支持度:关联规则在D中的支持度(support)是D中事务包含的百分比,即概率;
置信度(confidence):是包含X的事务中同时包含Y的百分比,即条件概率。
如果同时满足最小支持度阈值和最小置信度阈值,则认为关联规则是有趣的。这些阈值由用户或者专家设定。
示例:某销售手机的商场中,70%的手机销售中包含充电器的销售,而在所有交易中56%的销售同时包含手机和充电器。则在此例中,支持度为56%,置信度为70%。
您还没有登录,请您登录后再发表评论
数据挖掘是一种从海量数据中发现有价值知识的过程,而支持度和置信度是关联规则学习中的核心概念,常用于市场篮子分析、推荐系统等领域。本文将深入探讨这两个概念及其在实际应用中的意义。 首先,支持度(Support...
- **支持度**(Support)是指一个项目集(或规则的前件与后件的组合)在所有交易中出现的频率。它反映了一个规则或者项目集的普遍程度。 - **置信度**(Confidence)是指一个关联规则(例如A→B)成立的概率。即在...
计算规则的置信度:`confidence = support(XY) / support(X)`,若置信度超过最小置信度阈值,则保留该规则。 三、Apriori算法实现 在编程实现中,Apriori算法通常包括以下部分: 1. 数据预处理:清洗数据,去除...
置信度(Confidence)则衡量了当A发生时B发生的概率,计算公式为:置信度(A→B) = 支持度(A→B) / 支持度(A)。 Apriori算法的运行流程大致如下: 1. 初始化:从单个项开始,找出数据集中频繁出现的项。 2. 生成候选...
5. 关联规则的强度:支持度(Support)和置信度(Confidence)确定关联规则的强度。 关联规则挖掘问题: 关联规则挖掘问题是指给定事务的集合T,发现支持度大于等于minsup并且置信度大于等于minconf的所有规则。 ...
本篇文章主要浅析关联规则算法的原理,特别是如何通过支持度、置信度和提升度来评估规则的有效性。 支持度(Support)是衡量项集频繁程度的指标,它表示项集在所有交易中出现的比例。如果我们将项集视为“买了商品A...
规则的强度由支持度(support)和置信度(confidence)衡量。支持度是指规则涉及的项集在所有交易中出现的比例,置信度则是前提项集出现时结论项集出现的概率。 2. **Apriori原理**:Apriori算法基于两个关键原则:...
- **支持度(Support)**: 规则X→Y的支持度是交易集中包含X和Y的交易数与所有交易数的比例。 - **置信度(Confidence)**: 规则X→Y的置信度是指包含X和Y的交易数与包含X的交易数的比例。 关联规则挖掘的目标是从...
它基于两个核心原则:支持度(Support)和置信度(Confidence)。在数据挖掘和机器学习领域,Apriori算法是理解交易数据、市场篮子分析和推荐系统的基础。 1. **Apriori原理**: - **频繁项集**:如果一个项集在...
2. 支持度阈值和置信度阈值:一个规则被认为是有趣的,当它的支持度和置信度都超过了预先设定的最小值。 Apriori算法的工作流程如下: 1. 初始化:找出所有单个项的支持度,构建频繁1-项集L1。 2. 生成候选项集:...
挖掘强规则时,我们需要设定最小支持度和最小置信度阈值,只有当规则的支持度和置信度都超过这两个阈值时,该规则才被认为是有趣的。 关联规则挖掘过程分为两步:首先找出所有频繁项集,即支持度超过最小支持度阈值...
提升度等于支持度A和B除以支持度A和B的乘积,即lift = support(A, B) / (support(A) * support(B))。 关联规则挖掘通常分为两个主要步骤:频繁项集挖掘和强关联规则生成。首先,通过算法(如Apriori或FP-Growth)...
在案例分析中,首先计算了不同项集的支持度,然后根据设定的支持度和置信度阈值,评估了特定规则的合格性。这个过程是数据挖掘中规则生成的基础,并对结果的有效性提供了保证。通过这种方法,企业可以对交易数据进行...
支持度(Support)是衡量商品集合在所有交易中出现频率的指标,而置信度(Confidence)则表示在购买A商品的顾客中购买B商品的比例。 问题二要求在问题一的基础上,快速有效地找出那些商品最常被一起购买。Apriori...
而强关联规则则是指支持度(support)和置信度(confidence)都满足特定条件的规则。 1. 支持度(Support):表示项集在所有交易中出现的概率,计算公式为: 支持度(项集) = (项集出现的交易数) / (所有交易数) 2...
**置信度(Confidence)**:是衡量两个项集之间关联强度的指标,定义为A→B的支持度除以A的支持度。如果项集A→B的置信度高,意味着在购买A的交易中,同时购买B的概率也较高。 Apriori算法的核心思想是“先验性”:...
- 在这个项目中,我们将尝试不同的支持度和置信度阈值,观察它们如何影响生成的规则数量。较高的支持度意味着更普遍的关系,而较高的置信度则意味着更强的关联。 2. **最小长度调整**: - 先验算法,如Apriori,...
接下来是生成关联规则,这涉及到置信度(confidence)和提升度(lift)这两个关键指标。置信度衡量的是规则的可信程度,计算公式为:置信度(规则) = 支持度(项集A和项集B) / 支持度(项集A)。假设我们已经确定“感冒药”...
该算法主要通过迭代查找频繁项集,然后根据用户给定的支持度阈值(Support)和置信度阈值(Confidence)产生强关联规则。支持度是指一个项集在所有事务中出现的次数与总事务数的比值,代表了项集的普遍性;置信度则...
关联规则的评价指标通常包括支持度(Support)和置信度(Confidence): 1. 支持度:表示项集在所有交易中出现的比例,计算公式为:Support(A) = P(A) = | transactions containing A | / | total transactions | ...

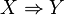 在D中的支持度(support)是D中事务包含
在D中的支持度(support)是D中事务包含 的百分比,即概率
的百分比,即概率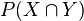 ;
; 。
。


相关推荐
数据挖掘是一种从海量数据中发现有价值知识的过程,而支持度和置信度是关联规则学习中的核心概念,常用于市场篮子分析、推荐系统等领域。本文将深入探讨这两个概念及其在实际应用中的意义。 首先,支持度(Support...
- **支持度**(Support)是指一个项目集(或规则的前件与后件的组合)在所有交易中出现的频率。它反映了一个规则或者项目集的普遍程度。 - **置信度**(Confidence)是指一个关联规则(例如A→B)成立的概率。即在...
计算规则的置信度:`confidence = support(XY) / support(X)`,若置信度超过最小置信度阈值,则保留该规则。 三、Apriori算法实现 在编程实现中,Apriori算法通常包括以下部分: 1. 数据预处理:清洗数据,去除...
置信度(Confidence)则衡量了当A发生时B发生的概率,计算公式为:置信度(A→B) = 支持度(A→B) / 支持度(A)。 Apriori算法的运行流程大致如下: 1. 初始化:从单个项开始,找出数据集中频繁出现的项。 2. 生成候选...
5. 关联规则的强度:支持度(Support)和置信度(Confidence)确定关联规则的强度。 关联规则挖掘问题: 关联规则挖掘问题是指给定事务的集合T,发现支持度大于等于minsup并且置信度大于等于minconf的所有规则。 ...
本篇文章主要浅析关联规则算法的原理,特别是如何通过支持度、置信度和提升度来评估规则的有效性。 支持度(Support)是衡量项集频繁程度的指标,它表示项集在所有交易中出现的比例。如果我们将项集视为“买了商品A...
规则的强度由支持度(support)和置信度(confidence)衡量。支持度是指规则涉及的项集在所有交易中出现的比例,置信度则是前提项集出现时结论项集出现的概率。 2. **Apriori原理**:Apriori算法基于两个关键原则:...
- **支持度(Support)**: 规则X→Y的支持度是交易集中包含X和Y的交易数与所有交易数的比例。 - **置信度(Confidence)**: 规则X→Y的置信度是指包含X和Y的交易数与包含X的交易数的比例。 关联规则挖掘的目标是从...
它基于两个核心原则:支持度(Support)和置信度(Confidence)。在数据挖掘和机器学习领域,Apriori算法是理解交易数据、市场篮子分析和推荐系统的基础。 1. **Apriori原理**: - **频繁项集**:如果一个项集在...
2. 支持度阈值和置信度阈值:一个规则被认为是有趣的,当它的支持度和置信度都超过了预先设定的最小值。 Apriori算法的工作流程如下: 1. 初始化:找出所有单个项的支持度,构建频繁1-项集L1。 2. 生成候选项集:...
挖掘强规则时,我们需要设定最小支持度和最小置信度阈值,只有当规则的支持度和置信度都超过这两个阈值时,该规则才被认为是有趣的。 关联规则挖掘过程分为两步:首先找出所有频繁项集,即支持度超过最小支持度阈值...
提升度等于支持度A和B除以支持度A和B的乘积,即lift = support(A, B) / (support(A) * support(B))。 关联规则挖掘通常分为两个主要步骤:频繁项集挖掘和强关联规则生成。首先,通过算法(如Apriori或FP-Growth)...
在案例分析中,首先计算了不同项集的支持度,然后根据设定的支持度和置信度阈值,评估了特定规则的合格性。这个过程是数据挖掘中规则生成的基础,并对结果的有效性提供了保证。通过这种方法,企业可以对交易数据进行...
支持度(Support)是衡量商品集合在所有交易中出现频率的指标,而置信度(Confidence)则表示在购买A商品的顾客中购买B商品的比例。 问题二要求在问题一的基础上,快速有效地找出那些商品最常被一起购买。Apriori...
而强关联规则则是指支持度(support)和置信度(confidence)都满足特定条件的规则。 1. 支持度(Support):表示项集在所有交易中出现的概率,计算公式为: 支持度(项集) = (项集出现的交易数) / (所有交易数) 2...
**置信度(Confidence)**:是衡量两个项集之间关联强度的指标,定义为A→B的支持度除以A的支持度。如果项集A→B的置信度高,意味着在购买A的交易中,同时购买B的概率也较高。 Apriori算法的核心思想是“先验性”:...
- 在这个项目中,我们将尝试不同的支持度和置信度阈值,观察它们如何影响生成的规则数量。较高的支持度意味着更普遍的关系,而较高的置信度则意味着更强的关联。 2. **最小长度调整**: - 先验算法,如Apriori,...
接下来是生成关联规则,这涉及到置信度(confidence)和提升度(lift)这两个关键指标。置信度衡量的是规则的可信程度,计算公式为:置信度(规则) = 支持度(项集A和项集B) / 支持度(项集A)。假设我们已经确定“感冒药”...
该算法主要通过迭代查找频繁项集,然后根据用户给定的支持度阈值(Support)和置信度阈值(Confidence)产生强关联规则。支持度是指一个项集在所有事务中出现的次数与总事务数的比值,代表了项集的普遍性;置信度则...
关联规则的评价指标通常包括支持度(Support)和置信度(Confidence): 1. 支持度:表示项集在所有交易中出现的比例,计算公式为:Support(A) = P(A) = | transactions containing A | / | total transactions | ...