
什么叫n+1次select查询问题?
在Session的缓存中存放的是相互关联的对象图。默认情况下,当Hibernate从数据库中加载Customer对象时,会同时加载所有关联的Order对象。以Customer和Order类为例,假定ORDERS表的CUSTOMER_ID外键允许为null,图1列出了CUSTOMERS表和ORDERS表中的记录。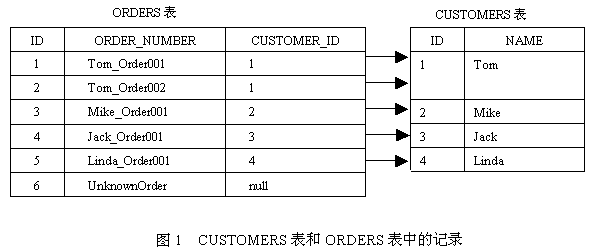 以下Session的find()方法用于到数据库中检索所有的Customer对象:
以下Session的find()方法用于到数据库中检索所有的Customer对象:
List customerLists=session.find("from Customer as c");
运行以上find()方法时,Hibernate将先查询CUSTOMERS表中所有的记录,然后根据每条记录的ID,到ORDERS表中查询有参照关系的记录,Hibernate将依次执行以下select语句:
select * from CUSTOMERS;
select * from ORDERS where CUSTOMER_ID=1;
select * from ORDERS where CUSTOMER_ID=2;
select * from ORDERS where CUSTOMER_ID=3;
select * from ORDERS where CUSTOMER_ID=4;
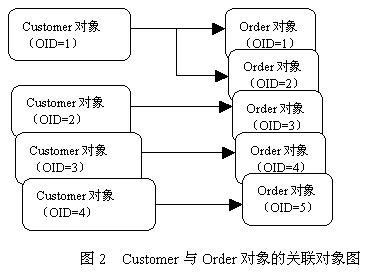
通过以上5条select语句,Hibernate最后加载了4个Customer对象和5个Order对象,在内存中形成了一幅关联的对象图,参见图2。
 Hibernate在检索与Customer关联的Order对象时,使用了默认的立即检索策略。这种检索策略存在两大不足:
Hibernate在检索与Customer关联的Order对象时,使用了默认的立即检索策略。这种检索策略存在两大不足:
(1) select语句的数目太多,需要频繁的访问数据库,会影响检索性能。如果需要查询n个Customer对象,那么必须执行n+1次select查询语句。这就是经典的n+1次select查询问题。这种检索策略没有利用SQL的连接查询功能,例如以上5条select语句完全可以通过以下1条select语句来完成:
select * from CUSTOMERS left outer join ORDERS
on CUSTOMERS.ID=ORDERS.CUSTOMER_ID
以上select语句使用了SQL的左外连接查询功能,能够在一条select语句中查询出CUSTOMERS表的所有记录,以及匹配的ORDERS表的记录。
(2)在应用逻辑只需要访问Customer对象,而不需要访问Order对象的场合,加载Order对象完全是多余的操作,这些多余的Order对象白白浪费了许多内存空间。
为了解决以上问题,Hibernate提供了其他两种检索策略:延迟检索策略和迫切左外连接检索策略。延迟检索策略能避免多余加载应用程序不需要访问的关联对象,迫切左外连接检索策略则充分利用了SQL的外连接查询功能,能够减少select语句的数目。



相关推荐
"ibatis解决多对一n+1问题"这个主题聚焦于MyBatis框架中如何高效地处理多对一关联查询,避免出现性能瓶颈的“n+1”问题。这个问题通常发生在查询一对多关系时,如果不对查询进行优化,会导致大量的额外数据库访问,...
然而,使用不当可能会导致性能瓶颈,其中最典型的就是“N+1次SELECT查询问题”。本文将深入探讨这个问题,以及如何通过优化检索策略来解决它。 N+1次SELECT查询问题源于Hibernate的默认行为。当从数据库中加载一个...
2. **连接查询(JOIN)**: 通过在SQL语句中使用JOIN操作,将原本的多次查询合并为一次,从而避免N+1问题。不过,这种方法需要注意的是,当数据量过大时,可能会导致内存压力增大。 3. **延迟加载(Lazy Loading)**...
标题中的“django ORM如何处理N+1查询”指的是在使用Django的Object-Relational Mapping (ORM)系统时,如何避免或解决常见的N+1查询问题。N+1查询问题通常发生在试图从关联模型中获取数据时,导致数据库执行过多的...
N+1问题发生在当我们执行一系列单独的SQL查询来获取关联数据,而不是一次性加载所有所需数据。这可能导致大量的数据库交互,从而降低系统性能。下面将详细介绍几种解决iBATIS中的N+1选择问题的方法。 1. **批处理...
这个问题出现在当我们需要获取一个对象及其关联对象时,通常会先执行一次主查询获取主对象,然后对每个主对象再单独执行一次查询来获取其关联对象,导致查询次数为N+1,其中N为主对象的数量。在高并发或大数据量的...
然而,如同其他ORM工具,Django ORM也可能导致一种性能问题,通常被称为“N+1查询”问题,或者更准确地说,“1+N查询问题”。 1+N查询问题指的是在进行数据检索时,对于一个主对象,我们需要额外单独查询多个关联...
N+1问题是数据库访问中最常见的一个性能问题,首先介绍一下什么是N+1问题: 举个例子,我们数据库中有两张表,一个是Customers,一个是Orders。Orders中含有一个外键customer_id,指向了Customers的主键id。 想要...
2. 使用二级缓存,在对象更新、删除、添加相对于查询要少得多时,二级缓存的应用将不怕 n+1 问题,因为即使第一次查询很慢,之后直接缓存命中也是很快的。 3. 设定 fetch=join(annotation : @ManyToOne() @Fetch...
已检测到N + 1个查询:从`users`的WHERE`users.`id` = 20 LIMIT 1中选择SELECT`users`。*从`users` WHERE`users`.`id` = 21 LIMIT 1从`users` WHERE`users``.id`中选择``users..id''= 22 LIMIT 1 SELECT`users .. *...
Prisma如何解决N + 1问题-2020年Prisma日 该存储库包含2020年Prisma Day演讲“ Prisma如何解决N + 1问题”的相应代码。 结果 名称 要求/秒 字节/序列 阿波罗PG 2.6 625 kB 阿波罗棱镜发现 7.8 1.87兆字节 ...
- 但同时也可能导致“N+1”问题,即除了主表查询外,还需要额外的查询来加载每个关联的子记录,这在子记录较多时可能会导致性能下降。 **2. FetchType.LAZY:** - `LAZY`加载方式则是延迟加载,即只有当真正访问到...
5. **查询**:在描述中提到了查询,这可能包括了基本的SELECT语句以及更复杂的联接、分组、排序等操作。使用LINQ,开发者可以方便地编写这些查询,然后由EF自动转换为相应的SQL语句。 6. **存储过程**:存储过程是...
N+1 queries detected: SELECT `users`.* FROM `users` WHERE `users`.`id` = 20 LIMIT 1 SELECT `users`.* FROM `users` WHERE `users`.`id` = 21 LIMIT 1 SELECT `users`.* FROM `users` WHERE `users`.`id` =...
GraphQL :: QueryResolver GraphQL :: QueryResolver是一个附加,它可使您的字段解析器将ActiveRecord发出的N + 1个SELECT最小化。 GraphQL :: QueryResolver将分析传入的GraphQL查询中的AST,并尝试将查询选择与...
Goone goone在go中找到N + 1(严格来说是for循环中的调用SQL)查询例子package mainimport ("database/sql""fmt""log"_ "github.com/go-sql-driver/mysql")type Person struct {Name stringJobID int}type Job ...
使用 TOP n [PERCENT]选项限制返回的数据行数,TOP n 说明返回 n 行,而 TOP n PERCENT 时,说明 n 是表示百分数,指定返回的行数等于总行数的百分之几。例如: SELECT TOP 2 * FROM testtable SELECT TOP 20 ...
int[] nums = new int[n+1]; nums[0]=1; nums[1]=1; for (int i =2;i<n;i++){ nums[i] = nums[i-2]+nums[i-1]; } return nums[n-1]; } ``` 在上面的代码中,我们使用数组来存储斐波那契数列的每一项值,然后...