- 浏览: 61725 次
- 性别:

- 来自: 北京
-

最新评论
-
scu_cxh:
您好,我在学习hadoop方面的东西,想做一个对task监控的 ...
JobClient应用概述 -
bennie19870116:
看不到图呢...
Eclipse下配置使用Hadoop插件
一、环境
1、hadoop 0.20.2
2、操作系统Linux
二、背景
1、为何使用Partitioner,主要是想reduce的结果能够根据key再次分类输出到不同的文件夹中。
2、结果能够直观,同时做到对数据结果的简单的统计分析。
三、实现
1、输入的数据文件内容如下(1条数据内容少,1条数据内容超长,3条数据内容正常):
kaka 1 28
hua 0 26
chao 1
tao 1 22
mao 0 29 22
2、目的是为了分别输出结果,正确的结果输出到一个文本,太短的数据输出到一个文本,太长的输出到一个文本,共三个文本输出。
3、代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MyPartitioner {
public static class MyPartitionerMap extends Mapper<LongWritable, Text, Text, Text> {
protected void map(LongWritable key, Text value,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text>.Context context)
throws java.io.IOException, InterruptedException {
String arr_value[] = value.toString().split("\t");
if (arr_value.length > 3) {
context.write(new Text("long"), value);
} else if (arr_value.length < 3) {
context.write(new Text("short"), value);
} else {
context.write(new Text("right"), value);
}
}
}
/**
* partitioner的输入就是map的输出
*
* @author Administrator
*/
public static class MyPartitionerPar extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value, int numPartitions) {
int result = 0;
if (key.equals("long")) {
result = 0 % numPartitions;
} else if (key.equals("short")) {
result = 1 % numPartitions;
} else if (key.equals("right")) {
result = 2 % numPartitions;
}
return result;
}
}
public static class MyPartitionerReduce extends Reducer<Text, Text, NullWritable, Text> {
protected void reduce(Text key, java.lang.Iterable<Text> value, Context context) throws java.io.IOException,
InterruptedException {
for (Text val : value) {
context.write(NullWritable.get(), val);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: MyPartitioner <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "MyPartitioner");
job.setNumReduceTasks(5);
job.setJarByClass(MyPartitioner.class);
job.setMapperClass(MyPartitionerMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(MyPartitionerPar.class);
job.setReducerClass(MyPartitionerReduce.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4、通过key值的不同,对输出的内容切分(切分依据是根据key来做)。虽然设置了5个reduce,但是最终输出的reduce只有3个有内容。截图如下
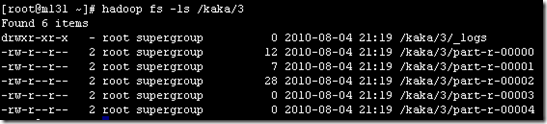
可以看到有3个文本是有值的,其他文本没有值。
四、总结
1、partitioner主要就是为了对结果输出按照key进行分类,在上面的例子中将三种不同的数据分类输出到了三个结果文本中。
2、partitioner输入<k,v>就是map输出的<k,v>
3、需要说明的是,partitioner是将reduce输出做了分区,并不是仅仅是针对输出的文本分区。可以将partitioner中的代码替换为:
return (key.hashCode() & Integer.MAX_VALUE) % numPartitions;
4、如果按照代码中的方式来输出,如果判断条件过多,不仅显得代码复杂冗余,而且效率也不高。所以如果是判断条件过多,又不是严格要求
必须每个条件必须输出到一个文件,可以采用上面的方法,输出到一个reduce分区,虽然结果可能是在一个文件中,但是输出是经过排序的。
4、文档写的比较简单,主要是看看实现目标和代码内容,如果有写的不对的地方欢迎发邮件dajuezhao@gmail.com


发表评论

-
Hadoop的基准测试工具使用(部分转载)
2011-01-21 11:58 1627一、背景由于以前没有� ... -
分布式集群中的硬件选择
2011-01-21 11:58 1051一、背景最近2个月时间一直在一个阴暗的地下室的角落里工作,主要 ... -
Map/Reduce的内存使用设置
2011-01-21 11:57 1660一、背景今天采用10台� ... -
Hadoop开发常用的InputFormat和OutputFormat(转)
2011-01-21 11:55 1494Hadoop中的Map Reduce框架依 ... -
SecondaryNamenode应用摘记
2010-11-04 15:54 1080一、环境 Hadoop 0.20.2、JDK 1.6、 ... -
Zookeeper分布式安装手册
2010-10-27 09:41 1342一、安装准备1、下载zookeeper-3.3.1,地址:ht ... -
Hadoop分布式安装
2010-10-27 09:41 1023一、安装准备1、下载hadoop 0.20.2,地址:http ... -
Map/Reduce使用杂记
2010-10-27 09:40 980一、硬件环境1、CPU:Intel(R) Core(TM)2 ... -
Hadoop中自定义计数器
2010-10-27 09:40 1545一、环境1、hadoop 0.20.22、操作系统Linux二 ... -
Map/Reduce中的Combiner的使用
2010-10-27 09:38 1210一、作用1、combiner最基本是实现本地key的聚合,对m ... -
Hadoop中DBInputFormat和DBOutputFormat使用
2010-10-27 09:38 2459一、背景 为了方便MapReduce直接访问关系型数据 ... -
Hadoop的MultipleOutputFormat使用
2010-10-27 09:37 1711一、背景 Hadoop的MapReduce中多文件输出默 ... -
Map/Reduce中公平调度器配置
2010-10-27 09:37 1553一、背景一般来说,JOB� ... -
无法启动Datanode的问题
2010-10-27 09:37 2406一、背景早上由于误删namenode上的hadoop文件夹,在 ... -
Map/Reduce的GroupingComparator排序简述
2010-10-27 09:36 1356一、背景排序对于MR来说是个核心内容,如何做好排序十分的重要, ... -
Map/Reduce中分区和分组的问题
2010-10-27 09:35 1149一、为什么写分区和分组在排序中的作用是不一样的,今天早上看书, ... -
关于Map和Reduce最大的并发数设置
2010-10-27 09:34 1258一、环境1、hadoop 0.20.22、操作系统 Linux ... -
关于集群数据负载均衡
2010-10-27 09:33 908一、环境1、hadoop 0.20.22、操作系统 Linux ... -
Map/Reduce执行流程简述
2010-10-27 09:33 998一、背景最近总在弄MR的东西,所以写点关于这个方面的内容,总结 ... -
Hadoop集群中关于SSH认证权限的问题
2010-10-27 09:32 911今天回北京了,想把在外地做的集群移植回来,需要修改ip地址和一 ...
相关推荐
Map/Reduce介绍。一些基本基础介绍。
它的灵感来源于函数式编程语言,特别是 Lisp 中的 Map 和 Reduce 操作。通过这种抽象,程序员可以专注于业务逻辑,而框架负责处理分布式计算的底层细节,如数据分布、容错和负载均衡。 在实际应用中,MapReduce ...
2. **数据预处理**:使用Map/Reduce框架对收集到的数据进行清洗、去重等预处理操作。 3. **索引构建**:构建倒排索引,以便快速定位包含特定关键词的文档。 4. **查询处理**:用户发起查询请求后,搜索引擎会根据倒...
Eclipse是一款广泛使用的Java集成开发环境,可以用来编写和调试Hadoop Map/Reduce程序。通过以下步骤在Eclipse中配置Hadoop: 1. 设置Hadoop主目录,指向Hadoop安装位置。 2. 创建Hadoop的远程工作区,指定HDFS中的...
MapReduce的设计理念源于Google的同名论文,它通过将大规模数据处理任务分解为两个阶段:Map(映射)和Reduce(化简),使得海量数据能够在多台计算机上并行处理,极大地提高了数据处理效率。 Map阶段是数据处理的...
本篇文章将深入探讨“远程调用执行Hadoop Map/Reduce”的概念、原理及其实现过程,同时结合标签“源码”和“工具”,我们将涉及到如何通过编程接口与Hadoop集群进行交互。 Hadoop MapReduce是一种编程模型,用于大...
本文将深入探讨云计算的三大关键技术:Dynamo、Bigtable和Map/Reduce,并对比分析它们的设计理念和应用场景。 首先,Dynamo是亚马逊公司开发的一种分布式键值存储系统,主要用于支持大规模的在线服务,如S3存储服务...
该模块介绍了使用 Map/Reduce 的并行编程概念--这是有效使用地球引擎分析大量数据的关键。您将学习如何使用地球引擎 API 计算各种光谱指数,进行云遮蔽,然后使用 Map/reduce 将这些计算应用于图像集合。您还将学习...
标题中的“在solr文献检索中用map/reduce”指的是使用Apache Solr,一个流行的开源搜索引擎,结合Hadoop的MapReduce框架来处理大规模的分布式搜索任务。MapReduce是一种编程模型,用于处理和生成大型数据集,它将...
win7_64eclispe插件 解决An internal error occurred during: "Map/Reduce location status updater". org/codehaus/jackson/map/JsonMappingException 重新编译包
- **Reduce**: reduce() 函数属于 functools 模块,用于累积地对序列中的元素执行某个函数操作。 **3. 实战案例** 例如,我们可以使用lambda表达式配合map()函数来实现列表元素的平方操作: ```python numbers = ...
标题中的“map/reduce template”指的是MapReduce编程模型的一个模板或框架,它是Apache Hadoop项目的核心部分,用于处理和生成大数据集。MapReduce的工作原理分为两个主要阶段:Map阶段和Reduce阶段,它允许程序员...
Hadoop Map/Reduce 框架是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上 T 级别的数据集。该框架由一个单独的 master JobTracker ...
在对Map/Reduce算法进行分析的基础上,利用开源Hadoop软件设计出高容错高性能的分布式搜索引擎,以面对搜索引擎对海量数据的处理和存储问题
同时为该系统定义一组关于作业的建立、管理和维护的通信规程,即拓扑管理协议.SPATE系统解决了在线Map/Reduce流数据处理过程中要求实时性及可扩展性的问题.实验验证了拓扑管理协议的有效性,拓扑管理协议能有效管理...
不过本文的Skynet没这么恐怖,它是一个ruby版本的Google Map/Reduce框架的名字而已。 Google的Map/Reduce框架实在太有名气了,他可以把一个任务切分为很多份,交给n台计算机并行执行,返回的结果再并行的归并,最后...
它由两部分组成:`Map`阶段和`Reduce`阶段。MapReduce框架负责调度任务、管理计算节点和处理系统故障等底层细节。 ### MapReduce实现案例分析 根据题目要求,我们需要连接`student.txt`和`student_score.txt`这两...
总的来说,这篇研究论文揭示了如何通过改进的Map/Reduce算法在云计算环境中优化Web数据挖掘的过程,强调了这种方法在应对大规模数据挑战中的潜力,并为未来的研究提供了有价值的参考。随着互联网数据的持续增长,...