最近面试,遇到了一些题目,记下来。
项目访问量?
项目访问量,也叫页面浏览量( PV(page view)),我所在的项目,大概有2000W的PV,成交量在每天100-200W单。最高峰有400W单
平均访问量QPS(Query Per Second) ,每秒查询量。总PV/有效时间。1000W/(16*60*60)=173.6111111111111
16为16小时
socket的使用?
直接使用socket很少,进程间的通信通常使用hessian、netty、mina等框架
bio、nio、AIO
bio:blocking IO,阻塞IO。单线程,阻塞;IO操作未完成,线程不可进行其它操作。多线程,占用资源。JDK1.4之前用
nio:non-blocking IO,非阻塞IO
BIO与NIO都是同步的
MyBatis在mysql、oracle分页?
mysql> select pname from product;
+--------+
| pname |
+--------+
| 产品1 |
| 产品2 |
| 产品三 |
+--------+
3 rows in set (0.00 sec)
这个地方是说,从product中选出所有的pname来,一共有三条记录。
MySQL中的分页非常简单,我们可以使用limit
比如:
mysql> select pname from product limit 0,2;
+-------+
| pname |
+-------+
| 产品1 |
| 产品2 |
+-------+
2 rows in set (0.00 sec)
Limit用法如下:
第一个参数是指要开始的地方,第二个参数是指每页显示多少条数据;注意:第一页用0表示。
oracle分页查询格式:
SELECT * FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM TABLE_NAME) A
WHERE ROWNUM <= 40
)
WHERE RN >= 21
其中最内层的查询SELECT * FROM TABLE_NAME表示不进行翻页的原始查询语句。ROWNUM <= 40和RN >= 21控制分页查询的每页的范围。
上面给出的这个分页查询语句,在大多数情况拥有较高的效率。分页的目的就是控制输出结果集大小,将结果尽快的返回。在上面的分页查询语句中,这种考虑主要体现在WHERE ROWNUM <= 40这句上。
选择第21到40条记录存在两种方法,一种是上面例子中展示的在查询的第二层通过ROWNUM <= 40来控制最大值,在查询的最外层控制最小值。而另一种方式是去掉查询第二层的WHERE ROWNUM <= 40语句,在查询的最外层控制分页的最小值和最大值。这是,查询语句如下:
SELECT * FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM TABLE_NAME) A
)
WHERE RN BETWEEN 21 AND 40
对比这两种写法,绝大多数的情况下,第一个查询的效率比第二个高得多。
这是由于CBO优化模式下,Oracle可以将外层的查询条件推到内层查询中,以提高内层查询的执行效率。对于第一个查询语句,第二层的查询条件WHERE ROWNUM <= 40就可以被Oracle推入到内层查询中,这样Oracle查询的结果一旦超过了ROWNUM限制条件,就终止查询将结果返回了。
而第二个查询语句,由于查询条件BETWEEN 21 AND 40是存在于查询的第三层,而Oracle无法将第三层的查询条件推到最内层(即使推到最内层也没有意义,因为最内层查询不知道RN代表什么)。因此,对于第二个查询语句,Oracle最内层返回给中间层的是所有满足条件的数据,而中间层返回给最外层的也是所有数据。数据的过滤在最外层完成,显然这个效率要比第一个查询低得多。
Hibernate、Mybatis技术选型?
项目大小(大mybatis,小hibernate),二次开发(mybatis更灵活)
mybatis细精度优化,数据超过万条,mybatis更快一些
都是ORM(对象关系映射)框架。hibernate是全自动,增删改查都是操作对象,返回结果也是对象。其实,为了使增、删、改,特别是查更灵活,这些操作更倾向于使用sql,而将查询结果封装成对象,这就是Mybaits所谓的半自动化。
left join,right join,inner join,full join哪个效率更高?
inner join>left join=right join>full join
LEFT JOIN 不管怎么样是把左边的表整体放到MEMORY里面去运算。
INNER JOIN是过滤了一遍,然后把相同的结果放到MEMORY里面去运算。
JVM调优
除了栈外,还有系统运行时的寄存器等,也是存储程序运行数据的。这样,以栈或寄存器中的引用为起点,我们可以找到堆中的对象,又从这些对象找到对堆中其他对象的引用,这种引用逐步扩展,最终以null引用或者基本类型结束,这样就形成了一颗以Java栈中引用所对应的对象为根节点的一颗对象树,如果栈中有多个引用,则最终会形成多颗对象树。在这些对象树上的对象,都是当前系统运行所需要的对象,不能被垃圾回收。而其他剩余对象,则可以视为无法被引用到的对象,可以被当做垃圾进行回收。
串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。
对于串行收集和并行收集而言,在进行垃圾回收工作时,需要暂停整个运行环境,而只有垃圾回收程序在运行,因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长
并发收集器:可以保证大部分工作都并发进行(应用不停止),垃圾回收只暂停很少的时间,此收集器适合对响应时间要求比较高的中、大规模应用。使用-XX:+UseConcMarkSweepGC打开。
并发收集器主要减少年老代的暂停时间,他在应用不停止的情况下使用独立的垃圾回收线程,跟踪可达对象。在每个年老代垃圾回收周期中,在收集初期并发收集器 会对整个应用进行简短的暂停,在收集中还会再暂停一次。第二次暂停会比第一次稍长,在此过程中多个线程同时进行垃圾回收工作。
多线程在编写的时候应该注意什么?多线程如何使用?
使用线程池,通过 ThreadPoolExecutor去创建。
ThreadPoolExecutor构造函数如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
corePoolSize 代表该线程中允许的核心线程数,要和工作的线程数量区分开来,两者不
等价(工作的线程数量一定不大于corePoolSize,即当超过后,会将线程
放入队列中),可以理解为一个ArrayList集合中,默认空间是10,但存放的
元素的数量 不一定是10, 在这里这个10就寓指corePoolSize ,存放元
素的个数是工作线程数量
少于corePoolSize,就创建核心线程。超过时,就放入workQueue ,workQueue 放不下时,就创建线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
maximumPoolSize 这个参数的意思就是该线程池所允许的最大线程数量
keepAliveTime 这个参数的意思就是空余线程的存活时间,注意这个值并不会对所有线程起作用,如果线程池中的线程数少于等于核心线程数 corePoolSize,那么这些线程不会因为空闲太长时间而被关闭,当然,也可以通过调用allowCoreThreadTimeOut方法使核心线程数内的线程也可以被回收。
unit 时间单位
workQueue 阻塞队列,在此作用就是用来存放线程。
threadFactory 线程工厂
RejectedExecutionHandler 拒绝策略,即当加入线程失败(比如maximumPoolSize 为100,当工作的线程数+队列的线程数大于100,就会拒绝,此时挂执行这个handler),采用该handler来处理
拒绝策略可以有如下几种:
AbortPolicy
该策略是线程池的默认策略。使用该策略时,如果线程池队列满了丢掉这个任务并且抛出RejectedExecutionException异常
DiscardPolicy
这个策略和AbortPolicy的slient版本,如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常。
DiscardOldestPolicy
这个策略从字面上也很好理解,丢弃最老的。也就是说如果队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列。
因为队列是队尾进,队头出,所以队头元素是最老的,因此每次都是移除对头元素后再尝试入队
CallerRunsPolicy
使用此策略,如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行。就像是个急脾气的人,我等不到别人来做这件事就干脆自己干。
自定义
如果以上策略都不符合业务场景,那么可以自己定义一个拒绝策略,只要实现RejectedExecutionHandler接口,并且实现rejectedExecution方法就可以了。具体的逻辑就在rejectedExecution方法里去定义就OK了。
如下代码的执行目的是执行15个任务
1、核心池大小是6,workQueue是5。所以首选创建6个线程,来执行任务
2、当第7-11个任务过来时,放入workQueue
3、第12-15个任务过来,workQueue放不下了,这时创建新线程去执行。这时7-11还在queue中
4、当有线程执行完任务是,开始执行workQueue中的任务
5、最终,全部任务执行完毕
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.*;
import java.util.*;
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
//设置核心池大小
int corePoolSize = 6;
//设置线程池最大能接受多少线程
int maximumPoolSize = 100;
//当前线程数大于corePoolSize、小于maximumPoolSize时,超出corePoolSize的线程数的生命周期
long keepActiveTime = 200;
//设置时间单位,秒
TimeUnit timeUnit = TimeUnit.SECONDS;
//设置线程池缓存队列的排队策略为FIFO,并且指定缓存队列大小为5
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<Runnable>(5);
//创建ThreadPoolExecutor线程池对象,并初始化该对象的各种参数
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepActiveTime, timeUnit,workQueue);
//往线程池中循环提交线程
for (int i = 0; i < 15; i++) {
//创建线程类对象
MyTask myTask = new MyTask(i);
//开启线程
executor.execute(myTask);
//获取线程池中线程的相应参数
System.out.println("线程池中线程数目:" +executor.getPoolSize() + ",队列中等待执行的任务数目:"+executor.getQueue().size() + ",已执行完的任务数目:"+executor.getCompletedTaskCount());
}
//待线程池以及缓存队列中所有的线程任务完成后关闭线程池。
executor.shutdown();
}
}
import java.text.*;
import java.util.*;
public class MyTask implements Runnable {
private int num;
public MyTask(int num) {
this.num = num;
}
@Override
public void run() {
System.out.println("正在执行task " + num );
try {
Thread.currentThread().sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("task " + num + "执行完毕");
}
}
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
1)FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
解决方案:
1、使用ThreadFactoryBuilder(谷歌guava框架)
2、spring也提供了相似的工具
参见https://blog.csdn.net/more_try/article/details/81506501
不再建议程序员使用较为方便的 Executors 工厂方法 Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)、Executors.newFixedThreadPool(int)(固定大小线程池)和 Executors.newSingleThreadExecutor()(单个后台线程),它们均为大多数使用场景预定义了设置
在java中大致有这几种线程池
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。,可以作一个定时器使用。
newCachedThreadPool 创建一个可缓存线程池,如果线程池长度超过需要的线程数量,可灵活回收空闲线程,若无可回收,则新建线程。
newSingleThreadExecutor 创建一个单线程化的线程池, 它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行,可以控制线程的执行顺序
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待,当创建的线程池数量为1的时候。也类似于单线程化的线程池,当为1的时候,也可控制线程的执行顺序
newCachedThreadPool:
创建一个可缓存线程池
优点:很灵活,弹性的线程池线程管理,用多少线程给多大的线程池,不用后及时回收,用则新建
缺点:一旦线程无限增长,会导致内存溢出。
newFixedThreadPool :
优点:创建一个固定大小线程池,超出的线程会在队列中等待。
缺点:不支持自定义拒绝策略,大小固定,难以扩展
newScheduledThreadPool :
优点:创建一个固定大小线程池,可以定时或周期性的执行任务。
缺点:任务是单线程方式执行,一旦一个任务失败其他任务也受影响
newSingleThreadExecutor :
优点:创建一个单线程的线程池,保证线程的顺序执行
缺点:不适合并发。。不懂为什么这种操作要用线程池。。为什么不直接用队列
统一缺点:不支持自定义拒绝策略。
泛型的使用?
泛型,即“参数化类型”,将类型由原来的具体的类型参数化。泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
泛型,让类型更灵活,同时也可在编译时限制。增加程序员编程的便捷性以及安全性而创建的一种机制。
虚拟机中没有泛型,只有普通类和普通方法
所有泛型类的类型参数在编译时都会被擦除
创建泛型对象时请指明类型,让编译器尽早的做参数检查
struts工作流程?
springMVC工作流程?
http://www.iteye.com/news/32924

用户发送请求至前端控制器DispatcherServlet
· DispatcherServlet收到请求调用HandlerMapping处理器映射器。
· 处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
· DispatcherServlet通过HandlerAdapter处理器适配器调用处理器
· 执行处理器(Controller,也叫后端控制器)。
· Controller执行完成返回ModelAndView
· HandlerAdapter将controller执行结果● ModelAndView返回给DispatcherServlet
· DispatcherServlet将ModelAndView传给● ViewReslover视图解析器
· ViewReslover解析后返回具体View
· DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)。
· DispatcherServlet响应用户。
从上面可以看出,DispatcherServlet有接受请求,响应结果,转发等作用。有了DispatcherServlet之后,可以减少组件之间的耦合度。
spring IOC\AOP?
IOC(Inversion of Control)控制反转,是通过DI(Dependency Injection)来实现的。是Spring的核心,Spring之所以叫做Spring容器,就是因为Spring能通过IOC来进行bean的管理。Spring来负责控制对象的生命周期和对象间的关系。
比如controller层,依赖于service层,DI就将service的实例注入到controller中,不需要在controller中创建service实例。
IOC的实现原理是:工厂+反射,根据配置,动态创建出对象。
AOP的实现原理是动态代理
缓存技术?
memcache、redis
分布式事务
分布式事务可以使用MyCat
三段式提交
(1)CanCommit 阶段:三阶段提交的 CanCommit 阶段其实和二阶段提交的准备阶段很像,协调者向参与者发送 commit 请求,参与者如果可以提交就返回 Yes 响应,否则返回 No 响应。
(2)PreCommit 阶段:协调者根据参与者的反应情况来决定是否可以记录事务的 PreCommit操作。根据响应情况,有以下两种可能。
- 假如协调者从所有参与者那里获得的反馈都是 Yes 响应,则执行事务。
- 假如有任何一个参与者向协调者发送了 No 响应,或者等待超时之后协调者都没有接到参与者的响应,则执行事务的中断。
(3)DoCommit阶段:该阶段进行真正的事务提交,也可以分为执行提交、中断事务两种执行情况。
执行提交的过程如下。
- 协调者接收到参与者发送的ACK响应后,将从预提交状态进入提交状态,并向所有参与者发送doCommit请求。
- 事务提交参与者接收到doCommit请求之后,执行正式的事务提交,并在完成事务提交之后释放所有的事务资源。
- 事务提交完之后,向协调者发送ACK响应。
- 协调者接收到所有参与者的ACK响应之后,完成事务。中断事务的过程如下。
- 协调者向所有参与者发送abort请求。
- 参与者接收到 abort 请求之后,利用其在第 2 个阶段记录的 undo 信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
- 参与者完成事务回滚之后,向协调者发送 ACK 消息。
- 协调者接收到参与者反馈的 ACK 消息之后,执行事务的中断。
HashMap实现分析(源码)
HashMap 的实例有两个参数影响其性能:初始容量(默认16) 和加载因子(默认.75)。
当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构)
在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。
若很多映射关系要存入HashMap中,在创建之初,可以设置较大的初始容量, 用来减少rehash操作
HashMap是非线程安全的,
-
如果多个线程同时访问哈希映射,并且至少有一个线程在结构上修改了映射,那么它必须在外部进行同步。 (结构修改是指添加或删除一个或多个映射的任何操作;仅改变与实例已经包含的密钥相关联的值不是结构修改。)这通常通过对自然地封装映射的一些对象进行同步来实现。 如果没有这样的对象存在,应该使用Collections.synchronizedMap方法“包装”。 这最好在创建时完成,以防止意外的不同步访问地图:
Map m = Collections.synchronizedMap(new HashMap(...));
由所有此类的“collection 视图方法”所返回的迭代器都是快速失败(faile-fast) 的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的 remove 方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒在将来不确定的时间发生任意不确定行为的风险。 下面这句话比较顺
如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
数据结构:数组+链表/红黑树
ArrayList源码实现:数组
链表分为单向链表与双向链表。LinkedList为双向链表,存储有上一个节点和下一个节点的Node。
1、初始化
resize():创建newCap大小的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
2、赋值
putVal()
a)hash碰撞,若碰撞不上,入数组
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
key的Hash值为HashCode运算得到的,高16位不变,然后高16位与低16位想异或。异或得到0或1的比例为50%。这样做的目的是将数组填满。
hash(key)
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
b)若碰撞上了,且Key相同,替换value。
c)若碰撞上了,且Key不同,入链表
p.next = newNode(hash, key, value, null);
d)若链表长度超过阀值(8),则将链表改为红黑树
TREEIFY_THRESHOLD = 8
e)若map里存储数据大小超过阀值=数组初始大小*加载因子,则扩容
if (++size > threshold)
resize();
不超过初始化最大容量(MAXIMUM_CAPACITY),则扩容两倍
newThr = oldThr << 1;
扩容后,遍历原map,对新map赋值
//元素后无值情况
newTab[e.hash & (newCap - 1)] = e;
//红黑树情况
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//链表情况
3、取值
三种情况:在数组中、在链表中、在红黑树中
数组:
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
链表:
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
红黑树:
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
HashMap如何顺序存储与读取?线程安全Map?
可以使用LinkedHashMap,它维护着一个运行于所有条目的双向链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)
如下代码会输出一些null,此代码不能说明HashMap是非线程安全的。
开5个线程存,5个线程取,会出去环形链接,这是非线程安全的正确测试方法,后续补充
new Thread(new Runnable() {
@Override
public void run() {
for(int i=0;i < 100000;i++){
map.put(i,"aa"+i*56732);
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
for(int i=0;i < 10000;i++){
System.out.println(i+":"+map.get(i));
}
}
}).start();
HashTable是线程安全的,它会在get和put方法上,加上synchronized。锁的粒度粗,影响性能
CurrentLinkList源码,数组与链表的性能比较
分布式锁
http://chenjinbo1983.iteye.com/blog/2432174
java性能调优
JVM调优,其余待补充
Jconsole调试工具 ,jemeter
zookeeper的使用
多线程回调
10W个数,取最大的那个
Collections.max()是这样做的:遍历,最大的赋给变量
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll) {
Iterator<? extends T> i = coll.iterator();
T candidate = i.next();
while (i.hasNext()) {
T next = i.next();
if (next.compareTo(candidate) > 0)
candidate = next;
}
return candidate;
}
10W个数,取最大的10个
1、分成100份,一份100个数
2、每份找10个最大的
3、100份,再合并比较,找出最大的
10W个数,找出现次数最数最多的10个
netty聊天室,设计思路?未读数
常用集合?List下发些常用类?线程安全List?
用过哪些队列?队列提交方式?Future是什么?
netty,mina技术选型?
sql explain如何用?
表中,ABC三个字段创建索引。只查询AB是否会命中这个索引?
mysql分库分表
数据库扩展性:
1、scale up 向上升级,硬件升级
2、scale out向外升级、水平扩展,加节点
数据库拆分:垂直拆分和水平拆分
垂直拆分:表结构发生变化
拆字段、拆表、拆数据库
1个字段拆出两个表或多个表,一个表拆出两个或多个表,1个数据库拆出多个库
拆分原因:
1、磁盘空间不够
show global variables like "%datadir%"; -- 查看数据存储路径
du -csh * -- 进入操作系统相应目录,查目录大小
2、某个模块或某些表负载过大
3、某个业务模块需迁移
迁移方法:主从
水平拆分:根据高标识字段进行拆分
实现方式
1、对字段取模
2、按照范围:时间、范围
3、按照用户自定义哈希函数
拆分时,标识字段相同的数据,在同一个分片上,尽量不使用分布式事务。这样可以用Join,和事务。
设计一个大型分布式架构

数据库层分库分表(根据服务不同,进行分库。同时数据量大的表,进行分库分表)
应用层,采用微服务架构。底层多个服务,服务与数据库之间有缓存层。服务层上,是具体业务层。
HTTP请求报头和响应报头中的内容?
https://blog.csdn.net/u010256388/article/details/68491509
HTTP请求报文由3部分组成(请求行+请求头+请求体):
请求行包含:请求方法(get、post)、请求地址、请求的协议(HTTP/1.1)
请求头包含:
Accept:客户端接受什么类型的响应,如text/plain、image/png。Accept属性的值可以为一个或多个MIME类型
Cookie:客户端Cookie,由之前服务器通过Set-Cookie设置的一个HTTP协议Cookie
Referer:请求是从哪个URL过来的,假如你通过google搜索出一个商家的广告页面,你对这个广告页面感兴趣,鼠标一点发送一个请求报文到商家的网站,这个请求报文的Referer报文头属性值就是http://www.google.com
Cache-Control:用来指定当前的请求/回复中的,是否使用缓存机制。如:Cache-Control: no-cache
Host:表示服务器的域名以及服务器所监听的端口号
User-Agent:浏览器的身份标识字符串,如Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/60.0
Accept-Charset:字符集,例如 ISO-8859-1
Accept-Encoding: 编码方式,如gzip 或 compress
session共享(一致性)
对于分布式系统,如何保证Session一致性。
1、使用nginx的IP_hash,但有缺点,如nginx必须位于最前端,新增节点,需修改Nginx配置
2、session后端存储,可以存在缓存或数据库中。建议存缓存中。缺点是,需多调用一次
也可以使用cookie或session同步,但个人建议使用缓存。
怎么看ofo、mobike
技术上,地图,大并发
有成就感的事件?
通用邮件系统收件人、抄送、密送,Jquery实现
Android自学半个月,然后第一个月就完成一个Android项目
点对点通信,亚信、联创接口封装
EOMS动态表单
攻克了什么技术难点?
spring boot spring cloud
我对自己的评价
能带团队、能独立完成项目、有系统设计能力
UML的使用?
UML可以用visio,rose画
UML有六大关系?
UML定义的关系主要有六种:依赖、类属、关联、实现、聚合和组合。这些类间关系的理解和使用是掌握和应用UML的关键,而也就是这几种关系,往往会让初学者迷惑。这里给出这六种主要UML关系的说明和类图描述,一看之下,清晰明了;以下就分别介绍这几种关系:
继承
指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;在Java中此类关系通过关键字extends明确标识,在设计时一般没有争议性;
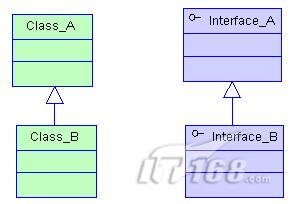
实现
指的是一个class类实现interface接口(可以是多个)的功能;实现是类与接口之间最常见的关系;在Java中此类关系通过关键字implements明确标识,在设计时一般没有争议性;

依赖
可以简单的理解,就是一个类A使用到了另一个类B,而这种使用关系是具有偶然性的、、临时性的、非常弱的,但是B类的变化会影响到A;比如某人要过河,需 要借用一条船,此时人与船之间的关系就是依赖;表现在代码层面,为类B作为参数被类A在某个method方法中使用;
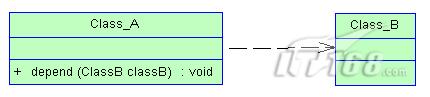
关联
他体现的是两个类、或者类与接口之间语义级别的一种强依赖关系,比如我和我的朋友;这种关系比依赖更强、不存在依赖关系的偶然性、关系也不是临时性的,一 般是长期性的,而且双方的关系一般是平等的、关联可以是单向、双向的;表现在代码层面,为被关联类B以类属性的形式出现在关联类A中,也可能是关联类A引 用了一个类型为被关联类B的全局变量;

聚合
聚合是关联关系的一种特例,他体现的是整体与部分、拥有的关系,即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享;比如计算机与CPU 、公司与员工的关系等;表现在代码层面,和关联关系是一致的,只能从语义级别来区分;
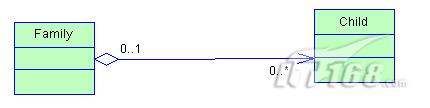
组合
组合也是关联关系的一种特例,他体现的是一种contains-a的关系,这种关系比聚合更强,也称为强聚合;他同样体现整体与部分间的关系,但此时整体 与部分是不可分的,整体的生命周期结束也就意味着部分的生命周期结束;比如你和你的大脑;表现在代码层面,和关联关系是一致的,只能从语义级别来区分;
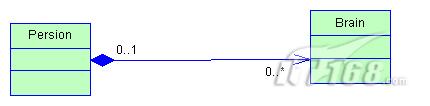
对于继承、实现这两种关系没多少疑问,他们体现的是一种类与类、或者类与接口间的纵向关系;其他的四者关系则体现的是类与类、或者类与接口间的引用、横向 关系,是比较难区分的,有很多事物间的关系要想准备定位是很难的,前面也提到,这几种关系都是语义级别的,所以从代码层面并不能完全区分各种关系;但总的 来说,后几种关系所表现的强弱程度依次为:组合>聚合>关联>依赖。
UML中有九种建模的图标,即:
•用例图
•类图
•对象图
•顺序图(时序图)
•协作图
•状态图
•活动图
•组件图
•配置图
springMVC和struts2比较?
项目刚刚换了web层框架,放弃了struts2改用springMvc
当初还框架的时候目的比较单纯---springmvc支持rest,小生对restful url由衷的喜欢

不用不知道 一用就发现开发效率确实比struts2高
我们用struts2时采用的传统的配置文件的方式,并没有使用传说中的0配置
springMvc可以认为已经100%零配置了(除了配置springmvc-servlet.xml外)
比较了一下strus2与spring3 mvc的差别 ?
struts2框架是类级别的拦截 ,每次来了请求就创建一个Action,然后调用setter getter方法把request中的数据注入
struts2实际上是通过setter getter方法与request打交道的
struts2中,一个Action对象对应一个request上下文
springMvc不同,springMvc是方法级别的拦截 ,拦截到方法后根据参数上的注解,把request数据注入进去
在springMvc中,一个方法对应一个request上下文
好了 我们来整理一下
struts2是类级别的拦截 , 一个类对应一个request上下文,
springMvc是方法级别的拦截 ,一个方法对应一个request上下文,而方法同时又跟一个url对应
所以说从架构本身上 springMvc就容易实现restful url
而struts2的架构实现起来要费劲
因为struts2 action的一个方法可以对应一个url
而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了
springMvc的方法之间基本上独立的,独享request response数据
请求数据通过参数获取,处理结果通过ModelMap交回给框架
方法之间不共享变量
而struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的
这不会影响程序运行,却给我们编码读程序时带来麻烦
我对rest风格理解:url定位资源,易读,没有什么.jsp,.do之类的,参数不放在url中。REST是一种程序设计的风格
项目中异常的使用?
1. 异常机制
异常机制是指当程序出现错误后,程序如何处理。具体来说,异常机制提供了程序退出的安全通道。当出现错误后,程序执行的流程发生改变,程序的控制权转移到异常处理器。
传统的处理异常的办法是,函数返回一个特殊的结果来表示出现异常(通常这个特殊结果是大家约定俗称的),调用该函数的程序负责检查并分析函数返回的结果。 这样做有如下的弊端:例如函数返回-1代表出现异常,但是如果函数确实要返回-1这个正确的值时就会出现混淆;可读性降低,将程序代码与处理异常的代码混 爹在一起;由调用函数的程序来分析错误,这就要求客户程序员对库函数有很深的了解。
异常处理的流程:
① 遇到错误,方法立即结束,并不返回一个值;同时,抛出一个异常对象 。
② 调用该方法的程序也不会继续执行下去,而是搜索一个可以处理该异常的异常处理器,并执行其中的代码 。
2 异常的分类
异常的分类:
① 异常的继承结构:基类为Throwable,Error和Exception继承Throwable,RuntimeException和 IOException等继承Exception。
② Error和RuntimeException及其子类成为未检查异常(unchecked),其它异常成为已检查异常(checked)。
每个类型的异常的特点
Error体系 :
Error类体系描述了Java运行系统中的内部错误以及资源耗尽的情形。应用程序不应该抛出这种类型的对象(一般是由虚拟机抛出)。如果出现这种错误, 除了尽力使程序安全退出外,在其他方面是无能为力的。所以,在进行程序设计时,应该更关注Exception体系。
Exception体系包括RuntimeException体系和其他非RuntimeException的体系 :
① RuntimeException:RuntimeException体系包括错误的类型转换、数组越界访问和试图访问空指针等等。处理 RuntimeException的原则是:如果出现RuntimeException,那么一定是程序员的错误。例如,可以通过检查数组下标和数组边界 来避免数组越界访问异常。
②其他非RuntimeException(IOException等等):这类异常一般是外部错误,例如试图从文件尾后读取数据等,这并不是程序本身的错误,而是在应用环境中出现的外部错误。
3 异常的使用方法
声明方法抛出异常
① 语法:throws(略)
② 为什么要声明方法抛出异常?
方法是否抛出异常与方法返回值的类型一样重要。假设方法抛出异常时,没有声明该方法将抛出异常,那么客户程序员可以调用这个方法而且不用编写处理异常的代码。那么,一旦出现异常,那么这个异常就没有合适的异常控制器来解决。
③ 为什么抛出的异常一定是已检查异常?
RuntimeException与Error可以在任何代码中产生,它们不需要由程序员显示的抛出,一旦出现错误,那么相应的异常会被自动抛出。而已检查异常是由程序员抛出的,这分为两种情况:客户程序员调用会抛出异常的库函数(库函数的异常由库程序员抛出);客户程序员自己使用throw语句抛出异常。遇到Error,程序员一般是无能为力的;遇到RuntimeException,那么一定是程序存在逻辑错误,要对程序进行修改(相当于调试的一种 方法);只有已检查异常才是程序员所关心的,程序应该且仅应该抛出或处理已检查异常。
注意:覆盖父类某方法的子类方法不能抛出比父类方法更多的异常,所以,有时设计父类的方法时会声明抛出异常,但实际的实现方法的代码却并不抛出异常,这样做的目的就是为了方便子类方法覆盖父类方法时可以抛出异常。
如何抛出异常
① 语法:throw(略)
② 抛出什么异常?对于一个异常对象,真正有用的信息时异常的对象类型,而异常对象本身毫无意义。比如一个异常对象的类型是 ClassCastException,那么这个类名就是唯一有用的信息。所以,在选择抛出什么异常时,最关键的就是选择异常的类名能够明确说明异常情况的类。
③ 异常对象通常有两种构造函数:一种是无参数的构造函数;另一种是带一个字符串的构造函数,这个字符串将作为这个异常对象除了类型名以外的额外说明。
④ 创建自己的异常:当Java内置的异常都不能明确的说明异常情况的时候,需要创建自己的异常。需要注意的是,唯一有用的就是类型名这个信息,所以不要在异常类的设计上花费精力。
捕获异常
如果一个异常没有被处理,那么,对于一个非图形界面的程序而言,该程序会被中止并输出异常信息;对于一个图形界面程序,也会输出异常的信息,但是程序并不中止,而是返回用错误页面。
语法:try、catch和finally(略),控制器模块必须紧接在try块后面。若掷出一个异常,异常控制机制会搜寻参数与异常类型相符的第一个控 制器随后它会进入那个catch 从句,并认为异常已得到控制。一旦catch 从句结束对控制器的搜索也会停止。
捕获多个异常(注意语法与捕获的顺序)(略)
finally的用法与异常处理流程(略)
异常处理做什么?对于Java来说,由于有了垃圾收集,所以异常处理并不需要回收内存。但是依然有一些资源需要程序员来收集,比如文件、网络连接和图片等资源。
应该声明方法抛出异常还是在方法中捕获异常?原则:捕捉并处理哪些知道如何处理的异常,而传递哪些不知道如何处理的异常。
再次抛出异常
①为什么要再次抛出异常? 在本级中,只能处理一部分内容,有些处理需要在更高一级的环境中完成,所以应该再次抛出异常。这样可以使每级的异常处理器处理它能够处理的异常。
②异常处理流程 :对应与同一try块的catch块将被忽略,抛出的异常将进入更高的一级。
4 关于异常的其他问题
① 过度使用异常 :首先,使用异常很方便,所以程序员一般不再愿意编写处理错误的代码,而仅仅是简简单单的抛出一个异常。这样做是不对的,对于完全已知的错误,应该编写处理这种错误的代码,增加程序的鲁棒性。另外,异常机制的效率很差。
② 将异常与普通错误区分开:对于普通的完全一致的错误,应该编写处理这种错误的代码,增加程序的鲁棒性。只有外部的不能确定和预知的运行时错误才需要使用异常。
③ 异常对象中包含的信息 :一般情况下,异常对象唯一有用的信息就是类型信息。但使用异常带字符串的构造函数时,这个字符串还可以作为额外的信息。调用异常对象的 getMessage()、toString()或者printStackTrace()方法可以分别得到异常对象的额外信息、类名和调用堆栈的信息。并 且后一种包含的信息是前一种的超集。






相关推荐
[消防文员面试题目]消防面试题目.pdf
Java常见笔试_面试题目深度剖析
部分面试题目如下: 自我介绍 成绩排名简单介绍 项目介绍:最难的地方,创新点 最有压力的时候,如何处理 英语水平 对德赛西威的认识 如何看待卷 如何看待加班 ### 德赛西威面试经历分享 德赛西威作为一家知名的...
这份资源"Java常见笔试、面试题目深度剖析"显然是为了帮助求职者更好地准备相关考试而设计的。以下将对Java笔试和面试的一些核心知识点进行详细的阐述: 1. **基础语法**:Java的基础包括变量、数据类型、运算符、...
Java作为一门广泛使用的编程语言,其笔试和面试题目往往涵盖了多个核心领域。下面将对这些领域进行深入解析,帮助你更好地准备Java相关的技术面试。 ### 字符串(String) 字符串在Java中是常用的数据结构,面试中...
标题 "iOS 面试题目及答案" 指出了文件内容主要围绕iOS开发相关的面试题目和答案展开,覆盖了iOS开发中的一些核心概念和技术点。描述部分说明这些面试题目非常全面,涉及了Objective-C、Cocoa Touch以及Xcode的使用...
C语言面试题目集 本资源摘要信息涵盖了C语言面试题目集,包括了C语言的基础知识、面试常见的问题、数据结构、算法、网络协议等方面的知识点。 一、C语言基础知识 1. static关键字的使用:static关键字可以用来...
数通HCIE RS面试题目解析 在计算机网络领域,HCIE(Huawei Certified Internetwork Expert)是华为公司推出的认证项目之一,旨在评估网络工程师的技术能力和实践经验。HCIE RS( Routing and Switching)是HCIE认证...
本压缩包包含的“ASP.NET上海面试题目(经典)”资料,提供了130道面试题目,涵盖了ASP.NET、SQL Server等关键知识点,对于准备在上海地区寻求ASP.NET相关工作的求职者来说,具有很高的参考价值。 以下是部分题目...
这份"大公司C++面试题目集锦"包含的两份文档——"c++试题(1).doc"和"c++试题(2).doc",无疑是帮助你巩固知识、提升技能的关键资源。以下是基于这些文件可能涵盖的一些重要知识点的详细解析: 1. **基础语法**:...
### 各个大公司模数电面试题目解析 #### 基尔霍夫定律 - **定义**: 基尔霍夫定律是电路理论的基础之一,由德国物理学家古斯塔夫·罗伯特·基尔霍夫提出。该定律分为基尔霍夫电流定律(KCL)和基尔霍夫电压定律(KVL)...
"C++面试题目分析" 本文档提供了17道经典的C++面试题目,涵盖了C++语言的各种基础语法和算法,包括字符串处理、数字处理、数组处理等。每个题目都提供了详细的解释和参考答案,旨在帮助读者更好地理解C++语言的实现...
**Windchill常见面试题目汇总** Windchill是一款由PTC公司开发的基于Web的企业产品生命周期管理(PLM)系统,主要用于产品数据管理和协同工作。它涵盖了产品设计、工程、制造、服务等整个生命周期,旨在提高产品的...
华为公司作为全球知名的IT巨头,其面试题目往往涵盖了计算机科学和技术的多个领域,旨在测试应聘者的综合素质和专业技能。从提供的文件名来看,我们可以推测这些面试题目可能涉及到算法、技术支持以及可能的一些行业...
【标题】:“2018最新BAT+面试题目”涵盖了中国顶级互联网公司——百度(Baidu)、阿里巴巴(Alibaba)和腾讯(Tencent)在2018年招聘过程中的热门面试问题。这些题目旨在测试候选人在技术、逻辑思维、问题解决以及...
《世界500强面试题目及评点》是两份重要的资源,主要针对那些渴望进入全球顶级企业工作的人群。这些公司通常会设置独特的面试环节,以全面评估候选人的综合素质和专业技能。以下是对这两部分内容的详细解读。 在500...
本资料包“c++面试题目题目集合 完美的笔试面试”包含了丰富的C++面试题,旨在帮助求职者提升应对笔试和面试的能力。 一、C++基础 1. **变量与数据类型**:理解基本数据类型(如int, float, double, char)以及...
本文将深入探讨集体面试流程以及无领导小组讨论面试题目的精讲,帮助求职者更好地准备,以期在职场竞争中脱颖而出。 集体面试流程通常包含几个关键的步骤,首先是公司展示,这是为了让面试者初步了解公司的背景和...
### 数据结构面试题目解析 1. **题目一**:“链表与数组的不同之处” - 数组是顺序存储的,访问时间复杂度为O(1),但插入删除操作可能需要移动大量元素,时间复杂度为O(n)。 - 链表是链式存储,访问时间复杂度为O...