- 浏览: 4414980 次
- 性别:

- 来自: 厦门
-

文章分类
- 全部博客 (634)
- Oracle日常管理 (142)
- Oracle体系架构 (45)
- Oracle Tuning (52)
- Oracle故障诊断 (35)
- RAC/DG/OGG (64)
- Oracle11g New Features (48)
- DataWarehouse (15)
- SQL, PL/SQL (14)
- DB2日常管理 (9)
- Weblogic (11)
- Shell (19)
- AIX (12)
- Linux/Unix高可用性 (11)
- Linux/Unix日常管理 (66)
- Linux桌面应用 (37)
- Windows (2)
- 生活和工作 (13)
- 私人记事 (0)
- Python (9)
- CBO (15)
- Cognos (2)
- ORACLE 12c New Feature (2)
- PL/SQL (2)
- SQL (1)
- C++ (2)
- Hadoop大数据 (5)
- 机器学习 (3)
- 非技术 (1)
最新评论
-
di1984HIT:
xuexilee!!!
Oracle 11g R2 RAC高可用连接特性 – SCAN详解 -
aneyes123:
谢谢非常有用那
PL/SQL的存储过程和函数(原创) -
jcjcjc:
写的很详细
Oracle中Hint深入理解(原创) -
di1984HIT:
学习了,学习了
Linux NTP配置详解 (Network Time Protocol) -
avalonzst:
大写的赞..
AIX内存概述(原创)
一次某优化工具厂商的朋友,发来一个案例请求协助诊断,朋友的优化工具在客户的环境中执行某个 SQL 查询时,需要 10 分钟时间才能出结果,这是无法接受的,而同样的查询在其他环境上都可以快速的获得输出结果,数据库环境是 9.2.0.8 。
首先我获得了一个 10046 跟踪文件,通过 tkprof 格式化之后,这个 SQL 的输出结果展现出来。
首先该
SQL
代码如下:
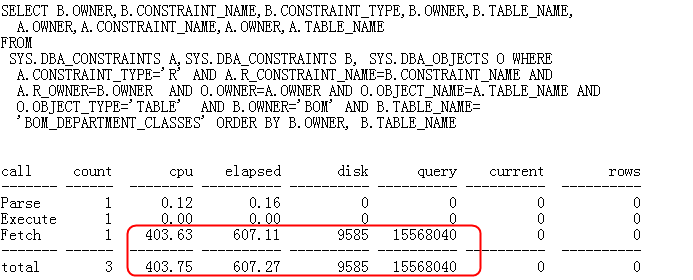
该段 SQL 的 Elapsed 时间超过了 600 秒, Query 模式逻辑读也非常高,对于一个优化工具来说显然是不可接受的。
接下来的跟踪文件中显示了 SQL 的执行计划:
Rows Row Source Operation
------- ---------------------------------------------------
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS OUTER
0 NESTED LOOPS OUTER
0 NESTED LOOPS
0 NESTED LOOPS
0 NESTED LOOPS
1935557 NESTED LOOPS
2863 NESTED LOOPS
2863 NESTED LOOPS
2863 NESTED LOOPS
1 NESTED LOOPS
1 TABLE ACCESS BY INDEX ROWID USER$
1 INDEX UNIQUE SCAN I_USER1 (object id 44)
1 TABLE ACCESS BY INDEX ROWID USER$
1 INDEX UNIQUE SCAN I_USER1 (object id 44)
2863 TABLE ACCESS FULL CDEF$
2863 TABLE ACCESS BY INDEX ROWID CON$
2863 INDEX UNIQUE SCAN I_CON2 (object id 49)
2863 TABLE ACCESS CLUSTER USER$
2863 INDEX UNIQUE SCAN I_USER# (object id 11)
1935557 VIEW
1935557 UNION-ALL PARTITION
1935557 FILTER
1935557 NESTED LOOPS
2863 TABLE ACCESS BY INDEX ROWID USER$
2863 INDEX UNIQUE SCAN I_USER1 (object id 44)
1935557 TABLE ACCESS FULL OBJ$
0 TABLE ACCESS BY INDEX ROWID IND$
0 INDEX UNIQUE SCAN I_IND1 (object id 39)
0 FILTER
0 NESTED LOOPS
0 TABLE ACCESS BY INDEX ROWID USER$
0 INDEX UNIQUE SCAN I_USER1 (object id 44)
0 INDEX RANGE SCAN I_LINK1 (object id 113)
0 TABLE ACCESS BY INDEX ROWID CON$
1935557 INDEX UNIQUE SCAN I_CON2 (object id 49)
0 TABLE ACCESS BY INDEX ROWID CON$
0 INDEX UNIQUE SCAN I_CON1 (object id 48)
0 TABLE ACCESS BY INDEX ROWID CDEF$
0 INDEX UNIQUE SCAN I_CDEF1 (object id 50)
0 TABLE ACCESS BY INDEX ROWID CON$
0 INDEX UNIQUE SCAN I_CON2 (object id 49)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS BY INDEX ROWID OBJ$
0 INDEX UNIQUE SCAN I_OBJ1 (object id 36)
0 TABLE ACCESS CLUSTER USER$
0 INDEX UNIQUE SCAN I_USER# (object id 11)
以上执行计划中,最可疑的部分是对于 OBJ$ 的全表扫描,这个环节的行数返回有 1 , 935 , 557 行,这个量级一直向上传递,所以我们首先怀疑这里的执行计划选择错误,如果选择索引,执行性能肯定会有极大的不同。
可是 10046 的跟踪事件显示的信息比较有限不能够准确定位错误的原因,我请朋友通过 10053 事件来生成一个执行计划的跟踪, 10053 使用极为简便,通过如下方式就可以捕获 SQL 的解析过程:
alter session set events '10053 trace name context forever,level 1';
explain plan for you_select_query;
例如:
SQL> alter session set events '10053 trace name context forever,level 1';
Session altered.
SQL> explain plan for select count(*) from obj$;
Explained.
然后在 udump 目录下就可以找到 10053 生成的跟踪文件,在该文件中,找到了查询相关表的统计信息,其中 OBJ$ 的信息如下所示,其中 CDN ( CarDiNality )指表中包含的记录数量,此处显示 OBJ$ 表中有 24 万左右的记录,使用了 2941 个数据块:
***********************
Table stats Table: OBJ$ Alias: SYS_ALIAS_1
TOTAL :: CDN: 245313 NBLKS: 2941 AVG_ROW_LEN: 79
Column: OWNER# Col#: 3 Table: OBJ$ Alias: SYS_ALIAS_1
NDV: 221 NULLS: 0 DENS: 4.5249e-03 LO: 0 HI: 259
NO HISTOGRAM: #BKT: 1 #VAL: 2
-- Index stats
INDEX NAME: I_OBJ1 COL#: 1
TOTAL :: LVLS: 1 #LB: 632 #DK: 245313 LB/K: 1 DB/K: 1 CLUF: 4184
INDEX NAME: I_OBJ2 COL#: 3 4 5 12 13 6
TOTAL :: LVLS: 2 #LB: 1904 #DK: 245313 LB/K: 1 DB/K: 1 CLUF: 180286
INDEX NAME: I_OBJ3 COL#: 15
TOTAL :: LVLS: 1 #LB: 19 #DK: 2007 LB/K: 1 DB/K: 1 CLUF: 340
_OPTIMIZER_PERCENT_PARALLEL = 0
***************************************
而在前面的 10046 跟踪信息中,显示 OBJ$ 包含大约 200 万条记录,这是非常巨大的不同,对于 USER$ 表,显示具有 2863 条记录,而统计信息中显示仅有 253 条记录:
***********************
Table stats Table: USER$ Alias: U
TOTAL :: CDN: 253 NBLKS: 16 AVG_ROW_LEN: 82
Column: USER# Col#: 1 Table: USER$ Alias: U
NDV: 253 NULLS: 0 DENS: 3.9526e-03 LO: 0 HI: 261
NO HISTOGRAM: #BKT: 1 #VAL: 2
-- Index stats
INDEX NAME: I_USER# COL#: 1
TOTAL :: LVLS: 0 #LB: 1 #DK: 258 LB/K: 1 DB/K: 1 CLUF: 13
INDEX NAME: I_USER1 COL#: 2
TOTAL :: LVLS: 0 #LB: 1 #DK: 253 LB/K: 1 DB/K: 1 CLUF: 87
***********************
这说明数据字典中记录的统计信息与真实情况不符合,导致了 SQL 选择了错误的执行计划,在使用 CBO 的 Oracle9i 数据库中,这种情况极为普遍,通过删除表的统计信息,或者重新收集正确的统计信息,可以使 SQL 执行恢复到正常合理的范畴内。在 Oracle10g 开始的自动统计信息收集,就是为了防止出现统计信息陈旧的现象。
以下是通过 dbms_stats 包清除和重新收集表的统计信息的简单参考:
SQL> exec dbms_stats.delete_table_stats(user,'OBJ$');
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.gather_table_stats(user,'OBJ$');
PL/SQL procedure successfully completed.
基于这样的判断我们建议客户做出修正,最后的客户反馈结果是:按照你的建议,在更新
OBJ$
的统计信息后,该语句的执行时间由
10
分钟减少到了
2
分钟。接下来,按照类似的思路,又更新了
USER$
,
CON$,CDEF$
表的统计信息,这时,语句的执行时间减少到了零点几秒。至此,问题解决。
参考至:http://www.eygle.com/archives/2011/02/dba_event_10046_10053.html
如有错误,欢迎指正
邮箱:czmcj@163.com


评论
这篇是eyegle写的
发表评论

-
Oracle Redo 并行机制
2017-04-07 11:31 990Redo log 是用于恢复和一个高级特性的重要数据,一个r ... -
Append Values and how not to break the database
2015-09-29 20:12 752With the advent of the /*+ APP ... -
基于案例学习sql优化第6周脚本
2015-04-13 04:29 0===============BEGIN=========== ... -
Oracle表高水平位的优化与监控
2015-02-13 09:21 2227高水平位虚高的案例 --构造表drop table t p ... -
Oracle行迁移和行链接详解(原创)
2015-02-13 09:00 12239行迁移成 因:当发出u ... -
Parse CPU to Parse Elapsd%的理解
2015-01-19 13:59 1441Parse CPU to Parse Elapsd%是指sq ... -
ALTER INDEX COALESCE: 10g Improvements
2014-08-02 21:34 933I thought it might be worth me ... -
Differences and Similarities Between Index Coalesce and Shrink Space
2014-08-02 21:21 963As already discussed, ALTER IN ... -
Alter index coalesce VS shrink space
2014-08-02 17:56 102910g中引入了对索引的shrink功能,索引shrink操 ... -
SQL Plan Management Creating SQL plan baselines(原创)
2014-08-01 23:56 1366SQL Plan Management SQL Plan ... -
WITH Clause : Subquery Factoring
2014-07-23 08:43 1192Subquery Factoring The WIT ... -
Query Transformations : Subquery unnesting(原创)
2014-07-23 08:42 2913Subquery Unnesting Subqueries ... -
Automating Parallelism
2014-07-17 17:49 841Parallel query, the essence of ... -
Parallel Execution: Large/Shared Pool and ORA-4031 (文档 ID 238680.1)
2014-07-17 17:47 2102Applies toOracle Database - En ... -
Optimizer Transformations: Star Transformation
2014-06-30 07:32 793Star transformation was intro ... -
Star Transformation And Cardinality Estimates
2014-06-30 07:33 895If you want to make use of Orac ... -
Optimizer statistics-driven direct path read decision for full table scans
2014-06-06 16:09 1085Hello all fellow Oracle geeks ... -
Cut out from Ask Tom-- Thanks for the question regarding "10053", version 9.2.6
2014-03-09 23:38 1442You AskedDear tom,A. your new ... -
ORACLE SQL TUNING各种技巧及复杂实例
2014-02-25 23:17 6523一.优化器模式ORACLE的优化器共有3种:a. RULE ... -
Oracle Predicate Pushing(原创)
2014-02-22 21:17 4630IntroductionThe join predicate ...
相关推荐
《Oracle DBA手记2:数据库诊断案例与内部恢复实践》是一本专为Oracle数据库管理员(DBA)设计的专业书籍,旨在深入探讨Oracle数据库的诊断技巧和内部恢复策略。本书结合实际案例,提供了丰富的实战经验,帮助读者...
Oracle_DBA手记1-数据库诊断案例与性能优化实践.pdf
[OracleDBA手记:数据库诊断案例与性能优化实践].《OracleDBA手记》编委会.高清文字版.pdf
Oracle DBA 手记:数据库诊断案例与性能优化实践是Oracle数据库管理系统(Database Administration System)的实践指南,旨在帮助DBA(DataBase Administrator)更好地诊断和优化数据库性能。以下是该资源的知识点...
一共两卷,免费提供,请分别下载后再解压...Oracle_DBA手记1-数据库诊断案例与性能优化实践 另有免费下载资源: Oracle_DBA手记3-数据库性能优化与内部原理解析.pdf Oracle_DBA手记2-数据库诊断案例与内部恢复实践.pdf
《Oracle DBA手记:数据库诊断案例与性能优化实践》针对性的对oracle进行讲解,书很好。
《Oracle DBA手记:数据库诊断案例与性能优化实践》针对性的对oracle案例进行讲解 ,书很好
《Oracle DBA手记:数据库诊断案例与性能优化实践》针对性的对案例进行讲解,很好,值得拥有。
Oracle DBA 性能优化 和数据库诊断案例,了解原理和方式
Oracle_DBA手记1-2-数据库诊断案例与性能优化实践.zip
Oracle_DBA手记1-数据库诊断案例与性能优化实践 Oracle_DBA手记1-数据库诊断案例与性能优化实践 Oracle_DBA手记1-数据库诊断案例与性能优化实践 Oracle_DBA手记1-数据库诊断案例与性能优化实践 另有免费下载资源: ...
《oracle dba手记2:数据库诊断案例与内部恢复实践》由多位数据库技术专家和爱好者合著而成,集合了各行业dba的工作经验与思考,包含了精心挑选的数据库诊断案例与数据库恢复实践。内容涉及oracle典型错误的分析和...
Oracle_DBA手记2-数据库诊断案例与内部恢复实践.pdf
一共三部,共16卷,别人制作的时候就是16卷.上传我都有点闲麻烦。 高清 中文 完整版 Oracle_DBA手记第1部 第2部 第3部打包下载 Oracle DBA手记3:数据库性能优化与...Oracle DBA手记:数据库诊断案例与性能优化实践 407页
本书由多位工作在数据库维护一线的工程师合著而成,包含了精心挑选的数据库诊断案例与性能优化实践经验,内容涉及oracle典型错误的分析和诊断,各种sql优化方法(包括调整索引,处理表碎片,优化分页查询,改善执行...
Oracle.DBA手记·4:数据安全警示录
[Oracle.DBA手记_数据库诊断案例与性能优化实践].《Oracle.DBA手记》编委会.扫描版 作 者:《Oracle DBA手记》编委会 编 出 版 社:电子工业出版社 出版时间:2010-1-1 页 数:407 内容简介 本书由多位工作在...
本书由多位工作在数据库维护一线的工程师合著而成,包含了精心挑选的数据库诊断案例与性能优化实践经验,内容涉及oracle典型错误的分析和诊断,各种sql优化方法(包括调整索引,处理表碎片,优化分页查询,改善执行...