
1.Region定位
在Google的BigTable体系中,tablet的存储地址通过3层目录结构来定位的,如图所示:
注:tablet等同与HBase中的Region
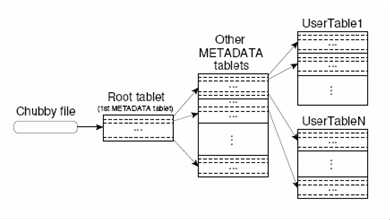
图释说明:
(1)METADATATable
METADATATable是系统预定义的Table,当用户自定义表格被拆分成多个tablet之后,METADATA Table用来存储这些tablet的地址,在目录层级中处于第3层
(2)Root tablet
METADATA表格在分布式存储过程中也会被拆分成多个tablet,其中第一个tablet比较特殊,用来存储其他tablet的地址,称之为Roottablet,在目录层级中处于第2层
(3)Chunbby file
用来存储Roottablet的地址,在目录结构中处于顶层
这样,客户端可通过Chubby file遍历到任何tablet的地址
在HBase中:
Region的概念等同于tablet
.META.表格等同于METADATATable
而-ROOT-表格等同于Chunbby file
这样,客户端可通过-ROOT- Table遍历到任何Region的地址,并把这些地址在本地进行缓存,以加快下次查询效率
2.Region分配
在HBase中,MasterServer负责将Region分配给RegionServer
首先,看一下BigTable中tablet如何分配:
当master机器启动的时候,它会处理如下事情:
(1)首先在Chunbby中获取masterlock,在分布式部署中,系统中只能有一个master处于运行状态,当其获得master锁之后,其他的master机器将会进入等待状态
(2)master会扫描Chunbby目录,以获取处于运行状态的table server(RegionServer)
(3)master会和每一台tabletserver进行通信,来记录哪些tablet已经成功分配
(4)master会扫描METADATA表格,如果发现有tablet不在已分配记录中,则将其分配到合适的tablet server
在HBase中,是通过如下API来完成Region的分配过程:
(1)Master在启动的时候,会去调用AssignmentManager类
(2)AssignmentManager通过查找.META.表格来获取Region信息
(3)如果Region尚未分配,则调用LoadBalancerFactory将其分配,默认的分配器(DefaultLoadBalancer)会将该Region分配给一个随机的RegionServer
(4)更新.META.表格信息
3.数据存储
在HDFS中,HBase的数据存储呈如下目录结构:
<hbase>
|__<table>
|__<region>
|__<columnFamily>
|__<storeFile>
StoreFile是基于Google的SSTable来实现的,每个SSTable相当于一个持久存储的、多维的、可序列化Map,Map的key和value都是可解释型字符数组,可从中提炼出具体的rowKey、timestamp、columnKey和columnValue等信息。在物理存储上SSTable由多个Block块组成,SSTable记录了每个Block快的索引位置,并且在被访问的时候将这些块索引加载到内存,以便系统快速定位Block块所在磁盘位置。
4.Region Serving
在Google的BigTable体系中,tablet会持久化存储到GFS文件系统中,如图:

图释说明:
(1)当有写操作到达时,系统首先会将信息写入到tablet log,然后把所提交的数据存储在memtable上,这样,tablet log就记录了每次写操作的日志信息以及操作的数据信息,当需要执行undo/redo操作式,可通过遍历查找该tablet log来实现撤销/恢复的功能。
写操作提交之后,数据并没有持久化存储到本地硬盘上,而是放到了memtable里,memtable是存储在内存当中的,当其大小达到一定上限之后,才持久化存储到SSTable File中去,随后进行数据的压缩处理(参考5-数据压缩)
(2)因为memtable也存储了相关的数据信息,而且是写操作提交后的最新信息,所以查询操作的数据来源有两方面,一方面是SSTable Files,另一方面是memtable。
(3)tablet恢复
当tablet数据需要恢复到历史版本时,tablet server首先会查询METADATA表格,从中获取该tablet的元数据信息,包括:
存储该tablet的SSTable文件
Tablet的恢复点(存储在tabletlog中)
随后,tablet server会把要恢复的相关记录加载到内存,根据tablet log所记录的操作日志来重新构建memtable
5.数据压缩
数据压缩主要有3中方式,分别是:
(1)Minor compaction:
当memtable的大小达到一定上限之后便会被系统冻结。此时,一个新的memtable将会创建,而被冻结的memtable将会持久化储存到SSTable文件中去。
(2)Merging compaction:
每一个minor compaction都会生成一个SSTable文件,当minor compaction操作较多时, SSTable文件将会包含很多实体的历史信息,造成数据冗余,解决办法是系统会定期执行merging compaction,将相关SSTable存储的实体进行合并,以保证实体信息处于最新版本,为查询提供方便。
(3)Major compaction:
将所有的SSTable合并成一个SSTable称之为major compaction,Major compaction通常用来回收逻辑上已被删除的数据,以节省磁盘空间。
http://blog.csdn.net/javaman_chen/article/details/7200405



相关推荐
对于源码级别的理解,可以查看HBase的源代码,了解Replication的具体实现细节。同时,HBase提供了命令行工具以及Admin API来管理和监控复制状态。 总的来说,HBase的Replication功能是保证数据可靠性和一致性的...
- **HBase的历史**:HBase起源于一个叫做Hadoop的项目中的子项目,最初是为了实现一个类似于Bigtable的功能而创建的。 - **术语介绍**: - **背景层**(Backdrop):HBase运行于Hadoop之上,利用Hadoop提供的分布式...
描述中提到“封装操作hbase的东西,不分类型”,这暗示了我们可能看到一个C#类库,该库为HBase操作提供了一种抽象和统一的接口,允许开发者无需关心底层实现细节即可进行数据读写。这种封装可以提高代码的可读性和可...
首先,手册从介绍 HBase 入手,然后通过快速入门指南引导用户搭建起单机版的 HBase 环境,接着深入探讨了 HBase 的配置细节,包括配置文件和运行模式等内容。此外,手册还介绍了一些基本的准备工作,比如安装 Java ...
**HBase** 是一个开源的、分布式的、面向列的数据库系统,它运行在 **Hadoop** 文件系统之上,旨在处理大规模数据集。《HBase 权威指南》是一本由 Lars George 编写的专业书籍,首次发布于2011年9月,主要针对那些...
通过《Learning HBase中文版》这本书的学习,读者不仅能够全面理解HBase的技术细节,还能获得在实际项目中部署和管理HBase的经验。无论是开发人员还是运维人员,都能从中受益,提升自己在大数据领域的技能。
而Phoenix是一个开源的SQL层,它构建在HBase之上,提供了高性能的数据库查询能力。本示例将详细解释如何将Spring Boot与Phoenix和HBase集成,以创建一个完整的数据访问解决方案。 首先,我们需要在Spring Boot项目...
它还提供了自动配置功能,根据应用环境自动设置HBase的相关配置,如Zookeeper地址、HBase连接池等。 `HbaseTemplate`是Spring Data HBase中的一个核心组件,它是对HBase操作的抽象封装,提供了一种更加面向对象的...
HBase是Apache软件基金会开发的一个开源、分布式、版本化、基于列族的NoSQL数据库,它构建在Hadoop文件系统(HDFS)之上,专为处理海量数据而设计。源码包“hbase-0.98.1-src.tar.gz”提供了HBase 0.98.1版本的完整...
HBase是一个分布式、基于列族的NoSQL数据库,它构建于Hadoop之上,提供实时访问大量结构化数据的能力。下面是详细的步骤和相关知识点: 1. **复制和解压HBase**: - 首先,你需要将HBase的压缩包复制到 `/usr` ...
《HBase权威指南》这本书不仅为读者提供了关于HBase的基础知识和技术细节,还深入探讨了如何将HBase应用于实际场景中。对于想要了解或使用HBase的企业和个人来说,这是一本不可或缺的手册。无论是评估HBase是否适用...
HBase作为一款高性能、支持无限水平扩展的在线...综上所述,2018 Apache HBase 技术实战专刊详细介绍了HBase的多个方面,包括其生态、组件、应用场景、技术细节、运维实践等,旨在为HBase爱好者提供全面的技术参考。
- **定义**:HBase是一个分布式的、面向列的开源数据库,它基于Google Bigtable论文的思想构建而成,主要运行在Hadoop之上,提供类似Bigtable的功能。HBase的设计目标是为了处理大规模的数据集(TB乃至PB级别),...
这本书的源代码包含了丰富的示例和实践案例,对于想要深入了解HBase工作原理和技术细节的开发者来说,无疑是一份宝贵的资源。 首先,我们来了解一下HBase的核心概念。HBase是基于列族的存储模型,这意味着数据被...
重要的配置项**:强调了一些对HBase性能和功能至关重要的配置项,提醒用户注意这些配置项的重要性。 - **10. 动态配置**:介绍了如何在HBase运行时动态更改某些配置项的方法。 #### 三、升级 **11. HBase 版本号...
其次,书中会详细介绍HBase的高级概念,如HBase表设计的最佳实践、如何利用协处理器来扩展HBase的功能,以及如何使用其他的HBase客户端。这些内容适合有一定数据库和Hadoop背景知识的读者深入学习。 在深入掌握...