
 
дЄАиѓіеИ∞RESTпЉМжИСжГ≥е§ІеЃґзЪДзђђдЄАеПНеЇФе∞±жШѓвАЬеХКпЉМе∞±жШѓйВ£зІНеЙНеРОеП∞йАЪдњ°жЦєеЉПгАВвАЭдљЖжШѓеЬ®и¶Бж±Виѓ¶зїЖиЃ≤ињ∞еЃГжЙАжПРеЗЇзЪДеРДдЄ™зЇ¶жЭЯпЉМдї•еПКе¶ВдљХеЉАеІЛжР≠еїЇRESTжЬНеК°жЧґпЉМеНіеЊИе∞СжЬЙдЇЇиГље§ЯжЄЕжЩ∞еЬ∞иѓіеЗЇеЃГеИ∞еЇХжШѓдїАдєИпЉМйЬАи¶БйБµеЃИдїАдєИж†ЈзЪДеЗЖеИЩгАВ
гААгААеЬ®жВ®е∞ЖзЬЛеИ∞зЪДињЩдЄАзѓЗжЦЗзЂ†дЄ≠пЉМжИСдїђе∞ЖеѓєRESTпЉМе∞§еЕґжШѓеЯЇдЇОHTTPзЪДRESTжЬНеК°ињЫи°Миѓ¶зїЖеЬ∞дїЛзїНгАВйАЪињЗињЩдЇЫжЦЗзЂ†пЉМжВ®дЄНдїЕеПѓдї•дЇЖиІ£еИ∞дїАдєИжШѓRESTпЉМжЫіиГљжЄЕжЩ∞еЬ∞дЇЖиІ£еИ∞жВ®еЬ®зЉЦеЖЩRESTжЬНеК°жЧґжЙАйЬАи¶БйБµеЃИзЪДеРДдЄ™еЃИеИЩпЉМиЃЊиЃ°RESTful APIжЧґйЬАи¶БиАГиЩСзЪДеРДзІНеЫ†зі†дї•еПКеЃЮзО∞ињЗз®ЛдЄ≠еПѓиГљйБЗеИ∞зЪДйЧЃйҐШз≠ЙеЖЕеЃєгАВ
 
RESTз§ЇдЊЛ
гААгААжИСжГ≥пЉМеЊИе§ЪиѓїиАЕеПѓиГљеєґдЄН姙жЄЕж•ЪRESTеИ∞еЇХжШѓдЄАдЄ™дїАдєИж¶ВењµгАВйВ£дєИпЉМй¶ЦеЕИиЃ©жИСдїђжЭ•зЬЛдЄАдЄ™зЃАеНХзЪДеЯЇдЇОHTTPзЪДRESTжЬНеК°з§ЇдЊЛгАВ
гААгААеБЗиЃЊзФ®жИЈж≠£еЬ®иЃњйЧЃдЄАдЄ™зФµе≠РеХЖеК°зљСзЂЩwww.egoods.comгАВиѓ•зљСзЂЩеѓєеЕґжЙАйФАеФЃзЪДеРДдЄ™зЙ©еУБињЫи°МдЇЖиѓ¶зїЖеИЖз±їгАВељУзФ®жИЈзЩїељХиѓ•зљСзЂЩињЫи°Миі≠зЙ©жЧґпЉМдїЦй¶ЦеЕИйЬАи¶БеЬ®иѓ•зљСзЂЩдЄКйАЙжЛ©еЕґжЙАйЬАи¶БеѓїжЙЊзЙ©еУБзЪДеИЖз±їпЉМињЫиАМеИЧеЗЇе±ЮдЇОиѓ•еИЖз±їзЪДеРДдЄ™зЙ©еУБгАВ
 
 
 
гААгААељУзДґпЉМиЩљзДґдїОдЄЪеК°йАїиЊСзЪДиІТеЇ¶жЭ•иѓіињЩдЄ™жµБз®ЛйЭЮеЄЄзЃАеНХпЉМдљЖеЃЮйЩЕдЄКжµПиІИеЩ®еРСеРОеП∞еПСйАБдЇЖе§ЪдЄ™иѓЈж±ВпЉЪй°µйЭҐйАїиЊСеЬ®й°µйЭҐеК†иљљжЧґе∞Жй¶ЦеЕИеЊЧеИ∞жЙАжЬЙзЪДеХЖеУБеИЖз±їпЉМеєґе∞ЖињЩдЇЫеИЖз±їжШЊз§ЇеЬ®дЇЖй°µйЭҐдЄ≠гАВеЬ®зФ®жИЈйАЙжЛ©дЇЖдЄАдЄ™еИЖз±їзЪДжЧґеАЩпЉМй°µйЭҐйАїиЊСе∞ЖеПСйАБдЄАдЄ™иѓЈж±ВеЊЧеИ∞иѓ•еИЖз±їзЪДиѓ¶зїЖдњ°жБѓпЉМеєґеПСйАБеП¶е§ЦдЄАдЄ™иѓЈж±ВжЭ•еЊЧеИ∞иѓ•еИЖз±їзЪДеХЖеУБеИЧи°®пЉЪ


гААгААеЬ®йАЪињЗжµПиІИеЩ®зЪДи∞ГиѓХеКЯиГљжЯ•зЬЛињЩдЇЫиѓЈж±ВзЪДжЧґеАЩпЉМжИСдїђеПѓдї•зЬЛеИ∞еЕґй¶ЦеЕИеРСwww.egoods.com/api/categoriesеПСйАБдЄАдЄ™GETиѓЈж±ВпЉМдї•еПЦеЊЧжЙАжЬЙзЪДеХЖеУБеИЖз±їпЉЪ
1 GET /api/categories 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
гААгААиАМжЬНеК°зЂѓе∞ЖињФеЫЮжЙАжЬЙзЪДз±їеИЂпЉЪ

1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 [
6 {
7 "label" : "й£ЯеУБ",
8 "url" : "/api/categories/1"
9 }, {
10 "label" : "жЬНи£Е",
11 "url" : "/api/categories/2"
12 }
13 ...
14 {
15 "label" : "зФµе≠РиЃЊе§З",
16 "url" : "/api/categories/25"
17 }
18 ]
гААгААиѓ•еУНеЇФињФеЫЮдЇЖдЄАдЄ™зФ®JSONи°®з§ЇзЪДжХ∞зїДгАВиѓ•жХ∞зїДдЄ≠зЪДжѓПдЄ™еЕГзі†еМЕеРЂдЇЖдЄ§йГ®еИЖдњ°жБѓпЉЪзФ®жИЈиГље§ЯиѓїжЗВзЪДи°®з§ЇеИЖз±їеРНзІ∞зЪДlabelдї•еПКзЫЄеЇФеИЖз±їжЙАеѓєеЇФзЪДURLгАВеЕґдЄ≠LabelжЙАиЃ∞ељХзЪДеИЖз±їеРНзІ∞е∞ЖеЬ®й°µйЭҐдЄ≠жШЊз§ЇзїЩзФ®жИЈгАВиАМеЬ®зФ®жИЈж†єжНЃlabelжЙАж†Зз§ЇзЪДеИЖз±їеРНйАЙжЛ©дЇЖдЄАдЄ™еИЖз±їзЪДжЧґеАЩпЉМй°µйЭҐйАїиЊСдЉЪеПЦеЊЧиѓ•еИЖз±їжЙАеѓєеЇФзЪДURLеєґеРСиѓ•URL еПСйАБиѓЈж±ВпЉМдї•еЊЧеИ∞иѓ•еИЖз±їзЪДиѓ¶зїЖдњ°жБѓгАВдЊЛе¶ВеЬ®зФ®жИЈзВєеЗїдЇЖвАЬй£ЯеУБвАЭињЩдЄ™еИЖз±їзЪДжЧґеАЩпЉМжµПиІИеЩ®е∞ЖдЉЪеРСжЬНеК°еЩ®еПСйАБе¶ВдЄЛзЪДиѓЈж±ВпЉЪ
1 GET /api/categories/1 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
гААгААињЩдЄАжђ°пЉМй°µйЭҐйАїиЊСж†єжНЃзФ®жИЈеѓєеИЖз±їзЪДйАЙжЛ©вАЬй£ЯеУБвАЭжЭ•еЊЧеИ∞дЇЖеЕґжЙАеѓєеЇФзЪДURLпЉМеєґеРСиѓ•URLеПСйАБдЇЖдЄАдЄ™GETиѓЈж±ВгАВиАМиѓ•иѓЈж±ВжЙАеЊЧеИ∞зЪДеУНеЇФеИЩдЄЇпЉЪ
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: xxx
{
"url" : "/api/categories/1",
"label" : "Food",
"items_url" : "/api/items?category=1",
"brands" : [
{
"label" : "еПЛиЗ£",
"brand_key" : "32073",
"url" : "/api/brands/32073"
}, {
"label" : "дєРдЇЛ",
"brand_key" : "56632",
"url" : "/api/brands/56632"
}
...
],
"hot_searches" : вА¶
}
гААгААиѓ•еУНеЇФзХ•дЄЇе§НжЭВгАВй¶ЦеЕИпЉМеУНеЇФдЄ≠зЪДURLж†Зз§ЇдЇЖвАЬй£ЯеУБвАЭеИЖз±їжЙАеѓєеЇФзЪДURLгАВиАМlabelе±ЮжАІеИЩеТМеЙНйЭҐдЄАж†ЈпЉМзФ®жЭ•еЬ®й°µйЭҐдЄКжШЊз§ЇеИЖз±їзЪДеРНзІ∞гАВдЄАдЄ™иЊГдЄЇзЙєжЃКзЪДе±ЮжАІеИЩжШѓitems_urlгАВеЕґзФ®жЭ•ж†Зз§ЇиОЈеПЦе±ЮдЇОй£ЯеУБеИЖз±їзЪДеРДдЄ™дЇІеУБзЪДURLгАВиАМе±ЮжАІbrandsеИЩзФ®жЭ•еИЧеЗЇеЬ®вАЬй£ЯеУБвАЭеИЖз±їдЄ≠зЪДиСЧеРНеУБзЙМпЉМдЊЛе¶ВеПЛиЗ£пЉМдєРдЇЛз≠ЙгАВињЩдЇЫеУБзЙМ襀зїДзїЗдЄЇдЄАдЄ™еѓєи±°жХ∞зїДпЉМиАМжХ∞зїДдЄ≠зЪДжѓПдЄ™еѓєи±°йГљжЛ•жЬЙlabelпЉМurlз≠Йе±ЮжАІгАВеЬ®ињЩдЇЫе±ЮжАІзЪДеЄЃеК©дЄЛпЉМй°µйЭҐеПѓдї•еИЧеЗЇињЩдЇЫиСЧеРНеУБзЙМзЪДеРНзІ∞пЉМеєґеЕБиЃЄзФ®жИЈйАЪињЗзВєеЗїиЈ≥иљђеИ∞ињЩдЇЫеУБзЙМжЙАеѓєеЇФзЪДй°µйЭҐдЄКгАВйЩ§дЇЖињЩдЇЫе±ЮжАІдєЛе§ЦпЉМFoodеИЖз±їињШеМЕеРЂдЇЖеЕґеЃГдЄАз≥їеИЧе±ЮжАІпЉМе¶Ви°®з§ЇељУеЙНеЕґеЃГзФ®жИЈж≠£еЬ®жРЬ糥зЪДhot_searchesе±ЮжАІз≠ЙпЉМињЩйЗМе∞±дЄНеЖНиµШињ∞гАВ
гААгААиѓ•еУНеЇФжЬЙдЄАдЄ™йЧЃйҐШпЉМйВ£е∞±жШѓзђ¶еРИзФ®жИЈз≠ЫйАЙжЭ°дїґзЪДеРДдЄ™дЇІеУБеєґж≤°жЬЙеМЕеРЂеЬ®иѓ•еУНеЇФдЄ≠гАВињЩжШѓеЫ†дЄЇй°µйЭҐжЙАеИЧеЗЇзЪДеРДдЄ™дЇІеУБжШѓж†єжНЃзФ®жИЈжЙАиЃЊзљЃзЪДз≠ЫйАЙжЭ°дїґпЉМеН≥еЕґйАЙжЛ©зЪДеУБзЙМдї•еПКжРЬ糥еЕ≥йФЃе≠ЧиАМеПШеМЦзЪДгАВеЫ†ж≠§пЉМй°µйЭҐйАїиЊСдЉЪж†єжНЃе±ЮжАІitems_urlдї•еПКзФ®жИЈжЙАиЃЊеЃЪзЪДжРЬ糥жЭ°дїґзїДеРИжИРдЄЇзЫЃж†ЗURLпЉМеЖНжђ°еПСйАБиѓЈж±ВеИ∞еРОеП∞пЉМдї•иѓЈж±ВйЬАи¶БеЬ®й°µйЭҐдЄ≠е±ХзО∞зЪДеРДдЄ™зЙ©еУБгАВ
гААгААдЊЛе¶ВзФ®жИЈеЬ®еП™жГ≥жµПиІИе±ЮдЇОдєРдЇЛеУБзЙМзЪДй£ЯеУБжЧґпЉМеЕґеПѓдї•йТ©йАЙдєРдЇЛињЩдЄ™еУБзЙМпЉМйВ£дєИж≠§жЧґзЪДURLе∞ЖзФ±й£ЯзЙ©еИЖз±їзЪДitems_urlдї•еПКи°®з§ЇжМЙзЕІеУБзЙМињЫи°Мз≠ЫйАЙзЪДURLеПВжХ∞еЕ±еРМзїДжИРпЉЪ
1 GET /api/items?category=1&brand_key=56632 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
гААгААзО∞еЬ®иЃ©жИСдїђжЭ•жАїзїУдЄАдЄЛдЄКйЭҐжЙАе±Хз§ЇзЪДеЯЇдЇОHTTPзЪДRESTз≥їзїЯзЪДжХідЄ™ињРи°МжµБз®ЛгАВеЬ®еЉАеІЛзЪДжЧґеАЩпЉМжИСдїђжЛњеИ∞дЇЖжЙАжЬЙеИЖз±їзЪДеИЧи°®гАВеИЧи°®дЄ≠зЪДеРДдЄ™жЭ°зЫЃдЄНдїЕдїЕеМЕеРЂдЇЖзФ®жИЈеПѓдї•зЬЛеИ∞зЪДеИЖз±їеРНзІ∞з≠Йдњ°жБѓпЉМжЫіжЛ•жЬЙдЄАдЄ™йҐЭе§ЦзЪДURLе±ЮжАІгАВеЬ®зФ®жИЈйАЙжЛ©иѓ•еИЧи°®дЄ≠зЪДдЄАй°єжЧґпЉМй°µйЭҐйАїиЊСе∞ЖдЉЪеРСеѓєеЇФзЪДURLеПСйАБдЄАдЄ™иѓЈж±ВпЉМдї•иОЈеЊЧиѓ•й°єзЫЃзЪДиѓ¶зїЖдњ°жБѓгАВеЬ®ињЩдЄ™иѓ¶зїЖдњ°жБѓдЄ≠пЉМдЄАдЇЫеЖЕеЃєеПИеМЕеРЂдЇЖдЄАдЇЫеЕґеЃГзЪДURLпЉМдїОиАМдљњеЊЧй°µйЭҐйАїиЊСеПИиГљйАЪињЗиѓ•URLе±ЮжАІеПСйАБиѓЈж±ВгАВ
гААгААжВ®дєЯиЃЄдЉЪиѓіпЉМеУОпЉМињЩдЄНеТМжИСдїђзО∞жЬЙз≥їзїЯзЪДињРи°МжµБз®ЛдЄАж†ЈзЪДеШЫгАВжШѓзЪДгАВеЬ®дЄКйЭҐжЙАдЄЊеЗЇзЪДдЊЛе≠РдЄ≠пЉМжИСдїђдєЯжЫіеБПйЗНеЬ∞жППињ∞дЇЖRESTз≥їзїЯжЙАйЬАи¶БеЕЈжЬЙзЪДHATEOASпЉИHypermedia As The Engine Of Application StateпЉЙзЙєжАІгАВж≠£жШѓзФ±дЇОињЩдЄ™зЙєжАІеЈ≤зїПеЬ®е§ІеЃґжЙАеИЫеїЇзЪДз≥їзїЯйЗМйЭҐеєњж≥ЫеЬ∞дљњзФ®дЇЖпЉМеЫ†ж≠§жИСжЫіеЄМжЬЫдїОзЖЯжВЙзЪДеЬ∞жЦєеЕ•жЙЛпЉМиАМдЄНжШѓеЉАеІЛе∞±йЭЮеЄЄжХЩжЭ°еЬ∞иѓіRESTдЄАеЃЪи¶БињЩж†ЈпЉМдЄАеЃЪи¶БйВ£ж†ЈпЉМеЊТеҐЮдЇЖе≠¶дє†зЪДйЪЊеЇ¶гАВ
гААгААеПНињЗжЭ•иѓіпЉМдЄКйЭҐжЙАе±Хз§ЇзЪДRESTжЬНеК°еєґдЄНеЕЈжЬЙеЕЄеЮЛжАІгАВеЬ®еЕЕеИЖдЇЖиІ£дЇЖRESTеРОпЉМжВ®дЉЪеПСзО∞пЉМRESTеЬ®з≥їзїЯиЃЊиЃ°дЄКзЪДиІЖиІТе∞ЖдЄНеЖНжККжµБз®ЛжФЊеЬ®дЇЖжЬАдЉШеЕИзЪДдљНзљЃгАВ
гААгААиАМеЬ®еРОйЭҐзЪДзЂ†иКВдЄ≠пЉМжИСдїђеИЩдЉЪйАРжЄРе±ХеЉАпЉМиѓ¶зїЖеЬ∞дїЛзїНе¶ВдљХеИЫеїЇдЄАдЄ™зЇѓж≠£зЪДеЯЇдЇОHTTPзЪДRESTжЬНеК°гАВ
 
RESTзЪДеЃЪдєЙ
гААгААOKпЉМзО∞еЬ®иЃ©жИСдїђжЭ•зЬЛзЬЛRESTзЪДеЃЪдєЙгАВWikipediaжШѓињЩж†ЈжППињ∞еЃГзЪДпЉЪ
 
Representational State Transfer (REST) is a software architecture style consisting of guidelines and best practices for creating scalable web services. REST is a coordinated set of constraints applied to the design of components in a distributed hypermedia system that can lead to a more performant and maintainable architecture.
 
гААгААдїОдЄКйЭҐзЪДеЃЪдєЙдЄ≠пЉМжИСдїђеПѓдї•еПСзО∞RESTеЕґеЃЮжШѓдЄАзІНзїДзїЗWebжЬНеК°зЪДжЮґжЮДпЉМиАМеєґдЄНжШѓжИСдїђжГ≥и±°зЪДйВ£ж†ЈжШѓеЃЮзО∞WebжЬНеК°зЪДдЄАзІНжЦ∞зЪДжКАжЬѓпЉМжЫіж≤°жЬЙи¶Бж±ВдЄАеЃЪи¶БдљњзФ®HTTPгАВеЕґзЫЃж†ЗжШѓдЄЇдЇЖеИЫеїЇеЕЈжЬЙиЙѓе•љжЙ©е±ХжАІзЪДеИЖеЄГеЉПз≥їзїЯгАВ
гААгААеПНињЗжЭ•пЉМдљЬдЄЇдЄАзІНжЮґжЮДпЉМеЕґжПРеЗЇдЇЖдЄАз≥їеИЧжЮґжЮДзЇІзЇ¶жЭЯгАВињЩдЇЫзЇ¶жЭЯжЬЙпЉЪ
- дљњзФ®еЃҐжИЈ/жЬНеК°еЩ®ж®°еЮЛгАВеЃҐжИЈеТМжЬНеК°еЩ®дєЛйЧійАЪињЗдЄАдЄ™зїЯдЄАзЪДжО•еП£жЭ•дЇТзЫЄйАЪиЃѓгАВ
- е±Вжђ°еМЦзЪДз≥їзїЯгАВеЬ®дЄАдЄ™RESTз≥їзїЯдЄ≠пЉМеЃҐжИЈзЂѓеєґдЄНдЉЪеЫЇеЃЪеЬ∞дЄОдЄАдЄ™жЬНеК°еЩ®жЙУдЇ§йБУгАВ
- жЧ†зКґжАБгАВеЬ®дЄАдЄ™RESTз≥їзїЯдЄ≠пЉМжЬНеК°зЂѓеєґдЄНдЉЪдњЭе≠ШжЬЙеЕ≥еЃҐжИЈзЪДдїїдљХзКґжАБгАВдєЯе∞±жШѓиѓіпЉМеЃҐжИЈзЂѓиЗ™иЇЂиіЯиі£зФ®жИЈзКґжАБзЪДзїіжМБпЉМеєґеЬ®жѓПжђ°еПСйАБиѓЈж±ВжЧґйГљйЬАи¶БжПРдЊЫиґ≥е§ЯзЪДдњ°жБѓгАВ
- еПѓзЉУе≠ШгАВRESTз≥їзїЯйЬАи¶БиГље§ЯжБ∞ељУеЬ∞зЉУе≠ШиѓЈж±ВпЉМдї•е∞љйЗПеЗПе∞СжЬНеК°зЂѓеТМеЃҐжИЈзЂѓдєЛйЧізЪДдњ°жБѓдЉ†иЊУпЉМдї•жПРйЂШжАІиГљгАВ
- зїЯдЄАзЪДжО•еП£гАВдЄАдЄ™RESTз≥їзїЯйЬАи¶БдљњзФ®дЄАдЄ™зїЯдЄАзЪДжО•еП£жЭ•еЃМжИРе≠Рз≥їзїЯдєЛйЧідї•еПКжЬНеК°дЄОзФ®жИЈдєЛйЧізЪДдЇ§дЇТгАВињЩдљњеЊЧRESTз≥їзїЯдЄ≠зЪДеРДдЄ™е≠Рз≥їзїЯеПѓдї•зЛђиЗ™еЃМжИРжЉФеМЦгАВ
гААгААе¶ВжЮЬдЄАдЄ™з≥їзїЯжї°иґ≥дЇЖдЄКйЭҐжЙАеИЧеЗЇзЪДдЇФжЭ°зЇ¶жЭЯпЉМйВ£дєИиѓ•з≥їзїЯе∞±иҐЂзІ∞дЄЇжШѓRESTfulзЪДгАВ
гААгААдЄЛйЭҐжИСдїђеЖНжђ°йАЪињЗзФµе≠РеХЖеК°зљСзЂЩegoodsињЩдЄ™з§ЇдЊЛжЭ•еЄЃеК©жИСдїђзРЖиІ£ињЩдЇЫзЇ¶жЭЯгАВй¶ЦеЕИпЉМegoodsжШѓдЄАдЄ™зФµе≠РеХЖеК°зљСзЂЩгАВзФ®жИЈйЬАи¶БйАЪињЗжµПиІИеЩ®пЉМжЙЛжЬЇжИЦиАЕзљСзЂЩжЙАеПСеЄГзЪДжµПиІИеЇФзФ®жЭ•иЃњйЧЃиѓ•зљСзЂЩзЪДеЖЕеЃєгАВеЫ†ж≠§еЕґдљњзФ®зЪДиЗ™зДґжШѓеЃҐжИЈ/жЬНеК°еЩ®ж®°еЮЛгАВиАМеЬ®жµПиІИињЗз®ЛдЄ≠пЉМзФ®жИЈйЬАи¶БиЃњйЧЃдЄНеРМз±їеЮЛзЪДжХ∞жНЃпЉМе¶ВеХЖеУБжППињ∞гАБиі≠зЙ©иљ¶з≠Йдњ°жБѓгАВињЩдЇЫдњ°жБѓеПѓиГљзФ±egoodsзљСзЂЩжЬНеК°дЄ≠дЄНеРМзЪДжЬНеК°еЩ®жЭ•жПРдЊЫзЪДпЉМеЫ†ж≠§еЬ®зФ®жИЈжµПиІИињЗз®ЛдЄ≠еПѓиГљйЬАи¶БдЄОдЄНж≠ҐдЄАдЄ™жЬНеК°еЩ®ињЫи°МдЇ§дЇТгАВе¶ВжЮЬеЬ®жЬНеК°зЂѓдњЭе≠ШдЇЖжЬЙеЕ≥еЃҐжИЈзЪДдїїдљХзКґжАБпЉМйВ£дєИеЬ®зФ®жИЈдЄОдЄНеРМжЬНеК°еЩ®ињЫи°МдЇ§дЇТзЪДжЧґеАЩпЉМеЃҐжИЈзЪДзКґжАБе∞±йЬАи¶БеЬ®ињЩдЇЫжЬНеК°дєЛйЧіињЫи°МеРМж≠•пЉМе§Іе§ІеЬ∞еҐЮеК†дЇЖз≥їзїЯзЪДе§НжЭВеЇ¶гАВеЫ†ж≠§пЉМRESTи¶Бж±ВеЃҐжИЈзЂѓиЗ™и°МзїіжК§зКґжАБпЉМеєґеЬ®жѓПжђ°еПСйАБиѓЈж±ВзЪДжЧґеАЩжПРдЊЫиЗ™иЇЂжЙАеВ®е≠ШзЪДе§ДзРЖиѓ•иѓЈж±ВжЙАењЕйЬАзЪДдњ°жБѓгАВиАМжБ∞ељУеЬ∞дљњзФ®зЉУе≠ШињЩдЄАжЭ°дєЯйЭЮеЄЄеЃєжШУзРЖиІ£гАВеЬ®еЃҐжИЈзЂѓиѓЈж±ВдЄАдЄ™иЗ™дЄКжђ°иѓЈж±ВеРОж≤°жЬЙеПСзФЯињЗеПШеМЦзЪДдњ°жБѓжЧґпЉМе¶ВдЇІеУБеИЖз±їеИЧи°®пЉМжЬНеК°зЂѓдїЕдїЕйЬАи¶БињФеЫЮдЄАдЄ™304еУНеЇФеН≥еПѓгАВ
гААгААињЩйЗМжВ®еПѓдї•зЬЛеИ∞пЉМеЙНеЫЫжЭ°зЇ¶жЭЯдЄ≠йЩ§дЇЖжЧ†зКґжАБињЩжЭ°зЇ¶жЭЯиЊГдЄЇзЙєеИЂдєЛе§ЦпЉМеЕґеЃГдЄЙжЭ°зЇ¶жЭЯеЬ®еЯЇдЇОHTTPзЪДWebжЬНеК°дЄ≠йГљеЊИеЄЄиІБпЉМдєЯиЊГеЃєжШУиЊЊжИРгАВиАМжЧ†зКґжАБзЇ¶жЭЯеЬ®еЕґеЃГз±їеЮЛзЪДWebжЬНеК°дЄ≠еєґдЄНеНБеИЖеЄЄиІБпЉМеЫ†ж≠§е¶ВдљХйБњеЕНињЭеПНиѓ•зЇ¶жЭЯжШѓеЬ®еЃЮзО∞RESTжЬНеК°жЧґжЬАеЄЄиЃ®иЃЇзЪДиѓЭйҐШгАВеЕґдЄНдїЕдїЕдЉЪељ±еУНеИ∞еЊИе§ЪеКЯиГљзЪДиЃЊиЃ°пЉМжЫіжШѓRESTз≥їзїЯжЙ©е±ХжАІзЪДеЕ≥йФЃгАВеЫ†ж≠§еЬ®еРОйЭҐзЪДзЂ†иКВдЄ≠пЉМжИСдїђдЉЪеѓєжЧ†зКґжАБзЇ¶жЭЯеНХзЛђињЫи°МиЃ≤иІ£гАВ
гААгААеЬ®зЃАеНХеЬ∞дїЛзїНдЇЖеЙНеЫЫдЄ™зЇ¶жЭЯдєЛеРОпЉМжИСдїђе∞±йЬАи¶БзЭАйЗНиЃ≤иІ£зїЯдЄАжО•еП£ињЩдЄ™зЇ¶жЭЯдЇЖгАВеПѓдї•иѓіпЉМеЙНйЭҐзЪДеЫЫдЄ™зЇ¶жЭЯеЃЮйЩЕдЄКйГљиЊГдЄЇеЃєжШУиЊЊжИРгАВеФѓдЄАйЬАи¶Бж≥®жДПзЪДжЧ†йЭЮжШѓжШѓеР¶жЯРдЇЫжКАжЬѓеЃЮзО∞ињЭеПНдЇЖињЩдЇЫзЇ¶жЭЯгАВиАМзђђдЇФжЭ°зЇ¶жЭЯпЉМзїЯдЄАжО•еП£пЉМеПѓдї•иѓіжШѓRESTжЬНеК°иЃЊиЃ°зЪДж†ЄењГжЙАеЬ®пЉМдєЯжШѓеЖ≥еЃЪRESTжЬНеК°иЃЊиЃ°зЪДжИРиі•дєЛе§ДгАВеЬ®еЃЮзО∞дЄАдЄ™еЯЇдЇОHTTPзЪДRESTжЬНеК°жЧґпЉМиљѓдїґеЉАеПСдЇЇеСШдЄНдїЕдїЕйЬАи¶БиАГиЩСRESTжЙАиЃЊзљЃзЪДдЄАз≥їеИЧзЇ¶жЭЯпЉМжЫійЬАи¶БиАГиЩСHTTPеРДзїДжИРзЪДиѓ≠жДПпЉМHTTPзЫЄеЕ≥жКАжЬѓе¶ВдљХдЄОRESTжЬНеК°зЇ¶жЭЯзїУеРИпЉМе¶ВдљХдњЭжМБеЙНеРОеРСеЕЉеЃєжАІдї•еПКе¶ВдљХињЫи°МзЙИжЬђзЃ°зРЖз≠ЙйЧЃйҐШпЉМжЙНиГљзїЩеЗЇдЄАдЄ™иЗ™зДґзЪДпЉМеЕЈжЬЙиЊГйЂШжШУзФ®жАІеТМиЊГеЉЇзФЯеСљеКЫзЪДRESTз≥їзїЯгАВ
гААгААиАМеЬ®дїЛзїНзїЯдЄАжО•еП£зЇ¶жЭЯдєЛеЙНпЉМжИСдїђеИЩйЬАи¶БдЇЖиІ£дЄАдЄЛеТМRESTеѓЖеИЗзЫЄеЕ≥зЪДдЄ§дЄ™еРНиѓНпЉЪиµДжЇРеТМзКґжАБгАВеПѓдї•иѓіпЉМиµДжЇРжШѓRESTз≥їзїЯзЪДж†ЄењГж¶ВењµгАВжЙАжЬЙзЪДиЃЊиЃ°йГљдЉЪдї•иµДжЇРдЄЇдЄ≠ењГпЉМеМЕжЛђе¶ВдљХеѓєиµДжЇРињЫи°МжЈїеК†пЉМжЫіжЦ∞пЉМжЯ•жЙЊдї•еПКдњЃжФєз≠ЙгАВиАМиµДжЇРжЬђиЇЂеИЩжЛ•жЬЙдЄАз≥їеИЧзКґжАБгАВеЬ®жѓПжђ°еѓєиµДжЇРињЫи°МжЈїеК† пЉМеИ†йЩ§жИЦдњЃжФєзЪДжЧґеАЩпЉМиµДжЇРе∞±е∞ЖдїОдЄАдЄ™зКґжАБиљђзІїеИ∞еП¶е§ЦдЄАдЄ™зКґжАБгАВ
гААгААжѓФе¶ВиѓіпЉМеЬ®egoodsдЄ≠пЉМеХЖеУБзЪДеИЖз±їе∞±жШѓдЄАзІНиµДжЇРгАВиѓ•иµДжЇРжЬЙеЊИе§ЪеЃЮдЊЛпЉМеМЕжЛђи°®з§Їй£ЯеУБзЪДеИЖз±їпЉМеЕґжЙАеѓєеЇФзЪДURLжШѓвАЬ/api/categories/1вАЭгАВеРМж†ЈеЬ∞пЉМй£ЯеУБзЪДеУБзЙМдєЯжШѓдЄАзІНиµДжЇРгАВињЩдЇЫиµДжЇРзЪДеЃЮдЊЛйГљеѓєеЇФзЭАдЄАдЄ™ељУеЙНзЪДзКґжАБгАВеЬ®дњЃжФєдЇЖдЄАдЄ™иµДжЇРеЃЮдЊЛдєЛеРОпЉМжѓФе¶ВдњЃжФєдЇЖй£ЯеУБеИЖз±їдЄ≠зЪДзГ≠жРЬеЕ≥йФЃе≠ЧпЉМйВ£дєИеЕґе∞ЖеѓєеЇФзЭАдЄАдЄ™жЦ∞зЪДзКґжАБгАВињЩзІНзКґжАБдєЛйЧізЪДеПШеМЦ襀зІ∞дЄЇжШѓзКґжАБзЪДиљђзІїгАВ
гААгААеЬ®е§Іж¶ВдЇЖиІ£дЇЖRESTз≥їзїЯдЄ≠зЪДиµДжЇРеТМзКґжАБзЪДеЃЪдєЙеРОпЉМжИСдїђжЭ•зЬЛзЬЛзїЯдЄАжО•еП£ињЩдЄ™зЇ¶жЭЯгАВиѓ•зЇ¶жЭЯеПИеМЕеРЂдЇЖеЫЫдЄ™е≠РзЇ¶жЭЯпЉЪ
- жѓПдЄ™иµДжЇРйГљжЛ•жЬЙдЄАдЄ™иµДжЇРж†ЗиѓЖгАВжѓПдЄ™иµДжЇРзЪДиµДжЇРж†ЗиѓЖеПѓдї•зФ®жЭ•еФѓдЄАеЬ∞ж†ЗжШОиѓ•иµДжЇРгАВ
- жґИжБѓзЪДиЗ™жППињ∞жАІгАВеЬ®RESTз≥їзїЯдЄ≠жЙАдЉ†йАТзЪДжґИжБѓйЬАи¶БиГље§ЯжПРдЊЫиЗ™иЇЂе¶ВдљХ襀е§ДзРЖзЪДиґ≥е§Ядњ°жБѓгАВдЊЛе¶Виѓ•жґИжБѓжЙАдљњзФ®зЪДMIMEз±їеЮЛпЉМжШѓеР¶еσ俕襀зЉУе≠Шз≠ЙгАВ
- иµДжЇРзЪДиЗ™жППињ∞жАІгАВдЄАдЄ™RESTз≥їзїЯжЙАињФеЫЮзЪДиµДжЇРйЬАи¶БиГље§ЯжППињ∞иЗ™иЇЂпЉМеєґжПРдЊЫиґ≥е§ЯзЪДзФ®дЇОжУНдљЬиѓ•иµДжЇРзЪДдњ°жБѓпЉМе¶Ве¶ВдљХеѓєиµДжЇРињЫи°МжЈїеК†пЉМеИ†йЩ§дї•еПКдњЃжФєз≠ЙжУНдљЬгАВдєЯе∞±жШѓиѓіпЉМдЄАдЄ™еЕЄеЮЛзЪДRESTжЬНеК°дЄНйЬАи¶БйҐЭе§ЦзЪДжЦЗж°£еѓєе¶ВдљХжУНдљЬиµДжЇРињЫи°МиѓіжШОгАВ
- HATEOASгАВеН≥еЃҐжИЈеП™еПѓдї•йАЪињЗжЬНеК°зЂѓжЙАињФеЫЮеРДзїУжЮЬдЄ≠жЙАеМЕеРЂзЪДдњ°жБѓжЭ•еЊЧеИ∞дЄЛдЄАж≠•жУНдљЬжЙАйЬАи¶БзЪДдњ°жБѓпЉМе¶ВеИ∞еЇХжШѓеРСеУ™дЄ™URLеПСйАБиѓЈж±Вз≠ЙгАВдєЯе∞±жШѓиѓіпЉМдЄАдЄ™еЕЄеЮЛзЪДRESTжЬНеК°дЄНйЬАи¶БйҐЭе§ЦзЪДжЦЗж°£ж†Зз§ЇйАЪињЗеУ™дЇЫURLиЃњйЧЃзЙєеЃЪз±їеЮЛзЪДиµДжЇРпЉМиАМжШѓйАЪињЗжЬНеК°зЂѓињФеЫЮзЪДеУНеЇФжЭ•ж†Зз§ЇеИ∞еЇХиГљеЬ®иѓ•иµДжЇРдЄКжЙІи°МдїАдєИж†ЈзЪДжУНдљЬгАВдЄАдЄ™RESTжЬНеК°зЪДеЃҐжИЈзЂѓдєЯдЄНйЬАи¶БзЯ•йБУдїїдљХжЬЙеЕ≥еУ™йЗМжЬЙдїАдєИж†ЈзЪДиµДжЇРињЩзІНдњ°жБѓгАВ
гААгААзО∞еЬ®пЉМиЃ©жИСдїђдїНзДґдї•egoodsдљЬдЄЇз§ЇдЊЛжЭ•иІ£йЗКдЄАдЄЛдЄКйЭҐеЫЫдЄ™е≠РзЇ¶жЭЯгАВ
гААгААеЬ®еЙНйЭҐзЪДзЂ†иКВдЄ≠пЉМжИСдїђеЈ≤зїПзЬЛеИ∞дЇЖдїОegoodsжЙАињФеЫЮзЪДи°®з§Їй£ЯеУБињЩдЄ™еИЖз±їзЪДеУНеЇФпЉЪ
1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 {
6 "url" : "/api/categories/1",
7 "label" : "Food",
8 "items_url" : "/api/items?category=1",
9 "brands" : [
10 {
11 "label" : "еПЛиЗ£",
12 "brand_key" : "32073",
13 "url" : "/api/brands/32073"
14 }, {
15 "label" : "дєРдЇЛ",
16 "brand_key" : "56632",
17 "url" : "/api/brands/56632"
18 }
19 ...
20 ],
21 "hot_searches" : вА¶
22 }
гААгААй¶ЦеЕИжИСдїђзЬЛеИ∞зЪДжШѓпЉМиѓ•еУНеЇФйАЪињЗContent-TypeеУНеЇФе§іжЭ•ж†Зз§ЇеУНеЇФдЄ≠жЙАеМЕеРЂзЪДдњ°жБѓжШѓжМЙзЕІJSONж†ЉеЉПжЭ•зїДзїЗзЪДгАВеЬ®зЬЛеИ∞дЇЖиѓ•еУНеЇФе§ідЄ≠жЙАж†Зз§ЇзЪДж†ЉеЉПдєЛеРОпЉМжґИжБѓзЪДжО•жФґжЦєе∞±еПѓдї•жМЙзЕІJSONзЪДж†ЉеЉПзРЖиІ£жИЦеИЖжЮРиѓ•еУНеЇФдЄ≠зЪДиіЯиљљгАВињЩдєЯдЊњжШѓжґИжБѓзЪДиЗ™жППињ∞жАІгАВ
гААгААељУзДґпЉМжґИжБѓзЪДиЗ™жППињ∞жАІдЄНдїЕдїЕеМЕеРЂе¶ВдљХиІ£жЮРеЕґжЙАжРЇеЄ¶зЪДиіЯиљљгАВеЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTз≥їзїЯдЄ≠пЉМжИСдїђеПѓдї•йАЪињЗдљњзФ®е§ІйГ®еИЖHTTPж†ЗеЗЖжЙАжПРдЊЫзЪДеКЯиГљжЭ•жПРйЂШжґИжБѓзЪДиЗ™жППињ∞жАІгАВзФ±дЇОињЩдЇЫеКЯиГљеЈ≤зїПжЛ•жЬЙдЇЖеЃМе§ЗзЪДжЦЗж°£пЉМ襀府姲зЪДиљѓдїґеЉАеПСдЇЇеСШжЙАзЖЯзЯ•пЉМеєґеЊЧеИ∞дЇЖдЉЧе§ЪжµПиІИеЩ®еОВеХЖдї•еПКWebз±їеЇУзЪДжФѓжМБпЉМеЫ†ж≠§ж†єжНЃињЩдЇЫж†ЗеЗЖеЃЮзО∞RESTжЬНеК°еЕЈжЬЙиЊГйЂШзЪДжґИжБѓиЗ™жППињ∞жАІгАВдЄЊдЊЛжЭ•иѓіпЉМе¶ВжЮЬеЬ®иѓЈж±ВдЄ≠ж†ЗжШОдЇЖIf-Modified-Sinceе§іпЉМйВ£дєИжЬНеК°зЂѓе∞ЖеПѓиГљињФеЫЮдЄАдЄ™304 Not ModifiedеУНеЇФгАВеЬ®зЬЛеИ∞иѓ•еУНеЇФзЪДжЧґеАЩпЉМжµПиІИеЩ®жИЦеЕґеЃГжµПиІИеЈ•еЕЈеПѓдї•дїОзЉУе≠ШдЄ≠еПЦеЊЧдЄКдЄАжђ°еЊЧеИ∞зЪДзїУжЮЬгАВеЫ†ж≠§пЉМеЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTз≥їзїЯдЄ≠пЉМе¶ВдљХеЗЖз°ЃеЬ∞дљњзФ®HTTPеНПиЃЃжШѓдЄАй°єйЭЮеЄЄйЗНи¶БзЪДеЖЕеЃєгАВ
гААгААеЬ®иОЈзЯ•дЇЖе¶ВдљХеѓєеУНеЇФжЙАжРЇеЄ¶зЪДиіЯиљљињЫи°МиІ£жЮРдєЛеРОпЉМжИСдїђе∞±жЭ•зЬЛзЬЛиµДжЇРзЪДиЗ™жППињ∞жАІгАВеЬ®дЄКйЭҐзЪДз§ЇдЊЛдЄ≠пЉМжЬНеК°зЂѓеУНеЇФдљњзФ®дЇЖJSONи°®з§ЇдЇЖй£ЯеУБеИЖз±їгАВиѓ•и°®з§Їй¶ЦеЕИйАЪињЗlabelе±ЮжАІжППињ∞дЇЖиЗ™еЈ±жШѓдЄАдЄ™дїАдєИеИЖз±їгАВжО•дЄЛжЭ•пЉМеЕґйАЪињЗbrandsе±ЮжАІи°®з§ЇдЇЖиѓ•еИЖз±їдЄ≠зЪДиСЧеРНеУБзЙМпЉМеєґйАЪињЗhot_searchesж†Зз§ЇдЇЖеЬ®иѓ•еИЖз±їдЄ≠зЪДзГ≠жРЬеЕ≥йФЃе≠ЧгАВеПѓдї•зЬЛеИ∞пЉМиѓ•иіЯиљљдЄ≠зЪДжЙАжЬЙе±ЮжАІйГљжЄЕжЩ∞еЬ∞жППињ∞дЇЖиЗ™иЇЂжЙАи°®иЊЊзЪДеРЂдєЙгАВ
гААгААйВ£еЬ®иѓ•иµДжЇРи°®з§ЇдЄ≠зЪДurlе±ЮжАІжШѓдїАдєИжДПжАЭпЉЯеЃЮйЩЕдЄКињЩжШѓдЄЇе≠РзЇ¶жЭЯвАЬжѓПдЄ™иµДжЇРйГљжЛ•жЬЙдЄАдЄ™иµДжЇРж†ЗиѓЖвАЭжЙАжЈїеК†зЪДдЄАдЄ™е±ЮжАІгАВиѓ•е≠РзЇ¶жЭЯи¶Бж±ВжѓПдЄ™иµДжЇРзЪДиµДжЇРж†ЗиѓЖеПѓдї•зФ®жЭ•еФѓдЄАеЬ∞ж†ЗжШОиѓ•иµДжЇРгАВеѓєдЇОзљСзїЬеЇФзФ®жЭ•иѓіпЉМиµДжЇРж†ЗиѓЖе∞±жШѓURIгАВиАМеЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДз≥їзїЯдЄ≠пЉМжЬАиЗ™зДґзЪДиµДжЇРж†Зз§ЇдЊњжШѓURLгАВеЬ®и°®з§ЇеНХдЄ™иµДжЇРзЪДжЧґеАЩпЉМињЩдЄ™URLеЄЄеЄЄдЉЪеМЕеРЂзЭАиµДжЇРеЬ®иѓ•з±їиµДжЇРдЄ≠зЪДIDгАВ
гААгААеЬ®жЬђжЦЗзЪДеЕґеЃГзЂ†иКВдЄ≠пЉМжИСдїђе∞±е∞Ждї•ињЩзІНжЦєеЉПжЭ•еМЇеИЖURLеТМIDпЉЪURLзФ®жЭ•жМЗеРСиµДжЇРжЙАеЬ®зЪДеЬ∞еЭАпЉМиАМIDеИЩи°®з§Їиѓ•иµДжЇРеЬ®иѓ•з±їеЮЛиµДжЇРдЄ≠зЪДIDгАВиѓЈиѓїиАЕдЄАеЃЪи¶БиЃ∞еЊЧињЩдЄ§дЄ™жЬѓиѓ≠жЙАеѓєеЇФзЪДдЄНеРМжДПдєЙпЉМдї•йШ≤ж≠ҐзРЖиІ£йФЩиѓѓгАВ
гААгААзО∞еЬ®ињШжЬЙдЄАйГ®еИЖй£ЯеУБеИЖз±їи°®з§ЇдЄ≠зЪДе±ЮжАІж≤°жЬЙ襀иЃ≤иІ£пЉМйВ£е∞±жШѓеЬ®иѓ•и°®з§ЇдЄ≠зЪДеРДдЄ™URLгАВињЩжШѓдЄЇе≠РзЇ¶жЭЯHATEOASжЬНеК°зЪДгАВеЬ®зФ®жИЈзЬЛеИ∞items_urlе±ЮжАІжЧґпЉМеЕґе∞±еПѓдї•йАЪињЗеРСиѓ•URLеПСйАБGETжґИжБѓеЊЧеИ∞е±ЮдЇОй£ЯеУБеИЖз±їдЄ≠зЪДжЙАжЬЙеХЖеУБзЪДеИЧи°®гАВиАМеЬ®еХЖеУБеУБзЙМзЪДи°®з§ЇдЄ≠дєЯжЛ•жЬЙдЄАдЄ™urlе±ЮжАІгАВдєЯе∞±жШѓиѓіпЉМеРСиѓ•URLеПСйАБдЄАдЄ™GETиѓЈж±ВдєЯиГље§ЯеЊЧеИ∞зЫЄеЇФеУБзЙМзЪДиѓ¶зїЖдњ°жБѓгАВ
гААгААжВ®еПѓиГљдЉЪйЧЃпЉЪжЧҐзДґеЬ®дїЛзїНHATEOASжЧґиѓіRESTжЬНеК°еєґдЄНйЬАи¶БжЦЗж°£жЭ•еСКиѓЙзФ®жИЈеУ™йЗМжЛ•жЬЙдїАдєИж†ЈзЪДиµДжЇРпЉМйВ£зФ®жИЈеЇФиѓ•е¶ВдљХзЯ•йБУеРС/api/categoriesеПСйАБGETиѓЈж±Ве∞±иГљеЊЧеИ∞жЙАжЬЙзЪДеИЖз±їеСҐпЉЯж†ЗеЗЖзЪДеБЪж≥ХеИЩжШѓеРС/apiзЫіжО•еПСйАБдЄАдЄ™GETиѓЈж±ВпЉЪ
1 GET /api 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
гААгААиАМеЬ®ињФеЫЮзЪДеУНеЇФдЄ≠е∞Жж†Зз§ЇеЗЇREST APIзЪДзЙИжЬђдї•еПКжЙАжЬЙеПѓдї•иЃњйЧЃзЪДиµДжЇРз≠Йдњ°жБѓпЉЪ
1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 {
6 "version": "1.0",
7 "resources": [
8 {
9 "label" : "Categories",
10 "description" : "Product categories",
11 "uri": "/api/categories"
12 }, {
13 "label" : "Items",
14 "description" : "All items on sell",
15 "uri": "/api/items"
16 }
17 ]
18 }
гААгААеПѓдї•зЬЛеИ∞пЉМеЬ®иѓ•еУНеЇФдЄ≠еИЧеЗЇдЇЖеσ俕襀聜йЧЃзЪДдЄ§зІНиµДжЇРпЉЪи°®з§ЇеХЖеУБеИЖз±їзЪДCategoriesдї•еПКи°®з§ЇеХЖеУБзЪДItemsгАВеЬ®йЬАи¶БиЃњйЧЃзЙєеЃЪз±їеЮЛзЪДиµДжЇРжЧґпЉМиљѓдїґеЉАеПСдЇЇеСШеПѓдї•йАЪињЗзЫіжО•еРСињЩдЄ§зІНиµДжЇРжЙАеѓєеЇФзЪДURIеПСйАБGETиѓЈж±ВеН≥еПѓгАВ
гААгААOKпЉМзЫЄдњ°зО∞еЬ®иѓїиАЕеЈ≤зїПдЇЖиІ£дЇЖRESTжЬНеК°жЙАжПРдЊЫзЪДеРДзІНзЇ¶жЭЯгАВйВ£дєИеЬ®еРОйЭҐзЪДзЂ†иКВдЄ≠пЉМжИСдїђе∞ЖдЉЪйАРж≠•иЃ≤иІ£е¶ВдљХиЃЊиЃ°дЄАдЄ™еЯЇдЇОHTTPзЪДRESTжЬНеК°гАВ
 
иµДжЇРиѓЖеИЂ
гААгААеЬ®дЄАиИђжГЕеЖµдЄЛпЉМеѓєиµДжЇРзЪДиѓЖеИЂйАЪеЄЄйГљжШѓRESTжЬНеК°иЃЊиЃ°зЪДзђђдЄАж≠•гАВеЬ®еЗЖз°ЃеЬ∞иѓЖеИЂеЗЇдЇЖеРДиµДжЇРдєЛеРОпЉМжАОдєИзФ®HTTPиІДиМГдЄ≠зЪДеРДзїДжИРжЭ•и°®з§ЇињЩдЇЫиµДжЇРдЊњжШѓй°ЇзРЖжИРзЂ†зЪДдЇЛжГЕгАВеЬ®жЬђиКВдЄ≠пЉМжИСдїђе∞Жеѓєе¶ВдљХиѓЖеИЂRESTз≥їзїЯдЄ≠зЪДиµДжЇРињЫи°МиЃ≤иІ£гАВ
гААгААеЬ®йАЪеЄЄзЪДиљѓдїґеЉАеПСињЗз®ЛдЄ≠пЉМжИСдїђеЄЄеЄЄйЬАи¶БеИЖжЮРиЊЊжИРжЯРдЄ™зЫЃж†ЗжЙАйЬАи¶БдљњзФ®зЪДдЄЪеК°йАїиЊСпЉМеєґдЄЇдЄЪеК°йАїиЊСзЪДжЙІи°МжПРдЊЫдЄАз≥їеИЧињРи°МжО•еП£гАВеЬ®дЄАдЇЫWebжЬНеК°дЄ≠пЉМињЩдЇЫжО•еП£еЄЄеЄЄи°®иЊЊдЇЖжЯРдЄ™еК®дљЬпЉМе¶Ве∞ЖеХЖеУБжФЊеЕ•иі≠зЙ©иљ¶пЉМжПРдЇ§иЃҐеНХз≠ЙгАВињЩдЄАз≥їеИЧеК®дљЬзїДеРИеЬ®дЄАиµЈе∞±еПѓдї•зїДжИРеЃМжИРзЫЃж†ЗжЙАйЬАи¶БжЙІи°МзЪДдЄЪеК°йАїиЊСгАВеЬ®йЬАи¶Би∞ГзФ®ињЩдЇЫжО•еП£зЪДжЧґеАЩпЉМиљѓдїґеЉАеПСдЇЇеСШйЬАи¶БеРСињЩдЇЫжО•еП£жЙАеЬ®зЪДURLеПСйАБдЄАдЄ™иѓЈж±ВпЉМдїОиАМй©±дљњжЬНеК°жЙІи°Миѓ•еК®дљЬгАВ
гААгААиАМеЬ®RESTжЬНеК°дЄ≠пЉМжИСдїђжЙАжПРдЊЫзЪДеРДдЄ™жО•еП£еИЩйЬАи¶БжШѓдЄАз≥їеИЧиµДжЇРпЉМиАМдЄЪеК°йАїиЊСйЬАи¶БйАЪињЗеѓєиµДжЇРзЪДжУНдљЬжЭ•еЃМжИРгАВдєЯе∞±жШѓиѓіпЉМRESTжЬНеК°дЄ≠зЪДAPIе∞ЖдЄНеЖНдї•жЙІи°МдЇЖдїАдєИеК®дљЬдЄЇдЄ≠ењГпЉМиАМжШѓдї•иµДжЇРдЄЇдЄ≠ењГгАВдЄАдЇЫеѓєиµДжЇРзЪДйАЪзФ®жУНдљЬжЬЙжЈїеК†пЉМеПЦеЊЧпЉМдњЃжФєпЉМеИ†йЩ§пЉМдї•еПКеѓєзђ¶еРИзЙєеЃЪжЭ°дїґзЪДиµДжЇРињЫи°МеИЧи°®жУНдљЬгАВ
гААгААдїНзДґиЃ©жИСдїђдї•дЄКйЭҐжЙАдЄЊзЪДвАЬе∞ЖеХЖеУБжФЊеЕ•иі≠зЙ©иљ¶вАЭињЩдЄ™жУНдљЬдЄЇдЊЛгАВеЬ®дЄАдЄ™RESTз≥їзїЯдЄ≠пЉМиі≠зЙ©иљ¶е∞Ж襀жКљи±°дЄЇдЄАдЄ™иµДжЇРпЉМиАМвАЬе∞ЖеХЖеУБжФЊеЕ•иі≠зЙ©иљ¶вАЭињЩдЄ™жУНдљЬе∞ЖиҐЂиІ£йЗКдЄЇеѓєиі≠зЙ©иљ¶ињЩдЄ™иµДжЇРзЪДжЫіжЦ∞пЉЪжЫіжЦ∞иі≠зЙ©иљ¶пЉМдї•дљњзЙєеЃЪеХЖеУБеМЕеРЂеЬ®иі≠зЙ©иљ¶еЖЕгАВ
гААгААеПѓиГљеѓєдЇОеИЪеИЪе≠¶дє†RESTзЪДеРДдљНиѓїиАЕиАМи®АпЉМињЩзІНдї•иµДжЇРдЄЇдЄ≠ењГзЪДжППињ∞жЦєж≥ХжЬЙдЇЫеИЂжЙ≠гАВињЩзІНжППињ∞жЦєж≥ХзЪДз°ЃжЬЙеИЂдЇОеЊИе§ЪWebжЬНеК°йВ£ж†Јдї•еК®дљЬдЄЇдЄ≠ењГгАВиАМдЄОдєЛеѓєеЇФзЪДеИЩжШѓз≥їзїЯиЃЊиЃ°ж≠•й™§зЪДжФєеПШпЉЪжИСдїђе∞ЖдЄНеЖНй¶ЦеЕИжШѓеИЂеЃМжИРдЄЪеК°йАїиЊСжЙАйЬАзЪДеРДеК®дљЬпЉМиАМжШѓжФѓжМБдЄЪеК°йАїиЊСжЙАйЬАи¶БзЪДеРДиµДжЇРгАВйВ£дєИжИСдїђеЇФиѓ•е¶ВдљХжКљи±°еЗЇињЩдЇЫиµДжЇРеСҐпЉЯй¶ЦеЕИпЉМжИСдїђеѓєжЯРдЄ™жУНдљЬдЄНи¶БеЖНеЕ≥ж≥®еЃГжЙАжЙІи°МзЪДеК®дљЬпЉМиАМжШѓеЕ≥ењГеЃГжЙАжУНдљЬзЪДеЃЊиѓ≠гАВйАЪеЄЄжГЕеЖµдЄЛпЉМиѓ•еЃЊиѓ≠е∞±дЉЪжШѓRESTз≥їзїЯдЄ≠зЪДиµДжЇРгАВ
гААгААеЬ®ињЩйЗМпЉМжИСдїђе∞±дї•вАЬжПРдЇ§иЃҐеНХвАЭдљЬдЄЇз§ЇдЊЛжЭ•е±Хз§Їе¶ВдљХжКљи±°иµДжЇРгАВ
гААгААй¶ЦеЕИпЉМеЬ®вАЬжПРдЇ§иЃҐеНХвАЭињЩдЄ™еК®дљЬдЄ≠пЉМиЃҐеНХжШѓеЃЊиѓ≠гАВеЫ†ж≠§еѓєдЇОиѓ•дЄЪеК°йАїиЊСпЉМеЕґе∞ЖдљЬдЄЇдЄАдЄ™иµДжЇРе≠ШеЬ®гАВйЩ§ж≠§дєЛе§ЦпЉМеЬ®иЃҐеНХдЄ≠ињШйЬАи¶БеМЕеРЂдЄАз≥їеИЧдњ°жБѓпЉМдЊЛе¶ВиЃҐеНХдЄ≠жЙАеМЕеРЂзЪДеХЖеУБпЉМиЃҐеНХжЙАе±ЮдЇЇз≠ЙгАВдЄАжЧ¶ињЩдЇЫйГљеσ俕襀胕RESTз≥їзїЯдЄ≠зЪДеЕґеЃГиµДжЇРдљњзФ®пЉМйВ£дєИеЃГдїђдєЯе∞ЖжИРдЄЇзЛђзЂЛзЪДиµДжЇРгАВ
гААгААдљЖжШѓжЬЙжЧґеАЩпЉМдЄАдЄ™еК®дљЬеПѓиГљеєґдЄНе≠ШеЬ®зЭАеЃГжЙАжУНдљЬзЪДеЃЊиѓ≠гАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМжИСдїђе∞±йЬАи¶БиАГиЩСиѓ•еК®дљЬдЇІзФЯжИЦжґИйЩ§дЇЖеУ™дЄ™еЃЮдљУпЉМжИЦиАЕеУ™дЄ™еЃЮдљУзЪДзКґжАБеПСзФЯдЇЖеПШеМЦгАВињЩдЄ™еПСзФЯдЇЖеПШеМЦзЪДеЃЮдљУеЃЮйЩЕдЄКе∞±жШѓдЄАзІНиµДжЇРгАВдЊЛе¶ВеѓєдЇОзЩїйЩЖињЩдЄАи°МдЄЇпЉМеЕґеЃЮйЩЕдЄКеЬ®жЬНеК°зЂѓеИЫеїЇдЇЖдЄАдЄ™дЉЪиѓЭеЃЮдЊЛгАВиѓ•дЉЪиѓЭеЃЮдЊЛдЄ≠еИЩеМЕеРЂдЇЖзЩїйЩЖIPпЉМзЩїйЩЖжЧґйЧіпЉМдї•еПКзЩїйЩЖжЧґжЙАзФ®зЪДеЗ≠иѓБз≠ЙгАВеЖНжѓФе¶ВеѓєдЇОзФ®жИЈжЫіжФєеѓЖз†БињЩзІНи°МдЄЇпЉМеЕґжЙАжУНдљЬзЪДиµДжЇРе∞±жШѓзФ®жИЈиµДжЦЩгАВ
гААгААеЬ®жКљи±°иµДжЇРзЪДињЗз®ЛдЄ≠пЉМжИСдїђйЬАи¶БжМЙзЕІиЗ™й°ґеРСдЄЛзЪДжЦєеЉПпЉМеН≥й¶ЦеЕИиЊ®иѓЖеЗЇз≥їзїЯдЄ≠зЪДжЬАдЄїи¶БиµДжЇРпЉМзДґеРОеЖНиЊ®иѓЖињЩдЇЫдЄїи¶БиµДжЇРзЪДе≠РиµДжЇРпЉМеєґдЊЭжђ°ињЫи°Мињ≠дї£гАВ
гААгААеѓєдЄїиµДжЇРзЪДжКљеПЦдЄїи¶БйАЪињЗеИЖжЮРдЄЪеК°йАїиЊСжЭ•еЃМжИРгАВеЬ®еЊЧеИ∞еКЯиГљйЬАж±Вдї•еРОпЉМжИСдїђй¶ЦеЕИи¶БеИЖжЮРињЩдЇЫдЄЪеК°йАїиЊСжЙАжУНдљЬзЪДеЃЊиѓ≠гАВињЩдЇЫеЃЊиѓ≠еПѓиГљжЬЙдЄ§зІНжГЕеЖµпЉЪдЄїиµДжЇРжИЦиАЕеЕґеЃГиµДжЇРзЪДе≠РиµДжЇРгАВдЄїиµДжЇРеЃЮйЩЕдЄКе∞±жШѓиГље§ЯзЛђзЂЛе≠ШеЬ®зЪДдЄАз≥їеИЧиµДжЇРгАВиАМе≠РиµДжЇРеИЩйЬАи¶БдЊЭйЩДдЇОдЄїиµДжЇРдєЛдЄКжЙНиГљи°®иЊЊеЃЮйЩЕзЪДжДПдєЙгАВеРМжЧґеРДдЄ™е≠РиµДжЇРдєЯеПѓиГљжЛ•жЬЙиЗ™иЇЂзЪДе≠РиµДжЇРгАВ
гААгААеИ§жЦ≠дЄАдЄ™иµДжЇРжШѓеР¶жШѓе≠РиµДжЇРзЪДдЄАдЄ™жЦєж≥Хе∞±жШѓзЬЛеЃГжШѓеР¶иГљзЛђзЂЛеЬ∞и°®з§ЇеЕґеЕЈдљУеРЂдєЙгАВдЊЛе¶ВеѓєдЇОдЄАдЄ™egoodsдЄКжЙАйФАеФЃзЪДеХЖеУБпЉМеЕґеРНзІ∞пЉМдїЈж†ЉпЉМзЃАдїЛз≠Йе±ЮжАІеПѓдї•жЄЕжЩ∞еЬ∞жППињ∞иѓ•еХЖеУБеИ∞еЇХжШѓдїАдєИпЉМеИ∞еЇХе¶ВдљХйФАеФЃгАВеЫ†ж≠§ињЩдЇЫеХЖеУБеЃЮйЩЕдЄКжШѓдЄАдЄ™дЄїиµДжЇРгАВдљЖжШѓжѓПзІНеХЖеУБжЙАжФѓжМБзЪДйВЃйАТжЬНеК°йЬАи¶БжШѓдЄАдЄ™е≠РиµДжЇРпЉЪдЄАдЄ™еХЖеУБеПѓдї•жФѓжМБе§ЪзІНйВЃйАТжЬНеК°гАВињЩдЇЫйВЃйАТжЬНеК°ж†єжНЃжіЊйАБиЈЭз¶їз≠ЙйЬАи¶БдЄНеРМзЪДдїЈж†ЉпЉМдєЯжПРдЊЫдЇЖдЄНеРМзЪДйВЃйАТйАЯеЇ¶гАВзФ±дЇОињЩдЇЫйВЃйАТжЬНеК°дЄОеХЖеЃґеТМйВЃйАТжЬНеК°еЕђеПЄжЙАиЊЊжИРзЪДжЬНеК°дїЈж†ЉжЬЙеЕ≥пЉМеєґдЄФдЉЪзФ±дЇОеХЖеУБйЗНйЗПзЪДеПШеМЦиАМеПШеМЦпЉМеЫ†ж≠§ињЩдЇЫйВЃйАТжЬНеК°еєґдЄНиГљдЄЇеЕґеЃГеХЖеЃґжЙАжПРдЊЫзЪДйВЃйАТжЬНеК°дљЬдЄЇеПВиАГпЉМеЫ†ж≠§еЕґеЇФиѓ•дљЬдЄЇиѓ•еХЖеУБзЪДдЄАдЄ™е≠РиµДжЇРгАВ
гААгААжИЦиАЕдєЯеПѓдї•иѓіпЉМе¶ВжЮЬдЄАдЄ™иµДжЇРжШѓдЄїиµДжЇРпЉМйВ£дєИеЕґеσ俕襀дЄНеРМзЪДиµДжЇРеЃЮдЊЛеМЕеРЂеЉХзФ®иАМдЄНдЉЪдЇІзФЯж≠ІдєЙгАВиАМе¶ВжЮЬдЄАдЄ™иµДжЇРжШѓе≠РиµДжЇРпЉМйВ£дєИ襀дЄНеРМзЪДиµДжЇРеЃЮдЊЛеЉХзФ®еПѓиГљдЉЪдЇІзФЯж≠ІдєЙгАВ
гААгААдљЖжШѓйЬАи¶Бж≥®жДПзЪДжШѓпЉМдЄАзІНиµДжЇРеПѓиГљжЬЙе§ЪзІНдЄНеРМзЪДи°®зО∞嚥еЉПгАВдЊЛе¶ВеѓєдЇОеЬ®дљњзФ®еИЧи°®е±Хз§ЇеРДдЄ™еХЖеУБзЪДжЧґеАЩпЉМegoodsеП™йЬАи¶Бе±Хз§ЇеХЖеУБзЪДеРНзІ∞пЉМдЄАдЄ™еѓєиѓ•еХЖеУБзЪДзЃАеНХжППињ∞пЉМеХЖеУБзЪДдїЈж†Љдї•еПКдЄАеЉ†еХЖеУБзЪДзЕІзЙЗгАВиАМеЬ®зФ®жИЈжЙУеЉАдЇЖиѓ•еХЖеУБй°µдєЛеРОпЉМй°µйЭҐеИЩйЬАи¶БжШЊз§ЇжЫіиѓ¶е∞љзЪДдњ°жБѓпЉМе¶ВеХЖеУБзЪДйЗНйЗПпЉМеХЖеУБжЙАеЬ®еЬ∞з≠Йз≠ЙгАВ
гААгААйЩ§ж≠§дєЛе§ЦпЉМиµДжЇРеИЧи°®дєЯжЬЙеПѓиГљжЛ•жЬЙе§ЪзІНдЄНеРМзЪДи°®зО∞嚥еЉПгАВдЄЊдЊЛжЭ•иѓіпЉМе¶ВжЮЬegoodsдЄКе±ЮдЇОжЯРдЄ™еИЖз±їзЪДеХЖеУБ姙е§ЪпЉМйЬАи¶БеИЖй°µжШЊз§ЇпЉМйВ£дєИињЩзІНеИЖй°µжШѓеР¶дєЯеЇФиѓ•жШѓдЄАзІНиµДжЇРпЉЯз≠Фж°ИжШѓпЉМињЩдЇЫеИЖй°µеєґдЄНжШѓдЄАзІНиµДжЇРпЉМиАМеЕґеП™жШѓиµДжЇРеИЧи°®зЪДдЄАзІНи°®зО∞жЦєеЉПгАВеЬ®жѓПй°µжЙАеМЕеРЂеХЖеУБжХ∞йЗПпЉМжОТеЇПиІДеИЩз≠ЙжЭ°дїґеПСзФЯеПШеМЦзЪДжЧґеАЩпЉМиѓ•иµДжЇРеИЧи°®дЄ≠жЙАеМЕеРЂзЪДеРДдЄ™еХЖеУБдєЯдЉЪеПСзФЯеПШеМЦгАВ
гААгААйВ£дєИе¶ВдљХеИ§жЦ≠жИСдїђдЄЇRESTжЬНеК°жЙАеЃЪдєЙзЪДиµДжЇРжШѓеР¶еРИзРЖеСҐпЉЯдЄАиИђжГЕеЖµдЄЛпЉМжИСйГљдљњзФ®дЄЛйЭҐзЪДдЄАдЇЫеИ§жЦ≠жЦєж≥ХпЉЪ
гААгААй¶ЦеЕИпЉМжИСдїђйЬАи¶БиАГиЩСеѓєиѓ•иµДжЇРзЪДCRUDжШѓеР¶жЬЙжДПдєЙпЉМдїОиАМй™МиѓБиµДжЇРзЪДеЃЪдєЙжШѓеР¶еРИзРЖгАВе∞±дї•еИЪеИЪиѓіеИ∞зЪДеИЧи°®зЪДеИЖй°µжШЊз§ЇдЄЇдЊЛпЉМжИСдїђеПѓдї•жГ≥и±°дЄАдЄЛе¶ВдљХеѓєеИЖй°µињЫи°МжЈїеК†еТМеИ†йЩ§пЉЯдЄАжЧ¶еИ†йЩ§дЇЖиѓ•еИЖй°µпЉМйВ£дєИе±ЮдЇОиѓ•еИЖй°µдЄ≠зЪДеРДдЄ™еХЖеУБдєЯеЇФ胕襀еИ†йЩ§дєИпЉЯиАМдЄФеИ†йЩ§дЇЖеИЖй°µXзЪДжХ∞жНЃеРОпЉМеОЯжЬђX + 1еИЖй°µзЪДжХ∞жНЃе∞Же±Хз§ЇеЬ®XеИЖй°µдЄ≠гАВеЊИжШЊзДґпЉМе∞ЖеХЖеУБзЪДеИЖй°µеЃЪдєЙдЄЇиµДжЇРеєґдЄНеРИзРЖгАВ
гААгААеЕґжђ°пЉМжИСдїђйЬАи¶Бж£АжЯ•иµДжЇРжШѓеР¶йЬАи¶БйЩ§CRUDдєЛе§ЦзЪДеК®иѓНжЭ•жУНдљЬгАВиѓ•жЦєж≥ХзФ®жЭ•ж£АжЯ•иµДжЇРдЄ≠жШѓеР¶ињШжЬЙе≠РиµДжЇРж≤°жЬЙ襀жКљи±°гАВе¶ВжЮЬиѓ•иµДжЇРињШйЬАи¶БйҐЭе§ЦзЪДеК®иѓНпЉМйВ£дєИжИСдїђе∞±йЬАи¶БиАГиЩСињЩдЇЫжУНдљЬеИ∞еЇХеЉХиµЈдЇЖдїАдєИж†ЈзЪДзКґжАБеПШеМЦпЉМињЫиАМжКљи±°еЗЇиѓ•иµДжЇРзЪДе≠РиµДжЇРгАВ
гААгААйЩ§ж≠§дєЛе§ЦпЉМжИСдїђињШйЬАи¶Бж£АжЯ•ињЩдЇЫиµДжЇРжШѓеР¶ж؃襀жХідљУдљњзФ®пЉМеИЫеїЇеТМеИ†йЩ§гАВиѓ•жЦєж≥ХзФ®жЭ•жОҐжµЛжШѓеР¶дЄАдЄ™е≠РиµДжЇРеЇФиѓ•жШѓдЄАдЄ™дЄїиµДжЇРгАВе¶ВжЮЬеЬ®еИ†йЩ§дЄАдЄ™иµДжЇРзЪДжЧґеАЩпЉМеЕґе≠РиµДжЇРињШеσ俕襀еЕґеЃГиµДжЇРйЗНзФ®пЉМйВ£дєИиѓ•е≠РиµДжЇРеЃЮйЩЕдЄКеЕЈжЬЙиЊГйЂШзЪДйЗНзФ®жАІпЉМеЇФиѓ•жШѓдЄАдЄ™дЄїиµДжЇРгАВ
 
иµДжЇРзЪДURLиЃЊиЃ°
гААгААеЬ®еЙНйЭҐеЈ≤зїПжПРеИ∞ињЗпЉМзїЯдЄАжО•еП£зЇ¶жЭЯдЄ≠зЪДзђђдЄАжЭ°е≠РзЇ¶жЭЯе∞±жШѓжѓПдЄ™иµДжЇРйГљжЛ•жЬЙдЄАдЄ™иµДжЇРж†ЗиѓЖгАВеЬ®ж≠£з°ЃеЬ∞иЊ®иѓЖеЗЇдЇЖдЄАдЄ™иµДжЇРдєЛеРОпЉМжИСдїђе∞±йЬАи¶БдЄЇињЩдЇЫиµДжЇРеИЖйЕНеЕґжЙАеѓєеЇФзЪДURIгАВдЄАдЄ™иµДжЇРжЙАеѓєеЇФзЪДURIеПѓиГљжЬЙе§ЪзІНи°®з§ЇжЦєеЉПпЉМе¶ВеИ∞еЇХжШѓзФ®еНХжХ∞ињШжШѓе§НжХ∞и°®з§ЇиµДжЇРз≠ЙгАВеЫ†ж≠§еЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTз≥їзїЯдЄ≠пЉМе¶ВдљХзїДзїЗйТИеѓєеРДдЄ™иµДжЇРзЪДURLеЃЮйЩЕдЄКжШѓжЬАйЗНи¶БзЪДдЄАйГ®еИЖгАВжѓХзЂЯдЄАдЄ™жШОз°ЃзЪДпЉМжЬЙжДПдєЙеєґдЄФз®≥еЃЪзЪДAPIжО•еП£еЃЮйЩЕдЄКжШѓеѓєжЬНеК°еѓєзФ®жИЈзЪДдЄАзІНжЙњиѓЇгАВ
гААгААеЬ®HTTPдЄ≠пЉМдЄАдЄ™URLдЄїи¶БзФ±дї•дЄЛеЗ†дЄ™йГ®еИЖзїДжИРпЉЪ
- еНПиЃЃгАВеН≥HTTPдї•еПКHTTPSгАВ
- дЄїжЬЇеРНеТМзЂѓеП£гАВе¶Вwww.egoods.com:8421
- иµДжЇРзЪДзЫЄеѓєиЈѓеЊДгАВе¶В/api/categoriesгАВ
- иѓЈж±ВеПВжХ∞гАВеН≥зФ±йЧЃеПЈеЉАеІЛзЪДзФ±йФЃеАЉеѓєзїДжИРзЪДе≠Чзђ¶дЄ≤пЉЪ?page=1&page_size=20
гААгААеЬ®дЄЇдЄАдЄ™иµДжЇРиЃЊиЃ°еЕґжЙАеѓєеЇФзЪДURLжЧґпЉМжИСдїђйЬАи¶БзЭАйЗНиАГиЩСзђђдЄЙйГ®еИЖеТМзђђеЫЫйГ®еИЖзїДжИРгАВ
 
йАЪињЗURLжЭ•и°®з§ЇиµДжЇР
гААгААеЬ®иЊ®иѓЖеЗЇдЇЖRESTз≥їзїЯдЄ≠зЪДеРДдЄ™иµДжЇРдї•еРОпЉМжИСдїђе∞±йЬАи¶БеЉАеІЛдЄЇињЩдЇЫиµДжЇРиЃЊиЃ°еРДиЗ™жЙАеѓєеЇФзЪДURLдЇЖгАВ
гААгААй¶ЦеЕИи¶БдїЛзїНзЪДжШѓпЉМжЙАжЬЙзЪДиµДжЇРйГљеЇФиѓ•е≠ШеЬ®дЇОдЄАдЄ™зЫЄеѓєиЈѓеЊДдєЛдЄЛгАВиѓЈиѓїиАЕеЫЮењЖдєЛеЙНжИСдїђдїЛзїНзЪДйАЪињЗеРС/apiеПСйАБдЄАдЄ™GETиѓЈж±ВеЊЧеИ∞жЙАжЬЙеσ俕襀聜йЧЃзЪДиµДжЇРињЩдЄ™з§ЇдЊЛпЉЪ
1 GET /api
2 Host: www.egoods.com
3 Authorization: Basic xxxxxxxxxxxxxxxxxxx
4 Accept: application/json
5
6 HTTP/1.1 200 OK
7 Content-Type: application/json
8 Content-Length: xxx
9
10 {
11 "version": "1.0",
12 "resources": [
13 {
14 "label" : "Categories",
15 "description" : "Product categories",
16 "uri": "/api/categories"
17 }, {
18 "label" : "Items",
19 "description" : "All items on sell",
20 "uri": "/api/items"
21 }
22 ]
23 }
гААгААеЫ†ж≠§еѓєдЇОдїОеРСиѓ•зЫЄеѓєиЈѓеЊДеПСйАБиѓЈж±ВжЙНиГљеЊЧеИ∞зЪДеРДдЄ™дЄїиµДжЇРжЭ•иѓіпЉМе∞ЖеЃГдїђзљЃдЇОзЫЄеѓєиЈѓеЊД/apiдєЛдЄЛжШѓйЭЮеЄЄеРИзРЖзЪДгАВ
гААгААйЩ§дЇЖињЩдЄ™еОЯеЫ†дєЛе§ЦпЉМAPIзЪДзЙИжЬђжЫіињ≠дєЯжШѓдЄАдЄ™иАГиЩСгАВеБЗе¶ВиљѓдїґеЉАеПСдЇЇеСШйЬАи¶БеЉАеПСдЄАдЄ™жЦ∞зЙИжЬђзЪДREST APIпЉМйВ£дєИдїЦеПѓиГље∞±йЬАи¶БйЗНжЦ∞жКљи±°еєґеЃЪдєЙз≥їзїЯдЄ≠зЪДеРДдЄ™иµДжЇРгАВдљЖжШѓе¶ВжЮЬдЄ§дЄ™зЙИжЬђзЪДAPIдЄ≠йГљжЛ•жЬЙдЄАдЄ™categoriesиµДжЇРпЉМеєґдЄФз≥їзїЯдЄЇдЇЖдњЭжМБеРОеРСеЕЉеЃєжАІеРМжЧґдњЭзХЩдЇЖдЄ§дЄ™зЙИжЬђзЪДAPIпЉМйВ£дєИе∞ЖеП™жЬЙдЄАдЄ™иµДжЇРеПѓдї•дљњзФ®/categoriesињЩдЄ™зЫЄеѓєиЈѓеЊДгАВдєЯж≠£еЫ†дЄЇе¶Вж≠§пЉМе∞ЖињЩдЇЫиµДжЇРзљЃдЇОзЫЄеѓєиЈѓеЊД/apiдєЛдЄЛпЉМеєґеЬ®зђђдЇМдЄ™зЙИжЬђзЪДAPIеЗЇзО∞дєЛеРОе∞ЖжЦ∞зЪДиµДжЇРжКљи±°зљЃдЇО/api-v2дЄЛжШѓдЄАзІНиЊГдЄЇжµБи°МзЪДеБЪж≥ХгАВ
гААгААеЬ®жШОз°ЃдЇЖжЙАжЬЙзЪДиµДжЇРйГљеЇФиѓ•зљЃдЇО/apiињЩж†ЈдЄАдЄ™зЫЄеѓєиЈѓеЊДдЄЛдєЛеРОпЉМжИСдїђе∞±жЭ•иЃ≤иІ£е¶ВдљХдЄЇиµДжЇРеЃЪдєЙеѓєеЇФзЪДURLгАВдЄАдЄ™жЬАзЃАеНХзЪДжГЕеЖµжШѓпЉЪжМЗеЃЪдЄїиµДжЇРжЙАеѓєеЇФзЪДURLгАВзФ±дЇОдЄїиµДжЇРжШѓдЄАз±їзЛђзЂЛзЪДиµДжЇРпЉМеЫ†ж≠§еЃГеЇФиѓ•зЫіжО•зљЃдЇО/apiдЄЛгАВдЊЛе¶ВegoodsзљСзЂЩдЄ≠зЪДдЇІеУБеИЖз±їе∞±жШѓдЄАдЄ™дЄїиµДжЇРпЉМжИСдїђдЉЪдЄЇеЕґеИЖйЕНе¶ВдЄЛURLпЉЪ
1 /api/categories
гААгААиАМеѓєдЇОеЕґеЃГдЄїиµДжЇРпЉМе¶ВegoodsзљСзЂЩдЄ≠зЪДдЇІеУБпЉМжИСдїђдєЯдЉЪдЄЇеЕґиµЛдЇИдЄАдЄ™еЕЈжЬЙз±їдЉЉзїУжЮДзЪДURLпЉЪ
1 /api/items
гААгААињЩж†ЈпЉМжѓПз±їдЄїиµДжЇРйГље∞ЖжЛ•жЬЙдЄАдЄ™зЙєеЃЪдЇОиѓ•з±їиµДжЇРзЪДURLгАВињЩдЇЫURLе∞±еѓєеЇФзЭАзЫЄеЇФиµДжЇРеЃЮдЊЛзЪДйЫЖеРИгАВ
гААгААе¶ВжЮЬйЬАи¶Би°®з§ЇжЯРдЄ™дЄїиµДжЇРз±їеЮЛдЄ≠зЪДзЙєеЃЪеЃЮдЊЛпЉМйВ£дєИжИСдїђе∞±йЬАи¶БеЬ®иѓ•з±їдЄїиµДжЇРжЙАеѓєеЇФзЪДURLдєЛеРОжЈїеК†иѓ•еЃЮдЊЛзЪДIDгАВе¶ВegoodsзљСзЂЩдЄ≠зЪДй£ЯеУБеИЖз±їзЪДIDдЄЇ1пЉМйВ£дєИеЕґжЙАеѓєеЇФзЪДURLе∞±е∞ЖжШѓпЉЪ
1 /api/categories/1
гААгААдЄАдЄ™иЊГдЄЇзЙєжЃКзЪДжГЕеЖµеИЩжШѓпЉМеѓєдЇОжЯРзІНз±їеЮЛзЪДдЄїиµДжЇРпЉМжХідЄ™з≥їзїЯе∞ЖжЬЙдЄФдїЕжЬЙдЄАдЄ™иѓ•з±їеЮЛиµДжЇРзЪДеЃЮдЊЛгАВйВ£дєИиѓ•иµДжЇРе∞ЖдЄНеЖНйЬАи¶БйАЪињЗIDжЭ•иЃњйЧЃгАВжИСиГљжГ≥еИ∞зЪДдЄАдЄ™дЊЛе≠Ре∞±жШѓеѓєжХідЄ™з≥їзїЯињЫи°МдїЛзїНзЪДиµДжЇРгАВиѓ•иµДжЇРеЃЮдЊЛжЙАеѓєеЇФзЪДURLе∞ЖжШѓпЉЪ
1 /api/about
гААгААиАМдЄАдЄ™иµДжЇРеЃЮдЊЛдЄ≠ињШеПѓиГљжЛ•жЬЙе≠РиµДжЇРгАВињЩдЇЫе≠РиµДжЇРдЄОиµДжЇРеЃЮдЊЛдєЛйЧізЪДеЕ≥з≥їдЄїи¶БжЬЙдЄ§зІНжГЕеЖµпЉЪиµДжЇРеЃЮдЊЛеМЕеРЂдЇЖдЄАдЄ™е≠РиµДжЇРзЪДйЫЖеРИпЉМдї•еПКиµДжЇРеЃЮдЊЛдїЕдїЕеПѓдї•еМЕеРЂдЄАдЄ™е≠РиµДжЇРгАВеѓєдЇОиµДжЇРеЃЮдЊЛеМЕеРЂдЇЖдЄАдЄ™е≠РиµДжЇРйЫЖеРИзЪДжГЕеЖµпЉМжИСдїђйЬАи¶Бе∞Жиѓ•е≠РиµДжЇРйЫЖеРИзЪДURLзљЃдЇОиѓ•иµДжЇРзЪДзЫЄеѓєиЈѓеЊДдЄЛгАВдЊЛе¶ВеѓєдЇОegoodsдЄКжЙАйФАеФЃзЪДIDдЄЇ23456зЪДеХЖеУБжЙАжПРдЊЫзЪДйВЃйАТжЬНеК°пЉМжИСдїђе∞ЖдљњзФ®е¶ВдЄЛзЪДURLпЉЪ
1 /api/items/23456/shipments
гААгААеЬ®иѓ•URIдЄ≠пЉМ/api/items/23456еѓєеЇФзЪДе∞±жШѓеХЖеУБжЬђиЇЂпЉМиАМиѓ•еХЖеУБжЙАжПРдЊЫзЪДйВЃйАТжЬНеК°еИЩжШѓиѓ•еХЖеУБзЪДе≠РиµДжЇРгАВдЄОдЄїиµДжЇРзЙєеЃЪеЃЮдЊЛжЙАеЕЈжЬЙзЪДURIз±їдЉЉпЉМеЕґдЄ≠дЄАдЄ™IDдЄЇ87256зЪДйВЃйАТжЬНеК°жЙАеѓєеЇФзЪДURIеИЩдЄЇпЉЪ
1 /api/items/23456/shipments/87256
гААгААе¶ВжЮЬиµДжЇРеЃЮдЊЛдїЕдїЕеПѓдї•еМЕеРЂдЄАдЄ™е≠РиµДжЇРпЉМйВ£дєИеѓєиѓ•е≠РиµДжЇРзЪДиЃњйЧЃдєЯе∞ЖдЄНеЖНйЬАи¶БIDгАВе¶ВељУеЙНеХЖеУБзЪДжКШжЙ£дњ°жБѓпЉЪ
1 /api/items/23456/discount
 
еНХжХ∞¬†vs. е§НжХ∞
гААгААжО•дЄЛжЭ•и¶БиАГиЩСзЪДдЄАзВєжШѓпЉМиµДжЇРеЬ®URLдЄ≠йЬАи¶БзФ±еНХжХ∞и°®з§ЇињШжШѓе§НжХ∞и°®з§ЇпЉЯињЩеЬ®stackoverflowз≠ЙдЉЧе§ЪиЃЇеЭЫдЄКеЈ≤зїПжИРдЄЇдЇЖдЄАдЄ™зїПдєЕдЄНи°∞зЪДиѓЭйҐШгАВжИСдїђзЯ•йБУпЉМеЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTз≥їзїЯдЄ≠пЉМдЄАдЄ™иµДжЇРжЙАеѓєеЇФзЪДURLеЃЮйЩЕдЄКдєЯе∞±жШѓеѓєеЕґињЫи°МжУНдљЬзЪДURLгАВеЫ†ж≠§йАВељУеЬ∞дљњзФ®еНХжХ∞еТМе§НжХ∞еѓєдЇОиѓ•з≥їзїЯзЪДзФ®жИЈиАМи®АжЬЙдЄАеЃЪзЪДжМЗз§ЇдљЬзФ®гАВеЬ®stackoverflowдЄКзЪДдЄАдЄ™еЄЄиІБиІВзВєжШѓпЉЪе¶ВжЮЬдЄАдЄ™URLжЙАеѓєеЇФзЪДиµДжЇРжШѓдљњзФ®е§НжХ∞и°®з§ЇзЪДпЉМйВ£дєИиѓ•з±їеЮЛзЪДиµДжЇРеПѓиГљжЬЙе§ЪдЄ™гАВеѓєиѓ•URLеПСйАБGetиѓЈж±ВеПѓиГљињФеЫЮиѓ•иµДжЇРзЪДдЄАдЄ™еИЧи°®гАВеПНдєЛпЉМе¶ВжЮЬдЄАдЄ™URLжЙАеѓєеЇФзЪДиµДжЇРжШѓдљњзФ®еНХжХ∞и°®з§ЇзЪДпЉМйВ£дєИиѓ•з±їеЮЛзЪДиµДжЇРе∞ЖеП™жЬЙдЄАдЄ™пЉМеЫ†ж≠§еѓєиѓ•URLеПСйАБGetиѓЈж±Ве∞ЖеП™ињФеЫЮиѓ•иµДжЇРзЪДдЄАдЄ™еЃЮдЊЛгАВ
гААгААдї•egoodsдЄ≠зЪДеХЖеУБеИЖз±їдЄЇдЊЛгАВзФ±дЇОдЄАдЄ™зљСзЂЩжЙАеФЃеНЦзЪДеХЖеУБеПѓиГљжЬЙе§ЪзІНз±їеИЂпЉМеЫ†ж≠§еЕґйЬАи¶БеЬ®URLдЄ≠дљњзФ®е§НжХ∞嚥еЉПпЉЪ/api/categoriesгАВиАМеѓєдЇОдЄАдЄ™иѓ•зљСзЂЩзЪДзФ®жИЈиАМи®АпЉМзФ±дЇОеЕґеП™дЉЪжЬЙдЄАдЄ™дЄ™дЇЇеБПе•љиЃЊзљЃпЉМеЫ†ж≠§еЕґURLеИЩйЬАи¶БдљњзФ®еНХжХ∞嚥еЉПпЉЪ/api/users/{user_id}/preferenceгАВ
гААгААдљ†еПѓиГљдЉЪйЧЃпЉЪе¶ВжЮЬйЬАи¶БеЊЧеИ∞еЕЈжЬЙзЙєеЃЪIDзЪДжЯРдЄ™еЃЮдЊЛжЧґпЉМжИСдїђеЇФиѓ•еѓєиѓ•иµДжЇРдљњзФ®еНХжХ∞ињШжШѓе§НжХ∞еСҐпЉЯз≠Фж°ИжШѓе§НжХ∞гАВињЩжШѓеЫ†дЄЇеЬ®йАЪињЗзЙєеЃЪIDиЃњйЧЃжЯРдЄ™иµДжЇРзЪДеЃЮдЊЛеЃЮйЩЕдЄКе∞±жШѓдїОиѓ•иµДжЇРзЪДйЫЖеРИдЄ≠еПЦеЗЇзЙєеЃЪеЃЮдЊЛгАВеЫ†ж≠§и°®з§Їиѓ•иµДжЇРйЫЖеРИзЪДURLеЃЮйЩЕдЄКдїНзДґйЬАи¶БдљњзФ®е§НжХ∞嚥еЉПпЉМиАМеЕґеРОжЙАдљњзФ®зЪДIDеИЩж†ЗжШОдЇЖеЕґжЙАиЃњйЧЃзЪДжШѓиµДжЇРдЄ≠зЪДеНХдЄАеЃЮдЊЛпЉМеЫ†ж≠§еРСињЩдЄ™URLеПСйАБGetиѓЈж±Ве∞ЖињФеЫЮиѓ•иµДжЇРзЪДеНХдЄАеЃЮдЊЛгАВ
гААгААе∞±дї•вАЬй£ЯеУБвАЭеИЖз±їдЄЇдЊЛгАВиѓ•еИЖз±їжЙАеѓєеЇФзЪДURLдЄЇ/api/categories/1гАВиѓ•URLдЄ≠зЪДеЙНеНКйГ®еИЖ/api/categoriesи°®з§ЇegoodsзљСзЂЩдЄ≠жЙАжЬЙеИЖз±їзЪДйЫЖеРИпЉМиАМ1еИЩи°®з§ЇеЬ®иѓ•еИЖз±їйЫЖеРИдЄ≠зЪДIDдЄЇ1зЪДеИЖз±їгАВ
 
зЫЄеѓєиЈѓеЊД vs. иѓЈж±ВеПВжХ∞
гААгААеП¶дЄАдЄ™зїПеЄЄеѓЉиЗізЦСжГСзЪДеЬ∞жЦєе∞±жШѓйТИеѓєиµДжЇРзЪДжЯРдЄАзІНзЙєеЊБпЉМжИСдїђеИ∞еЇХжШѓе∞ЖеЕґеЃЪдєЙдЄЇURLдЄ≠зЫЄеѓєиЈѓеЊДзЪДдЄАйГ®еИЖињШжШѓдљЬдЄЇиѓЈж±ВеПВжХ∞гАВ
гААгААиѓЈиАГиЩСдЄЛйЭҐдЄАдЄ™дЊЛе≠РгАВеЬ®egoodsзљСзЂЩдЄ≠пЉМжИСдїђеФЃеНЦзЪДжЙЛжЬЇдЄїи¶БжЬЙиЛєжЮЬпЉМдЄЙжШЯз≠ЙеУБзЙМгАВйВ£дєИеЬ®дЄЇињЩдЇЫжЙЛжЬЇиЃЊиЃ°URLзЪДжЧґеАЩпЉМжИСдїђжШѓеР¶йЬАи¶БжМЙзЕІеУБзЙМеѓєињЩдЇЫжЙЛжЬЇињЫи°МзїЖеИЖпЉМдїОиАМзФ®жИЈеП™и¶БйАЪињЗеРС/api/mobiles/brands/appleеПСйАБиѓЈж±Ве∞±иГљеИЧеЗЇжЙАжЬЙзЪДиЛєжЮЬжЙЛжЬЇпЉЯињШжШѓиѓіпЉМзЫіжО•е∞ЖжЙЛжЬЇзЪДеУБзЙМзљЃдЇОиѓЈж±ВеПВжХ∞дЄ≠пЉМдїОиАМйАЪињЗ/api/mobiles?brand=appleжЭ•еИЧеЗЇжЙАжЬЙзЪДиЛєжЮЬжЙЛжЬЇпЉЯ
гААгААеЬ®еИ§жЦ≠еИ∞еЇХжШѓдљњзФ®иѓЈж±ВеПВжХ∞ињШжШѓзЫЄеѓєиЈѓеЊДжЧґпЉМжИСдїђдЄАиИђеИЖдЄЇдЄЛйЭҐеЗ†ж≠•гАВ
гААгААй¶ЦеЕИпЉМеПѓйАЙеПВжХ∞дЄАиИђйГљеЇФзљЃдЇОиѓЈж±ВеПВжХ∞дЄ≠гАВдїНдї•egoodsдЄ≠зЪДжЙЛжЬЇдЄЇдЊЛгАВеЬ®йАЙжЛ©жЙЛжЬЇжЧґпЉМзФ®жИЈеПѓдї•йАЙжЛ©еУБзЙМдї•еПКйҐЬиЙ≤гАВе¶ВжЮЬе∞ЖеУБзЙМеТМйҐЬиЙ≤йГљеЃЪдєЙеЬ®зЫЄеѓєURLдЄ≠пЉМйВ£дєИеЕЈжЬЙзЙєеЃЪеУБзЙМеТМйҐЬиЙ≤зЪДжЙЛжЬЇе∞ЖеПѓдї•йАЪињЗдЄ§дЄ™дЄНеРМзЪДURLиЃњйЧЃпЉЪ/api/mobiles/brand/{brand}/color/{color}дї•еПК/api/mobiles/color/{color}/brand/{brand}гАВе∞±зФ®жИЈиАМи®АпЉМеЕґеєґжЧ†ж≥ХдЇЖиІ£ињЩдЄ§дЄ™URLжЙАи°®з§ЇзЪДжШѓеРМдЄАз±їиµДжЇРињШжШѓдЄНеРМз±їеЮЛзЪДиµДжЇРгАВељУзДґпЉМжВ®еПѓдї•иѓіпЉМжИСдїђеП™зФ®/api/mobiles/brand/{brand}/color/{color}гАВдљЖжШѓиѓ•URLе∞ЖжЧ†ж≥Хе§ДзРЖзФ®жИЈдїЕдїЕйАЙжЛ©дЇЖйҐЬиЙ≤пЉМеНіж≤°жЬЙйАЙжЛ©еУБзЙМзЪДжГЕеЖµгАВ
гААгААеЕґжђ°пЉМдЄНжШѓжЙАжЬЙе≠Чзђ¶йГљеПѓдї•еЬ®URLдЄ≠襀䚜зФ®пЉМе¶Вж±Йе≠ЧпЉМж†ЗзВєгАВдЄЇдЇЖе§ДзРЖињЩзІНжГЕеЖµпЉМеМЕеРЂињЩдЇЫе≠Чзђ¶зЪДз≠ЫйАЙжЭ°дїґйЬАи¶БзљЃдЇОиѓЈж±ВеПВжХ∞дЄ≠гАВ
гААгААжЬАеРОпЉМе¶ВжЮЬиѓ•зЙєеЊБдЄЛеМЕеРЂе≠РиµДжЇРпЉМйВ£дєИеЃГиЗ™иЇЂдєЯе∞±жШѓдЄАдЄ™иµДжЇРпЉМеЫ†ж≠§йЬАи¶Бдї•зЫЄеѓєиЈѓеЊДзЪДжЦєеЉПе±ХзО∞еЃГгАВдЊЛе¶ВеЬ®egoodsзљСзЂЩдЄ≠пЉМжѓПдїґеХЖеУБжЙАе±ЮдЇОзЪДеИЖз±їдїЕдїЕжШѓеЃГзЪДдЄАдЄ™зЙєеЊБгАВдљЖжШѓдЄАдЄ™еИЖз±їжЫіеМЕеРЂдЇЖе±ЮдЇОеЃГзЪДеРДдЄ™еУБзЙМдї•еПКзГ≠жРЬеЕ≥йФЃе≠Чз≠ЙдЉЧе§Ъдњ°жБѓгАВеЫ†ж≠§еЃГеЕґеЃЮжШѓдЄАдЄ™иµДжЇРпЉМйЬАи¶БеЬ®URIиЈѓеЊДдЄ≠и°®з§ЇеЃГгАВ
гААгААжАїзЪДжЭ•иѓіпЉМжЧҐзДґдљњзФ®HTTPжЭ•жЮДеїЇRESTз≥їзїЯпЉМйВ£дєИжИСдїђе∞±йЬАи¶БйБµеЃИURLеРДзїДжИРдЄ≠зЪДеРЂдєЙпЉЪURLдЄ≠зЪДзЫЄеѓєиЈѓеЊДе∞ЖзФ®жЭ•ж†Зз§ЇвАЬWhat I wantвАЭпЉМдєЯжЧҐеѓєеЇФзЭАиµДжЇРпЉЫиАМиѓЈж±ВеПВжХ∞еИЩзФ®жЭ•ж†Зз§ЇвАЬHow I wantвАЭпЉМеН≥жЯ•зЬЛиµДжЇРзЪДжЦєеЉПгАВ
 
дљњзФ®еРИйАВзЪДеК®иѓН
гААгААеЬ®зЯ•йБУдЇЖе¶ВдљХдЄЇжѓПзІНиµДжЇРеЃЪдєЙURIдєЛеРОпЉМжИСдїђжЭ•зЬЛзЬЛе¶ВдљХжУНдљЬињЩдЇЫиµДжЇРгАВ
гААгААй¶ЦеЕИпЉМеЬ®дЄАдЄ™иµДжЇРзЪДзФЯеСљеС®жЬЯдєЛеЖЕеЄЄеЄЄдЉЪеПСзФЯдЄАз≥їеИЧйАЪзФ®дЇЛдїґпЉИCRUDпЉЙгАВдЄАеЉАеІЛпЉМдЄАдЄ™иµДжЇРеєґдЄНе≠ШеЬ®гАВеП™жЬЙзФ®жИЈжИЦRESTжЬНеК°еИЫеїЇдЇЖиѓ•иµДжЇРдї•еРОеЕґжЙНе≠ШеЬ®пЉМдєЯеН≥жШѓдЄКйЭҐжЙАеИЧеЗЇзЪДйАЪзФ®дЇЛдїґдЄ≠зЪДCпЉМCreateгАВеЬ®дЄАдЄ™иµДжЇРеИЫеїЇеЃМжѓХдї•еРОпЉМзФ®жИЈеПѓиГљдЉЪдїОжЬНеК°зЂѓиѓЈж±Виѓ•иµДжЇРзЪДи°®з§ЇпЉМдєЯе∞±жШѓдЄКйЭҐжЙАеИЧеЗЇзЪДйАЪзФ®дЇЛдїґзЪДRпЉМRetrieveгАВеЬ®зЙєеЃЪжГЕеЖµдЄЛпЉМзФ®жИЈеПѓиГљеЖ≥еЃЪи¶БжЫіжЦ∞иѓ•иµДжЇРпЉМеЫ†ж≠§дЉЪдљњзФ®дЄКйЭҐзЪДйАЪзФ®дЇЛдїґдЄ≠зЪДUпЉМеН≥UpdateжЭ•жЫіжЦ∞иµДжЇРгАВиАМеЬ®иµДжЇРдЄНеЖНйЬАи¶БзЪДжЧґеАЩпЉМзФ®жИЈеПѓиГљйЬАи¶БйАЪињЗйАЪзФ®дЇЛдїґDпЉМеН≥DeleteжЭ•еИ†йЩ§иѓ•иµДжЇРгАВеРМжЧґзФ®жИЈжЬЙжЧґдєЯйЬАи¶БеИЧеЗЇе±ЮдЇОзЙєеЃЪз±їеЮЛиµДжЇРзЪДиµДжЇРеЃЮдЊЛпЉМеН≥йАЪињЗListжУНдљЬжЭ•еЊЧеИ∞е±ЮдЇОзЙєеЃЪз±їеЮЛзЪДиµДжЇРзЪДеИЧи°®гАВ
гААгААеЬ®еЙНйЭҐзЪДиЃ≤иІ£дЄ≠жИСдїђеЈ≤зїПжПРеИ∞ињЗпЉМеЬ®RESTз≥їзїЯдЄ≠зЪДжѓПдЄ™иµДжЇРйГљжЬЙдЄАдЄ™зЙєеЃЪзЪДURIдЄОдєЛеѓєеЇФгАВHTTPеНПиЃЃжПРдЊЫдЇЖе§ЪзІНеЬ®URIдЄКжУНдљЬзЪДеК®иѓНпЉМе¶ВGETпЉМPUTпЉМPOSTдї•еПКDELETEз≠ЙгАВеЫ†ж≠§еЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTжЬНеК°дЄ≠пЉМжИСдїђйЬАи¶БдљњзФ®ињЩдЇЫHTTPеК®иѓНжЭ•и°®з§Їе¶ВдљХеѓєињЩдЇЫиµДжЇРињЫи°МCRUDжУНдљЬгАВиАМеЬ®дїАдєИжГЕеЖµдЄЛеИ∞еЇХдљњзФ®еУ™дЄ™еК®иѓНеИЩжШѓзФ±ињЩдЇЫеК®иѓНжЬђиЇЂеЬ®HTTPеНПиЃЃдЄ≠зЪДжДПдєЙжЙАеЖ≥еЃЪзЪДгАВ
гААгААињЩеЕґдЄ≠GETеТМDELETEдЄ§дЄ™еК®иѓНзЪДеРЂдєЙиЊГдЄЇжЄЕжЩ∞пЉЪ
 
The GET method means retrieve whatever information (in the form of an entity) is identified by the Request-URI.
The DELETE method requests that the origin server delete the resource identified by the Request-URI.
 
гААгААдєЯе∞±жШѓиѓіпЉМеЬ®йЬАи¶БиѓїеПЦжЯРдЄ™иµДжЇРзЪДжЧґеАЩпЉМжИСдїђеРСиѓ•иµДжЇРжЙАеѓєеЇФзЪДURIеПСйАБдЄАдЄ™GETиѓЈж±ВеН≥еПѓгАВз±їдЉЉзЪДпЉМеЬ®йЬАи¶БеИ†йЩ§дЄАдЄ™иµДжЇРзЪДжЧґеАЩпЉМжИСдїђеП™йЬАи¶БеРСиѓ•иµДжЇРжЙАеѓєеЇФзЪДURIеПСйАБдЄАдЄ™DELETEиѓЈж±ВеН≥еПѓгАВиАМеЬ®еЄМжЬЫеЊЧеИ∞жЯРз±їеЮЛиµДжЇРзЪДеИЧи°®зЪДжЧґеАЩпЉМжИСдїђеПѓдї•зЫіжО•еРСиѓ•з±їеЮЛиµДжЇРжЙАеѓєеЇФзЪДURIеПСйАБдЄАдЄ™GETиѓЈж±ВгАВ
гААгААиАМеК®иѓНPUTеТМPOSTеИЩжШѓиЊГдЄЇеЃєжШУжЈЈжЈЖзЪДдЄ§дЄ™еК®иѓНгАВеЬ®HTTPиІДиМГдЄ≠пЉМPOSTзЪДеЃЪдєЙе¶ВдЄЛжЙАз§ЇпЉЪ
 
гААгААThe POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line
 
гААгААдєЯе∞±жШѓиѓіпЉМPOSTеК®иѓНдЉЪеЬ®зЫЃж†ЗURIдєЛдЄЛеИЫеїЇдЄАдЄ™жЦ∞зЪДе≠РиµДжЇРгАВдЊЛе¶ВеЬ®еРСжЬНеК°зЂѓеПСйАБдЄЛйЭҐзЪДиѓЈж±ВжЧґпЉМRESTз≥їзїЯе∞ЖеИЫеїЇдЄАдЄ™жЦ∞зЪДеИЖз±їпЉЪ
1 POST /api/categories
2 Host: www.egoods.com
3 Authorization: Basic xxxxxxxxxxxxxxxxxxx
4 Accept: application/json
5
6 {
7 "label" : "Electronics",
8 вА¶вА¶
9 }
гААгАА
гААгААиАМPUTзЪДеЃЪдєЙеИЩжЫідЄЇжЩ¶жґ©дЄАдЇЫпЉЪ
 
The PUT method requests that the enclosed entity be stored under the supplied Request-URI. If the Request-URI refers to an already existing resource, the enclosed entity SHOULD be considered as a modified version of the one residing on the origin server. If the Request-URI does not point to an existing resource, and that URI is capable of being defined as a new resource by the requesting user agent, the origin server can create the resource with that URI."
 
гААгААдєЯе∞±жШѓиѓіпЉМPUTеИЩжШѓж†єжНЃиѓЈж±ВеИЫеїЇжИЦдњЃжФєзЙєеЃЪдљНзљЃзЪДиµДжЇРгАВж≠§жЧґеРСжЬНеК°зЂѓеПСйАБзЪДиѓЈж±ВзЪДзЫЃж†ЗURIйЬАи¶БеМЕеРЂжЙАе§ДзРЖиµДжЇРзЪДIDпЉЪ
1 POST /api/categories/8fa866a1-735a-4a56-b69c-d7e79896015e
2 Host: www.egoods.com
3 Authorization: Basic xxxxxxxxxxxxxxxxxxx
4 Accept: application/json
5
6 {
7 "label" : "Electronics",
8 вА¶вА¶
9 }
гААгААеПѓдї•зЬЛеИ∞пЉМдЄ§иАЕйГљжЬЙеИЫеїЇзЪДеРЂдєЙпЉМдљЖжШѓжДПдєЙеНідЄНеРМгАВеЬ®еЖ≥еЃЪеИ∞еЇХжШѓдљњзФ®PUTињШжШѓPOSTжЭ•еИЫеїЇиµДжЇРзЪДжЧґеАЩпЉМиљѓдїґеЉАеПСдЇЇеСШйЬАи¶БиАГиЩСдЄАз≥їеИЧйЧЃйҐШпЉЪ
гААгААй¶ЦеЕИе∞±жШѓиµДжЇРзЪДIDжШѓе¶ВдљХзФЯжИРзЪДгАВе¶ВжЮЬеЄМжЬЫеЃҐжИЈзЂѓеЬ®еИЫеїЇиµДжЇРзЪДжЧґеАЩжШЊеЉПеЬ∞жМЗеЃЪиѓ•иµДжЇРзЪДIDпЉМйВ£дєИе∞±йЬАи¶БдљњзФ®PUTгАВиАМеЬ®зФ±жЬНеК°зЂѓдЄЇиѓ•иµДжЇРиЗ™еК®иµЛдЇИIDзЪДжЧґеАЩпЉМжИСдїђе∞±йЬАи¶БеЬ®еИЫеїЇиµДжЇРжЧґдљњзФ®POSTгАВеЬ®еЖ≥еЃЪдљњзФ®PUTеИЫеїЇиµДжЇРзЪДжЧґеАЩпЉМйШ≤ж≠ҐиµДжЇРURIдЄОеЕґеЃГиµДжЇРжЙАеЕЈжЬЙзЪДURIйЗНе§НзЪДдїїеК°йЬАи¶БзФ±еЃҐжИЈзЂѓжЭ•дњЭиѓБгАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМеЃҐжИЈзЂѓеЄЄеЄЄдљњзФ®GUID/UUIDдљЬдЄЇе∞ЖиµДжЇРзЪДIDгАВдљЖжШѓеИ∞еЇХдљњзФ®GUID/UUIDињШжШѓзФ±жЬНеК°зЂѓжЭ•зФЯжИРIDдЄНдїЕдїЕеТМRESTжЬЙеЕ≥пЉМжЫідЉЪеѓєжХ∞жНЃеЇУжАІиГљз≠Йе§ЪдЄ™жЦєйЭҐдЇІзФЯељ±еУНгАВеЫ†ж≠§еЬ®еЖ≥еЃЪдљњзФ®еЃГдїђдєЛеЙНи¶БдїФзїЖеЬ∞иАГиЩСжЄЕж•ЪгАВ
гААгААеРМжЧґйЬАи¶Бж≥®жДПзЪДжШѓпЉМеЫ†дЄЇRESTи¶Бж±ВеЃҐжИЈеП™еПѓдї•йАЪињЗжЬНеК°зЂѓињФеЫЮзїУжЮЬдЄ≠жЙАеМЕеРЂзЪДдњ°жБѓжЭ•еЊЧеИ∞дЄЛдЄАж≠•жУНдљЬжЙАйЬАи¶БзЪДдњ°жБѓпЉМеЫ†ж≠§еЃҐжИЈзЂѓдїЕдїЕеПѓдї•еЖ≥еЃЪиµДжЇРзЪДIDпЉМиАМURIдЄ≠зЪДеЕґеЃГйГ®еИЖеИЩйЬАи¶БдїОдєЛеЙНеЊЧеИ∞зЪДеУНеЇФдЄ≠еПЦеЊЧгАВ
гААгААдљЖжШѓиљѓдїґеЉАеПСдЇЇеСШеЄЄеЄЄдЉЪињЫеЕ•еП¶е§ЦдЄАдЄ™иѓѓеМЇеЊИе§ЪдЇЇиЃ§дЄЇRESTжЬНеК°дЄ≠зЪДHATEOASеП™иГљйАЪињЗHyperlinkеЃМжИРгАВеЃЮйЩЕдЄКеЬ®RoyеѓєRESTзЪДеЃЪдєЙдЄ≠дљњзФ®зЪДжШѓHypermediaпЉМеН≥еУНеЇФдЄ≠зЪДжЙАжЬЙе§Ъе™ТдљУдњ°жБѓгАВе∞±еГПRoyеЬ®еЕґдЄ™дЇЇзљСзЂЩдЄКжЙАиѓіпЉИhttp://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-drivenпЉЙпЉЪ
 
A REST API must not define fixed resource names or hierarchies (an obvious coupling of client and server). Servers must have the freedom to control their own namespace. Instead, allow servers to instruct clients on how to construct appropriate URIs, such as is done in HTML forms and URI templates, by defining those instructions within media types and link relations.
 
гААгААеП¶е§ЦдЄАдЄ™йЬАи¶БиАГиЩСзЪДеЫ†зі†еИЩжШѓPUTзЪДз≠ЙеєВжАІжШѓеР¶еѓєRESTз≥їзїЯзЪДиЃЊиЃ°жЬЙжЙАеЄЃеК©гАВзФ±дЇОеЬ®еРМдЄАдЄ™URIдЄКи∞ГзФ®дЄ§жђ°PUTжЙАеЊЧеИ∞зЪДзїУжЮЬзЫЄеРМгАВеЫ†ж≠§зФ®жИЈеЬ®ж≤°жЬЙжО•еИ∞PUTиѓЈж±ВеУНеЇФжЧґеПѓдї•жФЊењГеЬ∞йЗНе§НеПСйАБиѓ•еУНеЇФгАВињЩеЬ®зљСзїЬдЄҐеМЕиЊГдЄЇдЄ•йЗНжЧґжШѓдЄАдЄ™йЭЮеЄЄе•љзЪДеКЯиГљгАВеПНињЗжЭ•пЉМеЬ®еРМдЄАдЄ™URIдЄКи∞ГзФ®дЄ§жђ°POSTе∞ЖеПѓиГљеИЫеїЇдЄ§дЄ™зЛђзЂЛзЪДе≠РиµДжЇРгАВ
гААгААйЩ§ж≠§дєЛе§ЦпЉМињШйЬАи¶БиАГиЩСжШѓеР¶е∞ЖиµДжЇРзЪДеИЫеїЇеТМжЫіжЦ∞ељТзїУдЄЇдЄАдЄ™APIеПѓдї•зЃАеМЦзФ®жИЈеѓєRESTжЬНеК°зЪДдљњзФ®гАВзФ®жИЈеПѓдї•йАЪињЗPUTеК®иѓНжЭ•еРМжЧґеЃМжИРеИЫеїЇеТМжЫіжЦ∞дЄАдЄ™иµДжЇРињЩдЄ§зІНдЄНеРМзЪДдїїеК°гАВињЩж†ЈзЪДе•ље§ДеЬ®дЇОзЃАеМЦдЇЖRESTжЬНеК°жЙАжПРдЊЫзЪДжО•еП£пЉМдљЖжШѓеПНињЗжЭ•дєЯиЃ©дЄАдЄ™APIжЙІи°МдЇЖдЄ§зІНдЄНеРМзЪДдїїеК°пЉМеЬ®дЄАеЃЪз®ЛеЇ¶дЄКињЭеПНдЇЖAPIиЃЊиЃ°жЧґжѓПдЄ™APIйГљйЬАи¶БжЬЙжШОз°ЃзЪДжДПдєЙињЩдЄАеОЯеИЩгАВ
гААгААеЫ†ж≠§еЬ®еЖ≥еЃЪеИ∞еЇХдљњзФ®POSTињШжШѓPUTжЭ•еЃМжИРиµДжЇРзЪДеИЫеїЇдєЛеЙНпЉМиѓЈиАГиЩСдЄКйЭҐжЙАеИЧеЗЇзЪДдЄЙжЭ°йЧЃйҐШпЉМдї•з°ЃеЃЪеИ∞еЇХеУ™дЄ™еК®иѓНжЫіеК†йАВеРИгАВ
гААгААйЩ§ж≠§дєЛе§ЦпЉМеП¶е§ЦдЄАеѓєз±їдЉЉзЪДеК®иѓНеИЩжШѓPUTеТМPATCHгАВдЄ§иАЕдєЛйЧізЪДдЄНеРМеИЩеЬ®дЇОPUTжШѓеѓєжХідЄ™иµДжЇРзЪДжЫіжЦ∞пЉМиАМPATCHеИЩжШѓеѓєйГ®еИЖиµДжЇРзЪДжЫіжЦ∞гАВиАМиѓ•еК®иѓНзЪДе±АйЩРжАІеИЩеЬ®дЇОеѓєиѓ•еК®иѓНзЪДжФѓжМБз®ЛеЇ¶гАВжѓХзЂЯеЬ®жЯРдЇЫз±їеЇУдЄ≠еєґж≤°жЬЙжПРдЊЫеОЯзФЯзЪДеѓєPATCHеК®иѓНзЪДжФѓжМБгАВ
 
дљњзФ®ж†ЗеЗЖзЪДзКґжАБз†Б
гААгААеЬ®дЄОRESTжЬНеК°ињЫи°МдЇ§дЇТзЪДжЧґеАЩпЉМзФ®жИЈйЬАи¶БйАЪињЗжЬНеК°жЙАињФеЫЮзЪДдњ°жБѓеЖ≥еЃЪеЕґжЙАеПСйАБзЪДиѓЈж±ВжШѓеж襀йАВељУеЬ∞е§ДзРЖгАВињЩйГ®еИЖеКЯиГљжШѓзФ±RESTжЬНеК°еЃЮзО∞жЧґжЙАдљњзФ®зЪДеНПиЃЃжЙАеЖ≥еЃЪзЪДпЉМдЄОRESTжЮґжЮДжЧ†еЕ≥гАВиАМеЬ®еЯЇдЇОHTTPзЪДRESTжЬНеК°дЄ≠пЉМиѓ•еКЯиГље∞±зФ±HTTPеУНеЇФзЪДзКґжАБз†БпЉИStatus CodeпЉЙжЭ•еЃМжИРгАВеЫ†ж≠§еЬ®иЃЊиЃ°дЄАдЄ™RESTжЬНеК°жЧґпЉМжИСдїђйЬАи¶БйҐЭе§ЦеЬ∞ж≥®жДПжШѓеР¶ињФеЫЮдЇЖж≠£з°ЃзЪДзКґжАБз†БгАВ
гААгААдљЖжШѓињЩдЇЫйҐДеЃЪдєЙзЪДHTTPзКґжАБз†БеєґдЄНиГљжї°иґ≥жЙАжЬЙзЪДжГЕеЖµгАВжЬЙжЧґеАЩдЄАдЄ™RESTжЬНеК°жЙАеЄМжЬЫињФеЫЮзЪДйФЩиѓѓдњ°жБѓиГље§ЯжЫіеК†з≤Њз°ЃеЬ∞жППињ∞йЧЃйҐШпЉМдЊЛе¶ВеЬ®зФ®жИЈйЗНиЃЊеѓЖз†БжЧґпЉМжИСдїђйЬАи¶БеЬ®зФ®жИЈжЙАиЊУеЕ•еОЯеѓЖз†БдЄОз≥їзїЯдЄ≠жЙАиЃ∞ељХзЪДеѓЖз†БдЄНеМєйЕНжЧґињФеЫЮвАЬжВ®жЙАиЊУеЕ•зЪДеѓЖз†БжЬЙиѓѓвАЭињЩж†ЈзЪДжґИжБѓгАВеЬ®HTTPеНПиЃЃдЄ≠пЉМжИСдїђеєґж≤°жЬЙеКЮж≥ХжЙЊеИ∞дЄАдЄ™иГље§Яз≤Њз°ЃеЬ∞и°®з§Їиѓ•жДПдєЙзЪДзКґжАБз†БгАВ
гААгААеЫ†ж≠§еЬ®йАЪеЄЄжГЕеЖµдЄЛпЉМRESTжЬНеК°йГљдЉЪеЬ®еУНеЇФдЄ≠йҐЭе§ЦеЬ∞жПРдЊЫдЄАдЄ™иѓіжШОжАІзЪДиіЯиљљжЭ•еСКзЯ•зФ®жИЈеИ∞еЇХдЇІзФЯдЇЖдїАдєИйЧЃйҐШгАВдЊЛе¶ВеѓєдЇОдЄКйЭҐзЪДйЗНиЃЊеѓЖз†Б姱賕зЪДжГЕеЖµпЉМжЬНеК°зЂѓеПѓиГљдЉЪињФеЫЮе¶ВдЄЛеУНеЇФпЉЪ
1 HTTP/1.1 400 Bad Request
2 Content-Type: application/json
3 Content-Length: xxx
4
5 {
6 "error_id" : "100045",
7 "header" : "Reset password failed",
8 "description" : "The original password is not correct"
9 }
гААгААдЄКйЭҐзЪДз§ЇдЊЛеУНеЇФдЄ≠дЄїи¶БеМЕеРЂдї•дЄЛзЪДиѓіжШОжАІдњ°жБѓпЉЪ
- жЬНеК°зЂѓеУНеЇФзЪДзКґжАБз†БгАВй°µйЭҐйАїиЊСеПѓдї•йАЪињЗеИ§жЦ≠иѓ•зКґжАБз†БжШѓеР¶жШѓ4XXжИЦ5XXжЭ•еИ§жЦ≠жШѓеР¶иѓЈж±ВеЗЇйФЩпЉМдїОиАМеЬ®й°µйЭҐдЄ≠е±Хз§ЇдЄАдЄ™и≠¶еСКеѓєиѓЭж°ЖгАВ
- жЬНеК°жЙАжПРдЊЫзЪДеЖЕйГ®йФЩиѓѓIDгАВйАЪеЄЄжГЕеЖµдЄЛпЉМиѓ•еЖЕйГ®йФЩиѓѓIDдєЯйЬАи¶БеЬ®и≠¶еСКеѓєиѓЭж°ЖдЄ≠е±Хз§ЇеЗЇжЭ•гАВдїОиАМеЕБиЃЄиљѓдїґзФ®жИЈж†єжНЃеЖЕйГ®йФЩиѓѓIDжЭ•иОЈеПЦжФѓжМБжЬНеК°гАВ
- йФЩиѓѓзЪДж†ЗйҐШеПКзЃАињ∞гАВйАЪињЗиѓ•йФЩиѓѓзЪДж†ЗйҐШеПКзЃАињ∞пЉМиљѓдїґзФ®жИЈиГље§ЯдЇЖиІ£з≥їзїЯеЖЕйГ®еИ∞еЇХеПСзФЯдЇЖдїАдєИпЉМеєґеЬ®жШѓзФ®жИЈиЊУеЕ•йФЩиѓѓзЪДжЧґеАЩеЕБиЃЄзФ®жИЈиЗ™и°МдњЃжФєйФЩиѓѓеєґйЗНжЦ∞еПСйАБж≠£з°ЃзЪДиѓЈж±ВгАВ
гААгААеЬ®иѓ•йФЩиѓѓдЄ≠пЉМжЬАеЕ≥йФЃзЪДељУе±ЮжЬНеК°зЂѓзЪДеУНеЇФдї£з†БгАВдЄАдЄ™еУНеЇФдї£з†БдЄНдїЕдїЕж†Зз§ЇдЇЖиѓЈж±ВжШѓеР¶жИРеКЯпЉМжЫіжЬЙзФ®жИЈиѓ•е¶ВдљХжУНдљЬзЪДеРЂдєЙгАВдЊЛе¶ВеѓєдЇО401 UnauthorizedеУНеЇФдї£з†БиАМи®АпЉМеЕґи°®з§Їиѓ•еУНеЇФж≤°жЬЙжПРдЊЫдЄАдЄ™еРИж≥ХзЪДиЇЂдїљеЗ≠иѓБпЉМеЫ†ж≠§йЬАи¶БзФ®жИЈй¶ЦеЕИжЙІи°МзЩїйЩЖжУНдљЬдї•еЊЧеИ∞дЄАдЄ™еРИж≥ХзЪДиЇЂдїљеЗ≠иѓБпЉМзДґеРОиѓ•иµДжЇРеПѓиГље∞±еσ俕襀聜йЧЃдЇЖгАВиАМ403 ForbiddenеУНеЇФдї£з†БеИЩи°®з§ЇељУеЙНиѓЈж±ВеЈ≤зїПжПРдЊЫдЇЖдЄАдЄ™еРИж≥ХзЪДиЇЂдїљеЗ≠иѓБпЉМдљЖжШѓиѓ•иЇЂдїљеЗ≠иѓБеєґж≤°жЬЙиЃњйЧЃиѓ•иµДжЇРзЪДжЭГйЩРпЉМеЫ†ж≠§дљњзФ®иѓ•иЇЂдїљеЗ≠иѓБзЩїйЩЖйЗНжЦ∞зЩїйЩЖз≥їзїЯз≠ЙжУНдљЬеєґдЄНиГљиІ£еЖ≥йЧЃйҐШгАВ
гААгААеЫ†ж≠§еЬ®ињФеЫЮйФЩиѓѓдњ°жБѓдєЛеЙНпЉМиљѓдїґеЉАеПСдЇЇеСШй¶ЦеЕИйЬАи¶БиАГиЩСжЄЕж•ЪеЬ®еУНеЇФдЄ≠еИ∞еЇХеЇФиѓ•дљњзФ®дїАдєИж†ЈзЪДеУНеЇФдї£з†БгАВиАМж≠£з°ЃеЬ∞йАЙжЛ©еУНеЇФдї£з†БеИЩеїЇзЂЛеЬ®иљѓдїґеЉАеПСдЇЇеСШеѓєињЩдЇЫеУНеЇФдї£з†БжЛ•жЬЙдЄАдЄ™ж≠£з°ЃзЪДзРЖиІ£зЪДеЙНжПРдЄЛгАВ
гААгААељУзДґпЉМи¶Бе∞ЖжЙАжЬЙзЪДеУНеЇФдї£з†БеЃМеЕ®зРЖиІ£дєЯйЬАи¶Бе§ІйЗПзЪДеЈ•дљЬпЉМиАМдЄФRESTжЬНеК°зЪДзФ®жИЈдєЯеПѓиГљеєґж≤°жЬЙйВ£дєИе§ЪзЪДйҐЖеЯЯзЯ•иѓЖжЭ•дЇЖиІ£жЙАжЬЙзЪДеУНеЇФдї£з†БзЪДеРЂдєЙгАВеЫ†ж≠§еЬ®еЊИе§ЪеЯЇдЇОHTTPзЪДRESTз≥їзїЯдЄ≠пЉМз≥їзїЯеЬ®ж†Зз§ЇйФЩиѓѓжЧґеП™дљњзФ®дЄАз≥їеИЧеЄЄзФ®зЪДеУНеЇФдї£з†БпЉМе¶В400пЉМ401пЉМ403пЉМ404пЉМ405пЉМ500пЉМ503з≠ЙгАВеЬ®зФ®жИЈиѓЈж±В襀е§ДзРЖжЧґпЉМз≥їзїЯе∞ЖињФеЫЮ200 OKпЉМи°®з§ЇиѓЈж±ВеЈ≤зїП襀е§ДзРЖгАВиАМеЬ®е§ДзРЖжЧґеПСзФЯйФЩиѓѓжЧґеИЩе∞љйЗПдљњзФ®ињЩдЇЫеУНеЇФдї£з†БжЭ•и°®з§ЇгАВе¶ВжЮЬдЄАдЄ™йФЩиѓѓиЊГдЄЇе§НжЭВпЉМйВ£дєИзЫіжО•ињФеЫЮ400жИЦ500пЉМеєґеЬ®еУНеЇФзЪДиіЯиљљдЄ≠жПРдЊЫеЕЈдљУзЪДйФЩиѓѓдњ°жБѓгАВ
гААгААдЄНеЊЧдЄНиѓізЪДжШѓпЉМињЩзІНеБЪж≥ХжЬЙжЧґжШЊеЊЧзЃАеНХз≤ЧжЪіпЉМе∞§еЕґжШѓеѓєдЇОдЄАдЄ™еЉАжФЊеє≥еП∞иАМи®АеИЩжЫіжШѓиЗіеСљзЪДгАВељУдЄАдЄ™зђђдЄЙжЦєеОВеХЖдЄЇдЄАдЄ™еЉАжФЊеє≥еП∞еЉАеПСдЄАдЄ™еЇФзФ®иљѓдїґпЉМеНіжѓПжђ°еП™иГљеЊЧеИ∞дЄАдЄ™400йФЩиѓѓпЉМйВ£дєИеЕґеЖЕйГ®еЇФзФ®йАїиЊСе∞ЖжЧ†ж≥ХеИ§жЦ≠еИ∞еЇХжШѓеУ™йЗМеЗЇдЇЖйЧЃйҐШгАВдЄЇдЇЖиГљиЃ©зФ®жИЈзЯ•йБУињЩйЗМдЇІзФЯдЇЖйФЩиѓѓпЉМиѓ•зђђдЄЙжЦєиљѓдїґеП™иГље∞ЖеЉАжФЊеє≥еП∞жЙАзїЩеЗЇзЪДдњ°жБѓзЫіжО•жШЊз§ЇзїЩзФ®жИЈгАВдљЖжШѓињЩдЇЫдњ°жБѓеЃЮйЩЕдЄКжШѓеїЇзЂЛеЬ®еЉАжФЊеє≥еП∞ињЩдЄ™иѓ≠еҐГдЄЛзЪДпЉМеЫ†ж≠§еѓєдЇОзђђдЄЙжЦєеОВеХЖзЪДзФ®жИЈиАМи®АпЉМињЩдЇЫдњ°жБѓжЩ¶жґ©йЪЊжЗВпЉМзФЪиЗ≥еПѓиГљдЄАзВєеЄЃеК©дєЯж≤°жЬЙгАВ
гААгААдєЯе∞±жШѓиѓіпЉМеИ∞еЇХе¶ВдљХзїДзїЗињЩдЇЫеУНеЇФдї£з†БйЬАи¶БзФ®жИЈж†єжНЃжЙАзЉЦеЖЩзЪДй°єзЫЃеЖ≥еЃЪпЉМе∞§еЕґжШѓиѓ•дЇІеУБзЪДдљњзФ®иАЕжЭ•еЖ≥еЃЪгАВеЬ®еЃЪдєЙдЄАдЄ™еє≥еП∞жЧґпЉМе∞љйЗПдљњзФ®жЫіе§ЪзЪДHTTPеУНеЇФдї£з†БпЉМеЫ†дЄЇзФ®жИЈжЮБжЬЙеПѓиГљйАЪињЗиѓ•еє≥еП∞зЉЦеЖЩиЗ™еЈ±зЪДзђђдЄЙжЦєиљѓдїґгАВиАМеЬ®дЄЇдЄАдЄ™жЩЃйАЪзЪДдЇІеУБеЃЪдєЙREST APIжЧґпЉМе∞ЖеУНеЇФдї£з†БеЃЪеЊЧйЭЮеЄЄдЄУдЄЪеПѓиГљеПНиАМеѓЉиЗіжШУзФ®жАІзЪДдЄЛйЩНгАВ
гААгААеП¶е§ЦдЄАзВєйЬАи¶БиѓіжШОзЪДжШѓпЉМдЄ™дЇЇдЄНеїЇиЃЃдљњзФ®WikipediaжЯ•жЙЊеРДдЄ™зКґжАБз†БзЪДеРЂдєЙпЉМиАМеЇФиѓ•дљњзФ®RFCжЙАжППињ∞зЪДеРДзКґжАБз†БзЪДеЃЪдєЙгАВ IANAжПРдЊЫдЇЖдЄАеЉ†еРДдЄ™зКґжАБз†БжЙАеѓєеЇФзЪДRFCеНПиЃЃзЪДеИЧи°®пЉМдїОиАМеПѓдї•еЊИеЃєжШУеЬ∞жЙЊеИ∞еРДдЄ™зКґжАБз†БжЙАеѓєеЇФзЪДRFCеНПиЃЃдї•еПКеЕґжЙАеЬ®зЪДзЂ†иКВгАВиѓ•еИЧи°®зЪДеЬ∞еЭАдЄЇпЉЪhttp://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml
гААгААдєЛжЙАдї•дЄНеїЇиЃЃдљњзФ®WikipediaзЪДеОЯеЫ†дЄїи¶БжЬЙдЄ§зВєпЉЪ
- жППињ∞дЄНе§Яиѓ¶зїЖгАВеЬ®RFCеЃЪдєЙдЄ≠пЉМжѓПдЄ™зКґжАБз†БйГљеѓєеЇФзЭАдЄАжЃµжИЦе§ЪжЃµжЦЗе≠ЧпЉМеєґдЄФиІ£йЗКйЭЮеЄЄжЄЕжЩ∞гАВиАМеЬ®WikipediaдЄ≠пЉМжѓПдЄ™зКґжАБз†БеЄЄеЄЄеП™жЬЙдЄАеП•иѓЭгАВ
- дЄНе§ЯеЗЖз°ЃгАВеЬ®WikipediaзЪДReferenceиКВдЄ≠пЉМжИСдїђеПѓдї•зЬЛеИ∞дЄАз≥їеИЧзЙєеЃЪеє≥еП∞жЙАеЃЪдєЙзЪДзКґжАБз†БпЉМе¶ВSpring FrameworkжЙАеЃЪдєЙзЪД420 Method Failureз≠ЙгАВињЩйЭЮеЄЄеЕЈжЬЙиѓѓеѓЉжАІгАВ
 
йАЙжЛ©йАВељУзЪДи°®з§ЇзїУжЮД
гААгААжО•дЄЛжЭ•жИСдїђи¶БиЃ≤иІ£зЪДе∞±жШѓе¶ВдљХдЄЇиµДжЇРеЃЪдєЙдЄАдЄ™жБ∞ељУзЪДи°®з§ЇгАВ
гААгААй¶ЦеЕИйЬАи¶БеЉЇи∞ГзЪДжШѓпЉМRESTеєґж≤°жЬЙиІДеЃЪеЕґжЬНеК°дЄ≠йЬАи¶БдљњзФ®дїАдєИж†ЉеЉПжЭ•и°®з§ЇиµДжЇРгАВи°®з§ЇиµДжЇРжЧґжЙАеПѓдї•йАЙеПЦзЪД谮积嚥еЉПеЃЮйЩЕдЄКжШѓзФ±еЃЮзО∞RESTжЙАдљњзФ®зЪДеНПиЃЃеЖ≥еЃЪзЪДгАВиАМеЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTжЬНеК°дЄ≠пЉМжИСдїђеПѓдї•дљњзФ®JSONпЉМдєЯеПѓдї•дљњзФ®XMLпЉМзФЪиЗ≥жШѓиЗ™еЃЪдєЙзЪДMIMEз±їеЮЛжЭ•и°®з§ЇиµДжЇРгАВињЩдЇЫи°®зО∞嚥еЉПеЄЄеЄЄжШѓз≠ЙжХИзЪДгАВзЫЄдњ°иѓїиАЕеЈ≤зїПзЬЛеИ∞пЉМжЬђз≥їеИЧжЦЗзЂ†дЉЪдљњзФ®JSONжЭ•и°®з§ЇињЩдЇЫиµДжЇРгАВ
гААгААдЄАдЄ™RESTжЬНеК°еЄЄеЄЄдЉЪеРМжЧґжФѓжМБе§ЪзІНеЃҐжИЈзЂѓгАВињЩдЇЫеЃҐжИЈзЂѓеПѓиГљдЉЪдљњзФ®дЄНеРМзЪДеНПиЃЃжЭ•дЄОжЬНеК°ињЫи°Мж≤ЯйАЪгАВиАМдЄФе∞±зЃЧжШѓдљњзФ®зЫЄеРМзЪДеНПиЃЃпЉМдЄНеРМзЪДеЃҐжИЈзЂѓжЙАеПѓдї•жО•еПЧзЪДиіЯ蚚谮积嚥еЉПдєЯдЉЪжЬЙжЙАдЄНеРМгАВеЫ†ж≠§еЃҐжИЈзЂѓйЬАи¶БдЄОRESTжЬНеК°еНПеХЖеЬ®йАЪиЃѓињЗз®ЛдЄ≠жЙАдљњзФ®зЪДиіЯиљљгАВ
гААгААеЃҐжИЈзЂѓеТМжЬНеК°зЂѓеѓєжЙАдљњзФ®иіЯиљљз±їеЮЛзЪДеНПеХЖйАЪеЄЄйГљжМЙзЕІеНПиЃЃжЙАиІДеЃЪзЪДж†ЗеЗЖеНПеХЖињЗз®ЛжЭ•еЃМжИРгАВдЊЛе¶ВеѓєдЇОдЄАдЄ™еЯЇдЇОHTTPзЪДRESTжЬНеК°пЉМжИСдїђе∞±йЬАи¶БдљњзФ®Acceptе§іжЭ•ж†Зз§ЇеЃҐжИЈзЂѓжЙАеПѓдї•жО•еПЧзЪДиіЯиљљз±їеЮЛпЉЪ
1 GET /api/categories 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
гААгААиАМеЬ®жЬНеК°зЂѓжФѓжМБзЪДжГЕеЖµдЄЛпЉМињФеЫЮзЪДеУНеЇФе∞±е∞ЖдљњзФ®иѓ•MIMEз±їеЮЛзїДзїЗеЕґиіЯиљљпЉЪ
1 HTTP/1.1 200 OK 2 Content-Type: application/json 3 Content-Length: xxx
гААгААеЬ®ињЩйЗМжИСдїђеЖНйЗНе§НдЄАжђ°пЉЪRESTжШѓдЄАзІНзїДзїЗWebжЬНеК°зЪДжЮґжЮДпЉМеЕґеП™еЬ®жЮґжЮДжЦєйЭҐжПРеЗЇдЇЖдЄАз≥їеИЧзЇ¶жЭЯгАВеПѓдї•иѓіпЉМжЙАжЬЙеѓєRESTзЪДиЃ≤иІ£йГљеЈ≤зїПеЬ®еЙНдЄ§дЄ™зЂ†иКВпЉМеН≥вАЬRESTзЪДеЃЪдєЙвАЭдї•еПКвАЬиµДжЇРиѓЖеИЂвАЭдЄ≠еЃМжИРдЇЖгАВиАМжЬЙеЕ≥еЃҐжИЈзЂѓеТМжЬНеК°зЂѓе¶ВдљХињЫи°Мж≤ЯйАЪпЉМдЄЇиµДжЇРеЃЪдєЙдїАдєИж†ЈзЪДURIпЉМдљњзФ®дїАдєИж†ЉеЉПзЪДжХ∞жНЃињЫи°Мж≤ЯйАЪз≠ЙиЃ®иЃЇйГљжШѓеЬ®йШРињ∞е¶ВдљХе∞ЖRESTжЮґжЮДжЙАжПРеЗЇзЪДеРДзІНзЇ¶жЭЯеТМеЯЇдЇОHTTPеНПиЃЃзЪДWebжЬНеК°зїУеРИеЬ®дЄАиµЈгАВжѓХзЂЯеЬ®йАЪеЄЄжГЕеЖµдЄЛпЉМеЃЮзО∞дЄАдЄ™еНХзЇѓзЪДжКАжЬѓдЄНйЪЊпЉМдљЖжШѓе¶ВдљХе∞Же§ЪзІНжКАжЬѓиІДиМГиЗ™зДґеЬ∞жЈЈеРИеЬ®дЄАиµЈпЉМжЮДжИРдЄАдЄ™иЗ™зДґзЪДпЉМжИРзЖЯз®≥еЃЪзЪДиІ£еЖ≥жЦєж°ИжЙНжШѓй°єзЫЃеЉАеПСдЄ≠зЪДйЪЊзВєгАВHTTPеНПиЃЃеєґдЄНжШѓдЄЇRESTжЮґжЮДжЙАеЃЪдєЙзЪДпЉМеЫ†ж≠§е¶ВдљХзФ®HTTPеНПиЃЃжЭ•жБ∞ељУеЬ∞жППињ∞дЄАдЄ™RESTжЬНеК°жЙНжШѓжЬђжЦЗжЙАзЭАйЗНдїЛзїНзЪДгАВ
 
иіЯиљљзЪДиЗ™жППињ∞жАІ
гААгААеЬ®еЙНйЭҐеѓєRESTжПРеЗЇзЪДеЗ†дЄ™зЇ¶жЭЯзЪДиЃ≤иІ£дЄ≠жИСдїђеЈ≤зїПжПРеИ∞ињЗпЉМRESTз≥їзїЯдЄ≠жЙАдЉ†йАТзЪДеРДдЄ™жґИжБѓзЪДиіЯиљљйЬАи¶БжПРдЊЫиґ≥е§ЯзЪДзФ®дЇОжУНдљЬиѓ•иµДжЇРзЪДдњ°жБѓпЉМе¶Ве¶ВдљХеѓєиµДжЇРињЫи°МжЈїеК†пЉМеИ†йЩ§дї•еПКдњЃжФєз≠ЙжУНдљЬпЉМеєґеПѓдї•ж†єжНЃиіЯиљљдЄ≠жЙАеМЕеРЂзЪДеѓєеЕґеЃГеРДиµДжЇРзЪДеЉХзФ®жЭ•иЃњйЧЃеРДдЄ™иµДжЇРгАВињЩдєЯеѓєиіЯиљљзЪДиЗ™жППињ∞жАІжПРеЗЇдЇЖжЫійЂШзЪДи¶Бж±ВгАВ
гААгААй¶ЦеЕИиЃ©жИСдїђеЫЮе§ізЬЛзЬЛegoodsзФµе≠РеХЖеК°зљСзЂЩеѓєй£ЯеУБеИЖз±їзЪДжППињ∞пЉЪ
1 {
2 "uri" : "/api/categories/1",
3 "label" : "Food",
4 "items_url" : "/api/items?category=1",
5 "brands" : [
6 {
7 "label" : "еПЛиЗ£",
8 "brand_key" : "32073",
9 "url" : "/api/brands/32073"
10 }, {
11 "label" : "дєРдЇЛ",
12 "brand_key" : "56632",
13 "url" : "/api/brands/56632"
14 }
15 ...
16 ],
17 "hot_searches" : вА¶
18 }
гААгААжИСжГ≥иѓїиАЕеЬ®зЬЛеИ∞иѓ•еУНеЇФдєЛеРОеПѓиГље∞±еЈ≤зїПжШОзЩљдЇЖеЊИе§ЪеЯЯзЪДеРЂдєЙгАВдљЖињШжШѓиЃ©жИСдїђдЊЭжђ°еѓєињЩдЇЫеЯЯињЫи°МиЃ≤иІ£гАВ
гААгААзђђдЄАдЄ™и¶БиЃ≤иІ£зЪДжШѓurlеЯЯгАВиѓ•еЯЯзФ®жЭ•ж†Зз§Їиѓ•иµДжЇРжЙАеѓєеЇФзЪДURLгАВеПѓиГљжВ®дЉЪйЧЃпЉЪжЧҐзДґжИСдїђе∞±жШѓдїОињЩдЄ™URLињФеЫЮзЪДиѓ•иµДжЇРпЉМйВ£дєИдЄЇдїАдєИжИСдїђињШйЬАи¶БеЬ®иѓ•иµДжЇРдЄ≠дњЭе≠ШдЄАдЄ™еЃГжЙАеѓєеЇФзЪДURLеСҐпЉЯй¶ЦеЕИињЩжШѓеЫ†дЄЇеЬ®зїЯдЄАжО•еП£зЇ¶жЭЯдЄ≠и¶Бж±ВжѓПдЄ™иµДжЇРйГљжЛ•жЬЙдЄАдЄ™иµДжЇРж†ЗиѓЖгАВеЬ®ињЩйЗМжИСдїђдљњзФ®URLдљЬдЄЇж†ЗиѓЖгАВиАМеП¶дЄАдЇЫеЯЇдЇОHTTPзЪДRESTз≥їзїЯдЄ≠пЉМзФ®жЭ•дљЬдЄЇиµДжЇРж†ЗиѓЖзЪДеЄЄеЄЄжШѓиѓ•иµДжЇРзЪДIDгАВдЄ™дЇЇжЫіеАЊеРСдЇОдљњзФ®URLзЪДеОЯеЫ†еИЩжШѓпЉЪеЬ®жЯРдЇЫжГЕеЖµдЄЛпЉМе¶ВеѓєжЯРдЄ™иµДжЇРеЃЪжЧґеИЈжЦ∞дї•ињЫи°МзЫСжОІзЪДжЧґеАЩпЉМURLеПѓдї•зЫіжΕ襀䚜зФ®гАВ
гААгААжО•дЄЛжЭ•жШѓlabelеЯЯгАВеЕґзФ®жЭ•иЃ∞ељХзФ®дЇОе±Хз§ЇзїЩзФ®жИЈзЪДеИЖз±їеРНгАВ
гААгААitems_urlеЯЯеИЩзФ®жЭ•и°®з§ЇеПЦеЊЧе±ЮдЇОиѓ•еИЖз±їзЙ©еУБеИЧи°®зЪДURLгАВж≥®жДПињЩйЗМжИСдљњзФ®дЇЖеРОзЉА_urlдї•жШОз°Ѓж†ЗжШОеЕґжШѓдЄАдЄ™URLпЉМйЬАи¶БйАЪињЗиЈ≥иљђжЭ•еПЦеЊЧеЃЮйЩЕзЪДжХ∞жНЃгАВ
гААгААдЄЛдЄАдЄ™еЯЯbrandsеИЩзФ®жЭ•и°®з§Їе±ЮдЇОиѓ•еИЖз±їзЪДиСЧеРНеХЖеУБеУБзЙМгАВињЩйЗМжИСдїђдљњзФ®дЇЖдЄАдЄ™жХ∞зїДпЉМиАМжХ∞зїДдЄ≠зЪДжѓПдЄ™еЕГзі†йГљи°®з§ЇдЇЖдЄАдЄ™еУБзЙМгАВжѓПдЄ™еУБзЙМзЪДи°®з§ЇйГљеМЕеРЂдЇЖдЄАдЄ™е±Хз§ЇзїЩзФ®жИЈзЪДlabelпЉМеЬ®жРЬ糥жЧґжЙАдљњзФ®зЪДйФЃпЉМдї•еПКиѓ•еУБзЙМжЙАеѓєеЇФзЪДurlгАВжВ®еПѓиГљдЉЪжААзЦСдЄЇдїАдєИжИСдїђдїЕдїЕжПРдЊЫдЇЖињЩдєИе∞СзЪДеЯЯгАВињЩжШѓеЫ†дЄЇдїЦдїђдїЕдїЕжШѓеѓєињЩдЄ™еУБзЙМзЪДеЉХзФ®пЉМиАМеєґйЭЮжШѓжККиѓ•иµДжЇРзЪДиѓ¶зїЖдњ°жБѓйГљеМЕеРЂињЫжЭ•дЇЖзЪДзЉШжХЕгАВеЬ®зФ®жИЈеЄМжЬЫжЯ•зЬЛиѓ•еУБзЙМзЪДиѓ¶зїЖдњ°жБѓзЪДжЧґеАЩпЉМдїЦйЬАи¶БеРСиѓ•еУБзЙМеЉХзФ®дЄ≠жЙАж†ЗжШОзЪДеУБзЙМзЪДURLеПСйАБдЄАдЄ™GETиѓЈж±ВгАВ
гААгААиАМзФ±дЇОhot_searchesеЯЯзЪДзїДжИРеПКдљњзФ®еЯЇжЬђдЄКдЄОbrandsеЯЯз±їдЉЉпЉМеЫ†ж≠§ињЩйЗМдЄНеЖНиµШињ∞гАВ
гААгААеЬ®е§ІиЗіеЬ∞дЇЖиІ£дЇЖй£ЯеУБеИЖз±їзЪДJSONи°®з§ЇдЄ≠еРДдЄ™еЯЯзЪДеРЂдєЙеРОпЉМжИСдїђе∞±е∞ЖеЉАеІЛиЃ≤иІ£е¶ВдљХиЗ™и°МеЃЪдєЙиµДжЇРзЪДJSONи°®з§ЇгАВеѓєдЇОдЄАдЄ™зЃАеНХзЪДпЉМдЄНеМЕеРЂдїїдљХе≠РиµДжЇРдї•еПКеѓєеЕґеЃГиµДжЇРзЪДеЉХзФ®зЪДиµДжЇРпЉМжИСдїђеП™йЬАи¶БйАЪињЗдЄАдЄ™еМЕеРЂзЃАеНХе±ЮжАІзЪДJSONжЭ•и°®з§ЇеЃГгАВдЊЛе¶ВеѓєдЇОдЄАдЄ™еУБзЙМпЉМжИСдїђеПѓиГљдїЕдїЕжПРдЊЫдЇЖдЄАз≥їеИЧжППињ∞жАІдњ°жБѓпЉЪеУБзЙМзЪДеРНзІ∞пЉМдї•еПКеѓєеУБзЙМзЪДзЃАеНХжППињ∞гАВйВ£дєИеЃГжЙАеѓєеЇФзЪДJSONи°®з§ЇеПѓдї•и°®з§ЇдЄЇпЉЪ
1 {
2 "uri" : "/api/brands/32059",
3 "label" : "Dole",
4 "description" : "An American-based agricultural multinational corporation."
5 }
гААгААиАМеЬ®еП¶дЄАдЄ™иµДжЇРдЄ≠пЉМеПѓиГљеМЕеРЂдЇЖеѓєеЕґеЃГиµДжЇРзЪДеЉХзФ®гАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМжИСдїђе∞±йЬАи¶БеЬ®и°®з§ЇеѓєеЕґеЃГиµДжЇРињЫи°МеЉХзФ®зЪДеЯЯдЄ≠йАЪињЗURLжЭ•ж†ЗжШО襀еЉХзФ®иµДжЇРзЪДдљНзљЃгАВдЊЛе¶ВдЄАдїґDoleжЮЬж±БдЄ≠пЉМеПѓиГље∞±йЬАи¶БеМЕеРЂеѓєеУБзЙМDoleзЪДеЉХзФ®пЉЪ
1 {
2 "uri" : "/api/items/1438299",
3 "label" : "Dole Grape Juice",
4 "price" : "$3.99",
5 "brand" : {
6 "label" : "Dole"
7 "uri" : "/api/brands/32059"
8 }
9 вА¶вА¶
10 }
гААгААеЬ®дЄКйЭҐзЪДDoleжЮЬж±БзЪДи°®з§ЇдЄ≠пЉМжИСдїђеПѓдї•зЬЛеИ∞еЃГзЪДbrandеЯЯе∞±жШѓеѓєеУБзЙМзЪДеЉХзФ®гАВиѓ•еЉХзФ®дЄ≠еМЕеРЂдЇЖиѓ•еУБзЙМзЪДеУБзЙМеРНзІ∞дї•еПКдЄАдЄ™жМЗеРСиѓ•еУБзЙМзЪДURLгАВ
гААгААеЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTз≥їзїЯдЄ≠пЉМжИСдїђеЄЄеЄЄеЬ®иµДжЇРзЪДеЉХзФ®дЄ≠еМЕеРЂдЄАеЃЪйЗПзЪДжППињ∞дњ°жБѓгАВињЩдЄїи¶БеЫ†дЄЇдЄ§зВєпЉЪ
- жПРйЂШжАІиГљгАВеЬ®дЄАдЄ™еѓєиµДжЇРзЪДеЉХзФ®дЄ≠жЈїеК†дЇЖзФ®дЇОжШЊз§ЇзЪДе±ЮжАІеРОпЉМеЃҐжИЈзЂѓй°µйЭҐеПѓдї•йБњеЕНеЖНжђ°йАЪињЗurlеПСйАБиѓЈж±ВеЊЧеИ∞иµДжЇРзЪДеЕЈдљУжППињ∞пЉМдї•еЊЧеИ∞зФ®дЇОжШЊз§ЇзЪДдњ°жБѓгАВ
- иЗ™жППињ∞жАІзЪДи¶Бж±ВгАВе¶ВжЮЬдЄАдЄ™иµДжЇРдЄ≠еМЕеРЂдЇЖдЄАдЄ™еѓєеЕґеЃГиµДжЇРињЫи°МеЉХзФ®зЪДжХ∞зїДпЉМйВ£дєИзФ®жИЈе∞±йЬАи¶БйАЪињЗиѓ•ж†Зз≠ЊжЭ•еЖ≥еЃЪеИ∞еЇХиЃњйЧЃеә䪙襀еЉХзФ®зЪДиµДжЇРгАВ
гААгААељУзДґпЉМе¶ВжЮЬйЬАи¶БеЬ®е±Хз§ЇDoleжЮЬж±БзЪДй°µйЭҐдЄ≠йЬАи¶БDoleињЩдЄ™еУБзЙМзЪДеЃМжХідњ°жБѓпЉМжИСдїђдєЯеПѓдї•е∞ЖеЃГзЫіжО•еµМеИ∞DoleжЮЬж±БзЪДи°®з§ЇдЄ≠пЉЪ
1 {
2 "uri" : "/api/items/1438299",
3 "label" : "Dole Grape Juice",
4 "price" : "$3.99",
5 "brand" : {
6 "uri" : "/api/brands/32059",
7 "label" : "Dole",
8 "description" : "An American-based agricultural multinational corporation."
9 }
10 вА¶вА¶
11 }
гААгААељУзДґпЉМе¶ВжЮЬдЄАдЄ™иµДжЇРзЪД谮积姙ињЗе§НжЭВпЉМиАМдЄФжЬЙдЇЫе±ЮжАІеЃЮйЩЕдЄКжШѓзЫЄдЇТеЕ≥иБФзЪДпЉМйВ£дєИжИСдїђдєЯеПѓдї•йАЪињЗдЄАдЄ™е±ЮжАІе∞ЖеЃГдїђељТзїУеЬ®дЄАиµЈпЉЪ
1 {
2 "uri" : "/api/items/1438299",
3 "label" : "Dole Grape Juice",
4 "price" : "$3.99",
5 "brand" : {
6 "uri" : "/api/brands/32059",
7 "label" : "Dole",
8 "description" : "An American-based agricultural multinational corporation."
9 }
10 "nutrient component" : {
11 "sugar" : "14.5",
12 "protein" : "0.3",
13 "fat" : "0.1"
14 }
15 вА¶вА¶
16 }
гААгААеЬ®дЄКйЭҐзЪДDoleжЮЬж±БзЪДи°®з§ЇдЄ≠пЉМжИСдїђдљњзФ®еЯЯnutrient componentжЭ•и°®з§ЇжЙАжЬЙзЪДиР•еЕїжИРеИЖпЉМиАМиѓ•еЯЯеЖЕйГ®зЪДеРДдЄ™е≠РеЯЯеИЩзФ®жЭ•и°®з§ЇдЄАз≥їеИЧзЫЄеЕ≥зЪДиР•еЕїжИРеИЖжЙАеН†жѓФдЊЛгАВ
гААгААеП¶е§ЦпЉМеЬ®дЄНеРМзЪДжГЕеЖµдЄЛпЉМжИСдїђињШеПѓиГљеѓєеРМдЄАдЄ™иµДжЇРжПРдЊЫдЄНеРМзЪДи°®зО∞嚥еЉПгАВдЊЛе¶ВеЬ®дЄАдЄ™иµДжЇРжЮБдЄЇе§НжЭВпЉМеЕґJSONи°®з§ЇзФЪиЗ≥еПѓдї•иЊЊеИ∞еЗ†зЩЊKзЪДжЧґеАЩпЉМжИСдїђеПѓдї•дЄЇиѓ•иµДжЇРжПРдЊЫдЄАдЄ™зЃАеМЦзЙИжЬђпЉМдї•еЬ®йЭЮењЕи¶БзЪДжГЕеЖµдЄЛеЗПе∞СдЉ†иЊУзЪДжХ∞жНЃйЗПгАВ
гААгААдЊЛе¶ВеЬ®egoodsдЄ≠пЉМжИСдїђдЉЪе∞ЖжЯРдЇЫзЙ©зЊОдїЈеїЙзЪДеХЖеУБзљЃдЇОеЃГзЪДй¶Цй°µдЄКпЉМдї•еРЄеЉХзФ®жИЈиі≠дє∞гАВеЬ®зФ®жИЈе∞ЖйЉ†ж†ЗзІїеК®еИ∞жЯРдЄ™еХЖеУБдЄКеєґеБЬзХЩдЄАжЃµжЧґйЧіжЧґпЉМжИСдїђдЉЪдЄЇзФ®жИЈе±Хз§ЇдЄАдЄ™TooltipпЉМеєґеЬ®иѓ•TooltipдЄ≠е±Хз§Їиѓ•еХЖеУБзЪДдЄАйГ®еИЖдњ°жБѓгАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМеРСжЬНеК°зЂѓиѓЈж±Виѓ•еХЖеУБзЪДжЙАжЬЙдњ°жБѓдї•е±Хз§ЇTooltipдЊњжШЊеЊЧжЬЙдЇЫжХИзОЗдљОдЄЛдЇЖгАВ
гААгААжЬЙжЧґеАЩпЉМдЄАдЄ™иµДжЇРеПѓиГљеєґдЄНжФѓжМБзЙєеЃЪзФ®жИЈжЙІи°МжЯРдЄ™жУНдљЬгАВдЊЛе¶ВдЄАдЄ™зЃ°зРЖеСШжЙАеИЫеїЇзЪДиµДжЇРеПѓиГљеѓєжЩЃйАЪзФ®жИЈеП™иѓїгАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМжИСдїђйЬАи¶Бз¶Бж≠ҐжЩЃйАЪзФ®жИЈеѓєиѓ•иµДжЇРзЪДдњЃжФєеТМеИ†йЩ§гАВдЄЇдЇЖиГљжШОз°ЃеЬ∞еСКзЯ•зФ®жИЈдїЦжЙАеЕЈжЬЙзЪДжЭГйЩРпЉМжИСдїђйЬАи¶БдЄАдЄ™иГљжШЊеЉПеЬ∞ж†Зз§ЇзФ®жИЈеПѓдї•еЬ®дЄАдЄ™иµДжЇРдЄКжЙАжЙІи°МжУНдљЬзЪДзїДжИРгАВеЬ®RESTеУНеЇФдЄ≠пЉМињЩзІНзїДжИР襀зІ∞дЄЇHypermedia ControlsгАВдЊЛе¶ВеѓєдЇОдЄАдЄ™жЩЃйАЪзФ®жИЈпЉМеЕґдїОegoodsдЄ≠жЙАињФеЫЮзЪДеИЖз±їеИЧи°®е∞Же¶ВдЄЛжЙАз§ЇпЉЪ
1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 [
6 {
7 "label" : "Food",
8 "uri" : "/api/categories/1",
9 "actions" : ["GET"]
10 }, {
11 "label" : "Clothes",
12 "uri" : "/api/categories/2",
13 "actions" : ["GET"]
14 }
15 ...
16 {
17 "label" : "Electronics",
18 "uri" : "/api/categories/25",
19 "actions" : ["GET"]
20 }
21 ]
гААгААеПѓдї•зЬЛеИ∞пЉМеЬ®дЄКйЭҐзЪДеИЖз±їеИЧи°®дЄ≠пЉМжИСдїђйАЪињЗactionsеЯЯжШЊеЉПеЬ∞ж†Зз§ЇдЇЖзФ®жИЈеПѓдї•еЬ®еРДдЄ™з±їеИЂдЄКжЙАиГљжЙІи°МзЪДжУНдљЬгАВиАМеѓєдЇОзЃ°зРЖеСШпЉМеЕґињШеПѓдї•жЙІи°МдњЃжФєпЉМеИ†йЩ§з≠ЙжУНдљЬпЉЪ
1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 [
6 {
7 "label" : "Food",
8 "uri" : "/api/categories/1",
9 "actions" : ["GET", "PUT", "DELETE"]
10 }, {
11 "label" : "Clothes",
12 "uri" : "/api/categories/2",
13 "actions" : ["GET", "PUT", "DELETE"]
14 }
15 ...
16 {
17 "label" : "Electronics",
18 "uri" : "/api/categories/25",
19 "actions" : ["GET", "PUT", "DELETE"]
20 }
21 ]
гААгААиАМеЬ®дЄАз≥їеИЧиЊГдЄЇиСЧеРНзЪДRESTз≥їзїЯдЄ≠пЉМе¶ВSun Cloud APIпЉМеЕґжЫіжШѓйАЪињЗHypermedia ControlsеЃЪдєЙдЇЖйЩ§CRUDдєЛе§ЦзЪДеК®иѓНгАВе¶ВеѓєдЇОдЄАдЄ™иЩЪжЛЯжЬЇпЉМеЕґеЬ®ињРи°МзКґжАБдЄЛеПѓдї•жЙІи°МеБЬж≠ҐеСљдї§пЉМиАМеЬ®еБЬж≠ҐзКґжАБдЄЛеПѓдї•жЙІи°МеРѓеК®еСљдї§пЉЪ
1 {
2 "vms" : [
3 {
4 "id" : "1",
5 ......
6 "status" : "stopped",
7 "links" : [
8 {
9 "rel" : "start",
10 "method" : "post",
11 "uri" : "vms/1?op=start"
12 }
13 ]
14 }, {
15 "id" : "2",
16 ......
17 "status" : "started",
18 "links" : [
19 {
20 "rel" : "stop",
21 "method" : "post",
22 "uri" : "vms/2?op=stop"
23 }
24 ]
25 }
26 ]
27 }
гААгААдљЖжШѓдЄАдЄ™еЄЄиІБзЪДиІВзВєжШѓпЉЪе¶ВжЮЬдЄАдЄ™иµДжЇРйЬАи¶БйЩ§CRUDдєЛе§ЦзЪДйҐЭе§ЦзЪДеК®иѓНпЉМйВ£дєИињЩзІНйЬАж±ВеЄЄеЄЄи°®з§ЇжИСдїђеѓєдЇОжЯРдЄ™иµДжЇРзЪДеЃЪдєЙеєґдЄНжШѓеНБеИЖеРИзРЖгАВеЫ†ж≠§еЬ®йБЗеИ∞ињЩзІНжГЕеЖµжЧґпЉМиљѓдїґеЉАеПСдЇЇеСШй¶ЦеЕИйЬАи¶БиАГиЩСдЄЇиµДжЇРжЈїеК†йҐЭе§ЦзЪДеК®иѓНжШѓеР¶еРИйАВгАВ
 
жЧ†зКґжАБзЇ¶жЭЯ
гААгААеЬ®Roy FieldingзЪДиЃЇжЦЗдЄ≠пЉМеЕґдЄЇRESTжЈїеК†дЇЖдЄАдЄ™жЧ†зКґжАБзЇ¶жЭЯпЉЪ
 
We next add a constraint to the client-server interaction: communication must be stateless in nature вА¶ such that each request from client to server must contain all of the information necessary to understand the request, and cannot take advantage of any stored context on the server. Session state is therefore kept entirely on the client.
 
гААгААдїОдЄКйЭҐзЪДйЩИињ∞дЄ≠еПѓдї•зЬЛеИ∞пЉМеЬ®дЄАдЄ™RESTз≥їзїЯдЄ≠пЉМзФ®жИЈзЪДзКґжАБдЉЪйЪПзЭАиѓЈж±ВеЬ®еЃҐжИЈзЂѓеТМжЬНеК°зЂѓдєЛйЧіжЭ•еЫЮдЉ†йАТгАВињЩдєЯдЊњжШѓRESTињЩдЄ™зЉ©еЖЩдЄ≠STпЉИState TransferпЉЙзЪДжЭ•еОЖгАВ
гААгААдЄЇRESTз≥їзїЯжЈїеК†ињЩдЄ™зЇ¶жЭЯжЬЙдїАдєИе•ље§ДеСҐпЉЯдЄїи¶БињШжШѓеЯЇдЇОйЫЖзЊ§жЙ©е±ХжАІзЪДиАГиЩСгАВе¶ВжЮЬRESTжЬНеК°дЄ≠иЃ∞ељХдЇЖзФ®жИЈзЫЄеЕ≥зЪДзКґжАБпЉМйВ£дєИеЬ®йЫЖзЊ§дЄ≠пЉМињЩдЇЫзФ®жИЈзЫЄеЕ≥зЪДзКґжАБе∞±йЬАи¶БеПКжЧґеЬ∞еЬ®йЫЖзЊ§дЄ≠зЪДеРДдЄ™жЬНеК°еЩ®дєЛйЧіеРМж≠•гАВеѓєзФ®жИЈзКґжАБзЪДеРМж≠•е∞ЖдЉЪжШѓдЄАдЄ™йЭЮеЄЄж£ШжЙЛзЪДйЧЃйҐШпЉЪељУдЄАдЄ™зФ®жИЈзЪДзЫЄеЕ≥зКґжАБеЬ®дЄАдЄ™жЬНеК°еЩ®дЄКеПСзФЯдЇЖжЫіжФєпЉМйВ£дєИеЬ®дїАдєИжЧґеАЩпЉМдїАдєИжГЕеЖµдЄЛеѓєињЩдЇЫзКґжАБињЫи°МеРМж≠•пЉЯе¶ВжЮЬиѓ•зКґжАБеРМж≠•жШѓеРМж≠•ињЫи°МзЪДпЉМйВ£дєИеРМжЧґеИЈжЦ∞е§ЪдЄ™жЬНеК°еЩ®дЄКзЪДзФ®жИЈзКґжАБе∞ЖеѓЉиЗіеѓєзФ®жИЈиѓЈж±ВзЪДе§ДзРЖеПШеЊЧеЉВеЄЄзЉУжЕҐгАВе¶ВжЮЬиѓ•еРМж≠•жШѓеЉВж≠•зЪДпЉМйВ£дєИзФ®жИЈеЬ®еПСйАБдЄЛдЄАдЄ™иѓЈж±ВжЧґпЉМеЕґеЃГжЬНеК°еЩ®е∞ЖеПѓиГљзФ±дЇОзФ®жИЈзКґжАБдЄНеРМж≠•зЪДеОЯеЫ†жЧ†ж≥Хж≠£з°ЃеЬ∞е§ДзРЖзФ®жИЈзЪДиѓЈж±ВгАВйЩ§ж≠§дєЛе§ЦпЉМе¶ВжЮЬйЫЖзЊ§ињЫи°МдЇЖдЄНеБЬжЬЇзЪДж®™еРСжЙ©е±ХпЉМйВ£дєИзФ®жИЈзКґжАБзЪДеРМж≠•йЬАи¶Бе¶ВдљХеЃМжИРпЉЯињЩдЇЫеЃЮйЩЕдЄКйГљжШѓйЭЮеЄЄйЪЊдї•е§ДзРЖзЪДйЧЃйҐШгАВ
гААгААдљЖжШѓзО∞жЬЙзЪДеЊИе§ЪиЊГдЄЇжµБи°МзЪДжКАжЬѓеПКиІДиМГеЃЮйЩЕдЄКйГљж≤°жЬЙйЩРеИґзФ®жИЈзЪДиѓЈж±ВжШѓжЧ†зКґжАБзЪДгАВзЫЄдњ°жВ®зЯ•йБУпЉМдЄАдЄ™жКАжЬѓжИЦиІДиМГеЃЮйЩЕдЄКйГљжЛ•жЬЙдЄАдЄ™зФЯжАБеЬИгАВеЬ®иѓ•зФЯжАБеЬИдєЛеЖЕзЪДеРДжКАжЬѓдєЛйЧіеПѓдї•иЊГе•љеЬ∞е•СеРИеЬ®дЄАиµЈгАВе∞§еЕґжШѓпЉМжЬЙдЇЫжКАжЬѓеЃЮйЩЕдЄКе∞±дЉЪдї•иѓ•зФЯжАБеЬИдЄ≠зЪДж†ЄењГжКАжЬѓжИЦиІДиМГжЙАеїЇзЂЛзЪДеБЗиЃЊдєЛдЄКжЭ•еЃЮзО∞иЗ™еЈ±зЪДеКЯиГљгАВе¶ВжЮЬеЄМжЬЫз¶Бж≠Ґиѓ•еБЗиЃЊпЉМйВ£дєИиЃ©жЯРдЇЫжКАжЬѓеЈ•дљЬиµЈжЭ•е∞±жШѓйЭЮеЄЄеЫ∞йЪЊзЪДдЇЛжГЕдЇЖгАВ
гААгААе∞±дї•жР≠еїЇеЯЇдЇОHTTPзЪДRESTжЬНеК°дЄЇдЊЛгАВеЬ®HTTPдЄ≠пЉМдЄАдЄ™йЗНи¶БзЪДеКЯиГље∞±жШѓCookieеТМSessionзЪДдљњзФ®пЉИRFC6265пЉЙгАВиѓ•еКЯиГљдЉЪеЬ®жЬНеК°еЩ®йЗМдњЭзХЩдЄАдЄ™зКґжАБгАВеЫ†ж≠§еЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTз≥їзїЯдЄ≠пЉМжИСдїђеЄЄеЄЄйЬАи¶БйБњеЕНдљњзФ®ињЩдЇЫеЬ®жЬНеК°еЩ®йЗМйЭҐдњЭзХЩзКґжАБзЪДжКАжЬѓгАВдљЖжШѓжЯРдЇЫжКАжЬѓпЉМе¶ВзФ®жИЈзЪДзЩїйЩЖпЉМеЃЮйЩЕдЄКеЄЄеЄЄйЬАи¶БеЬ®жЬНеК°еЩ®дЄ≠жЈїеК†дЄАдЄ™зКґжАБгАВ
гААгААжЙАдї•еЬ®stackoverflowдЄ≠пЉМжИСдїђеЄЄеЄЄдЉЪзЬЛеИ∞жЬЙдЇЇйЧЃпЉЪжИСзО∞еЬ®дљњзФ®дЇЖињЩж†ЈдЄАзІНиІ£еЖ≥жЦєж°ИгАВињЩж†ЈеЃЮзО∞жШѓдЄНжШѓRESTfulпЉЯж≠§жЧґдЄАдЇЫдЇЇе∞±дЉЪиѓіпЉМињЩдЄНжШѓRESTfulгАВдљЖжШѓpure RESTfulеТМalmost RESTfulдєЛйЧізЪДеМЇеИЂдЄїи¶БињШжШѓеЬ®дЇОдЄАдЄ™жШѓзРЖиЃЇпЉМдЄАдЄ™жШѓеЈ•з®ЛгАВеЬ®еЈ•з®ЛдЄ≠пЉМиљїеЊЃеЬ∞ињЭеПНдЇЖдЄАдЄ™еЗЖеИЩеєґдЄНдЄАеЃЪдї£и°®ињЩдЄ™иІ£еЖ≥жЦєж°ИдЄАжЧ†жШѓе§ДгАВиАМжШѓи¶БзЬЛйБµеЃИиѓ•еЗЖеИЩеТМиљїеЊЃеЬ∞ињЭеПНдЇЖиѓ•еЗЖеИЩдєЛеРОеЈ•дљЬйЗПзЪДе§Іе∞Пдї•еПКеРОжЬЯзЪДзїіжК§жИРжЬђпЉЪдєЛжЙАдї•жПРеЗЇдЄАз≥їеИЧеЗЖеИЩпЉМйВ£жШѓеЫ†дЄЇйБµеЃИиѓ•еЗЖеИЩжЛ•жЬЙдЄАеЃЪзЪДе•ље§ДгАВе¶ВжЮЬеѓєиѓ•еЗЖеИЩзЪДиљїеЊЃињЭеПНеПѓдї•еЗПе∞Се§ІйЗПзЪДеЈ•дљЬйЗПпЉМиАМдЄФйБµеЃИеЗЖеИЩзЪДе•ље§Деєґж≤°жЬЙжґИ姱пЉМжИЦиАЕжШѓйАЪињЗеП¶дЄАж†ЈжКАжЬѓеПѓдї•ењЂйАЯеЬ∞йЗНжЦ∞иОЈеЊЧиѓ•е•ље§ДпЉМйВ£дєИеѓєеЗЖеИЩзЪДиљїеЊЃињЭеПНжШѓеАЉеЊЧзЪДгАВ
 
Authentication
гААгААеЕґеЃЮеЬ®дЄКдЄАиКВдЄ≠пЉМжИСдїђеЈ≤зїПжПРеЗЇдЇЖжЧ†зКґжАБзЇ¶жЭЯзїЩRESTеЃЮзО∞еЄ¶жЭ•зЪДйЇїзГ¶пЉЪзФ®жИЈзЪДзКґжАБжШѓйЬАи¶БеЕ®йГ®дњЭе≠ШеЬ®еЃҐжИЈзЂѓзЪДгАВељУзФ®жИЈйЬАи¶БжЙІи°МжЯРдЄ™жУНдљЬзЪДжЧґеАЩпЉМеЕґйЬАи¶Бе∞ЖжЙАжЬЙзЪДжЙІи°Миѓ•иѓЈж±ВжЙАйЬАи¶БзЪДдњ°жБѓжЈїеК†еИ∞иѓЈж±ВдЄ≠гАВиѓ•иѓЈж±Ве∞ЖеПѓиÚ襀RESTжЬНеК°йЫЖзЊ§дЄ≠зЪДдїїжДПжЬНеК°еЩ®е§ДзРЖпЉМиАМдЄНйЬАи¶БжЛЕењГиѓ•жЬНеК°еЩ®дЄ≠жШѓеР¶е≠ШжЬЙзФ®жИЈзЫЄеЕ≥зЪДзКґжАБгАВ
гААгААдљЖжШѓеЬ®зО∞жЬЙзЪДеРДзІНеЯЇдЇОHTTPзЪДWebжЬНеК°дЄ≠пЉМжИСдїђеЄЄеЄЄдљњзФ®дЉЪиѓЭжЭ•зЃ°зРЖзФ®жИЈзКґжАБпЉМиЗ≥е∞СжШѓзФ®жИЈзЪДзЩїйЩЖзКґжАБгАВеЫ†ж≠§пЉМRESTз≥їзїЯзЪДжЧ†зКґжАБзЇ¶жЭЯеЃЮйЩЕдЄКеєґдЄНжШѓдЄАдЄ™еѓєдЉ†зїЯзФ®жИЈзЩїељХеКЯиГљеПЛе•љзЪДзЇ¶жЭЯпЉЪеЬ®дЉ†зїЯзЩїйЩЖињЗз®ЛдЄ≠пЉМеЕґжЬђиЇЂе∞±жШѓйАЪињЗзФ®жИЈжЙАжПРдЊЫзЪДзФ®жИЈеРНеТМеѓЖз†Бз≠ЙеЬ®жЬНеК°зЂѓеИЫеїЇдЄАдЄ™зФ®жИЈзЪДзЩїйЩЖзКґжАБпЉМиАМRESTзЪДжЧ†зКґжАБзЇ¶жЭЯдЄЇдЇЖж®™еРСжЙ©е±ХжАІеНідЄНжГ≥и¶БињЩзІНзКґжАБгАВиАМињЩдєЯе∞±жШѓдЄЇеЯЇдЇОHTTPзЪДRESTжЬНеК°жЈїеК†иЇЂдїљй™МиѓБеКЯиГљзЪДеЫ∞йЪЊдєЛе§ДгАВ
гААгААдЄЇдЇЖиІ£еЖ≥иѓ•йЧЃйҐШпЉМжЬАдЄЇзїПеЕЄдєЯжЬАзђ¶еРИRESTиІДиМГзЪДеЃЮзО∞жШѓеЬ®жѓПжђ°еПСйАБиѓЈж±ВзЪДжЧґеАЩйГље∞ЖзФ®жИЈзЪДзФ®жИЈеРНеТМеѓЖз†БйГљеПСйАБзїЩжЬНеК°еЩ®гАВиАМжЬНеК°еЩ®е∞Жж†єжНЃиѓЈж±ВдЄ≠зЪДзФ®жИЈеРНеТМеѓЖз†Би∞ГзФ®зЩїйЩЖжЬНеК°пЉМдї•дїОиѓ•жЬНеК°дЄ≠еЊЧеИ∞зФ®жИЈжЙАеѓєеЇФзЪДIdentityеТМеЕґжЙАеЕЈжЬЙзЪДжЭГйЩРгАВжО•дЄЛжЭ•пЉМеЬ®RESTжЬНеК°дЄ≠ж†єжНЃзФ®жИЈзЪДжЭГйЩРжЭ•иЃњйЧЃиµДжЇРгАВ

 
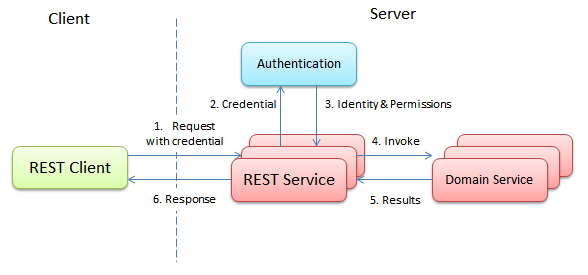
гААгААињЩйЗМжЬЙдЄАдЄ™йЧЃйҐШе∞±жШѓзЩїйЩЖзЪДжАІиГљгАВйЪПзЭАз≥їзїЯељУеЙНзЪДеК†еѓЖзЃЧж≥ХиґКжЭ•иґКе§НжЭВпЉМзЩїйЩЖеЈ≤зїПдЄНеЖНжШѓдЄАдЄ™иљїйЗПзЇІзЪДжУНдљЬгАВеЫ†ж≠§зФ®жИЈжЙАеПСйАБзЪДжѓПжђ°иѓЈж±ВйГљи¶Бж±ВдЄАжђ°зЩїйЩЖеѓєдЇОжХідЄ™з≥їзїЯиАМи®Ае∞±жШѓдЄАдЄ™еЈ®е§ІзЪДзУґйҐИгАВ
гААгААеЬ®ељУеЙНпЉМиІ£еЖ≥иѓ•йЧЃйҐШзЪДжЦєж≥ХдЄїи¶БжШѓдЄАдЄ™зЛђзЂЛзЪДзЉУе≠Шз≥їзїЯпЉМе¶ВжХідЄ™йЫЖзЊ§еФѓдЄАзЪДзЩїйЩЖжЬНеК°еЩ®гАВдљЖжШѓзЉУе≠Шз≥їзїЯжЬђиЇЂжЙАе≠ШеВ®зЪДдїНзДґжШѓзФ®жИЈзЪДзЩїйЩЖзКґжАБгАВеЫ†ж≠§иѓ•иІ£еЖ≥жЦєж°Ие∞ЖдїНзДґиљїеЊЃеЬ∞ињЭеПНдЇЖRESTзЪДжЧ†зКґжАБзЇ¶жЭЯгАВ
гААгААињШжЬЙдЄАдЄ™з±їдЉЉзЪДжЦєж≥ХжШѓйАЪињЗжЈїеК†дЄАдЄ™дї£зРЖжЭ•еЃМжИРзЪДгАВиѓ•дї£зРЖдЉЪеЃМжИРзФ®жИЈзЪДзЩїйЩЖеєґиОЈеЊЧиѓ•зФ®жИЈжЙАжЛ•жЬЙзЪДжЭГйЩРгАВжО•дЄЛжЭ•пЉМиѓ•дї£зРЖдЉЪе∞ЖдЄОзКґжАБжЬЙеЕ≥зЪДдњ°жБѓдїОиѓЈж±ВдЄ≠еИ†йЩ§пЉМеєґжЈїеК†зФ®жИЈзЪДжЭГйЩРдњ°жБѓгАВеЬ®зїПињЗдЇЖињЩзІНе§ДзРЖдєЛеРОпЉМињЩдЇЫиѓЈж±Ве∞±еПѓдї•иљђеПСеИ∞еЕґеРОзЪДеРДдЄ™жЬНеК°еЩ®дЄКдЇЖгАВиљђеПСзЫЃзЪДеЬ∞жЙАеЬ®зЪДжЬНеК°еЩ®еИЩдЉЪеБЗиЃЊжЙАжЬЙдЉ†еЕ•зЪДиѓЈж±ВйГљжШѓеРИж≥ХзЪДеєґзЫіжО•еѓєињЩдЇЫиѓЈж±ВињЫи°Ме§ДзРЖгАВ
 
 

 
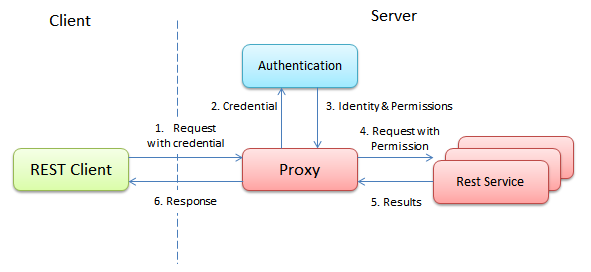
гААгААеПѓдї•зЬЛеИ∞пЉМжЧ†иЃЇжШѓдЄАдЄ™зЛђзЂЛзЪДзЩїйЩЖжЬНеК°еЩ®ињШжШѓдЄЇжХідЄ™йЫЖзЊ§жЈїеК†дЄАдЄ™дї£зРЖпЉМз≥їзїЯдЄ≠йГље∞ЖжЬЙдЄАдЄ™еЬ∞жЦєдњЭзХЩдЇЖзФ®жИЈзЪДзЩїйЩЖзКґжАБгАВињЩеЃЮйЩЕдЄКеТМеЬ®йЫЖзЊ§дЄ≠еѓєдЉЪиѓЭйЫЖдЄ≠ињЫи°МзЃ°зРЖеєґж≤°жЬЙдїАдєИдЄНеРМгАВдєЯе∞±жШѓиѓіпЉМжИСдїђжЙАе∞ЭиѓХзЪДйАЪињЗз¶Бж≠ҐдљњзФ®дЉЪиѓЭжЭ•иЊЊжИРеЃМеЕ®зЪДжЧ†зКґжАБеєґдЄНзО∞еЃЮгАВеЫ†ж≠§еЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTжЬНеК°дЄ≠пЉМдЄЇзЩїйЩЖеКЯиГљдљњзФ®йЫЖдЄ≠зЃ°зРЖзЪДдЉЪиѓЭжШѓеРИзРЖзЪДгАВ
гААгААжЧҐзДґжИСдїђжФЊжЭЊдЇЖеѓєRESTз≥їзїЯзЪДжЧ†зКґжАБзЇ¶жЭЯпЉМйВ£дєИдЄАдЄ™RESTз≥їзїЯжЙАеПѓдї•дљњзФ®зЪДзЩїйЩЖжЬЇеИґе∞ЖдЄїи¶БеИЖдЄЇдї•дЄЛдЄ§зІНпЉЪ
гААгАА1.¬†¬† еЯЇдЇОHTTPSзЪДBasic Access Authentication
еЕґе•ље§ДжШѓеЕґжШУдЇОеЃЮзО∞пЉМиАМдЄФдЄїжµБзЪДжµПиІИеЩ®йГљжПРдЊЫдЇЖеѓєиѓ•еКЯиГљзЪДжФѓжМБгАВдљЖжШѓзФ±дЇОзЩїйЩЖз™ЧеП£йГљжШѓзФ±жµПиІИеЩ®жЙАжПРдЊЫзЪДпЉМеЫ†ж≠§еЕґдЄОдЇІеУБе§ЦиІВжЬЙеЊИе§ІдЄНеРМгАВйЩ§ж≠§дєЛе§ЦпЉМжµПиІИеЩ®йГљж≤°жЬЙжПРдЊЫзЩїеЗЇзЪДеКЯиГљпЉМдєЯж≤°жЬЙжПРдЊЫжЙЊеЫЮеѓЖз†Бз≠ЙеКЯиГљгАВ
гААгАА2.¬†¬† еЯЇдЇОCookieеПКSessionзЪДзЃ°зРЖ
еЬ®дљњзФ®CookieжЭ•зЃ°зРЖзФ®жИЈзЪДж≥®еЖМзКґжАБзЪДжЧґеАЩпЉМеЕґеЃЮйЩЕдЄКе∞±жШѓе∞ЖжЬНеК°зЂѓжЙАињФеЫЮзЪДCookieеЬ®жѓПжђ°еПСйАБиѓЈж±ВзЪДжЧґеАЩжЈїеК†еИ∞иѓЈж±ВдЄ≠гАВиЩљзДґиѓіињЩдЄ™CookieеєґйЭЮе≠ШеВ®дЇЖзФ®жИЈеЇФзФ®зЪДзКґжАБпЉМдљЖжШѓеЕґеЃЮйЩЕе≠ШеВ®дЇЖзФ®жИЈзЪДзЩїйЩЖзКґжАБгАВеЫ†ж≠§еЃҐжИЈзЂѓзЪДиІТеЇ¶жЭ•иЃ≤пЉМзФ±жЬНеК°зЂѓзЃ°зРЖзЪДSessionеєґдЄНзђ¶еРИRESTжЙАеА°еѓЉзЪДжЧ†зКґжАБзЪДи¶Бж±ВгАВ
гААгААеПѓдї•иѓіпЉМдЄКйЭҐзЪДдЄ§зІНжЦєж≥ХеРДжЬЙдЉШеК£гАВеПѓиГљзђђдЇМзІНжЦєж≥ХдїОеЃҐжИЈзЂѓзЪДиІТеЇ¶зЬЛжЭ•еєґдЄНжШѓRESTfulзЪДпЉМдљЖжШѓеЕґдЉШеКњеИЩеЬ®дЇОеЊИе§Ъз±їеЇУйГљзЫіжО•жПРдЊЫдЇЖеѓєиѓ•еКЯиГљзЪДжФѓжМБпЉМдїОиАМзЃАеМЦдЇЖдЉЪиѓЭзЃ°зРЖжЬНеК°еЩ®зЪДеЃЮзО∞гАВ
гААгААеЬ®ињЩйЗМй°ЇдЊњжПРдЄАеП•пЉМе¶ВжЮЬй°єзЫЃиґ≥е§Яе§ІпЉМе∞ЖдЄАдЇЫSSOдЇІеУБйЫЖжИРеИ∞жЬНеК°дЄ≠дєЯжШѓдЄНйФЩзЪДйАЙжЛ©гАВ
 
зЙИжЬђзЃ°зРЖ
гААгААеЬ®еЙНйЭҐеЈ≤зїПжПРеИ∞ињЗпЉМдЄАдЄ™RESTз≥їзїЯдЄЇиµДжЇРжЙАжКљи±°еЗЇзЪДURIеЃЮйЩЕдЄКжШѓеѓєзФ®жИЈзЪДдЄАзІНжЙњиѓЇгАВдљЖеПНињЗжЭ•иѓіпЉМиљѓдїґеЉАеПСдЇЇеСШдєЯеЊИйЪЊйҐДзЯ•дЄАдЄ™иµДжЇРзЪДеРДжЦєйЭҐзЙєеЊБе¶ВдљХеЬ®жЬ™жЭ•еПСзФЯеПШеМЦпЉМдїОиАМжПРдЊЫдЄАдЄ™ж∞ЄињЬдЄНеПШзЪДURIгАВ
гААгААеЬ®дЄАдЄ™RESTз≥їзїЯйАРжЄРеПСе±ХзЪДињЗз®ЛдЄ≠пЉМжЦ∞зЪДе±ЮжАІпЉМжЦ∞зЪДиµДжЇРе∞ЖйАРжЄР襀棿еК†еИ∞иѓ•з≥їзїЯдЄ≠гАВеЬ®ињЩдЇЫжЫіжФєињЗз®ЛдЄ≠пЉМиµДжЇРзЪДURIпЉМиЃњйЧЃиµДжЇРзЪДеК®иѓНпЉМеУНеЇФдЄ≠зЪДStatus Codeе∞ЖдЄНиГљеПСзФЯеПШеМЦгАВж≠§жЧґиљѓдїґеЉАеПСдЇЇеСШжЙАеБЪзЪДеЈ•дљЬе∞±жШѓеЬ®зО∞жЬЙз≥їзїЯдЄКзїіжК§REST APIзЪДеРОеРСеЕЉеЃєжАІгАВ
гААгААељУиµДжЇРеПСзФЯдЇЖињЗе§ЪзЪДеПШеМЦпЉМеОЯжЬЙзЪДURIиЃЊиЃ°еЈ≤зїПеЊИйЪЊеЕЉеЃєзО∞жЬЙиµДжЇРеЇФжЬЙзЪДеЃЪдєЙжЧґпЉМиљѓдїґеЉАеПСдЇЇеСШе∞±йЬАи¶БиАГиЩСжШѓеР¶еЇФиѓ•жПРдЊЫдЄАдЄ™жЦ∞зЙИжЬђзЪДREST APIгАВйВ£дєИжИСдїђиѓ•е¶ВдљХеѓєиµДжЇРзЪДзЙИжЬђињЫи°МзЃ°зРЖеСҐпЉЯ
гААгААй¶ЦеЕИи¶БиАГиЩСзЪДе∞±жШѓпЉМжЦ∞APIзЪДзЙИжЬђдњ°жБѓжШѓеР¶еЇФељУеМЕеРЂеЬ®иµДжЇРзЪДURIдЄ≠гАВињЩеЬ®еРДиСЧеРНиЃЇеЭЫдЄ≠дїНзДґжШѓдЄАдЄ™дЇЙиЃЃиЊГе§ІзЪДиѓЭйҐШгАВдЄАзІНиІВзВєиЃ§дЄЇеЬ®дЄНеРМзЙИжЬђзЪДAPIдЄ≠пЉМдЄАдЄ™иµДжЇРжЛ•жЬЙдЄНеРМзЪДеЬ∞еЭАеЬ®дЄАеЃЪз®ЛеЇ¶дЄКињЭеПНдЇЖHATEOASпЉЪURIеП™жШѓзФ®жЭ•жМЗеЃЪдЄАдЄ™иµДжЇРжЙАеЬ®зЪДдљНзљЃпЉМиАМдЄНжШѓиѓ•иµДжЇРе¶ВдљХ襀жКљи±°гАВе¶ВжЮЬдЄАдЄ™иµДжЇРзФ±дЄНеРМзЪДURIж†Зз§ЇеЕґдЄНеРМзЪДи°®зО∞嚥еЉПпЉМйВ£дєИзФ®жИЈе∞ЖжЧ†ж≥ХйАЪињЗдЄАдЄ™еУНеЇФдЄ≠жЙАж†Зз§ЇзЪДURIеЊЧеИ∞еЕґеЃГURIжЙАжМЗеРСзЪД谮积嚥еЉПгАВиАМдЄФеЬ®URIдЄ≠жЈїеК†дЇЖжЬЙеЕ≥зЙИжЬђзЪДдњ°жБѓдєЯе∞±ж†Зз§ЇзЭАеЕґеПѓиГљдЉЪйЪПзЭАжЧґйЧізЪДжО®зІїеПСзФЯеПШеМЦгАВ
гААгААдЄАзІНдљњзФ®зЛђзЂЛURIзЪДжЦєж≥ХжШѓеЯЇдЇОAcceptе§ігАВеЬ®дЄАдЄ™иѓЈж±ВдЄ≠пЉМжИСдїђеЄЄеЄЄж†ЗжШОдЇЖAcceptе§іпЉМдї•ж†Зз§ЇеЃҐжИЈзЂѓеЄМжЬЫеЊЧеИ∞зЪДи°®зО∞嚥еЉПгАВеЬ®иѓ•е§ідЄ≠пЉМзФ®жИЈеПѓдї•жЈїеК†жЙАиѓЈж±ВзЪДиµДжЇРзЪДзЙИжЬђдњ°жБѓпЉЪ
1 GET /api/categories/1 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/vnd.ambergarden.egoods-v3+json
гААгААиАМеЬ®жО•жФґеИ∞иѓ•иѓЈж±ВдєЛеРОпЉМжЬНеК°зЂѓе∞ЖињФеЫЮиѓ•иµДжЇРзЪДзђђдЄЙдЄ™зЙИжЬђпЉЪ
1 HTTP/1.1 200 OK
2 Content-Type: application/vnd.ambergarden.egoods-v3+json
3 Content-Length: xxx
4
5 {
6 "uri" : "/api/categories/1",
7 "label" : "Food",
8 вА¶вА¶
9 }
гААгААеПѓдї•зЬЛеИ∞пЉМиѓ•жЦєж≥ХжШѓйЭЮеЄЄдЄ•ж†ЉеЬ∞йБµеЃИRESTз≥їзїЯжЙАжПРеЗЇзЪДзЇ¶жЭЯзЪДгАВдљЖеЕґдєЯеєґдЄНжШѓж≤°жЬЙзЉЇзВєпЉЪжЈїеК†дЄАдЄ™иЗ™еЃЪдєЙMIMEз±їеЮЛпЉИCustom MIME TypeпЉЙдєЯжШѓдЄАдЄ™еЊИйЇїзГ¶зЪДжµБз®ЛпЉМиАМдЄФеЬ®еЊИе§ЪзО∞жЬЙжКАжЬѓдЄ≠йГљж≤°жЬЙеЊИе•љеЬ∞жФѓжМБеЃГпЉМе¶ВHTML5дЄ≠зЪДFormгАВеЫ†ж≠§ињЩзІНжЦєж°ИзЪДзЉЇзВєжШѓеѓєREST APIзФ®жИЈеєґдЄНйВ£дєИеПЛе•љгАВ
гААгААйЩ§ж≠§дєЛе§ЦпЉМеП¶дЄАзІНеЯЇдЇОйЗНеЃЪеРСзЪДиІ£еЖ≥жЦєж°ИдєЯ襀жПРеЗЇгАВиѓ•жЦєж°ИеЕБиЃЄдЄАдЄ™RESTз≥їзїЯжПРдЊЫе§ЪдЄ™зЙИжЬђзЪДAPIпЉМеєґеЬ®URIдЄ≠ж†ЗжШОзЙИжЬђеПЈпЉЪ
1 /api/v2/categories 2 /api/v1/categories
гААгААињЩж†ЈзФ®жИЈеПѓдї•йАЙжЛ©дљњзФ®зЙєеЃЪзЙИжЬђзЪДREST APIжЭ•еЃЮзО∞еЃҐжИЈзЂѓеКЯиГљгАВзФ±дЇОеЕґдљњзФ®еЫЇеЃЪзЙИжЬђзЪДAPIпЉМеЫ†ж≠§еєґдЄНе≠ШеЬ®зЭАдЄАдЄ™иµДжЇРжЬЙе§ЪзІНи°®з§ЇпЉМињЫиАМињЭеПНдЇЖHATEOASзЇ¶жЭЯзЪДйЧЃйҐШгАВ
гААгААеЬ®RESTз≥їзїЯзЪДAPIйЪПжЧґйЧійАРжЄРеПСе±ХеЗЇдЉЧе§ЪзЙИжЬђзЪДжЧґеАЩпЉМз≥їзїЯеѓєAPIзЪДзїіжК§дєЯе∞ЖжИРдЄЇдЄАдЄ™иЊГе§ІзЪДйЧЃйҐШгАВж≠§жЧґе∞±йЬАи¶БйАРжЄРйААељєдЄАдЇЫеєідї£дєЕињЬзЪДAPI зЙИжЬђгАВеѓєињЩдЇЫзЙИжЬђзЪДйААељєдЄїи¶БеИЖдЄЇдЄ§ж≠•пЉЪй¶ЦеЕИе∞ЖеЕґж†ЗдЄЇињЗжЬЯзЪДпЉМдљЖжШѓињШеЬ®дЄАжЃµжЧґйЧіеЖЕжФѓжМБгАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМеѓєињЩдЇЫеЈ≤зїПињЗжЬЯзЪДAPIзЪДиЃњйЧЃе∞ЖеЊЧеИ∞3XXеУНеЇФпЉМе¶В301 Moved PermanentlyпЉМдї•йАЪзЯ•зФ®жИЈиѓ•URIжЙАж†Зз§ЇзЪДиµДжЇРйЬАи¶БдљњзФ®жЦ∞зЙИжЬђзЪДURIињЫи°МиЃњйЧЃгАВиАМеЖНзїПињЗдЄАжЃµжЧґйЧіеРОпЉМеИЩе∞ЖињЗжЬЯзЪДREST APIж†ЗиЃ∞дЄЇеЇЯеЉГзЪДгАВж≠§жЧґзФ®жИЈеЬ®иЃњйЧЃињЩдЇЫURIжЧґе∞ЖињФеЫЮ4XXеУНеЇФпЉМе¶В410 GoneгАВ
гААгААжО•дЄЛжЭ•пЉМиѓ•RESTз≥їзїЯињШеПѓдї•жПРдЊЫдЄАдЄ™йАЪзФ®зЪДREST APIжО•еП£пЉМеєґдЄОжЬАжЦ∞зЙИжЬђзЪДAPIдњЭжМБдЄАиЗіпЉЪ
1 /api/categories
гААгААињЩж†ЈзФ®жИЈињШеПѓдї•йАЙжЛ©дЄАзЫідљњзФ®жЬАжЦ∞зЙИжЬђзЪДAPIпЉМеП™жШѓеРМжЧґдєЯйЬАи¶БдЄАзЫіеѓєеЕґињЫи°МзїіжК§пЉМдї•дњЭжМБдЄОжЬАжЦ∞зЙИжЬђAPIзЪДеЕЉеЃєжАІгАВеЬ®RESTз≥їзїЯзЪДAPIйЪПзЭАжЧґйЧізЪДжО®зІїйАРжЄРеПСзФЯеПШеМЦзЪДжЧґеАЩпЉМиѓ•еЃҐжИЈзЂѓдєЯйЬАи¶БйАРжЄРжЫіжЦ∞иЗ™иЇЂзЪДеКЯиГљгАВ
гААгААдљЖжШѓиѓ•жЦєж≥ХжЬЙдЄАдЄ™йЧЃйҐШпЉЪзФ±йАЪзФ®URIжЙАиЊ®иѓЖеЗЇзЪДеРДдЄ™иµДжЇРйЬАи¶БжШѓз®≥еЃЪзЪДпЉМдЄНиГљеЬ®дЄАеЃЪжЧґйЧідєЛеРО襀еЇЯеЉГпЉМеР¶еИЩдЉЪзїЩзФ®жИЈеЄ¶жЭ•йЭЮеЄЄе§ІзЪДзїіжК§жАІзЪДйЇїзГ¶гАВдЄЊдЊЛжЭ•иѓіпЉМеБЗиЃЊеЃҐжИЈзЂѓйАїиЊСжЈїеК†дЇЖдЄАз≥їеИЧжУНдљЬеИЖз±їзЪДеКЯиГљгАВељУRESTз≥їзїЯеЖ≥еЃЪдЄНеЖНйЗЗзФ®еИЖз±їдљЬдЄЇеХЖеУБељТз±їзЪДж†ЗеЗЖпЉМйВ£дєИеЃҐжИЈзЂѓйАїиЊСдЄ≠дЄОеИЖз±їзЫЄеЕ≥зЪДеРДдЄ™еКЯиГљйГљйЬАи¶БињЫи°Ме§ІеєЕеЇ¶еЬ∞дњЃжФєгАВињЗдЇОйҐСзєБзЪДињЩзІНжФєеК®еЊИеЃєжШУеѓЉиЗізФ®жИЈеѓєиѓ•з≥їзїЯжЙАжПРдЊЫзЪДAPI姱еОїзїіжК§зЪДдњ°ењГгАВеЫ†ж≠§еЬ®жКљи±°иµДжЇРжЧґдЄАеЃЪи¶БеК™еКЫеЬ∞е∞ЖеРДдЄ™иµДжЇРзЪДиЊєзХМиЊ®иѓЖжЄЕж•ЪгАВиЩљзДґиѓіињЩеРђиµЈжЭ•еЊИеРУдЇЇпЉМдљЖжШѓеЬ®зїПињЗдїФзїЖиАГиЩСеРОињЩзІНжГЕеЖµињШжШѓиЊГдЄЇеЃєжШУйБњеЕНзЪДгАВ
гААгААдљЖжШѓеПНињЗжЭ•иѓіпЉМзРЖиЃЇеЄЄеЄЄдЄОеЃЮйЩЕжЬЙдЇЫиД±йТ©пЉМжЫідљХеЖµRESTжШѓеЬ®2000еєіеЈ¶еП≥жПРеЗЇзЪДпЉМжЧ†ж≥ХеБЪеИ∞иГље§ЯйҐДиІБеИ∞еНБдљЩеєіеРОжЙАдљњзФ®зЪДеРДй°єжКАжЬѓгАВеЫ†ж≠§еЬ®е∞љйЗПзђ¶еРИRESTжЙАжПРеЗЇзЪДеРДзЇ¶жЭЯдЄКжПРдЊЫдЄАдЄ™жЬАзЫіиІВзЪДпЉМеЕЈжЬЙжЬАйЂШжШУзФ®жАІзЪДAPIжЙНжШѓзОЛйБУгАВжЧ†йЩРеИґеЬ∞жПРдЊЫеРОеРСеЕЉеЃєжАІжШѓдЄАдЄ™йЭЮеЄЄеЫ∞йЪЊпЉМжИРжЬђйЭЮеЄЄйЂШзЪДдЇЛжГЕгАВеЫ†ж≠§еЬ®зЙИжЬђзЃ°зРЖињЩдЄАжЦєйЭҐдЄКжЭ•иѓіпЉМжИСдїђдєЯйЬАи¶Бе∞љйЗПеЕЉй°Њй°єзЫЃйЬАж±ВеТМеЃМеЕ®йБµдїОзРЖиЃЇињЩдЄ§иАЕдєЛйЧізЪДеє≥и°°гАВ
гААгААиАМеЬ®еРМдЄАдЄ™зЙИжЬђдєЛдЄ≠пЉМжИСдїђеИЩйЬАи¶БдњЭиѓБAPIзЪДеРОеРСеЕЉеЃєжАІгАВдєЯе∞±жШѓиѓіпЉМеЬ®жЈїеК†жЦ∞зЪДиµДжЇРдї•еПКдЄЇиµДжЇРжЈїеК†жЦ∞зЪДе±ЮжАІзЪДжЧґеАЩпЉМеОЯжЬЙзЪДеѓєиµДжЇРињЫи°МжУНдљЬзЪДAPIдєЯеЇФиѓ•жШѓеЈ•дљЬзЪДгАВ
гААгААеѓєдЇОдЄАдЄ™еЯЇдЇОHTTPзЪДRESTжЬНеК°иАМи®АпЉМиљѓдїґеЉАеПСдЇЇеСШйЬАи¶БйБµеЃИе¶ВдЄЛзЪДеЃИеИЩдї•дњЭжМБAPIзЪДеРОеРСеЕЉеЃєжАІпЉЪ
- дЄНиГљеЬ®иѓЈж±ВдЄ≠жЈїеК†жЦ∞зЪДењЕй°їзЪДеПВжХ∞гАВ
- дЄНиГљжЫіжФєжУНдљЬиµДжЇРзЪДеК®иѓНгАВ
- дЄНиГљжЫіжФєеУНеЇФзЪДHTTP statusгАВ
гААгААиАМеЙНеРСеЕЉеЃєжАІеИЩжШЊеЊЧж≤°жЬЙйВ£дєИйЗНи¶БдЇЖгАВRESTжЬНеК°зЪДеЙНеРСеЕЉеЃєжАІи¶Бж±ВзО∞жЬЙзЪДжЬНеК°еЕЉеЃєжЬ™жЭ•зЙИжЬђжЬНеК°зЪДеЃҐжИЈзЂѓгАВдљЖжШѓзФ±дЇОжЬНеК°жПРдЊЫеХЖжЙАжПРдЊЫзЪДжЬНеК°еЄЄеЄЄжШѓжЬАжЦ∞зЙИжЬђпЉМеЫ†ж≠§еѓєеЙНеРСеЕЉеЃєжАІжЬЙи¶Бж±ВзЪДжГЕеЖµеЊИе∞СеЗЇзО∞гАВеП¶е§ЦдЄАзВєжШѓпЉМдЄЇдЄАдЄ™жЬНеК°жПРдЊЫеЙНеРСеЕЉеЃєжАІеЕґеЃЮеєґдЄНйВ£дєИеЃєжШУгАВеЫ†дЄЇињЩи¶Бж±ВиљѓдїґеЉАеПСдЇЇеСШеѓєдЇІеУБзЪДжЬ™жЭ•жЦєеРСињЫи°МйЭЮеЄЄе§ЪзЪДеБЗиЃЊпЉМиАМдЄФињЩдЇЫеБЗиЃЊдЄНиГљжЬЙйФЩиѓѓгАВеПНињЗжЭ•пЉМињЩзІНеѓєжЬНеК°зЪДеЙНеРСеЕЉеЃєжАІзЪДи¶Бж±ВдЄїи¶БзФ±еЃҐжИЈзЂѓиЗ™иЇЂйАЪињЗдњЭжМБеРОеРСеЕЉеЃєжАІжЭ•еЃМжИРгАВ
 
жАІиГљ
гААгААжО•дЄЛжЭ•жИСдїђе∞±жЭ•зЃАеНХеЬ∞иѓіиѓіеЯЇдЇОHTTPзЪДRESTжЬНеК°дЄ≠зЪДжАІиГљйЧЃйҐШгАВеЬ®еЯЇдЇОHTTPзЪДRESTжЬНеК°дЄ≠пЉМжАІиГљжПРеНЗдЄїи¶БеИЖдЄЇдЄ§дЄ™жЦєйЭҐпЉЪRESTжЮґжЮДжЬђиЇЂеЬ®жПРйЂШжАІиГљжЦєйЭҐеБЪеЗЇзЪДеК™еКЫпЉМдї•еПКеЯЇдЇОHTTPеНПиЃЃзЪДдЉШеМЦгАВ
гААгААй¶ЦеЕИи¶БиЃ®иЃЇзЪДе∞±жШѓеѓєзЩїйЩЖжАІиГљзЪДдЉШеМЦгАВеЬ®еЙНйЭҐжИСдїђеЈ≤зїПдїЛзїНињЗпЉМеЬ®дЄАдЄ™еЯЇдЇОHTTPзЪДRESTжЬНеК°дЄ≠пЉМжѓПжђ°йГље∞ЖзФ®жИЈзЪДзФ®жИЈеРНеТМеѓЖз†БеПСйАБеИ∞жЬНеК°зЂѓеєґзФ±жЬНеК°зЂѓй™МиѓБињЩдЇЫдњ°жБѓжШѓеР¶еРИж≥ХжШѓдЄАдЄ™йЭЮеЄЄжґИиАЧиµДжЇРзЪДжµБз®ЛгАВеЫ†ж≠§жИСдїђеЄЄеЄЄйЬАи¶БеЬ®зЩїйЩЖжЬНеК°дЄ≠дљњзФ®дЄАдЄ™зЉУе≠ШпЉМжИЦиАЕжШѓдљњзФ®зђђдЄЙжЦєеНХзВєзЩїйЩЖпЉИSSOпЉЙз±їеЇУгАВ
гААгААйЩ§ж≠§дєЛе§ЦпЉМиљѓдїґеЉАеПСдЇЇеСШињШеПѓдї•йАЪињЗдЄЇеРМдЄАдЄ™иµДжЇРжПРдЊЫдЄНеРМзЪДи°®зО∞嚥еЉПжЭ•еЗПе∞СеЬ®зљСзїЬдЄКдЉ†иЊУзЪДжХ∞жНЃйЗПпЉМдїОиАМжПРйЂШRESTжЬНеК°зЪДжАІиГљгАВ
гААгААиАМеЬ®йЫЖзЊ§еЖЕйГ®жЬНеК°дєЛйЧіпЉМжИСдїђеИЩеПѓдї•дЄНеЖНдљњзФ®JSONпЉМXMLз≠ЙињЩзІНзФ®жИЈеПѓдї•иѓїжЗВзЪДиіЯиљљж†ЉеЉПпЉМиАМжШѓдљњзФ®дЇМињЫеИґж†ЉеЉПгАВињЩж†ЈеПѓдї•е§Іе§ІеЬ∞еЗПе∞СеЖЕйГ®зљСзїЬжЙАйЬАи¶БдЉ†иЊУзЪДжХ∞жНЃйЗПгАВињЩеЬ®еЖЕйГ®зљСзїЬдЇ§жНҐжХ∞жНЃйҐСзєБеєґдЄФжЙАдЉ†иЊУзЪДжХ∞жНЃйЗПеЈ®е§ІжЧґиЊГдЄЇжЬЙжХИгАВ
гААгААжО•дЄЛжЭ•е∞±жШѓRESTз≥їзїЯзЪДж®™еРСжЙ©е±ХгАВеЬ®RESTзЪДжЧ†зКґжАБзЇ¶жЭЯзЪДжФѓжМБдЄЛпЉМжИСдїђеПѓдї•еЊИеЃєжШУеЬ∞еРСRESTз≥їзїЯдЄ≠жЈїеК†дЄАдЄ™жЦ∞зЪДжЬНеК°еЩ®гАВ
гААгААйЩ§дЇЖињЩдЇЫеТМRESTжЮґжЮДжЬђиЇЂзЫЄеЕ≥зЪДжАІиГљжПРеНЗдєЛе§ЦпЉМжИСдїђињШеПѓдї•еЬ®е¶ВдљХжЫійЂШжХИеЬ∞дљњзФ®HTTPеНПиЃЃдЄКеК™еКЫгАВдЄАдЄ™жЬАеЄЄиІБзЪДжЦєж≥Хе∞±жШѓдљњзФ®жЭ°дїґиѓЈж±ВпЉИConditional RequestпЉЙгАВзЃАеНХеЬ∞иѓіпЉМжИСдїђеПѓдї•дљњзФ®е¶ВдЄЛзЪДHTTPе§іжЭ•жЬЙжЭ°дїґеЬ∞е≠ШеПЦиµДжЇРпЉЪ
- ETagпЉЪдЄАдЄ™еѓєзФ®жИЈдЄНйАПжШОзЪДзФ®жЭ•ж†Зз§ЇиµДжЇРеЃЮдЊЛзЪДеУИеЄМеАЉ
- Data-ModifiedпЉЪиµДжЇР襀жЫіжФєзЪДжЧґйЧі
- If-Modified-SinceпЉЪж†єжНЃиµДжЇРзЪДжЫіжФєжЧґйЧіжЬЙжЭ°дїґеЬ∞GetиµДжЇРгАВињЩе∞ЖеЕБиЃЄеЃҐжИЈзЂѓеѓєжЬ™жЫіжФєзЪДиµДжЇРдљњзФ®жЬђеЬ∞зЉУе≠ШгАВ
- If-None-MatchпЉЪж†єжНЃETagзЪДеАЉжЬЙжЭ°дїґеЬ∞GetиµДжЇРгАВ
- If-Unmodified-SinceпЉЪж†єжНЃиµДжЇРзЪДжЫіжФєжЧґйЧіжЬЙжЭ°дїґеЬ∞PutжИЦDeleteиµДжЇРгАВ
- If-MatchпЉЪж†єжНЃETagзЪДеАЉжЬЙжЭ°дїґеЬ∞PutжИЦDeleteиµДжЇРгАВ
гААгААељУзДґпЉМињЩйЗМжЙАжПРеИ∞зЪДдЄАз≥їеИЧжАІиГљдЉШеМЦжЦєж°ИеЃЮйЩЕдЄКдїЕдїЕжШѓжѓФиЊГеЄЄиІБзЪДпЉМдЄОеЯЇдЇОHTTPзЪДRESTжЬНеК°еЕ≥иБФиЊГе§ІзЪДжЦєж°ИгАВеП™жШѓй°ЊиЩСеИ∞ињЗе§ЪеЬ∞йЩИињ∞еТМRESTеЕ≥иБФдЄНе§ІзЪДиѓЭйҐШдЄАжЦєйЭҐжШЊеЊЧжѓФиЊГж≤°жЬЙжХИзОЗпЉМеП¶дЄАжЦєйЭҐдєЯжШѓеЫ†дЄЇйАЪињЗеЖЩеП¶дЄАдЄ™з≥їеИЧеНЪеЃҐеПѓдї•е∞ЖйЧЃйҐШйЩИињ∞еЊЧжЫіеК†жЄЕж•ЪпЉМеЫ†ж≠§еЬ®ињЩйЗМжИСдїђе∞ЖдЄНеЖНзїІзї≠иЃ®иЃЇжАІиГљзЫЄеЕ≥зЪДиѓЭйҐШгАВ
 
зЫЄеЕ≥иµДжЇР
AtomPubпЉЪhttp://atomenabled.org/гАВеЕґжШѓжЬАдЄЇеєњж≥ЫиЃ®иЃЇзЪДеєґеАЯйЙізЪДRESTfulжЬНеК°гАВеЕґзФ±дЉЧе§ЪHTTPеТМRESTдЄУеЃґжЙАзЉЦеЖЩпЉМзФЪиЗ≥еМЕжЛђRoy FieldingжЬђдЇЇдєЯеПВдЄОдЇОеЕґдЄ≠
Roy FieldingзЪДRESTиЃЇжЦЗпЉЪhttp://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm
Roy FieldingзЪДдЄ™дЇЇзљСзЂЩпЉЪhttp://roy.gbiv.com/untangled/гАВ
RFCеИЧи°®пЉЪhttp://www.ietf.org/rfc/
 
zz:https://www.cnblogs.com/loveis715/p/4669091.html




зЫЄеЕ≥жО®иНР
1. **RESTful URLиЃЊиЃ°еОЯеИЩ** - **иµДжЇРеѓЉеРС**пЉЪURLеЇФдї£и°®иµДжЇРпЉМе¶В/users/1и°®з§ЇзФ®жИЈIDдЄЇ1зЪДзФ®жИЈиµДжЇРгАВ - **еК®иѓНдЄОHTTPжЦєж≥ХеМєйЕН**пЉЪGETзФ®дЇОиОЈеПЦиµДжЇРпЉМPOSTзФ®дЇОеИЫеїЇиµДжЇРпЉМPUTзФ®дЇОжЫіжЦ∞иµДжЇРпЉМDELETEзФ®дЇОеИ†йЩ§иµДжЇРгАВ - **...
еЬ®жЬђзЂ†дЄ≠пЉМжИСдїђе∞ЖжЈ±еЕ•жОҐиЃ®Spring MVCж°ЖжЮґдЄ≠зЪДRESTfulй£Ож†ЉURLиЃЊиЃ°дї•еПКе¶ВдљХе§ДзРЖйЭЩжАБиµДжЇРгАВRESTпЉИRepresentational State TransferпЉЙжШѓдЄАзІНиљѓдїґжЮґжЮДй£Ож†ЉпЉМеЄЄзФ®дЇОWebжЬНеК°иЃЊиЃ°пЉМеЃГеЉЇи∞ГйАЪињЗHTTPжЦєж≥ХпЉИе¶ВGETгАБPOSTгАБPUTгАБ...
RESTзЪДж†ЄењГзРЖењµжШѓе∞ЖзљСзїЬдЄКзЪДжѓПдЄАдЄ™еЃЮдљУжКљи±°жИРиµДжЇРпЉМеєґйАЪињЗзїЯдЄАзЪДжО•еП£еѓєињЩдЇЫиµДжЇРињЫи°МжУНдљЬгАВ #### дЇМгАБRESTзЪДеЕ≥йФЃж¶Вењµ **1. иµДжЇР(Resource):** - RESTе∞ЖзљСзїЬдЄ≠зЪДжѓПдЄ™еЕГзі†иІЖдЄЇдЄАдЄ™иµДжЇРпЉМжЧ†иЃЇжШѓжЦЗжЬђгАБеЫЊзЙЗгАБйЯ≥йҐСињШжШѓ...
URLпЉИзїЯдЄАиµДжЇРеЃЪдљНзђ¶пЉЙжШѓURIзЪДдЄАдЄ™е≠Рз±їпЉМдЄїи¶БзФ®дЇОеЃЪдљНзљСзїЬиµДжЇРгАВ 1. **URIдЄ≠дЄНеЇФеМЕеРЂеК®иѓН** еЬ®RESTfulиЃЊиЃ°дЄ≠пЉМURIеЇФиѓ•дї£и°®иµДжЇРпЉМиАМдЄНжШѓжУНдљЬгАВеК®иѓНйАЪеЄЄе±ЮдЇОHTTPжЦєж≥ХпЉИGETгАБPOSTгАБPUTгАБDELETEз≠ЙпЉЙгАВдЊЛе¶ВпЉМдЄАдЄ™йФЩиѓѓзЪД...
йАЪињЗURLжЭ•иЃЊиЃ°з≥їзїЯзїУжЮДпЉМжКљи±°зЪДжШѓиµДжЇРпЉМиАМдЄНжШѓеѓєи±°гАБињЗз®ЛпЉМеЃМжИРзЪДжШѓзФ®жИЈжО•еП£ REST APIзЪДеЉАеПСж°ЖжЮґдїЛзїН:JSR-311,REST Web Servicesж°ЖжЮґ JAX-RSпЉМjavaжО•еП£пЉЫ### REST Web Applicationе§Ъе±Вж°ЖжЮґ REST еЇФзФ®еЬЇжЩѓпЉМйАВеРИеТМ...
RESTйАЪињЗеЃЪдєЙи°®ињ∞жЭ•еЃЮзО∞еѓєиµДжЇРзЪДиЃњйЧЃеТМжУНдљЬпЉМиАМURLпЉИUniform Resource LocatorпЉЙжШѓеЃЪдљНињЩдЇЫиµДжЇРзЪДж†ЗиѓЖзђ¶гАВ RESTжЮґжЮДй£Ож†ЉеЕЈжЬЙдї•дЄЛзЙєзВєпЉЪ 1. еЃҐжИЈ-жЬНеК°еЩ®жЮґжЮДпЉЪињЩзІНжЮґжЮДйАЪињЗеИЖз¶їзФ®жИЈзХМйЭҐеТМжХ∞жНЃе≠ШеВ®жЭ•жПРйЂШз≥їзїЯзЪДеПѓ...
- **иµДжЇРзЪДURLиЃЊиЃ°**пЉЪдЄНеЖНе∞ЖURLиІЖдЄЇжМЗеРСзЙєеЃЪжУНдљЬжИЦжЦєж≥ХзЪДиЈѓеЊДпЉМиАМжШѓе∞ЖеЕґиІЖдЄЇеѓєиµДжЇРжЬђиЇЂзЪДзЫіжО•еЉХзФ®гАВ - **HTTPеК®иѓНзЪДдљњзФ®**пЉЪGETзФ®дЇОж£А糥иµДжЇРпЉМPOSTзФ®дЇОеИЫеїЇжЦ∞иµДжЇРпЉМPUTзФ®дЇОжЫіжЦ∞зО∞жЬЙиµДжЇРпЉМDELETEзФ®дЇОеИ†йЩ§иµДжЇРгАВ...
жАїзїУжЭ•иѓіпЉМRESTжШѓдЄАзІНиЃЊиЃ°WebжЬНеК°зЪДзРЖењµпЉМеЃГжПРеА°дљњзФ®HTTPеНПиЃЃзЪДзЙєжАІжЭ•жУНдљЬиµДжЇРпЉМйАЪињЗURIеЃЪдљНиµДжЇРпЉМзФ®жЧ†зКґжАБзЪДжЦєеЉПе§ДзРЖиѓЈж±ВгАВеЬ®JavaзОѓеҐГдЄ≠пЉМеПѓдї•йАЪињЗJAX-RSеЃЮзО∞RESTful APIпЉМдљњзФ®JSONдљЬдЄЇжХ∞жНЃдЇ§жНҐж†ЉеЉПпЉМдї•еЃЮзО∞йЂШжХИгАБ...
зДґиАМпЉМеЬ®RESTжЦєеЉПдЄЛпЉМURLиЃЊиЃ°жЫіж≥®йЗНиµДжЇРзЪДи°®з§ЇпЉМе¶В`/products/123/edit`гАВињЩйЗМзЪД`products`и°®з§ЇиµДжЇРйЫЖеРИпЉМ`123`жШѓиµДжЇРзЪДеФѓдЄАж†ЗиѓЖпЉМиАМ`edit`и°®з§ЇжУНдљЬгАВ`RestActionMapper`дЉЪиІ£жЮРињЩзІНж†ЉеЉПзЪДURLпЉМеєґе∞ЖеЕґжШ†е∞ДеИ∞зЫЄеЇФзЪД...
йАЪињЗдї•дЄКзЯ•иѓЖзВєпЉМжИСдїђеПѓдї•зЬЛеЗЇ"RESTжЮґжЮДwebеЃЮдЊЛ"дЄїи¶БжШѓеЕ≥дЇОе¶ВдљХжЮДеїЇйБµеЊ™RESTеОЯеИЩзЪДWebжЬНеК°пЉМеМЕжЛђиµДжЇРзЃ°зРЖгАБHTTPжЦєж≥ХзЪДдљњзФ®гАБURLиЃЊиЃ°дї•еПКе¶ВдљХеЃЮзО∞жЧ†зКґжАБгАБзЉУе≠ШеТМеЃЙеЕ®жАІзЪДиАГиЩСгАВеЬ®"Restful1029"ињЩдЄ™еОЛзЉ©еМЕжЦЗдїґдЄ≠пЉМеПѓиГљ...
RESTпЉИRepresentational State TransferпЉМи°®ињ∞жАІзКґжАБиљђзІїпЉЙжШѓдЄАзІНиљѓдїґжЮґжЮДй£Ож†ЉпЉМдЄїи¶БеЇФзФ®дЇОWebжЬНеК°зЪДиЃЊиЃ°пЉМдї•жПРдЊЫзЃАжіБгАБжЧ†зКґжАБгАБеЯЇдЇОж†ЗеЗЖзЪДжО•еП£гАВREST Web ServiceжШѓйБµеЊ™RESTеОЯеИЩзЪДWebжЬНеК°пЉМеЃГйАЪињЗHTTPеНПиЃЃжЭ•еЃЮзО∞...
RESTful URLиЃЊиЃ°жШѓзО∞дї£WebжЬНеК°зЪДж†ЄењГеОЯеИЩдєЛдЄАпЉМеЃГеЉЇи∞ГиµДжЇРзЪДи°®ињ∞зКґжАБиљђзІїпЉМдљњеЊЧAPIжЫіеК†жЄЕжЩ∞гАБжШУдЇОзРЖиІ£еТМдљњзФ®гАВжЬђжХЩз®Ле∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХеЬ®Spring 3.0дЄ≠еЇФзФ®Spring MVCжЭ•жЮДйА†RESTful URLгАВ й¶ЦеЕИпЉМдЇЖиІ£REST...
RESTпЉИRepresentational State TransferпЉМи°®зО∞е±ВзКґжАБиљђзІїпЉЙжШѓдЄАзІНзФ®дЇОжЮДеїЇWebжЬНеК°зЪДжЮґжЮДй£Ож†ЉпЉМеЃГеЉЇи∞ГйАЪињЗзЃАеНХзЪДHTTPжЦєж≥ХпЉИGETгАБPOSTгАБPUTгАБDELETEпЉЙжЭ•жУНдљЬиµДжЇРпЉМдїОиАМеЃЮзО∞иљїйЗПзЇІгАБйЂШжХИеТМеПѓжЙ©е±ХзЪДз≥їзїЯиЃЊиЃ°гАВ...
- URLпЉЪиЊУеЕ•дљ†и¶БиЃњйЧЃзЪДREST APIзЪДеЬ∞еЭАпЉМеМЕжЛђеЯЇз°АURLеТМиµДжЇРиЈѓеЊДгАВ - е§ійГ®пЉИHeadersпЉЙпЉЪжЈїеК†дїїдљХењЕи¶БзЪДиѓЈж±Ве§іпЉМдЊЛе¶ВContent-TypeпЉИеЃЪдєЙиѓЈж±ВдљУзЪДжХ∞жНЃз±їеЮЛпЉЙжИЦAuthorizationпЉИзФ®дЇОиЇЂдїљй™МиѓБпЉЙгАВ - еПВжХ∞пЉЪеЬ®иѓЈж±ВдљУдЄ≠...
еЬ®ITи°МдЄЪдЄ≠пЉМRESTпЉИRepresentational State TransferпЉЙжШѓдЄАзІНзљСзїЬеЇФзФ®з®ЛеЇПзЪДиЃЊиЃ°й£Ож†ЉеТМеЉАеПСжЦєеЉПпЉМеЯЇдЇОHTTPеНПиЃЃпЉМдЄїи¶БзФ®дЇОWebжЬНеК°зЪДжЮДеїЇгАВRESTfulжЬНеК°жО•еП£дї•еЕґзЃАжіБгАБйЂШжХИзЪДзЙєзВєпЉМ襀府ж≥ЫеЇФзФ®дЇОеИЖеЄГеЉПз≥їзїЯеТМдЇТиБФзљСеЇФзФ®...
2. **URLдЄОиµДжЇРеЃЪдљН**пЉЪRESTжО•еП£зЪДURLиЃЊиЃ°еЇФжЄЕжЩ∞еЬ∞и°®з§ЇеЗЇжЙАжУНдљЬзЪДиµДжЇРгАВдЊЛе¶ВпЉМ`/users/{userId}`и°®з§ЇзФ®жИЈиµДжЇРпЉМеЕґдЄ≠{userId}жШѓеПШйЗПпЉМзФ®дЇОж†ЗиѓЖеЕЈдљУзЪДзФ®жИЈгАВ 3. **иѓЈж±Ве§і**пЉЪеЬ®и∞ГиѓХињЗз®ЛдЄ≠пЉМйЬАи¶БеЕ≥ж≥®иѓЈж±Ве§ідЄ≠зЪДContent...
еЬ®"REST webservicesе§ЪиµДжЇР"ињЩдЄ™дЄїйҐШдЄ≠пЉМжИСдїђдЄїи¶БеЕ≥ж≥®зЪДжШѓе¶ВдљХиЃЊиЃ°еТМеЃЮзО∞иГље§Яе§ДзРЖе§ЪдЄ™дЄНеРМз±їеЮЛиµДжЇРзЪДRESTful APIгАВињЩжґЙеПКеИ∞дї•дЄЛеЗ†дЄ™еЕ≥йФЃзЯ•иѓЖзВєпЉЪ 1. **иµДжЇРж®°еЮЛ**пЉЪеЬ®RESTжЮґжЮДдЄ≠пЉМжѓПдЄ™иµДжЇРйГљжЬЙдЄАдЄ™еФѓдЄАзЪДURIпЉМдЊЛе¶В...
RESTful APIеИЩжШѓйБµеЊ™RESTеОЯеИЩзЪДWebжЬНеК°жО•еП£иЃЊиЃ°иІДиМГпЉМеЃГеЉЇи∞ГиµДжЇРзЪДи°®ињ∞еТМзКґжАБиљђзІїпЉМдљњеЊЧз≥їзїЯжЫіеК†зЃАжіБгАБйЂШжХИгАВ еЬ®RESTful APIзЪДиЃЊиЃ°дЄ≠пЉМжѓПдЄ™жУНдљЬйГљеѓєеЇФдЇОHTTPеНПиЃЃдЄ≠зЪДдЄАдЄ™жЦєж≥ХпЉМе¶ВGETзФ®дЇОиОЈеПЦиµДжЇРпЉМPOSTзФ®дЇОеИЫеїЇиµДжЇР...
1. иµДжЇРпЉИResourceпЉЙзЪДж¶ВењµпЉЪзљСзїЬдЄКзЪДжѓПдЄ™еЃЮдљУйГљиІЖдЄЇдЄАдЄ™иµДжЇРпЉМиµДжЇРйАЪињЗеФѓдЄАзЪДURIпЉИUniform Resource IdentifierпЉЙињЫи°Мж†ЗиѓЖпЉМе¶ВURLгАВ 2. зїЯдЄАжО•еП£пЉЪRESTжЮґжЮДи¶Бж±ВдљњзФ®ж†ЗеЗЖеМЦзЪДжО•еП£жЭ•жУНдљЬиµДжЇРпЉМдЄїи¶БйАЪињЗHTTPжЦєж≥ХпЉИGET...