本人按照下面编译Hadoop
所说的方法在eclipse中编译hive没有成功。
在windows上重新装了一个ant1.8,在cmd中直接用ant编译成功。
eclipse中编译没有成功原因是 D:\workspace\hive\build-common.xml:392: java.lang.UnsupportedClassVersionError: Bad version number in .class file
即编译和运行的JDK版本不统一,修改如下
1.Window --> Preferences -->Java --> compiler中的compiler compliance level对应的下拉菜单中选择JDK版本6.0.
2.Window --> Preferences -->Java -->Installed JRES,然后在右边选择与步骤1版本一致的JDK版本
至此版本设置是统一的JDK6.0,还是报错,原因尚待查明。。。
===============================================================
以上问题的解决:
3.工程名右键-》properties-》builders-》选中新建的hive_builder(ant类型),edit-》JRE-》runtime JRE-》separate JRE-》选择外部安装的JDK6.0。
编译成功。
===============================================================
编译Hadoop
在这里,我们以编译Hadoop 家庭成员common 为例,对Hadoop 其它成员的编译方法是类似的。
3.1. 编译common成员
步骤1) 在Elipse 的Package 视图中单击右键,选择New->Java Project,如下图所示:
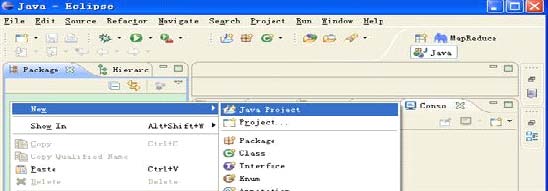
步骤2) 选择源代码目录,设置Project 名。
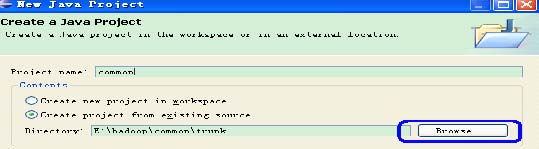
在上图所示的对话框中,点击Browse 按钮,选择common 源代码目录,并设置Projectname
为common。工程导入完成后,进入Eclipse 主界面,可以看到common 已经导入进来,但可以看到common
上有红叉叉,是因为Elipse 默认使用了Java Builder,而不是Ant Builder,所以下一步就是设置使用Ant Builder。
步骤3) 设置Builder 为Ant:右键common->Properties->Builders:
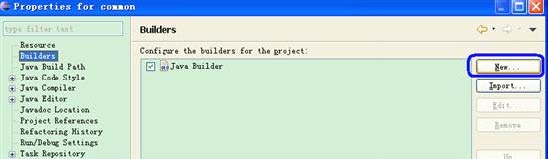
在上图所示的界面中,点击New 按钮,在弹出的对话框中选中Ant Builder,确定之后会弹出如下对话框:

点击Browse File System 按钮,选择common 源代码目录下的build.xml 文件,并设置Name
为common_Builder(Name 可以改成其它的,但建议使用common_Builder,因为这样名副其实),操作结果如下图所示:
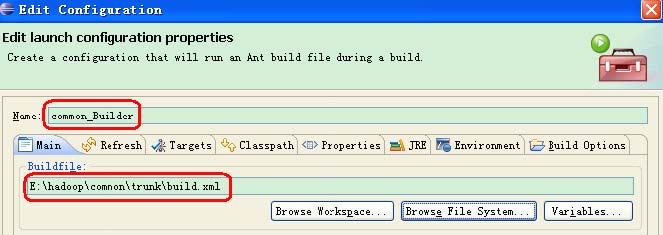
除上图所示的设置外,还需要设置如下图所示的Targets,建议设置成Manual Build 编译方式,而不是Auto Build
编译方式。因为在Auto Build 模式下,任何修改都会触发编译,而Manual Build
模式下,只在需要的时候,点击编译按钮或菜单编译即可。

Hadoop 各成员都需要编译成jar,所以做如下图所示的一个修改:

确定之后,返回如下图所示的Edit Configuration 对话框:

上面完成后,回到Builder 的主对话框,再将对话框中的Java Builder 下移,并将它前面的勾去掉。
进入Eclipse 主界面,由于之前选择了Manual Build,所以需要人工方式驱动编译,编译成功后,可以看到BUILD SUCCESSFUL 字样。

请注意:如果上图所示的菜单中的Build Automatically 被勾中,则在common 的右键菜单中可能不会出现Build 子菜单。
在编译过程中,Ant 会自动从网上下载所依赖的库。common 的编译成功结束后,可以在build 目录下找到编译后生成的文件hadoop-core-0.21.0-dev.jar。
3.2. 编译Hadoop其它成员
hdfs、mapreduce 和hive 的编译方式同common。
4. FAQ
4.1. 联网
确保可以上internet,Ant 需要自动下载很多第三方依赖库,如果不能联网,编译会复杂很多。
4.2. 编译hive
hive 的编译相对复杂些,而且默认它会编译多个版本的hive,建立修改shims 目录下的ivy.xml 文件,去掉不必要版本的编译。
4.3. 编译生成文件位置
common 编译后生成build\hadoop-core-0.21.0-dev.jar;
hdfs 编译后生成build\hadoop-hdfs-0.21.0-dev.jar;
mapreduce 编译后生成build\hadoop-mapred-0.21.0-dev.jar;
hive 编译后生成build\service\hive_service.jar,请注意并没有直接放在build 目录下;
hbase 编译后生成build\hbase-0.21.0-dev.jar;
有时候在编译某个时出错,可先跳过,编译其它的,Refresh 之后再编译。
分享到:





相关推荐
"dataiku hive udf"项目提供的是一套通用的Hive UDF源码,对于那些想深入开发Hadoop Hive应用的开发者来说,这是一个宝贵的资源。 首先,我们需要理解Hive UDF的类型。Hive UDF分为三种主要类别:UDF(User Defined...
在Eclipse中编译Hadoop源码的基本步骤如下: 1. **环境准备**:首先确保已经安装了JDK、Maven等相关开发环境。 2. **下载源码**:从Apache官方网站下载最新的Hadoop源码包。 3. **导入Eclipse**:将下载的源码导入...
根据描述,“kettle在表输出到星环inceptor数据库时,由于选择了DB连接类型为Hadoop Hive2,并且在Kettle的big-data-plugin插件的源码中默认关闭了批量提交的功能”,这导致了在创建DB连接时,...
- 学习如何编译Hadoop源码,这对于理解其内部工作原理和进行定制化开发至关重要。 - 使用Hadoop-Eclipse-Plugin插件,可以方便地在Eclipse中远程调试Hadoop程序,这对于在本地开发并在集群上运行程序很有帮助。 -...
这个压缩包文件“winutils-master”很可能包含了不同版本的winutils源码,供开发者根据自己的Hadoop版本选择和编译,以确保兼容性。对于Windows环境下的Hadoop开发者来说,掌握winutils的使用方法和原理是必不可少的...
例如,Eclipse插件不仅支持MapReduce开发,还可以与Hadoop的其他组件如Spark、Hive等集成。 综上所述,Hadoop-2.8.5是一个功能强大且稳定的版本,提供了丰富的工具和支持,适用于各种规模的数据处理需求。无论是...
7. **源码编译**:如果你需要修改或扩展Hadoop源码,你需要了解如何使用Maven来编译Hadoop。这包括下载源码,配置pom.xml文件,然后执行编译命令。 8. **开发工具选择**:除了Eclipse,还有MyEclipse等其他开发工具...
Apache Hive 是一个基于Hadoop的数据仓库工具,它允许用户通过SQL-like的语言(称为HQL,Hive Query Language...对于希望从事大数据分析、数据仓库设计和优化的工程师而言,深入研究Hive源码是提升专业技能的重要途径。
这个名为“hadoop-2.7.2-src”的压缩包包含的是Hadoop 2.7.2版本的源代码,是未编译的状态,意味着用户可以对其进行编译、修改和进一步定制,以满足特定的需求。 Hadoop 2.7.2是一个重要的版本,它在Hadoop 2.x系列...
此外,专刊还提供了源代码级别的Eclipse编译教程,这对于开发者来说尤其重要。通过Eclipse这样的集成开发环境(IDE),可以更方便地编写、测试和调试Hadoop应用程序。教程将指导读者如何设置Hadoop项目,导入相关依赖...
通常,开发者需要在Eclipse等集成开发环境中配置Hadoop源码,然后进行编译。在Windows和Linux环境下,安装步骤略有不同,包括设置环境变量、获取源码、构建项目以及解决依赖关系等。通过编译源码,开发者可以定制化...
最后,开发工具方面,Eclipse IDE是一个广泛使用的Java开发环境,也可以用来进行Hadoop项目的源码编译。无论是Linux还是Windows,开发者都需要掌握源码编译技术,以便于调试和优化Hadoop程序。 在搭建Hadoop环境的...
3. **源码软件**:源码软件意味着提供的是未经编译的程序代码,开发者可以查看、修改和再分发代码,有利于学习、调试和定制系统功能。 4. **数据采集**:系统可能集成了爬虫技术,从各种在线资源(如学校就业网站、...
大多数大数据软件都可以在集成开发环境中(如IntelliJ IDEA或Eclipse)进行开发和调试,需要安装相应的插件支持。例如,对于Spark开发,可以使用Scala IDE或IntelliJ的Spark和Hadoop插件。 以上是安装大数据软件的...