еүҚиЁҖпјҡеүҚж®өж—¶й—ҙеңЁзҪ‘дёҠзңӢеҲ°и…ҫи®ҜеҗҺеҸ°ејҖеҸ‘жҖ»зӣ‘bisonеҲҶдә«зҡ„дёҖзҜҮж–Үз« гҖҠжө…и°ҲиҝҮиҪҪдҝқжҠӨгҖӢпјҢиҜ»жқҘеҸ—зӣҠеҢӘжө…гҖӮ
еҲҡеҘҪиҮӘе·ұд№ҹеңЁеӨ„зҗҶзі»з»ҹиҜ·жұӮиҝҮиҪҪзҡ„й—®йўҳпјҢжҠҠиҮӘе·ұзҡ„дёҖдәӣеҝғеҫ—дҪ“дјҡжҖ»з»“еҮәжқҘжӢҝжқҘдёҺеӨ§е®¶дёҖиө·жҺўи®ЁгҖӮ
еңЁbisonзҡ„ж–Үз« дёӯи°ҲеҲ°пјҡеҜ№дәҺ延时ж•Ҹж„ҹзҡ„жңҚеҠЎпјҢеҪ“еӨ–йғЁиҜ·жұӮи¶…иҝҮзі»з»ҹеӨ„зҗҶиғҪеҠӣпјҢеҰӮжһңзі»з»ҹжІЎжңүеҒҡзӣё
еә”дҝқжҠӨпјҢеҸҜиғҪеҜјиҮҙеҺҶеҸІзҙҜи®Ўзҡ„и¶…ж—¶иҜ·жұӮиҫҫеҲ°дёҖе®ҡзҡ„规模пјҢеғҸйӣӘзҗғдёҖж ·еҪўжҲҗжҒ¶жҖ§еҫӘзҺҜпјҢз”ұдәҺзі»з»ҹеӨ„зҗҶзҡ„жҜҸдёӘ
иҜ·жұӮйғҪеӣ дёәи¶…ж—¶иҖҢж— ж•ҲпјҢзі»з»ҹеҜ№еӨ–е‘ҲзҺ°зҡ„жңҚеҠЎиғҪеҠӣдёә0пјҢдё”иҝҷз§Қжғ…еҶөдёҚиғҪиҮӘеҠЁжҒўеӨҚгҖӮжҲ‘们зҡ„зі»з»ҹе°ұжҳҜиҰҒе°Ҫ
йҮҸйҒҝе…Қиҝҷз§Қжғ…еҶөзҡ„еҮәзҺ°пјҢдёӢйқўе°ҶиҜҰз»ҶжқҘеҲҶжһҗдёҖдёӘзҺ°е®һдёӯзҡ„жЎҲдҫӢгҖӮ
дёҖ жңүиҝҮиҪҪй—®йўҳзҡ„зі»з»ҹ

ж•°жҚ®еӨ„зҗҶжөҒзЁӢ:
1) еүҚз«Ҝе°ҶиҜ·жұӮеҸ‘йҖҒз»ҷж•°жҚ®и§ЈжһҗеҸҠиҪ¬еҸ‘зі»з»ҹпјҢ
2пјүж•°жҚ®и§ЈжһҗеҸҠиҪ¬еҸ‘зі»з»ҹе°Ҷе°ҒиЈ…еҘҪзҡ„ж•°жҚ®еҸ‘йҖҒеҗҺеҸ°ж•°жҚ®иҜ·жұӮпјҢи®ҫзҪ®и¶…ж—¶ж—¶й—ҙпјҲеҒҮи®ҫ300msпјүпјҢзәҝзЁӢеҗҢжӯҘзӯүеҫ…еӨ„
зҗҶз»“жһңд»ҺеҗҺеҸ°иҝ”еӣһгҖӮ
3пјүеңЁ300msеҶ…жӯЈзЎ®иҝ”еӣһз»“жһңеҗҺпјҢеҲҷе°ҶеӨ„зҗҶзҡ„з»“жһңиҝ”еӣһз»ҷеүҚз«ҜпјҢеҰӮжһңеңЁ300msеҶ…и¶…ж—¶пјҢеҲҷе°Ҷж•°жҚ®еҸ‘йҖҒеҲ°дёҖж¬Ўи¶…
ж—¶еӨ„зҗҶзі»з»ҹпјҲеҒҮи®ҫи®ҫзҪ®и¶…ж—¶ж—¶й—ҙ500msпјүпјҢзәҝзЁӢеҗҢжӯҘзӯүеҫ…з»“жһңиҝ”еӣһгҖӮ
4пјүеңЁ500msеҶ…жӯЈзЎ®иҝ”еӣһз»“жһңеҗҺпјҢеҲҷе°ҶеӨ„зҗҶзҡ„з»“жһңиҝ”еӣһз»ҷеүҚз«ҜпјҢеҰӮжһңеҶҚдёҖж¬Ўи¶…ж—¶пјҢиҝ”еӣһдёҖдёӘй»ҳи®Өзҡ„еӨ„зҗҶз»“жһңз»ҷеүҚ
з«ҜпјҢеҗҺз«ҜеҜ№ж•°жҚ®иҝӣиЎҢжң¬ең°еҢ–пјҢ然еҗҺеҸҜд»Ҙе°Ҷж•°жҚ®еҸ‘йҖҒеҲ°зҰ»зәҝеӨ„зҗҶзі»з»ҹиҝӣиЎҢдәҢж¬ЎеӨ„зҗҶгҖӮ
ж•°жҚ®и§Јжһҗзҡ„жңәеҷЁдёәеӨҡж ёпјҢж•°жҚ®и§ЈжһҗеҸҠиҪ¬еҸ‘зі»з»ҹйҮҮз”Ёзҡ„жҳҜеҚ•иҝӣзЁӢеӨҡзәҝзЁӢжЁЎеһӢпјҢеңЁеүҚдёҖзҜҮж–Үз« гҖҠжө·йҮҸж•°жҚ®еӨ„зҗҶзі»еҲ—
д№ӢJavaзәҝзЁӢжұ дҪҝз”ЁгҖӢиҜҰз»ҶжҸҸиҝ°дәҶеӨҡзәҝзЁӢеӨ„зҗҶзҡ„е®һзҺ°пјҢйҮҮеҸ–зҡ„жҳҜж— з•ҢйҳҹеҲ—зәҝзЁӢжұ зҡ„е®һзҺ°пјҢиҝҷж ·д»Һе®ўжҲ·з«ҜжқҘзҡ„иҜ·жұӮпјҢдјҡиў«
иҝҷж ·еӨ„зҗҶ:
1) еҰӮжһңзәҝзЁӢжұ дёӯжңүз©әй—ІзәҝзЁӢпјҢдјҡе°ҶиҜ·жұӮзӣҙжҺҘдәӨз»ҷзәҝзЁӢеӨ„зҗҶгҖӮ
2) еҰӮжһңжІЎжңүз©әй—ІзәҝзЁӢпјҢе°ұе°ҶиҜ·жұӮдҝқеӯҳеҲ°д»»еҠЎйҳҹеҲ—гҖӮ
еҒҮи®ҫејҖ50дёӘзәҝзЁӢпјҢжҜҸдёӘзәҝзЁӢз§’е№іеқҮеӨ„зҗҶдёҖдёӘиҜ·жұӮпјҢйӮЈд№Ҳзі»з»ҹжҜҸз§’еҸҜд»ҘеӨ„зҗҶзҡ„жңҖеӨ§иҜ·жұӮж•°жҳҜ50дёӘгҖӮдёҖж—ҰеүҚз«Ҝж•°жҚ®иҜ·жұӮи¶…
иҝҮ50дёӘжҜҸз§’пјҢеңЁд»»еҠЎйҳҹеҲ—дёӯе°Ҷдјҡе Ҷз§ҜеӨ§йҮҸзҡ„иҜ·жұӮпјҢеүҚеҸ°дёҚж–ӯеҸ‘йҖҒиҝҮжқҘпјҢеҗҺжқҘеӨ„зҗҶдёҚиҝҮжқҘпјҢеүҚз«ҜеҸҲи®ҫзҪ®дәҶеҘ—жҺҘеӯ—и¶…ж—¶пјҢеҜј
иҮҙйҳҹеҲ—дёӯзҡ„еӨ§йҮҸиҜ·жұӮи¶…ж—¶пјҢзӣҙжҺҘдҪҝеҫ—еҗҺз«ҜзәҝзЁӢд»ҺйҳҹеҲ—дёӯеҸ–еҮәеҘ—жҺҘеӯ—и§Јжһҗзҡ„ж—¶еҖҷпјҢеҘ—жҺҘеӯ—е·Із»Ҹиў«еүҚеҸ°е…ій—ӯдәҶпјҢеј•еҸ‘I/OејӮеёёгҖӮ
е Ҷз§Ҝзҡ„йҮҸдёҖж—ҰйӣӘеҙ©пјҢе°ҶдҪҝеүҚеҸ°еҸ‘йҖҒиҝҮжқҘзҡ„иҜ·жұӮе…ЁйғЁI/OејӮеёёпјҢеҗҺеҸ°еӨ„зҗҶзі»з»ҹи·ҹжҢӮжҺүж— ејӮдәҶгҖӮ
дәҢ зӣёеҜ№е®Ңе–„зҡ„зі»з»ҹ
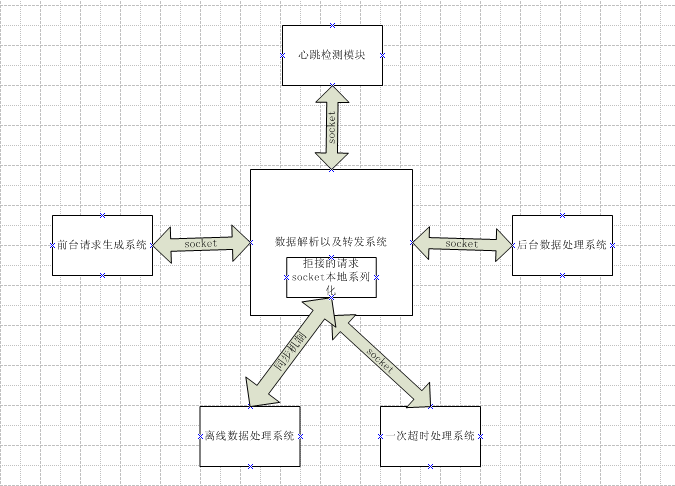
еңЁдёҠйқўзҡ„зі»з»ҹдёӯпјҢеҜ№иҜ·жұӮжҳҜжқҘиҖ…дёҚжӢ’зҡ„зҠ¶жҖҒпјҢе…·дҪ“жқҘи®Іе°ұжҳҜе°ҶжүҖжңүзҡ„иҜ·жұӮйғҪдҝқеӯҳеҲ°д»»еҠЎйҳҹеҲ—гҖӮиҜ·жұӮе Ҷз§ҜеҲ°дёҖе®ҡзЁӢеәҰпјҢ
йҳҹеҲ—дёӯзҡ„еҫҲеӨҡиҜ·жұӮйғҪи¶…ж—¶пјҢиҝҷжҳҜеҸҜд»ҘйҮҮеҸ–жё…з©әиҜ·жұӮйҳҹеҲ—зҡ„ж–№ејҸпјҢиҝҷдёӘеҸҜд»ҘйҖҡиҝҮйҮҮеҸ–дёҖе®ҡзҡ„зӣ‘жҺ§ж–№ејҸжқҘе®һзҺ°гҖӮдҫӢеҰӮдёҠеӣҫ
дёӯзҡ„еҝғи·ізӣ‘жҺ§жЁЎеқ—пјҢе®ғеҸҜд»ҘйҖҡиҝҮиҝҷж ·зҡ„ж–№ејҸжқҘе®һзҺ°пјҢе°ұжҳҜжЁЎжӢҹе®ўжҲ·з«Ҝзҡ„иҜ·жұӮпјҢжҜҸйҡ”дёҖе®ҡж—¶й—ҙеҸ‘йҖҒдёҖдәӣиҜ·жұӮиҝҮеҺ»пјҢеҰӮжһң
жңүеӨ§йғЁеҲҶйғҪжӯЈеёёиҝ”еӣһпјҢиҜҙжҳҺеҗҺз«ҜеӨ„зҗҶзі»з»ҹжӯЈеёёпјӣеҪ“еҮәзҺ°еӨ§йғЁеҲҶи¶…ж—¶зҡ„ж—¶еҖҷпјҢиҜҙжҳҺеҗҺеҸ°зі»з»ҹе·Із»ҸжҢӮжҺүдәҶпјҢиҝҷж—¶еҖҷйҮҚеҗҜж•°
жҚ®и§ЈжһҗеҸҠиҪ¬еҸ‘зі»з»ҹпјҢжё…з©әзі»з»ҹдёӯзҡ„д»»еҠЎиҜ·жұӮйҳҹеҲ—пјҢиҝҷж ·еҸҜд»ҘжҡӮж—¶еӨ„зҗҶиҜ·жұӮй«ҳеі°жңҹзҡ„жғ…еҶөгҖӮ
дҪҶжҳҜиҝҷдёӘж–№ејҸд№ҹжҳҜжІ»ж ҮдёҚжІ»жң¬зҡ„пјҢеҗҺеҸ°жңҖеӨҡеҸӘиғҪеӨ„зҗҶиҝҷд№ҲеӨҡиҜ·жұӮпјҢйҮҚеҗҜеҗҺз…§ж ·дјҡеҜјиҮҙеӨ§йҮҸе өеЎһеҜјиҮҙзі»з»ҹеҸҲжҢӮжҺүпјҢ
然еҗҺзӣ‘жҺ§зі»з»ҹеҸҲйҮҚеҗҜпјҢиҝҷж ·дјҡдҪҝеҫ—еҫҲеӨҡзҡ„иҜ·жұӮжІЎжңүеҫ—еҲ°жңүж•Ҳзҡ„еӨ„зҗҶпјҢеӨ§еӨ§йҷҚдҪҺзі»з»ҹзҡ„еӨ„зҗҶиғҪеҠӣгҖӮдёәдәҶдҝқиҜҒеҗҺеҸ°зі»з»ҹжҜҸ
ж—¶жҜҸеҲ»йғҪжңҖеӨ§йҷҗеәҰзҡ„еҸ‘жҢҘиҮӘе·ұзҡ„еӨ„зҗҶиғҪеҠӣпјҢеҪ“иҙҹиҪҪи¶…иҝҮзі»з»ҹиҮӘиә«зҡ„еӨ„зҗҶиғҪеҠӣж—¶пјҢжӢ’з»қиҜҘиҜ·жұӮгҖӮжӢ’з»қеҗҺеҸҜд»Ҙе°ҶиҜҘиҜ·жұӮжң¬
ең°зі»еҲ—еҢ–пјҢдҝқеӯҳзӣёе…ізҡ„ж•°жҚ®еҸ‘йҖҒеҲ°зҰ»зәҝж•°жҚ®еӨ„зҗҶзі»з»ҹиҝӣиЎҢеӨ„зҗҶгҖӮ
еңЁеүҚдёҖзҜҮж–Үз« гҖҠжө·йҮҸж•°жҚ®еӨ„зҗҶзі»еҲ—д№ӢJavaзәҝзЁӢжұ дҪҝз”ЁгҖӢ第еӣӣиҠӮдёӯжңүз•ҢйҳҹеҲ—зәҝзЁӢжұ дҪҝз”ЁдёӯжңүжҸҗеҲ°иҝҷз§Қж–№ејҸзҡ„е…·дҪ“е®һзҺ°гҖӮ
д»ҘдёҠйқўзҡ„зі»з»ҹдёәдҫӢпјҢжңүз•ҢзәҝзЁӢжұ еҸҜд»Ҙиҝҷж ·й…ҚзҪ®пјҢcorePoolSizeдёә30пјҢmaximumPoolSizeдёә50пјҢжңүз•ҢйҳҹеҲ—дёә
ArrayBlockingQueue<Runnable>(100)гҖӮ
иҝҷж ·зі»з»ҹеңЁеӨ„зҗҶиҜ·жұӮзҡ„ж—¶еҖҷйҮҮз”ЁеҰӮдёӢзӯ–з•Ҙпјҡ
1пјү еҪ“дёҖдёӘиҜ·жұӮиҝҮжқҘпјҢзәҝзЁӢжұ ејҖеҗҜдёҖдёӘзәҝзЁӢжқҘеӨ„зҗҶпјҢзӣҙеҲ°30дёӘзәҝзЁӢйғҪеңЁеӨ„зҗҶиҜ·жұӮгҖӮ
2пјү еҪ“зәҝзЁӢжұ дёӯжІЎжңүз©әй—ІзәҝзЁӢдәҶпјҢе°ұе°ҶиҜ·жұӮж·»еҠ еҲ°жңүз•ҢйҳҹеҲ—еҪ“дёӯпјҢзӣҙеҲ°йҳҹеҲ—ж»ЎдёәжӯўгҖӮ
3пјү еҪ“йҳҹеҲ—ж»Ўд»ҘеҗҺпјҢеңЁејҖеҗҜзәҝзЁӢжқҘеӨ„зҗҶж–°зҡ„иҜ·жұӮпјҢзӣҙеҲ°ејҖеҗҜзҡ„зәҝзЁӢж•°иҫҫеҲ°maximumPoolSizeгҖӮ
4пјү еҪ“ејҖеҗҜзҡ„зәҝзЁӢж•°иҫҫеҲ°maximumPoolSizeеҗҺпјҢд»»еҠЎйҳҹеҲ—еҸҲе·Із»Ҹж»ЎдәҶеҗҺпјҢжӯӨж—¶еҶҚиҝҮжқҘзҡ„иҜ·жұӮе°Ҷиў«жӢ’з»қпјҢиў«жӢ’з»қзҡ„иҜ·жұӮ
еңЁжң¬ең°зі»еҲ—еҢ–пјҢе°Ҷдҝқеӯҳзҡ„ж•°жҚ®еҗҢжӯҘеҲ°зҰ»зәҝж•°жҚ®зі»з»ҹиҝӣиЎҢеӨ„зҗҶгҖӮ
жө·йҮҸж•°жҚ®еӨ„зҗҶйғҪжҳҜйҮҮз”ЁеҲҶеёғејҸзҡ„пјҢжҜҸеҸ°жңәеҷЁзҡ„еӨ„зҗҶиғҪеҠӣжңүйҷҗпјҢеҸҜд»Ҙе°ҶиҜ·жұӮеҲҶеёғеҲ°дёҚеҗҢзҡ„жңәеҷЁдёҠеҺ»гҖӮеҰӮжһңжҜҸеҸ°жңәеҷЁиў«
жӢ’з»қзҡ„иҜ·жұӮж•°иҝҮеӨҡзҡ„ж—¶еҖҷпјҢе°ұиҰҒиҖғиҷ‘ж·»еҠ еӨ„зҗҶзҡ„жңәеҷЁдәҶгҖӮ
еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
еңЁжҠҖжңҜз ”з©¶йўҶеҹҹпјҢжң¬ж–Үзҡ„дҪңиҖ…зҺӢеҪ©зҺІпјҢжқҘиҮӘиҘҝе®үзҹіжІ№еӨ§еӯҰи®Ўз®—жңәеӯҰйҷўпјҢе…¶дё»иҰҒз ”з©¶ж–№еҗ‘дёәйҒҘж„ҹеҪұеғҸж•°жҚ®еӨ„зҗҶжҠҖжңҜпјҢе…¶е·ҘдҪңеұ•зӨәдәҶеҘ№е’ҢеҘ№зҡ„еӣўйҳҹеңЁжө·йҮҸж•°жҚ®еӨ„зҗҶж–№йқўзҡ„дё“й•ҝпјҢд»ҘеҸҠеңЁжһ„е»әй«ҳжҖ§иғҪи®Ўз®—жңәзҫӨжһ¶жһ„ж–№йқўзҡ„ж·ұеҺҡжҠҖжңҜз§ҜзҙҜгҖӮ...
еҗ„зі»з»ҹдёҡеҠЎеӨ„зҗҶж–№ејҸе’ҢжөҒзЁӢдёҚеҗҢпјҢеҜјиҮҙжҖ§иғҪжҢҮж ҮеӯҳеңЁе·®ејӮпјҢдёҚжҳҜжүҖжңүзі»з»ҹйғҪйңҖиҰҒжүҝжӢ…й«ҳеі°еҖјеӨ„зҗҶиғҪеҠӣпјҢеӣ жӯӨйңҖиҰҒеүҠеі°е’ҢжөҒйҮҸжҺ§еҲ¶еҠҹиғҪпјҢд»ҘеҸҠз»ҹдёҖзҡ„дә§иғҪзӣ‘жҺ§е’ҢиҝҮиҪҪдҝқжҠӨжңәеҲ¶гҖӮ еңЁзі»з»ҹдҝқжҠӨж–№йқўпјҢOFCзі»з»ҹеҖҹйүҙPIDпјҲжҜ”дҫӢ-з§ҜеҲҶ-еҫ®еҲҶ...
з»јдёҠжүҖиҝ°пјҢOFCзі»з»ҹдҪңдёәз”өе•ҶйўҶеҹҹеӨ„зҗҶжө·йҮҸи®ўеҚ•зҡ„ж ёеҝғ组件пјҢдёҚд»…йңҖиҰҒе…·еӨҮејәеӨ§зҡ„ж•°жҚ®еӨ„зҗҶиғҪеҠӣпјҢиҝҳйңҖиҰҒй«ҳеәҰзҡ„еҸҜжү©еұ•жҖ§е’ҢеҸҜйқ жҖ§пјҢд»ҘзЎ®дҝқеңЁйқўеҜ№ж—ҘзӣҠеўһй•ҝзҡ„и®ўеҚ•йҮҸж—¶дҫқ然иғҪеӨҹдҝқжҢҒй«ҳж•ҲзЁіе®ҡзҡ„иҝҗиЎҢгҖӮйҖҡиҝҮдёҠиҝ°жҠҖжңҜе®һзҺ°е’ҢдјҳеҢ–жҺӘж–Ҫ...
з»јдёҠжүҖиҝ°пјҢзҪ‘з»ңжёёжҲҸдёӯзҡ„зҪ‘з»ңжңҚеҠЎеҷЁз«Ҝжө·йҮҸж•°жҚ®еӨ„зҗҶж¶үеҸҠиҙҹиҪҪеқҮиЎЎгҖҒж•°жҚ®еӯҳеӮЁдјҳеҢ–гҖҒејӮжӯҘеӨ„зҗҶгҖҒеҲҶеёғејҸи®Ўз®—гҖҒ硬件й…ҚзҪ®е’Ңзӣ‘жҺ§зӯүеӨҡдёӘж–№йқўгҖӮжңүж•Ҳзҡ„ж•°жҚ®еӨ„зҗҶж–№жі•е’ҢиЈ…зҪ®еҜ№дәҺз»ҙжҢҒжёёжҲҸзҡ„жӯЈеёёиҝҗиЎҢпјҢжҸҗй«ҳзҺ©е®¶дҪ“йӘҢиҮіе…ійҮҚиҰҒгҖӮйҖҡиҝҮдёҚж–ӯ...
еңЁJ2EEзҺҜеўғдёӯпјҢеӨ„зҗҶй«ҳ并еҸ‘е’Ңжө·йҮҸж•°жҚ®жҳҜдёҖйЎ№еӨҚжқӮиҖҢйҮҚиҰҒзҡ„д»»еҠЎгҖӮиҝҷж¶үеҸҠеҲ°еӨҡдёӘж–№йқўзҡ„жҠҖжңҜж ҲпјҢеҢ…жӢ¬зі»з»ҹжһ¶жһ„и®ҫи®ЎгҖҒж•°жҚ®еә“...иҝҷдәӣжҠҖжңҜе’Ңзӯ–з•Ҙзҡ„зҒөжҙ»иҝҗз”ЁпјҢеҸҜд»Ҙеё®еҠ©ејҖеҸ‘иҖ…жһ„е»әеҮәиғҪеӨҹеә”еҜ№еӨ§и§„模并еҸ‘е’Ңжө·йҮҸж•°жҚ®жҢ‘жҲҳзҡ„й«ҳж•Ҳзі»з»ҹгҖӮ
### жө·йҮҸж•°жҚ®зҪ‘ж јеӯҳеӮЁдёҺеӨ„зҗҶ #### дёҖгҖҒжө·йҮҸж•°жҚ®зҪ‘ж јеӯҳеӮЁжһ¶жһ„ **1.1 еҲҶеұӮзҪ‘ж јжһ¶жһ„** - **зғӯж•°жҚ®еӯҳеӮЁ**: дҪҝз”Ёй«ҳйҖҹй—ӘеӯҳжҲ–еҶ…еӯҳжқҘеӯҳеӮЁз»Ҹеёёи®ҝй—®зҡ„зғӯж•°жҚ®пјҢзЎ®дҝқдҪҺ延иҝҹи®ҝй—®гҖӮ - **жё©ж•°жҚ®еӯҳеӮЁ**: йҮҮз”ЁеӣәжҖҒзЎ¬зӣҳ(SSD)жҲ–ж··еҗҲ...
еңЁеӨ§ж•°жҚ®ж—¶д»ЈиғҢжҷҜдёӢпјҢе…ЁзҗғеҚ«жҳҹеҜјиҲӘзі»з»ҹпјҲGNSSпјүжүҖйқўеҜ№зҡ„дё»иҰҒжҢ‘жҲҳеҢ…жӢ¬жө·йҮҸж•°жҚ®зҡ„еӯҳеӮЁгҖҒз®ЎзҗҶе’Ңй«ҳж•ҲеӨ„зҗҶгҖӮдј з»ҹзҡ„йӣҶдёӯејҸеӯҳеӮЁдёҺи®Ўз®—ж–№жі•еҫҖеҫҖйҡҫд»Ҙж»Ўи¶іеӨ§ж•°жҚ®зҡ„вҖң5VвҖқзү№жҖ§вҖ”вҖ”еҚідҪ“з§ҜпјҲVolumeпјүгҖҒйҖҹеәҰпјҲVelocityпјүгҖҒеӨҡж ·жҖ§...
еңЁиҝҷдёҖжЁЎеһӢдёӯпјҢзәҝзЁӢжұ иҙҹиҙЈз®ЎзҗҶеҗҺеҸ°ж•°жҚ®еӨ„зҗҶзҡ„зәҝзЁӢпјҢиҝһжҺҘжұ зЎ®дҝқж•°жҚ®еә“и®ҝй—®зҡ„й«ҳж•ҲжҖ§пјҢиҖҢж•°жҚ®CacheеҲҷз”ЁдәҺеӯҳеӮЁе’Ңеҝ«йҖҹжЈҖзҙўеёёз”Ёж•°жҚ®пјҢе…ұеҗҢжһ„жҲҗдәҶдёҖдёӘй«ҳж•ҲгҖҒзЁіе®ҡзҡ„жө·йҮҸж•°жҚ®еӨ„зҗҶзі»з»ҹгҖӮд»ҘзҪ‘з»ңзҹӯдҝЎе№іеҸ°зҡ„ж•°жҚ®еӨ„зҗҶдёәдҫӢпјҢиҜҘжЁЎеһӢ...
жҖ»з»“жқҘиҜҙпјҢзҪ‘з»ңжёёжҲҸйҖҡдҝЎзҪ‘з»ңзҡ„ж•°жҚ®еӨ„зҗҶзі»з»ҹжҳҜж•ҙдёӘжёёжҲҸиҝҗиЎҢзҡ„еҹәзҹіпјҢе®ғж—ўиҰҒеӨ„зҗҶжө·йҮҸж•°жҚ®пјҢеҸҲиҰҒдҝқиҜҒдҪҺ延иҝҹе’Ңй«ҳеҸҜйқ жҖ§гҖӮзҗҶ解并дјҳеҢ–иҝҷдёҖзі»з»ҹпјҢеҜ№дәҺејҖеҸ‘иҖ…жқҘиҜҙиҮіе…ійҮҚиҰҒпјҢеҜ№дәҺзҺ©е®¶жқҘиҜҙеҲҷж„Ҹе‘ізқҖжӣҙеҘҪзҡ„жёёжҲҸдҪ“йӘҢгҖӮ
иҜҘжЁЎеһӢзҡ„дё»иҰҒзӣ®зҡ„жҳҜжҸҗй«ҳзі»з»ҹеңЁеӨ„зҗҶжө·йҮҸж•°жҚ®ж—¶зҡ„ж•°жҚ®еӨ„зҗҶж•ҲзҺҮгҖӮеңЁеӨ§ж•°жҚ®зҺҜеўғдёӢпјҢз”ұдәҺж•°жҚ®зҡ„规模巨еӨ§гҖҒз§Қзұ»з№ҒеӨҡпјҢдј з»ҹзҡ„ж•°жҚ®еӨ„зҗҶж–№ејҸеҫҖеҫҖж— жі•ж»Ўи¶іе®һж—¶жҖ§е’Ңж•ҲзҺҮзҡ„йңҖжұӮгҖӮ и®әж–ҮгҖҠеҹәдәҺжҺҘ收дёҺеӨ„зҗҶеҲҶзҰ»зҡ„е®һж—¶еӨ§ж•°жҚ®еӨ„зҗҶжЁЎеһӢ...
жӯӨеӨ–пјҢж–Үз« и®Ёи®әдәҶеҲҶеёғејҸзі»з»ҹдёӯзҡ„ж•°жҚ®дёҖиҮҙжҖ§гҖҒе®№й”ҷжҖ§е’Ңе®үе…ЁжҖ§зӯүй—®йўҳпјҢиҝҷдәӣйғҪжҳҜжһ„е»әзЁіе®ҡгҖҒеҸҜйқ зҡ„жө·йҮҸж•°жҚ®жңҚеҠЎзі»з»ҹзҡ„е…ій”®еӣ зҙ гҖӮж•°жҚ®дёҖиҮҙжҖ§зЎ®дҝқдәҶеңЁеҲҶеёғејҸзҺҜеўғдёӯж•°жҚ®зҡ„дёҖиҮҙжҖ§зҠ¶жҖҒпјҢиҖҢе®№й”ҷжҖ§еҲҷдҝқиҜҒдәҶзі»з»ҹеңЁйғЁеҲҶиҠӮзӮ№ж•…йҡңж—¶...
жң¬ж–ҮжЎЈгҖҠйқўеҗ‘жө·йҮҸж•°жҚ®еӯҳеӮЁзҡ„Erasure-CodeеҲҶеёғејҸж–Ү件系з»ҹI/OдјҳеҢ–ж–№жі•.pdfгҖӢиҜҰз»Ҷд»Ӣз»ҚдәҶй’ҲеҜ№Erasure CodeеҲҶеёғејҸж–Ү件系з»ҹI/OжҖ§иғҪдјҳеҢ–зҡ„зӯ–з•ҘгҖӮ йҰ–е…ҲпјҢж–Ү件ж ҮйўҳвҖңйқўеҗ‘жө·йҮҸж•°жҚ®еӯҳеӮЁзҡ„Erasure-CodeеҲҶеёғејҸж–Ү件系з»ҹI/OдјҳеҢ–...
- ж–ҮжЎЈиҝҳжҸҗеҲ°дәҶжңӘжқҘзҡ„зӯ–з•ҘпјҢеҸҜиғҪеҢ…жӢ¬дјҳеҢ–жөӢиҜ•жЎҶжһ¶гҖҒжҸҗй«ҳжөӢиҜ•ж•ҲзҺҮгҖҒж”№иҝӣж•°жҚ®еӨ„зҗҶжөҒзЁӢзӯүпјҢд»Ҙжӣҙжңүж•Ҳең°з®ЎзҗҶйӘҢиҜҒж•°жҚ®иҝҮиҪҪгҖӮ 7. **жөӢиҜ•зұ»еҲ«дёҺиҰҶзӣ–иҢғеӣҙ**пјҡ - жөӢиҜ•зұ»еҲ«еҢ…жӢ¬еҠҹиғҪжөӢиҜ•гҖҒOpenJDKжҖ§иғҪжөӢиҜ•гҖҒеӨ–йғЁзі»з»ҹжөӢиҜ•е’Ң...
иҝҷз§Қжө·йҮҸж•°жҚ®зҡ„еӯҳеӮЁдёҺз®ЎзҗҶжҲҗдёәдәҶдёҖдёӘжҢ‘жҲҳпјҢеӣ дёәеҰӮжһңе…ЁйғЁдҫқиө–дёӯеҝғжңҚеҠЎеҷЁпјҢеҸҜиғҪдјҡеҜјиҮҙжңҚеҠЎеҷЁиҝҮиҪҪпјҢзҪ‘з»ңдәӨдә’йў‘з№ҒпјҢеҪұе“Қз”ЁжҲ·дҪ“йӘҢгҖӮеӣ жӯӨпјҢз ”з©¶еҰӮдҪ•еңЁжҷәиғҪ移еҠЁз»Ҳз«ҜдёҠиҝӣиЎҢж•°жҚ®еӯҳеӮЁе’ҢжҖ§иғҪдјҳеҢ–еҸҳеҫ—иҮіе…ійҮҚиҰҒгҖӮ 移еҠЁеӨ§ж•°жҚ®е…·жңү...
ж·ҳе®қзҪ‘ж•°жҚ®еӨ„зҗҶж–№жі•зҡ„з ”з©¶дё»иҰҒйӣҶдёӯеңЁеҰӮдҪ•жңүж•Ҳең°з®ЎзҗҶе’ҢеҲҶжһҗжө·йҮҸзҡ„з”ЁжҲ·ж•°жҚ®пјҢд»ҘжҸҗеҚҮз”өеӯҗе•ҶеҠЎзҡ„иҝҗиҗҘж•ҲзҺҮе’Ңз”ЁжҲ·дҪ“йӘҢгҖӮеңЁдә’иҒ”зҪ‘ж—¶д»ЈпјҢж·ҳе®қзҪ‘дҪңдёәдёӯеӣҪжңҖеӨ§зҡ„еңЁзәҝиҙӯзү©е№іеҸ°пјҢз§ҜзҙҜдәҶеӨ§йҮҸзҡ„з”ЁжҲ·иЎҢдёәж•°жҚ®пјҢиҝҷдәӣж•°жҚ®еҢ…жӢ¬дҪҶдёҚйҷҗдәҺ...
иҝҷз§Қж–№жі•иғҪеӨҹиҫғеҘҪең°еӨ„зҗҶзү№е®ҡзұ»еһӢзҡ„зү©е“ҒпјҢдҪҶеҜ№дәҺйқһз»“жһ„еҢ–ж•°жҚ®еӨ„зҗҶиҫғдёәеӣ°йҡҫгҖӮ 3. **еҹәдәҺеҚҸеҗҢиҝҮж»Өзҡ„жҺЁиҚҗзі»з»ҹ**пјҡеҚҸеҗҢиҝҮж»ӨжҳҜжңҖеёёз”Ёзҡ„дёӘжҖ§еҢ–жҺЁиҚҗж–№жі•д№ӢдёҖгҖӮе®ғеҲҶдёәдёӨз§Қдё»иҰҒеҪўејҸпјҡ - **еҹәдәҺз”ЁжҲ·зҡ„еҚҸеҗҢиҝҮж»Ө**пјҡйҖҡиҝҮеҜ»жүҫ...
йҖҡиҝҮеҲҶжһҗиҝҷдәӣжҠҖжңҜеңЁеӨ©ж–Үж•°жҚ®еӨ„зҗҶдёӯзҡ„еә”з”ЁпјҢж–Үз« иҜҒжҳҺдәҶеңЁж•°жҚ®й«ҳж•ҲеӯҳеӮЁж–№йқўзҡ„дёҚи¶іпјҢеҗҢж—¶еұ•зӨәдәҶдёҖдёӘеҹәдәҺCassandraзҡ„й«ҳжҖ§иғҪеӯҳеӮЁзі»з»ҹзҡ„еҸҜиЎҢжҖ§гҖӮ жҖ»з»“жқҘиҜҙпјҢж–Үз« ж·ұе…ҘеҲҶжһҗдәҶCassandraеңЁеӨ„зҗҶжө·йҮҸеӨ©ж–Үж•°жҚ®еӯҳеӮЁдёҺжЈҖзҙўдёӯзҡ„еә”з”Ё...
е®һйӘҢз»“жһңиЎЁжҳҺпјҢж”№иҝӣеҗҺзҡ„е№іеҸ°дёҚд»…жҸҗй«ҳдәҶж•°жҚ®еӨ„зҗҶйҖҹеәҰпјҢиҖҢдё”дҝқиҜҒдәҶж•°жҚ®еӨ„зҗҶзҡ„еҮҶзЎ®жҖ§пјҢиҝҷеҜ№дәҺи§ЈеҶідҝЎжҒҜиҝҮиҪҪе’ҢжҸҗй«ҳдҝЎжҒҜжЈҖзҙўж•ҲзҺҮе…·жңүйҮҚиҰҒзҡ„е®һйҷ…ж„Ҹд№үгҖӮ е…ій”®иҜҚеҢ…жӢ¬пјҡж–Үжң¬жҢ–жҺҳгҖҒHadoopгҖҒдә‘и®Ўз®—гҖҒж–Үжң¬ж•°жҚ®гҖӮж–Үжң¬жҢ–жҺҳжҢҮзҡ„жҳҜд»Һ...