
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。
Snowflake算法核心
把时间戳,工作机器id,序列号组合在一起。
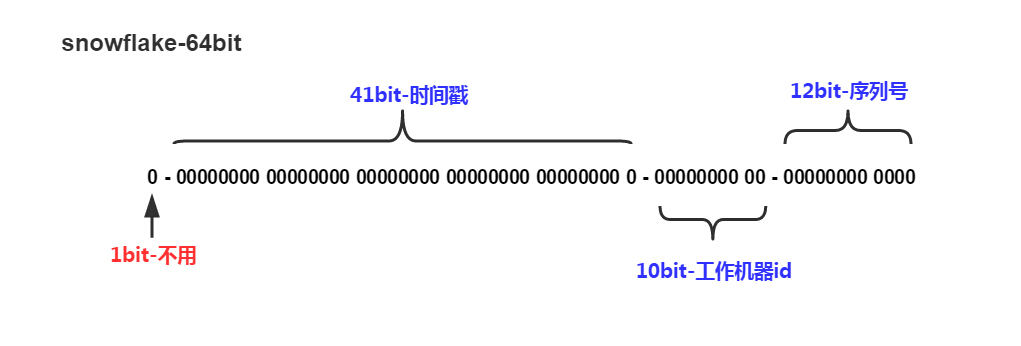
除了最高位bit标记为不可用以外,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。下文会具体分析。
Snowflake – 时间戳
这里时间戳的细度是毫秒级,具体代码如下,建议使用64位linux系统机器,因为有vdso,gettimeofday()在用户态就可以完成操作,减少了进入内核态的损耗。
|
1
2
3
4
5
6
|
uint64_t generateStamp(){ timeval tv;
gettimeofday(&tv, 0);
return (uint64_t)tv.tv_sec * 1000 + (uint64_t)tv.tv_usec / 1000;
} |
默认情况下有41个bit可以供使用,那么一共有T(1llu << 41)毫秒供你使用分配,年份 = T / (3600 * 24 * 365 * 1000) = 69.7年。如果你只给时间戳分配39个bit使用,那么根据同样的算法最后年份 = 17.4年。
Snowflake – 工作机器id
严格意义上来说这个bit段的使用可以是进程级,机器级的话你可以使用MAC地址来唯一标示工作机器,工作进程级可以使用IP+Path来区分工作进程。如果工作机器比较少,可以使用配置文件来设置这个id是一个不错的选择,如果机器过多配置文件的维护是一个灾难性的事情。
这里的解决方案是需要一个工作id分配的进程,可以使用自己编写一个简单进程来记录分配id,或者利用Mysql auto_increment机制也可以达到效果。

工作进程与工作id分配器只是在工作进程启动的时候交互一次,然后工作进程可以自行将分配的id数据落文件,下一次启动直接读取文件里的id使用。
PS:这个工作机器id的bit段也可以进一步拆分,比如用前5个bit标记进程id,后5个bit标记线程id之类:D
Snowflake – 序列号
序列号就是一系列的自增id(多线程建议使用atomic),为了处理在同一毫秒内需要给多条消息分配id,若同一毫秒把序列号用完了,则“等待至下一毫秒”。
|
1
2
3
4
5
6
7
8
|
uint64_t waitNextMs(uint64_t lastStamp){ uint64_t cur = 0;
do {
cur = generateStamp();
} while (cur <= lastStamp);
return cur;
} |
总体来说,是一个很高效很方便的GUID产生算法,一个int64_t字段就可以胜任,不像现在主流128bit的GUID算法,即使无法保证严格的id序列性,但是对于特定的业务,比如用做游戏服务器端的GUID产生会很方便。另外,在多线程的环境下,序列号使用atomic可以在代码实现上有效减少锁的密度。
转自
http://www.lanindex.com/twitter-snowflake,64位自增id算法详解/
参考代码
https://github.com/twitter/snowflake



相关推荐
雪花算法是Twitter开源的一种分布式ID生成算法,它能够生成全局唯一、递增且无碰撞的64位整数ID。这个算法在分布式系统中非常适用,因为传统的序列号生成方式在分布式环境中往往难以解决冲突问题。下面我们将详细...
传统的自增ID在多节点环境下容易出现冲突,而雪花算法(Snowflake)是Twitter开源的一种解决办法。laravel-snowflake就是Laravel对这个算法的实现,它能够生成类似于Twitter Snowflake的64位ID,这些ID由时间戳、...
- Snowflake算法由Twitter提出,通过时间戳、工作机器ID和序列号三部分组成,生成的ID是有序的,且长度适中。这种算法解决了数据库自增ID的并发性和自主性问题,但依赖于系统时钟同步。 在选择分布式ID生成方案时...
##### 4.1 数据库自增ID 利用数据库提供的自增功能是一种简单有效的解决方案。例如,MySQL提供了`AUTO_INCREMENT`属性,可以自动为表中的某列生成递增序列号。这种方式适用于单机环境或者小型分布式系统。 - **...
在实现分布式ID时,通常有几种方案:使用数据库自增ID、使用Redis的incr命令、使用UUID、Twitter的snowflake算法、利用Zookeeper生成唯一ID、MongoDB的ObjectId等。每种方案都有其优缺,需要根据实际情况选择合适的...
#### 四、基于Snowflake算法的分布式ID生成 针对以上几种方法存在的问题,可以借鉴Twitter的Snowflake算法思想,结合具体的业务场景和并发量需求,设计出适用于特定环境的分布式ID生成方案。Snowflake算法的核心...
2. Snowflake算法:Twitter开源的分布式ID生成器,它结合了时间戳、机器ID和序列号,确保生成的ID全局唯一且大部分情况下顺序递增。这种方案依赖时钟,如果时钟回拨,可能会导致ID冲突。 3. ShardingSphere的...
3. **数据库生成**:如MySQL的自增ID,简单可靠,但单点性能瓶颈明显,可通过主从复制提高可用性。 **四、分库分表策略选择** 1. **时间区间**:适用于时间序列数据,如日志记录,易于线性扩容,但非时间维度查询...