Ubuntu10.04下Mahout 安装步骤详解
经过一两天的熟悉,基本对Mahout的安装掌握了,下面给出详细安装步骤,带图
1 软件要求:
1. jdk-6u27-linux-i586.bin
2. apache-maven-2.2.1-bin.tar.gz
3. hadoop-0.20.204.0.tar.gz(不要用最新版,会报错)
4. mahout-distribution-0.5.tar.gz
2 关键步骤:
1. 复制软件到某文件夹下。
2. 解压软件。
3. 配置环境变量。/etc/profile
3 具体安装步骤:
1. 下载以上软件,JDK在Oracle官网下,maven,hadoop,mahout均在Apache官网下载。
2. 并将软件拷到/tmp下面,从U盘或者直接从网上Download.
红笔圈的四个文件,直接从U盘中拉到/tmp的目录下即可。
注:进入/tmp目录,按红笔所示步骤操作:
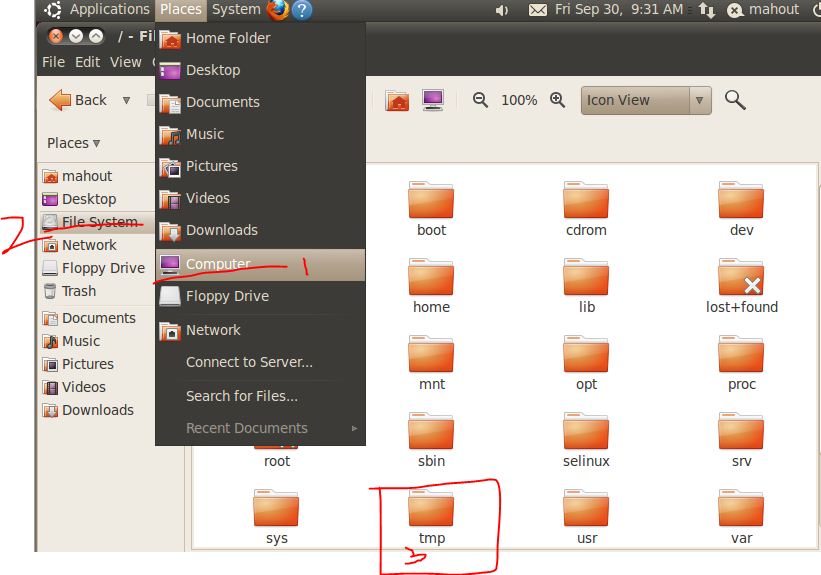
3. 将以上四个文件依次复制到/usr/mahout目录下【因tmp下的文件在下次重启后会消失,所以必须拷贝到其他目录下,而存在权限问题,需要用命令行方式拷贝,进入终端:如下图步骤所示】
4.
【mahout为新建目录,步骤为:cd /usr{切换目录到usr下}; mkdir mahout{新建mahout目录} 】
复制四个文件到/usr/mahout下:
à cp jdk-6u27-linux-i586.bin /usr/mahout
à cp apache-maven-2.2.1-bin.tar.gz /usr/mahout
à cp hadoop-0.20.204.0.tar.gz /usr/mahout
à cp mahout-distribution-0.5.tar.gz /usr/mahout
5. 如果不能正确复制,是由于权限问题,有两种方法解决问题:
第一种是为每个文件增加权限,然后在复制。
第二种为切换到超级用户(root/su)权限下:
用命令先激活su: sudo passwd root
先用第一次登陆的用户密码确认,在输入su超级用户的密码,输入一次,确认一次。
激活用户后在终端切换到su用户下,然后在操作以上复制步骤。
6. 解压以上文件:
对于*.bin的文件用./*.bin解压,对于,*.tar.gz或者*.tgz的文件用tar czvf *.tar.gz/ *.tgz方式来解压文件。
对以上文件一次如下:
à ./jdk-6u27-linux-i586.bin
à tar zxvf apache-maven-2.2.1-bin.tar.gz
à tar zxvf hadoop-0.20.204.0.tar.gz
à tar zxvf mahout-distribution-0.5.tar.gz
依次将文件解压到/usr/mahout目录下。
7. 配置环境变量:在/etc/profile文件最后面添加以下几行,
在终端中用gedit打开/etc/profile文件夹:sudo gedit /etc/profile,会出现如下窗口,添加以下内容,红笔圈的:
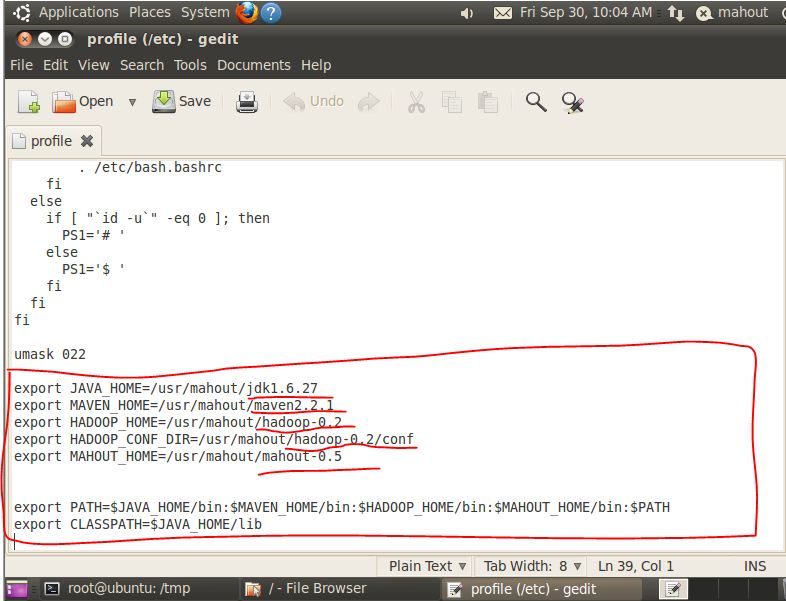
注意:是在umask 022后面添加以上内容,中间的东西不要修改错了,不然会出现启动不了系统的情况。红笔画横线的地方为你解压的文件目录名,根据自己解压的情况修改,我的是对目录全部重命了名的,如何重命名,Google找下(mv)。
之后保存文件并关闭gedit。其中冒号(:)表示连接,美元符($)表示输出变量。
在终端输入如下命令à source /etc/profile,重新导入/etc/profile文件。
8. 基本问题解决了,验证一下各环境变量【均在终端中输入】:
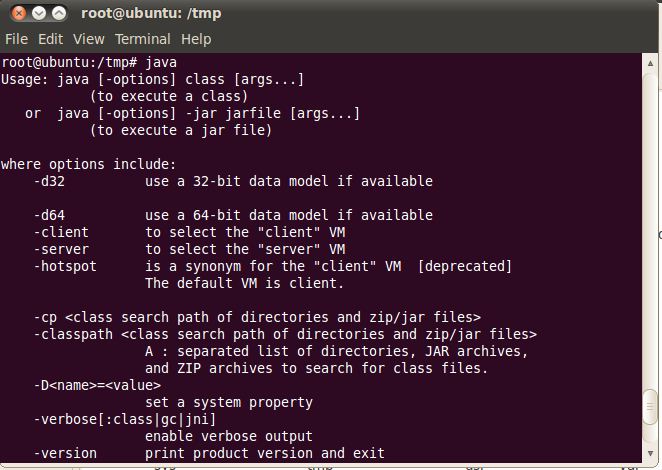
1) 验证JDK是否安装成功:javac,java
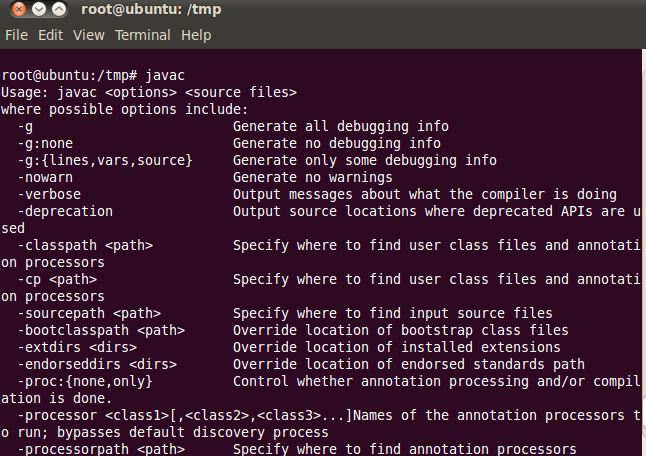
出现如上的图说明JDK中的PATH和CLASSPATH配置成功。
2) 验证maven是否安装成功:mvn
出现如上画面,maven安装成功。
3) 验证hadoop是否安装成功:hadoop

出现如上画面,hadoop安装成功。
4) 验证mahout是否安装成功:mahout

出现如上画面,mahout安装成功,。
4 单机测试:
数据准备
cd /tmp
wget http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data
hadoop fs -mkdir testdata
hadoop fs -put synthetic_control.data testdata
hadoop fs -lsr testdata
hadoop集群来执行聚类算法
cd /usr/local/mahout
mahout org.apache.mahout.clustering.syntheticcontrol.canopy.Job
mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
mahout org.apache.mahout.clustering.syntheticcontrol.fuzzykmeans.Job
mahout org.apache.mahout.clustering.syntheticcontrol.dirichlet.Job
mahout org.apache.mahout.clustering.syntheticcontrol.meanshift.Job
如果执行成功,在hdfs的/user/dev/output里面应该可以看到输出结果
GroupLens Data Sets
http://www.grouplens.org/node/12,包括MovieLens Data Sets、Wikilens Data Set、Book-Crossing Data Set、Jester Joke Data Set、EachMovie Data Set
下载1m的rating数据
mkdir 1m_rating
wget http://www.grouplens.org/system/files/million-ml-data.tar__0.gz
tar vxzf million-ml-data.tar__0.gz
rm million-ml-data.tar__0.gz
拷贝数据到grouplens代码的目录,我们先本地测试下mahout的威力
cp *.dat /usr/local/mahout/examples/src/main/java/org/apache/mahout/cf/taste/example/grouplens
cd /usr/local/mahout/examples/
执行
mvn -q exec:java -Dexec.mainClass="org.apache.mahout.cf.taste.example.grouplens.GroupLensRecommenderEvaluatorRunner"
如果不想做上面拷贝文件的操作,则指定输入文件位置就行,如下:
上传到hdfs
hadoop fs -copyFromLocal 1m_rating/ mahout_input/1mrating
mvn -q exec:java -Dexec.mainClass="org.apache.mahout.cf.taste.example.grouplens.GroupLensRecommenderEvaluatorRunner" -Dexec.args="-i mahout_input/1mrating"
5 说明及注意点:
1. haoop版本一定不能用最新版的,不然在输入hadoop是会抛出异常。
2. 在设置环境变量时有几种方法可以设置:/etc/environment, ~/.bashrc等方法,它们在Linux有不同的优先级,具体Google查询。
3. 在下面学习安装是一定要对Linux下的命令很熟悉,刚开始我在设置环境变量/etc/profile文件的时候,用vi /etc/profile命令,即:用vi编辑器的方式来修改文件,由于对vi不熟悉连删除一个字符都不知道,弄的相当的恼火。
6 环境扩充【安装Eclipse或者MyEclipse】:
安装Eclipse或者MyEclipse开发环境:
下载Linux下的文件:*.gtz或*.tar.gz,解压文件,找到*-install相关的一个文件双击,会自动 安装的(对于MyEclipse GA版),Eclipse解压后如果环境变量配置成功,可以直接双击Eclipse图标使用。若Eclipse找不到jre的错,将Eclipse下的Jre 中建一个软连接映射到JDK中的Jre,即可。
基本过程如上,还是简单吧....
后面开始数据挖掘之旅啦...



 Email:webmaster@csdn.net
Email:webmaster@csdn.net


相关推荐
分布式数据挖掘是现代大数据处理的关键技术之一,它利用多台计算机并行处理大规模数据,显著提高了数据挖掘的速度和效率。本项目"快速分布式数据挖掘(fast distributed data mining)"是基于MPI(Message Passing ...
从标题《对分布式数据挖掘解决方案的思考.pdf》和描述《对分布式数据挖掘解决方案的思考.pdf》中可以提炼出以下知识点: 1. 数据挖掘的挑战:传统数据挖掘解决方案存在计算能力有限的问题,尤其在数据挖掘算法迭代...
随着数据规模的不断扩大和数据处理精度要求的日益提高,传统的数据处理方法已不能满足需求,因此,采用云计算进行分布式数据挖掘成为了一个重要的研究方向。 分布式数据挖掘系统的核心在于算法设计,这些算法需要...
分布式数据挖掘简介,两个典型的分布式数据挖掘系统,分布式数据挖掘系统的特点探讨 。
分布式数据挖掘是一种将传统集中式数据挖掘技术应用在分布式计算环境中的创新方法。在信息技术、通信技术和网络技术的推动下,广电网、移动网、互联网等网络平台快速拓展,形成了大量的基于网络空间的分布式数据。...
分布式数据挖掘技术是信息处理领域的一项重要研究方向,它主要解决的是在分布式的海量数据环境中,如何高效、准确地进行数据挖掘的问题。网格服务作为一种新兴的分布式资源管理和计算模型,其目的是让分布在不同地理...
### 基于粗集和多Agent技术的分布式数据挖掘 #### 知识点解析: **1. 粗集理论在数据挖掘中的应用** 粗集理论作为一种处理不完整、不确定信息的有效工具,在数据挖掘领域得到了广泛应用。它通过定义概念的上、下...
在介绍基于XML的Web分布式数据挖掘系统研究之前,有必要先了解几个核心概念和关键技术。首先,Web数据挖掘是指从大量的Web页面中提取出有价值的信息和知识,这一过程包括从网页中抽取数据、分析网页内容和结构、识别...
基于相似性的分布式数据挖掘是一种高效处理大规模数据集的技术,其核心在于发现和利用不同数据资源之间的相似性,以此来减小数据挖掘的规模和复杂度。在信息时代,数据量的激增和数据库使用的迅速增长要求能够并行...
在这样的背景下,分布式数据挖掘技术的应用就显得尤为重要。 分布式数据挖掘是数据挖掘技术和分布式计算相结合的产物,它能够处理和分析分布于不同地理位置的数据库系统中的数据,以发现数据中的知识和模式。与传统...
在信息科技领域,分布式数据挖掘系统是处理大数据和实施高效分析的重要手段。Hadoop作为一种开源框架,已经成为了构建分布式系统的核心组件,它通过提供分布式文件系统HDFS和MapReduce并行编程模型,实现了数据存储...
在数据挖掘领域,隐私保护的分布式数据挖掘问题已经成为研究的焦点。随着数据挖掘工具的不断进步与普及,如何在挖掘数据的同时保护个人隐私和数据安全成了一个亟待解决的问题。博弈论作为分析和解决竞争和冲突的数学...
本文提出了一种基于移动agent技术和数据挖掘标准的分布式数据挖掘系统模型,该模型解决了传统集中式数据挖掘面临的挑战,并针对分布式数据源的集成和访问提出了有效的解决方案。移动agent技术为分布式数据挖掘系统...
分布式数据挖掘是随着信息技术飞速发展而产生的一项重要的技术,它利用分布式计算的方式处理存储在不同位置上的海量数据。分布式数据挖掘能够有效地提升数据处理效率,降低成本,但同时也面临着技术挑战。移动Agent...
分布式数据挖掘是一种应用数据挖掘技术对分散在网络中多个位置的数据进行分析的技术。随着信息技术的快速发展,互联网、移动网、广电网等多种现代网络及其衍生业务迅速扩张,形成泛在于网络空间的分布式计算环境。在...
### 基于分布式数据挖掘的电子商务推荐系统 #### 概述 随着电子商务的迅猛发展,推荐系统成为了提升用户体验和促进商品销售的关键技术之一。然而,传统的推荐系统面临诸多挑战,包括开放性不足、效率低下以及推荐...
在当前互联网和云计算技术日益发展的背景下,数据存储变得越来越分散,因此分布式数据挖掘技术得到了广泛的关注和应用。分布式数据挖掘指的是在不同的服务器或站点上,独立地进行数据挖掘工作,然后通过某种聚合方法...
【WebService 构架下的分布式数据挖掘】 随着信息技术的飞速发展,数据挖掘作为一种从大量数据中提取有价值信息的技术,已经成为各个领域关注的焦点。在Web Service构架下进行分布式数据挖掘,可以有效地解决大规模...