
1、二叉树的概念
二叉树(Binary Tree)是个有限元素的集合,该集合或者为空、或者由一个称为根(root)的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成。当集合为空时,称该二叉树为空二叉树。在二叉树中,一个元素也称作一个结点。
(1)结点的度。结点所拥有的子树的个数称为该结点的度。
(2)叶结点。度为0的结点称为叶结点,或者称为终端结点。
(3)分枝结点。度不为0的结点称为分支结点,或者称为非终端结点。一棵树的结点除叶结点外,其余的都是分支结点。
(4)左孩子、右孩子、双亲。树中一个结点的子树的根结点称为这个结点的孩子。这个结点称为它孩子结点的双亲。具有同一个双亲的孩子结点互称为兄弟。
(5)路径、路径长度。如果一棵树的一串结点n1,n2,…,nk有如下关系:结点ni是ni+1的父结点(1≤i<k),就把n1,n2,…,nk称为一条由n1至nk的路径。这条路径的长度是k-1。
(6)祖先、子孙。在树中,如果有一条路径从结点M到结点N,那么M就称为N的祖先,而N称为M的子孙。
(7)结点的层数。规定树的根结点的层数为1,其余结点的层数等于它的双亲结点的层数加1。
(8)树的深度。树中所有结点的最大层数称为树的深度。
(9)树的度。树中各结点度的最大值称为该树的度。
(10)满二叉树
在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子结点都在同一层上,这样的一棵二叉树称作满二叉树。
11)完全二叉树。
一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。完全二叉树的特点是:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。显然,一棵满二叉树必定是一棵完全二叉树,而完全二叉树未必是满二叉树。
二叉树的主要性质
性质1 一棵非空二叉树的第i层上最多有2i-1个结点(i≥1)。
性质2 一棵深度为k的二叉树中,最多具有2k-1个结点。
性质3 对于一棵非空的二叉树,如果叶子结点数为n0,度数为2的结点数为n2,则有: n0=n2+1。
性质4 具有n个结点的完全二叉树的深度k为[log2n]+1。
性质5 对于具有n个结点的完全二叉树,如果按照从上至下和从左到右的顺序对二叉树中的所有结点从1开始顺序编号,则对于任意的序号为i的结点,有:
(1)如果i>1,则序号为i的结点的双亲结点的序号为i/2(“/”表示整除);如果i=1,则序号为i的结点是根结点,无双亲结点。
(2)如果2i≤n,则序号为i的结点的左孩子结点的序号为2i;如果2i>n,则序号为i的结点无左孩子。
(3)如果2i+1≤n,则序号为i的结点的右孩子结点的序号为2i+1;如果2i+1>n,则序号为i的结点无右孩子
二叉树的遍历
二叉树的遍历是指按照某种顺序访问二叉树中的每个结点,使每个结点被访问一次且仅被访问一次。
1)先序遍历
根--->左子树--->右子树
先序遍历二叉树的递归算法如下:
void PreOrder(BiTree bt)
{/*先序遍历二叉树bt*/
if (bt==NULL) return; /*递归调用的结束条件*/
Visite(bt->data); /*访问结点的数据域*/
PreOrder(bt->lchild); /*先序递归遍历bt的左子树*/
PreOrder(bt->rchild); /*先序递归遍历bt的右子树*/
}
2)中序遍历
左子树--->根---->右子树
中序遍历二叉树的递归算法如下:
void InOrder(BiTree bt)
{/*中序遍历二叉树bt*/
if (bt==NULL) return; /*递归调用的结束条件*/
InOrder(bt->lchild); /*中序递归遍历bt的左子树*/
Visite(bt->data); /*访问结点的数据域*/
InOrder(bt->rchild); /*中序递归遍历bt的右子树*/
}
3)后序遍历
左子树--->右子树--->根
后序遍历二叉树的递归算法如下:
void PostOrder(BiTree bt)
{/*后序遍历二叉树bt*/
if (bt==NULL) return; /*递归调用的结束条件*/
PostOrder(bt->lchild); /*后序递归遍历bt的左子树*/
PostOrder(bt->rchild); /*后序递归遍历bt的右子树*/
Visite(bt->data); /*访问结点的数据域*/
}
层次遍历
所谓二叉树的层次遍历,是指从二叉树的第一层(根结点)开始,从上至下逐层遍历,在同一层中,则按从左到右的顺序对结点逐个访问。
在进行层次遍历时,可设置一个队列结构,遍历从二叉树的根结点开始,首先将根结点指针入队列,然后从对头取出一个元素,每取一个元素,执行下面两个操作:
(1)访问该元素所指结点;
(2)若该元素所指结点的左、右孩子结点非空,则将该元素所指结点的左孩子指针和右孩子指针顺序入队。
此过程不断进行,当队列为空时,二叉树的层次遍历结束。
2.哈夫曼树Haffman树
最优二叉树,是带权路径最短的树
假设有n个权值{w1,w2,w3,...,wn} ,是构造一颗有n个叶子节点的二叉树,每个叶子节点的权值为wi,则其中带权路径长度WPL最小的二叉树称为Haffman树。用于数据压缩,构建Haffman编码。
3.图
(1)有向图、无向图、完全图、度、深度遍历、广度遍历。
(2)无向图连通性,有向图的连通性,强连通分量,)
(3)最小生成树
Prim算法:从一个顶点按最小边连接邻接点,直到所有的点都连通。
Kruskal算法:从所有的连通边中挑出最小的边,依次挑选次小的边,以此类推,直到所有顶点都连通。
(4)单元最短路径
一.最短路径的最优子结构性质
该性质描述为:如果P(i,j)={Vi....Vk..Vs...Vj}是从顶点i到j的最短路径,k和s是这条路径上的一个中间顶点,那么P(k,s)必定是从k到s的最短路径。下面证明该性质的正确性。
假设P(i,j)={Vi....Vk..Vs...Vj}是从顶点i到j的最短路径,则有P(i,j)=P(i,k)+P(k,s)+P(s,j)。而P(k,s)不是从k到s的最短距离,那么必定存在另一条从k到s的最短路径P'(k,s),那么P'(i,j)=P(i,k)+P'(k,s)+P(s,j)<P(i,j)。则与P(i,j)是从i到j的最短路径相矛盾。因此该性质得证。
二.Dijkstra算法
由上述性质可知,如果存在一条从i到j的最短路径(Vi.....Vk,Vj),Vk是Vj前面的一顶点。那么(Vi...Vk)也必定是从i到k的最短路径。为了求出最短路径,Dijkstra就提出了以最短路径长度递增,逐次生成最短路径的算法。譬如对于源顶点V0,首先选择其直接相邻的顶点中长度最短的顶点Vi,那么当前已知可得从V0到达Vj顶点的最短距离dist[j]=min{dist[j],dist[i]+matrix[i][j]}。根据这种思路,
假设存在G=<V,E>,源顶点为V0,U={V0},dist[i]记录V0到i的最短距离,path[i]记录从V0到i路径上的i前面的一个顶点。
1.从V-U中选择使dist[i]值最小的顶点i,将i加入到U中;
2.更新与i直接相邻顶点的dist值。(dist[j]=min{dist[j],dist[i]+matrix[i][j]})
3.知道U=V,停止。
3.八大排序算法
(1)直接插入排序
基本思想:
将一个记录插入到已排序好的有序表中,从而得到一个新,记录数增1的有序表。即:先将序列的第1个记录看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
要点:设立哨兵,作为临时存储和判断数组边界之用。
插入排序算法是稳定的(排序前后相同元素顺序不变)
效率:
时间复杂度:O(n^2)稳定.
(2)交换排序-冒泡排序
基本思想:
在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
冒泡排序算法的改进
对冒泡排序常见的改进方法是加入一标志性变量exchange,用于标志某一趟排序过程中是否有数据交换,如果进行某一趟排序时并没有进行数据交换,则说明数据已经按要求排列好,可立即结束排序,避免不必要的比较过程。
本文再提供以下两种改进算法:
1.设置一标志性变量pos,用于记录每趟排序中最后一次进行交换的位置。由于pos位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。
2.传统冒泡排序中每一趟排序操作只能找到一个最大值或最小值,我们考虑利用在每趟排序中进行正向和反向两遍冒泡的方法一次可以得到两个最终值(最大者和最小者) , 从而使排序趟数几乎减少了一半。
效率:
时间复杂度:O(n^2),稳定.
(3)选择排序-简单选择排序
基本思想:
在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换;然后在剩下的数当中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素(最后一个数)比较为止。
操作方法:
第一趟,从n 个记录中找出关键码最小的记录与第一个记录交换;
第二趟,从第二个记录开始的n-1 个记录中再选出关键码最小的记录与第二个记录交换;
以此类推.....
第i 趟,则从第i 个记录开始的n-i+1 个记录中选出关键码最小的记录与第i 个记录交换,
直到整个序列按关键码有序。
简单选择排序的改进——二元选择排序
简单选择排序,每趟循环只能确定一个元素排序后的定位。我们可以考虑改进为每趟循环确定两个元素(当前趟最大和最小记录)的位置,从而减少排序所需的循环次数。改进后对n个数据进行排序,最多只需进行[n/2]趟循环即可。
效率:
时间复杂度:O(n^2)但是 不稳定.
(4)选择排序-堆排序
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
堆的定义如下:具有n个元素的序列(k1,k2,...,kn),当且仅当满足
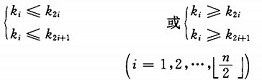
时称之为堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最小项(小顶堆)。
若以一维数组存储一个堆,则堆对应一棵完全二叉树,且所有非叶结点的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的。
初始时把要排序的n个数的序列看作是一棵顺序存储的二叉树(一维数组存储二叉树),调整它们的存储序,使之成为一个堆,将堆顶元素输出,得到n 个元素中最小(或最大)的元素,这时堆的根节点的数最小(或者最大)。然后对前面(n-1)个元素重新调整使之成为堆,输出堆顶元素,得到n 个元素中次小(或次大)的元素。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。称这个过程为堆排序。
因此,实现堆排序需解决两个问题:
1. 如何将n 个待排序的数建成堆;
2. 输出堆顶元素后,怎样调整剩余n-1 个元素,使其成为一个新堆。
算法不稳定,且效率为O(nlogn)
(5)快速排序
基本思想:
1)选择一个基准元素,通常选择第一个元素或者最后一个元素,
2)通过一趟排序讲待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的 元素值比基准值大。
3)此时基准元素在其排好序后的正确位置
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
分析:
快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的。但若初始序列按关键码有序或基本有序时,快排序反而蜕化为冒泡排序。为改进之,通常以“三者取中法”来选取基准记录,即将排序区间的两个端点与中点三个记录关键码居中的调整为支点记录。快速排序是一个不稳定的排序方法。
(6)希尔排序
希尔排序又叫缩小增量排序
基本思想:
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
操作方法:
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列个数k,对序列进行k 趟排序;
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
- 算法实现:我们简单处理增量序列:增量序列d = {n/2 ,n/4, n/8 .....1} n为要排序数的个数 ,即:先将要排序的一组记录按某个增量d(n/2,n为要排序数的个数)分成若干组子序列,每组中记录的下标相差d.对每组中全部元素进行直接插入排序,然后再用一个较小的增量(d/2)对它进行分组,在每组中再进行直接插入排序。继续不断缩小增量直至为1,最后使用直接插入排序完成排序。
- 算法不稳定,且效率为O(n1.3)
(7)归并排序
基本思想:
归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。算法稳定,且效率为O(nlogn)
(8)基数排序
基本思想:是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。算法稳定,且效率为O(n+r).
4.查找算法
顺序查找、二分查找、二叉树查找、索引查找、开放地址hash查找、拉链发hash查找



相关推荐
这份"数据结构复习资料"包含了全面的学习资源,特别是模拟题及答案,对于准备相关考试或提升编程技能来说极其有价值。 一、数据结构基础 数据结构主要分为两大类:线性结构和非线性结构。线性结构如数组、链表、栈...
数据结构复习资料 本文档是对数据结构的复习资料,涵盖了多种数据结构和算法,旨在帮助读者巩固和提高数据结构的知识和技能。 1. 带附加表头的有序单链表的保序插入: 在带附加表头的有序单链表中插入一个新的...
华南理工大学的“数据结构复习提纲二”文档无疑为备考的学生提供了宝贵的资源,涵盖了重要的概念、问题及其解答。在这个复习提纲中,我们可以期待找到关于以下关键知识点的详细内容: 1. **基本概念**:数据结构是...
【组成原理】 组成原理是计算机科学与技术领域中的基础课程,主要研究计算机硬件系统的组成和工作原理。...这份“西工大组原和数据结构复习资料”将涵盖这两个领域的关键知识点,是深入学习的好材料。
本压缩包“数据结构复习代码”包含了用于学习数据结构的相关代码,非常适合正在学习或复习数据结构的人士。 数据结构主要分为两大类:线性结构和非线性结构。线性结构包括数组、链表、栈和队列。数组是最基础的数据...
这份“数据结构复习题及答案”压缩包提供了丰富的学习材料,帮助学习者巩固和理解数据结构的基本概念、算法及其应用。 1. **基本概念** - **数据结构**:数据结构是指数据的组织方式,包括数组、链表、栈、队列、...
以下是基于“数据结构复习资料”这个主题,结合提供的压缩包文件内容,所涵盖的一些关键知识点的详细说明: 1. **数组**:数组是最基本的数据结构,它是由相同类型的元素按照特定顺序排列的集合。在数组中,每个...
【22考研】数据结构复习全书.pdf
"数据结构复习重点归纳笔记[清华严蔚敏版]" 数据结构是一门基础理论课,涉及到计算机科学和技术的多个领域。了解数据结构的知识点对计算机专业学生来说是非常重要的。本文将对数据结构的章节结构和重点内容进行归纳...
本文将针对“数据结构复习重点归纳(适于清华严版教材)”进行详细的解析,旨在帮助备考者明确复习要点。 首先,数据结构的章节结构通常分为:概论、线性表、栈和队列、串、多维数组和广义表、树和二叉树、图、查找...
在这个"数据结构复习资料 C++"的压缩包中,我们找到了一系列关于数据结构实现的文档和PPT,主要聚焦在线性表这一基础但重要的数据结构上。线性表是由n(n>=0)个相同类型元素构成的有限序列,是许多复杂数据结构的...
### 数据结构复习要点详解 #### 一、数据结构章节结构及重点构成 数据结构课程通常包含以下几个核心章节:概论、线性表、栈和队列、串、多维数组和广义表、树和二叉树、图、查找、内排序、外排序、文件、动态存储...
数据结构复习题整理(附答案) 本资源摘要信息涵盖了数据结构的基础知识点,包括算法、线性结构、非线性结构、链表、栈、队列、二叉树等。 一、算法 * 算法的重要特性:有穷性、确定性、可行性、输入、输出 * 好...
华南理工大学的这份数据结构复习提纲,无疑是学生们准备考试、巩固知识的重要参考资料。它涵盖了数据结构的基本概念、主要类型、算法设计与分析等方面的内容。 1. **基本概念** - 数据结构:数据元素的集合以及...
数据结构复习ppt 华中科技大学计算机学院
这份“数据结构复习作业及答案.rar”压缩包包含了多个章节的数据结构习题及其解答,对于即将进行期末考试的学生来说,无疑是一份宝贵的复习资源。 首先,我们来看第六章“树和二叉树作业及答案(100分).docx”。树...
这份"计算机考研数据结构复习指导Word版"提供了一条有效的学习路径,帮助考生们精准定位并攻克这个领域的关键点。 复习指导文档《复习指导(数据结构部分).doc》可能涵盖了以下内容: 1. **基本概念**:数据结构...
【北京邮电大学809数据结构复习指南】是一份由成功上岸北邮AI院的学长编写的详尽复习资料,旨在帮助备考北邮研究生考试的学生,特别是那些选择809数据结构作为专业课的考生。复习指南依据北邮研究生招生网的考试大纲...
本复习资料及试卷(C++版)是针对软件工程专业和计算机专业学生的重要学习资源,旨在帮助他们深入理解和掌握数据结构的基本概念、算法及其在C++编程中的实现。 1. **链表**:链表是一种动态数据结构,每个元素...
清华计算机考研数据结构复习提要,有助于帮助复习,理清思路,大家共同学习