
ж≠£еИЩи°®иЊЊеЉП30еИЖйТЯеЕ•йЧ®жХЩз®Л
еОЯжЦЗеЬ∞еЭАпЉЪhttp://deerchao.net/tutorials/regex/regex.htm
 
жЬђжЦЗзЫЃж†З
30еИЖйТЯеЖЕиЃ©дљ†жШОзЩљж≠£еИЩи°®иЊЊеЉПжШѓдїАдєИпЉМеєґеѓєеЃГжЬЙдЄАдЇЫеЯЇжЬђзЪДдЇЖиІ£пЉМиЃ©дљ†еПѓдї•еЬ®иЗ™еЈ±зЪДз®ЛеЇПжИЦзљСй°µйЗМдљњзФ®еЃГгАВ
е¶ВдљХдљњзФ®жЬђжХЩз®Л
жЬАйЗНи¶БзЪДжШѓвАФвАФиѓЈзїЩжИС30еИЖйТЯпЉМе¶ВжЮЬдљ†ж≤°жЬЙдљњзФ®ж≠£еИЩи°®иЊЊеЉПзЪДзїПй™МпЉМиѓЈдЄНи¶БиѓХеЫЊеЬ®30зІТеЖЕеЕ•йЧ®вАФвАФйЩ§йЭЮдљ†жШѓиґЕдЇЇ :)
еȀ襀дЄЛйЭҐйВ£дЇЫе§НжЭВзЪДи°®иЊЊеЉПеРУеАТпЉМеП™и¶БиЈЯзЭАжИСдЄАж≠•дЄАж≠•жЭ•пЉМдљ†дЉЪеПСзО∞ж≠£еИЩи°®иЊЊеЉПеЕґеЃЮеєґж≤°жЬЙжГ≥еГПдЄ≠зЪДйВ£дєИеЫ∞йЪЊгАВељУзДґпЉМе¶ВжЮЬдљ†зЬЛеЃМдЇЖињЩзѓЗжХЩз®ЛдєЛеРОпЉМеПСзО∞иЗ™еЈ±жШОзЩљдЇЖеЊИе§ЪпЉМеНіеПИеЗ†дєОдїАдєИйГљиЃ∞дЄНеЊЧпЉМйВ£дєЯжШѓеЊИж≠£еЄЄзЪДвАФвАФжИСиЃ§дЄЇпЉМж≤°жО•иІ¶ињЗж≠£еИЩи°®иЊЊеЉПзЪДдЇЇеЬ®зЬЛеЃМињЩзѓЗжХЩз®ЛеРОпЉМиГљжККжПРеИ∞ињЗзЪДиѓ≠ж≥ХиЃ∞дљП80%дї•дЄКзЪДеПѓиГљжАІдЄЇйЫґгАВињЩйЗМеП™жШѓиЃ©дљ†жШОзЩљеЯЇжЬђзЪДеОЯзРЖпЉМдї•еРОдљ†ињШйЬАи¶Бе§ЪзїГдє†пЉМе§ЪдљњзФ®пЉМжЙНиГљзЖЯзїГжОМжП°ж≠£еИЩи°®иЊЊеЉПгАВ
йЩ§дЇЖдљЬдЄЇеЕ•йЧ®жХЩз®ЛдєЛе§ЦпЉМжЬђжЦЗињШиѓХеЫЊжИРдЄЇеПѓдї•еЬ®жЧ•еЄЄеЈ•дљЬдЄ≠дљњзФ®зЪДж≠£еИЩи°®иЊЊеЉПиѓ≠ж≥ХеПВиАГжЙЛеЖМгАВе∞±дљЬиАЕжЬђдЇЇзЪДзїПеОЖжЭ•иѓіпЉМињЩдЄ™зЫЃж†ЗињШжШѓеЃМжИРеЊЧдЄНйФЩзЪДвАФвАФдљ†зЬЛпЉМжИСиЗ™еЈ±дєЯж≤°иГљжККжЙАжЬЙзЪДдЄЬи•њиЃ∞дЄЛжЭ•пЉМдЄНжШѓеРЧпЉЯ
жЄЕйЩ§ж†ЉеЉП¬†жЦЗжЬђж†ЉеЉПзЇ¶еЃЪпЉЪдЄУдЄЪжЬѓиѓ≠¬†еЕГе≠Чзђ¶/иѓ≠ж≥Хж†ЉеЉП¬†ж≠£еИЩи°®иЊЊеЉП¬†ж≠£еИЩи°®иЊЊеЉПдЄ≠зЪДдЄАйГ®еИЖ(зФ®дЇОеИЖжЮР)¬†еѓєеЕґињЫи°МеМєйЕНзЪДжЇРе≠Чзђ¶дЄ≤¬†еѓєж≠£еИЩи°®иЊЊеЉПжИЦеЕґдЄ≠дЄАйГ®еИЖзЪДиѓіжШО
йЪРиЧПиЊєж≥®¬†жЬђжЦЗеП≥иЊєжЬЙдЄАдЇЫж≥®йЗКпЉМдЄїи¶БжШѓзФ®жЭ•жПРдЊЫдЄАдЇЫзЫЄеЕ≥дњ°жБѓпЉМжИЦиАЕзїЩж≤°жЬЙз®ЛеЇПеСШиГМжЩѓзЪДиѓїиАЕиІ£йЗКдЄАдЇЫеЯЇжЬђж¶ВењµпЉМйАЪеЄЄеПѓдї•ењљзХ•гАВ
ж≠£еИЩи°®иЊЊеЉПеИ∞еЇХжШѓдїАдєИдЄЬи•њпЉЯ
е≠Чзђ¶жШѓиЃ°зЃЧжЬЇиљѓдїґе§ДзРЖжЦЗе≠ЧжЧґжЬАеЯЇжЬђзЪДеНХдљНпЉМеПѓиГљжШѓе≠ЧжѓНпЉМжХ∞е≠ЧпЉМж†ЗзВєзђ¶еПЈпЉМз©Їж†ЉпЉМжНҐи°Мзђ¶пЉМж±Йе≠Чз≠Йз≠ЙгАВе≠Чзђ¶дЄ≤жШѓ0дЄ™жИЦжЫіе§ЪдЄ™е≠Чзђ¶зЪДеЇПеИЧгАВжЦЗжЬђдєЯе∞±жШѓжЦЗе≠ЧпЉМе≠Чзђ¶дЄ≤гАВиѓіжЯРдЄ™е≠Чзђ¶дЄ≤еМєйЕНжЯРдЄ™ж≠£еИЩи°®иЊЊеЉПпЉМйАЪеЄЄжШѓжМЗињЩдЄ™е≠Чзђ¶дЄ≤йЗМжЬЙдЄАйГ®еИЖпЉИжИЦеЗ†йГ®еИЖеИЖеИЂпЉЙиГљжї°иґ≥и°®иЊЊеЉПзїЩеЗЇзЪДжЭ°дїґгАВ
еЬ®зЉЦеЖЩе§ДзРЖе≠Чзђ¶дЄ≤зЪДз®ЛеЇПжИЦзљСй°µжЧґпЉМзїПеЄЄдЉЪжЬЙжЯ•жЙЊзђ¶еРИжЯРдЇЫе§НжЭВиІДеИЩзЪДе≠Чзђ¶дЄ≤зЪДйЬАи¶БгАВж≠£еИЩи°®иЊЊеЉПе∞±жШѓзФ®дЇОжППињ∞ињЩдЇЫиІДеИЩзЪДеЈ•еЕЈгАВжНҐеП•иѓЭиѓіпЉМж≠£еИЩи°®иЊЊеЉПе∞±жШѓиЃ∞ељХжЦЗжЬђиІДеИЩзЪДдї£з†БгАВ
еЊИеПѓиГљдљ†дљњзФ®ињЗWindows/DosдЄЛзФ®дЇОжЦЗдїґжЯ•жЙЊзЪДйАЪйЕНзђ¶(wildcard)пЉМдєЯе∞±жШѓ*еТМ?гАВе¶ВжЮЬдљ†жГ≥жЯ•жЙЊжЯРдЄ™зЫЃељХдЄЛзЪДжЙАжЬЙзЪДWordжЦЗж°£зЪДиѓЭпЉМдљ†дЉЪжРЬ糥*.docгАВеЬ®ињЩйЗМпЉМ*дЉЪиҐЂиІ£йЗКжИРдїїжДПзЪДе≠Чзђ¶дЄ≤гАВеТМйАЪйЕНзђ¶з±їдЉЉпЉМж≠£еИЩи°®иЊЊеЉПдєЯжШѓзФ®жЭ•ињЫи°МжЦЗжЬђеМєйЕНзЪДеЈ•еЕЈпЉМеП™дЄНињЗжѓФиµЈйАЪйЕНзђ¶пЉМеЃГиГљжЫіз≤Њз°ЃеЬ∞жППињ∞дљ†зЪДйЬАж±ВвАФвАФељУзДґпЉМдї£дїЈе∞±жШѓжЫіе§НжЭВвАФвАФжѓФе¶Вдљ†еПѓдї•зЉЦеЖЩдЄАдЄ™ж≠£еИЩи°®иЊЊеЉПпЉМзФ®жЭ•жЯ•жЙЊжЙАжЬЙдї•0еЉАе§іпЉМеРОйЭҐиЈЯзЭА2-3дЄ™жХ∞е≠ЧпЉМзДґеРОжШѓдЄАдЄ™ињЮе≠ЧеПЈвАЬ-вАЭпЉМжЬАеРОжШѓ7жИЦ8дљНжХ∞е≠ЧзЪДе≠Чзђ¶дЄ≤(еГП010-12345678жИЦ0376-7654321)гАВ
еЕ•йЧ®
е≠¶дє†ж≠£еИЩи°®иЊЊеЉПзЪДжЬАе•љжЦєж≥ХжШѓдїОдЊЛе≠РеЉАеІЛпЉМзРЖиІ£дЊЛе≠РдєЛеРОеЖНиЗ™еЈ±еѓєдЊЛе≠РињЫи°МдњЃжФєпЉМеЃЮй™МгАВдЄЛйЭҐзїЩеЗЇдЇЖдЄНе∞СзЃАеНХзЪДдЊЛе≠РпЉМеєґеѓєеЃГдїђдљЬдЇЖиѓ¶зїЖзЪДиѓіжШОгАВ
еБЗиЃЊдљ†еЬ®дЄАзѓЗиЛ±жЦЗе∞ПиѓійЗМжЯ•жЙЊhiпЉМдљ†еПѓдї•дљњзФ®ж≠£еИЩи°®иЊЊеЉПhiгАВ
ињЩеЗ†дєОжШѓжЬАзЃАеНХзЪДж≠£еИЩи°®иЊЊеЉПдЇЖпЉМеЃГеПѓдї•з≤Њз°ЃеМєйЕНињЩж†ЈзЪДе≠Чзђ¶дЄ≤пЉЪзФ±дЄ§дЄ™е≠Чзђ¶зїДжИРпЉМеЙНдЄАдЄ™е≠Чзђ¶жШѓh,еРОдЄАдЄ™жШѓiгАВйАЪеЄЄпЉМе§ДзРЖж≠£еИЩи°®иЊЊеЉПзЪДеЈ•еЕЈдЉЪжПРдЊЫдЄАдЄ™ењљзХ•е§Іе∞ПеЖЩзЪДйАЙй°єпЉМе¶ВжЮЬйАЙдЄ≠дЇЖињЩдЄ™йАЙй°єпЉМеЃГеПѓдї•еМєйЕНhi,HI,Hi,hIињЩеЫЫзІНжГЕеЖµдЄ≠зЪДдїїжДПдЄАзІНгАВ
дЄНеєЄзЪДжШѓпЉМеЊИе§ЪеНХиѓНйЗМеМЕеРЂhiињЩдЄ§дЄ™ињЮзї≠зЪДе≠Чзђ¶пЉМжѓФе¶Вhim,history,highз≠Йз≠ЙгАВзФ®hiжЭ•жЯ•жЙЊзЪДиѓЭпЉМињЩйЗМиЊєзЪДhiдєЯдЉЪ襀жЙЊеЗЇжЭ•гАВе¶ВжЮЬи¶Бз≤Њз°ЃеЬ∞жЯ•жЙЊhiињЩдЄ™еНХиѓНзЪДиѓЭпЉМжИСдїђеЇФиѓ•дљњзФ®\bhi\bгАВ
\bжШѓж≠£еИЩи°®иЊЊеЉПиІДеЃЪзЪДдЄАдЄ™зЙєжЃКдї£з†БпЉИе•љеРІпЉМжЯРдЇЫдЇЇеПЂеЃГеЕГе≠Чзђ¶пЉМmetacharacterпЉЙпЉМдї£и°®зЭАеНХиѓНзЪДеЉАе§іжИЦзїУе∞ЊпЉМдєЯе∞±жШѓеНХиѓНзЪДеИЖзХМе§ДгАВиЩљзДґйАЪеЄЄиЛ±жЦЗзЪДеНХиѓНжШѓзФ±з©Їж†ЉпЉМж†ЗзВєзђ¶еПЈжИЦиАЕжНҐи°МжЭ•еИЖйЪФзЪДпЉМдљЖжШѓ\bеєґдЄНеМєйЕНињЩдЇЫеНХиѓНеИЖйЪФе≠Чзђ¶дЄ≠зЪДдїїдљХдЄАдЄ™пЉМеЃГеП™еМєйЕНдЄАдЄ™дљНзљЃгАВ
е¶ВжЮЬйЬАи¶БжЫіз≤Њз°ЃзЪДиѓіж≥ХпЉМ\bеМєйЕНињЩж†ЈзЪДдљНзљЃпЉЪеЃГзЪДеЙНдЄАдЄ™е≠Чзђ¶еТМеРОдЄАдЄ™е≠Чзђ¶дЄНеЕ®жШѓ(дЄАдЄ™жШѓ,дЄАдЄ™дЄНжШѓжИЦдЄНе≠ШеЬ®)\wгАВ
еБЗе¶Вдљ†и¶БжЙЊзЪДжШѓhiеРОйЭҐдЄНињЬе§ДиЈЯзЭАдЄАдЄ™LucyпЉМдљ†еЇФиѓ•зФ®\bhi\b.*\bLucy\bгАВ
ињЩйЗМпЉМ.жШѓеП¶дЄАдЄ™еЕГе≠Чзђ¶пЉМеМєйЕНйЩ§дЇЖжНҐи°Мзђ¶дї•е§ЦзЪДдїїжДПе≠Чзђ¶гАВ*еРМж†ЈжШѓеЕГе≠Чзђ¶пЉМдЄНињЗеЃГдї£и°®зЪДдЄНжШѓе≠Чзђ¶пЉМдєЯдЄНжШѓдљНзљЃпЉМиАМжШѓжХ∞йЗПвАФвАФеЃГжМЗеЃЪ*еЙНиЊєзЪДеЖЕеЃєеПѓдї•ињЮзї≠йЗНе§НдљњзФ®дїїжДПжђ°дї•дљњжХідЄ™и°®иЊЊеЉПеЊЧеИ∞еМєйЕНгАВеЫ†ж≠§пЉМ.*ињЮеЬ®дЄАиµЈе∞±жДПеС≥зЭАдїїжДПжХ∞йЗПзЪДдЄНеМЕеРЂжНҐи°МзЪДе≠Чзђ¶гАВзО∞еЬ®\bhi\b.*\bLucy\bзЪДжДПжАЭе∞±еЊИжШОжШЊдЇЖпЉЪеЕИжШѓдЄАдЄ™еНХиѓНhi,зДґеРОжШѓдїїжДПдЄ™дїїжДПе≠Чзђ¶(дљЖдЄНиГљжШѓжНҐи°М)пЉМжЬАеРОжШѓLucyињЩдЄ™еНХиѓНгАВ
жНҐи°Мзђ¶е∞±жШѓ'\n',ASCIIзЉЦз†БдЄЇ10(еНБеЕ≠ињЫеИґ0x0A)зЪДе≠Чзђ¶гАВ
е¶ВжЮЬеРМжЧґдљњзФ®еЕґеЃГеЕГе≠Чзђ¶пЉМжИСдїђе∞±иГљжЮДйА†еЗЇеКЯиГљжЫіеЉЇе§ІзЪДж≠£еИЩи°®иЊЊеЉПгАВжѓФе¶ВдЄЛйЭҐињЩдЄ™дЊЛе≠РпЉЪ
0\d\d-\d\d\d\d\d\d\d\dеМєйЕНињЩж†ЈзЪДе≠Чзђ¶дЄ≤пЉЪдї•0еЉАе§іпЉМзДґеРОжШѓдЄ§дЄ™жХ∞е≠ЧпЉМзДґеРОжШѓдЄАдЄ™ињЮе≠ЧеПЈвАЬ-вАЭпЉМжЬАеРОжШѓ8дЄ™жХ∞е≠Ч(дєЯе∞±жШѓдЄ≠еЫљзЪДзФµиѓЭеПЈз†БгАВељУзДґпЉМињЩдЄ™дЊЛе≠РеП™иГљеМєйЕНеМЇеПЈдЄЇ3дљНзЪДжГЕ嚥)гАВ
ињЩйЗМзЪД\dжШѓдЄ™жЦ∞зЪДеЕГе≠Чзђ¶пЉМеМєйЕНдЄАдљНжХ∞е≠Ч(0пЉМжИЦ1пЉМжИЦ2пЉМжИЦвА¶вА¶)гАВ-дЄНжШѓеЕГе≠Чзђ¶пЉМеП™еМєйЕНеЃГжЬђиЇЂвАФвАФињЮе≠Чзђ¶(жИЦиАЕеЗПеПЈпЉМжИЦиАЕдЄ≠ж®™зЇњпЉМжИЦиАЕйЪПдљ†жАОдєИзІ∞еСЉеЃГ)гАВ
дЄЇдЇЖйБњеЕНйВ£дєИе§ЪзГ¶дЇЇзЪДйЗНе§НпЉМжИСдїђдєЯеПѓдї•ињЩж†ЈеЖЩињЩдЄ™и°®иЊЊеЉПпЉЪ0\d{2}-\d{8}гАВињЩйЗМ\dеРОйЭҐзЪД{2}({8})зЪДжДПжАЭжШѓеЙНйЭҐ\dењЕй°їињЮзї≠йЗНе§НеМєйЕН2жђ°(8жђ°)гАВ
жµЛиѓХж≠£еИЩи°®иЊЊеЉП
еЕґеЃГеПѓзФ®зЪДжµЛиѓХеЈ•еЕЈ:
е¶ВжЮЬдљ†дЄНиІЙеЊЧж≠£еИЩи°®иЊЊеЉПеЊИйЪЊиѓїеЖЩзЪДиѓЭпЉМи¶БдєИдљ†жШѓдЄА䪙姩жЙНпЉМи¶БдєИпЉМдљ†дЄНжШѓеЬ∞зРГдЇЇгАВж≠£еИЩи°®иЊЊеЉПзЪДиѓ≠ж≥ХеЊИдї§дЇЇе§ізЦЉпЉМеН≥дљњеѓєзїПеЄЄдљњзФ®еЃГзЪДдЇЇжЭ•иѓідєЯжШѓе¶Вж≠§гАВзФ±дЇОйЪЊдЇОиѓїеЖЩпЉМеЃєжШУеЗЇйФЩпЉМжЙАдї•жЙЊдЄАзІНеЈ•еЕЈеѓєж≠£еИЩи°®иЊЊеЉПињЫи°МжµЛиѓХжШѓеЊИжЬЙењЕи¶БзЪДгАВ
дЄНеРМзЪДзОѓеҐГдЄЛж≠£еИЩи°®иЊЊеЉПзЪДдЄАдЇЫзїЖиКВжШѓдЄНзЫЄеРМзЪДпЉМжЬђжХЩз®ЛдїЛзїНзЪДжШѓеЊЃиљѓ .Net Framework 4.0 дЄЛж≠£еИЩи°®иЊЊеЉПзЪДи°МдЄЇпЉМжЙАдї•пЉМжИСеРСдљ†жО®иНРжИСзЉЦеЖЩзЪД.NetдЄЛзЪДеЈ•еЕЈ¬†ж≠£еИЩи°®иЊЊеЉПжµЛиѓХеЩ®гАВиѓЈеПВиАГиѓ•й°µйЭҐзЪДиѓіжШОжЭ•еЃЙи£ЕеТМињРи°Миѓ•иљѓдїґгАВ
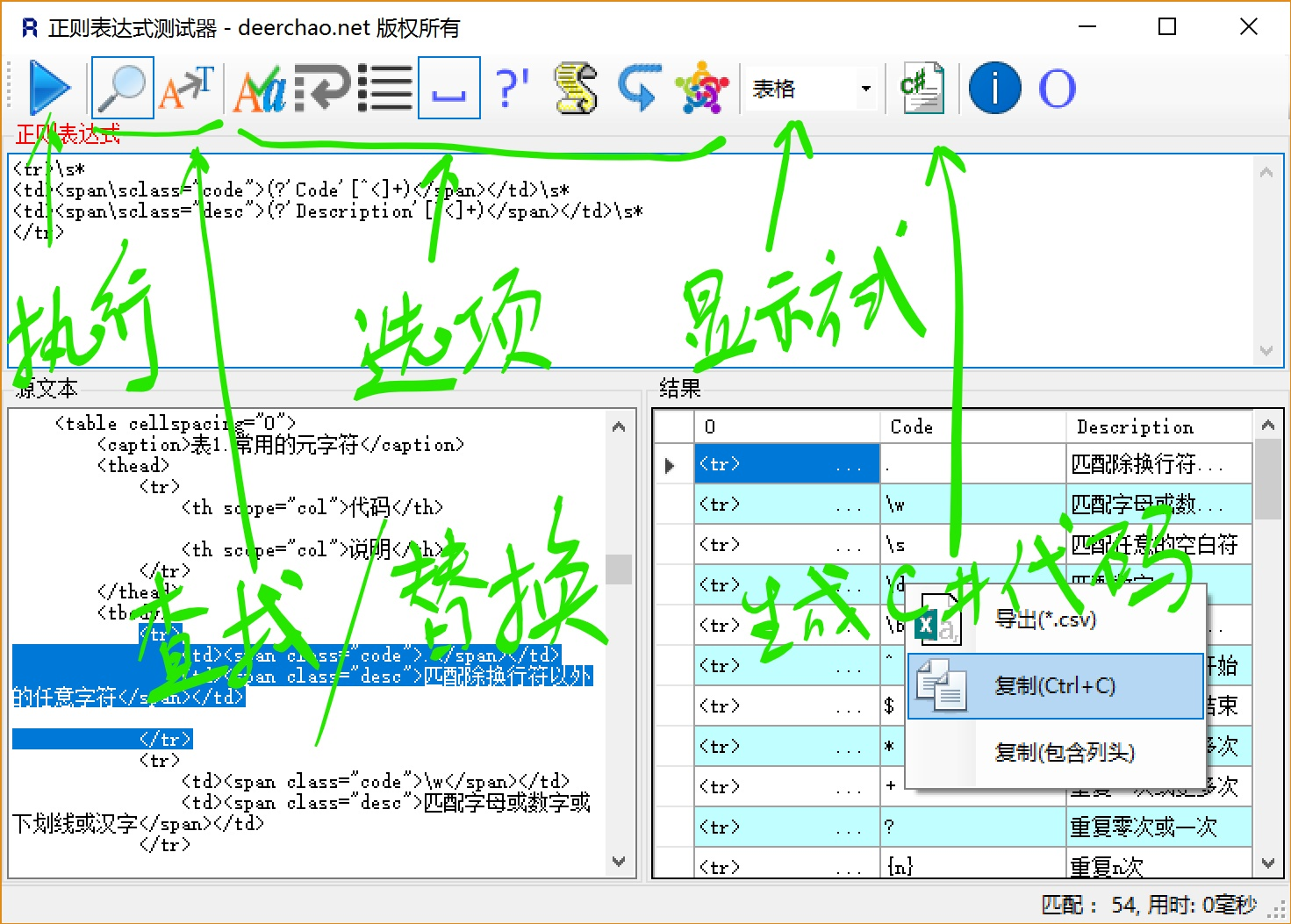
дЄЛйЭҐжШѓRegex TesterињРи°МжЧґзЪДжИ™еЫЊпЉЪ
еЕГе≠Чзђ¶
зО∞еЬ®дљ†еЈ≤зїПзЯ•йБУеЗ†дЄ™еЊИжЬЙзФ®зЪДеЕГе≠Чзђ¶дЇЖпЉМе¶В\b,.,*пЉМињШжЬЙ\d.ж≠£еИЩи°®иЊЊеЉПйЗМињШжЬЙжЫіе§ЪзЪДеЕГе≠Чзђ¶пЉМжѓФе¶В\sеМєйЕНдїїжДПзЪДз©ЇзЩљзђ¶пЉМеМЕжЛђз©Їж†ЉпЉМеИґи°®зђ¶(Tab)пЉМжНҐи°Мзђ¶пЉМдЄ≠жЦЗеЕ®иІТз©Їж†Љз≠ЙгАВ\wеМєйЕНе≠ЧжѓНжИЦжХ∞е≠ЧжИЦдЄЛеИТзЇњжИЦж±Йе≠Чз≠ЙгАВ
еѓєдЄ≠жЦЗ/ж±Йе≠ЧзЪДзЙєжЃКе§ДзРЖжШѓзФ±.NetжПРдЊЫзЪДж≠£еИЩи°®иЊЊеЉПеЉХжУОжФѓжМБзЪДпЉМеЕґеЃГзОѓеҐГдЄЛзЪДеЕЈдљУжГЕеЖµиѓЈжЯ•зЬЛзЫЄеЕ≥жЦЗж°£гАВ
дЄЛйЭҐжЭ•зЬЛзЬЛжЫіе§ЪзЪДдЊЛе≠РпЉЪ
\ba\w*\bеМєйЕНдї•е≠ЧжѓНaеЉАе§ізЪДеНХиѓНвАФвАФеЕИжШѓжЯРдЄ™еНХиѓНеЉАеІЛе§Д(\b)пЉМзДґеРОжШѓе≠ЧжѓНa,зДґеРОжШѓдїїжДПжХ∞йЗПзЪДе≠ЧжѓНжИЦжХ∞е≠Ч(\w*)пЉМжЬАеРОжШѓеНХиѓНзїУжЭЯе§Д(\b)гАВ
е•љеРІпЉМзО∞еЬ®жИСдїђиѓіиѓіж≠£еИЩи°®иЊЊеЉПйЗМзЪДеНХиѓНжШѓдїАдєИжДПжАЭеРІпЉЪе∞±жШѓдЄНе∞СдЇОдЄАдЄ™зЪДињЮзї≠зЪД\wгАВдЄНйФЩпЉМињЩдЄОе≠¶дє†иЛ±жЦЗжЧґи¶БиГМзЪДжИРеНГдЄКдЄЗдЄ™еРМеРНзЪДдЄЬи•њзЪДз°ЃеЕ≥з≥їдЄНе§І :)
\d+еМєйЕН1дЄ™жИЦжЫіе§ЪињЮзї≠зЪДжХ∞е≠ЧгАВињЩйЗМзЪД+жШѓеТМ*з±їдЉЉзЪДеЕГе≠Чзђ¶пЉМдЄНеРМзЪДжШѓ*еМєйЕНйЗНе§НдїїжДПжђ°(еПѓиГљжШѓ0жђ°)пЉМиАМ+еИЩеМєйЕНйЗНе§Н1жђ°жИЦжЫіе§Ъжђ°гАВ
\b\w{6}\b¬†еМєйЕНеИЪе•љ6дЄ™е≠Чзђ¶зЪДеНХиѓНгАВ
| . | еМєйЕНйЩ§жНҐи°Мзђ¶дї•е§ЦзЪДдїїжДПе≠Чзђ¶ |
| \w | еМєйЕНе≠ЧжѓНжИЦжХ∞е≠ЧжИЦдЄЛеИТзЇњжИЦж±Йе≠Ч |
| \s | еМєйЕНдїїжДПзЪДз©ЇзЩљзђ¶ |
| \d | еМєйЕНжХ∞е≠Ч |
| \b | еМєйЕНеНХиѓНзЪДеЉАеІЛжИЦзїУжЭЯ |
| ^ | еМєйЕНе≠Чзђ¶дЄ≤зЪДеЉАеІЛ |
| $ | еМєйЕНе≠Чзђ¶дЄ≤зЪДзїУжЭЯ |
ж≠£еИЩи°®иЊЊеЉПеЉХжУОйАЪеЄЄдЉЪжПРдЊЫдЄАдЄ™вАЬжµЛиѓХжМЗеЃЪзЪДе≠Чзђ¶дЄ≤жШѓеР¶еМєйЕНдЄАдЄ™ж≠£еИЩи°®иЊЊеЉПвАЭзЪДжЦєж≥ХпЉМе¶ВJavaScriptйЗМзЪДRegExp.test()жЦєж≥ХжИЦ.NETйЗМзЪДRegex.IsMatch()жЦєж≥ХгАВињЩйЗМзЪДеМєйЕНжШѓжМЗжШѓе≠Чзђ¶дЄ≤йЗМжЬЙж≤°жЬЙзђ¶еРИи°®иЊЊеЉПиІДеИЩзЪДйГ®еИЖгАВе¶ВжЮЬдЄНдљњзФ®^еТМ$зЪДиѓЭпЉМеѓєдЇО\d{5,12}иАМи®АпЉМдљњзФ®ињЩж†ЈзЪДжЦєж≥Хе∞±еП™иГљдњЭиѓБе≠Чзђ¶дЄ≤йЗМеМЕеРЂ5еИ∞12ињЮзї≠дљНжХ∞е≠ЧпЉМиАМдЄНжШѓжХідЄ™е≠Чзђ¶дЄ≤е∞±жШѓ5еИ∞12дљНжХ∞е≠ЧгАВ
еЕГе≠Чзђ¶^пЉИеТМжХ∞е≠Ч6еЬ®еРМдЄАдЄ™йФЃдљНдЄКзЪДзђ¶еПЈпЉЙеТМ$йГљеМєйЕНдЄАдЄ™дљНзљЃпЉМињЩеТМ\bжЬЙзВєз±їдЉЉгАВ^еМєйЕНдљ†и¶БзФ®жЭ•жЯ•жЙЊзЪДе≠Чзђ¶дЄ≤зЪДеЉАе§іпЉМ$еМєйЕНзїУе∞ЊгАВињЩдЄ§дЄ™дї£з†БеЬ®й™МиѓБиЊУеЕ•зЪДеЖЕеЃєжЧґйЭЮеЄЄжЬЙзФ®пЉМжѓФе¶ВдЄАдЄ™зљСзЂЩе¶ВжЮЬи¶Бж±Вдљ†е°ЂеЖЩзЪДQQеПЈењЕй°їдЄЇ5дљНеИ∞12дљНжХ∞е≠ЧжЧґпЉМеПѓдї•дљњзФ®пЉЪ^\d{5,12}$гАВ
ињЩйЗМзЪД{5,12}еТМеЙНйЭҐдїЛзїНињЗзЪД{2}жШѓз±їдЉЉзЪДпЉМеП™дЄНињЗ{2}еМєйЕНеП™иГљдЄНе§ЪдЄНе∞СйЗНе§Н2жђ°пЉМ{5,12}еИЩжШѓйЗНе§НзЪДжђ°жХ∞дЄНиГље∞СдЇО5жђ°пЉМдЄНиГље§ЪдЇО12жђ°пЉМеР¶еИЩйГљдЄНеМєйЕНгАВ
еЫ†дЄЇдљњзФ®дЇЖ^еТМ$пЉМжЙАдї•иЊУеЕ•зЪДжХідЄ™е≠Чзђ¶дЄ≤йГљи¶БзФ®жЭ•еТМ\d{5,12}жЭ•еМєйЕНпЉМдєЯе∞±жШѓиѓіжХідЄ™иЊУеЕ•ењЕй°їжШѓ5еИ∞12дЄ™жХ∞е≠ЧпЉМеЫ†ж≠§е¶ВжЮЬиЊУеЕ•зЪДQQеПЈиГљеМєйЕНињЩдЄ™ж≠£еИЩи°®иЊЊеЉПзЪДиѓЭпЉМйВ£е∞±зђ¶еРИи¶Бж±ВдЇЖгАВ
еТМењљзХ•е§Іе∞ПеЖЩзЪДйАЙй°єз±їдЉЉпЉМжЬЙдЇЫж≠£еИЩи°®иЊЊеЉПе§ДзРЖеЈ•еЕЈињШжЬЙдЄАдЄ™е§ДзРЖе§Ъи°МзЪДйАЙй°єгАВе¶ВжЮЬйАЙдЄ≠дЇЖињЩдЄ™йАЙй°єпЉМ^еТМ$зЪДжДПдєЙе∞±еПШжИРдЇЖеМєйЕНи°МзЪДеЉАеІЛе§ДеТМзїУжЭЯе§ДгАВ
е≠Чзђ¶иљђдєЙ
е¶ВжЮЬдљ†жГ≥жЯ•жЙЊеЕГе≠Чзђ¶жЬђиЇЂзЪДиѓЭпЉМжѓФе¶Вдљ†жЯ•жЙЊ.,жИЦиАЕ*,е∞±еЗЇзО∞дЇЖйЧЃйҐШпЉЪдљ†ж≤°еКЮж≥ХжМЗеЃЪеЃГдїђпЉМеЫ†дЄЇеЃГдїђдЉЪиҐЂиІ£йЗКжИРеИЂзЪДжДПжАЭгАВињЩжЧґдљ†е∞±еЊЧдљњзФ®\жЭ•еПЦжґИињЩдЇЫе≠Чзђ¶зЪДзЙєжЃКжДПдєЙгАВеЫ†ж≠§пЉМдљ†еЇФиѓ•дљњзФ®\.еТМ\*гАВељУзДґпЉМи¶БжЯ•жЙЊ\жЬђиЇЂпЉМдљ†дєЯеЊЧзФ®\\.
дЊЛе¶ВпЉЪdeerchao\.netеМєйЕНdeerchao.netпЉМC:\\WindowsеМєйЕНC:\WindowsгАВ
йЗНе§Н
дљ†еЈ≤зїПзЬЛињЗдЇЖеЙНйЭҐзЪД*,+,{2},{5,12}ињЩеЗ†дЄ™еМєйЕНйЗНе§НзЪДжЦєеЉПдЇЖгАВдЄЛйЭҐжШѓж≠£еИЩи°®иЊЊеЉПдЄ≠жЙАжЬЙзЪДйЩРеЃЪзђ¶(жМЗеЃЪжХ∞йЗПзЪДдї£з†БпЉМдЊЛе¶В*,{5,12}з≠Й)пЉЪ
| * | йЗНе§НйЫґжђ°жИЦжЫіе§Ъжђ° |
| + | йЗНе§НдЄАжђ°жИЦжЫіе§Ъжђ° |
| ? | йЗНе§НйЫґжђ°жИЦдЄАжђ° |
| {n} | йЗНе§Нnжђ° |
| {n,} | йЗНе§Нnжђ°жИЦжЫіе§Ъжђ° |
| {n,m} | йЗНе§НnеИ∞mжђ° |
дЄЛйЭҐжШѓдЄАдЇЫдљњзФ®йЗНе§НзЪДдЊЛе≠РпЉЪ
Windows\d+еМєйЕНWindowsеРОйЭҐиЈЯ1дЄ™жИЦжЫіе§ЪжХ∞е≠Ч
^\w+еМєйЕНдЄАи°МзЪДзђђдЄАдЄ™еНХиѓН(жИЦжХідЄ™е≠Чзђ¶дЄ≤зЪДзђђдЄАдЄ™еНХиѓНпЉМеЕЈдљУеМєйЕНеУ™дЄ™жДПжАЭеЊЧзЬЛйАЙй°єиЃЊзљЃ)
е≠Чзђ¶з±ї
и¶БжГ≥жЯ•жЙЊжХ∞е≠ЧпЉМе≠ЧжѓНжИЦжХ∞е≠ЧпЉМз©ЇзЩљжШѓеЊИзЃАеНХзЪДпЉМеЫ†дЄЇеЈ≤зїПжЬЙдЇЖеѓєеЇФињЩдЇЫе≠Чзђ¶йЫЖеРИзЪДеЕГе≠Чзђ¶пЉМдљЖжШѓе¶ВжЮЬдљ†жГ≥еМєйЕНж≤°жЬЙйҐДеЃЪдєЙеЕГе≠Чзђ¶зЪДе≠Чзђ¶йЫЖеРИ(жѓФе¶ВеЕГйЯ≥е≠ЧжѓНa,e,i,o,u),еЇФиѓ•жАОдєИеКЮпЉЯ
еЊИзЃАеНХпЉМдљ†еП™йЬАи¶БеЬ®жЦєжЛђеПЈйЗМеИЧеЗЇеЃГдїђе∞±и°МдЇЖпЉМеГП[aeiou]е∞±еМєйЕНдїїдљХдЄАдЄ™иЛ±жЦЗеЕГйЯ≥е≠ЧжѓНпЉМ[.?!]еМєйЕНж†ЗзВєзђ¶еПЈ(.жИЦ?жИЦ!)гАВ
жИСдїђдєЯеПѓдї•иљїжЭЊеЬ∞жМЗеЃЪдЄАдЄ™е≠Чзђ¶иМГеЫіпЉМеГП[0-9]дї£и°®зЪДеРЂжДПдЄО\dе∞±жШѓеЃМеЕ®дЄАиЗізЪДпЉЪдЄАдљНжХ∞е≠ЧпЉЫеРМзРЖ[a-z0-9A-Z_]дєЯеЃМеЕ®з≠ЙеРМдЇО\wпЉИе¶ВжЮЬеП™иАГиЩСиЛ±жЦЗзЪДиѓЭпЉЙгАВ
дЄЛйЭҐжШѓдЄАдЄ™жЫіе§НжЭВзЪДи°®иЊЊеЉПпЉЪ\(?0\d{2}[) -]?\d{8}гАВ
вАЬ(вАЭеТМвАЬ)вАЭдєЯжШѓеЕГе≠Чзђ¶пЉМеРОйЭҐзЪДеИЖзїДиКВйЗМдЉЪжПРеИ∞пЉМжЙАдї•еЬ®ињЩйЗМйЬАи¶БдљњзФ®иљђдєЙгАВ
ињЩдЄ™и°®иЊЊеЉПеПѓдї•еМєйЕНеЗ†зІНж†ЉеЉПзЪДзФµиѓЭеПЈз†БпЉМеГП(010)88886666пЉМжИЦ022-22334455пЉМжИЦ02912345678з≠ЙгАВжИСдїђеѓєеЃГињЫи°МдЄАдЇЫеИЖжЮРеРІпЉЪй¶ЦеЕИжШѓдЄАдЄ™иљђдєЙе≠Чзђ¶\(,еЃГиГљеЗЇзО∞0жђ°жИЦ1жђ°(?),зДґеРОжШѓдЄАдЄ™0пЉМеРОйЭҐиЈЯзЭА2дЄ™жХ∞е≠Ч(\d{2})пЉМзДґеРОжШѓ)жИЦ-жИЦз©Їж†ЉдЄ≠зЪДдЄАдЄ™пЉМеЃГеЗЇзО∞1жђ°жИЦдЄНеЗЇзО∞(?)пЉМжЬАеРОжШѓ8дЄ™жХ∞е≠Ч(\d{8})гАВ
еИЖжЮЭжЭ°дїґ
дЄНеєЄзЪДжШѓпЉМеИЪжЙНйВ£дЄ™и°®иЊЊеЉПдєЯиГљеМєйЕН010)12345678жИЦ(022-87654321ињЩж†ЈзЪДвАЬдЄНж≠£з°ЃвАЭзЪДж†ЉеЉПгАВи¶БиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМжИСдїђйЬАи¶БзФ®еИ∞еИЖжЮЭжЭ°дїґгАВж≠£еИЩи°®иЊЊеЉПйЗМзЪДеИЖжЮЭжЭ°дїґжМЗзЪДжШѓжЬЙеЗ†зІНиІДеИЩпЉМе¶ВжЮЬжї°иґ≥еЕґдЄ≠дїїжДПдЄАзІНиІДеИЩйГљеЇФиѓ•ељУжИРеМєйЕНпЉМеЕЈдљУжЦєж≥ХжШѓзФ®|жККдЄНеРМзЪДиІДеИЩеИЖйЪФеЉАгАВеРђдЄНжШОзЩљпЉЯж≤°еЕ≥з≥їпЉМзЬЛдЊЛе≠РпЉЪ
0\d{2}-\d{8}|0\d{3}-\d{7}ињЩдЄ™и°®иЊЊеЉПиГљеМєйЕНдЄ§зІНдї•ињЮе≠ЧеПЈеИЖйЪФзЪДзФµиѓЭеПЈз†БпЉЪдЄАзІНжШѓдЄЙдљНеМЇеПЈпЉМ8дљНжЬђеЬ∞еПЈ(е¶В010-12345678)пЉМдЄАзІНжШѓ4дљНеМЇеПЈпЉМ7дљНжЬђеЬ∞еПЈ(0376-2233445)гАВ
\(?0\d{2}\)?[- ]?\d{8}|0\d{2}[- ]?\d{8}ињЩдЄ™и°®иЊЊеЉПеМєйЕН3дљНеМЇеПЈзЪДзФµиѓЭеПЈз†БпЉМеЕґдЄ≠еМЇеПЈеПѓдї•зФ®е∞ПжЛђеПЈжЛђиµЈжЭ•пЉМдєЯеПѓдї•дЄНзФ®пЉМеМЇеПЈдЄОжЬђеЬ∞еПЈйЧіеПѓдї•зФ®ињЮе≠ЧеПЈжИЦз©Їж†ЉйЧійЪФпЉМдєЯеПѓдї•ж≤°жЬЙйЧійЪФгАВдљ†еПѓдї•иѓХиѓХзФ®еИЖжЮЭжЭ°дїґжККињЩдЄ™и°®иЊЊеЉПжЙ©е±ХжИРдєЯжФѓжМБ4дљНеМЇеПЈзЪДгАВ
\d{5}-\d{4}|\d{5}ињЩдЄ™и°®иЊЊеЉПзФ®дЇОеМєйЕНзЊОеЫљзЪДйВЃжФњзЉЦз†БгАВзЊОеЫљйВЃзЉЦзЪДиІДеИЩжШѓ5дљНжХ∞е≠ЧпЉМжИЦиАЕзФ®ињЮе≠ЧеПЈйЧійЪФзЪД9дљНжХ∞е≠ЧгАВдєЛжЙАдї•и¶БзїЩеЗЇињЩдЄ™дЊЛе≠РжШѓеЫ†дЄЇеЃГиГљиѓіжШОдЄАдЄ™йЧЃйҐШпЉЪдљњзФ®еИЖжЮЭжЭ°дїґжЧґпЉМи¶Бж≥®жДПеРДдЄ™жЭ°дїґзЪДй°ЇеЇПгАВе¶ВжЮЬдљ†жККеЃГжФєжИР\d{5}|\d{5}-\d{4}зЪДиѓЭпЉМйВ£дєИе∞±еП™дЉЪеМєйЕН5дљНзЪДйВЃзЉЦ(дї•еПК9дљНйВЃзЉЦзЪДеЙН5дљН)гАВеОЯеЫ†жШѓеМєйЕНеИЖжЮЭжЭ°дїґжЧґпЉМе∞ЖдЉЪдїОеЈ¶еИ∞еП≥еЬ∞жµЛиѓХжѓПдЄ™жЭ°дїґпЉМе¶ВжЮЬжї°иґ≥дЇЖжЯРдЄ™еИЖжЮЭзЪДиѓЭпЉМе∞±дЄНдЉЪеОїеЖНзЃ°еЕґеЃГзЪДжЭ°дїґдЇЖгАВ
еИЖзїД
жИСдїђеЈ≤зїПжПРеИ∞дЇЖжАОдєИйЗНе§НеНХдЄ™е≠Чзђ¶пЉИзЫіжО•еЬ®е≠Чзђ¶еРОйЭҐеК†дЄКйЩРеЃЪзђ¶е∞±и°МдЇЖпЉЙпЉЫдљЖе¶ВжЮЬжГ≥и¶БйЗНе§Не§ЪдЄ™е≠Чзђ¶еПИиѓ•жАОдєИеКЮпЉЯдљ†еПѓдї•зФ®е∞ПжЛђеПЈжЭ•жМЗеЃЪе≠Ри°®иЊЊеЉП(дєЯеПЂеБЪеИЖзїД)пЉМзДґеРОдљ†е∞±еПѓдї•жМЗеЃЪињЩдЄ™е≠Ри°®иЊЊеЉПзЪДйЗНе§Нжђ°жХ∞дЇЖпЉМдљ†дєЯеПѓдї•еѓєе≠Ри°®иЊЊеЉПињЫи°МеЕґеЃГдЄАдЇЫжУНдљЬ(еРОйЭҐдЉЪжЬЙдїЛзїН)гАВ
(\d{1,3}\.){3}\d{1,3}жШѓдЄАдЄ™зЃАеНХзЪДIPеЬ∞еЭАеМєйЕНи°®иЊЊеЉПгАВи¶БзРЖиІ£ињЩдЄ™и°®иЊЊеЉПпЉМиѓЈжМЙдЄЛеИЧй°ЇеЇПеИЖжЮРеЃГпЉЪ\d{1,3}еМєйЕН1еИ∞3дљНзЪДжХ∞е≠ЧпЉМ(\d{1,3}\.){3}еМєйЕНдЄЙдљНжХ∞е≠ЧеК†дЄКдЄАдЄ™иЛ±жЦЗеП•еПЈ(ињЩдЄ™жХідљУдєЯе∞±жШѓињЩдЄ™еИЖзїД)йЗНе§Н3жђ°пЉМжЬАеРОеЖНеК†дЄКдЄАдЄ™дЄАеИ∞дЄЙдљНзЪДжХ∞е≠Ч(\d{1,3})гАВ
IPеЬ∞еЭАдЄ≠жѓПдЄ™жХ∞е≠ЧйГљдЄНиГље§ІдЇО255. зїПеЄЄжЬЙдЇЇйЧЃжИС, 01.02.03.04 ињЩж†ЈеЙНйЭҐеЄ¶жЬЙ0зЪДжХ∞е≠Ч, жШѓдЄНжШѓж≠£з°ЃзЪДIPеЬ∞еЭАеСҐ? з≠Фж°ИжШѓ: жШѓзЪД, IP еЬ∞еЭАйЗМзЪДжХ∞е≠ЧеПѓдї•еМЕеРЂжЬЙеЙНеѓЉ 0 (leading zeroes).
дЄНеєЄзЪДжШѓпЉМеЃГдєЯе∞ЖеМєйЕН256.300.888.999ињЩзІНдЄНеПѓиГље≠ШеЬ®зЪДIPеЬ∞еЭАгАВе¶ВжЮЬиГљдљњзФ®зЃЧжЬѓжѓФиЊГзЪДиѓЭпЉМжИЦиЃЄиГљзЃАеНХеЬ∞иІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМдљЖжШѓж≠£еИЩи°®иЊЊеЉПдЄ≠еєґдЄНжПРдЊЫеЕ≥дЇОжХ∞е≠¶зЪДдїїдљХеКЯиГљпЉМжЙАдї•еП™иГљдљњзФ®еЖЧйХњзЪДеИЖзїДпЉМйАЙжЛ©пЉМе≠Чзђ¶з±їжЭ•жППињ∞дЄАдЄ™ж≠£з°ЃзЪДIPеЬ∞еЭАпЉЪ((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)гАВ
зРЖиІ£ињЩдЄ™и°®иЊЊеЉПзЪДеЕ≥йФЃжШѓзРЖиІ£2[0-4]\d|25[0-5]|[01]?\d\d?пЉМињЩйЗМжИСе∞±дЄНзїЖиѓідЇЖпЉМдљ†иЗ™еЈ±еЇФиѓ•иГљеИЖжЮРеЊЧеЗЇжЭ•еЃГзЪДжДПдєЙгАВ
еПНдєЙ
жЬЙжЧґйЬАи¶БжЯ•жЙЊдЄНе±ЮдЇОжЯРдЄ™иГљзЃАеНХеЃЪдєЙзЪДе≠Чзђ¶з±їзЪДе≠Чзђ¶гАВжѓФе¶ВжГ≥жЯ•жЙЊйЩ§дЇЖжХ∞е≠Чдї•е§ЦпЉМеЕґеЃГдїїжДПе≠Чзђ¶йГљи°МзЪДжГЕеЖµпЉМињЩжЧґйЬАи¶БзФ®еИ∞еПНдєЙпЉЪ
| \W | еМєйЕНдїїжДПдЄНжШѓе≠ЧжѓНпЉМжХ∞е≠ЧпЉМдЄЛеИТзЇњпЉМж±Йе≠ЧзЪДе≠Чзђ¶ |
| \S | еМєйЕНдїїжДПдЄНжШѓз©ЇзЩљзђ¶зЪДе≠Чзђ¶ |
| \D | еМєйЕНдїїжДПйЭЮжХ∞е≠ЧзЪДе≠Чзђ¶ |
| \B | еМєйЕНдЄНжШѓеНХиѓНеЉАе§іжИЦзїУжЭЯзЪДдљНзљЃ |
| [^x] | еМєйЕНйЩ§дЇЖxдї•е§ЦзЪДдїїжДПе≠Чзђ¶ |
| [^aeiou] | еМєйЕНйЩ§дЇЖaeiouињЩеЗ†дЄ™е≠ЧжѓНдї•е§ЦзЪДдїїжДПе≠Чзђ¶ |
дЊЛе≠РпЉЪ\S+еМєйЕНдЄНеМЕеРЂз©ЇзЩљзђ¶зЪДе≠Чзђ¶дЄ≤гАВ
<a[^>]+>еМєйЕНзФ®е∞ЦжЛђеПЈжЛђиµЈжЭ•зЪДдї•aеЉАе§ізЪДе≠Чзђ¶дЄ≤гАВ
еРОеРСеЉХзФ®
дљњзФ®е∞ПжЛђеПЈжМЗеЃЪдЄАдЄ™е≠Ри°®иЊЊеЉПеРОпЉМеМєйЕНињЩдЄ™е≠Ри°®иЊЊеЉПзЪДжЦЗжЬђ(дєЯе∞±жШѓж≠§еИЖзїДжНХиОЈзЪДеЖЕеЃє)еПѓдї•еЬ®и°®иЊЊеЉПжИЦеЕґеЃГз®ЛеЇПдЄ≠дљЬињЫдЄАж≠•зЪДе§ДзРЖгАВйїШиЃ§жГЕеЖµдЄЛпЉМжѓПдЄ™еИЖзїДдЉЪиЗ™еК®жЛ•жЬЙдЄАдЄ™зїДеПЈпЉМиІДеИЩжШѓпЉЪдїОеЈ¶еРСеП≥пЉМдї•еИЖзїДзЪДеЈ¶жЛђеПЈдЄЇж†ЗењЧпЉМзђђдЄАдЄ™еЗЇзО∞зЪДеИЖзїДзЪДзїДеПЈдЄЇ1пЉМзђђдЇМдЄ™дЄЇ2пЉМдї•ж≠§з±їжО®гАВ
еСГвА¶вА¶еЕґеЃЮ,зїДеПЈеИЖйЕНињШдЄНеГПжИСеИЪиѓіеЊЧйВ£дєИзЃАеНХпЉЪ
- еИЖзїД0еѓєеЇФжХідЄ™ж≠£еИЩи°®иЊЊеЉП
- еЃЮйЩЕдЄКзїДеПЈеИЖйЕНињЗз®ЛжШѓи¶БдїОеЈ¶еРСеП≥жЙЂжППдЄ§йБНзЪДпЉЪзђђдЄАйБНеП™зїЩжЬ™еСљеРНзїДеИЖйЕНпЉМзђђдЇМйБНеП™зїЩеСљеРНзїДеИЖйЕНпЉНпЉНеЫ†ж≠§жЙАжЬЙеСљеРНзїДзЪДзїДеПЈйГље§ІдЇОжЬ™еСљеРНзЪДзїДеПЈ
- дљ†еПѓдї•дљњзФ®(?:exp)ињЩж†ЈзЪДиѓ≠ж≥ХжЭ•еЙ•е§ЇдЄАдЄ™еИЖзїДеѓєзїДеПЈеИЖйЕНзЪДеПВдЄОжЭГпЉО
еРОеРСеЉХзФ®зФ®дЇОйЗНе§НжРЬ糥еЙНйЭҐжЯРдЄ™еИЖзїДеМєйЕНзЪДжЦЗжЬђгАВдЊЛе¶ВпЉМ\1дї£и°®еИЖзїД1еМєйЕНзЪДжЦЗжЬђгАВйЪЊдї•зРЖиІ£пЉЯиѓЈзЬЛз§ЇдЊЛпЉЪ
\b(\w+)\b\s+\1\bеПѓдї•зФ®жЭ•еМєйЕНйЗНе§НзЪДеНХиѓНпЉМеГПgo go, жИЦиАЕkitty kittyгАВињЩдЄ™и°®иЊЊеЉПй¶ЦеЕИжШѓдЄАдЄ™еНХиѓНпЉМдєЯе∞±жШѓеНХиѓНеЉАеІЛе§ДеТМзїУжЭЯе§ДдєЛйЧізЪДе§ЪдЇОдЄАдЄ™зЪДе≠ЧжѓНжИЦжХ∞е≠Ч(\b(\w+)\b)пЉМињЩдЄ™еНХиѓНдЉЪ襀жНХиОЈеИ∞зЉЦеПЈдЄЇ1зЪДеИЖзїДдЄ≠пЉМзДґеРОжШѓ1дЄ™жИЦеЗ†дЄ™з©ЇзЩљзђ¶(\s+)пЉМжЬАеРОжШѓеИЖзїД1дЄ≠жНХиОЈзЪДеЖЕеЃєпЉИдєЯе∞±жШѓеЙНйЭҐеМєйЕНзЪДйВ£дЄ™еНХиѓНпЉЙ(\1)гАВ
дљ†дєЯеПѓдї•иЗ™еЈ±жМЗеЃЪе≠Ри°®иЊЊеЉПзЪДзїДеРНгАВи¶БжМЗеЃЪдЄАдЄ™е≠Ри°®иЊЊеЉПзЪДзїДеРНпЉМиѓЈдљњзФ®ињЩж†ЈзЪДиѓ≠ж≥ХпЉЪ(?<Word>\w+)(жИЦиАЕжККе∞ЦжЛђеПЈжНҐжИР'дєЯи°МпЉЪ(?'Word'\w+)),ињЩж†Је∞±жКК\w+зЪДзїДеРНжМЗеЃЪдЄЇWordдЇЖгАВи¶БеПНеРСеЉХзФ®ињЩдЄ™еИЖзїДжНХиОЈзЪДеЖЕеЃєпЉМдљ†еПѓдї•дљњзФ®\k<Word>,жЙАдї•дЄКдЄАдЄ™дЊЛе≠РдєЯеПѓдї•еЖЩжИРињЩж†ЈпЉЪ\b(?<Word>\w+)\b\s+\k<Word>\bгАВ
дљњзФ®е∞ПжЛђеПЈзЪДжЧґеАЩпЉМињШжЬЙеЊИе§ЪзЙєеЃЪзФ®йАФзЪДиѓ≠ж≥ХгАВдЄЛйЭҐеИЧеЗЇдЇЖжЬАеЄЄзФ®зЪДдЄАдЇЫпЉЪ
| (exp) | еМєйЕНexp,еєґжНХиОЈжЦЗжЬђеИ∞иЗ™еК®еСљеРНзЪДзїДйЗМ |
| (?<name>exp) | еМєйЕНexp,еєґжНХиОЈжЦЗжЬђеИ∞еРНзІ∞дЄЇnameзЪДзїДйЗМпЉМдєЯеПѓдї•еЖЩжИР(?'name'exp) |
| (?:exp) | еМєйЕНexp,дЄНжНХиОЈеМєйЕНзЪДжЦЗжЬђпЉМдєЯдЄНзїЩж≠§еИЖзїДеИЖйЕНзїДеПЈ |
| (?=exp) | еМєйЕНexpеЙНйЭҐзЪДдљНзљЃ |
| (?<=exp) | еМєйЕНexpеРОйЭҐзЪДдљНзљЃ |
| (?!exp) | еМєйЕНеРОйЭҐиЈЯзЪДдЄНжШѓexpзЪДдљНзљЃ |
| (?<!exp) | еМєйЕНеЙНйЭҐдЄНжШѓexpзЪДдљНзљЃ |
| (?#comment) | ињЩзІНз±їеЮЛзЪДеИЖзїДдЄНеѓєж≠£еИЩи°®иЊЊеЉПзЪДе§ДзРЖдЇІзФЯдїїдљХељ±еУНпЉМзФ®дЇОжПРдЊЫж≥®йЗКиЃ©дЇЇйШЕиѓї |
жИСдїђеЈ≤зїПиЃ®иЃЇдЇЖеЙНдЄ§зІНиѓ≠ж≥ХгАВзђђдЄЙдЄ™(?:exp)дЄНдЉЪжФєеПШж≠£еИЩи°®иЊЊеЉПзЪДе§ДзРЖжЦєеЉПпЉМеП™жШѓињЩж†ЈзЪДзїДеМєйЕНзЪДеЖЕеЃєдЄНдЉЪеГПеЙНдЄ§зІНйВ£ж†ЈиҐЂжНХиОЈеИ∞жЯРдЄ™зїДйЗМйЭҐпЉМдєЯдЄНдЉЪжЛ•жЬЙзїДеПЈгАВвАЬжИСдЄЇдїАдєИдЉЪжГ≥и¶БињЩж†ЈеБЪпЉЯвАЭвАФвАФе•љйЧЃйҐШпЉМдљ†иІЙеЊЧдЄЇдїАдєИеСҐпЉЯ
йЫґеЃљжЦ≠и®А
еЬ∞зРГдЇЇпЉМжШѓдЄНжШѓиІЙеЊЧињЩдЇЫжЬѓиѓ≠еРНзІ∞姙е§НжЭВпЉМ姙йЪЊиЃ∞дЇЖпЉЯжИСдєЯжЬЙеРМжДЯгАВзЯ•йБУжЬЙињЩдєИдЄАзІНдЄЬи•ње∞±и°МдЇЖпЉМеЃГеПЂдїАдєИпЉМйЪПеЃГеОїеРІпЉБдЇЇиЛ•жЧ†еРНпЉМдЊњеПѓдЄУењГзїГеЙСпЉЫзЙ©иЛ•жЧ†еРНпЉМдЊњеПѓйЪПжДПеПЦиИНвА¶вА¶
жО•дЄЛжЭ•зЪДеЫЫдЄ™зФ®дЇОжЯ•жЙЊеЬ®жЯРдЇЫеЖЕеЃє(дљЖеєґдЄНеМЕжЛђињЩдЇЫеЖЕеЃє)дєЛеЙНжИЦдєЛеРОзЪДдЄЬи•њпЉМдєЯе∞±жШѓиѓіеЃГдїђеГП\b,^,$йВ£ж†ЈзФ®дЇОжМЗеЃЪдЄАдЄ™дљНзљЃпЉМињЩдЄ™дљНзљЃеЇФиѓ•жї°иґ≥дЄАеЃЪзЪДжЭ°дїґ(еН≥жЦ≠и®А)пЉМеЫ†ж≠§еЃГдїђдєЯ襀зІ∞дЄЇйЫґеЃљжЦ≠и®АгАВжЬАе•љињШжШѓжЛњдЊЛе≠РжЭ•иѓіжШОеРІпЉЪ
жЦ≠и®АзФ®жЭ•е£∞жШОдЄАдЄ™еЇФиѓ•дЄЇзЬЯзЪДдЇЛеЃЮгАВж≠£еИЩи°®иЊЊеЉПдЄ≠еП™жЬЙељУжЦ≠и®АдЄЇзЬЯжЧґжЙНдЉЪзїІзї≠ињЫи°МеМєйЕНгАВ
(?=exp)дєЯеПЂйЫґеЃљеЇ¶ж≠£йҐДжµЛеЕИи°МжЦ≠и®АпЉМеЃГжЦ≠и®АиЗ™иЇЂеЗЇзО∞зЪДдљНзљЃзЪДеРОйЭҐиГљеМєйЕНи°®иЊЊеЉПexpгАВжѓФе¶В\b\w+(?=ing\b)пЉМеМєйЕНдї•ingзїУе∞ЊзЪДеНХиѓНзЪДеЙНйЭҐйГ®еИЖ(йЩ§дЇЖingдї•е§ЦзЪДйГ®еИЖ)пЉМе¶ВжЯ•жЙЊI'm singing while you're dancing.жЧґпЉМеЃГдЉЪеМєйЕНsingеТМdancгАВ
(?<=exp)дєЯеПЂйЫґеЃљеЇ¶ж≠£еЫЮй°ЊеРОеПСжЦ≠и®АпЉМеЃГжЦ≠и®АиЗ™иЇЂеЗЇзО∞зЪДдљНзљЃзЪДеЙНйЭҐиГљеМєйЕНи°®иЊЊеЉПexpгАВжѓФе¶В(?<=\bre)\w+\bдЉЪеМєйЕНдї•reеЉАе§ізЪДеНХиѓНзЪДеРОеНКйГ®еИЖ(йЩ§дЇЖreдї•е§ЦзЪДйГ®еИЖ)пЉМдЊЛе¶ВеЬ®жЯ•жЙЊreading a bookжЧґпЉМеЃГеМєйЕНadingгАВ
еБЗе¶Вдљ†жГ≥и¶БзїЩдЄАдЄ™еЊИйХњзЪДжХ∞е≠ЧдЄ≠жѓПдЄЙдљНйЧіеК†дЄАдЄ™йАЧеПЈ(ељУзДґжШѓдїОеП≥иЊєеК†иµЈдЇЖ)пЉМдљ†еПѓдї•ињЩж†ЈжЯ•жЙЊйЬАи¶БеЬ®еЙНйЭҐеТМйЗМйЭҐжЈїеК†йАЧеПЈзЪДйГ®еИЖпЉЪ((?<=\d)\d{3})+\bпЉМзФ®еЃГеѓє1234567890ињЫи°МжЯ•жЙЊжЧґзїУжЮЬжШѓ234567890гАВ
дЄЛйЭҐињЩдЄ™дЊЛе≠РеРМжЧґдљњзФ®дЇЖињЩдЄ§зІНжЦ≠и®АпЉЪ(?<=\s)\d+(?=\s)еМєйЕНдї•з©ЇзЩљзђ¶йЧійЪФзЪДжХ∞е≠Ч(еЖНжђ°еЉЇи∞ГпЉМдЄНеМЕжЛђињЩдЇЫз©ЇзЩљзђ¶)гАВ
иіЯеРСйЫґеЃљжЦ≠и®А
еЙНйЭҐжИСдїђжПРеИ∞ињЗжАОдєИжЯ•жЙЊдЄНжШѓжЯРдЄ™е≠Чзђ¶жИЦдЄНеЬ®жЯРдЄ™е≠Чзђ¶з±їйЗМзЪДе≠Чзђ¶зЪДжЦєж≥Х(еПНдєЙ)гАВдљЖжШѓе¶ВжЮЬжИСдїђеП™жШѓжГ≥и¶Бз°ЃдњЭжЯРдЄ™е≠Чзђ¶ж≤°жЬЙеЗЇзО∞пЉМдљЖеєґдЄНжГ≥еОїеМєйЕНеЃГжЧґжАОдєИеКЮпЉЯдЊЛе¶ВпЉМе¶ВжЮЬжИСдїђжГ≥жЯ•жЙЊињЩж†ЈзЪДеНХиѓН--еЃГйЗМйЭҐеЗЇзО∞дЇЖе≠ЧжѓНq,дљЖжШѓqеРОйЭҐиЈЯзЪДдЄНжШѓе≠ЧжѓНu,жИСдїђеПѓдї•е∞ЭиѓХињЩж†ЈпЉЪ
\b\w*q[^u]\w*\bеМєйЕНеМЕеРЂеРОйЭҐдЄНжШѓе≠ЧжѓНuзЪДе≠ЧжѓНqзЪДеНХиѓНгАВдљЖжШѓе¶ВжЮЬе§ЪеБЪжµЛиѓХ(жИЦиАЕдљ†жАЭзїіиґ≥е§ЯжХПйФРпЉМзЫіжО•е∞±иІВеѓЯеЗЇжЭ•дЇЖ)пЉМдљ†дЉЪеПСзО∞пЉМе¶ВжЮЬqеЗЇзО∞еЬ®еНХиѓНзЪДзїУе∞ЊзЪДиѓЭпЉМеГПIraq,BenqпЉМињЩдЄ™и°®иЊЊеЉПе∞±дЉЪеЗЇйФЩгАВињЩжШѓеЫ†дЄЇ[^u]жАїи¶БеМєйЕНдЄАдЄ™е≠Чзђ¶пЉМжЙАдї•е¶ВжЮЬqжШѓеНХиѓНзЪДжЬАеРОдЄАдЄ™е≠Чзђ¶зЪДиѓЭпЉМеРОйЭҐзЪД[^u]е∞ЖдЉЪеМєйЕНqеРОйЭҐзЪДеНХиѓНеИЖйЪФзђ¶(еПѓиГљжШѓз©Їж†ЉпЉМжИЦиАЕжШѓеП•еПЈжИЦеЕґеЃГзЪДдїАдєИ)пЉМеРОйЭҐзЪД\w*\bе∞ЖдЉЪеМєйЕНдЄЛдЄАдЄ™еНХиѓНпЉМдЇОжШѓ\b\w*q[^u]\w*\bе∞±иГљеМєйЕНжХідЄ™Iraq fightingгАВиіЯеРСйЫґеЃљжЦ≠и®АиГљиІ£еЖ≥ињЩж†ЈзЪДйЧЃйҐШпЉМеЫ†дЄЇеЃГеП™еМєйЕНдЄАдЄ™дљНзљЃпЉМеєґдЄНжґИиієдїїдљХе≠Чзђ¶гАВзО∞еЬ®пЉМжИСдїђеПѓдї•ињЩж†ЈжЭ•иІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉЪ\b\w*q(?!u)\w*\bгАВ
йЫґеЃљеЇ¶иіЯйҐДжµЛеЕИи°МжЦ≠и®А(?!exp)пЉМжЦ≠и®Аж≠§дљНзљЃзЪДеРОйЭҐдЄНиГљеМєйЕНи°®иЊЊеЉПexpгАВдЊЛе¶ВпЉЪ\d{3}(?!\d)еМєйЕНдЄЙдљНжХ∞е≠ЧпЉМиАМдЄФињЩдЄЙдљНжХ∞е≠ЧзЪДеРОйЭҐдЄНиГљжШѓжХ∞е≠ЧпЉЫ\b((?!abc)\w)+\bеМєйЕНдЄНеМЕеРЂињЮзї≠е≠Чзђ¶дЄ≤abcзЪДеНХиѓНгАВ
еРМзРЖпЉМжИСдїђеПѓдї•зФ®(?<!exp),йЫґеЃљеЇ¶иіЯеЫЮй°ЊеРОеПСжЦ≠и®АжЭ•жЦ≠и®Аж≠§дљНзљЃзЪДеЙНйЭҐдЄНиГљеМєйЕНи°®иЊЊеЉПexpпЉЪ(?<![a-z])\d{7}еМєйЕНеЙНйЭҐдЄНжШѓе∞ПеЖЩе≠ЧжѓНзЪДдЄГдљНжХ∞е≠ЧгАВ
иѓЈиѓ¶зїЖеИЖжЮРи°®иЊЊеЉП(?<=<(\w+)>).*(?=<\/\1>)пЉМињЩдЄ™и°®иЊЊеЉПжЬАиГљи°®зО∞йЫґеЃљжЦ≠и®АзЪДзЬЯж≠£зФ®йАФгАВ
дЄАдЄ™жЫіе§НжЭВзЪДдЊЛе≠РпЉЪ(?<=<(\w+)>).*(?=<\/\1>)еМєйЕНдЄНеМЕеРЂе±ЮжАІзЪДзЃАеНХHTMLж†Зз≠ЊеЖЕйЗМзЪДеЖЕеЃєгАВ(?<=<(\w+)>)жМЗеЃЪдЇЖињЩж†ЈзЪДеЙНзЉАпЉЪ襀е∞ЦжЛђеПЈжЛђиµЈжЭ•зЪДеНХиѓН(жѓФе¶ВеПѓиГљжШѓ<b>)пЉМзДґеРОжШѓ.*(дїїжДПзЪДе≠Чзђ¶дЄ≤),жЬАеРОжШѓдЄАдЄ™еРОзЉА(?=<\/\1>)гАВж≥®жДПеРОзЉАйЗМзЪД\/пЉМеЃГзФ®еИ∞дЇЖеЙНйЭҐжПРињЗзЪДе≠Чзђ¶иљђдєЙпЉЫ\1еИЩжШѓдЄАдЄ™еПНеРСеЉХзФ®пЉМеЉХзФ®зЪДж≠£жШѓжНХиОЈзЪДзђђдЄАзїДпЉМеЙНйЭҐзЪД(\w+)еМєйЕНзЪДеЖЕеЃєпЉМињЩж†Је¶ВжЮЬеЙНзЉАеЃЮйЩЕдЄКжШѓ<b>зЪДиѓЭпЉМеРОзЉАе∞±жШѓ</b>дЇЖгАВжХідЄ™и°®иЊЊеЉПеМєйЕНзЪДжШѓ<b>еТМ</b>дєЛйЧізЪДеЖЕеЃє(еЖНжђ°жПРйЖТпЉМдЄНеМЕжЛђеЙНзЉАеТМеРОзЉАжЬђиЇЂ)гАВ
ж≥®йЗК
е∞ПжЛђеПЈзЪДеП¶дЄАзІНзФ®йАФжШѓйАЪињЗиѓ≠ж≥Х(?#comment)жЭ•еМЕеРЂж≥®йЗКгАВдЊЛе¶ВпЉЪ2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)гАВ
и¶БеМЕеРЂж≥®йЗКзЪДиѓЭпЉМжЬАе•љжШѓеРѓзФ®вАЬењљзХ•ж®°еЉПйЗМзЪДз©ЇзЩљзђ¶вАЭйАЙй°єпЉМињЩж†ЈеЬ®зЉЦеЖЩи°®иЊЊеЉПжЧґиГљдїїжДПзЪДжЈїеК†з©Їж†ЉпЉМTabпЉМжНҐи°МпЉМиАМеЃЮйЩЕдљњзФ®жЧґињЩдЇЫйГље∞Ж襀圚зХ•гАВеРѓзФ®ињЩдЄ™йАЙй°єеРОпЉМеЬ®#еРОйЭҐеИ∞ињЩдЄАи°МзїУжЭЯзЪДжЙАжЬЙжЦЗжЬђйГље∞Ж襀ељУжИРж≥®йЗКењљзХ•жОЙгАВдЊЛе¶ВпЉМжИСдїђеПѓдї•еЙНйЭҐзЪДдЄАдЄ™и°®иЊЊеЉПеЖЩжИРињЩж†ЈпЉЪ
(?<= # жЦ≠и®Аи¶БеМєйЕНзЪДжЦЗжЬђзЪДеЙНзЉА
<(\w+)> # жЯ•жЙЊе∞ЦжЛђеПЈжЛђиµЈжЭ•зЪДе≠ЧжѓНжИЦжХ∞е≠Ч(еН≥HTML/XMLж†Зз≠Њ)
) # еЙНзЉАзїУжЭЯ
.* # еМєйЕНдїїжДПжЦЗжЬђ
(?= # жЦ≠и®Аи¶БеМєйЕНзЪДжЦЗжЬђзЪДеРОзЉА
<\/\1> # жЯ•жЙЊе∞ЦжЛђеПЈжЛђиµЈжЭ•зЪДеЖЕеЃєпЉЪеЙНйЭҐжШѓдЄАдЄ™"/"пЉМеРОйЭҐжШѓеЕИеЙНжНХиОЈзЪДж†Зз≠Њ
) # еРОзЉАзїУжЭЯ
иі™е©™дЄОжЗТжГ∞
ељУж≠£еИЩи°®иЊЊеЉПдЄ≠еМЕеРЂиГљжО•еПЧйЗНе§НзЪДйЩРеЃЪзђ¶жЧґпЉМйАЪеЄЄзЪДи°МдЄЇжШѓпЉИеЬ®дљњжХідЄ™и°®иЊЊеЉПиГљеЊЧеИ∞еМєйЕНзЪДеЙНжПРдЄЛпЉЙеМєйЕНе∞љеПѓиГље§ЪзЪДе≠Чзђ¶гАВдї•ињЩдЄ™и°®иЊЊеЉПдЄЇдЊЛпЉЪa.*bпЉМеЃГе∞ЖдЉЪеМєйЕНжЬАйХњзЪДдї•aеЉАеІЛпЉМдї•bзїУжЭЯзЪДе≠Чзђ¶дЄ≤гАВе¶ВжЮЬзФ®еЃГжЭ•жРЬ糥aababзЪДиѓЭпЉМеЃГдЉЪеМєйЕНжХідЄ™е≠Чзђ¶дЄ≤aababгАВињЩ襀зІ∞дЄЇиі™е©™еМєйЕНгАВ
жЬЙжЧґпЉМжИСдїђжЫійЬАи¶БжЗТжГ∞еМєйЕНпЉМдєЯе∞±жШѓеМєйЕНе∞љеПѓиГље∞СзЪДе≠Чзђ¶гАВеЙНйЭҐзїЩеЗЇзЪДйЩРеЃЪзђ¶йГљеσ俕襀蚐еМЦдЄЇжЗТжГ∞еМєйЕНж®°еЉПпЉМеП™и¶БеЬ®еЃГеРОйЭҐеК†дЄКдЄАдЄ™йЧЃеПЈ?гАВињЩж†Ј.*?е∞±жДПеС≥зЭАеМєйЕНдїїжДПжХ∞йЗПзЪДйЗНе§НпЉМдљЖжШѓеЬ®иГљдљњжХідЄ™еМєйЕНжИРеКЯзЪДеЙНжПРдЄЛдљњзФ®жЬАе∞СзЪДйЗНе§НгАВзО∞еЬ®зЬЛзЬЛжЗТжГ∞зЙИзЪДдЊЛе≠РеРІпЉЪ
a.*?bеМєйЕНжЬАзЯ≠зЪДпЉМдї•aеЉАеІЛпЉМдї•bзїУжЭЯзЪДе≠Чзђ¶дЄ≤гАВе¶ВжЮЬжККеЃГеЇФзФ®дЇОaababзЪДиѓЭпЉМеЃГдЉЪеМєйЕНaabпЉИзђђдЄАеИ∞зђђдЄЙдЄ™е≠Чзђ¶пЉЙеТМabпЉИзђђеЫЫеИ∞зђђдЇФдЄ™е≠Чзђ¶пЉЙгАВ
дЄЇдїАдєИзђђдЄАдЄ™еМєйЕНжШѓaabпЉИзђђдЄАеИ∞зђђдЄЙдЄ™е≠Чзђ¶пЉЙиАМдЄНжШѓabпЉИзђђдЇМеИ∞зђђдЄЙдЄ™е≠Чзђ¶пЉЙпЉЯзЃАеНХеЬ∞иѓіпЉМеЫ†дЄЇж≠£еИЩи°®иЊЊеЉПжЬЙеП¶дЄАжЭ°иІДеИЩпЉМжѓФжЗТжГ∞пЉПиі™е©™иІДеИЩзЪДдЉШеЕИзЇІжЫійЂШпЉЪжЬАеЕИеЉАеІЛзЪДеМєйЕНжЛ•жЬЙжЬАйЂШзЪДдЉШеЕИжЭГвАФвАФThe match that begins earliest winsгАВ
| *? | йЗНе§НдїїжДПжђ°пЉМдљЖе∞љеПѓиГље∞СйЗНе§Н |
| +? | йЗНе§Н1жђ°жИЦжЫіе§Ъжђ°пЉМдљЖе∞љеПѓиГље∞СйЗНе§Н |
| ?? | йЗНе§Н0жђ°жИЦ1жђ°пЉМдљЖе∞љеПѓиГље∞СйЗНе§Н |
| {n,m}? | йЗНе§НnеИ∞mжђ°пЉМдљЖе∞љеПѓиГље∞СйЗНе§Н |
| {n,}? | йЗНе§Нnжђ°дї•дЄКпЉМдљЖе∞љеПѓиГље∞СйЗНе§Н |
е§ДзРЖйАЙй°є
еЬ®C#дЄ≠пЉМдљ†еПѓдї•дљњзФ®Regex(String, RegexOptions)жЮДйА†еЗљжХ∞жЭ•иЃЊзљЃж≠£еИЩи°®иЊЊеЉПзЪДе§ДзРЖйАЙй°єгАВе¶ВпЉЪRegex regex = new Regex(@"\ba\w{6}\b", RegexOptions.IgnoreCase);
дЄКйЭҐдїЛзїНдЇЖеЗ†дЄ™йАЙй°єе¶ВењљзХ•е§Іе∞ПеЖЩпЉМе§ДзРЖе§Ъи°Мз≠ЙпЉМињЩдЇЫйАЙй°єиГљзФ®жЭ•жФєеПШе§ДзРЖж≠£еИЩи°®иЊЊеЉПзЪДжЦєеЉПгАВдЄЛйЭҐжШѓ.NetдЄ≠еЄЄзФ®зЪДж≠£еИЩи°®иЊЊеЉПйАЙй°єпЉЪ
| IgnoreCase(ењљзХ•е§Іе∞ПеЖЩ) | еМєйЕНжЧґдЄНеМЇеИЖе§Іе∞ПеЖЩгАВ |
| Multiline(е§Ъи°Мж®°еЉП) | жЫіжФє^еТМ$зЪДеРЂдєЙпЉМдљњеЃГдїђеИЖеИЂеЬ®дїїжДПдЄАи°МзЪДи°Мй¶ЦеТМи°Ме∞ЊеМєйЕНпЉМиАМдЄНдїЕдїЕеЬ®жХідЄ™е≠Чзђ¶дЄ≤зЪДеЉАе§іеТМзїУе∞ЊеМєйЕНгАВ(еЬ®ж≠§ж®°еЉПдЄЛ,$зЪДз≤Њз°ЃеРЂжДПжШѓ:еМєйЕН\nдєЛеЙНзЪДдљНзљЃдї•еПКе≠Чзђ¶дЄ≤зїУжЭЯеЙНзЪДдљНзљЃ.) |
| Singleline(еНХи°Мж®°еЉП) | жЫіжФє.зЪДеРЂдєЙпЉМдљњеЃГдЄОжѓПдЄАдЄ™е≠Чзђ¶еМєйЕНпЉИеМЕжЛђжНҐи°Мзђ¶\nпЉЙгАВ |
| IgnorePatternWhitespace(ењљзХ•з©ЇзЩљ) | ењљзХ•и°®иЊЊеЉПдЄ≠зЪДйЭЮиљђдєЙз©ЇзЩљеєґеРѓзФ®зФ±#ж†ЗиЃ∞зЪДж≥®йЗКгАВ |
| ExplicitCapture(жШЊеЉПжНХиОЈ) | дїЕжНХиОЈеЈ≤襀жШЊеЉПеСљеРНзЪДзїДгАВ |
дЄАдЄ™зїП媪襀йЧЃеИ∞зЪДйЧЃйҐШжШѓпЉЪжШѓдЄНжШѓеП™иГљеРМжЧґдљњзФ®е§Ъи°Мж®°еЉПеТМеНХи°Мж®°еЉПдЄ≠зЪДдЄАзІНпЉЯз≠Фж°ИжШѓпЉЪдЄНжШѓгАВињЩдЄ§дЄ™йАЙй°єдєЛйЧіж≤°жЬЙдїїдљХеЕ≥з≥їпЉМйЩ§дЇЖеЃГдїђзЪДеРНе≠ЧжѓФиЊГзЫЄдЉЉпЉИдї•иЗ≥дЇОиЃ©дЇЇжДЯеИ∞зЦСжГСпЉЙдї•е§ЦгАВ
еє≥и°°зїД/йАТељТеМєйЕН
ињЩйЗМдїЛзїНзЪДеє≥и°°зїДиѓ≠ж≥ХжШѓзФ±.Net FrameworkжФѓжМБзЪДпЉЫеЕґеЃГиѓ≠и®АпЉПеЇУдЄНдЄАеЃЪжФѓжМБињЩзІНеКЯиГљпЉМжИЦиАЕжФѓжМБж≠§еКЯиГљдљЖйЬАи¶БдљњзФ®дЄНеРМзЪДиѓ≠ж≥ХгАВ
жЬЙжЧґжИСдїђйЬАи¶БеМєйЕНеГП( 100 * ( 50 + 15 ) )ињЩж†ЈзЪДеПѓеµМе•ЧзЪДе±Вжђ°жАІзїУжЮДпЉМињЩжЧґзЃАеНХеЬ∞дљњзФ®\(.+\)еИЩеП™дЉЪеМєйЕНеИ∞жЬАеЈ¶иЊєзЪДеЈ¶жЛђеПЈеТМжЬАеП≥иЊєзЪДеП≥жЛђеПЈдєЛйЧізЪДеЖЕеЃє(ињЩйЗМжИСдїђиЃ®иЃЇзЪДжШѓиі™е©™ж®°еЉПпЉМжЗТжГ∞ж®°еЉПдєЯжЬЙдЄЛйЭҐзЪДйЧЃйҐШ)гАВеБЗе¶ВеОЯжЭ•зЪДе≠Чзђ¶дЄ≤йЗМзЪДеЈ¶жЛђеПЈеТМеП≥жЛђеПЈеЗЇзО∞зЪДжђ°жХ∞дЄНзЫЄз≠ЙпЉМжѓФе¶В( 5 / ( 3 + 2 ) ) )пЉМйВ£жИСдїђзЪДеМєйЕНзїУжЮЬйЗМдЄ§иАЕзЪДдЄ™жХ∞дєЯдЄНдЉЪзЫЄз≠ЙгАВжЬЙж≤°жЬЙеКЮж≥ХеЬ®ињЩж†ЈзЪДе≠Чзђ¶дЄ≤йЗМеМєйЕНеИ∞жЬАйХњзЪДпЉМйЕНеѓєзЪДжЛђеПЈдєЛйЧізЪДеЖЕеЃєеСҐпЉЯ
дЄЇдЇЖйБњеЕН(еТМ\(жККдљ†зЪДе§ІиДСељїеЇХжРЮз≥КжґВпЉМжИСдїђињШжШѓзФ®е∞ЦжЛђеПЈдї£жЫњеЬЖжЛђеПЈеРІгАВзО∞еЬ®жИСдїђзЪДйЧЃйҐШеПШжИРдЇЖе¶ВдљХжККxx <aa <bbb> <bbb> aa> yyињЩж†ЈзЪДе≠Чзђ¶дЄ≤йЗМпЉМжЬАйХњзЪДйЕНеѓєзЪДе∞ЦжЛђеПЈеЖЕзЪДеЖЕеЃєжНХиОЈеЗЇжЭ•пЉЯ
ињЩйЗМйЬАи¶БзФ®еИ∞дї•дЄЛзЪДиѓ≠ж≥ХжЮДйА†пЉЪ
- (?'group')¬†жККжНХиОЈзЪДеЖЕеЃєеСљеРНдЄЇgroup,еєґеОЛеЕ•е†Жж†И(Stack)
- (?'-group')¬†дїОе†Жж†ИдЄКеЉєеЗЇжЬАеРОеОЛеЕ•е†Жж†ИзЪДеРНдЄЇgroupзЪДжНХиОЈеЖЕеЃєпЉМе¶ВжЮЬе†Жж†ИжЬђжЭ•дЄЇз©ЇпЉМеИЩжЬђеИЖзїДзЪДеМєйЕН姱賕
- (?(group)yes|no)¬†е¶ВжЮЬе†Жж†ИдЄКе≠ШеЬ®дї•еРНдЄЇgroupзЪДжНХиОЈеЖЕеЃєзЪДиѓЭпЉМзїІзї≠еМєйЕНyesйГ®еИЖзЪДи°®иЊЊеЉПпЉМеР¶еИЩзїІзї≠еМєйЕНnoйГ®еИЖ
- (?!)¬†йЫґеЃљиіЯеРСеЕИи°МжЦ≠и®АпЉМзФ±дЇОж≤°жЬЙеРОзЉАи°®иЊЊеЉПпЉМиѓХеЫЊеМєйЕНжАїж؃姱賕
е¶ВжЮЬдљ†дЄНжШѓдЄАдЄ™з®ЛеЇПеСШпЉИжИЦиАЕдљ†иЗ™зІ∞з®ЛеЇПеСШдљЖжШѓдЄНзЯ•йБУе†Жж†ИжШѓдїАдєИдЄЬи•њпЉЙпЉМдљ†е∞±ињЩж†ЈзРЖиІ£дЄКйЭҐзЪДдЄЙзІНиѓ≠ж≥ХеРІпЉЪзђђдЄАдЄ™е∞±жШѓеЬ®йїСжЭњдЄКеЖЩдЄАдЄ™"group"пЉМзђђдЇМдЄ™е∞±жШѓдїОйїСжЭњдЄКжУ¶жОЙдЄАдЄ™"group"пЉМзђђдЄЙдЄ™е∞±жШѓзЬЛйїСжЭњдЄКеЖЩзЪДињШжЬЙж≤°жЬЙ"group"пЉМе¶ВжЮЬжЬЙе∞±зїІзї≠еМєйЕНyesйГ®еИЖпЉМеР¶еИЩе∞±еМєйЕНnoйГ®еИЖгАВ
жИСдїђйЬАи¶БеБЪзЪДжШѓжѓПзҐ∞еИ∞дЇЖеЈ¶жЛђеПЈпЉМе∞±еЬ®еОЛеЕ•дЄАдЄ™"Open",жѓПзҐ∞еИ∞дЄАдЄ™еП≥жЛђеПЈпЉМе∞±еЉєеЗЇдЄАдЄ™пЉМеИ∞дЇЖжЬАеРОе∞±зЬЛзЬЛе†Жж†ИжШѓеР¶дЄЇз©ЇпЉНпЉНе¶ВжЮЬдЄНдЄЇз©ЇйВ£е∞±иѓБжШОеЈ¶жЛђеПЈжѓФеП≥жЛђеПЈе§ЪпЉМйВ£еМєйЕНе∞±еЇФ胕姱賕гАВж≠£еИЩи°®иЊЊеЉПеЉХжУОдЉЪињЫи°МеЫЮжЇѓ(жФЊеЉГжЬАеЙНйЭҐжИЦжЬАеРОйЭҐзЪДдЄАдЇЫе≠Чзђ¶)пЉМе∞љйЗПдљњжХідЄ™и°®иЊЊеЉПеЊЧеИ∞еМєйЕНгАВ
< #жЬАе§Це±ВзЪДеЈ¶жЛђеПЈ
[^<>]* #жЬАе§Це±ВзЪДеЈ¶жЛђеПЈеРОйЭҐзЪДдЄНжШѓжЛђеПЈзЪДеЖЕеЃє
(
(
(?'Open'<) #зҐ∞еИ∞дЇЖеЈ¶жЛђеПЈпЉМеЬ®йїСжЭњдЄКеЖЩдЄАдЄ™"Open"
[^<>]* #еМєйЕНеЈ¶жЛђеПЈеРОйЭҐзЪДдЄНжШѓжЛђеПЈзЪДеЖЕеЃє
)+
(
(?'-Open'>) #зҐ∞еИ∞дЇЖеП≥жЛђеПЈпЉМжУ¶жОЙдЄАдЄ™"Open"
[^<>]* #еМєйЕНеП≥жЛђеПЈеРОйЭҐдЄНжШѓжЛђеПЈзЪДеЖЕеЃє
)+
)*
(?(Open)(?!)) #еЬ®йБЗеИ∞жЬАе§Це±ВзЪДеП≥жЛђеПЈеЙНйЭҐпЉМеИ§жЦ≠йїСжЭњдЄКињШжЬЙж≤°жЬЙж≤°жУ¶жОЙзЪД"Open"пЉЫе¶ВжЮЬињШжЬЙпЉМеИЩеМєйЕН姱賕
> #жЬАе§Це±ВзЪДеП≥жЛђеПЈ
еє≥и°°зїДзЪДдЄАдЄ™жЬАеЄЄиІБзЪДеЇФзФ®е∞±жШѓеМєйЕНHTML,дЄЛйЭҐињЩдЄ™дЊЛе≠РеПѓдї•еМєйЕНеµМе•ЧзЪД<div>ж†Зз≠ЊпЉЪ<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>.
ињШжЬЙдЇЫдїАдєИдЄЬи•њж≤°жПРеИ∞
дЄКиЊєеЈ≤зїПжППињ∞дЇЖжЮДйА†ж≠£еИЩи°®иЊЊеЉПзЪДе§ІйЗПеЕГзі†пЉМдљЖжШѓињШжЬЙеЊИе§Ъж≤°жЬЙжПРеИ∞зЪДдЄЬи•њгАВдЄЛйЭҐжШѓдЄАдЇЫжЬ™жПРеИ∞зЪДеЕГзі†зЪДеИЧи°®пЉМеМЕеРЂиѓ≠ж≥ХеТМзЃАеНХзЪДиѓіжШОгАВдљ†еПѓдї•еЬ®зљСдЄКжЙЊеИ∞жЫіиѓ¶зїЖзЪДеПВиАГиµДжЦЩжЭ•е≠¶дє†еЃГдїђ--ељУдљ†йЬАи¶БзФ®еИ∞еЃГдїђзЪДжЧґеАЩгАВе¶ВжЮЬдљ†еЃЙи£ЕдЇЖMSDN Library,дљ†дєЯеПѓдї•еЬ®йЗМйЭҐжЙЊеИ∞.netдЄЛж≠£еИЩи°®иЊЊеЉПиѓ¶зїЖзЪДжЦЗж°£гАВињЩйЗМзЪДдїЛзїНеЊИзЃАзХ•пЉМе¶ВжЮЬдљ†йЬАи¶БжЫіиѓ¶зїЖзЪДдњ°жБѓпЉМиАМеПИж≤°жЬЙеЬ®зФµиДСдЄКеЃЙи£ЕMSDN Library,еПѓдї•жЯ•зЬЛеЕ≥дЇОж≠£еИЩи°®иЊЊеЉПиѓ≠и®АеЕГзі†зЪДMSDNеЬ®зЇњжЦЗж°£гАВ
| \a | жК•и≠¶е≠Чзђ¶(жЙУеН∞еЃГзЪДжХИжЮЬжШѓзФµиДСеШАдЄАе£∞) |
| \b | йАЪеЄЄжШѓеНХиѓНеИЖзХМдљНзљЃпЉМдљЖе¶ВжЮЬеЬ®е≠Чзђ¶з±їйЗМдљњзФ®дї£и°®йААж†Љ |
| \t | еИґи°®зђ¶пЉМTab |
| \r | еЫЮиљ¶ |
| \v | зЂЦеРСеИґи°®зђ¶ |
| \f | жНҐй°µзђ¶ |
| \n | жНҐи°Мзђ¶ |
| \e | Escape |
| \0nn | ASCIIдї£з†БдЄ≠еЕЂињЫеИґдї£з†БдЄЇnnзЪДе≠Чзђ¶ |
| \xnn | ASCIIдї£з†БдЄ≠еНБеЕ≠ињЫеИґдї£з†БдЄЇnnзЪДе≠Чзђ¶ |
| \unnnn | Unicodeдї£з†БдЄ≠еНБеЕ≠ињЫеИґдї£з†БдЄЇnnnnзЪДе≠Чзђ¶ |
| \cN | ASCIIжОІеИґе≠Чзђ¶гАВжѓФе¶В\cCдї£и°®Ctrl+C |
| \A | е≠Чзђ¶дЄ≤еЉАе§і(з±їдЉЉ^пЉМдљЖдЄНеПЧе§ДзРЖе§Ъи°МйАЙй°єзЪДељ±еУН) |
| \Z | е≠Чзђ¶дЄ≤зїУе∞ЊжИЦи°Ме∞Њ(дЄНеПЧе§ДзРЖе§Ъи°МйАЙй°єзЪДељ±еУН) |
| \z | е≠Чзђ¶дЄ≤зїУе∞Њ(з±їдЉЉ$пЉМдљЖдЄНеПЧе§ДзРЖе§Ъи°МйАЙй°єзЪДељ±еУН) |
| \G | ељУеЙНжРЬ糥зЪДеЉАе§і |
| \p{name} | UnicodeдЄ≠еСљеРНдЄЇnameзЪДе≠Чзђ¶з±їпЉМдЊЛе¶В\p{IsGreek} |
| (?>exp) | иі™е©™е≠Ри°®иЊЊеЉП |
| (?<x>-<y>exp) | еє≥и°°зїД |
| (?im-nsx:exp) | еЬ®е≠Ри°®иЊЊеЉПexpдЄ≠жФєеПШе§ДзРЖйАЙй°є |
| (?im-nsx) | дЄЇи°®иЊЊеЉПеРОйЭҐзЪДйГ®еИЖжФєеПШе§ДзРЖйАЙй°є |
| (?(exp)yes|no) | жККexpељУдљЬйЫґеЃљж≠£еРСеЕИи°МжЦ≠и®АпЉМе¶ВжЮЬеЬ®ињЩдЄ™дљНзљЃиГљеМєйЕНпЉМдљњзФ®yesдљЬдЄЇж≠§зїДзЪДи°®иЊЊеЉПпЉЫеР¶еИЩдљњзФ®no |
| (?(exp)yes) | еРМдЄКпЉМеП™жШѓдљњзФ®з©Їи°®иЊЊеЉПдљЬдЄЇno |
| (?(name)yes|no) | е¶ВжЮЬеСљеРНдЄЇnameзЪДзїДжНХиОЈеИ∞дЇЖеЖЕеЃєпЉМдљњзФ®yesдљЬдЄЇи°®иЊЊеЉПпЉЫеР¶еИЩдљњзФ®no |
| (?(name)yes) | еРМдЄКпЉМеП™жШѓдљњзФ®з©Їи°®иЊЊеЉПдљЬдЄЇno |
иБФз≥їдљЬиАЕ
е•љеРІ,жИСжЙњиЃ§,жИСй™ЧдЇЖдљ†,иѓїеИ∞ињЩйЗМдљ†иВѓеЃЪиК±дЇЖдЄНж≠Ґ30еИЖйТЯ.зЫЄдњ°жИС,ињЩжШѓжИСзЪДйФЩ,иАМдЄНжШѓеۆ䪯䚆姙琮.жИСдєЛжЙАдї•иѓі"30еИЖйТЯ",жШѓдЄЇдЇЖиЃ©дљ†жЬЙдњ°ењГ,жЬЙиАРењГзїІзї≠дЄЛеОї.жЧҐзДґдљ†зЬЛеИ∞дЇЖињЩйЗМ,йВ£иѓБжШОжИСзЪДйШіи∞ЛжИРеКЯдЇЖ.襀圚жВ†зЪДжДЯиІЙеЊИзИљеРІпЉЯ
и¶БжКХиѓЙжИС,жИЦиАЕиІЙеЊЧжИСеЕґеЃЮеПѓдї•ењљжВ†еЊЧжЫійЂШжШО,搥ињОжЭ• жИСзЪДеЊЃеНЪиЃ©жИСзЯ•йБУ. е¶ВжЮЬдљ†жЬЙеЕ≥дЇОж≠£еИЩи°®иЊЊеЉПзЪДйЧЃйҐШ, еПѓдї•еИ∞¬†
жИСзЪДеЊЃеНЪиЃ©жИСзЯ•йБУ. е¶ВжЮЬдљ†жЬЙеЕ≥дЇОж≠£еИЩи°®иЊЊеЉПзЪДйЧЃйҐШ, еПѓдї•еИ∞¬† stackoverflow¬†зљСзЂЩдЄКжПРйЧЃ, иЃ∞еЊЧи¶БжЈїеК† regex ж†Зз≠Њ. е¶ВжЮЬдљ†жЫідє†жГѓдЇОзФ®дЄ≠жЦЗдЇ§жµБ, еПѓдї•еИ∞еЊЃеНЪдЄКзФ® #ж≠£еИЩ# ж†Зз≠ЊжПРеЗЇйЧЃйҐШ.
stackoverflow¬†зљСзЂЩдЄКжПРйЧЃ, иЃ∞еЊЧи¶БжЈїеК† regex ж†Зз≠Њ. е¶ВжЮЬдљ†жЫідє†жГѓдЇОзФ®дЄ≠жЦЗдЇ§жµБ, еПѓдї•еИ∞еЊЃеНЪдЄКзФ® #ж≠£еИЩ# ж†Зз≠ЊжПРеЗЇйЧЃйҐШ.



зЫЄеЕ≥жО®иНР
жЬђжХЩз®ЛжЧ®еЬ®еЄЃеК©дљ†еЬ®30еИЖйТЯеЖЕењЂйАЯжОМжП°ж≠£еИЩи°®иЊЊеЉПзЪДеЯЇз°АзЯ•иѓЖпЉМдїОиАМжПРеНЗдљ†зЪДжЦЗжЬђе§ДзРЖжХИзОЗгАВ 1. **еЯЇжЬђж¶Вењµ** - **ж®°еЉПеМєйЕН**пЉЪж≠£еИЩи°®иЊЊеЉПжШѓжППињ∞дЄАз≥їеИЧе≠Чзђ¶жИЦзЙєеЃЪж®°еЉПзЪДе≠Чзђ¶дЄ≤пЉМзФ®дЇОеМєйЕНзђ¶еРИиѓ•ж®°еЉПзЪДжЦЗжЬђгАВ - **еЕГ...
ж≠£еИЩи°®иЊЊеЉП(Regular Expression, abbr. regex) еКЯиГљеЉЇе§ІпЉМиГље§ЯзФ®дЇОеЬ®дЄАе§ІдЄ≤е≠Чзђ¶йЗМжЙЊеИ∞жЙАйЬАдњ°жБѓгАВеЃГеИ©зФ®зЇ¶еЃЪдњЧжИРзЪДе≠Чзђ¶зїУжЮДи°®иЊЊеЉПжЭ•еПСзФЯдљЬзФ®гАВдЄНеєЄзЪДжШѓпЉМзЃАеНХзЪДж≠£еИЩи°®иЊЊеЉПеѓєдЇОдЄАдЇЫйЂШзЇІињРзФ®пЉМеКЯиГљињЬињЬдЄНе§ЯгАВиЛ•и¶БињЫи°М...
еНКеєіеЙНжИСеѓєж≠£еИЩи°®иЊЊеЉПдЇІзФЯдЇЖеЕіиґ£пЉМеЬ®зљСдЄКжЯ•жЙЊињЗдЄНе∞СиµДжЦЩпЉМзЬЛињЗдЄНе∞СзЪДжХЩз®ЛпЉМжЬАеРОеЬ®дљњзФ®дЄАдЄ™ж≠£еИЩи°®иЊЊеЉПеЈ•еЕЈRegexBuddyжЧґеПСзО∞дїЦзЪДжХЩз®ЛеЖЩзЪДйЭЮеЄЄе•љпЉМеПѓдї•иѓіжШѓжИСзЫЃеЙНиІБињЗжЬАе•љзЪДж≠£еИЩи°®иЊЊеЉПжХЩз®ЛгАВдЇОжШѓдЄАзЫіжГ≥жККдїЦзњїиѓСињЗжЭ•гАВ...
иµДжЇРиљђиљљиЗ™еЕґдїЦзљСзїЬиµДжЇРеєґзїПињЗжµЛиѓХ зЙИжЬђеПЈпЉЪ1.0.73 вАУ ...з≥їзїЯжЙЛжЬЇж≠£еИЩй™МиѓБж≠£еИЩи°®иЊЊеЉПжЦ∞еҐЮзФµдњ°188гАБ199еПЈжЃµгАВ ж®°жЭњеЇУпЉЪжЦ∞еҐЮеИЃеИЃеН°ж®°жЭњ[жЦ∞еєіеИЃе•љз§Љ е§Іе•ЦйЉ†дЇОжВ®]гАВ ж®°жЭњеЇУпЉЪжЦ∞еҐЮдєЭеЃЂж†Љж®°жЭњ[з¶ПйЉ†ињОжШ• 搥搥еЦЬеЦЬињЗжЦ∞еєі]гАВ
ISAPI_Rewrite жШѓдЄАжђЊйАВзФ®дЇОIISзЪДеКЯиГљеЉЇе§ІзЪДеЯЇдЇОж≠£еИЩи°®иЊЊеЉПзЪДURLе§ДзРЖж®°еЭЧгАВеЃГеЕЉеЃєApacheзЪДmod_rewriteзЪДиѓ≠ж≥ХпЉМдїОиАМдљњдїЕдїЕе§НеИґ.htaccessжЦЗдїґе∞±жККйЕНзљЃдїОappachзІїж§НеИ∞IISдЄ≠жИЦиАЕдїОIISзІїеАЉеИ∞appachдЄ≠еПШжИРеПѓиГљгАВиѓЈеПВйШЕ3.2...
EverythingжФѓжМБж≠£еИЩи°®иЊЊеЉПпЉМжИЦиАЕиѓіпЉМжФѓжМБдЄАдЇЫзЃАеНХзЪДж≠£еИЩи°®иЊЊеЉПгАВдљЖеѓєе§Іе§ЪжХ∞зФ®жИЈиАМи®АпЉМињЩеЈ≤зїПиґ≥е§ЯдЇЖпЉБEverythingжФѓжМБзЪДж≠£еИЩи°®иЊЊеЉПжЬЙпЉЪ | () ? * + . [] [^] ^ $ {m,n} rexзљСеПЛзЪДзњїиѓСгАВе¶ВжЮЬдљ†дЄНдЇЖиІ£дїАдєИжШѓж≠£еИЩи°®иЊЊеЉП...
йАЪињЗG.CNеТМB.CNжРЬ糥еРОеЊЧеЗЇдЇЖеЗ†зІНдЄНеРМзЪДжЦєж°ИпЉМдЊЛе¶ВзљСзЂЩз®ЛеЇПзЪДURLдЉ™и£Еж≥ХгАБжЬНеК°еЩ®зЂѓзЪДжФґиієжПТдїґж≥ХеТМISAPI-REWRITEзЪДиІДеИЩињЗжї§ж≥Хз≠ЙпЉМиАГиЩСиЗ™иЇЂзљСзЂЩзїУжЮДеТМйТ±еМЕзЪДеЫ∞йЪЊйЧЃйҐШпЉМжЬАзїИйАЙжЛ©дЇЖеРОиАЕ... зїПињЗжБґи°•ж≠£еИЩи°®иЊЊеЉПзЫЄеЕ≥жХЩз®ЛеєґеѓєеЙН
- **жЦЗжЬђжЯ•жЙЊеКЯиГљ**пЉЪжХЩжОИе¶ВдљХеЃЮзО∞жЦЗжЬђжРЬ糥еКЯиГљпЉМеМЕжЛђж≠£еИЩи°®иЊЊеЉПзЪДдљњзФ®гАВ ##### 5. йЉ†ж†ЗйФЃзЫШдЇЛдїґе§ДзРЖдЄОзКґжАБж†ПжШЊз§Ї - **дЇЛдїґе§ДзРЖ**пЉЪиІ£йЗКе¶ВдљХжНХиОЈеТМеУНеЇФйЉ†ж†ЗеТМйФЃзЫШдЇЛдїґпЉМеЃЮзО∞дЇ§дЇТеЉПеЇФзФ®гАВ - **зКґжАБж†ПжШЊз§Ї**пЉЪиѓіжШО...
`test` е±ЮжАІжШѓдЄАдЄ™ж≠£еИЩи°®иЊЊеЉПпЉМзФ®дЇОеМєйЕНжЦЗдїґиЈѓеЊДпЉЫ`use` е±ЮжАІеЃЪдєЙдЇЖдЄАдЄ™ loader жХ∞зїДпЉМеЃГеСКиѓЙ Webpack дљњзФ®еУ™дЇЫ loader е§ДзРЖ `.less` жЦЗдїґгАВ`style-loader` зФ®дЇОе∞Ж CSS ж≥®еЕ•еИ∞ DOM дЄ≠пЉМ`css-loader` зФ®дЇОе§ДзРЖ CSS ...
еЃГеПѓдї•еЄЃеК©дљ†е§ДзРЖеРДзІНеЈ•дљЬпЉМеМЕжЛђж≠£еИЩи°®иЊЊеЉПгАБ жЦЗж°£зФЯжИРгАБеНХеЕГжµЛиѓХгАБзЇњз®ЛгАБжХ∞жНЃеЇУгАБзљСй°µжµПиІИеЩ®гАБCGIгАБFTPгАБзФµе≠РйВЃдїґгАБXMLгАБXML-RPCгАБHTMLгАБWAVжЦЗдїґгАБеѓЖз†Бз≥їзїЯгАБGUIпЉИеی嚥зФ®жИЈ зХМйЭҐпЉЙгАБTkеТМеЕґдїЦдЄОз≥їзїЯжЬЙеЕ≥зЪДжУНдљЬгАВ...
MYSQLйЂШзЇІзЙєжАІ 81 4.1 йЫЖеРИеЗљжХ∞ 82 4.1.1 и°МеИЧиЃ°жХ∞ 82 4.1.2зїЯиЃ°...ж≠£еИЩи°®иЊЊеЉПж®°еЉПеМєйЕН 94 4.3.3 жАїзїУ 96 4.4 жЈ±еЕ•SELECTзЪДжߕ胥еКЯиГљ 96 4.4.1 еИЧеТМи°®зЪДеИЂеРН 96 4.4.1.1еИЧзЪДеИЂеРН 96 4.4.1.2 еЬ®...
MYSQLйЂШзЇІзЙєжАІ 81 4.1 йЫЖеРИеЗљжХ∞ 82 4.1.1 и°МеИЧиЃ°жХ∞ 82 4.1.2зїЯиЃ°...ж≠£еИЩи°®иЊЊеЉПж®°еЉПеМєйЕН 94 4.3.3 жАїзїУ 96 4.4 жЈ±еЕ•SELECTзЪДжߕ胥еКЯиГљ 96 4.4.1 еИЧеТМи°®зЪДеИЂеРН 96 4.4.1.1еИЧзЪДеИЂеРН 96 4.4.1.2 еЬ®...