langyu
- 浏览: 890966 次
- 性别:

- 来自: 杭州
-

最新评论
-
u013146595:
楼主你人呢,搬家了吗。还想看你的文章
读代码的“深度优先”与“广度优先”问题 -
zjut_ywf:
写的不错,比书上还具体,受益匪浅
MapReduce:详解Shuffle过程 -
sxzheng96:
seandeng888 写道Combiner阶段应该是在Par ...
MapReduce:详解Shuffle过程 -
sxzheng96:
belivem 写道你好,大神,我也是这一点不是很清楚,看了你 ...
MapReduce:详解Shuffle过程 -
jinsedeme0881:
引用77 楼 belivem 2015-07-11 引用你 ...
MapReduce:详解Shuffle过程



相关推荐
Job本地提交过程是MapReduce执行任务的一个重要环节,特别是在开发和调试阶段,理解这一过程对于优化性能和解决潜在问题至关重要。本文将深入源码层面,分析MapReduce Job在本地提交的详细步骤。 首先,我们来了解...
在Hadoop MapReduce框架中,Job的提交过程是整个分布式计算流程中的关键步骤。这个过程涉及到客户端、JobTracker(在Hadoop 2.x版本中被ResourceManager替代)和TaskTracker(在Hadoop 2.x版本中被NodeManager替代)...
文中没有详细说明如何运行作业,但在Hadoop MapReduce中,一般通过Hadoop命令行工具来提交作业,命令通常类似于“hadoop jar wc3.jar”。 整个过程大致如下: 1. 搭建Hadoop环境(以CDH5为基础)。 2. 编写或获取...
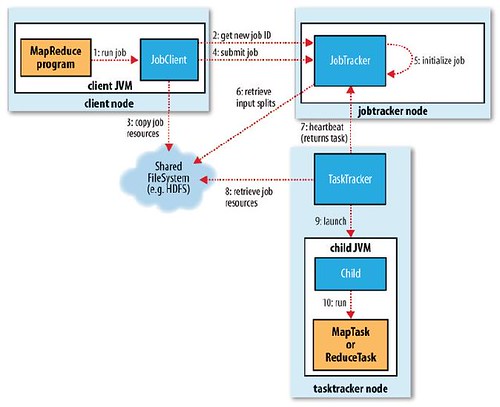
我们基于Hadoop1.2.1源码分析MapReduceV1的处理流程。MapReduceV1实现中,主要存在3个主要的...在编写好MapReduce程序以后,需要将Job提交给JobTracker,那么我们就需要了解在提交Job的过程中,在JobClient端都做了哪
作业提交过程涉及三个主要组件:JobClient、JobTracker和JobScheduler。JobClient是用户与Hadoop集群交互的前端接口,负责接收用户的作业提交命令。JobTracker是集群中负责资源管理和作业调度的核心组件。Job...
此外,通过Shell命令如`mapred job -status id`,可以在运行过程中和结束后跟踪作业状态,这有利于理解MapReduce的执行流程。 实验的总结与思考部分,强调了实验的目标在于理解和掌握MapReduce编程思想,了解...
4. **Java编程**:掌握编写MapReduce作业的Java代码,包括设置Job配置,定义Mapper和Reducer类,以及提交作业到集群。 5. **实战案例**:可能有实际的数据处理例子,如日志分析、网页排名计算等,帮助理解MapReduce...
5. **`Job`**:这是配置和提交MapReduce作业的主要类,你可以设置各种参数,如输入和输出路径,Mapper和Reducer类等。 **MapReduce实战** 在"MapReduce-master"这个项目中,你可能看到的是一系列示例代码,展示...
#### 六、MapReduce Job提交失败问题排查 从提供的信息来看,HDFS和YARN部分似乎运行正常,但是遇到了MapReduce提交Job执行失败的问题。这可能是由以下原因导致的: 1. **配置错误**:检查`mapred-site.xml`和`...
- 主类中设置Job配置,包括输入输出路径、Mapper和Reducer类等,并提交作业。 3. **上传数据到HDFS**: - 使用`hdfs dfs -put`命令将本地文件系统中的数据上传到HDFS,作为MapReduce作业的输入。 4. **编译和...
以上就是在Windows 7环境下提交Hadoop Job的全过程,涉及到Java环境配置、Hadoop安装与配置、MapReduce编程、Job提交和监控等多个环节。通过这个过程,你可以更好地理解Hadoop的工作原理和分布式计算的基本概念。
其运行过程可以大致分为map阶段和reduce阶段,而MapReduce编程模型允许将复杂的业务逻辑分解为多个MapReduce程序的串行运行。下面将详细阐述MapReduce的运行过程以及它的编程模型。 首先,MapReduce的运行过程大致...
4. **运行Job**:配置好MapReduce作业后,提交到Hadoop集群进行执行。集群会自动调度任务,将工作分配给各个节点。 5. **结果收集**:MapReduce完成后,最终的词频统计结果会被写入HDFS,可以进一步进行可视化或...
在Hadoop MapReduce中,服务器间的通信主要依赖于远程过程调用(RPC)机制。具体来说: - 客户端通过RPC接口向作业服务器提交作业。 - 作业服务器通过RPC接口分配任务给任务服务器。 - 任务服务器通过RPC接口向作业...
MapReduce模型的核心思想是将复杂的、运行在大规模集群上的并行计算过程高度抽象到了两个函数:Map和Reduce。 Map函数:它主要负责处理输入数据,将数据解析为一系列中间形式的键值对(Key-Value pair)。Map阶段...
Hadoop提供了丰富的工具来支持MapReduce作业的管理和调试,包括`hadoop jar`命令用于提交作业,`hadoop fs`用于文件系统操作,以及`job`和`task`命令用于查看作业和任务的状态。 总结,MapReduce是Hadoop处理大数据...
* 整个程序需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象。 Hadoop序列化: 1. 为什么要序列化?序列化可以存储活的对象,可以将活的对象发送到远程计算机。 2. 什么是序列化?序列化就是...
4. Job Submission and Monitoring:负责提交作业到集群并提供监控作业执行过程的功能。 5. Job Input:处理作业的输入数据,通常是读取HDFS中的数据。 6. Job Output:处理作业的输出数据,通常是将结果写回到HDFS...
在main方法中,我们首先获取了Job信息,然后加载了Mapper代码,设置了输入和输出路径,并提交了作业。 小结 本文详细介绍了MapReduce之数据清洗ETL的实现过程,包括Extract、Transform和Load三个阶段。我们通过...
《深入理解Hadoop MapReduce执行过程》 MapReduce是Apache Hadoop的核心组件之一,它为大规模数据处理提供了分布式计算框架。本文将从客户端、JobTracker、TaskTracker和Child四个角度,详细阐述MapReduce的工作...