- 浏览: 1774609 次
- 性别:

- 来自: 成都
-

文章分类
- 全部博客 (520)
- Oracle (10)
- Oracle错误集 (8)
- Oracle安装升级 (15)
- Oracle日常管理 (51)
- Oracle字符集 (7)
- Oracle备份恢复 (24)
- Oracle优化 (4)
- Oracle编程 (52)
- Oracle导入导出 (19)
- Oracle体系结构 (15)
- Oracle网络 (2)
- Oracle安全 (2)
- Oracle权限 (3)
- Oracle数据字典和性能视图 (2)
- Oracle常用地址 (5)
- SQLPLUS专栏 (7)
- SqlServer (13)
- SqlServer2005编程 (27)
- SqlServer2005管理 (15)
- MySQL (20)
- Dorado应用 (1)
- C# (24)
- Arcgis Server开发 (20)
- ArcSDE技术 (19)
- UML学习 (2)
- 设计模式 (2)
- JAVA EE (4)
- JavaScript (3)
- OFBIZ (27)
- JAVA WEB开发 (22)
- Linux&Unix (34)
- SHELL编程 (14)
- C语言 (11)
- 网络协议 (14)
- FREEMARKER (2)
- GROOVY (2)
- JAVA语言 (3)
- 防火墙 (0)
- PHP (2)
- Apache (2)
- Loader Runner (1)
- Nginx (3)
- 数据库理论 (2)
- maven (1)
最新评论
-
怼怼怼怼:
oracle的timestamp类型使用 -
怼怼怼怼:
oracle的timestamp类型使用 -
怼怼怼怼:
oracle的timestamp类型使用 -
pg_guo:
感谢
oracle中查看用户权限 -
xu234234:
5、MapResourceManager控件中添加了两个服务, ...
北京ArcGis Server应用基础培训笔记1
我们知道在导出文件中,记录着导出使用的字符集id,通过查看导出文件头的第2、3个字节,我们可以找到16进制表示的字符集ID,在Windows上,
我们可以使用UltraEdit等工具打开dmp文件,查看其导出字符集::
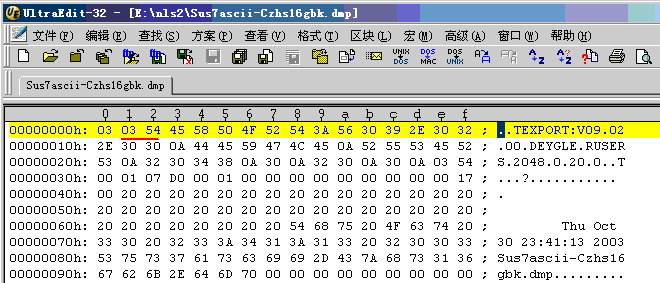
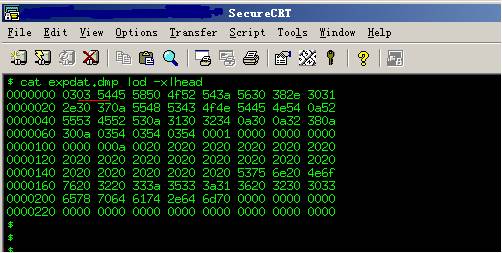
在Unix上我们可以通过以下命令来查看:
cat expdat.dmp | od -x | head
|
Oracle提供标准函数,对字符集名称及ID进行转换:
|
SQL> select nls_charset_id('ZHS16GBK') from dual;
NLS_CHARSET_ID('ZHS16GBK')
--------------------------
852
1 row selected.
SQL> select nls_charset_name(852) from dual;
NLS_CHAR
--------
ZHS16GBK
1 row selected.
十进制转换十六进制:
SQL> select to_char('852','xxxx') from dual;
TO_CH
-----
354
1 row selected.
|
对应上面的图中第2、3字节,我们知道该导出文件字符集为ZHS16GBk.
查询数据库中有效的字符集可以使用以下脚本:
|
col nls_charset_id for 9999
col nls_charset_name for a30
col hex_id for a20
select
nls_charset_id(value) nls_charset_id,
value nls_charset_name,
to_char(nls_charset_id(value),'xxxx') hex_id
from v$nls_valid_values
where parameter = 'CHARACTERSET'
order by nls_charset_id(value)
/
|
输出样例如下:
|
NLS_CHARSET_ID NLS_CHARSET_NAME HEX_ID
-------------- ------------------------------ -------------
1 US7ASCII 1
2 WE8DEC 2
3 WE8HP 3
4 US8PC437 4
5 WE8EBCDIC37 5
6 WE8EBCDIC500 6
7 WE8EBCDIC1140 7
8 WE8EBCDIC285 8
...................
850 ZHS16CGB231280 352
851 ZHS16MACCGB231280 353
852 ZHS16GBK 354
853 ZHS16DBCS 355
860 ZHT32EUC 35c
861 ZHT32SOPS 35d
862 ZHT16DBT 35e
863 ZHT32TRIS 35f
864 ZHT16DBCS 360
865 ZHT16BIG5 361
866 ZHT16CCDC 362
867 ZHT16MSWIN950 363
868 ZHT16HKSCS 364
870 AL24UTFFSS 366
871 UTF8 367
872 UTFE 368
..................................
|
在很多时候,当我们进行导入操作的时候,已经离开了源数据库,这时如果目标数据库的字符集和导出文件不一致,很多时候就需要进行特殊处理,
以下介绍几种方法,主要以US7ASCII和ZHS16GBK为例
1. 源数据库字符集为US7ASCII,导出文件字符集为US7ASCII或ZHS16GBK,目标数据库字符集为ZHS16GBK
在Oracle92中,我们发现对于这种情况,不论怎样处理,这个导出文件都无法正确导入到Oracle9i数据库中,这可能是因为Oracle9i的编码方案发生了较大改变。
以下是我们所做的简单测试,其中导出文件命名规则为:
S-Server ,后跟Server字符集
C-client , 后跟导出操作时客户端字符集
导入时客户端字符集设置在命令行完成,限于篇幅,我们省略了部分测试过程。
对于Oracle9iR2,我们的测试结果是US7ASCII字符集,不管怎样转换,都无法正确导入ZHS16GBK字符集的数据库中。
在进行导入操作时,如果字符不能正常转换,Oracle数据库会自动用一个”?”代替,也就是编码63。
|
E:\nls2>set NLS_LANG=AMERICAN_AMERICA.US7ASCII E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle tables=test Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:14:39 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in US7ASCII character set and AL16UTF16 NCHAR character set import server uses ZHS16GBK character set (possible charset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:14:50 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) ----------------------------- ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 2 rows selected. SQL> exit Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production E:\nls2>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle tables=test ignore=y Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:15:28 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in ZHS16GBK character set and AL16UTF16 NCHAR character set export client uses US7ASCII character set (possible charset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:15:34 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) -------------------------------------------------------------------------------- ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 4 rows selected. SQL> drop table test; Table dropped. SQL> exit Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production E:\nls2>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK E:\nls2>imp eygle/eygle file=Sus7ascii-Czhs16gbk.dmp fromuser=eygle touser=eygle tables=test ignore=y Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:17:21 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in ZHS16GBK character set and AL16UTF16 NCHAR character set . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:17:30 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) ---------------------------------------------- ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 2 rows selected. SQL> exit Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production E:\nls2>set NLS_LANG=AMERICAN_AMERICA.US7ASCII E:\nls2>imp eygle/eygle file=Sus7ascii-Czhs16gbk.dmp fromuser=eygle touser=eygle tables=test ignore=y Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:18:00 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in US7ASCII character set and AL16UTF16 NCHAR character set import server uses ZHS16GBK character set (possible charset conversion) export client uses ZHS16GBK character set (possible charset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:18:08 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) ---------------------------------------- ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 4 rows selected. SQL> |
对于这种情况,我们可以通过使用Oracle8i的导出工具,设置导出字符集为US7ASCII,导出后修改第二、三字符,修改 0001 为
0354,这样就可以将US7ASCII字符集的数据正确导入到ZHS16GBK的数据库中。
修改导出文件:
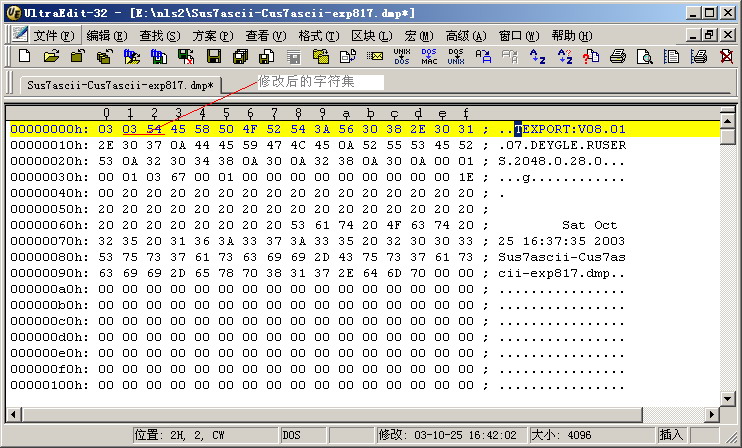
导入修改后的导出文件:
|
E:\nls2>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii-exp817.dmp fromuser=eygle touser=eygle tables=test Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:37:17 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V08.01.07 via conventional path import done in ZHS16GBK character set and AL16UTF16 NCHAR character set export server uses UTF8 NCHAR character set (possible ncharset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:37:23 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) -------------------------------------------------------------------------------- 测试 Typ=1 Len=4: 178,226,202,212 Test Typ=1 Len=4: 116,101,115,116 2 rows selected. SQL> |
2. 使用create database的方法
如果导出文件使用的字符集是US7ASCII,目标数据库的字符集是ZHS16GBK,我们可以使用create database的方法来修改,具体如下:
|
SQL> col parameter for a30 SQL> col value for a30 SQL> select * from v$nls_parameters; PARAMETER VALUE ------------------------------ ------------------------------ NLS_LANGUAGE AMERICAN NLS_TERRITORY AMERICA NLS_CURRENCY $ NLS_ISO_CURRENCY AMERICA NLS_NUMERIC_CHARACTERS ., NLS_CALENDAR GREGORIAN NLS_DATE_FORMAT DD-MON-RR NLS_DATE_LANGUAGE AMERICAN NLS_CHARACTERSET ZHS16GBK NLS_SORT BINARY ………………. 19 rows selected. SQL> create database character set us7ascii; create database character set us7ascii * ERROR at line 1: ORA-01031: insufficient privileges SQL> select * from v$nls_parameters; PARAMETER VALUE ------------------------------ ------------------------------ NLS_LANGUAGE AMERICAN NLS_TERRITORY AMERICA NLS_CURRENCY $ NLS_ISO_CURRENCY AMERICA NLS_NUMERIC_CHARACTERS ., NLS_CALENDAR GREGORIAN NLS_DATE_FORMAT DD-MON-RR NLS_DATE_LANGUAGE AMERICAN NLS_CHARACTERSET US7ASCII NLS_SORT BINARY ………….. 19 rows selected. SQL> exit Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production E:\nls2>set nls_lang=AMERICAN_AMERICA.US7ASCII E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle Import: Release 9.2.0.4.0 - Production on Sun Nov 2 14:53:26 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in US7ASCII character set and AL16UTF16 NCHAR character set import server uses ZHS16GBK character set (possible charset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Sun Nov 2 14:53:35 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select * from test; NAME ---------- 测试 test 2 rows selected. |
我们看到,当发出create database character set us7ascii;命令时,数据库v$nls_parameters中的字符集设置随之更改,该参数影响导入进程,
更改后可以正确导入数据,重起数据库后,该设置恢复。
提示:v$nls_paraemters来源于x$nls_parameters,该动态性能视图影响导入操作;而nls_database_parameters来源于props$数据表,影响数据存储。
3. Oracle提供的字符扫描工具csscan
我们说以上的方法只是应该在不得已的情况下使用,其本质是欺骗数据库,强制导入数据,可能损失元数据。
如果要确保数据的完整性,应该使用csscan扫描数据库,找出所有不兼容的字符,然后通过编写相应的脚本及代码,在转换之后进行更新,确保数据的正确性。
我们简单看一下csscan的使用。
要使用csscan之前,需要以sys用户身份创建相应数据字典对象:
|
E:\nls2>sqlplus "/ as sysdba"
SQL*Plus: Release 9.2.0.4.0 - Production on Sun Nov 2 19:42:07 2003
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
SQL> select instance_name from v$intance;
select instance_name from v$intance
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> select instance_name from v$instance;
INSTANCE_NAME
----------------
penny
1 row selected.
SQL> @?/rdbms/admin/csminst.sql
User created.
Grant succeeded.
………..
|
这个脚本创建相应用户(csmig)及数据字典对象,扫描信息会记录在相应的数据字典表里。
我们可以在命令行调用这个工具对数据库进行扫描:
E:\nls2>csscan FULL=Y FROMCHAR=ZHS16GBK TOCHAR=US7ASCII LOG=US7check.log CAPTURE=Y ARRAY=1000000 PROCESS=2
Character Set Scanner v1.1 : Release 9.2.0.1.0 - Production on Sun Nov 2 20:24:45 2003
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Username: eygle/eygle
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
Enumerating tables to scan...
. process 1 scanning SYS.SOURCE$[AAAABHAABAAAAIRAAA]
. process 2 scanning SYS.ATTRIBUTE$[AAAAEoAABAAAAhZAAA]
. process 2 scanning SYS.PARAMETER$[AAAAEoAABAAAAhZAAA]
. process 2 scanning SYS.METHOD$[AAAAEoAABAAAAhZAAA]
……..
. process 2 scanning SYSTEM.DEF$_AQERROR[AAAA8fAABAAACWJAAA]
. process 1 scanning WMSYS.WM$ENV_VARS[AAABeWAABAAAFMZAAA]
………………….
. process 2 scanning SYS.UGROUP$[AAAAA5AABAAAAGpAAA]
. process 2 scanning SYS.CON$[AAAAAcAABAAAACpAAA]
. process 1 scanning SYS.FILE$[AAAAARAABAAAABxAAA]
Creating Database Scan Summary Report...
Creating Individual Exception Report...
Scanner terminated successfully.
|
然后我们可以检查输出的日志来查看数据库扫描情况:
Database Scan Individual Exception Report [Database Scan Parameters] Parameter Value ------------------------------ ------------------------------------------------ Scan type Full database Scan CHAR data? YES Current database character set ZHS16GBK New database character set US7ASCII Scan NCHAR data? NO Array fetch buffer size 1000000 Number of processes 2 Capture convertible data? YES ------------------------------ ------------------------------------------------ [Data Dictionary individual exceptions] [Application data individual exceptions] User : EYGLE Table : TEST Column: NAME Type : VARCHAR2(10) Number of Exceptions : 1 Max Post Conversion Data Size: 4 ROWID Exception Type Size Cell Data(first 30 bytes) ------------------ ------------------ ----- ------------------------------ AAABpIAADAAAAAMAAA lossy conversion 测试 ------------------ ------------------ ----- ------------------------------ |
不能转换的数据将会被记录下来,我们可以根据这些信息在转换之后,对数据进行相应的更新,确保转换无误。


发表评论

-
有关NLS_DATE_FORMAT设置
2008-08-25 10:09 2493NLS_DATE_FORMAT is used if a da ... -
怎样修改查看Oracle字符集
2007-11-05 10:31 3825[Q]怎么样查看数据库字符集 [A]数据库服务器字符 ... -
Oracle客户端NLS_LANG设置
2007-11-05 10:29 352831. NLS_LANG 参数组成 NLS_LA ... -
字符集的基础知识
2007-11-01 10:14 1986我们知道,电子计算机� ... -
Oracle字符集更改
2007-11-01 10:08 5616数据库创建以后,如果需要修改字符集,通常需要重建数据库,通过导 ... -
Oracle字符集的两条基本原则
2007-11-01 10:07 1582要想在字符集方面少些错误与麻烦,需要坚持两条基本原则: 数据库 ...
相关推荐
- **字符集识别**:Oracle数据库支持多种字符集,如AL32UTF8、WE8ISO8859P1等,不同的字符集用于支持不同语言和特殊字符。在导入导出过程中,确保源和目标数据库的字符集兼容至关重要,否则可能导致乱码。 - **字符...
其中,simsun.ttc和simhei.ttf包含了宋体和黑体的字形数据,而simsun.xml和simhei.xml则是字体的元数据,用于描述字体的属性和结构,例如字符集、字形位置等。 在解决ecside导出文件乱码问题时,我们需要进行以下...
操作系统字符集决定了用户界面和文件系统中字符的显示方式,而Oracle字符集则用于数据库内部的数据存储和处理。两者必须匹配或至少兼容,否则会导致数据读取和显示的错误。例如,如果操作系统使用的是GBK编码,而...
在OracleXE环境中,数据库导入过程...总的来说,OracleXE的导入和字符集更改涉及多个层面,包括数据库对象的迁移、字符集的适配以及PL/SQL绑定文件的处理。理解和掌握这些知识点对于维护和管理OracleXE数据库至关重要。
5. **数据一致性**:在导入或导出数据时,正确设置字符集可以避免乱码问题,保证数据的完整性和一致性。 在开发过程中,实现字符集设定功能需要考虑以下技术点: - **编码转换算法**:如ICU(International ...
通常,Oracle数据库默认使用的是AL32UTF8编码,这是一种支持Unicode字符集的编码方式,能够正确处理包括中文在内的多种语言字符。然而,当你用某些工具(如Excel)打开CSV文件时,如果不指定正确的编码,就可能出现...
1. **字体检测**:源码可能包含一段用于遍历系统字体文件的代码,通过比较字体名称和字符集来识别是否为简体中文字体。 2. **字体替换**:当检测到报表中的中文字符未使用支持的字体时,源码会触发字体替换逻辑,...
- 设置字符集(`Response.Charset = "GB2312"`):指定Excel文件的编码,防止乱码。注意,这里的编码应与数据源的实际编码一致。 - 添加HTTP头信息(`Response.AppendHeader("Content-Disposition", "attachment;...
在提供的压缩包文件中,可以看到几个`.dic`文件,这些通常是OCR系统的字典文件,包含了可能的字符集及其对应概率,用于提高识别精度。`SYOCR_XHSB.exe`很可能是系统的执行文件,负责运行箱号识别的算法。`演示程序...
MySQL工具应确保正确识别源数据库的字符集,并在导出过程中保持一致,避免转换过程中的乱码。例如,` administrator-1.1.3-win.msi`可能内置了智能字符集检测和转换功能,以确保导出的SQL脚本在不同环境下的可读性。...
ArcGIS在导出DBF文件时,默认可能使用的是特定的字符集,而Excel可能不支持或识别这种字符集,导致打开时出现乱码。为了解决这一问题,Esri公司已经提供了官方的解决方案。根据提供的压缩包文件名称,我们可以推断出...
同时,为了适应中国知网的数据结构,可能需要对特定的XML标签或RIS字段进行定制化处理,例如处理中文字符集问题,以及中国特有的引文格式。 总的来说,解析中国知网导出的文献管理文件是一项涉及到文件读取、XML...
4. 导入导出数据时未指定正确的字符集。 "ORACLE_CHAR_ToolS"提供的工具可能包括了检查和转换字符集的脚本或程序,这些工具可以帮助用户: 1. 检测Oracle数据库当前的字符集设置。 2. 查看表和列的字符集信息。 3. ...
强调了能够学习12C版本dmp文件导入到11G的过程、解决特定的导入错误、使用PilotEditLite软件以及如何获取dmp文件的导出元数据和字符集信息。 标签“exp”指的是Oracle的导出工具(export),它用于生成dmp文件。在...
- 导出大型数据集时,考虑文件大小和处理效率,可能需要分割数据或选择压缩文件格式。 表格数据导出是日常工作中不可或缺的一部分,了解不同格式的特点和导出技巧能帮助我们更有效地管理和分享数据。无论是JSON的...
在MySQL管理器中,这一过程通常涉及到创建数据库结构的映射,然后将数据导出到文件(如SQL脚本),接着在目标系统中导入这些数据。对于少量数据,这个过程非常快速且有效,确保了业务连续性和数据完整性。 备份是...
例如,每行数据可以转换为逗号分隔值(CSV)格式,然后写入到文本文件中,这可以直接被Excel识别: ```易语言 .文件句柄 = 打开文件("output.csv", "w") .记录数 = .记录集.记录总数 循环 .记录数 .字段数组 = ....
在导出数据到Excel前,你需要创建一个CSV(逗号分隔值)文件,因为CSV文件可以被大多数电子表格软件(如Excel)识别。使用FileOutputStream和BufferedWriter来写入CSV文件,每行数据用换行符分隔,每个字段用逗号...
由于PDFMake默认不支持中文字符集,我们需要对其进行适当的配置。 首先,为了在PDF中正确显示中文,我们需要引入`vfs_fonts.js`。这是一个虚拟文件系统(VFS)字体文件,它包含了支持中文字符的字体,例如"STSong-...
对于导出文件编码:在TableExport的配置中指定UTF-8编码,例如`exportOptions: {format: {extension: 'xlsx', type: 'xlsx', worksheetName: 'Sheet1', bom: true}}`,其中`bom: true`表示添加Unicode字节顺序标记,...