气象数据集
-
关于MapReduce
MapReduce是一种可用于数据处理的编程模型,它本质上是并行运行的,因此可以将大规模的数据分析任务分发给任何一个拥有足够多机器的数据中心。MapReduce的优势在于处理大规模数据集,这里我们先看一个数据集。我们今天的目的是:在大批量的气象数据中,获取每年每月的最高气温。
-
数据格式
我们使用的数据来自于权威指南提供的美国国家气候数据中心,该数据按行为单位,每一行包含日期、气温、地点等等信息。比如下列数据为:1901年12月29日到31日的数据,相信细心的你会找到日期的,而温度是每一行的第87到92个字符(包含正负号)。
-
0029227070999991901122913004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-01561+99999100271ADDGF104991999999999999999999
-
0029227070999991901122920004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-02001+99999100501ADDGF107991999999999999999999
-
0029227070999991901123006004+62167+030650FM-12+010299999V0200701N003119999999N0000001N9-01501+99999100791ADDGF108991999999999999999999
-
0029227070999991901123013004+62167+030650FM-12+010299999V0200901N003119999999N0000001N9-01331+99999100901ADDGF108991999999999999999999
-
0029227070999991901123020004+62167+030650FM-12+010299999V0200701N002119999999N0000001N9-01221+99999100831ADDGF108991999999999999999999
-
0029227070999991901123106004+62167+030650FM-12+010299999V0200701N004119999999N0000001N9-01391+99999100521ADDGF108991999999999999999999
-
0029227070999991901123113004+62167+030650FM-12+010299999V0200701N003119999999N0000001N9-01391+99999100321ADDGF108991999999999999999999
-
0029227070999991901123120004+62167+030650FM-12+010299999V0200701N004119999999N0000001N9-01391+99999100281ADDGF108991999999999999999999
-
测试数据下载 Hadoop测试数据–气象数据集
使用MapReduce来分析数据
为了充分利用Hadoop提供的并行处理优势,我们需要将查询表示成MapReduce作业,完成某种本地端的小规模测试之后,就可以把作业部署到集群上运行。
- Map和Reduce
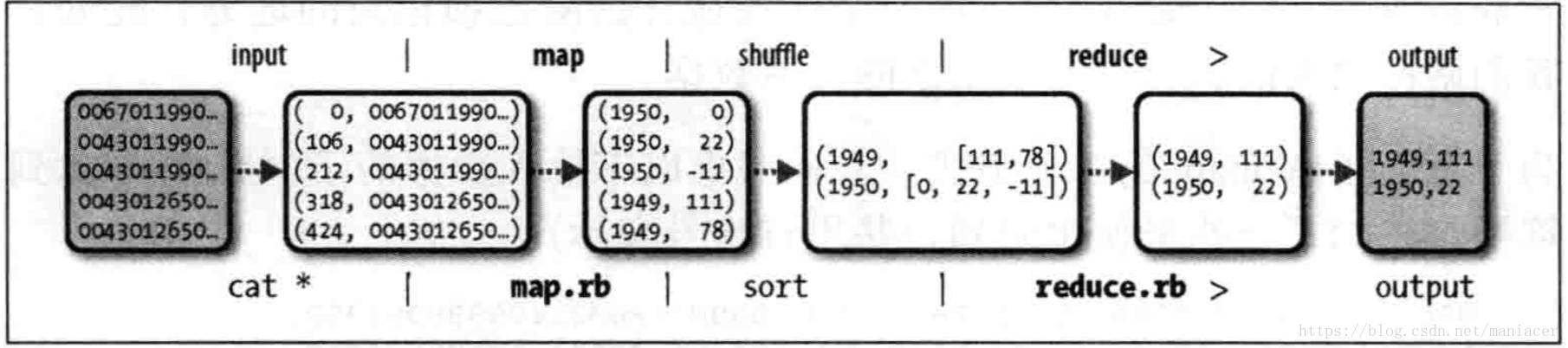
MapReduce任务过程分为两个处理阶段:Map阶段和Reduce阶段,每阶段都以 键-值 作为输入和输出,其类型又开发者根据实际情况自行决定。我们需要编写两个函数:Map函数和Reduce函数。
Map阶段的输入是你刚刚下载的气象数据集,每一行就是一条气象数据,Map的输入的值的格式就是文本格式(String),键就是每一行的起始位置相对于整片内容的偏移量,在这里无实际意义,给Long类型即可。Map函数实现的功能很简单,就是将每一行的数据进行截取,得到我们需要的年份、月份以及气温数据。
为了全面了解Map的工作方式,我们考虑以下输入数据的实例数据(将中间无用的数据省略了,并用省略号表示):
-
0029227070999991901123013004......N0000001N9-01391+99999100321A......
-
0029227070999991901123120004......N0000001N9-01391+99999100281A......
这些行以键值对的方式作为map输入
-
(0,0029227070999991901123013004......N0000001N9-01391+99999100321A......),
-
(106,0029227070999991901123120004......N0000001N9-01391+99999100281A......)
key是文件中的行起始位置的偏移量,Map函数本身不需要这个,所以将其忽略掉,Map函数只需要提取年份月份、气温信息,并将他们作为以下格式输出给Reduce:
-
-
-
-
Map 函数的输出经由Map Reduce框架处理后,最后发送给reduce函数。这个过程基于键来对键值对进行排序和分组。因此,reduce函数接收到的是如下输入:
-
-
-
每个年份月份后跟着一个气温集合,reduce函数只需要从这个气温集合中找出最大的一个值,就能找到当前月份最高气温了:
-
-
-
JAVA代码
MaxTemperatureMapper.java
-
import java.io.IOException;
-
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.LongWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Mapper;
-
-
public class MaxTemperatureMapper
-
extends Mapper<LongWritable, Text, Text, IntWritable> {
-
-
private static final int MISSING = 9999;
-
-
-
public void map(LongWritable key, Text value, Context context)
-
throws IOException, InterruptedException {
-
System.out.println("--------------------->>>>>,key:"+key+",value:"+value+"");
-
String line = value.toString();
-
String year = line.substring(15, 19);
-
-
if (line.charAt(87) == '+') {
-
airTemperature = Integer.parseInt(line.substring(88, 92));
-
-
airTemperature = Integer.parseInt(line.substring(87, 92));
-
-
String quality = line.substring(92, 93);
-
if (airTemperature != MISSING && quality.matches("[01459]")) {
-
System.out.println("--------------------->>>>>write,key:"+year+",value:"+airTemperature+"");
-
context.write(new Text(year), new IntWritable(airTemperature));
-
-
-
-
MaxTemperatureReducer.java
-
import java.io.IOException;
-
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapreduce.Reducer;
-
-
public class MaxTemperatureReducer
-
extends Reducer<Text, IntWritable, Text, IntWritable> {
-
-
-
public void reduce(Text key, Iterable<IntWritable> values,
-
-
throws IOException, InterruptedException {
-
System.out.println("--------reducer>> key:"+key+",values:"+values.toString());
-
int maxValue = Integer.MIN_VALUE;
-
for (IntWritable value : values) {
-
maxValue = Math.max(maxValue, value.get());
-
-
System.out.println("--------reducer>> maxValue:"+key+",maxValue:"+maxValue);
-
context.write(key, new IntWritable(maxValue));
-
-
打包成JAR文件
File->Project Structure

Build Artifacts-Build
对数据格式进行解释
数据来源于:NCDC 美国国家气候数据中心
位置
数据
含义
| 1-4 |
0029 |
|
| 5-10 |
029070 |
USAF weather station identifie |
| 11-15 |
99999 |
WBAN weather station identifier |
| 16-23 |
19010108 |
观察日期 |
| 24-27 |
1300 |
观察时间 |
| 28 |
4 |
|
| 29-34 |
+64333 |
纬度(1000倍) |
| 35-41 |
+023450 |
经度(1000倍) |
| 42-46 |
FM-12 |
|
| 47-51 |
+0005 |
海拔 |
| 52-56 |
99999 |
|
| 57-60 |
V020 |
|
| 61-63 |
230 |
风向 |
| 64 |
1 |
质量代码 |
| 65 |
N |
|
| 66-69 |
0118 |
|
| 70 |
1 |
质量代码 |
| 71-75 |
99999 |
云高(米) |
| 76 |
9 |
|
| 77 |
9 |
|
| 78 |
N |
|
| 79-84 |
000000 |
能见距离(米) |
| 85 |
1 |
质量代码 |
| 86 |
N |
|
| 87 |
9 |
|
| 88-92 |
-0033 |
空气温度(摄氏度*10) |
| 93 |
1 |
质量代码 |
| 94-98 |
+9999 |
露点温度(摄氏度*10) |
| 99 |
9 |
质量代码 |
| 100-104 |
10320 |
大气压(hectopascals x10) |
| 105 |
1 |
质量代码 |
分享到:




相关推荐
hadoop权威指南里全文贯穿案例提到的气象数据, 直接从附录提到的网站下载非常慢. 这里分享出来, 便于大家测试. 由于限制文件大小, 所以上传了1901-1942 年的数据, 对于测试学习足够了. 如果觉得少, 多复制几次, 将...
总的来说,《Hadoop权威指南4》结合源码,是一套全面的学习资料,涵盖了从理论到实践的各个方面,对于想要深入理解Hadoop并利用其处理大数据的人员来说,具有极高的参考价值。通过这本书和源码的学习,你可以提升...
《Hadoop权威指南》第四版的高清PDF版本提供了一个方便的学习资源,使得读者可以在不购买实体书的情况下,依然能够清晰地阅读和学习。然而,值得注意的是,尽管电子版方便,但理解Hadoop这样的复杂技术体系仍需要...
《Hadoop权威指南》是Hadoop领域的经典之作,它深入浅出地讲解了分布式计算系统的核心概念和技术。第二章通常会介绍Hadoop的基础知识,包括Hadoop的起源、设计哲学以及其在处理大规模数据时的核心组件。在这个上下...
《Hadoop权威指南》中文版是全面了解和深入学习Hadoop技术的重要参考资料,它涵盖了Hadoop生态系统中的核心组件以及相关的分布式计算概念。这本书详细解析了Hadoop的设计原理、架构、安装配置、操作维护以及实际应用...
Hadoop权威指南 大数据的存储与分析 第四版
《Hadoop权威指南(第4版)(修订版)》是一本深入探讨大数据存储与分析的重量级书籍,针对Hadoop生态系统提供了全面而详尽的指导。这本书不仅包含了中英文双语版本,还附带了源代码,使得读者可以更加直观地理解和实践...
《Hadoop权威指南》第三版是一本深度剖析Hadoop生态系统的经典著作,旨在帮助读者从基础知识到高级技术全面掌握这个大数据处理平台。Hadoop作为开源的分布式计算框架,以其高可扩展性和容错性,成为了大数据时代的...
本文带来的资源是hadoop权威指南第四版中文版,适合hadoop深入学习
《Hadoop权威指南》是大数据领域的一本经典著作,它深入浅出地介绍了Apache Hadoop这一开源分布式计算框架。Hadoop是由Doug Cutting和Mike Cafarella共同创建,最初是为了支持Google的MapReduce计算模型和Google ...
总结来说,《Hadoop权威指南》不仅介绍了Hadoop的基本概念和操作,还深入探讨了其在大数据处理中的应用和实践,是学习和掌握Hadoop不可或缺的参考资料。通过阅读这本书,你将能够掌握分布式计算的核心思想,为处理...
Hadoop权威指南 第四版 修订版&升级版 中文版 pdf格式。大家放心,绝对是中文版,不骗人。原文件很大,稍压缩了一下,页面依然非常清晰。无水印。共732页。 Tom White 著,王海 等译,清华大学出版社,2017年7月第4...
绝对第四版!绝对中文!绝对完整!绝对第四版!绝对中文!绝对完整! Hadoop权威指南 大数据 第四版 修订版&升级版 中文版 pdf格式。Tom White 著,王海 等译,清华大学出版社,最新第4版。
《Hadoop权威指南》是大数据领域的一本经典著作,它深入浅出地介绍了Hadoop这一开源框架,如何处理和分析海量数据。这本书的第4版不仅进行了修订,还增加了新的内容,使其更适合当前大数据环境的需求。 Hadoop是...
《Hadoop权威指南》(第3版) 修订版是一本专门为那些想要深入理解Hadoop技术的读者准备的专业书籍。Hadoop是当前大数据处理领域的重要工具,它基于分布式计算模型,能够处理和存储海量数据。这本书以其详尽的介绍和...
《HADOOP权威指南》第三版是一本全面深入解析Hadoop生态系统的经典之作,由知名的IT专家撰写,旨在为读者提供最全面、最权威的Hadoop学习资源。这本书以其详尽的内容、清晰的结构和实用的示例,深受广大开发者和数据...
《Hadoop权威指南》是大数据领域的一本经典之作,它深入浅出地介绍了Apache Hadoop这一分布式计算框架的原理和应用。第四版的配套源码和气象数据集为读者提供了丰富的实践材料,帮助理解Hadoop在处理大规模数据时的...
《Hadoop权威指南》是一本深入探讨大数据处理和分布式计算技术的经典著作,尤其对Hadoop生态系统的核心组件进行了详尽的阐述。这本书对于理解Hadoop集群、MapReduce编程模型以及HBase分布式数据库有着极大的帮助。接...