µÄźõĖŖõĖĆń»ć’╝ÜµĘśÕ«ØµŖƵ£»ÕÅæÕ▒Ģ’╝łJavaµŚČõ╗Ż’╝ÜÕłøķĆĀµŖƵ£»-TFS’╝ē
TFSńÜäÕ╝ĆÕÅæ’╝īĶ«®µĘśÕ«ØńÜäÕøŠńēćÕŖ¤ĶāĮÕŠŚÕł░õ║åÕģģÕłåńÜäÕÅæµīźŃĆéÕÉīTFSõĖƵĀĘ’╝īÕŠłÕżÜµŖƵ£»ķāĮµś»Õ£©õ║¦ÕōüńÜäµÄ©ÕŖ©õĖŗÕŠŚÕł░ÕÅæÕ▒ĢńÜäŃĆéÕ£©Ķ«▓õĖŗķØóńÜäµŖƵ£»õ╣ŗÕēŹ’╝īµ£ēÕ┐ģĶ”üĶ»┤Ķ»┤ķéŻõ║øÕ╣┤’╝īµłæõ╗¼õĖĆĶĄĘÕüÜĶ┐ćńÜäÕćĀõĖ¬õ║¦ÕōüŃĆé
ÕģłĶ»┤õĖ¬µ»öĶŠāµé▓Õē¦ńÜäŌĆöŌĆöŃĆÉÕøóĶ┤ŁŃĆæ’╝īĶ┐ÖõĖ¬ÕøóĶ┤ŁÕÅ»õĖŹµś»ńÄ░Õ£©µ╗ĪÕż¦ĶĪŚµīéńÜäķéŻń¦Źgrouponń▒╗Õ×ŗńÜ䵩ĪÕ╝Å’╝īÕ£©grouponÕć║ńö¤õ╣ŗÕēŹ’╝īÕ£©2006Õ╣┤’╝īµĘśÕ«ØńÜäõ║¦Õōüń╗ÅńÉåõĖĆ ńü»Õ░▒µÅÉÕć║õ║åŌĆ£ÕøóĶ┤ŁŌĆØĶ┐Öń¦Źõ║¦ÕōüŃĆéõĖĆńü»µ£ĆÕłØńÜäĶ«Šµā│µś»Ķ«®õ╣░Õ«ČÕ£©ńżŠÕī║ÕÅæĶĄĘÕøóĶ┤Ł’╝īŌĆ£ÕøóķĢ┐ŌĆصēŠÕł░ĶČ│Õż¤ńÜäõ║║õ╣ŗÕÉÄ’╝īÕÄ╗ĶĘ¤ÕŹ¢Õ«ČńĀŹõ╗Ę’╝īĶ┐Öń▒╗õ╝╝õ║ÄńÄ░Õ£©ĶśæĶÅćĶĪŚńÜäŌĆ£Ķć¬ńö▒ÕøóŌĆØŃĆéõĮåńö▒õ║Ä ń¦Źń¦ŹÕĤÕøĀ’╝īÕ£©Õ╝ĆÕÅæńÜ䵌ČÕĆÖõ║¦ÕōüńÜäÕŖ¤ĶāĮÕüÜõ║åĶŻüÕē¬’╝īĶʤµ£ĆÕłØńÜäĶ«Šµā│µ»öĶĄĘµØźÕüÅń”╗õ║åõĖĆńé╣’╝īÕÅśµłÉõ║åĶ«®ÕŹ¢Õ«ČĶ«ŠńĮ«ÕøóĶ┤Łõ╗Ę’╝īÕ£©õ╣░Õ«ČĶŠŠÕł░µīćÕ«ÜńÜäµĢ░ķćÅõ╣ŗÕÉÄ’╝īõ╗źÕøóĶ┤Łõ╗ʵłÉõ║żŃĆéĶ┐ÖõĖ¬ÕŖ¤ĶāĮ ń£ŗĶĄĘµØźµś»ń╗ōÕÉłõ║åµĘśÕ«ØõĖĆÕÅŻõ╗ĘÕÆīĶŹĘÕģ░µŗŹńÜäÕÅ”õĖĆń¦Źõ║żµśōµ©ĪÕ╝Å’╝īõĮåõĖŹÕ╣Ėµ▓Īµ£ēµö»µÆæõĖŗÕÄ╗’╝īĶ┐Öń¦Źõ║żµśōµ¢╣Õ╝ŵ£ĆÕż¦ńÜäÕ╝▒ńé╣Õ░▒µś»Ķ«®õ╣░Õ«Čń£ŗÕł░õ║åÕŹ¢Õ«ČńÜäÕ║Ģńēī’╝īÕŹ│õŠ┐ĶŠŠõĖŹÕł░ÕøóĶ┤ŁńÜäµĢ░ķćÅ’╝īõ╗¢ õ╗¼õ╣¤ÕŠĆÕøóĶ┤ŁńÜäõ╗ʵĀ╝õĖŖńĀŹŃĆéÕĮōµŚČõĖ║õ║åÕ╝ĢµĄüķćÅ’╝īµĘśÕ«ØńĮæÕ╝ĆĶŠ¤õ║åÕøóĶ┤ŁõĖōÕī║’╝īÕ«×Ķ»ÜńÜäÕŹ¢Õ«ČÕ£©ĶŠŠõĖŹÕł░ÕøóĶ┤ŁµĢ░ķćÅńÜ䵌ČÕĆÖ’╝īĶó½ńĀŹõ╗ĘńĀŹõ║Åõ║å’╝īńŗĪńīŠńÜäÕŹ¢Õ«ČÕ╣▓ĶäåµÅÉķ½śÕĤõ╗Ę’╝īÕł®ńö©Ķ┐ÖõĖ¬õĖōÕī║ÕüÜõ┐āķöĆŃĆéÕ£©µÄźõĖŗµØźńÜäõĖżÕ╣┤ķćīĶ┐ÖõĖ¬õ║¦Õōüµ▓”ĶÉĮµłÉõ║åõ┐āķöĆÕĘźÕģĘ’╝łĶ»ØĶ»┤ńÄ░Õ£©µ╗ĪÕż¦ĶĪŚńÜäÕøóĶ┤Ł’╝īÕģČÕ«×õ╣¤Õ░▒µś»õ┐āķöĆ’╝ēŃĆéĶ┐ÖõĖ¬õ║¦Õōü’╝īĶ«®ńĀöÕÅæõ║║ÕæśÕ»╣ŌĆ£õ║¦ÕōüŌĆØĶ┐ÖõĖ¬µ”éÕ┐Ąµ£ēõ║åµĘ▒Õł╗ńÜäĶ«żĶ»åŃĆé
┬Ā
┬Ā
ÕåŹĶ»┤õĖĆõĖ¬µø┤ÕŖĀµé▓Õē¦ńÜäŌĆöŌĆöŃĆɵłæńÜäµĘśÕ«ØŃĆæ’╝īµłæńÜäµĘśÕ«Øµś»ń╗Öõ╝ÜÕæśń«ĪńÉåĶć¬ÕĘ▒ńÜäÕĢåÕōüŃĆüõ║żµśōŃĆüµöČĶ┤¦Õ£░ÕØĆŃĆüĶ»äõ╗ĘŃĆüµŖĢĶ»ēńÜäÕ£░µ¢╣’╝īĶ┐ÖõĖ¬Õ£░µ¢╣ńö▒õ║ÄńÖ╗ÕĮĢõ╣ŗÕÉĵēŹĶāĮń£ŗÕł░’╝īµēĆõ╗źķŻÄµĀ╝ĶĘ¤Õż¢ ķØóÕ«īÕģ©õĖŹõĖƵĀĘ’╝īÕŠłķĢ┐µŚČķŚ┤ķāĮµ▓Īµ£ēõ╝śÕī¢Ķ┐ć’╝īµĀĘÕŁÉõĖæ’╝īńö©µłĘµōŹõĮ£õ╣¤õĖŹµ¢╣õŠ┐’╝īÕ”éµ×£õĖĆõĖ¬õ║║µ£ēÕŠłÕżÜÕĢåÕōü’╝īõĖŖõĖŗµ×Čķ£ĆĶ”üõĖĆõĖ¬õĖĆõĖ¬ńÜäµōŹõĮ£’╝īķØ×ÕĖĖķ║╗ńā”’╝łµā│µā│ķéŻõ║øÕŹ¢õ╣”ńÜä’╝ēŃĆéĶ┐ÖµŚČÕĆÖ õĖĆõĖ¬ķćŹĶ”üõ║║ńē®ńÖ╗Õ£║õ║å’╝īµē┐Õ┐Ś’╝łńÄ░Õ£©ńÜäĶśæĶÅćĶĪŚCEO’╝īõ╗¢Ķ«®µłæµŖŖõ╗¢µÅÅÕåÖńÜäÕĖģõĖĆńé╣’╝ē’╝īõ╗¢ń╗Öµłæõ╗¼µ╝öńż║õ║åµ£ĆńēøÕÅēńÜäÕēŹń½»õ║żõ║ƵŖƵ£»’╝īÕ░▒µś»GmailõĖŖķéŻń¦ŹAjaxńÜäõ║żõ║Ƶ¢╣ Õ╝Å’╝īÕÅ»õ╗źµŗ¢ÕŖ©ŃĆüÕÅ»õ╗źńö©ÕÅ│ķö«ŃĆüÕÅ»õ╗źń╗äÕÉłķö«ķĆēµŗ®ŃĆüµōŹõĮ£Õ«īµ»ĢĶ┐śõĖŹÕłĘµ¢░ķĪĄķØó’╝īń«ĪńÉåÕĢåÕōüՔ鵣ēńź×ÕŖ®’╝īÕĖģÕæåõ║åŃĆéµłæµś»Ķ┐ÖõĖ¬ķĪ╣ńø«ńÜäķĪ╣ńø«ń╗ÅńÉå’╝īõĖĆńü»µś»õ║¦Õōüń╗ÅńÉå’╝īµłæõ╗¼ÕåŹµŗēõĖŖõĖćÕēæ ÕÆīõĖĆõ╝ÖÕĘźń©ŗÕĖłÕ░▒Õ╝ƵÉ×õ║åŃĆéńāŁńü½µ£ØÕż®ńÜäÕ╣▓õ║åõĖēõĖ¬µ£ł’╝īÕ┐½Ķ”üÕ«īµłÉńÜ䵌ČÕĆÖ’╝īĶĆüķ®¼õĖŹń¤źķüōµĆÄõ╣łÕø×õ║ŗń¬üńäČÕć║ńÄ░Õ£©µłæĶ║½ÕÉÄ’╝īń£ŗµłæµōŹõĮ£õ║åõĖĆķüŹµ¢░ńēłµłæńÜäµĘśÕ«Øõ╣ŗÕÉÄ’╝īķŚ«µłæĶ┐Öµś»õĖŹµś»Õ«óµłĘ ń½»ĶĮ»õ╗Č’╝īµłæĶ»┤µś»ńĮæķĪĄ’╝īõ╗¢µŖōńŗéõ║å’╝īĶ»┤Ķ┐ÖĶĘ¤Õ«óµłĘń½»ĶĮ»õ╗ČõĖƵĀĘ’╝īķōŠµÄźÕ║ĢõĖŗĶ┐×ń║┐ķāĮµ£©µ£ē’╝īõĖŖõĖŗµ×Čńö©µ¢ćõ╗ČÕż╣ĶĪ©ńż║’╝īµłæķāĮõĖŹń¤źķüōµĆÄõ╣łµōŹõĮ£õ║å’╝īÕŹ¢Õ«ČĶé»Õ«Üõ╣¤õĖŹõ╝ÜńÄ®ŃĆé

┬Ā
┬Ā
ĶĆüķ®¼µ×£ńäȵś»ńź×õĖƵĀĘńÜäõ║║ńē®’╝īõ╗¢Ķ»┤ńÜäÕ║öķ¬īõ║å’╝īµĘśÕ«ØÕÄåÕÅ▓õĖŖń¼¼õĖĆõĖ¬ńŠż#õĮō#µĆ¦#õ║ŗ#õ╗ČńłåÕÅæõ║å’╝īĶ»Ģńö©Õ«īµ¢░ńēłµ£¼ńÜ䵳æńÜäµĘśÕ«Øõ╣ŗÕÉÄ’╝īÕŠłÕżÜÕŹ¢Õ«ČµäżµĆÆõ║å’╝īĶ»┤õĖŹõ╝ÜńÄ®ŃĆéõĖĆńü»Õ░▒ÕÆīµē┐Õ┐ŚõĖĆĶĄĘÕĢå ķćŵĆÄõ╣łµŖŖķĪĄķØóµö╣ÕŠŚÕāÅõĖ¬ńĮæķĪĄõĖĆńé╣’╝īµö╣õ║åÕŹŖõĖ¬µ£ł’╝īµäżµĆÆõŠØńäȵ▓Īµ£ēÕ╣│µü»ŃĆ鵳æÕŠłµŚĀÕźłÕ£░ń£ŗńØĆĶ┐ÖõĖżõĖ¬õ║║Õ£©ķéŻķćīÕØܵīü’╝īńäČÕÉÄĶʤĶĆüµØ┐õ╗¼ÕĢåķćŵĆÄõ╣łÕŖ×ŃĆéÕÉÄµØźµłæõ╗¼ńö©õ║åõĖĆõĖ¬ÕŠłµī½ńÜäµ¢╣µ│Ģ ń╗ÖĶć¬ÕĘ▒õĖĆõĖ¬ÕÅ░ķśČ’╝īÕł░Ķ«║ÕØøõĖŖĶ«®Õż¦Õ«ČµŖĢńź©Ķ”üõĖŹĶ”üõĮ┐ńö©µ¢░ńēłµłæńÜäµĘśÕ«Ø’╝īµŖĢńź©ń╗ōµ×£µś»õĖĆÕŹŖõ╗źõĖŖńÜäÕÅŹÕ»╣ŃĆéõ║ĵś»Ķ┐Öõ╣łÕŹüµØźõĖ¬õ║║ÕüÜõ║å3õĖ¬µ£łńÜäń│╗ń╗¤Ķó½µØƵÄēõ║åŃĆéĶ┐ÖĶ«®µłæķØ×ÕĖĖµ▓«õĖ¦’╝īõĮå µ£ĆńŚøĶŗ”ńÜäĶ┐śõĖŹµś»Ķ┐ÖõĖ¬’╝īµłæõ╗¼õĖŗń║┐õ╣ŗÕÉÄ’╝īÕÅ”Õż¢õĖƵŗ©ÕŹ¢Õ«ČõĖŹµ╗Īõ║å’╝īĶ»┤Ķ┐Öõ╣łÕźĮńÜäÕŖ¤ĶāĮµĆÄõ╣łµ▓Īµ£ēõ║å’╝¤ÕĢŖ~~~õĮĀõ╗¼µĆÄõ╣łõĖŹµŚ®ńé╣ń½ÖÕć║µØź’╝īõ║▓’╝¤Ķ┐ÖõĖ¬õ║¦ÕōüÕĖ”ń╗Öµłæõ╗¼ńÜ䵜»µ¢░µŖƵ£» ’╝łAjax’╝ēńÜäÕ░ØĶ»Ģ’╝īĶ┐śµ£ēÕ░▒µś»µ¢░µŖƵ£»Õ»╣ńö©µłĘµōŹõĮ£õ╣Āµā»ńÜäµö╣ÕÅś’╝īõĖĆÕ«ÜĶ”üµģÄõ╣ŗÕÅłµģÄŃĆéÕÅ”Õż¢Ķ┐śµ£ēõĖĆńé╣µ▓Īµ£ēµĆ╗ń╗ōÕźĮńÜäµĢÖĶ«Ł’╝īÕ░▒µś»Õ║öÕ»╣ńŠżõĮōõ║ŗõ╗ČńÜ䵌ČÕĆÖ’╝īµłæõ╗¼µēŗĶČ│µŚĀµÄ¬’╝īÕ£©ÕÉÄ µØźŃĆɵŗøĶ┤óĶ┐øÕ«ØŃĆæÕÆīµĘśÕ«ØÕĢåÕ¤ÄÕć║ńÄ░ńŠż#õĮō#µĆ¦#õ║ŗõ╗ČńÜ䵌ČÕĆÖ’╝īµłæÕÅæńÄ░µé▓Õē¦Õ£©ķ揵╝öŃĆé
┬Ā
Ķ»┤Õł░ŃĆɵŗøĶ┤óĶ┐øÕ«ØŃĆæ’╝īĶ┐ÖõĖ¬µś»µ£Ćµé▓Õē¦ńÜäõ║¦ÕōüŃĆéÕł░2006Õ╣┤õ║öõĖĆńÜ䵌ČÕĆÖ’╝īõĖĆõĖ¬ÕłÆµŚČõ╗ŻńÜäķĪ╣ńø«ÕÉ»ÕŖ©õ║å’╝łµłæĶŗ”ķĆ╝ńÜäĶ┐×ń╗ŁÕż▒ÕÄ╗õ║åõĖżõĖ¬õ║öõĖĆĶŖé’╝īÕēŹķØóõĖĆõĖ¬µś»2005Õ╣┤Õüܵö»õ╗śÕ«Ø ń│╗ń╗¤’╝ēŃĆéĶ┤óńź×Ķ»┤Ķ”üńö©µ£ĆÕźĮńÜäķĪ╣ńø«ķśĄÕ«╣’╝īµłæĶó½ķĆēõĖŁõ║å’╝īĶ┐ÖõĖĆõĖŗÕŁÉĶ«®µłæĶ¦ēÕŠŚµłæĶāĮÕłÆÕłåÕł░µ£ĆÕźĮńÜäÕæśÕĘźõ╣ŗń▒╗’╝īÕ£©ŃĆɵłæńÜäµĘśÕ«ØŃĆæĶ┐ÖõĖ¬õ║¦ÕōüõĖŁõĖźķćŹÕÅŚõ╝żńÜäÕ┐āÕÅłńŚŖµäłõ║åŃĆéĶ┐Öµś»õĖĆõĖ¬ÕĢå ÕōüP4PńÜäń│╗ń╗¤’╝īÕ░▒µś»µīēµłÉõ║żõ╗śĶ┤╣ŃĆ鵳æõ╗¼Ķ«żõĖ║ÕĘ▓ń╗ŵ£ēÕŠłÕżÜÕŹ¢Õ«Čµ£ēķÆ▒õ║å’╝īõĮåµĘśÕ«ØõĖŖĶ┐Öõ╣łÕżÜńÜäÕĢåÕōü’╝īõ╗¢õ╗¼ÕŠłķÜŠĶó½µēŠÕł░’╝īÕŹ¢Õ«Čµä┐µäÅĶŖ▒ķÆ▒Ķ«®ÕĢåÕōüµÄÆÕ£©ÕēŹķØóŃĆ鵳æõ╗¼ÕģüĶ«ĖÕŹ¢Õ«ČĶ┤Łõ╣░ Õ╣┐ÕæŖõĮŹ’╝īµŖŖõ╗¢ńÜäÕĢåÕōüµīēõĖĆÕ«Üń«Śµ│Ģń╗ÖõĖ¬µÄÆÕÉŹ’╝łń▒╗õ╝╝õ║ÄńÖŠÕ║”ńÜäń½×õ╗ʵÄÆÕÉŹ’╝īõĮåõĖŹõ╗ģõ╗ģń£ŗõ╗¢Õć║õ║åÕżÜÕ░æķÆ▒’╝īĶ┐śµ£ēõ┐Īńö©ŃĆüµłÉõ║żķćÅŃĆüĶó½µöČĶŚÅµĢ░ķćÅńŁēńŁē’╝īĶ┐ÖõĖ¬ń«Śµ│ĢµÉ×ńÜäÕĘ©ÕżŹµØé’╝ēŃĆéĶ┐Öµś» õĖĆõĖ¬ÕżÜõ╣łńēøÕÅēńÜäńøłÕł®µ©ĪÕ╝ÅÕĢŖ’╝ü
┬Ā
Ķ┐ÖõĖ¬ń│╗ń╗¤Ķ┐øĶĪīńÜäÕŠłķĪ║Õł®’╝īõĮåÕÅæÕĖāńÜ䵌ČÕĆÖ’╝īµø┤Õż¦ńÜäńŠż#õĮō#µĆ¦##õ║ŗõ╗ČÕć║µØźõ║å’╝īõ╣░Õ«Čõ╗¼Ķ┤©ń¢æ’╝ÜõĮĀõ╗¼õĖŹµś»µē┐Ķ»║3Õ╣┤õĖŹµöČĶ┤╣õ╣ł’╝¤µöČÕ╣┐ÕæŖĶ┤╣õĖŹµś»µöČĶ┤╣õ╣ł’╝¤ÕÉÄµØźµłæõ╗¼ńÜäń½×õ║ēÕ»╣µēŗÕÅłµÄ©µ│óÕŖ® µŠ£’╝īÕģ¼Õģ│Õģ¼ÕÅĖÕÆīÕ£łÕŁÉķćīÕÉäĶĘ»Õż¦õŠĀõĖŖĶ╣┐õĖŗĶĘ│’╝īńöÜĶć│ÕÉīĶĪīµÉ×õ║åõĖ¬ŌĆ£õĖĆķö«µÉ¼Õ«ČŌĆØńÜäÕŖ¤ĶāĮµØźµöČń║│µłæõ╗¼ńÜäõ╝ÜÕæśŃĆéõĖƵŚČõ╣ŗķŚ┤’╝īĶłåĶ«║ÕōŚńäČ’╝īÕÉäń¦Źń¤øÕż┤ķāĮµīćõ║åĶ┐ćµØźŃĆéõĖ║õ║åµöČÕ£║’╝īµłæõ╗¼ÕÅł õĖƵ¼ĪÕ£©Ķ«║ÕØøķćīķØóĶ«®ńö©µłĘµŖĢńź©Õå│Õ«Üõ║¦Õōüµś»ÕÉ”õĖŗń║┐’╝īÕÉīŃĆɵłæńÜäµĘśÕ«ØŃĆæõĖƵĀĘ’╝īõ╗źµé▓Õē¦µöČÕ£║ŃĆéõ╣¤Õ”éÕÉīŃĆɵłæńÜäµĘśÕ«ØŃĆæõĖƵĀĘ’╝īõĖŗń║┐ÕÉÄ’╝īõĖƵŗ©Õ░ØÕł░ńö£Õż┤ńÜäÕŹ¢Õ«ČĶ»┤’╝īĶ┐Öõ╣łÕźĮńÜäÕŖ¤ĶāĮµĆÄõ╣ł µ▓Īµ£ēõ║å’╝¤’╝łńø┤Õł░ÕÉÄµØźyahooõĖŁÕøĮÕÉłÕ╣ČĶ┐ćµØźõ╣ŗÕÉÄ’╝īÕ╝ĆÕÅæõ║åµĘśÕ«Øńø┤ķĆÜĶĮ”’╝īµēŹõ╗źń▒╗õ╝╝ńÜäõ║¦ÕōüÕĮóµĆüµ╗ĪĶČ│õ║åĶ┐Öķā©Õłåķ£Ćµ▒é’╝ē
┬Ā
ĶÖĮńäȵŗøĶ┤óĶ┐øÕ«ØÕż▒Ķ┤źõ║å’╝īõĮåĶ┐ÖõĖ¬ķĪ╣ńø«õĖŁÕ»╣µŖƵ£»ńÜäµÄóń┤óµø┤ÕŖĀµĘ▒Õģź’╝īĶ┐ÖķćīķØóńö©Õł░õ║åńö©µłĘĶĪīõĖ║Ķ┐ĮĶĖ¬ŃĆüAjaxńŁēŃĆéÕģČõĖŁµ£ēõĖĆõĖ¬µŖƵ£»ńÜäń╗åĶŖéķØ×ÕĖĖń╗ÅÕģĖ’╝īµĘśÕ«ØÕĢåÕōüĶ»”µāģķĪĄķØóµ»ÅÕż®ńÜä µĄüķćÅÕ£©10õ║┐õ╗źõĖŖ’╝īķćīķØóńÜäÕåģÕ«╣ķāĮµś»µöŠÕ£©ń╝ōÕŁśķćīńÜä’╝īÕüܵŗøĶ┤óĶ┐øÕ«ØńÜ䵌ČÕĆÖ’╝īµłæõ╗¼Ķ”üń╗ÖÕŹ¢Õ«ČµśŠńż║õ╗¢ńÜäÕĢåÕōüĶó½µĄÅĶ¦łńÜäµ¼ĪµĢ░’╝łĶ¦üõĖŗÕøŠ’╝ē’╝īĶ┐ÖõĖ¬µĢ░ÕŁŚÕ┐ģķĪ╗Õ«×µŚČµø┤µ¢░’╝īĶĆīńö©ń╝ōÕŁśńÜä Ķ»ØõĖĆĶł¼ķāĮµś»Õ╝鵣źµø┤µ¢░ńÜäŃĆéõ║ĵś»ÕĢåÕōüĶĪ©ķćīķØóÕó×ÕŖĀõ║åĶ┐ÖµĀĘõĖĆõĖ¬ÕŁŚµ«Ą’╝īµ»ÅÕó×ÕŖĀõĖĆõĖ¬PVĶ┐ÖõĖ¬ÕŁŚµ«ĄÕ░▒Ķ”üµø┤µ¢░õĖƵ¼ĪŃĆéÕÅæÕĖāõĖŖÕÄ╗õĖĆõĖ¬Õ░ŵŚČµĢ░µŹ«Õ║ōÕ░▒µīéµÄēõ║å’╝īµÆæõĖŹõĮÅĶ┐Öõ╣łķ½śńÜä updateŃĆéµĢ░µŹ«Õ║ōµÆæõĖŹõĮŵĆÄõ╣łÕŖ×’╝¤õĖĆĶł¼ńÜäń╝ōÕŁśńŁ¢ńĢźµś»õĖŹµö»µīüÕ«×µŚČµø┤µ¢░ńÜä’╝īĶ┐ÖµŚČÕĆÖÕżÜķÜåÕż¦ńź×µā│õ║åõĖ¬ÕŖ×µ│Ģ’╝īÕ£©apacheõĖŖķØóÕåÖõ║åõĖĆõĖ¬µ©ĪÕØŚ’╝īĶ┐ÖõĖ¬µĢ░ÕŁŚµĀ╣µ£¼õĖŹń╗ÅĶ┐ć õĖŗÕ▒éńÜäwebÕ«╣ÕÖ©’╝łÕŬń╗ÅĶ┐ćapache’╝ēÕ░▒ÕåÖÕģźõĖĆõĖ¬ķøåõĖŁÕ╝ÅńÜäń╝ōÕŁśÕī║õ║å’╝īĶ┐ÖõĖ¬ń╝ōÕŁśÕī║ńÜäµĢ░µŹ«ÕåŹÕ╝鵣źµø┤µ¢░Õł░µĢ░µŹ«Õ║ōŃĆéĶ┐ÖÕ░▒µś»µłæÕēŹķØóµÅÉÕł░ńÜä’╝īµłæõ╗¼µĢ┤õĖ¬ÕĢåÕōüĶ»”µāģńÜäķĪĄķØó ķāĮÕ£©ń╝ōÕŁśõĖŁõ║å’╝īµŖŖń╝ōÕŁśńö©Õł░õ║åµ×üĶć┤ŃĆé
┬Ā
’╝łĶ┐ÖõĖ¬ÕøŠń£¤õĖŹµś»Õ╣┐ÕæŖ’╝īõ║▓’╝ē
┬Ā
ķéŻõ╣łµÄźõĖŗµØź’╝īµłæõ╗¼Õ░▒Ķ»┤Ķ»┤ń╝ōÕŁśńÜäµŖƵ£»ÕɦŃĆé
┬Ā
µĘśÕ«ØÕ£©ÕŠłµŚ®Õ░▒Õ╝ĆÕ¦ŗõĮ┐ńö©ń╝ōÕŁśńÜäµŖƵ£»õ║å’╝īÕ£©2004Õ╣┤ńÜ䵌ČÕĆÖ’╝īµłæõ╗¼õĮ┐ńö©õĖĆõĖ¬ÕŽÕüÜESI’╝łEdge Side Includes’╝ēńÜäń╝ōÕŁśŃĆéÕ£©Õå│Õ«Üķććńö©ESIõ╣ŗÕēŹ’╝īÕżÜķÜåĶ»Ģńö©õ║åÕŠłÕżÜjavańÜäcache’╝īõĮåķāĮµ»öĶŠāķ插╝īÕÉÄµØźńö©õ║åoracle web cache’╝īõ╣¤ń╗ÅÕĖĖµīéµÄē’╝īoracle web cacheõ╣¤µö»µīüESI’╝īÕżÜķÜåńö▒µŁżÕÅæńÄ░õ║åESIĶ┐ÖõĖ¬ÕźĮõĖ£õĖ£ŃĆéESIµś»õĖĆń¦ŹµĢ░µŹ«ń╝ōÕå▓/ń╝ōÕŁśµ£ŹÕŖĪÕÖ©’╝īÕ«āµÅÉõŠøÕ░åWebńĮæķĪĄńÜäķā©Õłå’╝łĶ┐ÖķćīµīćķĪĄķØóńÜäńē浫Ą’╝ēĶ┐øĶĪīń╝ōÕå▓ /ń╝ōÕŁśńÜäµŖƵ£»ÕÅŖµ£ŹÕŖĪŃĆéńö▒OracleÕģ¼ÕÅĖÕÆīAkamai TechnologiesÕģ¼ÕÅĖÕłČÕ«ÜĶ¦äµĀ╝’╝īAkamaiÕģ¼ÕÅĖµÅÉõŠøÕ»╣Õ║öńÜäõ┐Īµü»õ╝ĀķĆüńÜäµ£ŹÕŖĪŃĆéõ╗źÕŠĆńÜäµĢ░µŹ«ń╝ōÕå▓µ£ŹÕŖĪÕÖ©ÕÆīõ┐Īµü»õ╝ĀķĆüµ£ŹÕŖĪõ╗źŌĆ£ķĪĄŌĆØõĖ║ÕŹĢõĮŹÕłČõĮ£’╝īÕżŹÕłČÕł░µĢ░µŹ« ń╝ōÕå▓µ£ŹÕŖĪÕÖ©õĖŁ’╝īÕżäńÉåķØÖµĆüķĪĄķØóÕŠłµ£ēµĢłŃĆéõĮåÕ£©ķØóÕ»╣ÕŖ©µĆüÕåģÕ«╣ńÜ䵌ČÕĆÖ’╝īÕ░▒ÕŠłķÜŠÕŠŚÕł░ķ½śµĢłńÄćŃĆéÕ£©ESIõĖŁµś»ķā©ÕłåńÜäń╝ōÕå▓ńĮæķĪĄ’╝īõĮ┐ńö©Õ¤║õ║ÄXMLńÜäµĀćĶ«░Ķ»ŁĶ©Ć’╝īµīćիܵā│Ķ”üń╝ōÕå▓ńÜä ķĪĄķØóķā©ÕłåŃĆéńö▒µŁż’╝īķĪĄķØóÕåģÕłåõĖ║ÕŖ©µĆüÕ£░ÕÅśµø┤ńÜäķā©ÕłåÕÆīķØÖµĆüńÜäõĖŹÕÅśµø┤ńÜäķā©Õłå’╝īÕŬÕ░åķØÖµĆüńÜäķā©Õłåµ£ēµĢłÕ£░ÕÅæķĆüÕł░µ£ŹÕŖĪÕÖ©õĖŁŃĆéµĘśÕ«ØńĮæńÜäµĢ░µŹ«ĶÖĮńäČÕż¦ķā©ÕłåķāĮµś»ÕŖ©µĆüõ║¦ńö¤ńÜä’╝īõĮåķĪĄķØó õĖŁńÜäķØÖµĆüńē浫Ąõ╣¤µ£ēÕŠłÕżÜ’╝īõŠŗÕ”éķĪĄķØóńÜäÕż┤ŃĆüÕ░Š’╝īÕĢåÕōüĶ»”µāģķĪĄķØóńÜäÕŹ¢Õ«Čõ┐Īµü»ńŁē’╝łÕ”éõĖŗÕøŠÕÅ│õŠ¦’╝ē’╝īĶ┐Öõ║øµ£ĆµŚ®ķāĮµś»õ╗ÄESIń╝ōÕŁśõĖŁĶ»╗ÕÅ¢ńÜäŃĆé
┬Ā
┬Ā
┬Ā
ESIĶ¦ŻÕå│õ║åķĪĄķØóń½»ķØÖµĆüńē浫ĄńÜäń╝ōÕŁś’╝īĶü¬µśÄńÜäĶ»╗ĶĆģÕÅ»ĶāĮķ®¼õĖŖÕ░▒µā│Õł░õ║å’╝īÕ£©ÕÉÄń½»ńÜäķéŻõ║øµĢ░µŹ«ĶāĮõĖŹĶāĮõĮ┐ńö©ń╝ōÕŁś’╝¤µśŠńäČõ╣¤µś»ÕÅ»õ╗źńÜä’╝īĶĆīõĖöµś»Õ┐ģķĪ╗ńÜäŃĆéõŠŗÕ”éõĖĆõĖ¬Õż¦ÕŹ¢Õ«ČńÜäÕĢåÕōü ÕÆīÕ║Śķō║’╝īõĖĆÕż®ńÜ䵥ÅĶ¦łķćÅÕÅ»ĶāĮµś»ÕćĀńÖŠõĖć’╝īõĖĆõĖ¬Õ░ÅÕŹ¢Õ«ČńÜäÕÅ»ĶāĮÕŬµ£ēÕćĀõĖ¬’╝īķéŻĶ┐ÖõĖ¬Õż¦ÕŹ¢Õ«ČńÜäńö©µłĘõ┐Īµü»Ķ”üµś»µ»Åµ¼ĪķāĮÕÄ╗µĢ░µŹ«Õ║ōķćīķØóÕÅ¢’╝īµśŠńäČõĖŹÕłÆń«Ś’╝īĶ”üµś»µŖŖĶ┐ÖõĖ¬õ┐Īµü»µöŠÕ£©ÕåģÕŁśķćī ķØó’╝īµ»Åµ¼ĪķāĮõ╗ÄÕåģÕŁśķćīÕÅ¢’╝īµĆ¦ĶāĮĶ”üÕźĮÕŠłÕżÜŃĆéĶ┐Öń¦ŹÕ║öńö©Õ£║µÖ»’╝īÕ░▒µś»memcachedĶ┐Öń¦ŹKey-Valueń╝ōÕŁśńÜäńö©µŁ”õ╣ŗÕ£░ŃĆéÕŬÕÅ»µā£Õ£©µĘśÕ«ØµĆźķ£ĆĶ”ü memcachedńÜ䵌ČÕĆÖ’╝īÕ«āĶ┐śµ▓Īµ£ēÕ┤Łķ£▓Õż┤Ķ¦Æ’╝łÕ«ā2003.6Õć║ńÄ░ńÜä’╝īõĮåĶ┐æÕćĀÕ╣┤µēŹńü½ńłåĶĄĘµØź’╝īÕĮōµŚČµ▓ĪÕÅæńÄ░Õ«ā’╝ēŃĆ鵳æõ╗¼ńÜäµ×ȵ×äÕĖłÕżÜķÜåÕż¦ńź×ÕåŹõĖƵ¼ĪÕć║µēŗõ║å’╝īõ╗¢ÕåÖõ║åõĖĆ õĖ¬ń╝ōÕŁśń│╗ń╗¤’╝īÕŽTBstore’╝īĶ┐Öµś»õĖĆõĖ¬ÕłåÕĖāÕ╝ÅńÜäÕ¤║õ║ÄBerkeley DBńÜäcacheń│╗ń╗¤’╝īµÄ©Õć║õ╣ŗÕÉÄÕ£©AlibabaķøåÕøóÕåģķā©õĮ┐ńö©ķØ×ÕĖĖÕ╣┐µ│ø’╝īńē╣Õł½µś»Õ»╣õ║ÄµĘśÕ«Ø’╝ītbstoreõĖŖÕ║öńö©õ║åESI’╝łÕ░▒µś»õĖŖķØóĶ»┤Ķ┐ćńÜäķéŻõĖ¬ESI’╝ēŃĆü checkcode’╝łķ¬īĶ»üńĀü’╝ēŃĆüdescription’╝łÕēŹµ¢ćĶ»┤Ķ┐ćńÜäÕĢåÕōüĶ»”µāģ’╝ēŃĆüstory’╝łÕ┐āµāģµĢģõ║ŗ’╝īÕĢåÕōüõ┐Īµü»ķćīķØóńÜäõĖĆõĖ¬Õż¦ÕŁŚµ«Ą’╝īķĢ┐Õ║”õ╗ģµ¼Īõ║ÄÕĢåÕōüĶ»” µāģ’╝ēŃĆüńö©µłĘõ┐Īµü»ńŁēńŁēÕåģÕ«╣ŃĆé
┬Ā
TBstoreńÜäÕłåÕĖāÕ╝Åń«Śµ│ĢÕ«×ńÄ░’╝ܵĀ╣µŹ«õ┐ØÕŁśńÜäkey’╝īÕ»╣keyĶ┐øĶĪīhashń«Śµ│Ģ’╝īÕÅ¢ÕŠŚhashÕĆ╝’╝īÕåŹÕ»╣hashÕĆ╝õĖĵĆ╗Cacheµ£ŹÕŖĪÕÖ©µĢ░µŹ«ÕÅ¢µ©ĪŃĆéńäČÕÉĵĀ╣µŹ«ÕÅ¢µ©ĪÕÉÄńÜäÕĆ╝’╝īµēŠÕł░µ£ŹÕŖĪÕÖ©ÕłŚĶĪ©õĖŁõĖŗµĀćõĖ║µŁżÕĆ╝Cacheµ£ŹÕŖĪÕÖ©ŃĆéńö▒java client apiÕ░üĶŻģÕ«×ńÄ░’╝īÕ║öńö©µŚĀķ£ĆÕģ│Õ┐ā’╝øĶ┐Öńé╣ÕÆīmemecachedńÜäÕ«×ńÄ░µ¢╣µĪłÕ«īÕģ©õĖĆĶć┤ŃĆé
┬Ā
TBstoreµ£ēõĖĆõĖ¬õ╝śńé╣’╝īĶ┐Öõ╣¤µś»Õ«āńÜäÕ╝▒ńé╣’╝īÕ«āńÜäÕŁśÕ驵ś»Õ¤║õ║ÄBerkeley DBńÜä’╝īĶĆīBerkeley DBÕ£©µĢ░µŹ«ķćÅĶČģĶ┐ćÕåģÕŁśńÜ䵌ČÕĆÖ’╝īÕ░▒Ķ”üÕŠĆńŻüńøśõĖŖÕåÖµĢ░µŹ«õ║å’╝īµēĆõ╗źĶ»┤Õ«āµś»ÕÅ»õ╗źÕüܵīüõ╣ģÕī¢ÕŁśÕé©ńÜäŃĆéõĮåµś»õĖƵŚ”ÕŠĆńŻüńøśÕåÖµĢ░µŹ«’╝īõĮ£õĖ║ń╝ōÕŁśńÜäµĆ¦ĶāĮÕ░▒Õż¦Õ╣ģÕ║”õĖŗķÖŹŃĆé
┬Ā
Ķ┐ÖµŚČÕÅłµ£ēõĖĆõĖ¬ķĪ╣ńø«’╝īµÄ©ÕŖ©õ║åµĘśÕ«ØÕ£©ń╝ōÕŁśµ¢╣ķØóńÜäµŖƵ£»µÅÉÕŹćŃĆéÕ£©2007Õ╣┤’╝īµłæõ╗¼µŖŖµĘśÕ«ØńÜäńö©µłĘõ┐Īµü»ńŗ¼ń½ŗÕć║µØź’╝īÕĮóµłÉõĖĆõĖ¬õĖŁÕ┐āń│╗ń╗¤UIC’╝łuser information center’╝ē’╝īÕøĀõĖ║µĘśÕ«ØµēƵ£ēńÜäÕŖ¤ĶāĮķāĮĶ”üõŠØĶĄ¢õ║Äńö©µłĘõ┐Īµü»’╝īµēĆõ╗źĶ┐ÖõĖ¬µ©ĪÕØŚÕ┐ģķĪ╗ÕŹĢńŗ¼µŗ┐Õć║µØź’╝īõĖŹńäČõ╗źÕÉÄń│╗ń╗¤µŚĀµ│Ģµē®Õ▒Ģõ║åŃĆéµŖŖUICµŗ┐Õć║µØźõ╗źÕÉÄ’╝īÕ║öńö©ń│╗ń╗¤Ķ«┐ķŚ« UIC’╝īUICĶ«┐ķŚ«µĢ░µŹ«Õ║ōÕÅ¢ÕŠŚńö©µłĘõ┐Īµü»’╝īń▓Śń▓Śń«ŚõĖĆõĖŗ’╝īµ»ÅÕż®Ķ”üÕÅ¢ÕćĀÕŹüõ║┐ńÜäńö©µłĘõ┐Īµü»’╝īńø┤µÄźµ¤źĶ»óµĢ░µŹ«Õ║ōńÜäĶ»Ø’╝īµśŠńäȵĢ░µŹ«Õ║ōĶ”üÕ┤®µ║āńÜä’╝īĶ┐ÖķćīÕ┐ģķĪ╗Ķ”üńö©ń╝ōÕŁśŃĆéõ║ĵś»ÕżÜķÜåõĖ║ UICõĖōķŚ©ÕåÖõ║åõĖĆõĖ¬ń╝ōÕŁśń│╗ń╗¤’╝īÕÅ¢ÕÉŹÕŽÕüÜtdbmŃĆétdbmµŖøÕ╝āõ║åBerkeley DBńÜäµīüõ╣ģÕŖ¤ĶāĮ’╝īµĢ░µŹ«Õģ©ķā©ÕŁśµöŠÕ£©ÕåģÕŁśõĖŁŃĆéÕł░2009Õ╣┤’╝īÕżÜķÜåÕÅłÕÅéĶĆāõ║åmemcachedńÜäÕåģÕŁśń╗ōµ×ä’╝īµö╣Ķ┐øõ║åtdbmńÜäķøåńŠżÕłåÕĖāµ¢╣Õ╝Å’╝īÕ£©ÕåģÕŁśÕł®ńö©ńÄćÕÆīÕÉ×ÕÉÉķćÅ µ¢╣ķØóÕÅłÕüÜõ║åÕż¦Õ╣ģµÅÉÕŹć’╝īµÄ©Õć║õ║åtdbm2.0ń│╗ń╗¤ŃĆé
┬Ā
ńö▒õ║ÄtdbmÕÆīTBstoreńÜäµĢ░µŹ«µÄźÕÅŻÕÆīńö©ķĆöķāĮÕŠłńøĖõ╝╝’╝īÕ╝ĆÕÅæÕøóķś¤µŖŖõ║īĶĆģÕÉłÕ╣Č’╝īµÄ©Õć║õ║åµĘśÕ«ØĶć¬ÕłøńÜäKVń╝ōÕŁśń│╗ń╗¤ŌĆöŌĆötairŃĆétairÕīģµŗ¼ń╝ōÕŁśÕÆīµīüõ╣ģÕī¢õĖżń¦ŹÕŁśÕé©ÕŖ¤ĶāĮŃĆétair õĮ£õĖ║õĖĆõĖ¬ÕłåÕĖāÕ╝Åń│╗ń╗¤’╝īµś»ńö▒õĖĆõĖ¬õĖŁÕ┐āµÄ¦ÕłČĶŖéńé╣ÕÆīõĖĆń│╗ÕłŚńÜäµ£ŹÕŖĪĶŖéńé╣ń╗䵳ÉŃĆ鵳æõ╗¼ń¦░õĖŁÕ┐āµÄ¦ÕłČĶŖéńé╣õĖ║config server’╝īµ£ŹÕŖĪĶŖéńé╣µś»data serverŃĆéconfig server Ķ┤¤Ķ┤Żń«ĪńÉåµēƵ£ēńÜädata server’╝īń╗┤µŖżdata serverńÜäńŖȵĆüõ┐Īµü»ŃĆédata server Õ»╣Õż¢µÅÉõŠøÕÉäń¦ŹµĢ░µŹ«µ£ŹÕŖĪ’╝īÕ╣Čõ╗źÕ┐āĶĘ│ńÜäÕĮóÕ╝ÅÕ░åĶć¬Ķ║½ńŖČÕåĄµ▒ćµŖźń╗Öconfig serverŃĆé config serverµś»µÄ¦ÕłČńé╣’╝īĶĆīõĖöµś»ÕŹĢńé╣’╝īńø«ÕēŹķććńö©õĖĆõĖ╗õĖĆÕżćńÜäÕĮóÕ╝ÅµØźõ┐ØĶ»üÕģČÕÅ»ķØĀµĆ¦ŃĆéµēƵ£ēńÜä data server Õ£░õĮŹķāĮµś»ńŁēõ╗ĘńÜäŃĆétairńÜäµ×ȵ×äÕøŠÕ”éõĖŗµēĆńż║’╝Ü
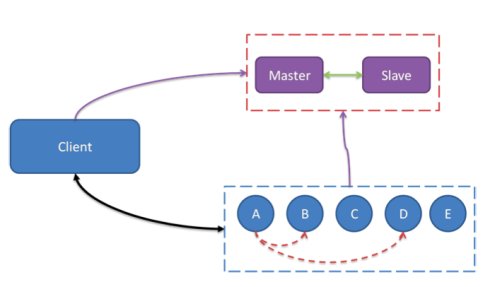
ķā©ńĮ▓ń╗ōµ×äÕøŠµś»Ķ┐ÖõĖ¬µĀĘÕŁÉńÜä’╝Ü
┬Ā
┬Ā
ńø«ÕēŹ’╝ītairµö»µÆæõ║åµĘśÕ«ØÕćĀõ╣ĵēƵ£ēń│╗ń╗¤ńÜäń╝ōÕŁśõ┐Īµü»ŃĆéTairÕĘ▓Õ╝Ƶ║É’╝īÕ£░ÕØĆcode.taobao.orgŃĆé
┬Ā
Õ£©ÕłøķĆĀõ║åTFSÕÆītairõ╣ŗÕÉÄ’╝īµĢ┤õĖ¬ń│╗ń╗¤ńÜäµ×ȵ×äÕÅ»õ╗źÕ”éõĖŗµēĆńż║’╝Ü
┬Ā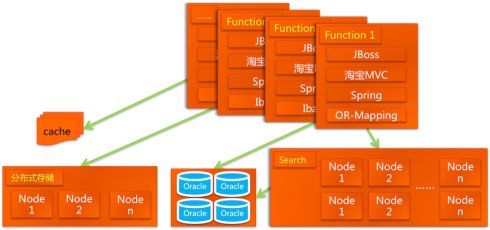
┬Ā
Õ£©Ķ┐ÖõĖ¬µŚČÕĆֵɣń┤óÕ╝ĢµōÄiSearchõ╣¤Ķ┐øĶĪīõ║åõĖƵ¼ĪÕŹćń║¦’╝īõ╣ŗÕēŹńÜäµÉ£ń┤óÕ╝Ģµōĵś»µŖŖµĢ░µŹ«ÕłåÕł░ÕżÜÕÅ░µ£║ÕÖ©õĖŖ’╝īõĮåµś»µ»Åõ╗ĮµĢ░µŹ«ÕŬµ£ēõĖĆõ╗Į’╝īńÄ░Õ£©µś»µ»Åõ╗ĮµĢ░µŹ«ÕÅśµłÉÕżÜõ╗Į’╝īµĢ┤õĖ¬ń│╗ń╗¤õ╗ÄõĖĆõĖ¬ÕŹĢĶĪīńÜäķā©ńĮ▓ÕÅśµłÉõ║åń¤®ķśĄŃĆéĶāĮÕż¤µö»µÆæµø┤Õż¦ńÜäĶ«┐ķŚ«ķćÅ’╝īÕ╣ČõĖöÕüÜÕł░ÕŠłķ½śńÜäÕÅ»ńö©µĆ¦ŃĆé
õĖŗõĖĆń»ć’╝ÜµĘśÕ«ØµŖƵ£»ÕÅæÕ▒Ģ’╝łÕłåÕĖāÕ╝ŵŚČõ╗Ż’╝ܵ£ŹÕŖĪÕī¢’╝ē





ńøĖÕģ│µÄ©ĶŹÉ
ķÜÅńØĆõĖÜÕŖĪńÜäÕó×ķĢ┐’╝īµĘśÕ«ØķĆɵĖÉĶ┐øÕģźõ║åJavaµŚČõ╗Ż’╝īÕ«īµłÉõ║åµŖƵ£»õĖŖńÜäĶä▒ĶāĵŹóķ¬©’╝īÕĮóµłÉõ║åÕØÜĶŗźńŻÉń¤│ńÜäń│╗ń╗¤ŃĆéÕ£©µŁżµ£¤ķŚ┤’╝īÕłøķĆĀµĆ¦ńÜäµŖƵ£»Õ”éTFSÕÆīTairÕŁśÕé©ń│╗ń╗¤Ķó½Õ╝ĆÕÅæÕć║µØź’╝īõ╗źµ╗ĪĶČ│µŚźńøŖÕó×ķĢ┐ńÜäÕŁśÕé©ÕÆīĶ«Īń«Śķ£Ćµ▒éŃĆé Ķ┐øÕģźÕłåÕĖāÕ╝ŵŚČõ╗ŻÕÉÄ’╝īµĘśÕ«ØńÜä...
Õł░õ║åV2.2ķśČµ«Ą’╝īµĘśÕ«ØÕ╝ĆÕ¦ŗÕłøķĆĀĶć¬ÕĘ▒ńÜäµŖƵ£»’╝īÕ╣ȵ×äÕ╗║õ║åÕłåÕĖāÕ╝ÅÕŁśÕé©TFSÕÆīÕłåÕĖāÕ╝Åń╝ōÕŁśTair-a-1e’╝īõ╗źÕÅŖÕłåÕĖāÕ╝ŵɣń┤óÕ╝ĢµōÄŃĆéÕ£©µ×ȵ×äõĖŖ’╝īµĘśÕ«Øķććńö©õ║åń▒╗ńø«Õ▒׵ƦõĮōń│╗’╝īÕ╣ČõĖöÕ╝ĆÕ¦ŗõĮ┐ńö©CDNµŖƵ£»µØźÕłåµĢŻń│╗ń╗¤Ķ┤¤ĶĮĮŃĆé Õ£©ÕżäńÉåCDNńÜäµ×ȵ×äõĖŖ’╝īµĘśÕ«ØõĮ┐ńö©...
- **JavaµŚČõ╗Ż**’╝ÜķÜÅńØĆõĖÜÕŖĪµē®Õ╝Ā’╝īµĘśÕ«Øķććńö©õ║åJavaµŖƵ£»µ×äÕ╗║ÕżŹµØéńÜäµ£ŹÕŖĪõĮōń│╗’╝īµÅÉÕŹćń│╗ń╗¤ń©│Õ«ÜµĆ¦ŃĆé - **ÕłøķĆĀµŖƵ£»**’╝ÜµĘśÕ«ØõĖŹµ¢ŁĶć¬õĖ╗ńĀöÕÅæµŖƵ£»’╝īÕ”éTair’╝łÕłåÕĖāÕ╝Åķö«ÕĆ╝ÕŁśÕé©ń│╗ń╗¤’╝ēŃĆüTuoDB’╝łÕłåÕĖāÕ╝ŵĢ░µŹ«Õ║ō’╝ēńŁē’╝īõ╗źÕ║öÕ»╣µĄĘķćŵĢ░µŹ«µīæµłśŃĆé...
ÕĄīÕģźÕ╝ÅÕģ½ĶéĪµ¢ćķØóĶ»ĢķóśÕ║ōĶĄäµ¢Öń¤źĶ»åÕ«ØÕģĖ-ÕŹÄõĖ║ńÜäķØóĶ»ĢĶ»Ģķóś.zip
Ķ«Łń╗āÕ»╝µÄ¦ń│╗ń╗¤Ķ«ŠĶ«Ī.pdf
ÕĄīÕģźÕ╝ÅÕģ½ĶéĪµ¢ćķØóĶ»ĢķóśÕ║ōĶĄäµ¢Öń¤źĶ»åÕ«ØÕģĖ-ńĮæń╗£ń╝¢ń©ŗ.zip
õ║║ĶäĖĶĮ¼µŁŻGANµ©ĪÕ×ŗńÜäķ½śµĢłÕÄŗń╝®.pdf
Õ░æÕä┐ń╝¢ń©ŗscratchķĪ╣ńø«µ║Éõ╗ŻńĀüµ¢ćõ╗ȵĪłõŠŗń┤ĀµØÉ-ÕćĀõĮĢÕå▓Õł║ ĶĮ¼ń×¼ÕŹ│ķĆØ.zip
Õ░æÕä┐ń╝¢ń©ŗscratchķĪ╣ńø«µ║Éõ╗ŻńĀüµ¢ćõ╗ȵĪłõŠŗń┤ĀµØÉ-ķĖĪĶøŗ.zip
ÕĄīÕģźÕ╝Åń│╗ń╗¤_USBĶ«ŠÕżćµ×ÜõĖŠõĖÄHIDķĆÜõ┐Ī_CH559ÕŹĢńēćµ£║USBõĖ╗µ£║ķö«ńøśķ╝ĀµĀćÕżŹÕÉłĶ«ŠÕżćµÄ¦ÕłČ_Õ¤║õ║ÄCH559ÕŹĢńēćµ£║ńÜäUSBõĖ╗µ£║µ©ĪÕ╝ÅĶ«ŠÕżćµ×ÜõĖŠõĖÄķö«ńøśķ╝ĀµĀćµĢ░µŹ«µöČÕÅæń│╗ń╗¤µö»µīüÕżŹÕÉłĶ«ŠÕżćĶ»åÕł½õĖÄHID
ÕĄīÕģźÕ╝ÅÕģ½ĶéĪµ¢ćķØóĶ»ĢķóśÕ║ōĶĄäµ¢Öń¤źĶ»åÕ«ØÕģĖ-linuxÕĖĖĶ¦üķØóĶ»Ģķóś.zip
ķØóÕÉæµÖ║µģ¦ÕĘźÕ£░ńÜäÕÄŗÕŖøµ£║Õ£©ń║┐µĢ░µŹ«ńÜäķóäĶŁ”Õ║öńö©Õ╝ĆÕÅæ.pdf
Õ¤║õ║ÄUnity3DńÜäķ▒╝ń▒╗Ķ┐ÉÕŖ©ĶĪīõĖ║ÕÅ»Ķ¦åÕī¢ńĀöń®Č.pdf
Õ░æÕä┐ń╝¢ń©ŗscratchķĪ╣ńø«µ║Éõ╗ŻńĀüµ¢ćõ╗ȵĪłõŠŗń┤ĀµØÉ-ķ£ŹµĀ╝µ▓āĶī©ķŁöµ│ĢÕŁ”µĀĪ.zip
Õ░æÕä┐ń╝¢ń©ŗscratchķĪ╣ńø«µ║Éõ╗ŻńĀüµ¢ćõ╗ȵĪłõŠŗń┤ĀµØÉ-ķćæÕĖüÕå▓Õł║.zip
ÕåģÕ«╣µ”éĶ”ü’╝ܵ£¼µ¢ćµĘ▒ÕģźµÄóĶ«©õ║åHarmonyOSń╝¢Ķ»æµ×äÕ╗║ÕŁÉń│╗ń╗¤ńÜäõĮ£ńö©ÕÅŖÕģȵŖƵ£»ń╗åĶŖéŃĆéõĮ£õĖ║ķĖ┐ĶÆÖµōŹõĮ£ń│╗ń╗¤ĶāīÕÉÄńÜäÕģ│ķö«µŖƵ£»õ╣ŗõĖĆ’╝īń╝¢Ķ»æµ×äÕ╗║ÕŁÉń│╗ń╗¤ķĆÜĶ┐ćGNÕÆīNinjaÕĘźÕģĘÕ«×ńÄ░õ║åķ½śµĢłńÜäµ║Éõ╗ŻńĀüÕł░µ£║ÕÖ©õ╗ŻńĀüńÜäĶĮ¼µŹó’╝īńĪ«õ┐Øõ║åń│╗ń╗¤ńÜäń©│Õ«ÜµĆ¦ÕÆīµĆ¦ĶāĮõ╝śÕī¢ŃĆéĶ»źń│╗ń╗¤õĖŹõ╗ģµö»µīüÕżÜń│╗ń╗¤ńēłµ£¼µ×äÕ╗║ŃĆüĶŖ»ńēćÕÄéÕĢåÕ«ÜÕłČ’╝īĶ┐śÕģĘÕżćÕ╝║Õż¦ńÜäĶ░āĶ»ĢõĖÄń╗┤µŖżĶāĮÕŖøŃĆéÕģČķ½śµĢłń╝¢Ķ»æķƤÕ║”ŃĆüńüĄµ┤╗µĆ¦ÕÆīÕÅ»µē®Õ▒ĢµĆ¦õĮ┐ÕģČÕ£©ÕŹÄõĖ║Ķ«ŠÕżćÕÆīÕģČõ╗¢µÖ║ĶāĮń╗łń½»õĖŁÕÅæµīźõ║åķćŹĶ”üõĮ£ńö©ŃĆéµ¢ćń½ĀĶ┐śµ»öĶŠāõ║åHarmonyOSń╝¢Ķ»æµ×äÕ╗║ÕŁÉń│╗ń╗¤õĖÄÕ«ēÕŹōÕÆīiOSń╝¢Ķ»æń│╗ń╗¤ńÜäÕ╝éÕÉī’╝īÕ╣ČÕ▒Ģµ£øõ║åÕģȵ£¬µØźńÜäÕÅæÕ▒ĢĶČŗÕŖ┐ÕÆīµŖƵ£»µ╝öĶ┐øµ¢╣ÕÉæŃĆé; ķĆéÕÉłõ║║ńŠż’╝ÜÕ»╣µōŹõĮ£ń│╗ń╗¤Õ║ĢÕ▒éµŖƵ£»µä¤Õģ┤ĶČŻńÜäÕ╝ĆÕÅæĶĆģŃĆüÕĘźń©ŗÕĖłÕÆīµŖƵ£»ńł▒ÕźĮĶĆģŃĆé; õĮ┐ńö©Õ£║µÖ»ÕÅŖńø«µĀć’╝ÜŌæĀõ║åĶ¦ŻHarmonyOSń╝¢Ķ»æµ×äÕ╗║ÕŁÉń│╗ń╗¤ńÜäÕ¤║µ£¼µ”éÕ┐ĄÕÆīÕĘźõĮ£ÕĤńÉå’╝øŌæĪµÄīµÅĪÕģČÕ£©õĖŹÕÉīĶ«ŠÕżćõĖŖńÜäÕ║öńö©ÕÆīõ╝śÕī¢ńŁ¢ńĢź’╝øŌæóÕ»╣µ»öHarmonyOSõĖÄÕ«ēÕŹōŃĆüiOSń╝¢Ķ»æń│╗ń╗¤ńÜäÕĘ«Õ╝é’╝øŌæŻµÄóń┤óÕģȵ£¬µØźÕÅæÕ▒Ģµ¢╣ÕÉæÕÆīµŖƵ£»µ╝öĶ┐øĶĘ»ÕŠäŃĆé; ÕģČõ╗¢Ķ»┤µśÄ’╝ܵ£¼µ¢ćĶ»”ń╗åõ╗ŗń╗Źõ║åHarmonyOSń╝¢Ķ»æµ×äÕ╗║ÕŁÉń│╗ń╗¤ńÜäµ×ȵ×äĶ«ŠĶ«ĪŃĆüµĀĖÕ┐āÕŖ¤ĶāĮÕÆīÕ«×ķÖģÕ║öńö©µĪłõŠŗ’╝īÕ╝║Ķ░āõ║åÕģČÕ£©õĖćńē®õ║ÆĶüöµŚČõ╗ŻńÜäķćŹĶ”üµĆ¦ÕÆīµĮ£ÕŖøŃĆéķśģĶ»╗µŚČÕ╗║Ķ««ķćŹńé╣Õģ│µ│©ń╝¢Ķ»æµ×äÕ╗║ÕŁÉń│╗ń╗¤ńÜäńŗ¼ńē╣õ╝śÕŖ┐ÕÅŖÕģČÕ»╣ķĖ┐ĶÆÖńö¤µĆüń│╗ń╗¤ńÜäµĘ▒Ķ┐£ÕĮ▒ÕōŹŃĆé
ÕĄīÕģźÕ╝ÅÕģ½ĶéĪµ¢ćķØóĶ»ĢķóśÕ║ōĶĄäµ¢Öń¤źĶ»åÕ«ØÕģĖ-ÕźćĶÖÄ360 2015µĀĪÕøŁµŗøĶüśC++ńĀöÕÅæÕĘźń©ŗÕĖłń¼öĶ»Ģķóś.zip
ÕĄīÕģźÕ╝ÅÕģ½ĶéĪµ¢ćķØóĶ»ĢķóśÕ║ōĶĄäµ¢Öń¤źĶ»åÕ«ØÕģĖ-ĶģŠĶ«»2014µĀĪÕøŁµŗøĶüśCĶ»ŁĶ©Ćń¼öĶ»Ģķóś’╝łķÖäńŁöµĪł’╝ē.zip
ÕÅīń¦ŹńŠżÕÅśÕ╝éńŁ¢ńĢźµö╣Ķ┐øRWCEń«Śµ│Ģõ╝śÕī¢µŹóńāŁńĮæń╗£.pdf
ÕåģÕ«╣µ”éĶ”ü’╝ܵ£¼µ¢ćĶ»”ń╗åõ╗ŗń╗Źõ║åÕ¤║õ║Äń×¼µŚČµŚĀÕŖ¤ÕŖ¤ńÄćńÉåĶ«║ńÜäõĖēńöĄÕ╣│µ£ēµ║ÉńöĄÕŖøµ╗żµ│óÕÖ©’╝łAPF’╝ēõ╗┐ń£¤ńĀöń®ČŃĆéõĖ╗Ķ”üÕåģÕ«╣µČĄńø¢Õ╣ČĶüöÕ×ŗAPFńÜäÕĘźõĮ£ÕĤńÉåŃĆüõĖēńøĖõĖēńöĄÕ╣│NPCń╗ōµ×äŃĆüĶ░ɵ│óµŻĆµĄŗµ¢╣µ│Ģ’╝łipiq’╝ēŃĆüÕÅīķŚŁńÄ»µÄ¦ÕłČńŁ¢ńĢź’╝łńöĄÕÄŗÕż¢ńÄ»+ńöĄµĄüÕåģńÄ»PIµÄ¦ÕłČ’╝ēõ╗źÕÅŖSVPWMń¤óķćÅĶ░āÕłČµŖƵ£»ŃĆéõ╗┐ń£¤ń╗ōµ×£µśŠńż║’╝īÕ£©APFµŖĢÕģźÕēŹÕÉÄ’╝īńöĄńĮæńöĄµĄüTHDõ╗Ä21.9%ķÖŹĶć│3.77%’╝īµśŠĶæŚµÅÉķ½śõ║åńöĄĶāĮĶ┤©ķćÅŃĆé ķĆéńö©õ║║ńŠż’╝Üõ╗Äõ║ŗńöĄÕŖøń│╗ń╗¤ńĀöń®ČŃĆüńöĄÕŖøńöĄÕŁÉµŖƵ£»Õ╝ĆÕÅæńÜäõĖōõĖÜõ║║ÕŻ½’╝īÕ░żÕģȵś»Õ»╣µ£ēµ║ÉńöĄÕŖøµ╗żµ│óÕÖ©ÕÅŖÕģČõ╗┐ń£¤µä¤Õģ┤ĶČŻńÜäÕĘźń©ŗÕĖłÕÆīµŖƵ£»õ║║ÕæśŃĆé õĮ┐ńö©Õ£║µÖ»ÕÅŖńø«µĀć’╝ÜķĆéńö©õ║Äķ£ĆĶ”üĶ¦ŻÕå│ńöĄÕŖøń│╗ń╗¤õĖŁĶ░ɵ│óµ▒Īµ¤ōÕÆīµŚĀÕŖ¤ĶĪźÕü┐ķŚ«ķóśńÜäńĀöń®ČķĪ╣ńø«ŃĆéńø«µĀ浜»ķĆÜĶ┐ćõ╗┐ń£¤ķ¬īĶ»üAPFńÜäµ£ēµĢłµĆ¦ÕÆīÕÅ»ĶĪīµĆ¦’╝īõ╝śÕī¢ńöĄÕŖøń│╗ń╗¤ńÜäńöĄĶāĮĶ┤©ķćÅŃĆé ÕģČõ╗¢Ķ»┤µśÄ’╝ܵ¢ćõĖŁµÅÉÕł░ńÜäõ╗┐ń£¤µ©ĪÕ×ŗµČēÕÅŖÕżÜõĖ¬Õģ│ķö«µ©ĪÕØŚ’╝īÕ”éõĖēńøĖõ║żµĄüńöĄÕÄŗµ©ĪÕØŚŃĆüķØ×ń║┐µĆ¦Ķ┤¤ĶĮĮŃĆüõ┐ĪÕÅĘķććķø嵩ĪÕØŚŃĆüLCµ╗żµ│óÕÖ©µ©ĪÕØŚńŁē’╝īĶ┐Öõ║øµ©ĪÕØŚńÜäĶ«ŠĶ«ĪÕÆīÕŹÅÕÉīÕĘźõĮ£Õ»╣õ║ÄÕ«×ńÄ░Ķē»ÕźĮńÜäĶ░ɵ│óµŖæÕłČÕÆīµŚĀÕŖ¤ĶĪźÕü┐Ķć│Õģ│ķćŹĶ”üŃĆé