┬Ā┬Ā ┬Ā┬ĀõĖĆŃĆüÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢµÅÅĶ┐░
┬Ā ┬Ā ┬Ā ┬Ā┬ĀµÄ©ĶŹÉń│╗ń╗¤Õ║öńö©µĢ░µŹ«Õłåµ×ɵŖƵ£»’╝īµēŠÕć║ńö©µłĘµ£ĆÕÅ»ĶāĮÕ¢£µ¼óńÜäõĖ£Ķź┐µÄ©ĶŹÉń╗Öńö©µłĘ’╝īńÄ░Õ£©ÕŠłÕżÜńöĄÕŁÉÕĢåÕŖĪńĮæń½ÖķāĮµ£ēĶ┐ÖõĖ¬Õ║öńö©ŃĆéńø«ÕēŹńö©ńÜäµ»öĶŠāÕżÜŃĆüµ»öĶŠāµłÉńå¤ńÜäµÄ©ĶŹÉń«Śµ│Ģµś»ÕŹÅÕÉīĶ┐ćµ╗ż’╝łCollaborative Filtering’╝īń«Ćń¦░CF’╝ēµÄ©ĶŹÉń«Śµ│Ģ’╝īCFńÜäÕ¤║µ£¼µĆصā│µś»µĀ╣µŹ«ńö©µłĘõ╣ŗÕēŹńÜäÕ¢£ÕźĮõ╗źÕÅŖÕģČõ╗¢Õģ┤ĶČŻńøĖĶ┐æńÜäńö©µłĘńÜäķĆēµŗ®µØźń╗Öńö©µłĘµÄ©ĶŹÉńē®ÕōüŃĆé
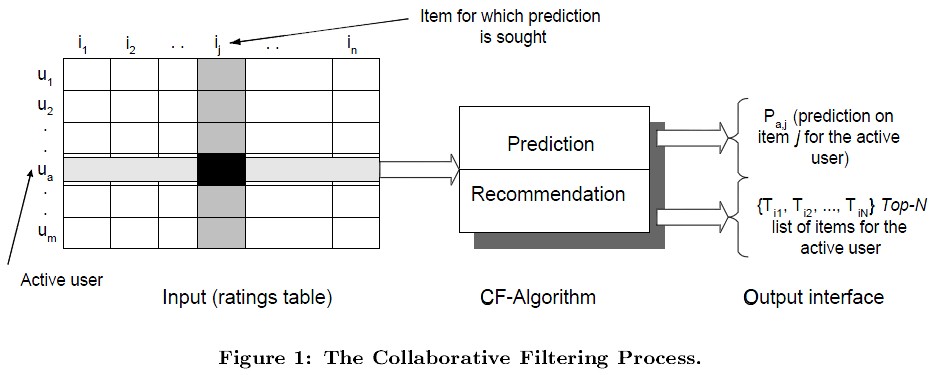
┬Ā ┬Ā ┬Ā ┬Ā┬ĀÕ”éÕøŠ1µēĆńż║’╝īÕ£©CFõĖŁ’╝īńö©m├ŚnńÜäń¤®ķśĄĶĪ©ńż║ńö©µłĘÕ»╣ńē®ÕōüńÜäÕ¢£ÕźĮµāģÕåĄ’╝īõĖĆĶł¼ńö©µēōÕłåĶĪ©ńż║ńö©µłĘÕ»╣ńē®ÕōüńÜäÕ¢£ÕźĮń©ŗÕ║”’╝īÕłåµĢ░ĶČŖķ½śĶĪ©ńż║ĶČŖÕ¢£µ¼óĶ┐ÖõĖ¬ńē®Õōü’╝ī0ĶĪ©ńż║µ▓Īµ£ēõ╣░Ķ┐ćĶ»źńē®ÕōüŃĆéÕøŠõĖŁĶĪīĶĪ©ńż║õĖĆõĖ¬ńö©µłĘ’╝īÕłŚĶĪ©ńż║õĖĆõĖ¬ńē®Õōü’╝īUijĶĪ©ńż║ńö©µłĘiÕ»╣ńē®ÕōüjńÜäµēōÕłåµāģÕåĄŃĆéCFÕłåõĖ║õĖżõĖ¬Ķ┐ćń©ŗ’╝īõĖĆõĖ¬õĖ║ķó䵥ŗĶ┐ćń©ŗ’╝īÕÅ”õĖĆõĖ¬õĖ║µÄ©ĶŹÉĶ┐ćń©ŗŃĆéķó䵥ŗĶ┐ćń©ŗµś»ķó䵥ŗńö©µłĘÕ»╣µ▓Īµ£ēĶ┤Łõ╣░Ķ┐ćńÜäńē®ÕōüńÜäÕÅ»ĶāĮµēōÕłåÕĆ╝’╝īµÄ©ĶŹÉµś»µĀ╣µŹ«ķó䵥ŗķśČµ«ĄńÜäń╗ōµ×£µÄ©ĶŹÉńö©µłĘµ£ĆÕÅ»ĶāĮÕ¢£µ¼óńÜäõĖĆõĖ¬µł¢Top-NõĖ¬ńē®ÕōüŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬Āõ║īŃĆüUser-basedń«Śµ│ĢõĖÄItem-basedń«Śµ│ĢÕ»╣µ»ö
┬Ā ┬Ā ┬Ā ┬Ā┬ĀCFń«Śµ│ĢÕłåõĖ║õĖżÕż¦ń▒╗’╝īõĖĆń▒╗õĖ║Õ¤║õ║ÄmemoryńÜä’╝łMemory-based’╝ē’╝īõ╣¤ÕŽդ║õ║Äńö©µłĘńÜä’╝łUser-based’╝ē’╝īÕÅ”õĖĆń▒╗õĖ║Õ¤║õ║ÄModelńÜä’╝łModel-based’╝ē’╝īõ╣¤ÕŽդ║õ║Äńē®ÕōüńÜä’╝łItem-based’╝ēŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬ĀUser-basedńÜäÕ¤║µ£¼µĆصā│µś»Õ”éµ×£ńö©µłĘAÕ¢£µ¼óńē®Õōüa’╝īńö©µłĘBÕ¢£µ¼óńē®ÕōüaŃĆübŃĆüc’╝īńö©µłĘCÕ¢£µ¼óaÕÆīc’╝īķéŻõ╣łĶ«żõĖ║ńö©µłĘAõĖÄńö©µłĘBÕÆīCńøĖõ╝╝’╝īÕøĀõĖ║õ╗¢õ╗¼ķāĮÕ¢£µ¼óa’╝īĶĆīÕ¢£µ¼óańÜäńö©µłĘÕÉīµŚČõ╣¤Õ¢£µ¼óc’╝īµēĆõ╗źµŖŖcµÄ©ĶŹÉń╗Öńö©µłĘAŃĆéĶ»źń«Śµ│Ģńö©µ£ĆĶ┐æķé╗Õ▒ģ’╝łnearest-neighbor’╝ēń«Śµ│ĢµēŠÕć║õĖĆõĖ¬ńö©µłĘńÜäķé╗Õ▒ģķøåÕÉł’╝īĶ»źķøåÕÉłńÜäńö©µłĘÕÆīĶ»źńö©µłĘµ£ēńøĖõ╝╝ńÜäÕ¢£ÕźĮ’╝īń«Śµ│ĢµĀ╣µŹ«ķé╗Õ▒ģńÜäÕüÅÕźĮÕ»╣Ķ»źńö©µłĘĶ┐øĶĪīķó䵥ŗŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬ĀUser-basedń«Śµ│ĢÕŁśÕ£©õĖżõĖ¬ķćŹÕż¦ķŚ«ķóś’╝Ü
┬Ā ┬Ā ┬Ā ┬Ā┬Ā1. µĢ░µŹ«ń©Ćń¢ÅµĆ¦ŃĆéõĖĆõĖ¬Õż¦Õ×ŗńÜäńöĄÕŁÉÕĢåÕŖĪµÄ©ĶŹÉń│╗ń╗¤õĖĆĶł¼µ£ēķØ×ÕĖĖÕżÜńÜäńē®Õōü’╝īńö©µłĘÕÅ»ĶāĮõ╣░ńÜäÕģČõĖŁõĖŹÕł░1%ńÜäńē®Õōü’╝īõĖŹÕÉīńö©µłĘõ╣ŗķŚ┤õ╣░ńÜäńē®ÕōüķćŹÕÅĀµĆ¦ĶŠāõĮÄ’╝īÕ»╝Ķć┤ń«Śµ│ĢµŚĀµ│ĢµēŠÕł░õĖĆõĖ¬ńö©µłĘńÜäķé╗Õ▒ģ’╝īÕŹ│ÕüÅÕźĮńøĖõ╝╝ńÜäńö©µłĘŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬Ā2. ń«Śµ│Ģµē®Õ▒ĢµĆ¦ŃĆéµ£ĆĶ┐æķé╗Õ▒ģń«Śµ│ĢńÜäĶ«Īń«ŚķćÅķÜÅńØĆńö©µłĘÕÆīńē®ÕōüµĢ░ķćÅńÜäÕó×ÕŖĀĶĆīÕó×ÕŖĀ’╝īõĖŹķĆéÕÉłµĢ░µŹ«ķćÅÕż¦ńÜäµāģÕåĄõĮ┐ńö©ŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬ĀIterm-basedńÜäÕ¤║µ£¼µĆصā│µś»ķóäÕģłµĀ╣µŹ«µēƵ£ēńö©µłĘńÜäÕÄåÕÅ▓ÕüÅÕźĮµĢ░µŹ«Ķ«Īń«Śńē®Õōüõ╣ŗķŚ┤ńÜäńøĖõ╝╝µĆ¦’╝īńäČÕÉĵŖŖõĖÄńö©µłĘÕ¢£µ¼óńÜäńē®ÕōüńøĖń▒╗õ╝╝ńÜäńē®ÕōüµÄ©ĶŹÉń╗Öńö©µłĘŃĆéĶ┐śµś»õ╗źõ╣ŗÕēŹńÜäõŠŗÕŁÉõĖ║õŠŗ’╝īÕÅ»õ╗źń¤źķüōńē®ÕōüaÕÆīcķØ×ÕĖĖńøĖõ╝╝’╝īÕøĀõĖ║Õ¢£µ¼óańÜäńö©µłĘÕÉīµŚČõ╣¤Õ¢£µ¼óc’╝īĶĆīńö©µłĘAÕ¢£µ¼óa’╝īµēĆõ╗źµŖŖcµÄ©ĶŹÉń╗Öńö©µłĘAŃĆé
┬Ā ┬Ā ┬Ā ┬Ā ÕøĀõĖ║ńē®Õōüńø┤µÄźńÜäńøĖõ╝╝µĆ¦ńøĖÕ»╣µ»öĶŠāÕø║Õ«Ü’╝īµēĆõ╗źÕÅ»õ╗źķóäÕģłÕ£©ń║┐õĖŗĶ«Īń«ŚÕźĮõĖŹÕÉīńē®Õōüõ╣ŗķŚ┤ńÜäńøĖõ╝╝Õ║”’╝īµŖŖń╗ōµ×£ÕŁśÕ£©ĶĪ©õĖŁ’╝īÕĮōµÄ©ĶŹÉµŚČĶ┐øĶĪīµ¤źĶĪ©’╝īĶ«Īń«Śńö©µłĘÕÅ»ĶāĮńÜäµēōÕłåÕĆ╝’╝īÕÅ»õ╗źÕÉīµŚČĶ¦ŻÕå│õĖŖķØóõĖżõĖ¬ķŚ«ķóśŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬ĀõĖēŃĆüItem-basedń«Śµ│ĢĶ»”ń╗åĶ┐ćń©ŗ
┬Ā ┬Ā ┬Ā ┬Ā┬Ā’╝ł1’╝ēńøĖõ╝╝Õ║”Ķ«Īń«Ś
┬Ā ┬Ā ┬Ā ┬Ā┬ĀItem-basedń«Śµ│Ģķ”¢ķĆēĶ«Īń«Śńē®Õōüõ╣ŗķŚ┤ńÜäńøĖõ╝╝Õ║”’╝īĶ«Īń«ŚńøĖõ╝╝Õ║”ńÜäµ¢╣µ│Ģµ£ēõ╗źõĖŗÕćĀń¦Ź’╝Ü
┬Ā ┬Ā ┬Ā ┬Ā┬Ā1. Õ¤║õ║ÄõĮÖÕ╝”’╝łCosine-based’╝ēńÜäńøĖõ╝╝Õ║”Ķ«Īń«Ś’╝īķĆÜĶ┐ćĶ«Īń«ŚõĖżõĖ¬ÕÉæķćÅõ╣ŗķŚ┤ńÜäÕż╣Ķ¦ÆõĮÖÕ╝”ÕĆ╝µØźĶ«Īń«Śńē®Õōüõ╣ŗķŚ┤ńÜäńøĖõ╝╝µĆ¦’╝īÕģ¼Õ╝ÅÕ”éõĖŗ’╝Ü

┬Ā ┬Ā ┬Ā ┬Ā┬ĀÕģČõĖŁÕłåÕŁÉõĖ║õĖżõĖ¬ÕÉæķćÅńÜäÕåģń¦»’╝īÕŹ│õĖżõĖ¬ÕÉæķćÅńøĖÕÉīõĮŹńĮ«ńÜäµĢ░ÕŁŚńøĖõ╣śŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬Ā2. Õ¤║õ║ÄÕģ│Ķüö’╝łCorrelation-based’╝ēńÜäńøĖõ╝╝Õ║”Ķ«Īń«Ś’╝īĶ«Īń«ŚõĖżõĖ¬ÕÉæķćÅõ╣ŗķŚ┤ńÜäPearson-rÕģ│ĶüöÕ║”’╝īÕģ¼Õ╝ÅÕ”éõĖŗ’╝Ü
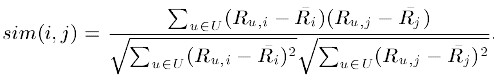
┬Ā ┬Ā ┬Ā ┬Ā┬ĀÕģČõĖŁ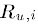 ĶĪ©ńż║ńö©µłĘuÕ»╣ńē®ÕōüińÜäµēōÕłå’╝ī
ĶĪ©ńż║ńö©µłĘuÕ»╣ńē®ÕōüińÜäµēōÕłå’╝ī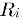 ĶĪ©ńż║ń¼¼iõĖ¬ńē®ÕōüµēōÕłåńÜäÕ╣│ÕØćÕĆ╝ŃĆé
ĶĪ©ńż║ń¼¼iõĖ¬ńē®ÕōüµēōÕłåńÜäÕ╣│ÕØćÕĆ╝ŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬Ā3. Ķ░āµĢ┤ńÜäõĮÖÕ╝”’╝łAdjusted Cosine’╝ēńøĖõ╝╝Õ║”Ķ«Īń«Ś’╝īńö▒õ║ÄÕ¤║õ║ÄõĮÖÕ╝”ńÜäńøĖõ╝╝Õ║”Ķ«Īń«Śµ▓Īµ£ēĶĆāĶÖæõĖŹÕÉīńö©µłĘńÜäµēōÕłåµāģÕåĄ’╝īÕÅ»ĶāĮµ£ēńÜäńö©µłĘÕüÅÕÉæõ║Äń╗Öķ½śÕłå’╝īĶĆīµ£ēńÜäńö©µłĘÕüÅÕÉæõ║Äń╗ÖõĮÄÕłå’╝īĶ»źµ¢╣µ│ĢķĆÜĶ┐ćÕćÅÕÄ╗ńö©µłĘµēōÕłåńÜäÕ╣│ÕØćÕĆ╝µČłķÖżõĖŹÕÉīńö©µłĘµēōÕłåõ╣Āµā»ńÜäÕĮ▒ÕōŹ’╝īÕģ¼Õ╝ÅÕ”éõĖŗ’╝Ü

┬Ā ┬Ā ┬Ā ┬Ā┬ĀÕģČõĖŁ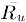 ĶĪ©ńż║ńö©µłĘuµēōÕłåńÜäÕ╣│ÕØćÕĆ╝ŃĆé
ĶĪ©ńż║ńö©µłĘuµēōÕłåńÜäÕ╣│ÕØćÕĆ╝ŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬Ā’╝ł2’╝ēķó䵥ŗÕĆ╝Ķ«Īń«Ś
┬Ā ┬Ā ┬Ā ┬Ā┬ĀµĀ╣µŹ«õ╣ŗÕēŹń«ŚÕźĮńÜäńē®Õōüõ╣ŗķŚ┤ńÜäńøĖõ╝╝Õ║”’╝īµÄźõĖŗµØźÕ»╣ńö©µłĘµ£¬µēōÕłåńÜäńē®ÕōüĶ┐øĶĪīķó䵥ŗ’╝īµ£ēõĖżń¦Źķó䵥ŗµ¢╣µ│Ģ’╝Ü
┬Ā ┬Ā ┬Ā ┬Ā┬Ā1. ÕŖĀµØāµ▒éÕÆīŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬Āńö©Ķ┐ćÕ»╣ńö©µłĘuÕĘ▓µēōÕłåńÜäńē®ÕōüńÜäÕłåµĢ░Ķ┐øĶĪīÕŖĀµØāµ▒éÕÆī’╝īµØāÕĆ╝õĖ║ÕÉäõĖ¬ńē®ÕōüõĖÄńē®ÕōüińÜäńøĖõ╝╝Õ║”’╝īńäČÕÉÄÕ»╣µēƵ£ēńē®ÕōüńøĖõ╝╝Õ║”ńÜäÕÆīµ▒éÕ╣│ÕØć’╝īĶ«Īń«ŚÕŠŚÕł░ńö©µłĘuÕ»╣ńē®ÕōüiµēōÕłå’╝īÕģ¼Õ╝ÅÕ”éõĖŗ’╝Ü
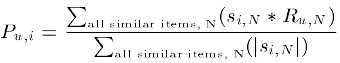
┬Ā ┬Ā ┬Ā ┬Ā┬ĀÕģČõĖŁ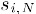 õĖ║ńē®ÕōüiõĖÄńē®ÕōüNńÜäńøĖõ╝╝Õ║”’╝ī
õĖ║ńē®ÕōüiõĖÄńē®ÕōüNńÜäńøĖõ╝╝Õ║”’╝ī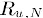 õĖ║ńö©µłĘuÕ»╣ńē®ÕōüNńÜäµēōÕłåŃĆé
õĖ║ńö©µłĘuÕ»╣ńē®ÕōüNńÜäµēōÕłåŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬Ā2. Õø×ÕĮÆŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬ĀÕÆīõĖŖķØóÕŖĀµØāµ▒éÕÆīńÜäµ¢╣µ│Ģń▒╗õ╝╝’╝īõĮåÕø×ÕĮÆńÜäµ¢╣µ│ĢõĖŹńø┤µÄźõĮ┐ńö©ńøĖõ╝╝ńē®ÕōüNńÜäµēōÕłåÕĆ╝’╝īÕøĀõĖ║ńö©õĮÖÕ╝”µ│Ģµł¢PearsonÕģ│Ķüöµ│ĢĶ«Īń«ŚńøĖõ╝╝Õ║”µŚČÕŁśÕ£©õĖĆõĖ¬Ķ»»Õī║’╝īÕŹ│õĖżõĖ¬µēōÕłåÕÉæķćÅÕÅ»ĶāĮńøĖĶĘص»öĶŠāĶ┐£’╝łµ¼¦µ░ÅĶĘØń”╗’╝ē’╝īõĮåµ£ēÕÅ»ĶāĮµ£ēÕŠłķ½śńÜäńøĖõ╝╝Õ║”ŃĆéÕøĀõĖ║õĖŹÕÉīńö©µłĘńÜäµēōÕłåõ╣Āµā»õĖŹÕÉī’╝īµ£ēńÜäÕüÅÕÉæµēōķ½śÕłå’╝īµ£ēńÜäÕüÅÕÉæµēōõĮÄÕłåŃĆéÕ”éµ×£õĖżõĖ¬ńö©µłĘķāĮÕ¢£µ¼óõĖƵĀĘńÜäńē®Õōü’╝īÕøĀõĖ║µēōÕłåõ╣Āµā»õĖŹÕÉī’╝īõ╗¢õ╗¼ńÜäµ¼¦Õ╝ÅĶĘØń”╗ÕÅ»ĶāĮµ»öĶŠāĶ┐£’╝īõĮåõ╗¢õ╗¼Õ║öĶ»źµ£ēĶŠāķ½śńÜäńøĖõ╝╝Õ║”ŃĆéÕ£©Ķ┐Öń¦ŹµāģÕåĄõĖŗńö©µłĘÕĤզŗńÜäńøĖõ╝╝ńē®ÕōüńÜäµēōÕłåÕĆ╝Ķ┐øĶĪīĶ«Īń«Śõ╝ÜķĆĀµłÉń│¤ń│ĢńÜäķó䵥ŗń╗ōµ×£ŃĆéķĆÜĶ┐ćńö©ń║┐µĆ¦Õø×ÕĮÆńÜäµ¢╣Õ╝Åķ揵¢░õ╝░ń«ŚõĖĆõĖ¬µ¢░ńÜäÕĆ╝’╝īĶ┐Éńö©õĖŖķØóÕÉīµĀĘńÜäµ¢╣µ│ĢĶ┐øĶĪīķó䵥ŗŃĆéķ揵¢░Ķ«Īń«ŚńÜäµ¢╣µ│ĢÕ”éõĖŗ’╝Ü

┬Ā ┬Ā ┬Ā ┬Ā┬ĀÕģČõĖŁńē®ÕōüNµś»ńē®ÕōüińÜäńøĖõ╝╝ńē®Õōü’╝ī ÕÆī
ÕÆī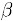 ķĆÜĶ┐ćÕ»╣ńē®ÕōüNÕÆīińÜäµēōÕłåÕÉæķćÅĶ┐øĶĪīń║┐µĆ¦Õø×ÕĮÆĶ«Īń«ŚÕŠŚÕł░’╝ī
ķĆÜĶ┐ćÕ»╣ńē®ÕōüNÕÆīińÜäµēōÕłåÕÉæķćÅĶ┐øĶĪīń║┐µĆ¦Õø×ÕĮÆĶ«Īń«ŚÕŠŚÕł░’╝ī õĖ║Õø×ÕĮƵ©ĪÕ×ŗńÜäĶ»»ÕĘ«ŃĆéÕģĘõĮōµĆÄõ╣łĶ┐øĶĪīń║┐µĆ¦Õø×ÕĮƵ¢ćń½ĀķćīķØóµ▓Īµ£ēĶ»┤µśÄ’╝īķ£ĆĶ”üµ¤źķśģÕÅ”Õż¢ńÜäńøĖÕģ│µ¢ćńī«ŃĆé
õĖ║Õø×ÕĮƵ©ĪÕ×ŗńÜäĶ»»ÕĘ«ŃĆéÕģĘõĮōµĆÄõ╣łĶ┐øĶĪīń║┐µĆ¦Õø×ÕĮƵ¢ćń½ĀķćīķØóµ▓Īµ£ēĶ»┤µśÄ’╝īķ£ĆĶ”üµ¤źķśģÕÅ”Õż¢ńÜäńøĖÕģ│µ¢ćńī«ŃĆé
┬Ā ┬Ā ┬Ā ┬Ā┬ĀÕøøŃĆüń╗ōĶ«║
┬Ā ┬Ā ┬Ā ┬Ā õĮ£ĶĆģķĆÜĶ┐ćÕ«×ķ¬īÕ»╣µ»öń╗ōµ×£ÕŠŚÕć║ń╗ōĶ«║’╝Ü1. Item-basedń«Śµ│ĢńÜäķó䵥ŗń╗ōµ×£µ»öUser-basedń«Śµ│ĢńÜäĶ┤©ķćÅĶ”üķ½śõĖĆńé╣ŃĆé2. ńö▒õ║ÄItem-basedń«Śµ│ĢÕÅ»õ╗źķóäÕģłĶ«Īń«ŚÕźĮńē®ÕōüńÜäńøĖõ╝╝Õ║”’╝īµēĆõ╗źÕ£©ń║┐ńÜäķó䵥ŗµĆ¦ĶāĮĶ”üµ»öUser-basedń«Śµ│ĢńÜäķ½śŃĆé3. ńö©ńē®ÕōüńÜäõĖĆõĖ¬Õ░Åķā©ÕłåÕŁÉķøåõ╣¤ÕÅ»õ╗źÕŠŚÕł░ķ½śĶ┤©ķćÅńÜäķó䵥ŗń╗ōµ×£ŃĆé
┬Ā ┬Ā ┬Ā ┬Ā ĶĮ¼ĶĮĮĶ»Ęµ│©µśÄÕć║Õżä’╝īÕĤµ¢ćÕ£░ÕØĆ’╝Ühttp://blog.csdn.net/huagong_adu/article/details/7362908
Õłåõ║½Õł░’╝Ü





ńøĖÕģ│µÄ©ĶŹÉ
### Õ¤║õ║ÄÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäÕĢåÕōüµÄ©ĶŹÉń│╗ń╗¤Ķ«ŠĶ«ĪõĖÄÕ«×ńÄ░ #### õĖĆŃĆüń╗¬Ķ«║ - **ķĆēķóśÕŖ©ÕøĀ**’╝ÜķÜÅńØĆõ║ÆĶüöńĮæµŖƵ£»ńÜäÕÅæÕ▒ĢÕÆīńöĄÕŁÉÕĢåÕŖĪÕ╣│ÕÅ░ńÜäÕģ┤ĶĄĘ’╝īÕ”éõĮĢÕ£©µĄĘķćÅńÜäÕĢåÕōüõ┐Īµü»õĖŁÕĖ«ÕŖ®ńö©µłĘµēŠÕł░õ╗¢õ╗¼ń£¤µŁŻµä¤Õģ┤ĶČŻńÜäÕĢåÕōüµłÉõĖ║õ║åÕĢåÕ«ČķØóõĖ┤ńÜäõĖĆõĖ¬ķćŹÕż¦...
ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│Ģ’╝łCollaborative Filtering’╝ēµś»õĖĆń¦Źń╗ÅÕģĖńÜäµÄ©ĶŹÉń«Śµ│Ģ’╝īÕģČÕ¤║µ£¼ÕĤńÉåµś»ŌĆ£ÕŹÅÕÉīÕż¦Õ«ČńÜäÕÅŹķ”łŃĆüĶ»äõ╗ĘÕÆīµäÅĶ¦ü’╝īõĖĆĶĄĘÕ»╣µĄĘķćÅńÜäõ┐Īµü»Ķ┐øĶĪīĶ┐ćµ╗ż’╝īõ╗ÄõĖŁńŁøķĆēÕć║ńö©µłĘÕÅ»ĶāĮµä¤Õģ┤ĶČŻńÜäõ┐Īµü»ŌĆØŃĆéÕ«āõĖ╗Ķ”üõŠØĶĄ¢õ║Äńö©µłĘÕÆīńē®Õōüõ╣ŗķŚ┤ńÜäĶĪīõĖ║Õģ│ń│╗...
Õ¤║õ║ÄÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäÕĢåÕōüµÄ©ĶŹÉń│╗ń╗¤µś»õĖĆń¦ŹÕĖĖĶ¦üńÜäµÄ©ĶŹÉń│╗ń╗¤’╝īÕ«āÕł®ńö©ńö©µłĘĶĪīõĖ║µĢ░µŹ«µØźķó䵥ŗńö©µłĘÕÅ»ĶāĮÕ¢£µ¼óńÜäÕĢåÕōüŃĆéÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢõĖ╗Ķ”üÕ¤║õ║ÄõĖżõĖ¬ÕÄ¤ÕłÖ’╝Üńö©µłĘ-ńö©µłĘÕŹÅÕÉīĶ┐ćµ╗żÕÆīńē®Õōü-ńē®ÕōüÕŹÅÕÉīĶ┐ćµ╗żŃĆé Õ£©Spring BootõĖŁµ×äÕ╗║Õ¤║õ║ÄÕŹÅÕÉīĶ┐ćµ╗ż...
ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢõĮ£õĖ║µÄ©ĶŹÉń│╗ń╗¤ńÜäķćŹĶ”üµŖƵ£»õ╣ŗõĖĆ’╝īÕ«āķĆÜĶ┐ćÕłåµ×ÉÕÆīµ»öĶŠāńö©µłĘõ╣ŗķŚ┤ńÜäÕüÅÕźĮÕģ│ń│╗’╝īÕ»╣ńö©µłĘĶ┐øĶĪīÕłåń╗䵳¢Õ»╣ńē®ÕōüĶ┐øĶĪīµÄ©ĶŹÉ’╝īÕĘ▓Õ╣┐µ│øÕ║öńö©õ║ÄńöĄÕŁÉÕĢåÕŖĪķóåÕ¤¤’╝īÕīģµŗ¼ńöĄÕĢåŃĆüĶ¦åķóæńĮæń½ÖŃĆüķ¤│õ╣ÉÕ╣│ÕÅ░ńŁēŃĆé ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢõĖ╗Ķ”üÕłåõĖ║õĖżń▒╗’╝ÜÕ¤║õ║Ä...
ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│Ģ javaµ║ÉńĀü ÕŹÅÕÉīĶ┐ćµ╗żÕĖĖÕĖĖĶó½ńö©õ║ÄÕłåĶŠ©µ¤ÉõĮŹńē╣Õ«ÜķĪŠÕ«óÕÅ»ĶāĮµä¤Õģ┤ĶČŻńÜäõĖ£Ķź┐’╝īĶ┐Öõ║øń╗ōĶ«║µØźĶć¬õ║ÄÕ»╣ÕģČõ╗¢ńøĖõ╝╝ķĪŠÕ«óÕ»╣Õō¬õ║øõ║¦Õōüµä¤Õģ┤ĶČŻńÜäÕłåµ×ÉŃĆéÕŹÅÕÉīĶ┐ćµ╗żõ╗źÕģČÕć║Ķē▓ńÜäķƤÕ║”ÕÆīÕüźÕŻ«µĆ¦’╝īÕ£©Õģ©ńÉāõ║ÆĶüöńĮæķóåÕ¤¤ńéÖµēŗÕÅ»ńāŁŃĆé
ŃĆŖÕ¤║õ║Äńē®ÕōüńÜäÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢÕ£©MapReduceµĪåµ×ČõĖŗńÜäÕ«×ńÄ░õĖÄÕ║öńö©ŃĆŗ ÕŹÅÕÉīĶ┐ćµ╗ż’╝łCollaborative Filtering’╝īń«Ćń¦░CF’╝ēµś»µÄ©ĶŹÉń│╗ń╗¤õĖŁµ£ĆÕĖĖńö©ńÜäõĖĆń¦Źń«Śµ│Ģ’╝īÕ«āÕ¤║õ║Äńö©µłĘńÜäĶĪīõĖ║µĢ░µŹ«µØźķó䵥ŗõ╗¢õ╗¼ÕÅ»ĶāĮµä¤Õģ┤ĶČŻõĮåÕ░ܵ£¬µÄźĶ¦”Ķ┐ćńÜäńē®ÕōüŃĆéĶĆīÕ¤║õ║Äńē®Õōü...
ńöĄÕĮ▒µÄ©ĶŹÉń│╗ń╗¤õĖŁĶ┐Éńö©ńÜäµÄ©ĶŹÉń«Śµ│Ģµś»Õ¤║õ║ÄÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│Ģ’╝łCollaborative Filtering Recommendation’╝ēŃĆéÕŹÅÕÉīĶ┐ćµ╗żµś»Õ£©õ┐Īµü»Ķ┐ćµ╗żÕÆīõ┐Īµü»ń│╗ń╗¤õĖŁµŁŻĶ┐ģķƤµłÉõĖ║õĖĆķĪ╣ÕŠłÕÅŚµ¼óĶ┐ÄńÜäµŖƵ£»ŃĆéõĖÄõ╝Āń╗¤ńÜäÕ¤║õ║ÄÕåģÕ«╣Ķ┐ćµ╗żńø┤µÄźÕłåµ×ÉÕåģÕ«╣Ķ┐øĶĪīµÄ©ĶŹÉõĖŹÕÉī’╝ī...
Javaµ»ĢõĖÜĶ«ŠĶ«ĪÕ¤║õ║Äńö©µłĘńÜäÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢÕ«×ńÄ░ńÜäÕĢåÕōüµÄ©ĶŹÉń│╗ń╗¤µ║ÉńĀü+µĢ░µŹ«Õ║ō’╝łķ½śÕłåķĪ╣ńø«’╝ē.zipĶ»źķĪ╣ńø«µś»õĖ¬õ║║ķ½śÕłåµ»ĢõĖÜĶ«ŠĶ«ĪķĪ╣ńø«µ║ÉńĀü’╝īÕĘ▓ĶÄĘÕ»╝ÕĖłµīćÕ»╝Ķ«żÕÅ»ķĆÜĶ┐ć’╝īķāĮń╗ÅĶ┐ćõĖźµĀ╝Ķ░āĶ»Ģ’╝īńĪ«õ┐ØÕÅ»õ╗źĶ┐ÉĶĪī’╝üµöŠÕ┐āõĖŗĶĮĮõĮ┐ńö©ŃĆé Javaµ»ĢõĖÜĶ«ŠĶ«ĪÕ¤║õ║Äńö©µłĘ...
### Õ¤║õ║ÄÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäõĖ¬µĆ¦Õī¢µÄ©ĶŹÉµŖƵ£»ńÜäńĀöń®Č #### õĖĆŃĆüńĀöń®ČĶāīµÖ»õĖĵäÅõ╣ē Õ£©õ║ÆĶüöńĮæõ┐Īµü»ńłåńéĖńÜ䵌Čõ╗ŻĶāīµÖ»õĖŗ’╝īńö©µłĘķØóõĖ┤ńØƵĄĘķćÅńÜäõ┐Īµü»ķĆēµŗ®ķÜŠķóśŃĆéÕ”éõĮĢõ╗ĵĄĘķćŵĢ░µŹ«õĖŁńŁøķĆēÕć║µ£Ćń¼”ÕÉłńö©µłĘÕģ┤ĶČŻńÜäÕåģÕ«╣µłÉõĖ║õ║åõĖĆõĖ¬õ║¤ÕŠģĶ¦ŻÕå│ńÜäķŚ«ķóśŃĆé...
Õ£©Ķ┐ÖõĖ¬µĢ░µŹ«ķøåõĖŁ’╝īµłæõ╗¼ķćŹńé╣µÄóĶ«©Õ¤║õ║Äńö©µłĘńÜäÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│Ģ’╝īĶ┐Öµś»õĖĆń¦ŹÕł®ńö©ńö©µłĘõ╣ŗķŚ┤ńÜäńøĖõ╝╝µĆ¦µØźÕüÜÕć║µÄ©ĶŹÉńÜäµ¢╣µ│ĢŃĆé ķ”¢Õģł’╝īµłæõ╗¼ķ£ĆĶ”üńÉåĶ¦Żń«Śµ│ĢńÜäÕ¤║µ£¼ÕĤńÉåŃĆéÕ¤║õ║Äńö©µłĘńÜäÕŹÅÕÉīĶ┐ćµ╗ż’╝łUser-Based Collaborative Filtering’╝īUBCF’╝ēÕüćĶ«Š...
Õ¤║õ║ÄSSM(Spring+SpringMVC+MyBatis)ÕÆīVue.jsńÜäÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńöĄÕĮ▒µÄ©ĶŹÉń│╗ń╗¤µś»õĖĆõĖ¬Õł®ńö©ńö©µłĘÕÄåÕÅ▓Ķ¦éÕĮ▒Ķ«░ÕĮĢÕÆīĶ»äÕłåµĢ░µŹ«’╝īķĆÜĶ┐ćÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢµØźķó䵥ŗńö©µłĘÕÅ»ĶāĮÕ¢£µ¼óńÜäńöĄÕĮ▒ńÜäń│╗ń╗¤ŃĆéĶ»źń│╗ń╗¤õĖ╗Ķ”üńö▒õ╗źõĖŗÕćĀõĖ¬µ©ĪÕØŚń╗䵳ɒ╝Ü ńö©µłĘń«ĪńÉ嵩ĪÕØŚ’╝Ü...
ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäÕøŠõ╣”µÄ©ĶŹÉń│╗ń╗¤-ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäÕøŠõ╣”µÄ©ĶŹÉń│╗ń╗¤ńÜäĶ«ŠĶ«ĪõĖÄÕ«×ńÄ░õ╗ŻńĀü-java-ssm-Õ¤║õ║ÄssmńÜäÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäÕøŠõ╣”µÄ©ĶŹÉń│╗ń╗¤ķĪ╣ńø«-õ╗ŻńĀü-µ║ÉńĀü-ķĪ╣ńø«-ń│╗ń╗¤-µ»ĢĶ«Š-ńĮæń½Ö 1ŃĆüµŖƵ£»µĀł’╝Üjava,s sm,vue’╝īajax’╝īmaven’╝īmysql’╝ī...
ŃĆŖÕ¤║õ║ÄÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜ䵌ģµĖĖµÄ©ĶŹÉń│╗ń╗¤Õ╝ĆÕÅæĶ»”Ķ¦ŻŃĆŗ Õ£©ÕĮōõ╗Ŗõ┐Īµü»ńłåńéĖńÜ䵌Čõ╗Ż’╝īõĖ¬µĆ¦Õī¢µÄ©ĶŹÉń│╗ń╗¤ÕĘ▓µłÉõĖ║µÅÉÕŹćńö©µłĘõĮōķ¬īŃĆüµÅÉķ½śńö©µłĘµ╗ĪµäÅÕ║”ńÜäķćŹĶ”üÕĘźÕģĘŃĆéµ£¼ķĪ╣ńø«ŌĆ£Õ¤║õ║ÄÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜ䵌ģµĖĖµÄ©ĶŹÉń│╗ń╗¤ŌĆصŁŻµś»õ╗źµŁżõĖ║ńø«µĀć’╝īń╗ōÕÉłJavaŃĆüJSPÕÆī...
ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│Ģõ╗ŻńĀü VSõĖŗĶ┐ÉĶĪī µĢ░µŹ«ķøåķććńö©MovieLens
ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│Ģµś»µÄ©ĶŹÉń│╗ń╗¤õĖŁńÜäõĖĆń¦ŹķćŹĶ”üµŖƵ£»’╝īÕ«āÕł®ńö©ńö©µłĘµł¢ńē®Õōüõ╣ŗķŚ┤ńÜäńøĖõ╝╝µĆ¦µØźķó䵥ŗµ£¬ń¤źĶ»äÕłåµł¢ÕüÅÕźĮ’╝īÕ╣Čõ╗źµŁżńö¤µłÉµÄ©ĶŹÉŃĆéÕ£©µ¢ćµĪŻŌĆ£Õ¤║õ║ÄPythonńÜäÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäĶ«ŠĶ«ĪõĖÄÕ«×ńÄ░.pdfŌĆØõĖŁ’╝īõ╗ŗń╗Źõ║åÕ”éõĮĢõĮ┐ńö©PythonĶ»ŁĶ©ĆĶ«ŠĶ«ĪÕÆīÕ«×ńÄ░ÕŹÅÕÉī...
ŃĆŖÕ¤║õ║ÄPythonõĖÄÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäÕøŠõ╣”µÄ©ĶŹÉń│╗ń╗¤Ķ«ŠĶ«ĪõĖÄÕ«×ńÄ░ŃĆŗ Õ£©ÕĮōõ╗Ŗõ┐Īµü»ńłåńéĖńÜ䵌Čõ╗Ż’╝īõĖ¬µĆ¦Õī¢µÄ©ĶŹÉń│╗ń╗¤ÕĘ▓ń╗ŵłÉõĖ║ÕÉäń▒╗Õ£©ń║┐µ£ŹÕŖĪõĖŹÕÅ»µł¢ń╝║ńÜäõĖĆķā©Õłå’╝īńē╣Õł½µś»Õ£©ÕøŠõ╣”µÄ©ĶŹÉķóåÕ¤¤ŃĆéµ£¼ķĪ╣ńø«ĶüÜńä”õ║ÄÕł®ńö©Pythonń╝¢ń©ŗĶ»ŁĶ©ĆÕÆīÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢµØźµ×äÕ╗║...
1. **ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢÕĤńÉå**’╝Ü - **ńö©µłĘ-ńö©µłĘÕŹÅÕÉīĶ┐ćµ╗ż**’╝ÜĶ┐Öń¦Źń«Śµ│ĢķĆÜĶ┐ćÕ»╗µēŠõĖÄńø«µĀćńö©µłĘµ£ēńøĖõ╝╝Ķ┤Łõ╣░ÕÄåÕÅ▓µł¢Ķ»äÕłåĶĪīõĖ║ńÜäÕģČõ╗¢ńö©µłĘ’╝īńäČÕÉĵĩĶŹÉõ╗¢õ╗¼Õ¢£µ¼óõĮåńø«µĀćńö©µłĘÕ░ܵ£¬µÄźĶ¦”ńÜäÕøŠõ╣”ŃĆé - **ńē®Õōü-ńē®ÕōüÕŹÅÕÉīĶ┐ćµ╗ż**’╝ÜĶ┐Öń¦Źµ¢╣µ│Ģµś»µēŠÕł░õĖÄ...
µŁżńĮæń½Öµś»õĖĆõĖ¬Õģ©Õōüń▒╗ńÜäĶ┤Łńē®ÕĢåÕ¤Äń│╗ń╗¤’╝īńäČÕÉÄÕ£©õ╝Āń╗¤ńÜäĶ┤Łńē®ÕĢåÕ¤ÄńÜäÕ¤║ńĪĆõĖŖķØóÕŖĀÕģźõ║åÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│Ģ’╝īÕīģµŗ¼õ║åÕ¤║õ║Äńö©µłĘńÜäÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢÕÆīÕ¤║õ║ÄÕĢåÕōüńÜäÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢŃĆéńö©µłĘÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│ĢńÜäµĀĖÕ┐āµĆصā│Õ£©õ║ĵĀ╣µŹ«ńö©µłĘĶ»äÕłåń¤®ķśĄĶ«Īń«Śńö©µłĘõĮÖÕ╝”...
ÕŹÅÕÉīĶ┐ćµ╗żń«Śµ│Ģµś»µÄ©ĶŹÉń│╗ń╗¤õĖŁÕĖĖńö©ńÜäõĖĆń¦ŹµŖƵ£»’╝īÕ░żÕģČÕ£©ńöĄÕĮ▒µÄ©ĶŹÉķóåÕ¤¤µ£ēńØĆÕ╣┐µ│øńÜäÕ║öńö©ŃĆéÕŹÅÕÉīĶ┐ćµ╗żńÜäÕ¤║µ£¼µĆصā│µś»ķĆÜĶ┐ćÕłåµ×Éńö©µłĘńÜäÕÄåÕÅ▓ĶĪīõĖ║’╝īÕ”éÕ»╣ńöĄÕĮ▒ńÜäĶ»äÕłå’╝īµØźµÄ©µĄŗńö©µłĘµ£¬µØźÕÅ»ĶāĮńÜäÕģ┤ĶČŻŃĆéÕ«āÕłåõĖ║Õ¤║õ║Äńö©µłĘ’╝łUser-Based’╝ēÕÆīÕ¤║õ║Äńē®Õōü...