项目引用jdbctemplate和druid从数据库中动态获取路由信息。
zuul作为一个网关,是用户请求的入口,担当鉴权、转发的重任,理应保持高可用性和具备动态配置的能力。
我画了一个实际中可能使用的配置框架,如图。
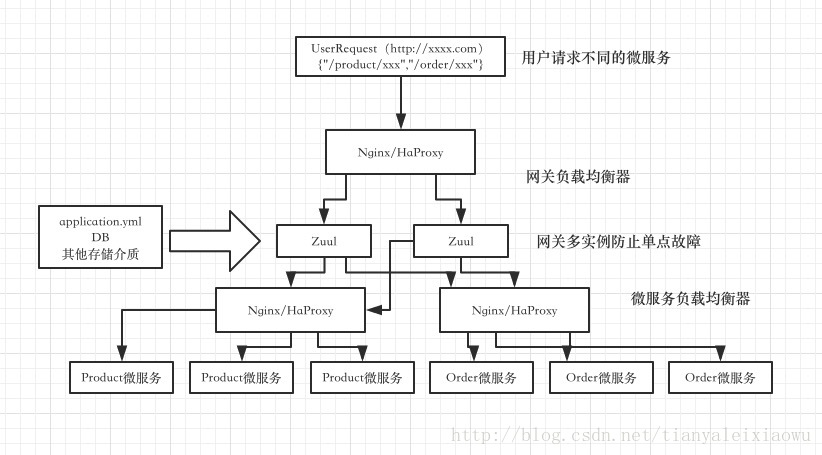
当用户发起请求后,首先通过并发能力强、能承担更多用户请求的负载均衡器进行第一步的负载均衡,将大量的请求分发至多个网关服务。这是分布式的第一步。如果是使用docker的话,并且使用rancher进行docker管理,那么可以很简单的使用rancher自带的负载均衡,创建HaProxy,将请求分发至多个Zuul的docker容器。使用多个zuul的原因即是避免单点故障,由于网关非常重要,尽量配置多个实例。
然后在Zuul网关中,执行完自定义的网关职责后,将请求转发至另一个HaProxy负载的微服务集群,同样是避免微服务单点故障和性能瓶颈。
最后由具体的微服务处理用户请求并返回结果。
那么为什么要设置zuul的动态配置呢,因为网关其特殊性,我们不希望它重启再加载新的配置,而且如果能实时动态配置,我们就可以完成无感知的微服务迁移替换,在某种程度还可以完成服务降级的功能。
zuul的动态配置也很简单,这里我们参考http://blog.csdn.net/u013815546/article/details/68944039 并使用他的方法,从数据库读取配置信息,刷新配置。
看实现类
配置文件里我们可以不配置zuul的任何路由,全部交给数据库配置。
-
package com.tianyalei.testzuul.config;
-
-
-
import org.slf4j.LoggerFactory;
-
import org.springframework.beans.BeanUtils;
-
import org.springframework.cloud.netflix.zuul.filters.RefreshableRouteLocator;
-
import org.springframework.cloud.netflix.zuul.filters.SimpleRouteLocator;
-
import org.springframework.cloud.netflix.zuul.filters.ZuulProperties;
-
import org.springframework.jdbc.core.BeanPropertyRowMapper;
-
import org.springframework.jdbc.core.JdbcTemplate;
-
import org.springframework.util.StringUtils;
-
-
import java.util.LinkedHashMap;
-
-
-
-
public class CustomRouteLocator extends SimpleRouteLocator implements RefreshableRouteLocator {
-
-
public final static Logger logger = LoggerFactory.getLogger(CustomRouteLocator.class);
-
-
private JdbcTemplate jdbcTemplate;
-
-
private ZuulProperties properties;
-
-
public void setJdbcTemplate(JdbcTemplate jdbcTemplate) {
-
this.jdbcTemplate = jdbcTemplate;
-
-
-
public CustomRouteLocator(String servletPath, ZuulProperties properties) {
-
super(servletPath, properties);
-
this.properties = properties;
-
logger.info("servletPath:{}", servletPath);
-
-
-
//父类已经提供了这个方法,这里写出来只是为了说明这一个方法很重要!!!
-
-
// protected void doRefresh() {
-
-
-
-
-
-
-
-
-
-
-
protected Map<String, ZuulProperties.ZuulRoute> locateRoutes() {
-
LinkedHashMap<String, ZuulProperties.ZuulRoute> routesMap = new LinkedHashMap<>();
-
//从application.properties中加载路由信息
-
routesMap.putAll(super.locateRoutes());
-
-
routesMap.putAll(locateRoutesFromDB());
-
-
LinkedHashMap<String, ZuulProperties.ZuulRoute> values = new LinkedHashMap<>();
-
for (Map.Entry<String, ZuulProperties.ZuulRoute> entry : routesMap.entrySet()) {
-
String path = entry.getKey();
-
// Prepend with slash if not already present.
-
if (!path.startsWith("/")) {
-
-
-
if (StringUtils.hasText(this.properties.getPrefix())) {
-
path = this.properties.getPrefix() + path;
-
if (!path.startsWith("/")) {
-
-
-
-
values.put(path, entry.getValue());
-
-
-
-
-
private Map<String, ZuulProperties.ZuulRoute> locateRoutesFromDB() {
-
Map<String, ZuulProperties.ZuulRoute> routes = new LinkedHashMap<>();
-
List<ZuulRouteVO> results = jdbcTemplate.query("select * from gateway_api_define where enabled = true ", new
-
BeanPropertyRowMapper<>(ZuulRouteVO.class));
-
for (ZuulRouteVO result : results) {
-
if (StringUtils.isEmpty(result.getPath()) ) {
-
-
-
if (StringUtils.isEmpty(result.getServiceId()) && StringUtils.isEmpty(result.getUrl())) {
-
-
-
ZuulProperties.ZuulRoute zuulRoute = new ZuulProperties.ZuulRoute();
-
-
BeanUtils.copyProperties(result, zuulRoute);
-
-
logger.error("=============load zuul route info from db with error==============", e);
-
-
routes.put(zuulRoute.getPath(), zuulRoute);
-
-
-
-
-
public static class ZuulRouteVO {
-
-
-
* The ID of the route (the same as its map key by default).
-
-
-
-
-
* The path (pattern) for the route, e.g. /foo/**.
-
-
-
-
-
* The service ID (if any) to map to this route. You can specify a physical URL or
-
* a service, but not both.
-
-
private String serviceId;
-
-
-
* A full physical URL to map to the route. An alternative is to use a service ID
-
* and service discovery to find the physical address.
-
-
-
-
-
* Flag to determine whether the prefix for this route (the path, minus pattern
-
* patcher) should be stripped before forwarding.
-
-
private boolean stripPrefix = true;
-
-
-
* Flag to indicate that this route should be retryable (if supported). Generally
-
* retry requires a service ID and ribbon.
-
-
private Boolean retryable;
-
-
-
-
-
-
-
-
public void setId(String id) {
-
-
-
-
public String getPath() {
-
-
-
-
public void setPath(String path) {
-
-
-
-
public String getServiceId() {
-
-
-
-
public void setServiceId(String serviceId) {
-
this.serviceId = serviceId;
-
-
-
-
-
-
-
public void setUrl(String url) {
-
-
-
-
public boolean isStripPrefix() {
-
-
-
-
public void setStripPrefix(boolean stripPrefix) {
-
this.stripPrefix = stripPrefix;
-
-
-
public Boolean getRetryable() {
-
-
-
-
public void setRetryable(Boolean retryable) {
-
this.retryable = retryable;
-
-
-
public Boolean getEnabled() {
-
-
-
-
public void setEnabled(Boolean enabled) {
-
-
-
-
-
package com.tianyalei.testzuul.config;
-
-
import org.springframework.beans.factory.annotation.Autowired;
-
import org.springframework.boot.autoconfigure.web.ServerProperties;
-
import org.springframework.cloud.netflix.zuul.filters.ZuulProperties;
-
import org.springframework.context.annotation.Bean;
-
import org.springframework.context.annotation.Configuration;
-
import org.springframework.jdbc.core.JdbcTemplate;
-
-
-
public class CustomZuulConfig {
-
-
-
ZuulProperties zuulProperties;
-
-
-
-
JdbcTemplate jdbcTemplate;
-
-
-
public CustomRouteLocator routeLocator() {
-
CustomRouteLocator routeLocator = new CustomRouteLocator(this.server.getServletPrefix(), this.zuulProperties);
-
routeLocator.setJdbcTemplate(jdbcTemplate);
-
-
-
-
下面的config类功能就是使用自定义的RouteLocator类,上面的类就是这个自定义类。
里面主要是一个方法,locateRoutes方法,该方法就是zuul设置路由规则的地方,在方法里做了2件事,一是从application.yml读取配置的路由信息,二是从数据库里读取路由信息,所以数据库里需要一个各字段和ZuulProperties.ZuulRoute一样的表,存储路由信息,从数据库读取后添加到系统的Map<String, ZuulProperties.ZuulRoute>中。
在实际的路由中,zuul就是按照Map<String, ZuulProperties.ZuulRoute>里的信息进行路由转发的。
建表语句:
-
create table `gateway_api_define` (
-
`id` varchar(50) not null,
-
`path` varchar(255) not null,
-
`service_id` varchar(50) default null,
-
`url` varchar(255) default null,
-
`retryable` tinyint(1) default null,
-
`enabled` tinyint(1) not null,
-
`strip_prefix` int(11) default null,
-
`api_name` varchar(255) default null,
-
-
) engine=innodb default charset=utf8
-
-
-
INSERT INTO gateway_api_define (id, path, service_id, retryable, strip_prefix, url, enabled) VALUES ('user', '/user/**', null,0,1, 'http://localhost:8081', 1);
-
INSERT INTO gateway_api_define (id, path, service_id, retryable, strip_prefix, url, enabled) VALUES ('club', '/club/**', null,0,1, 'http://localhost:8090', 1);
通过上面的两个类,再结合前面几篇讲过的zuul的使用,就可以自行测试一下在数据库里配置的信息能否在zuul中生效了。
数据库里的各字段分别对应原本在yml里配置的同名属性,如path,service_id,url等,等于把配置文件存到数据库里。
至于修改数据库值信息后(增删改),让zuul动态生效需要借助于下面的方法
-
package com.tianyalei.testzuul.config;
-
-
import org.springframework.beans.factory.annotation.Autowired;
-
import org.springframework.cloud.netflix.zuul.RoutesRefreshedEvent;
-
import org.springframework.cloud.netflix.zuul.filters.RouteLocator;
-
import org.springframework.context.ApplicationEventPublisher;
-
import org.springframework.stereotype.Service;
-
-
-
public class RefreshRouteService {
-
-
ApplicationEventPublisher publisher;
-
-
-
RouteLocator routeLocator;
-
-
public void refreshRoute() {
-
RoutesRefreshedEvent routesRefreshedEvent = new RoutesRefreshedEvent(routeLocator);
-
publisher.publishEvent(routesRefreshedEvent);
-
-
可以定义一个Controller,在Controller里调用refreshRoute方法即可,zuul就会重新加载一遍路由信息,完成刷新功能。通过修改数据库,然后刷新,经测试是正常的。
-
-
public class RefreshController {
-
-
RefreshRouteService refreshRouteService;
-
-
ZuulHandlerMapping zuulHandlerMapping;
-
-
@GetMapping("/refreshRoute")
-
public String refresh() {
-
refreshRouteService.refreshRoute();
-
return "refresh success";
-
-
-
@RequestMapping("/watchRoute")
-
public Object watchNowRoute() {
-
-
Map<String, Object> handlerMap = zuulHandlerMapping.getHandlerMap();
-
-
-
-
application.yml文件
spring:
application:
name: microservice-api-gateway
datasource:
driver-class-name: com.mysql.jdbc.Driver
initialize: true
name: base
url: jdbc:mysql://127.0.0.1:3306/test
username: tuping
password: 123456
initialSize: 5
minIdle: 5
maxIdle: 20
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
server:
port: 8050
eureka:
instance:
hostname: gateway
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
zuul:
ignored-services: microservice-provider-user # 需要忽视的服务(配置后将不会被路由)
routes:
api-a: # 可以随便写,在zuul上面唯一即可;当这里的值 = service-id时,service-id可以不写。
path: /api-a/** # 想要映射到的路径
service-id: CLOUD-RIBBON-MESSAGESYSTEM # Eureka中的serviceId
参考http://blog.csdn.net/u013815546/article/details/68944039,作者从源码角度讲解了动态配置的使用。




相关推荐
而在动态路由中,我们可以实现配置的实时更新,无需重启服务,提高系统的灵活性和响应速度。 3. **动态配置实现** 要实现动态路由,我们可以利用Spring Cloud Config服务来存储和管理路由规则。当路由规则发生变化...
SpringCloud Zuul 实现动态路由 Zuul 是在 Spring Cloud Netflix 平台上提供动态路由、监控、弹性、安全等边缘服务的框架,是 Netflix 基于 JVM 的路由器和服务器端负载均衡器,相当于是设备和 Netflix 流应用的 ...
SpringCloud Zuul是Spring Cloud生态系统中的一个边缘服务和API网关组件。它的主要功能是作为微服务架构中的统一入口,负责路由转发、过滤器处理、负载均衡以及安全控制等任务。Zuul允许开发者在微服务架构中实现...
SpringCloud Zuul是基于Spring Cloud框架的一个核心组件,它扮演着API网关的角色,负责路由转发、过滤器处理以及安全控制等任务。Zuul的主要功能包括动态路由、过滤器机制、安全控制、负载均衡、健康检查等。下面将...
**Spring Cloud Zuul** 是一个基于 Spring Framework 和 Netflix Zuul 的边缘服务工具,它作为微服务架构中的边缘服务器,提供动态路由、流量控制、安全、监控等功能。Zuul 主要是作为 API 网关,它负责处理所有来自...
SpringCloud Zuul Gateway 服务网关是Spring Cloud生态系统中的一个重要组件,它主要负责微服务架构中的路由转发和过滤器功能。Zuul是Netflix开源的一个边缘服务,而Gateway则是Spring Cloud针对Zuul进行的升级版,...
Spring Cloud Zuul 是一个基于 Netflix Zuul 的路由器和服务器端负载均衡器,它提供了动态路由、监控、弹性扩展、安全等功能。 Zuul 的重试机制是指在请求失败的情况下, Zuul 会自动重试该请求,以确保请求的可靠性...
在本实例中,我们主要探讨的是Spring Cloud框架中的几个关键组件——Zuul、Config、Eureka和Ribbon,这些都是微服务架构中的重要工具。让我们逐一解析这些组件及其作用。 首先,Spring Cloud Config是一个集中式的...
在 SpringCloud Gateway 中,动态路由主要通过以下几个组件实现: 1. **RouteDefinitionRepository**: 这是一个接口,用于存储和管理路由定义。你可以实现这个接口来存储路由信息在数据库、配置中心或其他持久化...
Spring Cloud Zuul就是这样一个功能强大的边缘服务,它实现了动态路由、过滤器等功能,允许对请求进行预处理和后处理。通过Zuul,我们可以实现诸如身份验证、监控、限流等高级功能,同时隐藏内部微服务的复杂性。 ...
Zuul是Spring Cloud生态中的一个关键组件,它扮演着边缘服务的角色,负责微服务间的路由转发和过滤器功能。本文将深入探讨Spring Cloud Zuul在微服务架构中的应用和重要性。 1. **Zuul简介** Zuul是Netflix开源的...
在深入探讨Spring Cloud和微服务构建的过程中,Spring Cloud Zuul是一个关键组件,它扮演着路由网关和熔断器的角色。本文将详细讲解Zuul的功能、原理以及如何在Spring Boot应用中集成和配置。 首先,Spring Cloud ...
- 文件名`configClient`可能指的是Spring Cloud Config Client,这是一个用于配置中心的组件,与Zuul一起使用时,Zuul的配置可以从Config Server获取,实现配置的动态更新。 总之,Spring Cloud Zuul是构建微服务...
在本篇学习笔记中,我们将深入探讨Spring Cloud框架中的一个重要组件——Spring Cloud Zuul,它是一个强大的路由网关。Zuul的主要职责是为微服务架构提供统一的入口,进行请求过滤、路由转发等操作,使得后端服务对...
Spring Cloud Zuul是基于Spring Boot实现的微服务网关,它提供路由转发、过滤器等功能,使得客户端可以方便地访问到后端微服务。在这个示例中,Zuul与Consul结合,使得Zuul能够动态地发现注册在Consul中的服务,实现...
在本文中,我们将主要介绍如何使用 Spring Cloud 的 Zuul 组件来实现 API 网关服务问题。 Zuul 是一个基于 Netflix Zuul 的 API 网关组件,它可以解决路由规则和服务实例的维护问题,以及一些校验(比如登录校验等)...
Spring Cloud Zuul 是 Spring Cloud Netflix 子项目的核心组件之一,可以作为微服务架构中的 API 网关使用,支持动态路由与过滤功能。API 网关为微服务架构中的服务提供了统一的访问入口,客户端通过 API 网关访问...