在JBoss Rules 学习(一):什么是Rule
中,
我们介绍了JBoss Rules中对Rule的表示,其中提到了JBoss
Rule中主要采用的RETE算法来进行规则匹配。下面将详细的介绍一下RETE算法在JBoss Rule中的实现,最后随便提一下JBoss
Rules中也可以使用的另一种规则匹配算法Leaps。
1.Rete
算法
:
Rete
在拉丁语中是
”net”
,有网络的意思。
RETE
算法可以分为两部分:规则编译(
rule compilation
)和运行时执行(
runtime execution
)。
编译算法描述了规则如何在
Production
Memory
中产生一个有效的辨别网络。用一个非技术性的词来说,一个辨别网络就是用来过滤数据。方法是通过数据在网络中的传播来过滤数据。在顶端节点将会有很多匹配的数据。当我们顺着网络向下走,匹配的数据将会越来越少。在网络的最底部是终端节点(
terminal nodes
)。在
Dr Forgy
的
1982
年的论文中,他描述了
4
种基本节点:
root , 1-input, 2-input and
terminal
。下图是
Drools
中的
RETE
节点类型:
Figure 1.
Rete Nodes
根节点(
RootNode
)是所有的对象进入网络的入口。然后,从根节点立即进入到
ObjectTypeNode
。
ObjectTypeNode
的作用是使引擎只做它需要做的事情。例如,我们有两个对象集:
Account
和
Order
。如果规则引擎需要对每个对象都进行一个周期的评估,那会浪费很多的时间。为了提高效率,引擎将只让匹配
object type
的对象通过到达节点。通过这种方法,如果一个应用
assert
一个新的
account
,它不会将
Order
对象传递到节点中。很多现代
RETE
实现都有专门的
ObjectTypeNode
。在一些情况下,
ObjectTypeNode
被用散列法进一步优化。
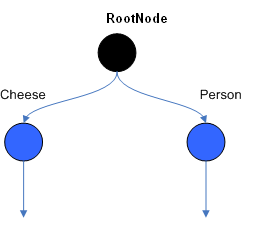
Figure 2 . ObjectTypeNodes
ObjectTypeNode
能够传播到
AlphaNodes,
LeftInputAdapterNodes
和
BetaNodes
。
1-input
节点通常被称为
AlphaNode
。
AlphaNodes
被用来评估字面条件(
literal conditions
)。虽然,
1982
年的论文只提到了相等条件(指的字面上相等),很多
RETE
实现支持其他的操作。例如,
Account.name
= = “Mr Trout”
是一个字面条件。当一条规则对于一种
object type
有多条的字面条件,这些字面条件将被链接在一起。这是说,如果一个应用
assert
一个
account
对象,在它能到达下一个
AlphaNode
之前,它必须先满足第一个字面条件。在
Dr. Forgy
的论文中,他用
IntraElement conditions
来表述。下面的图说明了
Cheese
的
AlphaNode
组合(
name = = “cheddar”
,
strength = = “strong”
):
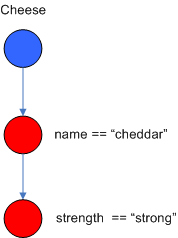
Figure 3. AlphaNodes
Drools
通过散列法优化了从
ObjectTypeNode
到
AlphaNode
的传播。每次一个
AlphaNode
被加到一个
ObjectTypeNode
的时候,就以字面值(
literal value
)作为
key
,以
AlphaNode
作为
value
加入
HashMap
。当一个新的实例进入
ObjectTypeNode
的时候,不用传递到每一个
AlphaNode
,它可以直接从
HashMap
中获得正确的
AlphaNode
,避免了不必要的字面检查。
<!-- [if !supportEmptyParas]-->
2-input
节点通常被称为
BetaNode
。
Drools
中有两种
BetaNode
:
JoinNode
和
NotNode
。
BetaNodes
被用来对
2
个对象进行对比。这两个对象可以是同种类型,也可以是不同类型。
我们约定
BetaNodes
的
2
个输入称为左边(
left
)和右边(
right
)。一个
BetaNode
的左边输入通常是
a list of objects
。在
Drools
中,这是一个数组。右边输入是
a single object
。两个
NotNode
可以完成‘
exists
’检查。
Drools
通过将索引应用在
BetaNodes
上扩展了
RETE
算法。下图展示了一个
JoinNode
的使用:

Figure 4 . JoinNode
注意到图中的左边输入用到了一个
LeftInputAdapterNode
,这个节点的作用是将一个
single Object
转化为一个单对象数组(
single Object Tuple
),传播到
JoinNode
节点。因为我们上面提到过左边输入通常是
a list of objects
。
<!-- [if !supportEmptyParas]-->
Terminal nodes
被用来表明一条规则已经匹配了它的所有条件(
conditions
)。
在这点,我们说这条规则有了一个完全匹配(
full match
)。在一些情况下,一条带有“或”条件的规则可以有超过一个的
terminal node
。
Drools
通过节点的共享来提高规则引擎的性能。因为很多的规则可能存在部分相同的模式,节点的共享允许我们对内存中的节点数量进行压缩,以提供遍历节点的过程。下面的两个规则就共享了部分节点:
rule
when
Cheese( $chedddar : name
==
"
cheddar
"
)
$person : Person( favouriteCheese
==
$cheddar )
then
System.out.println( $person.getName()
+
"
likes cheddar
"
);
end
<!-- <br><br>Code highlighting produced by Actipro CodeHighlighter (freeware)<br>http://www.CodeHighlighter.com/<br><br>-->
rule
when
Cheese( $chedddar : name
==
"
cheddar
"
)
$person : Person( favouriteCheese
!=
$cheddar )
then
System.out.println( $person.getName()
+
"
does likes cheddar
"
);
end
这里我们先不探讨这两条
rule
到的是什么意思,单从一个直观的感觉,这两条
rule
在它们的
LHS
中基本都是一样的,只是最后的
favouriteCheese
,一条规则是等于
$cheddar
,而另一条规则是不等于
$cheddar
。下面是这两条规则的节点图:
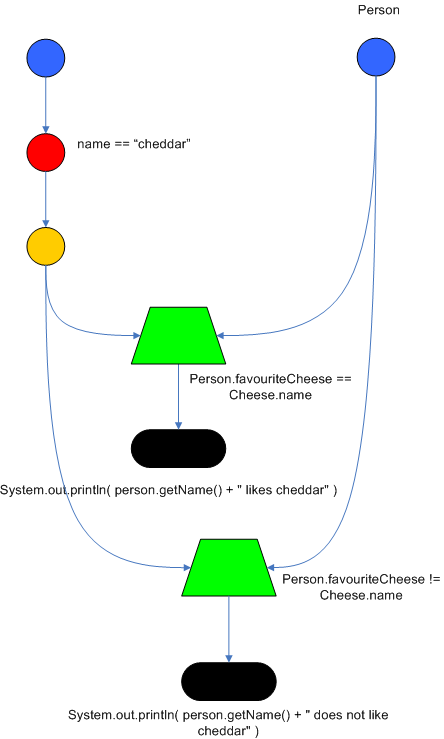
Figure 5 . Node
Sharing
从图上可以看到,编译后的
RETE
网络中,
AlphaNode
是共享的,而
BetaNode
不是共享的。上面说的相等和不相等就体现在
BetaNode
的不同。然后这两条规则有各自的
Terminal Node
。
<!-- [if !supportEmptyParas]-->
RETE
算法的第二个部分是运行时(
runtime
)。当一个应用
assert
一个对象,引擎将数据传递到
root
node
。从那里,它进入
ObjectTypeNode
并
沿着网络向下传播。当数据匹配一个节点的条件,节点就将它记录到相应的内存中。这样做的原因有以下几点:主要的原因是可以带来更快的性能。虽然记住完全或
部分匹配的对象需要内存,它提供了速度和可伸缩性的特点。当一条规则的所有条件都满足,这就是完全匹配。而只有部分条件满足,就是部分匹配。(我觉得引擎
在每个节点都有其对应的内存来储存满足该节点条件的对象,这就造成了如果一个对象是完全匹配,那这个对象就会在每个节点的对应内存中都存有其映象。)
2. Leaps
算法:
Production systems
的
Leaps
算法使用了一种“
lazy
”方法来评估条件(
conditions
)。一种
Leaps
算法的修改版本的实现,作为
Drools v3
的一部分,尝试结合
Leaps
和
RETE
方法的最好的特点来处理
Working Memory
中的
facts
。
古典的
Leaps
方法将所有的
asserted
的
facts
,按照其被
asserted
在
Working Memory
中的顺序(
FIFO
),放在主堆栈中。它一个个的检查
facts
,通过迭代匹配
data
type
的
facts
集合来找出每一个相关规则的匹配。当一个匹配的数据被发现时,系统记住此时的迭代位置以备待会的继续迭代,并且激发规则结果(
consequence
)。当结果(
consequence
)执行完成以后,系统就会继续处理处于主堆栈顶部的
fact
。如此反复。
分享到:





相关推荐
之前学习jboss rules 只能自己一点点的啃英文用户指南,后来终于找到了中文版的翻译版本,真是高兴,立即奉献给大家,让对规则引擎感兴趣的朋友也能一堵为快。 内容摘要:JBoss Rules 的前身是Codehaus的一个开源...
### JBoss Rules 学习知识点概述 #### 一、JBoss Rules 介绍 - **前身与演变**:JBoss Rules 的前身是 Codehaus 下的一个开源项目名为 Drools。随着其功能和技术的成熟,该项目被 JBoss 收购,并重新命名为 JBoss ...
它构成了大多数现代推理规则引擎的基础,如CLIPS、Jess、JBoss Rules/Drools、ILOG JRules、Fair Isaac Blaze Advisor等。Rete的发音有多种,如“REET”、“REE-tee”,或者在欧洲更常见的“re-tay”,源自拉丁语...
### jBoss Rules 用户指南知识点详解 #### 一、规则引擎概念及背景 ##### 1.1 什么是规则引擎 规则引擎是一种软件系统,它能够基于一组预定义的规则来处理数据,进而推导出结论或者执行特定的操作。规则引擎的...
规则引擎 Drools-JBoss Rules 规则引擎是人工智能(Artificial Intelligence)领域中的一种技术,用于实现专家系统,专家系统使用知识表示把知识编码简化成一个可用于推理的知识库。规则引擎是一个基于规则的方法...
### JBoss Rules 用户指南知识点详解 #### 一、规则引擎概念及背景 1. **规则引擎定义**: - 规则引擎是一种软件系统,它使用预定义的规则来处理数据,以得出结论或采取行动。 - **背景介绍**:规则引擎的发展...
- **Rete算法**:Drools内部采用了高效的Rete算法来执行规则匹配。 - **优化策略**:包括节点重用、冲突解决策略等,以提高规则匹配的速度和效率。 - **性能调优**:通过调整配置参数,如启用懒加载、使用并行...
2. **强大的推理引擎**:Drools 基于 Rete 网络算法实现,能够高效地处理复杂的规则集。 3. **灵活的集成选项**:Drools 可以作为独立的库集成到现有的 Java 应用程序中,也可以通过 Web 服务或 ESB 进行集成。 4. *...
它是大多数现代推理规则引擎(如CLIPS, Jess, JBoss Rules/Drools, ILOG JRules, Fair Isaac Blaze Advisor等)的基础。Rete算法是公共领域的,其发音可以是 'REET' 或 'REE-tee',欧洲人更常见的发音为 're-tay',...
学习Drools不仅涉及语法和API的使用,还需要理解Rete算法的工作原理。Rete算法是一种高效的模式匹配方法,用于在大量模式和对象之间查找匹配。它分为规则编辑和运行时执行两部分,能够有效地减少计算复杂性。 总的...
2005年,Drools项目加入JBoss项目,并更名为Jboss Rules。Drools遵循JSR-94规范,并在开源规则引擎领域一直处于领先地位。 3. **Drools5源码结构**: - **获取源码**:官方网址为http://www.jboss.org/drools/,...
6. **性能优化**:Drools采用高效的优化算法,如Rete算法,用于快速匹配规则和事实,提高决策执行速度。 7. **API和集成**:Drools提供了丰富的Java API,可以方便地在J2EE应用中集成。同时,它还支持Spring框架和...
由于其高效性和灵活性,DROOLS在Java开源社区中逐渐获得广泛应用,并最终被JBOSS收购,成为JBOSS应用服务器的一部分,名为JBOSS Rules。 【DROOLS的应用场景】 DROOLS适用于那些需要频繁调整业务规则的系统,比如...
它源于一个叫做Codehaus的开源项目,后来被纳入JBoss门下,并更名为JBossRules。Drools在JBoss应用服务器中作为规则引擎存在,并且是专门为Java语言定制的,基于CharlesForgy的RETE算法的实现。 RETE算法是专家系统...
Drools (JBoss Rules) 是一个开源的BRMS,它支持业务规则的定义、管理和执行。Drools的特点包括: - **易于使用:** 业务分析师和审查人员可以直接查看和修改规则。 - **标准化:** 符合业内标准,如JSR94。 - **高...
- **高性能**:采用高效的RETE算法实现高速处理能力。 #### 二、Drools的核心概念 **1. 规则引擎**: - **定义**:一种用于分离业务逻辑和应用程序代码的技术。 - **功能**:接受数据输入、解释业务规则并做出决策...
- **高性能**:基于高效的Rete算法,Drools能够快速处理复杂的业务规则集。 - **易于集成**:作为Java平台的一部分,Drools与现有的Java应用无缝集成,简化了开发和部署过程。 - **业务友好**:非技术人员如业务分析...
Drools,也被称为 JBoss Rules,是Red Hat公司下的一个开源项目,它是专为Java平台设计的、基于RETE算法的产生式规则引擎。Drools提供了一套完整的框架,包括规则定义、规则存储、规则执行以及规则生命周期管理等...
Drools最初是一个独立的开源项目,后来被JBoss收购,并更名为JBoss Rules。尽管名称有所变化,但它仍然保留了原有的功能特性,并且得到了进一步的发展和完善。 Drools的主要特点包括: - **易于访问的企业政策**:...