
еОЯжЦЗеЬ∞еЭАпЉЪhttps://www.cnblogs.com/aspwebchh/p/6652855.html
еЙНжЃµжЧґйЧіпЉМеЕђеПЄдЄАдЄ™жЦ∞дЄКзЇњзЪДзљСзЂЩеЗЇзО∞й°µйЭҐеУНеЇФйАЯеЇ¶зЉУжЕҐзЪДйЧЃйҐШпЉМ дЄАдљНиіЯиі£ињЩдЄ™й°єзЫЃзЪДдљЖеєґдЄНжШѓжРЮжКАжЬѓзЪДе¶єе≠РжЙЊеИ∞жИСпЉМиЃ©жИСжГ≥еКЮж≥ХжПРеНЗзљСзЂЩзЪДиЃњйЧЃйАЯеЇ¶ пЉМеЫ†дЄЇеЈ≤зїПжЬЙеЊИе§ЪзФ®жИЈжЭ•жКХиѓЙдЇЖгАВжИСзђђдЄАеПНеЇФиІЙзЪДжШѓжХ∞жНЃеЇУдЄКзЪДйЧЃйҐШпЉМеБЗи£ЕжАЭ糥дЇЖдЄАдЄЛпЉМжСЖзЭАдЄАеЙѓжЈ±ж≤ЙзВЂйЕЈзЪДж®°ж†ЈиѓіпЉЪвАЬжШѓдЄНжШѓжХ∞жНЃеЇУжߕ胥дЄКеЗЇйЧЃйҐШдЇЖпЉМ зїЩи°®еК†дЄК糥еЉХеРІвАЭпЉМзДґеРОе¶єе≠РжЭ•дЇЖдЄАеП•пЉЪвАЬзО∞еЬ®жИСдїђзљСзЂЩиЃњйЧЃйЗП姙姲пЉМеʆ糥еЉХжЬЙеПѓиГљеѓЉиЗіеЖЩеЕ•жХ∞жНЃжЧґжАІиГљдЄЛйЩНпЉМељ±еУНзФ®жИЈдљњзФ®зЪДвАЭгАВељУжЧґжИСе∞±ж•ЮдЇЖдЄАдЄЛпЉМ жЬЙзІНеЉЇи°Ми£ЕйАЉиҐЂжЛЖз©њзЪДжДЯиІЙпЉМеЬ®иЗ™еЈ±зЪДдЄУдЄЪйҐЖеЯЯе±ЕзĴ襀йЭЮдЄУдЄЪзЪДеРМе≠¶жХЩиВ≤пЉМ йЭҐе≠РдЄКзЬЯжЬЙзВєжМВдЄНдљПгАВ
еЕґеЃЮпЉМ жИСиѓіињЩдЄ™дЊЛе≠РеєґдЄНжШѓдЄЇе±ХзО∞жИСдїђеЕђеПЄзЪДеРМдЇЛдїђдЄУдЄЪиГљеКЫзЪДеЉЇе§ІгАБеБЪзЪДдЇІеУБж£ТгАБеЃЙеЕ®жАІйЂШгАБжАІиГљзЙЫйАЉпЉМ ињЮйЭЮжКАжЬѓзЪДеРМдЇЛдєЯжЗВеЊЧжКАжЬѓдЄКзЪДзїЖиКВгАВдЇЛеЃЮдЄКжИСеП™жШѓжГ≥иѓіжШОпЉМгАМжХ∞жНЃеЇУгАНеТМгАМжХ∞жНЃеЇУ糥еЉХгАНињЩдЄ§дЄ™дЄЬи•њжШѓеЬ®жЬНеК°еЩ®зЂѓеЉАеПСйҐЖеЯЯеЇФзФ®жЬАдЄЇеєњж≥ЫзЪДдЄ§дЄ™ж¶ВењµпЉМзЖЯзїГдљњзФ®жХ∞жНЃеЇУеТМжХ∞жНЃеЇУ糥еЉХжШѓеЉАеПСдЇЇеСШеЬ®и°МдЄЪеЖЕзФЯе≠ШзЪДењЕе§ЗжКАиГљпЉМиАМжճ姩еТМжКАжЬѓдЇЇеСШжЙУдЇ§йБУзЪДйЭЮжКАжЬѓдЇЇеСШдїђпЉМзФ±дЇОиА≥жњ°зЫЃжЯУдєЕдЇЖпЉМиЗ™зДґдєЯе∞±иГљиЃ≤дЄ™е§іе§іжШѓйБУдЇЖгАВ
дљњзԮ糥еЉХеЊИзЃАеНХпЉМеП™и¶БиГљеЖЩеИЫеїЇи°®зЪДиѓ≠еП•пЉМе∞±иВѓеЃЪиГљеЖЩеИЫ忯糥еЉХзЪДиѓ≠еП•пЉМи¶БзЯ•йБУињЩдЄ™дЄЦзХМдЄКжШѓдЄНе≠ШеЬ®дЄНдЉЪеИЫеїЇи°®зЪДжЬНеК°еЩ®зЂѓз®ЛеЇПеСШзЪДгАВзДґиАМпЉМ дЉЪдљњзԮ糥еЉХжШѓдЄАеЫЮдЇЛпЉМ иАМжЈ±еЕ•зРЖиІ£зіҐеЉХеОЯзРЖеПИиГљжБ∞еИ∞е•ље§ДдљњзԮ糥еЉХеПИжШѓеП¶дЄАеЫЮдЇЛпЉМињЩеЃМеЕ®ж؃䪧䪙姩壁еЬ∞еИЂзЪДеҐГзХМпЉИжИСиЗ™еЈ±дєЯињШж≤°жЬЙиЊЊеИ∞ињЩе±ВеҐГзХМпЉЙгАВеЊИе§ІдЄАйГ®дїљз®ЛеЇПеСШ僺糥еЉХзЪДдЇЖиІ£дїЕйЩРдЇОеИ∞вАЬеʆ糥еЉХиГљдљњжߕ胥еПШењЂвАЭињЩдЄ™ж¶ВењµдЄЇж≠ҐгАВ
-
дЄЇдїАдєИи¶БзїЩи°®еК†дЄКдЄїйФЃпЉЯ
-
дЄЇдїАдєИеʆ糥еЉХеРОдЉЪдљњжߕ胥еПШењЂпЉЯ
-
дЄЇдїАдєИеʆ糥еЉХеРОдЉЪдљњеЖЩеЕ•гАБдњЃжФєгАБеИ†йЩ§еПШжЕҐпЉЯ
-
дїАдєИжГЕеЖµдЄЛи¶БеРМжЧґеЬ®дЄ§дЄ™е≠ЧжЃµдЄК忯糥еЉХпЉЯ
ињЩдЇЫйЧЃйҐШдїЦдїђеПѓиГљдЄНдЄАеЃЪиГљиѓіеЗЇз≠Фж°ИгАВзЯ•йБУињЩдЇЫйЧЃйҐШзЪДз≠Фж°ИжЬЙдїАдєИе•ље§ДеСҐпЉЯе¶ВжЮЬеЉАеПСзЪДеЇФзФ®дљњзФ®зЪДжХ∞жНЃеЇУи°®дЄ≠еП™жЬЙ1дЄЗжЭ°жХ∞жНЃпЉМйВ£дєИдЇЖиІ£дЄОдЄНдЇЖиІ£зЬЯзЪДж≤°жЬЙеЈЃеИЂпЉМ зДґиАМпЉМ е¶ВжЮЬеЉАеПСзЪДеЇФзФ®жЬЙеЗ†зЩЊдЄКеНГдЄЗзФЪиЗ≥дЇњзЇІеИЂзЪДжХ∞жНЃпЉМйВ£дєИдЄНжЈ±еЕ•дЇЖиІ£зіҐеЉХзЪДеОЯзРЖпЉМ еЖЩеЗЇжЭ•з®ЛеЇПе∞±ж†єжЬђиЈСдЄНеК®пЉМе∞±е•љжѓФе¶ВжЮЬзїЩиіІиљ¶и£ЕдЄ™иљњиљ¶зЪДеЉХжУОпЉМињЩиіІиљ¶ињШиГљжЛЙзЪДеК®иіІеРЧпЉЯ
жО•дЄЛжЭ•е∞±иЃ≤иІ£дЄАдЄЛдЄКйЭҐжПРеЗЇзЪДеЗ†дЄ™йЧЃйҐШпЉМеЄМжЬЫеѓєйШЕиѓїиАЕжЬЙеЄЃеК©гАВ
зљСдЄКеЊИе§ЪиЃ≤иІ£зіҐеЉХзЪДжЦЗ瀆僺糥еЉХзЪДжППињ∞жШѓињЩж†ЈзЪДгАМ糥еЉХе∞±еГПдє¶зЪДзЫЃељХпЉМ йАЪињЗдє¶зЪДзЫЃељХе∞±еЗЖз°ЃзЪДеЃЪдљНеИ∞дЇЖдє¶з±НеЕЈдљУзЪДеЖЕеЃєгАНпЉМињЩеП•иѓЭжППињ∞зЪДйЭЮеЄЄж≠£з°ЃпЉМ дљЖе∞±еГПиД±дЇЖи£§е≠РжФЊе±БпЉМиѓідЇЖиЈЯж≤°иѓідЄАж†ЈпЉМйАЪињЗзЫЃељХжЯ•жЙЊдє¶зЪДеЖЕеЃєиЗ™зДґжШѓи¶БжѓФдЄАй°µдЄАй°µзЪДзњїдє¶жЙЊжЭ•зЪДењЂпЉМеРМж†ЈдљњзФ®зЪД糥еЉХзЪДдЇЇйЪЊеИ∞дЉЪдЄНзЯ•йБУпЉМйАЪињЗ糥еЉХеЃЪдљНеИ∞жХ∞жНЃжѓФзЫіжО•дЄАжЭ°дЄАжЭ°зЪДжߕ胥жЭ•зЪДењЂпЉМдЄНзДґдїЦдїђдЄЇдїАдєИи¶Б忯糥еЉХгАВ
жГ≥и¶БзРЖиІ£зіҐеЉХеОЯзРЖењЕй°їжЄЕж•ЪдЄАзІНжХ∞жНЃзїУжЮДгАМеє≥и°°ж†СгАН(йЭЮдЇМеПЙ)пЉМдєЯе∞±жШѓb treeжИЦиАЕ b+ treeпЉМйЗНи¶БзЪДдЇЛжГЕиѓідЄЙйБНпЉЪвАЬеє≥и°°ж†СпЉМеє≥и°°ж†СпЉМеє≥и°°ж†СвАЭгАВељУзДґпЉМ жЬЙзЪДжХ∞жНЃеЇУдєЯдљњзФ®еУИеЄМж°ґдљЬзԮ糥еЉХзЪДжХ∞жНЃзїУжЮД пЉМ зДґиАМпЉМ дЄїжµБзЪДRDBMSйГљжШѓжККеє≥и°°ж†СељУеБЪжХ∞жНЃи°®йїШиЃ§зЪД糥еЉХжХ∞жНЃзїУжЮДзЪДгАВ
жИСдїђеє≥жЧґеїЇи°®зЪДжЧґеАЩйГљдЉЪдЄЇи°®еК†дЄКдЄїйФЃпЉМ еЬ®жЯРдЇЫеЕ≥з≥їжХ∞жНЃеЇУдЄ≠пЉМ е¶ВжЮЬеїЇи°®жЧґдЄНжМЗеЃЪдЄїйФЃпЉМжХ∞жНЃеЇУдЉЪжЛТзїЭеїЇи°®зЪДиѓ≠еП•жЙІи°МгАВ дЇЛеЃЮдЄКпЉМ дЄАдЄ™еК†дЇЖдЄїйФЃзЪДи°®пЉМеєґдЄНиÚ襀зІ∞дєЛдЄЇгАМи°®гАНгАВдЄАдЄ™ж≤°еК†дЄїйФЃзЪДи°®пЉМеЃГзЪДжХ∞жНЃжЧ†еЇПзЪДжФЊзљЃеЬ®з£БзЫШе≠ШеВ®еЩ®дЄКпЉМдЄАи°МдЄАи°МзЪДжОТеИЧзЪДеЊИжХійљРпЉМ иЈЯжИСиЃ§зЯ•дЄ≠зЪДгАМи°®гАНеЊИжО•ињСгАВе¶ВжЮЬзїЩи°®дЄКдЇЖдЄїйФЃпЉМйВ£дєИи°®еЬ®з£БзЫШдЄКзЪДе≠ШеВ®зїУжЮДе∞±зФ±жХійљРжОТеИЧзЪДзїУжЮДиљђеПШжИРдЇЖж†СзКґзїУжЮДпЉМдєЯе∞±жШѓдЄКйЭҐиѓізЪДгАМеє≥и°°ж†СгАНзїУжЮДпЉМжНҐеП•иѓЭиѓіпЉМе∞±жШѓжХідЄ™и°®е∞±еПШжИРдЇЖдЄА䪙糥еЉХгАВж≤°йФЩпЉМ еЖНиѓідЄАйБНпЉМ жХідЄ™и°®еПШжИРдЇЖдЄА䪙糥еЉХпЉМдєЯе∞±жШѓжЙАи∞УзЪДгАМиБЪйЫЖ糥еЉХгАНгАВ ињЩе∞±жШѓдЄЇдїАдєИдЄАдЄ™и°®еП™иГљжЬЙдЄАдЄ™дЄїйФЃпЉМ дЄАдЄ™и°®еП™иГљжЬЙдЄАдЄ™гАМиБЪйЫЖ糥еЉХгАНпЉМеЫ†дЄЇдЄїйФЃзЪДдљЬзФ®е∞±жШѓжККгАМи°®гАНзЪДжХ∞жНЃж†ЉеЉПиљђжНҐжИРгАМ糥еЉХпЉИеє≥и°°ж†СпЉЙгАНзЪДж†ЉеЉПжФЊзљЃгАВ

дЄКеЫЊе∞±жШѓеЄ¶жЬЙдЄїйФЃзЪДи°®пЉИиБЪйЫЖ糥еЉХпЉЙзЪДзїУжЮДеЫЊгАВеЫЊзФїзЪДдЄНжШѓеЊИе•љпЉМ е∞Же∞±зЭАзЬЛгАВеЕґдЄ≠ж†СзЪДжЙАжЬЙзїУзВєпЉИеЇХйГ®йЩ§е§ЦпЉЙзЪДжХ∞жНЃйГљжШѓзФ±дЄїйФЃе≠ЧжЃµдЄ≠зЪДжХ∞жНЃжЮДжИРпЉМдєЯе∞±жШѓйАЪеЄЄжИСдїђжМЗеЃЪдЄїйФЃзЪДidе≠ЧжЃµгАВжЬАдЄЛйЭҐйГ®еИЖжШѓзЬЯж≠£и°®дЄ≠зЪДжХ∞жНЃгАВ еБЗе¶ВжИСдїђжЙІи°МдЄАдЄ™SQLиѓ≠еП•пЉЪ
select * from table where id = 1256;
й¶ЦеЕИж†єж́糥еЉХеЃЪдљНеИ∞1256ињЩдЄ™еАЉжЙАеЬ®зЪДеПґзїУзВєпЉМзДґеРОеЖНйАЪињЗеПґзїУзВєеПЦеИ∞idз≠ЙдЇО1256зЪДжХ∞жНЃи°МгАВ ињЩйЗМдЄНиЃ≤иІ£еє≥и°°ж†СзЪДињРи°МзїЖиКВпЉМ дљЖжШѓдїОдЄКеЫЊиГљзЬЛеЗЇпЉМж†СдЄАеЕ±жЬЙдЄЙе±ВпЉМ дїОж†єиКВзВєиЗ≥еПґиКВзВєеП™йЬАи¶БзїПињЗдЄЙжђ°жЯ•жЙЊе∞±иГљеЊЧеИ∞зїУжЮЬгАВе¶ВдЄЛеЫЊ
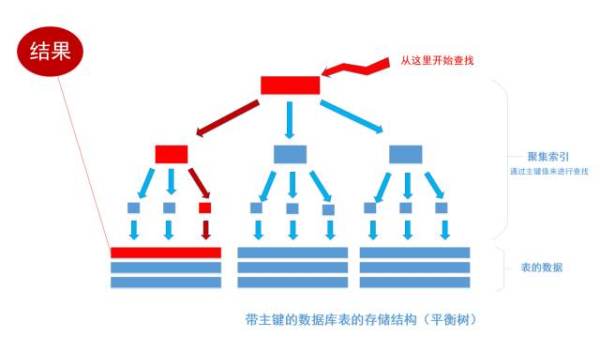
еБЗе¶ВдЄАеЉ†и°®жЬЙдЄАдЇњжЭ°жХ∞жНЃ пЉМйЬАи¶БжЯ•жЙЊеЕґдЄ≠жЯРдЄАжЭ°жХ∞жНЃпЉМжМЙзЕІеЄЄиІДйАїиЊСпЉМ дЄАжЭ°дЄАжЭ°зЪДеОїеМєйЕНзЪДиѓЭпЉМ жЬАеЭПзЪДжГЕеЖµдЄЛйЬАи¶БеМєйЕНдЄАдЇњжђ°жЙНиГљеЊЧеИ∞зїУжЮЬпЉМзФ®е§ІOж†ЗиЃ∞ж≥Хе∞±жШѓO(n)жЬАеЭПжЧґйЧіе§НжЭВеЇ¶пЉМињЩжШѓжЧ†ж≥ХжО•еПЧзЪДпЉМиАМдЄФињЩдЄАдЇњжЭ°жХ∞жНЃжШЊзДґдЄНиГљдЄАжђ°жАІиѓїеЕ•еЖЕе≠ШдЊЫз®ЛеЇПдљњзФ®пЉМ еЫ†ж≠§пЉМ ињЩдЄАдЇњжђ°еМєйЕНеЬ®дЄНзїПзЉУе≠ШдЉШеМЦзЪДжГЕеЖµдЄЛе∞±жШѓдЄАдЇњжђ°IOеЉАйФАпЉМдї•зО∞еЬ®з£БзЫШзЪДIOиГљеКЫеТМCPUзЪДињРзЃЧиГљеКЫпЉМ жЬЙеПѓиГљйЬАи¶БеЗ†дЄ™жЬИжЙНиГљеЊЧеЗЇзїУжЮЬ гАВе¶ВжЮЬжККињЩеЉ†и°®иљђжНҐжИРеє≥и°°ж†СзїУжЮДпЉИдЄАж£µйЭЮеЄЄиМВзЫЫеТМиКВзВєйЭЮеЄЄе§ЪзЪДж†СпЉЙпЉМеБЗиЃЊињЩж£µж†СжЬЙ10е±ВпЉМйВ£дєИеП™йЬАи¶Б10жђ°IOеЉАйФАе∞±иГљжЯ•жЙЊеИ∞жЙАйЬАи¶БзЪДжХ∞жНЃпЉМ йАЯеЇ¶дї•жМЗжХ∞зЇІеИЂжПРеНЗпЉМзФ®е§ІOж†ЗиЃ∞ж≥Хе∞±жШѓO(log n)пЉМnжШѓиЃ∞ељХжАїж†СпЉМеЇХжХ∞жШѓж†СзЪДеИЖеПЙжХ∞пЉМзїУжЮЬе∞±жШѓж†СзЪДе±Вжђ°жХ∞гАВжНҐи®АдєЛпЉМжЯ•жЙЊжђ°жХ∞жШѓдї•ж†СзЪДеИЖеПЙжХ∞дЄЇеЇХпЉМиЃ∞ељХжАїжХ∞зЪДеѓєжХ∞пЉМзФ®еЕђеЉПжЭ•и°®з§Їе∞±жШѓ

зФ®з®ЛеЇПжЭ•и°®з§Їе∞±жШѓMath.Log(100000000,10)пЉМ100000000жШѓиЃ∞ељХжХ∞пЉМ10жШѓж†СзЪДеИЖеПЙжХ∞пЉИзЬЯеЃЮзОѓеҐГдЄЛеИЖеПЙжХ∞ињЬдЄНж≠Ґ10пЉЙпЉМ зїУжЮЬе∞±жШѓжЯ•жЙЊжђ°жХ∞пЉМињЩйЗМзЪДзїУжЮЬдїОдЇњйЩНеИ∞дЇЖдЄ™дљНжХ∞гАВеЫ†ж≠§пЉМеИ©зԮ糥еЉХдЉЪдљњжХ∞жНЃеЇУжߕ胥жЬЙжГКдЇЇзЪДжАІиГљжПРеНЗгАВ
зДґиАМпЉМ дЇЛзЙ©йГљжШѓжЬЙдЄ§йЭҐзЪДпЉМ 糥еЉХиГљиЃ©жХ∞жНЃеЇУжߕ胥жХ∞жНЃзЪДйАЯеЇ¶дЄКеНЗпЉМ иАМдљњеЖЩеЕ•жХ∞жНЃзЪДйАЯеЇ¶дЄЛйЩНпЉМеОЯеЫ†еЊИзЃАеНХзЪДпЉМ еЫ†дЄЇеє≥и°°ж†СињЩдЄ™зїУжЮДењЕй°їдЄАзЫізїіжМБеЬ®дЄАдЄ™ж≠£з°ЃзЪДзКґжАБпЉМ еҐЮеИ†жФєжХ∞жНЃйГљдЉЪжФєеПШеє≥и°°ж†СеРДиКВзВєдЄ≠зЪД糥еЉХжХ∞жНЃеЖЕеЃєпЉМз†іеЭПж†СзїУжЮДпЉМ еЫ†ж≠§пЉМеЬ®жѓПжђ°жХ∞жНЃжФєеПШжЧґпЉМ DBMSењЕй°їеОїйЗНжЦ∞жҐ≥зРЖж†СпЉИ糥еЉХпЉЙзЪДзїУжЮДдї•з°ЃдњЭеЃГзЪДж≠£з°ЃпЉМињЩдЉЪеЄ¶жЭ•дЄНе∞ПзЪДжАІиГљеЉАйФАпЉМдєЯе∞±жШѓдЄЇдїАдєИ糥еЉХдЉЪзїЩжߕ胥俕е§ЦзЪДжУНдљЬеЄ¶жЭ•еЙѓдљЬзФ®зЪДеОЯеЫ†гАВ
иЃ≤еЃМиБЪйЫЖ糥еЉХ пЉМ жО•дЄЛжЭ•иБКдЄАдЄЛйЭЮиБЪйЫЖ糥еЉХпЉМ дєЯе∞±жШѓжИСдїђеє≥жЧґзїПеЄЄжПРиµЈеТМдљњзФ®зЪДеЄЄиІД糥еЉХгАВ
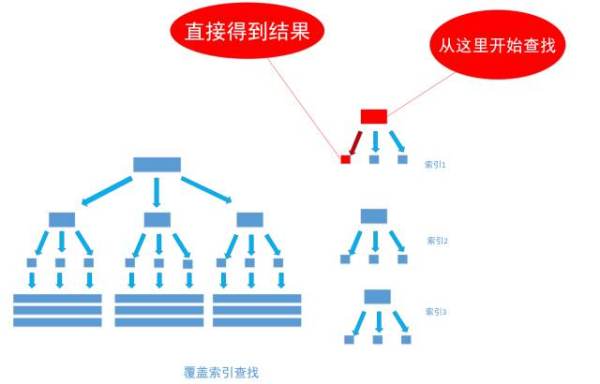
йЭЮиБЪйЫЖ糥еЉХеТМиБЪйЫЖ糥еЉХдЄАж†ЈпЉМ еРМж†ЈжШѓйЗЗзФ®еє≥и°°ж†СдљЬ䪯糥еЉХзЪДжХ∞жНЃзїУжЮДгАВ糥еЉХж†СзїУжЮДдЄ≠еРДиКВзВєзЪДеАЉжЭ•иЗ™дЇОи°®дЄ≠зЪД糥еЉХе≠ЧжЃµпЉМ еБЗе¶ВзїЩuserи°®зЪДnameе≠ЧжЃµеК†дЄК糥еЉХ пЉМ йВ£дєИ糥еЉХе∞±жШѓзФ±nameе≠ЧжЃµдЄ≠зЪДеАЉжЮДжИРпЉМеЬ®жХ∞жНЃжФєеПШжЧґпЉМ DBMSйЬАи¶БдЄАзЫізїіжʧ糥еЉХзїУжЮДзЪДж≠£з°ЃжАІгАВе¶ВжЮЬзїЩи°®дЄ≠е§ЪдЄ™е≠ЧжЃµеК†дЄК糥еЉХ пЉМ йВ£дєИе∞±дЉЪеЗЇзО∞е§ЪдЄ™зЛђзЂЛзЪД糥еЉХзїУжЮДпЉМжѓП䪙糥еЉХпЉИйЭЮиБЪйЫЖ糥еЉХпЉЙдЇТзЫЄдєЛйЧідЄНе≠ШеЬ®еЕ≥иБФгАВ е¶ВдЄЛеЫЊ

жѓПжђ°зїЩе≠ЧжЃµеїЇдЄАдЄ™жЦ∞糥еЉХпЉМ е≠ЧжЃµдЄ≠зЪДжХ∞жНЃе∞±дЉЪ襀е§НеИґдЄАдїљеЗЇжЭ•пЉМ зФ®дЇОзФЯжИР糥еЉХгАВ еЫ†ж≠§пЉМ зїЩи°®жЈїеʆ糥еЉХпЉМдЉЪеҐЮеК†и°®зЪДдљУзІѓпЉМ еН†зФ®з£БзЫШе≠ШеВ®з©ЇйЧігАВ
йЭЮиБЪйЫЖ糥еЉХеТМиБЪйЫЖ糥еЉХзЪДеМЇеИЂеЬ®дЇОпЉМ йАЪињЗиБЪйЫЖ糥еЉХеПѓдї•жЯ•еИ∞йЬАи¶БжЯ•жЙЊзЪДжХ∞жНЃпЉМ иАМйАЪињЗйЭЮиБЪйЫЖ糥еЉХеПѓдї•жЯ•еИ∞иЃ∞ељХеѓєеЇФзЪДдЄїйФЃеАЉ пЉМ еЖНдљњзФ®дЄїйФЃзЪДеАЉйАЪињЗиБЪйЫЖ糥еЉХжЯ•жЙЊеИ∞йЬАи¶БзЪДжХ∞жНЃпЉМе¶ВдЄЛеЫЊ

дЄНзЃ°дї•дїїдљХжЦєеЉПжߕ胥谮пЉМ жЬАзїИйГљдЉЪеИ©зФ®дЄїйФЃйАЪињЗиБЪйЫЖ糥еЉХжЭ•еЃЪдљНеИ∞жХ∞жНЃпЉМ иБЪйЫЖ糥еЉХпЉИдЄїйФЃпЉЙжШѓйАЪеЊАзЬЯеЃЮжХ∞жНЃжЙАеЬ®зЪДеФѓдЄАиЈѓеЊДгАВ
зДґиАМпЉМ жЬЙдЄАзІНдЊЛе§ЦеПѓдї•дЄНдљњзФ®иБЪйЫЖ糥еЉХе∞±иГљжߕ胥еЗЇжЙАйЬАи¶БзЪДжХ∞жНЃпЉМ ињЩзІНйЭЮдЄїжµБзЪДжЦєж≥Х зІ∞дєЛдЄЇгАМи¶ЖзЫЦ糥еЉХгАНжߕ胥пЉМ дєЯе∞±жШѓеє≥жЧґжЙАиѓізЪДе§НеРИ糥еЉХжИЦиАЕе§Ъе≠Ч恵糥еЉХжߕ胥гАВ жЦЗзЂ†дЄКйЭҐзЪДеЖЕеЃєеЈ≤зїПжМЗеЗЇпЉМ ељУдЄЇе≠ЧжЃµеїЇзЂЛ糥еЉХдї•еРОпЉМ е≠ЧжЃµдЄ≠зЪДеЖЕеЃєдЉЪ襀еРМж≠•еИ∞糥еЉХдєЛдЄ≠пЉМ е¶ВжЮЬдЄЇдЄА䪙糥еЉХжМЗеЃЪдЄ§дЄ™е≠ЧжЃµпЉМ йВ£дєИињЩдЄ™дЄ§дЄ™е≠ЧжЃµзЪДеЖЕеЃєйГљдЉЪ襀еРМж≠•иЗ≥糥еЉХдєЛдЄ≠гАВ
еЕИзЬЛдЄЛйЭҐињЩдЄ™SQLиѓ≠еП•
//еїЇзЂЛ糥еЉХ
create index index_birthday on user_info(birthday);
//жߕ胥зФЯжЧ•еЬ®1991еєі11жЬИ1жЧ•еЗЇзФЯзФ®жИЈзЪДзФ®жИЈеРН
select user_name from user_info where birthday = '1991-11-1'
ињЩеП•SQLиѓ≠еП•зЪДжЙІи°МињЗз®Ле¶ВдЄЛ
й¶ЦеЕИпЉМйАЪињЗйЭЮиБЪйЫЖ糥еЉХindex_birthdayжЯ•жЙЊbirthdayз≠ЙдЇО1991-11-1зЪДжЙАжЬЙиЃ∞ељХзЪДдЄїйФЃIDеАЉ
зДґеРОпЉМйАЪињЗеЊЧеИ∞зЪДдЄїйФЃIDеАЉжЙІи°МиБЪйЫЖ糥еЉХжЯ•жЙЊпЉМжЙЊеИ∞дЄїйФЃIDеАЉеѓєе∞±зЪДзЬЯеЃЮжХ∞жНЃпЉИжХ∞жНЃи°МпЉЙе≠ШеВ®зЪДдљНзљЃ
жЬАеРОпЉМ дїОеЊЧеИ∞зЪДзЬЯеЃЮжХ∞жНЃдЄ≠еПЦеЊЧuser_nameе≠ЧжЃµзЪДеАЉињФеЫЮпЉМ дєЯе∞±жШѓеПЦеЊЧжЬАзїИзЪДзїУжЮЬ
жИСдїђжККbirthdayе≠ЧжЃµдЄКзЪД糥еЉХжФєжИРеПМе≠ЧжЃµзЪДи¶ЖзЫЦ糥еЉХ
create index index_birthday_and_user_name on user_info(birthday, user_name);
ињЩеП•SQLиѓ≠еП•зЪДжЙІи°МињЗз®Ле∞±дЉЪеПШдЄЇ
йАЪињЗйЭЮиБЪйЫЖ糥еЉХindex_birthday_and_user_nameжЯ•жЙЊbirthdayз≠ЙдЇО1991-11-1зЪДеПґиКВзВєзЪДеЖЕеЃєпЉМзДґиАМпЉМ еПґиКВзВєдЄ≠йЩ§дЇЖжЬЙuser_nameи°®дЄїйФЃIDзЪДеАЉдї•е§ЦпЉМ user_nameе≠ЧжЃµзЪДеАЉдєЯеЬ®йЗМйЭҐпЉМ еЫ†ж≠§дЄНйЬАи¶БйАЪињЗдЄїйФЃIDеАЉзЪДжЯ•жЙЊжХ∞жНЃи°МзЪДзЬЯеЃЮжЙАеЬ®пЉМ зЫіжО•еПЦеЊЧеПґиКВзВєдЄ≠user_nameзЪДеАЉињФеЫЮеН≥еПѓгАВ йАЪињЗињЩзІНи¶ЖзЫЦ糥еЉХзЫіжО•жЯ•жЙЊзЪДжЦєеЉПпЉМ еПѓдї•зЬБзХ•дЄНдљњзФ®и¶ЖзЫЦ糥еЉХжЯ•жЙЊзЪДеРОйЭҐдЄ§дЄ™ж≠•й™§пЉМ е§Іе§ІзЪДжПРйЂШдЇЖжߕ胥жАІиГљпЉМе¶ВдЄЛеЫЊ
жХ∞жНЃеЇУ糥еЉХзЪДе§ІиЗіеЈ•дљЬеОЯзРЖе∞±жШѓеГПжЦЗдЄ≠жЙАињ∞пЉМ зДґиАМзїЖиКВжЦєйЭҐеПѓиГљдЉЪзХ•жЬЙеБПеЈЃпЉМињЩдљЖеєґдЄНдЉЪеѓєж¶ВењµйШРињ∞зЪДзїУжЮЬдЇІзФЯељ±еУН гАВ
 



зЫЄеЕ≥жО®иНР
Elasticsearch-жЈ±еЕ•зРЖиІ£зіҐеЉХеОЯзРЖ Elasticsearch дЄ≠糥еЉХпЉИIndexпЉЙзЪДж¶ВењµжШѓйЭЮеЄЄйЗНи¶БзЪДпЉМеЃГжШѓ Elasticsearch е≠ШеВ®жХ∞жНЃзЪДеЯЇжЬђеНХеЕГгАВ糥еЉХжШѓдЄАдЄ™еЕЈжЬЙз±їдЉЉзЙєжАІзЪДжЦЗж°£зЪДйЫЖеРИпЉМз±їжѓФдЉ†зїЯзЪДеЕ≥з≥їеЮЛжХ∞жНЃеЇУйҐЖеЯЯжЭ•иѓіпЉМ糥еЉХзЫЄељУдЇО ...
еЬ®жЈ±еЕ•зРЖиІ£ElasticsearchпЉИзЃАзІ∞ESпЉЙзЪД糥еЉХеОЯзРЖеЙНпЉМжИСдїђйЬАи¶БеЕИжШОзЩљеЯЇжЬђж¶ВењµгАВESжШѓдЄАзІНеИЖеЄГеЉПеЕ®жЦЗжРЬ糥еЉХжУОпЉМеЃГе∞ЖжХ∞жНЃе≠ШеВ®еܮ糥еЉХдЄ≠пЉМињЩдЇЫ糥еЉХз±їдЉЉдЇОеЕ≥з≥їеЮЛжХ∞жНЃеЇУдЄ≠зЪДжХ∞жНЃеЇУпЉМдљЖеЕЈе§ЗжЫійЂШзЪДеПѓжЙ©е±ХжАІеТМеЃЮжЧґжАІгАВ糥еЉХеПѓдї•...
### MySQL Innodb 糥еЉХеОЯзРЖиѓ¶иІ£ #### 1. еРДзІНж†С嚥зїУжЮД еЬ®жЈ±еЕ•жОҐиЃ®MySQL Innodb糥еЉХдєЛеЙНпЉМжИСдїђеЕИдЇЖиІ£еЗ†зІНеЯЇжЬђзЪДж†С嚥жХ∞жНЃзїУжЮДпЉМеМЕжЛђдЇМеПЙжРЬ糥ж†СгАБBж†СгАБB+ж†Сдї•еПКB*ж†СгАВ ##### 1.1 жРЬ糥дЇМеПЙж†СпЉИBinary Search TreeпЉЙ ...
MySQL 糥еЉХеОЯзРЖжЈ±еЕ•иІ£жЮРе∞ЖеЄ¶йҐЖжИСдїђзРЖиІ£жХ∞жНЃеЇУ糥еЉХзЪДеЈ•дљЬжЬЇеИґпЉМдї•еПКеЃГдїђе¶ВдљХжШЊиСЧжПРеНЗжߕ胥жАІиГљгАВй¶ЦеЕИпЉМжИСдїђжЭ•зЬЛдЄАдЄЛ糥еЉХзЪДеЯЇжЬђж¶ВењµгА 糥еЉХжШѓжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠зЪДеЕ≥йФЃзїДдїґпЉМеЃГжШѓдЄАдЄ™жОТеЇПзЪДжХ∞жНЃзїУжЮДпЉМзФ®дЇОеК†йАЯеѓєжХ∞жНЃеЇУи°®...
жЈ±еЕ•зРЖиІ£зіҐеЉХзЪДеОЯзРЖгАБз±їеЮЛпЉИе¶ВB-treeгАБHashз≠ЙпЉЙдї•еПКе¶ВдљХеИЫеїЇгАБзЃ°зРЖ糥еЉХеѓєдЇОжХ∞жНЃеЇУжАІиГљзЪДжПРеНЗиЗ≥еЕ≥йЗНи¶БгАВ 6. дЇЛеК°дЄОйФБжЬЇеИґпЉЪдЇЛеК°жШѓдњЭиѓБжХ∞жНЃдЄАиЗіжАІзЪДйЗНи¶БеЈ•еЕЈпЉМMySQLдЄ≠зЪДдЇЛеК°еЕЈжЬЙACIDпЉИеОЯе≠РжАІгАБдЄАиЗіжАІгАБйЪФз¶їжАІгАБжМБдєЕжАІ...
oracle 糥еЉХзЪДеОЯзРЖеОЯзРЖжЈ±еЕ•зРЖиІ£пЉБ
еЬ®жЈ±еЕ•жОҐиЃ®SQLжХ∞жНЃеЇУ糥еЉХеОЯзРЖдєЛеЙНпЉМжИСдїђеЕИжЭ•зРЖиІ£дЄАдЄЛ糥еЉХзЪДеЯЇжЬђж¶ВењµгАВ糥еЉХпЉМз±їдЉЉдЇОдє¶з±НдЄ≠зЪДзЫЃељХпЉМжШѓжХ∞жНЃеЇУдЄ≠дЄАзІНзЙєжЃКзЪДжХ∞жНЃзїУжЮДпЉМзФ®дЇОењЂйАЯеЃЪдљНжХ∞жНЃгАВеЃГеєґдЄНе≠ШеВ®еЃЮйЩЕзЪДжХ∞жНЃпЉМиАМжШѓе≠ШеВ®дЇЖжХ∞жНЃи°МзЪДдљНзљЃдњ°жБѓпЉМдљњеЊЧжХ∞жНЃеЇУ...
MySQLжШѓдЄЦзХМдЄКжЬАеПЧ搥ињОзЪДеЕ≥з≥їеЮЛжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдєЛдЄАпЉМ糥еЉХжШѓеЕґж†ЄењГжАІиГљдЉШеМЦеЈ•еЕЈгАВжЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®MySQL糥еЉХзЪДжЬђиі®гАБ...еЬ®йЭҐиѓХдЄ≠пЉМеЕЈе§ЗињЩдЇЫзЯ•иѓЖдЄНдїЕиГље±ХзО∞еѓєжХ∞жНЃеЇУз≥їзїЯзЪДжЈ±еЕ•зРЖиІ£пЉМдєЯиГљеЄЃеК©дљ†еЬ®иІ£еЖ≥еЃЮйЩЕйЧЃйҐШжЧґжЄЄеИГжЬЙдљЩгАВ
зРЖиІ£жХ∞жНЃй°µзЪДе≠ШеВ®зїУжЮДеѓєдЇОжЈ±еЕ•е≠¶дє†жХ∞жНЃеЇУ糥еЉХеОЯзРЖгАБжߕ胥дЉШеМЦеЕЈжЬЙиЗ≥еЕ≥йЗНи¶БзЪДдљЬзФ®гАВеЬ®дїЛзїН糥еЉХеОЯзРЖеТМжߕ胥еОЯзРЖдєЛеЙНпЉМжИСдїђењЕй°їеЕИжЄЕж•ЪеЬ∞дЇЖиІ£жХ∞жНЃй°µеЬ®з£БзЫШдЄКзЪДзЙ©зРЖзїДзїЗжЦєеЉПгАВ й¶ЦеЕИпЉМжХ∞жНЃеЇУдЄ≠зЪДжЙАжЬЙжХ∞жНЃпЉМеМЕжЛђжИСдїђжЙАеїЇзЂЛзЪД...
MYSQL йЭҐиѓХйҐШеТМ糥еЉХеОЯзРЖзРЖиІ£ MYSQL жХ∞жНЃеЇУжШѓељУеЙНжЬАжµБи°МзЪДеЕ≥з≥їеЮЛжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдєЛдЄАпЉМиАМ糥еЉХжШѓ MYSQL дЄ≠жЬАйЗНи¶БзЪДдЉШеМЦжКАжЬѓдєЛдЄАгАВжЬђжЦЗе∞ЖдїО糥еЉХзЪДеЃЪдєЙгАБ糥еЉХзЪДдЉШзВєеТМзЉЇзВєгАБ糥еЉХзЪДдљњзФ®еЬЇжЩѓгАБ糥еЉХзЪДз±їеЮЛгАБMYSQL 糥еЉХзЪД...
жАїдєЛпЉМжЈ±еЕ•зРЖиІ£MySQLеОЯзРЖеТМдЉШеМЦжґЙеПКдЉЧе§ЪжЦєйЭҐпЉМдїОжЮґжЮДеИ∞е≠ШеВ®гАБжߕ胥гАБ糥еЉХгАБдЇЛеК°гАБжАІиГљи∞ГдЉШз≠ЙпЉМжѓПдЄ™зОѓиКВйГљеѓєжХ∞жНЃеЇУзЪДжАІиГљжЬЙйЗНе§Іељ±еУНгАВйАЪињЗеѓєињЩдЇЫзЯ•иѓЖзЪДжОМжП°пЉМжИСдїђеПѓдї•жЫіе•љеЬ∞иЃЊиЃ°гАБзЃ°зРЖеТМзїіжК§MySQLжХ∞жНЃеЇУпЉМжПРеНЗз≥їзїЯзЪД...
жЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®жХ∞жНЃеЇУдЄ≠зЪД糥еЉХеОЯзРЖпЉМеМЕжЛђиБЪйЫЖ糥еЉХдЄОйЭЮиБЪйЫЖ糥еЉХзЪДж¶ВењµгАБеМЇеИЂдї•еПКеЃГдїђеЬ®еЃЮйЩЕеЇФзФ®дЄ≠зЪДйАЙжЛ©з≠ЦзХ•гАВ #### иБЪйЫЖ糥еЉХпЉИClustered IndexпЉЙ иБЪйЫЖ糥еЉХжШѓдЄАзІНзЙєжЃКзЪД糥еЉХз±їеЮЛпЉМеЃГеЖ≥еЃЪдЇЖи°®дЄ≠и°МзЪДзЙ©зРЖе≠ШеВ®й°ЇеЇПгАВеЬ®...
жАїзїУиµЈжЭ•пЉМжЈ±еЕ•зРЖиІ£зіҐеЉХзїУжЮДеѓєдЇОжХ∞жНЃеЇУиЃЊиЃ°еТМжАІиГљи∞ГдЉШиЗ≥еЕ≥йЗНи¶БгАВж≠£з°ЃеЬ∞еИ©зԮ糥еЉХеПѓдї•жШЊиСЧжПРеНЗжߕ胥жХИзОЗпЉМдљЖеРМжЧґдєЯйЬАи¶Беє≥и°°еЕґеѓєеЖЩжУНдљЬзЪДељ±еУНгАВеЫ†ж≠§пЉМжХ∞жНЃеЇУзЃ°зРЖеСШеТМеЉАеПСдЇЇеСШйЬАи¶Бж†єжНЃеЕЈдљУеЇФзФ®зЪДйЬАж±ВеТМжХ∞жНЃзЙєжАІпЉМи∞®жЕОеЬ∞...
йАЪињЗжЈ±еЕ•зРЖиІ£зіҐеЉХеОЯзРЖпЉМзїУеРИзФ®жИЈи°МдЄЇеТМжߕ胥殰еЉПпЉМжИСдїђеПѓдї•жЬЙйТИеѓєжАІеЬ∞еїЇзЂЛеТМдЉШеМЦ糥еЉХпЉМдїОиАМжПРеНЗжХ∞жНЃеЇУзЪДжХідљУжАІиГљгАВеЬ®еЃЮйЩЕжУНдљЬдЄ≠пЉМеЇФжМБзї≠зЫСжОІеТМеИЖжЮРжХ∞жНЃеЇУжАІиГљпЉМдЄНжЦ≠и∞Гжճ糥еЉХз≠ЦзХ•пЉМдї•йАВеЇФдЄНжЦ≠еПШеМЦзЪДеЇФзФ®йЬАж±ВгАВ еЕ≥йФЃиѓН...
Apache Lucene жШѓдЄАдЄ™йЂШжАІиГљгАБеЕ®жЦЗж£А糥еЇУпЉМзФ±JavaзЉЦеЖЩпЉМеЕґж†ЄењГиЃЊиЃ°зЫЃж†ЗжШѓжПРдЊЫдЄАдЄ™зБµжіїгАБеПѓжЙ©е±ХзЪДжРЬ糥еКЯиГљгАВеЃГеЕБиЃЄеЉАеПСиАЕеЬ®иЗ™еЈ±зЪДеЇФзФ®з®ЛеЇПдЄ≠...дЇЖиІ£еєґжОМжП°LuceneзЪД糥еЉХеОЯзРЖеТМеЃЮиЈµпЉМеѓєдЇОеЉАеПСйЂШжАІиГљзЪДжРЬ糥еЇФзФ®иЗ≥еЕ≥йЗНи¶БгАВ
3. **糥еЉХеОЯзРЖ**пЉЪMySQLдЄ≠зЪД糥еЉХжЬЙB-TreeгАБHashгАБR-Treeз≠Йе§ЪзІНз±їеЮЛгАВB-TreeжШѓжЬАеЄЄиІБзЪДпЉМзФ®дЇОењЂйАЯеЃЪдљНжХ∞жНЃпЉЫHash糥еЉХйАВзФ®дЇОз≠ЙеАЉжߕ胥пЉМдљЖдЄНжФѓжМБиМГеЫіжߕ胥гАВдЇЖиІ£зіҐеЉХзЪДеИЫеїЇгАБдљњзФ®еТМдЉШеМЦпЉМеПѓдї•жШЊиСЧжПРеНЗжߕ胥йАЯеЇ¶гАВ 4. **...
иБФеРИ糥еЉХжߕ胥еОЯзРЖпЉЪ иБФеРИ糥еЉХжШѓзФ±е§ЪдЄ™е≠ЧжЃµзїДжИРзЪД糥еЉХзїУжЮДпЉМеЃГзЪДжХ∞жНЃй°µеЖЕйГ®жМЙзЕІиБФеРИ糥еЉХзЪДе≠ЧжЃµй°ЇеЇПињЫи°МжОТеЇПгАВдї•жЬђж°ИдЊЛдЄ≠зЪДе≠¶зФЯдњ°жБѓ...еЫ†ж≠§пЉМжЈ±еЕ•зРЖиІ£иБФеРИ糥еЉХзЪДжߕ胥еОЯзРЖеТМеЕ®еАЉеМєйЕНиІДеИЩеѓєдЇОжХ∞жНЃеЇУжАІиГљи∞ГдЉШжШѓиЗ≥еЕ≥йЗНи¶БзЪДгАВ
MySQLжХ∞жНЃеЇУдЄ≠зЪД糥еЉХжШѓжПРеНЗжߕ胥жАІиГљзЪДеЕ≥йФЃеЈ•еЕЈпЉМеЃГзЪДеЈ•дљЬеОЯзРЖеТМиЃЊиЃ°зїЖиКВеѓєдЇОжХ∞жНЃеЇУзЃ°зРЖеСШеТМеЉАеПСиАЕжЭ•иѓіиЗ≥еЕ≥йЗНи¶БгАВиЃ©жИСдїђжЈ±еЕ•жОҐиЃ®дЄАдЄЛж†ЗйҐШеТМжППињ∞дЄ≠жПРеПКзЪДеЗ†дЄ™еЕ≥йФЃж¶ВењµгАВ й¶ЦеЕИпЉМжИСдїђжЭ•зЬЛзЬЛ糥еЉХзЪДе≠ШеВ®зїУжЮДгАВеЬ®MySQLдЄ≠пЉМ...
еЬ®дЄ™дЇЇеЉАеПСињЗз®ЛдЄ≠пЉМжЈ±еЕ•зРЖиІ£еєґеЇФзФ®ињЩдЇЫеОЯзРЖиЗ≥еЕ≥йЗНи¶БгАВжЬђжЦЗе∞ЖеЫізїХжХ∞жНЃеЇУдЄ≠зЪД糥еЉХж¶ВењµгАБиБЪжЧП糥еЉХгАБдЄїйФЃдї•еПКжߕ胥дЉШеМЦињЫи°Миѓ¶ињ∞гАВ й¶ЦеЕИпЉМжХ∞жНЃеЇУ糥еЉХжШѓдЄАзІНзЙєжЃКзЪДжЦЗдїґпЉМзФ±жХ∞жНЃеЇУзЃ°зРЖз≥їзїЯиЗ™еК®еИЫеїЇеТМзїіжК§пЉМеЕґдљЬзФ®з±їдЉЉдЇОдє¶з±Н...