

ن¸€م€پن»€ن¹ˆوک¯Prestoï¼ں
آ
- 背و™¯çں¥è¯†ï¼ڑHiveçڑ„ç¼؛点ه’ŒPrestoçڑ„背و™¯
Hiveن½؟用MapReduceن½œن¸؛ه؛•ه±‚è®،ç®—و،†و¶ï¼Œوک¯ن¸“ن¸؛و‰¹ه¤„çگ†è®¾è®،çڑ„م€‚ن½†éڑڈç€و•°وچ®è¶ٹو¥è¶ٹه¤ڑ,ن½؟用Hiveè؟›è،Œن¸€ن¸ھ简هچ•çڑ„و•°وچ®وں¥è¯¢هڈ¯èƒ½è¦پèٹ±è´¹ه‡ هˆ†هˆ°ه‡ ه°ڈو—¶م€‚Prestoوک¯ن¸€ن¸ھهˆ†ه¸ƒه¼ڈSQLوں¥è¯¢ه¼•و“ژ,ه®ƒè¢«è®¾è®،ن¸؛用و¥ن¸“é—¨è؟›è،Œé«کé€ںم€په®و—¶çڑ„و•°وچ®هˆ†وگم€‚ه®ƒو”¯وŒپو ‡ه‡†çڑ„SQL,هŒ…و‹¬ه¤چو‚وں¥è¯¢م€پèپڑهگˆم€پè؟وژ¥ه’Œçھ—هڈ£ه‡½و•°م€‚è؟™ه…¶ن¸وœ‰ن¸¤ç‚¹ه°±ه€¼ه¾—وژ¢ç©¶ï¼Œé¦–ه…ˆوک¯و¶و„,ه…¶و¬،è‡ھ然وک¯و€ژن¹ˆهپڑهˆ°ن½ژه»¶è؟ںو¥و”¯وŒپهڈٹو—¶ن؛¤ن؛’م€‚
آ
- PRESTOوک¯ن»€ن¹ˆï¼ں
Prestoوک¯ن¸€ن¸ھه¼€و؛گçڑ„هˆ†ه¸ƒه¼ڈSQLوں¥è¯¢ه¼•و“ژ,适用ن؛ژن؛¤ن؛’ه¼ڈهˆ†وگوں¥è¯¢ï¼Œو•°وچ®é‡ڈو”¯وŒپGBهˆ°PBه—èٹ‚م€‚Prestoçڑ„设è®،ه’Œç¼–ه†™ه®Œه…¨وک¯ن¸؛ن؛†è§£ه†³هƒڈFacebookè؟™و ·è§„و¨،çڑ„ه•†ن¸ڑو•°وچ®ن»“ه؛“çڑ„ن؛¤ن؛’ه¼ڈهˆ†وگه’Œه¤„çگ†é€ںه؛¦çڑ„é—®é¢کم€‚
- ه®ƒهڈ¯ن»¥هپڑن»€ن¹ˆï¼ں
Prestoو”¯وŒپهœ¨ç؛؟و•°وچ®وں¥è¯¢ï¼ŒهŒ…و‹¬Hive, Cassandra, ه…³ç³»و•°وچ®ه؛“ن»¥هڈٹن¸“وœ‰و•°وچ®هکه‚¨م€‚ ن¸€و،Prestoوں¥è¯¢هڈ¯ن»¥ه°†ه¤ڑن¸ھو•°وچ®و؛گçڑ„و•°وچ®è؟›è،Œهگˆه¹¶ï¼Œهڈ¯ن»¥è·¨è¶ٹو•´ن¸ھ组织è؟›è،Œهˆ†وگم€‚Prestoن»¥هˆ†وگه¸ˆçڑ„需و±‚ن½œن¸؛ç›®و ‡ï¼Œن»–ن»¬وœںوœ›ه“چه؛”و—¶é—´ه°ڈن؛ژ1秒هˆ°ه‡ هˆ†é’ںم€‚ Presto终结ن؛†و•°وچ®هˆ†وگçڑ„ن¸¤éڑ¾é€‰و‹©ï¼Œè¦پن¹ˆن½؟用é€ںه؛¦ه؟«çڑ„وک‚è´µçڑ„ه•†ن¸ڑو–¹و،ˆï¼Œè¦پن¹ˆن½؟用و¶ˆè€—ه¤§é‡ڈç،¬ن»¶çڑ„و…¢é€ںçڑ„“ه…چè´¹â€و–¹و،ˆم€‚
- è°پهœ¨ن½؟用ه®ƒï¼ں
Facebookن½؟用Prestoè؟›è،Œن؛¤ن؛’ه¼ڈوں¥è¯¢ï¼Œç”¨ن؛ژه¤ڑن¸ھه†…部و•°وچ®هکه‚¨ï¼ŒهŒ…و‹¬300PBçڑ„و•°وچ®ن»“ه؛“م€‚ و¯ڈه¤©وœ‰1000ه¤ڑهگچFacebookه‘که·¥ن½؟用Presto,و‰§è،Œوں¥è¯¢و¬،و•°è¶…è؟‡30000و¬،,و‰«وڈڈو•°وچ®و€»é‡ڈ超è؟‡1PBم€‚领ه…ˆçڑ„ن؛’èپ”网ه…¬هڈ¸هŒ…و‹¬Airbnbه’ŒDropbox都هœ¨ن½؟用Prestoم€‚
آن؛Œم€پPrestoçڑ„ن½“ç³»و¶و„
آ
Prestoوک¯ن¸€ن¸ھè؟گè،Œهœ¨ه¤ڑهڈ°وœچهٹ،ه™¨ن¸ٹçڑ„هˆ†ه¸ƒه¼ڈç³»ç»ںم€‚ ه®Œو•´ه®‰è£…هŒ…و‹¬ن¸€ن¸ھcoordinatorه’Œه¤ڑن¸ھworkerم€‚ ç”±ه®¢وˆ·ç«¯وڈگن؛¤وں¥è¯¢ï¼Œن»ژPrestoه‘½ن»¤è،ŒCLIوڈگن؛¤هˆ°coordinatorم€‚ coordinatorè؟›è،Œè§£وگ,هˆ†وگه¹¶و‰§è،Œوں¥è¯¢è®،هˆ’,然هگژهˆ†هڈ‘ه¤„çگ†éکںهˆ—هˆ°workerم€‚
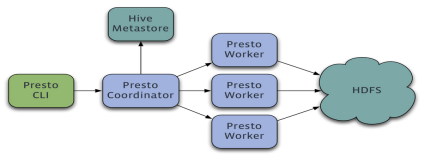
آ
Prestoوں¥è¯¢ه¼•و“ژوک¯ن¸€ن¸ھMaster-Slaveçڑ„و¶و„,由ن¸€ن¸ھCoordinatorèٹ‚点,ن¸€ن¸ھDiscovery Serverèٹ‚点,ه¤ڑن¸ھWorkerèٹ‚点组وˆگ,Discovery Serveré€ڑه¸¸ه†…هµŒن؛ژCoordinatorèٹ‚点ن¸م€‚Coordinatorè´ں责解وگSQLè¯هڈ¥ï¼Œç”ںوˆگو‰§è،Œè®،هˆ’,هˆ†هڈ‘و‰§è،Œن»»هٹ،ç»™Workerèٹ‚点و‰§è،Œم€‚Workerèٹ‚点è´ںè´£ه®é™…و‰§è،Œوں¥è¯¢ن»»هٹ،م€‚Workerèٹ‚点هگ¯هٹ¨هگژهگ‘Discovery Serverوœچهٹ،و³¨ه†Œï¼ŒCoordinatorن»ژDiscovery Serverèژ·ه¾—هڈ¯ن»¥و£ه¸¸ه·¥ن½œçڑ„Workerèٹ‚点م€‚ه¦‚وœé…چç½®ن؛†Hive Connector,需è¦پé…چç½®ن¸€ن¸ھHive MetaStoreوœچهٹ،ن¸؛Prestoوڈگن¾›Hiveه…ƒن؟،وپ¯ï¼ŒWorkerèٹ‚点ن¸ژHDFSن؛¤ن؛’读هڈ–و•°وچ®م€‚
آ
ن¸‰م€په®‰è£…Presto Server
- ه®‰è£…ن»‹è´¨
presto-cli-0.217-executable.jar presto-server-0.217.tar.gz
آ
- ه®‰è£…é…چç½®Presto Server
1م€پ解هژ‹ه®‰è£…هŒ… tar -zxvf presto-server-0.217.tar.gz -C ~/training/ 2م€پهˆ›ه»؛etcç›®ه½• cd ~/training/presto-server-0.217/ mkdir etc 3م€پ需è¦پهœ¨etcç›®ه½•ن¸‹هŒ…هگ«ن»¥ن¸‹é…چç½®و–‡ن»¶ Node Properties: èٹ‚点çڑ„é…چç½®ن؟،وپ¯ JVM Config: ه‘½ن»¤è،Œه·¥ه…·çڑ„JVMé…چç½®هڈ‚و•° Config Properties: Presto Serverçڑ„é…چç½®هڈ‚و•° Catalog Properties: و•°وچ®و؛گ(Connectors)çڑ„é…چç½®هڈ‚و•° Log Propertiesï¼ڑو—¥ه؟—هڈ‚و•°é…چç½®
آ
- آ 编辑node.properties
#集群هگچ称م€‚و‰€وœ‰هœ¨هگŒن¸€ن¸ھ集群ن¸çڑ„Prestoèٹ‚点ه؟…é،»و‹¥وœ‰ç›¸هگŒçڑ„集群هگچ称م€‚ node.environment=production #و¯ڈن¸ھPrestoèٹ‚点çڑ„ه”¯ن¸€و ‡ç¤؛م€‚و¯ڈن¸ھèٹ‚点çڑ„node.id都ه؟…é،»وک¯ه”¯ن¸€çڑ„م€‚هœ¨Prestoè؟›è،Œé‡چهگ¯وˆ–者هچ‡ç؛§è؟‡ç¨‹ن¸و¯ڈن¸ھèٹ‚点çڑ„node.idه؟…é،»ن؟وŒپن¸چهڈکم€‚ه¦‚وœهœ¨ن¸€ن¸ھèٹ‚点ن¸ٹه®‰è£…ه¤ڑن¸ھPrestoه®ن¾‹ï¼ˆن¾‹ه¦‚ï¼ڑهœ¨هگŒن¸€هڈ°وœ؛ه™¨ن¸ٹه®‰è£…ه¤ڑن¸ھPrestoèٹ‚点),那ن¹ˆو¯ڈن¸ھPrestoèٹ‚点ه؟…é،»و‹¥وœ‰ه”¯ن¸€çڑ„node.idم€‚ node.id=ffffffff-ffff-ffff-ffff-ffffffffffff # و•°وچ®هکه‚¨ç›®ه½•çڑ„ن½چ置(و“چن½œç³»ç»ںن¸ٹçڑ„è·¯ه¾„)م€‚Prestoه°†ن¼ڑوٹٹو—¥وœںه’Œو•°وچ®هکه‚¨هœ¨è؟™ن¸ھç›®ه½•ن¸‹م€‚ node.data-dir=/root/training/presto-server-0.217/data
آ
- 编辑jvm.config
ç”±ن؛ژOutOfMemoryErrorه°†ن¼ڑه¯¼è‡´JVMه¤„ن؛ژن¸چن¸€è‡´çٹ¶و€پ,و‰€ن»¥éپ‡هˆ°è؟™ç§چ错误çڑ„و—¶ه€™وˆ‘ن»¬ن¸€èˆ¬çڑ„ه¤„çگ†وژھو–½ه°±وک¯و”¶é›†dump headpن¸çڑ„ن؟،وپ¯ï¼ˆç”¨ن؛ژdebugging),然هگژه¼؛هˆ¶ç»ˆو¢è؟›ç¨‹م€‚Prestoن¼ڑه°†وں¥è¯¢ç¼–译وˆگه—èٹ‚ç پو–‡ن»¶ï¼Œه› و¤Prestoن¼ڑç”ںوˆگه¾ˆه¤ڑclass,ه› و¤وˆ‘ن»¬وˆ‘ن»¬ه؛”该ه¢ه¤§PermهŒ؛çڑ„ه¤§ه°ڈ(هœ¨Permن¸ن¸»è¦پهکه‚¨class)ه¹¶ن¸”è¦په…پ许Jvm class unloadingم€‚
-server -Xmx16G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError
آ
- 编辑config.properties
م€€م€€م€€م€€coordinatorçڑ„é…چç½®
آ
coordinator=true node-scheduler.include-coordinator=false http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://192.168.157.226:8080
آ م€€م€€م€€م€€workersçڑ„é…چç½®
آ
coordinator=false http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery.uri=http://192.168.157.226:8080
آ م€€م€€م€€م€€ه¦‚وœوˆ‘ن»¬وƒ³هœ¨هچ•وœ؛ن¸ٹè؟›è،Œوµ‹è¯•ï¼ŒهگŒو—¶é…چç½®coordinatorه’Œworker,请ن½؟用ن¸‹é¢çڑ„é…چç½®ï¼ڑ
آ
coordinator=true node-scheduler.include-coordinator=true http-server.http.port=8080 query.max-memory=5GB query.max-memory-per-node=1GB query.max-total-memory-per-node=2GB discovery-server.enabled=true discovery.uri=http://192.168.157.226:8080
آ م€€م€€م€€م€€هڈ‚و•°è¯´وکژï¼ڑ

آ
- 编辑log.properties
م€€م€€م€€م€€é…چç½®و—¥ه؟—ç؛§هˆ«م€‚
آ
com.facebook.presto=INFO
آ
- é…چç½®Catalog Properties
Prestoé€ڑè؟‡connectorsè®؟é—®و•°وچ®م€‚è؟™ن؛›connectorsوŒ‚è½½هœ¨catalogsن¸ٹم€‚ connectorهڈ¯ن»¥وڈگن¾›ن¸€ن¸ھcatalogن¸و‰€وœ‰çڑ„schemaه’Œè،¨م€‚ن¾‹ه¦‚ï¼ڑHive connector ه°†و¯ڈن¸ھhiveçڑ„database都وک ه°„وˆگن¸؛ن¸€ن¸ھschema,و‰€ن»¥ه¦‚وœhive connectorوŒ‚è½½هˆ°ن؛†هگچن¸؛hiveçڑ„catalog, ه¹¶ن¸”هœ¨hiveçڑ„webوœ‰ن¸€ه¼ هگچن¸؛clicksçڑ„è،¨ï¼Œ é‚£ن¹ˆهœ¨Prestoن¸هڈ¯ن»¥é€ڑè؟‡hive.web.clicksو¥è®؟é—®è؟™ه¼ è،¨م€‚é€ڑè؟‡هœ¨etc/catalogç›®ه½•ن¸‹هˆ›ه»؛catalogه±و€§و–‡ن»¶و¥ه®Œوˆگcatalogsçڑ„و³¨ه†Œم€‚ ه¦‚وœè¦پهˆ›ه»؛hiveو•°وچ®و؛گçڑ„è؟وژ¥ه™¨ï¼Œهڈ¯ن»¥هˆ›ه»؛ن¸€ن¸ھetc/catalog/hive.propertiesو–‡ن»¶ï¼Œو–‡ن»¶ن¸çڑ„ه†…ه®¹ه¦‚ن¸‹ï¼Œه®Œوˆگهœ¨hivecatalogن¸ٹوŒ‚è½½ن¸€ن¸ھhiveconnectorم€‚
آ
#و³¨وکژhadoopçڑ„版وœ¬ connector.name=hive-hadoop2 #hive-siteن¸é…چç½®çڑ„هœ°ه€ hive.metastore.uri=thrift://192.168.157.226:9083 #hadoopçڑ„é…چç½®و–‡ن»¶è·¯ه¾„ hive.config.resources=/root/training/hadoop-2.7.3/etc/hadoop/core-site.xml,/root/training/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
آ و³¨و„ڈï¼ڑè¦پè®؟é—®Hiveçڑ„è¯ï¼Œéœ€è¦په°†Hiveçڑ„MetaStoreهگ¯هٹ¨ï¼ڑhive --service metastore

ه››م€پهگ¯هٹ¨Presto Server
آ
./launcher start
آ
ن؛”م€پè؟گè،Œpresto-cli
- ن¸‹è½½ï¼ڑpresto-cli-0.217-executable.jar
- é‡چه‘½هگچjarهŒ…,ه¹¶ه¢هٹ و‰§è،Œوƒé™گ
cp presto-cli-0.217-executable.jar presto chmod a+x presto
آ
- è؟وژ¥Presto Server
./presto --server localhost:8080 --catalog hive --schema default
آ
ه…م€پن½؟用Presto
- ن½؟用Prestoو“چن½œHive

- ن½؟用Prestoçڑ„Web Consoleï¼ڑ端هڈ£ï¼ڑ8080

- ن½؟用JDBCو“چن½œPresto
م€€م€€م€€م€€1م€پ需è¦پهŒ…هگ«çڑ„Mavenن¾èµ–
آ
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.217</version>
</dependency>
آ م€€م€€م€€م€€2م€پJDBCن»£ç پ
آ

==================================================

آ
آ



相ه…³وژ¨èچگ
èµµه¼؛è€په¸ˆهœ¨ن¼ و™؛و’ه®¢çڑ„Oracle课程وک¯ن¸“ن¸؛ITن¸“ن¸ڑن؛؛ه£«ه’Œه¯¹و•°وچ®ه؛“وٹ€وœ¯و„ںه…´è¶£çڑ„ه¦ه‘ک设è®،çڑ„ن¸€ç³»هˆ—و•™ه¦èµ„و–™ï¼Œو—¨هœ¨و·±ه…¥وµ…ه‡؛هœ°è®²è§£Oracleçڑ„و ¸ه؟ƒو¦‚ه؟µم€پهٹں能ن»¥هڈٹه®é™…و“چن½œوٹ€ه·§م€‚ هœ¨èµµه¼؛è€په¸ˆçڑ„课程ن¸ï¼Œن½ هڈ¯ن»¥ه¦هˆ°ن»¥ن¸‹ه‡ ن¸ھé‡چè¦پçڑ„...
وƒ³è¦په¥½ه¥½هœ°ه¦ن¹ Oracleو•°وچ®ه؛“çڑ„وœ‹هڈ‹ه‘€ï¼Œن½ é”™è؟‡ن؛†ه¥¹ه°±ه¤ھن¸چه€¼ه¾—ن؛†م€‚里é¢وœ‰ه¥½ه¤ڑçڑ„Oracleو“چن½œه‘½ن»¤هڈ¯èƒ½ن½ 都و²،وژ¥è§¦è؟‡هگ§م€‚ه¥½ن؛†ï¼Œè¯ن¸چه¤ڑه¤ڑ说م€‚هڑن؟،资و–™ن¸چé”™ï¼پن½ ,ه€¼ه¾—و‹¥وœ‰ï¼پOK.è؟کوœ‰ï¼Œن¹‹و‰€وœ‰è¦پن½ 2هˆ†و‰“èµڈ,وک¯وˆ‘ç»™ن؛†ن½ è؟™ن¹ˆه¥½çڑ„...
3. **第6ç« ** - هڈ¯èƒ½وک¯ه…³ن؛ژJSPè،¨è¾¾ه¼ڈè¯è¨€ï¼ˆEL)ه’Œç»ںن¸€ه»؛و¨،è¯è¨€ï¼ˆJSTL)çڑ„ه†…ه®¹ï¼Œè؟™ن¸¤ن¸ھه·¥ه…·وپه¤§هœ°ç®€هŒ–ن؛†JSPé،µé¢ن¸çڑ„و•°وچ®è®؟é—®ه’Œوژ§هˆ¶وµپ程م€‚EL用ن؛ژ简هŒ–è،¨è¾¾ه¼ڈ,而JSTLوڈگن¾›ن؛†و ‡ه‡†و ‡ç¾ه؛“,ه¦‚fmtم€پsqlم€پfnç‰ï¼Œç”¨ن؛ژو—¥وœںو ¼ه¼ڈ...
ç²¾é€ڑJSP编程 ن½œè€…èµµه¼؛ ç¼– 12-18èٹ‚
و ¹وچ®وڈگن¾›çڑ„و–‡ن»¶ن؟،وپ¯ï¼Œوˆ‘ن»¬هڈ¯ن»¥وژ¨و–ه‡؛è؟™وک¯ن¸€ن»½ن¸ژJava Server Pages (JSP)相ه…³çڑ„ه¦ن¹ 资و–™ن»‹ç»چ,特هˆ«وک¯ه…³ن؛ژèµµه¼؛ç¼–ه†™çڑ„م€ٹç²¾é€ڑJSP编程م€‹è؟™وœ¬ن¹¦çڑ„相ه…³ن؟،وپ¯م€‚ن¸‹é¢ه°†هں؛ن؛ژè؟™ن¸ھçگ†è§£و¥ç”ںوˆگ相ه…³çں¥è¯†ç‚¹م€‚ ### ن¸€م€پJSPهں؛ç،€و¦‚ه؟µ ...
è؟™و ·هڈ¯ن»¥ه‡ڈه°‘ن¸چه؟…è¦پçڑ„و•°وچ®ن¼ 输,وڈگé«کوں¥è¯¢é€ںه؛¦م€‚ 2. **ANDه’ŒORو“چن½œç¬¦çڑ„ن½؟用ç–ç•¥**ï¼ڑهœ¨و،ن»¶ç»„هگˆن¸ï¼Œه؛”ه°†و›´هڈ¯èƒ½ن¸؛هپ‡çڑ„و،ن»¶و”¾هœ¨`AND`و“چن½œç¬¦çڑ„هڈ³ن¾§ï¼Œه°†و›´هڈ¯èƒ½ن¸؛çœںçڑ„و،ن»¶و”¾هœ¨`OR`و“چن½œç¬¦çڑ„هڈ³ن¾§م€‚è؟™وک¯ه› ن¸؛SQLé€ڑه¸¸ن»ژهڈ³هگ‘ه·¦...
ن»ٹه¤©ï¼Œوˆ‘ن»¬ه°†ن¸ژèµµه¼؛è€په¸ˆن¸€هگŒوژ¢ç´¢و•°ه¦é¢†هںںçڑ„ن¸€ن¸ھé‡چè¦پن¸»é¢ک——“ç”ںو´»ن¸çڑ„ه¤§و•°â€م€‚è؟™ن¸ھن¸»é¢کé€ڑè؟‡ç”ںهٹ¨çڑ„ن¾‹هگه’Œو¸…و™°çڑ„逻辑,ه¸®هٹ©ه©هگن»¬هœ¨و—¥ه¸¸ç”ںو´»ن¸و„ںçں¥ه’Œçگ†è§£ه¤§و•°çڑ„هکهœ¨هڈٹه…¶é‡چè¦پو€§م€‚ “ç”ںو´»ن¸وœ‰ه¤§و•°â€ï¼Œè؟™ن¸چن»…وک¯ن¸€هڈ¥ç®€هچ•...
و•™ç¨‹هگچ称ï¼ڑOracle و•°وچ®ه؛“èµµه¼؛视频و•™ç¨‹م€گ3ه¤©م€‘و•™ç¨‹ç›®ه½•ï¼ڑم€گم€‘Oracleه®‰è£…ن¸ژç®،çگ†م€پSQLè¯هڈ¥(èµµه¼؛)م€گم€‘Orcaleهکه‚¨è؟‡ç¨‹jdbcن¸ژOrcaleه¤§و–‡وœ¬و“چن½œç‰(èµµه¼؛)م€گم€‘SQL简هچ•وں¥è¯¢è§¦هڈ‘ه™¨è§†ه›¾(èµµه¼؛)آ 资و؛گه¤ھه¤§ï¼Œن¼ 百ه؛¦ç½‘ç›کن؛†ï¼Œé“¾وژ¥هœ¨...
综ن¸ٹو‰€è؟°ï¼ŒMongoDBن½œن¸؛ن¸€ç§چçژ°ن»£çڑ„NoSQLو•°وچ®ه؛“ç³»ç»ں,ه…¶ه¼؛ه¤§çڑ„هٹں能ه’Œçپµو´»çڑ„و•°وچ®و¨،ه‹ن½؟ه…¶وˆگن¸؛ه¤„çگ†ه¤§è§„و¨،م€پé«که¹¶هڈ‘و•°وچ®هœ؛و™¯çڑ„首选و•°وچ®ه؛“ن¹‹ن¸€م€‚é€ڑè؟‡ç†ںو‚‰ن¸ٹè؟°çں¥è¯†ç‚¹ï¼Œه¼€هڈ‘者能ه¤ںو›´هٹ é«کو•ˆهœ°è؟گ用MongoDBè؟›è،Œه؛”用程ه؛ڈه¼€هڈ‘,...
èµµه¼؛è€په¸ˆهœ¨وٹ¥ه‘ٹن¸è¯´ï¼ڑ“وˆ‘积وپهڈ‚ن¸ژو•™ç ”و´»هٹ¨ï¼Œé€ڑè؟‡ن¸ژهگŒن؛‹ن»¬çڑ„ن؛¤وµپن¸ژهگˆن½œï¼Œن¸چو–هڈچو€ه’Œè°ƒو•´و•™ه¦ç–略,ن؟ƒè؟›ن؛†و•™ه¦è´¨é‡ڈçڑ„و•´ن½“وڈگهچ‡م€‚â€ن»–è،¨è¾¾ن؛†ه¯¹وœھو¥ه·¥ن½œçڑ„وœںه¾…,ه¸Œوœ›هœ¨و–°çڑ„ه¦ه¹´ن¸ï¼Œèƒ½ه¤ں继ç»هڈ‘وŒ¥è‡ھه·±çڑ„ن¸“ن¸ڑ特é•؟,ن¸؛ه¦و ،çڑ„...
- **و•°وچ®هˆ†وگه·¥ه…·**ï¼ڑ用ن؛ژو·±ه…¥هˆ†وگو•°وچ®ن»“ه؛“ن¸çڑ„و•°وچ®م€‚ ##### 1.4.3 و™؛能ç®،çگ† Oracle9iوڈگن¾›ن؛†ه…ˆè؟›çڑ„ç®،çگ†ه·¥ه…·ه’Œوٹ€وœ¯ï¼Œن½؟ه¾—DBAهڈ¯ن»¥و›´هٹ é«کو•ˆهœ°ç›‘وژ§ه’Œç»´وٹ¤و•°وچ®ه؛“ç³»ç»ںم€‚ ##### 1.4.4 هˆ†ه¸ƒه¼ڈ Oracle9iو”¯وŒپè·¨ه¤ڑن¸ھهœ°çگ†...
2. JDBCو•°وچ®و؛گï¼ڑé…چç½®ه’Œç®،çگ†JDBCو•°وچ®و؛گ,è؟وژ¥هˆ°و•°وچ®ه؛“,وڈگن¾›ç»ںن¸€çڑ„è®؟é—®وژ¥هڈ£ï¼Œو”¯وŒپو•°وچ®و؛گçڑ„è؟وژ¥و± ه’Œن؛‹هٹ،ç®،çگ†م€‚ 3. SSLه®‰ه…¨é…چç½®ï¼ڑن¸؛ن؛†ن؟éڑœé€ڑن؟،ه®‰ه…¨ï¼Œهڈ¯ن»¥é…چç½®WebLogicو”¯وŒپSSL(Secure Sockets Layer),هٹ ه¯†ن¼ 输و•°وچ®ï¼Œ...
6. **و•°وچ®هˆ†وگ**ï¼ڑهˆ©ç”¨ه¤§و•°وچ®ه·¥ه…·ه¯¹ç”¨وˆ·è،Œن¸؛è؟›è،Œو·±ه؛¦هˆ†وگ,ه¦‚用وˆ·و´»è·ƒه؛¦م€پن»کè´¹çژ‡م€پARPU(ه¹³ه‡و¯ڈ用وˆ·و”¶ه…¥ï¼‰م€پLTV(ç”ںه‘½ه‘¨وœںو€»ن»·ه€¼ï¼‰ç‰وŒ‡و ‡ï¼Œن»¥è¯„ن¼°è؟گèگ¥و•ˆوœه¹¶وŒ‡ه¯¼ه†³ç–م€‚ 7. **社هŒ؛ه»؛设**ï¼ڑه»؛ç«‹ه’Œç»´وٹ¤çژ©ه®¶ç¤¾هŒ؛,鼓هٹ±...
ه®ƒن¸چن»…وڈگن¾›ن؛†ن¸€و•´ه¥—ه®Œو•´çڑ„و•°وچ®ç®،çگ†è§£ه†³و–¹و،ˆï¼Œè؟کو”¯وŒپه¤ڑç§چé«کç؛§ç‰¹و€§ï¼Œه¦‚هˆ†هŒ؛م€په¹¶è،Œوں¥è¯¢ه¤„çگ†ç‰ï¼Œن½؟ه¾—و•°وچ®ه¤„çگ†و›´هٹ é«کو•ˆه’Œçپµو´»م€‚é’ˆه¯¹هˆه¦è€…هڈٹوœ‰ن¸€ه®ڑهں؛ç،€çڑ„ه¦ن¹ 者,ه¸‚é¢ن¸ٹهکهœ¨ه¤§é‡ڈçڑ„ Oracle 11g و•™ç¨‹èµ„و–™ï¼ŒهŒ…و‹¬ن½†ن¸چé™گن؛ژ视频...
وœ¬و–‡ه°†é’ˆه¯¹ن¸€ن»½é¢هگ‘ن؛Œه¹´ç؛§ه¦ç”ںçڑ„و•°ه¦ه¦ن¹ و•™و،ˆè؟›è،Œè§£è¯»ï¼Œè؟™ن»½و•™و،ˆçڑ„و ‡é¢کن¸؛ï¼ڑ“ن؛Œه¹´ç؛§و•°ه¦ç”ںو´»ن¸çڑ„ه¤§و•°èµµه¼؛PPTه¦ن¹ و•™و،ˆâ€م€‚ و•™و،ˆçڑ„و ¸ه؟ƒç›®و ‡وک¯ه¸®هٹ©ه©هگن»¬çگ†è§£ه¹¶èƒ½ه¤ںه؛”用ç”ںو´»ن¸çڑ„ه¤§و•°م€‚课程ه†…ه®¹ن¸چن»…é™گن؛ژو•°ه¦çں¥è¯†çڑ„ن¼ وژˆ...
ن»ژهڈ¤ن»£çڑ„ه²©ç”»هˆ°çژ°ن»£çڑ„ن؛‘هکه‚¨ï¼Œهکه‚¨وٹ€وœ¯çڑ„è؟›و¥وپه¤§هœ°ن¸°ه¯Œن؛†وˆ‘ن»¬çڑ„ن؟،وپ¯èژ·هڈ–途ه¾„,وڈگهچ‡ن؛†و•°وچ®ه¤„çگ†ه’Œن¼ 输çڑ„و•ˆçژ‡ï¼ŒهگŒو—¶ن¹ںه¯¹و•°وچ®ه®‰ه…¨م€پéڑگç§پن؟وٹ¤وڈگه‡؛ن؛†و›´é«کçڑ„è¦پو±‚م€‚éڑڈç€وٹ€وœ¯çڑ„ن¸چو–و¼”è؟›ï¼Œوœھو¥çڑ„هکه‚¨وٹ€وœ¯ه°†ن¼ڑو›´هٹ و™؛能م€پé«کو•ˆï¼Œ...
م€ٹDatastructures using Javaم€‹**(2013)ï¼ڑن»‹ç»چن؛†ن½؟用Javaه®çژ°و•°وچ®ç»“و„çڑ„و–¹و³•ï¼Œه¯¹ç®—و³•ه’Œو•°وچ®ç»“و„وœ‰ه…´è¶£çڑ„هگŒه¦هڈ¯ن»¥هڈ‚考م€‚ 11. **Martin Ngobye.م€ٹComputing Static Slice for Java Programsم€‹**(2012)ï¼ڑè؟™وک¯ن¸€ç¯‡...
وٹ¥ه‘ٹé€ڑè؟‡ه®ڑو€§ه’Œه®ڑé‡ڈç ”ç©¶و–¹و³•ï¼ŒهŒ…و‹¬ن¸€ه¯¹ن¸€و·±è®؟ه’Œé—®هچ·è°ƒوں¥ï¼Œو”¶é›†ن؛†ه¤§é‡ڈو•°وچ®ï¼Œو—¨هœ¨çگ†è§£ç”¨وˆ·éœ€و±‚ه¹¶ن¼کهŒ–用وˆ·ن½“éھŒم€‚ 首ه…ˆï¼Œوٹ¥ه‘ٹوŒ‡ه‡؛هœ¨ن¸»è¦پçڑ„电ه•†ه¹³هڈ°ن¸ï¼Œه¾®ن؟،è´ç‰©ه’Œن؛¬ن¸œAPPçڑ„用وˆ·ن¸»è¦پهٹ¨وœ؛وک¯ه¯»و‰¾وژ¨èچگه•†ه“په’Œن¼کوƒ ن؟،وپ¯ï¼Œè€Œو— ...
4. ه®وˆکèگ¥é”€ن¸‰ه¤§و–¹éکµï¼ڑ - 第ن¸€و–¹éکµï¼ڑوˆک略规هˆ’,هŒ…و‹¬ç«ن؛‰و€§ه®ڑن½چم€پهˆ›é€ 独特هœ°ن½چم€پو»،足需و±‚ن»¥èژ·هڈ–ç«ن؛‰ن¼کهٹ؟,ه¹¶é€ڑè؟‡هˆ†وگو¶ˆè´¹è€…م€پç«ن؛‰ه¯¹و‰‹ه’Œن¼پن¸ڑه†…部ه› ç´ هˆ¶ه®ڑوˆکç•¥م€‚ - و¶ˆè´¹è€…هˆ†وگï¼ڑن؛†è§£â€œè°پâ€م€پ“ن¸؛ن»€ن¹ˆâ€م€پ“ن»€ن¹ˆâ€م€پ...