
еҲҶи§Је’ҢеҗҲ并пјҡJava д№ҹж“…й•ҝиҪ»жқҫзҡ„并иЎҢзј–зЁӢпјҒ
дҪңиҖ…пјҡJulien Ponge
Java SE 7 жҸҗдҫӣзҡ„ж–°еҲҶи§Ј/еҗҲ并任еҠЎеҰӮдҪ•дҪҝзј–еҶҷ并иЎҢзЁӢеәҸеҸҳеҫ—жӣҙиҪ»жқҫпјҹ
2011 е№ҙ 7 жңҲеҸ‘еёғ
дёӢиҪҪпјҡ![]() Java SE 7
Java SE 7![]() зӨәдҫӢд»Јз Ғ (Zip)
зӨәдҫӢд»Јз Ғ (Zip)
еӨҡж ёеӨ„зҗҶеҷЁзҺ°еңЁе·Іе№ҝжіӣеә”з”ЁдәҺжңҚеҠЎеҷЁгҖҒеҸ°ејҸжңәе’Ңдҫҝжҗәжңә硬件гҖӮе®ғ们иҝҳжү©еұ•еҲ°еҲ°жӣҙе°Ҹзҡ„и®ҫеӨҮпјҢеҰӮжҷәиғҪз”өиҜқе’Ңе№іжқҝз”өи„‘гҖӮз”ұдәҺиҝӣзЁӢзҡ„зәҝзЁӢеҸҜд»ҘеңЁеӨҡдёӘеҶ…ж ёдёҠ并иЎҢжү§иЎҢпјҢеӣ жӯӨеӨҡж ёеӨ„зҗҶеҷЁдёә并еҸ‘зј–зЁӢжү“ејҖдәҶдёҖжүҮжүҮж–°зҡ„еӨ§й—ЁгҖӮдёәе®һзҺ°еә”з”ЁзЁӢеәҸзҡ„жңҖеӨ§жҖ§иғҪпјҢдёҖйЎ№йҮҚиҰҒзҡ„жҠҖжңҜе°ұжҳҜе°ҶеҜҶйӣҶеһӢд»»еҠЎжӢҶеҲҶжҲҗеҸҜд»Ҙ并иЎҢжү§иЎҢзҡ„иӢҘе№Іе°Ҹеқ—пјҢд»ҘдҫҝжңҖеӨ§зЁӢеәҰеҲ©з”Ёи®Ўз®—иғҪеҠӣгҖӮ
дј з»ҹдёҠпјҢеӨ„зҗҶ并еҸ‘пјҲ并иЎҢпјүзј–зЁӢдёҖзӣҙеҫҲеӣ°йҡҫпјҢеӣ дёәжӮЁдёҚеҫ—дёҚеӨ„зҗҶзәҝзЁӢеҗҢжӯҘе’Ңе…ұдә«ж•°жҚ®зҡ„й—®йўҳгҖӮGroovy (GPar)гҖҒScala е’Ң Clojure зӨҫеҢәзҡ„еҠӘеҠӣе·Із»ҸиҜҒжҳҺпјҢдәә们еҜ№ Java е№іеҸ°дёҠ并еҸ‘зј–зЁӢзҡ„иҜӯиЁҖзә§ж”ҜжҢҒзҡ„е…ҙи¶ЈеҚҒеҲҶејәзғҲгҖӮиҝҷдәӣзӨҫеҢәйғҪе°қиҜ•жҸҗдҫӣе…Ёйқўзҡ„зј–зЁӢжЁЎеһӢе’Ңй«ҳж•Ҳзҡ„е®һзҺ°пјҢд»ҘеұҸи”ҪдёҺеӨҡзәҝзЁӢе’ҢеҲҶеёғејҸеә”з”ЁзЁӢеәҸзӣёе…ізҡ„йҡҫзӮ№гҖӮдҪҶдёҚеә”и®Өдёә Java иҜӯиЁҖжң¬иә«еңЁиҝҷж–№йқўйҖҠиүІгҖӮJava Platform, Standard Edition (Java SE) 5 еҸҠеҗҺжқҘзҡ„ Java SE 6 еј•е…ҘдәҶдёҖз»„зЁӢеәҸеҢ…пјҢеҸҜд»ҘжҸҗдҫӣејәеӨ§зҡ„并еҸ‘жһ„е»әеқ—гҖӮJava SE 7 йҖҡиҝҮж·»еҠ 并иЎҢж”ҜжҢҒиҝӣдёҖжӯҘеўһејәдәҶиҝҷдәӣжһ„е»әеқ—гҖӮ
дёӢж–ҮйҰ–е…Ҳз®ҖеҚ•еӣһйЎҫдәҶ Java 并еҸ‘зј–зЁӢпјҢд»Һж—©жңҹзүҲжң¬д»ҘжқҘе·Із»ҸеӯҳеңЁзҡ„дҪҺзә§жңәеҲ¶ејҖе§ӢгҖӮ然еҗҺеңЁд»Ӣз»Қ Java SE 7 дёӯз”ұеҲҶи§Ј/еҗҲ并жЎҶжһ¶жҸҗдҫӣзҡ„ж–°еўһеҹәжң¬еҠҹиғҪеҲҶи§Ј/еҗҲ并任еҠЎд№ӢеүҚпјҢе…Ҳд»Ӣз»Қ java.util.concurrent зЁӢеәҸеҢ…ж·»еҠ зҡ„дё°еҜҢеҹәе…ғгҖӮж–Үдёӯз»ҷеҮәдәҶиҝҷдәӣж–° API зҡ„зӨәдҫӢз”Ёжі•гҖӮжңҖеҗҺпјҢеңЁз»“жқҹд№ӢеүҚеҜ№ж–№жі•иҝӣиЎҢдәҶи®Ёи®әгҖӮ
дёӢйқўпјҢжҲ‘们еҒҮе®ҡиҜ»иҖ…жӢҘжңү Java SE 5 жҲ– Java SE 6 зј–зЁӢиғҢжҷҜгҖӮеңЁжӯӨиҝҮзЁӢдёӯпјҢжҲ‘们иҝҳе°Ҷд»Ӣз»Қ Java SE 7 дёҖдәӣе®һз”Ёзҡ„иҜӯиЁҖеҸ‘еұ•гҖӮ
Java 并еҸ‘зј–зЁӢ
дј з»ҹзәҝзЁӢ
иҝҮеҺ»пјҢJava 并еҸ‘зј–зЁӢеҢ…жӢ¬йҖҡиҝҮ java.lang.Thread зұ»е’Ң java.lang.Runnable жҺҘеҸЈзј–еҶҷзәҝзЁӢпјҢ然еҗҺзЎ®дҝқе…¶д»Јз Ғд»ҘжӯЈзЎ®гҖҒдёҖиҮҙзҡ„ж–№ејҸеҜ№е…ұдә«еҸҜеҸҳеҜ№иұЎиҝӣиЎҢж“ҚдҪң并йҒҝе…Қй”ҷиҜҜзҡ„иҜ»/еҶҷж“ҚдҪңпјҢеҗҢж—¶дёҚдјҡдә§з”ҹз”ұдәҺй”Ғдәүз”ЁжқЎд»¶жүҖеҜјиҮҙзҡ„жӯ»й”ҒгҖӮд»ҘдёӢжҳҜеҹәжң¬зәҝзЁӢж“ҚдҪңзҡ„зӨәдҫӢпјҡ
Thread thread = new Thread() {
@Override public void run() {
System.out.println(">>> I am running in a separate thread!");
}
};
thread.start();
thread.join();
жң¬зӨәдҫӢдёӯзҡ„д»Јз ҒжүҖеҒҡзҡ„еҸӘжҳҜеҲӣе»әдёҖдёӘзәҝзЁӢпјҢиҜҘзәҝзЁӢе°ҶдёҖдёӘеӯ—з¬ҰдёІжү“еҚ°еҲ°ж ҮеҮҶиҫ“еҮәжөҒгҖӮдё»зәҝзЁӢйҖҡиҝҮи°ғз”Ё join() зӯүеҫ…жүҖеҲӣе»әзҡ„пјҲеӯҗпјүзәҝзЁӢе®ҢжҲҗгҖӮ
иҝҷж ·зӣҙжҺҘж“ҚдҪңзәҝзЁӢеҜ№дәҺз®ҖеҚ•зӨәдҫӢжқҘиҜҙжҳҜдёҚй”ҷпјҢдҪҶеҜ№дәҺ并еҸ‘зј–зЁӢпјҢиҝҷз§Қд»Јз ҒеҫҲеҝ«е°ұе®№жҳ“дә§з”ҹй”ҷиҜҜпјҢе°Өе…¶жҳҜеҪ“еӨҡдёӘзәҝзЁӢйңҖиҰҒеҗҲдҪңжү§иЎҢдёҖдёӘеӨ§еһӢд»»еҠЎж—¶гҖӮеңЁиҝҷж ·зҡ„жғ…еҶөдёӢпјҢйңҖиҰҒеҚҸи°ғе…¶жҺ§еҲ¶жөҒгҖӮ
дҫӢеҰӮпјҢжҹҗдёӘзәҝзЁӢжү§иЎҢзҡ„е®ҢжҲҗеҸҜиғҪдҫқиө–дәҺе…¶д»–зәҝзЁӢжү§иЎҢе®ҢжҲҗгҖӮйҖҡеёёдәә们зҶҹзҹҘзҡ„зӨәдҫӢжҳҜз”ҹдә§иҖ…/дҪҝз”ЁиҖ…зҡ„дҫӢеӯҗпјҢеҰӮжһңдҪҝз”ЁиҖ…зҡ„йҳҹеҲ—е·Іж»ЎеҲҷз”ҹдә§иҖ…еә”зӯүеҫ…дҪҝз”ЁиҖ…пјҢеҪ“йҳҹеҲ—дёәз©әж—¶дҪҝз”ЁиҖ…еә”зӯүеҫ…з”ҹдә§иҖ…гҖӮиҝҷдёҖиҰҒжұӮеҸҜйҖҡиҝҮе…ұдә«зҠ¶жҖҒе’ҢжқЎд»¶йҳҹеҲ—еҫ—еҲ°ж»Ўи¶іпјҢдҪҶжӮЁд»ҚйңҖиҰҒйҖҡиҝҮеҜ№е…ұдә«зҠ¶жҖҒеҜ№иұЎдҪҝз”Ё java.lang.Object.notify() е’Ң java.lang.Object.wait() жқҘдҪҝз”ЁеҗҢжӯҘпјҢиҝҷеҫҲе®№жҳ“еҮәй”ҷгҖӮ
жңҖеҗҺпјҢдёҖдёӘеёёи§Ғзҡ„й—®йўҳжҳҜеҜ№еӨ§ж®өд»Јз Ғз”ҡиҮіжҳҜж•ҙдёӘж–№жі•дҪҝз”ЁеҗҢжӯҘе’ҢжҸҗдҫӣдә’ж–ҘгҖӮе°Ҫз®ЎжӯӨж–№жі•еҸҜдә§з”ҹзәҝзЁӢе®үе…Ёзҡ„д»Јз ҒпјҢдҪҶз”ұдәҺжҺ’йҷӨе®һйҷ…дёҠиҝҮй•ҝжүҖеј•иө·зҡ„жңүйҷҗ并иЎҢеәҰпјҢиҜҘж–№жі•йҖҡеёёеҜјиҮҙжҖ§иғҪеҸҳе·®гҖӮ
жӯЈеҰӮи®Ўз®—дёӯз»ҸеёёеҸ‘з”ҹзҡ„йӮЈж ·пјҢж“ҚдҪңдҪҺзә§еҹәе…ғд»Ҙе®һзҺ°еӨҚжқӮж“ҚдҪңдјҡжү“ејҖй”ҷиҜҜд№Ӣй—ЁпјҢеӣ жӯӨејҖеҸ‘дәәе‘ҳеә”жғіеҠһжі•е°ҶеӨҚжқӮжҖ§е°ҒиЈ…еңЁй«ҳж•Ҳзҡ„й«ҳзә§еә“дёӯгҖӮJava SE 5 жӯЈеҘҪдёәжҲ‘们жҸҗдҫӣдәҶиҝҷз§ҚиғҪеҠӣгҖӮ
java.util.concurrent зЁӢеәҸеҢ…зҡ„дё°еҜҢеҹәе…ғ
Java SE 5 еј•е…ҘдәҶдёҖдёӘеҗҚдёә java.util.concurrent зҡ„зЁӢеәҸеҢ…зі»еҲ—пјҢJava SE 6 еҜ№е…¶иҝӣиЎҢдәҶиҝӣдёҖжӯҘзҡ„еўһејәгҖӮиҜҘзЁӢеәҸеҢ…зі»еҲ—жҸҗдҫӣдәҶд»ҘдёӢ并еҸ‘зј–зЁӢеҹәе…ғгҖҒйӣҶеҗҲе’Ңзү№жҖ§пјҡ
-
жү§иЎҢеҷЁжҳҜеҜ№дј з»ҹзәҝзЁӢзҡ„еўһејәпјҢеӣ дёәе®ғ们жҳҜд»ҺзәҝзЁӢжұ з®ЎзҗҶжҠҪиұЎиҖҢжқҘзҡ„гҖӮе®ғ们жү§иЎҢдёҺдј йҖ’еҲ°зәҝзЁӢзҡ„д»»еҠЎзұ»дјјзҡ„д»»еҠЎпјҲе®һйҷ…дёҠпјҢеҸҜе°ҒиЈ…е®һзҺ° java.lang.Runnable зҡ„е®һдҫӢпјүгҖӮжңүдәӣе®һзҺ°жҸҗдҫӣдәҶзәҝзЁӢжұ е’Ңи°ғеәҰзӯ–з•ҘгҖӮиҖҢдё”пјҢеҸҜд»ҘйҖҡиҝҮеҗҢжӯҘе’ҢејӮжӯҘж–№ејҸиҺ·еҸ–жү§иЎҢз»“жһңгҖӮ
-
зәҝзЁӢе®үе…ЁйҳҹеҲ—е…Ғи®ёеңЁе№¶еҸ‘д»»еҠЎд№Ӣй—ҙдј йҖ’ж•°жҚ®гҖӮеә•еұӮж•°жҚ®з»“жһ„е’Ң并еҸ‘иЎҢдёәжңүзқҖдё°еҜҢзҡ„е®һзҺ°пјҢеә•еұӮж•°жҚ®з»“жһ„зҡ„е®һзҺ°еҢ…жӢ¬ж•°з»„еҲ—иЎЁгҖҒй“ҫжҺҘеҲ—иЎЁжҲ–еҸҢз«ҜйҳҹеҲ—зӯүпјҢ并еҸ‘иЎҢдёәзҡ„е®һзҺ°еҢ…жӢ¬йҳ»еЎһгҖҒж”ҜжҢҒдјҳе…Ҳзә§жҲ–延иҝҹзӯүгҖӮ
-
з»ҶзІ’еәҰзҡ„超时延иҝҹ规иҢғпјҢеӣ дёә java.util.concurrent зЁӢеәҸеҢ…дёӯзҡ„еӨ§йғЁеҲҶзұ»еқҮж”ҜжҢҒ超时延иҝҹгҖӮдҫӢеҰӮпјҢеҰӮжһңд»»еҠЎеңЁи§„е®ҡж—¶й—ҙиҢғеӣҙеҶ…ж— жі•е®ҢжҲҗпјҢжү§иЎҢеҷЁе°Ҷдёӯж–ӯд»»еҠЎжү§иЎҢгҖӮ
-
дё°еҜҢзҡ„еҗҢжӯҘжЁЎејҸпјҢдёҚд»…д»…жҳҜ Java дёӯдҪҺзә§еҗҢжӯҘеқ—жүҖжҸҗдҫӣзҡ„дә’ж–ҘгҖӮиҝҷдәӣжЁЎејҸеҢ…жӢ¬дҝЎеҸ·жҲ–еҗҢжӯҘйҡңзўҚзӯүеёёз”ЁиҜӯжі•гҖӮ
-
й«ҳж•ҲгҖҒ并еҸ‘зҡ„ж•°жҚ®йӣҶеҗҲпјҲжҳ е°„гҖҒеҲ—иЎЁе’ҢйӣҶпјүпјҢйҖҡиҝҮдҪҝз”ЁеҶҷж—¶еӨҚеҲ¶е’Ңз»ҶзІ’еәҰй”ҒйҖҡеёёеҸҜеңЁеӨҡзәҝзЁӢдёҠдёӢж–Үдёӯдә§з”ҹеҮәиүІзҡ„жҖ§иғҪгҖӮ
-
еҺҹеӯҗеҸҳйҮҸпјҢеҸҜд»ҘдҪҝејҖеҸ‘дәәе‘ҳе…ҚдәҺдәІиҮӘжү§иЎҢеҗҢжӯҘи®ҝй—®гҖӮиҝҷдәӣеҸҳйҮҸе°ҒиЈ…дәҶеёёз”Ёзҡ„еҹәе…ғзұ»еһӢпјҢеҰӮж•ҙеһӢжҲ–еёғе°”еҖјпјҢд»ҘеҸҠеҜ№е…¶д»–еҜ№иұЎзҡ„еј•з”ЁгҖӮ
-
и¶…еҮәеӣәжңүй”ҒжүҖжҸҗдҫӣзҡ„й”Ғе®ҡ/йҖҡзҹҘеҠҹиғҪиҢғеӣҙзҡ„еӨҡз§Қй”ҒпјҢдҫӢеҰӮпјҢж”ҜжҢҒйҮҚж–°иҝӣе…ҘгҖҒиҜ»/еҶҷй”Ғе®ҡгҖҒи¶…ж—¶жҲ–еҹәдәҺиҪ®иҜўзҡ„й”Ғе®ҡе°қиҜ•гҖӮ
дҫӢеҰӮпјҢиҖғиҷ‘д»ҘдёӢзЁӢеәҸпјҡ
жіЁж„Ҹпјҡз”ұдәҺ Java SE 7 еј•е…Ҙзҡ„ж–°зҡ„ж•ҙж•°ж–Үжң¬пјҢеҸҜд»ҘеңЁд»»ж„ҸдҪҚзҪ®жҸ’е…ҘдёӢеҲ’зәҝд»ҘжҸҗй«ҳеҸҜиҜ»жҖ§пјҲдҫӢеҰӮпјҢ1_000_000пјүгҖӮ
import java.util.*;
import java.util.concurrent.*;
import static java.util.Arrays.asList;
public class Sums {
static class Sum implements Callable<Long> {
private final long from;
private final long to;
Sum(long from, long to) {
this.from = from;
this.to = to;
}
@Override
public Long call() {
long acc = 0;
for (long i = from; i <= to; i++) {
acc = acc + i;
}
return acc;
}
}
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(2);
List <Future<Long>> results = executor.invokeAll(asList(
new Sum(0, 10), new Sum(100, 1_000), new Sum(10_000, 1_000_000)
));
executor.shutdown();
for (Future<Long> result : results) {
System.out.println(result.get());
}
}
}
иҜҘзӨәдҫӢзЁӢеәҸеҲ©з”Ёжү§иЎҢеҷЁжқҘи®Ўз®—еӨҡдёӘй•ҝж•ҙеһӢзҡ„е’ҢгҖӮеҶ…йғЁ Sum зұ»е®һзҺ°дәҶжү§иЎҢеҷЁз”ЁдәҺи®Ўз®—з»“жһңзҡ„ Callable жҺҘеҸЈпјҢ并еҸ‘е·ҘдҪңеңЁ call() ж–№жі•еҶ…жү§иЎҢгҖӮjava.util.concurrent.Executors зұ»жҸҗдҫӣдәҶеӨҡз§Қе®һз”Ёж–№жі•пјҢеҰӮжҸҗдҫӣйў„й…ҚзҪ®жү§иЎҢеҷЁжҲ–е°Ҷдј з»ҹ java.lang.Runnable еҜ№иұЎе°ҒиЈ…еҲ° Callable е®һдҫӢдёӯгҖӮдёҺ Runnable зӣёжҜ”пјҢдҪҝз”Ё Callable зҡ„дјҳеҠҝеңЁдәҺ Callable иғҪеӨҹжҳҫејҸиҝ”еӣһдёҖдёӘеҖјгҖӮ
жң¬зӨәдҫӢдҪҝз”ЁдёҖдёӘжү§иЎҢеҷЁе°Ҷе·ҘдҪңеҲҶжҙҫз»ҷдёӨдёӘзәҝзЁӢгҖӮExecutorService.invokeAll() ж–№жі•жҺҘеҸ— Callable е®һдҫӢзҡ„йӣҶеҗҲпјҢ并еңЁиҝ”еӣһд№ӢеүҚзӯүеҫ…жүҖжңүиҝҷдәӣе®һдҫӢе®ҢжҲҗгҖӮе®ғдјҡиҝ”еӣһ Future еҜ№иұЎзҡ„еҲ—иЎЁпјҢиҝҷдәӣеҜ№иұЎе…ЁйғҪиЎЁзӨәи®Ўз®—зҡ„вҖңжңӘжқҘвҖқз»“жһңгҖӮеҰӮжһңжҲ‘们д»ҘејӮжӯҘж–№ејҸе·ҘдҪңпјҢе°ұеҸҜд»ҘжөӢиҜ•жҜҸдёӘ Future еҜ№иұЎжқҘжЈҖжҹҘе…¶еҜ№еә”зҡ„ Callable жҳҜеҗҰе·Іе®ҢжҲҗе·ҘдҪңпјҢ并жЈҖжҹҘе…¶жҳҜеҗҰеј•еҸ‘дәҶејӮеёёпјҢз”ҡиҮіеҸҜд»ҘеҸ–ж¶Ҳе…¶е·ҘдҪңгҖӮзӣёеҸҚпјҢеҪ“дҪҝз”Ёжҷ®йҖҡдј з»ҹзәҝзЁӢж—¶пјҢеҝ…йЎ»йҖҡиҝҮе…ұдә«зҡ„еҸҜеҸҳеёғе°”еҖјеҜ№еҸ–ж¶ҲйҖ»иҫ‘иҝӣиЎҢзј–з ҒпјҢ并з”ұдәҺе®ҡжңҹжЈҖжҹҘжӯӨеёғе°”еҖјиҖҢеҮҸзј“д»Јз Ғзҡ„жү§иЎҢгҖӮеӣ дёә invokeAll() е®№жҳ“дә§з”ҹйҳ»еЎһпјҢжҲ‘们еҸҜд»ҘзӣҙжҺҘеҜ№ Future е®һдҫӢиҝӣиЎҢйҒҚеҺҶ并иҜ»еҸ–е…¶и®Ўз®—е’ҢгҖӮ
иҝҳйңҖжіЁж„ҸпјҢеҝ…йЎ»е…ій—ӯжү§иЎҢеҷЁжңҚеҠЎгҖӮеҰӮжһңжңӘе…ій—ӯпјҢеҲҷеңЁдё»ж–№жі•йҖҖеҮәж—¶ Java иҷҡжӢҹжңәе°ҶдёҚдјҡйҖҖеҮәпјҢеӣ дёәзҺҜеўғдёӯиҝҳжңүжҙ»еҠЁзәҝзЁӢгҖӮ
еҲҶи§Ј/еҗҲ并任еҠЎ
жҰӮиҝ°
дёҺдј з»ҹзәҝзЁӢзӣёжҜ”пјҢжү§иЎҢеҷЁжҳҜдёҖеӨ§иҝӣжӯҘпјҢеӣ дёәеҸҜд»Ҙз®ҖеҢ–并еҸ‘д»»еҠЎзҡ„з®ЎзҗҶгҖӮжңүдәӣзұ»еһӢзҡ„з®—жі•иҰҒжұӮд»»еҠЎеҲӣе»әеӯҗд»»еҠЎе№¶дёҺе…¶д»–д»»еҠЎдә’зӣёйҖҡдҝЎд»Ҙе®ҢжҲҗд»»еҠЎгҖӮиҝҷдәӣжҳҜвҖңеҲҶиҖҢжІ»д№ӢвҖқзҡ„з®—жі•пјҢд№ҹз§°дёәвҖңжҳ е°„еҪ’зәҰвҖқпјҢзұ»дјјеҮҪж•°иҜӯиЁҖдёӯзҡ„йҪҗеҗҚеҮҪж•°гҖӮе…¶жҖқи·ҜжҳҜе°Ҷз®—жі•иҰҒеӨ„зҗҶзҡ„ж•°жҚ®з©әй—ҙжӢҶеҲҶжҲҗиҫғе°Ҹзҡ„зӢ¬з«Ӣеқ—гҖӮиҝҷжҳҜвҖңжҳ е°„вҖқйҳ¶ж®өгҖӮдёҖж—Ұеқ—йӣҶеӨ„зҗҶе®ҢжҜ•д№ӢеҗҺпјҢе°ұеҸҜд»Ҙе°ҶйғЁеҲҶз»“жһң收йӣҶиө·жқҘеҪўжҲҗжңҖз»Ҳз»“жһңгҖӮиҝҷжҳҜвҖңеҪ’зәҰвҖқйҳ¶ж®өгҖӮ
дёҖдёӘз®ҖеҚ•зҡ„зӨәдҫӢжҳҜжӮЁеёҢжңӣи®Ўз®—дёҖдёӘеӨ§еһӢж•ҙж•°ж•°з»„зҡ„жҖ»е’ҢпјҲеҸӮи§Ғеӣҫ 1пјүгҖӮеҒҮе®ҡеҠ жі•жҳҜеҸҜдәӨжҚўзҡ„пјҢеҸҜд»Ҙе°Ҷж•°з»„еҲ’еҲҶдёәиҫғе°Ҹзҡ„йғЁеҲҶпјҢ并еҸ‘зәҝзЁӢеҜ№иҝҷдәӣйғЁеҲҶи®Ўз®—йғЁеҲҶе’ҢгҖӮ然еҗҺе°ҶйғЁеҲҶе’ҢзӣёеҠ пјҢи®Ўз®—жҖ»е’ҢгҖӮеӣ дёәеҜ№дәҺжӯӨз®—жі•пјҢзәҝзЁӢеҸҜд»ҘеңЁж•°з»„зҡ„дёҚеҗҢеҢәеҹҹдёҠзӢ¬з«ӢиҝҗиЎҢпјҢжүҖд»ҘдёҺеҜ№ж•°з»„дёӯжҜҸдёӘж•ҙж•°еҫӘзҺҜжү§иЎҢзҡ„еҚ•зәҝзЁӢз®—жі•зӣёжҜ”пјҢжӯӨз®—жі•еңЁеӨҡж ёжһ¶жһ„дёҠеҸҜд»ҘзңӢеҲ°жҳҺжҳҫзҡ„жҖ§иғҪжҸҗеҚҮгҖӮ
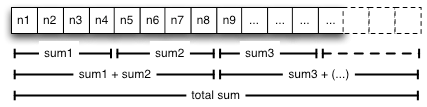
еӣҫ 1пјҡж•ҙж•°ж•°з»„зҡ„йғЁеҲҶе’Ң
дҪҝз”Ёжү§иЎҢеҷЁи§ЈеҶід»ҘдёҠй—®йўҳеҫҲз®ҖеҚ•пјҡе°Ҷж•°з»„еҲҶдёә n дёӘеҸҜз”Ёзү©зҗҶеӨ„зҗҶеҚ•е…ғпјҢеҲӣе»ә Callable е®һдҫӢд»Ҙи®Ўз®—жҜҸдёӘйғЁеҲҶе’ҢпјҢе°ҶйғЁеҲҶе’ҢжҸҗдәӨз»ҷз®ЎзҗҶ n дёӘзәҝзЁӢзҡ„зәҝзЁӢжұ зҡ„жү§иЎҢеҷЁпјҢ然еҗҺ收йӣҶз»“жһңд»Ҙи®Ўз®—жңҖз»Ҳе’ҢгҖӮ
дҪҶеҜ№дәҺе…¶д»–зұ»еһӢзҡ„з®—жі•е’Ңж•°жҚ®з»“жһ„пјҢжү§иЎҢи®ЎеҲ’йҖҡеёёдёҚдјҡеҰӮжӯӨз®ҖеҚ•гҖӮе°Өе…¶жҳҜпјҢж ҮиҜҶвҖңи¶іеӨҹе°ҸвҖқеҸҜйҖҡиҝҮй«ҳж•Ҳж–№ејҸзӢ¬з«ӢеӨ„зҗҶзҡ„ж•°жҚ®еқ—зҡ„вҖңжҳ е°„вҖқйҳ¶ж®өйў„е…ҲдёҚзҹҘйҒ“ж•°жҚ®з©әй—ҙжӢ“жү‘з»“жһ„гҖӮеҜ№еҹәдәҺеӣҫеҪўе’ҢеҹәдәҺж ‘зҡ„ж•°жҚ®з»“жһ„жқҘиҜҙе°ӨдёәеҰӮжӯӨгҖӮеңЁиҝҷдәӣжғ…еҶөдёӢпјҢз®—жі•еә”еҲӣе»әвҖңеҗ„йғЁеҲҶвҖқзҡ„еұӮж¬Ўз»“жһ„пјҢеңЁиҝ”еӣһйғЁеҲҶз»“жһңд№ӢеүҚзӯүеҫ…еӯҗд»»еҠЎе®ҢжҲҗгҖӮе°Ҫз®Ўзұ»дјјеӣҫ 1 дёӯзҡ„数组并йқһжңҖдјҳпјҢдҪҶеҸҜд»ҘдҪҝз”ЁеӨҡзә§е№¶еҸ‘йғЁеҲҶе’Ңи®Ўз®—пјҲдҫӢеҰӮпјҢеңЁеҸҢж ёеӨ„зҗҶеҷЁдёҠе°Ҷж•°з»„еҲҶдёә 4 дёӘеӯҗд»»еҠЎпјүгҖӮ
з”ЁдәҺе®һзҺ°еҲҶиҖҢжІ»д№Ӣз®—жі•зҡ„жү§иЎҢеҷЁзҡ„й—®йўҳдёҺеҲӣе»әеӯҗд»»еҠЎж— е…іпјҢеӣ дёә Callable еҸҜиҮӘз”ұеҗ‘е…¶жү§иЎҢеҷЁжҸҗдәӨж–°зҡ„еӯҗд»»еҠЎпјҢ然еҗҺд»ҘеҗҢжӯҘжҲ–ејӮжӯҘж–№ејҸзӯүеҫ…е…¶з»“жһңгҖӮй—®йўҳеҮәеңЁе№¶иЎҢдёҠпјҡеҪ“ Callable зӯүеҫ…еҸҰдёҖдёӘ Callable зҡ„з»“жһңж—¶пјҢе®ғиў«зҪ®дәҺзӯүеҫ…зҠ¶жҖҒпјҢеӣ жӯӨжөӘиҙ№дәҶеӨ„зҗҶжҺ’йҳҹзӯүеҫ…жү§иЎҢзҡ„еҸҰдёҖдёӘ Callable зҡ„жңәдјҡгҖӮ
йҖҡиҝҮ Doug Lea зҡ„еҠӘеҠӣпјҢеңЁ Java SE 7 дёӯж·»еҠ еҲ° java.util.concurrent зЁӢеәҸеҢ…зҡ„еҲҶи§Ј/еҗҲ并жЎҶжһ¶еЎ«иЎҘдәҶиҝҷдёҖз©әзҷҪгҖӮJava SE 5 е’Ң Java SE 6 зүҲжң¬зҡ„ java.util.concurrent её®еҠ©еӨ„зҗҶ并еҸ‘пјҢJava SE 7 дёӯеҸҰеӨ–еўһеҠ дәҶдёҖдәӣеҠҹиғҪеё®еҠ©еӨ„зҗҶ并иЎҢгҖӮ
з”ЁдәҺж”ҜжҢҒ并иЎҢзҡ„ж–°еўһеҠҹиғҪ
ж ёеҝғж–°еўһеҠҹиғҪжҳҜдё“з”ЁдәҺиҝҗиЎҢе®һзҺ° ForkJoinTask е®һдҫӢзҡ„ж–°зҡ„ ForkJoinPool жү§иЎҢеҷЁгҖӮForkJoinTask еҜ№иұЎж”ҜжҢҒеҲӣе»әеӯҗд»»еҠЎе№¶зӯүеҫ…еӯҗд»»еҠЎе®ҢжҲҗгҖӮйҖҡиҝҮиҝҷдәӣжҳҺзЎ®зҡ„иҜӯд№үпјҢжү§иЎҢеҷЁиғҪеӨҹйҖҡиҝҮеңЁд»»еҠЎзӯүеҫ…еҸҰдёҖд»»еҠЎе®ҢжҲҗ并且жңүеҫ…еӨ„зҗҶд»»еҠЎиҰҒиҝҗиЎҢж—¶вҖңзӘғеҸ–вҖқдҪңдёҡпјҢд»ҺиҖҢеңЁе…¶еҶ…йғЁзәҝзЁӢжұ дёӯеҲҶжҙҫд»»еҠЎгҖӮ
ForkJoinTask еҜ№иұЎжңүдёӨз§Қзү№е®ҡж–№жі•пјҡ
-
fork() ж–№жі•е…Ғи®ёи®ЎеҲ’ ForkJoinTask ејӮжӯҘжү§иЎҢгҖӮиҝҷе…Ғи®ёд»ҺзҺ°жңү ForkJoinTask еҗҜеҠЁж–°зҡ„ ForkJoinTaskгҖӮ
- иҖҢ join() ж–№жі•е…Ғи®ё ForkJoinTask зӯүеҫ…еҸҰдёҖдёӘ ForkJoinTask е®ҢжҲҗгҖӮ
д»»еҠЎд№Ӣй—ҙзҡ„еҗҲдҪңйҖҡиҝҮ fork() е’Ң join() жқҘе®һзҺ°пјҢеҰӮеӣҫ 2 жүҖзӨәгҖӮиҜ·жіЁж„ҸпјҢfork() е’Ң join() ж–№жі•еҗҚдёҚеә”дёҺе…¶ POSIX еҜ№еә”йЎ№пјҲиҝӣзЁӢеҸҜйҖҡиҝҮе®ғеӨҚеҲ¶иҮӘиә«пјүж··ж·ҶгҖӮе…¶дёӯпјҢfork() д»…еңЁ ForkJoinPool дёӯи°ғеәҰдёҖдёӘж–°д»»еҠЎпјҢдҪҶдёҚеҲӣе»әеӯҗ Java иҷҡжӢҹжңәгҖӮ

еӣҫ 2пјҡFork е’Ң Join д»»еҠЎд№Ӣй—ҙзҡ„еҗҲдҪң
жңүдёӨз§Қзұ»еһӢзҡ„ ForkJoinTask е®һзҺ°пјҡ
-
RecursiveAction зҡ„е®һдҫӢиЎЁзӨәдёҚдә§з”ҹиҝ”еӣһеҖјзҡ„жү§иЎҢгҖӮ
- зӣёеҸҚпјҢRecursiveTask зҡ„е®һдҫӢдјҡдә§з”ҹиҝ”еӣһеҖјгҖӮ
йҖҡеёёпјҢдјҳе…ҲйҖүжӢ© RecursiveTaskпјҢеӣ дёәеӨ§еӨҡж•°зҡ„еҲҶиҖҢжІ»д№Ӣз®—жі•иҝ”еӣһж•°жҚ®йӣҶзҡ„и®Ўз®—еҖјгҖӮеҜ№дәҺд»»еҠЎзҡ„жү§иЎҢпјҢжҸҗдҫӣдәҶдёҚеҗҢзҡ„еҗҢжӯҘе’ҢејӮжӯҘйҖүйЎ№пјҢд»ҺиҖҢжңүеҸҜиғҪе®һзҺ°з»ҶиҮҙзҡ„жЁЎејҸгҖӮ
зӨәдҫӢпјҡи®Ўз®—жҹҗдёӘеҚ•иҜҚеңЁж–ҮжЎЈдёӯеҮәзҺ°зҡ„ж¬Ўж•°
дёәдәҶиҜҙжҳҺж–°зҡ„еҲҶи§Ј/еҗҲ并жЎҶжһ¶зҡ„з”Ёжі•пјҢжҲ‘们дёҫдёҖдёӘз®ҖеҚ•зӨәдҫӢпјҡи®Ўз®—жҹҗдёӘеҚ•иҜҚеңЁдёҖз»„ж–ҮжЎЈдёӯеҮәзҺ°зҡ„ж¬Ўж•°гҖӮйҰ–е…ҲпјҢеҲҶи§Ј/еҗҲ并任еҠЎеә”дҪңдёәвҖңзәҜвҖқеҶ…еӯҳдёӯз®—жі•иҝҗиЎҢпјҢе…¶дёӯдёҚж¶үеҸҠ I/O ж“ҚдҪңгҖӮеҗҢж—¶пјҢеә”е°ҪеҸҜиғҪйҒҝе…Қд»»еҠЎд№Ӣй—ҙйҖҡиҝҮе…ұдә«зҠ¶жҖҒзҡ„йҖҡдҝЎпјҢеӣ дёәиҝҷж„Ҹе‘ізқҖеҸҜиғҪеҝ…йЎ»жү§иЎҢй”Ғе®ҡгҖӮзҗҶжғіжғ…еҶөдёӢпјҢд»…еҪ“дёҖдёӘд»»еҠЎеҲҶеҮәеҸҰдёҖдёӘд»»еҠЎжҲ–дёҖдёӘд»»еҠЎе№¶е…ҘеҸҰдёҖдёӘд»»еҠЎж—¶пјҢд»»еҠЎд№Ӣй—ҙжүҚиҝӣиЎҢйҖҡдҝЎгҖӮ
жҲ‘们зҡ„еә”з”ЁзЁӢеәҸиҝҗиЎҢеңЁж–Ү件зӣ®еҪ•з»“жһ„дёҠпјҢе°ҶжҜҸдёӘж–Ү件зҡ„еҶ…е®№еҠ иҪҪеҲ°еҶ…еӯҳдёӯгҖӮеӣ жӯӨпјҢйңҖиҰҒд»ҘдёӢзұ»жқҘиЎЁзӨәиҜҘжЁЎеһӢгҖӮж–ҮжЎЈиЎЁзӨәдёәдёҖзі»еҲ—иЎҢпјҡ
class Document {
private final List<String> lines;
Document(List<String> lines) {
this.lines = lines;
}
List<String> getLines() {
return this.lines;
}
static Document fromFile(File file) throws IOException {
List<String> lines = new LinkedList<>();
try(BufferedReader reader = new BufferedReader(new FileReader(file))) {
String line = reader.readLine();
while (line != null) {
lines.add(line);
line = reader.readLine();
}
}
return new Document(lines);
}
}
жіЁж„ҸпјҡеҰӮжһңжӮЁжҳҜеҲқж¬ЎжҺҘи§Ұ Java SE7пјҢfromFile() ж–№жі•жңүдёӨзӮ№дјҡдҪҝжӮЁж„ҹеҲ°жғҠ讶пјҡ
-
LinkedList дҪҝз”Ёе°–жӢ¬еҸ·иҜӯжі• (<>) е‘ҠзҹҘзј–иҜ‘еҷЁжҺЁж–ӯйҖҡз”Ёзұ»еһӢеҸӮж•°гҖӮз”ұдәҺиЎҢжҳҜ List<String>пјҢLinkedList<> жү©еұ•дёә LinkedList<String>гҖӮдҪҝз”Ёе°–жӢ¬еҸ·иҝҗз®—з¬ҰпјҢеҜ№дәҺйӮЈдәӣиғҪеңЁзј–иҜ‘ж—¶иҪ»жқҫжҺЁж–ӯзҡ„зұ»еһӢе°ұдёҚеҝ…еҶҚйҮҚеӨҚпјҢд»ҺиҖҢдҪҝеҫ—йҖҡз”Ёзұ»еһӢзҡ„еӨ„зҗҶжӣҙиҪ»жқҫгҖӮ
-
try еқ—дҪҝз”Ёж–°зҡ„иҮӘеҠЁиө„жәҗз®ЎзҗҶиҜӯиЁҖзү№жҖ§гҖӮеңЁ try еқ—зҡ„ејҖеӨҙеҸҜд»ҘдҪҝз”Ёе®һзҺ° java.lang.AutoCloseable зҡ„д»»дҪ•зұ»гҖӮж— и®әжҳҜеҗҰеј•еҸ‘ејӮеёёпјҢеҪ“жү§иЎҢзҰ»ејҖ try еқ—ж—¶пјҢеңЁжӯӨеЈ°жҳҺзҡ„д»»дҪ•иө„жәҗйғҪе°ҶжӯЈеёёе…ій—ӯгҖӮеңЁ Java SE 7 д№ӢеүҚпјҢжӯЈеёёе…ій—ӯеӨҡдёӘиө„жәҗеҫҲеҝ«дјҡеҸҳжҲҗдёҖеңәеөҢеҘ— if/try/catch/finally еқ—зҡ„жўҰйӯҮпјҢиҝҷз§ҚеөҢеҘ—еқ—йҖҡеёёеҫҲйҡҫжӯЈзЎ®зј–еҶҷгҖӮ
дәҺжҳҜж–Ү件еӨ№жҲҗдёәдёҖдёӘз®ҖеҚ•зҡ„еҹәдәҺж ‘зҡ„з»“жһ„пјҡ
class Folder {
private final List<Folder> subFolders;
private final List<Document> documents;
Folder(List<Folder> subFolders, List<Document> documents) {
this.subFolders = subFolders;
this.documents = documents;
}
List<Folder> getSubFolders() {
return this.subFolders;
}
List<Document> getDocuments() {
return this.documents;
}
static Folder fromDirectory(File dir) throws IOException {
List<Document> documents = new LinkedList<>();
List<Folder> subFolders = new LinkedList<>();
for (File entry : dir.listFiles()) {
if (entry.isDirectory()) {
subFolders.add(Folder.fromDirectory(entry));
} else {
documents.add(Document.fromFile(entry));
}
}
return new Folder(subFolders, documents);
}
}
зҺ°еңЁжҲ‘们еҸҜд»ҘејҖе§Ӣе®һзҺ°дё»зұ»пјҡ
import java.io.*;
import java.util.*;
import java.util.concurrent.*;
public class WordCounter {
String[] wordsIn(String line) {
return line.trim().split("(\\s|\\p{Punct})+");
}
Long occurrencesCount(Document document, String searchedWord) {
long count = 0;
for (String line : document.getLines()) {
for (String word : wordsIn(line)) {
if (searchedWord.equals(word)) {
count = count + 1;
}
}
}
return count;
}
}
occurrencesCount ж–№жі•еҲ©з”Ё wordsIn ж–№жі•иҝ”еӣһжҹҗдёӘеҚ•иҜҚеңЁж–ҮжЎЈдёӯеҮәзҺ°зҡ„ж¬Ўж•°пјҢwordsIn ж–№жі•еңЁдёҖиЎҢдёӯз”ҹжҲҗиҜҘеҚ•иҜҚзҡ„ж•°з»„гҖӮдёәжӯӨпјҢиҜҘж–№жі•еҹәдәҺз©әж је’Ңж ҮзӮ№еӯ—з¬ҰеҜ№иЎҢиҝӣиЎҢжӢҶеҲҶгҖӮ
жҲ‘们е°Ҷе®һзҺ°дёӨз§Қзұ»еһӢзҡ„еҲҶи§Ј/еҗҲ并任еҠЎгҖӮзӣҙи§Ӯең°иҜҙпјҢдёҖдёӘж–Ү件еӨ№дёӯжҹҗдёӘеҚ•иҜҚеҮәзҺ°зҡ„ж¬Ўж•°жҳҜиҜҘеҚ•иҜҚеңЁжҜҸдёӘеӯҗж–Ү件еӨ№е’Ңж–ҮжЎЈдёӯеҮәзҺ°зҡ„ж¬Ўж•°зҡ„жҖ»е’ҢгҖӮеӣ жӯӨпјҢжҲ‘们е°ҶжңүдёҖдёӘд»»еҠЎз”ЁдәҺи®Ўз®—ж–ҮжЎЈдёӯеҮәзҺ°зҡ„ж¬Ўж•°пјҢиҝҳжңүдёҖдёӘд»»еҠЎз”ЁдәҺи®Ўз®—ж–Ү件еӨ№дёӯеҮәзҺ°зҡ„ж¬Ўж•°гҖӮеҗҺдёҖзұ»еһӢеҲҶеҮәеӯҗд»»еҠЎпјҢ然еҗҺе°Ҷеӯҗд»»еҠЎеҗҲ并д»Ҙ收йӣҶиҝҷдәӣеӯҗд»»еҠЎзҡ„з»“жһңгҖӮ
д»»еҠЎзӣёе…іжҖ§жҳ“дәҺжҺҢжҸЎпјҢеӣ дёәе®ғзӣҙжҺҘжҳ е°„еә•еұӮж–ҮжЎЈжҲ–ж–Ү件еӨ№ж ‘з»“жһ„пјҢеҰӮеӣҫ 3 дёӯжүҖзӨәгҖӮеҲҶи§Ј/еҗҲ并жЎҶжһ¶йҖҡиҝҮзЎ®дҝқеҸҜд»ҘеңЁж–Ү件еӨ№д»»еҠЎзӯүеҫ… join() ж“ҚдҪңж—¶жү§иЎҢдёҖдёӘеҫ…еӨ„зҗҶж–ҮжЎЈжҲ–ж–Ү件еӨ№зҡ„еӯ—ж•°и®Ўз®—д»»еҠЎжқҘдҪҝ并иЎҢжңҖеӨ§еҢ–гҖӮ

еӣҫ 3пјҡеҲҶи§Ј/еҗҲ并еӯ—ж•°и®Ўз®—д»»еҠЎ
йҰ–е…Ҳд»Ӣз»Қ DocumentSearchTaskпјҢе®ғи®Ўз®—жҹҗдёӘеҚ•иҜҚеңЁж–ҮжЎЈдёӯеҮәзҺ°зҡ„ж¬Ўж•°пјҡ
class DocumentSearchTask extends RecursiveTask<Long> {
private final Document document;
private final String searchedWord;
DocumentSearchTask(Document document, String searchedWord) {
super();
this.document = document;
this.searchedWord = searchedWord;
}
@Override
protected Long compute() {
return occurrencesCount(document, searchedWord);
}
}
еӣ дёәжҲ‘们зҡ„д»»еҠЎдә§з”ҹеҖјпјҢиҝҷдәӣд»»еҠЎжү©еұ•дәҶ RecursiveTask 并жҺҘеҸ— Long дҪңдёәйҖҡз”Ёзұ»еһӢпјҢеӣ дёәеҮәзҺ°зҡ„ж¬Ўж•°е°Ҷз”ұдёҖдёӘ long еһӢж•ҙж•°иЎЁзӨәгҖӮcompute() ж–№жі•жҳҜжүҖжңү RecursiveTask зҡ„ж ёеҝғгҖӮжӯӨеӨ„пјҢе®ғеҸӘжҳҜ委жүҳдёҠиҝ° occurrencesCount() ж–№жі•гҖӮзҺ°еңЁжҲ‘们еҸҜд»ҘеӨ„зҗҶ FolderSearchTask зҡ„е®һзҺ°пјҢиҜҘд»»еҠЎиҝҗиЎҢеңЁж ‘з»“жһ„зҡ„ж–Ү件еӨ№е…ғзҙ дёҠпјҡ
class FolderSearchTask extends RecursiveTask<Long> {
private final Folder folder;
private final String searchedWord;
FolderSearchTask(Folder folder, String searchedWord) {
super();
this.folder = folder;
this.searchedWord = searchedWord;
}
@Override
protected Long compute() {
long count = 0L;
List<RecursiveTask<Long>> forks = new LinkedList<>();
for (Folder subFolder : folder.getSubFolders()) {
FolderSearchTask task = new FolderSearchTask(subFolder, searchedWord);
forks.add(task);
task.fork();
}
for (Document document : folder.getDocuments()) {
DocumentSearchTask task = new DocumentSearchTask(document, searchedWord);
forks.add(task);
task.fork();
}
for (RecursiveTask<Long> task : forks) {
count = count + task.join();
}
return count;
}
}
еңЁиҜҘд»»еҠЎдёӯпјҢcompute() ж–№жі•зҡ„е®һзҺ°еҸӘжҳҜдёәе·ІйҖҡиҝҮе…¶жһ„йҖ еҮҪж•°дј йҖ’зҡ„жҜҸдёӘж–Ү件еӨ№е…ғзҙ еҲҶи§Јж–ҮжЎЈе’Ңж–Ү件еӨ№д»»еҠЎгҖӮ然еҗҺе°ҶеҗҲ并жүҖжңүиҝҷдәӣд»»еҠЎд»Ҙи®Ўз®—е…¶йғЁеҲҶе’Ң并иҝ”еӣһиҜҘйғЁеҲҶе’ҢгҖӮ
зҺ°еңЁжҲ‘们еҸӘе·®дёҖз§Қж–№жі•жқҘеҗҜеҠЁеҲҶи§Ј/еҗҲ并жЎҶжһ¶дёҠзҡ„еӯ—ж•°и®Ўз®—ж“ҚдҪңпјҢд»ҘеҸҠдёҖдёӘеҲҶи§Ј/еҗҲ并жұ жү§иЎҢеҷЁпјҡ
private final ForkJoinPool forkJoinPool = new ForkJoinPool();
Long countOccurrencesInParallel(Folder folder, String searchedWord) {
return forkJoinPool.invoke(new FolderSearchTask(folder, searchedWord));
}
еҲқе§Ӣ FolderSearchTask е°ҶеҗҜеҠЁжүҖжңүиҝҷдәӣж“ҚдҪңгҖӮForkJoinPool зҡ„ invoke() ж–№жі•е…Ғи®ёзӯүеҫ…и®Ўз®—е®ҢжҲҗгҖӮеңЁдёҠйқўзҡ„дҫӢеӯҗдёӯпјҢ
ForkJoinPool жҳҜйҖҡиҝҮе…¶з©әжһ„йҖ еҮҪж•°жқҘдҪҝз”Ёзҡ„гҖӮ并иЎҢеәҰе°ҶдёҺеҸҜз”Ёзҡ„硬件еӨ„зҗҶеҚ•е…ғзҡ„ж•°зӣ®зӣёеҢ№й…ҚпјҲдҫӢеҰӮпјҢеңЁе…·жңүеҸҢж ёеӨ„зҗҶеҷЁзҡ„и®Ўз®—жңәдёҠ并иЎҢеәҰе°Ҷдёә 2пјүгҖӮ
зҺ°еңЁжҲ‘们еҸҜд»Ҙзј–еҶҷдёҖдёӘ main() ж–№жі•пјҢиҜҘж–№жі•д»Һе‘Ҫд»ӨиЎҢеҸӮж•°жҺҘеҸ—иҰҒеңЁе…¶дёҠиҝҗиЎҢзҡ„ж–Ү件еӨ№д»ҘеҸҠиҰҒжҗңзҙўзҡ„еӯ—пјҡ
public static void main(String[] args) throws IOException {
WordCounter wordCounter = new WordCounter();
Folder folder = Folder.fromDirectory(new File(args[0]));
System.out.println(wordCounter.countOccurrencesOnSingleThread(folder, args[1]));
}
иҜҘзӨәдҫӢзҡ„е®Ңж•ҙжәҗд»Јз ҒиҝҳеҢ…жӢ¬жӯӨз®—жі•жӣҙдј з»ҹзҡ„еҹәдәҺйҖ’еҪ’зҡ„е®һзҺ°пјҢиҜҘе®һзҺ°е·ҘдҪңеңЁеҚ•зәҝзЁӢдёҠпјҡ
Long countOccurrencesOnSingleThread(Folder folder, String searchedWord) {
long count = 0;
for (Folder subFolder : folder.getSubFolders()) {
count = count + countOccurrencesOnSingleThread(subFolder, searchedWord);
}
for (Document document : folder.getDocuments()) {
count = count + occurrencesCount(document, searchedWord);
}
return count;
}
и®Ёи®ә
еңЁ Oracle зҡ„ Sun Fire T2000 жңҚеҠЎеҷЁдёҠиҝӣиЎҢдәҶдёҖж¬ЎйқһжӯЈејҸжөӢиҜ•пјҢе…¶дёӯеҸҜд»ҘжҢҮе®ҡ Java иҷҡжӢҹжңәеҸҜз”Ёзҡ„еҶ…ж ёж•°гҖӮеҗҢж—¶иҝҗиЎҢдәҶдёҠдҫӢзҡ„еҲҶи§Ј/еҗҲ并е’ҢеҚ•зәҝзЁӢеҪўејҸд»ҘжүҫеҮә import еңЁ JDK жәҗд»Јз Ғж–Ү件дёӯеҮәзҺ°зҡ„ж¬Ўж•°гҖӮ
еӨҡж¬ЎиҝҗиЎҢдәҶиҝҷдәӣеҸҳеҢ–еҪўејҸд»ҘзЎ®дҝқ Java иҷҡжӢҹжңәзғӯзӮ№дјҳеҢ–жңүи¶іеӨҹзҡ„ж—¶й—ҙе®ҢжҲҗйғЁзҪІгҖӮ收йӣҶдәҶ 2 дёӘгҖҒ4 дёӘгҖҒ8 дёӘе’Ң 12 дёӘеҶ…ж ёзҡ„жңҖдҪіжү§иЎҢж—¶й—ҙпјҢ然еҗҺи®Ўз®—дәҶеҠ йҖҹпјҲеҚіеҚ•зәҝзЁӢдёҠзҡ„ж—¶й—ҙ/еҲҶи§Ј-еҗҲ并дёҠзҡ„ж—¶й—ҙд№ӢжҜ”пјүгҖӮз»“жһңеҸҚжҳ еңЁеӣҫ 4 е’ҢиЎЁ 1 дёӯгҖӮ
жӯЈеҰӮжӮЁзңӢеҲ°зҡ„пјҢеҸӘйңҖжһҒе°‘зҡ„еҠӘеҠӣеҚіеҸҜеңЁеҶ…ж ёж•°дёҠиҺ·еҫ—иҝ‘д№ҺзәҝжҖ§зҡ„еҠ йҖҹпјҢеӣ дёәеҲҶи§Ј/еҗҲ并жЎҶжһ¶дјҡиҙҹиҙЈжңҖеӨ§еҢ–并иЎҢеәҰгҖӮ
иЎЁ 1пјҡйқһжӯЈејҸжөӢиҜ•жү§иЎҢж—¶й—ҙе’ҢеҠ йҖҹ
|
еҶ…ж ёж•° |
еҚ•зәҝзЁӢжү§иЎҢж—¶й—ҙ (ms) |
еҲҶи§Ј/еҗҲ并жү§иЎҢж—¶й—ҙ (ms) |
еҠ йҖҹ |
|
2 |
18798 |
11026 |
1.704879376 |
|
4 |
19473 |
8329 |
2.337975747 |
|
8 |
18911 |
4208 |
4.494058935 |
|
12 |
19410 |
2876 |
6.748956885 |
В
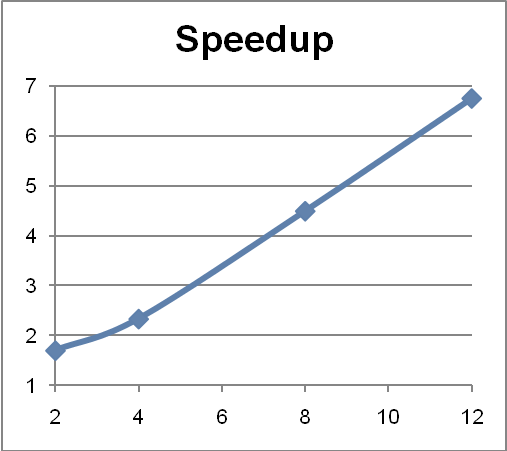
еӣҫ 4пјҡеҠ йҖҹпјҲзәөиҪҙпјүдёҺеҶ…ж ёж•°пјҲжЁӘиҪҙпјүжңүе…і
жҲ‘们иҝҳеҸҜд»ҘеҜ№и®Ўз®—иҝӣиЎҢдјҳеҢ–пјҢеҲҶи§Јд»»еҠЎдҪҝе…¶еңЁиЎҢзә§иҖҢдёҚжҳҜеңЁж–ҮжЎЈзә§иҝҗиЎҢгҖӮиҝҷе°ҶдҪҝ并еҸ‘д»»еҠЎжңүеҸҜиғҪеңЁеҗҢдёҖж–ҮжЎЈзҡ„дёҚеҗҢиЎҢдёҠиҝҗиЎҢгҖӮдҪҶиҝҷжңүзӮ№зүөејәгҖӮе®һйҷ…дёҠпјҢеҲҶи§Ј/еҗҲ并任еҠЎеә”жү§иЎҢвҖңи¶іеӨҹвҖқж•°йҮҸзҡ„и®Ўз®—д»Ҙе…ӢжңҚеҲҶи§Ј/еҗҲ并зәҝзЁӢжұ е’Ңд»»еҠЎз®ЎзҗҶзҡ„ејҖй”ҖгҖӮеңЁиЎҢзә§е·ҘдҪңе°ҶиҝҮдәҺзҗҗзўҺпјҢд»ҺиҖҢеҪұе“ҚиҜҘж–№жі•зҡ„ж•ҲзҺҮгҖӮ
жүҖеҢ…еҗ«зҡ„жәҗд»Јз ҒиҝҳжҸҗдҫӣеҹәдәҺеҜ№ж•ҙж•°ж•°з»„жү§иЎҢеҗҲ并-жҺ’еәҸз®—жі•зҡ„еҸҰдёҖдёӘеҲҶи§Ј/еҗҲ并зӨәдҫӢгҖӮиҝҷеҫҲжңүи¶ЈпјҢеӣ дёәе®ғдҪҝз”Ё RecursiveAction жқҘе®һзҺ°пјҢиҜҘеҲҶи§Ј/еҗҲ并任еҠЎеҜ№ join() ж–№жі•зҡ„и°ғз”ЁдёҚдјҡдә§з”ҹеҖјгҖӮзӣёеҸҚпјҢд»»еҠЎе°Ҷе…ұдә«еҸҜеҸҳзҠ¶жҖҒпјҡиҰҒжҺ’еәҸзҡ„ж•°з»„гҖӮеҗҢж ·пјҢе®һйӘҢжҳҫзӨәеҶ…ж ёж•°зӣ®дёҠеӯҳеңЁиҝ‘д№ҺзәҝжҖ§зҡ„еҠ йҖҹгҖӮ
жҖ»з»“
жң¬ж–Үи®Ёи®әдәҶ Java 并еҸ‘зј–зЁӢпјҢйҮҚзӮ№ејәи°ғ Java SE 7 дёәз®ҖеҢ–并иЎҢзЁӢеәҸзј–еҶҷиҖҢжҸҗдҫӣзҡ„ж–°зҡ„еҲҶи§Ј/еҗҲ并任еҠЎгҖӮжң¬ж–ҮжҳҫзӨәпјҢеҸҜд»ҘдҪҝз”Ёе’Ңз»„еҗҲдё°еҜҢзҡ„еҹәе…ғжқҘзј–еҶҷеҸҜеҲ©з”ЁеӨҡж ёеӨ„зҗҶеҷЁзҡ„й«ҳжҖ§иғҪзЁӢеәҸпјҢиҖҢе®Ңе…Ёж— йңҖеӨ„зҗҶзәҝзЁӢе’Ңе…ұдә«зҠ¶жҖҒеҗҢжӯҘзҡ„дҪҺзә§ж“ҚдҪңгҖӮжң¬ж–ҮеңЁжҹҗеҚ•иҜҚеҮәзҺ°ж¬Ўж•°и®Ўз®—зӨәдҫӢдёӯйҳҗйҮҠдәҶиҝҷдәӣж–° API зҡ„дҪҝз”ЁпјҢж—ўеј•дәәжіЁзӣ®еҸҲжҳ“дәҺжҺҢжҸЎгҖӮеңЁйқһжӯЈејҸжөӢиҜ•дёӯпјҢеңЁеҶ…ж ёж•°зӣ®дёҠеҸ–еҫ—дәҶиҝ‘д№ҺзәҝжҖ§зҡ„еҠ йҖҹгҖӮиҝҷдәӣз»“жһңжҳҫзӨәеҲҶи§Ј/еҗҲ并жЎҶжһ¶йқһеёёжңүз”Ёпјӣеӣ дёәжҲ‘们既дёҚеҝ…жӣҙж”№д»Јз ҒпјҢд№ҹдёҚеҝ…и°ғж•ҙд»Јз ҒжҲ– Java иҷҡжӢҹжңәпјҢеҚіеҸҜжңҖеӨ§зЁӢеәҰеҲ©з”ЁзЎ¬д»¶еҶ…ж ёгҖӮ
жӮЁиҝҳеҸҜд»Ҙе°ҶжӯӨжҠҖжңҜеә”з”ЁдәҺиҮӘе·ұзҡ„й—®йўҳе’Ңж•°жҚ®жЁЎеһӢгҖӮеҸӘиҰҒжӮЁжҢүж— йңҖ I/O е·ҘдҪңе’Ңй”Ғе®ҡзҡ„вҖңеҲҶиҖҢжІ»д№ӢвҖқзҡ„ж–№ејҸйҮҚж–°зј–еҶҷз®—жі•пјҢеҚіеҸҜзңӢеҲ°жҳҫи‘—зҡ„еҠ йҖҹгҖӮ
В
жң¬ж–ҮиҪ¬иҮӘпјҡ
http://www.oracle.com/technetwork/cn/articles/java/fork-join-422606-zhs.html



зӣёе…іжҺЁиҚҗ
гҖҗJAVAж–Үд»¶дј иҫ“е·Ҙе…·гҖ‘жҳҜдёҖдёӘз”ұдёӘдәәејҖеҸ‘иҖ…зј–еҶҷзҡ„е®һз”ЁзЁӢеәҸпјҢдё»иҰҒеҠҹиғҪжҳҜе®һзҺ°ж–Ү件зҡ„й«ҳж•ҲгҖҒе®үе…Ёдј иҫ“пјҢе°Өе…¶ж“…й•ҝеӨ„зҗҶеӨ§ж–Ү件гҖӮжӯӨе·Ҙе…·еҹәдәҺJavaзј–зЁӢиҜӯиЁҖпјҢеӣ жӯӨе…·еӨҮи·Ёе№іеҸ°зү№жҖ§пјҢеҸҜд»ҘеңЁеӨҡз§Қж“ҚдҪңзі»з»ҹдёҠиҝҗиЎҢпјҢеҰӮWindowsгҖҒLinuxе’Ң...
еёёи§Ғзҡ„з”ЁдәҺеҠЁжҖҒжҠҘиЎЁејҖеҸ‘зҡ„иҜӯиЁҖжңүPythonпјҲеҰӮPandasе’ҢMatplotlibеә“пјүгҖҒJavaпјҲеҰӮJasperReportsе’ҢBIRTпјүе’ҢJavaScriptпјҲеҰӮD3.jsе’ҢChart.jsпјүгҖӮиҝҷдәӣе·Ҙе…·жҸҗдҫӣдәҶдё°еҜҢзҡ„еҠҹиғҪпјҢеҰӮж•°жҚ®еӨ„зҗҶгҖҒеӣҫиЎЁз»ҳеҲ¶е’ҢдәӨдә’ејҸ组件гҖӮдҫӢеҰӮпјҢPython...
OptaplannerдҪҝз”ЁдәҶдёҖз§Қз§°дёәзәҰжқҹзј–зЁӢпјҲConstraint Programmingпјүзҡ„жҠҖжңҜпјҢе®ғз»“еҗҲдәҶжҗңзҙўз®—жі•е’Ңж•°еӯҰе»әжЁЎпјҢд»ҘеҜ»жүҫж»Ўи¶іжүҖжңүзәҰжқҹжқЎд»¶зҡ„жңҖдјҳи§ЈжҲ–иҝ‘дјјжңҖдјҳи§ЈгҖӮе…¶дёӯпјҢжҗңзҙўз®—жі•еҢ…жӢ¬жЁЎжӢҹйҖҖзҒ«пјҲSimulated AnnealingпјүгҖҒзҰҒеҝҢжҗңзҙў...
- **жҳ“дәҺдҪҝз”Ё**пјҡжҸҗдҫӣдәҶдё°еҜҢзҡ„APIпјҢж”ҜжҢҒJavaгҖҒScalaгҖҒPythonзӯүеӨҡз§Қзј–зЁӢиҜӯиЁҖгҖӮ - **йҖҡз”ЁжҖ§ејә**пјҡж”ҜжҢҒеӨҡз§Қи®Ўз®—жЁЎејҸпјҢеҢ…жӢ¬жү№еӨ„зҗҶгҖҒдәӨдә’ејҸжҹҘиҜўгҖҒжөҒеӨ„зҗҶгҖҒжңәеҷЁеӯҰд№ зӯүгҖӮ - **йҖӮз”ЁзҺҜеўғе№ҝ**пјҡеҸҜд»ҘеңЁеӨҡз§ҚйӣҶзҫӨз®ЎзҗҶзі»з»ҹдёӯ...
йҖҡиҝҮgoroutinesпјҲиҪ»йҮҸзә§зәҝзЁӢпјүе’ҢchannelsпјҢејҖеҸ‘иҖ…еҸҜд»ҘиҪ»жқҫең°е®һзҺ°еӨҡд»»еҠЎе№¶иЎҢеӨ„зҗҶпјҢиҝҷеҜ№дәҺе®һж—¶дҝЎжҒҜжӣҙж–°е’Ңеҝ«йҖҹе“Қеә”з”ЁжҲ·иҜ·жұӮиҮіе…ійҮҚиҰҒгҖӮеңЁз–«жғ…иө„и®ҜжҸҙеҠ©е№іеҸ°дёӯпјҢиҝҷеҸҜд»Ҙз”ЁдәҺеҗҢж—¶еӨ„зҗҶеӨҡдёӘж•°жҚ®жәҗзҡ„еҗҢжӯҘжӣҙж–°пјҢзЎ®дҝқдҝЎжҒҜзҡ„е®һж—¶жҖ§...
Javaзҡ„е№ҝжіӣйҮҮз”Ёе’ҢScalaзҡ„еҮҪж•°ејҸзј–зЁӢзү№жҖ§дҪҝеҫ—иҝҷдёӨиҖ…жҲҗдёәSparkејҖеҸ‘зҡ„еёёз”ЁйҖүжӢ©гҖӮ **SparkйӣҶжҲҗ**пјҡ жӯӨиҝһжҺҘеҷЁе®һзҺ°дәҶSparkзҡ„DataSource APIпјҢдҪҝеҫ—ArangoDBеҸҜд»ҘдҪңдёәж•°жҚ®жәҗе’Ңж•°жҚ®жҺҘ收еҷЁгҖӮз”ЁжҲ·еҸҜд»ҘеғҸж“ҚдҪңе…¶д»–Sparkж”ҜжҢҒзҡ„ж•°жҚ®...
3. **е…је®№жҖ§ж”№е–„**пјҡеўһејәдәҶдёҺе…¶д»–зј–зЁӢиҜӯиЁҖпјҲеҰӮC++гҖҒJavaзӯүпјүд№Ӣй—ҙзҡ„дәӨдә’иғҪеҠӣпјҢж–№дҫҝиҝӣиЎҢи·Ёе№іеҸ°ејҖеҸ‘гҖӮ #### дёүгҖҒwin32зүҲжң¬зү№зӮ№ win32зүҲжң¬жҢҮзҡ„жҳҜйҖӮз”ЁдәҺ32дҪҚWindowsж“ҚдҪңзі»з»ҹзҡ„Matlabе®үиЈ…еҢ…гҖӮе°Ҫз®ЎзҺ°д»Ји®Ўз®—жңәзі»з»ҹжҷ®йҒҚйҮҮз”Ё...
- **е®ҡд№ү**пјҡMapReduceжҳҜдёҖдёӘеҲҶеёғејҸиҝҗз®—зЁӢеәҸзҡ„зј–зЁӢжЎҶжһ¶пјҢз”ЁдәҺз®ҖеҢ–еӨ§и§„жЁЎж•°жҚ®йӣҶзҡ„并иЎҢеӨ„зҗҶгҖӮ - **дҪңз”Ё**пјҡе®ғе°Ҷз”ЁжҲ·зј–еҶҷзҡ„дёҡеҠЎйҖ»иҫ‘д»Јз Ғе’ҢиҮӘеёҰзҡ„й»ҳи®Ө组件ж•ҙеҗҲжҲҗдёҖдёӘе®Ңж•ҙзҡ„еҲҶеёғејҸиҝҗз®—зЁӢеәҸпјҢиғҪеӨҹжү©еұ•еҲ°ж•°еҚғеҸ°и®Ўз®—жңәдёҠиҝҗиЎҢ...