
基本数据类型
基本类型,或者叫做内置类型,是Java中不同于类(Class)的特殊类型。它们是我们编程中使用最频繁的类型。
Java是一种强类型语言,第一次申明变量必须说明数据类型,第一次变量赋值称为变量的初始化。
Java基本类型共有八种,基本类型可以分为三类:
字符类型char
布尔类型boolean
整数类型byte、short、int、long
浮点数类型float、double。
Java中的数值类型不存在无符号的,它们的取值范围是固定的,不会随着机器硬件环境或者操作系统的改变而改变。
实际上,Java中还存在另外一种基本类型void,它也有对应的包装类 java.lang.Void,不过我们无法直接对它们进行操作。
基本数据类型有什么好处
我们都知道在Java语言中,new一个对象是存储在堆里的,我们通过栈中的引用来使用这些对象;所以,对象本身来说是比较消耗资源的。
对于经常用到的类型,如int等,如果我们每次使用这种变量的时候都需要new一个Java对象的话,就会比较笨重。
所以,和C++一样,Java提供了基本数据类型,这种数据的变量不需要使用new创建,他们不会在堆上创建,而是直接在栈内存中存储,因此会更加高效。
整型的取值范围
Java中的整型主要包含byte、short、int和long这四种,表示的数字范围也是从小到大的,之所以表示范围不同主要和他们存储数据时所占的字节数有关。
先来个简答的科普,1字节=8位(bit)。java中的整型属于有符号数。
先来看计算中8bit可以表示的数字:
最小值:10000000 (-128)(-2^7)
较大值:01111111(127)(2^7-1)
整型的这几个类型中,
byte:byte用1个字节来存储,范围为-128(-2^7)到127(2^7-1),在变量初始化的时候,byte类型的默认值为0。
short:short用2个字节存储,范围为-32,768 (-2^15)到32,767 (2^15-1),在变量初始化的时候,short类型的默认值为0,一般情况下,因为Java本身转型的原因,可以直接写为0。
int:int用4个字节存储,范围为-2,147,483,648 (-2^31)到2,147,483,647 (2^31-1),在变量初始化的时候,int类型的默认值为0。
long:long用8个字节存储,范围为-9,223,372,036,854,775,808 (-2^63)到9,223,372,036, 854,775,807 (2^63-1),在变量初始化的时候,long类型的默认值为0L或0l,也可直接写为0。
超出范围怎么办
上面说过了,整型中,每个类型都有一定的表示范围,但是,在程序中有些计算会导致超出表示范围,即溢出。如以下代码:
int i = Integer.MAX_VALUE;
int j = Integer.MAX_VALUE;
int k = i + j;
System.out.println("i (" + i + ") + j (" + j + ") = k (" + k + ")");
输出结果:i (2147483647) + j (2147483647) = k (-2)
这就是发生了溢出,溢出的时候并不会抛异常,也没有任何提示。所以,在程序中,使用同类型的数据进行运算的时候,一定要注意数据溢出的问题。
包装类型
Java语言是一个面向对象的语言,但是Java中的基本数据类型却是不面向对象的,这在实际使用时存在很多的不便,为了解决这个不足,在设计类时为每个基本数据类型设计了一个对应的类进行代表,这样八个和基本数据类型对应的类统称为包装类(Wrapper Class)。
包装类均位于java.lang包,包装类和基本数据类型的对应关系如下表所示
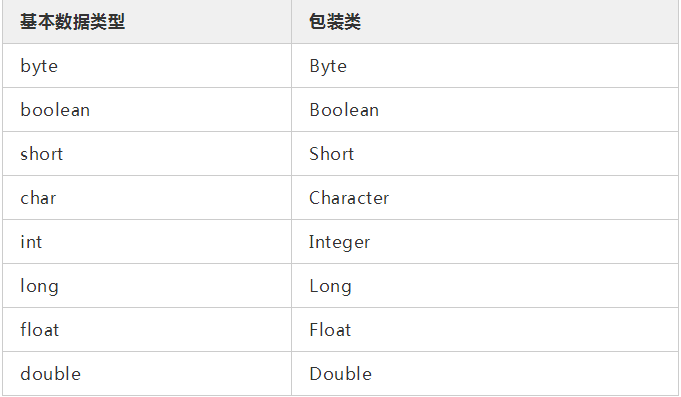
在这八个类名中,除了Integer和Character类以后,其它六个类的类名和基本数据类型一致,只是类名的第一个字母大写即可。
为什么需要包装类
很多人会有疑问,既然Java中为了提高效率,提供了八种基本数据类型,为什么还要提供包装类呢?
这个问题,其实前面已经有了答案,因为Java是一种面向对象语言,很多地方都需要使用对象而不是基本数据类型。比如,在集合类中,我们是无法将int 、double等类型放进去的。因为集合的容器要求元素是Object类型。
为了让基本类型也具有对象的特征,就出现了包装类型,它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
拆箱与装箱
那么,有了基本数据类型和包装类,肯定有些时候要在他们之间进行转换。比如把一个基本数据类型的int转换成一个包装类型的Integer对象。
我们认为包装类是对基本类型的包装,所以,把基本数据类型转换成包装类的过程就是打包装,英文对应于boxing,中文翻译为装箱。
反之,把包装类转换成基本数据类型的过程就是拆包装,英文对应于unboxing,中文翻译为拆箱。
在Java SE5之前,要进行装箱,可以通过以下代码:
Integer i = new Integer(10);
自动拆箱与自动装箱
在Java SE5中,为了减少开发人员的工作,Java提供了自动拆箱与自动装箱功能。
自动装箱: 就是将基本数据类型自动转换成对应的包装类。
自动拆箱:就是将包装类自动转换成对应的基本数据类型。
Integer i =10; //自动装箱
int b= i; //自动拆箱
Integer i=10 可以替代 Integer i = new Integer(10);,这就是因为Java帮我们提供了自动装箱的功能,不需要开发者手动去new一个Integer对象。
自动装箱与自动拆箱的实现原理
既然Java提供了自动拆装箱的能力,那么,我们就来看一下,到底是什么原理,Java是如何实现的自动拆装箱功能。
我们有以下自动拆装箱的代码:
public static void main(String[]args){
Integer integer=1; //装箱
int i=integer; //拆箱
}
对以上代码进行反编译后可以得到以下代码:
public static void main(String[]args){
Integer integer=Integer.valueOf(1);
int i=integer.intValue();
}
从上面反编译后的代码可以看出,int的自动装箱都是通过Integer.valueOf()方法来实现的,Integer的自动拆箱都是通过integer.intValue来实现的。如果读者感兴趣,可以试着将八种类型都反编译一遍 ,你会发现以下规律:
自动装箱都是通过包装类的valueOf()方法来实现的.自动拆箱都是通过包装类对象的xxxValue()来实现的。
哪些地方会自动拆装箱
我们了解过原理之后,在来看一下,什么情况下,Java会帮我们进行自动拆装箱。前面提到的变量的初始化和赋值的场景就不介绍了,那是最简单的也最容易理解的。
我们主要来看一下,那些可能被忽略的场景。
场景一、将基本数据类型放入集合类
我们知道,Java中的集合类只能接收对象类型,那么以下代码为什么会不报错呢?
List<Integer> li = new ArrayList<>();
for (int i = 1; i < 50; i ++){
li.add(i);
}
将上面代码进行反编译,可以得到以下代码:
List<Integer> li = new ArrayList<>();
for (int i = 1; i < 50; i += 2){
li.add(Integer.valueOf(i));
}
以上,我们可以得出结论,当我们把基本数据类型放入集合类中的时候,会进行自动装箱。
场景二、包装类型和基本类型的大小比较
有没有人想过,当我们对Integer对象与基本类型进行大小比较的时候,实际上比较的是什么内容呢?看以下代码:
Integer a=1;
System.out.println(a==1?"等于":"不等于");
Boolean bool=false;
System.out.println(bool?"真":"假");
对以上代码进行反编译,得到以下代码:
Integer a=1;
System.out.println(a.intValue()==1?"等于":"不等于");
Boolean bool=false;
System.out.println(bool.booleanValue?"真":"假");
可以看到,包装类与基本数据类型进行比较运算,是先将包装类进行拆箱成基本数据类型,然后进行比较的。
场景三、包装类型的运算
有没有人想过,当我们对Integer对象进行四则运算的时候,是如何进行的呢?看以下代码:
Integer i = 10;
Integer j = 20;
System.out.println(i+j);
反编译后代码如下:
Integer i = Integer.valueOf(10);
Integer j = Integer.valueOf(20);
System.out.println(i.intValue() + j.intValue());
我们发现,两个包装类型之间的运算,会被自动拆箱成基本类型进行。
场景四、三目运算符的使用
这是很多人不知道的一个场景,作者也是一次线上的血淋淋的Bug发生后才了解到的一种案例。看一个简单的三目运算符的代码:
boolean flag = true;
Integer i = 0;
int j = 1;
int k = flag ? i : j;
很多人不知道,其实在int k = flag ? i : j;这一行,会发生自动拆箱。反编译后代码如下:
boolean flag = true;
Integer i = Integer.valueOf(0);
int j = 1;
int k = flag ? i.intValue() : j;
这其实是三目运算符的语法规范:当第二,第三位操作数分别为基本类型和对象时,其中的对象就会拆箱为基本类型进行操作。
因为例子中,flag ? i : j;片段中,第二段的i是一个包装类型的对象,而第三段的j是一个基本类型,所以会对包装类进行自动拆箱。如果这个时候i的值为null,那么久会发生NPE。(自动拆箱导致空指针异常)
场景五、函数参数与返回值
这个比较容易理解,直接上代码了:
//自动拆箱
public int getNum1(Integer num) {
return num;
}
//自动装箱
public Integer getNum2(int num) {
return num;
}
自动拆装箱与缓存
Java SE的自动拆装箱还提供了一个和缓存有关的功能,我们先来看以下代码,猜测一下输出结果:
public static void main(String... strings) {
Integer integer1 = 3;
Integer integer2 = 3;
if (integer1 == integer2)
System.out.println("integer1 == integer2");
else
System.out.println("integer1 != integer2");
Integer integer3 = 300;
Integer integer4 = 300;
if (integer3 == integer4)
System.out.println("integer3 == integer4");
else
System.out.println("integer3 != integer4");
}
我们普遍认为上面的两个判断的结果都是false。虽然比较的值是相等的,但是由于比较的是对象,而对象的引用不一样,所以会认为两个if判断都是false的。
在Java中,==比较的是对象应用,而equals比较的是值。
所以,在这个例子中,不同的对象有不同的引用,所以在进行比较的时候都将返回false。奇怪的是,这里两个类似的if条件判断返回不同的布尔值。
上面这段代码真正的输出结果:
integer1 == integer2
integer3 != integer4
原因就和Integer中的缓存机制有关。在Java 5中,在Integer的操作上引入了一个新功能来节省内存和提高性能。整型对象通过使用相同的对象引用实现了缓存和重用。
适用于整数值区间-128 至 +127。
只适用于自动装箱。使用构造函数创建对象不适用。
具体的代码实现可以阅读Java中整型的缓存机制一文,这里不再阐述。
我们只需要知道,当需要进行自动装箱时,如果数字在-128至127之间时,会直接使用缓存中的对象,而不是重新创建一个对象。
其中的javadoc详细的说明了缓存支持-128到127之间的自动装箱过程。较大值127可以通过-XX:AutoBoxCacheMax=size修改。
实际上这个功能在Java 5中引入的时候,范围是固定的-128 至 +127。后来在Java 6中,可以通过java.lang.Integer.IntegerCache.high设置较大值。
这使我们可以根据应用程序的实际情况灵活地调整来提高性能。到底是什么原因选择这个-128到127范围呢?因为这个范围的数字是最被广泛使用的。 在程序中,第一次使用Integer的时候也需要一定的额外时间来初始化这个缓存。
在Boxing Conversion部分的Java语言规范(JLS)规定如下:
如果一个变量p的值是:
-128至127之间的整数(§3.10.1)
true 和 false的布尔值 (§3.10.3)
‘\u0000’至 ‘\u007f’之间的字符(§3.10.4)
范围内的时,将p包装成a和b两个对象时,可以直接使用a==b判断a和b的值是否相等。
自动拆装箱带来的问题
当然,自动拆装箱是一个很好的功能,大大节省了开发人员的精力,不再需要关心到底什么时候需要拆装箱。但是,他也会引入一些问题。
包装对象的数值比较,不能简单的使用==,虽然-128到127之间的数字可以,但是这个范围之外还是需要使用equals比较。
前面提到,有些场景会进行自动拆装箱,同时也说过,由于自动拆箱,如果包装类对象为null,那么自动拆箱时就有可能抛出NPE。
如果一个for循环中有大量拆装箱操作,会浪费很多资源。
from http://www.dataguru.cn/article-14105-1.html



相关推荐
Java集合详解1:一文读懂ArrayList,Vector与Stack使用方法和实现原理 Java集合详解2:Queue和LinkedList Java集合详解3:Iterator,fail-fast机制与比较器 Java集合详解4:HashMap和HashTable Java集合详解5:深入...
Java集合详解:一文读懂ArrayList,Vector与Stack使用方法和实现原理 Java集合详解:Queue和LinkedList Java集合详解:迭代器,快速失败机制与比较器 Java集合详解:HashMap和HashTable Java集合详解:深入理解...
ORTOOLS是Google开源的运筹优化工具,它的核心作用是将现实世界中的复杂问题转化为数学模型,并使用高效的求解算法来找出最优解或近似最优解。ORTOOLS覆盖了广泛的应用领域,包括但不限于企业资源规划、物流配送调度...
KUKA机器人相关资料
内容概要:本文详细介绍了利用Matlab实现模拟退火算法来优化旅行商问题(TSP)。首先阐述了TSP的基本概念及其在路径规划、物流配送等领域的重要性和挑战。接着深入讲解了模拟退火算法的工作原理,包括高温状态下随机探索、逐步降温过程中选择较优解或以一定概率接受较差解的过程。随后展示了具体的Matlab代码实现步骤,涵盖城市坐标的定义、路径长度的计算方法、模拟退火主循环的设计等方面。并通过多个实例演示了不同参数配置下的优化效果,强调了参数调优的重要性。最后讨论了该算法的实际应用场景,如物流配送路线优化,并提供了实用技巧和注意事项。 适合人群:对路径规划、物流配送优化感兴趣的科研人员、工程师及高校学生。 使用场景及目标:适用于需要解决复杂路径规划问题的场合,特别是涉及多个节点间最优路径选择的情况。通过本算法可以有效地减少路径长度,提高配送效率,降低成本。 其他说明:文中不仅给出了完整的Matlab代码,还包括了一些优化建议和技术细节,帮助读者更好地理解和应用这一算法。此外,还提到了一些常见的陷阱和解决方案,有助于初学者避开常见错误。
内容概要:本文详细介绍了如何利用Simulink进行自动代码生成,在STM32平台上实现带57次谐波抑制功能的霍尔场定向控制(FOC)。首先,文章讲解了所需的软件环境准备,包括MATLAB/Simulink及其硬件支持包的安装。接着,阐述了构建永磁同步电机(PMSM)霍尔FOC控制模型的具体步骤,涵盖电机模型、坐标变换模块(如Clark和Park变换)、PI调节器、SVPWM模块以及用于抑制特定谐波的陷波器的设计。随后,描述了硬件目标配置、代码生成过程中的注意事项,以及生成后的C代码结构。此外,还讨论了霍尔传感器的位置估算、谐波补偿器的实现细节、ADC配置技巧、PWM死区时间和换相逻辑的优化。最后,分享了一些实用的工程集成经验,并推荐了几篇有助于深入了解相关技术和优化控制效果的研究论文。 适合人群:从事电机控制系统开发的技术人员,尤其是那些希望掌握基于Simulink的自动代码生成技术,以提高开发效率和控制精度的专业人士。 使用场景及目标:适用于需要精确控制永磁同步电机的应用场合,特别是在面对高次谐波干扰导致的电流波形失真问题时。通过采用文中提供的解决方案,可以显著改善系统的稳定性和性能,降低噪声水平,提升用户体验。 其他说明:文中不仅提供了详细的理论解释和技术指导,还包括了许多实践经验教训,如霍尔传感器处理、谐波抑制策略的选择、代码生成配置等方面的实际案例。这对于初学者来说是非常宝贵的参考资料。
内容概要:本文详细介绍了基于西门子S7-200 PLC和组态王的机械手搬运控制系统的实现方案。首先,文章展示了梯形图程序的关键逻辑,如急停连锁保护、水平移动互锁以及定时器的应用。接着,详细解释了IO分配的具体配置,包括数字输入、数字输出和模拟量接口的功能划分。此外,还讨论了接线图的设计注意事项,强调了电磁阀供电和继电器隔离的重要性。组态王的画面设计部分涵盖了三层画面结构(总览页、参数页、调试页)及其动画脚本的编写。最后,分享了调试过程中遇到的问题及解决方案,如传感器抖动、输出互锁设计等。 适合人群:从事自动化控制领域的工程师和技术人员,尤其是对PLC编程和组态软件有一定基础的读者。 使用场景及目标:适用于自动化生产线中机械手搬运控制系统的开发与调试。目标是帮助读者掌握从硬件接线到软件逻辑的完整实现过程,提高系统的稳定性和可靠性。 其他说明:文中提供了大量实践经验,包括常见的错误和解决方案,有助于读者在实际工作中少走弯路。
内容概要:本文详细介绍了基于西门子1200PLC的污水处理项目,涵盖了PLC程序结构、通信配置、HMI设计以及CAD原理图等多个方面。PLC程序采用梯形图和SCL语言相结合的方式,实现了复杂的控制逻辑,如水位控制、曝气量模糊控制等。通讯配置采用了Modbus TCP和Profinet双协议,确保了设备间高效稳定的通信。HMI设计则注重用户体验,提供了详细的报警记录和趋势图展示。此外,CAD图纸详尽标注了设备位号,便于后期维护。操作说明书中包含了应急操作流程和定期维护建议,确保系统的长期稳定运行。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是对PLC编程、HMI设计和通信配置感兴趣的从业者。 使用场景及目标:适用于污水处理厂及其他类似工业控制系统的设计、实施和维护。目标是帮助工程师掌握完整的项目开发流程,提高系统的可靠性和效率。 其他说明:文中提供的具体代码片段和设计思路对于理解和解决实际问题非常有价值,建议读者结合实际项目进行深入学习和实践。
内容概要:本文详细介绍了基于5电平三相模块化多电平变流器(MMC)的虚拟同步发电机(VSG)控制系统的构建与仿真。首先,文章描述了MMC的基本结构和参数设置,包括子模块电容电压均衡策略和载波移相策略。接着,深入探讨了VSG控制算法的设计,特别是有功-频率和无功-电压下垂控制的具体实现方法。文中还展示了通过MATLAB-Simulink进行仿真的具体步骤,包括设置理想的直流电源和可编程三相源来模拟电网扰动。仿真结果显示,VSG控制系统能够在面对频率和电压扰动时迅速恢复稳定,表现出良好的调频调压性能。 适合人群:从事电力电子、电力系统自动化及相关领域的研究人员和技术人员。 使用场景及目标:适用于研究和开发新型电力电子设备,特别是在新能源接入电网时提高系统的稳定性。目标是通过仿真验证VSG控制的有效性,为实际应用提供理论支持和技术指导。 其他说明:文章提供了详细的代码片段和仿真配置,帮助读者更好地理解和重现实验结果。此外,还提到了一些常见的调试技巧和注意事项,如选择合适的仿真步长和参数配对调整。
内容概要:本文详细介绍了在一个复杂的工业自动化项目中,如何利用西门子S7-1200 PLC为核心,结合基恩士视觉相机、ABB机器人以及G120变频器等多种设备,构建了一个高效的立体库码垛系统。文中不仅探讨了不同设备之间的通信协议(如Modbus TCP和Profinet),还展示了SCL和梯形图混合编程的具体应用场景和技术细节。例如,通过SCL进行视觉坐标解析、机器人通信心跳维护等功能的实现,而梯形图则用于处理简单的状态切换和安全回路。此外,作者分享了许多实际调试过程中遇到的问题及其解决方案,强调了良好的注释习惯对于提高代码可维护性的关键作用。 适用人群:从事工业自动化领域的工程师和技术人员,尤其是对PLC编程、机器人控制及多种通信协议感兴趣的从业者。 使用场景及目标:适用于需要整合多种工业设备并确保它们能够稳定协作的工作环境。主要目标是在保证系统高精度的同时降低故障率,从而提升生产效率。 其他说明:文中提到的一些具体技术和方法可以作为类似项目的参考指南,帮助开发者更好地理解和应对复杂的工业控制系统挑战。
KUKA机器人相关资料
java脱敏工具类
内容概要:本文详细介绍了基于自抗扰控制(ADRC)的表贴式永磁同步电机(SPMSM)双环控制系统的建模与实现方法。该系统采用速度环一阶ADRC控制和电流环PI控制相结合的方式,旨在提高电机在复杂工况下的稳定性和响应速度。文章首先解释了选择ADRC的原因及其优势,接着展示了ADRC和PI控制器的具体实现代码,并讨论了在Matlab/Simulink环境中搭建模型的方法和注意事项。通过对不同工况下的仿真测试,验证了该控制策略的有效性,特别是在负载突变情况下的优越表现。 适合人群:从事电机控制、自动化控制及相关领域的研究人员和技术人员,尤其是对自抗扰控制感兴趣的工程师。 使用场景及目标:适用于需要高精度、高响应速度的工业伺服系统和其他高性能电机应用场景。目标是提升电机在复杂环境下的稳定性和抗扰能力,减少转速波动和恢复时间。 其他说明:文中提供了详细的代码示例和调试技巧,帮助读者更好地理解和实施该控制策略。同时,强调了在实际应用中需要注意的问题,如参数调整、输出限幅等。
java设计模式之责任链的使用demo
内容概要:本文详细介绍了两相交错并联Buck/Boost变换器的硬件结构和三种控制方式(开环、电压单环、双环)的实现方法及仿真结果。文中首先描述了该变换器的硬件结构特点,即四个MOS管组成的H桥结构,两相电感交错180度工作,从而有效减少电流纹波。接着,针对每种控制方式,具体讲解了其配置步骤、关键参数设置以及仿真过程中需要注意的问题。例如,在开环模式下,通过固定PWM占空比来观察原始波形;电压单环则引入PI控制器进行电压反馈调节;双环控制进一步增加了电流内环,实现了更为精确的电流控制。此外,文章还探讨了单向结构的特点,并提供了仿真技巧和避坑指南。 适合人群:从事电力电子研究的技术人员、高校相关专业师生。 使用场景及目标:适用于希望深入了解两相交错并联Buck/Boost变换器的工作原理和技术细节的研究者,旨在帮助他们掌握不同控制方式的设计思路和仿真方法。 其他说明:文中不仅提供了详细的理论解释,还有丰富的实例代码片段,便于读者理解和实践。同时,作者分享了许多宝贵的实践经验,有助于避免常见的仿真错误。
第二场c++A组
数控磨床编程.ppt
内容概要:本文详细介绍了利用COMSOL软件进行N2和CO2混合气体在热-流-固三场耦合作用下增强煤层气抽采的数值模拟。首先,通过设定煤岩材料参数,如热导率、杨氏模量等,构建了煤岩物理模型。接着,引入达西定律和Maxwell-Stefan扩散方程,建立了混合气体运移方程,考虑了气体膨胀系数和吸附特性。在应力场求解方面,采用自适应步长和阻尼系数调整,确保模型稳定。同时,探讨了温度场与气体运移的耦合机制,特别是在低温条件下CO2注入对煤体裂隙扩展的影响。最后,通过粒子追踪和流线图展示了气体运移路径和抽采效率的变化。 适合人群:从事煤层气开采、数值模拟以及相关领域的科研人员和技术工程师。 使用场景及目标:适用于需要优化煤层气抽采工艺的研究机构和企业,旨在通过数值模拟提高抽采效率并减少环境影响。 其他说明:文中提供了详细的MATLAB和COMSOL代码片段,帮助读者理解和复现模型。此外,强调了模型参数选择和求解器配置的重要性,分享了作者的实际经验和常见问题解决方法。
基于Bode的引线补偿器设计 计算给定G、相位裕度、交叉频率和安全裕度要求的引线补偿器。 计算给定电厂G、PM和Wc要求的铅补偿器,并运行ControlSystemDesigner进行验证。
KUKA机器人相关文档