
这篇文章将会从问题,技术背景,设计实现,代码范例这些角度去谈基于管道化和事件驱动模型的Web请求处理。其中的一些描述和例子也许不是很恰当,也希望得到更多的反馈。
问题的诞生与思考:
一. 依赖之苦
做过不少业务系统,最痛苦,最无奈的就是性能和稳定性依赖与外部系统处理能力和可用时间。而TOP是典型的Proxy模式,它自身的性能在传统的Web容器处理模式下依赖与后端服务处理能力。
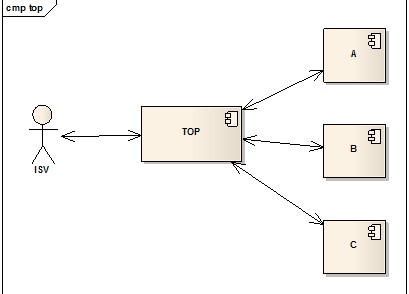
TOP在Web容器线程连接有限的情况下,最差的处理能力就是min(A,B,C),也就是一个时刻的处理都是在处理最慢的系统的请求。因此产生这么几个问题:a.通过压力测试评估TOP自身的处理能力,并且来预估所需要的服务器容量将变得很不可靠。 b.可能由于某一个后端服务的不正常导致正常服务也无法通过TOP被外部访问到,使得局部不可用演变成为整体不可用。
延展考虑,由于容器端线程不支持根据业务情况分配,因此无法实现静态或者动态的线程资源按业务重要性或者服务健康状况做调整,这样对于一个集成了众多重要程度不同,能力参差不齐的服务平台来说很难最有效的将合理的资源倾向于重要且健康的服务。
二. 轮询之苦
首先,耗时的业务处理,例如对于历史订单的数据查询,后台操作会消耗较多时间,而传统请求是阻塞式的,因此超时设置成了一个难题,设置太大,传统容器的连接资源有限,设置短了无法满足业务需求,为今之计只能够将一个请求拆成两个请求,一个是发起处理的通知请求,后面是轮询获取结果的请求。
其次,在业务系统设计中,或多或少的会有基于状态变更事件来触发事件处理的场景,淘宝的业务体系更是如此。买家和卖家分别是淘宝的两个角色,相互之间的操作贯穿于整个交易主流程(下单,付款,发货,确认收货),两个角色之间是通过交易这个虚拟对象的状态迁移来实现交互的,而状态迁移的动作是由任何一方无预见性的实施的,因此做工具的应用需要能够接受到状态变化事件通知,当前只能通过应用轮询获取数据来实现。
轮询一方面使得开发者软件设计复杂度高,自身系统消耗大(时间间隔设置,容错机制等等),另一方面使得TOP服务器压力增大,无效请求浪费系统资源。
三. 容器资源之苦
有人会说轮询这件事情干吗不直接将数据推送过去,告知这些ISV,反正他们也都是B/S结构,服务器提供回调地址就可以了。的却这是最常见的Notify的模式,淘宝内部也有一个Notify的中间件。但是在现在的网络状况下,主动推送数据到ISV的服务器上基本不靠谱,对方响应速度的快慢直接影响到我们投递这些数据需要多少服务器,投递的策略如何?(如何处理失败的投递消息,重试机制如何),从这里可见容器连接池之苦。另一方面从第一个苦描述中可以看到,其实如果容器资源足够多,那么就可以无限制放大入口,也就不会受之于后端的依赖系统处理能力,但今天大家看看自己传统的Web应用服务器(jboss,tomcat非apache,nginx)连接池配置的数字就知道这是不靠谱的。
技术背景概述:
管道化子任务切分:

我外婆以前是做白铁加工的,做一个锅子基本需要这些步骤,每个步骤都需要一些工具,传统最简单的做法就是一个人做到底,然后工具都摆在身边。(这也就是我们现在传统容器的模式,从请求进入到整个业务处理结束),要提高效率的做法如下:
1. 增加人手,依然采用一人处理到底的模式。在人和工具无限量的情况下是最简单和行之有效的方式。
2. 切割流程,最大化资源利用率,每个子任务所需的资源不同,因此在完成子任务后就将资源共享给其他人而不是占用所有资源到整个流程结束。这种优化带来的最明显的效果:
a) 轻量级子任务完成所需要消耗的资源最小化。(例如第一阶段处理消耗时间很短,那么锤子和钳子的需求量将会最小)
b) 重量级子任务能够得到更多的资源和线程来处理。如果第一阶段和第二阶段本身资源消耗是相互影响的,比如第一阶段资源分配消耗内存,第二阶段资源分配也消耗内存,那么第一阶段的资源占用少了以后,自然可以给第二阶段资源分配提供了便利,其次如果总资源有限,第一阶段也在等待资源的ready,那么此时的线程将会等待在第一阶段的资源分配上,此时线程空消耗,但如果降低了第一阶段的消耗,线程满负荷运作,则线程完成第一阶段所有任务后可以支援第二阶段的工作。
3. 当子任务可以“降级”的情况下,分解任务,根据资源状况来并行处理,并且适当的“丢弃”非关键子任务可以提高效率,增加稳定性。
总体上来说,可以把原本一个任务拆成管道形式的子任务(管道化也就是每个子任务的上一个任务的输出是当前子任务的输入),然后根据子任务的情况来选择是否交由不同的线程并行化执行。(这个判断很简单,子任务是否是有限资源且较轻量化的,子任务的资源占用多少是否会影响到其他任务的资源分配情况,如果这两点都不成立,则保持简单处理模式即可,最多可以将某一些子任务“降级”)
管道化的作用:1.将任务各个阶段梳理清楚。(降低子任务之间的耦合度,为并行或异步处理提供基础)。2.最大化资源利用率,便于流程整体优化。
事件驱动模式:
事件驱动模式其实在设计中被大规模使用,思路概括起来就是:对象脱离线程,状态脱离事务。回到第一个做锅子三个流程的实例说明,也许在第二阶段,某人拿起了一个已经完成第一阶段的半成品在等待第二阶段的资源Ready,这时候如果他放下这个半成品,先去做已经可以做工作的第一或者第三阶段的半成品,然后等到另一个人做完后释放第二阶段资源时通知他时,他在去安排做第二阶段的工作,那么效率会更高。
那么可以发现,管道化是从释放资源被占用的角度去提升整体工作效率,而事件驱动模式是从分离工作实施者和工作资源的角度去提升工作实施者的工作效率。一个是工作者是有限而宝贵资源,一个是子任务在完成过程中所需资源是宝贵资源。
由此看来,事件驱动模式与管道模式不同,应该是不需要有评判标准都可以实施的一种优化策略。其实不然,事件驱动模式也有自己的弱点:1.设计复杂。(过于松耦合的结构,使得原本事务中有顺序的操作需要更多的检查,容错和调度)2.性能可能会受到影响。(线程上下文的切换,中间结果的拷贝)3.延时问题产生。对于事件的产生一种是主动推送,一种是轮询,轮询就牵涉到时间片大小的问题,在性能和及时性权衡的情况下最后得出合理的设置,但是对于整个事务来说一定是消耗了。
上面描述的两个概念在后面的Web请求异步化处理及订阅模式中都会用到,同时在支持Servlet3及Comet Streaming(Comet push)的容器整体架构上都会被用到,优劣上面做了简单的描述,后面从业务架构到系统架构都会有最实在的设计说明。
业务架构设计:
基于上述问题,通过两步走来解决。首先采用支持打破传统http request生命周期管理的Web容器(很多人说可以自己写,其实Web容器写起来并不是最麻烦的,如何做好兼容和照顾好每一个细节才是漫长发展的道路)。其次在容器新的线程生命周期管理基础上封装业务框架,为开发者屏蔽底层异步化和事件驱动模式带来的复杂流程管理内容。

这篇文章将会从问题,技术背景,设计实现,代码范例这些角度去谈基于管道化和事件驱动模型的Web请求处理。建议从头看,能够从概念上更多的去理解和碰撞,其中的一些描述和例子也许不是很恰当,也希望得到更多的反馈。
业务架构设计:
基于上述问题,通过两步走来解决。首先采用支持打破传统http request生命周期管理的Web容器(很多人说可以自己写,其实Web容器写起来并不是最麻烦的,如何做好兼容和照顾好每一个细节才是漫长发展的道路)。其次在容器新的线程生命周期管理基础上封装业务框架,为开发者屏蔽底层异步化和事件驱动模式带来的复杂流程管理内容。

Pipe Service Framework:
基础管道体系:
很多时候设计和实现都会有很多细节上的差异,而这些差异往往是在事实验证后对体系的一种修订,也许修订后的结构不如修订前的清晰和优雅,但是确实在性能和结构上找到了平衡点,下面就看看两个基础管道体系的设计,后一个是前一个的演进。
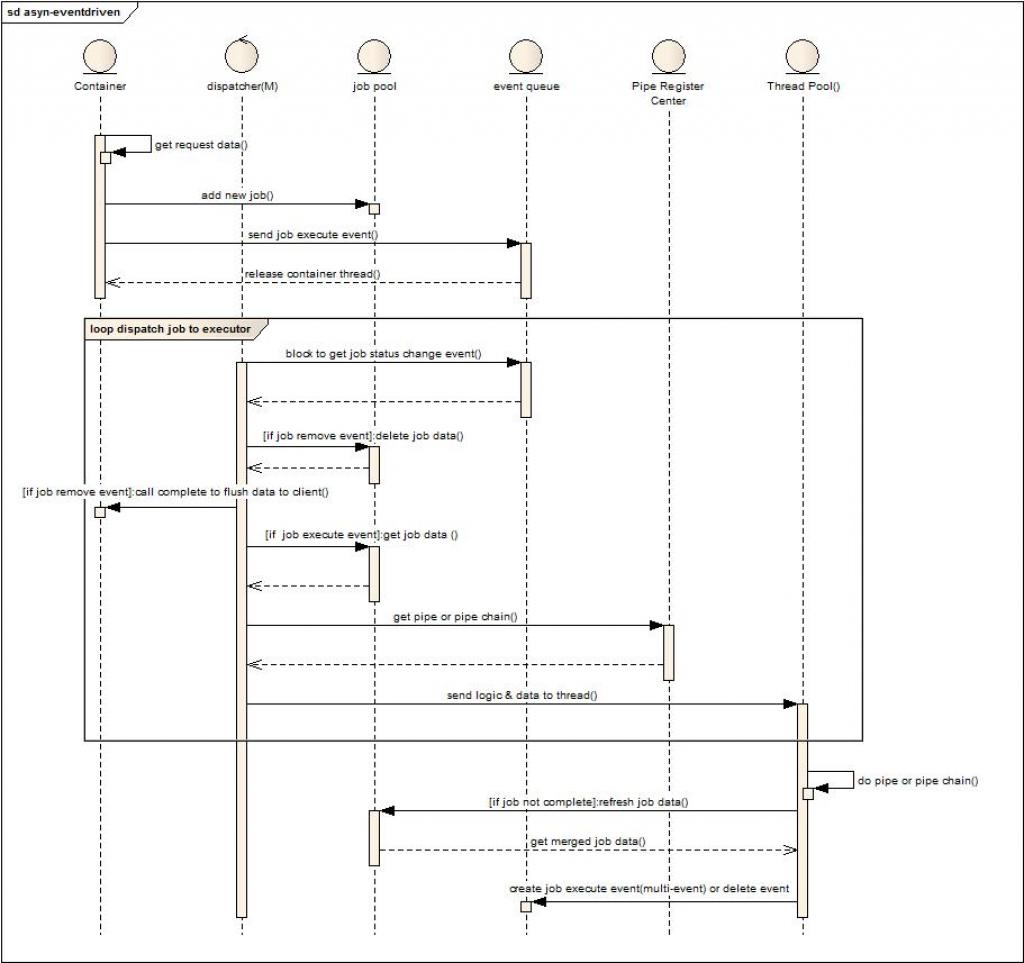
流程与角色说明:
角色分成:Container(传统的容器),dispatcher(任务派发线程数量根据性能要求可以是1-m个),job pool(存储任务数据的本地缓存),event queue(任务状态发生变化的事件存储队列),pipe register center(管道链注册中心,根据job的自描述信息给出相关处理的单个管道或者管道链),thread pool(用于处理业务请求的线程池)
流程描述如下:
1. 容器解析请求数据。
2. 创建任务并存储到job pool。
3. 发送job执行消息到消息队列。
4. 释放容器线程,挂起请求资源。
5. Dispatcher阻塞方式的从event queue获取事件消息。
6. 如果是删除任务事件消息,则将剩余未发送数据flush到客户端,结束本次Http会话。(删除任务消息是在任务走完所有管道或者任务执行超时或者任务执行失败产生)
7. 如果是执行任务消息事件,则从job pool获取任务数据。
8. 根据任务信息去pipe register center获取pipe或者pipe chain。
9. 将任务数据和管道信息发送给线程池。
10. 线程池分配线程执行任务,如果当前pipe chain执行后并没有完成job,则将job信息存储到job pool。(这块后面可以参看一下job 执行逻辑图)
11. 如果没有执行完毕,则可以创建一个或者多个执行事件激发下一次的处理,如果执行完毕,则创建一个删除任务消息激发任务结束处理。
问题:
1. 规范化带来的消息事件过多,线程切换消耗的问题。
2. Dispatcher自身任务是否繁重导致处理速度变慢。同时两套线程池管理麻烦(如果Dispatcher的个数为M也就可以看作另一个线程池)。
细节:
1. 利用容器本身支持请求挂起的方式,将容器线程池和业务线程池分割开来。
2. 如果所有子任务都是串行化且没有一个子任务是由外部系统来实施状态迁移,则可以在一个线程中完成所有子任务,减少线程切换和事件分发带来的消耗。最极端是退化到任务交由容器线程一并完成。
3. 当允许并行多个子任务执行时,只需要在并行子任务执行前的那个任务完成后,分发多个任务执行事件,并且任务执行事件指定要求处理的Pipe,就可以让分发器将当前任务分发给多个线程并行执行子任务,后续详细介绍子任务并行处理的过程。
4. Job会被多线程访问,因此必要的属性需要做成线程安全的。另一种模式就是抓取job的数据是个快照(clone),在结果产生后再锁住合并。
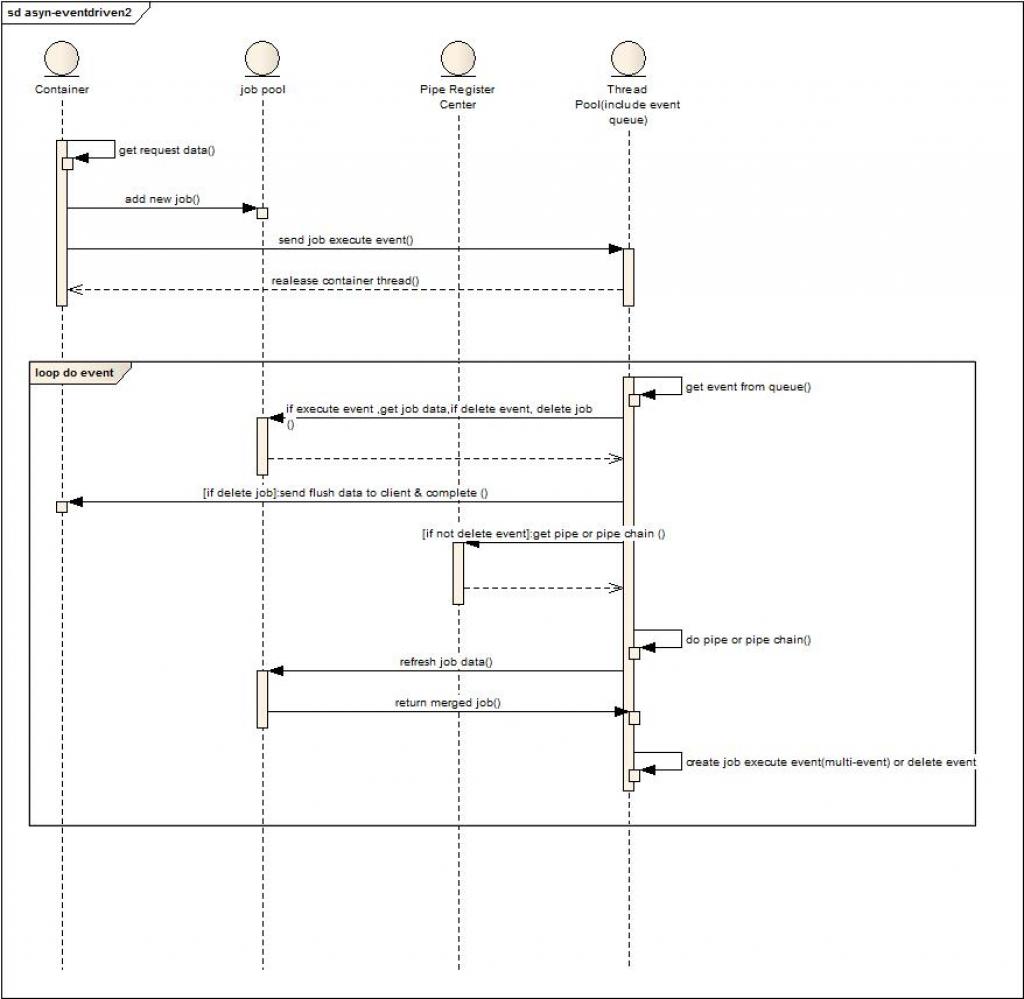
角色和流程说明:
上图角色将线程池和消息队列做了合并,去掉了dispatcher,event queue合并到了 Thread Pool中。
1. 容器解析请求参数。
2. 创建任务并放置到任务缓存中。
3. 发送执行任务事件到线程池。
4. 释放容器线程资源。
5. 线程池从自身事件队列中获取事件。
6. 如果是删除事件,则直接删除任务,并发送数据到客户端,结束本地会话。
7. 如果是执行事件,则从pipe register center获取pipe或者pipe chain。
8. 本地执行pipe或者pipe chain。
9. 更新job 数据到缓存。
10. 创建执行或者删除消息事件到本地线程池队列或者直接连续执行。
差异:
1. 将分发器的功能散落到各个实际业务操作线程上,提升处理效率。(增加了对于消息队列的竞争,不过这个代价不是很大)
2. 线程可以连续执行子任务,减少任务事件数量,减少线程切换代价。(类似于自旋锁的方式,自己可以尽量的完成可以完成的任务,带来的问题就是对于不同任务多阶段并行执行的策略有所减弱)
细节:
和第一种模式一样,可以退化这个模型到传统的一个web容器线程处理所有的子任务,减少线程切换代价。
四种方式的子任务执行说明:

传统的串行化任务执行模式,这种模式下可以交由单个线程全部执行,减少线程切换代价,另一方面假如3这个环节将会等待外部系统来更新状态并继续执行,那么到2执行完毕可以将job放入缓冲区,不产生事件消息,等外部操作完成后,创建执行事件消息,激发后续管道执行任务。(这种方式可以直接利用容器的挂起,来释放容器线程,而后续操作交由后台业务线程池执行)
这里有点说明一下,也是很多朋友问起的,关于上下文,原来的模式中上下文一种方式是通过方法参数不断传递,另一种方式保存在ThreadLocal中,而现在因为要切换线程可能就需要做拷贝或者线程之间传递。在后面几种模式中都建议直接将状态存储在本地缓存中共享,带来的问题就是多线程安全,一种方式是都获取此对象,然后操作时候做锁,一种是获得对象快照,然后合并结果时锁定。(这还是取决于多个线程之间处理是否需要看到对方的数据变化)
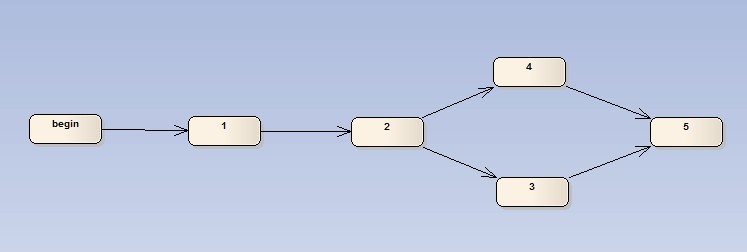
3,4两个任务可以并行完成,同时任何一个完成即可进入5,此时在2完成后,将会产生两个执行任务消息,并且自描述后续的Pipe,此时两个线程可以分别执行3,4,任何一个完毕后创建执行消息,激发任务处理进入到5流程中。(当发现已经进入5状态时,则忽略某个过期任务消息)
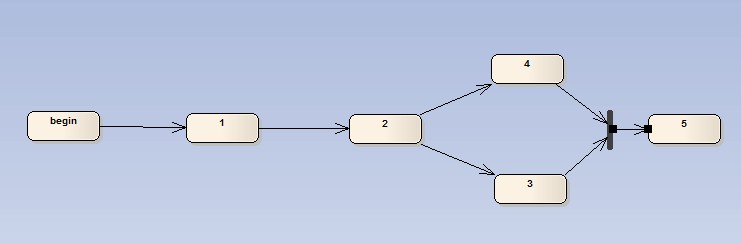
与上一个图的区别就是,3,4将不再是二选一,而是必须全执行完毕后才可以进入下一个阶段,因此job在执行后会先判断是否被并行的另一个任务执行过,确定全部都Ready,则发起创建执行消息。(在完成3或者4后都会判断当前合并结果是否符合进入下一环节的要求,符合再发起新的执行任务消息)

此图是2,3两种方案的结合,因此参照3的做法完成。
支持异步化请求处理模型:
上面的管道模型是较为通用的模型,但考虑到TOP现有业务状况和资源消耗在上述框架下定制了简单的异步支持模型:
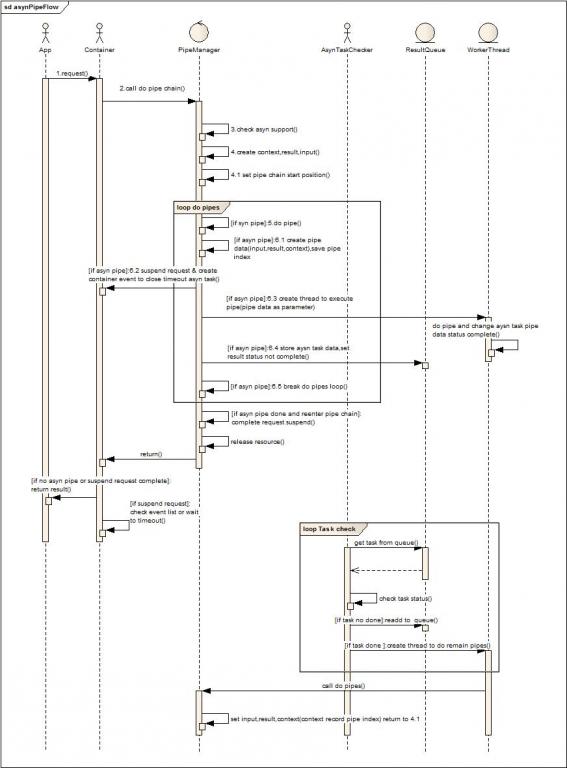
角色及流程说明:
App第三方ISV软件,Container Web容器,PipeManager管道注册管理者(区别于通用的管道注册中心在于他对于所有请求都只管理一套Pipe Chain,由他将请求数据传入,并管理整个子任务的执行和分发),AsynTaskChecker是异步执行任务状态变更事件的检查者(类似于前面的事件分发器角色),ResultQueue保存事件及事件所带的上下文,workerThead是工作线程池。
1. 应用发起服务请求。
2. 容器调用管道管理器去执行任务管道链。(解析参数通过Lazy方式解析字节流被离散放到了各个管道环节中)
3. 检查容器是否对异步支持。(便于多容器兼容)
4. 创建上下文和输入输出对象(输入输出是管道基本传递参数,后面给出类图结构可知,上下文则是放置在ThreadLocal的数据,在多个管道逻辑中共享)。
5. 设置管道链执行的起始点(为了异步化后再次进入管道链无需重新执行前面执行过的管道作处理)。
6. 循环执行管道链。
如有异步管道在管道链中:
a) 复制管道上下文,保存当前执行的管道位置。
b) 挂起请求,释放容器线程资源。
c) 创建线程执行异步化管道。
d) 保存任务到队列,等待外部处理结束改变任务状态。
e) 推出循环执行后续管道
7. 判断是否是异步执行后的重入,如果是则提交异步结束事件,让容器在这次管道链执行后自动提交数据到客户端,结束本地Http请求会话。
8. 释放上下文等线程本地资源。
9. 返回容器,容器判断是否有挂起请求,如果请求结束则返回结果到客户端。
10. 容器自检查从挂起到当前是否处于执行超时(每次挂起请求就会产生一个超时事件,容器循环的校验这些事件)
11. AsynTaskChecker循环的检查队列中的任务是否已经完成,如果状态变更为完成,则提交到给线程池继续执行后续的管道链。(处于性能考虑,可以将未完成的对象先不放入队列,等到后端服务处理完毕再放入,这样AsynTaskChecker消耗会大大降低,任务超时完全交给容器来处理,不由业务方来处理)
细节:
主要目的是将容器和业务线程池分开,这样业务线程池可以采用后面提到的权重线程池,通过对权重线程池的权重模型设置来满足根据业务或者根据服务健康状况来不均衡的分配线程执行不同的业务请求。
后端系统的NIO异步方式能够利用操作系统的中断来激发改变对象状态,节省前端业务线程等待消耗。(如果后端是非异步化的操作,那么执行线程只是从容器线程变为了业务线程,当然可以让业务线程更加轻量)
系统中尽量减少线程切换(能够一个线程干完的,尽量一个线程执行多个子任务),尽量减少内存拷贝复用对象(当然复用的代价就是同步问题,因此取决于数据操作冲突的概率选择使用快照还是引用)。
如果看不清楚,可以直接访问:http://www.blogjava.net/cenwenchu/archive/2010/11/25/339024.html
上图的设计省略了队列和检查者,直接交由业务线程阻塞方式等待返回,并直接执行后续的管道,其实也就是对第一种场景的简化,在后端服务非异步方式的情况下,推荐这种方式。
总的来说,任务切割执行在设计上会觉得很清晰,但是还是要看整体处理时间的分布,如果整个事务处理消耗的时间很短,那么切割带来的复杂度和内部消耗就会得不偿失,采用简单的方式来实现可以满足业务上的需求(分离容器和业务线程,根据业务需求和系统动态性能决定线程资源分配),也能保证性能。
权重线程池:
将请求全程处理从容器线程池分离到业务线程池后,可以使用带权重的线程池来动态调整请求线程资源分配,下面是一个简单的权重线程池的实现。
目标:执行的任务实现接口getkey来用于判断是否有空余线程可以执行请求处理任务。资源被分成两种:默认全局可使用资源,给特定请求预留资源。配置分成两种,限制最大使用线程数,预留特定请求的线程数。
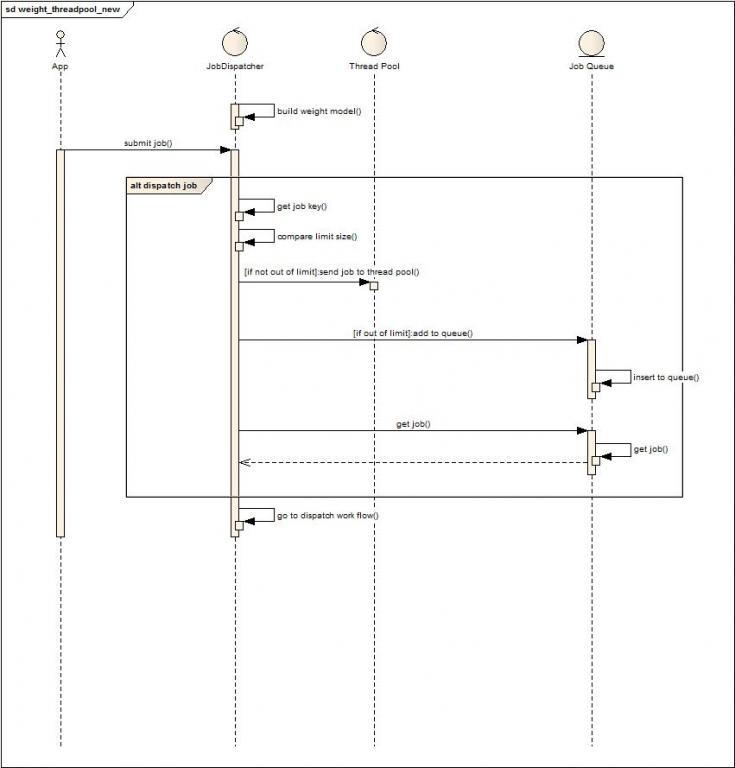
上图是简单的请求任务执行流程图,不多解释了。下图是状态转换图:
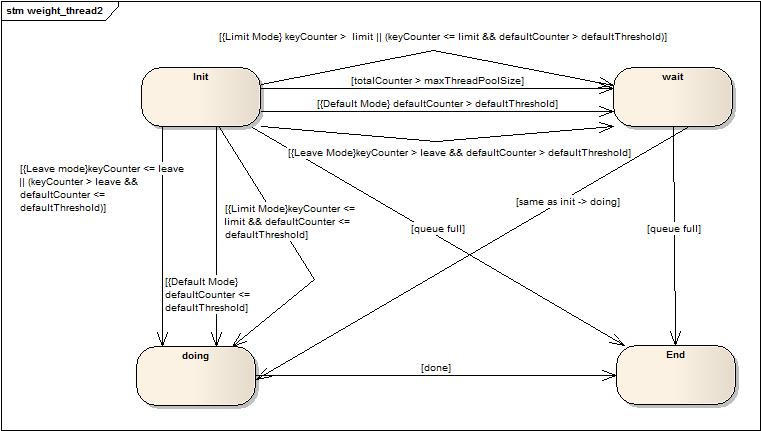
Wait到doing的转换和init到doing的转换一样,就没有重复画了。内部的一些标识解释(totalCounter全局的计数器,maxThreadPoolSize线程池最大线程数,defaultCounter是没有设置预留或者限制的请求的计数器,defaultThreshold是maxThreadPoolSize – sum(预留线程),keyCounter表示设置了预留或者限制的请求自身标识(自身标识通过getkey接口获得)计数器,leave表示某一类请求设置的预留的数值,limit表示某一类请求设置的限制的数值)
上图中大括号中的是场景描述,例如:{Limit Mode}keyCounter <= limit && defaultCounter <= defaultThreshold表示在设置了限制模式的场景下符合当前请求类型计数器(当前请求类型通过请求实现getkey接口返回数据来区别)小于限制且默认计数器小于默认阀值时状态转变。
一点小技巧:在存储预留和限制的阀值时,因为存储在一个map中,通过将阀值设置为负数来区分开,这样节省了区分阀值类型的工作。(这点可以在很多场景中考虑,比如说有多个类型的数据配置需要存储,可以通过数据区间的划分来判断是什么类型的,提高判断效率)
Comet Push Framework:
服务端实现:这期做了很简单的服务端实现,也是为了验证原型,标准的REST实现。
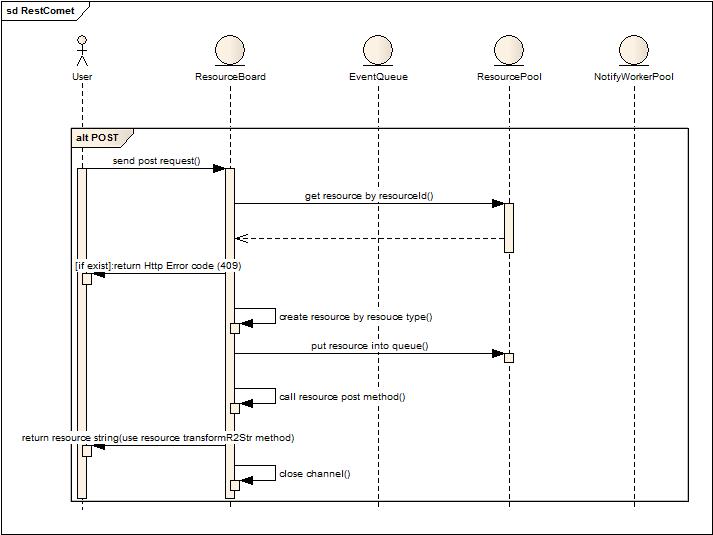
POST操作,用于新增资源,操作后得到资源返回,会话非长连接。

GET操作,获得当前请求的资源,会被加入到资源关注者列表中,保持长连接,用于资源变更后推送变更后的资源对象。
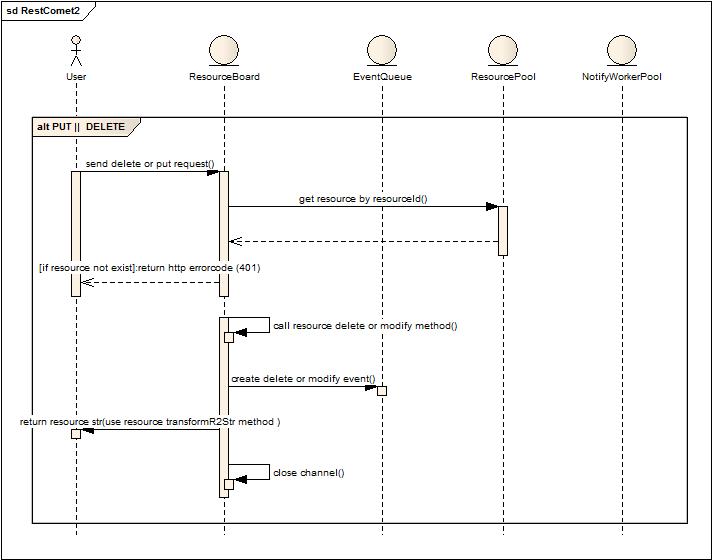
PUT或者Delete操作,短链接,同时产生变化事件,交由后台线程执行通知动作。
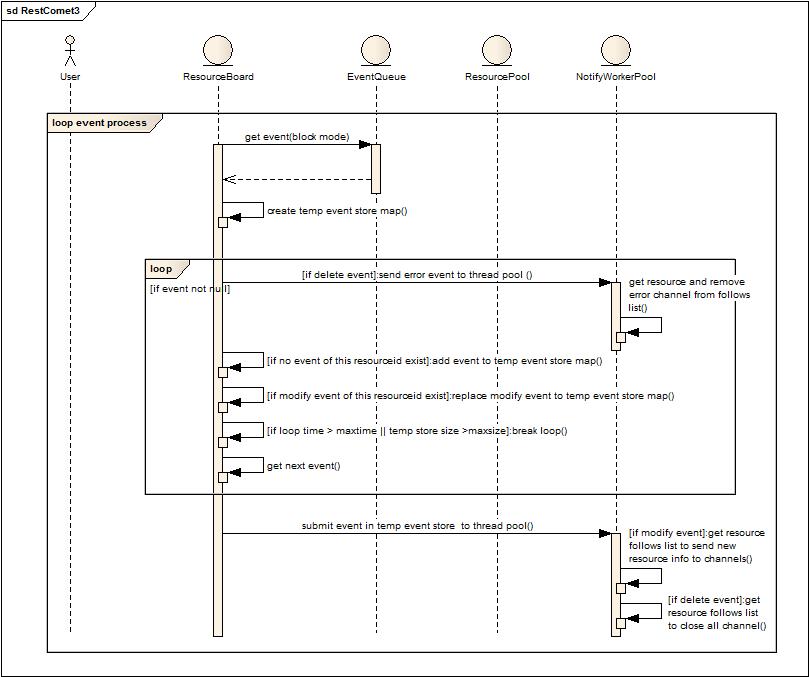
批量执行通知消息。
1. ResourceBoard阻塞式的从队列中获取事件通知。
2. 创建临时事件存储Map。
3. 如果存在通知事件,判断是否属于删除事件(此类事件发生在异常发生或者正常结束),如果是删除事件,立刻提交给后台线程池执行删除动作。(删除动作就是获取删除资源的follow列表,然后关闭所有follow的长连接)
4. 如果属于修改事件,判断当前资源的删除事件是否已经保存在临时存储Map中,如果有就不再加入修改事件直接忽略,否则就放入Map。
5. 判断当前循环累积事件是否超过一定时间或者存储的消息量已经超过一定值,如果是就跳出循环,如果否,则继续从队列中获取数据循环判断,直到队列为空。
6. 批量执行临时存储中的事件消息,如果是修改,则获取资源的follows来推送变更后的数据。
细节:
内部对于follow的有效性管理是在发送数据时判断的,如果出错就会产生删除事件。
对于消息批量处理主要是针对数据不断被修改,合并这些无用消息而作,但是某些场景也许就需要所有的修改痕迹,那就不能简单合并,因此资源需要提供类似合并的接口实现来保证获取的正确性。
问题:
海量长连接的支持。
采用简单的Http InnerFrame + js实现客户端增量展现会使得页面数据越来越多,到一定程度需要放弃连接重新建立follow,减轻客户端和服务端双重压力。XHR的方式在各种浏览器中支持的不一致。
代码实现,Demo及测试效果
待续….



相关推荐
MVC模式强调分离关注点,而Web Forms则基于传统的桌面编程模型,提供事件驱动的开发体验。 6. **ASP.NET Core**:作为ASP.NET的最新版本,ASP.NET Core是一个跨平台的高性能框架,支持.NET Core和.NET Framework。...
ASP.NET请求处理经历了从单一进程模型到多进程模型的转变,从用户模式到内核模式的优化,再到模块化设计的革新,这些改变不仅提升了性能,也增强了安全性和可管理性,为开发者提供了更强大的开发和部署环境。...
ASP.NET 页面对象模型是ASP.NET Web应用程序框架的核心组成部分,它描述了Web页面从请求到响应的生命周期,以及在此过程中各个对象如何交互。这个模型是微软.NET Framework的一部分,主要用于构建动态、数据驱动的...
- **特点**: 提供了直观的开发方式,基于组件(ASP.NET服务器控件)和事件驱动编程模型。 - **事件驱动编程模型**: 基于Windows Forms模型,ASP.NET页面是一个表单,包含文本区域、按钮或列表等ASP.NET服务器控件,...
WebForms是ASP.NET中的一个关键组件,它允许开发者使用类似桌面应用的控件和事件驱动模型来构建动态Web页面。WebForms将HTML、服务器端代码和客户端脚本紧密集成,使得在Web上构建交互式用户界面变得相对简单。另一...
总结来说,IIS作为Web服务器,通过HTTP.SYS驱动监听和接收HTTP请求,通过ISAPI和管道模型执行用户代码,同时提供了一套完善的架构来处理Web应用的生命周期,包括请求处理、中间件模块和业务逻辑的执行。了解这些原理...
ASP.NET 是一种由微软开发的基于 .NET Framework 的 Web 应用程序开发平台,它允许开发者使用各种高级特性,如事件驱动编程、组件模型和丰富的控件库来创建动态网页和 Web 应用程序。ASP.NET 不仅仅局限于 WebForms ...
此外,基于事件驱动的编程模型也是Delphi Web框架的一个特点,这使得响应用户请求和处理网络通信更加简单。 在"horse-3.1.6"这个文件名中,"horse"可能是框架的名字或者是其中的一个组件,而"3.1.6"则代表了版本号...
控件的事件驱动模型简化了Web开发。 3. **状态管理**:ASP.NET提供多种状态管理机制,包括视图状态(ViewState)、隐藏字段、Cookie、查询字符串和Session,以保持用户交互过程中的数据。 4. **配置系统**:ASP...
2. **Web Forms**:项目可能采用了ASP.NET Web Forms,这是一个基于控件的事件驱动模型,用于创建交互式的Web应用程序。开发者可以通过拖放控件到页面并编写后台代码来实现功能。 3. **数据访问层**:公交查询系统...
2. **Web Forms**:ASP.NET Web Forms是ASP.NET最早提供的编程模型,它通过服务器控件和事件驱动模型来模拟桌面应用程序的开发体验。书中会详细介绍如何创建、配置和使用Web Forms控件,以及如何处理页面事件。 3. ...
HTTP管道处理请求和响应,页面生命周期管理页面从加载到呈现的过程,而控件和事件模型则为用户交互提供支持。 三、Web Forms Web Forms是ASP.NET中最常见的开发模式,它允许开发者通过拖放控件和编写代码来构建交互...
6. **ASP.NET MVC或Web Forms**:根据项目结构,可能是基于MVC模式或传统的Web Forms模型开发的,这两者在处理用户请求和业务逻辑上有不同的方式。 7. **ASP.NET AJAX**:为了实现更好的用户体验,可能会使用ASP...
- Web Forms:ASP.NET的最初开发模式,基于控件的事件驱动模型。 - MVC(Model-View-Controller):一种轻量级、可测试的Web应用开发模式,鼓励分离关注点。 - Web API:用于构建RESTful服务的框架,支持JSON和...
在C#中,ASP.NET Core框架提供了一种强大的中间件机制,允许开发者串联多个处理程序,形成请求处理管道。中间件可以处理请求、响应,执行身份验证、日志记录、错误处理等任务。例如,这个项目可能包含了身份验证...
3. **Web Forms**:这是ASP.NET最原始的开发模型,它模拟了传统的Windows编程模型,提供了丰富的控件和事件驱动模型。Web Forms中的每一个页面对应于一个单独的.NET类,允许开发者通过代码处理用户交互。 4. **MVC...
ASP.NET 是微软公司开发的一种用于构建 Web 应用程序的框架,它基于 .NET Framework 或 .NET Core 平台,提供了丰富的服务器控件、事件驱动的编程模型以及强大的开发工具支持。通过源码学习 ASP.NET,可以深入理解其...
1. **Reactor**:Reactor是Spring Reactor项目中的核心组件,遵循发布-订阅(Publish-Subscribe)模式,提供了一种处理事件和事件驱动的编程模型。在Reactor Netty中,它负责事件的分发和管理。 2. **Channel**:...
ASP.NET是一个开源的服务器端Web开发平台,它提供了丰富的控件、事件驱动模型和自动状态管理,简化了Web应用的构建过程。通过ASP.NET,你可以使用各种编程语言,如C#、VB.NET或F#,编写Web应用。 二、ASP.NET的架构...