- 浏览: 759267 次
- 性别:

- 来自: 苏州
-

文章分类
最新评论
-
hsl313:
源码还有得下载吗?
利用AMF数据封装与Flash 进行Socket通讯 -
zhang5476499:
已看,谢谢讲解。
Mock单元测试 -
Buydeful:
...
关于JSP或HTML的命名规范 -
lliiqiang:
单一登陆最好采用踢掉方法,如果忘记退出,可以从别的地方控制方式 ...
Jquery选择器大全 -
lliiqiang:
web代码由后台动态生成,这种动态方式多种多样,多提供几种标准 ...
Jquery选择器大全
出自http://cnodejs.org,转载请注明出处和作者
作者:limu
原文:http://cnodejs.org/blog/?p=780
上周末参与了CNodeJS社区的第一次北京聚会,现场气氛非常的好.而作为一名前端开发,我在后面的讨论环节讲了下我对NodeJS的看法,主要回答的问题是”我为什么会向后端工程师推荐NodeJS”.这其实是去年年底大团队技术总结的话题之一,包含在我之前发过的PPT:团队年终技术Review中.因为之前没有准备,当天仓促上阵,也不知道说清楚了没,不如就在这里再详细展开记录下.
我想不仅仅是NodeJS,当我们要引入任何一种新技术前都必须要搞清楚几个问题:
1.我们遇到了什么问题?
2.这项新技术解决什么问题,是否契合我们遇到的问题?
3.我们遇到问题的多种解决方案中,当前这项新技术的优势体现在哪儿?
4.使用新技术,带来哪些新问题,严重么,我们能否解决掉?
我们的问题:Server端阻塞
NodeJS被设计用来解决服务端阻塞问题.通过一段简单的代码解释何为阻塞:
//根据ID,在数据库中Persons表中查出Name
var name = db.query("selcect name from persons where id=1");
//进程等待数据查询完毕,然后使用查询结果.
output("name");
这段代码的问题是在上面两个语句之间,在整个数据查询的过程中,当前程序进程往往只是在等待结果的返回.这就造成了进程的阻塞.对于高并发,I/O密集行的网络应用中,一方面进程很长时间处于等待状态,一方面为了应付新的请求不断的增加新的进程.这样的浪费会导致系统支持QPS远远小于后端数据服务的QPS,成为系统的瓶颈.而且这样的系统也特别容易被慢链接攻击(客户端故意不接收或减缓接收数据,加长进程等待事件).
如何解决阻塞问题
解决这个问题的办法是,建立一种事件机制,发起查询请求之后,立即将进程交出,当数据返回后触发事件,再继续处理数据:
//定义如何后续数据处理函数
function onDataLoad(name){
output("name");
}
//发起数据请求,同时指定数据返回后的回调函数
db.query("selcect name from persons where id=1",onDataLoad);
我们看到按照这个思路解决阻塞问题,首先我们要提供一套高效的异步事件调度机制.而主要用于处理浏览器端的各种交互事件的JavaScript.相对于其他语言,至少有两个关键点特别适合完成这个任务.
为什么JS适合解决阻塞问题
首先JavaScript是一种函数式编程语言,函数编程语言最重要的数学基础是λ演算(lambda calculus) — 即函数可以接受函数当作输入(参数)和输出(返回值).
函数可以作为其他函数的参数输入的这个特性,使得为事件指定回调函数变得很容易.特别是JavaScript还支持匿名函数.通过匿名函数的辅助,之前的代码可以进行简写如下.
db.query("selcect name from persons where id=1",function(name){
output(name);
});
还有一个关键问题是,异步回调的运行上下文保持(称状态保持),我看一段代码来说明何为状态保持.
//传统同步写法:将查询和结果打印抽象为一个方法
function main(){
var id = "1";
var name = db.query("selcect name from persons where id=" + id);
output("person id:" + id + ", name:" + name);
}
main();
前面的写法在传统的阻塞是编程中非常常见,但接下来进行异步改写时会遇到一些困扰.
//异步写法:
function main(){
var id = "1";
db.query("selcect name from persons where id=" + id,function(name){
output("person id:" + id + ", name:" + name);//n秒后数据返回后执行回调
});
}
main();
细心的同学可以注意到,当等待了n秒数据查询结果返回后执行回调时.回调函数中却仍然使用了main函数的局部变量”id”,而”id”已经在n秒前走出了其作用域,这是为什么呢?熟悉JavaScript的同学会淡然告诉您:”这是闭包(closures)~”.
其实在复杂的应用中,我们一定会遇到这类场景.即在函数运行时需要访问函数定义时的上下文数据(注意:一定要区分函数定义时和函数运行时这样的字眼和其代表的意义,不然很快就会糊涂).而在异步编程中,函数的定义和运行又分处不同的时间段,那么保持上下文的问题变得更加突出了.
在这个例子中,db.query作为一个公共的数据库查询方法,把”id”这个业务数据传入给db.query,交由其保存是不太合适的.但聪明的同学们可以抽象一下,让db.query再支持一个需要保持状态的数据对象传入,当数据查询完毕后可以把这些状态数据原封不动的回传.如下:
function main(){
var id = "1";
var currentState = new Object();
currentState.person_id = id;
db.query("selcect name from persons where id=" + id, function(name,state){
output("person id:" + state.person_id + ", name:" + name);
},currentState);//注意currentState是db.query的第三个参数
}
main();
记住这种重要的思路,我们再看看是否还能进一步的抽象?可以的,不过接下的动作之前,我们先要了解在JavaScript中一个函数也是一个对象.一个函数实例fn除了具备可函数体的定义之外,仍然可以在这个函数对象实例之上扩展属性,如fn.a=1;受到这个启发我们尝试把需要保持的状态直接绑定到函数实例上.
function main(){
var id = "1";
var currentState = new Object();
currentState.person_id = id;
function onDataLoad(name){
output("person id:" + onDataLoad.state.person_id + ", name:" + name);
}
onDataLoad.state = currentState ;//为函数指定state属性,用于保持状态
db.query("selcect name from persons where id=" + id, onDataLoad);
}
我们做了什么?生成了currentState对象,然后在函数onDataLoad定义时,将currentState绑定给onDataLoad这个函数实例.那么在onDataLoad运行时,就可以拿到定义时的state对象了.而闭包就是内置了这个过程而已.
在每个函数运行时,都有一个运行时对象称为Execution context,它包含如下variable object(VO,变量对象),scope chain(作用域链)和thisValue三部分.详见ECMA-262 JavaScript. The Core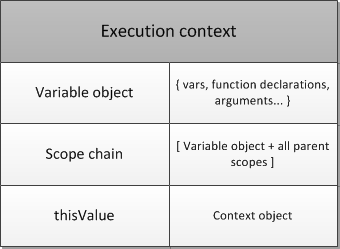
其中变量对象VO,包含了所有局部变量的引用.对于main函数,局部变量”id”存储在VO.id内.看起来用VO来代替我们的currentSate最合适了.但main函数还可能嵌套在其他函数之内,所以我们需要ScopeChain,它是一个包含当前运行函数VO和其所有父函数scope的数组.
所以在这个例子中,在onDataLoad函数定义时,就为默认为其绑定了一个[[scope]]属性指向其父函数的ExecutionContext的ScopeChain.而当函数onDataLoad执行时,就可以通过[[scope]]属性来访问父函数的VO对象来找到id,如果父函数的VO中没有id这个属性,就再继续向上查找其祖先的VO对象,直到找到id这个属性或到达最外层返回undefined.也正是因为这个引用,造成VO的引用计数不为0,在走出作用域时,才不会被垃圾回收.
很多人觉得闭包很难理解,其实我们只要能明确需要区分函数定义和函数运行这两个时机,记住闭包让函数在运行时能够访问到函数定义时的所处作用域内的所有变量.或者说函数定义时能访问到什么变量,那么在函数运行时通过相同的变量名一样能访问到.
关于状态保持是本文的重点,在我看到的多数NodeJS的介绍文章,并没有详解这里,我们只是知道了要解决阻塞问题,但是JavaScript解决阻塞问题的优势在哪里,做一一个前端开发,我想有必要详细解释一下.
其实说到状态保持还有一个类似的场景,比如用户从A页面提交表单到B页面,如果提交数据校验不通过,则需要返回A页面,同时保持用户在A页面填写的内容并提示用户修改不对的地方.从提交到返回显示这也是一个包含网络交互的异步过程.传统网页,用户的状态通过请求传递到服务端,交由后端状态保持(类似交给db.query的currentSate).而使用Ajax的网页,因为并未离开原页面,那么服务端只要负责校验用户提交的数据是否正确即可,发送错误,返回错误处相关信息即可,这就是所谓前端状态保持.可以看到这个场景里边服务端做的事情变少了,变纯粹了.正如我们的例子中db.query不再存储转发第三个state参数,变得更轻量.
我们看到通过JavaScript函数式语言特性,匿名函数支持和闭包很漂亮的解决了同步编程到异步编程转化过程中遇到的一系列最重要的问题.但JavaScript是否就是最好的?这就要回答我们引用新技术时需要考虑的最后一个问题了
使用NodeJS是否带来额外的困扰,如何解决
性能真的是最好么?不用比较我们也可以得到结论NodeJS,做无阻塞编程性能较难做到极致.何为极致,处理一个请求需要占用多少内存,多少cpu资源,多少带宽,如果有浪费就不是极致.阻塞式编程浪费了大量进程资源只是在等待,导致大量内存和cpu的浪费.NodeJs好很多,但也正是因为一些闭包等JS内建机制也会导致资源的浪费,看下面的代码
function main(){
var id = "1";
var str = "..."; //这里存储一个2M的字符串
db.query("selcect name from persons where id=" + id,function(name){
output("person id:" + id + ", name:" + name);//n秒后数据返回后执行回调
});
}
main();
直到数据查询完成,变量str所使用的2M内存不会被释放,而str保持下去可能并没有意义.前面已经解释过闭包的原理,闭包并没有智能到只包起来今后可能被访问到的对象.即使不了解闭包的原理,也可以通过一段简单脚本验证这点:
function main(){
var id = "1";
var str = "..."; //这里存储一个2M的字符串
window.setTimeout(function(){
debugger; //我们在这里设置断点
},10000)
}
main();
我们在回调函数当中只设置一个断点,并不指明我们要访问哪个变量.然后我们在控制台监视一下,id和str都是可以拿到的.
所以我来不负责任的预测一下,性能极端苛刻的场景,无阻塞是未来,但无阻塞发展下去,或者有更轻量的脚本引擎产生(lua?),或者V8JS引擎可能要调整可以disable闭包,或者我们可以通过给JS开发静态编译器在代码发布前优化我们的代码.
我之前谈到过JS静态编译器:“如果给JS代码发布正式使用前增加一个编译步骤,我们能做些什么”,动态语言的实时编译系统只完成了静态语言编译中的将代码转化为字节码的过程,而静态语言编译器的额外工作,如接口校验,全局性能优化等待.所以JS也需要一个静态的编译器来完成这些功能,Google利用ClouserComplier提供了系列编译指令,让JS更好的实现OO编程,我来利用静态编译器解决一些JS做细粒度模块化引入的性能方面的问题.而老赵最近的项目JSCEX,则也是利用JS发布前的编译环节重点解决异步编程的代码复杂度问题.
我们习惯于阻塞式编程的写法,切换到异步模式编程,往往对于太多多层次的callback嵌套弄得不知所措.所以老赵开发的JS静态编译器,借鉴F#的Computation Expressions,让大家遵守一些小的约定后,能够仍然保持同步编程的写法,写完的代码通过JSCEX编译为异步回调式的代码再交给JS引擎执行.
如果这个项目足够好用,那就也解决了一个使用NodeJS这种新技术,却加大编程复杂度这个额外引入的困扰.甚至可以沿着这个思路,在静态编译阶段优化内存使用.
NodeJS还要解决什么问题
说了这么多,无阻塞编程要做的还远不止这些.首先需要一个高效的JS引擎,高效的事件池和线程池.另外几乎所有和NodeJS交互的传统模块如文件系统,数据访问,HTTP解析,DNS解析都是阻塞式的,都需要额外改造.
正是NodeJS作者极其团队,认清问题问题以及JS解决问题方面的优势.之后贡献大量的智慧和精力解决这些问题后才有NodeJS的横空出世.
当前Node社区如此火热,千余开源的NodeJS模块,活跃在WebFramework,WebSocket,RPC,模板引擎,数据抓取服务,图形图像几乎所有工程领域.
后记
本文主要的信息来自nodejs作者在JSConf09,JSConf10上的分享.
而作为前端开发,着重讲了JavaScript函数式编程,闭包对于无阻塞开发的重要意义.我期待这篇文章能够给前端和后端同学都带来收获.
同样作为前端开发,不得再插几句,说说服务端JS能够解决的另一个问题:
当前的Web开发前后端使用不同的语言,很多相同的业务逻辑要前后端分别用不同语言重复实现.比如越来越多重度依赖JS的胖客户端应用,当客户浏览器禁用JavaScript时,则需要使用服务端语言将主业务流程再实现一次(这即是所谓的”渐进增强”).
当我们拥有了服务端JavaScript语言,我们自然就会想到能否利用NodeJS做到”一次开发,渐进增强”.解决掉这个为小量用户,浪费大量时间的恼人的问题.我们先要解决问题,这是使用NodeJS的最大动力.基于之前的统计,因为各种原因浏览器不支持JS的用户大概接近1%,至少淘宝绝对不会主动放弃这部分用户.至于在服务端也使用JS是否能够替掉LAMP架构,抑或NodeJS会对常见MVC架构带来何种冲击,V/C这些层是否能在前后端任意流动这些问题都是NodeJS解决问题后带来的额外话题.
“一次开发,渐进增强”这方面的实践,YAHOO仍然是先驱,早在一年多前开始YAHOO通过nodejs-yui3项目做了很多卓越的贡献,而淘宝自主开发的前端框架Kissy也有服务端运行的相关尝试,详见我的同事拔赤的分享.而接下来的几个月我也将在这方面做一些尝试,有一定积累后我将再写一篇文章更好的分析这个问题..
JS在诞生之时就不仅仅是浏览器端工具,如今JS能再一次回到服务端展示拳脚,感谢V8,感谢NodeJS作者,团队和社区的诸多贡献者,祝Node好运,JS好运.


发表评论

-
转:Node.js 究竟是什么?
2011-09-05 09:19 1053简介 如果您听说过 ... -
浅谈javascript面向对象编程
2010-06-23 07:27 1038http://www.ioldfish.cn/?p=238 ... -
Jquery的回车事件
2010-02-07 16:36 1476$('#simpleSearchProjectFilt ... -
Jquery选择器大全
2009-09-27 14:57 7288http://hi.baidu.com/lpk1/blog/i ... -
jquery的extend和fn.extend
2009-07-21 17:33 6836http://hzjavaeyer.group.iteye.c ... -
Jquery each中跳出循环
2009-07-20 17:22 7008continue可以使用return true break可 ... -
Javascript悟透(3)
2009-07-16 14:38 1248当然,这个代码仅仅展示了“语法甘露”的概念。我们还 ... -
Javascript悟透(2)
2009-07-16 14:34 1135但要注意的是,用构造函数操作this对象创建出来的每一 ... -
Javascript悟透
2009-07-16 14:32 1050http://www.cnblogs.com/leadzen/ ... -
Javascript的闭包
2009-07-16 08:52 1135http://www.felixwoo.com/archive ... -
Jquery技巧
2009-06-22 16:38 1048http://jquery.group.iteye.com/g ... -
jquery之dialog的键盘事件
2009-03-10 11:55 1949$('#input_text').keyup(functi ... -
jquery之 each,extend
2009-02-20 11:51 1859$.each(obj, fn):通用的迭代函数。可用于近似地迭 ... -
jquery之 radio,checkbox,select
2009-02-19 15:52 1610获取一组radio被选中项的值 var item = $( ... -
JQuery的dialog只显示一次
2009-02-17 14:47 3155需要先初始化,在打开。 但是感觉没有YUI的dialog灵活。 ... -
Ant学习
2009-02-03 09:01 18451、available 判断一个资源是否可用,结果保存在pro ... -
EXT动态载入JS
2007-12-27 13:56 2926<html> <head> < ... -
JS内存泄漏
2007-12-21 01:40 1524访问一般的站点,你会发现大多数站点都会出现这类问题。的确,如果 ... -
JSON并没有人们想象中的那样安全
2007-12-21 01:32 1608作者:Joe Walker 我最近� ... -
javascript常见错误解释
2007-12-21 01:08 1521JScript 语法错误是指当 JScript 语句违反了 J ...
相关推荐
### Node.js 在解决服务端阻塞问题中的角色与优势 ...无论是对于前端还是后端工程师来说,掌握Node.js都是非常有价值的技能之一。未来,随着技术的不断发展,Node.js的应用场景也将变得更加广泛。
它的出现不仅解决了特定场景下的性能瓶颈问题,更重要的是为前端工程师提供了一种高效的后端开发途径。通过降低学习门槛并促进前后端一体化,Node.js在提升整体开发效率方面展现出了显著的优势。 因此,在评估技术...
在本项目"Rule_validation_API"中,Flutterwave是一家知名的金融科技公司,他们针对Node.js后端工程师的全职职位(FullTime)设计了一次编码测试。这个测试主要关注的是使用JavaScript来构建API,尤其是规则验证部分...
Para ejecutar un proyecto hacemos node nombreArchivo.js 基本建议书NodeJS是一个JS框架,其名称是escribir codigo后端。 ModuloHttp.js入口模数档案库功能简单。 NodeJS是可变的模数(核模数)。 Posee modulos ...
### NodeJS基础知识与应用 #### 一、NodeJS概述 ...无论是作为前端工程师还是后端开发者,掌握NodeJS都能显著提升工作效率并拓展技术栈。随着NodeJS生态系统的不断完善和发展,它将继续在各个领域发挥重要作用。
1. **与产品经理、API服务器后端工程师紧密工作,实现高质量、用户友好的Web前端应用**:这强调了前后端开发人员之间的紧密合作,确保最终的产品既美观又实用。 2. **负责模块的Web应用实现**:这意味着候选人需要...
后端面试问答 点击 :star: 如果你喜欢这个项目。 拉取请求受到高度赞赏。 关注我获取技术更新。 目录 - Node JS 不。 问题 节点JS 1 2 3 4 5 6 7 8 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30...
传统模式下,服务器端UI层的处理更多由后端工程师主导,前端工程师只能根据后端提供的数据进行展示,导致前后端协作中存在沟通难题。 2. Node.js的变革 Node.js的诞生让JavaScript可以运行在服务器端,这一创新极大...
标题中提到的"为何需要nodejs",直接指向了一个前端开发中常见的面试题目,即讨论在已有多样化后端语言(比如Java、PHP、Python)的环境下,为何企业还需要Node.js作为服务端技术。这个问题考察的是面试者对技术广度...
5. **单页面应用后端**:与前端框架结合使用,为SPA提供数据支持。 #### 六、作者背景介绍 本书作者Mario Casciaro是一位热爱开源技术的软件工程师和技术领导者。他在很小的时候就开始接触编程,拥有丰富的编程...
你好呀 :waving_hand: :seedling: 我目前正在学习 Duy Tan 大学 :closed_mailbox_with_raised_flag: 如何联系我: : :love_letter: : 联系我: :boy: 我20岁了专业:软件工程师我的语言:Javascript、Typescript、C++...
:laptop_computer: 来自巴西居住在匈牙利 :telescope: 有兴趣使用前端或后端,并且目前正在学习Javascript,ReactJS,NodeJS和Python。 语言和工具: 注意:顶级语言并不表示我的技能水平或类似的水平,它是github...
:desktop_computer: 哈希/集线器 :desktop_computer:技术栈: 前端:React后端: Nodejs、express、MongoDB 版本控制: Git 和 GitHub 托管: gh-pages(前端),heroku(后端) 代码编辑器和工具:VS Code :...
后端面试问答 点击 :star: 如果你喜欢这个项目。 拉取请求受到高度赞赏。 目录 - Node JS 不。 问题 节点JS 1 2 3 4 5 6 7 8 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37...
FOT公司正在招聘一位全栈工程师,特别强调了对于React JS, React Native和TypeScript的熟练掌握,同时也提及了NodeJS的相关技能。这份远程工作的核心在于利用技术实现高效虚拟团队协作。以下是对这个职位的详细解析...
Node.js 的出现彻底改变了前端开发的格局,它将JavaScript引入了服务器端,打破了传统前端与后端的界限,促进了前后端分离的模式,并推动了Web开发的新趋势。以下几点是Node.js带给前端的重要变化: 1. **前后端...
swallow是一个后端基于和,前端基于和实现的应用,主要面向linux运维工程师使用,管理linux资产信息。演示功能特性服务器信息自动定时采集celery异步队列RBAC基于角色的权限访问控制RESTful API技术栈后端Ansible2.7...
总结,Node.js以其独特的设计和强大的生态,为开发者提供了高效、灵活的后端开发环境。深入理解Node.js的基础原理和实践技巧,是成为一名优秀的全栈工程师的重要步骤。通过持续学习和实践,你将能够驾驭这个强大的...
Express是一个轻量级的JavaScript框架,它基于NodeJS,为构建web应用程序提供了简洁的API,而MySQL则是广泛使用的开源关系型数据库系统。本文将探讨如何使用这两个工具进行基本的CRUD(Create、Read、Update、Delete...
Node.js CRUD Exam: 软件工程师开发人员的CRUD操作考试 在现代Web开发中,CRUD(创建、读取、更新、删除)是最基本的操作,它...对于想要提升Node.js后端开发能力的软件工程师来说,这是一个非常有价值的实践项目。