

Flink为了能够处理有边界的数据集和无边界的数据集,提供了对应的DataSet API和DataStream API。我们可以开发对应的Java程序或者Scala程序来完成相应的功能。下面举例了一些DataSet API中的基本的算子。
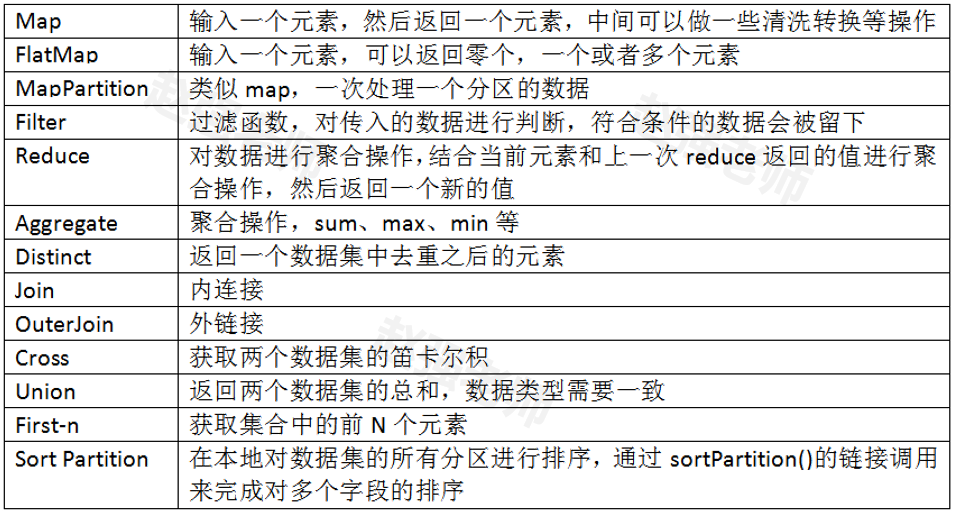
下面我们通过具体的代码来为大家演示每个算子的作用。
1、Map、FlatMap与MapPartition
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList<String> data = new ArrayList<String>();
data.add("I love Beijing");
data.add("I love China");
data.add("Beijing is the capital of China");
DataSource<String> text = env.fromCollection(data);
DataSet<List<String>> mapData = text.map(new MapFunction<String, List<String>>() {
public List<String> map(String data) throws Exception {
String[] words = data.split(" ");
//创建一个List
List<String> result = new ArrayList<String>();
for(String w:words){
result.add(w);
}
return result;
}
});
mapData.print();
System.out.println("*****************************************");
DataSet<String> flatMapData = text.flatMap(new FlatMapFunction<String, String>() {
public void flatMap(String data, Collector<String> collection) throws Exception {
String[] words = data.split(" ");
for(String w:words){
collection.collect(w);
}
}
});
flatMapData.print();
System.out.println("*****************************************");
/* new MapPartitionFunction<String, String>
第一个String:表示分区中的数据元素类型
第二个String:表示处理后的数据元素类型*/
DataSet<String> mapPartitionData = text.mapPartition(new MapPartitionFunction<String, String>() {
public void mapPartition(Iterable<String> values, Collector<String> out) throws Exception {
//针对分区进行操作的好处是:比如要进行数据库的操作,一个分区只需要创建一个Connection
//values中保存了一个分区的数据
Iterator<String> it = values.iterator();
while (it.hasNext()) {
String next = it.next();
String[] split = next.split(" ");
for (String word : split) {
out.collect(word);
}
}
//关闭链接
}
});
mapPartitionData.print();
2、Filter与Distinct
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList<String> data = new ArrayList<String>();
data.add("I love Beijing");
data.add("I love China");
data.add("Beijing is the capital of China");
DataSource<String> text = env.fromCollection(data);
DataSet<String> flatMapData = text.flatMap(new FlatMapFunction<String, String>() {
public void flatMap(String data, Collector<String> collection) throws Exception {
String[] words = data.split(" ");
for(String w:words){
collection.collect(w);
}
}
});
//去掉重复的单词
flatMapData.distinct().print();
System.out.println("*********************");
//选出长度大于3的单词
flatMapData.filter(new FilterFunction<String>() {
public boolean filter(String word) throws Exception {
int length = word.length();
return length>3?true:false;
}
}).print();
3、Join操作
//获取运行的环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//创建第一张表:用户ID 姓名
ArrayList<Tuple2<Integer, String>> data1 = new ArrayList<Tuple2<Integer,String>>();
data1.add(new Tuple2(1,"Tom"));
data1.add(new Tuple2(2,"Mike"));
data1.add(new Tuple2(3,"Mary"));
data1.add(new Tuple2(4,"Jone"));
//创建第二张表:用户ID 所在的城市
ArrayList<Tuple2<Integer, String>> data2 = new ArrayList<Tuple2<Integer,String>>();
data2.add(new Tuple2(1,"北京"));
data2.add(new Tuple2(2,"上海"));
data2.add(new Tuple2(3,"广州"));
data2.add(new Tuple2(4,"重庆"));
//实现join的多表查询:用户ID 姓名 所在的程序
DataSet<Tuple2<Integer, String>> table1 = env.fromCollection(data1);
DataSet<Tuple2<Integer, String>> table2 = env.fromCollection(data2);
table1.join(table2).where(0).equalTo(0)
/*第一个Tuple2<Integer,String>:表示第一张表
* 第二个Tuple2<Integer,String>:表示第二张表
* Tuple3<Integer,String, String>:多表join连接查询后的返回结果 */
.with(new JoinFunction<Tuple2<Integer,String>, Tuple2<Integer,String>, Tuple3<Integer,String, String>>() {
public Tuple3<Integer, String, String> join(Tuple2<Integer, String> table1,
Tuple2<Integer, String> table2) throws Exception {
return new Tuple3<Integer, String, String>(table1.f0,table1.f1,table2.f1);
} }).print();
4、笛卡尔积
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //创建第一张表:用户ID 姓名 ArrayList<Tuple2<Integer, String>> data1 = new ArrayList<Tuple2<Integer,String>>(); data1.add(new Tuple2(1,"Tom")); data1.add(new Tuple2(2,"Mike")); data1.add(new Tuple2(3,"Mary")); data1.add(new Tuple2(4,"Jone")); //创建第二张表:用户ID 所在的城市 ArrayList<Tuple2<Integer, String>> data2 = new ArrayList<Tuple2<Integer,String>>(); data2.add(new Tuple2(1,"北京")); data2.add(new Tuple2(2,"上海")); data2.add(new Tuple2(3,"广州")); data2.add(new Tuple2(4,"重庆")); //实现join的多表查询:用户ID 姓名 所在的程序 DataSet<Tuple2<Integer, String>> table1 = env.fromCollection(data1); DataSet<Tuple2<Integer, String>> table2 = env.fromCollection(data2); //生成笛卡尔积 table1.cross(table2).print();
5、First-N
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//这里的数据是:员工姓名、薪水、部门号
DataSet<Tuple3<String, Integer,Integer>> grade =
env.fromElements(new Tuple3<String, Integer,Integer>("Tom",1000,10),
new Tuple3<String, Integer,Integer>("Mary",1500,20),
new Tuple3<String, Integer,Integer>("Mike",1200,30),
new Tuple3<String, Integer,Integer>("Jerry",2000,10));
//按照插入顺序取前三条记录
grade.first(3).print();
System.out.println("**********************");
//先按照部门号排序,在按照薪水排序
grade.sortPartition(2, Order.ASCENDING).sortPartition(1, Order.ASCENDING).print();
System.out.println("**********************");
//按照部门号分组,求每组的第一条记录
grade.groupBy(2).first(1).print();
6、外链接操作
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//创建第一张表:用户ID 姓名
ArrayList<Tuple2<Integer, String>> data1 = new ArrayList<Tuple2<Integer,String>>();
data1.add(new Tuple2(1,"Tom"));
data1.add(new Tuple2(3,"Mary"));
data1.add(new Tuple2(4,"Jone"));
//创建第二张表:用户ID 所在的城市
ArrayList<Tuple2<Integer, String>> data2 = new ArrayList<Tuple2<Integer,String>>();
data2.add(new Tuple2(1,"北京"));
data2.add(new Tuple2(2,"上海"));
data2.add(new Tuple2(4,"重庆"));
//实现join的多表查询:用户ID 姓名 所在的程序
DataSet<Tuple2<Integer, String>> table1 = env.fromCollection(data1);
DataSet<Tuple2<Integer, String>> table2 = env.fromCollection(data2);
//左外连接
table1.leftOuterJoin(table2).where(0).equalTo(0)
.with(new JoinFunction<Tuple2<Integer,String>, Tuple2<Integer,String>, Tuple3<Integer,String,String>>() {
public Tuple3<Integer, String, String> join(Tuple2<Integer, String> table1,
Tuple2<Integer, String> table2) throws Exception {
// 左外连接表示等号左边的信息会被包含
if(table2 == null){
return new Tuple3<Integer, String, String>(table1.f0,table1.f1,null);
}else{
return new Tuple3<Integer, String, String>(table1.f0,table1.f1,table2.f1);
}
}
}).print();
System.out.println("***********************************");
//右外连接
table1.rightOuterJoin(table2).where(0).equalTo(0)
.with(new JoinFunction<Tuple2<Integer,String>, Tuple2<Integer,String>, Tuple3<Integer,String,String>>() {
public Tuple3<Integer, String, String> join(Tuple2<Integer, String> table1,
Tuple2<Integer, String> table2) throws Exception {
//右外链接表示等号右边的表的信息会被包含
if(table1 == null){
return new Tuple3<Integer, String, String>(table2.f0,null,table2.f1);
}else{
return new Tuple3<Integer, String, String>(table2.f0,table1.f1,table2.f1);
}
}
}).print();
System.out.println("***********************************");
//全外连接
table1.fullOuterJoin(table2).where(0).equalTo(0)
.with(new JoinFunction<Tuple2<Integer,String>, Tuple2<Integer,String>, Tuple3<Integer,String,String>>() {
public Tuple3<Integer, String, String> join(Tuple2<Integer, String> table1, Tuple2<Integer, String> table2)
throws Exception {
if(table1 == null){
return new Tuple3<Integer, String, String>(table2.f0,null,table2.f1);
}else if(table2 == null){
return new Tuple3<Integer, String, String>(table1.f0,table1.f1,null);
}else{
return new Tuple3<Integer, String, String>(table1.f0,table1.f1,table2.f1);
}
}
}).print();



相关推荐
赵强老师在传智播客的Oracle课程是专为IT专业人士和对数据库技术感兴趣的学员设计的一系列教学资料,旨在深入浅出地讲解Oracle的核心概念、功能以及实际操作技巧。 在赵强老师的课程中,你可以学到以下几个重要的...
想要好好地学习Oracle数据库的朋友呀,你错过了她就太不值得了。里面有好多的Oracle操作命令可能你都没接触过吧。好了,话不多多说。坚信资料不错!你,值得拥有!OK.还有,之所有要你2分打赏,是我给了你这么好的...
精通JSP编程 作者赵强 编 12-18节
《精通JSP编程》是赵强先生的一部深入解析JSP技术的专业著作,该书针对JSP编程进行了全面且深入的讲解,旨在帮助读者掌握JSP的核心概念和技术,提升Web应用开发能力。根据提供的文件名列表,我们可以推测书籍的章节...
今天,我们将与赵强老师一同探索数学领域的一个重要主题——“生活中的大数”。这个主题通过生动的例子和清晰的逻辑,帮助孩子们在日常生活中感知和理解大数的存在及其重要性。 “生活中有大数”,这不仅是一句简单...
根据提供的文件信息,我们可以推断出这是一份与Java Server Pages (JSP)相关的学习资料介绍,特别是关于赵强编写的《精通JSP编程》这本书的相关信息。下面将基于这个理解来生成相关知识点。 ### 一、JSP基础概念 ...
在Oracle数据库的学习中,SQL优化是一项至关重要的技能,因为它直接影响到数据库的性能和查询效率。以下是一些关于SQL优化的关键知识点: 1. **使用列名代替通配符(*)**:在编写SQL查询时,避免使用`*`来获取所有列...
教程名称:Oracle 数据库赵强视频教程【3天】教程目录:【】Oracle安装与管理、SQL语句(赵强)【】Orcale存储过程jdbc与Orcale大文本操作等(赵强)【】SQL简单查询触发器视图(赵强) 资源太大,传百度网盘了,链接在...
MongoDB是一种流行的NoSQL数据库,它以其高性能、高可用性以及易扩展的特性在现代数据库系统中占据了一席之地。本文将从NoSQL的基础概念出发,逐步深入介绍MongoDB的核心特性、架构、安装、数据操作和管理等方面的...
本资料包“day2013-0110-webLogic配置和集群(赵强).zip”包含了关于WebLogic的配置与集群搭建的详细教程,旨在帮助用户深入了解WebLogic的核心功能和管理技巧。 一、WebLogic基础配置 1. 安装与启动:首先,我们...
本文将针对一份面向二年级学生的数学学习教案进行解读,这份教案的标题为:“二年级数学生活中的大数赵强PPT学习教案”。 教案的核心目标是帮助孩子们理解并能够应用生活中的大数。课程内容不仅限于数学知识的传授...
《信息存储技术的发展》 信息存储技术,作为信息技术的基石之一,从早期的岩画、古书,到现代的半导体、磁盘、光存储,再到先进的集群存储和虚拟化技术,其发展历程见证了人类社会的巨大变革。...
这种模式的优势在于能够实时互动,方便教师与学生之间的沟通,并且便于资源的分享。培训内容包括文字、图片、实验演示以及在线讨论等多方面内容,力求让学员全方位掌握 Oracle 数据库的知识。 - **理论教学**:占...
【标题】"java代码-46 赖赵强"所指的可能是一个关于Java编程的项目或示例,由开发者赖赵强创建。在这个项目中,他可能分享了一段特定的Java代码,用于解决某种问题或者实现一个功能。这个标题暗示了这是一个与Java...
微信购物首页用户调研报告主要关注了微信购物首页用户的浏览动机、痛点以及不同用户群体的行为特征。报告通过定性和定量研究方法,包括一对一深访和问卷调查,收集了大量数据,旨在理解用户需求并优化用户体验。...