
在我们大量使用分布式数据库、分布式计算集群的时候,是否会遇到这样的一些问题:
l 我想分析一下用户行为(pageviews),以便我能设计出更好的广告位
l 我想对用户的搜索关键词进行统计,分析出当前的流行趋势。这个很有意思,在经济学上有个长裙理论,就是说,如果长裙的销量高了,说明经济不景气了,因为姑娘们没钱买各种丝袜了。
l 有些数据,我觉得存数据库浪费,直接存硬盘又怕到时候操作效率低。
这个时候,我们就可以用到分布式消息系统了。虽然上面的描述更偏向于一个日志系统,但确实kafka在实际应用中被大量的用于日志系统。
首先我们要明白什么是消息系统,在kafka官网上对kafka的定义叫:A distributed publish-subscribe messaging system。publish-subscribe是发布和订阅的意思,所以更准确的说kafka是一个消息订阅和发布的系统。publish-subscribe这个概念很重要,因为kafka的设计理念就可以从这里说起。
我们将消息的发布(publish)暂时称作producer,将消息的订阅(subscribe)表述为consumer,将中间的存储阵列称作broker,这样我们就可以大致描绘出这样一个场面:
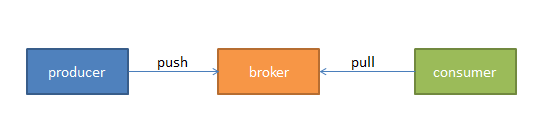
生产者(蓝色,蓝领么,总是辛苦点儿)将数据生产出来,丢给broker进行存储,消费者需要消费数据了,就从broker中去拿出数据来,然后完成一系列对数据的处理。
事实上,kafka producer发送消息到topic上,consumer到topic上取消息。(topics运行在具体的broker(或者说是kafka服务器)上)
乍一看这也太简单了,不是说了它是分布式么,难道把producer、broker和consumer放在三台不同的机器上就算是分布式了么。我们看kafka官方给出的图:
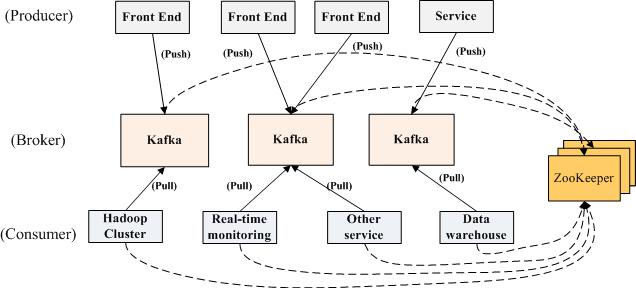
多个broker协同合作,producer和consumer部署在各个业务逻辑中被频繁的调用,三者通过zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布与订阅系统就完成了。图上有个细节需要注意,producer到broker的过程是push,也就是有数据就推送到broker,而consumer到broker的过程是pull,是通过consumer主动去拉数据的,而不是broker把数据主动发送到consumer端的。
这样一个系统到底在哪里体现出了它的高性能,我们看官网上的描述:
- Persistent messaging with O(1) disk structures that provide constant time performance even with many TB of stored messages.
- High-throughput: even with very modest hardware Kafka can support hundreds of thousands of messages per second.
- Explicit support for partitioning messages over Kafka servers and distributing consumption over a cluster of consumer machines while maintaining per-partition ordering semantics.
- Support for parallel data load into Hadoop.
至于为什么会有O(1)这样的效率,为什么能有很高的吞吐量我们在后面的文章中都会讲述,今天我们主要关注的还是kafka的设计理念。了解完了性能,我们来看下kafka到底能用来做什么,除了我开始的时候提到的之外,我们看看kafka已经实际在跑的,用在哪些方面:
- LinkedIn - Apache Kafka is used at LinkedIn for activity stream data and operational metrics. This powers various products like LinkedIn Newsfeed, LinkedIn Today in addition to our offline analytics systems like Hadoop.
- Tumblr - http://highscalability.com/blog/2012/2/13/tumblr-architecture-15-billion-page-views-a-month-and-harder.html
- Mate1.com Inc. - Apache kafka is used at Mate1 as our main event bus that powers our news and activity feeds, automated review systems, and will soon power real time notifications and log distribution.
- Tagged - Apache Kafka drives our new pub sub system which delivers real-time events for users in our latest game - Deckadence. It will soon be used in a host of new use cases including group chat and back end stats and log collection.
- Boundary - Apache Kafka aggregates high-flow message streams into a unified distributed pubsub service, brokering the data for other internal systems as part of Boundary's real-time network analytics infrastructure.
- DataSift - Apache Kafka is used at DataSift as a collector of monitoring events and to track user's consumption of data streams in real time. http://highscalability.com/blog/2011/11/29/datasift-architecture-realtime-datamining-at-120000-tweets-p.html
- Wooga - We use Kafka to aggregate and process tracking data from all our facebook games (which are hosted at various providers) in a central location.
- AddThis - Apache Kafka is used at AddThis to collect events generated by our data network and broker that data to our analytics clusters and real-time web analytics platform.
- Urban Airship - At Urban Airship we use Kafka to buffer incoming data points from mobile devices for processing by our analytics infrastructure.
- Metamarkets - We use Kafka to collect realtime event data from clients, as well as our own internal service metrics, that feed our interactive analytics dashboards.
- SocialTwist - We use Kafka internally as part of our reliable email queueing system.
- Countandra - We use a hierarchical distributed counting engine, uses Kafka as a primary speedy interface as well as routing events for cascading counting
- FlyHajj.com - We use Kafka to collect all metrics and events generated by the users of the website.
至此你应该对kafka是一个什么样的系统有所体会,并能了解他的基本结构,还有就是他能用来做什么。那么接下来,我们再回到producer、consumer、broker以及zookeeper这四者的关系中来。

我们看上面的图,我们把broker的数量减少,只有一台。现在假设我们按照上图进行部署:
l Server-1 broker其实就是kafka的server,因为producer和consumer都要去连它。Broker主要还是做存储用。
l Server-2是zookeeper的server端,zookeeper的具体作用你可以去官网查,在这里你可以先想象,它维持了一张表,记录了各个节点的IP、端口等信息(以后还会讲到,它里面还存了kafka的相关信息)。
l Server-3、4、5他们的共同之处就是都配置了zkClient,更明确的说,就是运行前必须配置zookeeper的地址,道理也很简单,这之间的连接都是需要zookeeper来进行分发的。
l Server-1和Server-2的关系,他们可以放在一台机器上,也可以分开放,zookeeper也可以配集群。目的是防止某一台挂了。
简单说下整个系统运行的顺序:
1. 启动zookeeper的server
2. 启动kafka的server
3. Producer如果生产了数据,会先通过zookeeper找到broker,然后将数据存放进broker
4. Consumer如果要消费数据,会先通过zookeeper找对应的broker,然后消费。



相关推荐
kafka消息队列学习笔记,kafka消息队列学习笔记,kafka消息队列学习笔记,kafka消息队列学习笔记,kafka消息队列学习笔记,kafka消息队列学习笔记,kafka消息队列学习笔记,kafka消息队列学习笔记,kafka消息队列...
10. 代码实践《kafka学习代码》中可能包含了一些示例,涵盖了producer、consumer的创建、消息发送与接收、配置调整等内容,是深入理解Kafka工作原理和使用技巧的重要参考资料。 总结,Kafka作为一个分布式流处理...
kafka学习笔记(一) ================= 本人整理的学习笔记,该笔记目前只有第一版,适合初学者初步了解kafka
本套学习笔记将带你深入理解Kafka的核心概念、架构设计以及实战技巧。 一、Kafka概述 Kafka是一个高吞吐量的分布式发布订阅消息系统,它的主要特性包括持久化、分区、复制和并行处理。Kafka的设计目标是提供低延迟...
【Kafka学习笔记】 Kafka是由LinkedIn开发的分布式日志系统,后来成为Apache顶级开源项目。它是一个设计为高吞吐、低延迟的系统,特别适用于处理和存储大量实时数据。Kafka的主要特点包括分布式、分区、多副本以及...
【Kafka学习笔记】 Kafka是一款高性能的分布式消息中间件,广泛应用于大数据实时处理和流处理领域。它具有高吞吐量、低延迟、可扩展性以及容错性等特点,常用于日志收集、监控数据聚合、用户行为追踪等多个场景。 ...
### Kafka学习笔记精要 #### 一、为什么需要消息系统 在现代软件开发中,消息系统扮演着极其重要的角色,特别是在分布式系统中。Kafka作为一款高性能的消息队列中间件,其价值在于解决了传统分布式系统中常见的...
《Kafka学习笔记》 Apache Kafka是一款开源的流处理平台,由LinkedIn开发并捐赠给了Apache软件基金会。它最初设计为一个高吞吐量、低延迟的消息队列系统,但现在已经成为大数据领域的重要组件,广泛用于实时数据...
在本课程中,你将学习到,Kafka架构原理、安装配置使用、详细的Kafka写入数据和处理数据以及写出数据的流程、新旧版本对比及运用、分区副本机制的详解、内部存储策略、高阶API直接消费数据、等等
### Kafka 学习笔记知识点详解 #### 一、Kafka简介 Kafka是一款开源的分布式消息系统,由LinkedIn公司开发并贡献给Apache基金会。它基于发布/订阅模型,支持流处理,广泛应用于日志收集、网站活动跟踪、聚合统计、...
### Kafka学习详细文档笔记 #### 一、入门 **1、简介** Kafka是由LinkedIn开源的一款分布式的流处理平台,其核心功能在于消息传递。它能够处理大量的实时数据流,并且具备高性能、高吞吐量的特点。Kafka采用发布...
1. Producer API:允许应用程序向Kafka的Topics发布消息。 2. Consumer API:允许应用程序订阅Kafka的Topics,并且消费消息。 3. Streams API:允许应用程序扮演消息流处理者的角色,例如消费来自topicA的消息,处理...
Kafka学习笔记,全网最全
kafka4.0学习笔记
kafka安装和监控头平台
1、kafka消息系统的介绍 2、producer有分区类 3、kafka支持的副本模式 4、kafka消费者偏移量考察 5、kafka自定义消费者 6、kafka自定义生产者 7、kafka带分区生产者 8、flume集成kafka的几种方式
排版紧凑易于阅读,笔记详细适合初学者下载学习,有详细的实践代码和说明,欢迎下载学习
kafka简单工程
【Kafka基础知识】 Kafka是一种高吞吐量、分布式的发布订阅消息系统,最初由LinkedIn开发,后来成为Apache...通过深入学习Kafka,你将能够构建高效、可靠的消息传递系统,为大数据处理和实时分析提供强有力的支持。
### 1. 为什么需要消息系统 - **解耦**:消息队列使生产者和消费者之间的依赖关系降低,两者可以独立开发和扩展。 - **冗余**:消息持久化,防止数据丢失,确保消息被完全处理。 - **扩展性**:通过增加处理进程,...