- жµПиІИ: 72542 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еЃЬеЃЊ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2017-01 ( 3)
- 2016-09 ( 2)
- 2016-08 ( 1)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
дЄАиЗіжАІhashзЃЧж≥ХеЬ®memcachedдЄ≠зЪДдљњзФ®
дЄАгАБж¶Вињ∞
1гАБжИСдїђзЪДmemcacheеЃҐжИЈзЂѓпЉИињЩйЗМжИСзЬЛзЪДspymemcacheзЪДжЇРз†БпЉЙпЉМдљњзФ®дЇЖдЄАиЗіжАІhashзЃЧж≥ХketamaињЫи°МжХ∞жНЃе≠ШеВ®иКВзВєзЪДйАЙжЛ©гАВдЄОеЄЄиІДзЪДhashзЃЧж≥ХжАЭиЈѓдЄНеРМпЉМеП™жШѓеѓєжИСдїђи¶Бе≠ШеВ®жХ∞жНЃзЪДkeyињЫи°МhashиЃ°зЃЧпЉМеИЖйЕНеИ∞дЄНеРМиКВзВєе≠ШеВ®гАВдЄАиЗіжАІhashзЃЧж≥ХжШѓеѓєжИСдїђи¶Бе≠ШеВ®жХ∞жНЃзЪДжЬНеК°еЩ®ињЫи°МhashиЃ°зЃЧпЉМињЫиАМз°ЃиЃ§жѓПдЄ™keyзЪДе≠ШеВ®дљНзљЃгАВ
2гАБеЄЄиІДhashзЃЧж≥ХзЪДеЇФзФ®дї•еПКеЕґеЉКзЂѓ
жЬАеЄЄиІДзЪДжЦєеЉПиОЂињЗдЇОhashеПЦж®°зЪДжЦєеЉПгАВжѓФе¶ВйЫЖзЊ§дЄ≠еПѓзФ®жЬЇеЩ®йАВйЗПдЄЇNпЉМйВ£дєИkeyеАЉдЄЇKзЪДзЪДжХ∞жНЃиѓЈж±ВеЊИзЃАеНХзЪДеЇФиѓ•иЈѓзФ±еИ∞hash(K) mod NеѓєеЇФзЪДжЬЇеЩ®гАВзЪДз°ЃпЉМињЩзІНзїУжЮДжШѓзЃАеНХзЪДпЉМдєЯжШѓеЃЮзФ®зЪДгАВдљЖжШѓеЬ®дЄАдЇЫйЂШйАЯеПСе±ХзЪДwebз≥їзїЯдЄ≠пЉМињЩж†ЈзЪДиІ£еЖ≥жЦєж°ИдїНжЬЙдЇЫзЉЇйЩЈгАВйЪПзЭАз≥їзїЯиЃњйЧЃеОЛеКЫзЪДеҐЮйХњпЉМзЉУе≠Шз≥їзїЯдЄНеЊЧдЄНйАЪињЗеҐЮеК†жЬЇеЩ®иКВзВєзЪДжЦєеЉПжПРйЂШйЫЖзЊ§зЪДзЫЄеЇФйАЯеЇ¶еТМжХ∞жНЃжЙњиљљйЗПгАВеҐЮеК†жЬЇеЩ®жДПеС≥зЭАжМЙзЕІhashеПЦж®°зЪДжЦєеЉПпЉМеЬ®еҐЮеК†жЬЇеЩ®иКВзВєзЪДињЩдЄАжЧґеИїпЉМе§ІйЗПзЪДзЉУе≠ШеСљдЄНдЄ≠пЉМзЉУе≠ШжХ∞жНЃйЬАи¶БйЗНжЦ∞еїЇзЂЛпЉМзФЪиЗ≥жШѓињЫи°МжХідљУзЪДзЉУе≠ШжХ∞жНЃињБзІїпЉМзЮђйЧідЉЪзїЩDBеЄ¶жЭ•жЮБйЂШзЪДз≥їзїЯиіЯиљљпЉМиЃЊзљЃеѓЉиЗіDBжЬНеК°еЩ®еЃХжЬЇгАВ
3гАБиЃЊиЃ°еИЖеЄГеЉПcacheз≥їзїЯжЧґпЉМдЄАиЗіжАІhashзЃЧж≥ХеПѓдї•еЄЃжИСдїђиІ£еЖ≥еУ™дЇЫйЧЃйҐШпЉЯ
еИЖеЄГеЉПзЉУе≠ШиЃЊиЃ°ж†ЄењГзВєпЉЪеЬ®иЃЊиЃ°еИЖеЄГеЉПcacheз≥їзїЯзЪДжЧґеАЩпЉМжИСдїђйЬАи¶БиЃ©keyзЪДеИЖеЄГеЭЗи°°пЉМеєґдЄФеЬ®еҐЮеК†cache serverеРОпЉМcacheзЪДињБзІїеБЪеИ∞жЬАе∞СгАВ
ињЩйЗМжПРеИ∞зЪДдЄАиЗіжАІhashзЃЧж≥ХketamaзЪДеБЪж≥ХжШѓпЉЪйАЙжЛ©еЕЈдљУзЪДжЬЇеЩ®иКВзВєдЄНеЬ®еП™дЊЭиµЦйЬАи¶БзЉУе≠ШжХ∞жНЃзЪДkeyзЪДhashжЬђиЇЂдЇЖпЉМиАМжШѓжЬЇеЩ®иКВзВєжЬђиЇЂдєЯињЫи°МдЇЖhashињРзЃЧгАВ
дЇМгАБдЄАиЗіжАІеУИеЄМзЃЧж≥ХжГЕжЩѓжППињ∞пЉИиљђиљљпЉЙ
1гАБ hashжЬЇеЩ®иКВзВє
й¶ЦеЕИж±ВеЗЇжЬЇеЩ®иКВзВєзЪДhashеАЉпЉИжАОдєИзЃЧжЬЇеЩ®иКВзВєзЪДhashпЉЯipеПѓдї•дљЬдЄЇhashзЪДеПВжХ∞еРІгАВгАВељУзДґињШжЬЙеЕґдїЦзЪДжЦєж≥ХдЇЖпЉЙпЉМзДґеРОе∞ЖеЕґеИЖеЄГеИ∞0пљЮ2^32зЪДдЄАдЄ™еЬЖзОѓдЄКпЉИй°ЇжЧґйТИеИЖеЄГпЉЙгАВе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ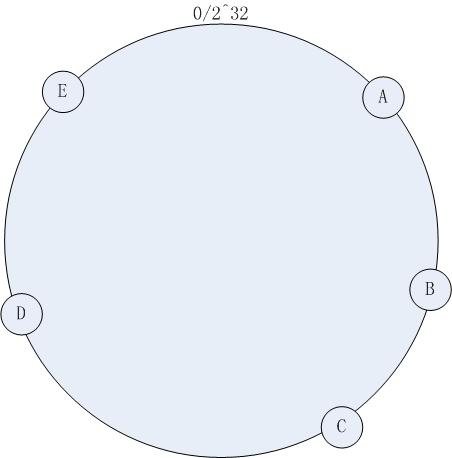
еЫЊдЄА
йЫЖзЊ§дЄ≠жЬЙжЬЇеЩ®пЉЪA , B, C, D, EдЇФеП∞жЬЇеЩ®пЉМйАЪињЗдЄАеЃЪзЪДhashзЃЧж≥ХжИСдїђе∞ЖеЕґеИЖеЄГеИ∞е¶ВдЄКеЫЊжЙАз§ЇзЪДзОѓдЄКгАВ
2гАБиЃњйЧЃжЦєеЉП
е¶ВжЮЬжЬЙдЄАдЄ™еЖЩеЕ•зЉУе≠ШзЪДиѓЈж±ВпЉМеЕґдЄ≠KeyеАЉдЄЇKпЉМиЃ°зЃЧеЩ®hashеАЉHash(K)пЉМ Hash(K) еѓєеЇФдЇОеЫЊ вАУ 1зОѓдЄ≠зЪДжЯРдЄАдЄ™зВєпЉМе¶ВжЮЬиѓ•зВєеѓєеЇФж≤°жЬЙжШ†е∞ДеИ∞еЕЈдљУзЪДжЯРдЄАдЄ™жЬЇеЩ®иКВзВєпЉМйВ£дєИй°ЇжЧґйТИжЯ•жЙЊпЉМзЫіеИ∞зђђдЄАжђ°жЙЊеИ∞жЬЙжШ†е∞ДжЬЇеЩ®зЪДиКВзВєпЉМиѓ•иКВзВєе∞±жШѓз°ЃеЃЪзЪДзЫЃж†ЗиКВзВєпЉМе¶ВжЮЬиґЕињЗдЇЖ2^32дїНзДґжЙЊдЄНеИ∞иКВзВєпЉМеИЩеСљдЄ≠зђђдЄАдЄ™жЬЇеЩ®иКВзВєгАВжѓФе¶В Hash(K) зЪДеАЉдїЛдЇОA~BдєЛйЧіпЉМйВ£дєИеСљдЄ≠зЪДжЬЇеЩ®иКВзВєеЇФиѓ•жШѓBиКВзВєпЉИе¶ВдЄКеЫЊ пЉЙгАВ
3гАБеҐЮеК†иКВзВєзЪДе§ДзРЖ
е¶ВдЄКеЫЊ вАУ 1пЉМеЬ®еОЯжЬЙйЫЖзЊ§зЪДеЯЇз°АдЄКжђ≤еҐЮеК†дЄАеП∞жЬЇеЩ®FпЉМеҐЮеК†ињЗз®Ле¶ВдЄЛпЉЪ
иЃ°зЃЧжЬЇеЩ®иКВзВєзЪДHashеАЉпЉМе∞ЖжЬЇеЩ®жШ†е∞ДеИ∞зОѓдЄ≠зЪДдЄАдЄ™иКВзВєпЉМе¶ВдЄЛеЫЊпЉЪ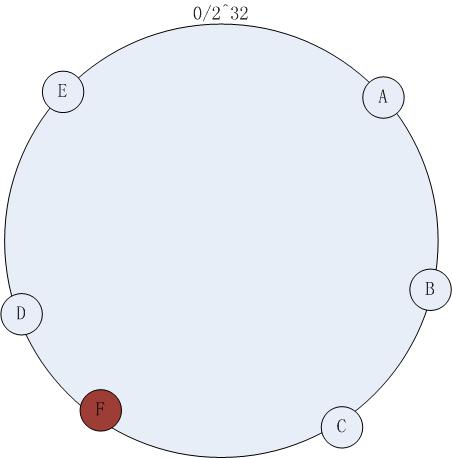
еЫЊдЇМ
еҐЮеК†жЬЇеЩ®иКВзВєFдєЛеРОпЉМиЃњйЧЃз≠ЦзХ•дЄНжФєеПШпЉМдЊЭзДґжМЙзЕІпЉИ2пЉЙдЄ≠зЪДжЦєеЉПиЃњйЧЃпЉМж≠§жЧґзЉУе≠ШеСљдЄНдЄ≠зЪДжГЕеЖµдЊЭзДґдЄНеПѓйБњеЕНпЉМдЄНиГљеСљдЄ≠зЪДжХ∞жНЃжШѓhash(K)еЬ®еҐЮеК†иКВзВєдї•еЙНиРљеЬ®CпљЮFдєЛйЧізЪДжХ∞жНЃгАВе∞љзЃ°дЊЭзДґе≠ШеЬ®иКВзВєеҐЮеК†еЄ¶жЭ•зЪДеСљдЄ≠йЧЃйҐШпЉМдљЖжШѓжѓФиЊГдЉ†зїЯзЪД hashеПЦж®°зЪДжЦєеЉПпЉМдЄАиЗіжАІhashеЈ≤зїПе∞ЖдЄНеСљдЄ≠зЪДжХ∞жНЃйЩНеИ∞дЇЖжЬАдљОгАВ
Consistent HashingжЬАе§ІйЩРеЇ¶еЬ∞жКСеИґдЇЖhashйФЃзЪДйЗНжЦ∞еИЖеЄГгАВеП¶е§Ци¶БеПЦеЊЧжѓФиЊГе•љзЪДиіЯиљљеЭЗи°°зЪДжХИжЮЬпЉМеЊАеЊАеЬ®жЬНеК°еЩ®жХ∞йЗПжѓФиЊГе∞СзЪДжЧґеАЩйЬАи¶БеҐЮеК†иЩЪжЛЯиКВзВєжЭ•дњЭиѓБжЬНеК°еЩ®иГљеЭЗеМАзЪДеИЖеЄГеЬ®еЬЖзОѓдЄКгАВеЫ†дЄЇдљњзФ®дЄАиИђзЪДhashжЦєж≥ХпЉМжЬНеК°еЩ®зЪДжШ†е∞ДеЬ∞зВєзЪДеИЖеЄГйЭЮеЄЄдЄНеЭЗеМАгАВдљњзФ®иЩЪжЛЯиКВзВєзЪДжАЭжГ≥пЉМдЄЇжѓПдЄ™зЙ©зРЖиКВзВєпЉИжЬНеК°еЩ®пЉЙеЬ®еЬЖдЄКеИЖйЕН100пљЮ200дЄ™зВєгАВињЩж†Је∞±иГљжКСеИґеИЖеЄГдЄНеЭЗеМАпЉМжЬАе§ІйЩРеЇ¶еЬ∞еЗПе∞ПжЬНеК°еЩ®еҐЮеЗПжЧґзЪДзЉУе≠ШйЗНжЦ∞еИЖеЄГгАВзФ®жИЈжХ∞жНЃжШ†е∞ДеЬ®иЩЪжЛЯиКВзВєдЄКпЉМе∞±и°®з§ЇзФ®жИЈжХ∞жНЃзЬЯж≠£е≠ШеВ®дљНзљЃжШѓеЬ®иѓ•иЩЪжЛЯиКВзВєдї£и°®зЪДеЃЮйЩЕзЙ©зРЖжЬНеК°еЩ®дЄКгАВ
дЄЛйЭҐжЬЙдЄАдЄ™еЫЊжППињ∞дЇЖйЬАи¶БдЄЇжѓПеП∞зЙ©зРЖжЬНеК°еЩ®еҐЮеК†зЪДиЩЪжЛЯиКВзВєгАВ
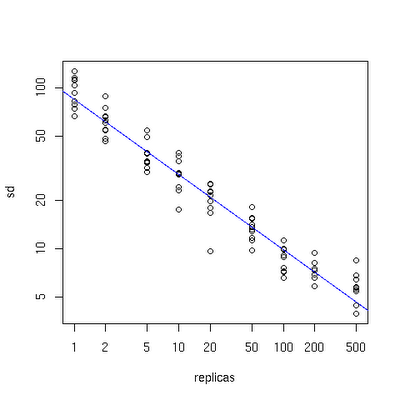
еЫЊдЄЙ
xиљіи°®з§ЇзЪДжШѓйЬАи¶БдЄЇжѓПеП∞зЙ©зРЖжЬНеК°еЩ®жЙ©е±ХзЪДиЩЪжЛЯиКВзВєеАНжХ∞(scale)пЉМyиљіжШѓеЃЮйЩЕзЙ©зРЖжЬНеК°еЩ®жХ∞пЉМеПѓдї•зЬЛеЗЇпЉМељУзЙ©зРЖжЬНеК°еЩ®зЪДжХ∞йЗПеЊИе∞ПжЧґпЉМйЬАи¶БжЫіе§ІзЪДиЩЪжЛЯиКВзВєпЉМеПНдєЛеИЩйЬАи¶БжЫіе∞СзЪДиКВзВєпЉМдїОеЫЊдЄКеПѓдї•зЬЛеЗЇпЉМеЬ®зЙ©зРЖжЬНеК°еЩ®жЬЙ10еП∞жЧґпЉМеЈЃдЄНе§ЪйЬАи¶БдЄЇжѓПеП∞жЬНеК°еЩ®еҐЮеК†100~200дЄ™иЩЪжЛЯиКВзВєжЙНиГљиЊЊеИ∞зЬЯж≠£зЪДиіЯиљљеЭЗи°°гАВ
дЄЙгАБдї•spymemcacheжЇРз†БжЭ•жЉФз§ЇиЩЪжЛЯиКВзВєеЇФзФ®
1гАБдЄКиЊєжППињ∞зЪДдЄАиЗіжАІHashзЃЧж≥ХжЬЙдЄ™жљЬеЬ®зЪДйЧЃйҐШжШѓ:
пЉИ1пЉЙгАБе∞ЖиКВзВєhashеРОдЉЪдЄНеЭЗеМАеЬ∞еИЖеЄГеЬ®зОѓдЄКпЉМињЩж†Је§ІйЗПkeyеЬ®еѓїжЙЊиКВзВєжЧґпЉМдЉЪе≠ШеЬ®keyеСљдЄ≠еРДдЄ™иКВзВєзЪДж¶ВзОЗеЈЃеИЂиЊГе§ІпЉМжЧ†ж≥ХеЃЮзО∞жЬЙжХИзЪДиіЯиљљеЭЗи°°гАВ
пЉИ2пЉЙгАБе¶ВжЬЙдЄЙдЄ™иКВзВєNode1,Node2,Node3пЉМеИЖеЄГеЬ®зОѓдЄКжЧґдЄЙдЄ™иКВзВєжМ®зЪДеЊИињСпЉМиРљеЬ®зОѓдЄКзЪДkeyеѓїжЙЊиКВзВєжЧґпЉМе§ІйЗПkeyй°ЇжЧґйТИжАїжШѓеИЖйЕНзїЩNode2пЉМиАМеЕґеЃГдЄ§дЄ™иКВзº襀жЙЊеИ∞зЪДж¶ВзОЗйГљдЉЪеЊИе∞ПгАВ
2гАБињЩзІНйЧЃйҐШзЪДиІ£еЖ≥жЦєж°ИеПѓдї•жЬЙ:
жФєеЦДHashзЃЧж≥ХпЉМеЭЗеМАеИЖйЕНеРДиКВзВєеИ∞зОѓдЄКпЉЫпЉїеЉХжЦЗпЉљдљњзФ®иЩЪжЛЯиКВзВєзЪДжАЭжГ≥пЉМдЄЇжѓПдЄ™зЙ©зРЖиКВзВєпЉИжЬНеК°еЩ®пЉЙеЬ®еЬЖдЄКеИЖйЕН100пљЮ200дЄ™зВєгАВињЩж†Је∞±иГљжКСеИґеИЖеЄГдЄНеЭЗеМАпЉМжЬАе§ІйЩРеЇ¶еЬ∞еЗПе∞ПжЬНеК°еЩ®еҐЮеЗПжЧґзЪДзЉУе≠ШйЗНжЦ∞еИЖеЄГгАВзФ®жИЈжХ∞жНЃжШ†е∞ДеЬ®иЩЪжЛЯиКВзВєдЄКпЉМе∞±и°®з§ЇзФ®жИЈжХ∞жНЃзЬЯж≠£е≠ШеВ®дљНзљЃжШѓеЬ®иѓ•иЩЪжЛЯиКВзВєдї£и°®зЪДеЃЮйЩЕзЙ©зРЖжЬНеК°еЩ®дЄКгАВ
еЬ®жЯ•зЬЛSpy Memcached clientжЧґпЉМеПСзО∞еЃГйЗЗзФ®дЄАзІНзІ∞дЄЇKetamaзЪДHashзЃЧж≥ХпЉМдї•иЩЪжЛЯиКВзВєзЪДжАЭжГ≥пЉМиІ£еЖ≥MemcachedзЪДеИЖеЄГеЉПйЧЃйҐШгАВ
3гАБжЇРз†БиѓіжШО
иѓ•clientйЗЗзФ®TreeMapе≠ШеВ®жЙАжЬЙиКВзВєпЉМж®°жЛЯдЄАдЄ™з΃嚥зЪДйАїиЊСеЕ≥з≥їгАВеЬ®ињЩдЄ™зОѓдЄ≠пЉМиКВзВєдєЛеЙНжШѓе≠ШеЬ®й°ЇеЇПеЕ≥з≥їзЪДпЉМжЙАдї•TreeMapзЪДkeyењЕй°їеЃЮзО∞ComparatorжО•еП£гАВ
йВ£иКВзВєжШѓжАОж†ЈжФЊеЕ•ињЩдЄ™зОѓдЄ≠зЪДеСҐпЉЯ
- protectedvoidsetKetamaNodes(List<MemcachedNode>nodes){
- TreeMap<Long,MemcachedNode>newNodeMap=newTreeMap<Long,MemcachedNode>();
- intnumReps=config.getNodeRepetitions();
- for(MemcachedNodenode:nodes){
- //Ketamadoessomespecialworkwithmd5whereitreuseschunks.
- if(hashAlg==HashAlgorithm.KETAMA_HASH){
- for(inti=0;i<numReps/4;i++){
- byte[]digest=HashAlgorithm.computeMd5(config.getKeyForNode(node,i));
- for(inth=0;h<4;h++){
- Longk=((long)(digest[3+h*4]&0xFF)<<24)
- |((long)(digest[2+h*4]&0xFF)<<16)
- |((long)(digest[1+h*4]&0xFF)<<8)
- |(digest[h*4]&0xFF);
- newNodeMap.put(k,node);
- getLogger().debug("Addingnode%sinposition%d",node,k);
- }
- }
- }else{
- for(inti=0;i<numReps;i++){
- newNodeMap.put(hashAlg.hash(config.getKeyForNode(node,i)),node);
- }
- }
- }
- assertnewNodeMap.size()==numReps*nodes.size();
- ketamaNodes=newNodeMap;
protected void setKetamaNodes(List<MemcachedNode> nodes) {
TreeMap<Long, MemcachedNode> newNodeMap = new TreeMap<Long, MemcachedNode>();
int numReps= config.getNodeRepetitions();
for(MemcachedNode node : nodes) {
// Ketama does some special work with md5 where it reuses chunks.
if(hashAlg == HashAlgorithm.KETAMA_HASH) {
for(int i=0; i<numReps / 4; i++) {
byte[] digest=HashAlgorithm.computeMd5(config.getKeyForNode(node, i));
for(int h=0;h<4;h++) {
Long k = ((long)(digest[3+h*4]&0xFF) << 24)
| ((long)(digest[2+h*4]&0xFF) << 16)
| ((long)(digest[1+h*4]&0xFF) << 8)
| (digest[h*4]&0xFF);
newNodeMap.put(k, node);
getLogger().debug("Adding node %s in position %d", node, k);
}
}
} else {
for(int i=0; i<numReps; i++) {
newNodeMap.put(hashAlg.hash(config.getKeyForNode(node, i)), node);
}
}
}
assert newNodeMap.size() == numReps * nodes.size();
ketamaNodes = newNodeMap;
дЄКйЭҐзЪДжµБз®Ле§Іж¶ВеПѓдї•ињЩж†ЈељТзЇ≥:еЫЫдЄ™иЩЪжЛЯзїУзВєдЄЇдЄАзїДпЉМдї•getKeyForNodeжЦєж≥ХеЊЧеИ∞ињЩзїДиЩЪжЛЯиКВзВєзЪДnameпЉМMd5зЉЦз†БеРОпЉМжѓПдЄ™иЩЪжЛЯзїУзВєеѓєеЇФMd5з†Б16дЄ™е≠ЧиКВдЄ≠зЪД4дЄ™пЉМзїДжИРдЄАдЄ™longеЮЛжХ∞еАЉпЉМеБЪдЄЇињЩдЄ™иЩЪжЛЯзїУзВєеЬ®зОѓдЄ≠зЪДжГЯдЄАkeyгАВзђђ10и°МkдЄЇдїАдєИжШѓLongеЮЛзЪДеСҐпЉЯе∞±жШѓеЫ†дЄЇLongеЮЛеЃЮзО∞дЇЖComparatorжО•еП£гАВ
е§ДзРЖеЃМж≠£еЉПзїУзВєеЬ®зОѓдЄКзЪДеИЖеЄГеРОпЉМеПѓдї•еЉАеІЛkeyеЬ®зОѓдЄКеѓїжЙЊиКВзВєзЪДжЄЄжИПдЇЖгАВ
еѓєдЇОжѓПдЄ™keyињШжШѓеЊЧеЃМжИРдЄКйЭҐзЪДж≠•й™§:иЃ°зЃЧеЗЇMd5пЉМж†єжНЃMd5зЪДе≠ЧиКВжХ∞зїДпЉМйАЪињЗKemata HashзЃЧж≥ХеЊЧеИ∞keyеЬ®ињЩдЄ™зОѓдЄ≠зЪДдљНзљЃгАВ
- MemcachedNodegetNodeForKey(longhash){
- finalMemcachedNoderv;
- if(!ketamaNodes.containsKey(hash)){
- //Java1.6addsaceilingKeymethod,butI'mstillstuckin1.5
- //inalotofplaces,soI'mdoingthismyself.
- SortedMap<Long,MemcachedNode>tailMap=getKetamaNodes().tailMap(hash);
- if(tailMap.isEmpty()){
- hash=getKetamaNodes().firstKey();
- }else{
- hash=tailMap.firstKey();
- }
- }
- rv=getKetamaNodes().get(hash);
- returnrv;
- }
MemcachedNode getNodeForKey(long hash) {
final MemcachedNode rv;
if(!ketamaNodes.containsKey(hash)) {
// Java 1.6 adds a ceilingKey method, but I'm still stuck in 1.5
// in a lot of places, so I'm doing this myself.
SortedMap<Long, MemcachedNode> tailMap=getKetamaNodes().tailMap(hash);
if(tailMap.isEmpty()) {
hash=getKetamaNodes().firstKey();
} else {
hash=tailMap.firstKey();
}
}
rv=getKetamaNodes().get(hash);
return rv;
}
дЄКиЊєдї£з†БзЪДеЃЮзО∞е∞±жШѓеЬ®зОѓдЄКй°ЇжЧґйТИжЯ•жЙЊпЉМж≤°жЙЊеИ∞е∞±еОїзЪДзђђдЄАдЄ™пЉМзДґеРОе∞±зЯ•йБУеѓєеЇФзЪДзЙ©зРЖиКВзВєдЇЖгАВ
еЫЫгАБеЇФзФ®еЬЇжЩѓеИЖжЮР
1гАБmemcacheзЪДaddжЦєж≥ХпЉЪйАЪињЗдЄАиЗіжАІhashзЃЧж≥Хз°ЃиЃ§ељУеЙНеЃҐжИЈзЂѓеѓєеЇФзЪДcacheserverзЪДhashеАЉдї•еПКи¶Бе≠ШеВ®жХ∞жНЃkeyзЪДhashињЫи°МеѓєеЇФпЉМз°ЃиЃ§cacheserverпЉМиОЈеПЦconnectionињЫи°МжХ∞жНЃе≠ШеВ®
2гАБmemcacheзЪДgetжЦєж≥ХпЉЪйАЪињЗдЄАиЗіжАІhashзЃЧж≥Хз°ЃиЃ§ељУеЙНеЃҐжИЈзЂѓеѓєеЇФзЪДcacheserverзЪДhashеАЉдї•еПКи¶БжПРеПЦжХ∞жНЃзЪДhashеАЉпЉМињЫиАМз°ЃиЃ§е≠ШеВ®зЪДcacheserverпЉМиОЈеПЦconnectionињЫи°МжХ∞жНЃжПРеПЦ
дЇФгАБжАїзїУ
1гАБдЄАиЗіжАІhashзЃЧж≥ХеП™жШѓеЄЃжИСдїђеЗПе∞СcacheйЫЖзЊ§дЄ≠зЪДжЬЇеЩ®жХ∞йЗПеҐЮеЗПзЪДжЧґеАЩпЉМcacheзЪДжХ∞жНЃиГљињЫи°МжЬАе∞СйЗНеїЇгАВеП™и¶БcacheйЫЖзЊ§зЪДserverжХ∞йЗПжЬЙеПШеМЦпЉМењЕзДґдЇІзФЯжХ∞жНЃеСљдЄ≠зЪДйЧЃйҐШ
2гАБеѓєдЇОжХ∞жНЃзЪДеИЖеЄГеЭЗи°°йЧЃйҐШпЉМйАЪињЗиЩЪжЛЯиКВзВєзЪДжАЭжГ≥жЭ•иЊЊеИ∞еЭЗи°°еИЖйЕНгАВељУзДґпЉМжИСдїђcache serverиКВзВєиґКе∞Се∞±иґКйЬАи¶БиЩЪжЛЯиКВзВєињЩдЄ™жЦєеЉПжЭ•еЭЗи°°иіЯиљљгАВ
3гАБжИСдїђзЪДcacheеЃҐжИЈзЂѓж†єжЬђдЄНдЉЪзїіжК§дЄАдЄ™mapжЭ•иЃ∞ељХжѓПдЄ™keyе≠ШеВ®еЬ®еУ™йЗМпЉМйГљжШѓйАЪињЗkeyзЪДhashеТМcacheserverпЉИдєЯиЃЄipеПѓдї•дљЬдЄЇеПВжХ∞пЉЙзЪДhashиЃ°зЃЧељУеЙНзЪДkeyеЇФиѓ•е≠ШеВ®еЬ®еУ™дЄ™иКВзВєдЄКгАВ
4гАБељУжИСдїђзЪДcacheиКВзВєеі©жЇГдЇЖгАВжИСдїђењЕеЃЪ䪥姱йГ®еИЖcacheжХ∞жНЃпЉМеєґдЄФи¶Бж†єжНЃжіїзЭАзЪДcache serverеТМkeyињЫи°МжЦ∞зЪДдЄАиЗіжАІеМєйЕНиЃ°зЃЧгАВжЬЙеПѓиГљеѓєйГ®еИЖж≤°жЬЙ䪥姱зЪДжХ∞жНЃдєЯи¶БеБЪйЗНеїЇ...
5гАБиЗ≥дЇОж≠£еЄЄеИ∞иЊЊжХ∞жНЃе≠ШеВ®иКВзВєпЉМе¶ВдљХжЙЊеИ∞keyеѓєеЇФзЪДжХ∞жНЃпЉМйВ£е∞±жШѓcache serverжЬђиЇЂзЪДеЖЕйГ®зЃЧж≥ХеЃЮзО∞дЇЖпЉМж≠§е§ДдЄНеБЪжППињ∞гАВ
ињЩйЗМеП™жШѓйТИеѓєжХ∞жНЃзЪДе≠ШеВ®жЦєеЉПдї•еПКжПРеПЦжЦєеЉПињЫи°МдЇЖжµБз®Ле±Хз§ЇгАВ
иљђиљљпЉЪhttp://blog.csdn.net/kongqz/article/details/6695417


- 2015-08-13 09:05
- жµПиІИ 221
- иѓДиЃЇ(0)
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМпЉИDistributed Hash Table, DHTпЉЙжКАжЬѓпЉМжЧ®еЬ®иІ£еЖ≥еЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠жХ∞жНЃеИЖеЄГдЄНеЭЗеМАзЪДйЧЃйҐШгАВKetamaзЃЧж≥ХжШѓеЯЇдЇОдЄАиЗіжАІеУИеЄМзЪДдЄАзІНдЉШеМЦеЃЮзО∞пЉМзФ±Last.fmеЕђеПЄзЪДSimon WillisonжПРеЗЇпЉМеЕґзЫЃж†ЗжШѓеЬ®...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠иІ£еЖ≥жХ∞жНЃеИЖеПСеТМиіЯиљљеЭЗи°°йЧЃйҐШзЪДзЃЧж≥ХпЉМзЙєеИЂжШѓеЬ®зЉУе≠Шз≥їзїЯе¶ВMemcachedжИЦRedisдЄ≠еєњж≥ЫеЇФзФ®гАВеЃГжЬАжЧ©еЬ®1997еєізЪДиЃЇжЦЗгАКConsistent Hashing and Random TreesгАЛдЄ≠襀жПРеЗЇпЉМжЧ®еЬ®еЕЛжЬНдЉ†зїЯеУИеЄМ...
дЄАиЗіжАІHashзЃЧж≥ХйАЪињЗеЈІе¶ЩзЪДиЃЊиЃ°пЉМдЄНдїЕиІ£еЖ≥дЇЖдЉ†зїЯеУИеЄМжЦєж≥ХеЬ®еК®жАБзОѓеҐГдЄ≠е≠ШеЬ®зЪДйЧЃйҐШпЉМињШдЄЇеИЖеЄГеЉПз≥їзїЯзЪДз®≥еЃЪжАІгАБеПѓжЙ©е±ХжАІеТМжАІиГљжПРдЊЫдЇЖжЬЙеКЫжФѓжМБгАВйАЪињЗзРЖиІ£еЕґж†ЄењГеОЯзРЖеТМеЇФзФ®пЉМжИСдїђеПѓдї•жЫіе•љеЬ∞еЇФеѓєеИЖеЄГеЉПзОѓеҐГдЄЛзЪДжМСжИШпЉМеєґжЮДеїЇ...
дЄАиЗіжАІеУИеЄМзЃЧж≥Х(Consistent Hashing)жШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠еє≥и°°жХ∞жНЃеИЖеЄГзЪДз≠ЦзХ•пЉМе∞§еЕґйАВзФ®дЇОзЉУе≠ШжЬНеК°е¶ВMemcachedжИЦRedisгАВеЃГзЪДж†ЄењГжАЭжГ≥жШѓйАЪињЗеУИеЄМеЗљжХ∞е∞Жеѓєи±°жШ†е∞ДеИ∞дЄАдЄ™еЫЇеЃЪе§Іе∞ПзЪДз΃嚥穯йЧідЄ≠пЉМзДґеРОе∞ЖжЬНеК°еЩ®дєЯжШ†е∞ДеИ∞ињЩдЄ™...
ж≠§е§ЦпЉМдЄАиЗіжАІеУИеЄМзЃЧж≥ХеЬ®еИЖеЄГеЉПзЉУе≠Ше¶ВMemcachedгАБRedisдЄ≠дєЯеЊЧеИ∞дЇЖеєњж≥ЫеЇФзФ®гАВеЃГдЄНдїЕзЃАеМЦдЇЖжХ∞жНЃеИЖеЄГзЪДйАїиЊСпЉМињШеЕБиЃЄеК®жАБжЙ©е±ХеТМжФґзЉ©йЫЖзЊ§иІДж®°пЉМжЧ†йЬАе§ІиІДж®°зЪДжХ∞жНЃињБзІїгАВ еЬ®жЦЗдїґеРНдЄЇвАЬdistribute-mysqlвАЭзЪДеОЛзЉ©еМЕдЄ≠пЉМеПѓиГљ...
- **еИЖеЄГеЉПзЉУе≠Ш**пЉЪе¶ВMemcachedгАБRedisйЫЖзЊ§дЄ≠пЉМдЄАиЗіжАІеУИеЄМзФ®дЇОз°ЃеЃЪжХ∞жНЃеЇФиѓ•е≠ШеВ®еЬ®еУ™дЄ™иКВзВєдЄКгАВ - **иіЯиљљеЭЗи°°**пЉЪеЬ®иіЯиљљеЭЗи°°еЩ®дЄ≠пЉМдЄАиЗіжАІеУИеЄМеПѓдї•зФ®жЭ•еИЖйЕНиѓЈж±ВеИ∞дЄНеРМзЪДжЬНеК°еЩ®пЉМйБњеЕНеЬ®еК®жАБи∞ГжХіжЬНеК°еЩ®жХ∞йЗПжЧґе§ІйЗПиѓЈж±В...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХпЉИConsistent HashingпЉЙжШѓдЄАзІНзЙєжЃКзЪДеУИеЄМзЃЧж≥ХпЉМиЃЊиЃ°зЫЃзЪДжШѓдЄЇдЇЖеЬ®еИЖеЄГеЉПзЉУе≠Шз≥їзїЯдЄ≠иІ£еЖ≥иКВзВєеК®жАБеҐЮеЗПжЧґеѓЉиЗізЪДжХ∞жНЃеИЖеЄГдЄНеЭЗйЧЃйҐШгАВиѓ•зЃЧж≥ХжЬАжЧ©еЬ®1997еєізЪДиЃЇжЦЗгАКConsistent Hashing and Random TreesгАЛдЄ≠襀...
6. **еЇФзФ®еЬЇжЩѓ**пЉЪдЄАиЗіжАІеУИеЄМеЬ®еИЖеЄГеЉПзЉУе≠Шз≥їзїЯе¶ВMemcachedеТМRedisдЄ≠襀府ж≥ЫдљњзФ®пЉМеРМжЧґеЬ®CDN(Content Delivery Network)гАБиіЯиљљеЭЗи°°еЩ®з≠ЙеЬЇжЩѓдєЯжЬЙеЇФзФ®гАВ 7. **дЉШзЉЇзВє**пЉЪKetamaдЄАиЗіжАІеУИеЄМзЃЧж≥ХзЪДдЉШзВєеЬ®дЇОеЗПе∞СдЇЖеЫ†иКВзВє...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМпЉИDistributed Hash Table, DHTпЉЙжКАжЬѓпЉМеЃГиІ£еЖ≥дЇЖеЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠жХ∞жНЃеИЖзЙЗеТМиіЯиљљеЭЗи°°зЪДйЧЃйҐШгАВеЬ®дЉ†зїЯзЪДеУИеЄМзЃЧж≥ХдЄ≠пЉМе¶ВжЮЬеҐЮеК†жИЦеЗПе∞СжЬНеК°еЩ®иКВзВєпЉМдЉЪеѓЉиЗіе§ІйЗПжХ∞жНЃйЗНжЦ∞еИЖйЕНпЉМиАМдЄАиЗіжАІеУИеЄМ...
дЄАиЗіжАІеУИеЄМзЃЧж≥ХеЇФзФ®еПКдЉШеМЦжШѓITйҐЖеЯЯдЄ≠еИЖеЄГеЉПз≥їзїЯиЃЊиЃ°зЪДж†ЄењГжКАжЬѓдєЛдЄАпЉМзЙєеИЂжШѓеЬ®е§ДзРЖе§ІиІДж®°жХ∞жНЃеИЖеЄГдЄОзЉУе≠Шз≥їзїЯдЄ≠пЉМеЕґйЗНи¶БжАІдЄНи®АиАМеЦїгАВжЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®дЄАиЗіжАІеУИеЄМзЃЧж≥ХзЪДеЯЇжЬђж¶ВењµгАБеЈ•дљЬеОЯзРЖдї•еПКеЬ®еЃЮйЩЕеЬЇжЩѓдЄ≠зЪДеЇФзФ®еТМдЉШеМЦ...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМи°®пЉИDHT, Distributed Hash TableпЉЙзЃЧж≥ХпЉМдЄїи¶БзФ®дЇОиІ£еЖ≥еЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠жХ∞жНЃе≠ШеВ®еТМж£А糥зЪДйЧЃйҐШпЉМе∞§еЕґжШѓеЬ®еК®жАБжЙ©е±ХйЫЖзЊ§иКВзВєжЧґпЉМиГље§Яе∞љеПѓиГљеЬ∞еЗПе∞СзЉУе≠ШйЗНеїЇпЉМдњЭжМБз≥їзїЯ...
1. "дЄАиЗіжАІеУИеЄМеѓєзЉУе≠ШеСљдЄ≠зОЗзЪДељ±еУНеЃЮй™МжК•еСК.doc"пЉЪињЩдїљжЦЗж°£еПѓиГљиѓ¶зїЖдїЛзїНдЇЖе¶ВдљХдљњзФ®дЄАиЗіжАІеУИеЄМзЃЧж≥ХжЭ•еИЖйЕНеТМж£А糥жХ∞жНЃеЬ®MemcachedдЄ≠зЪДе≠ШеВ®пЉМдї•еПКиѓ•зЃЧж≥Хе¶ВдљХељ±еУНзЉУе≠ШзЪДеСљдЄ≠зОЗгАВдЄАиЗіжАІеУИеЄМжШѓиІ£еЖ≥еИЖеЄГеЉПзЉУе≠ШдЄ≠жХ∞жНЃеИЖеЄГдЄНеЭЗ...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНеИЖеЄГеЉПеУИеЄМпЉИDistributed Hash TableпЉМDHTпЉЙзЃЧж≥ХпЉМдЄїи¶БзФ®дЇОиІ£еЖ≥еЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠зЪДжХ∞жНЃе≠ШеВ®еТМж£А糥йЧЃйҐШгАВеЬ®дЇСиЃ°зЃЧгАБзЉУе≠Шз≥їзїЯпЉИе¶ВRedisгАБMemcachedпЉЙдї•еПКиіЯиљљеЭЗи°°з≠ЙйҐЖеЯЯеєњж≥ЫеЇФзФ®...
еЬ®еЃЮйЩЕеЇФзФ®дЄ≠пЉМдЄАиЗіжАІеУИеЄМзЃЧж≥ХйАЪеЄЄзФ®дЇОеИЖеЄГеЉПзЉУе≠Шз≥їзїЯдЄ≠пЉМе¶ВRedisгАБMemcachedйЫЖзЊ§гАВйАЪињЗдЄАиЗіжАІеУИеЄМпЉМз≥їзїЯиГље§ЯеЃЮзО∞дї•дЄЛзЫЃж†ЗпЉЪ - **иКВзВєеК®жАБжЙ©е±Х**пЉЪељУз≥їзїЯйЬАи¶БжЙ©е±ХиКВзВєжЧґпЉМдЄАиЗіжАІеУИеЄМеПѓдї•дњЭиѓБеП™жЬЙйГ®еИЖзЉУе≠ШжХ∞жНЃйЬАи¶Б...
дЄАиЗіжАІеУИеЄМ(Consistent Hashing)жШѓдЄАзІНеИЖеЄГеЉПеУИеЄМи°®(DHT, Distributed Hash Table)зЪДзЃЧж≥ХпЉМдЄїи¶БзФ®дЇОиІ£еЖ≥еЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠жХ∞жНЃеИЖзЙЗгАБиіЯиљљеЭЗи°°гАБзЉУе≠ШеИЖеПСз≠ЙйЧЃйҐШгАВеЬ®дЇСиЃ°зЃЧеТМе§ІжХ∞жНЃйҐЖеЯЯпЉМдЄАиЗіжАІеУИеЄМзЃЧж≥ХжЬЙзЭАеєњж≥ЫзЪДеЇФзФ®пЉМ...
### еИЖеЄГеЉПSessionиІ£еЖ≥жЦєж°ИдЄОдЄАиЗіжАІHashиѓ¶иІ£ #### дЄАгАБйЧЃйҐШиГМжЩѓеПКжПРеЗЇ ...еРМжЧґпЉМдЄАиЗіжАІHashзЃЧж≥ХдљЬдЄЇдЄАзІНдЉШеМЦжХ∞жНЃеИЖеЄГзЪДжКАжЬѓпЉМдєЯеЬ®еИЖеЄГеЉПзОѓеҐГдЄ≠еПСжМ•зЭАйЗНи¶БдљЬзФ®гАВеЉАеПСиАЕеЇФж†єжНЃеЃЮйЩЕеЬЇжЩѓеТМжКАжЬѓж†ИзЪДзЙєзВєйАЙжЛ©жЬАйАВеРИзЪДжЦєж°ИгАВ
дЄАиЗіжАІеУИеЄМзЃЧж≥ХпЉИConsistent HashingпЉЙжШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠еЃЮзО∞иіЯиљљеЭЗи°°зЪДзЃЧж≥ХпЉМе∞§еЕґеЬ®еИЖеЄГеЉПзЉУе≠Ше¶ВMemcachedеТМRedisз≠ЙеЬЇжЩѓдЄЛеєњж≥ЫдљњзФ®гАВеЃГиІ£еЖ≥дЇЖдЉ†зїЯеУИеЄМзЃЧж≥ХеЬ®иКВзВєеҐЮеЗПжЧґеѓЉиЗізЪДе§ІйЗПжХ∞жНЃињБзІїйЧЃйҐШпЉМжПРйЂШдЇЖз≥їзїЯзЪДеПѓзФ®...
дЄАиЗіжАІеУИеЄМпЉИConsistent HashingпЉЙжШѓдЄАзІНеЬ®еИЖеЄГеЉПз≥їзїЯдЄ≠иІ£еЖ≥жХ∞жНЃеИЖзЙЗйЧЃйҐШзЪДзЃЧж≥ХпЉМеЃГдљњеЊЧеЬ®иКВзВєеК†еЕ•жИЦз¶їеЉАжЧґпЉМеП™йЬАи¶Бе∞СйЗПзЪДжХ∞жНЃињБзІїе∞±иГљдњЭжМБз≥їзїЯзЪДз®≥еЃЪжАІгАВеЬ®ињЩдЄ™дЄКдЄЛжЦЗдЄ≠пЉМ`libconhash`жШѓдЄАдЄ™дЄУйЧ®еЃЮзО∞дЄАиЗіжАІеУИеЄМзЪД...
memcached ињШжФѓжМБдЄАиЗіжАІ Hash зЃЧж≥ХпЉМдї•з°ЃдњЭжХ∞жНЃзЪДеИЖеЄГеЉПе≠ШеВ®гАВ memcached зЪДеЇФзФ®еЬЇжЩѓ memcached еєњж≥ЫеЇФзФ®дЇОеРДзІН Web еЇФзФ®з®ЛеЇПдЄ≠пЉМеМЕжЛђз§ЊдЇ§е™ТдљУгАБзФµеХЖеє≥еП∞гАБеНЪеЃҐеє≥еП∞з≠ЙгАВmemcached еПѓдї•зФ®дЇОзЉУе≠ШзФ®жИЈжХ∞жНЃгАБжЦЗзЂ†жХ∞жНЃ...