- жµПиІИ: 511301 жђ°
- жАІеИЂ:

- жЭ•иЗ™: ж≤ИйШ≥
-

жЦЗзЂ†еИЖз±ї
- еЕ®йГ®еНЪеЃҐ (437)
- WindowsиЃЊзљЃ (2)
- oracleжХ∞жНЃеЇУ (39)
- bug--jsp (4)
- j2se (13)
- js (40)
- bug-tomcatдЄНиГљеРѓеК®з®ЛеЇП (1)
- Hibernate (29)
- eclipse (20)
- java (65)
- иЃЊиЃ°ж®°еЉП (6)
- bug (18)
- PL/SQL (11)
- еЙНеП∞ (5)
- жЭВи∞И (25)
- UML (1)
- jdbcзЉЦз®Л (2)
- жКАжЬѓи∞Гз†Ф (1)
- жХ∞жНЃйАЪдњ° (2)
- ios (1)
- servletиЗ™е≠¶зђФиЃ∞ (10)
- tomcat (9)
- SQLе≠¶дє†зђФиЃ∞ (6)
- javaеЈ•еЕЈ (1)
- жХ∞жНЃеЇУиЃЊиЃ° (4)
- javascript (10)
- jsp (11)
- struts (17)
- ajax (7)
- linix/Unix (6)
- иµДжЇР (3)
- spring (14)
- зЃЧж≥Х (5)
- иЃ°зЃЧжЬЇзљСзїЬ (2)
- http (5)
- c++ (2)
- webеЇФзФ® (3)
- jvm (5)
- javaдЄ≠зЪДе≠Чзђ¶зЉЦз†Б (14)
- javaдї£з†БеЇУ (2)
- classloader (1)
- иѓїдє¶зђФиЃ∞ (1)
- c (1)
- еЉАжЇРиљѓдїґ (1)
- svn (1)
- AOP (1)
- javaеЇПеИЧеМЦ (1)
- е§ЪзЇњз®Л (4)
- The legendary programmers (1)
- Apache http Server (1)
- html tag (3)
- struts1.Xе≠¶дє†зђФиЃ∞ (5)
- buffalo (1)
- иЗ™еЈ±жФґиЧП (0)
- TOEFL(IBT) (1)
- зљСзїЬзњїеҐЩ (0)
- зЉЦиѓСеОЯзРЖ (1)
- дє¶з±НжО®иНР (1)
- css (10)
- javaeeзОѓеҐГжР≠еїЇиµДжЦЩ (1)
- еЉАжЇРеЈ•еЕЈ (1)
- зЊОеЫљзФЯжії (1)
- springиЗ™е≠¶ (3)
- log4j (3)
- зЃЧж≥ХдЄОжХ∞жНЃзїУжЮД (5)
- зЧЕжѓТпЉМжПТдїґе§ДзРЖе§ІеЕ® (1)
- flex (2)
- webservice (1)
- git (7)
- cs (1)
- html (4)
- javaee (6)
- еЉАиљ¶ (0)
- springmvc (3)
- дЇТиБФзљСжЮґжЮД (2)
- intellij idea (18)
- maven (15)
- mongodb (2)
- nginx (1)
- react (3)
- javaеЯЇз°АдЊЛе≠Р (2)
- springboot (2)
- еЯєиЃ≠ (5)
- mysql (3)
- жХ∞жНЃеЇУ (3)
- зФЯжії (2)
- intellij (3)
- linux (2)
- os (3)
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 2)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2019-02 ( 1)
- 2018-12 ( 2)
- 2018-11 ( 1)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
жљЗжіТ姩洃пЉЪ
[color=blue][color=cyan]        ...
oracle йАЪињЗ nvl( )еЗљжХ∞sql жߕ胥жЧґдЄЇ з©ЇеАЉ иµЛйїШиЃ§еАЉ -
hekai1990пЉЪ
еПЧжХЩдЇЖ..
oracleдЄ≠зЪДvarchar2
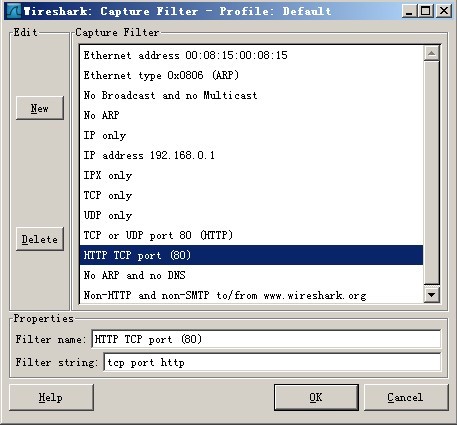
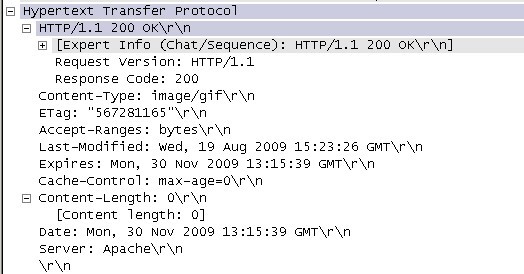
httpеНПиЃЃе≠¶дє†з≥їеИЧ ¬† HTTPжШѓHyper Text Transfer ProtocolпЉИиґЕжЦЗжЬђдЉ†иЊУеНПиЃЃпЉЙзЪДзЉ©еЖЩгАВеЃГзЪДеПСе±ХжШѓдЄЗзїізљСеНПдЉЪпЉИWorld Wide Web ConsortiumпЉЙеТМInternetеЈ•дљЬе∞ПзїДIETFпЉИInternet Engineering Task ForceпЉЙеРИдљЬзЪДзїУжЮЬпЉМпЉИдїЦдїђпЉЙжЬАзїИеПСеЄГдЇЖдЄАз≥їеИЧзЪДRFCпЉМRFC 1945еЃЪдєЙдЇЖHTTP/1.0зЙИжЬђгАВеЕґдЄ≠жЬАиСЧеРНзЪДе∞±жШѓRFC 2616гАВRFC 2616еЃЪдєЙдЇЖдїК姩жЩЃйБНдљњзФ®зЪДдЄАдЄ™зЙИжЬђвАФвАФHTTP 1.1гАВ HTTPеНПиЃЃпЉИHyperText Transfer ProtocolпЉМиґЕжЦЗжЬђдЉ†иЊУеНПиЃЃпЉЙжШѓзФ®дЇОдїОWWWжЬНеК°еЩ®дЉ†иЊУиґЕжЦЗжЬђеИ∞жЬђеЬ∞жµПиІИеЩ®зЪДдЉ†йАБеНПиЃЃгАВеЃГеПѓдї•дљњжµПиІИеЩ®жЫіеК†йЂШжХИпЉМдљњзљСзїЬдЉ†иЊУеЗПе∞СгАВеЃГдЄНдїЕдњЭиѓБиЃ°зЃЧжЬЇж≠£з°ЃењЂйАЯеЬ∞дЉ†иЊУиґЕжЦЗжЬђжЦЗж°£пЉМињШз°ЃеЃЪдЉ†иЊУжЦЗж°£дЄ≠зЪДеУ™дЄАйГ®еИЖпЉМдї•еПКеУ™йГ®еИЖеЖЕеЃєй¶ЦеЕИжШЊз§Ї(е¶ВжЦЗжЬђеЕИдЇОеی嚥)з≠ЙгАВ HTTPжШѓдЄАдЄ™еЇФзФ®е±ВеНПиЃЃпЉМзФ±иѓЈж±ВеТМеУНеЇФжЮДжИРпЉМжШѓдЄАдЄ™ж†ЗеЗЖзЪДеЃҐжИЈзЂѓжЬНеК°еЩ®ж®°еЮЛгАВHTTPжШѓдЄАдЄ™жЧ†зКґжАБзЪДеНПиЃЃгАВ HTTPеНПиЃЃйАЪеЄЄжЙњиљљдЇОTCPеНПиЃЃдєЛдЄКпЉМжЬЙжЧґдєЯжЙњиљљдЇОTLSжИЦSSLеНПиЃЃе±ВдєЛдЄКпЉМињЩдЄ™жЧґеАЩпЉМе∞±жИРдЇЖжИСдїђеЄЄиѓізЪДHTTPSгАВе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ йїШиЃ§HTTPзЪДзЂѓеП£еПЈдЄЇ80пЉМHTTPSзЪДзЂѓеП£еПЈдЄЇ443гАВ HTTPеНПиЃЃж∞ЄињЬйГљжШѓеЃҐжИЈзЂѓеПСиµЈиѓЈж±ВпЉМжЬНеК°еЩ®еЫЮйАБеУНеЇФгАВиІБдЄЛеЫЊпЉЪ ињЩж†Је∞±йЩРеИґдЇЖдљњзФ®HTTPеНПиЃЃпЉМжЧ†ж≥ХеЃЮзО∞еЬ®еЃҐжИЈзЂѓж≤°жЬЙеПСиµЈиѓЈж±ВзЪДжЧґеАЩпЉМжЬНеК°еЩ®е∞ЖжґИжБѓжО®йАБзїЩеЃҐжИЈзЂѓгАВ HTTPеНПиЃЃжШѓдЄАдЄ™жЧ†зКґжАБзЪДеНПиЃЃпЉМеРМдЄАдЄ™еЃҐжИЈзЂѓзЪДињЩжђ°иѓЈж±ВеТМдЄКжђ°иѓЈж±ВжШѓж≤°жЬЙеѓєеЇФеЕ≥з≥їгАВ дЄАжђ°HTTPжУНдљЬзІ∞дЄЇдЄАдЄ™дЇЛеК°пЉМеЕґеЈ•дљЬињЗз®ЛеПѓеИЖдЄЇеЫЫж≠•пЉЪ 1пЉЙй¶ЦеЕИеЃҐжИЈжЬЇдЄОжЬНеК°еЩ®йЬАи¶БеїЇзЂЛињЮжО•гАВеП™и¶БеНХеЗїжЯРдЄ™иґЕзЇІйУЊжО•пЉМHTTPзЪДеЈ•дљЬеЉАеІЛгАВ 2пЉЙеїЇзЂЛињЮжО•еРОпЉМеЃҐжИЈжЬЇеПСйАБдЄАдЄ™иѓЈж±ВзїЩжЬНеК°еЩ®пЉМиѓЈж±ВжЦєеЉПзЪДж†ЉеЉПдЄЇпЉЪзїЯдЄАиµДжЇРж†ЗиѓЖзђ¶пЉИURLпЉЙгАБеНПиЃЃзЙИжЬђеПЈпЉМеРОиЊєжШѓMIMEдњ°жБѓеМЕжЛђиѓЈж±ВдњЃй•∞зђ¶гАБеЃҐжИЈжЬЇдњ°жБѓеТМеПѓиГљзЪДеЖЕеЃєгАВ 3пЉЙжЬНеК°еЩ®жО•еИ∞иѓЈж±ВеРОпЉМзїЩдЇИзЫЄеЇФзЪДеУНеЇФдњ°жБѓпЉМеЕґж†ЉеЉПдЄЇдЄАдЄ™зКґжАБи°МпЉМеМЕжЛђдњ°жБѓзЪДеНПиЃЃзЙИжЬђеПЈгАБдЄАдЄ™жИРеКЯжИЦйФЩиѓѓзЪДдї£з†БпЉМеРОиЊєжШѓMIMEдњ°жБѓеМЕжЛђжЬНеК°еЩ®дњ°жБѓгАБеЃЮдљУдњ°жБѓеТМеПѓиГљзЪДеЖЕеЃєгАВ 4пЉЙеЃҐжИЈзЂѓжО•жФґжЬНеК°еЩ®жЙАињФеЫЮзЪДдњ°жБѓйАЪињЗжµПиІИеЩ®жШЊз§ЇеЬ®зФ®жИЈзЪДжШЊз§Їе±ПдЄКпЉМзДґеРОеЃҐжИЈжЬЇдЄОжЬНеК°еЩ®жЦ≠еЉАињЮжО•гАВ е¶ВжЮЬеЬ®дї•дЄКињЗз®ЛдЄ≠зЪДжЯРдЄАж≠•еЗЇзО∞йФЩиѓѓпЉМйВ£дєИдЇІзФЯйФЩиѓѓзЪДдњ°жБѓе∞ЖињФеЫЮеИ∞еЃҐжИЈзЂѓпЉМжЬЙжШЊз§Їе±ПиЊУеЗЇгАВеѓєдЇОзФ®жИЈжЭ•иѓіпЉМињЩдЇЫињЗз®ЛжШѓзФ±HTTPиЗ™еЈ±еЃМжИРзЪДпЉМзФ®жИЈеП™и¶БзФ®йЉ†ж†ЗзВєеЗїпЉМз≠ЙеЊЕдњ°жБѓжШЊз§Їе∞±еПѓдї•дЇЖгАВ жЙУеЉАWiresharkпЉМйАЙжЛ©еЈ•еЕЈж†ПдЄКзЪДвАЬCaptureвАЭ->вАЬOptionsвАЭпЉМзХМйЭҐйАЙжЛ©е¶ВеЫЊ1жЙАз§ЇпЉЪ еЫЊ1 иЃЊзљЃCaptureйАЙй°є дЄАиИђиѓїиАЕеП™йЬАи¶БйАЙжЛ©жЬАдЄКиЊєзЪДдЄЛжЛЙж°ЖпЉМйАЙжЛ©еРИйАВзЪДDeviceпЉМиАМеРОзВєеЗївАЬCapture FilterвАЭпЉМж≠§е§ДйАЙжЛ©зЪДжШѓвАЬHTTP TCP portпЉИ80пЉЙвАЭпЉМйАЙжЛ©еРОзВєеЗїдЄКеЫЊзЪДвАЬStartвАЭеЉАеІЛжКУеМЕгАВ еЫЊ2 йАЙжЛ©Capture Filter дЊЛе¶ВеЬ®жµПиІИеЩ®дЄ≠жЙУеЉАhttp://image.baidu.com/пЉМжКУеМЕе¶ВеЫЊ3жЙАз§ЇпЉЪ еЫЊ3¬† ¬†жКУеМЕ еЬ®дЄКеЫЊдЄ≠пЉМеПѓжЄЕжЩ∞зЪДзЬЛеИ∞еЃҐжИЈзЂѓжµПиІИеЩ®пЉИipдЄЇ192.168.2.33пЉЙдЄОжЬНеК°еЩ®зЪДдЇ§дЇТињЗз®ЛпЉЪ 1пЉЙNo1пЉЪжµПиІИеЩ®пЉИ192.168.2.33пЉЙеРСжЬНеК°еЩ®пЉИ220.181.50.118пЉЙеПСеЗЇињЮжО•иѓЈж±ВгАВж≠§дЄЇTCPдЄЙжђ°жП°жЙЛзђђдЄАж≠•пЉМж≠§жЧґдїОеЫЊдЄ≠еПѓдї•зЬЛеЗЇпЉМдЄЇSYNпЉМseq:X¬†пЉИx=0пЉЙ 2пЉЙNo2пЉЪжЬНеК°еЩ®пЉИ220.181.50.118пЉЙеЫЮеЇФдЇЖжµПиІИеЩ®пЉИ192.168.2.33пЉЙзЪДиѓЈж±ВпЉМеєґи¶Бж±Вз°ЃиЃ§пЉМж≠§жЧґдЄЇпЉЪSYNпЉМACKпЉМж≠§жЧґseqпЉЪyпЉИyдЄЇ0пЉЙпЉМACKпЉЪx+1пЉИдЄЇ1пЉЙгАВж≠§дЄЇдЄЙжђ°жП°жЙЛзЪДзђђдЇМж≠•пЉЫ 3пЉЙNo3пЉЪжµПиІИеЩ®пЉИ192.168.2.33пЉЙеЫЮеЇФдЇЖжЬНеК°еЩ®пЉИ220.181.50.118пЉЙзЪДз°ЃиЃ§пЉМињЮжО•жИРеКЯгАВдЄЇпЉЪACKпЉМж≠§жЧґseqпЉЪx+1пЉИдЄЇ1пЉЙпЉМACKпЉЪy+1пЉИдЄЇ1пЉЙгАВж≠§дЄЇдЄЙжђ°жП°жЙЛзЪДзђђдЄЙж≠•пЉЫ 4пЉЙNo4пЉЪжµПиІИеЩ®пЉИ192.168.2.33пЉЙеПСеЗЇдЄАдЄ™й°µйЭҐHTTPиѓЈж±ВпЉЫ 5пЉЙNo5пЉЪжЬНеК°еЩ®пЉИ220.181.50.118пЉЙз°ЃиЃ§пЉЫ 6пЉЙNo6пЉЪжЬНеК°еЩ®пЉИ220.181.50.118пЉЙеПСйАБжХ∞жНЃпЉЫ 7пЉЙNo7пЉЪеЃҐжИЈзЂѓжµПиІИеЩ®пЉИ192.168.2.33пЉЙз°ЃиЃ§пЉЫ 8пЉЙNo14пЉЪеЃҐжИЈзЂѓпЉИ192.168.2.33пЉЙеПСеЗЇдЄАдЄ™еЫЊзЙЗHTTPиѓЈж±ВпЉЫ 9пЉЙNo15пЉЪжЬНеК°еЩ®пЉИ220.181.50.118пЉЙеПСйАБзКґжАБеУНеЇФз†Б200 OK вА¶вА¶ жѓПдЄ™е§іеЯЯзФ±дЄАдЄ™еЯЯеРНпЉМеЖТеПЈпЉИ:пЉЙеТМеЯЯеАЉдЄЙйГ®еИЖзїДжИРгАВеЯЯеРНжШѓе§Іе∞ПеЖЩжЧ†еЕ≥зЪДпЉМеЯЯеАЉеЙНеПѓдї•жЈїеК†дїїдљХжХ∞йЗПзЪДз©Їж†Љзђ¶пЉМе§іеЯЯеσ俕襀жЙ©е±ХдЄЇе§Ъи°МпЉМеЬ®жѓПи°МеЉАеІЛе§ДпЉМдљњзФ®иЗ≥е∞СдЄАдЄ™з©Їж†ЉжИЦеИґи°®зђ¶гАВ еЬ®жКУеМЕзЪДеЫЊдЄ≠пЉМNo14зВєеЉАеПѓзЬЛеИ∞е¶ВеЫЊ4жЙАз§ЇпЉЪ еЫЊ4 httpиѓЈж±ВжґИжБѓ ¬†¬†¬†¬†¬†¬†¬†еЫЮеЇФзЪДжґИжБѓе¶ВеЫЊ5жЙАз§ЇпЉЪ еЫЊ5 httpзКґжАБеУНеЇФдњ°жБѓ Hostе§іеЯЯжМЗеЃЪиѓЈж±ВиµДжЇРзЪДIntenetдЄїжЬЇеТМзЂѓеП£еПЈпЉМењЕй°їи°®з§ЇиѓЈж±ВurlзЪДеОЯеІЛжЬНеК°еЩ®жИЦзљСеЕ≥зЪДдљНзљЃгАВHTTP/1.1иѓЈж±ВењЕй°їеМЕеРЂдЄїжЬЇе§іеЯЯпЉМеР¶еИЩз≥їзїЯдЉЪдї•400зКґжАБз†БињФеЫЮгАВ еЫЊ5дЄ≠hostйВ£и°МдЄЇпЉЪ Refererе§іеЯЯеЕБиЃЄеЃҐжИЈзЂѓжМЗеЃЪиѓЈж±ВuriзЪДжЇРиµДжЇРеЬ∞еЭАпЉМињЩеПѓдї•еЕБиЃЄжЬНеК°еЩ®зФЯжИРеЫЮйААйУЊи°®пЉМеПѓзФ®жЭ•зЩїйЩЖгАБдЉШеМЦcacheз≠ЙгАВдїЦдєЯеЕБиЃЄеЇЯйЩ§зЪДжИЦйФЩиѓѓзЪДињЮжО•зФ±дЇОзїіжК§зЪДзЫЃзЪД襀蜚誙гАВе¶ВжЮЬиѓЈж±ВзЪДuriж≤°жЬЙиЗ™еЈ±зЪДuriеЬ∞еЭАпЉМRefererдЄНиÚ襀еПСйАБгАВе¶ВжЮЬжМЗеЃЪзЪДжШѓйГ®еИЖuriеЬ∞еЭАпЉМеИЩж≠§еЬ∞еЭАеЇФиѓ•жШѓдЄАдЄ™зЫЄеѓєеЬ∞еЭАгАВ еЬ®еЫЊ4дЄ≠пЉМRefererи°МзЪДеЖЕеЃєдЄЇпЉЪ User-Agentе§іеЯЯзЪДеЖЕеЃєеМЕеРЂеПСеЗЇиѓЈж±ВзЪДзФ®жИЈдњ°жБѓгАВ еЬ®еЫЊ4дЄ≠пЉМUser-Agentи°МзЪДеЖЕеЃєдЄЇпЉЪ Cache-ControlжМЗеЃЪиѓЈж±ВеТМеУНеЇФйБµеЊ™зЪДзЉУе≠ШжЬЇеИґгАВеЬ®иѓЈж±ВжґИжБѓжИЦеУНеЇФжґИжБѓдЄ≠иЃЊзљЃCache-ControlеєґдЄНдЉЪдњЃжФєеП¶дЄАдЄ™жґИжБѓе§ДзРЖињЗз®ЛдЄ≠зЪДзЉУе≠Ше§ДзРЖињЗз®ЛгАВиѓЈж±ВжЧґзЪДзЉУе≠ШжМЗдї§еМЕжЛђno-cacheгАБno-storeгАБmax-ageгАБmax-staleгАБmin-freshгАБonly-if-cachedпЉМеУНеЇФжґИжБѓдЄ≠зЪДжМЗдї§еМЕжЛђpublicгАБprivateгАБno-cacheгАБno-storeгАБno-transformгАБmust-revalidateгАБproxy-revalidateгАБmax-ageгАВ еЬ®еЫЊ5дЄ≠зЪДиѓ•е§іеЯЯдЄЇпЉЪ Dateе§іеЯЯи°®з§ЇжґИжБѓеПСйАБзЪДжЧґйЧіпЉМжЧґйЧізЪДжППињ∞ж†ЉеЉПзФ±rfc822еЃЪдєЙгАВдЊЛе¶ВпЉМDate:Mon,31Dec200104:25:57GMTгАВDateжППињ∞зЪДжЧґйЧіи°®з§ЇдЄЦзХМж†ЗеЗЖжЧґпЉМжНҐзЃЧжИРжЬђеЬ∞жЧґйЧіпЉМйЬАи¶БзЯ•йБУзФ®жИЈжЙАеЬ®зЪДжЧґеМЇгАВ еЫЊ5дЄ≠пЉМиѓ•е§іеЯЯе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ дЄАдЄ™дЉ†иЊУе±ВзЪДеЃЮйЩЕзОѓжµБпЉМеЃГжШѓеїЇзЂЛеЬ®дЄ§дЄ™зЫЄдЇТйАЪиЃѓзЪДеЇФзФ®з®ЛеЇПдєЛйЧігАВ еЬ®http1.1пЉМrequestеТМreponseе§ідЄ≠йГљжЬЙеПѓиГљеЗЇзО∞дЄАдЄ™connectionзЪДе§іпЉМж≠§headerзЪДеРЂдєЙжШѓељУclientеТМserverйАЪдњ°жЧґеѓєдЇОйХњйУЊжО•е¶ВдљХињЫи°Ме§ДзРЖгАВ еЬ®http1.1дЄ≠пЉМclientеТМserverйГљжШѓйїШиЃ§еѓєжЦєжФѓжМБйХњйУЊжО•зЪДпЉМ¬†е¶ВжЮЬclientдљњзФ®http1.1еНПиЃЃпЉМдљЖеПИдЄНеЄМжЬЫдљњзФ®йХњйУЊжО•пЉМеИЩйЬАи¶БеЬ®headerдЄ≠жМЗжШОconnectionзЪДеАЉдЄЇcloseпЉЫе¶ВжЮЬserverжЦєдєЯдЄНжГ≥жФѓжМБйХњйУЊжО•пЉМеИЩеЬ®responseдЄ≠дєЯйЬАи¶БжШОз°ЃиѓіжШОconnectionзЪДеАЉдЄЇcloseгАВдЄНиЃЇrequestињШжШѓresponseзЪДheaderдЄ≠еМЕеРЂдЇЖеАЉдЄЇcloseзЪДconnectionпЉМйГљи°®жШОељУеЙНж≠£еЬ®дљњзФ®зЪДtcpйУЊжО•еЬ®ељУ姩胣ж±Ве§ДзРЖеЃМжѓХеРОдЉЪ襀жЦ≠жОЙгАВдї•еРОclientеЖНињЫи°МжЦ∞зЪДиѓЈж±ВжЧґе∞±ењЕй°їеИЫеїЇжЦ∞зЪДtcpйУЊжО•дЇЖгАВ HTTPйАЪиЃѓзЪДеЯЇжЬђеНХдљНпЉМеМЕжЛђдЄАдЄ™зїУжЮДеМЦзЪДеЕЂеЕГзїДеЇПеИЧеєґйАЪињЗињЮжО•дЉ†иЊУгАВ дЄАдЄ™дїОеЃҐжИЈзЂѓеИ∞жЬНеК°еЩ®зЪДиѓЈж±Вдњ°жБѓеМЕжЛђеЇФзФ®дЇОиµДжЇРзЪДжЦєж≥ХгАБиµДжЇРзЪДж†ЗиѓЖзђ¶еТМеНПиЃЃзЪДзЙИжЬђеПЈгАВ дЄАдЄ™дїОжЬНеК°еЩ®ињФеЫЮзЪДдњ°жБѓеМЕжЛђHTTPеНПиЃЃзЪДзЙИжЬђеПЈгАБиѓЈж±ВзЪДзКґжАБ(дЊЛе¶ВвАЬжИРеКЯвАЭжИЦвАЬж≤°жЙЊеИ∞вАЭ)еТМжЦЗж°£зЪДMIMEз±їеЮЛгАВ зФ±URIж†ЗиѓЖзЪДзљСзїЬжХ∞жНЃеѓєи±°жИЦжЬНеК°гАВ жХ∞жНЃиµДжЇРжИЦжЭ•иЗ™жЬНеК°иµДжЇРзЪДеЫЮжШ†зЪДдЄАзІНзЙєжЃКи°®з§ЇжЦєж≥ХпЉМеЃГеПѓиÚ襀еМЕеЫіеЬ®дЄАдЄ™иѓЈж±ВжИЦеУНеЇФдњ°жБѓдЄ≠гАВдЄАдЄ™еЃЮдљУеМЕжЛђеЃЮдљУе§ідњ°жБѓеТМеЃЮдљУзЪДжЬђиЇЂеЖЕеЃєгАВ дЄАдЄ™дЄЇеПСйАБиѓЈж±ВзЫЃзЪДиАМеїЇзЂЛињЮжО•зЪДеЇФзФ®з®ЛеЇПгАВ еИЭеІЛеМЦдЄАдЄ™иѓЈж±ВзЪДеЃҐжИЈжЬЇгАВеЃГдїђжШѓжµПиІИеЩ®гАБзЉЦиЊСеЩ®жИЦеЕґеЃГзФ®жИЈеЈ•еЕЈгАВ дЄАдЄ™жО•еПЧињЮжО•еєґеѓєиѓЈж±ВињФеЫЮдњ°жБѓзЪДеЇФзФ®з®ЛеЇПгАВ жШѓдЄАдЄ™зїЩеЃЪиµДжЇРеПѓдї•еЬ®еЕґдЄКй©їзХЩжИЦ襀еИЫеїЇзЪДжЬНеК°еЩ®гАВ дЄАдЄ™дЄ≠йЧіз®ЛеЇПпЉМеЃГеПѓдї•еЕЕељУдЄАдЄ™жЬНеК°еЩ®пЉМдєЯеПѓдї•еЕЕељУдЄАдЄ™еЃҐжИЈжЬЇпЉМдЄЇеЕґеЃГеЃҐжИЈжЬЇеїЇзЂЛиѓЈж±ВгАВиѓЈж±ВжШѓйАЪињЗеПѓиГљзЪДзњїиѓСеЬ®еЖЕйГ®жИЦзїПињЗдЉ†йАТеИ∞еЕґеЃГзЪДжЬНеК°еЩ®дЄ≠гАВдЄАдЄ™дї£зРЖеЬ®еПСйАБиѓЈж±Вдњ°жБѓдєЛеЙНпЉМењЕй°їиІ£йЗКеєґдЄФе¶ВжЮЬеПѓиГљйЗНеЖЩеЃГгАВ дї£зРЖзїПеЄЄдљЬдЄЇйАЪињЗйШ≤зБЂеҐЩзЪДеЃҐжИЈжЬЇзЂѓзЪДйЧ®жИЈпЉМдї£зРЖињШеПѓдї•дљЬдЄЇдЄАдЄ™еЄЃеК©еЇФзФ®жЭ•йАЪињЗеНПиЃЃе§ДзРЖж≤°жЬЙ襀зФ®жИЈдї£зРЖеЃМжИРзЪДиѓЈж±ВгАВ дЄАдЄ™дљЬдЄЇеЕґеЃГжЬНеК°еЩ®дЄ≠йЧіе™ТдїЛзЪДжЬНеК°еЩ®гАВдЄОдї£зРЖдЄНеРМзЪДжШѓпЉМзљСеЕ≥жО•еПЧиѓЈж±Ве∞±е•љи±°еѓєиҐЂиѓЈж±ВзЪДиµДжЇРжЭ•иѓіеЃГе∞±жШѓжЇРжЬНеК°еЩ®пЉЫеПСеЗЇиѓЈж±ВзЪДеЃҐжИЈжЬЇеєґж≤°жЬЙжДПиѓЖеИ∞еЃГеЬ®еРМзљСеЕ≥жЙУдЇ§йБУгАВ зљСеЕ≥зїПеЄЄдљЬдЄЇйАЪињЗйШ≤зБЂеҐЩзЪДжЬНеК°еЩ®зЂѓзЪДйЧ®жИЈпЉМзљСеЕ≥ињШеПѓдї•дљЬдЄЇдЄАдЄ™еНПиЃЃзњїиѓСеЩ®дї•дЊње≠ШеПЦйВ£дЇЫе≠ШеВ®еЬ®йЭЮHTTPз≥їзїЯдЄ≠зЪДиµДжЇРгАВ жШѓдљЬдЄЇдЄ§дЄ™ињЮжО•дЄ≠зїІзЪДдЄ≠дїЛз®ЛеЇПгАВдЄАжЧ¶жњАжіїпЉМйАЪйБУ䌜襀聧䪯дЄНе±ЮдЇОHTTPйАЪиЃѓпЉМе∞љзЃ°йАЪйБУеПѓиГљж؃襀дЄАдЄ™HTTPиѓЈж±ВеИЭеІЛеМЦзЪДгАВељУ襀дЄ≠зїІзЪДињЮжО•дЄ§зЂѓеЕ≥йЧ≠жЧґпЉМйАЪйБУдЊњжґИ姱гАВељУдЄАдЄ™йЧ®жИЈ(Portal)ењЕй°їе≠ШеЬ®жИЦдЄ≠дїЛ(Intermediary)дЄНиГљиІ£йЗКдЄ≠зїІзЪДйАЪиЃѓжЧґйАЪйБУ襀зїПеЄЄдљњзФ®гАВ еПНеЇФдњ°жБѓзЪДе±АеЯЯе≠ШеВ®гАВ гАКhttp_зЩЊеЇ¶зЩЊзІСгАЛпЉЪhttp://baike.baidu.com/view/9472.htm гАКзїУжЮЬзЉЦз†БеТМhttpзКґжАБеУНеЇФз†БгАЛпЉЪhttp://blog.tieniu1980.cn/archives/377 гАКеИЖжЮРTCPзЪДдЄЙжђ°жП°жЙЛгАЛпЉЪ гАКдљњзФ®WiresharkжЭ•ж£АжµЛдЄАжђ°HTTPињЮжО•ињЗз®ЛгАЛпЉЪ http://blog.163.com/wangbo_tester/blog/static/12806792120098174162288/ гАКhttpеНПиЃЃзЪДеЗ†дЄ™йЗНи¶Бж¶ВењµгАЛпЉЪhttp://nc.mofcom.gov.cn/news/10819972.html гАКhttpеНПиЃЃдЄ≠connectionе§ізЪДдљЬзФ®гАЛпЉЪ RFC 1945еЃЪдєЙдЇЖHTTP/1.0зЙИжЬђпЉМRFC 2616еЃЪдєЙдЇЖHTTP/1.1зЙИжЬђгАВ зђФиАЕеЬ®blogдЄКжПРдЊЫдЇЖињЩдЄ§дЄ™RFCдЄ≠жЦЗзЙИзЪДдЄЛиљљеЬ∞еЭАгАВ RFC1945дЄЛиљљеЬ∞еЭАпЉЪ http://www.blogjava.net/Files/amigoxie/RFC1945пЉИHTTPпЉЙдЄ≠жЦЗзЙИ.rar RFC2616дЄЛиљљеЬ∞еЭАпЉЪ http://www.blogjava.net/Files/amigoxie/RFC2616пЉИHTTPпЉЙдЄ≠жЦЗзЙИ.rar HTTP/1.0¬†жѓПжђ°иѓЈж±ВйГљйЬАи¶БеїЇзЂЛжЦ∞зЪДTCPињЮжО•пЉМињЮжО•дЄНиГље§НзФ®гАВHTTP/1.1¬†жЦ∞зЪДиѓЈж±ВеПѓдї•еЬ®дЄКжђ°иѓЈж±ВеїЇзЂЛзЪДTCPињЮжО•дєЛдЄКеПСйАБпЉМињЮжО•еПѓдї•е§НзФ®гАВдЉШзВєжШѓеЗПе∞СйЗНе§НињЫи°МTCPдЄЙжђ°жП°жЙЛзЪДеЉАйФАпЉМжПРйЂШжХИзОЗгАВ ж≥®жДПпЉЪеЬ®еРМдЄАдЄ™TCPињЮжО•дЄ≠пЉМжЦ∞зЪДиѓЈж±ВйЬАи¶Бз≠ЙдЄКжђ°иѓЈж±ВжФґеИ∞еУНеЇФеРОпЉМжЙНиГљеПСйАБгАВ HTTP1.1еЬ®RequestжґИжБѓе§ійЗМе§іе§ЪдЇЖдЄАдЄ™HostеЯЯ, HTTP1.0еИЩж≤°жЬЙињЩдЄ™еЯЯгАВ EgпЉЪ ¬†¬†¬†¬†еПѓиГљHTTP1.0зЪДжЧґеАЩиЃ§дЄЇпЉМеїЇзЂЛTCPињЮжО•зЪДжЧґеАЩеЈ≤зїПжМЗеЃЪдЇЖIPеЬ∞еЭАпЉМињЩдЄ™IPеЬ∞еЭАдЄКеП™жЬЙдЄАдЄ™hostгАВ (жО•жФґжЦєеРС) жЧ†иЃЇжШѓHTTP1.0ињШжШѓHTTP1.1пЉМйГљи¶БиГљиІ£жЮРдЄЛйЭҐдЄЙзІНdate/time stampпЉЪ ¬†¬†¬†¬†¬†¬† (еПСйАБжЦєеРС) HTTP1.0и¶Бж±ВдЄНиГљзФЯжИРзђђдЄЙзІНasctimeж†ЉеЉПзЪДdate/time stampпЉЫ HTTP1.1еИЩи¶Бж±ВеП™зФЯжИРRFC 1123(зђђдЄАзІН)ж†ЉеЉПзЪДdate/time stampгАВ зКґжАБеУНеЇФз†Б100 (Continue)¬†зКґжАБдї£з†БзЪДдљњзФ®пЉМеЕБиЃЄеЃҐжИЈзЂѓеЬ®еПСrequestжґИжБѓbodyдєЛеЙНеЕИзФ®request headerиѓХжОҐдЄАдЄЛserverпЉМзЬЛserverи¶БдЄНи¶БжО•жФґrequest bodyпЉМеЖНеЖ≥еЃЪи¶БдЄНи¶БеПСrequest bodyгАВ еЃҐжИЈзЂѓеЬ®Requestе§ійГ®дЄ≠еМЕеРЂ ¬†¬†¬†¬†¬†¬† ServerзЬЛеИ∞дєЛеРОеСҐе¶ВжЮЬеЫЮ100 (Continue)¬†ињЩдЄ™зКґжАБдї£з†БпЉМеЃҐжИЈзЂѓе∞±зїІзї≠еПСrequest bodyгАВињЩдЄ™жШѓHTTP1.1жЙНжЬЙзЪДгАВ еП¶е§ЦеЬ®HTTP/1.1дЄ≠ињШеҐЮеК†дЇЖ101гАБ203гАБ205з≠Йз≠ЙжАІзКґжАБеУНеЇФз†Б HTTP1.1еҐЮеК†дЇЖOPTIONS, PUT, DELETE, TRACE, CONNECTињЩдЇЫRequestжЦєж≥Х. ¬†¬†¬†¬†¬†¬† Method¬†¬†¬†¬†¬†¬†¬†¬† = "OPTIONS"¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ; Section 9.2 ¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† | "GET"¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ; Section 9.3 ¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† | "HEAD"¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ; Section 9.4 ¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† | "POST"¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ; Section 9.5 ¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† | "PUT"¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ; Section 9.6 ¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† | "DELETE"¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ; Section 9.7 ¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† | "TRACE"¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ; Section 9.8 ¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† | "CONNECT"¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† ; Section 9.9 ¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† | extension-method ¬†¬†¬†¬†¬†¬† extension-method = token иѓЈж±ВжґИжБѓж†ЉеЉПе¶ВдЄЛжЙАз§ЇпЉЪ иѓЈж±Ви°М йАЪзФ®дњ°жБѓе§і|иѓЈж±Ве§і|еЃЮдљУе§і CRLF(еЫЮиљ¶жНҐи°М) еЃЮдљУеЖЕеЃє еЕґдЄ≠вАЬиѓЈж±Ви°МвАЭдЄЇпЉЪиѓЈж±Ви°М¬†=¬†жЦєж≥Х¬†[з©Їж†Љ]¬†иѓЈж±ВURI [з©Їж†Љ]¬†зЙИжЬђеПЈ¬†[еЫЮиљ¶жНҐи°М] иѓЈж±Ви°МеЃЮдЊЛпЉЪ Eg1пЉЪ ¬†¬†¬†¬†¬†¬† Eg2пЉЪ POST¬†http://192.168.2.217:8080/index.jsp HTTP/1.1 HTTPиѓЈж±ВжґИжБѓеЃЮдЊЛпЉЪ ¬† ¬†¬†¬†¬†¬†¬† HTTPзЪДиѓЈж±ВжЦєж≥ХеМЕжЛђе¶ВдЄЛеЗ†зІНпЉЪ q¬†¬†¬†¬†¬†¬†GET q¬†¬†¬†¬†¬†¬†POST q¬†¬†¬†¬†¬†¬†HEAD q¬†¬†¬†¬†¬†¬†PUT q¬†¬†¬†¬†¬†¬†DELETE q¬†¬†¬†¬†¬†¬†OPTIONS q¬†¬†¬†¬†¬†¬†TRACE q¬†¬†¬†¬†¬†¬†CONNECT HTTPеУНеЇФжґИжБѓзЪДж†ЉеЉПе¶ВдЄЛжЙАз§ЇпЉЪ зКґжАБи°М йАЪзФ®дњ°жБѓе§і|еУНеЇФе§і|еЃЮдљУе§і CRLF еЃЮдљУеЖЕеЃє еЕґдЄ≠пЉЪзКґжАБи°М¬†=¬†зЙИжЬђеПЈ¬†[з©Їж†Љ]¬†зКґжАБз†Б¬†[з©Їж†Љ]¬†еОЯеЫ†¬†[еЫЮиљ¶жНҐи°М] зКґжАБи°МдЄЊдЊЛпЉЪ Eg1пЉЪ ¬†¬†¬†¬†¬† Eg2пЉЪ ¬†¬†¬†¬† HTTPеУНеЇФжґИжБѓеЃЮдЊЛе¶ВдЄЛжЙАз§ЇпЉЪ 2.3.2¬†httpзЪДзКґжАБеУНеЇФз†Б 100вАФвАФеЃҐжИЈењЕй°їзїІзї≠еПСеЗЇиѓЈж±В 101вАФвАФеЃҐжИЈи¶Бж±ВжЬНеК°еЩ®ж†єжНЃиѓЈж±ВиљђжНҐHTTPеНПиЃЃзЙИжЬђ 200вАФвАФдЇ§жШУжИРеКЯ 202вАФвАФжО•еПЧеТМе§ДзРЖгАБдљЖе§ДзРЖжЬ™еЃМжИР 203вАФвАФињФеЫЮдњ°жБѓдЄНз°ЃеЃЪжИЦдЄНеЃМжХі 204вАФвАФиѓЈж±ВжФґеИ∞пЉМдљЖињФеЫЮдњ°жБѓдЄЇз©Ї 205вАФвАФжЬНеК°еЩ®еЃМжИРдЇЖиѓЈж±ВпЉМзФ®жИЈдї£зРЖењЕй°їе§НдљНељУеЙНеЈ≤зїПжµПиІИињЗзЪДжЦЗдїґ 206вАФвАФжЬНеК°еЩ®еЈ≤зїПеЃМжИРдЇЖйГ®еИЖзФ®жИЈзЪДGETиѓЈж±В 300вАФвАФиѓЈж±ВзЪДиµДжЇРеПѓеЬ®е§Ъе§ДеЊЧеИ∞ 301вАФвАФеИ†йЩ§иѓЈж±ВжХ∞жНЃ 302вАФвАФеЬ®еЕґдїЦеЬ∞еЭАеПСзО∞дЇЖиѓЈж±ВжХ∞жНЃ 303вАФвАФеїЇиЃЃеЃҐжИЈиЃњйЧЃеЕґдїЦURLжИЦиЃњйЧЃжЦєеЉП 304вАФвАФеЃҐжИЈзЂѓеЈ≤зїПжЙІи°МдЇЖGETпЉМдљЖжЦЗдїґжЬ™еПШеМЦ 305вАФвАФиѓЈж±ВзЪДиµДжЇРењЕй°їдїОжЬНеК°еЩ®жМЗеЃЪзЪДеЬ∞еЭАеЊЧеИ∞ 306вАФвАФеЙНдЄАзЙИжЬђHTTPдЄ≠дљњзФ®зЪДдї£з†БпЉМзО∞и°МзЙИжЬђдЄ≠дЄНеЖНдљњзФ® 307вАФвАФзФ≥жШОиѓЈж±ВзЪДиµДжЇРдЄіжЧґжАІеИ†йЩ§ 400вАФвАФйФЩиѓѓиѓЈж±ВпЉМе¶Виѓ≠ж≥ХйФЩиѓѓ 401вАФвАФжЬ™жОИжЭГ HTTP 401.1 -¬†жЬ™жОИжЭГпЉЪзЩїељХ姱賕 гААгААHTTP 401.2 -¬†жЬ™жОИжЭГпЉЪжЬНеК°еЩ®йЕНзљЃйЧЃйҐШеѓЉиЗізЩїељХ姱賕 гААгААHTTP 401.3 - ACL¬†з¶Бж≠ҐиЃњйЧЃиµДжЇР гААгААHTTP 401.4 -¬†жЬ™жОИжЭГпЉЪжОИжЭГ襀з≠ЫйАЙеЩ®жЛТзїЭ HTTP 401.5 -¬†жЬ™жОИжЭГпЉЪISAPI¬†жИЦ¬†CGI¬†жОИжЭГ姱賕 402вАФвАФдњЭзХЩжЬЙжХИChargeToе§іеУНеЇФ 403вАФвАФз¶Бж≠ҐиЃњйЧЃ HTTP 403.1¬†з¶Бж≠ҐиЃњйЧЃпЉЪз¶Бж≠ҐеПѓжЙІи°МиЃњйЧЃ гААгААHTTP 403.2 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪз¶Бж≠ҐиѓїиЃњйЧЃ гААгААHTTP 403.3 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪз¶Бж≠ҐеЖЩиЃњйЧЃ гААгААHTTP 403.4 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪи¶Бж±В¬†SSL гААгААHTTP 403.5 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪи¶Бж±В¬†SSL 128 гААгААHTTP 403.6 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪIP¬†еЬ∞еЭА襀жЛТзїЭ гААгААHTTP 403.7 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪи¶Бж±ВеЃҐжИЈиѓБдє¶ гААгААHTTP 403.8 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪз¶Бж≠ҐзЂЩзВєиЃњйЧЃ гААгААHTTP 403.9 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪињЮжО•зЪДзФ®жИЈињЗе§Ъ гААгААHTTP 403.10 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪйЕНзљЃжЧ†жХИ гААгААHTTP 403.11 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪеѓЖз†БжЫіжФє гААгААHTTP 403.12 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪжШ†е∞ДеЩ®жЛТзїЭиЃњйЧЃ гААгААHTTP 403.13 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪеЃҐжИЈиѓБдє¶еЈ≤襀еРКйФА гААгААHTTP 403.15 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪеЃҐжИЈиЃњйЧЃиЃЄеПѓињЗе§Ъ гААгААHTTP 403.16 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪеЃҐжИЈиѓБдє¶дЄНеПѓдњ°жИЦиАЕжЧ†жХИ HTTP 403.17 -¬†з¶Бж≠ҐиЃњйЧЃпЉЪеЃҐжИЈиѓБдє¶еЈ≤зїПеИ∞жЬЯжИЦиАЕе∞ЪжЬ™зФЯжХИ 404вАФвАФж≤°жЬЙеПСзО∞жЦЗдїґгАБжߕ胥жИЦURl 405вАФвАФзФ®жИЈеЬ®Request-Lineе≠ЧжЃµеЃЪдєЙзЪДжЦєж≥ХдЄНеЕБиЃЄ 406вАФвАФж†єжНЃзФ®жИЈеПСйАБзЪДAcceptжЛЦпЉМиѓЈж±ВиµДжЇРдЄНеПѓиЃњйЧЃ 407вАФвАФз±їдЉЉ401пЉМзФ®жИЈењЕй°їй¶ЦеЕИеЬ®дї£зРЖжЬНеК°еЩ®дЄКеЊЧеИ∞жОИжЭГ 408вАФвАФеЃҐжИЈзЂѓж≤°жЬЙеЬ®зФ®жИЈжМЗеЃЪзЪДй•њжЧґйЧіеЖЕеЃМжИРиѓЈж±В 409вАФвАФеѓєељУеЙНиµДжЇРзКґжАБпЉМиѓЈж±ВдЄНиГљеЃМжИР 410вАФвАФжЬНеК°еЩ®дЄКдЄНеЖНжЬЙж≠§иµДжЇРдЄФжЧ†ињЫдЄАж≠•зЪДеПВиАГеЬ∞еЭА 411вАФвАФжЬНеК°еЩ®жЛТзїЭзФ®жИЈеЃЪдєЙзЪДContent-Lengthе±ЮжАІиѓЈж±В 412вАФвАФдЄАдЄ™жИЦе§ЪдЄ™иѓЈж±Ве§іе≠ЧжЃµеЬ®ељУеЙНиѓЈж±ВдЄ≠йФЩиѓѓ 413вАФвАФиѓЈж±ВзЪДиµДжЇРе§ІдЇОжЬНеК°еЩ®еЕБиЃЄзЪДе§Іе∞П 414вАФвАФиѓЈж±ВзЪДиµДжЇРURLйХњдЇОжЬНеК°еЩ®еЕБиЃЄзЪДйХњеЇ¶ 415вАФвАФиѓЈж±ВиµДжЇРдЄНжФѓжМБиѓЈж±Вй°єзЫЃж†ЉеЉП 416вАФвАФиѓЈж±ВдЄ≠еМЕеРЂRangeиѓЈж±Ве§іе≠ЧжЃµпЉМеЬ®ељУеЙНиѓЈж±ВиµДжЇРиМГеЫіеЖЕж≤°жЬЙrangeжМЗз§ЇеАЉпЉМиѓЈж±ВдєЯдЄНеМЕеРЂIf-RangeиѓЈж±Ве§іе≠ЧжЃµ 417вАФвАФжЬНеК°еЩ®дЄНжї°иґ≥иѓЈж±ВExpectе§іе≠ЧжЃµжМЗеЃЪзЪДжЬЯжЬЫеАЉпЉМе¶ВжЮЬжШѓдї£зРЖжЬНеК°еЩ®пЉМеПѓиГљжШѓдЄЛдЄАзЇІжЬНеК°еЩ®дЄНиГљжї°иґ≥иѓЈж±ВйХњгАВ гААгААHTTP 500 -¬†еЖЕйГ®жЬНеК°еЩ®йФЩиѓѓ гААгААHTTP 500.100 -¬†еЖЕйГ®жЬНеК°еЩ®йФЩиѓѓ¬†- ASP¬†йФЩиѓѓ гААгААHTTP 500-11¬†жЬНеК°еЩ®еЕ≥йЧ≠ гААгААHTTP 500-12¬†еЇФзФ®з®ЛеЇПйЗНжЦ∞еРѓеК® гААгААHTTP 500-13 -¬†жЬНеК°еٮ姙ењЩ гААгААHTTP 500-14 -¬†еЇФзФ®з®ЛеЇПжЧ†жХИ гААгААHTTP 500-15 -¬†дЄНеЕБиЃЄиѓЈж±В¬†global.asa гААгААError 501 -¬†жЬ™еЃЮзО∞ HTTP 502 -¬†зљСеЕ≥йФЩиѓѓ ¬†¬†¬†¬†¬†¬†¬†еЬ®WindowsдЄЛпЉМеПѓдљњзФ®еСљдї§з™ЧеП£ињЫи°МhttpзЃАеНХжµЛиѓХгАВ ¬†¬†¬†¬†¬†¬†¬†иЊУеЕ•cmdињЫеЕ•еСљдї§з™ЧеП£пЉМеЬ®еСљдї§и°МйФЃеЕ•е¶ВдЄЛеСљдї§еРОжМЙеЫЮиљ¶пЉЪ ¬†¬†¬†¬†¬†¬†¬†иАМеРОеЬ®з™ЧеП£дЄ≠жМЙдЄЛвАЬCtrl+]вАЭеРОжМЙеЫЮиљ¶еПѓиЃ©ињФеЫЮзїУжЮЬеЫЮжШЊгАВ жО•зЭАеЉАеІЛеПСиѓЈж±ВжґИжБѓпЉМдЊЛе¶ВеПСйАБе¶ВдЄЛиѓЈж±ВжґИжБѓиѓЈж±ВbaiduзЪДй¶Цй°µжґИжБѓпЉМдљњзФ®зЪДHTTPеНПиЃЃдЄЇHTTP/1.1пЉЪ ¬†¬†¬†ж≥®жДПпЉЪcopyе¶ВдЄКзЪДжґИжБѓеИ∞еСљдї§з™ЧеП£еРОйЬАи¶БжМЙдЄ§дЄ™еЫЮиљ¶жНҐи°МжЙНиГљеЊЧеИ∞еУНеЇФзЪДжґИжБѓпЉМзђђдЄАдЄ™еЫЮиљ¶жНҐи°МжШѓеЬ®еСљдї§еРОйФЃеЕ•еЫЮиљ¶жНҐи°МпЉМжШѓHTTPеНПиЃЃи¶Бж±ВзЪДгАВзђђдЇМдЄ™жШѓз°ЃиЃ§иЊУеЕ•пЉМеПСйАБиѓЈж±ВгАВ еПѓзЬЛеИ∞ињФеЫЮдЇЖ200 OKзЪДжґИжБѓпЉМе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ ¬†¬†¬†¬†¬†¬†¬†еПѓзЬЛеИ∞пЉМељУйЗЗзФ®HTTP/1.1жЧґпЉМињЮжО•дЄНжШѓеЬ®иѓЈж±ВзїУжЭЯеРОе∞±жЦ≠еЉАзЪДгАВиЛ•йЗЗзФ®HTTP1.0пЉМеЬ®еСљдї§з™ЧеП£йФЃеЕ•пЉЪ ¬†¬†¬†¬†¬†¬†ж≠§жЧґеПѓдї•зЬЛеИ∞иѓЈж±ВзїУжЭЯдєЛеРОй©ђдЄКжЦ≠еЉАгАВ ¬†¬†¬†¬†¬†¬†¬†иѓїиАЕињШеПѓдї•е∞ЭиѓХеЬ®дљњзФ®GETжИЦPOSTз≠ЙжЧґпЉМеЄ¶дЄКе§іеЯЯдњ°жБѓпЉМдЊЛе¶ВйФЃеЕ•е¶ВдЄЛдњ°жБѓпЉЪ 2.5¬†еЄЄзФ®зЪДиѓЈж±ВжЦєеЉП ¬†¬†¬†¬†¬†¬†¬†еЄЄзФ®зЪДиѓЈж±ВжЦєеЉПжШѓGETеТМPOST. l¬†¬†¬†¬†¬†¬†¬†¬†¬†GETжЦєеЉПпЉЪжШѓдї•еЃЮдљУзЪДжЦєеЉПеЊЧеИ∞зФ±иѓЈж±ВURIжЙАжМЗеЃЪиµДжЇРзЪДдњ°жБѓпЉМе¶ВжЮЬиѓЈж±ВURIеП™жШѓдЄАдЄ™жХ∞жНЃдЇІзФЯињЗз®ЛпЉМйВ£дєИжЬАзїИи¶БеЬ®еУНеЇФеЃЮдљУдЄ≠ињФеЫЮзЪДжШѓе§ДзРЖињЗз®ЛзЪДзїУжЮЬжЙАжМЗеРСзЪДиµДжЇРпЉМиАМдЄНжШѓе§ДзРЖињЗз®ЛзЪДжППињ∞гАВ l¬†¬†¬†¬†¬†¬†¬†¬†¬†POSTжЦєеЉПпЉЪзФ®жЭ•еРСзЫЃзЪДжЬНеК°еЩ®еПСеЗЇиѓЈж±ВпЉМи¶Бж±ВеЃГжО•еПЧ襀йЩДеЬ®иѓЈж±ВеРОзЪДеЃЮдљУпЉМеєґжККеЃГељУдљЬиѓЈж±ВйШЯеИЧдЄ≠иѓЈж±ВURIжЙАжМЗеЃЪиµДжЇРзЪДйЩДеК†жЦ∞е≠Рй°єпЉМPost襀职聰жИРзФ®зїЯдЄАзЪДжЦєж≥ХеЃЮзО∞дЄЛеИЧеКЯиГљпЉЪ 1пЉЪеѓєзО∞жЬЙиµДжЇРзЪДиІ£йЗКпЉЫ 2пЉЪеРСзФµе≠РеЕђеСКж†ПгАБжЦ∞йЧїзїДгАБйВЃдїґеИЧи°®жИЦз±їдЉЉиЃ®иЃЇзїДеПСдњ°жБѓпЉЫ 3пЉЪжПРдЇ§жХ∞жНЃеЭЧпЉЫ 4пЉЪйАЪињЗйЩДеК†жУНдљЬжЭ•жЙ©е±ХжХ∞жНЃеЇУ¬†гАВ дїОдЄКйЭҐжППињ∞еПѓдї•зЬЛеЗЇпЉМGetжШѓеРСжЬНеК°еЩ®еПС糥еПЦжХ∞жНЃзЪДдЄАзІНиѓЈж±ВпЉЫиАМPostжШѓеРСжЬНеК°еЩ®жПРдЇ§жХ∞жНЃзЪДдЄАзІНиѓЈж±ВпЉМи¶БжПРдЇ§зЪДжХ∞жНЃдљНдЇОдњ°жБѓе§іеРОйЭҐзЪДеЃЮдљУдЄ≠гАВ GETдЄОPOSTжЦєж≥ХжЬЙдї•дЄЛеМЇеИЂпЉЪ пЉИ1пЉЙ¬†¬†¬†еЬ®еЃҐжИЈзЂѓпЉМGetжЦєеЉПеЬ®йАЪињЗURLжПРдЇ§жХ∞жНЃпЉМжХ∞жНЃеЬ®URLдЄ≠еПѓдї•зЬЛеИ∞пЉЫPOSTжЦєеЉПпЉМжХ∞жНЃжФЊзљЃеЬ®HTML HEADERеЖЕжПРдЇ§гАВ пЉИ2пЉЙ¬†¬† GETжЦєеЉПжПРдЇ§зЪДжХ∞жНЃжЬАе§ЪеП™иГљжЬЙ1024е≠ЧиКВпЉМиАМPOSTеИЩж≤°жЬЙж≠§йЩРеИґгАВ пЉИ3пЉЙ¬†¬†¬†еЃЙеЕ®жАІйЧЃйҐШгАВж≠£е¶ВеЬ®пЉИ1пЉЙдЄ≠жПРеИ∞пЉМдљњзФ®¬†Get¬†зЪДжЧґеАЩпЉМеПВжХ∞дЉЪжШЊз§ЇеЬ®еЬ∞еЭАж†ПдЄКпЉМиАМ¬†Post¬†дЄНдЉЪгАВжЙАдї•пЉМе¶ВжЮЬињЩдЇЫжХ∞жНЃжШѓдЄ≠жЦЗжХ∞жНЃиАМдЄФжШѓйЭЮжХПжДЯжХ∞жНЃпЉМйВ£дєИдљњзФ®¬†getпЉЫе¶ВжЮЬзФ®жИЈиЊУеЕ•зЪДжХ∞жНЃдЄНжШѓдЄ≠жЦЗе≠Чзђ¶иАМдЄФеМЕеРЂжХПжДЯжХ∞жНЃпЉМйВ£дєИињШжШѓдљњзФ®¬†postдЄЇе•љгАВ пЉИ4пЉЙ¬†¬†¬†еЃЙеЕ®зЪДеТМеєВз≠ЙзЪДгАВжЙАи∞УеЃЙеЕ®зЪДжДПеС≥зЭАиѓ•жУНдљЬзФ®дЇОиОЈеПЦдњ°жБѓиАМйЭЮдњЃжФєдњ°жБѓгАВеєВз≠ЙзЪДжДПеС≥зЭАеѓєеРМдЄАURL¬†зЪДе§ЪдЄ™иѓЈж±ВеЇФиѓ•ињФеЫЮеРМж†ЈзЪДзїУжЮЬгАВеЃМжХізЪДеЃЪдєЙеєґдЄНеГПзЬЛиµЈжЭ•йВ£ж†ЈдЄ•ж†ЉгАВжНҐеП•иѓЭиѓіпЉМGET¬†иѓЈж±ВдЄАиИђдЄНеЇФдЇІзФЯеЙѓдљЬзФ®гАВдїОж†єжЬђдЄКиЃ≤пЉМеЕґзЫЃж†ЗжШѓељУзФ®жИЈжЙУеЉАдЄАдЄ™йУЊжО•жЧґпЉМе•єеПѓдї•з°Ѓдњ°дїОиЗ™иЇЂзЪДиІТеЇ¶жЭ•зЬЛж≤°жЬЙжФєеПШиµДжЇРгАВжѓФе¶ВпЉМжЦ∞йЧїзЂЩзВєзЪДе§ізЙИдЄНжЦ≠жЫіжЦ∞гАВиЩљзДґзђђдЇМжђ°иѓЈж±ВдЉЪињФеЫЮдЄНеРМзЪДдЄАжЙєжЦ∞йЧїпЉМиѓ•жУНдљЬдїНзĴ襀聧䪯жШѓеЃЙеЕ®зЪДеТМеєВз≠ЙзЪДпЉМеЫ†дЄЇеЃГжАїжШѓињФеЫЮељУеЙНзЪДжЦ∞йЧїгАВеПНдєЛдЇ¶зДґгАВPOST¬†иѓЈж±Ве∞±дЄНйВ£дєИиљїжЭЊдЇЖгАВPOST¬†и°®з§ЇеПѓиГљжФєеПШжЬНеК°еЩ®дЄКзЪДиµДжЇРзЪДиѓЈж±ВгАВдїНзДґдї•жЦ∞йЧїзЂЩзВєдЄЇдЊЛпЉМиѓїиАЕеѓєжЦЗзЂ†зЪДж≥®иІ£еЇФиѓ•йАЪињЗ¬†POST¬†иѓЈж±ВеЃЮзО∞пЉМеЫ†дЄЇеЬ®ж≥®иІ£жПРдЇ§дєЛеРОзЂЩзВєеЈ≤зїПдЄНеРМдЇЖпЉИжѓФжЦєиѓіжЦЗзЂ†дЄЛйЭҐеЗЇзО∞дЄАжЭ°ж≥®иІ£пЉЙгАВ HTTPжЬАеЄЄиІБзЪДиѓЈж±Ве§іе¶ВдЄЛпЉЪ l¬†¬†¬†¬†¬†¬†¬†¬†¬†AcceptпЉЪжµПиІИеЩ®еПѓжО•еПЧзЪДMIMEз±їеЮЛпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Accept-CharsetпЉЪжµПиІИеЩ®еПѓжО•еПЧзЪДе≠Чзђ¶йЫЖпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Accept-EncodingпЉЪжµПиІИеЩ®иГље§ЯињЫи°МиІ£з†БзЪДжХ∞жНЃзЉЦз†БжЦєеЉПпЉМжѓФе¶ВgzipгАВServletиГље§ЯеРСжФѓжМБgzipзЪДжµПиІИеЩ®ињФеЫЮзїПgzipзЉЦз†БзЪДHTMLй°µйЭҐгАВиЃЄе§ЪжГЕ嚥дЄЛињЩеПѓдї•еЗПе∞С5еИ∞10еАНзЪДдЄЛиљљжЧґйЧіпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Accept-LanguageпЉЪжµПиІИеЩ®жЙАеЄМжЬЫзЪДиѓ≠и®АзІНз±їпЉМељУжЬНеК°еЩ®иГље§ЯжПРдЊЫдЄАзІНдї•дЄКзЪДиѓ≠и®АзЙИжЬђжЧґи¶БзФ®еИ∞пЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†AuthorizationпЉЪжОИжЭГдњ°жБѓпЉМйАЪеЄЄеЗЇзО∞еЬ®еѓєжЬНеК°еЩ®еПСйАБзЪДWWW-Authenticateе§ізЪДеЇФз≠ФдЄ≠пЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†ConnectionпЉЪи°®з§ЇжШѓеР¶йЬАи¶БжМБдєЕињЮжО•гАВе¶ВжЮЬServletзЬЛеИ∞ињЩйЗМзЪДеАЉдЄЇвАЬKeep-AliveвАЭпЉМжИЦиАЕзЬЛеИ∞иѓЈж±ВдљњзФ®зЪДжШѓHTTP 1.1пЉИHTTP 1.1йїШиЃ§ињЫи°МжМБдєЕињЮжО•пЉЙпЉМеЃГе∞±еПѓдї•еИ©зФ®жМБдєЕињЮжО•зЪДдЉШзВєпЉМељУй°µйЭҐеМЕеРЂе§ЪдЄ™еЕГзі†жЧґпЉИдЊЛе¶ВAppletпЉМеЫЊзЙЗпЉЙпЉМжШЊиСЧеЬ∞еЗПе∞СдЄЛиљљжЙАйЬАи¶БзЪДжЧґйЧігАВи¶БеЃЮзО∞ињЩдЄАзВєпЉМServletйЬАи¶БеЬ®еЇФз≠ФдЄ≠еПСйАБдЄАдЄ™Content-Lengthе§іпЉМжЬАзЃАеНХзЪДеЃЮзО∞жЦєж≥ХжШѓпЉЪеЕИжККеЖЕеЃєеЖЩеЕ•ByteArrayOutputStreamпЉМзДґеРОеЬ®ж≠£еЉПеЖЩеЗЇеЖЕеЃєдєЛеЙНиЃ°зЃЧеЃГзЪДе§Іе∞ПпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-LengthпЉЪи°®з§ЇиѓЈж±ВжґИжБѓж≠£жЦЗзЪДйХњеЇ¶пЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†CookieпЉЪињЩжШѓжЬАйЗНи¶БзЪДиѓЈж±Ве§ідњ°жБѓдєЛдЄАпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†FromпЉЪиѓЈж±ВеПСйАБиАЕзЪДemailеЬ∞еЭАпЉМзФ±дЄАдЇЫзЙєжЃКзЪДWebеЃҐжИЈз®ЛеЇПдљњзФ®пЉМжµПиІИеЩ®дЄНдЉЪзФ®еИ∞еЃГпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†HostпЉЪеИЭеІЛURLдЄ≠зЪДдЄїжЬЇеТМзЂѓеП£пЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†If-Modified-SinceпЉЪеП™жЬЙељУжЙАиѓЈж±ВзЪДеЖЕеЃєеЬ®жМЗеЃЪзЪДжЧ•жЬЯдєЛеРОеПИзїПињЗдњЃжФєжЙНињФеЫЮеЃГпЉМеР¶еИЩињФеЫЮ304вАЬNot ModifiedвАЭеЇФз≠ФпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†PragmaпЉЪжМЗеЃЪвАЬno-cacheвАЭеАЉи°®з§ЇжЬНеК°еЩ®ењЕй°їињФеЫЮдЄАдЄ™еИЈжЦ∞еРОзЪДжЦЗж°£пЉМеН≥дљњеЃГжШѓдї£зРЖжЬНеК°еЩ®иАМдЄФеЈ≤зїПжЬЙдЇЖй°µйЭҐзЪДжЬђеЬ∞жЛЈиіЭпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†RefererпЉЪеМЕеРЂдЄАдЄ™URLпЉМзФ®жИЈдїОиѓ•URLдї£и°®зЪДй°µйЭҐеЗЇеПСиЃњйЧЃељУеЙНиѓЈж±ВзЪДй°µйЭҐгАВ l¬†¬†¬†¬†¬†¬†¬†¬†¬†User-AgentпЉЪжµПиІИеЩ®з±їеЮЛпЉМе¶ВжЮЬServletињФеЫЮзЪДеЖЕеЃєдЄОжµПиІИеЩ®з±їеЮЛжЬЙеЕ≥еИЩиѓ•еАЉйЭЮеЄЄжЬЙзФ®пЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†UA-PixelsпЉМUA-ColorпЉМUA-OSпЉМUA-CPUпЉЪзФ±жЯРдЇЫзЙИжЬђзЪДIEжµПиІИеЩ®жЙАеПСйАБзЪДйЭЮж†ЗеЗЖзЪДиѓЈж±Ве§іпЉМи°®з§Їе±ПеєХе§Іе∞ПгАБйҐЬиЙ≤жЈ±еЇ¶гАБжУНдљЬз≥їзїЯеТМCPUз±їеЮЛгАВ HTTPжЬАеЄЄиІБзЪДеУНеЇФе§іе¶ВдЄЛжЙАз§ЇпЉЪ l¬†¬†¬†¬†¬†¬†¬†¬†¬†AllowпЉЪжЬНеК°еЩ®жФѓжМБеУ™дЇЫиѓЈж±ВжЦєж≥ХпЉИе¶ВGETгАБPOSTз≠ЙпЉЙпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-EncodingпЉЪжЦЗж°£зЪДзЉЦз†БпЉИEncodeпЉЙжЦєж≥ХгАВеП™жЬЙеЬ®иІ£з†БдєЛеРОжЙНеПѓдї•еЊЧеИ∞Content-Typeе§іжМЗеЃЪзЪДеЖЕеЃєз±їеЮЛгАВеИ©зФ®gzipеОЛзЉ©жЦЗж°£иГље§ЯжШЊиСЧеЬ∞еЗПе∞СHTMLжЦЗж°£зЪДдЄЛиљљжЧґйЧігАВJavaзЪДGZIPOutputStreamеПѓдї•еЊИжЦєдЊњеЬ∞ињЫи°МgzipеОЛзЉ©пЉМдљЖеП™жЬЙUnixдЄКзЪДNetscapeеТМWindowsдЄКзЪДIE 4гАБIE 5жЙНжФѓжМБеЃГгАВеЫ†ж≠§пЉМServletеЇФиѓ•йАЪињЗжЯ•зЬЛAccept-Encodingе§іпЉИеН≥request.getHeader("Accept-Encoding")пЉЙж£АжЯ•жµПиІИеЩ®жШѓеР¶жФѓжМБgzipпЉМдЄЇжФѓжМБgzipзЪДжµПиІИеЩ®ињФеЫЮзїПgzipеОЛзЉ©зЪДHTMLй°µйЭҐпЉМдЄЇеЕґдїЦжµПиІИеЩ®ињФеЫЮжЩЃйАЪй°µйЭҐпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-LengthпЉЪи°®з§ЇеЖЕеЃєйХњеЇ¶гАВеП™жЬЙељУжµПиІИеЩ®дљњзФ®жМБдєЕHTTPињЮжО•жЧґжЙНйЬАи¶БињЩдЄ™жХ∞жНЃгАВе¶ВжЮЬдљ†жГ≥и¶БеИ©зФ®жМБдєЕињЮжО•зЪДдЉШеКњпЉМеПѓдї•жККиЊУеЗЇжЦЗж°£еЖЩеЕ•ByteArrayOutputStramпЉМеЃМжИРеРОжЯ•зЬЛеЕґе§Іе∞ПпЉМзДґеРОжККиѓ•еАЉжФЊеЕ•Content-Lengthе§іпЉМжЬАеРОйАЪињЗbyteArrayStream.writeTo(response.getOutputStream()еПСйАБеЖЕеЃєпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-TypeпЉЪ¬†и°®з§ЇеРОйЭҐзЪДжЦЗж°£е±ЮдЇОдїАдєИMIMEз±їеЮЛгАВServletйїШиЃ§дЄЇtext/plainпЉМдљЖйАЪеЄЄйЬАи¶БжШЊеЉПеЬ∞жМЗеЃЪдЄЇtext/htmlгАВзФ±дЇОзїПеЄЄи¶БиЃЊзљЃContent-TypeпЉМеЫ†ж≠§HttpServletResponseжПРдЊЫдЇЖдЄАдЄ™дЄУзФ®зЪДжЦєж≥ХsetContentTyepгАВ¬†еПѓеЬ®web.xmlжЦЗдїґдЄ≠йЕНзљЃжЙ©е±ХеРНеТМMIMEз±їеЮЛзЪДеѓєеЇФеЕ≥з≥їпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†DateпЉЪељУеЙНзЪДGMTжЧґйЧігАВдљ†еПѓдї•зФ®setDateHeaderжЭ•иЃЊзљЃињЩдЄ™е§ідї•йБњеЕНиљђжНҐжЧґйЧіж†ЉеЉПзЪДйЇїзГ¶пЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†ExpiresпЉЪжМЗжШОеЇФиѓ•еЬ®дїАдєИжЧґеАЩиЃ§дЄЇжЦЗж°£еЈ≤зїПињЗжЬЯпЉМдїОиАМдЄНеЖНзЉУе≠ШеЃГгАВ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Last-ModifiedпЉЪжЦЗж°£зЪДжЬАеРОжФєеК®жЧґйЧігАВеЃҐжИЈеПѓдї•йАЪињЗIf-Modified-SinceиѓЈж±Ве§іжПРдЊЫдЄАдЄ™жЧ•жЬЯпЉМиѓ•иѓЈж±Ве∞Ж襀иІЖдЄЇдЄАдЄ™жЭ°дїґGETпЉМеП™жЬЙжФєеК®жЧґйЧіињЯдЇОжМЗеЃЪжЧґйЧізЪДжЦЗж°£жЙНдЉЪињФеЫЮпЉМеР¶еИЩињФеЫЮдЄАдЄ™304пЉИNot ModifiedпЉЙзКґжАБгАВLast-ModifiedдєЯеПѓзФ®setDateHeaderжЦєж≥ХжЭ•иЃЊзљЃпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†LocationпЉЪи°®з§ЇеЃҐжИЈеЇФељУеИ∞еУ™йЗМеОїжПРеПЦжЦЗж°£гАВLocationйАЪеЄЄдЄНжШѓзЫіжО•иЃЊзљЃзЪДпЉМиАМжШѓйАЪињЗHttpServletResponseзЪДsendRedirectжЦєж≥ХпЉМиѓ•жЦєж≥ХеРМжЧґиЃЊзљЃзКґжАБдї£з†БдЄЇ302пЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†RefreshпЉЪи°®з§ЇжµПиІИеЩ®еЇФиѓ•еЬ®е§Ъе∞СжЧґйЧідєЛеРОеИЈжЦ∞жЦЗж°£пЉМдї•зІТиЃ°гАВйЩ§дЇЖеИЈжЦ∞ељУеЙНжЦЗж°£дєЛе§ЦпЉМдљ†ињШеПѓдї•йАЪињЗsetHeader("Refresh", "5; URL=http://host/path")иЃ©жµПиІИеЩ®иѓїеПЦжМЗеЃЪзЪДй°µйЭҐгАВж≥®жДПињЩзІНеКЯиГљйАЪеЄЄжШѓйАЪињЗиЃЊзљЃHTMLй°µйЭҐHEADеМЇзЪД<META HTTP-EQUIV="Refresh" CONTENT="5;URL=http://host/path">еЃЮзО∞пЉМињЩжШѓеЫ†дЄЇпЉМиЗ™еК®еИЈжЦ∞жИЦйЗНеЃЪеРСеѓєдЇОйВ£дЇЫдЄНиГљдљњзФ®CGIжИЦServletзЪДHTMLзЉЦеЖЩиАЕеНБеИЖйЗНи¶БгАВдљЖжШѓпЉМеѓєдЇОServletжЭ•иѓіпЉМзЫіжО•иЃЊзљЃRefreshе§іжЫіеК†жЦєдЊњгАВж≥®жДПRefreshзЪДжДПдєЙжШѓвАЬNзІТдєЛеРОеИЈжЦ∞жЬђй°µйЭҐжИЦиЃњйЧЃжМЗеЃЪй°µйЭҐвАЭпЉМиАМдЄНжШѓвАЬжѓПйЪФNзІТеИЈжЦ∞жЬђй°µйЭҐжИЦиЃњйЧЃжМЗеЃЪй°µйЭҐвАЭгАВеЫ†ж≠§пЉМињЮзї≠еИЈжЦ∞и¶Бж±ВжѓПжђ°йГљеПСйАБдЄАдЄ™Refreshе§іпЉМиАМеПСйАБ204зКґжАБдї£з†БеИЩеПѓдї•йШїж≠ҐжµПиІИеЩ®зїІзї≠еИЈжЦ∞пЉМдЄНзЃ°жШѓдљњзФ®Refreshе§іињШжШѓ<META HTTP-EQUIV="Refresh" ...>гАВж≥®жДПRefreshе§ідЄНе±ЮдЇОHTTP 1.1ж≠£еЉПиІДиМГзЪДдЄАйГ®еИЖпЉМиАМжШѓдЄАдЄ™жЙ©е±ХпЉМдљЖNetscapeеТМIEйГљжФѓжМБеЃГгАВ еЃЮдљУе§ізФ®еЭРеЃЮдљУеЖЕеЃєзЪДеЕГдњ°жБѓпЉМжППињ∞дЇЖеЃЮдљУеЖЕеЃєзЪДе±ЮжАІпЉМеМЕжЛђеЃЮдљУдњ°жБѓз±їеЮЛпЉМйХњеЇ¶пЉМеОЛзЉ©жЦєж≥ХпЉМжЬАеРОдЄАжђ°дњЃжФєжЧґйЧіпЉМжХ∞жНЃжЬЙжХИжАІз≠ЙгАВ l¬†¬†¬†¬†¬†¬†¬†¬†¬†AllowпЉЪGET,POST l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-EncodingпЉЪжЦЗж°£зЪДзЉЦз†БпЉИEncodeпЉЙжЦєж≥ХпЉМдЊЛе¶ВпЉЪgzipпЉМиІБвАЬ2.5¬†еУНеЇФе§івАЭпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-LanguageпЉЪеЖЕеЃєзЪДиѓ≠и®Аз±їеЮЛпЉМдЊЛе¶ВпЉЪzh-cnпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-LengthпЉЪи°®з§ЇеЖЕеЃєйХњеЇ¶пЉМegпЉЪ80пЉМеПѓеПВиАГвАЬ2.5еУНеЇФе§івАЭпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-LocationпЉЪи°®з§ЇеЃҐжИЈеЇФељУеИ∞еУ™йЗМеОїжПРеПЦжЦЗж°£пЉМдЊЛе¶ВпЉЪhttp://www.dfdf.org/dfdf.htmlпЉМеПѓеПВиАГвАЬ2.5еУНеЇФе§івАЭпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-MD5пЉЪMD5¬†еЃЮдљУзЪДдЄАзІНMD5жСШи¶БпЉМзФ®дљЬж†°й™МеТМгАВеПСйАБжЦєеТМжО•еПЧжЦєйГљиЃ°зЃЧMD5жСШи¶БпЉМжО•еПЧжЦєе∞ЖеЕґиЃ°зЃЧзЪДеАЉдЄОж≠§е§іж†ЗдЄ≠дЉ†йАТзЪДеАЉињЫи°МжѓФиЊГгАВEg1пЉЪContent-MD5: <base64 of 128 MD5 digest>гАВEg2пЉЪdfdfdfdfdfdfdff==пЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-RangeпЉЪйЪПйГ®еИЖеЃЮдљУдЄАеРМеПСйАБпЉЫж†ЗжШО襀жПТеЕ•е≠ЧиКВзЪДдљОдљНдЄОйЂШдљНе≠ЧиКВеБПзІїпЉМдєЯж†ЗжШОж≠§еЃЮдљУзЪДжАїйХњеЇ¶гАВEg1пЉЪContent-Range: 1001-2000/5000пЉМeg2пЉЪbytes 2543-4532/7898 l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-TypeпЉЪж†ЗжШОеПСйАБжИЦиАЕжО•жФґзЪДеЃЮдљУзЪДMIMEз±їеЮЛгАВEgпЉЪtext/html; charset=GB2312¬†¬†¬†¬†¬†¬†дЄїз±їеЮЛ/е≠Рз±їеЮЛпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†ExpiresпЉЪдЄЇ0иѓБжШОдЄНзЉУе≠ШпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Last-ModifiedпЉЪWEB¬†жЬНеК°еЩ®иЃ§дЄЇеѓєи±°зЪДжЬАеРОдњЃжФєжЧґйЧіпЉМжѓФе¶ВжЦЗдїґзЪДжЬАеРОдњЃжФєжЧґйЧіпЉМеК®жАБй°µйЭҐзЪДжЬАеРОдЇІзФЯжЧґйЧіз≠Йз≠ЙгАВдЊЛе¶ВпЉЪLast-ModifiedпЉЪTue, 06 May 2008 02:42:43 GMT. еЬ®HTTPжґИжБѓдЄ≠пЉМдєЯеПѓдї•дљњзФ®дЄАдЇЫеЖНHTTP1.1ж≠£еЉПиІДиМГйЗМж≤°жЬЙеЃЪдєЙзЪДе§іе≠ЧжЃµпЉМињЩдЇЫе§іе≠ЧжЃµзїЯзІ∞дЄЇиЗ™еЃЪдєЙзЪДHTTPе§іжИЦиАЕжЙ©е±Хе§іпЉМдїЦдїђйАЪ媪襀ељУдљЬжШѓдЄАзІНеЃЮдљУе§іе§ДзРЖгАВ зО∞еЬ®жµБи°МзЪДжµПиІИеЩ®еЃЮйЩЕдЄКйГљжФѓжМБCookie,Set-Cookie,RefreshеТМContent-Dispositionз≠ЙеЗ†дЄ™еЄЄзФ®зЪДжЙ©е±Хе§іе≠ЧжЃµгАВ l¬†¬†¬†¬†¬†¬†¬†¬†¬†RefreshпЉЪ1;url=http://www.dfdf.org¬† //ињЗ1зІТиЈ≥иљђеИ∞жМЗеЃЪдљНзљЃпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-DispositionпЉЪе§іе≠ЧжЃµ,еПѓеПВиАГвАЬ2.5еУНеЇФе§івАЭпЉЫ l¬†¬†¬†¬†¬†¬†¬†¬†¬†Content-TypeпЉЪWEB¬†жЬНеК°еЩ®еСКиѓЙжµПиІИеЩ®иЗ™еЈ±еУНеЇФзЪДеѓєи±°зЪДз±їеЮЛгАВ eg1пЉЪContent-TypeпЉЪapplication/xml¬†пЉЫ eg2пЉЪapplicaiton/octet-streamпЉЫ Content-DispositionпЉЪattachment; filename=aaa.zipгАВ гАКHTTP1.1еТМHTTP1.0зЪДеМЇеИЂгАЛпЉЪ http://blog.csdn.net/yanghehong/archive/2009/05/28/4222594.aspx гАКHTTPиѓЈж±ВпЉИGETеТМPOSTеМЇеИЂпЉЙеТМеУНеЇФгАЛпЉЪ http://www.blogjava.net/honeybee/articles/164008.html гАКHTTPиѓЈж±Ве§іж¶Вињ∞_зЩЊеЇ¶зЯ•йБУгАЛпЉЪ http://zhidao.baidu.com/question/32517427.html гАКеЃЮдљУе§іеТМжЙ©е±Хе§ігАЛпЉЪ http://www.cnblogs.com/tongzhiyong/archive/2008/03/16/1108776.html CookieеТМSessionйГљдЄЇдЇЖзФ®жЭ•дњЭе≠ШзКґжАБдњ°жБѓпЉМйГљжШѓдњЭе≠ШеЃҐжИЈзЂѓзКґжАБзЪДжЬЇеИґпЉМеЃГдїђйГљжШѓдЄЇдЇЖиІ£еЖ≥HTTPжЧ†зКґжАБзЪДйЧЃйҐШиАМжЙАеБЪзЪДеК™еКЫгАВ SessionеПѓдї•зФ®CookieжЭ•еЃЮзО∞пЉМдєЯеПѓдї•зФ®URLеЫЮеЖЩзЪДжЬЇеИґжЭ•еЃЮзО∞гАВзФ®CookieжЭ•еЃЮзО∞зЪДSessionеПѓдї•иЃ§дЄЇжШѓеѓєCookieжЫійЂШзЇІзЪДеЇФзФ®гАВ CookieеТМSessionжЬЙдї•дЄЛжШОжШЊзЪДдЄНеРМзВєпЉЪ 1пЉЙCookieе∞ЖзКґжАБдњЭе≠ШеЬ®еЃҐжИЈзЂѓпЉМSessionе∞ЖзКґжАБдњЭе≠ШеЬ®жЬНеК°еЩ®зЂѓпЉЫ 2пЉЙCookiesжШѓжЬНеК°еЩ®еЬ®жЬђеЬ∞жЬЇеЩ®дЄКе≠ШеВ®зЪДе∞ПжЃµжЦЗжЬђеєґйЪПжѓПдЄАдЄ™иѓЈж±ВеПСйАБиЗ≥еРМдЄАдЄ™жЬНеК°еЩ®гАВCookieжЬАжЧ©еЬ®RFC2109дЄ≠еЃЮзО∞пЉМеРОзї≠RFC2965еБЪдЇЖеҐЮеЉЇгАВзљСзїЬжЬНеК°еЩ®зФ®HTTPе§іеРСеЃҐжИЈзЂѓеПСйАБcookiesпЉМеЬ®еЃҐжИЈзїИзЂѓпЉМжµПиІИеЩ®иІ£жЮРињЩдЇЫcookiesеєґе∞ЖеЃГдїђдњЭе≠ШдЄЇдЄАдЄ™жЬђеЬ∞жЦЗдїґпЉМеЃГдЉЪиЗ™еК®е∞ЖеРМдЄАжЬНеК°еЩ®зЪДдїїдљХиѓЈж±ВзЉЪдЄКињЩдЇЫcookiesгАВSessionеєґж≤°жЬЙеЬ®HTTPзЪДеНПиЃЃдЄ≠еЃЪдєЙпЉЫ 3пЉЙSessionжШѓйТИеѓєжѓПдЄАдЄ™зФ®жИЈзЪДпЉМеПШйЗПзЪДеАЉдњЭе≠ШеЬ®жЬНеК°еЩ®дЄКпЉМзФ®дЄАдЄ™sessionIDжЭ•еМЇеИЖжШѓеУ™дЄ™зФ®жИЈsessionеПШйЗП,ињЩдЄ™еАЉжШѓйАЪињЗзФ®жИЈзЪДжµПиІИеЩ®еЬ®иЃњйЧЃзЪДжЧґеАЩињФеЫЮзїЩжЬНеК°еЩ®пЉМељУеЃҐжИЈз¶БзФ®cookieжЧґпЉМињЩдЄ™еАЉдєЯеПѓиГљиЃЊзљЃдЄЇзФ±getжЭ•ињФеЫЮзїЩжЬНеК°еЩ®пЉЫ 4пЉЙе∞±еЃЙеЕ®жАІжЭ•иѓіпЉЪељУдљ†иЃњйЧЃдЄАдЄ™дљњзФ®session¬†зЪДзЂЩзВєпЉМеРМжЧґеЬ®иЗ™еЈ±жЬЇе≠РдЄКеїЇзЂЛдЄАдЄ™cookieпЉМеїЇиЃЃеЬ®жЬНеК°еЩ®зЂѓзЪДSESSIONжЬЇеИґжЫіеЃЙеЕ®дЇЫ.еЫ†дЄЇеЃГдЄНдЉЪдїїжДПиѓїеПЦеЃҐжИЈе≠ШеВ®зЪДдњ°жБѓгАВ SessionжЬЇеИґжШѓдЄАзІНжЬНеК°еЩ®зЂѓзЪДжЬЇеИґпЉМжЬНеК°еЩ®дљњзФ®дЄАзІНз±їдЉЉдЇОжХ£еИЧи°®зЪДзїУжЮДпЉИдєЯеПѓиГље∞±жШѓдљњзФ®жХ£еИЧи°®пЉЙжЭ•дњЭе≠Шдњ°жБѓгАВ ељУз®ЛеЇПйЬАи¶БдЄЇжЯРдЄ™еЃҐжИЈзЂѓзЪДиѓЈж±ВеИЫеїЇдЄАдЄ™sessionзЪДжЧґеАЩпЉМжЬНеК°еЩ®й¶ЦеЕИж£АжЯ•ињЩдЄ™еЃҐжИЈзЂѓзЪДиѓЈж±ВйЗМжШѓеР¶еЈ≤еМЕеРЂдЇЖдЄАдЄ™sessionж†ЗиѓЖ¬†-¬†зІ∞дЄЇ¬†session¬†idпЉМе¶ВжЮЬеЈ≤еМЕеРЂдЄАдЄ™session¬†idеИЩиѓіжШОдї•еЙНеЈ≤зїПдЄЇж≠§еЃҐжИЈзЂѓеИЫеїЇињЗsessionпЉМжЬНеК°еЩ®е∞±жМЙзЕІsession¬†idжККињЩдЄ™¬†sessionж£А糥еЗЇжЭ•дљњзФ®пЉИе¶ВжЮЬж£А糥дЄНеИ∞пЉМеПѓиГљдЉЪжЦ∞еїЇдЄАдЄ™пЉЙпЉМе¶ВжЮЬеЃҐжИЈзЂѓиѓЈж±ВдЄНеМЕеРЂsession¬†idпЉМеИЩдЄЇж≠§еЃҐжИЈзЂѓеИЫеїЇдЄАдЄ™sessionеєґдЄФзФЯжИРдЄАдЄ™дЄОж≠§sessionзЫЄеЕ≥иБФзЪДsession¬†idпЉМsession¬†idзЪДеАЉеЇФиѓ•жШѓдЄАдЄ™жЧҐдЄНдЉЪйЗНе§НпЉМеПИдЄНеЃєжШУ襀жЙЊеИ∞иІДеЊЛдї•дїњйА†зЪДе≠Чзђ¶дЄ≤пЉМињЩдЄ™¬†session¬†idе∞Ж襀еЬ®жЬђжђ°еУНеЇФдЄ≠ињФеЫЮзїЩеЃҐжИЈзЂѓдњЭе≠ШгАВ жЬНеК°еЩ®зїЩжѓПдЄ™SessionеИЖйЕНдЄАдЄ™еФѓдЄАзЪДJSESSIONIDпЉМеєґйАЪињЗCookieеПСйАБзїЩеЃҐжИЈзЂѓгАВ ељУеЃҐжИЈзЂѓеПСиµЈжЦ∞зЪДиѓЈж±ВзЪДжЧґеАЩпЉМе∞ЖеЬ®Cookieе§ідЄ≠жРЇеЄ¶ињЩдЄ™JSESSIONIDгАВињЩж†ЈжЬНеК°еЩ®иГље§ЯжЙЊеИ∞ињЩдЄ™еЃҐжИЈзЂѓеѓєеЇФзЪДSessionгАВ жµБз®Ле¶ВдЄЛеЫЊжЙАз§ЇпЉЪ URLеЫЮеЖЩжШѓжМЗжЬНеК°еЩ®еЬ®еПСйАБзїЩжµПиІИеЩ®й°µйЭҐзЪДжЙАжЬЙйУЊжО•дЄ≠йГљжРЇеЄ¶JSESSIONIDзЪДеПВжХ∞пЉМињЩж†ЈеЃҐжИЈзЂѓзВєеЗїдїїдљХдЄАдЄ™йУЊжО•йГљдЉЪжККJSESSIONIDеЄ¶дЉЪжЬНеК°еЩ®гАВ е¶ВжЮЬзЫіжО•еЬ®жµПиІИеЩ®иЊУеЕ•жЬНеК°зЂѓиµДжЇРзЪДurlжЭ•иѓЈж±Виѓ•иµДжЇРпЉМйВ£дєИSessionжШѓеМєйЕНдЄНеИ∞зЪДгАВ TomcatеѓєSessionзЪДеЃЮзО∞пЉМжШѓдЄАеЉАеІЛеРМжЧґдљњзФ®CookieеТМURLеЫЮеЖЩжЬЇеИґпЉМе¶ВжЮЬеПСзО∞еЃҐжИЈзЂѓжФѓжМБCookieпЉМе∞±зїІзї≠дљњзФ®CookieпЉМеБЬж≠ҐдљњзФ®URLеЫЮеЖЩгАВе¶ВжЮЬеПСзО∞Cookie襀з¶БзФ®пЉМе∞±дЄАзЫідљњзФ®URLеЫЮеЖЩгАВjspеЉАеПСе§ДзРЖеИ∞SessionзЪДжЧґеАЩпЉМеѓєй°µйЭҐдЄ≠зЪДйУЊжО•иЃ∞еЊЧдљњзФ®response.encodeURL()¬†гАВ 1пЉЙSessionиґЕжЧґпЉЪSessionеЬ®жМЗеЃЪжЧґйЧіеЖЕ姱жХИпЉМдЊЛе¶В30еИЖйТЯпЉМиЛ•еЬ®30еИЖйТЯеЖЕж≤°жЬЙжУНдљЬпЉМеИЩSessionдЉЪ姱жХИпЉМдЊЛе¶ВеЬ®web.xmlдЄ≠ињЫи°МдЇЖе¶ВдЄЛиЃЊзљЃпЉЪ <session-config>¬† 2пЉЙдљњзФ®session.invalidate()жШОз°ЃзЪДеОїжОЙSessionгАВ 1пЉЙCookieпЉЪеЃҐжИЈзЂѓе∞ЖжЬНеК°еЩ®иЃЊзљЃзЪДCookieињФеЫЮеИ∞жЬНеК°еЩ®пЉЫ 2пЉЙSet-CookieпЉЪжЬНеК°еЩ®еРСеЃҐжИЈзЂѓиЃЊзљЃCookieпЉЫ 3пЉЙCookie2¬†(RFC2965)пЉЙпЉЪеЃҐжИЈзЂѓжМЗз§ЇжЬНеК°еЩ®жФѓжМБCookieзЪДзЙИжЬђпЉЫ 4пЉЙSet-Cookie2¬†(RFC2965)пЉЪжЬНеК°еЩ®еРСеЃҐжИЈзЂѓиЃЊзљЃCookieгАВ жЬНеК°еЩ®еЬ®еУНеЇФжґИжБѓдЄ≠зФ®Set-Cookieе§іе∞ЖCookieзЪДеЖЕеЃєеЫЮйАБзїЩеЃҐжИЈзЂѓпЉМеЃҐжИЈзЂѓеЬ®жЦ∞зЪДиѓЈж±ВдЄ≠е∞ЖзЫЄеРМзЪДеЖЕеЃєжРЇеЄ¶еЬ®Cookieе§ідЄ≠еПСйАБзїЩжЬНеК°еЩ®гАВдїОиАМеЃЮзО∞дЉЪиѓЭзЪДдњЭжМБгАВ жµБз®Ле¶ВдЄЛеЫЊжЙАз§ЇпЉЪ WEBзЉУе≠Ш(cache)дљНдЇОWebжЬНеК°еЩ®еТМеЃҐжИЈзЂѓдєЛйЧігАВ зЉУе≠ШдЉЪж†єжНЃиѓЈж±ВдњЭе≠ШиЊУеЗЇеЖЕеЃєзЪДеЙѓжЬђпЉМдЊЛе¶Вhtmlй°µйЭҐпЉМеЫЊзЙЗпЉМжЦЗдїґпЉМељУдЄЛдЄАдЄ™иѓЈж±ВжЭ•еИ∞зЪДжЧґеАЩпЉЪе¶ВжЮЬжШѓзЫЄеРМзЪДURLпЉМзЉУе≠ШзЫіжО•дљњзФ®еЙѓжЬђеУНеЇФиЃњйЧЃиѓЈж±ВпЉМиАМдЄНжШѓеРСжЇРжЬНеК°еЩ®еЖНжђ°еПСйАБиѓЈж±ВгАВ HTTPеНПиЃЃеЃЪдєЙдЇЖзЫЄеЕ≥зЪДжґИжБѓе§іжЭ•дљњWEBзЉУе≠Ше∞љеПѓиГље•љзЪДеЈ•дљЬгАВ q¬†¬†¬†¬†¬†¬†еЗПе∞СзЫЄеЇФеїґињЯпЉЪеЫ†дЄЇиѓЈж±ВдїОзЉУе≠ШжЬНеК°еЩ®пЉИз¶їеЃҐжИЈзЂѓжЫіињСпЉЙиАМдЄНжШѓжЇРжЬНеК°еٮ襀зЫЄеЇФпЉМињЩдЄ™ињЗз®ЛиАЧжЧґжЫіе∞СпЉМиЃ©webжЬНеК°еЩ®зЬЛдЄКеОїзЫЄеЇФжЫіењЂгАВ q¬†¬†¬†¬†¬†¬†еЗПе∞СзљСзїЬеЄ¶еЃљжґИиАЧпЉЪељУеЙѓжܐ襀йЗНзФ®жЧґдЉЪеЗПдљОеЃҐжИЈзЂѓзЪДеЄ¶еЃљжґИиАЧпЉЫеЃҐжИЈеПѓдї•иКВзЬБеЄ¶еЃљиієзФ®пЉМжОІеИґеЄ¶еЃљзЪДйЬАж±ВзЪДеҐЮйХњеєґжЫіжШУдЇОзЃ°зРЖгАВ q¬†¬†¬†¬†¬†¬†ExpiresпЉЪжМЗз§ЇеУНеЇФеЖЕеЃєињЗжЬЯзЪДжЧґйЧіпЉМж†ЉжЮЧе®Бж≤їжЧґйЧіGMT q¬†¬†¬†¬†¬†¬†Cache-ControlпЉЪжЫізїЖиЗізЪДжОІеИґзЉУе≠ШзЪДеЖЕеЃє q¬†¬†¬†¬†¬†¬†Last-ModifiedпЉЪеУНеЇФдЄ≠иµДжЇРжЬАеРОдЄАжђ°дњЃжФєзЪДжЧґйЧі q¬†¬†¬†¬†¬†¬†ETagпЉЪеУНеЇФдЄ≠иµДжЇРзЪДж†°й™МеАЉпЉМеЬ®жЬНеК°еЩ®дЄКжЯРдЄ™жЧґжЃµжШѓеФѓдЄАж†ЗиѓЖзЪДгАВ q¬†¬†¬†¬†¬†¬†DateпЉЪжЬНеК°еЩ®зЪДжЧґйЧі q¬†¬†¬†¬†¬†¬†If-Modified-SinceпЉЪеЃҐжИЈзЂѓе≠ШеПЦзЪДиѓ•иµДжЇРжЬАеРОдЄАжђ°дњЃжФєзЪДжЧґйЧіпЉМеРМLast-ModifiedгАВ q¬†¬†¬†¬†¬†¬†If-None-MatchпЉЪеЃҐжИЈзЂѓе≠ШеПЦзЪДиѓ•иµДжЇРзЪДж£Ай™МеАЉпЉМеРМETagгАВ жЬНеК°еЩ®жФґеИ∞иѓЈж±ВжЧґпЉМдЉЪеЬ®200OKдЄ≠еЫЮйАБиѓ•иµДжЇРзЪДLast-ModifiedеТМETagе§іпЉМеЃҐжИЈзЂѓе∞Жиѓ•иµДжЇРдњЭе≠ШеЬ®cacheдЄ≠пЉМеєґиЃ∞ељХињЩдЄ§дЄ™е±ЮжАІгАВељУеЃҐжИЈзЂѓйЬАи¶БеПСйАБзЫЄеРМзЪДиѓЈж±ВжЧґпЉМдЉЪеЬ®иѓЈж±ВдЄ≠жРЇеЄ¶If-Modified-SinceеТМIf-None-MatchдЄ§дЄ™е§ігАВдЄ§дЄ™е§ізЪДеАЉеИЖеИЂжШѓеУНеЇФдЄ≠Last-ModifiedеТМETagе§ізЪДеАЉгАВжЬНеК°еЩ®йАЪињЗињЩдЄ§дЄ™е§іеИ§жЦ≠жЬђеЬ∞иµДжЇРжЬ™еПСзФЯеПШеМЦпЉМеЃҐжИЈзЂѓдЄНйЬАи¶БйЗНжЦ∞дЄЛиљљпЉМињФеЫЮ304еУНеЇФгАВеЄЄиІБжµБз®Ле¶ВдЄЛеЫЊжЙАз§ЇпЉЪ HTTP/1.1дЄ≠зЉУе≠ШзЪДзЫЃзЪДжШѓдЄЇдЇЖеЬ®еЊИе§ЪжГЕеЖµдЄЛеЗПе∞СеПСйАБиѓЈж±ВпЉМеРМжЧґеЬ®иЃЄе§ЪжГЕеЖµдЄЛеПѓдї•дЄНйЬАи¶БеПСйАБеЃМжХіеУНеЇФгАВеЙНиАЕеЗПе∞СдЇЖзљСзїЬеЫЮиЈѓзЪДжХ∞йЗПпЉЫHTTPеИ©зФ®дЄАдЄ™вАЬињЗжЬЯпЉИexpirationпЉЙвАЭжЬЇеИґжЭ•дЄЇж≠§зЫЃзЪДгАВеРОиАЕеЗПе∞СдЇЖзљСзїЬеЇФзФ®зЪДеЄ¶еЃљпЉЫHTTPзФ®вАЬй™МиѓБпЉИvalidationпЉЙвАЭжЬЇеИґжЭ•дЄЇж≠§зЫЃзЪДгАВ HTTPеЃЪдєЙдЇЖ3зІНзЉУе≠ШжЬЇеИґпЉЪ 1пЉЙFreshnessпЉЪеЕБиЃЄдЄАдЄ™еЫЮеЇФжґИжБѓеПѓдї•еЬ®жЇРжЬНеК°еЩ®дЄН襀йЗНжЦ∞ж£АжЯ•пЉМеєґдЄФеПѓдї•зФ±жЬНеК°еЩ®еТМеЃҐжИЈзЂѓжЭ•жОІеИґгАВдЊЛе¶ВпЉМExpiresеЫЮеЇФе§ізїЩдЇЖдЄАдЄ™жЦЗж°£дЄНеПѓзФ®зЪДжЧґйЧігАВCache-ControlдЄ≠зЪДmax-ageж†ЗиѓЖжМЗжШОдЇЖзЉУе≠ШзЪДжЬАйХњжЧґйЧіпЉЫ 2пЉЙValidationпЉЪзФ®жЭ•ж£АжЯ•дї•дЄАдЄ™зЉУе≠ШзЪДеЫЮеЇФжШѓеР¶дїНзДґеПѓзФ®гАВдЊЛе¶ВпЉМе¶ВжЮЬдЄАдЄ™еЫЮеЇФжЬЙдЄАдЄ™Last-ModifiedеЫЮеЇФе§іпЉМзЉУе≠ШиГље§ЯдљњзФ®If-Modified-SinceжЭ•еИ§жЦ≠жШѓеР¶еЈ≤жФєеПШпЉМдї•дЊњеИ§жЦ≠ж†єжНЃжГЕеЖµеПСйАБиѓЈж±ВпЉЫ 3пЉЙInvalidationпЉЪ¬†еЬ®еП¶дЄАдЄ™иѓЈж±ВйАЪињЗзЉУе≠ШзЪДжЧґеАЩпЉМеЄЄеЄЄжЬЙдЄАдЄ™еЙѓдљЬзФ®гАВдЊЛе¶ВпЉМе¶ВжЮЬдЄАдЄ™URLеЕ≥иБФеИ∞дЄАдЄ™зЉУе≠ШеЫЮеЇФпЉМдљЖжШѓеЕґеРОиЈЯзЭАPOSTгАБPUTеТМDELETEзЪДиѓЈж±ВзЪДиѓЭпЉМзЉУе≠Ше∞±дЉЪињЗжЬЯгАВ q¬†¬†¬†¬†¬†¬†HTTPеНПиЃЃзЪДGETжЦєж≥ХпЉМжФѓжМБеП™иѓЈж±ВжЯРдЄ™иµДжЇРзЪДжЯРдЄАйГ®еИЖпЉЫ q¬†¬†¬†¬†¬†¬†206 Partial Content¬†йГ®еИЖеЖЕеЃєеУНеЇФпЉЫ q¬†¬†¬†¬†¬†¬†Range¬†иѓЈж±ВзЪДиµДжЇРиМГеЫіпЉЫ q¬†¬†¬†¬†¬†¬†Content-Range¬†еУНеЇФзЪДиµДжЇРиМГеЫіпЉЫ q¬†¬†¬†¬†¬†¬†еЬ®ињЮжО•жЦ≠еЉАйЗНињЮжЧґпЉМеЃҐжИЈзЂѓеП™иѓЈж±Виѓ•иµДжЇРжЬ™дЄЛиљљзЪДйГ®еИЖпЉМиАМдЄНжШѓйЗНжЦ∞иѓЈж±ВжХідЄ™иµДжЇРпЉМжЭ•еЃЮзО∞жЦ≠зВєзї≠дЉ†гАВ еИЖеЭЧиѓЈж±ВиµДжЇРеЃЮдЊЛпЉЪ Eg1пЉЪRange: bytes=306302-¬†пЉЪиѓЈж±ВињЩдЄ™иµДжЇРдїО306302дЄ™е≠ЧиКВеИ∞жЬЂе∞ЊзЪДйГ®еИЖпЉЫ Eg2пЉЪContent-Range: bytes 306302-604047/604048пЉЪеУНеЇФдЄ≠жМЗз§ЇжРЇеЄ¶зЪДжШѓиѓ•иµДжЇРзЪДзђђ306302-604047зЪДе≠ЧиКВпЉМиѓ•иµДжЇРеЕ±604048дЄ™е≠ЧиКВпЉЫ еЃҐжИЈзЂѓйАЪињЗеєґеПСзЪДиѓЈж±ВзЫЄеРМиµДжЇРзЪДдЄНеРМзЙЗжЃµпЉМжЭ•еЃЮзО∞еѓєжЯРдЄ™иµДжЇРзЪДеєґеПСеИЖеЭЧдЄЛиљљгАВдїОиАМиЊЊеИ∞ењЂйАЯдЄЛиљљзЪДзЫЃзЪДгАВзЫЃеЙНжµБи°МзЪДFlashGetеТМињЕйЫЈеЯЇжЬђйГљжШѓињЩдЄ™еОЯзРЖгАВ е§ЪзЇњз®ЛдЄЛиљљзЪДеОЯзРЖпЉЪ q¬†¬†¬†¬†¬†¬†дЄЛиљљеЈ•еЕЈеЉАеРѓе§ЪдЄ™еПСеЗЇHTTPиѓЈж±ВзЪДзЇњз®ЛпЉЫ q¬†¬†¬†¬†¬†¬†жѓПдЄ™httpиѓЈж±ВеП™иѓЈж±ВиµДжЇРжЦЗдїґзЪДдЄАйГ®еИЖпЉЪContent-Range: bytes 20000-40000/47000пЉЫ q¬†¬†¬†¬†¬†¬†еРИеєґжѓПдЄ™зЇњз®ЛдЄЛиљљзЪДжЦЗдїґгАВ HTTPSпЉИеЕ®зІ∞пЉЪHypertext Transfer Protocol over Secure Socket LayerпЉЙпЉМжШѓдї•еЃЙеЕ®дЄЇзЫЃж†ЗзЪДHTTPйАЪйБУпЉМзЃАеНХиЃ≤жШѓHTTPзЪДеЃЙеЕ®зЙИгАВеН≥HTTPдЄЛеК†еЕ•SSLе±ВпЉМHTTPSзЪДеЃЙеЕ®еЯЇз°АжШѓSSLпЉМеЫ†ж≠§еК†еѓЖзЪДиѓ¶зїЖеЖЕеЃєиѓЈзЬЛSSLгАВ иІБдЄЛеЫЊпЉЪ httpsжЙАзФ®зЪДзЂѓеП£еПЈжШѓ443гАВ жЬЙдЄ§зІНеЯЇжЬђзЪДеК†иІ£еѓЖзЃЧж≥Хз±їеЮЛпЉЪ 1пЉЙеѓєзІ∞еК†еѓЖпЉЪеѓЖйТ•еП™жЬЙдЄАдЄ™пЉМеК†еѓЖиІ£еѓЖдЄЇеРМдЄАдЄ™еѓЖз†БпЉМдЄФеК†иІ£еѓЖйАЯеЇ¶ењЂпЉМеЕЄеЮЛзЪДеѓєзІ∞еК†еѓЖзЃЧж≥ХжЬЙDESгАБAESз≠ЙпЉЫ 2пЉЙйЭЮеѓєзІ∞еК†еѓЖпЉЪеѓЖйТ•жИРеѓєеЗЇзО∞пЉИдЄФж†єжНЃеЕђйТ•жЧ†ж≥ХжО®зЯ•зІБйТ•пЉМж†єжНЃзІБйТ•дєЯжЧ†ж≥ХжО®зЯ•еЕђйТ•пЉЙпЉМеК†еѓЖиІ£еѓЖдљњзФ®дЄНеРМеѓЖйТ•пЉИеЕђйТ•еК†еѓЖйЬАи¶БзІБйТ•иІ£еѓЖпЉМзІБйТ•еК†еѓЖйЬАи¶БеЕђйТ•иІ£еѓЖпЉЙпЉМзЫЄеѓєеѓєзІ∞еК†еѓЖйАЯеЇ¶иЊГжЕҐпЉМеЕЄеЮЛзЪДйЭЮеѓєзІ∞еК†еѓЖзЃЧж≥ХжЬЙRSAгАБDSAз≠ЙгАВ дЄЛйЭҐзЬЛдЄАдЄЛhttpsзЪДйАЪдњ°ињЗз®ЛпЉЪ httpsйАЪдњ°зЪДдЉШзВєпЉЪ 1пЉЙеЃҐжИЈзЂѓдЇІзФЯзЪДеѓЖйТ•еП™жЬЙеЃҐжИЈзЂѓеТМжЬНеК°еЩ®зЂѓиГљеЊЧеИ∞пЉЫ 2пЉЙеК†еѓЖзЪДжХ∞жНЃеП™жЬЙеЃҐжИЈзЂѓеТМжЬНеК°еЩ®зЂѓжЙНиГљеЊЧеИ∞жШОжЦЗпЉЫ 3пЉЙеЃҐжИЈзЂѓеИ∞жЬНеК°зЂѓзЪДйАЪдњ°жШѓеЃЙеЕ®зЪДгАВ дї£зРЖжЬНеК°еЩ®иЛ±жЦЗеЕ®зІ∞жШѓProxy ServerпЉМеЕґеКЯиГље∞±жШѓдї£зРЖзљСзїЬзФ®жИЈеОїеПЦеЊЧзљСзїЬдњ°жБѓгАВ嚥豰зЪДиѓіпЉЪеЃГжШѓзљСзїЬдњ°жБѓзЪДдЄ≠иљђзЂЩгАВ дї£зРЖжЬНеК°еЩ®жШѓдїЛдЇОжµПиІИеЩ®еТМWebжЬНеК°еЩ®дєЛйЧізЪДдЄАеП∞жЬНеК°еЩ®пЉМжЬЙдЇЖеЃГдєЛеРОпЉМжµПиІИеЩ®дЄНжШѓзЫіжО•еИ∞WebжЬНеК°еЩ®еОїеПЦеЫЮзљСй°µиАМжШѓеРСдї£зРЖжЬНеК°еЩ®еПСеЗЇиѓЈж±ВпЉМRequestдњ°еПЈдЉЪеЕИйАБеИ∞дї£зРЖжЬНеК°еЩ®пЉМзФ±дї£зРЖжЬНеК°еЩ®жЭ•еПЦеЫЮжµПиІИеЩ®жЙАйЬАи¶БзЪДдњ°жБѓеєґдЉ†йАБзїЩдљ†зЪДжµПиІИеЩ®гАВ иАМдЄФпЉМе§ІйГ®еИЖдї£зРЖжЬНеК°еЩ®йГљеЕЈжЬЙзЉУеЖ≤зЪДеКЯиГљпЉМе∞±е•љи±°дЄАдЄ™е§ІзЪДCacheпЉМеЃГжЬЙеЊИе§ІзЪДе≠ШеВ®з©ЇйЧіпЉМеЃГдЄНжЦ≠е∞ЖжЦ∞еПЦеЊЧжХ∞жНЃеВ®е≠ШеИ∞еЃГжЬђжЬЇзЪДе≠ШеВ®еЩ®дЄКпЉМе¶ВжЮЬжµПиІИеЩ®жЙАиѓЈж±ВзЪДжХ∞жНЃеЬ®еЃГжЬђжЬЇзЪДе≠ШеВ®еЩ®дЄКеЈ≤зїПе≠ШеЬ®иАМдЄФжШѓжЬАжЦ∞зЪДпЉМйВ£дєИеЃГе∞±дЄНйЗНжЦ∞дїОWebжЬНеК°еЩ®еПЦжХ∞жНЃпЉМиАМзЫіжО•е∞Же≠ШеВ®еЩ®дЄКзЪДжХ∞жНЃдЉ†йАБзїЩзФ®жИЈзЪДжµПиІИеЩ®пЉМињЩж†Је∞±иГљжШЊиСЧжПРйЂШжµПиІИйАЯеЇ¶еТМжХИзОЗгАВ жЫійЗНи¶БзЪДжШѓпЉЪProxy Server(дї£зРЖжЬНеК°еЩ®)жШѓInternetйУЊиЈѓзЇІзљСеЕ≥жЙАжПРдЊЫзЪДдЄАзІНйЗНи¶БзЪДеЃЙеЕ®еКЯиГљпЉМеЃГзЪДеЈ•дљЬдЄїи¶БеЬ®еЉАжФЊз≥їзїЯдЇТиБФ(OSI)ж®°еЮЛзЪДеѓєиѓЭе±ВгАВ дЄїи¶БеКЯиГље¶ВдЄЛпЉЪ 1пЉЙз™Бз†іиЗ™иЇЂIPиЃњйЧЃйЩРеИґпЉМиЃњйЧЃеЫље§ЦзЂЩзВєгАВе¶ВпЉЪжХЩиВ≤зљСгАБ169зљСз≠ЙзљСзїЬзФ®жИЈеПѓдї•йАЪињЗдї£зРЖиЃњйЧЃеЫље§ЦзљСзЂЩпЉЫ 2пЉЙиЃњйЧЃдЄАдЇЫеНХдљНжИЦеЫҐдљУеЖЕйГ®иµДжЇРпЉМе¶ВжЯРе§Іе≠¶FTP(еЙНжПРжШѓиѓ•дї£зРЖеЬ∞еЭАеЬ®иѓ•иµДжЇРзЪДеЕБиЃЄиЃњйЧЃиМГеЫідєЛеЖЕ)пЉМдљњзФ®жХЩиВ≤зљСеЖЕеЬ∞еЭАжЃµеЕНиієдї£зРЖжЬНеК°еЩ®пЉМе∞±еПѓдї•зФ®дЇОеѓєжХЩиВ≤¬†зљСеЉАжФЊзЪДеРДз±їFTPдЄЛиљљдЄКдЉ†пЉМдї•еПКеРДз±їиµДжЦЩжߕ胥еЕ±дЇЂз≠ЙжЬНеК°пЉЫ 3пЉЙз™Бз†ідЄ≠еЫљзФµдњ°зЪДIPе∞БйФБпЉЪдЄ≠еЫљзФµдњ°зФ®жИЈжЬЙеЊИе§ЪзљСзЂЩж؃襀йЩРеИґиЃњйЧЃзЪДпЉМињЩзІНйЩРеИґжШѓдЇЇдЄЇзЪДпЉМдЄНеРМServeеѓєеЬ∞еЭАзЪДе∞БйФБжШѓдЄНеРМзЪДгАВжЙАдї•дЄНиГљиЃњйЧЃжЧґеПѓдї•жНҐдЄАдЄ™еЫљ¬†е§ЦзЪДдї£зРЖжЬНеК°еЩ®иѓХиѓХпЉЫ 4пЉЙжПРйЂШиЃњйЧЃйАЯеЇ¶пЉЪйАЪеЄЄдї£зРЖжЬНеК°еЩ®йГљиЃЊзљЃдЄАдЄ™иЊГе§ІзЪДз°ђзЫШзЉУеЖ≤еМЇпЉМељУжЬЙе§ЦзХМзЪДдњ°жБѓйАЪињЗжЧґпЉМеРМжЧґдєЯе∞ЖеЕґдњЭе≠ШеИ∞зЉУеЖ≤еМЇдЄ≠пЉМељУеЕґдїЦзФ®жИЈеЖНиЃњйЧЃзЫЄеРМзЪДдњ°жБѓжЧґпЉМ¬†еИЩзЫіжО•зФ±зЉУеЖ≤еМЇдЄ≠еПЦеЗЇдњ°жБѓпЉМдЉ†зїЩзФ®жИЈпЉМдї•жПРйЂШиЃњйЧЃйАЯеЇ¶пЉЫ 5пЉЙйЪРиЧПзЬЯеЃЮIPпЉЪдЄКзљСиАЕдєЯеПѓдї•йАЪињЗињЩзІНжЦєж≥ХйЪРиЧПиЗ™еЈ±зЪДIPпЉМеЕНеПЧжФїеЗїгАВ httpдї£зРЖзЪДеЫЊз§ЇиІБдЄЛеЫЊпЉЪ еѓєдЇОеЃҐжИЈзЂѓжµПиІИеЩ®иАМи®АпЉМhttpдї£зРЖжЬНеК°еЩ®зЫЄељУдЇОжЬНеК°еЩ®гАВ иАМеѓєдЇОWebжЬНеК°еЩ®иАМи®АпЉМhttpдї£зРЖжЬНеК°еЩ®еПИжЛЕељУдЇЖеЃҐжИЈзЂѓзЪДиІТиЙ≤гАВ иЩЪжЛЯдЄїжЬЇпЉЪжШѓеЬ®зљСзїЬжЬНеК°еЩ®дЄКеИТеИЖеЗЇдЄАеЃЪзЪДз£БзЫШз©ЇйЧідЊЫзФ®жИЈжФЊзљЃзЂЩзВєгАБеЇФзФ®зїДдїґз≠ЙпЉМжПРдЊЫењЕи¶БзЪДзЂЩзВєеКЯиГљдЄОжХ∞жНЃе≠ШжФЊгАБдЉ†иЊУеКЯиГљгАВ¬†¬† жЙАи∞УиЩЪжЛЯдЄїжЬЇпЉМдєЯеПЂвАЬзљСзЂЩз©ЇйЧівАЭе∞±жШѓжККдЄАеП∞ињРи°МеЬ®дЇТиБФзљСдЄКзЪДжЬНеК°еЩ®еИТеИЖжИРе§ЪдЄ™вАЬиЩЪжЛЯвАЭзЪДжЬНеК°еЩ®пЉМжѓПдЄАдЄ™иЩЪжЛЯдЄїжЬЇйГљеЕЈжЬЙзЛђзЂЛзЪДеЯЯеРНеТМеЃМжХізЪДInternetжЬНеК°еЩ®пЉИжФѓжМБWWWгАБFTPгАБE-mailз≠ЙпЉЙеКЯиГљгАВдЄАеП∞жЬНеК°еЩ®дЄКзЪДдЄНеРМиЩЪжЛЯдЄїжЬЇжШѓеРДиЗ™зЛђзЂЛзЪДпЉМеєґзФ±зФ®жИЈиЗ™и°МзЃ°зРЖгАВдљЖдЄАеП∞жЬНеК°еЩ®дЄїжЬЇеП™иГље§ЯжФѓжМБдЄАеЃЪжХ∞йЗПзЪДиЩЪжЛЯдЄїжЬЇпЉМељУиґЕињЗињЩдЄ™жХ∞йЗПжЧґпЉМзФ®жИЈе∞ЖдЉЪжДЯеИ∞жАІиГљжА•еЙІдЄЛйЩНгАВ иЩЪжЛЯдЄїжЬЇжШѓзФ®еРМдЄАдЄ™WEBжЬНеК°еЩ®пЉМдЄЇдЄНеРМеЯЯеРНзљСзЂЩжПРдЊЫжЬНеК°зЪДжКАжЬѓгАВApacheгАБTomcatз≠ЙеЭЗеПѓйАЪињЗйЕНзљЃеЃЮзО∞ињЩдЄ™еКЯиГљгАВ зЫЄеЕ≥зЪДHTTPжґИжБѓе§іпЉЪHostгАВ дЊЛе¶ВпЉЪHost:¬†www.baidu.com еЃҐжИЈзЂѓеПСйАБHTTPиѓЈж±ВзЪДжЧґеАЩпЉМдЉЪжРЇеЄ¶Hostе§іпЉМHostе§іиЃ∞ељХзЪДжШѓеЃҐжИЈзЂѓиЊУеЕ•зЪДеЯЯеРНгАВињЩж†ЈжЬНеК°еЩ®еПѓдї•ж†єжНЃHostе§із°ЃиЃ§еЃҐжИЈи¶БиЃњйЧЃзЪДжШѓеУ™дЄАдЄ™еЯЯеРНгАВ гАКзРЖиІ£CookieеТМSessionжЬЇеИґгАЛпЉЪ http://sumongh.javaeye.com/blog/82498 гАКжµЕжЮРHTTPеНПиЃЃгАЛпЉЪ гАКhttpдї£зРЖ_зЩЊеЇ¶зЩЊзІСгАЛпЉЪ http://baike.baidu.com/view/1159398.htm гАКиЩЪжЛЯдЄїжЬЇ_зЩЊеЇ¶зЩЊзІСгАЛпЉЪ http://baike.baidu.com/view/7383.htm гАКhttps_зЩЊеЇ¶зЩЊзІСгАЛпЉЪ
1.¬†еЯЇз°Аж¶ВењµзѓЗ
1.1¬†дїЛзїН
1.2¬†еЬ®TCP/IPеНПиЃЃж†ИдЄ≠зЪДдљНзљЃ
    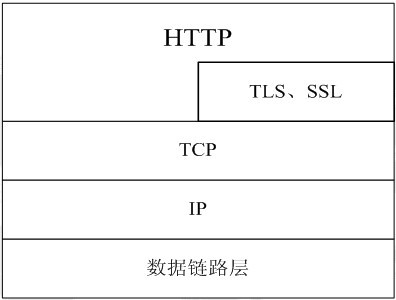
1.3¬†HTTPзЪДиѓЈж±ВеУНеЇФж®°еЮЛ
   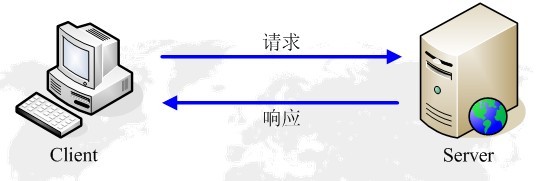
1.4¬†еЈ•дљЬжµБз®Л
1.5¬†дљњзФ®WiresharkжКУTCPгАБhttpеМЕ
                            
    http://www.blogjava.net/images/blogjava_net/amigoxie/40799/o_http%e5%8d%8f%e8%ae%ae%e5%ad%a6%e4%b9%a0-%e6%a6%82%e5%bf%b5-3.jpg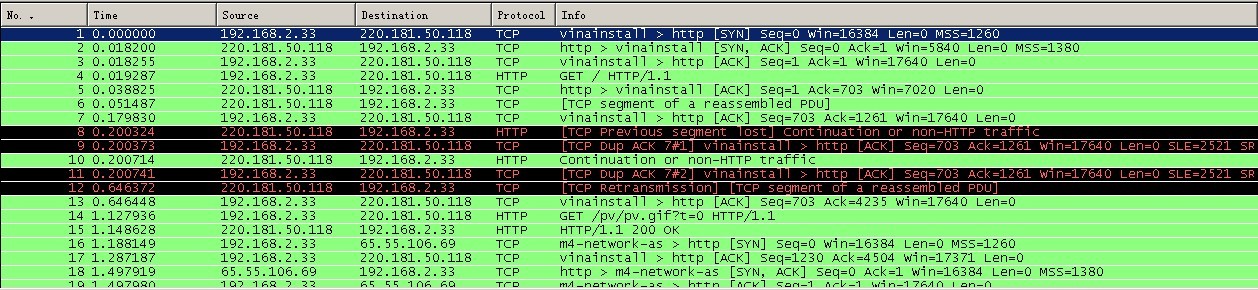
1.6¬†е§іеЯЯ
  http://www.blogjava.net/images/blogjava_net/amigoxie/40799/o_http%e5%8d%8f%e8%ae%ae%e5%ad%a6%e4%b9%a0-%e6%a6%82%e5%bf%b5-4.jpg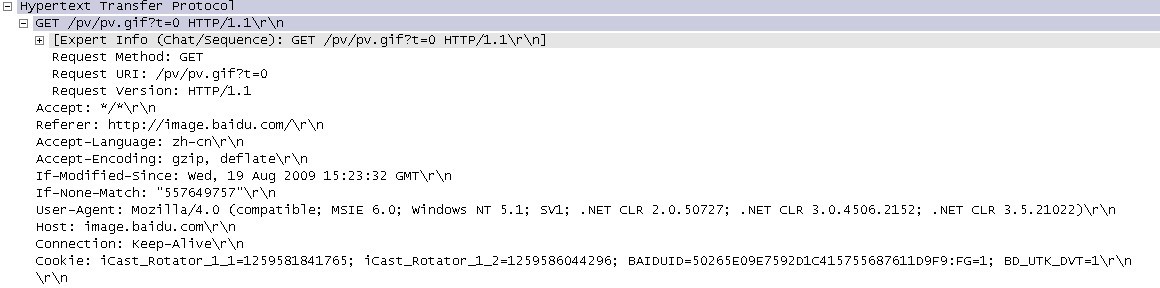
1.6.1¬†hostе§іеЯЯ
   ![]()
1.6.2¬†Refererе§іеЯЯ
   ![]()
1.6.3¬†User-Agentе§іеЯЯ
  http://www.blogjava.net/images/blogjava_net/amigoxie/40799/o_http%e5%8d%8f%e8%ae%ae%e5%ad%a6%e4%b9%a0-%e6%a6%82%e5%bf%b5-8.jpg
1.6.4¬†Cache-Controlе§іеЯЯ
   ![]()
1.6.5¬†Dateе§іеЯЯ
   ![]()
¬†1.7¬†HTTPзЪДеЗ†дЄ™йЗНи¶Бж¶Вењµ
1.7.1ињЮжО•пЉЪConnection
1.7.2жґИжБѓпЉЪMessage
1.7.3иѓЈж±ВпЉЪRequest
1.7.4еУНеЇФпЉЪResponse
1.7.5иµДжЇРпЉЪResource
1.7.6еЃЮдљУпЉЪEntity
1.7.7еЃҐжИЈжЬЇпЉЪClient
1.7.8зФ®жИЈдї£зРЖпЉЪUserAgent
1.7.9жЬНеК°еЩ®пЉЪServer
1.7.10жЇРжЬНеК°еЩ®пЉЪOriginserver
1.7.11дї£зРЖпЉЪProxy
1.7.12зљСеЕ≥пЉЪGateway
1.7.13йАЪйБУпЉЪTunnel
1.7.14зЉУе≠ШпЉЪCache
¬†¬†¬† йЩДељХпЉЪеПВиАГиµДжЦЩ
2.¬†еНПиЃЃиѓ¶иІ£зѓЗ
2.1¬†HTTP/1.0еТМHTTP/1.1зЪДжѓФиЊГ
2.1.1еїЇзЂЛињЮжО•жЦєйЭҐ
2.1.2¬†HostеЯЯ
     GET /pub/WWW/TheProject.html HTTP/1.1    Host: www.w3.org
    GET /pub/WWW/TheProject.html HTTP/1.1    Host: www.w3.org
2.1.3жЧ•жЬЯжЧґйЧіжИ≥
Sun, 06 Nov 1994 08:49:37 GMT ; RFC 822, updated by RFC 1123Sunday, 06-Nov-94 08:49:37 GMT ; RFC 850, obsoleted by RFC 1036Sun Nov 6 08:49:37 1994       ; ANSI C's asctime() format
2.1.4зКґжАБеУНеЇФз†Б
Expect: 100-continue
2.1.5иѓЈж±ВжЦєеЉП
2.2¬†HTTPиѓЈж±ВжґИжБѓ
2.2.1иѓЈж±ВжґИжБѓж†ЉеЉП
GET /index.html HTTP/1.1
GET /hello.htm HTTP/1.1Accept: */*Accept-Language: zh-cnAccept-Encoding: gzip, deflateIf-Modified-Since: Wed, 17 Oct 2007 02:15:55 GMTIf-None-Match: W/"158-1192587355000"User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)Host: 192.168.2.162:8080Connection: Keep-Alive
2.2.2иѓЈж±ВжЦєж≥Х
2.3 HTTPеУНеЇФжґИжБѓ
2.3.1еУНеЇФжґИжБѓж†ЉеЉП
HTTP/1.0 200 OK 
HTTP/1.1 400 Bad Request
HTTP/1.1 200 OKETag: W/"158-1192590101000"Last-Modified: Wed, 17 Oct 2007 03:01:41 GMTContent-Type: text/htmlContent-Length: 158Date: Wed, 17 Oct 2007 03:01:59 GMTServer: Apache-Coyote/1.1
2.3.2.1 ¬†1**пЉЪиѓЈж±ВжФґеИ∞пЉМзїІзї≠е§ДзРЖ
2.3.2.2 ¬†2**пЉЪжУНдљЬжИРеКЯжФґеИ∞пЉМеИЖжЮРгАБжО•еПЧ
201вАФвАФжПРз§ЇзЯ•йБУжЦ∞жЦЗдїґзЪДURL
2.3.2.3 ¬†3**пЉЪеЃМжИРж≠§иѓЈж±ВењЕй°їињЫдЄАж≠•е§ДзРЖ
2.3.2.4 ¬†4**пЉЪиѓЈж±ВеМЕеРЂдЄАдЄ™йФЩиѓѓиѓ≠ж≥ХжИЦдЄНиГљеЃМжИР
2.3.2.5 ¬†5**пЉЪжЬНеК°еЩ®жЙІи°МдЄАдЄ™еЃМеЕ®жЬЙжХИиѓЈж±В姱賕
2.4¬†дљњзФ®telnetињЫи°МhttpжµЛиѓХ
telnet www.baidu.com 80
GET /index.html HTTP/1.1
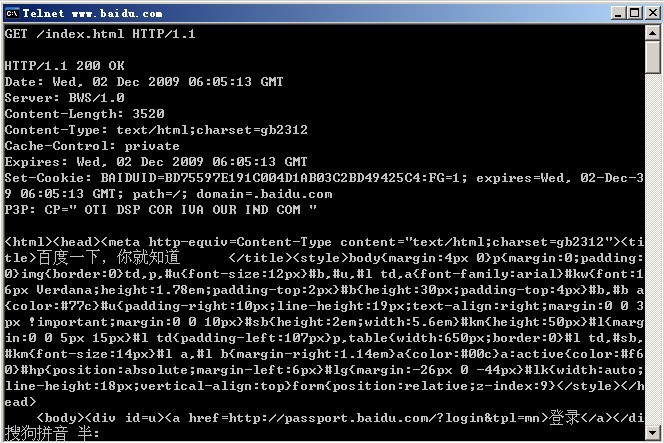 GET /index.html HTTP/1.0
GET /index.html HTTP/1.1connection: closeHost: www.baidu.com
GET /index.html HTTP/1.0
GET /index.html HTTP/1.1connection: closeHost: www.baidu.com
¬†2.6¬†иѓЈж±Ве§і
2.7¬†еУНеЇФе§і
2.8еЃЮдљУе§і
2.8жЙ©е±Хе§і
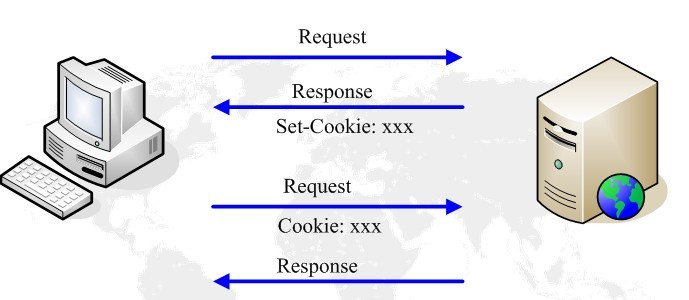
¬†¬†йЩДељХпЉЪеПВиАГиµДжЦЩ3.1 CookieеТМSession
3.1.1дЄ§иАЕжѓФиЊГ
3.1.2¬†SessionжЬЇеИґ
3.1.6¬†SessionзЪДеЃЮзО∞жЦєеЉП
3.1.6.1 ¬†дљњзФ®CookieжЭ•еЃЮзО∞
    
3.1.6.2 ¬†дљњзФ®URLеЫЮжШЊжЭ•еЃЮзО∞
3.1.3еЬ®J2EEй°єзЫЃдЄ≠Session姱жХИзЪДеЗ†зІНжГЕеЖµ
¬† ¬†¬† ¬†¬†¬†<session-timeout>30</session-timeout> //еНХдљНпЉЪеИЖйТЯ
    </session-config>
3.1.4дЄОCookieзЫЄеЕ≥зЪДHTTPжЙ©е±Хе§і
3.1.5CookieзЪДжµБз®Л
3.2¬†зЉУе≠ШзЪДеЃЮзО∞еОЯзРЖ
3.2.1дїАдєИжШѓWebзЉУе≠Ш
3.2.2зЉУе≠ШзЪДдЉШзВє
3.2.3дЄОзЉУе≠ШзЫЄеЕ≥зЪДHTTPжЙ©е±ХжґИжБѓе§і
3.2.4еЃҐжИЈзЂѓзЉУе≠ШзФЯжХИзЪДеЄЄиІБжµБз®Л

3.2.5¬†WebзЉУе≠ШжЬЇеИґ
3.3¬†жЦ≠зВєзї≠дЉ†еТМе§ЪзЇњз®ЛдЄЛиљљзЪДеЃЮзО∞еОЯзРЖ
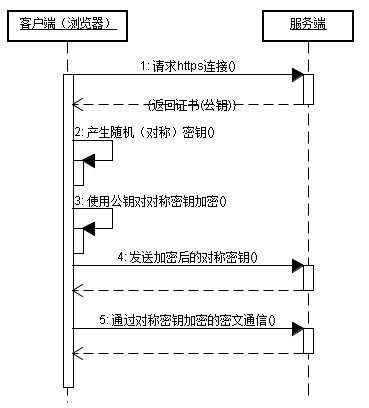
3.4 httpsйАЪдњ°ињЗз®Л
3.4.1дїАдєИжШѓhttps
   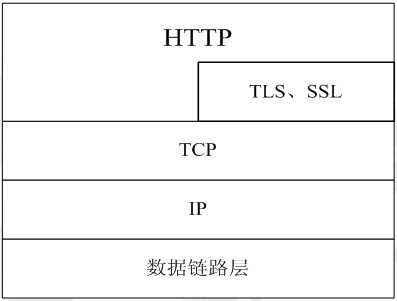
3.4.2¬†httpsзЪДеЃЮзО∞еОЯзРЖ
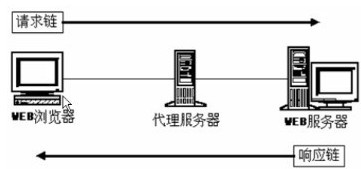
3.5 httpдї£зРЖ
3.5.1¬†httpдї£зРЖжЬНеК°еЩ®
3.5.2¬†httpдї£зРЖжЬНеК°еЩ®зЪДдЄїи¶БеКЯиГљ
3.5.3¬†httpдї£зРЖеЫЊз§Ї
3.6¬†иЩЪжЛЯдЄїжЬЇзЪДеЃЮзО∞
3.6.1дїАдєИжШѓиЩЪжЛЯдЄїжЬЇ
3.6.2иЩЪжЛЯдЄїжЬЇзЪДеЃЮзО∞еОЯзРЖ
йЩДељХпЉЪеПВиАГиµДжЦЩ
{kind=link}


- 2012-06-13 14:59
- жµПиІИ 1388
- иѓДиЃЇ(0)
- еИЖз±ї:дЇТиБФзљС
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
гАРиљђгАСељїеЇХеЉДжЗВHTTPзЉУе≠ШжЬЇеИґеПКеОЯзРЖ
2017-09-08 07:47 793еЙНи®А Http зЉУе≠ШжЬЇеИґдљЬдЄ ... -
http:the definitive guideе≠¶дє†иЃ∞ељХ
2012-09-16 18:50 1628chapter1~4зЃАеНХдїЛзїНдЇЖhttpеНПиЃЃзЪДoverview, ... -
гАРиљђгАСjava(Web)дЄ≠зЫЄеѓєиЈѓеЊДпЉМзїЭеѓєиЈѓеЊДйЧЃйҐШжАїзїУ
2012-08-09 16:49 1196еЙНи®АпЉЪ¬†еЙНдЄАжЃµжЧґйЧіпЉМзФ±дЇОеЬ®е§ДзРЖWebеЇФзФ®дЄЛзЪДжЦЗдїґеИЫеїЇдЄОзІїеК® ... -
HttpеНПиЃЃзЪДзЉЦз†Б
2012-08-09 15:56 2643зФ®GetжЦєеЉПдЉ†дЄ≠жЦЗеПВжХ∞е≠ ...
зЫЄеЕ≥жО®иНР
жЈ±еЕ•зРЖиІ£HTTPеНПиЃЃ
HTTP жШѓ Hyper Text Transfer ProtocolпЉИиґЕжЦЗжЬђдЉ†иЊУеНПиЃЃпЉЙзЪДзЉ©еЖЩгАВеЃГзЪДеПСе±ХжШѓдЄЗ зїізљСеНПдЉЪпЉИWorld Wide Web ConsortiumпЉЙеТМ Internet еЈ•дљЬе∞ПзїД IETFпЉИInternet Engineering Task ForceпЉЙеРИдљЬзЪДзїУжЮЬпЉМпЉИдїЦдїђпЉЙжЬАзїИеПСеЄГ...
HTTPпЉИиґЕжЦЗжЬђдЉ†иЊУеНПиЃЃпЉЙжШѓдЇТиБФзљСдЄКеЇФзФ®жЬАдЄЇеєњж≥ЫзЪДдЄАзІНзљСзїЬеНПиЃЃпЉМеЃГеЃЪдєЙ...HTTPеНПиЃЃзЪДжЈ±еЕ•е≠¶дє†ињШеМЕжЛђиѓЈж±ВжЦєж≥ХгАБзКґжАБз†БгАБе§ійГ®е≠ЧжЃµгАБзЉУе≠Шз≠ЦзХ•гАБеИЖеЭЧдЉ†иЊУзЉЦз†Бз≠Йе§ЪдЄ™жЦєйЭҐпЉМињЩдЇЫйГљжШѓжЮДеїЇйЂШжХИгАБеЃЙеЕ®зЪДWebжЬНеК°зЪДеЕ≥йФЃзїДжИРйГ®еИЖгАВ
жЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХе∞ЖдЄ≤еП£жХ∞жНЃиљђжНҐдЄЇHTTPеНПиЃЃжХ∞жНЃпЉМеєґе∞ЖеЕґеПСйАБеИ∞дЇСзЂѓпЉМдї•еПКжЇРз†БиљѓдїґзЪДиЈ®еє≥еП∞зЙєжАІгАВ дЄ≤еП£йАЪдњ°пЉМдєЯзІ∞дЄЇUARTпЉИйАЪзФ®еЉВж≠•жФґеПСдЉ†иЊУеЩ®пЉЙпЉМжШѓдЄАзІНеЄЄиІБдЇОеµМеЕ•еЉПз≥їзїЯгАБеНХзЙЗжЬЇеТМиЃ°зЃЧжЬЇдЄ≠зЪДжО•еП£пЉМзФ®дЇОиЃЊе§ЗйЧізЪД...
дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАЪињЗеЃЮйЩЕзЪДжУНдљЬпЉМеЄЃеК©е≠¶дє†иАЕжЫіеК†зЫіиІВеЬ∞зРЖиІ£HTTPеНПиЃЃзЪДеЈ•дљЬжЬЇеИґпЉМеК†жЈ±зРЖиЃЇзЯ•иѓЖзЪДзРЖиІ£пЉМиГље§ЯжЫіе•љеЬ∞еЇФзФ®дЇОзљСзїЬеЇФзФ®з®ЛеЇПзЪДиЃЊиЃ°дЄОдЉШеМЦгАВ еЕґдїЦиѓіжШОпЉЪдЄЇдЇЖиЊЊеИ∞жЬАе•љзЪДе≠¶дє†жХИжЮЬпЉМжО®иНРзїУеРИWiresharkиљѓдїґжЭ•жНХжНЙ...
иѓ•еЈ•еЕЈзЪДжЇРз†БжПРдЊЫдЇЖжЈ±еЕ•зРЖиІ£ињЩдЄ™ињЗз®ЛзЪДжЬЇдЉЪпЉМеЉАеПСиАЕеПѓдї•жЯ•зЬЛеєґдњЃжФєдї£з†Бдї•йАВеЇФзЙєеЃЪзЪДз°ђдїґиЃЊе§ЗгАБйАЪдњ°еНПиЃЃжИЦжЬНеК°еЩ®йЬАж±ВгАВеѓєдЇОе≠¶дє†зљСзїЬзЉЦз®ЛгАБеµМеЕ•еЉПз≥їзїЯеЉАеПСдї•еПКзЙ©иБФзљСеЇФзФ®зЪДдЇЇжЭ•иѓіпЉМињЩжШѓдЄАдЄ™еЃЭиіµзЪДиµДжЇРгАВ еЬ®еИЖжЮРеТМдљњзФ®...
гАКжЈ±еЕ•зРЖиІ£LinuxзљСзїЬжКАжЬѓеЖЕеєХгАЛжШѓдЄАжЬђдЄУж≥®дЇОжОҐиЃ®LinuxжУНдљЬз≥їзїЯдЄЛзљСзїЬжКАжЬѓзЪДдЄУдЄЪдє¶з±НпЉМжЧ®еЬ®еЄЃеК©иѓїиАЕжЈ±еЕ•еЙЦжЮРLinuxзљСзїЬжХ∞жНЃеМЕзЪДжµБеРСпЉМдїОиАМжЫіе•љеЬ∞ињЫи°МзљСзїЬжКУеМЕеИЖжЮРпЉМеєґдЄЇе≠¶дє†LinuxеЖЕж†ЄжЇРз†БжПРдЊЫзРЖиЃЇеЯЇз°АгАВиѓ•дє¶еЖЕеЃєеєњж≥ЫдЄФ...
гАКжЈ±еЕ•зРЖиІ£LTE-AгАЛињЩжЬђдє¶йАЪињЗжЈ±еЕ•жµЕеЗЇзЪДжЦєеЉПпЉМи¶ЖзЫЦдЇЖLTE-Aж†ЗеЗЖзЪДе§ЪдЄ™жЦєйЭҐпЉМеМЕжЛђеНПиЃЃж†ИзїУжЮДгАБиµДжЇРеИЖйЕНгАБдЉ†иЊУж®°еЉПдї•еПКжОІеИґдњ°йБУз≠ЙгАВињЩдЇЫзЯ•иѓЖзВєеѓєдЇОжЧ†зЇњйАЪдњ°жЦ∞жЙЛиАМи®АпЉМжШѓйЭЮеЄЄеЃЭиіµзЪДеЕ•йЧ®жЭРжЦЩгАВйАЪињЗе≠¶дє†пЉМиѓїиАЕеПѓдї•йАРж≠•жЮДеїЇ...
жЈ±еЕ•зРЖиІ£HTTPеНПиЃЃ[ж±ЗзЉЦ].pdf
еЉХи®А121.1 зЙИжЬђиѓіжШО 121.2 зЂ†иКВзЉЦжОТ 121.3 и°МжЦЗиІДеЃЪ 12зђђ 2 зЂ†.FIX еНПиЃЃдїЛзїН 142.1 еНПиЃЃж¶Вињ∞ 142.2 FIX жґИжБѓеЃЪдєЙиѓ≠ж≥Х
гАКжЈ±еЕ•зРЖиІ£иЃ°зЃЧжЬЇзљСзїЬгАЛжШѓзОЛиЊЊиАБеЄИзЪДдЄАйГ®зїПеЕЄиСЧдљЬпЉМдЄїи¶БжґµзЫЦдЇЖзљСзїЬеЯЇз°АеТМTCP/IPеНПиЃЃж†ИзЪДжЈ±еЇ¶иІ£жЮРгАВињЩжЬђдє¶дЄНдїЕжПРдЊЫдЇЖеЕ®йЭҐзЪДзРЖиЃЇзЯ•иѓЖпЉМињШеМЕеРЂдЇЖеЃЮйЩЕеЇФзФ®еТМйЧЃйҐШиІ£з≠ФпЉМжШѓе≠¶дє†иЃ°зЃЧжЬЇзљСзїЬзЪДйЗНи¶БеПВиАГиµДжЦЩгАВ й¶ЦеЕИпЉМдїОж†ЗйҐШ...
гАКжЈ±еЕ•зРЖиІ£LinuxзљСзїЬжКАжЬѓеЖЕеєХгАЛжШѓдЄАжЬђдЄУж≥®дЇОLinuxжУНдљЬз≥їзїЯзљСзїЬжКАжЬѓзЪДдЄУдЄЪдє¶з±НпЉМеѓєдЇОжГ≥и¶БжЈ±еЕ•е≠¶дє†LinuxеЖЕж†ЄзљСзїЬж®°еЭЧзЪДеЉАеПСиАЕжЭ•иѓіпЉМжШѓдЄАдїљжЮБеЕЈдїЈеАЉзЪДеПВиАГиµДжЦЩгАВињЩжЬђдє¶жґµзЫЦдЇЖдїОеЇХе±ВзљСзїЬиЃЊе§Зй©±еК®еИ∞йЂШе±ВзљСзїЬеНПиЃЃе§ДзРЖзЪДеЕ®...
USB йАЪдњ°еНПиЃЃжЈ±еЕ•зРЖиІ£
гАКжЈ±еЕ•зРЖиІ£LinuxеЖЕж†ЄгАЛжШѓдЄАжЬђжЈ±еПЧ搥ињОзЪДдє¶з±НпЉМеЃГдЄЇиѓїиАЕжП≠з§ЇдЇЖLinuxжУНдљЬз≥їзїЯзЪДеЖЕеЬ®ињРдљЬжЬЇеИґпЉМжЧ®еЬ®еЄЃеК©иѓїиАЕжЈ±еЕ•зРЖиІ£LinuxеЖЕж†ЄзЪДеЈ•дљЬеОЯзРЖгАВињЩжЬђдє¶зЪДзђђдЄЙзЙИжШѓдЄ≠жЦЗйЂШжЄЕзЙИжЬђпЉМеЄ¶жЬЙдє¶з≠ЊпЉМдљњеЊЧе≠¶дє†ињЗз®ЛжЫідЄЇдЊњжНЈгАВеЬ®ињЩдЄ™...
дїОзїЩеЃЪзЪДдњ°жБѓжЭ•зЬЛпЉМдЄїи¶БеЕ≥ж≥®зВєеЬ®дЇОгАКжЈ±еЕ•зРЖиІ£LinuxеЖЕж†ЄгАЛињЩжЬђдє¶зЪДзђђдЄЙзЙИдЄ≠жЦЗзЙИпЉМдї•еПКдЄОLinuxзЫЄеЕ≥зЪДзЯ•иѓЖгАВзФ±дЇОйГ®еИЖдњ°жБѓйЗНе§НдЄФжЧ†еЃЮйЩЕеЖЕеЃєпЉМжИСдїђе∞ЖйЗНзВєжФЊеЬ®дє¶еРНеПКжППињ∞дЄКпЉМдї•ж≠§жЭ•зФЯжИРзЫЄеЕ≥зЯ•иѓЖзВєгАВ ### жЈ±еЕ•зРЖиІ£Linux...
гАКжЈ±еЕ•зРЖиІ£LinuxзљСзїЬжКАжЬѓеЖЕеєХгАЛжШѓдЄАжЬђдЄУж≥®дЇОжОҐиЃ®LinuxжУНдљЬз≥їзїЯзљСзїЬжКАжЬѓзЪДдЄУдЄЪдє¶з±НпЉМжґµзЫЦдЇЖдїОеЇХе±ВзљСзїЬиЃЊе§Зй©±еК®еИ∞дЄКе±ВеНПиЃЃж†ИзЪДеЕ®йЭҐеЖЕеЃєгАВиѓ•дє¶дЄНдїЕжПРдЊЫдЇЖдЄ≠жЦЗзЙИпЉМињШйЩДеЄ¶дЇЖиЛ±жЦЗзЙИпЉМеѓєдЇОе≠¶дє†еТМз†Фз©ґLinuxзљСзїЬжКАжЬѓзЪДиѓїиАЕжЭ•...
иЩљзДґжЧ©еЕИзЪД TCP/IPзїПй™МжШѓжЬЙзФ®зЪДпЉМдљЖеИЭе≠¶иАЕйАЪињЗгАКжЈ±еЕ•зРЖиІ£LinuxзљСзїЬеЖЕеєХгАЛдїНзДґеПѓдї•е≠¶дє†еИ∞еНПиЃЃжЬђиЇЂеТМе§ІйЗПзЪДеЇФзФ®дњ°жБѓгАВдЄАжЧ¶ељїеЇХжОМжП°дЇЖињЩдЇЫзљСзїЬеЈ•еЕЈпЉМдљ†е∞±еПѓдї•дљњзФ®гАКжЈ±еЕ•зРЖиІ£LinuxзљСзїЬеЖЕеєХгАЛињЩжЬђдє¶жЙАйЩДзЪДдї£з†БпЉМеЗЖз°ЃеЬ∞...