 memcached 简介
memcached 简介
memcache是一个高性能的分布式的内存对象缓存系统,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。Memcache是danga.com的一个项目,最早是为 LiveJournal 服务的,最初为了加速 LiveJournal 访问速度而开发的,后来被很多大型的网站采用。目前全世界不少人使用这个缓存项目来构建自己大负载的网站,来分担数据库的压力。起初作者编写它可能是为了提高动态网页应用,为了减轻数据库检索的压力,来做的这个缓存系统。它的缓存是一种分布式的,也就是可以允许不同主机上的多个用户同时访问这个缓存系统,这种方法不仅解决了共享内存只能是单机的弊端,同时也解决了数据库检索的压力,最大的优点是提高了访问获取数据的速度!基于memcache作者对分布式 cache的理解和解决方案。 memcache完全可以用到其他地方 比如分布式数据库, 分布式计算等领域。
memcached 协议
memcached 协议简单的说有一组规定好的字符串组成,例如:
socket.write "get #{cache_key}\r\n"
socket.write "gets #{cache_key}\r\n"
socket.write "incr #{cache_key} #{amount}#{noreply}\r\n"
memcached 和nginx 结合使用:
原文地址:
http://www.igvita.com/2008/02/11/nginx-and-memcached-a-400-boost/
配置例子:
location /dynamic_request {
# append an extenstion for proper MIME type detection
if ($args ~* format=json) { rewrite ^/dynamic_request/?(.*)$ /dynamic_request.js$1 break; }
if ($args ~* format=xml) { rewrite ^/dynamic_request/?(.*)$ /dynamic_request.xml$1 break; }
memcached_pass 127.0.0.1:11211;
error_page 404 = @dynamic_request;
}
架构图:
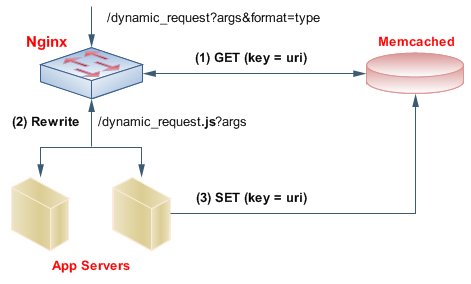 memcached 内部数据存储分析:
memcached 内部数据存储分析:
memcached 的数据结构可以简单的有slab -> chunks 来描述,slab 可以理解为一个内存块,一个slab是memcached一次申请内存的最小单位,在memcache中,一个slab大小默认为1M,每个slab被划分为若干个chunk,每个chunk里保存一个item,slab安装自己的id分别组成链表,这些链表又按id挂在一个slabclass数组上,整个结构看起来有点像二维数组。slabclass的长度在memcached 1.1中是21,在memcached 1.2中是200。
slab有一个初始chunk大小,memcached1.1中是1字节,memcached1.2中是80字节,
memcached 1.2中有一个factor值,默认为1.25, memcached -help 查看一下参数factor
SlabClass(1.2版本)
id 从 0 开始
|------| 0 slab
| id1 | ------->|-------|
| id2 | |chunk| -> item {key:value} 这个根据slabId 计算chunk大小
| .. | | .... |
|------| 199
class SlabClass
{
int size #chunk size
int perslab chunk个数
Array *slot #空闲槽
int slabs #slab 数量
Array * slab_list 指针数值 1M slab #不够就申请slab,并加入slab_list 中。
}
find slab id
unsigned int slabs_clsid(const size_t size) {
int res = POWER_SMALLEST;
if (size == 0)
return 0;
while (size > slabclass[res].size)
if (res++ == power_largest) /* won't fit in the biggest slab */
return 0;
return res;
}
以下是根据slabid计算chunk大小的公式(1.2版本):
chunk 大小 = 初始大小 * factor ^ id
slab_id = 0
chunk 大小 = 80字节 * 1.25 ^ 0
slab_id = 1
chunk 大小 = 80字节 * 1.25 ^ 1
id = 0 的slab 永远都是 80字节每个chunk,除非你重编译源码
那么 id为0的slab有 (1024* 1024)/80= 13107 个chunk
memcached1.2版本 会初始化 id 到 40.
:~> memcached -vvv
slab class 1: chunk size 96 perslab 10922
slab class 2: chunk size 120 perslab 8738
slab class 3: chunk size 152 perslab 6898
slab class 4: chunk size 192 perslab 5461
slab class 5: chunk size 240 perslab 4369
slab class 6: chunk size 304 perslab 3449
slab class 7: chunk size 384 perslab 2730
slab class 8: chunk size 480 perslab 2184
slab class 9: chunk size 600 perslab 1747
slab class 10: chunk size 752 perslab 1394
slab class 11: chunk size 944 perslab 1110
slab class 12: chunk size 1184 perslab 885
slab class 13: chunk size 1480 perslab 708
slab class 14: chunk size 1856 perslab 564
slab class 15: chunk size 2320 perslab 451
slab class 16: chunk size 2904 perslab 361
slab class 17: chunk size 3632 perslab 288
slab class 18: chunk size 4544 perslab 230
slab class 19: chunk size 5680 perslab 184
slab class 20: chunk size 7104 perslab 147
slab class 21: chunk size 8880 perslab 118
slab class 22: chunk size 11104 perslab 94
slab class 23: chunk size 13880 perslab 75
slab class 24: chunk size 17352 perslab 60
slab class 25: chunk size 21696 perslab 48
slab class 26: chunk size 27120 perslab 38
slab class 27: chunk size 33904 perslab 30
slab class 28: chunk size 42384 perslab 24
slab class 29: chunk size 52984 perslab 19
slab class 30: chunk size 66232 perslab 15
slab class 31: chunk size 82792 perslab 12
slab class 32: chunk size 103496 perslab 10
slab class 33: chunk size 129376 perslab 8
slab class 34: chunk size 161720 perslab 6
slab class 35: chunk size 202152 perslab 5
slab class 36: chunk size 252696 perslab 4
slab class 37: chunk size 315872 perslab 3
slab class 38: chunk size 394840 perslab 2
slab class 39: chunk size 493552 perslab 2
slab class 40: chunk size 616944 perslab 1
slab class 41: chunk size 771184 perslab 1
slab class 42: chunk size 1048576 perslab 1
<26 server listening (auto-negotiate)
<27 send buffer was 124928, now 268435456
<28 send buffer was 124928, now 268435456
直到 chunk 大小为1M,最有一个slab_id中对应的chunk只有一个。
那么memcached为什么使用这种方式存储那,是因为通过chunk的大小就能得到slab_id,从而找到slab,但是,这样做有一个缺点就是空间利用率下降了,chunk的大小可能不会是1M的整数倍.
计算slab_id公式如下:
factor^id = chunk 大小 / 初始大小
id = log(chunk 大小 / 初始大小 ) / log(factor)
这样通过chunk 大小就能得到 slab id 了.
例如:
id = log(80字节 / 80字节) / log(1.25) = 0
你知道了slab和chunk的关系,就可以改变factor 来优化你的memcached了。
需要提醒的是,因为id=0的chunk为80字节,如果你保存的数据超过80字节,性能会有一些损耗。
修改chunk size
/* 修改slab.c 文件中的 slabs_init方法 */
while (++i < POWER_LARGEST && size <= settings.item_size_max / factor) {
/* Make sure items are always n-byte aligned */
if (size % CHUNK_ALIGN_BYTES)
size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES);
slabclass[i].size = 200 /*size;*/
slabclass[i].perslab = 5000 /*settings.item_size_max / slabclass[i].size;*/
size *= factor;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
}
slab class 1: chunk size 200 perslab 5000
slab class 2: chunk size 200 perslab 5000
slab class 3: chunk size 200 perslab 5000
slab class 4: chunk size 200 perslab 5000
slab class 5: chunk size 200 perslab 5000
slab class 6: chunk size 200 perslab 5000
slab class 7: chunk size 200 perslab 5000
slab class 8: chunk size 200 perslab 5000
slab class 9: chunk size 200 perslab 5000
# Item_Size Max_age 1MB_pages Count Full?
1 200 B 245 s 2 5139 no
# Item_Size Max_age 1MB_pages Count Full?
1 200 B 245 s 5 21966 no
根据以上代码我发现,memcache slab 只取一个 slab_class ,需要如下修改
/* 修改slabs_clsid */
unsigned int slabs_clsid(size_t size) {
return 1;
}
/* 修改slab_init */
void slabs_init(const size_t limit, const double factor, const bool prealloc) {
//while (++i < POWER_LARGEST && size <= settings.item_size_max / factor) {
// /* Make sure items are always n-byte aligned */
// if (size % CHUNK_ALIGN_BYTES)
// size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES);
//
// slabclass[i].size = 200;//size;
// slabclass[i].perslab = 5000;/*settings.item_size_max / slabclass[i].size;*/
// size *= factor;
// if (settings.verbose > 1) {
// fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
// i, slabclass[i].size, slabclass[i].perslab);
// }
// }
i = 1;
power_largest = i;
slabclass[1].size = 200; //settings.item_size_max;
slabclass[1].perslab = 5000;
//slabclass[power_largest].size = settings.item_size_max;
//slabclass[power_largest].perslab = 1;
如下结果
slab class 1: chunk size 200 perslab 5000
# Item_Size Max_age 1MB_pages Count Full?
1 200 B 7 s 3 10137 no
Memcached一些特性和限制
在 Memcached 中可以保存的item数据量是没有限制的,只有内存足够
最大30天的数据过期时间, 设置为永久的也会在这个时间过期,常量REALTIME_MAXDELTA 60*60*24*30 控制
最大键长为250字节,大于该长度无法存储,常量KEY_MAX_LENGTH 250 控制
单个item最大数据是1MB,超过1MB数据不予存储,常量POWER_BLOCK 1048576 进行控制,它是默认的slab大小
最大同时连接数是200,通过 conn_init()中的freetotal 进行控制,最大软连接数是1024,通过 settings.maxconns=1024 进行控制
跟空间占用相关的参数:settings.factor=1.25, settings.chunk_size=48, 影响slab的数据占用和步进方式
在新版本中可以使用 -I 来设置slab滴大小
-I Override the size of each slab page. Adjusts max item size
(default: 1mb, min: 1k, max: 128m)
As far as this list is concerned, if you run a 32-bit
Linux OS, memcached can only use 2GB of memory for the entire process. That
includes the memory needed for connections. If you run a 64-bit Linux OS you do not have this limit
分享到:





相关推荐
BaseCache是基础缓存,用于存储实际数据,可以自定义实现,如使用EhCache或Memcached。EvictionCache负责在缓存达到特定大小后应用排除算法(如LRU或FIFO)来清理数据。DecoratorCache在数据存取前后提供额外的功能...
SOH-SVM算法:斑点鬣狗优化技术对支持向量机的改进与解析,优化算法助力机器学习:SOH-SVM改进及源码解析与参考,SOH-SVM:斑点鬣狗优化算法改进支持向量机:SOH-SVM。 代码有注释,附源码和参考文献,便于新手理解,~ ,SOH-SVM; 斑点鬣狗优化算法; 代码注释; 源码; 参考文献,SOH-SVM算法优化:附详解代码与参考
美赛教程&建模&数据分析&案例分析
GESPC++3级大纲
电动汽车充电负荷预测:基于出行链分析与OD矩阵的蒙特卡洛模拟研究,电动汽车充电负荷预测:基于出行链分析与OD矩阵的蒙特卡洛模拟方法,电动汽车充电负荷预测,出行链,OD矩阵,蒙特卡洛模拟 ,电动汽车充电负荷预测; 出行链; OD矩阵; 蒙特卡洛模拟,基于出行链的电动汽车充电负荷预测研究:蒙特卡洛模拟与OD矩阵分析
柯尼卡美能达Konica Minolta bizhub 205i 驱动
内容概要:本文全面介绍使用示波器进行一系列电学实验和项目的内容。从基础实验,如示波器的操作入门和常见波形的测量,再到进阶部分,比如电路故障排除与复杂项目设计,旨在帮助学生掌握示波器的各项技能。文中不仅提供了详尽的操作流程指导,还包括针对每个阶段的学习目标设定、预期成果评估和所需注意事项。最终通过对示波器的深入理解和熟练运用,在实际应用场景(如构造简单设备或是进行音频处理)达到创新解决问题的目的。 适用人群:面向有志于深入理解电工仪器及其应用的学生或者技术人员,尤其是刚开始接触或正在强化自己这方面能力的学习者。 使用场景及目标:①作为培训材料支持初学者快速上手专业级电工测试设备—示波器;②用于教学环节辅助讲解电学概念以及实际操作技巧;③鼓励用户参与更高层次的DIY工程任务从而培养解决问题的能力.
标题中的“ntc热敏电阻 MF52AT 10K 3950精度1%STM32采集带数字滤波”表明我们要讨论的是一个使用STM32微控制器进行数据采集的系统,该系统中包含NTC热敏电阻MF52AT作为温度传感器。NTC热敏电阻是一种负温度系数的电阻器,其阻值随温度升高而降低。MF52AT型号的热敏电阻具有10K欧姆的标称电阻和3950的B值,表示在特定温度下(通常为25℃)的阻值和温度特性曲线。精度1%意味着该电阻的阻值有1%的允许误差,这对于温度测量应用来说是相当高的精度。 描述中提到的“MF52AT热敏电阻STM32数据采集2路”,暗示我们有两个这样的热敏电阻连接到STM32微控制器的模拟输入端口,用于采集温度数据。STM32是一款基于ARM Cortex-M内核的微控制器,广泛应用于各种嵌入式系统中,包括温度监测等应用。由于STM32内部集成了多个ADC(模拟数字转换器),因此它可以同时处理多路模拟输入信号。 "带滤波,项目中实际运用,温差范围在±0.5度",这表明在实际应用中,数据采集系统采用了某种数字滤波技术来提高信号质量,可能是低通滤波、滑动平均滤波或更复杂的数字信号处理算法。
SSM框架整合是Java开发中常见的技术栈,包括Spring、SpringMVC和Mybatis三个核心组件。这个压缩包提供了一个已经验证过的整合示例,帮助开发者理解和实践这三大框架的协同工作。 Spring框架是Java企业级应用的基石,它提供了一种依赖注入(Dependency Injection,DI)的方式,使得对象之间的依赖关系得以解耦,便于管理和服务。Spring还提供了AOP(面向切面编程)功能,用于实现如日志记录、事务管理等跨切面关注点的处理。 SpringMVC是Spring框架的一部分,专门用于构建Web应用程序。它采用了模型-视图-控制器(Model-View-Controller,MVC)设计模式,将业务逻辑、数据展示和用户交互分离,提高了代码的可维护性和可扩展性。在SpringMVC中,请求被DispatcherServlet接收,然后分发到相应的处理器,处理器执行业务逻辑后返回结果,最后由视图解析并展示给用户。 Mybatis是一个优秀的持久层框架,它简化了JDBC的繁琐操作,支持SQL语句的动态编写,使得开发者可以直接使用SQL来操作数据库,同时还能保持数
分割资源UE5.3.z25
Matlab 2021及以上版本:电气工程与自动化仿真实践——电力电子变换器微网建模与仿真研究,涵盖Boost、Buck整流逆变器闭环控制及光伏蓄电池电路等多重电气仿真,基于Matlab 2021及以上的电气工程与自动化仿真研究:电力电子变换器微网建模与Boost、Buck整流逆变器闭环控制及光伏蓄电池电路等多电气仿真分析,电气工程及其自动化仿真 Matlab simulink 电力电子变器微网建模仿真 仅限matlab版本2021及以上 Boost,Buck,整流逆变器闭环控制 光伏蓄电池电路等多种电气仿真 ,电气工程; Matlab simulink; 电力电子变换器; 微网建模仿真; Boost; Buck; 整流逆变器; 闭环控制; 光伏蓄电池电路; 电气仿真,Matlab 2021版电气工程自动化仿真研究:微网建模与控制策略
移动机器人路径规划,python入门程序
《DeepSeek从入门到精通》是清华大学推出的一套深度学习学习资源,内容涵盖基础知识、实用技巧和前沿应用,适合不同水平的学习者。通过系统化的学习路径,帮助你在深度学习领域快速成长。无论你是初学者还是
考虑新能源消纳的火电机组深度调峰策略:建立成本模型与经济调度,实现风电全额消纳的优化方案,考虑新能源消纳的火电机组深度调峰策略与经济调度模型研究,考虑新能源消纳的火电机组深度调峰策略 摘要:本代码主要做的是考虑新能源消纳的火电机组深度调峰策略,以常规调峰、不投油深度调峰、投油深度调峰三个阶段,建立了火电机组深度调峰成本模型,并以风电全额消纳为前提,建立了经济调度模型。 约束条件主要考虑煤燃烧约束、系统旋转备用功率约束、启停、爬坡、储热约束等等。 复现结果非常良好,结果图展示如下: 1、代码非常精品,有注释方便理解; ,核心关键词:新能源消纳;火电机组深度调峰策略;常规调峰;不投油深度调峰;投油深度调峰;成本模型;经济调度模型;煤燃烧约束;系统旋转备用功率约束;启停约束;爬坡约束;储热约束。,新能源优化调度策略:火电机组深度调峰及经济调度研究
"数字设计原理与实践" 数字设计是计算机科学和电子工程两个领域的交叉点,涉及到数字电路的设计和实现。本书籍《数字设计-原理与实践》旨在为读者提供一个系统的数字设计指南,从基本原理到实际应用,涵盖了数字设计的方方面面。 1. 数字设计的定义和目标 数字设计是指使用数字电路和系统来实现特定的功能目标的设计过程。在这个过程中,设计师需要考虑到各种因素,如电路的可靠性、功耗、面积等,以确保设计的数字电路能够满足实际应用的需求。 2. 数字设计的基本原理 数字设计的基本原理包括数字电路的基本元件,如逻辑门、 Flip-Flop、计数器、加法器等,以及数字电路的设计方法,如Combinational Logic、Sequential Logic和 Finite State Machine等。 3. 数字设计的设计流程 数字设计的设计流程通常包括以下几个步骤: * 需求分析:确定设计的目标和约束条件。 *电路设计:根据需求设计数字电路。 * 仿真验证:使用软件工具对设计的数字电路进行仿真和验证。 * 实现和测试:将设计的数字电路实现并进行测试。 4. 数字设计在实际应用中的应用 数字设计在实际应用中
基于Simulink仿真的直流电机双闭环控制系统设计与分析:转速电流双闭环PWM控制策略及7天报告研究,基于Simulink仿真的直流电机双闭环控制系统分析与设计报告:转速电流双闭环PWM控制策略的7天实践,直流电机双闭环控制系统仿真 simulink仿真 7d 转速电流双闭环 PWM 含有报告哈 ,直流电机; 双闭环控制系统; Simulink仿真; 7d; 转速电流双闭环; PWM; 报告,7天完成双闭环控制系统仿真报告:直流电机转速电流PWM管理与Simulink仿真研究
三目标微电网能量调度优化:经济、环境友好与高效能分配的协同策略研究,微粒群算法在三目标微电网能量调度中的应用:经济、环境友好与优化调度的综合研究,微电网 能量调度 三目标微网调度, 经济调度 环境友好调度 优化调度 微电网能量调度问题的求解 问题描述: - 微电网:包含多个能量源,包括DG(分布式发电设备,如太阳能光伏板、微型燃气轮机等)、MT(燃油发电机)和FC(燃料电池)。 - 目标:通过合理分配各种能源的发电功率,满足负荷需求,同时使得微电网的发电成本最小化。 解决方法: 微粒群算法(Particle Swarm Optimization, PSO): - 步骤: - 初始化微粒群:根据给定的微电网问题约束,随机生成一定数量的微粒(粒子),每个粒子代表一种发电方案,包含DG、MT和FC的发电功率分配情况。 - 适应度函数:对每个粒子,计算其对应的发电成本,作为其适应度值。 - 更新速度和位置:根据当前适应度值和历史最优适应度值,通过PSO算法的公式,更新每个粒子的速度和位置,以寻找更优的发电功率分配。 - 约束处理:根据问题约束条件,
《无感滑膜技术:Microchip1078代码移植至ST芯片的实践指南》——新手必备的反正切算法与电子资料整合方案,《无感滑膜技术:Microchip1078代码移植至ST芯片的实践指南》——新手必备的反正切算法与电子资料全解析,无感滑膜,反正切,microchip1078代码移植到st芯片上,新手学习必备。 可以提供提供相应文档和keil工程,电子资料, ,无感滑膜; 反正切; microchip1078代码移植; ST芯片; 新手学习; 文档; Keil工程; 电子资料,无感滑膜算法移植至ST芯片的Microchip1078代码迁移指南
风光柴储混合微电网系统中的储能电池与互补能量管理技术研究及MATLAB模拟实现,风光柴储混合微电网系统中的储能电池与互补能量管理技术:基于MATLAB的智能调控体系,风光柴储+混合微电网+储能电池系统+互补能量管理+MATLA ,核心关键词:风光柴储; 混合微电网; 储能电池系统; 互补能量管理; MATLA;,风光柴储混合微网能量管理系统及储能电池应用
永磁同步电机PMSM无感FOC驱动与位置估算源码分享:跨平台兼容、高速动态响应、无需初始角度辨识,永磁同步电机PMSM无感FOC驱动与位置估算源码分享:跨平台兼容、高速动态响应、无需初始角度辨识,永磁同步电机pmsm无感foc驱动代码 位置估算源码 无刷直流电机无感foc源码,无感foc算法源码 若需要,可提供硬件 速度位置估算部分代码所使用变量全部使用国际标准单位,使用不到60行代码实现完整的位置速度观测器。 提供完整的观测器文档,供需要的朋友参考 程序使用自研观测器,代码全部是源码,不含任何库文件 送simulink仿真 代码可读性极好,关键变量注明单位 模块间完全解耦 高级工程师磁链法位置估算代码 跨平台兼容,提供ti平台或at32平台工程 电流环pi参数自动计算 效果如图 实现0速闭环启动 2hz以内转速角度收敛 动态响应性能好 无需初始角度辨识 电阻电感允许一定误差 ,核心关键词: 1. 永磁同步电机 (PMSM) 无感 FOC 驱动代码 2. 位置估算源码 3. 无刷直流电机无感 FOC 源码 4. 无感 FOC 算法源码 5. 硬件支持(可选) 6. 速度位置估算部分