- 浏览: 117570 次
- 性别:

- 来自: 北京
-

文章分类
最新评论
BigTable是什么?Google的Paper对其作了充分的说明。字面上看就是一张大表,其实和我们想象的传统数据库的表还是有些差别的。松散数据可以说是介于Map Entry(key & value)和DB Row之间的一种数据。在我使用Memcache的时候,有时候的需求是需要存储的不仅仅是简单的一个key对应一个value,可能我需要类似于数据库表结构中多属性的存储,但是又不会有传统数据库表结构中那么多关联关系的需求,其实这类数据就是所谓的松散数据。BigTable最浅显来看就是一张很大的表,表的属性可以根据需求去动态增加,但是又没有表与表之间关联查询的需求。
互联网应用有一个最大的特点,就是速度,功能再强大,速度慢,还是会被舍弃。因此在大访问量的网站都采取前后的缓存来提升性能和响应时间。对于Map Entry类型的数据,集中式分布式Cache都有很多选择,对于传统的关系型数据,从MySQL到Oracle都给了很好的支持,唯有松散数据这类数据,采用前后两种解决方案都不能最大化它的处理能力。因此BigTable才有了它用武之地。
HBase 是一个针对结构化数据的可伸缩、分布式和面向列的动态模式数据库。它能有效和可靠地管理分布在数千个商品服务器上的大规模数据(千兆兆字节或更多)。 HBase 根据 Google 的 Bigtable 数据库建模,是 Apache Software Foundation 的 Hadoop 项目的子项目。
最适合使用Hbase存储的数据是非常稀疏的数据(非结构化或者半结构化的数据)。Hbase之所以擅长存储这类数据,是因为Hbase是column- oriented列导向的存储机制,而我们熟知的RDBMS都是row- oriented行导向的存储机制(郁闷的是我看过N本关于关系数据库的介绍从来没有提到过row- oriented行导向存储这个概念)。在列导向的存储机制下对于Null值得存储是不占用任何空间的。比如,如果某个表 UserTable有10列,但在存储时只有一列有数据,那么其他空值的9列是不占用存储空间的(普通的数据库MySql是如何占用存储空间的呢?)。
Hbase适合存储非结构化的稀疏数据的另一原因是他对列集合 column families 处理机制。 打个比方,ruby和python这样的动态语言和c++、java类的编译语言有什么不同? 对于我来说,最显然的不同就是你不需要为变量预先指定一个类型。Ok ,现在Hbase为未来的DBA也带来了这个激动人心的特性,你只需要告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。
Hbase还有很多特性,比如不支持join查询,但你存储时可以用:parent-child tuple 的方式来变相解决。
注意:在撰写本文时,HBase 的最新版本是 V0.19.3。本文提供的信息适用于这个版本。
数据模型
HBase 数据被建模为多维映射,其中值(表单元)通过 4 个键索引:
value = Map(TableName, RowKey, ColumnKey, Timestamp) |
其中:
-
TableName是一个字符串。 -
RowKey和ColumnKey是二进制值(Java 类型byte[])。 -
Timestamp是一个 64 位整数(Java 类型long)。 -
value是一个未解释的字节数组(Java™ 类型byte[])。
二进制数据被编码为 Base64,以便通过网络传输。
行键是表的主键,通常是一个字符串。行通过行键按字典顺序排序。
存储在表中的信息的结构为列族(column family),您可以将这种结构视为类别。每个列族可以拥有任意数量的成员,它们通过标签(或修饰符)识别。column键由族名、:号和标签组成。例如,对于系列info和成员date,列键为info:date。
一个 HBase 表模式定义多个列族,但当您向表中插入一行时,应用程序能够在运行时创建新成员。对于一个列族,表中的不同行可以拥有不同数量的成员。换句话说,HBase 支持一个动态模式模型。
表 1 展示了一个名为Persons的 HBase 表的简单示例,该表有两个列族:name和contact。
| 000001 | t3 | contact:http research.google.com/people/jeff/ | |
| t2 | name:first Jeffrey | ||
| t1 | name:last Dean | ||
| 000002 | t5 | name:first Gabriel | |
| t4 | name:last Mateescu |
一个空单元没有与单元的键相关联的值。在表 1 中,与键(000002, contact:http, t4)关联的单元为空。空单元不存储在 HBase 中,读取空单元类似于根据不存在的键从映射提取值。HBase 表以这种方法适应稀疏的行。
对于任意行,一次只能访问一个列族的一个成员(这与关系数据库不同,在关系数据库中,一个查询可以访问来自一个行中的多个列的单元)。您可以将一个行中的一个列族的成员视为子行。
表被分解为多个表区域,等同于 Bigtable片(tablet)。一个区域包含某个范围中的行。将一个表分解为多个区域是高效处理大型表的关键机制。
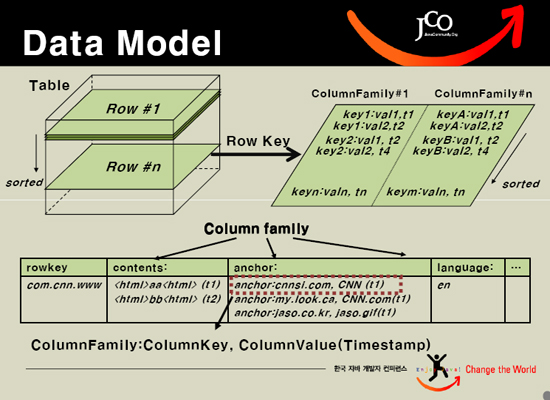
HBASE中的每一张表,就是所谓的BigTable。BigTable会存储一系列的行记录,行记录有三个基本类型的定义:Row Key,Time Stamp,Column。Row Key是行在BigTable中的唯一标识,Time Stamp是每次数据操作对应关联的时间戳,可以看作类似于SVN的版本,Column定义为:<family>:<label>,通过这两部分可以唯一的指定一个数据的存储列,family的定义和修改需要对HBASE作类似于DB的DDL操作,而对于label的使用,则不需要定义直接可以使用,这也为动态定制列提供了一种手段。family另一个作用其实在于物理存储优化读写操作,同family的数据物理上保存的会比较临近,因此在业务设计的过程中可以利用这个特性。
看一下逻辑数据模型:
|
Row Key |
Time Stamp |
Column"contents:" |
Column"anchor:" |
Column"mime:" |
|
|
"com.cnn.www" |
t9 |
"anchor:cnnsi.com" |
"CNN" |
||
|
t8 |
"anchor:my.look.ca" |
"CNN.com" |
|||
|
t6 |
"<html>..." |
"text/html" |
|||
|
t5 |
"<html>..." |
||||
|
t3 |
"<html>..." |
|
上表中有一列,列的唯一标识为com.cnn.www,每一次逻辑修改都有一个timestamp关联对应,一共有四个列定义:<contents:>,<anchor:cnnsi.com>,<anchor:my.look.ca>,<mime:>。如果用传统的概念来将BigTable作解释,那么BigTable可以看作一个DB Schema,每一个Row就是一个表,Row key就是表名,这个表根据列的不同可以划分为多个版本,同时每个版本的操作都会有时间戳关联到操作的行。
再看一下HBASE的物理数据模型:
|
Row Key |
Time Stamp |
Column"contents:" |
|
"com.cnn.www" |
t6 |
"<html>..." |
|
t5 |
"<html>..." |
|
|
t3 |
"<html>..." |
|
Row Key |
Time Stamp |
Column"anchor:" |
|
|
"com.cnn.www" |
t9 |
"anchor:cnnsi.com" |
"CNN" |
|
t8 |
"anchor:my.look.ca" |
"CNN.com" |
|
Row Key |
Time Stamp |
Column"mime:" |
|
"com.cnn.www" |
t6 |
"text/html" |
物理数据模型其实就是将逻辑模型中的一个Row分割成为根据Column family存储的物理模型。
对于BigTable的数据模型操作的时候,会锁定Row,并保证Row的原子操作。


发表评论

-
hadoop分布式文件系统架构与设计
2011-02-17 11:09 768引言 Hadoop分布式� ... -
saas与云计算的区别
2011-03-11 16:59 712SAAS与云计算的区别 SAAS� ... -
MapReduce 简介
2011-03-21 15:00 16091. 介绍MapReduce是goog ... -
用 Hadoop 进行分布式并行编程, 第 1 部分
2011-03-21 16:25 708基本概念与安装部署 曹 羽中( ... -
用 Hadoop 进行分布式并行编程, 第 2 部分
2011-03-21 17:38 593用 Hadoop 进行分布式并行编程, 第 2 ... -
用 Hadoop 进行分布式并行编程, 第 3 部分
2011-03-21 17:55 859部署到分布式环境 曹 羽中(c ... -
HBase简介
2011-07-15 13:49 735HBase – Hadoop Database,是一个高 ... -
hadoop0.20.2配置 in linux(ubuntu)
2011-10-05 16:09 763配置ssh 创建密钥,这里p后面是空密码,不推荐使用空密码 ... -
hadoop0.20.2下相关问题处理方法
2011-10-26 10:52 1240Problem:NameNode is not formatt ... -
zookeeper简介
2011-11-03 15:00 891ZooKeeper是作为分布式应� ... -
hbase集群配置
2011-11-07 16:09 915环境 hbase-0.90.4 hadoop-0.20.2 ... -
分布式服务框架 Zookeeper -- 管理分布式环境中的数据
2011-11-08 13:56 804安装和配置详解 本文介绍的 Zookeeper ... -
zookeeper锁机制
2011-11-08 13:58 873加锁: ZooKeeper将按照如下方式实现加锁的操 ... -
zookeeper相关问题解决
2011-11-08 15:11 793Error contacting service. It is ...
相关推荐
列簇是HBase数据模型中的一个重要的概念,它可以看作是一组列的集合。每个列簇都有自己的物理存储配置,比如是否压缩、是否缓存到内存等。表中的每一行都包含相同的列簇集合,即使某些列簇对于某行没有列,相应的列...
HBase数据模型采用列式存储,每个列族下可以有无限多的列。在存储时,每个列族的列数据不会混合存储,而是以列族为单位顺序存储。这种设计对于读写大量稀疏数据特别有效,因为它只读取相关的列族数据。 4. 物理存储...
3. HBase数据模型 4. 常用shell操作 5. shell管理操作 6. Hbase Java编程 7. HBase高可用 8. HBase架构 第二章 陌陌海量存储案例 1. 案例介绍 2. 打招呼消息数据集介绍 3. 准备工作 4. 陌陌消息HBase表结构设计 5. ...
《HBase数据可视化系统构建详解》 在大数据领域,HBase作为一款分布式列式数据库,因其高并发、低延迟和大规模存储的特点,被广泛应用在实时数据处理和分析中。然而,对于非技术人员来说,直接操作HBase命令行进行...
本文来自于csdn,主要为对HBase简介,HBase数据模型及物理模型,HBase架构及工作原理。HBase是一个构建在HDFS之上的,分布式的、面向列的开源数据库HBase是GoogleBigTable的开源实现,它主要用于存储海量数据个人...
【HBase数据模型】 HBase的数据模型包括表、行和列。数据以表格的形式逻辑存储,每行都有一个可排序的主键(Row Key)和任意多的列。列由列族(Column Family)组织,列族内可以动态增加列。数据是非常稀疏的,因为...
HBase数据模型主要包括三部分: 1. Row Key:行键,Table的主键,Table中的记录按照Row Key排序 2. Timestamp:时间戳,每次数据操作对应的时间戳,可以看作是数据的version number 3. Column Family:列簇,Table...
1.2 HBase数据模型 HBase的数据模型逻辑上与关系型数据库类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensional map。 1.2.1 HBase逻辑结构 HBase的...
通过这份手册,用户可以更深入地了解 HBase 的工作原理,掌握在生产环境中如何高效地管理和操作 HBase 集群,以及如何针对不同的业务需求设计合适的 HBase 数据模型和架构。文档中提供的配置示例和最佳实践将对用户...
##### HBase数据模型 HBase的数据模型基于列族,具有以下特点: - **非结构化或半结构化数据**:支持稀疏二维数据存储,对于空字段不进行存储。 - **灵活的Schema**:无需预先定义所有列,可以随时动态增减列。 - **...
3. **HBase数据模型** - **Key-Value存储**: 每个单元格都是键值对形式,键由行键和列族名+列限定符组成,值附带时间戳。 - **多版本**: 每个单元格可以存储多个版本的数据,通过时间戳区分。 4. **HBase与Hadoop...
2. **HBase数据模型** - **列族和列**:列族是预定义的,存储相关的列集合。列在使用时动态创建,列族内的列可无限扩展。 - ** Region 分区**:HBase通过Region进行数据分区,Region会根据行键自动划分,随着数据...
#### 四、HBase数据模型 HBase的数据模型基于键值对,每个单元格通过一个四元组唯一标识: - 行键(Row Key):用于唯一标识一条记录。 - 列族(Column Family):数据被组织成列族,每个列族可以包含多个列。 - 列...
主要包括HBase数据模型介绍,虚拟机及HBase服务的启动停止步骤,以及HBase表的创建、查询、插入、删除等操作的具体语法和实例展示。此外,还提供了HBase Python 编程的基本方法和批量数据导入的操作步骤,结合思考题...
#### HBase数据模型 HBase采用了独特的数据模型设计,主要包括以下几个方面: 1. **Table & Column Family**:HBase中的表由一系列行键(Row Key)、列簇(Column Family)和版本号(Timestamp)组成。列簇是表的...
3. **HBase数据模型**:详细解释行键、列族、列和时间戳的概念,以及它们在实际应用中的作用。 4. **Region管理和负载均衡**:理解Region的生命周期、分裂机制以及如何优化Region Server的负载。 5. **HBase读写...