- æĩč§: 166992 æŽĄ
- æ§åŦ:

- æĨčŠ: æå·
-

æįŦ åįąŧ
įĪūåšįå
- æįčĩčŪŊ ( 0)
- æįčŪšå ( 15)
- æįéŪį ( 0)
åæĄĢåįąŧ
- 2010-04 ( 2)
- 2010-01 ( 3)
- 2009-12 ( 3)
- æīåĪåæĄĢ...
ææ°čŊčŪš
-
aspnetdbïž
åĨ―æįŦ ïžæčŋ°įåūæļ
æĨæį―ã
HBASEæūæĢæ°æŪååĻčŪūčŪĄåčŊ -
sdh5724ïž
rain2005 åéčŋäļŠäļčĨŋäļšäŧäđäļįĻminaåĒïžäļšäŧäđčĶčŠ ...
åŪĒæ·įŦŊNIOåŪč·ĩåæ -
rain2005ïž
čŋäļŠäļčĨŋäļšäŧäđäļįĻminaåĒïžäļšäŧäđčĶčŠå·ąå.
åŪĒæ·įŦŊNIOåŪč·ĩåæ -
sdh5724ïž
åįåĒ. įäļå°å
åŪĒæ·įŦŊNIOåŪč·ĩåæ -
sdh5724ïž
æķäšïž åĻįïž æäđįšéååéĄé åĪ§åã
åŪĒæ·įŦŊNIOåŪč·ĩåæ
åšäšMapReduceįé į―ŪåæĨåŋåæįŧäŧķ
åšäšMapReduceįé į―ŪåæĨåŋåæįŧäŧķ
Author:æūįŋïžæåïž
Email:fangweng@taobao.com
Blog: http://blog.csdn.net/cenwenchu79/
įŪå―
åæčŋįĻįå―åĻæåŪäđïž
åšäšå―äŧĪčĄæđåžæ§čĄéķæŪĩæ§äŧŧåĄ
éæąåšæŊ
äŧæĩ·éįčŪŋéŪæĨåŋäļåæåūå°įģŧįŧåĨåš·æ åĩïžäļåĄåĒéŋčķåŋã
įŧäŧķåč―čŪūčŪĄå
ģéŪįđ
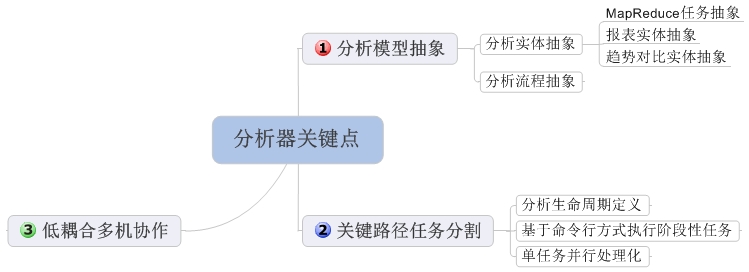
åū1 įŧäŧķåč―čŪūčŪĄįđæčŋ°åū
        čŋäļŠįŧäŧķäļäž įŧįMapReduceæĄæķïžäūåĶHadoopïžįäļåäđåĪåĻäšïž
1ïžÂ č§ĢåģéŪéĒåäū§éäšæĨåŋåæįŧčŪĄåčķåŋåŊđæŊãéčŋæ―蹥åæåŊđ蹥ïžåææĩįĻïžåæįŧæåŪåķäšé į―ŪæĻĄååč§åč§ĢæåĪįåžæïžåŪį°é į―ŪæŋäŧĢįžį åŪį°čŠåŪäđåæã
2ïžÂ åŊđäšåĪæšåä―éįĻæūæĢæđåžïžįŪååĪæšåä―æ§åķæĩįĻã
čŪūčŪĄįđåæ
åææĻĄåæ―蹥
        åææĻĄåæ―蹥äļŧčĶåäļšäļĪéĻåïžåææĻĄåæ―蹥ååææĩįĻæ―蹥ãåææĻĄåæ―čąĄå°ąæŊå°MapReduceįKey-ValueįŧčŪĄïžč―Žåæäļšäž įŧæäđäļįæĨčĄĻįŧæã
        åæįčūå Ĩ:
        c1,c2,c3,c4,c5,c6âĶ(éåļļæ åĩäļå°ąæŊįĻäļåŪįååēįŽĶäļå åŪđįŧåčĩ·æĨįåįŽĶäļē)
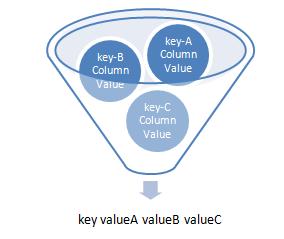
        MapReduceåŊäŧĨåĪįįïž
    
        åĶäļåūïžäž įŧæĨčĄĻįäļčĄåŊäŧĨįä―æŊåĪäļŠįļåkeyä―äļåįŧčŪĄåæŪĩįŧåįįŧæã
   Â
        äūåĶïžčūå Ĩįæ°æŪįŧæåĶäļïž
        æåĄåį§°ïžæåĄįąŧåïžæåĄäļčĄæ°æŪæĩéïžæåĄåĪįįŧæïžéčŊŊį ïžïžæåĄčæķ
        éĢäđåŪåķåĶäļMapReduceįŧåïž
        KeyïžæåĄåį§°ïžValueïžæåĄäļčĄæ°æŪæĩéæŧåã
        KeyïžæåĄåį§°ïžValueïžæåĄčæķæŧåã
        KeyïžæåĄåį§°ïžValueïžæåĄåđģåčæķã
   KeyïžæåĄåį§°ïžValueïžæåĄæåĪ§čæķã
        KeyïžæåĄåį§°ïžValueïžæåĄæå°čæķã
        éĢäđå°čŋäšMapReduceåĪįåįKey-valueåĻįŧåäļæŽĄå°ąåŊäŧĨåūå°ïž
        KeyïžæåĄåį§°ïžValueïžæåĄäļčĄæ°æŪæĩéæŧåïžæåĄčæķæŧåïžæåĄåđģåčæķïžæåĄæåĪ§čæķïžæåĄæå°čæķã
        åŊäŧĨįåšïžį°åĻå°ąå·ēįŧæäļšäšæäŧŽäž įŧæäđäļįæĨčĄĻįŧæã
     åæåŪä―æ―蹥ïž

åū2 åŪä―æ―蹥įąŧåū
AliasåŊđ蹥
åŊđKeyåValueįææķéčĶæåŪæŊåŊđéĢäļåæč å åä―åæïžå æĪéčĶįīæĨæåŪåå·ïžä―æŊå―æĨåŋæ°æŪįŧææđåäŧĨåïžéĢäđå°ąäžå―ąåææįé į―Ūïžäļšäšäūŋäšä―ŋįĻåįŧīæĪïžčŪūåŪäšAliasæĨč§éŋįīæĨä―ŋįĻåå·ïžå ·ä―įä―ŋįĻåŊäŧĨåįæåįé į―ŪčŊīæã
ReportEntryåŊđ蹥
MapReduceįKey-ValueåĪįååč§åįåŪäđã
keysčĄĻįĪšįækeyįå(åŊäŧĨįīæĨä―ŋįĻčĄå·æč ä―ŋįĻAlias)ïžMapå°ąæŊéčŋåŊđkeysįåŪäđå°keyįåįĻįđåŪįååēįŽĶäļēččĩ·æĨå―Ēææ°įkeyäļēïžįķåæ đæŪåéĒvalueExpressionįčĄĻčūūåžč·åūvalueïžčĄĻčūūåžæŊæéčŋåŊđåįįŪåïž+-*/ïžįčŪĄįŪïžäđæŊæåŊđäšå ķäŧReportentryįčŪĄįŪč·åūvalueïžã
valueExpressionæŊRecudeįįŪååŪäđãå―åæ―蹥ReportEntryValueTypeåŪäđįéĢäšįąŧåïžmin(åæå°)ïžmax(åæåĪ§)ïžsumïžæŧåïžïžaverageïžåđģåïžïžcount(æŧæŽĄæ°)ïžplain(æ éåĪįïžčŋäļŧčĶįĻäšæūįĪškeyéĢäšå)ãå ·ä―ä―ŋįĻåįåéĒįé į―ŪčŊīæã
conditionsåŊäŧĨčŋæŧĪäļįŽĶåč§åįčūå ĨãïžæŊæįŪåįæĄäŧķčĄĻčūūåžįŧåïž
valueFilteråŊäŧĨčŋæŧĪčŪĄįŪåäļįŽĶååŪäđįįŧæãïžæŊæįŪåįæĄäŧķčĄĻčūūåžįŧåïž
MapClass,MapParams,ReduceClass,ReduceParamsæŊįĻäšåĶææŧĄčķģäļäšį°æč§åįæ åĩäļčŠåŪäđMap,ReduceïžéčĶåŪį°åŊđåšįæĨåĢIReportMapæč IReportReduceã
FormatåŊäŧĨåŊđæåįįŧæåĻčūåšįæķåæ žåžåäļäļïžå―ååŠæŊæå°æ°įđroundã
ReportåŊđ蹥
                å åŦäšäļäļŠååĪäļŠReportEntryåŊđ蹥ïžåæķäđæŊæåĻReportäļåŪäđReportEntryåŊđ蹥ïžåšåŦåĻäšæŊåĶéčĶå°čŋäļŠReportEntryå ąäšŦįŧå ķäŧReportïžãfileæåŪäšå°äžčūåšįæäŧķåį§°ã
Report AlertåŊđ蹥
                æĨčĄĻįįŧææŊäļåĪĐįæ°æŪïžåŠč―åäļäšįšĩåæŊčūïžåĶæéčĶåŊđåĪåĪĐįæ°æŪä―æĻŠåæŊčūäŧĨåčķåŋåæïžå°ąéčĶå°åĪåĪĐįæĨčĄĻįŧåčĩ·æĨåæãå ·ä―é į―Ūäđåč§åéĒįæ°æŪåŪäđã
åææĩįĻæ―蹥ïž
åææĩįĻåĶäļïž

åū3 åææĩįĻæ―蹥
æĩįĻäļåŊäŧĨæĐåąįåĻįŽŽäļæĨåįŽŽåæĨïžįŽŽäļæĨå―ąåäšKeyįįæïžå―įŪåįåįŧåæåįŽĶäļēæ æģæŧĄčķģįækeyįæ åĩäļåŊæĐåąïžïžįŽŽåæĨå―ąåvalueįįæãïžå―mapįvalueįæäŧĨåReduceæ æģæŧĄčķģéæąįæ åĩäļåŊæĐåąïžïžčĶä―ŋįĻminïžmaxâĶäŧĨåĪįreduceïžåŊäŧĨįīæĨåĻReduceClassäļä―åĪįïžįķåä―ŋįĻplainčūåšåŪį°ã
čŋį§æĩįĻæŊäž įŧįMapReduceįåæģåĨ―åĪåĻäšåŊäŧĨåŊđčūå ĨåŠčŊŧåäļæŽĄïžæĩ·éįæĨåŋæäŧķäļšäšåĪį§æĄäŧķåæïžååĪčŊŧåæŽčšŦå°ąæŊæåĪ§įæčïžãåŊäŧĨįå°åĻæäŧķIOæä―äļïžäļäžéįåææĻĄåé į―ŪįåĒåĪčåĒéŋïžäļéīæ°æŪäđäļäžéįæĨčĄĻįŧåįäļåččŋåŋŦčĻčïžåŠčĶæĨčĄĻåĪįĻEntryčķģåĪåĪïžã
å ģéŪč·ŊåūäŧŧåĄååē
åæčŋįĻįå―åĻæåŪäđïž
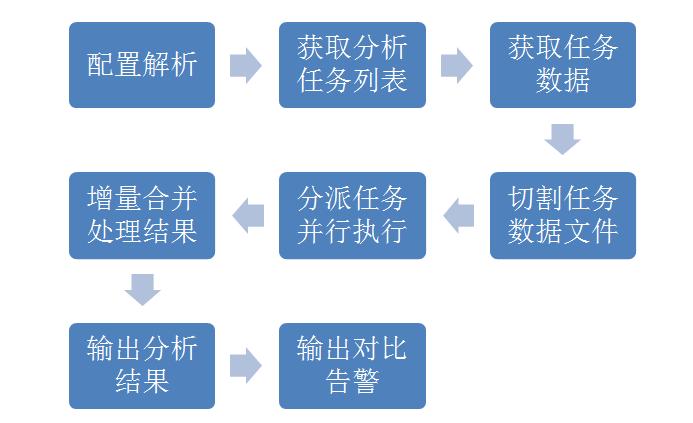
åū4 åæčŋįĻįå―åĻæåŪäđ
åéķæŪĩčŪūčŪĄæčŋ°:ïžčŋäšéķæŪĩé―æŊæĨåĢįæđæģåŪäđïž
é į―Ūč§ĢæïžčŋčĄæč――å Ĩ,æŊæåĻįšŋé į―Ūæīæ°,æéŦįģŧįŧįĩæīŧæ§ãïžæŽå°æč URLčĩæšïž
č·ååæåčĄĻïžč·åčĶåæįæäŧķåčĄĻïžåđķæ đæŪæŽå°å·ēææ°æŪį°įķïžéæĐæ§įįæéčĶč·åįæäŧķæ°æŪã
č·åäŧŧåĄæ°æŪïžäŧåĪéĻæäŧķįģŧįŧæč æ°æŪåšč·åūæ°æŪã
ååēäŧŧåĄæ°æŪæäŧķïžæ đæŪé į―ŪįæäŧķååĪ§å°ïžå°äŧŧåĄæäŧķååēå°åéįåãå―ååŪį°äšåŪé ååēåčæååēãTIPS:ååēå·Ĩä―åŊäŧĨæŊåđķčĄåĪįšŋįĻåŪį°ïžåŪé ååēæŊæķčCPUåå åįïžįđåŦæŊä―ŋįĻįŪĄéįæđåžïžå æĪéčĶčŊäž°čĩæšæ åĩæĨåžįšŋįĻãčæååēïžåŠæŊåŧšįŦčææäŧķïžåŪäđåĨ―åŊđåšå°åŪä―æäŧķįåčĩ·å§ãåč ååēæķåæķččūåĪ§ïžæ§čĄåææķåæįšŋįĻåđēæ°čūå°æįéŦïžåč ååēæķæ åĪŠåĪ§æķčïžæ§čĄåææķäžæåđēæ°æįäļæŊåūéŦãïžčŋäļŠåå čŋæēĄæįŧæĨïžæĩčŊæææŊčŋæ ·ïž
åæīūäŧŧåĄåđķæ§čĄïžåæšåĪįšŋįĻæč åĪæšåđķčĄæ§čĄåææĩįĻãįąäšåæšäžåå°CPUåIOįéåķïžå―å°čūūäļåŪæ°éįšŋįĻäŧĨåïžåææįåčéä―ïžå æĪæäžæååļåžįéæąã
åĒéååđķåĪįįŧæïžåæīūåĨ―äŧŧåĄäŧĨåïžåĪįšŋįĻæč åĪæšåđķæ§åææķïžåŊäŧĨæ đæŪæ§čĄįæ åĩéĻååĒéåžååđķåĪįįŧæïžå―ææäŧŧåĄåŪæäŧĨåïžįŧæååđķįŧæã
čūåšåæįŧæïžåŊäŧĨæ đæŪéæąæĨååŧšæĨčĄĻæ žåžãå―åéįĻäšcsvįæäŧķæ žåžæĨååŧšæĨčĄĻïžæäšé čŊŧåä―ŋįĻãåæķäđä―äšå ĨåšåĪįïžäđåŊäŧĨįīæĨįĻGoogle Chart APIååŧšåūå―ĒåįHtmlã
čūåšåŊđæŊåčĶïžæŊæå―æĨéåžéĒčĶïžå―æĨäļæĻæĨïžå―æĨäļäļåĻåæïžå―æĨäļäļæåææ°æŪæĻŠååŊđæŊïžå°čūūéåžįæéĒčĶéĄĩéĒã
åšäšå―äŧĪčĄæđåžæ§čĄéķæŪĩæ§äŧŧåĄ
        įąäšæīäļŠåææĩįĻå·ēįŧæŊäŧŧåĄåäšïžå æĪåšįĻåŠéčĶå ·åĪå―äŧĪæĨæķåč―å°ąåŊäŧĨäŧäŧŧä―äļæĨåžå§æ§čĄåææĩįĻïžäđåŊäŧĨéæĐæ§čĄå°äŧŧä―æĨéŠĪįīæĨčŋåæč čūåšäļéīįŧæã
        å―ååšįĻåŊåĻéčŋįåŽįŦŊåĢæ°æŪå ïžæĨæķå―äŧĪåđķæ§čĄã
åäŧŧåĄåđķčĄåĪįå
        åļæéčŋåđķčĄååĪįæĨæéŦæįïžå°ąåŋ éĄŧčĶåæåšæŊã
        äŧĨäļæ åĩäļéäšįĻåđķčĄåæ§čĄæĨæéŦæįïž
1ïžÂ äļēčĄåäŧŧåĄãïžäļäļäļŠäŧŧåĄįčūåšæäļšäļäļäļŠäŧŧåĄįčūå Ĩïžæč æŊæäŧŧåĄéĄšåšįéåķïž
2ïžÂ æ§čĄäŧŧåĄæķæå ąäšŦčĩæšįŦäšãäūåĶCPU,IO,į―įŧįįïžäļæŊåđķčĄæ°čķåĪ§čķåĨ―ïžå ģéŪčŋæŊčĶįčĩæšåé įķåĩäŧĨåįŦäšįķåĩã
3ïžÂ åđķčĄååžéåĪ§äšåļĶæĨįæķįãåšįĻåĪæåšĶïžåđķåæ§åķïžïžåđķčĄæŽčšŦéčĶįčĩæšæķčïžčŪĄįŪč―åïžįĐšéīååĻïžåļĶåŪ―æķčįïžčūåĪ§ãïžåĻMapReduceäļæķåå°äļįđå°ąæŊčŪĄįŪäŧĢäŧ·æŧæŊå°äšæ°æŪäž čūïžå æĪčŪĐæ°æŪé čŋčŪĄįŪïžäđå°ąč―æåĪ§æéŦæįïžåčŋæĨįïžåĶæäļšäšååļåžčå°æ°æŪčŋįĶŧäščŪĄįŪïžå°ąåūäļåŋåĪąäšïž
4ïžÂ æĩįĻįķéĒäļåĻäšå―ååđķčĄåĪįįäŧŧåĄãäđå°ąæŊå ģéŪč·ŊåūįéŪéĒã
åĻåææĩįĻäļïžåŊđäšæäŧķč·åïžæäŧķååēïžäŧŧåĄåæé―æŊåŊäŧĨååđķčĄååĪįïžä―æŊčŋæŊčĶæ đæŪäŧĨäļäļéåįæ åĩæĨččåđķčĄįč§æĻĄååæšåĪįšŋįĻæč åĪæšåĪįšŋįĻįæđåžæĨåïžæåæįã
ä―čĶååĪæšåä―

åū5 äļĪį§Master-SlaveæĻĄåž
        äļåūįŧäšäļĪį§Master-SlaveæĻĄåžïžįčĩ·æĨæēĄäŧäđåšåŦïžä―æŊįŪåĪīįæđåäļååļĶæĨįåä―æĻĄåžäđæåūåĪ§įåšåŦãHadoop MasterčīčīĢįŧīæĪäŧŧåĄįåæīūïžäŧŧåĄæ§čĄįæ§ïžäŧŧåĄååđķææīūåįæ§įå·Ĩä―ïžčæūæĢįM-SæĻĄåžïžMasteråĪäščĒŦåĻįķæïžMasterįčŪūčŪĄæīå įŪåååæķäđåĒå äšåĪįįįĩæīŧåšĶã
        įĻäļį§å―Ē蹥įæčŋ°æĨčŊīææūæĢæđåžäļįMaster-Slaveįåä―æĻĄåžãïžå°ąæŋåđīåšäđ°įŦč―ĶįĨĻæĨčŊīäšïž
1ïžÂ MasterčĶäđ°åŧæé―ïžæĶæąïžéŋæēïžå䚎ïžčĨŋåŪïžåđŋå·įįŦč―ĶįĨĻå10åž ãïžget Jobsïž
2ïžÂ SlaveAčįģŧäļMasterčĶæąéĒåäŧŧåĄïžMasterå°äđ°æé―įįŦč―ĶįĨĻäŧŧåĄäšĪįŧSlaveAïžå°äŧŧåĄæ įĪšäļšæĢåĻæ§čĄã(require job)
3ïžÂ SlaveAčŠå·ąæå ģįģŧåŧåžå§äđ°įĨĻã(do job)
4ïžÂ SlaveBčįģŧäļMasterčĶæąéĒåäŧŧåĄïžMasterå°äđ°æĶæąįįŦč―ĶįĨĻäŧŧåĄäšĪįŧSlaveBïžå°äŧŧåĄæ įĪšäļšæĢåĻæ§čĄã
5ïžÂ SlaveBčŠå·ąæå ģįģŧåžå§äđ°įĨĻã
6ïžÂ âĶâĶ
7ïžÂ Masteråį°SlaveAåĻéĒææķéīå čŋæēĄæčŋåïžå°äŧŧåĄéį―ŪäļšæŠåé ïžå čŪļå ķäŧSlaveæĨč·åäŧŧåĄã
8ïžÂ SlaveBå°äđ°å°įįĨĻįŧMasterïžMasterå°äŧŧåĄæ įĪšäļšåŪæïžåđķäļäļå ķåŪå·ēįŧåŪæįäŧŧåĄįŧčŪĄååđķã
9ïžÂ SlaveAčŋåïžä―æŊåį°äŧŧåĄå·ēįŧčĒŦåŦäššåŪæïžåæ åčåãïžčŪĄįŪčĩæščĒŦæĩŠčīđïž
10ïžÂ             Masteråį°ææäŧŧåĄå·ēįŧåŪæïžååäļįš§æąæĨïžæŽæŽĄäŧŧåĄå·ēįŧå ĻéĻåŪæïžčūåšįŧæã
å ķåŪäŧäļéĒįæčŋ°åŊäŧĨįå°MasterčŪūčŪĄååįŪåïžSlaveåč―äđåååäļïžåļĶæĨįäžåŋå°ąæŊåĪįįŪåïžæäļįŪĄįïžåæķäŧŧä―æķåé―å čŪļæ°įSlaveå å Ĩïžå ååĐįĻčĩæšãįžšįđå°ąæŊåŊč―åĻæäšSlaveäļæĢåļļįæķåäļįĨæ ïžæĩŠčīđäšéĻåæķéīïžïžäļčŋįąäšMasteräžæéĒæįŧæčŋåæķéīïžå æĪčŋäļŠæķéīčŪūį―Ūå°äļäšäžåå°æĩŠčīđæķéīįåšæŊïžä―äđåŊč―åļĶæĨéåĪåģåĻįäŧĢäŧ·ïžčŋéåŊäŧĨéčŋįŪæģæĨæåĪ§įĻåšĶéä―åžåļļčįđæķéīæķčïžåĒå Slaveææå·Ĩä―ã
MasterččīĢïžč·åäŧŧåĄåčĄĻïžåæīūäŧŧåĄïžįŧīæĪäŧŧåĄåčĄĻïžååđķåæįŧæïžåšæįŧįŧææĨčĄĻã
SlaveččīĢïžčŊ·æąäŧŧåĄïžæ§čĄäŧŧåĄïžčŋååæįŧæã
äļéĒäļĪäļŠåūæčŋ°äšå ·ä―įåĪæšåä―æĩįĻåäŧŧåĄįķæč―ŽæĒæ åĩã

åū6 åĪæšåä―åšæŽæĩįĻåū

åū7 äŧŧåĄįķæč―ŽæĒåū
éå―
éĄđįŪįŧæčŊīæïž

åū8 éĄđįŪå
åū
com.taobao.top.analysisïžåæšįååĪæšįįčŋčĄåŪäūįąŧåĻæĪå å ã
com.taobao.top.analysis.dataïžæ―蹥é į―ŪåŊđ蹥åŪäđã
com.taobao.top.analysis.jobmanagerïžæĩįĻæ―蹥æĨåĢååŪį°ã
com.taobao.top.analysis.transportïžNIOįåšåąéäŋĄåŪį°ã
com.taobao.top.analysis.mapïžMapæĨåĢåŪäđåčäūåŪį°ã
com.taobao.top.analysis.reduceïžReduceæĨåĢåŪäđåčäūåŪį°ã
com.taobao.top.analysis.utilïžå·Ĩå ·įąŧå ã
com.taobao.top.analysis.workerïžåđķčĄåĪįįå·Ĩä―č įšŋįĻåŪį°ã
å
·ä―é
į―ŪåčŊīæïž
top-report.xml
<?xml version="1.0" encoding="UTF-8"?>
<top_reports>
 <!-- å
ĻåąæĄäŧķčŠåĻäžåšįĻå°ææįentityäļïž
  å
·ä―conditionįåŪäđåä―ŋįĻæđåžåįåéĒentityäļconditionįåŪäđ -->
 <global-condition value="$logflag$!=session"/>
   <global-condition value="$RECORD_LENGTH$>16&$RECORD_LENGTH$<26"/>
  Â
   <!-- å
ĻåąæĄäŧķčŠåĻäžåšįĻå°ææįentityäļïž
  å
·ä―valuefilterįåŪäđåä―ŋįĻæđåžåįåéĒentityäļvaluefilterįåŪäđ
   <global-valuefilter value=""/>
  Â
   -->
 <!-- åŦåïžįĻäšåŪäđåææäŧķäļįåïž
  éēæĒå äļšåįį§ŧä―åŊžčīæīäļŠæĨčĄĻé―éčĶäŋŪæđïžåĪäļŠåŦååŊäŧĨåŊđåšäļäļŠå,keyäŧĢčĄĻåæ°åž -->
   <aliases>
    <alias name="logflag" key="1"/>
  Â
    <alias name="remoteIp" key="1"/>
    <alias name="partnerId" key="2"/>
    <alias name="format" key="3"/>
    <alias name="appKey" key="4"/>
    <alias name="apiName" key="5"/>
    <alias name="readBytes" key="6"/>
    <alias name="errorCode" key="7"/>
    <alias name="subErrorCode" key="8"/>
    <alias name="localIp" key="9"/>
    <alias name="nick" key="10"/>
    <alias name="version" key="11"/>
    <alias name="signMethod" key="12"/>
   Â
    <alias name="timestamp1" key="13"/>
    <alias name="timestamp2" key="14"/>
    <alias name="timestamp3" key="15"/>
    <alias name="timestamp4" key="16"/>
    <alias name="timestamp5" key="17"/>
    <alias name="timestamp6" key="18"/>
   Â
    <alias name="timestamp7" key="19"/>
    <alias name="timestamp8" key="20"/>
    <alias name="timestamp9" key="21"/>
    <alias name="timestamp10" key="22"/>
    <alias name="timestamp11" key="23"/>
    <alias name="timestamp12" key="24"/>
    <alias name="timestamp13" key="25"/>
   </aliases>
  Â
   <!-- įŧčŪĄåįåŪäđ:
    idæŊåŊäļįīĒåžïž
    namečĄĻįĪšåĻæĨčĄĻäļæūįĪšįåį§°ïž
    keyåŊäŧĨæŊaliasäđåŊäŧĨįīæĨåŪäđåå·ïžäļæĻčïžäļŧčĶčĄĻįĪšåŊđéĢäļåæč
å åä―äļšäļŧéŪčŋčĄįŧčŪĄäūåĶkey=apinamečĄĻįĪšåŊđapiNameä―åįąŧįŧčŪĄïž
     įļåįapinameįįšŠå―ä―äļšäļįŧä―åéĒvalueįčŋįŪïžkeyæäŋįåGLOBAL_KEYäŧĢčĄĻåŊđææčŪ°å―ä―æŧčŪĄįŧčŪĄ
    valuečĄĻįĪščŪĄįŪæđåžå―åæŊæïžmin,max,average,count,sum,plainãååŦäŧĢčĄĻįŧčŪĄæå°åžïžæåĪ§åžïžåđģååžïžčŪĄæ°,æŧåãplainčĄĻįĪšįīæĨæūįĪšïžäļčŽįĻäšäļŧéŪåįæūįĪš
     åæķmin,max,average,sum,plainæŊæčĄĻčūūåžïžįĻ$$åīčĩ·æĨįäŧĢčĄĻåïžentry()čĄĻįĪšåŊđįŧčŪĄåįentryä―åæŽĄčŪĄįŪåūå°æ°įentryįįŧæã
    conditiončĄĻįĪškeyįčŋæŧĪæĄäŧķïžæŊæåŊđåįčŋæŧĪæĄäŧķïžæŊæåĪ§äšïžå°äšïžäļįäš,åĪ§äšįäš,å°äšįäšįčĄĻčūūåžïžåĪ§äšå°äšéčĶč―Žäđïžïž
     åæķåŊäŧĨåĪäļŠæĄäŧķäļēčįĻ&äļēčãæģĻæïžčĄĻčūūåžäļäļæŊææįĐšæ žã
    valuefilterčĄĻįĪšvalueįčŋæŧĪæĄäŧķïžæŊæčŪĄįŪåšæĨįįŧæčŋæŧĪïžæåĪ§äšïžå°äšïžäļįäš,åĪ§äšįäš,å°äšįäšïžæŊåĶæŊæ°åïžisnumberïž,åĪ§äšå°äšéčĶč―Žäđïž
     åæķåŊäŧĨåĪäļŠæĄäŧķäļēčįĻ&äļēčãæģĻæïžčĄĻčūūåžäļäļæŊææįĐšæ žã
    æŊæčŠåŪäđmapåreduceå―æ°ïžčäūåĶäļïž
     mapClass="com.taobao.top.analysis.map.TimeMap" mapParams="xxx=xxx"
   reduceClass="com.taobao.top.analysis.reduce.TimeReduce" reduceParams="xxx=xxx"
    -->
 <entrys>
  <ReportEntry id="1" name="æåĄčŊ·æąæŧæŽĄæ°" key="apiName" value="count()"/>
  <ReportEntry id="2" name="čŪŋéŪæåæŽĄæ°" key="apiName" value="count()" condition="$errorCode$=0" />
  <ReportEntry id="3" name="čŪŋéŪåĪąčīĨæŽĄæ°" key="apiName" value="count()" condition="$errorCode$!=0" />
  <ReportEntry id="4" name="äļåĄåđģååĪįæķéī" key="apiName" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="5" name="TOPåđģååĪįæķéī" key="apiName" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="6" name="äļåĄåĪįæå°æķéī" key="apiName" value="min($timestamp4$ - $timestamp3$)" valuefilter=">=0&isnumber"/>
  <ReportEntry id="7" name="äļåĄåĪįæåĪ§æķéī" key="apiName" value="max($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber"/>
  <ReportEntry id="8" name="TIPæåĄč°įĻååĪįæķéī" key="apiName" value="average($timestamp3$ - $timestamp1$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="9" name="TIPæåĄč°įĻååĪįæķéī" key="apiName" value="average($timestamp5$ - $timestamp4$)" valuefilter=">=0&<10000&isnumber&round:3"/> Â
  <ReportEntry id="10" name="æĨåŋåčūåšæķčæķéī" key="apiName" value="average($timestamp6$ - $timestamp5$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="api_AverageSuccessTIPTimeConsume" name="æåčŊ·æąTOPåĪįåđģåæķéī" key="apiName" condition="$errorCode$=0"
   value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&isnumber&round:3"/>
  <ReportEntry id="api_AverageFailTIPTimeConsume" name="åĪąčīĨčŊ·æąTOPåĪįåđģåæķéī" key="apiName" condition="$errorCode$!=0"
   value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&isnumber&round:3"/>Â
 Â
 Â
  <ReportEntry id="11" name="čŪŋéŪæŧæ°" key="GLOBAL_KEY" value="count()" />
  <ReportEntry id="12" name="æåæŧæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$=0" />
  <ReportEntry id="13" name="åĪąčīĨæŧæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$!=0" />
  <ReportEntry id="14" name="äļåĄåđģåæķčæķéī(ms)" key="GLOBAL_KEY" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="15" name="TOPåđģåæķčæķéī(ms)" key="GLOBAL_KEY" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
   Â
 Â
  <ReportEntry id="16" name="éčŊŊæŽĄæ°" key="errorCode" value="count()" condition="$errorCode$!=0" />
 Â
 Â
  <ReportEntry id="17" name="åæščŪŋéŪæŧé" key="localIp" value="count()" />
  <ReportEntry id="18" name="åæščŪŋéŪæåé" key="localIp" value="count()" condition="$errorCode$=0" />
  <ReportEntry id="19" name="åæščŪŋéŪåĪąčīĨé" key="localIp" value="count()" condition="$errorCode$!=0" />
  <ReportEntry id="20" name="åæšäļåĄåđģåæķčæķéī(ms)" key="localIp" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="21" name="åæšTOPåđģåæķčæķéī(ms)" key="localIp" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
 Â
 Â
  <ReportEntry id="22" name="åšįĻčŪŋéŪæŧé" key="appKey" value="count()" />
  <ReportEntry id="23" name="åšįĻæåčŪŋéŪæŧé" key="appKey" value="count()" condition="$errorCode$=0" />
  <ReportEntry id="24" name="åšįĻåĪąčīĨčŪŋéŪæŧé" key="appKey" value="count()" condition="$errorCode$!=0"/>
  <ReportEntry id="25" name="åšįĻčŪŋéŪäļåĄåđģåčæķ(ms)" key="appKey" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="26" name="åšįĻčŪŋéŪTOPåđģåčæķ(ms)" key="appKey" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
 Â
  <ReportEntry id="27" name="æķéīæŪĩå
čŪŋéŪæŧé" key="timestamp1" value="count()"
   mapClass="com.taobao.top.analysis.map.TimeMap"/>
  <ReportEntry id="28" name="æķéīæŪĩå
čŪŋéŪæåæŧé" key="timestamp1" value="count()" condition="$errorCode$=0"
   mapClass="com.taobao.top.analysis.map.TimeMap"/>
  <ReportEntry id="29" name="æķéīæŪĩå
čŪŋéŪåĪąčīĨæŧé" key="timestamp1" value="count()" condition="$errorCode$!=0"
   mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
  <ReportEntry id="30" name="æķéīæŪĩå
čŪŋéŪäļåĄåđģåčæķ(ms)" key="timestamp1" value="average($timestamp4$ - $timestamp3$)"
   mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
  <ReportEntry id="31" name="æķéīæŪĩå
čŪŋéŪTOPåđģåčæķ(ms)" key="timestamp1" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)"
   mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
  Â
 Â
  <ReportEntry id="api_sysFailCount" name="TOPåđģå°įš§éčŊŊé" key="apiName" value="count()"
     condition="$errorCode$<100&$errorCode$>0" />
  <ReportEntry id="api_serviceSysFailCount" name="æåĄįģŧįŧįš§éčŊŊé(900å°901)" key="apiName" value="count()"
     condition="$errorCode$<902&$errorCode$>899" />
  <ReportEntry id="api_serviceSysFailCount1" name="æåĄįģŧįŧįš§éčŊŊé(åĪ§äš901)" key="apiName" value="count()"
     condition="$errorCode$>901"/>
  <ReportEntry id="api_serviceAPIFailCount" name="æåĄäļåĄįš§éčŊŊé" key="apiName" value="count()"
     condition="$errorCode$>100&$errorCode$<900"/>
  <ReportEntry id="api_serviceSysFailTotalCount" name="æåĄįģŧįŧįš§æŧéčŊŊé" key="apiName" value="count()"
     condition="$errorCode$>899" />
   Â
 Â
 </entrys>
Â
Â
 <!--
  æĨčĄĻåŪäđïž
  idäļšæĨčĄĻäļŧéŪïžéĪäšæ°åäđåŊäŧĨįĻčąæåįŽĶäļē
  fileäļšæĨčĄĻäŋåįåį§°ïžäļåŧščŪŪä―ŋįĻäļæ
  entryListæčŋ°äšæĨčĄĻå
åŦįææįentryïžåŊäŧĨåžįĻäļéĒåŪäđįå
Ļåąæ§įentryïžäđåŊäŧĨå
éĻåŪäđį§æįentryã
 Â
 -->
 <reports>
    <report id="0" file="totalTIPConsumeReport">
     <entryList>
    <entry name="TOPč·ååæ°čæķ" key="GLOBAL_KEY" value="average($timestamp7$)" condition="$errorCode$=0"/>
    <entry name="TOPč·ååæ°æå°čæķ" key="GLOBAL_KEY" value="min($timestamp7$)" condition="$errorCode$=0"/>
    <entry name="TOPč·ååæ°æåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp7$)" condition="$errorCode$=0"/>
     Â
    <entry name="č·åAPIäŋĄæŊčæķ" key="GLOBAL_KEY" value="average($timestamp8$)" condition="$errorCode$=0"/>
    <entry name="č·åAPIäŋĄæŊæå°čæķ" key="GLOBAL_KEY" value="min($timestamp8$)" condition="$errorCode$=0"/>
    <entry name="č·åAPIäŋĄæŊæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp8$)" condition="$errorCode$=0"/>
     Â
    <entry name="åĪįåčŪŪåŋ
éåæ°čæķ" key="GLOBAL_KEY" value="average($timestamp9$)" condition="$errorCode$=0"/>
    <entry name="åĪįåčŪŪåŋ
éåæ°æå°čæķ" key="GLOBAL_KEY" value="min($timestamp9$)" condition="$errorCode$=0"/>
    <entry name="åĪįåčŪŪåŋ
éåæ°æåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp9$)" condition="$errorCode$=0"/>
     Â
     Â
    <entry name="éĒįéŧååæ ĄéŠčæķ" key="GLOBAL_KEY" value="average($timestamp10$)" condition="$errorCode$=0"/>
    <entry name="éĒįéŧååæ ĄéŠæå°čæķ" key="GLOBAL_KEY" value="min($timestamp10$)" condition="$errorCode$=0"/>
    <entry name="éĒįéŧååæ ĄéŠæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp10$)" condition="$errorCode$=0"/>
     Â
    <entry name="åčŪŪåŊéåæ°æ ĄéŠčæķ" key="GLOBAL_KEY" value="average($timestamp11$)" condition="$errorCode$=0"/>
    <entry name="åčŪŪåŊéåæ°æ ĄéŠæå°čæķ" key="GLOBAL_KEY" value="min($timestamp11$)" condition="$errorCode$=0"/>
    <entry name="åčŪŪåŊéåæ°æ ĄéŠæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp11$)" condition="$errorCode$=0"/>
     Â
    <entry name="äļåĄåŋ
éåæ°æ ĄéŠčæķ" key="GLOBAL_KEY" value="average($timestamp12$)" condition="$errorCode$=0"/>
    <entry name="äļåĄåŋ
éåæ°æ ĄéŠæå°čæķ" key="GLOBAL_KEY" value="min($timestamp12$)" condition="$errorCode$=0"/>
    <entry name="äļåĄåŋ
éåæ°æ ĄéŠæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp12$)" condition="$errorCode$=0"/>
     Â
    <entry name="äļåĄåŊéåæ°æ ĄéŠčæķ" key="GLOBAL_KEY" value="average($timestamp13$)" condition="$errorCode$=0"/>
    <entry name="äļåĄåŊéåæ°æ ĄéŠæå°čæķ" key="GLOBAL_KEY" value="min($timestamp13$)" condition="$errorCode$=0"/>
    <entry name="äļåĄåŊéåæ°æ ĄéŠæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp13$)" condition="$errorCode$=0"/>
    </entryList>
    </report>
Â
  <report id="1" file="totalReport">
   <entryList>
    <entry id="11"/>
    <entry name="čŪŋéŪæŧæĩé(M)" key="GLOBAL_KEY" value="sum($readBytes$/#1000000#)" valuefilter=">=0&isnumber&round:4"/>
    <entry id="12"/>
    <entry name="čŪŋéŪæåį" key="GLOBAL_KEY" value="plain(entry(12)/entry(11))" valuefilter=">=0&isnumber&round:4"/>
    <entry id="13"/>
    <entry name="åđģå°įģŧįŧéčŊŊį(å æŧéčŊŊįūåæŊ)" key="GLOBAL_KEY" value="plain(entry(sysFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
    <entry name="æåĄįģŧįŧéčŊŊį(å æŧéčŊŊįūåæŊ)" key="GLOBAL_KEY" value="plain(entry(serviceSysFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
    <entry name="æåĄäļåĄéčŊŊį(å æŧéčŊŊįūåæŊ)" key="GLOBAL_KEY" value="plain(entry(serviceAPIFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
    <entry id="14"/>
    <entry id="15"/>
    <entry name="TOPæååĪįåđģåčæķ" key="GLOBAL_KEY"
     value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" condition="$errorCode$=0" valuefilter=">=0&isnumber&round:3"/>
    <entry id="sysFailCount" name="åđģå°įģŧįŧéčŊŊæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$<100&$errorCode$>0"/>
    <entry id="serviceSysFailCount" name="æåĄįģŧįŧéčŊŊæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$>899"/>
    <entry id="serviceAPIFailCount" name="æåĄäļåĄéčŊŊæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$>100&$errorCode$<900"/>
   </entryList>
  </report>
Â
  <report id="2" file="apiReport">
   <entryList>
      <entry name="æåĄåį§°" key="apiName" value="plain($apiName$)" />
    <entry id="1"/>
    <entry name="å æŧéæŊäū" key="apiName" value="plain(entry(1)/entry(sum:1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="2"/>
    <entry name="æåĄčŊ·æąæåį" key="apiName" value="plain(entry(2)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="3"/>
    <entry id="4"/>
    <entry id="5"/>
    <entry name="TOPå æŧåĪįæķéīįūåæŊ" key="apiName" value="plain(entry(5)/entry(5+4))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_AverageSuccessTIPTimeConsume"/>
    <entry id="api_AverageFailTIPTimeConsume"/>
    <entry id="6"/>
    <entry id="7"/>
    <entry id="8"/>
    <entry id="9"/>
    <entry id="10"/>
    <entry id="api_sysFailCount"/>
    <entry id="api_serviceSysFailTotalCount"/>
    <entry id="api_serviceAPIFailCount"/>
   </entryList>
  </report>
 Â
  <report id="3" file="errorCodeReport">
   <entryList>
      <entry id="33" name="éčŊŊį " key="errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
    <entry id="16"/>
    <entry name="éčŊŊæŊäū" key="errorCode" value="plain(entry(16)/entry(sum:16))" condition="$errorCode$!=0" valuefilter=">=0&isnumber&round:3"/>
   </entryList>
  </report>
 Â
  <report id="4" file="machineReport">
   <entryList>
      <entry name="æåĄåĻIP" key="localIp" value="plain($localIp$)" />
    <entry id="17"/>
    <entry name="å æŧéæŊäū" key="localIp" value="plain(entry(17)/entry(sum:17))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="18"/>
    <entry name="æåį" key="localIp" value="plain(entry(18)/entry(17))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="19"/>
    <entry id="20"/>
    <entry id="21"/>
    <entry name="TOPå æŧåĪįæķéīæŊåž" key="localIp" value="plain(entry(21)/entry(20+21))" valuefilter=">=0&isnumber&round:3"/>
   </entryList>
  </report>
 Â
  <report id="5" file="appReport">
   <entryList>
      <entry name="åšįĻID" key="appKey" value="plain($appKey$)" />
    <entry id="22"/>
    <entry name="å æŧčŪŋéŪæŊäū" key="appKey" value="plain(entry(22)/entry(sum:22))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="23"/>
    <entry name="åšįĻčŪŋéŪæåį" key="appKey" value="plain(entry(23)/entry(22))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="24"/>
    <entry id="25"/>
    <entry id="26"/>
   </entryList>
  </report>
 Â
  <report id="6" file="periodReport">
   <entryList>
      <entry name="æķéīæŪĩ" key="timestamp1" value="plain($timestamp1$)"
       mapClass="com.taobao.top.analysis.map.TimeMap"
       reduceClass="com.taobao.top.analysis.reduce.TimeReduce"/>
    <entry id="27"/>
    <entry name="å čŊ·æąæŧéæŊäū" key="timestamp1" value="plain(entry(27)/entry(sum:27))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="28"/>
    <entry name="čŊ·æąæåį" key="timestamp1" value="plain(entry(28)/entry(27))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="29"/>
    <entry id="30"/>
    <entry id="31"/>
   </entryList>
  </report>
 Â
  <report id="7" file="appAPIReport">
   <entryList>
      <entry name="åšįĻID" key="appKey,apiName" value="plain($appKey$)" condition="$errorCode$=0"/>
      <entry name="æåĄåį§°" key="appKey,apiName" value="plain($apiName$)" condition="$errorCode$=0"/>
    <entry id="app_api_successCount" name="čŪŋéŪæåæŧé" key="appKey,apiName" value="count()" condition="$errorCode$=0"/>
   </entryList>
  </report>
 Â
  <report id="8" file="errorCodeAndSubErrorCodeReport">
   <entryList>
      <entry name="éčŊŊį " key="errorCode,subErrorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>Â
      <entry name="åéčŊŊį " key="errorCode,subErrorCode" value="plain($subErrorCode$)" condition="$errorCode$!=0"/>
    <entry name="éčŊŊæŧæ°" key="errorCode,subErrorCode" value="count()" condition="$errorCode$!=0"/>
   </entryList>
  </report>
 Â
   Â
  <report id="9" file="apiFailDetailReport">
   <entryList>
      <entry name="æåĄåį§°" key="apiName" value="plain($apiName$)" />
    <entry id="1"/>
    <entry id="3"/>
    <entry name="åĪąčīĨæ°å æåĄčŊ·æąéæŊäū" key="apiName" value="plain(entry(3)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry name="åĪąčīĨæ°å åĪąčīĨæŧéæŊäū" key="apiName" value="plain(entry(3)/entry(sum:3))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_sysFailCount"/>
    <entry name="åđģå°įš§éčŊŊå æŧæåĄčŊ·æąæŊäū" key="apiName" value="plain(entry(api_sysFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_serviceSysFailCount"/>
    <entry name="æåĄįģŧįŧįš§éčŊŊé(900å°901)å æŧæåĄčŊ·æąæŊäū" key="apiName" value="plain(entry(api_serviceSysFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_serviceSysFailCount1"/>
    <entry name="æåĄįģŧįŧįš§éčŊŊé(åĪ§äš901)å æŧæåĄčŊ·æąæŊäū" key="apiName" value="plain(entry(api_serviceSysFailCount1)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_serviceAPIFailCount"/>
    <entry name="æåĄäļåĄįš§éčŊŊå æŧæåĄčŊ·æąæŊäū" key="apiName" value="plain(entry(api_serviceAPIFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
   </entryList>
  </report>
 Â
  <report id="10" file="appApiErrorReport">
   <entryList>
      <entry name="åšįĻID" key="appKey,apiName,errorCode" value="plain($appKey$)" condition="$errorCode$!=0"/>
      <entry name="æåĄåį§°" key="appKey,apiName,errorCode" value="plain($apiName$)" condition="$errorCode$!=0"/>
      <entry name="éčŊŊį " key="appKey,apiName,errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
    <entry name="éčŊŊæŽĄæ°" key="appKey,apiName,errorCode" value="count()" condition="$errorCode$!=0"/>
   </entryList>
  </report>
 Â
  <report id="11" file="verionAndSignTypeReport">
   <entryList>
      <entry name="įæŽå·" key="version,signMethod" value="plain($version$)" condition="$errorCode$=0"/>
      <entry name="įūåįąŧå" key="version,signMethod" value="plain($signMethod$)" condition="$errorCode$=0"/>
      <entry name="čŪŋéŪæåæŧæ°" key="version,signMethod" value="count()" condition="$errorCode$=0"/>
   </entryList>
  </report>
 Â
  <report id="12" file="appErrorCodeReport">
   <entryList>
      <entry name="åšįĻID" key="appKey,errorCode" value="plain($appKey$)" condition="$errorCode$!=0"/>
      <entry name="éčŊŊį " key="appKey,errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
      <entry name="éčŊŊæŧæ°" key="appKey,errorCode" value="count()" condition="$errorCode$!=0"/>
   </entryList>
  </report>
Â
 </reports>
Â
 <alerts>
  <!-- åŊđæŊåčĶ alerttype:now,day,week,monthã
  valveäŧĢčĄĻéåžïž<(nowįąŧåäŧĢčĄĻå°äšåčĶ,åĶææŊåææŊčūäŧĢčĄĻäļéčķ
čŋ)ïž
  >(nowįąŧåäŧĢčĄĻåĪ§äšåčĶïžåĶææŊåææŊčūäŧĢčĄĻäļå)ïžæēĄæįŽĶå·äŧĢčĄĻįŧåŊđåžčķ
čŋåčĶ-->
  <alert reportId="1" entryname="čŪŋéŪæåį" alerttype="now" valve="<0.9" />
  <alert reportId="1" entryname="čŪŋéŪæŧæ°" alerttype="day" valve="5000000" />
  <alert reportId="1" entryname="čŪŋéŪæåį" alerttype="day" valve="<0.01" />
  <alert reportId="1" entryname="åđģå°įģŧįŧéčŊŊį" alerttype="day" valve=">0.05" />
  <alert reportId="1" entryname="æåĄįģŧįŧéčŊŊį" alerttype="day" valve=">0.05" />
  <alert reportId="1" entryname="æåĄäļåĄéčŊŊį" alerttype="day" valve=">0.05" />
  <alert reportId="1" entryname="TOPåđģåæķčæķéī(ms)" alerttype="day" valve=">10" />
  <alert reportId="1" entryname="äļåĄåđģåæķčæķéī(ms)" alerttype="day" valve=">10" />
 Â
  <alert reportId="2" keyentry="æåĄåį§°" entryname="å æŧéæŊäū" alerttype="day" valve=">0.01" />
  <alert reportId="2" keyentry="æåĄåį§°" entryname="æåĄčŊ·æąæåį" alerttype="day" valve="<0.01" />
  <alert reportId="2" keyentry="æåĄåį§°" entryname="äļåĄåđģååĪįæķéī" alerttype="day" valve=">20" />
  <alert reportId="2" keyentry="æåĄåį§°" entryname="TOPåđģååĪįæķéī" alerttype="day" valve=">20" />
 Â
  <alert reportId="3" keyentry="éčŊŊį " entryname="éčŊŊæŊäū" alerttype="day" valve=">0.01" />
 Â
  <alert reportId="4" keyentry="æåĄåĻIP" entryname="æåį" alerttype="day" valve="<0.01" />
 Â
  <alert reportId="5" keyentry="åšįĻID" entryname="å æŧčŪŋéŪæŊäū" alerttype="day" valve="0.01" />
  <alert reportId="5" keyentry="åšįĻID" entryname="åšįĻčŪŋéŪæåį" alerttype="day" valve="<0.05" />
 Â
  <alert reportId="7" keyentry="åšįĻID,æåĄåį§°" entryname="čŪŋéŪæåæŧé" alerttype="day" valve=">10000000" />
 Â
  <alert reportId="9" keyentry="æåĄåį§°" entryname="åĪąčīĨæ°å æŧéæŊäū" alerttype="day" valve=">0.01" />
 Â
  <alert reportId="10" keyentry="åšįĻID,æåĄåį§°,éčŊŊį " entryname="éčŊŊæŽĄæ°" alerttype="day" valve=">10000" />
 Â
  <alert reportId="11" keyentry="įæŽå·,įūåįąŧå" entryname="čŪŋéŪæåæŧæ°" alerttype="day" valve="<1000000" />
 Â
  <alert reportId="12" keyentry="åšįĻID,éčŊŊį " entryname="éčŊŊæŧæ°" alerttype="day" valve=">100000" />
 Â
 </alerts>
Â
</top_reports>
<top_reports>
 <!-- å ĻåąæĄäŧķčŠåĻäžåšįĻå°ææįentityäļïž
Â Â å ·ä―conditionįåŪäđåä―ŋįĻæđåžåįåéĒentityäļconditionįåŪäđ -->
 <global-condition value="$logflag$!=session"/>
   <global-condition value="$RECORD_LENGTH$>16&$RECORD_LENGTH$<26"/>
  Â
   <!-- å ĻåąæĄäŧķčŠåĻäžåšįĻå°ææįentityäļïž
Â Â å ·ä―valuefilterįåŪäđåä―ŋįĻæđåžåįåéĒentityäļvaluefilterįåŪäđ
   <global-valuefilter value=""/>
  Â
   -->
  éēæĒå äļšåįį§ŧä―åŊžčīæīäļŠæĨčĄĻé―éčĶäŋŪæđïžåĪäļŠåŦååŊäŧĨåŊđåšäļäļŠå,keyäŧĢčĄĻåæ°åž -->
   <aliases>
    <alias name="logflag" key="1"/>
  Â
    <alias name="remoteIp" key="1"/>
    <alias name="partnerId" key="2"/>
    <alias name="format" key="3"/>
    <alias name="appKey" key="4"/>
    <alias name="apiName" key="5"/>
    <alias name="readBytes" key="6"/>
    <alias name="errorCode" key="7"/>
    <alias name="subErrorCode" key="8"/>
    <alias name="localIp" key="9"/>
    <alias name="nick" key="10"/>
    <alias name="version" key="11"/>
    <alias name="signMethod" key="12"/>
   Â
    <alias name="timestamp1" key="13"/>
    <alias name="timestamp2" key="14"/>
    <alias name="timestamp3" key="15"/>
    <alias name="timestamp4" key="16"/>
    <alias name="timestamp5" key="17"/>
    <alias name="timestamp6" key="18"/>
   Â
    <alias name="timestamp7" key="19"/>
    <alias name="timestamp8" key="20"/>
    <alias name="timestamp9" key="21"/>
    <alias name="timestamp10" key="22"/>
    <alias name="timestamp11" key="23"/>
    <alias name="timestamp12" key="24"/>
    <alias name="timestamp13" key="25"/>
   </aliases>
  Â
   <!-- įŧčŪĄåįåŪäđ:
    idæŊåŊäļįīĒåžïž
    namečĄĻįĪšåĻæĨčĄĻäļæūįĪšįåį§°ïž
    keyåŊäŧĨæŊaliasäđåŊäŧĨįīæĨåŪäđåå·ïžäļæĻčïžäļŧčĶčĄĻįĪšåŊđéĢäļåæč å åä―äļšäļŧéŪčŋčĄįŧčŪĄäūåĶkey=apinamečĄĻįĪšåŊđapiNameä―åįąŧįŧčŪĄïž
     įļåįapinameįįšŠå―ä―äļšäļįŧä―åéĒvalueįčŋįŪïžkeyæäŋįåGLOBAL_KEYäŧĢčĄĻåŊđææčŪ°å―ä―æŧčŪĄįŧčŪĄ
    valuečĄĻįĪščŪĄįŪæđåžå―åæŊæïžmin,max,average,count,sum,plainãååŦäŧĢčĄĻįŧčŪĄæå°åžïžæåĪ§åžïžåđģååžïžčŪĄæ°,æŧåãplainčĄĻįĪšįīæĨæūįĪšïžäļčŽįĻäšäļŧéŪåįæūįĪš
     åæķmin,max,average,sum,plainæŊæčĄĻčūūåžïžįĻ$$åīčĩ·æĨįäŧĢčĄĻåïžentry()čĄĻįĪšåŊđįŧčŪĄåįentryä―åæŽĄčŪĄįŪåūå°æ°įentryįįŧæã
    conditiončĄĻįĪškeyįčŋæŧĪæĄäŧķïžæŊæåŊđåįčŋæŧĪæĄäŧķïžæŊæåĪ§äšïžå°äšïžäļįäš,åĪ§äšįäš,å°äšįäšįčĄĻčūūåžïžåĪ§äšå°äšéčĶč―Žäđïžïž
     åæķåŊäŧĨåĪäļŠæĄäŧķäļēčįĻ&äļēčãæģĻæïžčĄĻčūūåžäļäļæŊææįĐšæ žã
    valuefilterčĄĻįĪšvalueįčŋæŧĪæĄäŧķïžæŊæčŪĄįŪåšæĨįįŧæčŋæŧĪïžæåĪ§äšïžå°äšïžäļįäš,åĪ§äšįäš,å°äšįäšïžæŊåĶæŊæ°åïžisnumberïž,åĪ§äšå°äšéčĶč―Žäđïž
     åæķåŊäŧĨåĪäļŠæĄäŧķäļēčįĻ&äļēčãæģĻæïžčĄĻčūūåžäļäļæŊææįĐšæ žã
    æŊæčŠåŪäđmapåreduceå―æ°ïžčäūåĶäļïž
     mapClass="com.taobao.top.analysis.map.TimeMap" mapParams="xxx=xxx"
   reduceClass="com.taobao.top.analysis.reduce.TimeReduce" reduceParams="xxx=xxx"
    -->
 <entrys>
  <ReportEntry id="1" name="æåĄčŊ·æąæŧæŽĄæ°" key="apiName" value="count()"/>
  <ReportEntry id="2" name="čŪŋéŪæåæŽĄæ°" key="apiName" value="count()" condition="$errorCode$=0" />
  <ReportEntry id="3" name="čŪŋéŪåĪąčīĨæŽĄæ°" key="apiName" value="count()" condition="$errorCode$!=0" />
  <ReportEntry id="4" name="äļåĄåđģååĪįæķéī" key="apiName" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="5" name="TOPåđģååĪįæķéī" key="apiName" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="6" name="äļåĄåĪįæå°æķéī" key="apiName" value="min($timestamp4$ - $timestamp3$)" valuefilter=">=0&isnumber"/>
  <ReportEntry id="7" name="äļåĄåĪįæåĪ§æķéī" key="apiName" value="max($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber"/>
  <ReportEntry id="8" name="TIPæåĄč°įĻååĪįæķéī" key="apiName" value="average($timestamp3$ - $timestamp1$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="9" name="TIPæåĄč°įĻååĪįæķéī" key="apiName" value="average($timestamp5$ - $timestamp4$)" valuefilter=">=0&<10000&isnumber&round:3"/> Â
  <ReportEntry id="10" name="æĨåŋåčūåšæķčæķéī" key="apiName" value="average($timestamp6$ - $timestamp5$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="api_AverageSuccessTIPTimeConsume" name="æåčŊ·æąTOPåĪįåđģåæķéī" key="apiName" condition="$errorCode$=0"
   value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&isnumber&round:3"/>
  <ReportEntry id="api_AverageFailTIPTimeConsume" name="åĪąčīĨčŊ·æąTOPåĪįåđģåæķéī" key="apiName" condition="$errorCode$!=0"
   value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&isnumber&round:3"/>Â
 Â
 Â
  <ReportEntry id="11" name="čŪŋéŪæŧæ°" key="GLOBAL_KEY" value="count()" />
  <ReportEntry id="12" name="æåæŧæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$=0" />
  <ReportEntry id="13" name="åĪąčīĨæŧæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$!=0" />
  <ReportEntry id="14" name="äļåĄåđģåæķčæķéī(ms)" key="GLOBAL_KEY" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="15" name="TOPåđģåæķčæķéī(ms)" key="GLOBAL_KEY" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
   Â
 Â
  <ReportEntry id="16" name="éčŊŊæŽĄæ°" key="errorCode" value="count()" condition="$errorCode$!=0" />
 Â
 Â
  <ReportEntry id="17" name="åæščŪŋéŪæŧé" key="localIp" value="count()" />
  <ReportEntry id="18" name="åæščŪŋéŪæåé" key="localIp" value="count()" condition="$errorCode$=0" />
  <ReportEntry id="19" name="åæščŪŋéŪåĪąčīĨé" key="localIp" value="count()" condition="$errorCode$!=0" />
  <ReportEntry id="20" name="åæšäļåĄåđģåæķčæķéī(ms)" key="localIp" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="21" name="åæšTOPåđģåæķčæķéī(ms)" key="localIp" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
 Â
 Â
  <ReportEntry id="22" name="åšįĻčŪŋéŪæŧé" key="appKey" value="count()" />
  <ReportEntry id="23" name="åšįĻæåčŪŋéŪæŧé" key="appKey" value="count()" condition="$errorCode$=0" />
  <ReportEntry id="24" name="åšįĻåĪąčīĨčŪŋéŪæŧé" key="appKey" value="count()" condition="$errorCode$!=0"/>
  <ReportEntry id="25" name="åšįĻčŪŋéŪäļåĄåđģåčæķ(ms)" key="appKey" value="average($timestamp4$ - $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
  <ReportEntry id="26" name="åšįĻčŪŋéŪTOPåđģåčæķ(ms)" key="appKey" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" valuefilter=">=0&<10000&isnumber&round:3"/>
 Â
  <ReportEntry id="27" name="æķéīæŪĩå čŪŋéŪæŧé" key="timestamp1" value="count()"
   mapClass="com.taobao.top.analysis.map.TimeMap"/>
  <ReportEntry id="28" name="æķéīæŪĩå čŪŋéŪæåæŧé" key="timestamp1" value="count()" condition="$errorCode$=0"
   mapClass="com.taobao.top.analysis.map.TimeMap"/>
  <ReportEntry id="29" name="æķéīæŪĩå čŪŋéŪåĪąčīĨæŧé" key="timestamp1" value="count()" condition="$errorCode$!=0"
   mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
  <ReportEntry id="30" name="æķéīæŪĩå čŪŋéŪäļåĄåđģåčæķ(ms)" key="timestamp1" value="average($timestamp4$ - $timestamp3$)"
   mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
  <ReportEntry id="31" name="æķéīæŪĩå čŪŋéŪTOPåđģåčæķ(ms)" key="timestamp1" value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)"
   mapClass="com.taobao.top.analysis.map.TimeMap" valuefilter=">=0&isnumber&round:3"/>
  Â
 Â
  <ReportEntry id="api_sysFailCount" name="TOPåđģå°įš§éčŊŊé" key="apiName" value="count()"
     condition="$errorCode$<100&$errorCode$>0" />
  <ReportEntry id="api_serviceSysFailCount" name="æåĄįģŧįŧįš§éčŊŊé(900å°901)" key="apiName" value="count()"
     condition="$errorCode$<902&$errorCode$>899" />
  <ReportEntry id="api_serviceSysFailCount1" name="æåĄįģŧįŧįš§éčŊŊé(åĪ§äš901)" key="apiName" value="count()"
     condition="$errorCode$>901"/>
  <ReportEntry id="api_serviceAPIFailCount" name="æåĄäļåĄįš§éčŊŊé" key="apiName" value="count()"
     condition="$errorCode$>100&$errorCode$<900"/>
  <ReportEntry id="api_serviceSysFailTotalCount" name="æåĄįģŧįŧįš§æŧéčŊŊé" key="apiName" value="count()"
     condition="$errorCode$>899" />
   Â
 Â
 </entrys>
Â
Â
 <!--
  æĨčĄĻåŪäđïž
  idäļšæĨčĄĻäļŧéŪïžéĪäšæ°åäđåŊäŧĨįĻčąæåįŽĶäļē
  fileäļšæĨčĄĻäŋåįåį§°ïžäļåŧščŪŪä―ŋįĻäļæ
  entryListæčŋ°äšæĨčĄĻå åŦįææįentryïžåŊäŧĨåžįĻäļéĒåŪäđįå Ļåąæ§įentryïžäđåŊäŧĨå éĻåŪäđį§æįentryã
 Â
 -->
 <reports>
    <report id="0" file="totalTIPConsumeReport">
     <entryList>
    <entry name="TOPč·ååæ°čæķ" key="GLOBAL_KEY" value="average($timestamp7$)" condition="$errorCode$=0"/>
    <entry name="TOPč·ååæ°æå°čæķ" key="GLOBAL_KEY" value="min($timestamp7$)" condition="$errorCode$=0"/>
    <entry name="TOPč·ååæ°æåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp7$)" condition="$errorCode$=0"/>
     Â
    <entry name="č·åAPIäŋĄæŊčæķ" key="GLOBAL_KEY" value="average($timestamp8$)" condition="$errorCode$=0"/>
    <entry name="č·åAPIäŋĄæŊæå°čæķ" key="GLOBAL_KEY" value="min($timestamp8$)" condition="$errorCode$=0"/>
    <entry name="č·åAPIäŋĄæŊæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp8$)" condition="$errorCode$=0"/>
     Â
    <entry name="åĪįåčŪŪåŋ éåæ°čæķ" key="GLOBAL_KEY" value="average($timestamp9$)" condition="$errorCode$=0"/>
    <entry name="åĪįåčŪŪåŋ éåæ°æå°čæķ" key="GLOBAL_KEY" value="min($timestamp9$)" condition="$errorCode$=0"/>
    <entry name="åĪįåčŪŪåŋ éåæ°æåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp9$)" condition="$errorCode$=0"/>
     Â
     Â
    <entry name="éĒįéŧååæ ĄéŠčæķ" key="GLOBAL_KEY" value="average($timestamp10$)" condition="$errorCode$=0"/>
    <entry name="éĒįéŧååæ ĄéŠæå°čæķ" key="GLOBAL_KEY" value="min($timestamp10$)" condition="$errorCode$=0"/>
    <entry name="éĒįéŧååæ ĄéŠæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp10$)" condition="$errorCode$=0"/>
     Â
    <entry name="åčŪŪåŊéåæ°æ ĄéŠčæķ" key="GLOBAL_KEY" value="average($timestamp11$)" condition="$errorCode$=0"/>
    <entry name="åčŪŪåŊéåæ°æ ĄéŠæå°čæķ" key="GLOBAL_KEY" value="min($timestamp11$)" condition="$errorCode$=0"/>
    <entry name="åčŪŪåŊéåæ°æ ĄéŠæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp11$)" condition="$errorCode$=0"/>
     Â
    <entry name="äļåĄåŋ éåæ°æ ĄéŠčæķ" key="GLOBAL_KEY" value="average($timestamp12$)" condition="$errorCode$=0"/>
    <entry name="äļåĄåŋ éåæ°æ ĄéŠæå°čæķ" key="GLOBAL_KEY" value="min($timestamp12$)" condition="$errorCode$=0"/>
    <entry name="äļåĄåŋ éåæ°æ ĄéŠæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp12$)" condition="$errorCode$=0"/>
     Â
    <entry name="äļåĄåŊéåæ°æ ĄéŠčæķ" key="GLOBAL_KEY" value="average($timestamp13$)" condition="$errorCode$=0"/>
    <entry name="äļåĄåŊéåæ°æ ĄéŠæå°čæķ" key="GLOBAL_KEY" value="min($timestamp13$)" condition="$errorCode$=0"/>
    <entry name="äļåĄåŊéåæ°æ ĄéŠæåĪ§čæķ" key="GLOBAL_KEY" value="max($timestamp13$)" condition="$errorCode$=0"/>
    </report>
Â
  <report id="1" file="totalReport">
   <entryList>
    <entry id="11"/>
    <entry name="čŪŋéŪæŧæĩé(M)" key="GLOBAL_KEY" value="sum($readBytes$/#1000000#)" valuefilter=">=0&isnumber&round:4"/>
    <entry id="12"/>
    <entry name="čŪŋéŪæåį" key="GLOBAL_KEY" value="plain(entry(12)/entry(11))" valuefilter=">=0&isnumber&round:4"/>
    <entry id="13"/>
    <entry name="åđģå°įģŧįŧéčŊŊį(å æŧéčŊŊįūåæŊ)" key="GLOBAL_KEY" value="plain(entry(sysFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
    <entry name="æåĄįģŧįŧéčŊŊį(å æŧéčŊŊįūåæŊ)" key="GLOBAL_KEY" value="plain(entry(serviceSysFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
    <entry name="æåĄäļåĄéčŊŊį(å æŧéčŊŊįūåæŊ)" key="GLOBAL_KEY" value="plain(entry(serviceAPIFailCount)/entry(13))" valuefilter=">=0&isnumber&round:4"/>
    <entry id="14"/>
    <entry id="15"/>
    <entry name="TOPæååĪįåđģåčæķ" key="GLOBAL_KEY"
     value="average($timestamp6$ - $timestamp1$ - $timestamp4$ + $timestamp3$)" condition="$errorCode$=0" valuefilter=">=0&isnumber&round:3"/>
    <entry id="sysFailCount" name="åđģå°įģŧįŧéčŊŊæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$<100&$errorCode$>0"/>
    <entry id="serviceSysFailCount" name="æåĄįģŧįŧéčŊŊæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$>899"/>
    <entry id="serviceAPIFailCount" name="æåĄäļåĄéčŊŊæ°" key="GLOBAL_KEY" value="count()" condition="$errorCode$>100&$errorCode$<900"/>
   </entryList>
  </report>
Â
  <report id="2" file="apiReport">
   <entryList>
      <entry name="æåĄåį§°" key="apiName" value="plain($apiName$)" />
    <entry id="1"/>
    <entry name="å æŧéæŊäū" key="apiName" value="plain(entry(1)/entry(sum:1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="2"/>
    <entry name="æåĄčŊ·æąæåį" key="apiName" value="plain(entry(2)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="3"/>
    <entry id="4"/>
    <entry id="5"/>
    <entry name="TOPå æŧåĪįæķéīįūåæŊ" key="apiName" value="plain(entry(5)/entry(5+4))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_AverageSuccessTIPTimeConsume"/>
    <entry id="api_AverageFailTIPTimeConsume"/>
    <entry id="6"/>
    <entry id="7"/>
    <entry id="8"/>
    <entry id="9"/>
    <entry id="10"/>
    <entry id="api_sysFailCount"/>
    <entry id="api_serviceSysFailTotalCount"/>
    <entry id="api_serviceAPIFailCount"/>
   </entryList>
  </report>
 Â
  <report id="3" file="errorCodeReport">
   <entryList>
      <entry id="33" name="éčŊŊį " key="errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
    <entry id="16"/>
    <entry name="éčŊŊæŊäū" key="errorCode" value="plain(entry(16)/entry(sum:16))" condition="$errorCode$!=0" valuefilter=">=0&isnumber&round:3"/>
   </entryList>
  </report>
 Â
  <report id="4" file="machineReport">
   <entryList>
      <entry name="æåĄåĻIP" key="localIp" value="plain($localIp$)" />
    <entry id="17"/>
    <entry name="å æŧéæŊäū" key="localIp" value="plain(entry(17)/entry(sum:17))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="18"/>
    <entry name="æåį" key="localIp" value="plain(entry(18)/entry(17))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="19"/>
    <entry id="20"/>
    <entry id="21"/>
    <entry name="TOPå æŧåĪįæķéīæŊåž" key="localIp" value="plain(entry(21)/entry(20+21))" valuefilter=">=0&isnumber&round:3"/>
   </entryList>
  </report>
 Â
  <report id="5" file="appReport">
   <entryList>
      <entry name="åšįĻID" key="appKey" value="plain($appKey$)" />
    <entry id="22"/>
    <entry name="å æŧčŪŋéŪæŊäū" key="appKey" value="plain(entry(22)/entry(sum:22))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="23"/>
    <entry name="åšįĻčŪŋéŪæåį" key="appKey" value="plain(entry(23)/entry(22))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="24"/>
    <entry id="25"/>
    <entry id="26"/>
   </entryList>
  </report>
 Â
  <report id="6" file="periodReport">
   <entryList>
      <entry name="æķéīæŪĩ" key="timestamp1" value="plain($timestamp1$)"
       mapClass="com.taobao.top.analysis.map.TimeMap"
       reduceClass="com.taobao.top.analysis.reduce.TimeReduce"/>
    <entry id="27"/>
    <entry name="å čŊ·æąæŧéæŊäū" key="timestamp1" value="plain(entry(27)/entry(sum:27))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="28"/>
    <entry name="čŊ·æąæåį" key="timestamp1" value="plain(entry(28)/entry(27))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="29"/>
    <entry id="30"/>
    <entry id="31"/>
   </entryList>
  </report>
 Â
  <report id="7" file="appAPIReport">
   <entryList>
      <entry name="åšįĻID" key="appKey,apiName" value="plain($appKey$)" condition="$errorCode$=0"/>
      <entry name="æåĄåį§°" key="appKey,apiName" value="plain($apiName$)" condition="$errorCode$=0"/>
    <entry id="app_api_successCount" name="čŪŋéŪæåæŧé" key="appKey,apiName" value="count()" condition="$errorCode$=0"/>
   </entryList>
  </report>
 Â
  <report id="8" file="errorCodeAndSubErrorCodeReport">
   <entryList>
      <entry name="éčŊŊį " key="errorCode,subErrorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>Â
      <entry name="åéčŊŊį " key="errorCode,subErrorCode" value="plain($subErrorCode$)" condition="$errorCode$!=0"/>
    <entry name="éčŊŊæŧæ°" key="errorCode,subErrorCode" value="count()" condition="$errorCode$!=0"/>
   </entryList>
  </report>
 Â
   Â
  <report id="9" file="apiFailDetailReport">
   <entryList>
      <entry name="æåĄåį§°" key="apiName" value="plain($apiName$)" />
    <entry id="1"/>
    <entry id="3"/>
    <entry name="åĪąčīĨæ°å æåĄčŊ·æąéæŊäū" key="apiName" value="plain(entry(3)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry name="åĪąčīĨæ°å åĪąčīĨæŧéæŊäū" key="apiName" value="plain(entry(3)/entry(sum:3))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_sysFailCount"/>
    <entry name="åđģå°įš§éčŊŊå æŧæåĄčŊ·æąæŊäū" key="apiName" value="plain(entry(api_sysFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_serviceSysFailCount"/>
    <entry name="æåĄįģŧįŧįš§éčŊŊé(900å°901)å æŧæåĄčŊ·æąæŊäū" key="apiName" value="plain(entry(api_serviceSysFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_serviceSysFailCount1"/>
    <entry name="æåĄįģŧįŧįš§éčŊŊé(åĪ§äš901)å æŧæåĄčŊ·æąæŊäū" key="apiName" value="plain(entry(api_serviceSysFailCount1)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
    <entry id="api_serviceAPIFailCount"/>
    <entry name="æåĄäļåĄįš§éčŊŊå æŧæåĄčŊ·æąæŊäū" key="apiName" value="plain(entry(api_serviceAPIFailCount)/entry(1))" valuefilter=">=0&isnumber&round:3"/>
   </entryList>
  </report>
 Â
  <report id="10" file="appApiErrorReport">
   <entryList>
      <entry name="åšįĻID" key="appKey,apiName,errorCode" value="plain($appKey$)" condition="$errorCode$!=0"/>
      <entry name="æåĄåį§°" key="appKey,apiName,errorCode" value="plain($apiName$)" condition="$errorCode$!=0"/>
      <entry name="éčŊŊį " key="appKey,apiName,errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
    <entry name="éčŊŊæŽĄæ°" key="appKey,apiName,errorCode" value="count()" condition="$errorCode$!=0"/>
   </entryList>
  </report>
 Â
  <report id="11" file="verionAndSignTypeReport">
   <entryList>
      <entry name="įæŽå·" key="version,signMethod" value="plain($version$)" condition="$errorCode$=0"/>
      <entry name="įūåįąŧå" key="version,signMethod" value="plain($signMethod$)" condition="$errorCode$=0"/>
      <entry name="čŪŋéŪæåæŧæ°" key="version,signMethod" value="count()" condition="$errorCode$=0"/>
   </entryList>
  </report>
 Â
  <report id="12" file="appErrorCodeReport">
   <entryList>
      <entry name="åšįĻID" key="appKey,errorCode" value="plain($appKey$)" condition="$errorCode$!=0"/>
      <entry name="éčŊŊį " key="appKey,errorCode" value="plain($errorCode$)" condition="$errorCode$!=0"/>
      <entry name="éčŊŊæŧæ°" key="appKey,errorCode" value="count()" condition="$errorCode$!=0"/>
   </entryList>
  </report>
Â
 </reports>
Â
 <alerts>
  <!-- åŊđæŊåčĶ alerttype:now,day,week,monthã
  valveäŧĢčĄĻéåžïž<(nowįąŧåäŧĢčĄĻå°äšåčĶ,åĶææŊåææŊčūäŧĢčĄĻäļéčķ čŋ)ïž
  >(nowįąŧåäŧĢčĄĻåĪ§äšåčĶïžåĶææŊåææŊčūäŧĢčĄĻäļå)ïžæēĄæįŽĶå·äŧĢčĄĻįŧåŊđåžčķ čŋåčĶ-->
  <alert reportId="1" entryname="čŪŋéŪæåį" alerttype="now" valve="<0.9" />
  <alert reportId="1" entryname="čŪŋéŪæŧæ°" alerttype="day" valve="5000000" />
  <alert reportId="1" entryname="čŪŋéŪæåį" alerttype="day" valve="<0.01" />
  <alert reportId="1" entryname="åđģå°įģŧįŧéčŊŊį" alerttype="day" valve=">0.05" />
  <alert reportId="1" entryname="æåĄįģŧįŧéčŊŊį" alerttype="day" valve=">0.05" />
  <alert reportId="1" entryname="æåĄäļåĄéčŊŊį" alerttype="day" valve=">0.05" />
  <alert reportId="1" entryname="TOPåđģåæķčæķéī(ms)" alerttype="day" valve=">10" />
  <alert reportId="1" entryname="äļåĄåđģåæķčæķéī(ms)" alerttype="day" valve=">10" />
 Â
  <alert reportId="2" keyentry="æåĄåį§°" entryname="å æŧéæŊäū" alerttype="day" valve=">0.01" />
  <alert reportId="2" keyentry="æåĄåį§°" entryname="æåĄčŊ·æąæåį" alerttype="day" valve="<0.01" />
  <alert reportId="2" keyentry="æåĄåį§°" entryname="äļåĄåđģååĪįæķéī" alerttype="day" valve=">20" />
  <alert reportId="2" keyentry="æåĄåį§°" entryname="TOPåđģååĪįæķéī" alerttype="day" valve=">20" />
 Â
  <alert reportId="3" keyentry="éčŊŊį " entryname="éčŊŊæŊäū" alerttype="day" valve=">0.01" />
 Â
  <alert reportId="4" keyentry="æåĄåĻIP" entryname="æåį" alerttype="day" valve="<0.01" />
 Â
  <alert reportId="5" keyentry="åšįĻID" entryname="å æŧčŪŋéŪæŊäū" alerttype="day" valve="0.01" />
  <alert reportId="5" keyentry="åšįĻID" entryname="åšįĻčŪŋéŪæåį" alerttype="day" valve="<0.05" />
 Â
  <alert reportId="7" keyentry="åšįĻID,æåĄåį§°" entryname="čŪŋéŪæåæŧé" alerttype="day" valve=">10000000" />
 Â
  <alert reportId="9" keyentry="æåĄåį§°" entryname="åĪąčīĨæ°å æŧéæŊäū" alerttype="day" valve=">0.01" />
 Â
  <alert reportId="10" keyentry="åšįĻID,æåĄåį§°,éčŊŊį " entryname="éčŊŊæŽĄæ°" alerttype="day" valve=">10000" />
 Â
  <alert reportId="11" keyentry="įæŽå·,įūåįąŧå" entryname="čŪŋéŪæåæŧæ°" alerttype="day" valve="<1000000" />
 Â
  <alert reportId="12" keyentry="åšįĻID,éčŊŊį " entryname="éčŊŊæŧæ°" alerttype="day" valve=">100000" />
 Â
 </alerts>
Â
</top_reports>


- 2010-01-12 21:58
- æĩč§ 1667
- čŊčŪš(0)
- æĨįæīåĪ
åčĄĻčŊčŪš

-
åšįĻæķæčŪūčŪĄâéēįŦâįŧéŠåäšŦ
2009-08-27 00:59 926 åšįĻæķæčŪūčŪĄâéēįŦâįŧéŠåäšŦ Author : åēæå(æ· ... -
åŪĒæ·įŦŊNIOåŪč·ĩåæ
2009-09-24 08:57 2778åžéŪïžNIOåĻæåĄįŦŊįåšįĻå·ēįŧčĒŦåđŋäļšįæïžä―æŊåĻåŪĒæ·įŦŊįä―ŋįĻïž ... -
MapReduceâåæšįâæĨåŋåæåŪč·ĩįđæŧī
2009-10-30 12:27 3024Authorïžæūįŋïžæåïž Ema ... -
åļļįĻæĻĄåžįįŧčéŪéĒįčŪūčŪĄįĻģåŪæ§
2009-11-10 01:52 1482Â Author : åēæå(æ·åŪčą ... -
2009įéæĐåå·Ĩä―æŧįŧåĪ§įšē
2009-11-27 00:58 1555Â Â äŧåđīblogæīæ°įéåšĶæ ... -
įĻåšåæŊäļæŊåŠåĻäđčŠå·ąįäļäšĐäļåå°
2009-12-08 00:54 1230Authorïžæūįŋïžæåïž Em ... -
Lazy Request Parameter Parser
2009-12-08 01:51 1654Authorïžæūįŋïžæåïž Emailïžfangweng@t ... -
ååĻMapReduceéŪéĒįååĪå
2009-12-09 13:09 1477Â Â Â äļåå·Ķåģæķå°äļäļŠ ... -
äžåæč°
2010-01-27 01:45 1305Â äžåæč° Author :æūįŋ ... -
Q1ææŊįđæŧī
2010-04-02 02:26 1563Â Author:æūįŋïžæåïž Date:2010/4/2 Â ... -
åžæĨæĻĄåžäļįWebčŊ·æąïžææŊäŧįŧįŊïž
2010-04-20 08:50 2436Â Authorïžæūįŋïžæåïž Date: 2010/4/14 ...
įļå ģæĻč
### åšäšHadoopéįūĪįååļåžæĨåŋåæįģŧįŧį įĐķ #### äļãHadoopåå ķåĻæĨåŋåæäļįåšįĻčæŊ éįäščį―ææŊįéĢéååąïžåįąŧWeb2.0į―įŦãįĩåååĄåđģå°äŧĨååĪ§åį―įŧæļļæ䚧įäšįĐšåįæ°æŪéãčŋäšįģŧįŧåĻčŋčĄčŋįĻäļäž...
įķčïžäž įŧįįŧčĨåæįģŧįŧïžåĶåšäšå°åæšå å ģįģŧåæ°æŪåšįæķæïžåĻåĪįæĩ·ééįŧæåæ°æŪæđéĒååĻåąéæ§ïžå æĪåžå ĨåšäšX86æķæįHadoopåđģå°åSparkįåĪ§æ°æŪåĪįææŊæäļšäšäļį§čķåŋã #### å ģéŪææŊäļčæŊ **Spark**...
æ éĒäļįâhadoopåŪį°į―įŦæĩéæ°æŪåæïžMapReduce+hiveïžįĻåš+čŊīæ.rarâæįæŊäļäļŠä―ŋįĻHadoopæĄæķïžįŧåMapReduceåHiveææŊčŋčĄį―įŦæĩéæ°æŪåæįéĄđįŪãčŋäļŠéĄđįŪåŊč―å åŦäšįĻåšäŧĢį ãé į―ŪæäŧķäŧĨåčŊĶįŧįä―ŋįĻčŊīæ...
åžåč åŊäŧĨååŧšMapReduceéĄđįŪïžåŊžå Ĩįļå ģįHadoopåšïžčŪūį―Ūčūå Ĩåčūåšč·ŊåūïžįčģåŊäŧĨįīæĨåĻEclipseå éĻæĨįä―äļįæ§čĄæĨåŋåįæ§įķæã åĻæäūįåįžĐå æäŧķåį§°åčĄĻäļïžæäŧŽåŊäŧĨįå°äļäšäļHadoopįļå ģįå ģéŪæäŧķïž 1....
äļšäščŋčĄčŋäļŠMapReduceä―äļïžä― éčĶé į―ŪHadoopįŊåĒïžįķåä―ŋįĻHadoopį`hadoop jar`å―äŧĪæäšĪ`MrTemperature.jar`ïžåčŪūčŊĨįĻåščĒŦæå æäšJARæäŧķïžå°éįūĪãæ§čĄåŪæåïžįŧæå°äŋååĻHDFSįäļäļŠæåŪä―į―ŪïžåŊäŧĨčŋäļæĨ...
æ éĒäļį"åšäšspark+flume+kafka+hbaseįåŪæķæĨåŋåĪįåæįģŧįŧ"æŊæäļäļŠéæįãįĻäšåŪæķæ°æŪåĪįååæįč§ĢåģæđæĄãčŋäļŠįģŧįŧåĐįĻäšåäļŠå ģéŪįŧäŧķïžApache SparkãApache FlumeãApache KafkaåApache HBaseïžčŋäšé―...
æ éĒæåį"åŪæīįåĪ§æ°æŪäščŪĄįŪčŊūįĻ Hadoopæ°æŪåæåđģå°įģŧåčŊūįĻ Hadoop 04 MapReduce"æŊäļéĻäļæģĻäšHadoopįæįģŧįŧäļįæ ļåŋįŧäŧķMapReduceįæįĻãMapReduceæŊGoogleæåšįäļį§ååļåžčŪĄįŪæĻĄåïžåđŋæģåšįĻäšåĪ§æ°æŪåĪį...
æŽæææĒčŪĻįâåšäšHadoopįæĩ·éæĨåŋæ°æŪåĪįâæĢæŊåĻčŋæ ·įčæŊäļïžéåŊđäž įŧåæšåĪįæđæģåĻæĩ·éæ°æŪåĪįæđéĒæéĒäļīįåąéæ§ïžæåšäšäļį§æ°įč§ĢåģæđæĄã åĻåĪįæĩ·éæ°æŪæķïžäž įŧįåæšæđæģååĻææūįååĻåčŪĄįŪįķéĒ...
įģŧįŧæķæčŪūčŪĄå æŽäšäļŠäļŧčĶéĻåïžFlumeééæĨåŋïžMapReduceæ°æŪéĒåĪįïžHiveæ°æŪåæïžSqoopæ°æŪåŊžåščģMySQLïžäŧĨåWEBįģŧįŧåŪį°æ°æŪåŊč§åã 2. **æĻĄååžå - æ°æŪéé** ä―ŋįĻApache FlumeæåŧšæĨåŋééįģŧįŧæŊéĶčĶ...
6. æ§č―äžåïžæ đæŪæļļææ°æŪįįđįđåäļåĄéæąïžåŊč―éčĶåŊđHadoopé į―ŪčŋčĄč°äžïžæŊåĶč°æīBlockåĪ§å°ãMapReduceįæ§―ä―æ°éįã įŧžäļæčŋ°ïžåšäšHadoopįæļļææ°æŪåæįģŧįŧéčŋJavaįžįĻåŪį°ïžč―åĪææå°åĪįååææĩ·é...
1. `mapreduce.job.log4j-properties`: æåŪčŠåŪäđįæĨåŋé į―Ūæäŧķč·Ŋåūã 2. `mapreduce.joblogs.aggregate_retention`: čŪūį―ŪčåæĨåŋäŋįįæķéīïžåä―äļšå°æķã 3. `mapreduce.application.log-file`: æåŪåšįĻįĻåšį...
PigæŊåšäšMapReduceįéŦįš§æĨčŊĒčŊčĻïžå čŪļįĻæ·įĻSQL-likečŊæģčŋčĄæ°æŪåæãChukwaæŊåšäšHadoopįåĪ§č§æĻĄéįūĪįæ§įģŧįŧïžįĻäšæ°æŪæķéååĪįã įĩåčĄäļįåĪ§æ°æŪåææĻĄåéåļļæķåæ°æŪæ―åãæ žåžæļ æīåDFSååĻäļäļŠæĨéŠĪ...
æĪé į―ŪæåŪäš MapReduce ä―ŋįĻ YARN ä―äļšæĄæķã ##### yarn-site.xml é į―ŪįĪšäū ```xml <name>yarn.resourcemanager.hostname <value>hdp-nn-01 <name>yarn.nodemanager.aux-services <value>mapreduce_...
HadoopæŊåĪ§æ°æŪåĪįéĒåįæ ļåŋå·Ĩå ·äđäļïžå°Īå ķæ éŋåĪįæĩ·éæ°æŪéïžčMapReduceæŊHadoopįäļäļŠæ ļåŋįŧäŧķïžåŪéčŋå°äŧŧåĄåč§ĢæåĪäļŠåäŧŧåĄïžįķååđķčĄåĪįčŋäšåäŧŧåĄïžæįŧå°įŧææīåïžäŧčæéŦæ°æŪåĪįæįã æŽäđĶį...
æŽæå°æ·ąå ĨæĒčŪĻåšäšHadoopæĄæķæåŧšįåĪ§æ°æŪåĪįäļåæįģŧįŧïžįđåŦæŊåĶä―åĐįĻHadoopįæææŊæĨæåååææĻĄæįåžåļļæ°æŪïžäŧĨååĶä―æĻĄæåšåŪæķčŪĄįŪåĪįåšæŊã äļãHadoopæĄæķåšįĄ HadoopæĄæķįæ ļåŋįŧäŧķå æŽHDFS...
åĻHadoopįæįģŧįŧäļïžMapReduceæŊåĪįåĪ§æ°æŪįå ģéŪįŧäŧķãåŪæŊäļį§ååļåžčŪĄįŪæĻĄåïžå°åĪ§åæ°æŪéååēæå°åïžįķååĻéįūĪäļįåĪäļŠčįđäļåđķčĄåĪįã2.xįæŽįMapReduceåžå ĨäšäļäšéčĶįæđčŋïžåĒåžšäšå ķæ§č―åįĻģåŪæ§ã...
MapReduce æŊäļį§ååļåžčŪĄįŪæĻĄåïžįąGoogleæåšïžäļŧčĶįĻäšåĪįååææĩ·éæ°æŪãåŪäļŧčĶįąäļĪäļŠäļŧčĶéķæŪĩįŧæïžMapéķæŪĩåReduceéķæŪĩïžåæķäūčĩäšHadoopįHDFSïžHadoop Distributed File Systemïžä―äļšåšåąæ°æŪååĻįģŧįŧã ...
MapReduceæŊApache HadoopéĄđįŪįæ ļåŋįŧäŧķïžįĻäšåđķčĄåĪįåčŪĄįŪåĪ§åæ°æŪéã åĻåĪ§æ°æŪéĒåïžHiveéåļļčĒŦįĻä―æ°æŪäŧåšå·Ĩå ·ïžåŪæäūäšSQL-likeįčŊčĻïžHQLïžæĨæĨčŊĒåįŪĄįååĻåĻHadoopæäŧķįģŧįŧïžHDFSïžäļįæ°æŪïžčHBase...