Lucene.netжПРдЊЫдЇЖеЊИеЕ®йЭҐзЪДжХ∞жНЃжРЬ糥жУНдљЬпЉМдљ†еПѓдї•еИ©зФ®Lucene.netж£А糥з£БзЫШдЄ≠зЪДжЦЗдїґпЉМзљСй°µпЉМжХ∞жНЃеЇУдЄ≠зЪДжХ∞жНЃпЉМдљЖжШѓеЙНжПРжШѓйҐДеЕИеѓєжХ∞жНЃеИЫ忯糥еЉХгАВ
Lucene糥еЉХињЗз®ЛеИЖдЄЇдЄЙдЄ™дЄїи¶БзЪДжУНдљЬйШґжЃµпЉЪе∞ЖжХ∞жНЃиљђжНҐжИРжЦЗжЬђгАБеИЖжЮРжЦЗжЬђгАБеєґе∞ЖеИЖжЮРињЗзЪДжЦЗжЬђдњЭе≠ШеИ∞糥еЉХеЇУдЄ≠гАВе¶ВеЫЊжЙАз§ЇпЉЪ
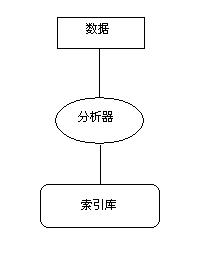
1.жХ∞жНЃиљђжИРжЦЗжЬђпЉЪй°їе∞ЖжХ∞жНЃиљђжНҐжИРLuceneиГље§Яе§ДзРЖзЪДж†ЉеЉПвАФвАФзЇѓжЦЗжЬђе≠Чзђ¶жµБгАВ
2.еИЖжЮРжЦЗжЬђпЉЪеЃМжИРдЇЖйТИеѓєеЊЕ糥еЉХжХ∞жНЃзЪДйҐДе§ДзРЖжУНдљЬпЉМеєґеИЫеїЇдЇЖеЄ¶жЬЙиЛ•еє≤дЄ™еЯЯзЪДDocumentеѓєи±°пЉМе∞±еПѓдї•и∞ГзФ®IndexWriterзЪДaddDocument(Document)жЦєж≥ХпЉМе∞ЖжХ∞жНЃдЉ†йАТзїЩLuceneжЭ•ињЫи°М糥еЉХжУНдљЬгАВеЬ®еѓєжХ∞жНЃињЫи°М糥еЉХе§ДзРЖжЧґпЉМLuceneдЉЪй¶ЦеЕИеИЖжЮРпЉИanalyzeпЉЙжХ∞жНЃдљњдєЛжЫіеК†йАВеРИ襀糥еЉХгАВ
3.е∞ЖеИЖжЮРињЗзЪДжЦЗжЬђдњЭе≠ШеИ∞糥еЉХеЇУдЄ≠пЉЪеѓєиЊУеЕ•жХ∞жНЃеИЖжЮРе§ДзРЖеЃМдєЛеРОпЉМе∞±еПѓдї•е∞ЖзїУжЮЬеЖЩеЕ•еИ∞糥еЉХжЦЗдїґдЄ≠гАВLuceneе∞ЖиЊУеЕ•жХ∞жНЃдї•дЄАзІНзІ∞дЄЇеАТжОТ糥еЉХпЉИinverted indexпЉЙзЪДжХ∞жНЃзїУжЮДињЫи°Ме≠ШеВ®гАВеЬ®ињЫи°МеЕ≥йФЃе≠ЧењЂйАЯжЯ•жЙЊжЧґпЉМињЩзІНжХ∞жНЃзїУжЮДиГље§ЯжЬЙжХИеЬ∞еИ©зФ®з£БзЫШз©ЇйЧігАВ
дЄЛйЭҐдїЛзїНдЄЛLucene.netдЄ≠е§ДзРЖ糥еЉХзЪДз±їпЉЪ
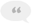 IndexWriter
IndexWriter
IndexWriterж؃糥еЉХдЄ≠иіЯиі£жУНдљЬзЪДж†ЄењГпЉМеЃГиіЯиі£жКК糥еЉХжЦЗдїґеЖЩеЕ•е≠ШеВ®дїЛиі®пЉМжШѓжОІеИґйАїиЊСе≠ШеВ®иљђжНҐдЄЇзЙ©зРЖе≠ШеВ®зЪДзЇљеЄ¶гАВ
Document
Documentе∞±жШѓдЄАжЭ°иЩЪжЛЯиЃ∞ељХпЉМеПѓдї•зРЖиІ£дЄЇжХ∞жНЃйЗМзЪДдЄАи°МгАВж≠£жШѓжЬЙдЇЖеЃГпЉМжЙНдљњжИСдїђеПѓдї•еЊИжЦєдЊњеєґдЄФжШУдЇОзРЖиІ£еЬ∞жУНдљЬ糥еЉХжЦЗдїґгАВеЃГдЄАиИђиЃ∞ељХдЇЖйЬАи¶БзФ®еИ∞зЪДдЄАдЄ™жЦЗж°£зЪДе±ЮжАІпЉМељУзДґпЉМињЩйЬАи¶БеТМFieldиБФеРИдљњзФ®гАВ
Field
Fieldз±їе∞±жШѓжХ∞жНЃеЇУйЗМзЪДдЄАеИЧгАВдЄАдЄ™жЦЗж°£жЬЙж†ЗйҐШпЉМеЖЕеЃєпЉМдљЬиАЕпЉМеИЫеїЇжЧґйЧіињЩеЫЫдЄ™е±ЮжАІзЪДиѓЭпЉМйВ£дєИе∞±йЬАи¶БеЫЫдЄ™FieldдњЭе≠ШињЩдЇЫе±ЮжАІпЉМзДґеРОжККеЫЫдЄ™FieldеК†еЕ•еИ∞DocumentдЄ≠гАВ
FieldзЪДжЮДйА†еЗљжХ∞жѓФиЊГе§ЪгАВеЕґдЄ≠StoreпЉМIndexеТМTermVectorжШѓйАЪињЗеЖЕйГ®з±їжМЗеЃЪзЪДгАВ
(1)--Store жЬЙдЄЙдЄ™йАЙй°єпЉЪ
Field.Store.COMPRESS谮积襀еОЛзЉ©е≠ШеВ®пЉЫ
Field.Store.YESи°®з§ЇеВ®е≠ШпЉЫ
Field.Store.NOи°®з§ЇдЄН襀е≠ШеВ®гАВ
(2)--IndexзЪДйАЙй°єжЬЙеЫЫдЄ™пЉЪ
Field.Index.NOи°®з§ЇдЄНеїЇзЂЛ糥еЉХпЉЫ
Field.Index.TOKENIZEDи°®з§ЇеИЖиѓНеРО糥еЉХпЉЫ
Index.NO_NORMSи°®з§ЇеАЉе≠ШеВ®еЖЕеЃєпЉЫ
Field.Index.UN_TOKENIZEDи°®з§ЇдЄНеИЖиѓН糥еЉХгАВ
(3)--TermVectorињЩдЄ™еПВжХ∞дєЯдЄНеЄЄзФ®пЉМеЃГжЬЙдЇФдЄ™йАЙй°єгАВ
Field.TermVector.NOи°®з§ЇдЄН糥еЉХTokenзЪДдљНзљЃе±ЮжАІпЉЫ
Field.TermVector.WITH_OFFSETSи°®з§ЇйҐЭе§Ц糥еЉХTokenзЪДзїУжЭЯзВєпЉЫ
Field.TermVector.WITH_POSITIONSи°®з§ЇйҐЭе§Ц糥еЉХTokenзЪДељУеЙНдљНзљЃпЉЫ
Field.TermVector.WITH_POSITIONS_OFFSETSи°®з§ЇйҐЭе§Ц糥еЉХTokenзЪДељУеЙНеТМзїУжЭЯдљНзљЃпЉЫ
Field.TermVector.YESеИЩи°®з§Їе≠ШеВ®еРСйЗПгАВ
йАЪињЗеЃЮдЊЛзФЯжИРжХ∞ж́糥еЉХпЉЪ
ињЩйЗМжИСе∞ЖжХ∞жНЃдњЭе≠ШеЬ®AccessжХ∞жНЃеЇУдЄ≠пЉМеѓєAccessжХ∞жНЃеЇУдЄ≠зЪДжХ∞жНЃињЫи°М糥еЉХпЉЪ
дњЭе≠ШжХ∞жНЃзЪДи°®пЉЪжХ∞жНЃеЇУдЄ≠дњЭе≠ШдЇЖ1000жЭ°жХ∞жНЃ
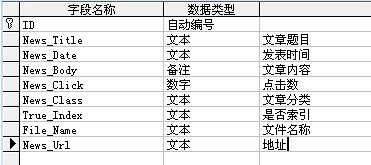
дЄЇжХ∞жНЃеИЫ忯糥еЉХдї£з†БпЉЪ

 Code
Code
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->usingSystem;
usingSystem.Data;
usingSystem.Configuration;
usingSystem.Web;
usingSystem.Web.Security;
usingSystem.Web.UI;
usingSystem.Web.UI.WebControls;
usingSystem.Web.UI.WebControls.WebParts;
usingSystem.Web.UI.HtmlControls;
usingSystem.Collections.Generic;
usingSystem.Text;
usingSystem.IO;
usingSystem.Text.RegularExpressions;
usingSystem.Data.SqlClient;
usingLucene.Net.Analysis;
usingLucene.Net.Documents;
usingLucene.Net.Index;
usingLucene.Net.Analysis.KTDictSeg;
usingLuceneSearch;
///<summary>
///CreateIndexзЪДжСШи¶БиѓіжШО
///</summary>
publicclassCreateIndex
{
//иѓНеЇУиЈѓеЊД
publicstringwordPath;
publicstringindexDirectory;
//еЃЪдєЙдЄАдЄ™IndexWriter
protectedIndexWriterwriter=null;
//йЬАи¶БеѓЉеЗЇзЪДжХ∞зЫЃ
publicintallNum;
//ељУеЙНеЃМжИРзЪДжХ∞зЫЃ
publicintcompleteNum;
//йЬАи¶БзФЯжИРзЪДи°®
publicDataTabledt;
DAL.OperSqlos=newDAL.OperSql();
publicCreateIndex()
{
}
publicvoidGetIndex(intinum)
{
//еЃЪдєЙеИЖжЮРеЩ®
AnalyzerKTDAnalyzer=newKTDictSegAnalyzer(wordPath);
//PerFieldAnalyzerWrapperеПѓдї•еѓєдЄНеРМзЪДFieldињЫи°МдЄНеРМзЪДеИЖжЮР
PerFieldAnalyzerWrapperwrapper=newPerFieldAnalyzerWrapper(KTDAnalyzer);
wrapper.AddAnalyzer("ID",KTDAnalyzer);
wrapper.AddAnalyzer("News_Url",KTDAnalyzer);
wrapper.AddAnalyzer("News_Date",KTDAnalyzer);
//еИ§жЦ≠жШѓеР¶еЈ≤жЬЙ糥еЉХ
boolisure=!IndexReader.IndexExists(indexDirectory);
//еИЫ忯糥еЉХзЪДжХ∞жНЃжЭ°жХ∞
allNum=dt.Rows.Count;
//еИЫеїЇIndexWriter
writer=newIndexWriter(indexDirectory,wrapper,isure);
writer.SetUseCompoundFile(true);//жШЊеЉП职皁糥еЉХдЄЇе§НеРИ糥еЉХ
writer.SetMaxFieldLength(int.MaxValue);//иЃЊзљЃеЯЯжЬАе§ІйХњеЇ¶дЄЇжЬАе§ІеАЉ
writer.SetMergeFactor(allNum+100);//иЃЊзљЃжѓП100дЄ™жЃµеРИеєґжИРдЄАдЄ™е§ІжЃµ
writer.SetMaxMergeDocs(10000);//иЃЊзљЃдЄАдЄ™жЃµзЪДжЬАе§ІжЦЗж°£жХ∞
writer.SetMaxBufferedDocs(1000);//иЃЊзљЃеЬ®жКК糥еЉХеЖЩеЕ•з£БзЫШеЙНеЖЕе≠ШйЗМжЦЗж°£зЪДзЉУе≠ШдЄ™жХ∞
//еИЫеїЇIndexReader
IndexReaderreader=null;
boolneedre=inum==1;
reader=IndexReader.Open(indexDirectory);
for(inti=0;i<dt.Rows.Count;i++)
{
completeNum=i+1;
stringbody=parseHtml(dt.Rows[i]["News_Body"].ToString());
stringtitle=parseHtml(dt.Rows[i]["News_Title"].ToString());
if(title.Length>2&&body.Length>2)
{
if(needre)
{
Termterm=newTerm("ID",dt.Rows[i]["ID"].ToString());
reader.DeleteDocuments(term);
}
Documentdocument=newDocument();
document.Add(newField("ID",dt.Rows[i]["ID"].ToString()??"",Field.Store.YES,Field.Index.UN_TOKENIZED));
document.Add(newField("News_Title",title,Field.Store.NO,Field.Index.TOKENIZED));
document.Add(newField("News_Body",body,Field.Store.NO,Field.Index.TOKENIZED));
document.Add(newField("News_Url",dt.Rows[i]["News_Url"].ToString()??"",Field.Store.YES,Field.Index.UN_TOKENIZED));
document.Add(newField("News_Date",DateField.DateToString(Convert.ToDateTime(dt.Rows[i]["News_Date"].ToString()))??"",Field.Store.YES,Field.Index.UN_TOKENIZED));
writer.AddDocument(document);;
}
}
reader.Close();
writer.Optimize();
writer.Close();
}
}
дЉ†еЕ•еПВжХ∞пЉМзФЯжИР糥еЉХжЦЗдїґпЉЪ
Code
<!--<br /><br />Code highlighting produced by Actipro CodeHighlighter (freeware)<br />http://www.CodeHighlighter.com/<br /><br />-->try
{
ci.wordPath=Server.MapPath("App_Data")+@"\";//иѓНеЇУиЈѓеЊД;
ci.indexDirectory=Server.MapPath("index")+@"\";//иѓНеЇУиЈѓеЊД;
ci.dt=dt;
ci.GetIndex(1);
}
еЕґдЄ≠dtжШѓдњЭе≠ШжХ∞жНЃзЪДDataTableпЉМwordpathжШѓеИЖиѓНеЩ®зЪДиѓНеЇУжЦЗдїґchsstopwords.txtпЉМengstopwords.txtпЉМdict.dctзЪДиЈѓеЊДпЉМindexDirectoryжШѓзФЯжИР糥еЉХжЦЗдїґзЪДиЈѓеЊДгАВ
зФЯжИР糥еЉХжИРеКЯеРОпЉМжИСдїђдЉЪеЬ®indexжЦЗдїґе§єдЄЛзЬЛеИ∞зФЯжИРзЪДжЦЗдїґпЉЪ
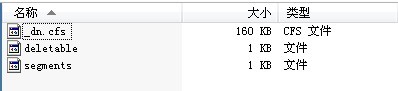
ињЩж†ЈпЉМжИСдїђе∞±еИЫеїЇе•љдЇЖжХ∞жНЃзЪД糥еЉХгАВж£А糥жХ∞жНЃзЪДжЧґеАЩпЉМжИСдїђе∞±еПѓдї•еИ©зФ®еЃГењЂйАЯзЪДеѓєжХ∞жНЃињЫи°Мж£А糥гАВ
еИЖдЇЂеИ∞пЉЪ





зЫЄеЕ≥жО®иНР
жАїзЪДжЭ•иѓіпЉМзїУеРИLucene.NetеТМзЫШеП§еИЖиѓНпЉМеЉАеПСиАЕеПѓдї•ењЂйАЯжР≠еїЇеЗЇдЄАдЄ™еКЯиГљеЃМеЦДзЪДдЄ≠жЦЗжРЬ糥еЉХжУОпЉМдЄЇзФ®жИЈжПРдЊЫењЂйАЯгАБз≤ЊеЗЖзЪДдњ°жБѓж£А糥жЬНеК°гАВйАЪињЗжЈ±еЕ•зРЖиІ£Lucene.NetзЪДеЖЕйГ®жЬЇеИґеТМзЫШеП§еИЖиѓНзЪДеЈ•дљЬеОЯзРЖпЉМеПѓдї•ињЫдЄАж≠•дЉШеМЦжРЬ糥жАІиГљпЉМ...
ињЩдЄ™еОЛзЉ©еМЕеМЕеРЂдЇЖLucene.netзЪДжЇРз†БеТМдЄ≠жЦЗе≠¶дє†жЦЗж°£пЉМжЧ®еЬ®еЄЃеК©еЉАеПСиАЕжЈ±еЕ•зРЖиІ£еєґеИ©зФ®Lucene.netжЭ•жЮДеїЇйЂШжХИгАБеКЯиГљеЉЇе§ІзЪДзљСзЂЩеЖЕйГ®жРЬ糥еЉХжУОгАВ **дЄАгАБLucene.netеЯЇз°А** Lucene.netжПРдЊЫдЇЖеѓєжЦЗжЬђжХ∞жНЃзЪД糥еЉХеТМжРЬ糥еКЯиГљпЉМеЃГ...
жЬђжЦЗе∞Жиѓ¶зїЖдїЛзїНLucene.NetзЪДеЯЇжЬђзФ®ж≥ХпЉМеМЕжЛђзОѓеҐГжР≠еїЇгАБеЯЇжЬђеЇФзФ®жµБз®ЛпЉИ糥еЉХеИЫеїЇдЄОжЦЗж°£жРЬ糥пЉЙгАБе§Ъе≠ЧжЃµжРЬ糥俕еПКдЄАдЇЫйЂШзЇІзЙєжАІгАВ #### дЇМгАБзОѓеҐГжР≠еїЇ еЬ®дљњзФ®Lucene.NetдєЛеЙНпЉМйЬАз°ЃдњЭеЈ≤еЃЙи£Е.NET FrameworkжИЦ.NET CoreзОѓеҐГпЉМ...
йАЪињЗињЩдЄ™DemoпЉМе≠¶дє†иАЕеПѓдї•жЈ±еЕ•дЇЖиІ£Lucene.NETзЪДеЈ•дљЬеОЯзРЖпЉМжОМжП°е¶ВдљХеЬ®.NETзОѓеҐГдЄ≠жР≠еїЇеЕ®жЦЗжРЬ糥еЉХжУОпЉМдї•еПКе¶ВдљХиЗ™еЃЪдєЙAnalyzerдї•йАВеЇФзЙєеЃЪзЪДжРЬ糥йЬАж±ВгАВињЩеѓєдЇОжПРеНЗеЉАеПСиАЕеЬ®дњ°жБѓж£А糥йҐЖеЯЯзЪДжКАиГљеТМиБМдЄЪзЂЮдЇЙеКЫиЗ≥еЕ≥йЗНи¶БгАВ
- **зљСзЂЩжРЬ糥**пЉЪиЃЄе§ЪзљСзЂЩеИ©зФ® Lucene.NET жПРдЊЫеЖЕйГ®жРЬ糥еКЯиГљпЉМжПРйЂШзФ®жИЈдљУй™МгАВ - **дЉБдЄЪзЯ•иѓЖеЇУ**пЉЪдЉБдЄЪеПѓдї•жЮДеїЇеЯЇдЇО Lucene.NET зЪДзЯ•иѓЖж£А糥з≥їзїЯпЉМеЄЃеК©еСШеЈ•ењЂйАЯжЯ•жЙЊдњ°жБѓгАВ - **жЦЗж°£зЃ°зРЖз≥їзїЯ**пЉЪжФѓжМБеѓєе§ІйЗПжЦЗж°£ињЫи°МйЂШжХИ...
1. **糥еЉХеИЫеїЇ**пЉЪй¶ЦеЕИпЉМйЬАи¶Беѓєи¶БжРЬ糥зЪДжХ∞жНЃињЫи°МйҐДе§ДзРЖпЉМеМЕжЛђеИЖиѓНгАБеОїйЩ§еБЬзФ®иѓНз≠ЙпЉМзДґеРОе∞Же§ДзРЖеРОзЪДжХ∞жНЃжЮДеїЇдЄЇLucene.NetзЪД糥еЉХгАВ 2. **糥еЉХе≠ШеВ®**пЉЪ糥еЉХдЉЪ襀жМБдєЕеМЦе≠ШеВ®пЉМдї•дЊњеРОзї≠жߕ胥䚜зФ®гАВеПѓдї•йАЙжЛ©еЖЕе≠ШгАБз°ђзЫШжИЦиАЕ...
ињЩдЄ™й°єзЫЃзЪДдЄїи¶БзЫЃзЪДжШѓиІ£еЖ≥еЬ®LuceneдЄ≠еѓєдЄ≠жЦЗжЦЗжЬђињЫи°М糥еЉХеТМжРЬ糥жЧґзЪДжХИзОЗеТМеЗЖз°ЃжАІйЧЃйҐШгАВ 1. **jiebaеИЖиѓНеЇУ**пЉЪ JiebaжШѓдЄАдЄ™еЉАжЇРзЪДPythonеЇУпЉМдЄУйЧ®зФ®дЇОдЄ≠жЦЗеИЖиѓНгАВеЃГжПРдЊЫдЇЖз≤Њз°Ѓж®°еЉПгАБеЕ®ж®°еЉПеТМжРЬ糥еЉХжУОж®°еЉПз≠ЙдЄНеРМзЪДеИЖиѓН...
дЊЛе¶ВпЉМDictSeg.dllеТМLucene.Net.Analysis.Cn.dllеПѓдї•еНПеРМеЈ•дљЬпЉМеѓєиЊУеЕ•зЪДдЄ≠жЦЗжЦЗжЬђињЫи°МеИЖиѓНе§ДзРЖпЉМзДґеРОдљњзФ®Lucene.NetеИЫ忯糥еЉХпЉЫеЬ®жߕ胥йШґжЃµпЉМHighlighter.Net.DLLеПѓдї•зФ®жЭ•йЂШдЇЃжШЊз§ЇеМєйЕНзЪДжߕ胥зїУжЮЬгАВињЩеЫЫдЄ™зїДдїґзїУеРИеЬ®дЄАиµЈ...
ињЩдЄ™жЇРдї£з†БжПРдЊЫдЇЖеЃЮзО∞ињЩдЄАеКЯиГљзЪДеЃМжХіж°ЖжЮґпЉМеЄЃеК©еЉАеПСиАЕењЂйАЯжР≠еїЇиЗ™еЈ±зЪДзЂЩеЖЕжРЬ糥еЉХжУОгАВдї•дЄЛжШѓеѓєиѓ•з≥їзїЯзЪДдЄАдЇЫеЕ≥йФЃзЯ•иѓЖзВєзЪДиѓ¶зїЖиѓіжШОпЉЪ 1. ASP.NETеЯЇз°АпЉЪASP.NETжШѓеЊЃиљѓжПРдЊЫзЪДдЄАдЄ™зФ®дЇОжЮДеїЇWebеЇФзФ®з®ЛеЇПзЪДеЉАеПСеє≥еП∞пЉМеЃГеЯЇдЇО...
еЬ®ITйҐЖеЯЯпЉМжРЬ糥еЉХжУОзЪДжР≠еїЇжШѓдЄАй°єе§НжЭВиАМйЗНи¶БзЪДдїїеК°пЉМеЃГжґЙеПКеИ∞жХ∞жНЃзЪД糥еЉХгАБжߕ胥еТМж£А糥гАВжЬђзѓЗе∞ЖйЗНзВєиЃ®иЃЇе¶ВдљХдљњзФ®JavaеТМLuceneеЇУжЭ•жЮДеїЇдЄАдЄ™еЯЇз°АзЪДжРЬ糥еЉХжУОгАВLuceneжШѓдЄАдЄ™йЂШжАІиГљгАБеЕ®жЦЗжЬђжРЬ糥еЇУпЉМзФ±ApacheиљѓдїґеЯЇйЗСдЉЪеЉАеПСпЉМ...
- йАЪињЗдЄАдЄ™зЃАеНХзЪДз§ЇдЊЛжЭ•е±Хз§Їе¶ВдљХдљњзФ®LuceneеИЫ忯糥еЉХдї•еПКе¶ВдљХжЙІи°МеЯЇжЬђзЪДеЕ®жЦЗжРЬ糥жУНдљЬгАВ #### дЄЙгАБLuceneеЖЕзљЃQueryеѓєи±° - LuceneжПРдЊЫдЇЖе§ЪзІНжߕ胥僺豰пЉМе¶ВTermQueryгАБBooleanQueryгАБPhraseQueryз≠ЙпЉМињЩдЇЫеѓєи±°зФ®дЇОжЮДйА†...
- **еЇФзФ®йЫЖжИР**пЉЪжПРдЊЫдЇЖеЕЈдљУзЪДз§ЇдЊЛпЉМиѓіжШОе¶ВдљХе∞ЖLuceneйЫЖжИРеИ∞зО∞жЬЙзЪДJavaеЇФзФ®дЄ≠пЉМдї•дЊњењЂйАЯжР≠еїЇжРЬ糥жЬНеК°гАВ - **зЂ†иКВ4пЉЪжЦЗжЬђеИЖжЮР** - **еИЖжЮРеЩ®**пЉЪжЈ±еЕ•иЃ≤иІ£дЇЖLuceneдЄ≠зЪДеИЖжЮРеЩ®зїДдїґпЉМеМЕжЛђеИЖиѓНеЩ®гАБињЗжї§еЩ®з≠ЙпЉМдї•еПКе¶ВдљХ...
LuceneжШѓдЄАдЄ™йЂШжАІиГљгАБеЕ®жЦЗж£А糥еЇУпЉМеЃГжШѓеЉАжЇРзЪДJavaй°єзЫЃпЉМдљЖдєЯжЬЙ.NETзЙИжЬђпЉИеРНдЄЇLucene.NETпЉЙгАВLuceneжПРдЊЫдЇЖ糥еЉХеТМжРЬ糥еКЯиГљпЉМиГље§ЯйЂШжХИеЬ∞е§ДзРЖе§ІйЗПжЦЗжЬђжХ∞жНЃгАВеЃГжФѓжМБеАТжОТ糥еЉХгАБTF-IDFиѓДеИЖгАБеЄГе∞Фжߕ胥гАБзЯ≠иѓ≠жߕ胥з≠Йе§ЪзІНж£А糥...
еЉАеПСиАЕеПѓдї•дљњзФ®LuceneжЭ•еИЫ忯糥еЉХпЉМе∞ЖзљСзЂЩеЖЕеЃєжИЦиАЕеЕґдїЦе§ІйЗПжЦЗжЬђжХ∞жНЃиљђжНҐжИРеПѓдЊЫењЂйАЯжߕ胥зЪД嚥еЉПгАВLuceneжФѓжМБеРДзІНжРЬ糥籿еЮЛпЉМеМЕжЛђж®°з≥КжРЬ糥гАБзЯ≠иѓ≠жРЬ糥еТМиМГеЫіжРЬ糥пЉМдї•еПКйЂШзЇІзЪДеЄГе∞ФињРзЃЧпЉМдљњеЊЧжРЬ糥еКЯиГљжЫіеК†зБµжіїеТМз≤Њз°ЃгАВ еЬ®...
ињЩйЬАи¶БиЃЊиЃ°еРИзРЖзЪДеИЖз±їзїУжЮДпЉМеєґеИ©зФ®еЕ®жЦЗжРЬ糥еЉХжУОпЉИе¶ВLucene.NETпЉЙжИЦиАЕжХ∞жНЃеЇУзЪДеЕ®жЦЗ糥еЉХеКЯиГљињЫи°МйЂШжХИзЪДжЦЗж°£жРЬ糥гАВ 6. **зЙИжЬђжОІеИґ**пЉЪдЄЇдњЭиѓБжЦЗж°£зЪДеЃМжХіжАІпЉМз≥їзїЯеЇФжФѓжМБзЙИжЬђжОІеИґпЉМеЕБиЃЄзФ®жИЈжЯ•зЬЛеОЖеП≤зЙИжЬђеТМжБҐе§НжЧІзЙИгАВињЩ...
еЉАеПСиАЕеПѓиГљйАЪињЗSQLжߕ胥жИЦиАЕйЫЖжИРеЕ®жЦЗжРЬ糥еЉХжУОпЉИе¶ВLucene.NETпЉЙжЭ•еЃЮзО∞еѓєеЄЦе≠РеЖЕеЃєзЪДењЂйАЯжЯ•жЙЊгАВ 6. еЫЮе§НдЄОйАЪзЯ•пЉЪ зФ®жИЈйЧізЪДдЇ§жµБйАЪињЗеЄЦе≠РеЫЮе§НеЃЮзО∞пЉМињЩйЬАи¶Бе§ДзРЖеєґеПСжЫіжЦ∞еТМеЃЮжЧґйАЪзЯ•гАВASP.NETеПѓдї•зїУеРИAJAXжКАжЬѓеЃЮзО∞жЧ†еИЈжЦ∞зЪД...
еХЖеУБжРЬ糥еКЯиГљеПѓдї•йАЪињЗLucene.NETињЩж†ЈзЪДеЕ®жЦЗжРЬ糥еЉХжУОеЃЮзО∞пЉМжПРйЂШжߕ胥жХИзОЗеТМеЗЖз°ЃжАІгАВ 3. иі≠зЙ©иљ¶еТМиЃҐеНХе§ДзРЖпЉЪиі≠зЙ©иљ¶еКЯиГљйЬАи¶БиЈЯиЄ™зФ®жИЈзЪДйАЙиі≠еХЖеУБпЉМињЩеПѓдї•йАЪињЗSessionеѓєи±°еЃЮзО∞гАВиЃҐеНХе§ДзРЖжґЙеПКеХЖеУБзїУзЃЧгАБеЇУе≠ШжЫіжЦ∞еТМжФѓдїШжО•еП£...
4. **еЕ®жЦЗжРЬ糥еЉХжУО**пЉЪеИ©зФ®Lucene.NETеЃЮзО∞еЉЇе§ІзЪДеЫЊдє¶жРЬ糥еКЯиГљпЉМжФѓжМБйЂШжХИзЪДжЦЗжЬђж£А糥гАВ 5. **RESTful APIиЃЊиЃ°**пЉЪз°ЃдњЭеЙНзЂѓдЄОеРОзЂѓзЪДйАЪдњ°иІДиМГеТМйЂШжХИгАВ 6. **UI/UXиЃЊиЃ°**пЉЪеИЫеїЇзЫіиІВдЄФзФ®жИЈеПЛе•љзЪДзХМйЭҐпЉМдЊњдЇОзФ®жИЈжµПиІИгАБжРЬ糥...
дЄЇдЇЖеЃЮзО∞ењЂйАЯгАБз≤ЊеЗЖзЪДжРЬ糥пЉМз≥їзїЯеПѓиГљйЬАи¶БйЫЖжИРеЕ®жЦЗжРЬ糥еЉХжУОпЉМе¶ВElasticsearchжИЦLucene.NETгАВC#жПРдЊЫдЄОињЩдЇЫеЉХжУОзЪДAPIжО•еП£пЉМйАЪињЗзЉЦеЖЩжߕ胥иѓ≠еП•жЭ•ж£А糥еМєйЕНзЪДзЯ•иѓЖжЭ°зЫЃгАВ 4. жЭГйЩРзЃ°зРЖпЉЪ з≥їзїЯеЇФеЕЈе§ЗзФ®жИЈиЇЂдїљй™МиѓБеТМжОИжЭГжЬЇеИґ...