
使用Spring实现读写分离( MySQL实现主从复制)
1. 背景
我们一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是说采用数据库集群的方案,
其中一个是主库,负责写入数据,我们称之为:写库;
其它都是从库,负责读取数据,我们称之为:读库;
那么,对我们的要求是:
1、读库和写库的数据一致;
2、写数据必须写到写库;
3、读数据必须到读库;
2. 方案
解决读写分离的方案有两种:应用层解决和中间件解决。
2.1. 应用层解决:
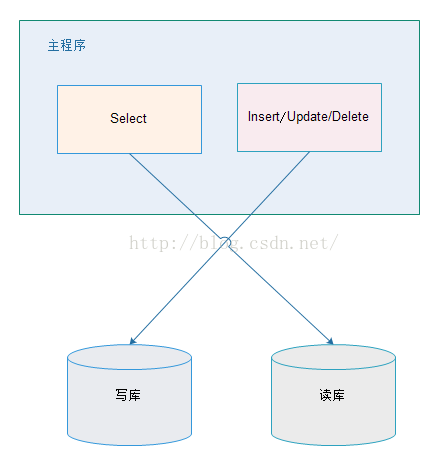
优点:
1、多数据源切换方便,由程序自动完成;
2、不需要引入中间件;
3、理论上支持任何数据库;
缺点:
1、由程序员完成,运维参与不到;
2、不能做到动态增加数据源;
2.2. 中间件解决
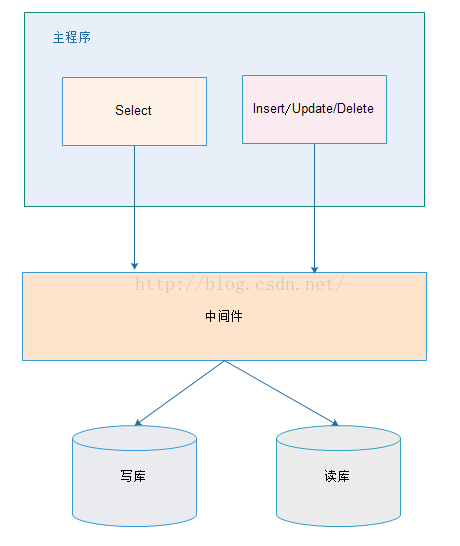
优缺点:
优点:
1、源程序不需要做任何改动就可以实现读写分离;
2、动态添加数据源不需要重启程序;
缺点:
1、程序依赖于中间件,会导致切换数据库变得困难;
2、由中间件做了中转代理,性能有所下降;
相关中间件产品使用:
mysql-proxy:http://hi.baidu.com/geshuai2008/item/0ded5389c685645f850fab07
Amoeba for MySQL:http://www.iteye.com/topic/188598和http://www.iteye.com/topic/1113437
3. 使用Spring基于应用层实现
3.1. 原理
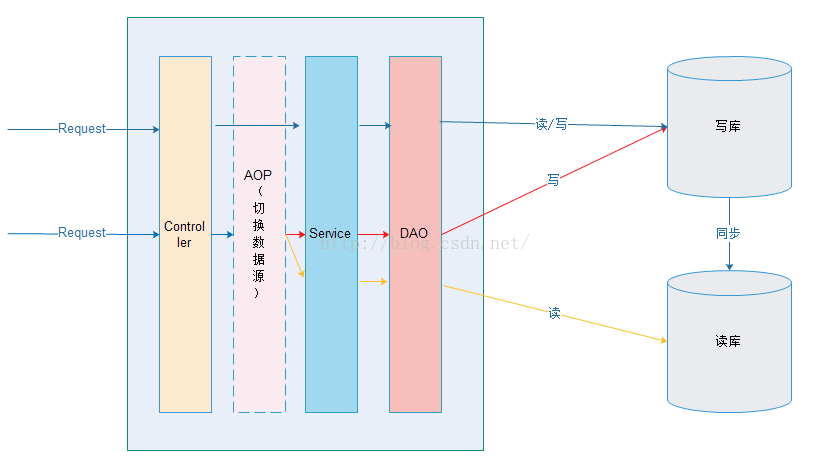
在进入Service之前,使用AOP来做出判断,是使用写库还是读库,判断依据可以根据方法名判断,比如说以query、find、get等开头的就走读库,其他的走写库。
3.2. DynamicDataSource
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法即可
*
* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成。
*
* @author zhijun
*
*/
public class DynamicDataSource extends AbstractRoutingDataSource{
@Override
protected Object determineCurrentLookupKey() {
// 使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源key
return DynamicDataSourceHolder.getDataSourceKey();
}
}
3.3. DynamicDataSourceHolder
<pre name="code" class="java">/**
*
* 使用ThreadLocal技术来记录当前线程中的数据源的key
*
* @author zhijun
*
*/
public class DynamicDataSourceHolder {
//写库对应的数据源key
private static final String MASTER = "master";
//读库对应的数据源key
private static final String SLAVE = "slave";
//使用ThreadLocal记录当前线程的数据源key
private static final ThreadLocal<String> holder = new ThreadLocal<String>();
/**
* 设置数据源key
* @param key
*/
public static void putDataSourceKey(String key) {
holder.set(key);
}
/**
* 获取数据源key
* @return
*/
public static String getDataSourceKey() {
return holder.get();
}
/**
* 标记写库
*/
public static void markMaster(){
putDataSourceKey(MASTER);
}
/**
* 标记读库
*/
public static void markSlave(){
putDataSourceKey(SLAVE);
}
}
3.4. DataSourceAspect
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.JoinPoint;
/**
* 定义数据源的AOP切面,通过该Service的方法名判断是应该走读库还是写库
*
* @author zhijun
*
*/
public class DataSourceAspect {
/**
* 在进入Service方法之前执行
*
* @param point 切面对象
*/
public void before(JoinPoint point) {
// 获取到当前执行的方法名
String methodName = point.getSignature().getName();
if (isSlave(methodName)) {
// 标记为读库
DynamicDataSourceHolder.markSlave();
} else {
// 标记为写库
DynamicDataSourceHolder.markMaster();
}
}
/**
* 判断是否为读库
*
* @param methodName
* @return
*/
private Boolean isSlave(String methodName) {
// 方法名以query、find、get开头的方法名走从库
return StringUtils.startsWithAny(methodName, "query", "find", "get");
}
}
3.5. 配置2个数据源
3.5.1. jdbc.properties
jdbc.master.driver=com.mysql.jdbc.Driver jdbc.master.url=jdbc:mysql://127.0.0.1:3306/mybatis_1128?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true jdbc.master.username=root jdbc.master.password=123456 jdbc.slave01.driver=com.mysql.jdbc.Driver jdbc.slave01.url=jdbc:mysql://127.0.0.1:3307/mybatis_1128?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true jdbc.slave01.username=root jdbc.slave01.password=123456
3.5.2. 定义连接池
<!-- 配置连接池 -->
<bean id="masterDataSource" class="com.jolbox.bonecp.BoneCPDataSource"
destroy-method="close">
<!-- 数据库驱动 -->
<property name="driverClass" value="${jdbc.master.driver}" />
<!-- 相应驱动的jdbcUrl -->
<property name="jdbcUrl" value="${jdbc.master.url}" />
<!-- 数据库的用户名 -->
<property name="username" value="${jdbc.master.username}" />
<!-- 数据库的密码 -->
<property name="password" value="${jdbc.master.password}" />
<!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 -->
<property name="idleConnectionTestPeriod" value="60" />
<!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 -->
<property name="idleMaxAge" value="30" />
<!-- 每个分区最大的连接数 -->
<property name="maxConnectionsPerPartition" value="150" />
<!-- 每个分区最小的连接数 -->
<property name="minConnectionsPerPartition" value="5" />
</bean>
<!-- 配置连接池 -->
<bean id="slave01DataSource" class="com.jolbox.bonecp.BoneCPDataSource"
destroy-method="close">
<!-- 数据库驱动 -->
<property name="driverClass" value="${jdbc.slave01.driver}" />
<!-- 相应驱动的jdbcUrl -->
<property name="jdbcUrl" value="${jdbc.slave01.url}" />
<!-- 数据库的用户名 -->
<property name="username" value="${jdbc.slave01.username}" />
<!-- 数据库的密码 -->
<property name="password" value="${jdbc.slave01.password}" />
<!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 -->
<property name="idleConnectionTestPeriod" value="60" />
<!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 -->
<property name="idleMaxAge" value="30" />
<!-- 每个分区最大的连接数 -->
<property name="maxConnectionsPerPartition" value="150" />
<!-- 每个分区最小的连接数 -->
<property name="minConnectionsPerPartition" value="5" />
</bean>
3.5.3. 定义DataSource
<!-- 定义数据源,使用自己实现的数据源 --> <bean id="dataSource" class="cn.itcast.usermanage.spring.DynamicDataSource"> <!-- 设置多个数据源 --> <property name="targetDataSources"> <map key-type="java.lang.String"> <!-- 这个key需要和程序中的key一致 --> <entry key="master" value-ref="masterDataSource"/> <entry key="slave" value-ref="slave01DataSource"/> </map> </property> <!-- 设置默认的数据源,这里默认走写库 --> <property name="defaultTargetDataSource" ref="masterDataSource"/> </bean>
3.6. 配置事务管理以及动态切换数据源切面
3.6.1. 定义事务管理器
<!-- 定义事务管理器 --> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource" /> </bean>
3.6.2. 定义事务策略
<!-- 定义事务策略 --> <tx:advice id="txAdvice" transaction-manager="transactionManager"> <tx:attributes> <!--定义查询方法都是只读的 --> <tx:method name="query*" read-only="true" /> <tx:method name="find*" read-only="true" /> <tx:method name="get*" read-only="true" /> <!-- 主库执行操作,事务传播行为定义为默认行为 --> <tx:method name="save*" propagation="REQUIRED" /> <tx:method name="update*" propagation="REQUIRED" /> <tx:method name="delete*" propagation="REQUIRED" /> <!--其他方法使用默认事务策略 --> <tx:method name="*" /> </tx:attributes> </tx:advice>
3.6.3. 定义切面
<!-- 定义AOP切面处理器 --> <bean class="cn.itcast.usermanage.spring.DataSourceAspect" id="dataSourceAspect" /> <aop:config> <!-- 定义切面,所有的service的所有方法 --> <aop:pointcut id="txPointcut" expression="execution(* xx.xxx.xxxxxxx.service.*.*(..))" /> <!-- 应用事务策略到Service切面 --> <aop:advisor advice-ref="txAdvice" pointcut-ref="txPointcut"/> <!-- 将切面应用到自定义的切面处理器上,-9999保证该切面优先级最高执行 --> <aop:aspect ref="dataSourceAspect" order="-9999"> <aop:before method="before" pointcut-ref="txPointcut" /> </aop:aspect> </aop:config>
4. 改进切面实现,使用事务策略规则匹配
之前的实现我们是将通过方法名匹配,而不是使用事务策略中的定义,我们使用事务管理策略中的规则匹配。
4.1. 改进后的配置
<span style="white-space:pre"> </span><!-- 定义AOP切面处理器 --> <bean class="cn.itcast.usermanage.spring.DataSourceAspect" id="dataSourceAspect"> <!-- 指定事务策略 --> <property name="txAdvice" ref="txAdvice"/> <!-- 指定slave方法的前缀(非必须) --> <property name="slaveMethodStart" value="query,find,get"/> </bean>
4.2. 改进后的实现
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.commons.lang3.StringUtils;
import org.aspectj.lang.JoinPoint;
import org.springframework.transaction.interceptor.NameMatchTransactionAttributeSource;
import org.springframework.transaction.interceptor.TransactionAttribute;
import org.springframework.transaction.interceptor.TransactionAttributeSource;
import org.springframework.transaction.interceptor.TransactionInterceptor;
import org.springframework.util.PatternMatchUtils;
import org.springframework.util.ReflectionUtils;
/**
* 定义数据源的AOP切面,该类控制了使用Master还是Slave。
*
* 如果事务管理中配置了事务策略,则采用配置的事务策略中的标记了ReadOnly的方法是用Slave,其它使用Master。
*
* 如果没有配置事务管理的策略,则采用方法名匹配的原则,以query、find、get开头方法用Slave,其它用Master。
*
* @author zhijun
*
*/
public class DataSourceAspect {
private List<String> slaveMethodPattern = new ArrayList<String>();
private static final String[] defaultSlaveMethodStart = new String[]{ "query", "find", "get" };
private String[] slaveMethodStart;
/**
* 读取事务管理中的策略
*
* @param txAdvice
* @throws Exception
*/
@SuppressWarnings("unchecked")
public void setTxAdvice(TransactionInterceptor txAdvice) throws Exception {
if (txAdvice == null) {
// 没有配置事务管理策略
return;
}
//从txAdvice获取到策略配置信息
TransactionAttributeSource transactionAttributeSource = txAdvice.getTransactionAttributeSource();
if (!(transactionAttributeSource instanceof NameMatchTransactionAttributeSource)) {
return;
}
//使用反射技术获取到NameMatchTransactionAttributeSource对象中的nameMap属性值
NameMatchTransactionAttributeSource matchTransactionAttributeSource = (NameMatchTransactionAttributeSource) transactionAttributeSource;
Field nameMapField = ReflectionUtils.findField(NameMatchTransactionAttributeSource.class, "nameMap");
nameMapField.setAccessible(true); //设置该字段可访问
//获取nameMap的值
Map<String, TransactionAttribute> map = (Map<String, TransactionAttribute>) nameMapField.get(matchTransactionAttributeSource);
//遍历nameMap
for (Map.Entry<String, TransactionAttribute> entry : map.entrySet()) {
if (!entry.getValue().isReadOnly()) {//判断之后定义了ReadOnly的策略才加入到slaveMethodPattern
continue;
}
slaveMethodPattern.add(entry.getKey());
}
}
/**
* 在进入Service方法之前执行
*
* @param point 切面对象
*/
public void before(JoinPoint point) {
// 获取到当前执行的方法名
String methodName = point.getSignature().getName();
boolean isSlave = false;
if (slaveMethodPattern.isEmpty()) {
// 当前Spring容器中没有配置事务策略,采用方法名匹配方式
isSlave = isSlave(methodName);
} else {
// 使用策略规则匹配
for (String mappedName : slaveMethodPattern) {
if (isMatch(methodName, mappedName)) {
isSlave = true;
break;
}
}
}
if (isSlave) {
// 标记为读库
DynamicDataSourceHolder.markSlave();
} else {
// 标记为写库
DynamicDataSourceHolder.markMaster();
}
}
/**
* 判断是否为读库
*
* @param methodName
* @return
*/
private Boolean isSlave(String methodName) {
// 方法名以query、find、get开头的方法名走从库
return StringUtils.startsWithAny(methodName, getSlaveMethodStart());
}
/**
* 通配符匹配
*
* Return if the given method name matches the mapped name.
* <p>
* The default implementation checks for "xxx*", "*xxx" and "*xxx*" matches, as well as direct
* equality. Can be overridden in subclasses.
*
* @param methodName the method name of the class
* @param mappedName the name in the descriptor
* @return if the names match
* @see org.springframework.util.PatternMatchUtils#simpleMatch(String, String)
*/
protected boolean isMatch(String methodName, String mappedName) {
return PatternMatchUtils.simpleMatch(mappedName, methodName);
}
/**
* 用户指定slave的方法名前缀
* @param slaveMethodStart
*/
public void setSlaveMethodStart(String[] slaveMethodStart) {
this.slaveMethodStart = slaveMethodStart;
}
public String[] getSlaveMethodStart() {
if(this.slaveMethodStart == null){
// 没有指定,使用默认
return defaultSlaveMethodStart;
}
return slaveMethodStart;
}
}
5. 一主多从的实现
很多实际使用场景下都是采用“一主多从”的架构的,所有我们现在对这种架构做支持,目前只需要修改DynamicDataSource即可。
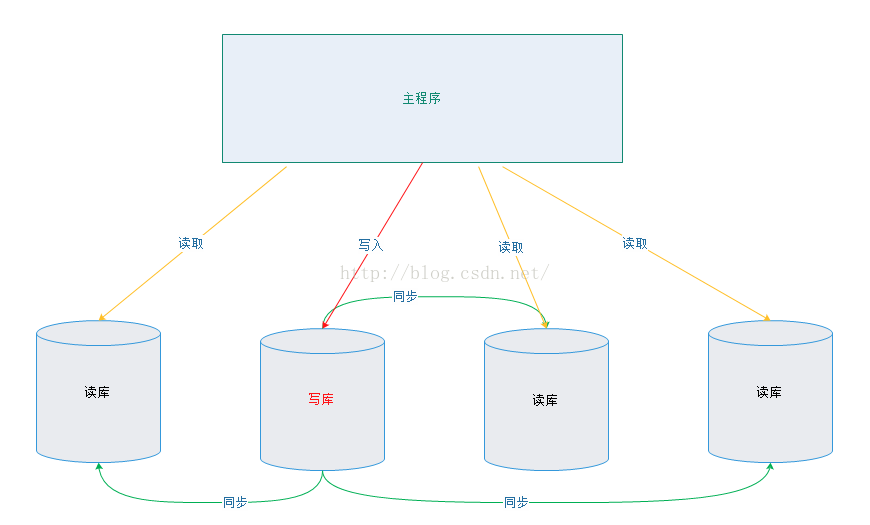
5.1. 实现
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
import javax.sql.DataSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.util.ReflectionUtils;
/**
* 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法即可
*
* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成。
*
* @author zhijun
*
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
private static final Logger LOGGER = LoggerFactory.getLogger(DynamicDataSource.class);
private Integer slaveCount;
// 轮询计数,初始为-1,AtomicInteger是线程安全的
private AtomicInteger counter = new AtomicInteger(-1);
// 记录读库的key
private List<Object> slaveDataSources = new ArrayList<Object>(0);
@Override
protected Object determineCurrentLookupKey() {
// 使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源key
if (DynamicDataSourceHolder.isMaster()) {
Object key = DynamicDataSourceHolder.getDataSourceKey();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("当前DataSource的key为: " + key);
}
return key;
}
Object key = getSlaveKey();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("当前DataSource的key为: " + key);
}
return key;
}
@SuppressWarnings("unchecked")
@Override
public void afterPropertiesSet() {
super.afterPropertiesSet();
// 由于父类的resolvedDataSources属性是私有的子类获取不到,需要使用反射获取
Field field = ReflectionUtils.findField(AbstractRoutingDataSource.class, "resolvedDataSources");
field.setAccessible(true); // 设置可访问
try {
Map<Object, DataSource> resolvedDataSources = (Map<Object, DataSource>) field.get(this);
// 读库的数据量等于数据源总数减去写库的数量
this.slaveCount = resolvedDataSources.size() - 1;
for (Map.Entry<Object, DataSource> entry : resolvedDataSources.entrySet()) {
if (DynamicDataSourceHolder.MASTER.equals(entry.getKey())) {
continue;
}
slaveDataSources.add(entry.getKey());
}
} catch (Exception e) {
LOGGER.error("afterPropertiesSet error! ", e);
}
}
/**
* 轮询算法实现
*
* @return
*/
public Object getSlaveKey() {
// 得到的下标为:0、1、2、3……
Integer index = counter.incrementAndGet() % slaveCount;
if (counter.get() > 9999) { // 以免超出Integer范围
counter.set(-1); // 还原
}
return slaveDataSources.get(index);
}
}
6. MySQL主从复制
6.1. 原理
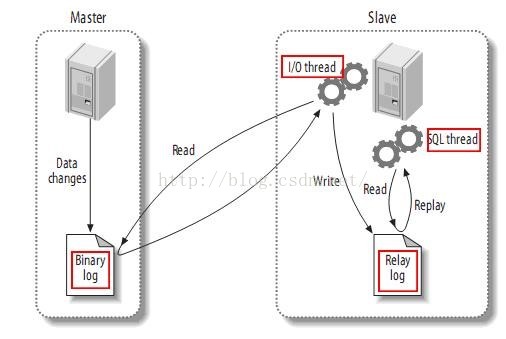
mysql主(称master)从(称slave)复制的原理:
1、master将数据改变记录到二进制日志(binarylog)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events)
2、slave将master的binary logevents拷贝到它的中继日志(relay log)
3、slave重做中继日志中的事件,将改变反映它自己的数据(数据重演)
mysql主从配置请参考以下地址:
http://code.iteye.com/blog/2423089



相关推荐
## 使用Spring实现读写分离(MySQL实现主从复制) ### 概述 随着业务量的增长和技术的发展,单一数据库往往无法满足日益增长的数据处理需求。对于读多写少的应用场景,采用数据库集群的方式进行读写分离是一种常见...
通过上述步骤,我们可以实现基于SpringMVC、MyBatis和Druid的读写分离,以及Windows上的MySQL主从复制。这将大大提高系统的可伸缩性和可用性,降低单点故障的风险。在实际项目中,还可以根据业务需求进一步优化,...
“使用Spring实现读写分离(MySQL实现主从复制).docx”文档可能会提供更详尽的文字说明和代码示例,帮助你更好地理解视频中的内容,并在自己的项目中实现这一技术。 至于“mysql.zip”,“sql”和“mysql资料”...
MySQL主从复制是一种数据同步机制,可以实现数据的实时或接近实时的同步。这种机制允许一个或多个从服务器接收来自主服务器的更新,从而保持数据的一致性。 **主从复制原理**: 1. **主服务器**(Master)将数据更改...
springboot+mybatis+mysql实现读写...先在建好mysql主从数据库的配置,然后在代码中根据读写分离或强制读取master数据库中的数据 mysql数据库设置主从,参考: https://my.oschina.net/zhangmaoyuan/blog/3120556
MySQL的主从复制是实现读写分离的基础。主库上的所有写操作都会被记录到二进制日志(binlog),从库会定期或者实时地从主库获取这些日志并应用到自己的数据上,从而保持与主库数据的一致性。 **4. Spring配置** 在...
Spring AOP 实现读写分离(MySQL实现主从复制)-附件资源
本文将深入探讨如何利用Spring AOP(面向切面编程)实现应用层的MySQL读写分离,并结合一主多从的配置来进行详细讲解。 首先,我们需要理解MySQL的主从复制机制。在主从复制中,数据的写操作(INSERT、UPDATE、...
通过这个Demo,开发者可以了解到如何在Spring、MySQL、MyBatis和SpringMVC的环境中实现读写分离,以及如何配置和管理主从复制。这不仅有助于提升系统的性能,还有助于实现高可用性,是现代Web应用程序设计的重要一环...
在SpringBoot中实现MySQL的读写分离,我们需要依赖于Spring Data JPA或MyBatis等持久层框架,并结合配置中心(如Apache ZooKeeper或Consul)来动态管理读写数据库的地址。以下是具体步骤: 1. **设置主从复制**:在...
5. **MySQL主从复制**:MySQL的主从复制是实现读写分离的基础。主数据库的写操作会同步到从数据库,确保数据的一致性。主从复制可以通过异步或半同步的方式进行,根据业务需求选择合适的模式。 6. **Spring配置读写...
MySQL主从集群是一种常见的数据库高可用性和负载均衡解决方案,它通过数据复制技术使得多个数据库实例之间保持数据同步,其中一个是主节点,负责处理所有写操作,其他是从节点,用于读取数据,从而实现读写分离。...
本篇文章将详细讲解如何在SpringBoot项目中结合MybatisPlus实现多数据源配置,以及主从库的读写分离。 首先,我们要理解什么是SpringBoot和MybatisPlus。SpringBoot是由Pivotal团队提供的全新框架,其目的是简化...
通过spring实现的读写分离例子 当然,需要提前在db层配置好mysql的主从配置 mysql主从配置:http://blog.csdn.net/u013614451/article/details/48901541
Spring Boot 结合 MySQL 的主从复制可以轻松实现这一目标。在本篇文章中,我们将探讨如何在Spring Boot应用中配置读写分离,以及使用MySQL Router作为中间件。 首先,了解MySQL的主从复制是非常必要的。在一个典型...
在数据库读写分离的场景下,Spring可以通过配置不同的数据源,实现对主从库的管理和切换。例如,通过`@Qualifier`注解来指定使用哪个数据源,或者利用AOP在特定方法上动态切换。 3. **MyBatis**:MyBatis是一个优秀...
MySQL主从配置是数据库高可用性和负载均衡的一种常见策略,尤其在Windows环境下,为了实现读写分离、主从复制和一主多从架构,可以极大地提高数据库系统的性能和稳定性。结合Spring框架,我们可以轻松地在应用程序中...
最后,提到的**MySQL主从配置**文件可能包含了具体的MySQL复制设置,如主库和从库的服务器ID、binlog格式、复制用户等。这通常需要在MySQL服务器上手动配置,并且需要确保主从同步的正确性和实时性。 总结来说,...