- 浏览: 12100872 次
- 性别:

- 来自: 深圳
-

文章分类
最新评论
-
笨蛋咯:
获取不到信息?
C#枚举硬件设备 -
guokaiwhu:
能把plan的数据结构图画出来,博主的耐心和细致令人佩服。
PostgreSQL服务过程中的那些事二:Pg服务进程处理简单查询五:规划成plantree -
gao807877817:
学习
BitmapFactory.Options详解 -
GB654:
楼主,我想问一下,如何在创建PPT时插入备注信息,虽然可以解析 ...
java转换ppt,ppt转成图片,获取备注,获取文本 -
jpsb:
多谢 ,不过我照搬你的sql查不到,去掉utl_raw.cas ...
关于oracle中clob字段查询的问题
字符集问题的初步探讨(五)
原文链接:
http://www.eygle.com/special/NLS_CHARACTER_SET_05.htm
原文发表于itpub技术丛书《Oracle数据库DBA专题技术精粹》,未经许可,严禁转载本文.
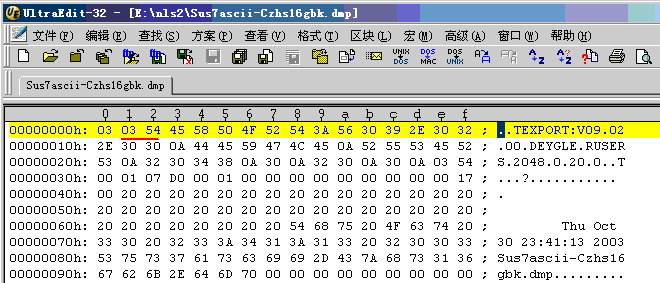
我们知道在导出文件中,记录着导出使用的字符集id,通过查看导出文件头的第2、3个字节,我们可以找到16进制表示的字符集ID,在Windows上,
我们可以使用UltraEdit等工具打开dmp文件,查看其导出字符集::
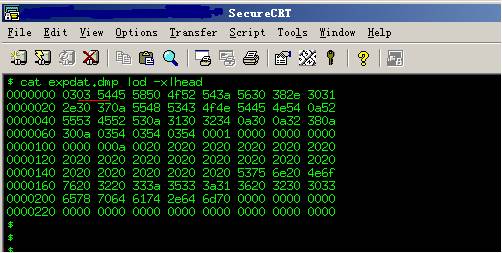
在Unix上我们可以通过以下命令来查看:
|
Oracle提供标准函数,对字符集名称及ID进行转换:
|
对应上面的图中第2、3字节,我们知道该导出文件字符集为ZHS16GBk.
查询数据库中有效的字符集可以使用以下脚本:
col nls_charset_id for 9999 col nls_charset_name for a30 col hex_id for a20 select nls_charset_id(value) nls_charset_id, value nls_charset_name, to_char(nls_charset_id(value),'xxxx') hex_id from v$nls_valid_values where parameter = 'CHARACTERSET' order by nls_charset_id(value) / |
输出样例如下:
NLS_CHARSET_ID NLS_CHARSET_NAME HEX_ID |
在很多时候,当我们进行导入操作的时候,已经离开了源数据库,这时如果目标数据库的字符集和导出文件不一致,很多时候就需要进行特殊处理,
以下介绍几种方法,主要以US7ASCII和ZHS16GBK为例
1. 源数据库字符集为US7ASCII,导出文件字符集为US7ASCII或ZHS16GBK,目标数据库字符集为ZHS16GBK
在Oracle92中,我们发现对于这种情况,不论怎样处理,这个导出文件都无法正确导入到Oracle9i数据库中,这可能是因为Oracle9i的编码方案发生了较大改变。
以下是我们所做的简单测试,其中导出文件命名规则为:
S-Server ,后跟Server字符集
C-client , 后跟导出操作时客户端字符集
导入时客户端字符集设置在命令行完成,限于篇幅,我们省略了部分测试过程。
对于Oracle9iR2,我们的测试结果是US7ASCII字符集,不管怎样转换,都无法正确导入ZHS16GBK字符集的数据库中。
在进行导入操作时,如果字符不能正常转换,Oracle数据库会自动用一个”?”代替,也就是编码63。
E:\nls2>set NLS_LANG=AMERICAN_AMERICA.US7ASCII E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle tables=test Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:14:39 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in US7ASCII character set and AL16UTF16 NCHAR character set import server uses ZHS16GBK character set (possible charset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:14:50 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) ----------------------------- ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 2 rows selected. SQL> exit Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production E:\nls2>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle tables=test ignore=y Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:15:28 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in ZHS16GBK character set and AL16UTF16 NCHAR character set export client uses US7ASCII character set (possible charset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:15:34 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) -------------------------------------------------------------------------------- ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 4 rows selected. SQL> drop table test; Table dropped. SQL> exit Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production E:\nls2>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK E:\nls2>imp eygle/eygle file=Sus7ascii-Czhs16gbk.dmp fromuser=eygle touser=eygle tables=test ignore=y Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:17:21 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in ZHS16GBK character set and AL16UTF16 NCHAR character set . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:17:30 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) ---------------------------------------------- ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 2 rows selected. SQL> exit Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production E:\nls2>set NLS_LANG=AMERICAN_AMERICA.US7ASCII E:\nls2>imp eygle/eygle file=Sus7ascii-Czhs16gbk.dmp fromuser=eygle touser=eygle tables=test ignore=y Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:18:00 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in US7ASCII character set and AL16UTF16 NCHAR character set import server uses ZHS16GBK character set (possible charset conversion) export client uses ZHS16GBK character set (possible charset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:18:08 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) ---------------------------------------- ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 ???? Typ=1 Len=4: 63,63,63,63 test Typ=1 Len=4: 116,101,115,116 4 rows selected. SQL> |
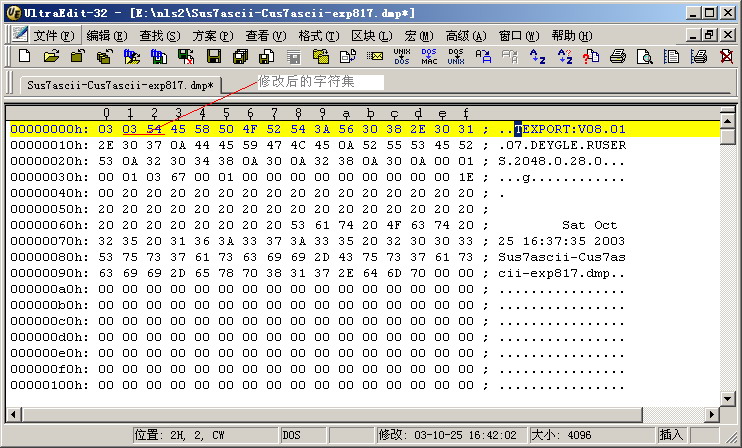
对于这种情况,我们可以通过使用Oracle8i的导出工具,设置导出字符集为US7ASCII,导出后修改第二、三字符,修改 0001 为
0354,这样就可以将US7ASCII字符集的数据正确导入到ZHS16GBK的数据库中。
修改导出文件:
导入修改后的导出文件:
E:\nls2>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii-exp817.dmp fromuser=eygle touser=eygle tables=test Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:37:17 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V08.01.07 via conventional path import done in ZHS16GBK character set and AL16UTF16 NCHAR character set export server uses UTF8 NCHAR character set (possible ncharset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:37:23 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select name,dump(name) from test; NAME DUMP(NAME) -------------------------------------------------------------------------------- 测试 Typ=1 Len=4: 178,226,202,212 Test Typ=1 Len=4: 116,101,115,116 2 rows selected. SQL> |
2. 使用create database的方法
如果导出文件使用的字符集是US7ASCII,目标数据库的字符集是ZHS16GBK,我们可以使用create database的方法来修改,具体如下:
SQL> col parameter for a30 SQL> col value for a30 SQL> select * from v$nls_parameters; PARAMETER VALUE ------------------------------ ------------------------------ NLS_LANGUAGE AMERICAN NLS_TERRITORY AMERICA NLS_CURRENCY $ NLS_ISO_CURRENCY AMERICA NLS_NUMERIC_CHARACTERS ., NLS_CALENDAR GREGORIAN NLS_DATE_FORMAT DD-MON-RR NLS_DATE_LANGUAGE AMERICAN NLS_CHARACTERSET ZHS16GBK NLS_SORT BINARY ………………. 19 rows selected. SQL> create database character set us7ascii; create database character set us7ascii * ERROR at line 1: ORA-01031: insufficient privileges SQL> select * from v$nls_parameters; PARAMETER VALUE ------------------------------ ------------------------------ NLS_LANGUAGE AMERICAN NLS_TERRITORY AMERICA NLS_CURRENCY $ NLS_ISO_CURRENCY AMERICA NLS_NUMERIC_CHARACTERS ., NLS_CALENDAR GREGORIAN NLS_DATE_FORMAT DD-MON-RR NLS_DATE_LANGUAGE AMERICAN NLS_CHARACTERSET US7ASCII NLS_SORT BINARY ………….. 19 rows selected. SQL> exit Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production E:\nls2>set nls_lang=AMERICAN_AMERICA.US7ASCII E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle Import: Release 9.2.0.4.0 - Production on Sun Nov 2 14:53:26 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Export file created by EXPORT:V09.02.00 via conventional path import done in US7ASCII character set and AL16UTF16 NCHAR character set import server uses ZHS16GBK character set (possible charset conversion) . . importing table "TEST" 2 rows imported Import terminated successfully without warnings. E:\nls2>sqlplus eygle/eygle SQL*Plus: Release 9.2.0.4.0 - Production on Sun Nov 2 14:53:35 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production SQL> select * from test; NAME ---------- 测试 test 2 rows selected. |
我们看到,当发出create database character set us7ascii;命令时,数据库v$nls_parameters中的字符集设置随之更改,该参数影响导入进程,
更改后可以正确导入数据,重起数据库后,该设置恢复。
提示:v$nls_paraemters来源于x$nls_parameters,该动态性能视图影响导入操作;而nls_database_parameters来源于props$数据表,影响数据存储。
3. Oracle提供的字符扫描工具csscan
我们说以上的方法只是应该在不得已的情况下使用,其本质是欺骗数据库,强制导入数据,可能损失元数据。
如果要确保数据的完整性,应该使用csscan扫描数据库,找出所有不兼容的字符,然后通过编写相应的脚本及代码,在转换之后进行更新,确保数据的正确性。
我们简单看一下csscan的使用。
要使用csscan之前,需要以sys用户身份创建相应数据字典对象:
|
这个脚本创建相应用户(csmig)及数据字典对象,扫描信息会记录在相应的数据字典表里。
我们可以在命令行调用这个工具对数据库进行扫描:
E:\nls2>csscan FULL=Y FROMCHAR=ZHS16GBK TOCHAR=US7ASCII LOG=US7check.log CAPTURE=Y ARRAY=1000000 PROCESS=2 Character Set Scanner v1.1 : Release 9.2.0.1.0 - Production on Sun Nov 2 20:24:45 2003 Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. Username: eygle/eygle Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options JServer Release 9.2.0.4.0 - Production Enumerating tables to scan... . process 1 scanning SYS.SOURCE$[AAAABHAABAAAAIRAAA] . process 2 scanning SYS.ATTRIBUTE$[AAAAEoAABAAAAhZAAA] . process 2 scanning SYS.PARAMETER$[AAAAEoAABAAAAhZAAA] . process 2 scanning SYS.METHOD$[AAAAEoAABAAAAhZAAA] …….. . process 2 scanning SYSTEM.DEF$_AQERROR[AAAA8fAABAAACWJAAA] . process 1 scanning WMSYS.WM$ENV_VARS[AAABeWAABAAAFMZAAA] …………………. . process 2 scanning SYS.UGROUP$[AAAAA5AABAAAAGpAAA] . process 2 scanning SYS.CON$[AAAAAcAABAAAACpAAA] . process 1 scanning SYS.FILE$[AAAAARAABAAAABxAAA] Creating Database Scan Summary Report... Creating Individual Exception Report... Scanner terminated successfully. |
然后我们可以检查输出的日志来查看数据库扫描情况:
Database Scan Individual Exception Report [Database Scan Parameters] Parameter Value ------------------------------ ------------------------------------------------ Scan type Full database Scan CHAR data? YES Current database character set ZHS16GBK New database character set US7ASCII Scan NCHAR data? NO Array fetch buffer size 1000000 Number of processes 2 Capture convertible data? YES ------------------------------ ------------------------------------------------ [Data Dictionary individual exceptions] [Application data individual exceptions] User : EYGLE Table : TEST Column: NAME Type : VARCHAR2(10) Number of Exceptions : 1 Max Post Conversion Data Size: 4 ROWID Exception Type Size Cell Data(first 30 bytes) ------------------ ------------------ ----- ------------------------------ AAABpIAADAAAAAMAAA lossy conversion 测试 ------------------ ------------------ ----- ------------------------------ |
不能转换的数据将会被记录下来,我们可以根据这些信息在转换之后,对数据进行相应的更新,确保转换无误。


发表评论

相关推荐
最后,"修改props$中字符集的恢复 - fengjin821的个人空间 - ITPUB个人空间 - powered by X-Space_files"和"字符集问题的初步探讨(三)-字符集的更改 - Oracle Life_files"可能是原始网页的资源文件夹,包含了图片、...
- 比如,在支持中文、英文等多种语言的应用程序中,使用Unicode字符集(如UTF8)可以避免乱码问题。 **3. 性能优化:** - 不同的字符集可能会对数据库性能产生影响,特别是在处理大量文本数据时。 - 选择合适的...
这样可以避免因不同环节采用不同字符集而导致的乱码问题。 2. **配置JSP页面**:在JSP页面头部明确声明字符集,例如`;charset=UTF-8" %>`。 3. **数据库配置**:根据实际情况调整数据库的字符集设置,确保与前端页面...
在Delphi编程环境中,ASCII值是字符编码的一种标准表示方式,每一个可打印的字符都有一个特定的ASCII值,这个值范围从0到127(对于标准的7位ASCII字符集)。例如,字母'A'的ASCII值是65,而'a'的ASCII值是97。 ### ...
本文将深入探讨基于Matlab的字符识别技术,以及如何通过连通域分析实现图像中的字母识别。 首先,我们要理解“字符识别”这一概念。字符识别是人工智能的一个分支,主要目标是让计算机系统能够识别并理解图像或文本...
在这一讲中,我们聚焦于形式语言与自动机中的计算理论初步,主要涉及对角语言、通用语言、问题归约以及与图灵机相关的概念。 首先,对角语言(Diagonalization Language)是一个重要的概念,它用于揭示某些语言的...
计算理论是计算机科学的基础,它探讨的是计算的可能性、复杂性和局限性。在第十三讲“形式语言与自动机:计算理论初步”中,主要涉及以下几个关键概念: 1. **对角语言与通用语言**:对角语言是一个特殊构造的语言...
人工智能的初步探讨,如机器学习和深度学习,也在这年的论文中有所体现。 2017年国家集训队论文集: 这一年,集训队的焦点扩展到了分布式计算和并行算法。学生们分析了P、NP和NPC问题,以及如何设计高效的分布式...
在本项目中,我们将探讨如何使用Python 3将图片转换为彩色字符的实现。这个过程涉及到计算机图形学、...通过实践这个项目,开发者可以深化对Python库的理解,提升解决问题的能力,并在乐趣中学习计算机视觉的初步知识。
下面,我们将深入探讨哈夫曼树的应用原理及其在实际项目中的实现步骤。 ### 哈夫曼树的构建与应用 #### 构建原理 哈夫曼树的构建基于最小生成树的概念,其核心思想是在给定一组字符及其出现频率的情况下,构建一颗...
4. 字符编码:如ASCII码和Unicode(UTF-8),它们如何表示各种字符,解决多语言字符集问题。 5. 浮点数表示:理解浮点数在计算机中的存储方式,如IEEE 754标准。 6. 数据类型:介绍不同类型的数据(如整型、浮点型、...
许智磊 -《浅谈补集转化思想在统计问题中的应用》 张 宁 -《猜数问题的研究》 张云亮 -《论对算法的选择》 周 源 -《浅析"最小表示法"思想在字符串循环同构问题中的应用》 ## 2004 何 林 -《信息学中守恒法...
- **字符集自定义**:除了预设的字符集,用户还可以自定义字符集,以达到更个性化的视觉效果。 - **输出尺寸**:程序允许用户设置输出字符画的宽度和高度,以适应不同的展示需求。 4. **代码结构**: - **main....
- 将“字符集”设为“使用 Unicode 字符集”(也可以选择多字节方式)。 - 在“C/C++”->“常规”中,修改“附加包含目录”,添加路径 `%PBNISDK170%\include`。 #### 四、PBNI 应用实例 假设我们需要实现一个 ...
本教程将深入探讨Kettle中的一些关键控件,以及如何在实际项目中应用它们。 1. 输入控件: - **数据库输入**:Kettle提供了多种方式从数据库中抽取数据,如"数据库输入"步骤,可以配置SQL查询来提取所需记录。通过...
在本教程“XML初步到精通”中,我们将深入探讨XML的基础概念、语法以及它在IT领域的广泛应用。 一、XML简介 XML起源于1998年,由万维网联盟(W3C)制定,它是一种可扩展的标记语言,旨在提供一种结构化的方式来组织...
在本项目中,我们主要探讨的是“基于深度学习的字符识别工程文件”,这涉及到一系列的机器学习和深度学习技术,特别是在计算机视觉领域的应用。以下是该项目的详细知识点: 1. **深度学习基础**:深度学习是一种...
本章详细讲解了正则表达式的语法,包括匹配字符、限定匹配、字符集、量词、子模式、匹配优先级等概念。同时,也介绍了高级正则表达式(AREs)和相关语法。 第10章讲述了名字空间的概念。在TCL中,名字空间用于创建...
接下来,我们探讨一下这个数据集在实际应用中的重要性。在港口操作、货物追踪、以及供应链管理等环节,自动识别箱号可以极大地提高效率,减少人为错误。通过机器学习和深度学习技术,我们可以构建出能够自动识别箱号...