- µĄÅĶ¦ł: 17262 µ¼Ī
- µĆ¦Õł½:

- µØźĶć¬: ÕīŚõ║¼
-

µ¢ćń½ĀÕłåń▒╗
ńżŠÕī║ńēłÕØŚ
- µłæńÜäĶĄäĶ«» ( 0)
- µłæńÜäĶ«║ÕØø ( 23)
- µłæńÜäķŚ«ńŁö ( 0)
ÕŁśµĪŻÕłåń▒╗
- 2013-04 ( 4)
- 2013-03 ( 3)
- 2013-01 ( 5)
- µø┤ÕżÜÕŁśµĪŻ...
µ£Ćµ¢░Ķ»äĶ«║
┬Ā
┬Ā ┬Ā µĢÖõĮĀÕ”éõĮĢĶ┐ģķƤń¦ÆµØƵÄē’╝Ü99%ńÜ䵥ĘķćŵĢ░µŹ«ÕżäńÉåķØóĶ»Ģķóś
õĮ£ĶĆģ’╝ÜJuly
Õć║Õżä’╝Üń╗ōµ×äõ╣ŗµ│Ģń«Śµ│Ģõ╣ŗķüōblog
┬Ā
ÕēŹĶ©Ć
┬Ā┬Ā õĖĆĶł¼ĶĆīĶ©Ć’╝īµĀćķóśÕɽµ£ēŌĆ£ń¦ÆµØĆŌĆØ’╝īŌĆ£99%ŌĆØ’╝īŌĆ£ÕÅ▓õĖŖµ£ĆÕģ©/µ£ĆÕ╝║ŌĆØńŁēĶ»Źµ▒ćńÜäÕŠĆÕŠĆķāĮĶä▒õĖŹõ║åÕōŚõ╝ŚÕÅ¢Õ«Āõ╣ŗÕ½ī’╝īõĮåĶ┐øõĖƵŁźµØźĶ«▓’╝īÕ”éµ×£Ķ»╗ĶĆģĶ»╗ńĮ󵣿µ¢ć’╝īÕŹ┤µŚĀõ╗╗õĮĢµöČĶÄĘ’╝īķéŻõ╣ł’╝īµłæõ╣¤ńöśµä┐ĶāīĶ┤¤Ķ┐ÖµĀĘńÜäńĮ¬ÕÉŹ’╝ī:-)’╝īÕÉīµŚČ’╝īµŁżµ¢ćÕÅ»õ╗źń£ŗÕüܵś»Õ»╣Ķ┐Öń»ćµ¢ćń½Ā’╝ÜÕŹüķüōµĄĘķćŵĢ░µŹ«ÕżäńÉåķØóĶ»ĢķóśõĖÄÕŹüõĖ¬µ¢╣µ│ĢÕż¦µĆ╗ń╗ōńÜäõĖĆĶł¼µŖĮĶ▒ĪµĆ¦µĆ╗ń╗ōŃĆé
┬Ā ┬Ā µ»Ģń½¤ÕÅŚµ¢ćń½ĀÕÆīńÉåĶ«║õ╣ŗķÖÉ’╝īµ£¼µ¢ćÕ░åµæÆÕ╝āń╗ØÕż¦ķā©ÕłåńÜäń╗åĶŖé’╝īÕŬĶ░łµ¢╣µ│Ģ/µ©ĪÕ╝ÅĶ«║’╝īõĖöµ│©ķćŹńö©µ£ĆķĆÜõ┐Śµ£Ćńø┤ńÖĮńÜäĶ»ŁĶ©ĆķśÉĶ┐░ńøĖÕģ│ķŚ«ķóśŃĆéµ£ĆÕÉÄ’╝īµ£ēõĖĆńé╣Õ┐ģķĪ╗Õ╝║Ķ░āńÜ䵜»’╝īÕģ©µ¢ćĶĪīµ¢ćµś»Õ¤║ õ║ÄķØóĶ»ĢķóśńÜäÕłåµ×ÉÕ¤║ńĪĆõ╣ŗõĖŖńÜä’╝īÕģĘõĮōÕ«×ĶĘĄĶ┐ćń©ŗõĖŁ’╝īĶ┐śµś»ÕŠŚÕģĘõĮōµāģÕåĄÕģĘõĮōÕłåµ×É’╝īõĖöÕ£║µÖ»õ╣¤Ķ┐£µ»öµ£¼µ¢ćµēĆĶ┐░ńÜäõ╗╗õĮĢõĖĆń¦ŹµāģÕåĄÕżŹµØéÕŠŚÕżÜŃĆé
┬Ā ┬Ā OK’╝īĶŗźµ£ēõ╗╗õĮĢķŚ«ķóś’╝īµ¼óĶ┐ÄķÜŵŚČõĖŹÕÉØĶĄÉµĢÖŃĆéĶ░óĶ░óŃĆé
õĮĢĶ░ōµĄĘķćŵĢ░µŹ«ÕżäńÉå’╝¤
┬Ā┬Ā µēĆĶ░ōµĄĘķćŵĢ░µŹ«ÕżäńÉå’╝īµŚĀķØ×Õ░▒µś»Õ¤║õ║ĵĄĘķćŵĢ░µŹ«õĖŖńÜäÕŁśÕé©ŃĆüÕżäńÉåŃĆüµōŹõĮ£ŃĆéõĮĢĶ░ōµĄĘķćÅ’╝īÕ░▒µś»µĢ░µŹ«ķćÅÕż¬Õż¦’╝īµēĆõ╗źÕ»╝Ķć┤Ķ”üõ╣łµś»µŚĀµ│ĢÕ£©ĶŠāń¤ŁµŚČķŚ┤ÕåģĶ┐ģķƤĶ¦ŻÕå│’╝īĶ”üõ╣łµś»µĢ░µŹ«Õż¬Õż¦’╝īÕ»╝Ķć┤µŚĀµ│ĢõĖƵ¼ĪµĆ¦ĶŻģÕģźÕåģÕŁśŃĆé
┬Ā┬Ā┬Ā ķéŻĶ¦ŻÕå│ÕŖ×µ│ĢÕæó?ķÆłÕ»╣µŚČķŚ┤’╝īµłæõ╗¼ÕÅ»õ╗źķććńö©ÕĘ¦Õ”ÖńÜäń«Śµ│ĢµÉŁķģŹÕÉłķĆéńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕ”éBloom filter/Hash/bit-map/ÕĀå/µĢ░µŹ«Õ║ōµł¢ÕĆƵÄÆń┤óÕ╝Ģ/trieµĀæ’╝īķÆłÕ»╣ń®║ķŚ┤’╝īµŚĀķØ×Õ░▒õĖĆõĖ¬ÕŖ×µ│Ģ’╝ÜÕż¦ĶĆīÕī¢Õ░Å’╝ÜÕłåĶĆīµ▓╗õ╣ŗ/hashµśĀÕ░ä’╝īõĮĀõĖŹµś»Ķ»┤Ķ¦äµ©ĪÕż¬Õż¦Õśø’╝īķéŻń«ĆÕŹĢÕĢŖ’╝īÕ░▒µŖŖĶ¦äµ©ĪÕż¦Õī¢õĖ║Ķ¦äµ©ĪÕ░ÅńÜä’╝īÕÉäõĖ¬Õć╗ńĀ┤õĖŹÕ░▒Õ«īõ║åÕśøŃĆé
┬Ā┬Ā┬Ā Ķć│õ║ĵēĆĶ░ōńÜäÕŹĢµ£║ÕÅŖķøåńŠżķŚ«ķóś’╝īķĆÜõ┐Śńé╣µØźĶ«▓’╝īÕŹĢµ£║Õ░▒µś»ÕżäńÉåĶŻģĶĮĮµĢ░µŹ«ńÜäµ£║ÕÖ©µ£ēķÖÉ(ÕŬĶ”üĶĆāĶÖæcpu’╝īÕåģÕŁś’╝īńĪ¼ńøśńÜäµĢ░µŹ«õ║żõ║Æ)’╝īĶĆīķøåńŠż’╝īµ£║ÕÖ©µ£ēÕżÜĶŠå’╝īķĆéÕÉłÕłåÕĖāÕ╝ÅÕżäńÉå’╝īÕ╣ČĶĪīĶ«Īń«Ś(µø┤ÕżÜĶĆāĶÖæĶŖéńé╣ÕÆīĶŖéńé╣ķŚ┤ńÜäµĢ░µŹ«õ║żõ║Æ)ŃĆé
┬Ā┬Ā┬Ā ÕåŹĶĆģ’╝īķĆÜĶ┐ćµ£¼blogÕåģńÜäµ£ēÕģ│µĄĘķćŵĢ░µŹ«ÕżäńÉåńÜäµ¢ćń½Ā’╝ÜBig Data Processing’╝īµłæõ╗¼ÕĘ▓ń╗ÅÕż¦Ķć┤ń¤źķüō’╝īÕżäńÉåµĄĘķćŵĢ░µŹ«ķŚ«ķóś’╝īµŚĀķØ×Õ░▒µś»’╝Ü
- ÕłåĶĆīµ▓╗õ╣ŗ/hashµśĀÕ░ä + hashń╗¤Ķ«Ī + ÕĀå/Õ┐½ķƤ/ÕĮÆÕ╣ȵÄÆÕ║Å’╝ø
- ÕÅīÕ▒éµĪČÕłÆÕłå
- Bloom filter/Bitmap’╝ø
- TrieµĀæ/µĢ░µŹ«Õ║ō/ÕĆƵÄÆń┤óÕ╝Ģ’╝ø
- Õż¢µÄÆÕ║Å’╝ø
- ÕłåÕĖāÕ╝ÅÕżäńÉåõ╣ŗHadoop/MapreduceŃĆé
┬Ā ┬Ā õĖŗķØó’╝īµ£¼µ¢ćń¼¼õĖĆķā©ÕłåŃĆüõ╗Äset/mapĶ░łÕł░hashtable/hash_map/hash_set’╝īń«ĆĶ”üõ╗ŗń╗ŹõĖŗset/map/multiset/multimap’╝īÕÅŖhash_set/hash_map/hash_multiset/hash_multimapõ╣ŗÕī║Õł½(õĖćõĖłķ½śµź╝Õ╣│Õ£░ĶĄĘ’╝īÕ¤║ńĪƵ£ĆķćŹĶ”ü)’╝īĶĆīµ£¼µ¢ćń¼¼õ║īķā©Õłå’╝īÕłÖķÆłÕ»╣õĖŖĶ┐░ķéŻ6ń¦Źµ¢╣µ│Ģµ©ĪÕ╝Åń╗ōÕÉłÕ»╣Õ║öńÜ䵥ĘķćŵĢ░µŹ«ÕżäńÉåķØóĶ»ĢķóśÕłåÕł½ÕģĘõĮōķśÉĶ┐░ŃĆé
ń¼¼õĖĆķā©ÕłåŃĆüõ╗Äset/mapĶ░łÕł░hashtable/hash_map/hash_set
┬Ā ┬Ā ń©ŹÕÉĵ£¼µ¢ćń¼¼õ║īķā©ÕłåõĖŁÕ░åÕżÜµ¼ĪµÅÉÕł░hash_map/hash_set’╝īõĖŗķØóń©Źń©Źõ╗ŗń╗ŹõĖŗĶ┐Öõ║øÕ«╣ÕÖ©’╝īõ╗źõĮ£õĖ║Õ¤║ńĪĆÕćåÕżćŃĆéõĖĆĶł¼µØźĶ»┤’╝īSTLÕ«╣ÕÖ©ÕłåõĖżń¦Ź’╝ī
- Õ║ÅÕłŚÕ╝ÅÕ«╣ÕÖ©(vector/list/deque/stack/queue/heap)’╝ī
- Õģ│ ĶüöÕ╝ÅÕ«╣ÕÖ©ŃĆéÕģ│ĶüöÕ╝ÅÕ«╣ÕÖ©ÕÅłÕłåõĖ║set(ķøåÕÉł)ÕÆīmap(µśĀÕ░äĶĪ©)õĖżÕż¦ń▒╗’╝īõ╗źÕÅŖĶ┐ÖõĖżÕż¦ń▒╗ńÜäĶĪŹńö¤õĮōmultiset(ÕżÜķö«ķøåÕÉł)ÕÆīmultimap(ÕżÜķö«µśĀÕ░ä ĶĪ©)’╝īĶ┐Öõ║øÕ«╣ÕÖ©ÕØćõ╗źRB-treeÕ«īµłÉŃĆ鵣żÕż¢’╝īĶ┐śµ£ēń¼¼3ń▒╗Õģ│ĶüöÕ╝ÅÕ«╣ÕÖ©’╝īÕ”éhashtable(µĢŻÕłŚĶĪ©)’╝īõ╗źÕÅŖõ╗źhashtableõĖ║Õ║ĢÕ▒éµ£║ÕłČÕ«īµłÉńÜä hash_set(µĢŻÕłŚķøåÕÉł)/hash_map(µĢŻÕłŚµśĀÕ░äĶĪ©)/hash_multiset(µĢŻÕłŚÕżÜķö«ķøåÕÉł)/hash_multimap(µĢŻÕłŚÕżÜķö«µśĀ Õ░äĶĪ©)ŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝īset/map/multiset/multimapķāĮÕåģÕɽõĖĆõĖ¬RB-tree’╝īĶĆīhash_set/hash_map/hash_multiset/hash_multimapķāĮÕåģÕɽõĖĆõĖ¬hashtableŃĆé
┬Ā ┬Ā µēĆĶ░ōÕģ│ĶüöÕ╝ÅÕ«╣ÕÖ©’╝īń▒╗õ╝╝Õģ│ĶüöÕ╝ŵĢ░µŹ«Õ║ō’╝īµ»Åń¼öµĢ░µŹ«µł¢µ»ÅõĖ¬Õģāń┤ĀķāĮµ£ēõĖĆõĖ¬ķö«ÕĆ╝(key)ÕÆīõĖĆõĖ¬Õ«×ÕĆ╝(value)’╝īÕŹ│µēĆĶ░ōńÜäKey-Value(ķö«-ÕĆ╝Õ»╣)ŃĆéÕĮōÕģā ń┤ĀĶó½µÅÆÕģźÕł░Õģ│ĶüöÕ╝ÅÕ«╣ÕÖ©õĖŁµŚČ’╝īÕ«╣ÕÖ©Õåģķā©ń╗ōµ×ä(RB-tree/hashtable)õŠ┐õŠØńģ¦ÕģČķö«ÕĆ╝Õż¦Õ░Å’╝īõ╗źµ¤Éń¦Źńē╣Õ«ÜĶ¦äÕłÖÕ░åĶ┐ÖõĖ¬Õģāń┤ĀµöŠńĮ«õ║ÄķĆéÕĮōõĮŹńĮ«ŃĆé
┬Ā
┬Ā
┬Āµ»öÕ”é’╝īÕ£©MongoDBõĖŁ’╝īµ¢ćµĪŻ(document)µś»µ£ĆÕ¤║µ£¼ńÜäµĢ░µŹ«ń╗äń╗ćÕĮóÕ╝Å’╝īµ»ÅõĖ¬µ¢ćµĪŻõ╗źKey-Value’╝łķö«-ÕĆ╝Õ»╣’╝ēńÜäµ¢╣Õ╝Åń╗äń╗ćĶĄĘµØźŃĆéõĖĆõĖ¬µ¢ćµĪŻÕÅ»õ╗ź
µ£ēÕżÜõĖ¬Key-Valueń╗äÕÉł’╝īµ»ÅõĖ¬ValueÕÅ»õ╗źµś»õĖŹÕÉīńÜäń▒╗Õ×ŗ’╝īµ»öÕ”éStringŃĆüIntegerŃĆüListńŁēńŁēŃĆé┬Ā
{ "name" : "July", ┬Ā
┬Ā "sex" : "male", ┬Ā
┬Ā ┬Ā "age" : 23 } ┬Ā
set/map/multiset/multimap
┬Ā ┬Ā set’╝īÕÉīmapõĖƵĀĘ’╝īµēƵ£ēÕģāń┤ĀķāĮõ╝ܵĀ╣µŹ«Õģāń┤ĀńÜäķö«ÕĆ╝Ķć¬ÕŖ©Ķó½µÄÆÕ║Å’╝īÕøĀõĖ║set/mapõĖżĶĆģńÜäµēƵ£ēÕÉäń¦ŹµōŹõĮ£’╝īķāĮÕŬµś»ĶĮ¼ĶĆīĶ░āńö©RB-treeńÜäµōŹõĮ£ĶĪīõĖ║’╝īõĖŹĶ┐ć’╝īÕĆ╝ÕŠŚµ│©µäÅńÜ䵜»’╝īõĖżĶĆģķāĮõĖŹÕģüĶ«ĖõĖżõĖ¬Õģāń┤Āµ£ēńøĖÕÉīńÜäķö«ÕĆ╝ŃĆé
┬Ā
┬Ā
õĖŹÕÉīńÜ䵜»’╝ÜsetńÜäÕģāń┤ĀõĖŹÕāÅmapķ鯵ĀĘÕÅ»õ╗źÕÉīµŚČµŗźµ£ēÕ«×ÕĆ╝(value)ÕÆīķö«ÕĆ╝(key)’╝īsetÕģāń┤ĀńÜäķö«ÕĆ╝Õ░▒µś»Õ«×ÕĆ╝’╝īÕ«×ÕĆ╝Õ░▒µś»ķö«ÕĆ╝’╝īĶĆīmapńÜäµēƵ£ēÕģāń┤ĀķāĮ
µś»pair’╝īÕÉīµŚČµŗźµ£ēÕ«×ÕĆ╝(value)ÕÆīķö«ÕĆ╝(key)’╝īpairńÜäń¼¼õĖĆõĖ¬Õģāń┤ĀĶó½Ķ¦åõĖ║ķö«ÕĆ╝’╝īń¼¼õ║īõĖ¬Õģāń┤ĀĶó½Ķ¦åõĖ║Õ«×ÕĆ╝ŃĆé
┬Ā ┬Ā Ķć│õ║Ämultiset/multimap’╝īõ╗¢õ╗¼ńÜäńē╣µĆ¦ÕÅŖńö©µ│ĢÕÆīset/mapÕ«īÕģ©ńøĖÕÉī’╝īÕö»õĖĆńÜäÕĘ«Õł½Õ░▒Õ£©õ║ÄÕ«āõ╗¼ÕģüĶ«Ėķö«ÕĆ╝ķćŹÕżŹ’╝īÕŹ│µēƵ£ēńÜäµÅÆÕģźµōŹõĮ£Õ¤║õ║ÄRB-treeńÜäinsert_equal()ĶĆīķØ×insert_unique()ŃĆé
hash_set/hash_map/hash_multiset/hash_multimap
┬Ā
┬Ā
hash_set/hash_map’╝īõĖżĶĆģńÜäõĖĆÕłćµōŹõĮ£ķāĮµś»Õ¤║õ║Ähashtableõ╣ŗõĖŖŃĆéõĖŹÕÉīńÜ䵜»’╝īhash_setÕÉīsetõĖƵĀĘ’╝īÕÉīµŚČµŗźµ£ēÕ«×ÕĆ╝ÕÆīķö«ÕĆ╝’╝īõĖö
Õ«×Ķ┤©Õ░▒µś»ķö«ÕĆ╝’╝īķö«ÕĆ╝Õ░▒µś»Õ«×ÕĆ╝’╝īĶĆīhash_mapÕÉīmapõĖƵĀĘ’╝īµ»ÅõĖĆõĖ¬Õģāń┤ĀÕÉīµŚČµŗźµ£ēõĖĆõĖ¬Õ«×ÕĆ╝(value)ÕÆīõĖĆõĖ¬ķö«ÕĆ╝(key)’╝īµēĆõ╗źÕģČõĮ┐ńö©µ¢╣Õ╝Å’╝īÕÆīõĖŖķØó
ńÜämapÕ¤║µ£¼ńøĖÕÉīŃĆéõĮåńö▒õ║Ähash_set/hash_mapķāĮµś»Õ¤║õ║Ähashtableõ╣ŗõĖŖ’╝īµēĆõ╗źõĖŹÕģĘÕżćĶć¬ÕŖ©µÄÆÕ║ÅÕŖ¤ĶāĮŃĆéõĖ║õ╗Ćõ╣ł?ÕøĀõĖ║hashtable
µ▓Īµ£ēĶć¬ÕŖ©µÄÆÕ║ÅÕŖ¤ĶāĮŃĆé
┬Ā ┬Ā Ķć│õ║Ähash_multiset/hash_multimapńÜäńē╣µĆ¦õĖÄõĖŖķØóńÜämultiset/multimapÕ«īÕģ©ńøĖÕÉī’╝īÕö»õĖĆńÜäÕĘ«Õł½Õ░▒µś»Õ«āõ╗¼ńÜäÕ║ĢÕ▒éÕ«×ńÄ░µ£║ÕłČµś»hashtable’╝īµēĆõ╗źÕ«āõ╗¼ńÜäÕģāń┤ĀķāĮõĖŹõ╝ÜĶó½Ķć¬ÕŖ©µÄÆÕ║Å’╝īõĖŹĶ┐ćõ╣¤ķāĮÕģüĶ«Ėķö«ÕĆ╝ķćŹÕżŹŃĆé
┬Ā ┬Ā µēĆõ╗ź’╝īń╗╝õĖŖ’╝īĶ»┤ńÖĮõ║å’╝īõ╗Ćõ╣łµĀĘńÜäń╗ōµ×äÕå│Õ«ÜÕģČõ╗Ćõ╣łµĀĘńÜäµĆ¦Ķ┤©’╝īÕøĀõĖ║set/map/multiset/multimapķāĮµś»Õ¤║õ║ÄRB-treeõ╣ŗõĖŖ’╝īµēĆõ╗źµ£ēĶć¬ÕŖ©µÄÆÕ║ÅÕŖ¤ĶāĮ’╝īĶĆīhash_set/hash_map/hash_multiset/hash_multimapķāĮµś»Õ¤║õ║Ähashtableõ╣ŗõĖŖ’╝īµēĆõ╗źõĖŹÕɽµ£ēĶć¬ÕŖ©µÄÆÕ║ÅÕŖ¤ĶāĮ’╝īĶć│õ║ÄÕŖĀõĖ¬ÕēŹń╝Ćmulti_µŚĀķØ×Õ░▒µś»ÕģüĶ«Ėķö«ÕĆ╝ķćŹÕżŹĶĆīÕĘ▓ŃĆé
┬Ā ┬Ā µŁżÕż¢’╝īÕģ│õ║Äõ╗Ćõ╣łhash’╝īĶ»Ęń£ŗµŁżń»ćµ¢ćń½Ā’╝Ühttp://blog.csdn.net/v_JULY_v/article/details/6256463’╝øÕģ│õ║Äń║óķ╗æµĀæ’╝īĶ»ĘÕÅéń£ŗblogÕåģń│╗ÕłŚµ¢ćń½Ā’╝Ühttp://blog.csdn.net/v_july_v/article/category/774945’╝īÕģ│õ║Ähash_mapńÜäÕģĘõĮōõĮ┐ńö©’╝īÕÅ»ń£ŗń£ŗµŁżń»ćµ¢ćń½Ā’╝Ühttp://blog.csdn.net/sdhongjun/article/details/4517325ŃĆé
┬Ā ┬Ā OK’╝īµÄźõĖŗµØź’╝īĶ»Ęń£ŗµ£¼µ¢ćń¼¼õ║īķā©ÕłåŃĆüÕżäńÉåµĄĘķćŵĢ░µŹ«ķŚ«ķóśõ╣ŗÕģŁµŖŖÕ»åÕīÖŃĆé
┬Ā
ń¼¼õ║īķā©ÕłåŃĆüÕżäńÉåµĄĘķćŵĢ░µŹ«ķŚ«ķóśõ╣ŗÕģŁµŖŖÕ»åÕīÖ
Õ»åÕīÖõĖĆŃĆüÕłåĶĆīµ▓╗õ╣ŗ/HashµśĀÕ░ä + Hashń╗¤Ķ«Ī + ÕĀå/Õ┐½ķƤ/ÕĮÆÕ╣ȵÄÆÕ║Å
- ÕłåĶĆīµ▓╗õ╣ŗ/hashµśĀÕ░ä’╝ÜķÆłÕ»╣µĢ░µŹ«Õż¬Õż¦’╝īÕåģÕŁśÕÅŚķÖÉ’╝īÕŬĶāĮµś»’╝ܵŖŖÕż¦µ¢ćõ╗ČÕī¢µłÉ(ÕÅ¢µ©ĪµśĀÕ░ä)Õ░ŵ¢ćõ╗Č’╝īÕŹ│16ÕŁŚµ¢╣ķÆł’╝ÜÕż¦ĶĆīÕī¢Õ░Å’╝īÕÉäõĖ¬Õć╗ńĀ┤’╝īń╝®Õ░ÅĶ¦äµ©Ī’╝īķĆÉõĖ¬Ķ¦ŻÕå│
- hashń╗¤Ķ«Ī’╝ÜÕĮōÕż¦µ¢ćõ╗ČĶĮ¼Õī¢õ║åÕ░ŵ¢ćõ╗Č’╝īķéŻõ╣łµłæõ╗¼õŠ┐ÕÅ»õ╗źķććńö©ÕĖĖĶ¦äńÜähash_map(ip’╝īvalue)µØźĶ┐øĶĪīķóæńÄćń╗¤Ķ«ĪŃĆé
- ÕĀå/Õ┐½ķƤµÄÆÕ║Å’╝Üń╗¤Ķ«ĪÕ«īõ║åõ╣ŗÕÉÄ’╝īõŠ┐Ķ┐øĶĪīµÄÆÕ║Å(ÕÅ»ķććÕÅ¢ÕĀåµÄÆÕ║Å)’╝īÕŠŚÕł░µ¼ĪµĢ░µ£ĆÕżÜńÜäIPŃĆé
┬Ā ┬ĀÕģĘõĮōĶĆīĶ«║’╝īÕłÖµś»’╝Ü ŌĆ£ķ”¢Õģłµś»Ķ┐ÖõĖĆÕż®’╝īÕ╣ČõĖöµś»Ķ«┐ķŚ«ńÖŠÕ║”ńÜ䵌źÕ┐ŚõĖŁńÜäIPÕÅ¢Õć║µØź’╝īķĆÉõĖ¬ÕåÖÕģźÕł░õĖĆõĖ¬Õż¦µ¢ćõ╗ČõĖŁŃĆéµ│©µäÅÕł░IPµś»32õĮŹńÜä’╝īµ£ĆÕżÜµ£ēõĖ¬2^32õĖ¬IPŃĆéÕÉīµĀĘÕÅ»õ╗źķććńö©µśĀÕ░äńÜäµ¢╣ µ│Ģ’╝īµ»öՔ鵩Ī1000’╝īµŖŖµĢ┤õĖ¬Õż¦µ¢ćõ╗ȵśĀÕ░äõĖ║1000õĖ¬Õ░ŵ¢ćõ╗Č’╝īÕåŹµēŠÕć║µ»ÅõĖ¬Õ░ŵ¢ćõĖŁÕć║ńÄ░ķóæńÄćµ£ĆÕż¦ńÜäIP’╝łÕÅ»õ╗źķććńö©hash_mapĶ┐øĶĪīķóæńÄćń╗¤Ķ«Ī’╝īńäČÕÉÄÕåŹµēŠÕć║ķóæńÄć µ£ĆÕż¦ńÜäÕćĀõĖ¬’╝ēÕÅŖńøĖÕ║öńÜäķóæńÄćŃĆéńäČÕÉÄÕåŹÕ£©Ķ┐Ö1000õĖ¬µ£ĆÕż¦ńÜäIPõĖŁ’╝īµēŠÕć║ķéŻõĖ¬ķóæńÄćµ£ĆÕż¦ńÜäIP’╝īÕŹ│õĖ║µēƵ▒éŃĆéŌĆØ--ÕŹüķüōµĄĘķćŵĢ░µŹ«ÕżäńÉåķØóĶ»ĢķóśõĖÄÕŹüõĖ¬µ¢╣µ│ĢÕż¦µĆ╗ń╗ōŃĆé
┬Ā ┬Ā µ│©’╝ÜHashÕÅ¢µ©Īµś»õĖĆń¦ŹńŁēõ╗ʵśĀÕ░ä’╝īõĖŹõ╝ÜÕŁśÕ£©ÕÉīõĖĆõĖ¬Õģāń┤ĀÕłåµĢŻÕł░õĖŹÕÉīÕ░ŵ¢ćõ╗ČõĖŁÕÄ╗ńÜäµāģÕåĄ’╝īÕŹ│Ķ┐Öķćīķććńö©ńÜ䵜»mod1000ń«Śµ│Ģ’╝īķéŻõ╣łńøĖÕÉīńÜäIPÕ£©hashÕÉÄ’╝īÕŬÕÅ»ĶāĮĶÉĮÕ£©ÕÉīõĖĆõĖ¬µ¢ćõ╗ČõĖŁ’╝īõĖŹÕÅ»ĶāĮĶó½ÕłåµĢŻńÜäŃĆé
┬Ā ┬Ā ķéŻÕł░Õ║Ģõ╗Ćõ╣łµś»hashµśĀÕ░äÕæó’╝¤µłæµŹóõĖ¬Ķ¦ÆÕ║”õĖŠõĖ¬µĄģµśŠńø┤ńÖĮńÜäõŠŗÕŁÉ’╝īՔ鵣¼µ¢ćńÜäURLµś»’╝Ühttp://blog.csdn.net/v_july_v/article/details/7382693’╝īÕĮōµłæµŖŖĶ┐ÖõĖ¬URLÕÅæĶĪ©Õ£©ÕŠ«ÕŹÜõĖŖ’╝īõŠ┐Ķó½µśĀÕ░䵳Éõ║å’╝Ühttp://t.cn/zOixljh’╝īõ║ĵŁż’╝īµłæõ╗¼ÕÅæńÄ░URLµ£¼Ķ║½ńÜäķĢ┐Õ║”Ķó½ń╝®ń¤Łõ║å’╝īõĮåĶ┐ÖõĖżõĖ¬URLÕ»╣Õ║öńÜäµ¢ćń½ĀńÜ䵜»ÕÉīõĖĆń»ćÕŹ│µ£¼µ¢ćŃĆéOK’╝īµ£ēÕģ┤ĶČŻńÜä’╝īĶ┐śÕÅ»õ╗źÕåŹõ║åĶ¦ŻõĖŗõĖĆĶć┤µĆ¦hashń«Śµ│Ģ’╝īĶ¦üµŁżµ¢ćń¼¼õ║öķā©Õłå’╝Ühttp://blog.csdn.net/v_july_v/article/details/6879101ŃĆé
2ŃĆüµÉ£ń┤óÕ╝ĢµōÄõ╝ÜķĆÜĶ┐浌źÕ┐Śµ¢ćõ╗ȵŖŖńö©µłĘµ»Åµ¼ĪµŻĆń┤óõĮ┐ńö©ńÜäµēƵ£ēµŻĆń┤óõĖ▓ķāĮĶ«░ÕĮĢõĖŗµØź’╝īµ»ÅõĖ¬µ¤źĶ»óõĖ▓ńÜäķĢ┐Õ║”õĖ║1-255ÕŁŚĶŖéŃĆé
┬Ā┬Ā┬Ā ÕüćĶ«Šńø«ÕēŹµ£ēõĖĆÕŹāõĖćõĖ¬Ķ«░ÕĮĢ’╝łĶ┐Öõ║øµ¤źĶ»óõĖ▓ńÜäķćŹÕżŹÕ║”µ»öĶŠāķ½ś’╝īĶÖĮńäȵĆ╗µĢ░µś»1ÕŹāõĖć’╝īõĮåÕ”éµ×£ķÖżÕÄ╗ķćŹÕżŹÕÉÄ’╝īõĖŹĶČģĶ┐ć3ńÖŠõĖćõĖ¬ŃĆéõĖĆõĖ¬µ¤źĶ»óõĖ▓ńÜäķćŹÕżŹÕ║”ĶČŖķ½ś’╝īĶ»┤µśÄµ¤źĶ»óÕ«āńÜäńö©µłĘĶČŖÕżÜ’╝īõ╣¤Õ░▒µś»ĶČŖńāŁķŚ©’╝ē’╝īĶ»ĘõĮĀń╗¤Ķ«Īµ£ĆńāŁķŚ©ńÜä10õĖ¬µ¤źĶ»óõĖ▓’╝īĶ”üµ▒éõĮ┐ńö©ńÜäÕåģÕŁśõĖŹĶāĮĶČģĶ┐ć1GŃĆé
┬Ā ┬Ā ńö▒õĖŖķØóń¼¼1ķóś’╝īµłæõ╗¼ń¤źķüō’╝īµĢ░µŹ«Õż¦ÕłÖÕłÆõĖ║Õ░ÅńÜä’╝īõĮåÕ”éµ×£µĢ░µŹ«Ķ¦äµ©Īµ»öĶŠāÕ░Å’╝īĶāĮõĖƵ¼ĪµĆ¦ĶŻģÕģźÕåģÕŁśÕæó?µ»öÕ”éĶ┐Öń¼¼2ķóś’╝īĶÖĮńäȵ£ēõĖĆÕŹāõĖćõĖ¬Query’╝īõĮåµś»ńö▒õ║ÄķćŹÕżŹÕ║”µ»öĶŠā ķ½ś’╝īÕøĀµŁżõ║ŗÕ«×õĖŖÕŬµ£ē300õĖćńÜäQuery’╝īµ»ÅõĖ¬Query255Byte’╝īÕøĀµŁżµłæõ╗¼ÕÅ»õ╗źĶĆāĶÖæµŖŖõ╗¢õ╗¼ķāĮµöŠĶ┐øÕåģÕŁśõĖŁÕÄ╗’╝īĶĆīńÄ░Õ£©ÕŬµś»ķ£ĆĶ”üõĖĆõĖ¬ÕÉłķĆéńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕ£© Ķ┐Öķćī’╝īHash Tableń╗ØÕ»╣µś»µłæõ╗¼õ╝śÕģłńÜäķĆēµŗ®ŃĆéµēĆõ╗źµłæõ╗¼µæÆÕ╝āÕłåĶĆīµ▓╗õ╣ŗ/hashµśĀÕ░äńÜäµ¢╣µ│Ģ’╝īńø┤µÄźõĖŖhashń╗¤Ķ«Ī’╝īńäČÕÉĵÄÆÕ║ÅŃĆéSo’╝ī
- hash ń╗¤Ķ«Ī’╝ÜÕģłÕ»╣Ķ┐Öµē╣µĄĘķćŵĢ░µŹ«ķóäÕżäńÉå(ń╗┤µŖżõĖĆõĖ¬KeyõĖ║QueryÕŁŚõĖ▓’╝īValueõĖ║Ķ»źQueryÕć║ńÄ░µ¼ĪµĢ░ńÜäHashTable’╝īÕŹ│ hash_map(Query’╝īValue)’╝īµ»Åµ¼ĪĶ»╗ÕÅ¢õĖĆõĖ¬Query’╝īÕ”éµ×£Ķ»źÕŁŚõĖ▓õĖŹÕ£©TableõĖŁ’╝īķéŻõ╣łÕŖĀÕģźĶ»źÕŁŚõĖ▓’╝īÕ╣ČõĖöÕ░åValueÕĆ╝Ķ«ŠõĖ║1’╝øÕ”éµ×£Ķ»ź ÕŁŚõĖ▓Õ£©TableõĖŁ’╝īķéŻõ╣łÕ░åĶ»źÕŁŚõĖ▓ńÜäĶ«ĪµĢ░ÕŖĀõĖĆÕŹ│ÕÅ»ŃĆéµ£Ćń╗łµłæõ╗¼Õ£©O(N)ńÜ䵌ČķŚ┤ÕżŹµØéÕ║”Õåģńö©HashĶĪ©Õ«īµłÉõ║åń╗¤Ķ«Ī’╝ø
- ÕĀåµÄÆÕ║Å’╝Üń¼¼õ║īµŁźŃĆüÕƤÕŖ®ÕĀå Ķ┐ÖõĖ¬µĢ░µŹ«ń╗ōµ×ä’╝īµēŠÕć║Top K’╝īµŚČķŚ┤ÕżŹµØéÕ║”õĖ║NŌĆślogKŃĆéÕŹ│ÕƤÕŖ®ÕĀåń╗ōµ×ä’╝īµłæõ╗¼ÕÅ»õ╗źÕ£©logķćÅń║¦ńÜ䵌ČķŚ┤Õåģµ¤źµēŠÕÆīĶ░āµĢ┤/ń¦╗ÕŖ©ŃĆéÕøĀµŁż’╝īń╗┤µŖżõĖĆõĖ¬K(Ķ»źķóśńø«õĖŁµś»10)Õż¦Õ░ÅńÜäÕ░ŵĀ╣ÕĀå’╝īńäČÕÉÄķüŹ ÕÄå300õĖćńÜäQuery’╝īÕłåÕł½ÕÆīµĀ╣Õģāń┤ĀĶ┐øĶĪīÕ»╣µ»öµēĆõ╗ź’╝īµłæõ╗¼µ£Ćń╗łńÜ䵌ČķŚ┤ÕżŹµØéÕ║”µś»’╝ÜO’╝łN’╝ē + N'*O’╝łlogK’╝ē’╝ī’╝łNõĖ║1000õĖć’╝īNŌĆÖõĖ║300õĖć’╝ēŃĆé
┬Ā┬Ā┬Ā Õł½Õ┐śõ║åĶ┐Öń»ćµ¢ćń½ĀõĖŁµēĆĶ┐░ńÜäÕĀåµÄÆÕ║ŵĆØĶĘ»’╝ÜŌĆ£ń╗┤
µŖżkõĖ¬Õģāń┤ĀńÜäµ£ĆÕ░ÅÕĀå’╝īÕŹ│ńö©Õ«╣ķćÅõĖ║kńÜäµ£ĆÕ░ÅÕĀåÕŁśÕ驵£ĆÕģłķüŹÕÄåÕł░ńÜäkõĖ¬µĢ░’╝īÕ╣ČÕüćĶ«ŠÕ«āõ╗¼ÕŹ│µś»µ£ĆÕż¦ńÜäkõĖ¬µĢ░’╝īÕ╗║ÕĀåĶ┤╣µŚČO’╝łk’╝ē’╝īÕ╣ČĶ░āµĢ┤ÕĀå’╝łĶ┤╣µŚČO’╝łlogk’╝ē’╝ēÕÉÄ’╝ī
µ£ēk1>k2>...kmin’╝łkminĶ«ŠõĖ║Õ░ÅķĪČÕĀåõĖŁµ£ĆÕ░ÅÕģāń┤Ā’╝ēŃĆéń╗¦ń╗ŁķüŹÕÄåµĢ░ÕłŚ’╝īµ»Åµ¼ĪķüŹÕÄåõĖĆõĖ¬Õģāń┤Āx’╝īõĖÄÕĀåķĪČÕģāń┤Āµ»öĶŠā’╝īĶŗź
x>kmin’╝īÕłÖµø┤µ¢░ÕĀå’╝łńö©µŚČlogk’╝ē’╝īÕÉ”ÕłÖõĖŹµø┤µ¢░ÕĀåŃĆéĶ┐ÖµĀĘõĖŗµØź’╝īµĆ╗Ķ┤╣µŚČO’╝łk*logk+’╝łn-k’╝ē*logk’╝ē=O’╝łn*logk’╝ēŃĆ鵣żµ¢╣µ│Ģ
ÕŠŚńøŖõ║ÄÕ£©ÕĀåõĖŁ’╝īµ¤źµēŠńŁēÕÉäķĪ╣µōŹõĮ£µŚČķŚ┤ÕżŹµØéÕ║”ÕØćõĖ║logkŃĆéŌĆØ--ń¼¼õĖēń½Āń╗ŁŃĆüTop Kń«Śµ│ĢķŚ«ķóśńÜäÕ«×ńÄ░ŃĆé
┬Ā┬Ā┬Ā ÕĮōńäČ’╝īõĮĀõ╣¤ÕÅ»õ╗źķććńö©trieµĀæ’╝īÕģ│ķö«ÕŁŚÕ¤¤ÕŁśĶ»źµ¤źĶ»óõĖ▓Õć║ńÄ░ńÜäµ¼ĪµĢ░’╝īµ▓Īµ£ēÕć║ńÄ░õĖ║0ŃĆéµ£ĆÕÉÄńö©10õĖ¬Õģāń┤ĀńÜäµ£ĆÕ░ŵĩµØźÕ»╣Õć║ńÄ░ķóæńÄćĶ┐øĶĪīµÄÆÕ║ÅŃĆé
3ŃĆüµ£ēõĖĆõĖ¬1GÕż¦Õ░ÅńÜäõĖĆõĖ¬µ¢ćõ╗Č’╝īķćīķØóµ»ÅõĖĆĶĪīµś»õĖĆõĖ¬Ķ»Ź’╝īĶ»ŹńÜäÕż¦Õ░ÅõĖŹĶČģĶ┐ć16ÕŁŚĶŖé’╝īÕåģÕŁśķÖÉÕłČÕż¦Õ░ŵś»1MŃĆéĶ┐öÕø×ķóæµĢ░µ£Ćķ½śńÜä100õĖ¬Ķ»ŹŃĆé
┬Ā┬Ā ┬Ā ┬Ā ńö▒õĖŖķØóķéŻõĖżõĖ¬õŠŗķóś’╝īÕłåĶĆīµ▓╗õ╣ŗ + hashń╗¤Ķ«Ī + ÕĀå/Õ┐½ķƤµÄÆÕ║ÅĶ┐ÖõĖ¬ÕźŚĶĘ»’╝īµłæõ╗¼ÕĘ▓ń╗ÅÕ╝ĆÕ¦ŗµ£ēõ║åÕ▒ĪĶ»ĢõĖŹńłĮńÜäµä¤Ķ¦ēŃĆéõĖŗķØó’╝īÕåŹµŗ┐ÕćĀķüōÕåŹÕżÜÕżÜķ¬īĶ»üõĖŗŃĆéĶ»Ęń£ŗµŁżń¼¼3ķóś’╝ÜÕÅłµś»µ¢ćõ╗ČÕŠłÕż¦’╝īÕÅłµś»ÕåģÕŁśÕÅŚķÖÉ’╝īÕÆŗÕŖ×?Ķ┐śĶāĮµĆÄõ╣łÕŖ×Õæó?µŚĀķØ×Ķ┐śµś»’╝Ü
- Õłå ĶĆīµ▓╗õ╣ŗ/hashµśĀÕ░ä’╝ÜķĪ║Õ║ÅĶ»╗µ¢ćõ╗ČõĖŁ’╝īÕ»╣õ║ĵ»ÅõĖ¬Ķ»Źx’╝īÕÅ¢hash(x)%5000’╝īńäČÕÉĵīēńģ¦Ķ»źÕĆ╝ÕŁśÕł░5000õĖ¬Õ░ŵ¢ćõ╗Č’╝łĶ«░õĖ║ x0,x1,...x4999’╝ēõĖŁŃĆéĶ┐ÖµĀʵ»ÅõĖ¬µ¢ćõ╗ČÕż¦µ”鵜»200kÕĘ”ÕÅ│ŃĆéÕ”éµ×£ÕģČõĖŁńÜäµ£ēńÜäµ¢ćõ╗ČĶČģĶ┐ćõ║å1MÕż¦Õ░Å’╝īĶ┐śÕÅ»õ╗źµīēńģ¦ń▒╗õ╝╝ńÜäµ¢╣µ│Ģń╗¦ń╗ŁÕŠĆõĖŗÕłå’╝īńø┤Õł░ÕłåĶ¦ŻÕŠŚÕł░ ńÜäÕ░ŵ¢ćõ╗ČńÜäÕż¦Õ░ÅķāĮõĖŹĶČģĶ┐ć1MŃĆé
- hashń╗¤Ķ«Ī’╝ÜÕ»╣µ»ÅõĖ¬Õ░ŵ¢ćõ╗Č’╝īķććńö©trieµĀæ/hash_mapńŁēń╗¤Ķ«Īµ»ÅõĖ¬µ¢ćõ╗ČõĖŁÕć║ńÄ░ńÜäĶ»Źõ╗źÕÅŖńøĖÕ║öńÜäķóæńÄćŃĆé
- ÕĀå/ÕĮÆÕ╣ȵÄÆÕ║Å’╝ÜÕÅ¢Õć║Õć║ńÄ░ķóæńÄćµ£ĆÕż¦ńÜä100õĖ¬Ķ»Ź’╝łÕÅ»õ╗źńö©Õɽ100õĖ¬ń╗ōńé╣ńÜäµ£ĆÕ░ÅÕĀå’╝ē’╝īÕ╣ȵŖŖ100õĖ¬Ķ»ŹÕÅŖńøĖÕ║öńÜäķóæńÄćÕŁśÕģźµ¢ćõ╗Č’╝īĶ┐ÖµĀĘÕÅłÕŠŚÕł░õ║å5000õĖ¬µ¢ćõ╗ČŃĆéµ£ĆÕÉÄÕ░▒µś»µŖŖĶ┐Ö5000õĖ¬µ¢ćõ╗ČĶ┐øĶĪīÕĮÆÕ╣Č’╝łń▒╗õ╝╝õ║ÄÕĮÆÕ╣ȵÄÆÕ║Å’╝ēńÜäĶ┐ćń©ŗõ║åŃĆé
- ÕĀåµÄÆÕ║Å’╝ÜÕ£©µ»ÅÕÅ░ńöĄĶäæõĖŖµ▒éÕć║TOP10’╝īÕÅ»õ╗źķććńö©ÕīģÕɽ10õĖ¬Õģāń┤ĀńÜäÕĀåÕ«īµłÉ’╝łTOP10Õ░Å’╝īńö©µ£ĆÕż¦ÕĀå’╝īTOP10Õż¦’╝īńö©µ£ĆÕ░ÅÕĀå’╝ēŃĆéµ»öÕ”éµ▒éTOP10Õż¦’╝īµłæõ╗¼ķ”¢ÕģłÕÅ¢ÕēŹ10õĖ¬Õģāń┤ĀĶ░āµĢ┤µłÉµ£ĆÕ░ÅÕĀå’╝īÕ”éµ×£ÕÅæńÄ░’╝īńäČÕÉĵē½µÅÅÕÉÄķØóńÜäµĢ░µŹ«’╝īÕ╣ČõĖÄÕĀåķĪČÕģāń┤Āµ»öĶŠā’╝īÕ”éµ×£µ»öÕĀåķĪČÕģāń┤ĀÕż¦’╝īķéŻõ╣łńö©Ķ»źÕģāń┤Āµø┐µŹóÕĀåķĪČ’╝īńäČÕÉÄÕåŹĶ░āµĢ┤õĖ║µ£ĆÕ░ÅÕĀåŃĆéµ£ĆÕÉÄÕĀåõĖŁńÜäÕģāń┤ĀÕ░▒µś»TOP10Õż¦ŃĆé
- µ▒éÕć║µ»ÅÕÅ░ńöĄĶäæõĖŖńÜäTOP10ÕÉÄ’╝īńäČÕÉĵŖŖĶ┐Ö100ÕÅ░ńöĄĶäæõĖŖńÜäTOP10ń╗äÕÉłĶĄĘµØź’╝īÕģ▒1000õĖ¬µĢ░µŹ«’╝īÕåŹÕł®ńö©õĖŖķØóń▒╗õ╝╝ńÜäµ¢╣µ│Ģµ▒éÕć║TOP10Õ░▒ÕÅ»õ╗źõ║åŃĆé
a 49µ¼Īb 50µ¼Īc 2µ¼Īd 1µ¼Ī
┬Ā┬Ā┬Ā┬Ā┬ĀĶÖĮńäČń¼¼ õĖĆõĖ¬µ¢ćõ╗ČķćīÕć║µØźtop2µś»b’╝ł50µ¼Ī’╝ē,a’╝ł49µ¼Ī’╝ē,ń¼¼õ║īõĖ¬µ¢ćõ╗ČķćīÕć║µØźtop2µś»c’╝ł11µ¼Ī’╝ē,d’╝ł10µ¼Ī’╝ē,ńäČÕÉÄ2õĖ¬top2’╝Üb’╝ł50µ¼Ī’╝ēa’╝ł49 µ¼Ī’╝ēõĖÄc’╝ł11µ¼Ī’╝ēd’╝ł10µ¼Ī’╝ēÕĮÆÕ╣Č’╝īÕłÖń«ŚÕć║µēƵ£ēńÜäµ¢ćõ╗ČńÜätop2µś»b(50 µ¼Ī),a(49 µ¼Ī),õĮåÕ«×ķÖģõĖŖµś»a(58 µ¼Ī),b(51 µ¼Ī)ŃĆ鵜»ÕÉ”ń£¤µś»Õ”鵣żÕæó?Ķŗźń£¤Õ”鵣ż’╝īķéŻõĮ£õĮĢĶ¦ŻÕå│Õæó’╝¤a 9µ¼Īb 1µ¼Īc 11µ¼Īd 10µ¼Ī
┬Ā ┬Āńø┤µÄźõĖŖ’╝Ü
- hashµśĀÕ░ä’╝ÜķĪ║Õ║ÅĶ»╗ÕÅ¢10õĖ¬µ¢ćõ╗Č’╝īµīēńģ¦hash(query)%10ńÜäń╗ōµ×£Õ░åqueryÕåÖÕģźÕł░ÕÅ”Õż¢10õĖ¬µ¢ćõ╗Č’╝łĶ«░õĖ║’╝ēõĖŁŃĆéĶ┐ÖµĀʵ¢░ńö¤µłÉńÜäµ¢ćõ╗ȵ»ÅõĖ¬ńÜäÕż¦Õ░ÅÕż¦ń║”õ╣¤1G’╝łÕüćĶ«ŠhashÕćĮµĢ░µś»ķÜŵ£║ńÜä’╝ēŃĆé
- hashń╗¤Ķ«Ī’╝ܵēŠõĖĆÕÅ░ÕåģÕŁśÕ£©2GÕĘ”ÕÅ│ńÜäµ£║ÕÖ©’╝īõŠØµ¼ĪÕ»╣ńö©hash_map(query, query_count)µØźń╗¤Ķ«Īµ»ÅõĖ¬queryÕć║ńÄ░ńÜäµ¼ĪµĢ░ŃĆéµ│©’╝Ühash_map(query,query_count)µś»ńö©µØźń╗¤Ķ«Īµ»ÅõĖ¬queryńÜäÕć║ńÄ░µ¼ĪµĢ░’╝īõĖŹµś»ÕŁśÕé©õ╗¢õ╗¼ńÜäÕĆ╝’╝īÕć║ńÄ░õĖƵ¼Ī’╝īÕłÖcount+1ŃĆé
- ÕĀå/Õ┐½ķƤ/ÕĮÆÕ╣ȵÄÆÕ║Å’╝ÜÕł®ńö©Õ┐½ķƤ/ÕĀå/ÕĮÆÕ╣ȵÄÆÕ║ŵīēńģ¦Õć║ńÄ░µ¼ĪµĢ░Ķ┐øĶĪīµÄÆÕ║ÅŃĆéÕ░åµÄÆÕ║ÅÕźĮńÜäqueryÕÆīÕ»╣Õ║öńÜäquery_coutĶŠōÕć║Õł░µ¢ćõ╗ČõĖŁŃĆéĶ┐ÖµĀĘÕŠŚÕł░õ║å10õĖ¬µÄÆÕźĮÕ║ÅńÜäµ¢ćõ╗Č’╝łĶ«░õĖ║’╝ēŃĆéÕ»╣Ķ┐Ö10õĖ¬µ¢ćõ╗ČĶ┐øĶĪīÕĮÆÕ╣ȵÄÆÕ║Å’╝łÕåģµÄÆÕ║ÅõĖÄÕż¢µÄÆÕ║ÅńøĖń╗ōÕÉł’╝ēŃĆé
┬Ā ┬Ā ┬ĀķÖżµŁżõ╣ŗÕż¢’╝īµŁżķóśĶ┐śµ£ēõ╗źõĖŗõĖżõĖ¬µ¢╣µ│Ģ’╝Ü
┬Ā┬Ā┬Ā µ¢╣µĪł2’╝ÜõĖĆĶł¼queryńÜäµĆ╗ķćŵś»µ£ēķÖÉńÜä’╝īÕŬµś»ķćŹÕżŹńÜäµ¼ĪµĢ░µ»öĶŠāÕżÜĶĆīÕĘ▓’╝īÕÅ»ĶāĮÕ»╣õ║ĵēƵ£ēńÜäquery’╝īõĖƵ¼ĪµĆ¦Õ░▒ÕÅ»õ╗źÕŖĀÕģźÕł░ÕåģÕŁśõ║åŃĆéĶ┐ÖµĀĘ’╝īµłæõ╗¼Õ░▒ÕÅ»õ╗źķććńö©trieµĀæ/hash_mapńŁēńø┤µÄźµØźń╗¤Ķ«Īµ»ÅõĖ¬queryÕć║ńÄ░ńÜäµ¼ĪµĢ░’╝īńäČÕÉĵīēÕć║ńÄ░µ¼ĪµĢ░ÕüÜÕ┐½ķƤ/ÕĀå/ÕĮÆÕ╣ȵÄÆÕ║ÅÕ░▒ÕÅ»õ╗źõ║åŃĆé
┬Ā┬Ā┬Ā µ¢╣µĪł3’╝ÜõĖĵ¢╣µĪł1ń▒╗õ╝╝’╝īõĮåÕ£©ÕüÜÕ«īhash’╝īÕłåµłÉÕżÜõĖ¬µ¢ćõ╗ČÕÉÄ’╝īÕÅ»õ╗źõ║żń╗ÖÕżÜõĖ¬µ¢ćõ╗ČµØźÕżäńÉå’╝īķććńö©ÕłåÕĖāÕ╝ÅńÜäµ×ȵ×äµØźÕżäńÉå’╝łµ»öÕ”éMapReduce’╝ē’╝īµ£ĆÕÉÄÕåŹĶ┐øĶĪīÕÉłÕ╣ČŃĆé
6ŃĆü ń╗ÖÕ«ÜaŃĆübõĖżõĖ¬µ¢ćõ╗Č’╝īÕÉäÕŁśµöŠ50õ║┐õĖ¬url’╝īµ»ÅõĖ¬urlÕÉäÕŹĀ64ÕŁŚĶŖé’╝īÕåģÕŁśķÖÉÕłČµś»4G’╝īĶ«®õĮĀµēŠÕć║aŃĆübµ¢ćõ╗ČÕģ▒ÕÉīńÜäurl’╝¤
┬Ā ┬Ā ÕÅ»õ╗źõ╝░Ķ«Īµ»ÅõĖ¬µ¢ćõ╗ČÕ«ēńÜäÕż¦Õ░ÅõĖ║5G├Ś64=320G’╝īĶ┐£Ķ┐£Õż¦õ║ÄÕåģÕŁśķÖÉÕłČńÜä4GŃĆéµēĆõ╗źõĖŹÕÅ»ĶāĮÕ░åÕģČÕ«īÕģ©ÕŖĀĶĮĮÕł░ÕåģÕŁśõĖŁÕżäńÉåŃĆéĶĆāĶÖæķććÕÅ¢ÕłåĶĆīµ▓╗õ╣ŗńÜäµ¢╣µ│ĢŃĆé
-
ÕłåĶĆīµ▓╗õ╣ŗ/hashµśĀÕ░ä’╝ÜķüŹÕÄåµ¢ćõ╗Ča’╝īÕ»╣µ»ÅõĖ¬urlµ▒éÕÅ¢
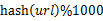 ’╝īńäČÕÉĵĀ╣µŹ«µēĆÕÅ¢ÕŠŚńÜäÕĆ╝Õ░åurlÕłåÕł½ÕŁśÕé©Õł░1000õĖ¬Õ░ŵ¢ćõ╗Č’╝łĶ«░õĖ║
’╝īńäČÕÉĵĀ╣µŹ«µēĆÕÅ¢ÕŠŚńÜäÕĆ╝Õ░åurlÕłåÕł½ÕŁśÕé©Õł░1000õĖ¬Õ░ŵ¢ćõ╗Č’╝łĶ«░õĖ║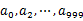 ’╝ēõĖŁŃĆéĶ┐ÖµĀʵ»ÅõĖ¬Õ░ŵ¢ćõ╗ČńÜäÕż¦ń║”õĖ║300MŃĆéķüŹÕÄåµ¢ćõ╗Čb’╝īķććÕÅ¢ÕÆīańøĖÕÉīńÜäµ¢╣Õ╝ÅÕ░åurlÕłåÕł½ÕŁśÕé©Õł░1000Õ░ŵ¢ćõ╗ČõĖŁ’╝łĶ«░õĖ║
’╝ēõĖŁŃĆéĶ┐ÖµĀʵ»ÅõĖ¬Õ░ŵ¢ćõ╗ČńÜäÕż¦ń║”õĖ║300MŃĆéķüŹÕÄåµ¢ćõ╗Čb’╝īķććÕÅ¢ÕÆīańøĖÕÉīńÜäµ¢╣Õ╝ÅÕ░åurlÕłåÕł½ÕŁśÕé©Õł░1000Õ░ŵ¢ćõ╗ČõĖŁ’╝łĶ«░õĖ║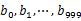 ’╝ēŃĆéĶ┐ÖµĀĘÕżäńÉåÕÉÄ’╝īµēƵ£ēÕÅ»ĶāĮńøĖÕÉīńÜäurlķāĮÕ£©Õ»╣Õ║öńÜäÕ░ŵ¢ćõ╗Č’╝ł
’╝ēŃĆéĶ┐ÖµĀĘÕżäńÉåÕÉÄ’╝īµēƵ£ēÕÅ»ĶāĮńøĖÕÉīńÜäurlķāĮÕ£©Õ»╣Õ║öńÜäÕ░ŵ¢ćõ╗Č’╝ł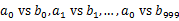 ’╝ēõĖŁ’╝īõĖŹÕ»╣Õ║öńÜäÕ░ŵ¢ćõ╗ČõĖŹÕÅ»ĶāĮµ£ēńøĖÕÉīńÜäurlŃĆéńäČÕÉĵłæõ╗¼ÕŬĶ”üµ▒éÕć║1000Õ»╣Õ░ŵ¢ćõ╗ČõĖŁńøĖÕÉīńÜäurlÕŹ│ÕÅ»ŃĆé
’╝ēõĖŁ’╝īõĖŹÕ»╣Õ║öńÜäÕ░ŵ¢ćõ╗ČõĖŹÕÅ»ĶāĮµ£ēńøĖÕÉīńÜäurlŃĆéńäČÕÉĵłæõ╗¼ÕŬĶ”üµ▒éÕć║1000Õ»╣Õ░ŵ¢ćõ╗ČõĖŁńøĖÕÉīńÜäurlÕŹ│ÕÅ»ŃĆé - hashń╗¤Ķ«Ī’╝ܵ▒éµ»ÅÕ»╣Õ░ŵ¢ćõ╗ČõĖŁńøĖÕÉīńÜäurlµŚČ’╝īÕÅ»õ╗źµŖŖÕģČõĖŁõĖĆõĖ¬Õ░ŵ¢ćõ╗ČńÜäurlÕŁśÕé©Õł░hash_setõĖŁŃĆéńäČÕÉÄķüŹÕÄåÕÅ”õĖĆõĖ¬Õ░ŵ¢ćõ╗ČńÜäµ»ÅõĖ¬url’╝īń£ŗÕģȵś»Õɔգ©ÕłÜµēŹµ×äÕ╗║ńÜähash_setõĖŁ’╝īÕ”éµ×£µś»’╝īķéŻõ╣łÕ░▒µś»Õģ▒ÕÉīńÜäurl’╝īÕŁśÕł░µ¢ćõ╗ČķćīķØóÕ░▒ÕÅ»õ╗źõ║åŃĆé
┬Ā ┬Ā OK’╝īµŁżń¼¼õĖĆń¦Źµ¢╣µ│Ģ’╝ÜÕłåĶĆīµ▓╗õ╣ŗ/hashµśĀÕ░ä + hashń╗¤Ķ«Ī + ÕĀå/Õ┐½ķƤ/ÕĮÆÕ╣ȵÄÆÕ║Å’╝īÕåŹń£ŗµ£ĆÕÉÄõĖēķüōķóś’╝īÕ”éõĖŗ’╝Ü
7ŃĆüµĆÄõ╣łÕ£©µĄĘķćŵĢ░µŹ«õĖŁµēŠÕć║ķćŹÕżŹµ¼ĪµĢ░µ£ĆÕżÜńÜäõĖĆõĖ¬’╝¤
┬Ā ┬Ā µ¢╣µĪł1’╝ÜÕģłÕüÜhash’╝īńäČÕÉĵ▒鵩ĪµśĀÕ░äõĖ║Õ░ŵ¢ćõ╗Č’╝īµ▒éÕć║µ»ÅõĖ¬Õ░ŵ¢ćõ╗ČõĖŁķćŹÕżŹµ¼ĪµĢ░µ£ĆÕżÜńÜäõĖĆõĖ¬’╝īÕ╣ČĶ«░ÕĮĢķćŹÕżŹµ¼ĪµĢ░ŃĆéńäČÕÉĵēŠÕć║õĖŖõĖƵŁźµ▒éÕć║ńÜäµĢ░µŹ«õĖŁķćŹÕżŹµ¼ĪµĢ░µ£ĆÕżÜńÜäõĖĆõĖ¬Õ░▒µś»µēƵ▒é’╝łÕģĘõĮōÕÅéĶĆāÕēŹķØóńÜäķóś’╝ēŃĆé
8ŃĆüõĖŖÕŹāõĖ浳¢õĖŖõ║┐µĢ░µŹ«’╝łµ£ēķćŹÕżŹ’╝ē’╝īń╗¤Ķ«ĪÕģČõĖŁÕć║ńÄ░µ¼ĪµĢ░µ£ĆÕżÜńÜäķÆ▒NõĖ¬µĢ░µŹ«ŃĆé
┬Ā ┬Ā µ¢╣µĪł1’╝ÜõĖŖÕŹāõĖ浳¢õĖŖõ║┐ńÜäµĢ░µŹ«’╝īńÄ░Õ£©ńÜäµ£║ÕÖ©ńÜäÕåģÕŁśÕ║öĶ»źĶāĮÕŁśõĖŗŃĆéµēĆõ╗źĶĆāĶÖæķććńö©hash_map/µÉ£ń┤óõ║īÕÅēµĀæ/ń║óķ╗æµĀæńŁēµØźĶ┐øĶĪīń╗¤Ķ«Īµ¼ĪµĢ░ŃĆéńäČÕÉÄÕ░▒µś»ÕÅ¢Õć║ÕēŹNõĖ¬Õć║ńÄ░µ¼ĪµĢ░µ£ĆÕżÜńÜäµĢ░µŹ«õ║å’╝īÕÅ»õ╗źńö©ń¼¼2ķóśµÅÉÕł░ńÜäÕĀåµ£║ÕłČÕ«īµłÉŃĆé
9ŃĆüõĖĆõĖ¬µ¢ćµ£¼µ¢ćõ╗Č’╝īÕż¦ń║”µ£ēõĖĆõĖćĶĪī’╝īµ»ÅĶĪīõĖĆõĖ¬Ķ»Ź’╝īĶ”üµ▒éń╗¤Ķ«ĪÕć║ÕģČõĖŁµ£Ćķóæń╣üÕć║ńÄ░ńÜäÕēŹ10õĖ¬Ķ»Ź’╝īĶ»Ęń╗ÖÕć║µĆصā│’╝īń╗ÖÕć║µŚČķŚ┤ÕżŹµØéÕ║”Õłåµ×ÉŃĆé
┬Ā ┬Ā ┬Āµ¢╣µĪł1’╝ÜĶ┐Öķ󜵜»ĶĆāĶÖæµŚČķŚ┤µĢłńÄćŃĆéńö©trieµĀæń╗¤Ķ«Īµ»ÅõĖ¬Ķ»ŹÕć║ńÄ░ńÜäµ¼ĪµĢ░’╝īµŚČķŚ┤ÕżŹµØéÕ║”µś»O(n*le)’╝łleĶĪ©ńż║ÕŹĢĶ»ŹńÜäÕ╣│ÕćåķĢ┐Õ║”’╝ēŃĆéńäČÕÉĵś»µēŠÕć║Õć║ńÄ░µ£Ćķóæń╣üńÜäÕēŹ 10õĖ¬Ķ»Ź’╝īÕÅ»õ╗źńö©ÕĀåµØźÕ«×ńÄ░’╝īÕēŹķØóńÜäķóśõĖŁÕĘ▓ń╗ÅĶ«▓Õł░õ║å’╝īµŚČķŚ┤ÕżŹµØéÕ║”µś»O(n*lg10)ŃĆéµēĆõ╗źµĆ╗ńÜ䵌ČķŚ┤ÕżŹµØéÕ║”’╝īµś»O(n*le)õĖÄO(n*lg10)õĖŁĶŠāÕż¦ńÜä Õō¬õĖĆõĖ¬ŃĆé
┬Ā ┬Ā µÄźõĖŗµØź’╝īÕÆ▒õ╗¼µØźń£ŗń¼¼õ║īń¦Źµ¢╣µ│Ģ’╝īÕÅīÕ▒鵏ģÕłÆÕłåŃĆé
Õ»åÕīÖõ║īŃĆüÕÅīÕ▒éµĪČÕłÆÕłå
ÕÅīÕ▒éµĪČÕłÆÕłå----ÕģČÕ«×µ£¼Ķ┤©õĖŖĶ┐śµś»ÕłåĶĆīµ▓╗õ╣ŗńÜäµĆصā│’╝īķćŹÕ£©ŌĆ£ÕłåŌĆØńÜäµŖĆÕʦõĖŖ’╝ü
ŃĆĆŃĆĆķĆéńö©ĶīāÕø┤’╝Üń¼¼kÕż¦’╝īõĖŁõĮŹµĢ░’╝īõĖŹķćŹÕżŹµł¢ķćŹÕżŹńÜäµĢ░ÕŁŚ
ŃĆĆŃĆĆÕ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝ÜÕøĀõĖ║Õģāń┤ĀĶīāÕø┤ÕŠłÕż¦’╝īõĖŹĶāĮÕł®ńö©ńø┤µÄźÕ»╗ÕØĆĶĪ©’╝īµēĆõ╗źķĆÜĶ┐ćÕżÜµ¼ĪÕłÆÕłå’╝īķĆɵŁźńĪ«Õ«ÜĶīāÕø┤’╝īńäČÕÉĵ£ĆÕÉÄÕ£©õĖĆõĖ¬ÕÅ»õ╗źµÄźÕÅŚńÜäĶīāÕø┤ÕåģĶ┐øĶĪīŃĆéÕÅ»õ╗źķĆÜĶ┐ćÕżÜµ¼Īń╝®Õ░Å’╝īÕÅīÕ▒éÕŬµś»õĖĆõĖ¬õŠŗÕŁÉŃĆé
ŃĆĆŃĆƵē®Õ▒Ģ’╝Ü
ŃĆĆŃĆĆķŚ«ķóśÕ«×õŠŗ’╝Ü
┬Ā ┬Ā ┬Ā ┬Ā┬Ā10ŃĆü2.5õ║┐õĖ¬µĢ┤µĢ░õĖŁµēŠÕć║õĖŹķćŹÕżŹńÜäµĢ┤µĢ░ńÜäõĖ¬µĢ░’╝īÕåģÕŁśń®║ķŚ┤õĖŹĶČ│õ╗źÕ«╣ń║│Ķ┐Ö2.5õ║┐õĖ¬µĢ┤µĢ░ŃĆé
ŃĆĆŃĆƵ£ēńé╣ÕāÅķĖĮÕĘóÕĤńÉå’╝īµĢ┤µĢ░õĖ¬µĢ░õĖ║2^32,õ╣¤Õ░▒µś»’╝īµłæõ╗¼ÕÅ»õ╗źÕ░åĶ┐Ö2^32õĖ¬µĢ░’╝īÕłÆÕłåõĖ║2^8õĖ¬Õī║Õ¤¤(µ»öÕ”éńö©ÕŹĢõĖ¬µ¢ćõ╗Čõ╗ŻĶĪ©õĖĆõĖ¬Õī║Õ¤¤)’╝īńäČÕÉÄÕ░åµĢ░µŹ«Õłåń”╗Õł░õĖŹÕÉīńÜäÕī║Õ¤¤’╝īńäČÕÉÄõĖŹÕÉīńÜäÕī║Õ¤¤Õ£©Õł®ńö©bitmapÕ░▒ÕÅ»õ╗źńø┤µÄźĶ¦ŻÕå│õ║åŃĆéõ╣¤Õ░▒µś»Ķ»┤ÕŬĶ”üµ£ēĶČ│Õż¤ńÜäńŻüńøśń®║ķŚ┤’╝īÕ░▒ÕÅ»õ╗źÕŠłµ¢╣õŠ┐ńÜäĶ¦ŻÕå│ŃĆé
┬Ā ┬Ā ┬Ā┬Ā┬Ā11ŃĆü5õ║┐õĖ¬intµēŠÕ«āõ╗¼ńÜäõĖŁõĮŹµĢ░ŃĆé
ŃĆĆ
ŃĆĆĶ┐ÖõĖ¬õŠŗÕŁÉµ»öõĖŖķØóķéŻõĖ¬µø┤µśÄµśŠŃĆéķ”¢Õģłµłæõ╗¼Õ░åintÕłÆÕłåõĖ║2^16õĖ¬Õī║Õ¤¤’╝īńäČÕÉÄĶ»╗ÕÅ¢µĢ░µŹ«ń╗¤Ķ«ĪĶÉĮÕł░ÕÉäõĖ¬Õī║Õ¤¤ķćīńÜäµĢ░ńÜäõĖ¬µĢ░’╝īõ╣ŗÕÉĵłæõ╗¼µĀ╣µŹ«ń╗¤Ķ«Īń╗ōµ×£Õ░▒ÕÅ»õ╗źÕłżµ¢ŁõĖŁõĮŹµĢ░
ĶÉĮÕł░ķéŻõĖ¬Õī║Õ¤¤’╝īÕÉīµŚČń¤źķüōĶ┐ÖõĖ¬Õī║Õ¤¤õĖŁńÜäń¼¼ÕćĀÕż¦µĢ░ÕłÜÕźĮµś»õĖŁõĮŹµĢ░ŃĆéńäČÕÉÄń¼¼õ║īµ¼Īµē½µÅŵłæõ╗¼ÕŬń╗¤Ķ«ĪĶÉĮÕ£©Ķ┐ÖõĖ¬Õī║Õ¤¤õĖŁńÜäķéŻõ║øµĢ░Õ░▒ÕÅ»õ╗źõ║åŃĆé
ŃĆĆŃĆĆÕ«×ķÖģõĖŖ’╝īÕ”éµ×£õĖŹµś»
intµś»int64’╝īµłæõ╗¼ÕÅ»õ╗źń╗ÅĶ┐ć3µ¼ĪĶ┐ÖµĀĘńÜäÕłÆÕłåÕŹ│ÕÅ»ķÖŹõĮÄÕł░ÕÅ»õ╗źµÄźÕÅŚńÜäń©ŗÕ║”ŃĆéÕŹ│ÕÅ»õ╗źÕģłÕ░åint64ÕłåµłÉ2^24õĖ¬Õī║Õ¤¤’╝īńäČÕÉÄńĪ«Õ«ÜÕī║Õ¤¤ńÜäń¼¼ÕćĀÕż¦µĢ░’╝īÕ£©Õ░åĶ»źÕī║
Õ¤¤ÕłåµłÉ2^20õĖ¬ÕŁÉÕī║Õ¤¤’╝īńäČÕÉÄńĪ«Õ«Üµś»ÕŁÉÕī║Õ¤¤ńÜäń¼¼ÕćĀÕż¦µĢ░’╝īńäČÕÉÄÕŁÉÕī║Õ¤¤ķćīńÜäµĢ░ńÜäõĖ¬µĢ░ÕŬµ£ē2^20’╝īÕ░▒ÕÅ»õ╗źńø┤µÄźÕł®ńö©direct addr
tableĶ┐øĶĪīń╗¤Ķ«Īõ║åŃĆé
┬Ā
Õ»åÕīÖõĖē’╝ÜBloom filter/Bitmap
Bloom filter
Õģ│õ║Äõ╗Ćõ╣łµś»Bloom filter’╝īĶ»ĘÕÅéń£ŗµŁżµ¢ć’╝ܵĄĘķćŵĢ░µŹ«ÕżäńÉåõ╣ŗBloom FilterĶ»”Ķ¦ŻŃĆé
ŃĆĆŃĆĆķĆéńö©ĶīāÕø┤’╝ÜÕÅ»õ╗źńö©µØźÕ«×ńÄ░µĢ░µŹ«ÕŁŚÕģĖ’╝īĶ┐øĶĪīµĢ░µŹ«ńÜäÕłżķ插╝īµł¢ĶĆģķøåÕÉłµ▒éõ║żķøå
ŃĆĆŃĆĆÕ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝Ü
ŃĆĆ
ŃĆĆÕ»╣õ║ÄÕĤńÉåµØźĶ»┤ÕŠłń«ĆÕŹĢ’╝īõĮŹµĢ░ń╗ä+kõĖ¬ńŗ¼ń½ŗhashÕćĮµĢ░ŃĆéÕ░åhashÕćĮµĢ░Õ»╣Õ║öńÜäÕĆ╝ńÜäõĮŹµĢ░ń╗äńĮ«1’╝īµ¤źµēŠµŚČÕ”éµ×£ÕÅæńÄ░µēƵ£ēhashÕćĮµĢ░Õ»╣Õ║öõĮŹķāĮµś»1Ķ»┤µśÄÕŁśÕ£©’╝īÕŠłµśÄ
µśŠĶ┐ÖõĖ¬Ķ┐ćń©ŗÕ╣ČõĖŹõ┐ØĶ»üµ¤źµēŠńÜäń╗ōµ×£µś»100%µŁŻńĪ«ńÜäŃĆéÕÉīµŚČõ╣¤õĖŹµö»µīüÕłĀķÖżõĖĆõĖ¬ÕĘ▓ń╗ŵÅÆÕģźńÜäÕģ│ķö«ÕŁŚ’╝īÕøĀõĖ║Ķ»źÕģ│ķö«ÕŁŚÕ»╣Õ║öńÜäõĮŹõ╝ÜńēĄÕŖ©Õł░ÕģČõ╗¢ńÜäÕģ│ķö«ÕŁŚŃĆéµēĆõ╗źõĖĆõĖ¬ń«ĆÕŹĢńÜäµö╣Ķ┐ø
Õ░▒µś» counting Bloom filter’╝īńö©õĖĆõĖ¬counterµĢ░ń╗äõ╗Żµø┐õĮŹµĢ░ń╗ä’╝īÕ░▒ÕÅ»õ╗źµö»µīüÕłĀķÖżõ║åŃĆé
ŃĆĆŃĆĆĶ┐śµ£ēõĖĆõĖ¬µ»öĶŠāķćŹĶ”üńÜäķŚ«ķóś’╝īÕ”éõĮĢ
µĀ╣µŹ«ĶŠōÕģźÕģāń┤ĀõĖ¬µĢ░n’╝īńĪ«Õ«ÜõĮŹµĢ░ń╗ämńÜäÕż¦Õ░ÅÕÅŖhashÕćĮµĢ░õĖ¬µĢ░ŃĆéÕĮōhashÕćĮµĢ░õĖ¬µĢ░k=(ln2)*(m/n)µŚČķöÖĶ»»ńÄćµ£ĆÕ░ÅŃĆéÕ£©ķöÖĶ»»ńÄćõĖŹÕż¦õ║ÄEńÜäµāģÕåĄõĖŗ’╝īm
Ķć│Õ░æĶ”üńŁēõ║Än*lg(1/E)µēŹĶāĮĶĪ©ńż║õ╗╗µäÅnõĖ¬Õģāń┤ĀńÜäķøåÕÉłŃĆéõĮåmĶ┐śÕ║öĶ»źµø┤Õż¦õ║ø’╝īÕøĀõĖ║Ķ┐śĶ”üõ┐ØĶ»übitµĢ░ń╗äķćīĶć│Õ░æõĖĆÕŹŖõĖ║0’╝īÕłÖmÕ║öĶ»ź>=nlg(1
/E)*lge Õż¦µ”éÕ░▒µś»nlg(1/E)1.44ÕĆŹ(lgĶĪ©ńż║õ╗ź2õĖ║Õ║ĢńÜäÕ»╣µĢ░)ŃĆé
ŃĆĆŃĆĆõĖŠõĖ¬õŠŗÕŁÉµłæõ╗¼ÕüćĶ«ŠķöÖĶ»»ńÄćõĖ║0.01’╝īÕłÖµŁżµŚČmÕ║öÕż¦µ”鵜»nńÜä13ÕĆŹŃĆéĶ┐ÖµĀĘkÕż¦µ”鵜»8õĖ¬ŃĆé
ŃĆĆŃĆƵ│©µäÅĶ┐ÖķćīmõĖÄnńÜäÕŹĢõĮŹõĖŹÕÉī’╝īmµś»bitõĖ║ÕŹĢõĮŹ’╝īĶĆīnÕłÖµś»õ╗źÕģāń┤ĀõĖ¬µĢ░õĖ║ÕŹĢõĮŹ(ÕćåńĪ«ńÜäĶ»┤µś»õĖŹÕÉīÕģāń┤ĀńÜäõĖ¬µĢ░)ŃĆéķĆÜÕĖĖÕŹĢõĖ¬Õģāń┤ĀńÜäķĢ┐Õ║”ķāĮµś»µ£ēÕŠłÕżÜbitńÜäŃĆéµēĆõ╗źõĮ┐ńö©bloom filterÕåģÕŁśõĖŖķĆÜÕĖĖķāĮµś»ĶŖéń£üńÜäŃĆé
ŃĆĆŃĆƵē®Õ▒Ģ’╝Ü
ŃĆĆ
ŃĆĆBloom filterÕ░åķøåÕÉłõĖŁńÜäÕģāń┤ĀµśĀÕ░äÕł░õĮŹµĢ░ń╗äõĖŁ’╝īńö©k’╝łkõĖ║ÕōłÕĖīÕćĮµĢ░õĖ¬µĢ░’╝ēõĖ¬µśĀÕ░äõĮŹµś»ÕÉ”Õģ©1ĶĪ©ńż║Õģāń┤ĀÕ£©õĖŹÕ£©Ķ┐ÖõĖ¬ķøåÕÉłõĖŁŃĆéCounting
bloom filter’╝łCBF’╝ēÕ░åõĮŹµĢ░ń╗äõĖŁńÜäµ»ÅõĖĆõĮŹµē®Õ▒ĢõĖ║õĖĆõĖ¬counter’╝īõ╗ÄĶĆīµö»µīüõ║åÕģāń┤ĀńÜäÕłĀķÖżµōŹõĮ£ŃĆéSpectral Bloom
Filter’╝łSBF’╝ēÕ░åÕģČõĖÄķøåÕÉłÕģāń┤ĀńÜäÕć║ńÄ░µ¼ĪµĢ░Õģ│ĶüöŃĆéSBFķććńö©counterõĖŁńÜäµ£ĆÕ░ÅÕĆ╝µØźĶ┐æõ╝╝ĶĪ©ńż║Õģāń┤ĀńÜäÕć║ńÄ░ķóæńÄćŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬Ā12ŃĆüń╗ÖõĮĀA,BõĖżõĖ¬µ¢ćõ╗Č’╝īÕÉäÕŁśµöŠ50õ║┐µØĪURL’╝īµ»ÅµØĪURLÕŹĀńö©64ÕŁŚĶŖé’╝īÕåģÕŁśķÖÉÕłČµś»4G’╝īĶ«®õĮĀµēŠÕć║A,Bµ¢ćõ╗ČÕģ▒ÕÉīńÜäURLŃĆéÕ”éµ×£µś»õĖēõĖ¬õ╣āĶć│nõĖ¬µ¢ćõ╗ČÕæó’╝¤
ŃĆĆ ŃĆƵĀ╣µŹ«Ķ┐ÖõĖ¬ķŚ«ķ󜵳æõ╗¼µØźĶ«Īń«ŚõĖŗÕåģÕŁśńÜäÕŹĀńö©’╝ī4G=2^32Õż¦µ”鵜»40õ║┐*8Õż¦µ”鵜»340õ║┐’╝īn=50õ║┐’╝īÕ”éµ×£µīēÕć║ķöÖńÄć0.01ń«Śķ£ĆĶ”üńÜäÕż¦µ”鵜»650õ║┐õĖ¬ bitŃĆéńÄ░Õ£©ÕÅ»ńö©ńÜ䵜»340õ║┐’╝īńøĖÕĘ«Õ╣ČõĖŹÕżÜ’╝īĶ┐ÖµĀĘÕÅ»ĶāĮõ╝ÜõĮ┐Õć║ķöÖńÄćõĖŖÕŹćõ║øŃĆéÕÅ”Õż¢Õ”éµ×£Ķ┐Öõ║øurlipµś»õĖĆõĖĆÕ»╣Õ║öńÜä’╝īÕ░▒ÕÅ»õ╗źĶĮ¼µŹóµłÉip’╝īÕłÖÕż¦Õż¦ń«ĆÕŹĢõ║åŃĆé
┬Ā ┬Ā ÕÉīµŚČ’╝īõĖŖµ¢ćńÜäń¼¼5ķóś’╝Üń╗ÖÕ«ÜaŃĆübõĖżõĖ¬µ¢ćõ╗Č’╝īÕÉäÕŁśµöŠ50õ║┐õĖ¬url’╝īµ»ÅõĖ¬urlÕÉäÕŹĀ64ÕŁŚĶŖé’╝īÕåģÕŁśķÖÉÕłČµś»4G’╝īĶ«®õĮĀµēŠÕć║aŃĆübµ¢ćõ╗ČÕģ▒ÕÉīńÜäurl’╝¤Õ”éµ×£ÕģüĶ«Ėµ£ē õĖĆÕ«ÜńÜäķöÖĶ»»ńÄć’╝īÕÅ»õ╗źõĮ┐ńö©Bloom filter’╝ī4GÕåģÕŁśÕż¦µ”éÕÅ»õ╗źĶĪ©ńż║340õ║┐bitŃĆéÕ░åÕģČõĖŁõĖĆõĖ¬µ¢ćõ╗ČõĖŁńÜäurlõĮ┐ńö©Bloom filterµśĀÕ░äõĖ║Ķ┐Ö340õ║┐bit’╝īńäČÕÉĵī©õĖ¬Ķ»╗ÕÅ¢ÕÅ”Õż¢õĖĆõĖ¬µ¢ćõ╗ČńÜäurl’╝īµŻĆµ¤źµś»ÕÉ”õĖÄBloom filter’╝īÕ”éµ×£µś»’╝īķéŻõ╣łĶ»źurlÕ║öĶ»źµś»Õģ▒ÕÉīńÜäurl’╝łµ│©µäÅõ╝ܵ£ēõĖĆÕ«ÜńÜäķöÖĶ»»ńÄć’╝ēŃĆé
Bitmap
┬Ā ┬Ā Ķć│õ║Äõ╗Ćõ╣łµś»Bitmap’╝īĶ»Ęń£ŗµŁżµ¢ć’╝Ühttp://blog.csdn.net/v_july_v/article/details/6685962ŃĆéõĖŗķØóÕģ│õ║ÄBitmapńÜäÕ║öńö©’╝īńø┤µÄźõĖŖķóś’╝īÕ”éõĖŗń¼¼9ŃĆü10ķüō’╝Ü
┬Ā┬Ā┬Ā┬Ā┬Ā 13ŃĆüÕ£©2.5õ║┐õĖ¬µĢ┤µĢ░õĖŁµēŠÕć║õĖŹķćŹÕżŹńÜäµĢ┤µĢ░’╝īµ│©’╝īÕåģÕŁśõĖŹĶČ│õ╗źÕ«╣ń║│Ķ┐Ö2.5õ║┐õĖ¬µĢ┤µĢ░ŃĆé
┬Ā
┬Ā µ¢╣µĪł1’╝Üķććńö©2-Bitmap’╝łµ»ÅõĖ¬µĢ░ÕłåķģŹ2bit’╝ī00ĶĪ©ńż║õĖŹÕŁśÕ£©’╝ī01ĶĪ©ńż║Õć║ńÄ░õĖƵ¼Ī’╝ī10ĶĪ©ńż║ÕżÜµ¼Ī’╝ī11µŚĀµäÅõ╣ē’╝ēĶ┐øĶĪī’╝īÕģ▒ķ£ĆÕåģÕŁś2^32 * 2
bit=1
GBÕåģÕŁś’╝īĶ┐śÕÅ»õ╗źµÄźÕÅŚŃĆéńäČÕÉĵē½µÅÅĶ┐Ö2.5õ║┐õĖ¬µĢ┤µĢ░’╝īµ¤źń£ŗBitmapõĖŁńøĖÕ»╣Õ║öõĮŹ’╝īÕ”éµ×£µś»00ÕÅś01’╝ī01ÕÅś10’╝ī10õ┐صīüõĖŹÕÅśŃĆéµēƵÅÅÕ«īõ║ŗÕÉÄ’╝īµ¤źń£ŗ
bitmap’╝īµŖŖÕ»╣Õ║öõĮŹµś»01ńÜäµĢ┤µĢ░ĶŠōÕć║ÕŹ│ÕÅ»ŃĆé
┬Ā ┬Ā µ¢╣µĪł2’╝Üõ╣¤ÕÅ»ķććńö©õĖÄń¼¼1ķóśń▒╗õ╝╝ńÜäµ¢╣µ│Ģ’╝īĶ┐øĶĪīÕłÆÕłåÕ░ŵ¢ćõ╗ČńÜäµ¢╣µ│ĢŃĆéńäČÕÉÄÕ£©Õ░ŵ¢ćõ╗ČõĖŁµēŠÕć║õĖŹķćŹÕżŹńÜäµĢ┤µĢ░’╝īÕ╣ȵÄÆÕ║ÅŃĆéńäČÕÉÄÕåŹĶ┐øĶĪīÕĮÆÕ╣Č’╝īµ│©µäÅÕÄ╗ķÖżķćŹÕżŹńÜäÕģāń┤ĀŃĆé
┬Ā┬Ā┬Ā┬Ā┬Ā 14ŃĆüĶģŠĶ«»ķØóĶ»Ģķóś’╝Üń╗Ö40õ║┐õĖ¬õĖŹķćŹÕżŹńÜäunsigned intńÜäµĢ┤µĢ░’╝īµ▓ĪµÄÆĶ┐ćÕ║ÅńÜä’╝īńäČÕÉÄÕåŹń╗ÖõĖĆõĖ¬µĢ░’╝īÕ”éõĮĢÕ┐½ķĆ¤Õłżµ¢ŁĶ┐ÖõĖ¬µĢ░µś»Õɔգ©ķéŻ40õ║┐õĖ¬µĢ░ÕĮōõĖŁ’╝¤
┬Ā ┬Ā µ¢╣µĪł1’╝Üfrome oo’╝īńö©õĮŹÕøŠ/BitmapńÜäµ¢╣µ│Ģ’╝īńö│Ķ»Ę512MńÜäÕåģÕŁś’╝īõĖĆõĖ¬bitõĮŹõ╗ŻĶĪ©õĖĆõĖ¬unsigned intÕĆ╝ŃĆéĶ»╗Õģź40õ║┐õĖ¬µĢ░’╝īĶ«ŠńĮ«ńøĖÕ║öńÜäbitõĮŹ’╝īĶ»╗ÕģźĶ”üµ¤źĶ»óńÜäµĢ░’╝īµ¤źń£ŗńøĖÕ║öbitõĮŹµś»ÕÉ”õĖ║1’╝īõĖ║1ĶĪ©ńż║ÕŁśÕ£©’╝īõĖ║0ĶĪ©ńż║õĖŹÕŁśÕ£©ŃĆé
Õ»åÕīÖÕøøŃĆüTrieµĀæ/µĢ░µŹ«Õ║ō/ÕĆƵÄÆń┤óÕ╝Ģ
TrieµĀæ
ŃĆĆŃĆĆķĆéńö©ĶīāÕø┤’╝ܵĢ░µŹ«ķćÅÕż¦’╝īķćŹÕżŹÕżÜ’╝īõĮåµś»µĢ░µŹ«ń¦Źń▒╗Õ░ÅÕÅ»õ╗źµöŠÕģźÕåģÕŁś
ŃĆĆŃĆĆÕ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝ÜÕ«×ńÄ░µ¢╣Õ╝Å’╝īĶŖéńé╣ÕŁ®ÕŁÉńÜäĶĪ©ńż║µ¢╣Õ╝Å
ŃĆĆŃĆƵē®Õ▒Ģ’╝ÜÕÄŗń╝®Õ«×ńÄ░ŃĆé
ŃĆĆŃĆĆķŚ«ķóśÕ«×õŠŗ’╝Ü
- µ£ē10õĖ¬µ¢ćõ╗Č’╝īµ»ÅõĖ¬µ¢ćõ╗Č1G’╝īµ»ÅõĖ¬µ¢ćõ╗ČńÜäµ»ÅõĖĆĶĪīķāĮÕŁśµöŠńÜ䵜»ńö©µłĘńÜäquery’╝īµ»ÅõĖ¬µ¢ćõ╗ČńÜäqueryķāĮÕÅ»ĶāĮķćŹÕżŹŃĆéĶ”üõĮĀµīēńģ¦queryńÜäķóæÕ║”µÄÆÕ║ÅŃĆé
- 1000õĖćÕŁŚń¼”õĖ▓’╝īÕģČõĖŁµ£ēõ║øµś»ńøĖÕÉīńÜä(ķćŹÕżŹ),ķ£ĆĶ”üµŖŖķćŹÕżŹńÜäÕģ©ķā©ÕÄ╗µÄē’╝īõ┐ØńĢÖµ▓Īµ£ēķćŹÕżŹńÜäÕŁŚń¼”õĖ▓ŃĆéĶ»ĘķŚ«µĆÄõ╣łĶ«ŠĶ«ĪÕÆīÕ«×ńÄ░’╝¤
- Õ»╗µēŠńāŁķŚ©µ¤źĶ»ó’╝ܵ¤źĶ»óõĖ▓ńÜäķćŹÕżŹÕ║”µ»öĶŠāķ½ś’╝īĶÖĮńäȵĆ╗µĢ░µś»1ÕŹāõĖć’╝īõĮåÕ”éµ×£ķÖżÕÄ╗ķćŹÕżŹÕÉÄ’╝īõĖŹĶČģĶ┐ć3ńÖŠõĖćõĖ¬’╝īµ»ÅõĖ¬õĖŹĶČģĶ┐ć255ÕŁŚĶŖéŃĆé
- õĖŖķØóńÜäń¼¼8ķóś’╝ÜõĖĆõĖ¬µ¢ćµ£¼µ¢ćõ╗Č’╝īÕż¦ń║”µ£ēõĖĆõĖćĶĪī’╝īµ»ÅĶĪīõĖĆõĖ¬Ķ»Ź’╝īĶ”üµ▒éń╗¤Ķ«ĪÕć║ÕģČõĖŁµ£Ćķóæń╣üÕć║ńÄ░ńÜäÕēŹ10õĖ¬Ķ»ŹŃĆéÕģČĶ¦ŻÕå│µ¢╣µ│Ģµś»’╝Üńö©trieµĀæń╗¤Ķ«Īµ»ÅõĖ¬Ķ»ŹÕć║ńÄ░ńÜäµ¼ĪµĢ░’╝īµŚČķŚ┤ÕżŹµØéÕ║”µś»O(n*le)’╝łleĶĪ©ńż║ÕŹĢĶ»ŹńÜäÕ╣│ÕćåķĢ┐Õ║”’╝ē’╝īńäČÕÉĵś»µēŠÕć║Õć║ńÄ░µ£Ćķóæń╣üńÜäÕēŹ10õĖ¬Ķ»ŹŃĆé
┬Ā ┬Ā µø┤ÕżÜµ£ēÕģ│TrieµĀæńÜäõ╗ŗń╗Ź’╝īĶ»ĘÕÅéĶ¦üµŁżµ¢ć’╝Üõ╗ÄTrieµĀæ’╝łÕŁŚÕģĖµĀæ’╝ēĶ░łÕł░ÕÉÄń╝ƵĀæŃĆé
µĢ░µŹ«Õ║ōń┤óÕ╝Ģ
ŃĆĆŃĆĆķĆéńö©ĶīāÕø┤’╝ÜÕż¦µĢ░µŹ«ķćÅńÜäÕó×ÕłĀµö╣µ¤ź
ŃĆĆŃĆĆÕ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝ÜÕł®ńö©µĢ░µŹ«ńÜäĶ«ŠĶ«ĪÕ«×ńÄ░µ¢╣µ│Ģ’╝īÕ»╣µĄĘķćŵĢ░µŹ«ńÜäÕó×ÕłĀµö╣µ¤źĶ┐øĶĪīÕżäńÉåŃĆé
┬Ā ┬Ā Õģ│õ║ĵĢ░µŹ«Õ║ōń┤óÕ╝ĢÕÅŖÕģČõ╝śÕī¢’╝īµø┤ÕżÜÕÅ»ÕÅéĶ¦üµŁżµ¢ć’╝Ühttp://www.cnblogs.com/pkuoliver/archive/2011/08/17/mass-data-topic-7-index-and-optimize.htmlŃĆéÕÉīµŚČ’╝īÕģ│õ║ÄMySQLń┤óÕ╝ĢĶāīÕÉÄńÜäµĢ░µŹ«ń╗ōµ×äÕÅŖń«Śµ│ĢÕĤńÉå’╝īĶ┐ÖķćīĶ┐śµ£ēõĖĆń»ćÕŠłÕźĮńÜäµ¢ćń½Ā’╝Ühttp://www.codinglabs.org/html/theory-of-mysql-index.htmlŃĆé
ÕĆƵÄÆń┤óÕ╝Ģ(Inverted index)
ŃĆĆŃĆĆķĆéńö©ĶīāÕø┤’╝ܵɣń┤óÕ╝ĢµōÄ’╝īÕģ│ķö«ÕŁŚµ¤źĶ»ó
ŃĆĆŃĆĆÕ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝ÜõĖ║õĮĢÕŽÕĆƵÄÆń┤óÕ╝Ģ’╝¤õĖĆń¦Źń┤óÕ╝Ģµ¢╣µ│Ģ’╝īĶó½ńö©µØźÕŁśÕé©Õ£©Õģ©µ¢ćµÉ£ń┤óõĖŗµ¤ÉõĖ¬ÕŹĢĶ»ŹÕ£©õĖĆõĖ¬µ¢ćµĪŻµł¢ĶĆģõĖĆń╗äµ¢ćµĪŻõĖŁńÜäÕŁśÕé©õĮŹńĮ«ńÜ䵜ĀÕ░äŃĆé
ŃĆĆõ╗źĶŗ▒µ¢ćõĖ║õŠŗ’╝īõĖŗķØ󵜻Ķ”üĶó½ń┤óÕ╝ĢńÜäµ¢ćµ£¼’╝Ü
┬Ā ┬Ā T0 = "it is what it is"
┬Ā ┬Ā T1 = "what is it"
┬Ā ┬Ā T2 = "it is a banana"
┬Ā ┬Ā µłæõ╗¼Õ░▒ĶāĮÕŠŚÕł░õĖŗķØóńÜäÕÅŹÕÉæµ¢ćõ╗Čń┤óÕ╝Ģ’╝Ü
┬Ā ┬Ā "a": ┬Ā ┬Ā ┬Ā{2}
┬Ā ┬Ā "banana": {2}
┬Ā ┬Ā "is": ┬Ā ┬Ā {0, 1, 2}
┬Ā ┬Ā "it": ┬Ā ┬Ā {0, 1, 2}
┬Ā ┬Ā "what": ┬Ā {0, 1}
ŃĆƵŻĆń┤óńÜäµØĪõ╗Č"what","is"ÕÆī"it"Õ░åÕ»╣Õ║öķøåÕÉłńÜäõ║żķøåŃĆé
ŃĆĆ
ŃĆƵŁŻÕÉæń┤óÕ╝ĢÕ╝ĆÕÅæÕć║µØźńö©µØźÕŁśÕ驵»ÅõĖ¬µ¢ćµĪŻńÜäÕŹĢĶ»ŹńÜäÕłŚĶĪ©ŃĆ鵣ŻÕÉæń┤óÕ╝ĢńÜ䵤źĶ»óÕŠĆÕŠĆµ╗ĪĶČ│µ»ÅõĖ¬µ¢ćµĪŻµ£ēÕ║Åķóæń╣üńÜäÕģ©µ¢ćµ¤źĶ»óÕÆīµ»ÅõĖ¬ÕŹĢĶ»ŹÕ£©µĀĪķ¬īµ¢ćµĪŻõĖŁńÜäķ¬īĶ»üĶ┐ÖµĀĘńÜ䵤źĶ»óŃĆéÕ£©µŁŻÕÉæń┤ó
Õ╝ĢõĖŁ’╝īµ¢ćµĪŻÕŹĀµŹ«õ║åõĖŁÕ┐āńÜäõĮŹńĮ«’╝īµ»ÅõĖ¬µ¢ćµĪŻµīćÕÉæõ║åõĖĆõĖ¬Õ«āµēĆÕīģÕɽńÜäń┤óÕ╝ĢķĪ╣ńÜäÕ║ÅÕłŚŃĆéõ╣¤Õ░▒µś»Ķ»┤µ¢ćµĪŻµīćÕÉæõ║åÕ«āÕīģÕɽńÜäķéŻõ║øÕŹĢĶ»Ź’╝īĶĆīÕÅŹÕÉæń┤óÕ╝ĢÕłÖµś»ÕŹĢĶ»ŹµīćÕÉæõ║åÕīģÕɽիāńÜäµ¢ćµĪŻ’╝ī
ÕŠłÕ«╣µśōń£ŗÕł░Ķ┐ÖõĖ¬ÕÅŹÕÉæńÜäÕģ│ń│╗ŃĆé
ŃĆĆŃĆƵē®Õ▒Ģ’╝Ü
ŃĆĆŃĆĆķŚ«ķóśÕ«×õŠŗ’╝ܵ¢ćµĪŻµŻĆń┤óń│╗ń╗¤’╝īµ¤źĶ»óķéŻõ║øµ¢ćõ╗ČÕīģÕɽõ║嵤ÉÕŹĢĶ»Ź’╝īµ»öÕ”éÕĖĖĶ¦üńÜäÕŁ”µ£»Ķ«║µ¢ćńÜäÕģ│ķö«ÕŁŚµÉ£ń┤óŃĆé
┬Ā ┬Ā Õģ│õ║ÄÕĆƵÄÆń┤óÕ╝ĢńÜäÕ║öńö©’╝īµø┤ÕżÜĶ»ĘÕÅéĶ¦ü’╝Üń¼¼õ║īÕŹüõĖēŃĆüÕøøń½Ā’╝ܵةµ░Åń¤®ķśĄµ¤źµēŠ’╝īÕĆƵÄÆń┤óÕ╝ĢÕģ│ķö«Ķ»ŹHashõĖŹķćŹÕżŹń╝¢ńĀüÕ«×ĶĘĄ’╝īÕÅŖń¼¼õ║īÕŹüÕģŁń½Ā’╝ÜÕ¤║õ║Äń╗ÖÕ«ÜńÜäµ¢ćµĪŻńö¤µłÉÕĆƵÄÆń┤óÕ╝ĢńÜäń╝¢ńĀüõĖÄÕ«×ĶĘĄŃĆé
Õ»åÕīÖõ║öŃĆüÕż¢µÄÆÕ║Å
ŃĆĆŃĆĆķĆéńö©ĶīāÕø┤’╝ÜÕż¦µĢ░µŹ«ńÜäµÄÆÕ║Å’╝īÕÄ╗ķćŹ
ŃĆĆŃĆĆÕ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝ÜÕż¢µÄÆÕ║ÅńÜäÕĮÆÕ╣ȵ¢╣µ│Ģ’╝īńĮ«µŹóķĆēµŗ®Ķ┤źĶĆģµĀæÕĤńÉå’╝īµ£Ćõ╝śÕĮÆÕ╣ȵĀæ
ŃĆĆŃĆƵē®Õ▒Ģ’╝Ü
ŃĆĆŃĆĆķŚ«ķóśÕ«×õŠŗ’╝Ü
ŃĆĆŃĆĆ1).µ£ēõĖĆõĖ¬1GÕż¦Õ░ÅńÜäõĖĆõĖ¬µ¢ćõ╗Č’╝īķćīķØóµ»ÅõĖĆĶĪīµś»õĖĆõĖ¬Ķ»Ź’╝īĶ»ŹńÜäÕż¦Õ░ÅõĖŹĶČģĶ┐ć16õĖ¬ÕŁŚĶŖé’╝īÕåģÕŁśķÖÉÕłČÕż¦Õ░ŵś»1MŃĆéĶ┐öÕø×ķóæµĢ░µ£Ćķ½śńÜä100õĖ¬Ķ»ŹŃĆé
ŃĆĆŃĆĆĶ┐ÖõĖ¬µĢ░µŹ«Õģʵ£ēÕŠłµśÄµśŠńÜäńē╣ńé╣’╝īĶ»ŹńÜäÕż¦Õ░ÅõĖ║16õĖ¬ÕŁŚĶŖé’╝īõĮåµś»ÕåģÕŁśÕŬµ£ē1MÕüÜhashµśÄµśŠõĖŹÕż¤’╝īµēĆõ╗źÕÅ»õ╗źńö©µØźµÄÆÕ║ÅŃĆéÕåģÕŁśÕÅ»õ╗źÕĮōĶŠōÕģźń╝ōÕå▓Õī║õĮ┐ńö©ŃĆé
┬Ā ┬Ā Õģ│õ║ÄÕżÜĶĘ»ÕĮÆÕ╣Čń«Śµ│ĢÕÅŖÕż¢µÄÆÕ║ÅńÜäÕģĘõĮōÕ║öńö©Õ£║µÖ»’╝īĶ»ĘÕÅéĶ¦üµŁżµ¢ć’╝Üń¼¼ÕŹüń½ĀŃĆüÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║ÅŃĆé
Õ»åÕīÖÕģŁŃĆüÕłåÕĖāÕ╝ÅÕżäńÉåõ╣ŗMapreduce
┬Ā ┬Ā ┬Ā ķĆéńö©ĶīāÕø┤’╝ܵĢ░µŹ«ķćÅÕż¦’╝īõĮåµś»µĢ░µŹ«ń¦Źń▒╗Õ░ÅÕÅ»õ╗źµöŠÕģźÕåģÕŁś
ŃĆĆŃĆĆÕ¤║µ£¼ÕĤńÉåÕÅŖĶ”üńé╣’╝ÜÕ░åµĢ░µŹ«õ║żń╗ÖõĖŹÕÉīńÜäµ£║ÕÖ©ÕÄ╗ÕżäńÉå’╝īµĢ░µŹ«ÕłÆÕłå’╝īń╗ōµ×£ÕĮÆń║”ŃĆé
ŃĆĆŃĆƵē®Õ▒Ģ’╝Ü
ŃĆĆŃĆĆķŚ«ķóśÕ«×õŠŗ’╝Ü
- The canonical example application of MapReduce is a process to count the appearances of each different word in a set of documents:
- µĄĘķćŵĢ░µŹ«ÕłåÕĖāÕ£©100ÕÅ░ńöĄĶäæõĖŁ’╝īµā│õĖ¬ÕŖ×µ│Ģķ½śµĢłń╗¤Ķ«ĪÕć║Ķ┐Öµē╣µĢ░µŹ«ńÜäTOP10ŃĆé
- õĖĆÕģ▒µ£ēNõĖ¬µ£║ÕÖ©’╝īµ»ÅõĖ¬µ£║ÕÖ©õĖŖµ£ēNõĖ¬µĢ░ŃĆéµ»ÅõĖ¬µ£║ÕÖ©µ£ĆÕżÜÕŁśO(N)õĖ¬µĢ░Õ╣ČÕ»╣Õ«āõ╗¼µōŹõĮ£ŃĆéÕ”éõĮĢµēŠÕł░N^2õĖ¬µĢ░ńÜäõĖŁµĢ░(median)’╝¤
┬Ā ┬Ā µø┤ÕżÜÕģĘõĮōķśÉĶ┐░Ķ»ĘÕÅéĶ¦ü’╝Üõ╗ÄHadhoopµĪåµ×ČõĖÄMapReduceµ©ĪÕ╝ÅõĖŁĶ░łµĄĘķćŵĢ░µŹ«ÕżäńÉå’╝īÕÅŖMapReduceµŖƵ£»ńÜäÕłØµŁźõ║åĶ¦ŻõĖÄÕŁ”õ╣ĀŃĆé
ÕÅéĶĆāµ¢ćńī«
- ÕŹüķüōµĄĘķćŵĢ░µŹ«ÕżäńÉåķØóĶ»ĢķóśõĖÄÕŹüõĖ¬µ¢╣µ│ĢÕż¦µĆ╗ń╗ō’╝ø
- µĄĘķćŵĢ░µŹ«ÕżäńÉåķØóĶ»Ģķóśķøåķö”õĖÄBit-mapĶ»”Ķ¦Ż’╝ø
- ÕŹüõĖĆŃĆüõ╗ÄÕż┤Õł░Õ░ŠÕĮ╗Õ║ĢĶ¦Żµ×ÉHashĶĪ©ń«Śµ│Ģ’╝ø
- µĄĘķćŵĢ░µŹ«ÕżäńÉåõ╣ŗBloom FilterĶ»”Ķ¦Ż’╝ø
- õ╗ÄTrieµĀæ’╝łÕŁŚÕģĖµĀæ’╝ēĶ░łÕł░ÕÉÄń╝ƵĀæ’╝ø
- ń¼¼õĖēń½Āń╗ŁŃĆüTop Kń«Śµ│ĢķŚ«ķóśńÜäÕ«×ńÄ░’╝ø
- ń¼¼ÕŹüń½ĀŃĆüÕ”éõĮĢń╗Ö10^7õĖ¬µĢ░µŹ«ķćÅńÜäńŻüńøśµ¢ćõ╗ȵÄÆÕ║Å’╝ø
- ń¼¼õ║īÕŹüõĖēŃĆüÕøøń½Ā’╝ܵةµ░Åń¤®ķśĄµ¤źµēŠ’╝īÕĆƵÄÆń┤óÕ╝ĢÕģ│ķö«Ķ»ŹHashõĖŹķćŹÕżŹń╝¢ńĀüÕ«×ĶĘĄ’╝ø
- ń¼¼õ║īÕŹüÕģŁń½Ā’╝ÜÕ¤║õ║Äń╗ÖÕ«ÜńÜäµ¢ćµĪŻńö¤µłÉÕĆƵÄÆń┤óÕ╝ĢńÜäń╝¢ńĀüõĖÄÕ«×ĶĘĄ’╝ø
- õ╗ÄHadhoopµĪåµ×ČõĖÄMapReduceµ©ĪÕ╝ÅõĖŁĶ░łµĄĘķćŵĢ░µŹ«ÕżäńÉå’╝ø
- ń¼¼ÕŹüÕģŁ~ń¼¼õ║īÕŹüń½Ā’╝ÜÕģ©µÄÆÕłŚ’╝īĶĘ│ÕÅ░ķśČ’╝īÕźćÕüȵÄÆÕ║Å’╝īń¼¼õĖĆõĖ¬ÕŬÕć║ńÄ░õĖƵ¼ĪńŁēķŚ«ķóś’╝ø
- http://blog.csdn.net/v_JULY_v/article/category/774945’╝ø
- STLµ║ÉńĀüÕē¢µ×Éń¼¼õ║öń½Ā’╝īõŠ»µŹĘĶæŚŃĆé
ÕÉÄĶ«░


- 2012-03-28 13:29
- µĄÅĶ¦ł 762
- Ķ»äĶ«║(0)
- Õłåń▒╗:µĢ░µŹ«Õ║ō
- µ¤źń£ŗµø┤ÕżÜ
ÕÅæĶĪ©Ķ»äĶ«║

-
fetchSize and batchSize
2013-04-22 09:30 1341ĶĮ¼õĖĆõĖ¬µø┤Ķ»”ń╗åńÜä’╝Ü hibernate.jdbc.fetch_ ... -
Õ║ÅÕłŚÕī¢
2013-04-18 09:16 643ÕĮōõĖżõĖ¬Ķ┐øń©ŗÕ£©Ķ┐øĶĪīĶ┐£ń©ŗķĆÜõ┐ĪµŚČ’╝īÕĮ╝µŁżÕÅ»õ╗źÕÅæķĆüÕÉäń¦Źń▒╗Õ×ŗńÜäµĢ░µŹ«ŃĆ鵌ĀĶ«║µś» ... -
Õ╝Ģńö©ń▒╗Õ×ŗ
2013-04-17 14:29 628JavaõĖŁńÜäÕ»╣Ķ▒ĪÕ╝Ģńö©õĖ╗Ķ”üµ£ ... -
ń©ŗń½ŗĶ░łµ×ȵ×äŃĆüµĢŵŹĘÕÆīSOAÕ«×ĶĘĄ
2013-04-02 15:36 728µŹ«µö»õ╗śÕ«ØÕģ¼ÕÅĖÕ«śµ¢╣µĢ░µŹ«’╝īµł¬µŁóÕł░2008Õ╣┤5µ£ł6µŚź’╝īõĮ┐ńö©µö»õ╗śÕ«Ø ... -
svnõĖēµŁź
2013-03-13 11:30 482µÉŁÕ╗║SVNµ£ŹÕŖĪ’╝īµ£ēµĢłńÜäń«ĪńÉåõ╗ŻńĀü’╝īõ╗źõĖŗõĖēµŁźÕÅ»õ╗źÕ┐½ķƤµÉ×Õ«ÜŃĆé1ŃĆü ... -
MemcachedÕłåÕĖāÕ╝ÅĶ»”Ķ¦Ż
2013-03-06 18:00 622MemcachedÕłåÕĖāÕ╝Åń«Śµ│ĢÕ£©ńĮæõĖŖõĖĆµÉ£ÕÅ»õ╗źµēŠÕł░õĖĆÕż¦ńēćõ║å’╝īõĖŹĶ┐ć ... -
java
2013-03-04 11:27 579ĶČŖµØźĶČŖÕżÜõ║║Õ╝ĆÕ¦ŗõĮ┐ńö©Ja ... -
Linux ńø«ÕĮĢń╗ōµ×ä
2013-01-16 10:50 657Õ»╣õ║ĵ»ÅõĖĆõĖ¬LinuxÕŁ”õ╣ĀĶĆģµØźĶ»┤’╝īõ║åĶ¦ŻLinuxµ¢ćõ╗Čń│╗ń╗¤ńÜäńø«ÕĮĢ ... -
gzipÕæĮõ╗ż
2013-01-16 10:47 710ÕćÅÕ░æµ¢ćõ╗ČÕż¦Õ░ŵ£ēõĖżõĖ¬µśÄµśŠńÜäÕźĮÕżä’╝īõĖƵś»ÕÅ»õ╗źÕćÅÕ░æÕŁśÕé©ń®║ķŚ┤’╝īõ║īµś»ķĆÜĶ┐ć ... -
ńö▒12306.cnĶ░łĶ░łńĮæń½ÖµĆ¦ĶāĮµŖƵ£»
2012-01-16 10:18 62912306.cnńĮæń½Öµīéõ║å’╝īĶó½Õģ©Õø ...
ńøĖÕģ│µÄ©ĶŹÉ
ŃĆŖPower Queryńö©ExcelńÄ®ĶĮ¼ÕĢåõĖܵÖ║ĶāĮµĢ░µŹ«ÕżäńÉåŃĆŗµś»õĖƵ£¼õĖōõĖ║µĢ░µŹ«Õłåµ×Éńł▒ÕźĮĶĆģÕÆīõĖōõĖÜõ║║ÕŻ½µēōķĆĀńÜäÕģźķŚ©µīćÕŹŚ’╝īÕ«āĶ»”Õ░ĮÕ£░ķśÉĶ┐░õ║åÕ”éõĮĢÕł®ńö©Power QueryĶ┐ÖõĖĆÕ╝║Õż¦ńÜäÕĘźÕģĘĶ┐øĶĪīķ½śµĢłńÜäµĢ░µŹ«ÕżäńÉåÕÆīÕĢåõĖܵÖ║ĶāĮÕłåµ×ÉŃĆéPower Query’╝īõĮ£õĖ║Microsoft ...
ŌĆ£µĄŗķćÅÕŖ®µēŗŌĆöÕÅśÕĮóńøæµĄŗµĢ░µŹ«ÕżäńÉåŌĆØĶĮ»õ╗ČÕ£©õŠ┐µÉ║Õ╝ŵł¢ÕÅ░Õ╝ÅÕŠ«µ£║ńÜäWindowsńÄ»ÕóāõĖŗĶ┐ÉĶĪī’╝īõĖ╗Ķ”üńö©õ║ÄÕÅśÕĮóńøæµĄŗÕĘźõĮ£ńÜäµĢ░µŹ«ÕżäńÉåŃĆéÕŻջ╣ńöĄÕŁÉÕģ©ń½Öõ╗¬’╝łTPS’╝ēŃĆüńöĄÕŁÉµ░┤Õćåõ╗¬(ELI)õ╗źÕÅŖÕĖĖĶ¦äÕ£░ķØóńöĄÕŁÉµĄŗķćÅõ╗¬ÕÖ©Ķć¬ÕŖ©Ķ«░ÕĮĢńÜäÕÅśÕĮóńøæµĄŗÕĤզŗĶ¦éµĄŗµĢ░µŹ«...
ŃĆŖÕł½Ķ»┤õĮĀµćéExcel’╝Ü500µŗøńÄ®ĶĮ¼ExcelĶĪ©µĀ╝õĖĵĢ░µŹ«ÕżäńÉåŃĆŗµś»õĖƵ£¼Õģ©ķØóõ╗ŗń╗ŹExcelÕ£©µĢ░µŹ«ń«ĪńÉåÕÆīÕłåµ×ÉķóåÕ¤¤ńÜäÕ«×ńö©µīćÕŹŚŃĆéĶ┐Öµ£¼õ╣”µŚ©Õ£©ķĆÜĶ┐ć500õĖ¬µŖĆÕʦÕÆīÕ«×õŠŗ’╝īÕĖ«ÕŖ®Ķ»╗ĶĆģµÄīµÅĪExcelńÜäÕÉäń¦ŹÕŖ¤ĶāĮ’╝īµÅÉÕŹćµĢ░µŹ«ÕżäńÉåµĢłńÄćŃĆéõ╣”õĖŁķÖäÕĖ”ńÜäÕ«īµĢ┤ÕģēńøśµĢ░µŹ«...
ŃĆŖńē®µÄóµĢ░µŹ«ÕżäńÉå’╝ܵĘ▒ÕģźĶ¦Żµ×ÉķćŹńŻüµĢ░µŹ«ÕżäńÉåĶĮ»õ╗ČŃĆŗ Õ£©Õ£░Ķ┤©ÕŗśµÄóķóåÕ¤¤’╝īķćŹńŻüµĢ░µŹ«ÕżäńÉåĶĮ»õ╗ȵē«µ╝öńØĆĶć│Õģ│ķćŹĶ”üńÜäĶ¦ÆĶē▓ŃĆ鵣żń▒╗ĶĮ»õ╗ČõĖōõĖ║ÕżäńÉåÕ£░ńÉāńē®ńÉåµĢ░µŹ«õĖŁńÜäķćŹÕŖøÕÆīńŻüÕ£║µĢ░µŹ«ĶĆīĶ«ŠĶ«Ī’╝īµŚ©Õ£©µÅŁńż║Õ£░ÕŻ│ń╗ōµ×ä’╝īÕ»╗µēŠń¤┐õ║¦ĶĄäµ║É’╝īõ╗źÕÅŖĶ┐øĶĪīÕ£░Ķ┤©ńüŠÕ«│...
### Ķ»”ń╗åńÜäMODISµĢ░µŹ«ÕżäńÉåµĄüń©ŗ #### õĖĆŃĆüµ”éĶ┐░ MODIS (Moderate Resolution Imaging Spectroradiometer) µś»õĖĆń¦ŹÕ£©Õ£░ńÉāĶ¦éµĄŗÕŹ½µś¤õĖŖµÉŁĶĮĮńÜäÕżÜÕģēĶ░▒µłÉÕāÅõ╗¬ÕÖ©’╝īÕ╣┐µ│øÕ║öńö©õ║ÄÕż¦µ░öŃĆüķÖåÕ£░ŃĆüµĄĘµ┤ŗńŁēńÄ»ÕóāńøæµĄŗķóåÕ¤¤ŃĆéMODISµĢ░µŹ«ÕżäńÉåµś»...
µĢ┤õĖ¬Landsat 8µĢ░µŹ«ÕżäńÉåµĄüń©ŗĶ”üµ▒éńö©µłĘń夵éēENVIĶĮ»õ╗ČńÜäÕ¤║µ£¼µōŹõĮ£ÕÆīķüźµä¤ÕøŠÕāÅÕżäńÉåńÜäńøĖÕģ│µ”éÕ┐Ą’╝īÕÉīµŚČõ╣¤ķ£ĆĶ”üÕ»╣Landsat 8ÕŹ½µś¤ńÜäõ╝Āµä¤ÕÖ©ńē╣µĆ¦ÕÆīµĢ░µŹ«õ║¦Õōüń▒╗Õ×ŗµ£ēµēĆõ║åĶ¦ŻŃĆéÕżäńÉåÕ«īµłÉńÜäµĢ░µŹ«ÕÅ»õ╗źńö©õ║ÄÕÉäń¦ŹÕ£░ĶĪ©ńøæµĄŗŃĆüńÄ»ÕóāĶ»äõ╝░õ╗źÕÅŖĶĄäµ║Éń«ĪńÉåńŁē...
ÕÅ»Õ░åµĢ░µŹ«õ╗ÄÕŁŚń¼”Õ×ŗĶĮ¼µŹóõĖ║µĢ░ÕĆ╝’╝īÕŹüÕłåµ¢╣õŠ┐’╝īÕīģµŗ¼Ķ┤¤µĢ░Õ░ŵĢ░Õ”échar 1.3Õ×ŗÕÅ»ĶĮ¼µŹóõĖ║doubleÕ×ŗ1.3Õ£©µĢ░µŹ«ÕżäńÉåõĖŁķØ×ÕĖĖÕźĮńö©
Õż®Õ«ØDiNi03µĢ░µŹ«ÕżäńÉåĶĮ»õ╗ČõĮ┐ńö©Ķ»┤µśÄ’╝Ü1.µ£¼ń©ŗÕ║ÅÕŬķĆéńö©õ║ÄÕż®Õ«ØDiNi03ńöĄÕŁÉµ░┤Õćåõ╗¬µĄŗÕŠŚńÜäń║┐ĶĘ»µ░┤ÕćåµĢ░µŹ«ÕżäńÉåŃĆé2.ń©ŗÕ║ÅĶāĮĶć¬ÕŖ©ÕēöķÖżĶČģķÖɵĢ░µŹ«ÕÅŖõĖŹÕÉłµĀ╝µĢ░µŹ«┬Ā’╝łĶ»ĘÕ£©õĖŗĶĮĮÕ«īµĢ░µŹ«ÕÉÄõĖŹĶ”üÕüÜõ╗╗õĮĢµö╣ÕŖ©’╝īõĖŹĶāĮÕłĀķÖżÕŁŚń¼”’╝ēŃĆé3.µĢ░µŹ«µ£ēµ╝ŵĄŗńÜäÕÅ»ĶāĮ...
# Õ¤║õ║ÄGUIńÜäĶ»»ÕĘ«ńÉåĶ«║õĖĵĢ░µŹ«ÕżäńÉå Ķ»Šń©ŗĶ«ŠĶ«ĪŌĆöŌĆöÕ¤║õ║ÄMatlab+GUIńÜäĶ»»ÕĘ«ńÉåĶ«║õĖĵĢ░µŹ«ÕżäńÉå 1. Ķ┐ÉĶĪīMatlabÕ╣ČĶĮ¼Õł░ÕĮōÕēŹńø«ÕĮĢ’╝ø 2. ńø┤µÄźĶ┐ÉĶĪīindexõĖ╗ńĢīķØóµ¢ćõ╗ČŃĆé 3. µĄŗĶ»ĢµĢ░µŹ«Õ»╝Õģź - ńŁēń▓ŠÕ║”µĄŗķćÅ’╝Ü`data1_1.txtŃĆüdata1_1.xls` - ...
Õ░Åիص▓ēķÖŹńøæµĄŗµĢ░µŹ«ÕżäńÉåÕłåµ×ÉĶĮ»õ╗Č2011’╝īĶ┐ÖõĖ¬ĶĮ»õ╗ČńÜäõĮ£ĶĆģµś»ÕĆ╝ÕŠŚµĄŗķćÅõ║║ÕŁ”õ╣ĀńÜä’╝īĶ┐Öµś»õĖ¬õĖŹķöÖńÜäĶĮ»õ╗Č’╝īńÄ░Õ£©ÕÉæÕż¦Õ«ČµÅÉõŠøõĖĆõĖŗ2011ńēłµ£¼ńÜäŃĆéÕÉäwindowsń│╗ń╗¤’╝łµ»öÕ”éwin7’╝ēÕ«ēĶŻģµŁżĶĮ»õ╗ȵŚČÕ”éµ×£Ķ»╗ÕÅ¢µ¢ćõ╗ČķöÖĶ»»’╝īĶ»ĘÕ░åÕ«ēÕģ©ĶĮ»õ╗ȵÜ鵌ČÕģ│ķŚŁ’╝łµŁżĶĮ»õ╗Č...
ńöĄÕŁÉµ░┤Õćåõ╗¬µĀ╝Õ╝ÅĶĮ¼µŹóõĖĵĢ░µŹ«ÕżäńÉåń©ŗÕ║ÅÕÅ»õ╗źµ¢æń½╣õĮĀµ©¬Õ┐½ńÜäÕżäńÉåõĮĀńÜäÕż¦ķćŵĢ░µŹ«ÕćÅĶĮ╗õĮĀńÜäÕĘźõĮ£Ķ┤¤µŗģ
Õ£©MATLABńÄ»ÕóāõĖŗĶ┐øĶĪīInSARµĢ░µŹ«ÕżäńÉå’╝īÕÅ»õ╗źÕģģÕłåÕł®ńö©ÕģČÕ╝║Õż¦ńÜäµĢ░ÕŁ”Ķ┐Éń«ŚÕÆīÕøŠÕāÅÕżäńÉåÕŖ¤ĶāĮŃĆéMATLABń╝¢ń©ŗńüĄµ┤╗’╝īÕģʵ£ēõĖ░Õ»īńÜäÕćĮµĢ░Õ║ōÕÆīÕÅ»Ķ¦åÕī¢ÕĘźÕģĘ’╝īõĮ┐ÕŠŚInSARÕżäńÉåÕÅśÕŠŚµø┤ÕŖĀõŠ┐µŹĘÕÆīķ½śµĢłŃĆéµ£¼ÕÄŗń╝®ÕīģõĖŁÕīģÕɽõ║åõĖĆõ║øńö▒õĖōõĖÜõ║║Õæśń╝¢ÕåÖńÜäMATLAB...
ķÖäĶĄĀµĪłõŠŗµĢ░µŹ«ÕÅ»ńø┤µÄźĶ┐ÉĶĪīmatlabń©ŗÕ║ÅŃĆé 3.õ╗ŻńĀüńē╣ńé╣’╝ÜÕÅéµĢ░Õī¢ń╝¢ń©ŗŃĆüÕÅéµĢ░ÕÅ»µ¢╣õŠ┐µø┤µö╣ŃĆüõ╗ŻńĀüń╝¢ń©ŗµĆØĶĘ»µĖģµÖ░ŃĆüµ│©ķćŖµśÄń╗åŃĆé 4.ķĆéńö©Õ»╣Ķ▒Ī’╝ÜĶ«Īń«Śµ£║’╝īńöĄÕŁÉõ┐Īµü»ÕĘźń©ŗŃĆüµĢ░ÕŁ”ńŁēõĖōõĖÜńÜäÕż¦ÕŁ”ńö¤Ķ»Šń©ŗĶ«ŠĶ«ĪŃĆüµ£¤µ£½Õż¦õĮ£õĖÜÕÆīµ»ĢõĖÜĶ«ŠĶ«ĪŃĆé
ptransbx.exeÕÆīptransbb.exeµś»Ķł╣ĶłČµŖźÕżäńÉåń©ŗÕ║Å’╝īĶ┤¤Ķ┤ŻÕ░åĶł╣ĶłČµŖźµĢ░µŹ«ÕŖĀÕģźÕł░ÕĪ½ÕøŠµĢ░µŹ«õĖŁŃĆéptranscs.exeµś»Õ¤ÄÕĖéķóäµŖźµŖźÕżäńÉåń©ŗÕ║Å’╝īĶ┤¤Ķ┤Żńö¤µłÉÕ¤ÄÕĖéķóäµŖźµĢ░µŹ«ŃĆépwdemi.exeÕÆīpwgako.exeµś»Õ«óĶ¦éÕłåµ×Éń©ŗÕ║Å’╝īĶ┤¤Ķ┤Żńö¤µłÉńŁēÕĆ╝ń║┐ÕÆīµĄüń║┐µĢ░µŹ«ŃĆé...
µ£¼µ¢ćõĖ╗Ķ”üõ╗ŗń╗Źõ║åÕó×ÕćŵīéķÆ®µĢ░µŹ«ÕżäńÉåÕĘźÕģĘńÜäĶ«ŠĶ«ĪõĖÄÕ«×ńÄ░’╝īµŚ©Õ£©Ķ¦ŻÕå│ÕŗśµĄŗÕ«ÜńĢīńĢīÕØĆńé╣ÕØɵĀćõ║żµŹóµĀ╝Õ╝ÅõĖÄ Shapefile µĀ╝Õ╝Åõ╣ŗķŚ┤ńÜäõ║ÆĶĮ¼ķŚ«ķóśŃĆéĶ»źÕĘźÕģĘķĆÜĶ┐ćń╝¢ń©ŗµēŗµ«ĄÕ«×ńÄ░õ║åõĖżń¦ŹµĀ╝Õ╝Åõ╣ŗķŚ┤ńÜäõ║ÆĶĮ¼’╝īµ¢╣õŠ┐õ║åÕó×ÕćŵīéķÆ®µĢ░µŹ«ńÜäÕżäńÉåŃĆé õĖĆŃĆüÕó×ÕćŵīéķÆ®...
Õ£©Õż¦µĢ░µŹ«ÕżäńÉåķóåÕ¤¤’╝īHadoopÕÆīSparkµś»õĖżõĖ¬Ķć│Õģ│ķćŹĶ”üńÜäµĪåµ×Č’╝īÕ«āõ╗¼õĖ║µĄĘķćŵĢ░µŹ«ńÜäÕŁśÕé©ŃĆüń«ĪńÉåÕÆīÕłåµ×ɵÅÉõŠøõ║åķ½śµĢłõĖöÕÅ»µē®Õ▒ĢńÜäĶ¦ŻÕå│µ¢╣µĪłŃĆéµ£¼ĶĄäµ║ÉÕīģÕɽõ║åÕ¤║õ║ÄĶ┐ÖõĖżõĖ¬µĪåµ×ČńÜäµĢ░µŹ«ń«Śµ│ĢÕÆīµ║Éõ╗ŻńĀü’╝īÕÅ»õ╗źÕĖ«ÕŖ®µłæõ╗¼µĘ▒ÕģźńÉåĶ¦ŻÕ╣ČÕ«×ĶĘĄÕż¦µĢ░µŹ«ÕżäńÉå...
Õż®Õ«ØńöĄÕŁÉµ░┤Õćåõ╗¬µĢ░µŹ«ÕżäńÉåĶĮ»õ╗Č’╝īķØ×ÕĖĖµ¢╣õŠ┐ŃĆéÕż®Õ«ØńöĄÕŁÉµ░┤Õćåõ╗¬µĢ░µŹ«ÕżäńÉåĶĮ»õ╗Č
µ£¼ķĪ╣ńø«µś»õ╗┐ńģ¦GSSIńÜäµÄóÕ£░ķøĘĶŠŠµĢ░µŹ«ÕżäńÉåĶĮ»õ╗ČÕłČõĮ£ńÜäõĖĆõĖ¬ń©ŗÕ║Å’╝īÕÅ»ĶāĮÕīģÕɽµĢ░µŹ«ķććķøåŃĆüķóäÕżäńÉåŃĆüµłÉÕāÅÕÆīĶ¦ŻķćŖńŁēÕŖ¤ĶāĮŃĆéµ║Éõ╗ŻńĀüÕÅ»ĶāĮµČēÕÅŖńÜäÕģ│ķö«µŖƵ£»ńé╣Õīģµŗ¼’╝Ü 1. **µĢ░µŹ«ķććķøå**’╝ܵÄóÕ£░ķøĘĶŠŠńÜäµĢ░µŹ«ķććķøåķĆÜÕĖĖµČēÕÅŖńĪ¼õ╗ČĶ«ŠÕżć’╝īÕ”éķøĘĶŠŠÕż®ń║┐ÕÆī...
µĆ╗ń╗ō’╝īĶ┐ÖõĖ¬ķĪ╣ńø«õĖŹõ╗ģµČĄńø¢õ║åSparkńÜäÕż¦µĢ░µŹ«ÕżäńÉåµŖƵ£»’╝īÕīģµŗ¼µĢ░µŹ«ĶÄĘÕÅ¢ŃĆüµĢ░µŹ«µĖģµ┤ŚŃĆüµĢ░µŹ«Õłåµ×ÉÕÆīµĢ░µŹ«ÕÅ»Ķ¦åÕī¢’╝īÕÉīµŚČõ╣¤õĮōńÄ░õ║åÕż¦µĢ░µŹ«Õ£©µ░öĶ▒ĪķóåÕ¤¤ńÜäÕ║öńö©õ╗ĘÕĆ╝ŃĆéķĆÜĶ┐ćĶ┐ÖµĀĘńÜäÕ«×ĶĘĄ’╝īÕŁ”ńö¤ĶāĮÕż¤µÄīµÅĪÕż¦µĢ░µŹ«ÕżäńÉåµĄüń©ŗ’╝īÕ╣Čõ║åĶ¦ŻÕ”éõĮĢÕł®ńö©Õż¦µĢ░µŹ«...