
下图是 hive 系统的整体结构图
![]()
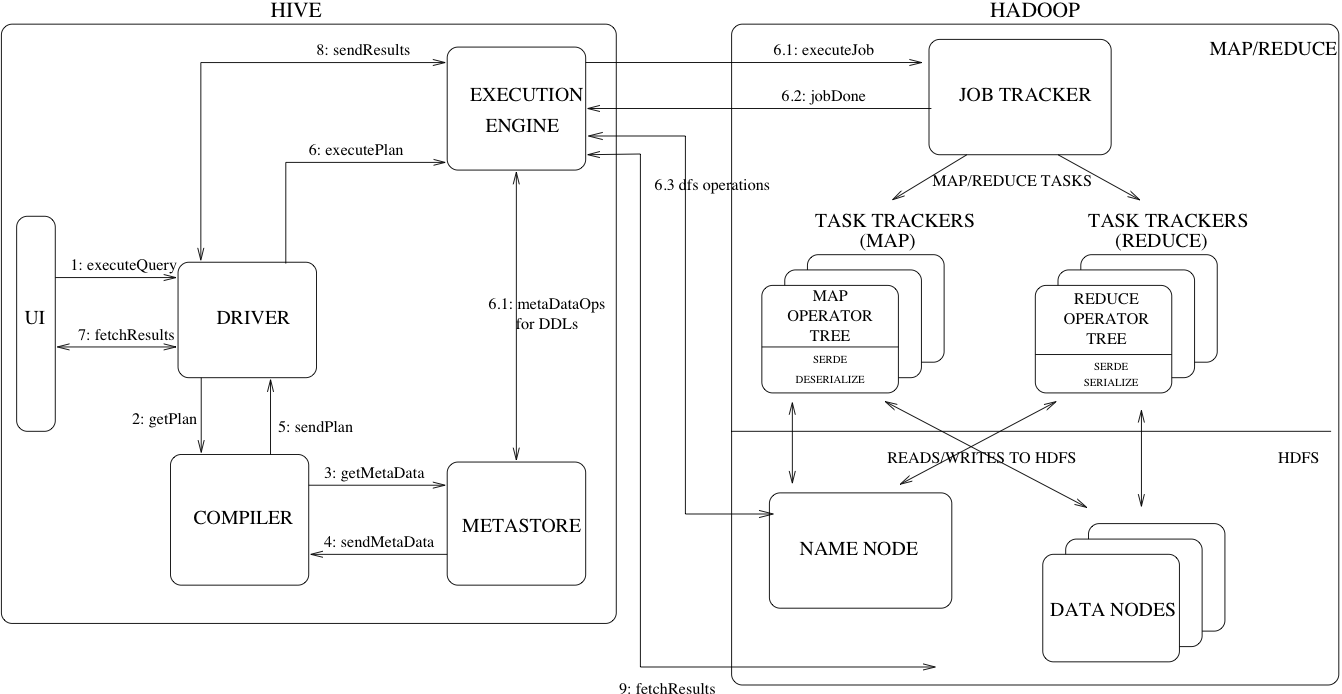
Hive 体系结构
上图显示了 Hive 的主要组件以及 Hive 跟 Hadoop 的交互过程,这些组件分别是:
UI:用户提交查询和其他操作到系统的用户接口。
Driver:接收查询的组件,负责 session 管理,提供基于 JDBC/ODBC 接口的执行和数据拉取 API。
Compiler:解析查询,对查询的不同部分做语法分析,生成执行计划。
Metastore:存储数据仓库中所有数据的结构信息,包括列名和列的类型信息;也负责数据读写的序列化和反序列化,以及定位数据对应的 HDFS 文件。
Execution Engine - 执行具体的执行计划。执行计划是一个状态的有向无环图(DAG),执行引擎管理图中状态的依赖关系,并进行调度。
Hive 数据模型
Hive 把数据组织成如下三级结构:
- Tables
- Partitions
- Buckets
Hive 除了支持基础类型之外,还支持数组、maps 和用户自定义类型。Hive 中用户是通过实现自己的对象 inspector 接口来自定义列类型以及他们的序列化逻辑。
元数据存储
Metastore 提供了两个非常重要但常常被忽略的特性:数据抽象和数据发现。数据抽象使得对数据的解释在表创建的时候就已经提供好了,之后每次查询都可以复用。
元数据对象
- Database
- Table
- Partition
元数据实现方案
Metastore 有两种实现方案:基于数据库的和基于文件的。
- 基于数据库的方案使用 DataNucleus 实现,该方案的好处是可以查询元数据,坏处是会有元数据同步和扩展的问题。
- 基于文件的方案的问题是没有一个很好的实现方法。
所以最终选择了基于关系数据库的 metastore 方案。
metastore 的访问有嵌入式和远程调用两种方式,远程调用是通过 Thrift 服务实现的,这样可以兼容非 Java 客户端;对于 Java 客户端可以直接使用嵌入方式。
Hive 查询语言
HiveQL 是一种类 SQL 查询语言,它在建表、加载数据和查询上大量模仿 SQL 语法。
HiveQL 支持嵌入用户自定义的 map-reduce 脚本,通过这些脚本可以在标准输入中按行读取数据再按行输出数据到标准输出。
另一个 HiveQL 的特性是多表插入,如果多个查询访问的是相同数据,只需要做一次数据扫描操作。
编译器
编译组件由下面四部分组成:
- Parser
- Semantic Analyser
这步中会做类型检查和类型的隐式转换;
对于涉及到划分的表,这里会收集所有的表达式,为后面的划分剪枝做准备;
这个步骤也会收集查询的指定采样。
- Logical Plan Generator
逻辑计划中的操作大体分为两类,一类是关系代数操作(filter、join 等),一类是 Hive 特有的操作(像 reduceSink 操作),这类特有的操作后续会被转换成 map-reduce 任务。
这个步骤中还会做一些查询优化的事情,比如:
- 把一系列 join 操作转换成一个单独的 multi-way join 操作
- 为 group by 执行一个 map-side 偏序聚合
- 把 group by 切分成两阶段来消除 reducer 的性能瓶颈问题
- Query Plan Generator
这个步骤中遍历逻辑计划树,把操作逐个分解成可以提交给 Hadoop 集群 map-reduce 框架的任务。查询计划也包括必要的采用和划分任务,最终这个计划被序列化到一个文件中。
翻译自:https://cwiki.apache.org/confluence/display/Hive/Design#



相关推荐
**二、Hive的体系架构与数据模型** 1. **用户接口** - **CLI (命令行界面)**:用户可以通过 CLI 直接与 Hive 交互,启动时会同时启动一个 Hive 实例。 - **Client (客户端)**:用于连接到 Hive Server,需要指定 ...
HIVE架构详解 HIVE架构是建立在Hadoop平台上的数据仓库基础构架,提供了一系列的工具,可以...HIVE架构是一个功能强大且复杂的系统,需要对其各个组件有深入的了解和掌握,以便更好地使用HIVE架构进行数据分析和挖掘。
* 数据存储:HIVE使用Hadoop分布式文件系统(HDFS)存储数据,而传统数据库使用关系数据库管理系统(RDBMS) * 数据处理:HIVE使用MapReduce处理数据,而传统数据库使用SQL查询 * 扩展性:HIVE具有高可扩展性,可以...
#### 二、Hive基本架构 Hive 的基本架构主要包括以下几个部分: 1. **用户接口**:用户可以通过命令行界面 (CLI)、Java Database Connectivity (JDBC) / Open Database Connectivity (ODBC) 或 Web 用户界面来与 ...
接着详细介绍了Hive的系统架构,包括基本组成模块、工作原理和几种外部访问方式,描述了Hive的具体应用及Hive HA原理;同时,介绍了新一代开源大数据分析引擎Impala及其与Hive的比较分析;最后,以单词统计为例,...
在大数据处理领域,Hive作为一个基于Hadoop的数据仓库系统,起着至关重要的作用。它允许用户使用SQL-like语言(HiveQL)对分布式存储的数据进行查询和分析。本文将深入探讨Hive SQL如何被编译成MapReduce任务,以及...
1. **架构**: Hive是一个数据仓库基础设施,依赖于Hadoop的分布式存储和计算能力,而SQL是一种通用的关系数据库查询语言。 2. **设置**: Hive基于开源的Hadoop生态系统,数据存储在HDFS中,而SQL通常用于关系型...
【大数据分析与应用Hadoop-Hive】的讲解涵盖了Hadoop生态系统、MapReduce的工作原理、Hive的应用架构以及实际的手厅数据过滤操作。以下是对这些知识点的详细阐述: ### 一、Hadoop生态 Hadoop是一个开源的大数据...
Hive的体系结构设计上借鉴了传统数据库的架构,因此它能够支持复杂的查询操作,并且具有很好的扩展性,能随着数据量的增长而进行水平扩展。Hive通过元数据存储来管理数据的结构信息,这些元数据是Hive能够执行复杂...
该系统架构如图所示: HiveServer2 集群 | |-- 节点 HiveServer2_1 |-- 节点 HiveServer2_2 其中,HiveServer2 是一个高可用性的集群,每个节点都可以作为主节点或备节点。节点 HiveServer2_1 和节点 HiveServer2_...
本教程将深入探讨Hive数仓的架构与设计,Hive SQL的基本语法及高级特性,以及如何自定义函数以满足特定需求,并详细解析Hive的重要参数配置。 1. Hive数仓: - 数据仓库概念:数据仓库是为决策支持系统设计的,...
Apache Hive是一个建立在Hadoop之上的数据仓库基础架构,它提供了一系列的工具,可以用来进行数据摘要、查询和分析。Hive定义了一种类SQL语言HiveQL,它允许熟悉SQL的开发者查询Hadoop中的数据。即使底层数据存储在...
- **数据修改**:Hive不推荐修改数据,因为它基于不可变的HDFS文件系统。 3. **Hive内部表和外部表的区别** - **内部表**:数据与元数据一起管理,删除时会同时删除数据和元数据。 - **外部表**:仅管理元数据,...
**1.2 Hive系统架构** Hive的架构主要基于HDFS和MapReduce。Hive的关键组成部分包括客户端和服务端组件,以及底层的HDFS和MapReduce计算框架。 - **客户端组件**: - **CLI (Command Line Interface)**: 命令行...
下面是对Hive的结构、架构、基本操作和数据存储的详细介绍。 Hive结构 Hive的结构主要包括三个部分:元数据库(Metastore)、查询编译器(Query Compiler)和执行引擎(Execution Engine)。其中,元数据库用于...
1. 存储文件系统不同,Hive 使用的是 Hadoop 的 HDFS,而关系数据库则是服务器本地的文件系统 2. 计算模型不同,Hive 使用的是 MapReduce,而关系数据库则是自己设计的计算模型 3. 实时性不同,关系数据库都是为实时...
Hadoop/Hive系统通过HDFS存储Web日志数据,并通过Hive处理这些数据,最终实现日志分析的功能。 设计Web日志分析系统时,需要考虑到以下几个核心功能模块: 1. 日志采集模块:负责实时或定时从Web服务器获取日志...
1. **Hive架构**:介绍Hive的组成部分,如Hive Metastore、Hive Driver、Hive Executor等,以及它们在数据处理流程中的角色。 2. **HQL语法**:详细解析Hive Query Language,包括SELECT、FROM、WHERE、GROUP BY、...
二、Hive架构 Hive的架构主要包括四个组件:客户端、元数据存储、Hive Server和执行引擎。客户端用于提交查询,元数据存储(通常使用MySQL或Derby)保存表和分区的信息,Hive Server处理客户端请求并解析HQL,执行...