µ£ĆĶ┐æÕćåÕżćõ╝śÕī¢õĖĆõĖ¬ń╝ōÕŁśńÜäõĖ£Ķź┐’╝īń£ŗõ║åõĖŗõĖĆĶć┤µĆ¦hashń«Śµ│Ģ’╝īńäČÕÉÄńĮæõĖŖńÜäĶĄäµ¢Öõ╣¤µ»öĶŠāµØéÕżÜ’╝īµēŠÕł░Ķ┐Öń»ćµĆ╗ń╗ōõĖŹķöÖńÜäµ¢ćń½Ā’╝īµĢģĶĮ¼ĶĮĮµØźŃĆé
┬Ā
ĶĮ¼ĶĮĮĶ欒╝Ühttp://blog.csdn.net/sparkliang/archive/2010/02/02/5279393.aspx
┬Ā
õĖĆĶć┤µĆ¦
hash
ń«Śµ│Ģ’╝ł
consistent
hashing
’╝ē
Õ╝Āõ║«
consistent hashing
ń«Śµ│ĢµŚ®Õ£©
1997
Õ╣┤Õ░▒Õ£©Ķ«║µ¢ć
Consistent
hashing and random trees
õĖŁĶó½µÅÉÕć║’╝īńø«ÕēŹÕ£©
cache
ń│╗ń╗¤õĖŁÕ║öńö©ĶČŖµØźĶČŖÕ╣┐µ│ø’╝ø
1
Õ¤║µ£¼Õ£║µÖ»
µ»öÕ”éõĮĀµ£ē
N
õĖ¬
cache
µ£ŹÕŖĪÕÖ©’╝łÕÉÄķØóń«Ćń¦░
cache
’╝ē’╝īķéŻõ╣łÕ”éõĮĢÕ░åõĖĆõĖ¬Õ»╣Ķ▒Ī
object
µśĀÕ░äÕł░
N
õĖ¬
cache
õĖŖÕæó’╝īõĮĀÕŠłÕÅ»ĶāĮõ╝Üķććńö©ń▒╗õ╝╝õĖŗķØóńÜäķĆÜńö©µ¢╣µ│ĢĶ«Īń«Ś
object
ńÜä
hash
ÕĆ╝’╝īńäČÕÉÄÕØćÕīĆńÜ䵜ĀÕ░äÕł░Õł░
N
õĖ¬
cache
’╝ø
hash(object)%N
õĖĆÕłćķāĮĶ┐ÉĶĪīµŁŻÕĖĖ’╝īÕåŹĶĆāĶÖæÕ”éõĖŗńÜäõĖżń¦ŹµāģÕåĄ’╝ø
1
õĖĆõĖ¬
cache
µ£ŹÕŖĪÕÖ©
m down
µÄēõ║å’╝łÕ£©Õ«×ķÖģÕ║öńö©õĖŁÕ┐ģķĪ╗Ķ”üĶĆāĶÖæĶ┐Öń¦ŹµāģÕåĄ’╝ē’╝īĶ┐ÖµĀʵēƵ£ēµśĀÕ░äÕł░
cache m
ńÜäÕ»╣Ķ▒ĪķāĮõ╝ÜÕż▒µĢł’╝īµĆÄõ╣łÕŖ×’╝īķ£ĆĶ”üµŖŖ
cache m
õ╗Ä
cache
õĖŁń¦╗ķÖż’╝īĶ┐ÖµŚČÕĆÖ
cache
µś»
N-1
ÕÅ░’╝īµśĀÕ░äÕģ¼Õ╝ÅÕÅśµłÉõ║å
hash(object)%(N-1)
’╝ø
2
ńö▒õ║ÄĶ«┐ķŚ«ÕŖĀķ插╝īķ£ĆĶ”üµĘ╗ÕŖĀ
cache
’╝īĶ┐ÖµŚČÕĆÖ
cache
µś»
N+1
ÕÅ░’╝īµśĀÕ░äÕģ¼Õ╝ÅÕÅśµłÉõ║å
hash(object)%(N+1)
’╝ø
1
ÕÆī
2
µäÅÕæ│ńØĆõ╗Ćõ╣ł’╝¤Ķ┐ÖµäÅÕæ│ńØĆń¬üńäČõ╣ŗķŚ┤ÕćĀõ╣ĵēƵ£ēńÜä
cache
ķāĮÕż▒µĢłõ║åŃĆéÕ»╣õ║ĵ£ŹÕŖĪÕÖ©ĶĆīĶ©Ć’╝īĶ┐Öµś»õĖĆÕ£║ńüŠķÜŠ’╝īµ┤¬µ░┤Ķł¼ńÜäĶ«┐ķŚ«ķāĮõ╝Üńø┤µÄźÕå▓ÕÉæÕÉÄÕÅ░µ£ŹÕŖĪÕÖ©’╝ø
ÕåŹµØźĶĆāĶÖæń¼¼õĖēõĖ¬ķŚ«ķóś’╝īńö▒õ║ÄńĪ¼õ╗ČĶāĮÕŖøĶČŖµØźĶČŖÕ╝║’╝īõĮĀÕÅ»ĶāĮµā│Ķ«®ÕÉÄķØóµĘ╗ÕŖĀńÜäĶŖéńé╣ÕżÜÕüÜńé╣µ┤╗’╝īµśŠńäČõĖŖķØóńÜä
hash
ń«Śµ│Ģõ╣¤ÕüÜõĖŹÕł░ŃĆé
┬Ā
µ£ēõ╗Ćõ╣łµ¢╣µ│ĢÕÅ»õ╗źµö╣ÕÅśĶ┐ÖõĖ¬ńŖČÕåĄÕæó’╝īĶ┐ÖÕ░▒µś»
consistent hashing...
2 hash
ń«Śµ│ĢÕÆīÕŹĢĶ░āµĆ¦
ŃĆĆŃĆĆ
Hash
ń«Śµ│ĢńÜäõĖĆõĖ¬ĶĪĪķćŵīćµĀ浜»ÕŹĢĶ░āµĆ¦’╝ł
Monotonicity
’╝ē’╝īÕ«Üõ╣ēÕ”éõĖŗ’╝Ü
ŃĆĆŃĆĆÕŹĢĶ░āµĆ¦µś»µīćÕ”éµ×£ÕĘ▓ń╗ŵ£ēõĖĆõ║øÕåģÕ«╣ķĆÜĶ┐ćÕōłÕĖīÕłåµ┤ŠÕł░õ║åńøĖÕ║öńÜäń╝ōÕå▓õĖŁ’╝īÕÅłµ£ēµ¢░ńÜäń╝ōÕå▓ÕŖĀÕģźÕł░ń│╗ń╗¤õĖŁŃĆéÕōłÕĖīńÜäń╗ōµ×£Õ║öĶāĮÕż¤õ┐ØĶ»üÕĤµ£ēÕĘ▓ÕłåķģŹńÜäÕåģÕ«╣ÕÅ»õ╗źĶó½µśĀÕ░äÕł░µ¢░ńÜäń╝ōÕå▓õĖŁÕÄ╗’╝īĶĆīõĖŹõ╝ÜĶó½µśĀÕ░äÕł░µŚ¦ńÜäń╝ōÕå▓ķøåÕÉłõĖŁńÜäÕģČõ╗¢ń╝ōÕå▓Õī║ŃĆé
Õ«╣µśōń£ŗÕł░’╝īõĖŖķØóńÜäń«ĆÕŹĢ
hash
ń«Śµ│Ģ
hash(object)%N
ķÜŠõ╗źµ╗ĪĶČ│ÕŹĢĶ░āµĆ¦Ķ”üµ▒éŃĆé
3 consistent hashing
ń«Śµ│ĢńÜäÕĤńÉå
consistent
hashing
µś»õĖĆń¦Ź
hash
ń«Śµ│Ģ’╝īń«ĆÕŹĢńÜäĶ»┤’╝īÕ£©ń¦╗ķÖż
/
µĘ╗ÕŖĀõĖĆõĖ¬
cache
µŚČ’╝īÕ«āĶāĮÕż¤Õ░ĮÕÅ»ĶāĮÕ░ÅńÜäµö╣ÕÅśÕĘ▓ÕŁśÕ£©
key
µśĀÕ░äÕģ│ń│╗’╝īÕ░ĮÕÅ»ĶāĮńÜäµ╗ĪĶČ│ÕŹĢĶ░āµĆ¦ńÜäĶ”üµ▒éŃĆé
õĖŗķØóÕ░▒µØźµīēńģ¦
5
õĖ¬µŁźķ¬żń«ĆÕŹĢĶ«▓Ķ«▓
consistent hashing
ń«Śµ│ĢńÜäÕ¤║µ£¼ÕĤńÉåŃĆé
3.1
ńÄ»ÕĮóhash
ń®║ķŚ┤
ĶĆāĶÖæķĆÜÕĖĖńÜä
hash
ń«Śµ│ĢķāĮµś»Õ░å
value
µśĀÕ░äÕł░õĖĆõĖ¬
32
õĖ║ńÜä
key
ÕĆ╝’╝īõ╣¤ÕŹ│µś»
0~2^32-1
µ¼Īµ¢╣ńÜäµĢ░ÕĆ╝ń®║ķŚ┤’╝øµłæõ╗¼ÕÅ»õ╗źÕ░åĶ┐ÖõĖ¬ń®║ķŚ┤µā│Ķ▒ĪµłÉõĖĆõĖ¬ķ”¢’╝ł
0
’╝ēÕ░Š’╝ł
2^32-1
’╝ēńøĖµÄźńÜäÕ£åńÄ»’╝īÕ”éõĖŗķØóÕøŠ
1
µēĆńż║ńÜäķ鯵ĀĘŃĆé

ÕøŠ
1
ńÄ»ÕĮó
hash
ń®║ķŚ┤
3.2
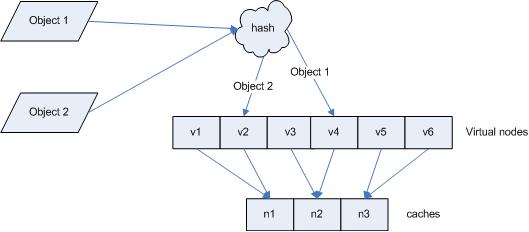
µŖŖÕ»╣Ķ▒ĪµśĀÕ░äÕł░hash
ń®║ķŚ┤
µÄźõĖŗµØźĶĆāĶÖæ
4
õĖ¬Õ»╣Ķ▒Ī
object1~object4
’╝īķĆÜĶ┐ć
hash
ÕćĮµĢ░Ķ«Īń«ŚÕć║ńÜä
hash
ÕĆ╝
key
Õ£©ńÄ»õĖŖńÜäÕłåÕĖāÕ”éÕøŠ
2
µēĆńż║ŃĆé
hash(object1) = key1;
ŌĆ” ŌĆ”
hash(object4) = key4;

ÕøŠ
2 4
õĖ¬Õ»╣Ķ▒ĪńÜä
key
ÕĆ╝ÕłåÕĖā
3.3
µŖŖcache
µśĀÕ░äÕł░hash
ń®║ķŚ┤
Consistent
hashing
ńÜäÕ¤║µ£¼µĆصā│Õ░▒µś»Õ░åÕ»╣Ķ▒ĪÕÆī
cache
ķāĮµśĀÕ░äÕł░ÕÉīõĖĆõĖ¬
hash
µĢ░ÕĆ╝ń®║ķŚ┤õĖŁ’╝īÕ╣ČõĖöõĮ┐ńö©ńøĖÕÉīńÜä
hash
ń«Śµ│ĢŃĆé
ÕüćĶ«ŠÕĮōÕēŹµ£ē
A,B
ÕÆī
C
Õģ▒
3
ÕÅ░
cache
’╝īķéŻõ╣łÕģȵśĀÕ░äń╗ōµ×£Õ░åÕ”éÕøŠ
3
µēĆńż║’╝īõ╗¢õ╗¼Õ£©
hash
ń®║ķŚ┤õĖŁ’╝īõ╗źÕ»╣Õ║öńÜä
hash
ÕĆ╝µÄÆÕłŚŃĆé
hash(cache A) = key A;
ŌĆ” ŌĆ”
hash(cache C) = key C;

ÕøŠ
3 cache
ÕÆīÕ»╣Ķ▒ĪńÜä
key
ÕĆ╝ÕłåÕĖā
┬Ā
Ķ»┤Õł░Ķ┐Öķćī’╝īķĪ║õŠ┐µÅÉõĖĆõĖŗ
cache
ńÜä
hash
Ķ«Īń«Ś’╝īõĖĆĶł¼ńÜäµ¢╣µ│ĢÕÅ»õ╗źõĮ┐ńö©
cache
µ£║ÕÖ©ńÜä
IP
Õ£░ÕØƵł¢ĶĆģµ£║ÕÖ©ÕÉŹõĮ£õĖ║
hash
ĶŠōÕģźŃĆé
3.4
µŖŖÕ»╣Ķ▒ĪµśĀÕ░äÕł░cache
ńÄ░Õ£©
cache
ÕÆīÕ»╣Ķ▒ĪķāĮÕĘ▓ń╗ÅķĆÜĶ┐ćÕÉīõĖĆõĖ¬
hash
ń«Śµ│ĢµśĀÕ░äÕł░
hash
µĢ░ÕĆ╝ń®║ķŚ┤õĖŁõ║å’╝īµÄźõĖŗµØźĶ”üĶĆāĶÖæńÜäÕ░▒µś»Õ”éõĮĢÕ░åÕ»╣Ķ▒ĪµśĀÕ░äÕł░
cache
õĖŖķØóõ║åŃĆé
Õ£©Ķ┐ÖõĖ¬ńÄ»ÕĮóń®║ķŚ┤õĖŁ’╝īÕ”éµ×£µ▓┐ńØĆķĪ║µŚČķÆłµ¢╣ÕÉæõ╗ÄÕ»╣Ķ▒ĪńÜä
key
ÕĆ╝Õć║ÕÅæ’╝īńø┤Õł░ķüćĶ¦üõĖĆõĖ¬
cache
’╝īķéŻõ╣łÕ░▒Õ░åĶ»źÕ»╣Ķ▒ĪÕŁśÕé©Õ£©Ķ┐ÖõĖ¬
cache
õĖŖ’╝īÕøĀõĖ║Õ»╣Ķ▒ĪÕÆī
cache
ńÜä
hash
ÕĆ╝µś»Õø║Õ«ÜńÜä’╝īÕøĀµŁżĶ┐ÖõĖ¬
cache
Õ┐ģńäȵś»Õö»õĖĆÕÆīńĪ«Õ«ÜńÜäŃĆéĶ┐ÖµĀĘõĖŹÕ░▒µēŠÕł░õ║åÕ»╣Ķ▒ĪÕÆī
cache
ńÜ䵜ĀÕ░äµ¢╣µ│Ģõ║åÕÉŚ’╝¤’╝ü
õŠØńäČń╗¦ń╗ŁõĖŖķØóńÜäõŠŗÕŁÉ’╝łÕÅéĶ¦üÕøŠ
3
’╝ē’╝īķéŻõ╣łµĀ╣µŹ«õĖŖķØóńÜäµ¢╣µ│Ģ’╝īÕ»╣Ķ▒Ī
object1
Õ░åĶó½ÕŁśÕé©Õł░
cache A
õĖŖ’╝ø
object2
ÕÆī
object3
Õ»╣Õ║öÕł░
cache C
’╝ø
object4
Õ»╣Õ║öÕł░
cache B
’╝ø
3.5
ĶĆāÕ»¤cache
ńÜäÕÅśÕŖ©
ÕēŹķØóĶ«▓Ķ┐ć’╝īķĆÜĶ┐ć
hash
ńäČÕÉĵ▒éõĮÖńÜäµ¢╣µ│ĢÕĖ”µØźńÜäµ£ĆÕż¦ķŚ«ķóśÕ░▒Õ£©õ║ÄõĖŹĶāĮµ╗ĪĶČ│ÕŹĢĶ░āµĆ¦’╝īÕĮō
cache
µ£ēµēĆÕÅśÕŖ©µŚČ’╝ī
cache
õ╝ÜÕż▒µĢł’╝īĶ┐øĶĆīÕ»╣ÕÉÄÕÅ░µ£ŹÕŖĪÕÖ©ķĆĀµłÉÕĘ©Õż¦ńÜäÕå▓Õć╗’╝īńÄ░Õ£©Õ░▒µØźÕłåµ×ÉÕłåµ×É
consistent
hashing
ń«Śµ│ĢŃĆé
3.5.1
ń¦╗ķÖż
cache
ĶĆāĶÖæÕüćĶ«Š
cache B
µīéµÄēõ║å’╝īµĀ╣µŹ«õĖŖķØóĶ«▓Õł░ńÜ䵜ĀÕ░äµ¢╣µ│Ģ’╝īĶ┐ÖµŚČÕÅŚÕĮ▒ÕōŹńÜäÕ░åõ╗ģµś»ķéŻõ║øµ▓┐
cache B
ķĆåµŚČķÆłķüŹÕÄåńø┤Õł░õĖŗõĖĆõĖ¬
cache
’╝ł
cache C
’╝ēõ╣ŗķŚ┤ńÜäÕ»╣Ķ▒Ī’╝īõ╣¤ÕŹ│µś»µ£¼µØźµśĀÕ░äÕł░
cache B
õĖŖńÜäķéŻõ║øÕ»╣Ķ▒ĪŃĆé
ÕøĀµŁżĶ┐Öķćīõ╗ģķ£ĆĶ”üÕÅśÕŖ©Õ»╣Ķ▒Ī
object4
’╝īÕ░åÕģČķ揵¢░µśĀÕ░äÕł░
cache C
õĖŖÕŹ│ÕÅ»’╝øÕÅéĶ¦üÕøŠ
4
ŃĆé

ÕøŠ
4 Cache B
Ķó½ń¦╗ķÖżÕÉÄńÜä
cache
µśĀÕ░ä
3.5.2
µĘ╗ÕŖĀ
cache
ÕåŹĶĆāĶÖæµĘ╗ÕŖĀõĖĆÕÅ░µ¢░ńÜä
cache D
ńÜäµāģÕåĄ’╝īÕüćĶ«ŠÕ£©Ķ┐ÖõĖ¬ńÄ»ÕĮó
hash
ń®║ķŚ┤õĖŁ’╝ī
cache D
Ķó½µśĀÕ░äÕ£©Õ»╣Ķ▒Ī
object2
ÕÆī
object3
õ╣ŗķŚ┤ŃĆéĶ┐ÖµŚČÕÅŚÕĮ▒ÕōŹńÜäÕ░åõ╗ģµś»ķéŻõ║øµ▓┐
cache D
ķĆåµŚČķÆłķüŹÕÄåńø┤Õł░õĖŗõĖĆõĖ¬
cache
’╝ł
cache B
’╝ēõ╣ŗķŚ┤ńÜäÕ»╣Ķ▒Ī’╝łÕ«āõ╗¼µś»õ╣¤µ£¼µØźµśĀÕ░äÕł░
cache C
õĖŖÕ»╣Ķ▒ĪńÜäõĖĆķā©Õłå’╝ē’╝īÕ░åĶ┐Öõ║øÕ»╣Ķ▒Īķ揵¢░µśĀÕ░äÕł░
cache D
õĖŖÕŹ│ÕÅ»ŃĆé
┬Ā
ÕøĀµŁżĶ┐Öķćīõ╗ģķ£ĆĶ”üÕÅśÕŖ©Õ»╣Ķ▒Ī
object2
’╝īÕ░åÕģČķ揵¢░µśĀÕ░äÕł░
cache D
õĖŖ’╝øÕÅéĶ¦üÕøŠ
5
ŃĆé

ÕøŠ
5
µĘ╗ÕŖĀ
cache D
ÕÉÄńÜ䵜ĀÕ░äÕģ│ń│╗
4
ĶÖܵŗ¤ĶŖéńé╣
ĶĆāķćÅ
Hash
ń«Śµ│ĢńÜäÕÅ”õĖĆõĖ¬µīćµĀ浜»Õ╣│ĶĪĪµĆ¦
(Balance)
’╝īÕ«Üõ╣ēÕ”éõĖŗ’╝Ü
Õ╣│ĶĪĪµĆ¦
ŃĆĆŃĆĆÕ╣│ĶĪĪµĆ¦µś»µīćÕōłÕĖīńÜäń╗ōµ×£ĶāĮÕż¤Õ░ĮÕÅ»ĶāĮÕłåÕĖāÕł░µēƵ£ēńÜäń╝ōÕå▓õĖŁÕÄ╗’╝īĶ┐ÖµĀĘÕÅ»õ╗źõĮ┐ÕŠŚµēƵ£ēńÜäń╝ōÕå▓ń®║ķŚ┤ķāĮÕŠŚÕł░Õł®ńö©ŃĆé
hash
ń«Śµ│ĢÕ╣ČõĖŹµś»õ┐ØĶ»üń╗ØÕ»╣ńÜäÕ╣│ĶĪĪ’╝īÕ”éµ×£
cache
ĶŠāÕ░æńÜäĶ»Ø’╝īÕ»╣Ķ▒ĪÕ╣ČõĖŹĶāĮĶó½ÕØćÕīĆńÜ䵜ĀÕ░äÕł░
cache
õĖŖ’╝īµ»öÕ”éÕ£©õĖŖķØóńÜäõŠŗÕŁÉõĖŁ’╝īõ╗ģķā©ńĮ▓
cache A
ÕÆī
cache C
ńÜäµāģÕåĄõĖŗ’╝īÕ£©
4
õĖ¬Õ»╣Ķ▒ĪõĖŁ’╝ī
cache A
õ╗ģÕŁśÕé©õ║å
object1
’╝īĶĆī
cache C
ÕłÖÕŁśÕé©õ║å
object2
ŃĆü
object3
ÕÆī
object4
’╝øÕłåÕĖāµś»ÕŠłõĖŹÕØćĶĪĪńÜäŃĆé
õĖ║õ║åĶ¦ŻÕå│Ķ┐Öń¦ŹµāģÕåĄ’╝ī
consistent hashing
Õ╝ĢÕģźõ║åŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØńÜäµ”éÕ┐Ą’╝īÕ«āÕÅ»õ╗źÕ”éõĖŗÕ«Üõ╣ē’╝Ü
ŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØ’╝ł
virtual node
’╝ēµś»Õ«×ķÖģĶŖéńé╣Õ£©
hash
ń®║ķŚ┤ńÜäÕżŹÕłČÕōü’╝ł
replica
’╝ē’╝īõĖĆÕ«×ķÖģõĖ¬ĶŖéńé╣Õ»╣Õ║öõ║åĶŗźÕ╣▓õĖ¬ŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØ’╝īĶ┐ÖõĖ¬Õ»╣Õ║öõĖ¬µĢ░õ╣¤µłÉõĖ║ŌĆ£ÕżŹÕłČõĖ¬µĢ░ŌĆØ’╝īŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØÕ£©
hash
ń®║ķŚ┤õĖŁõ╗ź
hash
ÕĆ╝µÄÆÕłŚŃĆé
õ╗Źõ╗źõ╗ģķā©ńĮ▓
cache A
ÕÆī
cache C
ńÜäµāģÕåĄõĖ║õŠŗ’╝īÕ£©ÕøŠ
4
õĖŁµłæõ╗¼ÕĘ▓ń╗Åń£ŗÕł░’╝ī
cache
ÕłåÕĖāÕ╣ČõĖŹÕØćÕīĆŃĆéńÄ░Õ£©µłæõ╗¼Õ╝ĢÕģźĶÖܵŗ¤ĶŖéńé╣’╝īÕ╣ČĶ«ŠńĮ«ŌĆ£ÕżŹÕłČõĖ¬µĢ░ŌĆØõĖ║
2
’╝īĶ┐ÖÕ░▒µäÅÕæ│ńØĆõĖĆÕģ▒õ╝ÜÕŁśÕ£©
4
õĖ¬ŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØ’╝ī
cache A1, cache A2
õ╗ŻĶĪ©õ║å
cache A
’╝ø
cache C1, cache C2
õ╗ŻĶĪ©õ║å
cache C
’╝øÕüćĶ«ŠõĖĆń¦Źµ»öĶŠāńÉåµā│ńÜäµāģÕåĄ’╝īÕÅéĶ¦üÕøŠ
6
ŃĆé

ÕøŠ
6
Õ╝ĢÕģźŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØÕÉÄńÜ䵜ĀÕ░äÕģ│ń│╗
┬Ā
µŁżµŚČ’╝īÕ»╣Ķ▒ĪÕł░ŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØńÜ䵜ĀÕ░äÕģ│ń│╗õĖ║’╝Ü
objec1->cache A2
’╝ø
objec2->cache A1
’╝ø
objec3->cache C1
’╝ø
objec4->cache C2
’╝ø
ÕøĀµŁżÕ»╣Ķ▒Ī
object1
ÕÆī
object2
ķāĮĶó½µśĀÕ░äÕł░õ║å
cache A
õĖŖ’╝īĶĆī
object3
ÕÆī
object4
µśĀÕ░äÕł░õ║å
cache C
õĖŖ’╝øÕ╣│ĶĪĪµĆ¦µ£ēõ║åÕŠłÕż¦µÅÉķ½śŃĆé
Õ╝ĢÕģźŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØÕÉÄ’╝īµśĀÕ░äÕģ│ń│╗Õ░▒õ╗Ä
{
Õ»╣Ķ▒Ī
->
ĶŖéńé╣
}
ĶĮ¼µŹóÕł░õ║å
{
Õ»╣Ķ▒Ī
->
ĶÖܵŗ¤ĶŖéńé╣
}
ŃĆ鵤źĶ»óńē®õĮōµēĆÕ£©
cache
µŚČńÜ䵜ĀÕ░äÕģ│ń│╗Õ”éÕøŠ
7
µēĆńż║ŃĆé
ÕøŠ
7
µ¤źĶ»óÕ»╣Ķ▒ĪµēĆÕ£©
cache
┬Ā
ŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØńÜä
hash
Ķ«Īń«ŚÕÅ»õ╗źķććńö©Õ»╣Õ║öĶŖéńé╣ńÜä
IP
Õ£░ÕØĆÕŖĀµĢ░ÕŁŚÕÉÄń╝ĆńÜäµ¢╣Õ╝ÅŃĆéõŠŗÕ”éÕüćĶ«Š
cache A
ńÜä
IP
Õ£░ÕØĆõĖ║
202.168.14.241
ŃĆé
Õ╝ĢÕģźŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØÕēŹ’╝īĶ«Īń«Ś
cache
A
ńÜä
hash
ÕĆ╝’╝Ü
Hash(ŌĆ£202.168.14.241ŌĆØ);
Õ╝ĢÕģźŌĆ£ĶÖܵŗ¤ĶŖéńé╣ŌĆØÕÉÄ’╝īĶ«Īń«ŚŌĆ£ĶÖܵŗ¤ĶŖéŌĆØńé╣
cache A1
ÕÆī
cache A2
ńÜä
hash
ÕĆ╝’╝Ü
Hash(ŌĆ£202.168.14.241#1ŌĆØ);┬Ā
// cache A1
Hash(ŌĆ£202.168.14.241#2ŌĆØ);┬Ā
// cache A2
5
Õ░Åń╗ō
Consistent
hashing
ńÜäÕ¤║µ£¼ÕĤńÉåÕ░▒µś»Ķ┐Öõ║ø’╝īÕģĘõĮōńÜäÕłåÕĖāµĆ¦ńŁēńÉåĶ«║Õłåµ×ÉÕ║öĶ»źµś»ÕŠłÕżŹµØéńÜä’╝īõĖŹĶ┐ćõĖĆĶł¼õ╣¤ńö©õĖŹÕł░ŃĆé
http://weblogs.java.net/blog/2007/11/27/consistent-hashing
õĖŖķØóµ£ēõĖĆõĖ¬
java
ńēłµ£¼ńÜäõŠŗÕŁÉ’╝īÕÅ»õ╗źÕÅéĶĆāŃĆé
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx
ĶĮ¼ĶĮĮõ║åõĖĆõĖ¬
PHP
ńēłńÜäÕ«×ńÄ░õ╗ŻńĀüŃĆé
http://www.codeproject.com/KB/recipes/lib-conhash.aspx
CĶ»ŁĶ©Ćńēłµ£¼
┬Ā
õĖĆõ║øÕÅéĶĆāĶĄäµ¢ÖÕ£░ÕØĆ’╝Ü
http://portal.acm.org/citation.cfm?id=258660
http://en.wikipedia.org/wiki/Consistent_hashing
http://www.spiteful.com/2008/03/17/programmers-toolbox-part-3-consistent-hashing/
┬Āhttp://weblogs.java.net/blog/2007/11/27/consistent-hashing
http://tech.idv2.com/2008/07/24/memcached-004/
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx
Õłåõ║½Õł░’╝Ü





ńøĖÕģ│µÄ©ĶŹÉ
õĖĆĶć┤µĆ¦ÕōłÕĖīń«Śµ│Ģ(Consistent Hashing)µś»õĖĆń¦ŹÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁÕ╣│ĶĪĪµĢ░µŹ«ÕłåÕĖāńÜäńŁ¢ńĢź’╝īÕ░żÕģČķĆéńö©õ║Äń╝ōÕŁśµ£ŹÕŖĪÕ”éMemcachedµł¢RedisŃĆéÕ«āńÜäµĀĖÕ┐āµĆصā│µś»ķĆÜĶ┐ćÕōłÕĖīÕćĮµĢ░Õ░åÕ»╣Ķ▒ĪµśĀÕ░äÕł░õĖĆõĖ¬Õø║Õ«ÜÕż¦Õ░ÅńÜäńÄ»ÕĮóń®║ķŚ┤õĖŁ’╝īńäČÕÉÄÕ░åµ£ŹÕŖĪÕÖ©õ╣¤µśĀÕ░äÕł░Ķ┐ÖõĖ¬...
Õ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁ’╝īÕĖĖÕĖĖķ£ĆĶ”üõĮ┐ńö©ń╝ōÕŁś’╝īĶĆīõĖöķĆÜÕĖĖµś»ķøåńŠż’╝īĶ«┐ķŚ«ń╝ōÕŁśÕÆīµĘ╗ÕŖĀń╝ōÕŁśķāĮķ£ĆĶ”üõĖĆõĖ¬ hash ń«Śµ│ĢµØźÕ»╗µēŠÕł░ÕÉłķĆéńÜä Cache ĶŖéńé╣ŃĆéõĮå’╝īķĆÜÕĖĖõĖŹµś»ńö©ÕÅ¢õĮÖhash’╝īĶĆīµś»õĮ┐ńö©µłæõ╗¼õ╗ŖÕż®ńÜäõĖ╗Ķ¦ÆŌĆöŌĆö õĖĆĶć┤µĆ¦ hash ń«Śµ│ĢŃĆé
### õĖĆĶć┤µĆ¦ Hash ń«Śµ│ĢĶ»”Ķ¦Ż #### õĖĆŃĆüÕ╝ĢĶ©Ć õĖĆĶć┤µĆ¦ Hash ń«Śµ│Ģµś»õĖĆń¦Źńē╣µ«ŖńÜäÕōłÕĖīń«Śµ│Ģ’╝īõĖ╗Ķ”üńö©õ║ÄĶ¦ŻÕå│ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁĶŖéńé╣Õó×ÕłĀµŚČµĢ░µŹ«ķćŹÕ«ÜõĮŹńÜäķŚ«ķóśŃĆéĶ»źń«Śµ│Ģµ£ĆµŚ®õ║Ä1997Õ╣┤Õ£©ŃĆŖConsistent hashing and random treesŃĆŗĶ┐Öń»ćĶ«║µ¢ćõĖŁ...
Õ«āµ£ĆµŚ®Õ£©1997Õ╣┤ńÜäĶ«║µ¢ćŃĆŖConsistent Hashing and Random TreesŃĆŗõĖŁĶó½µÅÉÕć║’╝īµŚ©Õ£©Õģŗµ£Źõ╝Āń╗¤ÕōłÕĖīń«Śµ│ĢÕ£©ÕŖ©µĆüµĘ╗ÕŖĀµł¢ÕłĀķÖżĶŖéńé╣µŚČÕ»╝Ķć┤ńÜäÕż¦ķćŵĢ░µŹ«Ķ┐üń¦╗ķŚ«ķóśŃĆé õ╝Āń╗¤ńÜäÕōłÕĖīń«Śµ│Ģõ╝ÜÕ░åÕ»╣Ķ▒ĪķĆÜĶ┐ćÕōłÕĖīÕćĮµĢ░µśĀÕ░äÕł░õĖĆõĖ¬Õø║իܵĢ░ķćÅńÜäµĪČ’╝łõŠŗÕ”é...
õĖĆĶć┤µĆ¦ÕōłÕĖī’╝łConsistent Hashing’╝ēµś»õĖĆń¦ŹÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁĶ¦ŻÕå│µĢ░µŹ«ÕłåńēćķŚ«ķóśńÜäń«Śµ│Ģ’╝īÕ«āÕ£©GoĶ»ŁĶ©ĆõĖŁńÜäÕ«×ńÄ░Õ»╣õ║ĵ×äÕ╗║ÕÅ»µē®Õ▒ĢõĖöÕ«╣ķöÖńÜäµ£ŹÕŖĪĶć│Õģ│ķćŹĶ”üŃĆéÕ£©GoÕ╝ĆÕÅæõĖŁ’╝īÕ░żÕģȵś»Õ£©µČēÕÅŖÕłåÕĖāÕ╝Åń╝ōÕŁśŃĆüĶ┤¤ĶĮĮÕØćĶĪĪńŁēÕ£║µÖ»õĖŗ’╝īõĖĆĶć┤µĆ¦ÕōłÕĖīĶāĮÕż¤...
õĖĆĶć┤µĆ¦ÕōłÕĖī’╝łConsistent Hashing’╝ēµś»õĖĆń¦Źńö©õ║ÄÕłåÕĖāÕ╝Åń│╗ń╗¤ńÜäÕōłÕĖīń«Śµ│Ģ’╝īõĖ╗Ķ”üÕ║öńö©õ║ÄÕłåÕĖāÕ╝Åń╝ōÕŁśŃĆüÕłåÕĖāÕ╝ŵĢ░µŹ«Õ║ōńŁēÕ£║µÖ»’╝īńø«ńÜ䵜»Õ£©ĶŖéńé╣ÕŖ©µĆüÕó×ÕćŵŚČõ┐صīüÕōłÕĖīĶĪ©ńÜäń©│Õ«ÜµĆ¦’╝īõ╗ÄĶĆīµ£ĆÕ░ÅÕī¢µĢ░µŹ«Ķ┐üń¦╗ńÜäÕĮ▒ÕōŹŃĆéÕ«āĶ¦ŻÕå│õ║åõ╝Āń╗¤ÕōłÕĖīÕÅ¢µ©Īµ¢╣µ│ĢÕ£©...
lua õĖĆĶć┤µĆ¦ÕōłÕĖīÕ¤║õ║Ä yaoweibin ńÜäõĖĆĶć┤µĆ¦ÕōłÕĖīÕłåµö»’╝ł ’╝ēÕ£© lua õĖŁķ揵¢░Õ«×ńÄ░õĖĆĶć┤µĆ¦ÕōłÕĖīńö©µ│Ģ local chash = require " chash "chash. add_upstream ( " 192.168.0.251 " )chash. add_upstream ( " 192.168.0.252 " )chash...
õĖĆĶć┤µĆ¦ÕōłÕĖīń«Śµ│Ģ’╝łConsistent Hashing’╝ēµś»õĖĆń¦ŹÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁÕ«×ńÄ░Ķ┤¤ĶĮĮÕØćĶĪĪńÜäń«Śµ│Ģ’╝īÕ░żÕģČÕ£©ÕłåÕĖāÕ╝Åń╝ōÕŁśÕ”éMemcachedÕÆīRedisńŁēÕ£║µÖ»õĖŗÕ╣┐µ│øõĮ┐ńö©ŃĆéÕ«āĶ¦ŻÕå│õ║åõ╝Āń╗¤ÕōłÕĖīń«Śµ│ĢÕ£©ĶŖéńé╣Õó×ÕćŵŚČÕ»╝Ķć┤ńÜäÕż¦ķćŵĢ░µŹ«Ķ┐üń¦╗ķŚ«ķóś’╝īµÅÉķ½śõ║åń│╗ń╗¤ńÜäÕÅ»ńö©...
### õĖĆĶć┤µĆ¦Hashń«Śµ│ĢńÜäÕĤńÉåÕÅŖÕ«×ńÄ░ #### õĖĆŃĆüÕ╝ĢĶ©Ć õĖĆĶć┤µĆ¦Hashń«Śµ│Ģµś»õĖĆń¦Źńö©õ║ÄĶ¦ŻÕå│ÕłåÕĖāÕ╝ÅńÄ»ÕóāõĖŗµĢ░µŹ«ÕŁśÕé©ÕÆīµŻĆń┤óķŚ«ķóśńÜäķćŹĶ”üµŖƵ£»ŃĆéÕ«āµ£ĆÕłØńö▒David KargerńŁēõ║║Õ£©1997Õ╣┤ńÜäĶ«║µ¢ćŃĆŖConsistent Hashing and Random Trees: ...
#fly-archflylibÕłøń½ŗńÜäÕÉäń¦ŹÕĖĖĶ¦üńÜäµ×ȵ×äµŖƵ£»ÕåģÕ«╣ÕłŚĶĪ©cassandra-demo cassandraµĢ░µŹ«Õ║ōńÜäÕģźķŚ©ń╝¢ń©ŗconsistent-hash Java implementation of consistent-hashingÕ¤║õ║ÄjavańÜäõĖĆĶć┤µĆ¦hashńÜäÕ«×ńÄ░õĖĆĶć┤µĆ¦hash(consistent-hashing)...
õĖĆĶć┤µĆ¦ÕōłÕĖī’╝łConsistent Hashing’╝ēµś»õĖĆń¦ŹÕłåÕĖāÕ╝ÅÕōłÕĖīĶĪ©’╝łDHT’╝ēńÜäń«Śµ│Ģ’╝īÕ«āõĖ╗Ķ”üÕ║öńö©õ║ÄÕłåÕĖāÕ╝Åń╝ōÕŁśŃĆüĶ┤¤ĶĮĮÕØćĶĪĪńŁēÕ£║µÖ»’╝īµŚ©Õ£©Ķ¦ŻÕå│Õ£©ÕŖ©µĆüµē®Õ▒Ģµł¢µöČń╝®ń│╗ń╗¤Ķ¦äµ©ĪµŚČ’╝īÕ░ĮķćÅÕćÅÕ░æµĢ░µŹ«Ķ┐üń¦╗ńÜäķŚ«ķóśŃĆéÕ£©Ķ┐ÖõĖ¬ń«ĆÕŹĢńÜäÕ«×ńÄ░õĖŁ’╝īµłæõ╗¼Õ░åµÄóĶ«©Õ”éõĮĢ...
ĶĘ│ĶĘāõĖĆĶć┤ÕōłÕĖīĶ«Īń«Ś ńöÜĶć│µ£ŹÕŖĪÕÖ©õ╣ŗķŚ┤ńÜäµĢ░µŹ«ÕłåÕĖāõ╣¤ķØ×ÕĖĖķćŹĶ”ü’╝ÜÕÅ”õĖĆõĖ¬ķćŹĶ”üµ¢╣ķØ󵜻ĶāĮÕż¤... Õģ│õ║ÄõĖĆĶć┤µĆ¦ÕōłÕĖī’╝īõĮ┐ńö©ńÜäń«Śµ│Ģµś»Ķ░ʵŁīńÜäĶ«║µ¢ćŌĆ£A Fast, Minimal Memory, Consistent Hash AlgorithmŌĆØõĖŁµÅÉÕć║ńÜäJump Consistent HashingŃĆé
õĖĆĶć┤µĆ¦ÕōłÕĖīń«Śµ│Ģ’╝łConsistent Hashing’╝ēµś»õĖĆń¦ŹÕĖĖńö©õ║ÄÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńÜäµĢ░µŹ«ÕłåńēćńŁ¢ńĢź’╝īÕ«āµ£ēµĢłÕ£░Ķ¦ŻÕå│õ║åµĢ░µŹ«Õ£©ÕżÜÕÅ░µ£ŹÕŖĪÕÖ©ķŚ┤ÕØćÕīĆÕłåÕĖāńÜäķŚ«ķóś’╝īÕÉīµŚČÕćÅÕ░æõ║åÕøĀĶŖéńé╣ÕŖĀÕģźµł¢ń”╗Õ╝ƵŚČńÜäµĢ░µŹ«Ķ┐üń¦╗µłÉµ£¼ŃĆé ķ”¢Õģł’╝īõĖĆĶć┤µĆ¦ÕōłÕĖīńÜäÕ¤║µ£¼ÕĤńÉåµś»Õ░å...
õĖĆĶć┤µĆ¦ÕōłÕĖīń«Śµ│Ģ’╝łConsistent Hashing’╝ēµś»õĖĆń¦Źńē╣µ«ŖńÜäÕōłÕĖīń«Śµ│Ģ’╝īĶ«ŠĶ«Īńø«ńÜ䵜»õĖ║õ║åÕ£©ÕłåÕĖāÕ╝Åń╝ōÕŁśń│╗ń╗¤õĖŁĶ¦ŻÕå│ĶŖéńé╣ÕŖ©µĆüÕó×ÕćŵŚČÕ»╝Ķć┤ńÜäµĢ░µŹ«ÕłåÕĖāõĖŹÕØćķŚ«ķóśŃĆéĶ»źń«Śµ│Ģµ£ĆµŚ®Õ£©1997Õ╣┤ńÜäĶ«║µ¢ćŃĆŖConsistent Hashing and Random TreesŃĆŗõĖŁĶó½...
õĖĆĶć┤µĆ¦ÕōłÕĖīń«Śµ│Ģ(Consistent Hashing)µś»õĖĆń¦Źńē╣µ«ŖńÜäÕōłÕĖīń«Śµ│Ģ’╝īĶ«ŠĶ«Īńø«ńÜ䵜»õĖ║õ║åÕ£©ÕłåÕĖāÕ╝Åń╝ōÕŁśń│╗ń╗¤õĖŁĶ¦ŻÕå│ĶŖéńé╣ÕŖ©µĆüÕó×ÕćŵŚČÕ»╝Ķć┤ńÜäķö«ÕĆ╝µśĀÕ░äÕż¦ķćÅÕÅśµø┤ńÜäķŚ«ķóśŃĆéÕ«āµ£ĆµŚ®Õ£©1997Õ╣┤ńÜäĶ«║µ¢ćŃĆŖConsistent hashing and random treesŃĆŗõĖŁĶó½...
8. µĢŻÕłŚÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńÜäÕ║öńö©’╝ÜõŠŗÕ”éõĖĆĶć┤µĆ¦ÕōłÕĖī’╝łConsistent Hashing’╝ē’╝īńö©õ║ÄÕ£©ÕłåÕĖāÕ╝Åń╝ōÕŁśÕÆīÕłåÕĖāÕ╝ŵĢ░µŹ«Õ║ōõĖŁÕłåķģŹĶŖéńé╣’╝īõ┐صīüÕ£©ĶŖéńé╣Õó×ÕćŵŚČÕ░ĮķćÅÕ░ÅńÜäÕĮ▒ÕōŹŃĆé 9. µĢŻÕłŚõĖÄÕ«ēÕģ©µĆ¦’╝ÜÕ£©Õ»åńĀüÕŁ”õĖŁ’╝īµĢŻÕłŚÕćĮµĢ░ÕĖĖńö©õ║ÄÕ»åńĀüÕŁśÕé©’╝īķĆÜĶ┐ć...
3. **õĖĆĶć┤µĆ¦ÕōłÕĖī’╝łConsistent Hashing’╝ē**’╝ÜÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁ’╝īõĖĆĶć┤µĆ¦ÕōłÕĖīµś»õĖĆń¦ŹĶ¦ŻÕå│ĶŖéńé╣ÕŖ©µĆüÕó×ÕłĀµŚČÕ░ĮķćÅÕćÅÕ░æķ揵¢░ÕłåÕĖāńÜäµĢ░µŹ«ķćÅńÜäń«Śµ│ĢŃĆéµ¢ćõ╗ČÕÉŹõĖ║`ConsistentHash.java`’╝īÕÅ»ĶāĮµś»õĖĆõĖ¬Õ«×ńÄ░õĖĆĶć┤µĆ¦ÕōłÕĖīńÜäń▒╗ŃĆéõĖĆĶć┤µĆ¦ÕōłÕĖīńÜäõĖ╗Ķ”ü...
õĖĆĶć┤µĆ¦ÕōłÕĖī(Consistent Hashing)µś»õĖĆń¦ŹÕłåÕĖāÕ╝ÅÕōłÕĖīĶĪ©(DHT, Distributed Hash Table)ńÜäń«Śµ│Ģ’╝īõĖ╗Ķ”üńö©õ║ÄĶ¦ŻÕå│Õ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁµĢ░µŹ«ÕłåńēćŃĆüĶ┤¤ĶĮĮÕØćĶĪĪŃĆüń╝ōÕŁśÕłåÕÅæńŁēķŚ«ķóśŃĆéÕ£©õ║æĶ«Īń«ŚÕÆīÕż¦µĢ░µŹ«ķóåÕ¤¤’╝īõĖĆĶć┤µĆ¦ÕōłÕĖīń«Śµ│Ģµ£ēńØĆÕ╣┐µ│øńÜäÕ║öńö©’╝ī...