Apache基金会下的一个顶级开源项目,最初由Yahoo!实验室研发,并随后捐赠给了Apache。它为分布式应用提供了一个高效、可靠且易于使用的协同服务框架。...
Zookeeper是一个开源的分布式协调服务,由雅虎创建并贡献给Apache基金会,广泛应用于大数据、云计算等领域的分布式系统中。它的设计目标是简化分布式环境下的数据管理与同步问题,提供了一种高度可靠且一致的数据...
Apache ZooKeeper 是一个分布式协调服务,它为分布式应用程序提供高度可靠的节点间通信、数据共享和一致性管理。这个“Zookeeper中文开发指南”是针对开发人员和系统管理员的一份宝贵的资源,它涵盖了从基础概念到...
Zookeeper 是一个分布式服务框架,由 Apache Hadoop 项目衍生而来,主要解决的是分布式环境中的数据一致性问题。它提供了一个类似文件系统的目录节点树结构,用于数据存储,并且支持多种重要的服务,例如统一命名...
首先,需要从Apache官网下载ZooKeeper的最新稳定版本,并确保系统已安装Java 6或更高版本。接着,设置环境变量,例如在`/etc/profile`中添加ZOOKEEPER_HOME和PATH。ZooKeeper的配置文件`zoo.cfg`通常位于`conf`目录...
《Zookeeper入门学习详解》 Zookeeper,一个分布式协调服务,是Apache Hadoop的一个子项目,主要用于解决分布式环境中的数据一致性问题。它提供了一种基于发布/订阅模式的消息系统,可以实现命名服务、配置管理、...
2. **Zookeeper**:Apache ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终将简单易用的接口和性能高效、...
内容概要:本文详细介绍了 Apache ZooKeeper 的基础知识、安装步骤以及基本操作。首先,从下载和解压安装包开始,然后逐步配置 ZooKeeper,启动和检查状态。接着,使用命令行工具进行基本的操作,如创建、查看、列出...
卡夫卡融合角色 这个Ansible角色旨在使用安装和配置Apache Kafka和Apache Zookeeper。 所有配置都可以通过var传递,您可以在查看必要var的列表,并根据需要自定义它们。入门先决条件Ansible 2.2 +,Python和Pip。 ...
**Zookeeper API(Java)入门详解** Zookeeper是一款分布式协调服务,由Apache基金会开发,它为分布式应用提供一致性服务,包括命名服务、配置管理、集群同步、分布式锁等。在Java开发中,我们通常会使用Zookeeper...
Zookeeper是Apache的一个分布式协调服务,它为分布式应用程序提供一致性服务。在Dubbo中,Zookeeper常作为服务注册中心,用于存储服务提供者的元数据和服务状态。 1. **服务注册**: 服务提供者启动后,将其元数据...