- 浏览: 411903 次
- 性别:

- 来自: 北京
-

文章分类
最新评论
-
秦时明月黑:
深入浅出,楼主很有功底
hive编译部分的源码结构 -
tywo45:
感觉好多错误,但还是支持!
HDFS+MapReduce+Hive+HBase十分钟快速入门 -
xbbHistory:
解析的很棒!!
Linux-VFS -
darrendu:
执行这个命令,bin/hadoop fs -ls /home/ ...
Hadoop示例程序WordCount运行及详解 -
moudaen:
请问楼主,我执行总后一条语句时,执行的是自带的1.sql,你当 ...
TPC-H on Hive
http://www.cnblogs.com/forfuture1978/archive/2010/11/19/1882279.html
三 MapReduce框架结构
1 角色
1.1 JobTracker
JobTracker 是一个master服务, JobTracker 负责调度job的每一个子任务task运行于TaskTracker 上,并监控它们,如果发现有失败的task就重新运行它。一般情况应该把JobTracker 部署在单独的机器上。
1.2 TaskTracker
TaskTracker 是 运行于多个节点上的slaver服务。TaskTracker 则负责直接执行每一个task。TaskTracker 都需要运行在HDFS的DataNode 上,
1.3 JobClient
每一个job都会在用户端通过JobClient 类将应用程序以及配置参数打包成jar文件存储在HDFS,并把路径提交到JobTracker ,然后由JobTracker 创建每一个Task (即MapTask 和ReduceTask )并将它们分发到各个TaskTracker 服务中去执行。
2 数据结构
2.1 Mapper和Reducer
运行于Hadoop的MapReduce应用程序最基本的组成部分包括一个Mapper 和一个Reducer 类,以及一个创建JobConf 的执行程序,在一些应用中还可以包括一个Combiner 类,它实际也是Reducer 的实现。
2.2 JobInProgress
JobClient 提交job后,JobTracker 会创建一个JobInProgress 来跟踪和调度这个job,并把它添加到job队列里。JobInProgress 会根据提交的job jar中定义的输入数据集(已分解成FileSplit )创建对应的一批TaskInProgress 用于监控和调度MapTask ,同时在创建指定数目的TaskInProgress 用于监控和调度ReduceTask ,缺省为1个ReduceTask 。
2.3 TaskInProgress
JobTracker 启动任务时通过每一个TaskInProgress 来launchTask,这时会把Task 对象(即MapTask 和ReduceTask )序列化写入相应的TaskTracker 服务中,TaskTracker 收到后会创建对应的TaskInProgress (此TaskInProgress 实现非JobTracker 中使用的TaskInProgress ,作用类似)用于监控和调度该Task 。启动具体的Task 进程是通过TaskInProgress 管理的TaskRunner 对象来运行的。TaskRunner 会自动装载job jar,并设置好环境变量后启动一个独立的java child进程来执行Task ,即MapTask 或者ReduceTask ,但它们不一定运行在同一个TaskTracker 中。
2.4 MapTask和ReduceTask
一个完整的job会自动依次执行Mapper 、Combiner (在JobConf 指定了Combiner 时执行)和Reducer ,其中Mapper 和Combiner 是由MapTask 调用执行,Reducer 则由ReduceTask 调用,Combiner 实际也是Reducer 接口类的实现。Mapper 会根据job jar中定义的输入数据集按<key1,value1>对读入,处理完成生成临时的<key2,value2>对,如果定义了Combiner ,MapTask 会在Mapper 完成调用该Combiner 将相同key的值做合并处理,以减少输出结果集。MapTask 的任务全完成即交给ReduceTask 进程调用Reducer 处理,生成最终结果<key3,value3>对。这个过程在下一部分再详细介绍。
下图描述了Map/Reduce框架中主要组成和它们之间的关系:
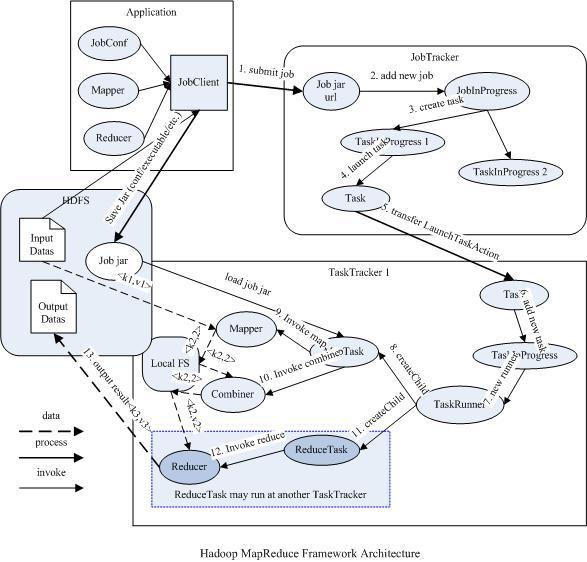
3 流程
一 道MapRedcue作业是通过JobClient.rubJob(job)向master节点的JobTracker提交的, JobTracker接到JobClient的请求后把其加入作业队列中。JobTracker一直在等待JobClient通过RPC提交作业,而 TaskTracker一直通过RPC向 JobTracker发送心跳heartbeat询问有没有任务可做,如果有,让其派发任务给它执行。如果JobTracker的作业队列不为空, 则TaskTracker发送的心跳将会获得JobTracker给它派发的任务。这是一道pull过程。slave节点的TaskTracker接到任 务后在其本地发起Task,执行任务。以下是简略示意图:
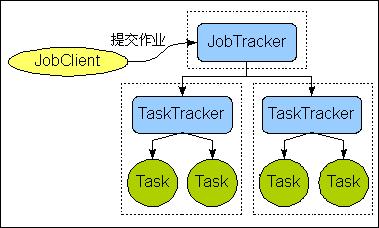
下面详细介绍一下Map/Reduce处理一个工作的流程。
四JobClient
在编写MapReduce程序时通常是上是这样写的:
Configuration conf = new Configuration(); // 读取hadoop配置
Job job = new Job(conf, "作业名称"); // 实例化一道作业
job.setMapperClass(Mapper类型);
job.setCombinerClass(Combiner类型);
job.setReducerClass(Reducer类型);
job.setOutputKeyClass(输出Key的类型);
job.setOutputValueClass(输出Value的类型);
FileInputFormat.addInputPath(job, new Path(输入hdfs路径));
FileOutputFormat.setOutputPath(job, new Path(输出hdfs路径));
// 其它初始化配置
JobClient.runJob(job);
1 配置Job
JobConf是用户描述一个job的接口。下面的信息是MapReduce过程中一些较关键的定制信息:
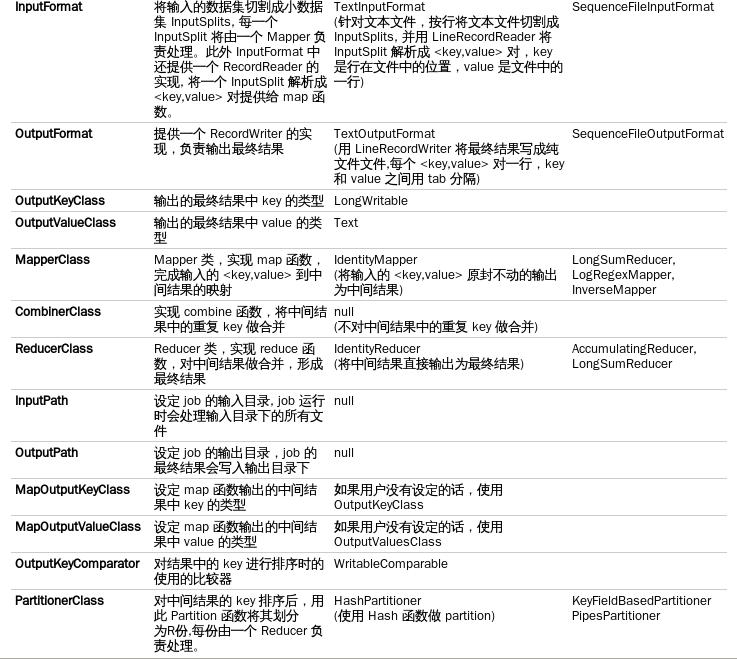
2 JobClient.runJob():运行Job并分解输入数据集
一个MapReduce的Job会通过JobClient 类根据用户在JobConf 类中定义的InputFormat 实现类来将输入的数据集分解成一批小的数据集,每一个小数据集会对应创建一个MapTask 来处理。JobClient 会使用缺省的FileInputFormat 类调用FileInputFormat .getSplits()方法生成小数据集,如果判断数据文件是isSplitable()的话,会将大的文件分解成小的FileSplit ,当然只是记录文件在HDFS里的路径及偏移量和Split大小。这些信息会统一打包到jobFile的jar中。
JobClient
然后使用submitJob(job)方法向
master提交作业。submitJob(job)内部是通过submitJobInternal(job)方法完成实质性的作业提交。
submitJobInternal(job)方法首先会向hadoop分布系统文件系统hdfs依次上传三个文件: job.jar,
job.split和job.xml。
job.xml: 作业配置,例如Mapper, Combiner, Reducer的类型,输入输出格式的类型等。
job.jar: jar包,里面包含了执行此任务需要的各种类,比如 Mapper,Reducer等实现。
job.split: 文件分块的相关信息,比如有数据分多少个块,块的大小(默认64m)等。
这
三个文件在hdfs上的路径由hadoop-default.xml文件中的mapreduce系统路径mapred.system.dir属性 +
jobid决定。mapred.system.dir属性默认是/tmp/hadoop-user_name/mapred/system。写完这三个文
件之后, 此方法会通过RPC调用master节点上的JobTracker.submitJob(job)方法
,此时作业已经提交完成。
3 提交Job
jobFile的提交过程是通过RPC模块(有单独一章来详细介绍)来实现的。大致过程是,JobClient 类中通过RPC实现的Proxy接口调用JobTracker 的submitJob()方法,而JobTracker 必须实现JobSubmissionProtocol接口。
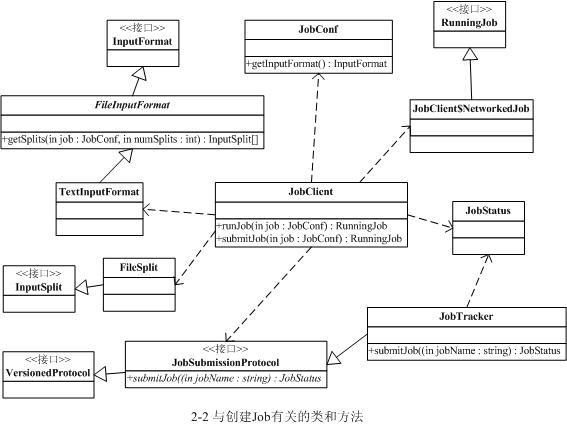
JobTracker 创建job成功后会给JobClient 传回一个JobStatus 对象用于记录job的状态信息,如执行时间、Map和Reduce任务完成的比例等。JobClient 会根据这个JobStatus 对象创建一个NetworkedJob 的RunningJob 对象,用于定时从JobTracker 获得执行过程的统计数据来监控并打印到用户的控制台。
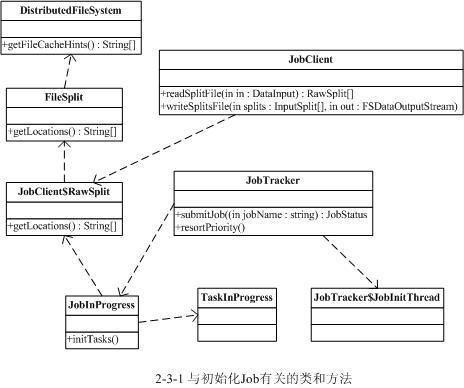
与创建Job过程相关的类和方法如下图所示
五 JobTracker
上面已经提到,job是统一由JobTracker 来调度的,具体的Task 分发给各个TaskTracker 节点来执行。下面来详细解析执行过程,首先先从JobTracker 收到JobClient 的提交请求开始。
1 JobTracker初始化Job
1.1 JobTracker.submitJob() 收到请求
当JobTracker 接收到新的job请求(即submitJob()函数被调用)后,会创建一个JobInProgress 对象并通过它来管理和调度任务。JobInProgress 在创建的时候会初始化一系列与任务有关的参数,调用到FileSystem,把在JobClient端上传的所有任务文件下载到本地的文件系统中的临时目录里。这其中包括上传的*.jar文件包、记录配置信息的xml、记录分割信息的文件。
1.2 JobTracker.JobInitThread 通知初始化线程
JobTracker 中的监听器类EagerTaskInitializationListener负责任务Task的初始化。JobTracker 使用jobAdded(job)加入job到EagerTaskInitializationListener 中 一个专门管理需要初 始化的队列里,即一个list成员变量jobInitQueue里。resortInitQueue方法根据作业的优先级排序。然后调用notifyAll()函数,会唤起一个用于初始化job的线程JobInitThread 来处理。JobInitThread 收到信号后即取出最靠前的job,即优先级别最高的job,调用TaskTrackerManager的initJob最终调用JobInProgress.initTasks()执行真正的初始化工作。
1.3 JobInProgress.initTasks() 初始化TaskInProgress
任务Task分两种: MapTask 和reduceTask,它们的管理对象都是TaskInProgress 。
首先JobInProgress 会创建Map的监控对象。在initTasks()函数里通过调用JobClient 的readSplitFile()获得已分解的输入数据的RawSplit 列表,然后根据这个列表创建对应数目的Map执行管理对象TaskInProgress 。在这个过程中,还会记录该RawSplit 块对应的所有在HDFS里的blocks所在的DataNode节点的host,这个会在RawSplit 创建时通过FileSplit 的getLocations()函数获取,该函数会调用DistributedFileSystem 的getFileCacheHints()获得(这个细节会在HDFS中讲解)。当然如果是存储在本地文件系统中,即使用LocalFileSystem 时当然只有一个location即“localhost”了。
创建这些TaskInProgress对象完毕后,initTasks()方法会通 过createCache()方法为这些TaskInProgress 对象产生一个未执行任务的Map缓存nonRunningMapCache。slave端的 TaskTracker向master发送心跳时,就可以直接从这个cache中取任务去执行。
其次JobInProgress 会创建Reduce的监控对象,这个比较简单,根据JobConf 里指定的Reduce数目创建,缺省只创建1个Reduce任务。监控和调度Reduce任务的是TaskInProgress 类,不过构造方法有所不同,TaskInProgress 会根据不同参数分别创建具体的MapTask 或者ReduceTask 。同样地,initTasks()也会通过createCache()方法产生nonRunningReduceCache成员。
JobInProgress 创建完TaskInProgress 后,最后构造JobStatus 并记录job正在执行中,然后再调用JobHistory .JobInfo .logStarted()记录job的执行日志。到这里JobTracker 里初始化job的过程全部结束。
2 JobTracker调度Job
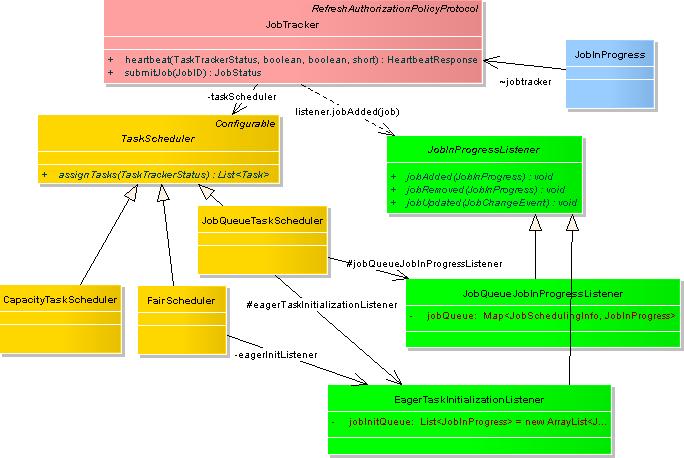
hadoop 默认的调度器是FIFO策略的JobQueueTaskScheduler,它有两个成员变量 jobQueueJobInProgressListener与上面说的eagerTaskInitializationListener。 JobQueueJobInProgressListener 是JobTracker的另一个监听器类,它包含了一个映射,用来管理和调度所有的JobInProgress。jobAdded(job)同时会加入job到JobQueueJobInProgressListener 中的映射。
JobQueueTaskScheduler 最 重要的方法是assignTasks ,他实现了工作调度。具体实现:JobTracker 接到TaskTracker 的heartbeat() 调用后,首先会检查上一个心跳响应是否完成,是没要求启动或重启任务,如果一切正常,则会处理心跳。首先它会检查 TaskTracker 端还可以做多少个 map 和 reduce 任务,将要派发的任务数是否超出这个数,是否超出集群的任务平均剩余可负载数。如果都没超出,则为此 TaskTracker 分配一个 MapTask 或 ReduceTask 。产生 Map 任务使用 JobInProgress 的 obtainNewMapTask() 方法,实质上最后调用了 JobInProgress 的 findNewMapTask() 访问 nonRunningMapCache 。
上面讲解任务初始化时说过,createCache()方法会在网络拓扑结构上挂上需要执行的 TaskInProgress。findNewMapTask()从近到远一层一层地寻找,首先是同一节点,然后在寻找同一机柜上的节点,接着寻找相同数 据中心下的节点,直到找了maxLevel层结束。这样的话,在JobTracker给TaskTracker派发任务的时候,可以迅速找到最近的 TaskTracker,让它执行任务。
最终生成一个Task类对象,该对象被封装在一个LanuchTaskAction 中,发回给TaskTracker,让它去执行任务。
产生 Reduce 任务过程类似,使用 JobInProgress.obtainNewReduceTask() 方法,实质上最后调用了 JobInProgress 的 findNewReduceTask() 访问 nonRuningReduceCache。
六 TaskTracker
1 TaskTracker加载Task到子进程
Task的执行实际是由TaskTracker 发起的,TaskTracker 会定期(缺省为10秒钟,参见MRConstants类中定义的HEARTBEAT_INTERVAL变量)与JobTracker 进行一次通信,报告自己Task的执行状态,接收JobTracker 的指令等。如果发现有自己需要执行的新任务也会在这时启动,即是在TaskTracker 调用JobTracker 的heartbeat()方法时进行,此调用底层是通过IPC层调用Proxy接口实现。下面一一简单介绍下每个步骤。
1.1 TaskTracker.run() 连接JobTracker
TaskTracker 的启动过程会初始化一系列参数和服务,然后尝试连接JobTracker (即必须实现InterTrackerProtocol 接口),如果连接断开,则会循环尝试连接JobTracker ,并重新初始化所有成员和参数。
1.2 TaskTracker.offerService() 主循环
如果连接JobTracker 服务成功,TaskTracker 就会调用offerService()函数进入主执行循环中。这个循环会每隔10秒与JobTracker 通讯一次,调用transmitHeartBeat(),获得HeartbeatResponse 信息。然后调用HeartbeatResponse 的getActions()函数获得JobTracker 传过来的所有指令即一个TaskTrackerAction 数组。再遍历这个数组,如果是一个新任务指令即LaunchTaskAction 则调用调用addToTaskQueue加入到待执行队列,否则加入到tasksToCleanup队列,交给一个taskCleanupThread线程来处理,如执行KillJobAction 或者KillTaskAction 等。
1.3 TaskTracker.transmitHeartBeat() 获取JobTracker指令
在transmitHeartBeat()函数处理中,TaskTracker 会创建一个新的TaskTrackerStatus 对象记录目前任务的执行状况,检查目前执行的Task数目以及本地磁盘的空间使用情况等,如果可以接收新的Task则设置heartbeat()的askForNewTask参数为true。然后通过IPC接口调用JobTracker 的heartbeat()方法发送过去,heartbeat()返回值TaskTrackerAction 数组。
1.4 TaskTracker.addToTaskQueue,交给TaskLauncher处理
TaskLauncher 是用来处理新任务的线程类,包含了一个待运行任务的队列 tasksToLaunch。TaskTracker.addToTaskQueue会调用TaskTracker的registerTask,创建 TaskInProgress对象来调度和监控任务,并把它加入到runningTasks队列中。同时将这个TaskInProgress加到 tasksToLaunch 中,并notifyAll()唤醒一个线程运行,该线程从队列tasksToLaunch取出一个待运行任务,调用TaskTracker的 startNewTask运行任务。
1.5 TaskTracker.startNewTask() 启动新任务
调用localizeJob()真正初始化Task并开始执行。
1.6 TaskTracker.localizeJob() 初始化job目录等
此 函数主要任务是初始化工作目录workDir,再将job jar包从HDFS复制到本地文件系统中,调用RunJar.unJar()将包解压到工作目录。然后创建一个RunningJob并调用 addTaskToJob()函数将它添加到runningJobs监控队列中。addTaskToJob方法把一个任务加入到该任务属于的 runningJob的tasks列表中。如果该任务属于的runningJob不存在,先新建,加到runningJobs中。完成后即调用 launchTaskForJob()开始执行Task。
1.7 TaskTracker.launchTaskForJob() 执行任务
启动Task的工作实际是调用TaskTracker$TaskInProgress的launchTask()函数来执行的。
1.8 TaskTracker$TaskInProgress.launchTask() 执行任务
执行任务前先调用localizeTask()更新一下jobConf文件并写入到本地目录中。然后通过调用Task的createRunner()方法创建TaskRunner对象并调用其start()方法最后启动Task独立的java执行子进程。
1.9 Task.createRunner() 创建启动Runner对象
Task 有两个实现版本,即MapTask 和ReduceTask ,它们分别用于创建Map和Reduce任务。MapTask 会创建MapTaskRunner 来启动Task子进程,而ReduceTask 则创建ReduceTaskRunner 来启动。
1.10 TaskRunner.start() 启动子进程
TaskRunner 负责将一个任务放到一个进程里面来执行。它会调用run()函数来处理,主要的工作就是初始化启动java子进程的一系列环境变量,包括设定工作目录 workDir,设置CLASSPATH环境变量等。然后装载job jar包。JvmManager用于管理该TaskTracker上所有运行的Task子进程。每一个进程都是由JvmRunner来管理的,它也是位于 单独线程中的。JvmManager的launchJvm方法,根据任务是map还是reduce,生成对应的JvmRunner并放到对应 JvmManagerForType的进程容器中进行管理。JvmManagerForType的reapJvm()
分配一个新的JVM 进程。如果JvmManagerForType槽满,就寻找idle的进程,如果是同Job的直接放进去,否则杀死这个进程,用一个新的进程代替。如果槽 没有满,那么就启动新的子进程。生成新的进程使用spawnNewJvm方法。spawnNewJvm使用JvmRunner线程的run方法,run方 法用于生成一个新的进程并运行它,具体实现是调用runChild。
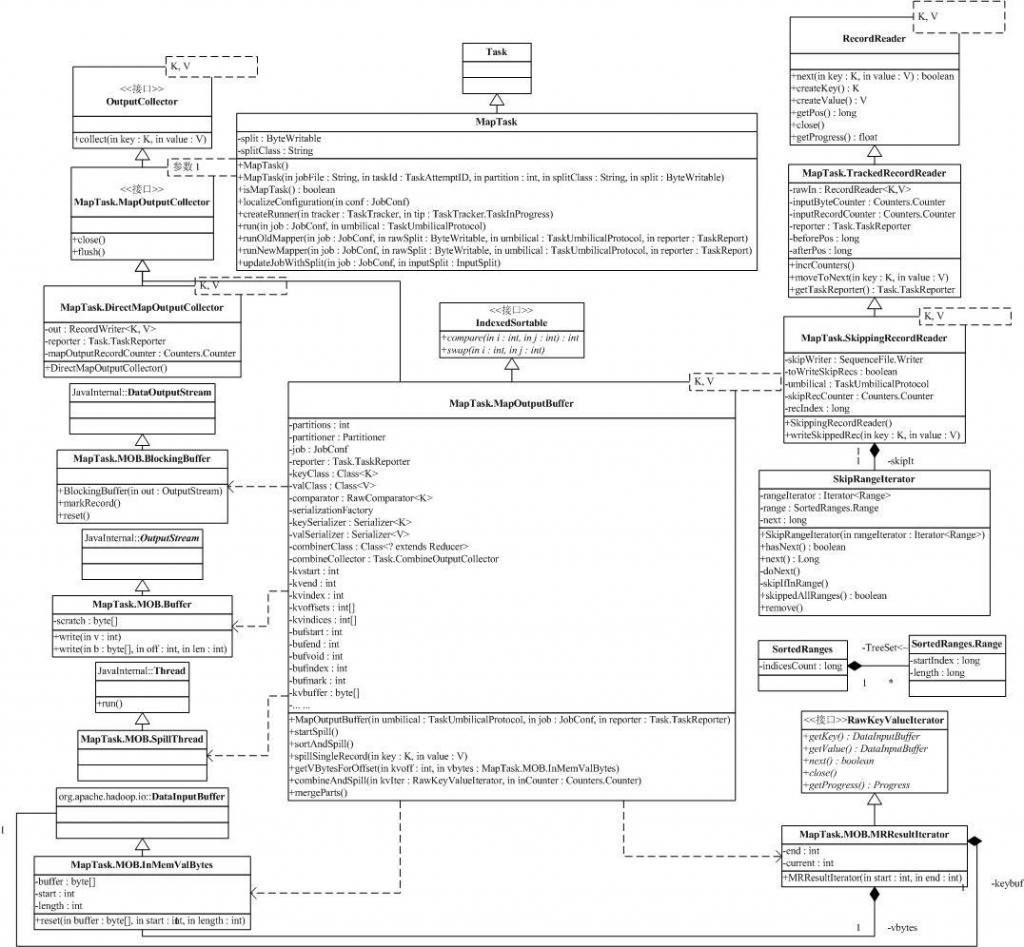
2 子进程执行MapTask
真实的执行载体,是Child,它包含一个 main函数,进程执行,会将相关参数传进来,它会拆解这些参数,通过getTask(jvmId)向父进程索取任务,并且构造出相关的Task实例,然后使用Task的run()启动任务。
2.1 run
方 法相当简单,配置完系统的TaskReporter后,就根据情况执行 runJobCleanupTask,runJobSetupTask,runTaskCleanupTask或执行Mapper。由于 MapReduce现在有两套API,MapTask需要支持这两套API,使得MapTask执行Mapper分为runNewMapper和 runOldMapper,我们分析runOldMapper。
2.2 runOldMapper
runOldMapper 最开始部分是构造Mapper处理的InputSplit,然后就开始创建Mapper的RecordReader,最终得到map的输入。之后构造 Mapper的输出,是通过MapOutputCollector进行的,也分两种情况,如果没有Reducer,那么,用 DirectMapOutputCollector,否则,用MapOutputBuffer。
构造完Mapper的输入输出,通过构造 配置文件中配置的MapRunnable,就可以执行Mapper了。目前系统有两个MapRunnable:MapRunner和 MultithreadedMapRunner。MapRunner是单线程执行器,比较简单,他会使用反射机制生成用户定义的Mapper接口实现类, 作为他的一个成员。
2.3 MapRunner的run方法
会先创建对应的key,value对象,然后,对 InputSplit的每一对<key,value>,调用用户实现的Mapper接口实现类的map方法,每处理一个数据对,就要使用 OutputCollector收集每次处理kv对后得到的新的kv对,把他们spill到文件或者放到内存,以做进一步的处理,比如排 序,combine等。
2.4 OutputCollector
OutputCollector的作用是收集每次调用map后得到的新的kv对,宁把他们spill到文件或者放到内存,以做进一步的处理,比如排序,combine等。
MapOutputCollector 有两个子类:MapOutputBuffer和DirectMapOutputCollector。 DirectMapOutputCollector用在不需要Reduce阶段的时候。如果Mapper后续有reduce任务,系统会使用 MapOutputBuffer做为输出, MapOutputBuffer使用了一个缓冲区对map的处理结果进行缓存,放在内存中,又使用几个数组对这个缓冲区进行管理。
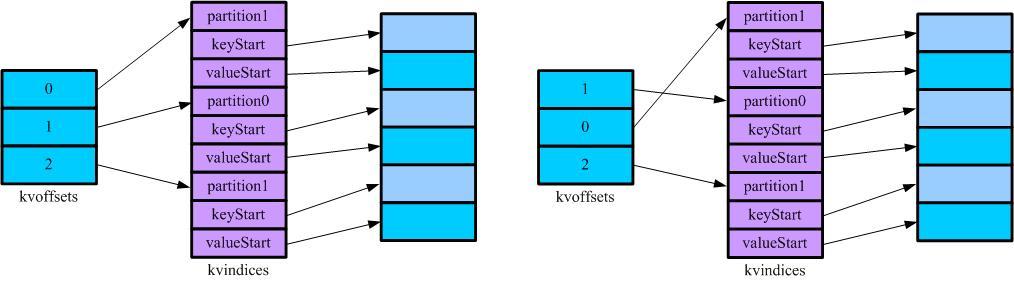
在适当的时机,缓冲区中的数据会被spill到硬盘中。
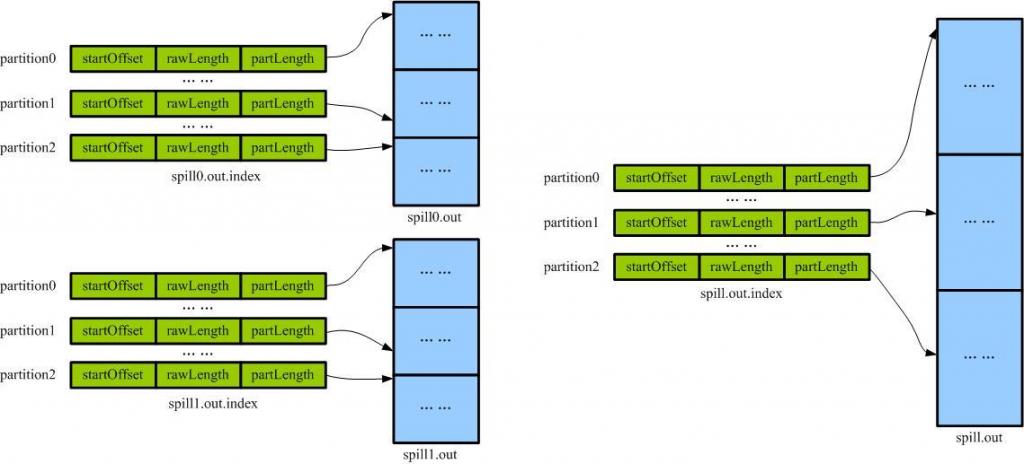
向硬盘中写数据的时机:
(1)当内存缓冲区不能容下一个太大的kv对时。spillSingleRecord方法。
(2)内存缓冲区已满时。SpillThread线程。
(3)Mapper的结果都已经collect了,需要对缓冲区做最后的清理。Flush方法。
2.5 spillThread线程:将缓冲区中的数据spill到硬盘中。
(1)需要spill时调用函数sortAndSpill,按照partition和key做排序。默认使用的是快速排序QuickSort。
(2)如果没有combiner,则直接输出记录,否则,调用CombinerRunner的combine,先做combin然后输出。
3 子进程执行ReduceTask
ReduceTask.run 方法开始和MapTask类似,包括initialize()初始化 ,runJobCleanupTask(),runJobSetupTask(),runTaskCleanupTask()。之后进入正式的工作,主要 有这么三个步骤:Copy、Sort、Reduce。
3.1 Copy
就是从执行各个Map任务的服务器那里,收罗到map的输出文件。拷贝的任务,是由ReduceTask.ReduceCopier 类来负责。
3.1.1 类图:
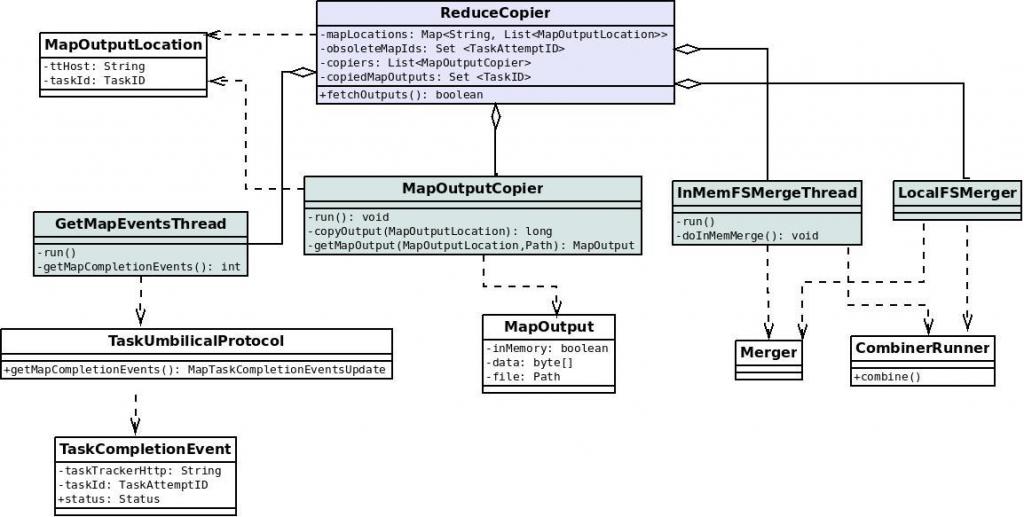
3.1.2 流程: 使用ReduceCopier.fetchOutputs开始
(1) 索取任务。使用GetMapEventsThread线程。该线程的run方法不停的调用getMapCompletionEvents方法,该方法又使 用RPC调用TaskUmbilicalProtocol协议的getMapCompletionEvents,方法使用所属的jobID向其父 TaskTracker询问此作业个Map任务的完成状况(TaskTracker要向JobTracker询问后再转告给它...)。返回一个数组 TaskCompletionEvent events[]。TaskCompletionEvent包含taskid和ip地址之类的信息。 (2)当获取到相关Map任务执行服务器的信息后,有一个线程MapOutputCopier开启,做具体的拷贝工作。 它会在一个单独的线程内,负责某个Map任务服务器上文件的拷贝工作。MapOutputCopier的run循环调用 copyOutput,copyOutput又调用getMapOutput,使用HTTP远程拷贝。
(3)getMapOutput远程拷贝过来的内容(当然也可以是本地了...),作为MapOutput对象存在,它可以在内存中也可以序列化在磁盘上,这个根据内存使用状况来自动调节。
(4) 同时,还有一个内存Merger线程InMemFSMergeThread和一个文件Merger线程LocalFSMerger在同步工作,它们将下载 过来的文件(可能在内存中,简单的统称为文件...),做着归并排序,以此,节约时间,降低输入文件的数量,为后续的排序工作减 负。InMemFSMergeThread的run循环调用doInMemMerge, 该方法使用工具类Merger实现归并,如果需要combine,则combinerRunner.combine。
3. 2 Sort
排序工作,就相当于上述排序工作的一个延续。它会在所有的文件都拷贝完毕后进行。使用工具类Merger归并所有的文件。经过这一个流程,一个合并了所有所需Map任务输出文件的新文件产生了。而那些从其他各个服务器网罗过来的 Map任务输出文件,全部删除了。
3.3 Reduce
Reduce 任务的最后一个阶段。他会准备好 keyClass("mapred.output.key.class"或"mapred.mapoutput.key.class"), valueClass("mapred.mapoutput.value.class"或"mapred.output.value.class")和 Comparator(“mapred.output.value.groupfn.class”或 “mapred.output.key.comparator.class”)。最后调用runOldReducer方法。(也是两套API,我们分析 runOldReducer)
3.3.1 runOldReducer
(1)输出方面。
它会准备一个 OutputCollector收集输出,与MapTask不同,这个OutputCollector更为简单,仅仅是打开一个 RecordWriter,collect一次,write一次。最大的不同在于,这次传入RecordWriter的文件系统,基本都是分布式文件系 统, 或者说是HDFS。
(2)输入方面,ReduceTask会用准备好的KeyClass、ValueClass、KeyComparator等等之类的自定义类,构造出Reducer所需的键类型, 和值的迭代类型Iterator(一个键到了这里一般是对应一组值)。
(3)有了输入,有了输出,不断循环调用自定义的Reducer,最终,Reduce阶段完成。


发表评论

-
Hadoop的Secondary NameNode方案
2012-11-13 10:39 1308http://book.51cto.com/art/20120 ... -
hadoop
2011-10-08 12:20 1139hadoop job解决 ... -
hadoop作业调优参数整理及原理
2011-04-15 14:02 13411 Map side tuning 参数 ... -
hadoop作业运行部分源码
2011-03-31 10:51 1460一、客户端 Map-Reduce的过程首先是由客户端提交 ... -
eclipse中编译hadoop(hive)源码
2011-03-24 13:20 3448本人按照下面编译Hadoop 所说的方法在eclipse中编 ... -
Configuration Parameters: What can you just ignore?
2011-03-11 15:16 900http://www.cloudera.com/blog/20 ... -
7 Tips for Improving MapReduce Performance
2011-03-11 15:06 1036http://www.cloudera.com/blog ... -
hadoop 源码分析一
2011-02-22 15:29 1246InputFormat : 将输入的� ... -
hadoop参数配置(mapreduce数据流)
2011-01-14 11:08 2933Hadoop配置文件设定了H ... -
混洗和排序
2011-01-05 19:33 3284在mapreduce过程中,map� ... -
hadoop中每个节点map和reduce个数的设置调优
2011-01-05 19:28 8489map red.tasktracker.map.tasks. ... -
hadoop profiling
2010-12-20 20:52 2667和debug task一样,profiling一个运行在分布 ... -
关于JVM内存设置
2010-12-20 20:49 1382运行map、reduce任务的JVM内存调整:(我当时是在jo ... -
HADOOP报错Incompatible namespaceIDs
2010-12-14 12:56 1045HADOOP报错Incomp ... -
node1-node6搭建hadoop
2010-12-13 18:42 1162环境: node1-node6 node1为主节点 ... -
hadoop启动耗时
2010-12-07 17:28 1354http://blog.csdn.net/AE86_FC/ar ... -
namenode 内部关键数据结构简介
2010-12-07 16:35 1307http://www.tbdata.org/archiv ... -
HDFS常用命令
2010-12-04 14:59 1344文件系统检查 bin/hadoop fsck [pa ... -
HDFS添加和删除节点
2010-12-04 14:45 2059From http://developer.yahoo.co ... -
hadoop 0.20 程式開發
2010-11-30 17:15 1318hadoop 0.20 程式開發 ecl ...
相关推荐
3. **Job设计**:学习如何使用Job来组织和协调Transformations,以及如何控制作业流程的逻辑,如错误处理、定时执行等。 4. **Transformation设计**:熟悉如何构建和优化转换,确保数据处理的效率和准确性。 5. **...
在深入了解Flink作业执行流程之前,我们首先要了解Flink的4层转化流程,从用户编写程序开始到最终物理执行计划的形成。 第一层转化,从用户编写的程序(Program)生成StreamGraph,这个过程主要是在用户代码中定义...
xxl-job是一个轻量级的任务调度平台,具备开源特性,其源码分析对于工程开发人员具有一定的参考价值。接下来,我们将详细介绍xxl-job的核心概念、架构特点以及源码分析过程中的关键知识点。 首先,xxl-job项目的...
从上述分析可以得知,Flink作业调度部署运行流程涉及到多个组件和步骤。JobMaster作为调度中心,协调各个TaskManager执行具体任务。而DefaultScheduler则负责具体的调度策略,包括资源的分配和任务的部署。...
2. **log目录**:存放服务的日志文件,便于排查问题和分析运行状态。 3. **conf目录**:包含配置文件,如`application.properties`,用户可以在这里修改Nacos地址、数据库连接信息等配置。 4. **lib目录**:存放项目...
在学习XXL-JOB时,不仅要理解其核心概念和组件,还需要深入源码分析调度流程、Spring启动过程,以及Java多线程和线程池的管理。同时,对于设计模式的理解也是必不可少的,这有助于我们更好地掌握系统的工作原理,...
总之,XXL-JOB-2.2.0源码的分析可以帮助我们理解分布式任务调度的实现细节,了解任务的分发、执行、监控等核心流程,为自定义任务处理和扩展提供指导。深入学习这些源码,不仅可以提升开发技能,也能提高解决实际...
通过控制台,用户可以追踪作业的历史运行记录,包括执行时间、执行结果、耗时等信息,这对于分析作业性能、排查故障至关重要。同时,实时的作业运行状态展示,让用户能及时了解作业当前的执行情况,如有无异常、...
在SpringBoot项目中集成XXL-Job,可以利用Spring的自动配置能力简化任务调度的开发流程。通常需要添加XXL-Job的相关依赖,并配置相应的调度和执行器地址,以便让SpringBoot应用成为XXL-Job的执行节点。 3. **源代码...
最后,Elastic-Job Lite Console的界面直观易用,提供了丰富的图表展示任务执行情况,如任务执行统计、失败原因分析等,便于开发者进行数据分析和优化。而且,它还支持API接口,方便与其他系统集成,实现更高级别的...
XXL-JOB是一款开源的分布式任务调度平台,其2.3.0版本...无论是简单的定时任务还是复杂的业务流程,XXL-JOB都能提供有力的支持。通过解压和学习这个压缩包中的内容,开发者可以更好地理解和利用XXL-JOB来提升项目效率。
6. **业务流程中的异步处理**: 在业务流程中,有些耗时操作可以通过XXL-JOB异步执行,提高系统响应速度。 总结来说,XXL-JOB作为一个强大而灵活的分布式任务调度框架,广泛应用于各种业务场景,提供了一套完整的...
Apache Sqoop 是一个用于在关系型...通过创建、查看、执行和删除job,我们可以更好地组织和自动化数据传输过程,特别是在结合调度工具如Oozie或Airflow时,能实现定时任务的自动化运行,从而提升整体的数据处理能力。
它为数据工程师和数据科学家提供了一个简易的方式来组织、调度以及执行他们编写的大数据处理作业,即Job。Azkaban通过定义一系列的Job来形成工作流,然后按照依赖关系顺序执行这些Job。每个Job通常包含一个或者多个...
4. **生成JobConf文件**:`Job`会将所有配置信息写入一个`JobConf`文件,这是Job运行所必需的配置文件,包含了作业的所有元数据。 5. **创建JobHistory文件**:为了记录作业的运行历史,MapReduce会在本地创建一个...
两者都提供了一种解耦任务执行和任务调度的方式,使得任务可以灵活地在分布式环境中运行。 2. **核心特性** - **分布式调度**:Elastic-Job 可以将一个大任务拆分成多个小任务,分布到不同的服务器上并行执行,...
本篇将详细阐述Hadoop中的MapReduce执行流程,包括其主要概念、数据结构和整体工作过程。 1. MapReduce执行的关键角色 - JobClient:MapReduce作业的起点,用户通过JobClient类提交作业,包含应用程序和配置信息。...
而业务流程则是具体执行任务的过程,如市场营销、设计开发、生产制造等。流程的质量和效率直接影响企业的经营效果和竞争力。 流程的重要性在于,它们构成了企业所有经营活动的基础,其输出直接关系到客户满意度。...
- **异常处理**:在任务代码中,要处理可能出现的异常,避免影响整个任务执行流程。 9. **集成Spring**: - **Spring Boot集成**:通过引入相关依赖和配置,可以将Elastic-job轻松集成到Spring Boot应用中。 - *...