
уј░тюетЁѕТіЏтЄ║жЌ«жбў№╝їтЂЄУ«ЙТюЅСИђСИфСИ╗ТЋ░ТЇ«СИГт┐ЃтюетїЌС║гM№╝їуёХтљјТюЅТѕљжЃйA№╝їСИіТхиBСИцСИфтю░Тќ╣ТЋ░ТЇ«СИГт┐Ѓ№╝їуј░тюеуџёжЌ«жбўТў»№╝їтЂЄУ«ЙТѕљжЃйСИіТхитљёУЄфуџёТЋ░ТЇ«СИГт┐ЃТюЅУ«░тйЋтЈўТЏ┤№╝їжюђУдЂтЁѕтљїТГЦтѕ░СИ╗ТЋ░ТЇ«СИГт┐Ѓ№╝їСИ╗ТЋ░ТЇ«СИГт┐ЃТЏ┤Тќ░т«їТѕљС╣Ітљј№╝їтюеТііТюђТќ░уџёТЋ░ТЇ«тѕєтЈЉтѕ░СИіТхи№╝їТѕљжЃйуџётю░Тќ╣ТЋ░ТЇ«СИГт┐ЃA№╝їтю░Тќ╣ТЋ░ТЇ«СИГт┐ЃТЏ┤Тќ░ТЋ░ТЇ«№╝їС┐ЮТїЂтњїСИ╗ТЋ░ТЇ«СИГт┐ЃСИђУЄ┤ТђД№╝ѕТЋ░ТЇ«т║Њу╗ЊТъёт«їтЁеСИђУЄ┤№╝ЅсђѓТЋ░ТЇ«ТЏ┤Тќ░уџёТХѕТЂ»Тў»жђџУ┐ЄСИђтЈ░СИГт┐ЃуџёMQУ┐ЏУАїУйгтЈЉсђѓ
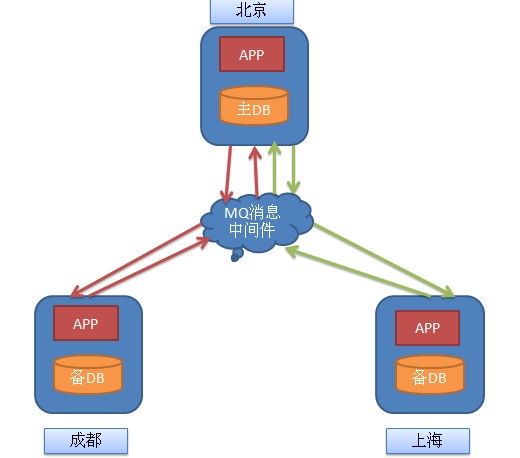
тЁѕТііжЌ«жбўу«ђтЇЋтїќтцёуљє№╝їтЂЄУ«ЙAтбътіаСИђТЮАУ«░тйЋMessage_A№╝їтЈЉжђЂтѕ░M№╝їBтбътіаСИђТЮАУ«░тйЋ MESSAGE_BтЈЉжђЂтѕ░M№╝їжЃйТў»жђџУ┐ЄMQТюЇтіАтЎеУ┐ЏУАїУйгтЈЉ№╝їжѓБС╣ѕMу│╗у╗ЪТјЦТћХтѕ░ТЮАТХѕТЂ»№╝їтбътіаСИцТЮАТЋ░ТЇ«№╝їжѓБС╣ѕMтюеТіітбътіауџёТХѕТЂ»уЙцтЈЉу╗ЎA№╝їB№╝їAтњїBТЅЙтѕ░УЄфти▒у╝║тц▒уџёТЋ░ТЇ«№╝їТЏ┤Тќ░ТЋ░ТЇ«т║ЊсђѓУ┐ЎТаит░▒т«їТѕљС║єСИђСИфТЋ░ТЇ«уџётљїТГЦсђѓ
С╗јТГБтИИТЃЁтєхСИІТЮЦуюІ№╝їжЃйТ▓АТюЅжЌ«жбў№╝їжђ╗УЙЉт«їтЁетљѕуљє№╝їСйєТў»У»иУђЃУЎЉС╗ЦСИІСИЅСИфжЌ«жбў
1 тдѓСйЋС┐ЮУ»ЂA->MуџёТХѕТЂ»№╝їMСИђт«џТјЦТћХтѕ░С║є№╝їтљїТаи№╝їтдѓСйЋС┐ЮУ»ЂM->AуџёТХѕТЂ»№╝їMСИђт«џТјЦТћХтѕ░С║є
2 тдѓТъюТЋ░ТЇ«жюђУдЂСИђУЄ┤ТђДТЏ┤Тќ░№╝їТ»ћтдѓAтЈЉжђЂС║єСИЅТЮАТХѕТЂ»у╗ЎM№╝їMУдЂС╣ѕтЁежЃеС┐ЮтГў№╝їУдЂС╣ѕтЁежЃеСИЇС┐ЮтГў№╝їСИЇУЃйтцЪтЈфС┐ЮтГўтЁХСИГуџётЄаТЮАУ«░тйЋсђѓТѕЉС╗гтЂЄУ«ЙТЏ┤Тќ░уџёТЋ░ТЇ«Тў»СИђТЮАТЮАтЈЉжђЂуџёсђѓ
3 тЂЄУ«ЙтљїТЌХAтЈЉжђЂС║єтцџТЮАТЏ┤Тќ░У»иТ▒ѓ№╝їтдѓСйЋС┐ЮУ»ЂжА║т║ЈТђДУдЂТ▒ѓ№╝Ъ
У┐ЎСИцСИфжЌ«жбўт░▒Тў»тѕєтИЃт╝Јуј»тбЃСИІТЋ░ТЇ«СИђУЄ┤ТђДуџёжЌ«жбў
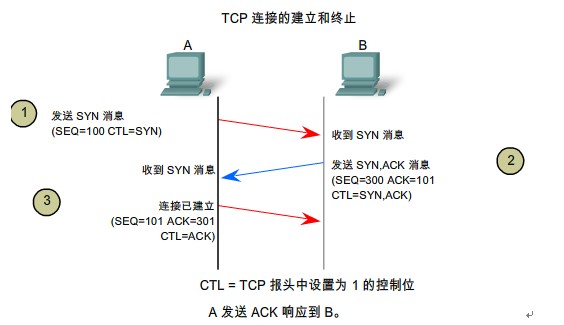
т»╣С║југгСИђСИфжЌ«жбў№╝їТ»ћУЙЃтЦйУДБтє│№╝їТѕЉС╗гтЁѕуюІуюІСИђСИфtcp/ipтЇЈУ««жЊЙТјЦт╗║уФІуџёУ┐ЄуеІ
ТѕЉС╗гуџёТђЮУи»тЈ»С╗ЦС╗јУ┐ЎСИфСИіжЮбтЄ║тЈЉ№╝їтюеу«ђтїќСИђСИІ№╝їт░▒СИђСИфУ»иТ▒ѓ№╝їСИђСИфт║ћуГћсђѓ
у«ђтЇЋуџёжђџС┐АТеАтъІТў»У┐ЎТаиуџё
A->M : СйаТћХтѕ░ТѕЉуџёСИђТЮАТХѕТЂ»Т▓АТюЅ№╝їТХѕТЂ»уџёIDТў»12345
M->A: ТѕЉТћХтѕ░С║єСйауџёСИђТЮАТХѕТЂ»ТЋ░ТЇ«№╝їТХѕТЂ»ТЋ░ТЇ«Тў»ID;12345
У┐ЎТаит░▒СИђСИфУ»иТ▒ѓ№╝їСИђСИфт║ћуГћ№╝їт░▒т«їТѕљС║єСИђТгАтЈ»жЮаТђДуџёС╝аУЙЊсђѓтдѓТъюAСИђУЄ┤Т▓АТюЅТћХтѕ░Mуџёт║ћуГћ№╝їт░▒СИЇТќГуџёжЄЇУ»ЋсђѓУ┐ЎСИфТЌХтђЎMт░▒т┐ЁжА╗С┐ЮУ»Ђт╣ѓуГЅТђДсђѓСИЇУЃйжЄЇтцЇуџётцёуљєТХѕТЂ»сђѓжѓБС╣ѕТюђТъЂуФ»уџёТЃЁтєхТў»№╝їТђјС╣ѕС╣ЪТћХСИЇтѕ░Mуџёт║ћуГћ№╝їУ┐ЎСИфТЌХтђЎТў»у│╗у╗ЪТЋЁжџюсђѓУЄфти▒ТБђТЪЦСИђСИІтљДсђѓ
У┐ЎС╣ѕУ«ЙУ«Ат░▒УдЂТ▒ѓ№╝їAтюетЈЉжђЂТХѕТЂ»уџёТЌХтђЎТїЂС╣ЁтїќУ┐ЎСИфТХѕТЂ»уџёТЋ░ТЇ«тєЁт«╣№╝їуёХтљјСИЇТќГуџёжЄЇУ»Ћ№╝їСИђТЌдТјЦТћХтѕ░Mуџёт║ћуГћ№╝їт░▒тѕажЎцУ┐ЎТЮАТХѕТЂ»сђѓтљїТаи№╝їMуФ»С╣ЪТў»СИђТаиуџёсђѓСИЇУдЂуЏИС┐АMQуџёТїЂС╣ЁтїќТю║тѕХ№╝їСИЇТў»тЙѕжЮаУ░▒уџёсђѓ
жѓБС╣ѕMу╗ЎAтЈЉжђЂТХѕТЂ»С╣ЪжЄЄтЈќу▒╗С╝╝уџётјЪуљєт░▒тЈ»С╗ЦС║єсђѓ
СИІжЮбтюеуюІуюІуггС║їСИфжЌ«жбў№╝їтдѓСйЋС┐ЮТїЂТЋ░ТЇ«уџёСИђУЄ┤ТђДТЏ┤Тќ░№╝їУ┐ЎСИфУ┐ўТў»тЈ»С╗ЦтЈѓУђЃTCP/IPуџётЇЈУ««сђѓ
ждќтЁѕAтЈЉжђЂСИђТЮАТХѕТЂ»у╗ЎM№╝џТѕЉУдЂтЈЉжђЂСИђТЅ╣ТХѕТЂ»ТЋ░ТЇ«у╗ЎСйа№╝їТЅ╣ТгАтЈиТў»10000№╝їТЋ░ТЇ«Тў»5ТЮАсђѓ
MтЈЉжђЂСИђТЮАТХѕТЂ»у╗ЎA№╝џok№╝їТѕЉтЄєтцЄтЦйС║є№╝їТЅ╣ТгАтЈиТў»10000№╝їтЈЉжђЂТќ╣СйаA
ТјЦуЮђAтЈЉжђЂ5ТЮАТХѕТЂ»у╗ЎM№╝їТХѕТЂ»IDтѕєтѕФСИ║1№╝ї2№╝ї3№╝ї4№╝ї5 №╝їТЅ╣ТгАтЈиТў»10000№╝ї
у┤ДТјЦуЮђ№╝їAтЈЉжђЂСИђСИфС┐АТЂ»у╗ЎM№╝џТѕЉти▓у╗Јт«їТѕљ5т░ЈТХѕТЂ»уџётЈЉжђЂ№╝їСйаУдЂТЈљС║цТЋ░ТЇ«ТЏ┤Тќ░С║є
ТјЦСИІТЮЦтЈ»УЃйтЈЉжђЂСИцуДЇТЃЁтєх
1 жѓБС╣ѕMтЈЉжђЂТХѕТЂ»у╗ЎA№╝џok№╝їТѕЉТћХтѕ░С║є5ТЮАТХѕТЂ»№╝їт╝ђтДІТЈљС║цТЋ░ТЇ«
2 жѓБС╣ѕMС╣ЪтЈ»С╗ЦтЈЉжђЂу╗ЎA№╝џТѕЉТћХтѕ░С║є5ТЮАТХѕТЂ»№╝їСйєТў»У┐ўу╝║т░Љ№╝їУ»иСйажЄЇТќ░тЈЉжђЂ№╝їжѓБС╣ѕAт░▒у╗Ду╗ГтЈЉжђЂ№╝їуЏ┤тѕ░AТћХтѕ░MТѕљтіЪуџёт║ћуГћсђѓ
ТЋ┤СИфУ┐ЄуеІуЏИтйЊтцЇТЮѓсђѓУ┐ЎСИфС╣Ът░▒Тў»ТЋ░ТЇ«СИђТЌдтѕєтИЃС║є№╝їтИдТЮЦТюђтцДуџёжЌ«жбўт░▒Тў»ТЋ░ТЇ«СИђУЄ┤ТђДуџёжЌ«жбўсђѓУ┐ЎСИфТѕљТюгжЮътИИжФўсђѓ
т»╣С║југгСИЅСИфжЌ«жбў№╝їУ┐ЎСИфт░▒Т»ћУЙЃтцЇТЮѓС║є
У┐ЎСИфТюђТаИт┐ЃуџёжЌ«жбўт░▒Тў»ТХѕТЂ»уџёжА║т║ЈТђД№╝їТѕЉС╗гтЈфУЃйтюеТ»ЈСИфТХѕТЂ»тЈЉСИђСИфТХѕТЂ»уџёт║ЈтѕЌтЈи№╝їСйєТў»У┐ўТў»Т▓АТюЅТюђтЦйУДБтє│У┐ЎСИфжЌ«жбўуџётіъТ│ЋсђѓтЏаСИ║ТХѕТЂ»ТјЦТћХТќ╣СИЇуЪЦжЂЊжА║т║ЈсђѓтЏаСИ║тЇ│Сй┐у╗ЎС╗ќС║єт║ЈтѕЌтЈи№╝їС╣ЪТ▓АТюЅтіъТ│ЋтЉіУ»ЅС╗ќ№╝їУ┐ЎСИфт║ћУ»ЦСйЋТЌХтцёуљєсђѓТюђтЦйуџётіъТ│ЋТў»тюеуггС║їуДЇТќ╣т╝ЈуџётЪ║уАђСйюСИ║СИђСИфТЅ╣ТгАТЮЦТЏ┤Тќ░сђѓ
У┐ЎСИфтЈфТў»С╗ЦТюђу«ђтЇЋуџёСЙІтГљТЮЦУ»┤ТўјСИђСИІтѕєтИЃт╝Ју│╗у╗ЪуџёУдЂС┐ЮУ»ЂТЋ░ТЇ«СИђУЄ┤ТђДТў»СИђС╗ХС╗БС╗итЙѕтцДуџёС║ІТЃЁсђѓтйЊуёХТюЅуџётЇџСИ╗С╝џУ»┤№╝їУ┐ЎСИфСйЋт┐ЁУ┐ЎС╣ѕтцЇТЮѓ№╝їуЏ┤ТјЦТЋ░ТЇ«т║ЊтљїТГЦСИЇт░▒тЈ»С╗ЦС║єсђѓУ┐ЎСИфСЙІтГљтйЊуёХТў»Т▓АТюЅжЌ«жбўуџё№╝їСИЄСИђУ┐ЎСИфтЄаСИфт║ЊуџёТеАтъІжЃйСИЇСИђТаи№╝їТѕЉтЈЉжђЂТХѕТЂ»УдЂтцёуљєуџёС║ІТЃЁСИЇСИђТаиуџёсђѓТђјС╣ѕтіъ№╝Ъ
тюеСИіТќЄ№╝їу«ђтЇЋуџёС╗Іу╗ЇС║єтѕєтИЃт╝ЈТЋ░ТЇ«уџётљїТГЦжЌ«жбў№╝їСИіжЮбуџёжЌ«жбўТ»ћУЙЃТійУ▒А№╝їтюеуЏ«тЅЇуџёС║њУЂћуйЉт║ћућеСИГУ┐ўтЙѕт░ЉУДЂ№╝їУ┐ЎТгАтюежђџУ┐ЄСИђСИфТ»ћУЙЃтИИУДЂуџёСЙІтГљ№╝їУ«ЕтцДт«ХТЏ┤Ти▒тЁЦуџёС║єУДБСИђСИІтѕєтИЃт╝Ју│╗у╗ЪУ«ЙУ«АСИГтЁ│С║јТЋ░ТЇ«СИђУЄ┤ТђДуџёжЌ«жбў
У┐ЎТгАТѕЉС╗гТІ┐ТѕЉС╗гу╗ЈтИИСй┐ућеуџётіЪУЃйТЮЦУђЃУЎЉтљД№╝їТюђУ┐ЉуйЉУ┤ГТ»ћУЙЃуЃГжЌе№╝їт░▒С╗ЦС║гСИюСИ║СЙІуџё№╝їТѕЉС╗гТЮЦуюІуюІС║гСИюуџёСИђСИфу«ђтЇЋуџёУ┤ГуЅЕТхЂуеІ
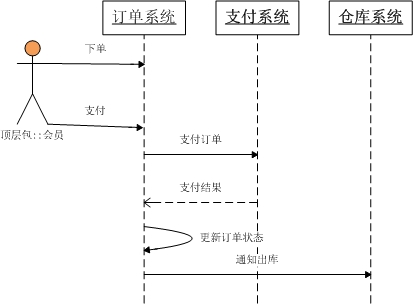
ућеТѕитюеС║гСИюСИіСИІС║єСИђСИфУ«бтЇЋ№╝їтЈЉуј░УЄфти▒тюеС║гСИюуџёУ┤дТѕижЄїжЮбТюЅСйЎжбЮ№╝їуёХтљјСй┐ућеСйЎжбЮТћ»С╗ў№╝їТћ»С╗ўТѕљтіЪС╣Ітљј№╝їУ«бтЇЋуіХТђЂС┐«Тћ╣СИ║Тћ»С╗ўТѕљтіЪ№╝їуёХтљјжђџуЪЦС╗Њт║ЊтЈЉУ┤ДсђѓтЂЄУ«ЙУ«бтЇЋу│╗у╗Ъ№╝їТћ»С╗ўу│╗у╗Ъ№╝їС╗Њт║Њу│╗у╗ЪТў»СИЅСИфуІгуФІуџёт║ћуће№╝їТў»уІгуФІжЃеуй▓уџё№╝їу│╗у╗ЪС╣ІжЌ┤жђџУ┐ЄУ┐юуеІТюЇтіАУ░Ѓућесђѓ
У«бтЇЋуџёТюЅСИЅСИфуіХТђЂ№╝џI:тѕЮтДІ P:ти▓Тћ»С╗ў W:ти▓тЄ║т║Њ№╝їУ«бтЇЋжЄЉжбЮ100, С╝џтЉўтИљТѕиСйЎжбЮ200
тдѓТъюТЋ┤СИфТхЂуеІТ»ћУЙЃжА║тѕЕ№╝їТГБтИИТЃЁтєхСИІ№╝їУ«бтЇЋуџёуіХТђЂС╝џтЈўСИ║I->P->W№╝їС╝џтЉўтИљТѕиСйЎжбЮ100№╝їУ«бтЇЋтЄ║т║Њсђѓ
СйєТў»тдѓТъюТхЂуеІСИЇжА║тѕЕС║є№╝ЪУђЃУЎЉС╗ЦСИІтЄауДЇТЃЁтєх
1№╝џУ«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗ЪТћ»С╗ўУ«бтЇЋ№╝їТћ»С╗ўТѕљтіЪ№╝їСйєТў»У┐ћтЏъу╗ЎУ«бтЇЋу│╗у╗ЪТЋ░ТЇ«УХЁТЌХ№╝їУ«бтЇЋУ┐ўТў»I№╝ѕтѕЮтДІуіХТђЂ№╝Ѕ№╝їСйєТў»ТГцТЌХС╝џтЉўтИљТѕиСйЎжбЮ100,С╝џтЉўУѓ»т«џС╝џжЕгСИіТЅЙС║гСИюжфѓС║гСИю№╝їСИ║тЋЦСИЇу╗ЎУђЂтГљтЈЉУ┤Д№╝їТѕЉжЃйС╗ўжњ▒С║є
2№╝џУ«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗ЪТѕљтіЪ№╝їуіХТђЂС╣Ъти▓у╗ЈТЏ┤Тќ░ТѕљтіЪ№╝їСйєТў»жђџуЪЦС╗Њт║ЊтЈЉУ┤Дтц▒У┤Ц№╝їУ┐ЎСИфТЌХтђЎУ«бтЇЋТў»P№╝ѕти▓Тћ»С╗ў№╝ЅуіХТђЂ№╝їТГцТЌХС╝џтЉўтИљТѕиСйЎжбЮТў»100,СйєТў»С╗Њт║ЊСИЇС╝џтЈЉУ┤ДсђѓС╝џтЉўС╣ЪУдЂжфѓС║гСИюсђѓ
3№╝џУ«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗ЪТѕљтіЪ№╝їуіХТђЂС╣Ъти▓у╗ЈТЏ┤Тќ░ТѕљтіЪ№╝їуёХтљјжђџуЪЦС╗Њт║ЊтЈЉУ┤Д№╝їС╗Њт║ЊтЉіУ»ЅУ«бтЇЋу│╗у╗Ъ№╝їТ▓АТюЅУ┤ДС║єсђѓУ┐ЎСИфТЌХтђЎТЋ░ТЇ«уіХТђЂтњїуггС║їуДЇТЃЁтєхСИђТаисђѓ
т»╣С║јжЌ«жбўСИђ№╝їТѕЉС╗гТЮЦтѕєТъљСИђСИІУДБтє│Тќ╣ТАѕ№╝їУЃйТЃ│тѕ░уџёУДБтє│Тќ╣ТАѕтдѓСИІ
1 тЂЄУ«ЙУ░ЃућеТћ»С╗ўу│╗у╗ЪТћ»С╗ўУ«бтЇЋуџёТЌХтђЎтЁѕСИЇТЅБжњ▒№╝їУ«бтЇЋуіХТђЂТЏ┤Тќ░т«їТѕљС╣Ітљј№╝їтюежђџуЪЦТћ»С╗ўу│╗у╗ЪСйаТЅБжњ▒
тдѓТъюжЄЄућеУ┐ЎуДЇУ«ЙУ«АТќ╣ТАѕ№╝їжѓБС╣ѕтюетљїСИђТЌХтѕ╗№╝їУ┐ЎСИфућеТѕи№╝їтЈѕТћ»С╗ўС║єтЈдтцќСИђугћУ«бтЇЋ№╝їУ«бтЇЋС╗иТа╝200№╝їжА║тѕЕт«їТѕљС║єТЋ┤СИфУ«бтЇЋТћ»С╗ўТхЂуеІ№╝їућ▒С║јтйЊтЅЇУ«бтЇЋуџёуіХТђЂти▓у╗ЈтЈўТѕљС║єТћ»С╗ўТѕљтіЪ№╝їСйєТў»т«ъжЎЁућеТѕити▓у╗ЈТ▓АТюЅжњ▒Тћ»С╗ўС║є№╝їУ┐ЎугћУ«бтЇЋуџёуіХТђЂт░▒СИЇСИђУЄ┤С║єсђѓтЇ│Сй┐ућеТѕитюетљїСИђСИфТЌХтѕ╗Т▓АТюЅУ┐ЏУАїтЈдтцќуџёУ«бтЇЋТћ»С╗ўУАїСИ║№╝їжђџуЪЦТћ»С╗ўу│╗у╗ЪТЅБжњ▒У┐ЎСИфтіеСйюС╣ЪТюЅтЈ»УЃйт«їСИЇТѕљ№╝їтЏаСИ║С╣ЪТюЅтЈ»УЃйтц▒У┤Ц№╝їтЈЇУђїтбътіаС║єу│╗у╗ЪуџётцЇТЮѓТђДсђѓ
2 У«бтЇЋу│╗у╗ЪУЄфтіетЈЉУхижЄЇУ»Ћ№╝їтцџжЄЇУ»ЋтЄаТгА№╝їСЙІтдѓСИЅТгА№╝їуЏ┤тѕ░ТЅБТгЙТѕљтіЪСИ║ТГбсђѓ
У┐ЎСИфуюІУхиТЮЦС╣ЪТў»СИЇжћЎуџёУђЃУЎЉ№╝їСйєТў»тњїУДБтє│Тќ╣ТАѕСИђТаи№╝їУДБтє│СИЇС║єжЌ«жбў№╝їУ┐ўС╝џтИдТЮЦТќ░уџёжЌ«жбў№╝їтЂЄУ«ЙУ«бтЇЋу│╗у╗ЪуггСИђТгАУ░ЃућеТћ»С╗ўу│╗у╗ЪТѕљтіЪ№╝їСйєТў»Т▓АТюЅтіъТ│ЋТћХтѕ░т║ћуГћ№╝їУ«бтЇЋу│╗у╗ЪтЈѕтЈЉУхиУ░Ѓуће№╝їт«їС║є№╝їжЄЇтцЇТћ»С╗ў№╝їСИђТгАУ«бтЇЋТћ»С╗ўС║є200сђѓ
тЂЄУ«ЙТћ»С╗ўу│╗у╗ЪТГБтюетЈЉтИЃ№╝їСйажЄЇУ»Ћтцџт░ЉТгАжЃйСИђТаи№╝їжЃйС╝џтц▒У┤ЦсђѓУ┐ЎСИфТЌХтђЎућеТѕитюеуГЅтЙЁ№╝їСйаТђјС╣ѕтцёуљє№╝Ъ
3 тюеуггС║їуДЇТќ╣ТАѕуџётЪ║уАђСИі№╝їТѕЉС╗гтЁѕУДБтє│У«бтЇЋуџёжЄЇтцЇТћ»С╗ўУАїСИ║№╝їТѕЉС╗гжюђУдЂтюеТћ»С╗ўу│╗у╗ЪСИіт»╣У«бтЇЋтЈиУ┐ЏУАїТјДтѕХ№╝їСИђугћУ«бтЇЋтдѓТъюти▓у╗ЈТћ»С╗ўТѕљтіЪ№╝їСИЇУЃйтюеУ┐ЏУАїТћ»С╗ўсђѓУ┐ћтЏъжЄЇтцЇТћ»С╗ўТаЄУ»єсђѓжѓБС╣ѕУ«бтЇЋу│╗у╗ЪТа╣ТЇ«У┐ћтЏъуџёТаЄУ»є№╝їТЏ┤Тќ░У«бтЇЋуіХТђЂсђѓ
ТјЦСИІТЮЦУДБтє│жЄЇУ»ЋжЌ«жбў№╝їТѕЉС╗гтЂЄУ«Йт║ћућеСИіжЄЇУ»ЋСИЅТгА№╝їтдѓТъюСИЅТгАжЃйтц▒У┤Ц№╝їтЁѕУ┐ћтЏъу╗ЎућеТѕиТЈљуц║Тћ»С╗ўу╗ЊТъюТюфуЪЦсђѓтЂЄУ«ЙУ┐ЎСИфТЌХтђЎућеТѕижЄЇТќ░тЈЉУхиТћ»С╗ў№╝їУ«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗Ъ№╝їтЈЉуј░У«бтЇЋти▓у╗ЈТћ»С╗ў№╝їжѓБС╣ѕу╗Ду╗ГСИІжЮбуџёТхЂуеІсђѓтдѓТъюС╝џтЉўТ▓АТюЅтЈЉУхиТћ»С╗ў№╝їу│╗у╗Ът«џТЌХ№╝ѕСИђтѕєжњЪСИђТгА№╝Ѕтј╗ТаИт»╣У«бтЇЋуіХТђЂ№╝їтдѓТъютЈЉуј░ти▓у╗ЈУбФТћ»С╗ў№╝їтѕЎу╗Ду╗Гтљју╗ГуџёТхЂуеІсђѓ
У┐ЎуДЇТќ╣ТАѕ№╝їућеТѕиСйЊжфїжЮътИИти«№╝їтЉіУ»ЅућеТѕиТћ»С╗ўу╗ЊТъюТюфуЪЦ№╝їућеТѕиСИђт«џС╝џжфѓСйа№╝їСйаСИФтњІтЏъС║ІТЃЁ№╝їТѕЉТўјТўјТћ»С╗ўС║є№╝їСйатЉіУ»ЅТѕЉТюфуЪЦсђѓтЂЄУ«ЙтЉіУ»ЅућеТѕиТћ»С╗ўтц▒У┤Ц№╝їСИЄСИђт«ъжЎЁТў»ТѕљтіЪуџётњІтіъсђѓСйатЉіУ»ЅућеТѕиТћ»С╗ўТѕљтіЪ№╝їСИЄСИђТћ»С╗ўтц▒У┤ЦтњІтіъсђѓ
4 уггСИЅуДЇТќ╣ТАѕУЃйтцЪУДБтє│У«бтЇЋтњїТћ»С╗ўТЋ░ТЇ«уџёСИђУЄ┤ТђДжЌ«жбў№╝їСйєТў»ућеТѕиСйЊжфїжЮътИИти«сђѓтйЊуёХУ┐ЎуДЇТЃЁтєхТ»ћУЙЃтЈ»УЃйТў»т░ЉТЋ░№╝їтЈ»С╗ЦуЅ║уЅ▓У┐ЎСИђжЃетѕєуџёућеТѕиСйЊжфї№╝їТѕЉС╗гУ┐ўТюЅТ▓АТюЅТЏ┤тЦйуџёУДБтє│Тќ╣ТАѕ№╝їТЌбУЃйуЁДжАЙућеТѕиСйЊжфї№╝їтЈѕУЃйтцЪС┐ЮУ»ЂУхёжЄЉуџёт«ЅтЁеТђДсђѓ
ТѕЉС╗гтєЇтЏъТЮЦуюІуюІуггСИђуДЇТќ╣ТАѕ№╝їТѕЉС╗гтЁѕСИЇТЅБжњ▒№╝їСйєТў»ТюЅТюеТюЅтіъТ│ЋУ«ЕУ┐ЎСИђжЃетѕєжњ▒СИЇУ«ЕућеТѕиСй┐уће№╝їт»╣С║є№╝їТѕЉС╗гтЁѕТііУ┐ЎСИђжЃетѕєжњ▒тє╗у╗ЊУхиТЮЦ№╝їУ«бтЇЋу│╗у╗ЪтЁѕУ░ЃућеТћ»С╗ўу│╗у╗ЪТѕљтіЪуџёТЌХтђЎ№╝їТћ»С╗ўу│╗у╗ЪтЁѕСИЇТЅБжњ▒№╝їУђїТў»тЁѕТііжњ▒тє╗у╗ЊУхиТЮЦ№╝їСИЇУ«ЕућеТѕиу╗ЎтЁХС╗ќУ«бтЇЋТћ»С╗ў№╝їуёХтљјуГЅУ«бтЇЋу│╗у╗ЪТііУ«бтЇЋуіХТђЂТЏ┤Тќ░СИ║Тћ»С╗ўТѕљтіЪуџёТЌХтђЎ№╝їтєЇжђџуЪЦТћ»С╗ўу│╗у╗Ъ№╝їСйаТЅБжњ▒тљД№╝їУ┐ЎСИфТЌХтђЎТћ»С╗ўу│╗у╗ЪТЅБжњ▒№╝їт«їТѕљтљју╗ГуџёТЊЇСйюсђѓ
уюІУхиТЮЦУ┐ЎСИфТќ╣ТАѕСИЇжћЎ№╝їТѕЉС╗гС╗ћу╗єтюетѕєТъљСИђСИІТхЂуеІ№╝їУ┐ЎСИфТќ╣ТАѕУ┐ўтГўтюеС╗ђС╣ѕжЌ«жбў№╝їтЂЄУ«ЙУ«бтЇЋу│╗у╗ЪтюеУ░ЃућеТћ»С╗ўу│╗у╗Ътє╗у╗ЊуџёТЌХтђЎ№╝їТћ»С╗ўу│╗у╗Ътє╗у╗ЊТѕљтіЪ№╝їСйєТў»У«бтЇЋу│╗у╗ЪУХЁТЌХ№╝їУ┐ЎСИфТЌХтђЎУ┐ћтЏъу╗ЎућеТѕи№╝їтЉіуЪЦућеТѕиТћ»С╗ўтц▒У┤Ц№╝їтдѓТъюућеТѕитєЇТгАТћ»С╗ўУ┐ЎугћУ«бтЇЋ№╝їжѓБС╣ѕућ▒С║јТћ»С╗ўу│╗у╗ЪУ┐ЏУАїТјДтѕХ№╝їтЉіУ»ЅУ«бтЇЋу│╗у╗Ътє╗у╗ЊТѕљтіЪ№╝їУ«бтЇЋу│╗у╗ЪТЏ┤Тќ░уіХТђЂ№╝їуёХтљјжђџуЪЦТћ»С╗ўу│╗у╗Ъ№╝їТЅБжњ▒тљДсђѓтдѓТъюУ┐ЎСИфТЌХтђЎжђџуЪЦтц▒У┤Ц№╝їТюеТюЅжЌ«жбў№╝їтЈЇТГБжњ▒жЃйти▓у╗ЈТў»тє╗у╗ЊуџёС║є№╝їућеТѕиСИЇУЃйуће№╝їТѕЉтЈфУдЂт«џТЌХТЅФТЈЈУ«бтЇЋтњїТћ»С╗ўуіХТђЂ№╝їУ┐ЏУАїТЅБжњ▒Уђїти▓сђѓ
жѓБС╣ѕтдѓТъютЈўТђЂуџёућеТѕижЄЇТќ░ТІЇСИІТЮЦСИђугћУ«бтЇЋ,100тЮЌжњ▒№╝їт»╣Тќ░уџёУ«бтЇЋУ┐ЏУАїТћ»С╗ў№╝їУ┐ЎСИфТЌХтђЎућ▒С║јтЁѕтЅЇжѓБСИђугћУ«бтЇЋуџёжњ▒УбФтє╗у╗ЊС║є№╝їУ┐ЎСИфТЌХтђЎућеТѕиСйЎжбЮтЅЕСйЎ100№╝їтє╗у╗Њ100№╝їтЈЉуј░тЈ»ућеуџёСйЎжбЮУХ│тцЪ№╝їжѓБт░▒уЏ┤ТјЦтюет»╣ућеТѕиТЅБжњ▒сђѓУ┐ЎСИфТЌХтђЎСйЎжбЮтЅЕСйЎ0№╝їтє╗у╗Њ100сђѓтЁѕтЅЇжѓБСИђугћТђјС╣ѕтіъ№╝їСИђСИфтіъТ│Ћт░▒Тў»т«џТЌХТЅФТЈЈ№╝їтЈЉуј░У«бтЇЋуіХТђЂТў»тѕЮтДІуџёУ»Ю№╝їт░▒т»╣ућеТѕиуџёТћ»С╗ўСйЎжбЮУ┐ЏУАїУДБтє╗тцёуљєсђѓУ┐ЎСИфТЌХтђЎућеТѕиуџёСйЎжбЮтЈўТѕљ100№╝їУ«бтЇЋТЋ░ТЇ«тњїТћ»С╗ўТЋ░ТЇ«тЈѕСИђУЄ┤С║єсђѓтЂЄУ«ЙтјЪтЁѕућеТѕиСйЎжбЮтЈфТюЅ100№╝їУбФтє╗у╗ЊС║є№╝їућеТѕижЄЇТќ░СИІтЇЋ№╝їТћ»С╗ўуџёТЌХтђЎт░▒тц▒У┤ЦС║єтЋі№╝їуџёуА«С╝џтЈЉућЪУ┐ЎСИђуДЇТЃЁтєх№╝їТЅђС╗ЦУдЂт░йтЈ»УЃйуџёС┐ЮУ»ЂтюеуггСИђТгАУ«бтЇЋу╗ЊТъюСИЇТўјуА«уџёТЃЁтєх№╝їт░йТЌЕУДБтє╗ућеТѕиСйЎжбЮ№╝їТ»ћтдѓ10уДњС╣ІтєЁсђѓСйєТў»СИЇу«АтдѓСйЋт┐ФжђЪ№╝їТђ╗ТюЅТЋ░ТЇ«СИЇСИђУЄ┤уџёТЌХтѕ╗№╝їУ┐ЎСИфТў»Т▓АТюЅтіъТ│ЋжЂ┐тЁЇуџёсђѓ
уггС║їуДЇТЃЁтєхтњїуггСИЅуДЇТЃЁтєхтдѓСйЋтцёуљє№╝їСИІТгАтюетѕєТъљтљДсђѓ
ућ▒С║јС║њУЂћуйЉуЏ«тЅЇУХіТЮЦУХіт╝║У░ЃтѕєтИЃт╝ЈТъХТъё№╝їтдѓТъюТў»С║цТўЊу▒╗у│╗у╗Ъ№╝їжЮбСИ┤уџёт░єС╝џТў»тѕєтИЃт╝ЈС║ІтіАСИіуџёТїЉТѕўсђѓтйЊуёХуЏ«тЅЇТюЅтЙѕтцџт╝ђТ║љуџётѕєтИЃт╝ЈС║ІтіАС║ДтЊЂ№╝їСЙІтдѓjava JPA№╝їСйєТў»У┐ЎуДЇУДБтє│Тќ╣ТАѕуџёТѕљТюгТў»жЮътИИжФўуџё№╝їУђїСИћт«ъуј░УхиТЮЦжЮътИИтцЇТЮѓ№╝їТЋѕујЄС╣ЪТ»ћУЙЃСйјСИІсђѓт»╣С║јТъЂуФ»уџёТЃЁтєх№╝џСЙІтдѓтЈЉтИЃ№╝їТЋЁжџюуџёТЌХтђЎжЃйТў»Т▓АТюЅтіъТ│ЋС┐ЮУ»Ђт╝║СИђУЄ┤ТђДуџёсђѓ
тюеСИіТќЄСИ╗УдЂС╗Іу╗ЇС║єТЋ░ТЇ«тѕєтИЃуџёТЃЁтєхСИІС┐ЮУ»ЂСИђУЄ┤ТђДуџёТЃЁтєх№╝їтюеуггС║їу»ЄТќЄуФажЄїжЮб№╝їТѕЉУ┐ЎжЄїТЈљтЄ║С║єСИЅСИфжЌ«жбў
1.У«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗ЪТћ»С╗ўУ«бтЇЋ№╝їТћ»С╗ўТѕљтіЪ№╝їСйєТў»У┐ћтЏъу╗ЎУ«бтЇЋу│╗у╗ЪТЋ░ТЇ«УХЁТЌХ№╝їУ«бтЇЋУ┐ўТў»I№╝ѕтѕЮтДІуіХТђЂ№╝Ѕ№╝їСйєТў»ТГцТЌХС╝џтЉўтИљТѕиСйЎжбЮ100,С╝џтЉўУѓ»т«џС╝џжЕгСИіТЅЙС║гСИюжфѓС║гСИю№╝їСИ║тЋЦСИЇу╗ЎУђЂтГљтЈЉУ┤Д№╝їТѕЉжЃйС╗ўжњ▒С║є
2.У«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗ЪТѕљтіЪ№╝їуіХТђЂС╣Ъти▓у╗ЈТЏ┤Тќ░ТѕљтіЪ№╝їСйєТў»жђџуЪЦС╗Њт║ЊтЈЉУ┤Дтц▒У┤Ц№╝їУ┐ЎСИфТЌХтђЎУ«бтЇЋТў»P№╝ѕти▓Тћ»С╗ў№╝ЅуіХТђЂ№╝їТГцТЌХС╝џтЉўтИљТѕиСйЎжбЮТў»100,СйєТў»С╗Њт║ЊСИЇС╝џтЈЉУ┤ДсђѓС╝џтЉўС╣ЪУдЂжфѓС║гСИюсђѓ
3.У«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗ЪТѕљтіЪ№╝їуіХТђЂС╣Ъти▓у╗ЈТЏ┤Тќ░ТѕљтіЪ№╝їуёХтљјжђџуЪЦС╗Њт║ЊтЈЉУ┤Д№╝їС╗Њт║ЊтЉіУ»ЅУ«бтЇЋу│╗у╗Ъ№╝їТ▓АТюЅУ┤ДС║єсђѓУ┐ЎСИфТЌХтђЎТЋ░ТЇ«уіХТђЂтњїуггС║їуДЇТЃЁтєхСИђТаисђѓ
жЄЇуѓ╣тѕєТъљУДБтє│С║єуггСИђСИфуџёжЌ«жбўС╗ЦтЈіуЏИт║ћуџёТќ╣ТАѕ№╝їтЈЉуј░тюеТЋ░ТЇ«тѕєтИЃуџёуј»тбЃСИІ№╝їтЙѕжџЙу╗Ют»╣уџёС┐ЮУ»ЂТЋ░ТЇ«СИђУЄ┤ТђД№╝ѕС╗╗СйЋСИђТ«хтї║жЌ┤№╝Ѕ№╝їСйєТў»ТюЅтіъТ│ЋжђџУ┐ЄСИђуДЇУАЦтЂ┐Тю║тѕХ№╝їТюђу╗ѕС┐ЮУ»ЂТЋ░ТЇ«уџёСИђУЄ┤ТђДсђѓ
тюеСИІжЮбтюетѕєТъљСИђСИІуггС║їСИфжЌ«жбў
У«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗ЪТѕљтіЪ№╝їуіХТђЂС╣Ъти▓у╗ЈТЏ┤Тќ░ТѕљтіЪ№╝їСйєТў»жђџуЪЦС╗Њт║ЊтЈЉУ┤Дтц▒У┤Ц№╝їУ┐ЎСИфТЌХтђЎУ«бтЇЋТў»P№╝ѕти▓Тћ»С╗ў№╝ЅуіХТђЂ№╝їТГцТЌХС╝џтЉўтИљТѕиСйЎжбЮТў»100,СйєТў»С╗Њт║ЊСИЇС╝џтЈЉУ┤ДсђѓС╝џтЉўС╣ЪУдЂжфѓС║гСИюсђѓ
жђџУ┐ЄтюеСИіСИђу»ЄТќЄуФажЄїжЮбтѕєТъљУ┐Є№╝їУ┐ЎСИфуЏИт»╣ТЮЦУ»┤Тў»Т»ћУЙЃу«ђтЇЋуџё№╝їТѕЉтЈ»С╗ЦжЄЄтЈќжЄЇУ»ЋТю║тѕХ№╝їтдѓТъютЈЉуј░жђџуЪЦС╗Њт║ЊтЈЉУ┤Дтц▒У┤Ц№╝їт░▒СИђУЄ┤жЄЇУ»Ћ№╝ї
У┐ЎжЄїжЮбТюЅСИцуДЇТќ╣т╝Ј№╝џ
1 т╝ѓТГЦТќ╣т╝Ј№╝џжђџУ┐Єу▒╗С╝╝MQ№╝ѕТХѕТЂ»жђџуЪЦ№╝ЅуџёТю║тѕХ№╝їУ┐ЎСИфТў»т╝ѓТГЦуџёжђџуЪЦ
2 тљїТГЦУ░Ѓуће№╝џу▒╗С╝╝С║јУ┐юуеІУ┐ЄуеІУ░Ѓуће
т»╣С║јтљїТГЦуџёУ░ЃућеуџёТќ╣т╝Ј№╝їТ»ћУЙЃу«ђтЇЋ№╝їТѕЉС╗гУЃйтцЪтЈіТЌХУјитЈќу╗ЊТъю№╝їт»╣С║јт╝ѓТГЦуџёжђџуЪЦ№╝їт░▒т┐ЁжА╗жЄЄућеУ»иТ▒ѓ№╝їт║ћуГћуџёТќ╣т╝ЈУ┐ЏУАї№╝їУ┐ЎСИђуѓ╣тюе№╝ѕтЁ│С║јтѕєтИЃт╝Ју│╗у╗ЪуџёТЋ░ТЇ«СИђУЄ┤ТђДжЌ«жбў(СИђ)№╝ЅжЄїжЮбТюЅС╗Іу╗ЇсђѓУ┐ЎжЄїжЮбт░▒СИЇтєЇжўљУ┐░сђѓ
ТЮЦуюІуюІуггСИЅСИфжЌ«жбў
У«бтЇЋу│╗у╗ЪУ░ЃућеТћ»С╗ўу│╗у╗ЪТѕљтіЪ№╝їуіХТђЂС╣Ъти▓у╗ЈТЏ┤Тќ░ТѕљтіЪ№╝їуёХтљјжђџуЪЦС╗Њт║ЊтЈЉУ┤Д№╝їС╗Њт║ЊтЉіУ»ЅУ«бтЇЋу│╗у╗Ъ№╝їТ▓АТюЅУ┤ДС║єсђѓУ┐ЎСИфТЌХтђЎТЋ░ТЇ«уіХТђЂтњїуггС║їуДЇТЃЁтєхСИђТаисђѓ
ТѕЉУДЅтЙЌУ┐ЎТў»СИђСИфтЙѕТюЅТёЈТђЮуџёжЌ«жбў№╝їТѕЉС╗гУ┐ўТў»УђЃУЎЉтЄауДЇУДБтє│уџёТќ╣ТАѕ
1 тюеС╝џтЉўСИІтЇЋуџёТЌХтѕ╗№╝їт░▒тЉіУ»ЅС╗Њт║Њ№╝їТѕЉУдЂСйаТііУ┤ДуЅЕуЋЎСИІТЮЦ№╝ї
2 тюеС╝џтЉўТћ»С╗ўУ«бтЇЋТЌХтђЎ№╝їтюеТћ»С╗ўС╣ІтЅЇТБђТЪЦС╗Њт║ЊТюЅТ▓АТюЅУ┤Д№╝їтдѓТъюТ▓АТюЅУ┤Д№╝їт░▒тЉіуЪЦС╝џтЉўТюеТюЅУ┤ДуЅЕС║є
3 тдѓТъюС╝џтЉўТћ»С╗ўТѕљтіЪ№╝їУ┐ЎСИфТЌХтђЎТ▓АТюЅУ┤ДС║є№╝їт░▒С╝џжђђТгЙу╗ЎућеТѕиТѕќУђЁуГЅтЙЁТюЅУ┤ДуџёТЌХтђЎтюетЈЉУ┤Д
ТГБтИИТЃЁтєх№╝їС║гСИюуџёС╗Њт║ЊСИђУѕгжЃйТў»ТюЅУ┤Дуџё№╝їТЅђС╗Цтй▒тЊЇтѕ░уџёС╝џтЉўтЙѕт░Љ№╝їСйєТў»тюеуДњТЮђтњїУљЦжћђуџёТЌХтђЎ№╝їУ┐ЎСИфТЌХтђЎт░▒СИЇСИђт«џС║є№╝їТѕЉС╗гУђЃУЎЉтЂЄУ«ЙС╗Њт║ЊТюЅ10тЈ░iphone
тдѓТъюжЄЄућеуггСИђуДЇТќ╣ТАѕ№╝ї
1 тюеС╝џтЉўСИІтЇЋуџёТЌХтђЎ№╝їуЏИтйЊС║јт║ЊтГўт░▒-1№╝їжѓБС╣ѕућеТѕиТЂХТёЈТІЇСИІТЮЦ№╝їТ▓АТюЅтј╗Тћ»С╗ў№╝їт░▒тй▒тЊЇтѕ░С║єтЁХС╗ќућеТѕиуџёУ┤ГС╣░сђѓС║гСИютЈ»С╗ЦУ«Йуй«СИђСИфУ«бтЇЋУХЁТЌХТЌХжЌ┤№╝їтдѓТъюУ┐ЎТ«хТЌХжЌ┤тєЁТ▓АТюЅТћ»С╗ў№╝їт░▒УЄфтіетЈќТХѕУ«бтЇЋ
2 тюеС╝џтЉўТћ»С╗ўС╣ІтЅЇ№╝їТБђТЪЦС╗Њт║ЊТюЅУ┤Д№╝їУ┐ЎуДЇТќ╣ТАѕС║є№╝їт»╣С║јућеТѕиСйЊжфїСИЇтЦй№╝їСйєТў»т»╣С║јС║гСИюТ»ћУЙЃтЦй№╝їУЄ│т░ЉТѕЉСИюУЦ┐жЃйтЇќтЄ║тј╗С║єсђѓжѓБС║ЏТ▓АТюЅтЈіТЌХС╗ўТгЙуџёућеТѕи№╝їтЈфУЃйТіЋУ»ЅС║єС║гСИюТЌаТЋЁтЈќТХѕУ«бтЇЋ
3 уггСИЅуДЇТќ╣ТАѕ№╝їУ┐ЎСИфТќ╣ТАѕСйЊжфїТЏ┤СИЇтЦй№╝їУђїСИћућеТѕиТёЪУДЅтЈЌтѕ░С║гСИюТг║У»ѕ№╝їСйєТў»т»╣С║јС║гСИюТЮЦУ»┤№╝їТ»ћуггС║їуДЇТќ╣ТАѕТЏ┤ТюЅуЏі№╝їТ»ЋуФЪТѕЉУ┐ўтЈ»С╗ЦтцџтЇќтЄ║СИђуѓ╣СИюУЦ┐сђѓ
СИфС║║УДЅтЙЌ№╝їС║гСИют║ћУ»ЦС╝џжЄЄућеуггС║їуДЇТѕќУђЁуггСИЅуДЇТќ╣т╝ЈТЮЦтцёуљєУ┐Ўу▒╗ТЃЁтєх№╝їТѕЉтюетЙ«тЇџСИіТљюу┤бС║є РђюС║гСИю ТЌаТЋЁтЈќТХѕУ«бтЇЋРђЮ№╝їтЈЉуј░ТъюуюЪтњїТѕЉжбёТќЎуџётцёуљєТќ╣т╝ЈсђѓСИЇУ┐ЄУЄ│С║јУ┐ЎжЄїуџёТЌаТЋЁтЈќТХѕТў»СИЇТў»ТіђТю»СИіуџётјЪтЏаТѕЉСИЇуЪЦжЂЊ№╝їтдѓТъюуюЪуџёТў»ТіђТю»СИіуџётјЪтЏа№╝їТѕЉУДЅтЙЌС║гСИютЈ»С╗ЦжЄЄућеСИЇтљїуџётцёуљєТќ╣ТАѕсђѓт»╣С║јуДњТЮђтњїС┐ЃжћђтЋєтЊЂ№╝їтЈ»С╗ЦУђЃУЎЉуггСИђуДЇТќ╣ТАѕ№╝їтцДтцџТЋ░С║║жЃйС╝џуЏ┤ТјЦС╗ўТгЙ№╝їТ»ЋуФЪСЙ┐т«ютЋі№╝їтдѓТъюућеТѕиТібСИЇтѕ░СЙ┐т«юуџёСИюУЦ┐№╝їТі▒ТђетйЊуёХтЙѕтцДС║єсђѓУ┐ЎТаитЈ»С╗ЦуЁДжАЙтцДтцџТЋ░ућеТѕиуџёСйЊжфїсђѓт»╣С║јСИђУѕгуџёУ«бтЇЋ№╝їтЈ»С╗ЦжЄЄућеуггС║їуДЇТѕќУђЁуггСИЅуДЇТќ╣т╝Ј№╝їУ┐ЎуДЇТЃЁтєхСИІ№╝їтЈЉућЪС╗ўТгЙС╣ІтљјС╗Њт║ЊТ▓АТюЅУ┤ДуџёТЃЁтєхС╝џТ»ћУЙЃт░Љ№╝їт╣ХСИћт░▒у«ЌтЈЉућЪС║є№╝їућеТѕиС╣ЪС╝џУДЅтЙЌТЌаТЅђУ░Њ№╝їтцДСИЇС║єжђђжњ▒тљЌ№╝їУ┐ЎТаит░▒тЈ»С╗Цт«ъуј░УЄфти▒уџётѕЕуЏіТюђтцДтїќУђїТюђСйјуеІт║дуџётЄЈт░ЉућеТѕиСйЊжфїсђѓ
УђїжЊЂжЂЊжЃетюеУ┐ЎСИфжЌ«жбўСИі№╝їжЄЄућеуџёТў»уггСИђуДЇТќ╣ТАѕ№╝їСИ║С╗ђС╣ѕтњїС║гСИюСИЇСИђТаи№╝їт░▒Тў»тЏаСИ║ућеТѕиСйЊжфї№╝їтдѓТъюућеТѕиТііуЦежЃйС╣░С║є№╝їСйатЉіУ»ЅТѕЉТюеТюЅуЦеС║є№╝їТЌЁт«бС╝џТЮђС║║уџёсђѓтЊѕтЊѕ№╝їСИЇУ┐ЄжЊЂжЂЊжЃеСИЇТІЁт┐ЃуЦетЇќСИЇтЄ║тј╗№╝їуггСИђуДЇТќ╣ТАѕт»╣С╗ќтй▒тЊЇТ▓АТюЅС╗ђС╣ѕсђѓ
У»┤С║єУ┐ЎС╣ѕтцџ№╝їт░▒Тў»У»┤ тѕєтИЃт╝Јуј»тбЃСИІ№╝ѕТЋ░ТЇ«тѕєтИЃ№╝ЅУдЂС╗╗СйЋТЌХтѕ╗С┐ЮУ»ЂТЋ░ТЇ«СИђУЄ┤ТђДТў»СИЇтЈ»УЃйуџё№╝їтЈфУЃйжЄЄтЈќтдЦтЇЈуџёТќ╣ТАѕТЮЦС┐ЮУ»ЂТЋ░ТЇ«Тюђу╗ѕСИђУЄ┤ТђДсђѓУ┐ЎСИфС╣Ът░▒Тў»УЉЌтљЇуџёCAPт«џуљєсђѓ
тюетЅЇжЮбСИЅу»ЄТќЄуФаСИГ№╝їС╗Іу╗ЇС║єтЁ│С║јтѕєтИЃт╝Ју│╗у╗ЪСИГТЋ░ТЇ«СИђУЄ┤ТђДуџёжЌ«жбў№╝їУ┐ЎСИђу»ЄСИ╗УдЂС╗Іу╗ЇCAPт«џуљєС╗ЦтЈіУЄфти▒т»╣CAPт«џуљєуџёС║єУДБсђѓ
CAPт«џуљєТў»2000т╣┤№╝їућ▒ Eric Brewer ТЈљтЄ║ТЮЦуџё
BrewerУ«цСИ║тюетѕєтИЃт╝Јуџёуј»тбЃСИІУ«ЙУ«АтњїжЃеуй▓у│╗у╗ЪТЌХ№╝їТюЅ3СИфТаИт┐ЃуџёжюђТ▒ѓ№╝їС╗ЦСИђуДЇуЅ╣Т«іуџётЁ│у│╗тГўтюесђѓУ┐ЎжЄїуџётѕєтИЃт╝Ју│╗у╗ЪУ»┤уџёТў»тюеуЅЕуљєСИітѕєтИЃуџёу│╗у╗Ъ№╝їТ»ћтдѓТѕЉС╗гтИИУДЂуџёwebу│╗у╗Ъсђѓ
У┐Ў3СИфТаИт┐ЃуџёжюђТ▒ѓТў»№╝џConsistency№╝їAvailabilityтњїPartition Tolerance№╝їУхІС║ѕС║єУ»ЦуљєУ«║тЈдтцќСИђСИфтљЇтГЌ №╝Ї CAPсђѓ
Consistency№╝џСИђУЄ┤ТђД№╝їУ┐ЎСИфтњїТЋ░ТЇ«т║ЊACIDуџёСИђУЄ┤ТђДу▒╗С╝╝№╝їСйєУ┐ЎжЄїтЁ│Т│еуџёТЅђТюЅТЋ░ТЇ«Уіѓуѓ╣СИіуџёТЋ░ТЇ«СИђУЄ┤ТђДтњїТГБуА«ТђД№╝їУђїТЋ░ТЇ«т║ЊуџёACIDтЁ│Т│еуџёТў»тюетюеСИђСИфС║ІтіАтєЁ№╝їт»╣ТЋ░ТЇ«уџёСИђС║Џу║дТЮЪсђѓ
Availability№╝џтЈ»ућеТђД№╝їтЁ│Т│еуџётюеТЪљСИфу╗Њуѓ╣уџёТЋ░ТЇ«Тў»тљдтЈ»уће№╝їтЈ»С╗ЦУ«цСИ║ТЪљСИђСИфУіѓуѓ╣уџёу│╗у╗ЪТў»тљдтЈ»уће№╝їжђџС┐АТЋЁжџюжЎцтцќсђѓ
Partition Tolerance№╝џтѕєтї║т«╣т┐ЇТђД№╝їТў»тљдтЈ»С╗Цт»╣ТЋ░ТЇ«У┐ЏУАїтѕєтї║сђѓУ┐ЎТў»УђЃУЎЉтѕ░ТђДУЃйтњїтЈ»С╝Иу╝ЕТђДсђѓ
СИ║С╗ђС╣ѕСИЇУЃйт«їтЁеС┐ЮУ»ЂУ┐ЎСИфСИЅуѓ╣С║є№╝їСИфС║║УДЅтЙЌСИ╗УдЂТў»тЏаСИ║СИђТЌдУ┐ЏУАїтѕєтї║С║є№╝їт░▒У»┤ТўјС║єт┐ЁжА╗Уіѓуѓ╣С╣ІжЌ┤т┐ЁжА╗У┐ЏУАїжђџС┐А№╝їТХЅтЈітѕ░жђџС┐А№╝їт░▒ТЌаТ│ЋуА«С┐ЮтюеТюЅжЎљуџёТЌХжЌ┤тєЁт«їТѕљТїЄт«џуџёУАїТќЄ№╝їтдѓТъюУдЂТ▒ѓСИцСИфТЊЇСйюС╣ІжЌ┤УдЂт«їТЋ┤уџёУ┐ЏУАї№╝їтЏаСИ║ТХЅтЈітѕ░жђџС┐А№╝їУѓ»т«џтГўтюеТЪљСИђСИфТЌХтѕ╗тЈфт«їТѕљСИђжЃетѕєуџёСИџтіАТЊЇСйю№╝їтюежђџС┐Ат«їТѕљуџёУ┐ЎСИђТ«хТЌХжЌ┤тєЁ№╝їТЋ░ТЇ«т░▒Тў»СИЇСИђУЄ┤ТђДуџёсђѓтдѓТъюУдЂТ▒ѓС┐ЮУ»ЂСИђУЄ┤ТђД№╝їжѓБС╣ѕт░▒т┐ЁжА╗тюежђџС┐Ат«їТѕљУ┐ЎСИђТ«хТЌХжЌ┤тєЁС┐ЮТіцТЋ░ТЇ«№╝їСй┐тЙЌС╗╗СйЋУ«┐жЌ«У┐ЎС║ЏТЋ░ТЇ«уџёТЊЇСйюСИЇтЈ»ућесђѓ
тдѓТъюТЃ│С┐ЮУ»ЂСИђУЄ┤ТђДтњїтЈ»ућеТђД№╝їжѓБС╣ѕТЋ░ТЇ«т░▒СИЇУЃйтцЪтѕєтї║сђѓСИђСИфу«ђтЇЋуџёуљєУДБт░▒Тў»ТЅђТюЅуџёТЋ░ТЇ«т░▒т┐ЁжА╗тГўТћЙтюеСИђСИфТЋ░ТЇ«т║ЊжЄїжЮб№╝їСИЇУЃйУ┐ЏУАїТЋ░ТЇ«т║ЊТІєтѕєсђѓУ┐ЎСИфт»╣С║јтцДТЋ░ТЇ«жЄЈ№╝їжФўт╣ХтЈЉуџёС║њУЂћуйЉт║ћућеТЮЦУ»┤№╝їТў»СИЇтЈ»ТјЦтЈЌуџёсђѓ
ТѕЉС╗гтЈ»С╗ЦТІ┐СИђСИфу«ђтЇЋуџёСЙІтГљТЮЦУ»┤Тўј№╝џтЂЄУ«ЙСИђСИфУ┤ГуЅЕу│╗у╗Ъ№╝їтЇќт«ХAтњїтЇќт«ХBтЂџС║єСИђугћС║цТўЊ100тЁЃ№╝їС║цТўЊТѕљтіЪС║є№╝їС╣░т«ХТііжњ▒у╗ЎтЇќт«Хсђѓ
У┐ЎжЄїжЮбтГўтюеСИцт╝аУАеуџёТЋ░ТЇ«№╝џTradeУАеAccountУАе №╝їТХЅтЈітѕ░СИЅТЮАТЋ░ТЇ«Trade(100),Account A ,Account B
тЂЄУ«Й tradeУАетњїaccountУАетюеСИђСИфТЋ░ТЇ«т║Њ№╝їжѓБС╣ѕтЈфжюђУдЂСй┐ућеТЋ░ТЇ«т║ЊуџёС║ІтіА№╝їт░▒тЈ»С╗ЦС┐ЮУ»ЂСИђУЄ┤ТђД№╝їтљїТЌХСИЇС╝џтй▒тЊЇтЈ»ућеТђДсђѓСйєТў»жџЈуЮђС║цТўЊжЄЈУХіТЮЦУХітцД№╝їТѕЉС╗гтЈ»С╗ЦУђЃУЎЉТїЅуЁДСИџтіАтѕєт║Њ№╝їТііС║цТўЊт║Њтњїaccountт║ЊтЇЋуІгтѕєт╝ђ№╝їУ┐ЎТаит░▒ТХЅтЈітѕ░tradeт║Њтњїaccountт║ЊУ┐ЏУАїжђџС┐А№╝їС╣Ът░▒Тў»тГўтюеС║єтѕєтї║№╝їжѓБС╣ѕТѕЉС╗гт░▒СИЇтЈ»УЃйтљїТЌХС┐ЮУ»ЂтЈ»ућеТђДтњїСИђУЄ┤ТђДсђѓ
ТѕЉС╗гтЂЄУ«ЙтѕЮтДІуіХТђЂ
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,I)
account(accountNo,balance) = account(A,300)
account(accountNo,balance) = account(B,10)
тюеуљєТЃ│ТЃЁтєхСИІ№╝їТѕЉС╗гТюЪТюЏуџёуіХТђЂТў»
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,S)
account(accountNo,balance) = account(A,200)
account(accountNo,balance) = account(B,110)
СйєТў»УђЃУЎЉтѕ░СИђС║Џт╝ѓтИИТЃЁтєх
тЂЄУ«Йтюеtrade(20121001,S)ТЏ┤Тќ░т«їТѕљС╣ІтЅЇ№╝їтИљТѕиAУ┐ЏУАїТЅБТгЙС╣Ітљј№╝їтИљТѕиAУ┐ЏУАїС║єтЈдтцќСИђугћ300ТгЙжњ▒уџёС║цТўЊ№╝їТііжњ▒ТХѕУ┤╣С║є№╝їжѓБС╣ѕт░▒тГўтюеСИђСИфуіХТђЂ
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,S)
account(accountNo,balance) = account(A,0)
account(accountNo,balance) = account(B,10)
С║ДућЪС║єТЋ░ТЇ«СИЇСИђУЄ┤уџёуіХТђЂ
ућ▒С║јУ┐ЎСИфТХЅтЈітѕ░УхёжЄЉСИіуџёжЌ«жбў№╝їт»╣УхёжЄЉУдЂТ▒ѓТ»ћУЙЃжФў№╝їТѕЉС╗гт┐ЁжА╗С┐ЮУ»ЂСИђУЄ┤ТђД№╝їжѓБС╣ѕТђјС╣ѕтіъ№╝їтЈфУЃйтюеУ┐ЏУАїtrade(A,B,20121001)С║цТўЊуџёТЌХтђЎ№╝їт»╣С║јС╗╗СйЋAуџётљју╗ГС║цТўЊУ»иТ▒ѓtrade(A,X,X)№╝їт┐ЁжА╗уГЅтѕ░Aт«їТѕљС╣Ітљј№╝їТЅЇУЃйтцЪУ┐ЏУАїтцёуљє№╝їС╣Ът░▒Тў»У»┤тюеУ┐ЏУАїtrade(A,B,20121001)уџёТЌХтђЎ№╝їAccount(A)уџёТЋ░ТЇ«Тў»СИЇтЈ»ућеуџёсђѓ
С╗╗СйЋТъХТъётИѕтюеУ«ЙУ«АтѕєтИЃт╝Јуџёу│╗у╗ЪуџёТЌХтђЎ№╝їжЃйт┐ЁжА╗тюеУ┐ЎСИЅУђЁС╣ІжЌ┤У┐ЏУАїтЈќУѕЇсђѓждќтЁѕт░▒Тў»Тў»тљджђЅТІЕтѕєтї║№╝їућ▒С║јтюеСИђСИфТЋ░ТЇ«тѕєтї║тєЁ№╝їТа╣ТЇ«ТЋ░ТЇ«т║ЊуџёACIDуЅ╣ТђД№╝їТў»тЈ»С╗ЦС┐ЮУ»ЂСИђУЄ┤ТђДуџё№╝їСИЇС╝џтГўтюетЈ»ућеТђДтњїСИђУЄ┤ТђДуџёжЌ«жбў№╝їтћ»СИђжюђУдЂУђЃУЎЉуџёт░▒Тў»ТђДУЃйжЌ«жбўсђѓт»╣С║јтЈ»ућеТђДтњїСИђУЄ┤ТђД№╝їтцДтцџТЋ░т║ћућет░▒т┐ЁжА╗С┐ЮУ»ЂтЈ»ућеТђД№╝їТ»ЋуФЪТў»С║њУЂћуйЉт║ћуће№╝їуЅ║уЅ▓С║єтЈ»ућеТђД№╝їуЏИтйЊС║јжЌ┤ТјЦуџётй▒тЊЇС║єућеТѕиСйЊжфї№╝їУђїтћ»СИђтЈ»С╗ЦУђЃУЎЉт░▒Тў»СИђУЄ┤ТђДС║єсђѓ
уЅ║уЅ▓СИђУЄ┤ТђД
т»╣С║јуЅ║уЅ▓СИђУЄ┤ТђДуџёТЃЁтєхТюђтцџуџёт░▒Тў»у╝ЊтГўтњїТЋ░ТЇ«т║ЊуџёТЋ░ТЇ«тљїТГЦжЌ«жбў№╝їТѕЉС╗гТііу╝ЊтГўуюІтЂџСИђСИфТЋ░ТЇ«тѕєтї║Уіѓуѓ╣№╝їТЋ░ТЇ«т║ЊуюІСйютЈдтцќСИђСИфУіѓуѓ╣№╝їУ┐ЎСИцСИфУіѓуѓ╣С╣ІжЌ┤уџёТЋ░ТЇ«тюеС╗╗СйЋТЌХтѕ╗жЃйТЌаТ│ЋС┐ЮУ»ЂСИђУЄ┤ТђДуџёсђѓтюеweb2.0У┐ЎТаиуџёСИџтіА№╝їт╝ђт┐ЃуйЉТЮЦСИЙСЙІтГљ№╝їУ«┐жЌ«СИђСИфућеТѕиуџёС┐АТЂ»уџёТЌХтђЎ№╝їтЈ»С╗ЦтЁѕУ«┐жЌ«у╝ЊтГўуџёТЋ░ТЇ«№╝їСйєТў»тдѓТъюућеТѕиС┐«Тћ╣С║єУЄфти▒уџёСИђС║ЏС┐АТЂ»№╝їждќтЁѕС┐«Тћ╣уџёТў»ТЋ░ТЇ«т║Њ№╝їуёХтљјтюежђџуЪЦу╝ЊтГўУ┐ЏУАїТЏ┤Тќ░№╝їУ┐ЎТ«хТюЪжЌ┤тєЁт░▒С╝џт»╝УЄ┤уџёТЋ░ТЇ«СИЇСИђУЄ┤№╝їућеТѕитЈ»УЃйУ«┐жЌ«уџёТў»СИђСИфУ┐ЄТюЪуџёу╝ЊтГў№╝їУђїСИЇТў»ТюђТќ░уџёТЋ░ТЇ«сђѓСйєТў»ућ▒С║јУ┐ЎС║ЏСИџтіАт»╣СИђУЄ┤ТђДуџёУдЂТ▒ѓТ»ћУЙЃжФў№╝їСИЇС╝џтИдТЮЦтцфтцДуџётй▒тЊЇсђѓ
т╝ѓтИИжћЎУ»»ТБђТхІтњїУАЦтЂ┐
У┐ўТюЅСИђуДЇуЅ║уЅ▓СИђУЄ┤ТђДуџёТќ╣Т│Ћт░▒Тў»жђџУ┐ЄСИђуДЇжћЎУ»»УАЦтЂ┐Тю║тѕХТЮЦУ┐ЏУАї№╝їтЈ»С╗ЦТІ┐СИіжЮбУ┤ГуЅЕуџёСЙІтГљТЮЦУ»┤№╝їтЂЄУ«ЙТѕЉС╗гТііСИџтіАжђ╗УЙЉжА║т║ЈУ░ЃТЋ┤СИђСИІ№╝їтЁѕТЅБС╣░т«Хжњ▒№╝їуёХтљјТЏ┤Тќ░С║цТўЊуіХТђЂ№╝їтюеТііжњ▒ТЅЊу╗ЎтЇќт«Х
ТѕЉС╗гтЂЄУ«ЙтѕЮтДІуіХТђЂ
account(accountNo,balance) = account(A,300)
account(accountNo,balance) = account(B,10)
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,I)
жѓБС╣ѕТюЅтЈ»УЃйтЄ║уј░
account(accountNo,balance) = account(A,200)
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,S)
account(accountNo,balance) = account(B,10)
жѓБС╣ѕт░▒тЄ║уј░С║єAТЅБТгЙТѕљтіЪ№╝їС║цТўЊуіХТђЂС╣ЪТѕљтіЪС║є№╝їСйєТў»жњ▒Т▓АТюЅТЅЊу╗ЎB№╝їУ┐ЎСИфТЌХтђЎтЈ»С╗ЦжђџУ┐ЄСИђСИфТЌХтђЎуџёт╝ѓтИИТЂбтцЇТю║тѕХ№╝їТііжњ▒ТЅЊу╗ЎB№╝їТюђу╗ѕуџёТЃЁтєхС┐ЮУ»ЂС║єСИђУЄ┤ТђД№╝їтюеСИђт«џТЌХжЌ┤тєЁТЋ░ТЇ«тЈ»УЃйТў»СИЇСИђУЄ┤уџё№╝їСйєТў»СИЇС╝џтй▒тЊЇтцфтцДсђѓ
СИцжўХТ«хТЈљС║цтЇЈУ««
тйЊуёХ№╝їУ┐ўТюЅСИђуДЇТќ╣т╝Јт░▒Тў»ТѕЉтЈдтцќСИђу»ЄТќЄуФажЄїжЮбсђіX/Open DTP-тѕєтИЃт╝ЈС║ІтіАТеАтъІсђІжЄїжЮбУ»┤уџё№╝їСйєТў»тєЇуггСИђжўХТ«хтњїуггС║їжўХТ«хС╣ІжЌ┤№╝їТЋ░ТЇ«С╣ЪтЈ»СИЇУЃйТў»СИђУЄ┤ТђДуџё№╝їС╣ЪтЈ»УЃйтЄ║уј░тљїТаиуџёТЃЁтєхт»╝УЄ┤т╝ѓтИИсђѓУђїСИћDTPуџётѕєтИЃт╝ЈС║ІтіАТеАтъІ жЎљтѕХтцфтцџ№╝їСЙІтдѓт┐ЁжА╗ТюЅт«ъуј░тЁХтіЪУЃйуџёуЏИтЁ│уџёт«╣тЎеТћ»ТїЂ№╝їт╣ХСИћУхёТ║љу«АуљєтЎеС╣Ът┐ЁжА╗т«ъуј░С║єXAУДёУїЃсђѓжЎљтѕХТ»ћУЙЃтцџсђѓ
тЏйтцќТюЅуџёТъХТъётИѕТюЅСИцуДЇТќ╣ТАѕтј╗УДБтє│CAPуџёжЎљтѕХ№╝їСйєТў»С╣ЪТў»Т»ћУЙЃжђѓтљѕуЅ╣т«џуџёСИџтіА№╝їУђїТ▓АТюЅжђџућеуџёУДБтє│Тќ╣ТАѕ№╝ї
ТјбуЪЦтѕєтї║->тѕєтї║тєЁТЊЇСйю->С║ІтљјУАЦтЂ┐
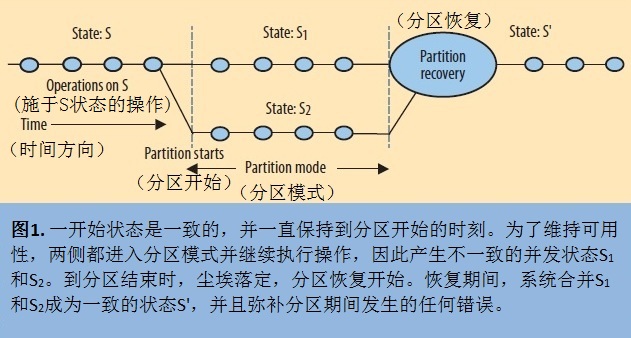
т░▒Тў»СИіжЮбС╗Іу╗Їуџёт╝ѓтИИТБђТхІТЂбтцЇТю║тѕХ№╝їУ┐ЎуДЇТю║тѕХтЁХт«ъУ┐ўТў»ТюЅжЎљтѕХ№╝ї
ждќтЁѕт»╣С║јтѕєтї║ТБђТхІТЊЇСйю№╝їСИЇтљїуџёСИџтіАТХЅтЈітѕ░уџётѕєтї║ТЊЇСйютЈ»УЃйСИЇСИђТаи
тѕєтї║тєЁТЊЇСйюжЎљтѕХ№╝џСИЇтљїуџёСИџтіАт»╣т║ћуџёу║дТЮЪСИЇСИђУЄ┤
С║ІтљјУАЦтЂ┐№╝џућ▒С║јСИџтіАу║дТЮЪСИЇСИђТаи№╝їУАЦтЂ┐Тќ╣т╝ЈС╣ЪСИЇСИђТаисђѓ
ТЅђС╗ЦУ┐ЎтЈфУЃйСйюСИ║СИђуДЇТђЮТЃ│№╝їСИЇУЃйтЂџСИђСИфжђџућеуџёУДБтє│Тќ╣ТАѕ



уЏИтЁ│ТјеУЇљ
У┐ЎС║ЏуаћуЕХТќ╣тљЉтЈ»УЃйтїЁТІгСйєСИЇжЎљС║ј№╝џтѕєтИЃт╝Ју│╗у╗ЪСИјС║ЉУ«Ау«ЌТіђТю»уџёу╗ЊтљѕсђЂУиетю░уљєтї║тЪЪтцџТЋ░ТЇ«СИГт┐ЃТъХТъёСИІуџёТЋ░ТЇ«СИђУЄ┤ТђДжЌ«жбўсђЂС╗ЦтЈітдѓСйЋтюеС┐ЮУ»ЂСИђУЄ┤ТђДуџётљїТЌХТЈљжФўу│╗у╗ЪТђДУЃйуГЅсђѓуљєУДБУ┐ЎС║ЏТќ╣тљЉт»╣ТјетіеСИђУЄ┤ТђДжбєтЪЪуаћуЕХуџётЈЉт▒ЋтЁиТюЅТїЄт»╝ТёЈС╣Ѕсђѓ ...
сђљТаЄжбўсђЉ№╝џРђютЪ║С║јТХѕТЂ»жўЪтѕЌуџётѕєтИЃт╝Ју│╗у╗ЪТЋ░ТЇ«СИђУЄ┤ТђДТќ╣Т│ЋуаћуЕХ.pdfРђЮ сђљТЉўУдЂсђЉ№╝џТюгТќЄСИ╗УдЂТјбУ«еС║єтюетѕєтИЃт╝Јуј»тбЃСИГтдѓСйЋС┐ЮТїЂТЋ░ТЇ«СИђУЄ┤ТђД№╝їжђџУ┐ЄтѕєТъљСИђСИфт«ъжЎЁуџёт«╣уЂЙу│╗у╗Ъ№╝їуаћуЕХС║єТЋ░ТЇ«тљїТГЦтњїТЋ░ТЇ«СИђУЄ┤ТђДуџёжЌ«жбўсђѓСйюУђЁТЈљтЄ║С║єСИђуДЇтѕЕуће...
2. **тѕєтИЃт╝Ју│╗у╗ЪуџётЅ»Сйюуће№╝џТЋ░ТЇ«СИђУЄ┤ТђДжЌ«жбў** т░йу«АтѕєтИЃт╝Ју│╗у╗ЪтИдТЮЦС║єУ»ИтцџтЦйтцё№╝їСйєТЋ░ТЇ«СИђУЄ┤ТђДТѕљСИ║СИџуЋїтЁ│Т│еуџёуёдуѓ╣сђѓтюетѕєтИЃт╝Јуј»тбЃСИГ№╝їСИџтіАжђ╗УЙЉтѕєТЋБтюеСИЇтљїуџёУіѓуѓ╣СИіТЅДУАї№╝їтдѓТъютљёУіѓуѓ╣жЌ┤уџёТЋ░ТЇ«тљїТГЦтЄ║уј░жЌ«жбў№╝їС╝џт»╝УЄ┤ТЋ░ТЇ«СИЇ...
тюетѕєтИЃт╝Ју│╗у╗ЪСИГ№╝їу╝ЊтГўСИђУЄ┤ТђДжЌ«жбўТў»у│╗у╗ЪТђДУЃйуџётЁ│жћ«сђѓућ▒С║јтѕєтИЃт╝Ју│╗у╗Ъућ▒тцџСИфУ«Ау«ЌУіѓуѓ╣у╗ёТѕљ№╝їУ┐ЎС║ЏУіѓуѓ╣тЈ»УЃйтѕєтИЃтюеСИЇтљїуџётю░уљєСйЇуй«№╝їтЏаТГцу│╗у╗ЪСИГуџёТЋ░ТЇ«ТІиУ┤ЮжюђУдЂС┐ЮТїЂСИђУЄ┤№╝їС╗ЦуА«С┐Юу│╗у╗ЪуџёТГБтИИУ┐љУАїсђѓу╝ЊтГўТіђТю»уџёт╝ЋтЁЦтЈ»С╗Цу╝ЊУДБТЋ░ТЇ«...
тюетѕєтИЃт╝ЈтГўтѓеу│╗у╗ЪСИГ№╝їТЋ░ТЇ«СИђУЄ┤ТђДТў»ТїЄтдѓСйЋуА«С┐ЮТЅђТюЅТЋ░ТЇ«тЅ»ТюгС┐ЮТїЂтљїТГЦ№╝їТЌаУ«║ТЋ░ТЇ«Тў»тюеУ┐ЏУАїУ»╗тЈќТЊЇСйюУ┐ўТў»тєЎтЁЦТЊЇСйюсђѓСИђУЄ┤ТђДУдЂТ▒ѓТЋ░ТЇ«тюетєЎтЁЦтљјУЃйтцЪУбФТГБуА«тю░тцЇтѕХтѕ░тљёСИфтЅ»ТюгСИі№╝їСИћСИЇС╝џтЄ║уј░жћЎС╣▒ТѕќжЂЌТ╝ЈсђѓСИ║т«ъуј░У┐ЎСИђуѓ╣№╝їтѕєтИЃт╝ЈтГўтѓе...
СИ║С║єСЙ┐С║јУ«еУ«║жЌ«жбў№╝їтЁѕу«ђтЇЋС╗Іу╗ЇСИІТЋ░ТЇ«СИђУЄ┤ТђДуџётЪ║уАђуљєУ«║сђѓтйЊТЏ┤Тќ░ТЊЇСйют«їТѕљС╣Ітљј№╝їС╗╗СйЋтцџСИфтљју╗ГУ┐ЏуеІТѕќУђЁу║┐уеІуџёУ«┐жЌ«жЃйС╝џУ┐ћтЏъТюђТќ░уџёТЏ┤Тќ░У┐Єуџётђ╝сђѓУ┐ЎуДЇТў»т»╣ућеТѕиТюђтЈІтЦйуџё№╝їт░▒Тў»ућеТѕиСИіСИђТгАтєЎС╗ђС╣ѕ№╝їСИІСИђТгАт░▒С┐ЮУ»ЂУЃйУ»╗тѕ░С╗ђС╣ѕсђѓТа╣ТЇ«...
тѕєтИЃт╝Ју│╗у╗ЪуџёУ«ЙУ«Атњїт«ъТќйжЮбт»╣уџёждќУдЂжЌ«жбўС╣ІСИђт░▒Тў»тдѓСйЋС┐ЮУ»ЂТЋ░ТЇ«СИђУЄ┤ТђДсђѓТЋ░ТЇ«СИђУЄ┤ТђДТў»тѕєтИЃт╝Ју│╗у╗ЪСИГСИђСИфТаИт┐ЃжЌ«жбў№╝їт«ЃТХЅтЈітѕ░у│╗у╗ЪСИГтљёСИфу╗ёС╗ХтюеТЋ░ТЇ«ТЏ┤Тќ░сђЂС║ІтіАтцёуљєуГЅТќ╣жЮбУЃйтцЪС┐ЮТїЂСИђУЄ┤уџёуіХТђЂсђѓжѓБС╣ѕ№╝їтѕєтИЃт╝Ју│╗у╗ЪтюежЮбСИ┤тљёуДЇСИџтіА...
тюеТјбУ«етѕєтИЃт╝Ју│╗у╗ЪС║ІтіАСИђУЄ┤ТђДУДБтє│Тќ╣ТАѕТЌХ№╝їТѕЉС╗гждќтЁѕжюђУдЂуљєУДБтѕєтИЃт╝Ју│╗у╗ЪуџёТаИт┐ЃТїЉТѕўС╣ІСИђт░▒Тў»тдѓСйЋтюеС┐ЮУ»ЂТЋ░ТЇ«СИђУЄ┤ТђДуџётљїТЌХ№╝їУ┐ўУдЂу╗┤ТїЂу│╗у╗ЪуџётЈ»ућеТђДтњїтѕєтї║т«╣жћЎТђДсђѓТа╣ТЇ«CAPт«џтЙІ№╝їСИђСИфтѕєтИЃт╝Ју│╗у╗ЪСИЇтЈ»УЃйтљїТЌХТ╗АУХ│У┐ЎСИЅСИфуЅ╣ТђДсђѓтюе...
жњѕт»╣тѕєтИЃт╝Ју│╗у╗ЪСИГТЋ░ТЇ«СИђУЄ┤ТђДуџёжЌ«жбў№╝їТюЅтЄауДЇСИЇтљїуџёт«џС╣ЅТќ╣Т│ЋТЮЦТЈЈУ┐░у│╗у╗ЪтюеСйЋуДЇуеІт║дСИіС┐ЮУ»ЂТЋ░ТЇ«уџёСИђУЄ┤ТђДсђѓ - **т╝║СИђУЄ┤ТђД№╝ѕтЇ│ТЌХСИђУЄ┤ТђД№╝Ѕ**№╝џтдѓТъюТЪљСИфт«бТѕиуФ»тєЎтЁЦС║єСИђСИфТќ░уџётђ╝№╝їтѕЎТЅђТюЅтљју╗Гт»╣У»Цтђ╝уџёУ»╗тЈќТЊЇСйюжЃйт░єУ┐ћтЏъУ┐ЎСИфТюђТќ░...
тюетѕєтИЃт╝Ју│╗у╗ЪСИГ№╝їућ▒С║јуйЉу╗ют╗ХУ┐ЪсђЂУіѓуѓ╣ТЋЁжџютњїт╣ХтЈЉТЊЇСйюуџётГўтюе№╝їС┐ЮТїЂТЋ░ТЇ«СИђУЄ┤ТђДТў»СИђжА╣ТъЂтЁиТїЉТѕўТђДуџёС╗╗тіАсђѓСИђУЄ┤ТђДТеАтъІтдѓт╝║СИђУЄ┤ТђДсђЂт╝▒СИђУЄ┤ТђДТѕќТюђу╗ѕСИђУЄ┤ТђД№╝їТЈљСЙЏС║єСИЇтљїуџёУДБтє│Тќ╣ТАѕТЮЦт╣│УААтЈ»ућеТђДтњїСИђУЄ┤ТђДсђѓPaxosу«ЌТ│Ћт░▒Тў»СИ║С║є...
тюетѕєтИЃт╝Ју│╗у╗ЪСИГ№╝їућ▒С║јТЋ░ТЇ«тѕєтИЃтюетцџСИфУіѓуѓ╣СИі№╝їТЋ░ТЇ«СИђУЄ┤ТђДТѕљСИ║С║єСИђСИфтЁ│жћ«ТїЉТѕўсђѓтѕєтИЃт╝ЈUDDIТ│етєїСИГт┐ЃжђџтИИућ▒тцџСИфтГљТ│етєїСИГт┐Ѓу╗ёТѕљ№╝їТ»ЈСИфтГљСИГт┐ЃтГўтѓеСИђжЃетѕєWebТюЇтіАуџёТ│етєїС┐АТЂ»сђѓУ┐ЎуДЇТъХТъёУЎйуёХТЈљжФўС║єТюЇтіАуџётЈ»ућеТђДтњїт«╣жћЎТђД№╝їСйєС╣Ъ...
тюетѕєтИЃт╝Ју│╗у╗ЪСИГ№╝їС┐ЮУ»ЂТЋ░ТЇ«СИђУЄ┤ТђДжђџтИИтѕєСИ║т╝║СИђУЄ┤ТђДтњїт╝▒СИђУЄ┤ТђДСИцуДЇТќ╣т╝Јсђѓт╝║СИђУЄ┤ТђДУдЂТ▒ѓу│╗у╗ЪСИГуџёС╗╗СйЋТЋ░ТЇ«ТЏ┤Тћ╣жЃйУЃйуФІтЇ│тЈЇТўатюеТЅђТюЅтЅ»ТюгСИі№╝їуА«С┐Ют╣ХтЈЉУ«┐жЌ«ТЌХТЋ░ТЇ«уџёСИђУЄ┤ТђД№╝їСйєУ┐ЎуДЇУдЂТ▒ѓтЈ»УЃйС╝џжЎЇСйју│╗у╗ЪуџётЈ»ућеТђДсђѓт╝▒СИђУЄ┤ТђД№╝ѕТюђу╗ѕ...
**CAP т«џуљє** Тў»уљєУДБтѕєтИЃт╝Ју│╗у╗ЪСИГТЋ░ТЇ«СИђУЄ┤ТђДжЌ«жбўуџётЪ║уАђсђѓУ»Цт«џуљєТїЄтЄ║№╝їтюетѕєтИЃт╝Ју│╗у╗ЪСИГ№╝їСИђУЄ┤ТђД№╝ѕConsistency№╝ЅсђЂтЈ»ућеТђД№╝ѕAvailability№╝Ѕтњїтѕєтї║т«╣жћЎТђД№╝ѕPartition Tolerance№╝ЅУ┐ЎСИЅСИфт▒ъТђДСИЇтЈ»УЃйтљїТЌХт«їтЁеТ╗АУХ│сђѓтЁиСйЊТЮЦУ»┤...
тєЁт«╣ТдѓУдЂ№╝џТќЄуФаТи▒тЁЦУ«еУ«║С║єтѕєтИЃт╝Ју│╗у╗ЪСИГСИђУЄ┤ТђДтЇЈУ««жЮбСИ┤уџёТїЉТѕўтЈіС╝ўтїќуГќуЋЦ№╝їуЅ╣тѕФТў»тЪ║С║јтіеТђЂУ┤ЪУййтЮЄУААсђЂТЋ░ТЇ«тцЇтѕХСИјтѕєуЅЄ№╝їтњїжФўТЋѕжђџС┐АуџёТќ╣ТАѕсђѓт«ъжфїу╗ЊТъюТўЙуц║С╝ўтїќуГќуЋЦУЃйтюежЎЇСйјт╗ХТЌХсђЂтбътцДтљътљљжЄЈС╗ЦтЈіТЈљжФўтЈ»ТЅЕт▒ЋТђДСИЅСИфТќ╣жЮбТўЙУЉЌ...
Paxosу«ЌТ│ЋТў»УДБтє│тѕєтИЃт╝Ју│╗у╗ЪСИГТЋ░ТЇ«СИђУЄ┤ТђДжЌ«жбўуџёСИђуДЇТюЅТЋѕтЇЈУ««сђѓPaxosу«ЌТ│ЋжђџУ┐ЄСИђу│╗тѕЌуџёжђџС┐АУ┐ЄуеІ№╝їуА«С┐ЮтюетѕєтИЃт╝Јуј»тбЃСИГт»╣ТЋ░ТЇ«уџёСИђУЄ┤ТђДУЙЙТѕљтЁ▒У»єсђѓPaxosу«ЌТ│ЋСИГуџётЈѓСИјУђЁтѕєСИ║ТЈљУ««УђЁ№╝ѕProposer№╝ЅсђЂТјЦтЈЌУђЁ№╝ѕAcceptor№╝ЅтњїтГдС╣аУђЁ...
С╝ау╗ЪуџётЪ║С║јSQLуџёТіђТю»тюежЏєСИГт╝ЈТЋ░ТЇ«т║ЊСИГтЈ»С╗ЦТюЅТЋѕУДБтє│ТЋ░ТЇ«СИЇСИђУЄ┤ТђД№╝їСйєтюетѕєтИЃт╝Јуј»тбЃСИГ№╝їућ▒С║јуйЉу╗ют╗ХУ┐ЪсђЂТЋ░ТЇ«тѕєтї║сђЂт╣ХтЈЉТЏ┤Тќ░уГЅжЌ«жбў№╝їСй┐тЙЌТЋ░ТЇ«СИђУЄ┤ТђДжџЙС╗ЦС┐ЮУ»Ђсђѓ тѕєтИЃт╝ЈТЋ░ТЇ«СИЇСИђУЄ┤ТђДТБђТхІСИ╗УдЂСЙЮУхќС║јтЄйТЋ░ТЮАС╗ХСЙЮУхќ...
Тђ╗у╗ЊТЮЦУ»┤№╝їТюгТќЄТЅђС╗Іу╗ЇуџётЪ║С║јТХѕТЂ»жђџС┐АуџётѕєтИЃт╝Ју│╗у╗ЪТюђу╗ѕСИђУЄ┤ТђДт╣│тЈ░№╝їжђџУ┐Єт╝ЋтЁЦт╣ѓуГЅТђДтјЪтѕЎтњїт╝║СИђУЄ┤ТђДС┐ЮУ»Ђ№╝їС╗ЦтЈіТъёт╗║жФўТЋѕуџёТХѕТЂ»уЏЉТјДТю║тѕХ№╝їТѕљтіЪУДБтє│С║єтѕєтИЃт╝Ју│╗у╗ЪСИГт╝ѓТГЦТХѕТЂ»жђџС┐АтИдТЮЦуџёТЋ░ТЇ«СИђУЄ┤ТђДжЌ«жбўсђѓтљїТЌХ№╝їжђџУ┐ЄТеАтЮЌтїќУ«ЙУ«А...
С╝ау╗ЪуџётЏаТъюСИђУЄ┤ТђДТеАтъІт╣ХТюфтЁЁтѕєУђЃУЎЉт«ЅтЁежБјжЎЕ№╝їтЏаТГц№╝їтюеС┐ЮжџюТЋ░ТЇ«СИђУЄ┤ТђДуџётљїТЌХ№╝їтдѓСйЋтюетѕєтИЃт╝ЈтГўтѓеу│╗у╗ЪСИГт«ъуј░тЈ»С┐Ау║дТЮЪТѕљСИ║СИђСИфС║ЪжюђУДБтє│уџёжЌ«жбўсђѓТюгТќЄСйюУђЁућ░С┐іт│░сђЂт╝аС┐іТХЏтњїујІтйджфЅТЈљтЄ║С║єСИђуДЇтЁиТюЅтЈ»С┐Ау║дТЮЪуџётѕєтИЃт╝ЈтГўтѓетЏаТъю...