д№ӢеүҚд№ҹжңүдёҖдәӣд»Ӣз»ҚеӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳзҡ„ж–Үз« пјҢдҫӢеҰӮLiveJournalзҡ„гҖҒebayзҡ„пјҢйғҪжҳҜйқһеёёеҖјеҫ—еҸӮиҖғзҡ„пјҢдёҚиҝҮж„ҹи§ү他们讲зҡ„жӣҙеӨҡзҡ„жҳҜжҜҸж¬Ўжј”еҸҳзҡ„з»“жһңпјҢиҖҢжІЎжңүеҫҲиҜҰз»Ҷзҡ„и®Ідёәд»Җд№ҲйңҖиҰҒеҒҡиҝҷж ·зҡ„жј”еҸҳпјҢеҶҚеҠ дёҠиҝ‘жқҘж„ҹи§үжңүдёҚе°‘еҗҢеӯҰйғҪеҫҲйҡҫжҳҺзҷҪдёәд»Җд№ҲдёҖдёӘзҪ‘з«ҷйңҖиҰҒйӮЈд№ҲеӨҚжқӮзҡ„жҠҖжңҜпјҢдәҺжҳҜжңүдәҶеҶҷиҝҷзҜҮж–Үз« зҡ„жғіжі•пјҢеңЁиҝҷзҜҮж–Үз« дёӯ е°Ҷйҳҗиҝ°дёҖдёӘжҷ®йҖҡзҡ„зҪ‘з«ҷеҸ‘еұ•жҲҗеӨ§еһӢзҪ‘з«ҷиҝҮзЁӢдёӯзҡ„дёҖз§Қиҫғдёәе…ёеһӢзҡ„жһ¶жһ„жј”еҸҳеҺҶзЁӢе’ҢжүҖйңҖжҺҢжҸЎзҡ„зҹҘиҜҶдҪ“зі»пјҢеёҢжңӣиғҪз»ҷжғід»ҺдәӢдә’иҒ”зҪ‘иЎҢдёҡзҡ„еҗҢеӯҰдёҖзӮ№еҲқжӯҘзҡ„жҰӮеҝөпјҢ:-)пјҢж–Үдёӯзҡ„дёҚеҜ№д№ӢеӨ„д№ҹиҜ·еҗ„дҪҚеӨҡз»ҷзӮ№е»әи®®пјҢи®©жң¬ж–ҮзңҹжӯЈиө·еҲ°жҠӣз –еј•зҺүзҡ„ж•ҲжһңгҖӮ
жһ¶жһ„жј”еҸҳ第дёҖжӯҘпјҡзү©зҗҶеҲҶзҰ»webserverе’Ңж•°жҚ®еә“
жңҖејҖе§ӢпјҢз”ұдәҺжҹҗдәӣжғіжі•пјҢдәҺжҳҜеңЁдә’иҒ”зҪ‘дёҠжҗӯе»әдәҶдёҖдёӘзҪ‘з«ҷпјҢиҝҷдёӘж—¶еҖҷз”ҡиҮіжңүеҸҜиғҪдё»жңәйғҪжҳҜз§ҹеҖҹзҡ„пјҢдҪҶз”ұдәҺиҝҷзҜҮж–Үз« жҲ‘们еҸӘе…іжіЁжһ¶жһ„зҡ„жј”еҸҳеҺҶзЁӢпјҢеӣ жӯӨе°ұеҒҮи®ҫиҝҷдёӘж—¶еҖҷ е·Із»ҸжҳҜжүҳз®ЎдәҶдёҖеҸ°дё»жңәпјҢ并且жңүдёҖе®ҡзҡ„еёҰе®ҪдәҶпјҢиҝҷдёӘж—¶еҖҷз”ұдәҺзҪ‘з«ҷе…·еӨҮдәҶдёҖе®ҡзҡ„зү№иүІпјҢеҗёеј•дәҶйғЁеҲҶдәәи®ҝй—®пјҢйҖҗжёҗдҪ еҸ‘зҺ°зі»з»ҹзҡ„еҺӢеҠӣи¶ҠжқҘи¶Ҡй«ҳпјҢе“Қеә”йҖҹеәҰи¶ҠжқҘи¶Ҡж…ўпјҢиҖҢиҝҷдёӘж—¶еҖҷжҜ”иҫғжҳҺжҳҫзҡ„жҳҜж•°жҚ®еә“е’Ңеә”з”Ёдә’зӣёеҪұе“ҚпјҢеә”з”ЁеҮәй—®йўҳдәҶпјҢж•°жҚ®еә“д№ҹеҫҲе®№жҳ“еҮәзҺ°й—®йўҳпјҢиҖҢж•°жҚ®еә“еҮәй—®йўҳзҡ„ж—¶еҖҷпјҢеә”з”Ёд№ҹе®№жҳ“еҮәй—®йўҳпјҢдәҺжҳҜиҝӣе…ҘдәҶ第дёҖжӯҘжј”еҸҳйҳ¶ж®өпјҡе°Ҷеә”з”Ёе’Ңж•°жҚ®еә“д»Һзү©зҗҶдёҠеҲҶзҰ»пјҢеҸҳжҲҗдәҶдёӨеҸ°жңәеҷЁпјҢиҝҷдёӘж—¶еҖҷжҠҖжңҜдёҠжІЎжңүд»Җд№Ҳж–°зҡ„иҰҒжұӮпјҢдҪҶдҪ еҸ‘зҺ°зЎ®е®һиө·еҲ°ж•ҲжһңдәҶпјҢзі»з»ҹеҸҲжҒўеӨҚеҲ°д»ҘеүҚзҡ„е“Қеә”йҖҹеәҰдәҶпјҢ并且ж”Ҝж’‘дҪҸдәҶжӣҙй«ҳзҡ„жөҒйҮҸпјҢ并且дёҚдјҡеӣ дёәж•°жҚ®еә“е’Ңеә”з”ЁеҪўжҲҗдә’зӣёзҡ„еҪұе“ҚгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ
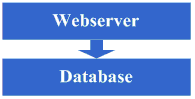
иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
иҝҷдёҖжӯҘжһ¶жһ„жј”еҸҳеҜ№жҠҖжңҜдёҠзҡ„зҹҘиҜҶдҪ“зі»еҹәжң¬жІЎжңүиҰҒжұӮгҖӮ
жһ¶жһ„жј”еҸҳ第дәҢжӯҘпјҡеўһеҠ йЎөйқўзј“еӯҳ
еҘҪжҷҜдёҚй•ҝпјҢйҡҸзқҖи®ҝй—®зҡ„дәәи¶ҠжқҘи¶ҠеӨҡпјҢдҪ еҸ‘зҺ°е“Қеә”йҖҹеәҰеҸҲејҖе§ӢеҸҳж…ўдәҶпјҢжҹҘжүҫеҺҹеӣ пјҢеҸ‘зҺ°жҳҜи®ҝй—®ж•°жҚ®еә“зҡ„ж“ҚдҪңеӨӘеӨҡпјҢеҜјиҮҙж•°жҚ®иҝһжҺҘз«һдәүжҝҖзғҲпјҢжүҖд»Ҙе“Қеә”еҸҳж…ўпјҢдҪҶж•°жҚ®еә“иҝһ жҺҘеҸҲдёҚиғҪејҖеӨӘеӨҡпјҢеҗҰеҲҷж•°жҚ®еә“жңәеҷЁеҺӢеҠӣдјҡеҫҲй«ҳпјҢеӣ жӯӨиҖғиҷ‘йҮҮз”Ёзј“еӯҳжңәеҲ¶жқҘеҮҸе°‘ж•°жҚ®еә“иҝһжҺҘиө„жәҗзҡ„з«һдәүе’ҢеҜ№ж•°жҚ®еә“иҜ»зҡ„еҺӢеҠӣпјҢиҝҷдёӘж—¶еҖҷйҰ–е…Ҳд№ҹи®ёдјҡйҖүжӢ©йҮҮз”Ёsquid зӯүзұ»дјјзҡ„жңәеҲ¶жқҘе°Ҷзі»з»ҹдёӯзӣёеҜ№йқҷжҖҒзҡ„йЎөйқўпјҲдҫӢеҰӮдёҖдёӨеӨ©жүҚдјҡжңүжӣҙж–°зҡ„йЎөйқўпјүиҝӣиЎҢзј“еӯҳпјҲеҪ“然пјҢд№ҹеҸҜд»ҘйҮҮз”Ёе°ҶйЎөйқўйқҷжҖҒеҢ–зҡ„ж–№жЎҲпјүпјҢиҝҷж ·зЁӢеәҸдёҠеҸҜд»ҘдёҚеҒҡдҝ®ж”№пјҢе°ұиғҪеӨҹ еҫҲеҘҪзҡ„еҮҸе°‘еҜ№webserverзҡ„еҺӢеҠӣд»ҘеҸҠеҮҸе°‘ж•°жҚ®еә“иҝһжҺҘиө„жәҗзҡ„з«һдәүпјҢOKпјҢдәҺжҳҜејҖе§ӢйҮҮз”ЁsquidжқҘеҒҡзӣёеҜ№йқҷжҖҒзҡ„йЎөйқўзҡ„зј“еӯҳгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ

иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
еүҚз«ҜйЎөйқўзј“еӯҳжҠҖжңҜпјҢдҫӢеҰӮsquidпјҢеҰӮжғіз”ЁеҘҪзҡ„иҜқиҝҳеҫ—ж·ұе…ҘжҺҢжҸЎдёӢsquidзҡ„е®һзҺ°ж–№ејҸд»ҘеҸҠзј“еӯҳзҡ„еӨұж•Ҳз®—жі•зӯүгҖӮ
жһ¶жһ„жј”еҸҳ第дёүжӯҘпјҡеўһеҠ йЎөйқўзүҮж®өзј“еӯҳ
еўһеҠ дәҶsquidеҒҡзј“еӯҳеҗҺпјҢж•ҙдҪ“зі»з»ҹзҡ„йҖҹеәҰзЎ®е®һжҳҜжҸҗеҚҮдәҶпјҢwebserverзҡ„еҺӢеҠӣд№ҹејҖе§ӢдёӢйҷҚдәҶпјҢдҪҶйҡҸзқҖи®ҝй—®йҮҸзҡ„еўһеҠ пјҢеҸ‘зҺ°зі»з»ҹеҸҲејҖе§ӢеҸҳзҡ„жңүдәӣж…ўдәҶпјҢеңЁе°қ еҲ°дәҶsquidд№Ӣзұ»зҡ„еҠЁжҖҒзј“еӯҳеёҰжқҘзҡ„еҘҪеӨ„еҗҺпјҢејҖе§ӢжғіиғҪдёҚиғҪи®©зҺ°еңЁйӮЈдәӣеҠЁжҖҒйЎөйқўйҮҢзӣёеҜ№йқҷжҖҒзҡ„йғЁеҲҶд№ҹзј“еӯҳиө·жқҘе‘ўпјҢеӣ жӯӨиҖғиҷ‘йҮҮз”Ёзұ»дјјESIд№Ӣзұ»зҡ„йЎөйқўзүҮж®өзј“еӯҳзӯ–з•ҘпјҢOKпјҢдәҺжҳҜејҖе§ӢйҮҮз”ЁESIжқҘеҒҡеҠЁжҖҒйЎөйқўдёӯзӣёеҜ№йқҷжҖҒзҡ„зүҮж®өйғЁеҲҶзҡ„зј“еӯҳгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ
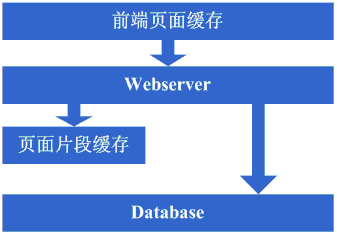
иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
йЎөйқўзүҮж®өзј“еӯҳжҠҖжңҜпјҢдҫӢеҰӮESIзӯүпјҢжғіз”ЁеҘҪзҡ„иҜқеҗҢж ·йңҖиҰҒжҺҢжҸЎESIзҡ„е®һзҺ°ж–№ејҸзӯүпјӣ
жһ¶жһ„жј”еҸҳ第еӣӣжӯҘпјҡж•°жҚ®зј“еӯҳ
еңЁйҮҮз”ЁESIд№Ӣзұ»зҡ„жҠҖжңҜеҶҚж¬ЎжҸҗй«ҳдәҶзі»з»ҹзҡ„зј“еӯҳж•ҲжһңеҗҺпјҢзі»з»ҹзҡ„еҺӢеҠӣзЎ®е®һиҝӣдёҖжӯҘйҷҚдҪҺдәҶпјҢдҪҶеҗҢж ·пјҢйҡҸзқҖи®ҝй—®йҮҸзҡ„еўһеҠ пјҢзі»з»ҹиҝҳжҳҜејҖе§ӢеҸҳж…ўпјҢз»ҸиҝҮжҹҘжүҫпјҢеҸҜиғҪдјҡеҸ‘зҺ°зі» з»ҹдёӯеӯҳеңЁдёҖдәӣйҮҚеӨҚиҺ·еҸ–ж•°жҚ®дҝЎжҒҜзҡ„ең°ж–№пјҢеғҸиҺ·еҸ–з”ЁжҲ·дҝЎжҒҜзӯүпјҢиҝҷдёӘж—¶еҖҷејҖе§ӢиҖғиҷ‘жҳҜдёҚжҳҜеҸҜд»Ҙе°Ҷиҝҷдәӣж•°жҚ®дҝЎжҒҜд№ҹзј“еӯҳиө·жқҘе‘ўпјҢдәҺжҳҜе°Ҷиҝҷдәӣж•°жҚ®зј“еӯҳеҲ°жң¬ең°еҶ…еӯҳпјҢж”№еҸҳе®ҢжҜ•еҗҺпјҢе®Ңе…Ёз¬ҰеҗҲйў„жңҹпјҢзі»з»ҹзҡ„е“Қеә”йҖҹеәҰеҸҲжҒўеӨҚдәҶпјҢж•°жҚ®еә“зҡ„еҺӢеҠӣд№ҹеҶҚеәҰйҷҚдҪҺдәҶдёҚе°‘гҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ
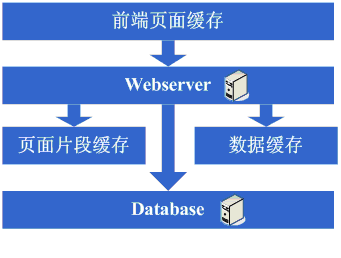
иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
зј“еӯҳжҠҖжңҜпјҢеҢ…жӢ¬еғҸMapж•°жҚ®з»“жһ„гҖҒзј“еӯҳз®—жі•гҖҒжүҖйҖүз”Ёзҡ„жЎҶжһ¶жң¬иә«зҡ„е®һзҺ°жңәеҲ¶зӯүгҖӮ
жһ¶жһ„жј”еҸҳ第дә”жӯҘпјҡ еўһеҠ webserver
еҘҪжҷҜдёҚй•ҝпјҢеҸ‘зҺ°йҡҸзқҖзі»з»ҹи®ҝй—®йҮҸзҡ„еҶҚеәҰеўһеҠ пјҢwebserverжңәеҷЁзҡ„еҺӢеҠӣеңЁй«ҳеі°жңҹдјҡдёҠеҚҮеҲ°жҜ”иҫғй«ҳпјҢиҝҷдёӘж—¶еҖҷејҖе§ӢиҖғиҷ‘еўһеҠ дёҖеҸ°webserverпјҢиҝҷд№ҹжҳҜдёәдәҶеҗҢж—¶и§ЈеҶіеҸҜз”ЁжҖ§зҡ„й—®йўҳпјҢйҒҝе…ҚеҚ•еҸ°зҡ„webserver downжңәзҡ„иҜқе°ұжІЎжі•дҪҝз”ЁдәҶпјҢеңЁеҒҡдәҶиҝҷдәӣиҖғиҷ‘еҗҺпјҢеҶіе®ҡеўһеҠ дёҖеҸ°webserverпјҢеўһеҠ дёҖеҸ°webserverж—¶пјҢдјҡзў°еҲ°дёҖдәӣй—®йўҳпјҢе…ёеһӢзҡ„жңүпјҡ
1гҖҒеҰӮдҪ•и®©и®ҝй—®еҲҶй…ҚеҲ°иҝҷдёӨеҸ°жңәеҷЁдёҠпјҢиҝҷдёӘж—¶еҖҷйҖҡеёёдјҡиҖғиҷ‘зҡ„ж–№жЎҲжҳҜApacheиҮӘеёҰзҡ„иҙҹиҪҪеқҮиЎЎж–№жЎҲпјҢжҲ–LVSиҝҷзұ»зҡ„иҪҜ件иҙҹиҪҪеқҮиЎЎж–№жЎҲпјӣ
2гҖҒеҰӮдҪ•дҝқжҢҒзҠ¶жҖҒдҝЎжҒҜзҡ„еҗҢжӯҘпјҢдҫӢеҰӮз”ЁжҲ·sessionзӯүпјҢиҝҷдёӘж—¶еҖҷдјҡиҖғиҷ‘зҡ„ж–№жЎҲжңүеҶҷе…Ҙж•°жҚ®еә“гҖҒеҶҷе…ҘеӯҳеӮЁгҖҒcookieжҲ–еҗҢжӯҘsessionдҝЎжҒҜзӯүжңәеҲ¶зӯүпјӣ
3гҖҒеҰӮдҪ•дҝқжҢҒж•°жҚ®зј“еӯҳдҝЎжҒҜзҡ„еҗҢжӯҘпјҢдҫӢеҰӮд№ӢеүҚзј“еӯҳзҡ„з”ЁжҲ·ж•°жҚ®зӯүпјҢиҝҷдёӘж—¶еҖҷйҖҡеёёдјҡиҖғиҷ‘зҡ„жңәеҲ¶жңүзј“еӯҳеҗҢжӯҘжҲ–еҲҶеёғејҸзј“еӯҳпјӣ
4гҖҒеҰӮдҪ•и®©дёҠдј ж–Ү件иҝҷдәӣзұ»дјјзҡ„еҠҹиғҪ继з»ӯжӯЈеёёпјҢиҝҷдёӘж—¶еҖҷйҖҡеёёдјҡиҖғиҷ‘зҡ„жңәеҲ¶жҳҜдҪҝз”Ёе…ұдә«ж–Ү件系з»ҹжҲ–еӯҳеӮЁзӯүпјӣ
еңЁи§ЈеҶідәҶиҝҷдәӣй—®йўҳеҗҺпјҢз»ҲдәҺжҳҜжҠҠwebserverеўһеҠ дёәдәҶдёӨеҸ°пјҢзі»з»ҹз»ҲдәҺжҳҜеҸҲжҒўеӨҚеҲ°дәҶд»ҘеҫҖзҡ„йҖҹеәҰгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ
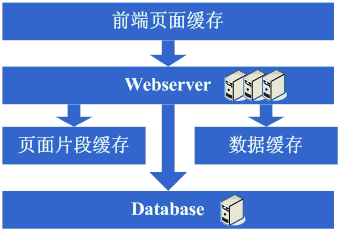
иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
иҙҹиҪҪеқҮиЎЎжҠҖжңҜпјҲеҢ…жӢ¬дҪҶдёҚйҷҗдәҺ硬件иҙҹиҪҪеқҮиЎЎгҖҒиҪҜ件иҙҹиҪҪеқҮиЎЎгҖҒиҙҹиҪҪз®—жі•гҖҒlinuxиҪ¬еҸ‘еҚҸи®®гҖҒжүҖйҖүз”Ёзҡ„жҠҖжңҜзҡ„е®һзҺ°з»ҶиҠӮзӯүпјүгҖҒдё»еӨҮжҠҖжңҜпјҲеҢ…жӢ¬дҪҶдёҚйҷҗдәҺARPж¬әйӘ—гҖҒlinux heart-beatзӯүпјүгҖҒзҠ¶жҖҒдҝЎжҒҜжҲ–зј“еӯҳеҗҢжӯҘжҠҖжңҜпјҲеҢ…жӢ¬дҪҶдёҚйҷҗдәҺCookieжҠҖжңҜгҖҒUDPеҚҸи®®гҖҒзҠ¶жҖҒдҝЎжҒҜе№ҝж’ӯгҖҒжүҖйҖүз”Ёзҡ„зј“еӯҳеҗҢжӯҘжҠҖжңҜзҡ„е®һзҺ°з»ҶиҠӮзӯүпјүгҖҒе…ұдә«ж–Ү件жҠҖжңҜпјҲеҢ…жӢ¬дҪҶдёҚйҷҗдәҺNFSзӯүпјүгҖҒеӯҳеӮЁжҠҖжңҜпјҲеҢ…жӢ¬дҪҶдёҚйҷҗдәҺеӯҳеӮЁи®ҫеӨҮзӯүпјүгҖӮ
жһ¶жһ„жј”еҸҳ第е…ӯжӯҘпјҡеҲҶеә“
дә«еҸ—дәҶдёҖж®өж—¶й—ҙзҡ„зі»з»ҹи®ҝй—®йҮҸй«ҳйҖҹеўһй•ҝзҡ„е№ёзҰҸеҗҺпјҢеҸ‘зҺ°зі»з»ҹеҸҲејҖе§ӢеҸҳж…ўдәҶпјҢиҝҷж¬ЎеҸҲжҳҜд»Җд№ҲзҠ¶еҶөе‘ўпјҢз»ҸиҝҮжҹҘжүҫпјҢеҸ‘зҺ°ж•°жҚ®еә“еҶҷе…ҘгҖҒжӣҙж–°зҡ„иҝҷдәӣж“ҚдҪңзҡ„йғЁеҲҶж•°жҚ®еә“иҝһжҺҘзҡ„ иө„жәҗз«һдәүйқһеёёжҝҖзғҲпјҢеҜјиҮҙдәҶзі»з»ҹеҸҳж…ўпјҢиҝҷдёӢжҖҺд№ҲеҠһе‘ўпјҢжӯӨж—¶еҸҜйҖүзҡ„ж–№жЎҲжңүж•°жҚ®еә“йӣҶзҫӨе’ҢеҲҶеә“зӯ–з•ҘпјҢйӣҶзҫӨж–№йқўеғҸжңүдәӣж•°жҚ®еә“ж”ҜжҢҒзҡ„并дёҚжҳҜеҫҲеҘҪпјҢеӣ жӯӨеҲҶеә“дјҡжҲҗдёәжҜ”иҫғжҷ®йҒҚзҡ„зӯ–з•ҘпјҢеҲҶеә“д№ҹе°ұж„Ҹе‘ізқҖиҰҒеҜ№еҺҹжңүзЁӢеәҸиҝӣиЎҢдҝ®ж”№пјҢдёҖйҖҡдҝ®ж”№е®һзҺ°еҲҶеә“еҗҺпјҢдёҚй”ҷпјҢзӣ®ж ҮиҫҫеҲ°дәҶпјҢзі»з»ҹжҒўеӨҚз”ҡиҮійҖҹеәҰжҜ”д»ҘеүҚиҝҳеҝ«дәҶгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ
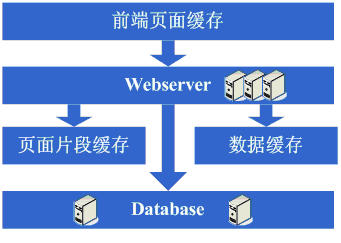
иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
иҝҷдёҖжӯҘжӣҙеӨҡзҡ„жҳҜйңҖиҰҒд»ҺдёҡеҠЎдёҠеҒҡеҗҲзҗҶзҡ„еҲ’еҲҶпјҢд»Ҙе®һзҺ°еҲҶеә“пјҢе…·дҪ“жҠҖжңҜз»ҶиҠӮдёҠжІЎжңүе…¶д»–зҡ„иҰҒжұӮпјӣ
дҪҶеҗҢж—¶йҡҸзқҖж•°жҚ®йҮҸзҡ„еўһеӨ§е’ҢеҲҶеә“зҡ„иҝӣиЎҢпјҢеңЁж•°жҚ®еә“зҡ„и®ҫи®ЎгҖҒи°ғдјҳд»ҘеҸҠз»ҙжҠӨдёҠйңҖиҰҒеҒҡзҡ„жӣҙеҘҪпјҢеӣ жӯӨеҜ№иҝҷдәӣж–№йқўзҡ„жҠҖжңҜиҝҳжҳҜжҸҗеҮәдәҶеҫҲй«ҳзҡ„иҰҒжұӮзҡ„гҖӮ
жһ¶жһ„жј”еҸҳ第дёғжӯҘпјҡеҲҶиЎЁгҖҒDALе’ҢеҲҶеёғејҸзј“еӯҳ
йҡҸзқҖзі»з»ҹзҡ„дёҚж–ӯиҝҗиЎҢпјҢж•°жҚ®йҮҸејҖе§ӢеӨ§е№…еәҰеўһй•ҝпјҢиҝҷдёӘж—¶еҖҷеҸ‘зҺ°еҲҶеә“еҗҺжҹҘиҜўд»Қ然дјҡжңүдәӣж…ўпјҢдәҺжҳҜжҢүз…§еҲҶеә“зҡ„жҖқжғіејҖе§ӢеҒҡеҲҶиЎЁзҡ„е·ҘдҪңпјҢеҪ“然пјҢиҝҷдёҚеҸҜйҒҝе…Қзҡ„дјҡйңҖиҰҒеҜ№зЁӢеәҸ иҝӣиЎҢдёҖдәӣдҝ®ж”№пјҢд№ҹи®ёеңЁиҝҷдёӘж—¶еҖҷе°ұдјҡеҸ‘зҺ°еә”з”ЁиҮӘе·ұиҰҒе…іеҝғеҲҶеә“еҲҶиЎЁзҡ„规еҲҷзӯүпјҢиҝҳжҳҜжңүдәӣеӨҚжқӮзҡ„пјҢдәҺжҳҜиҗҢз”ҹиғҪеҗҰеўһеҠ дёҖдёӘйҖҡз”Ёзҡ„жЎҶжһ¶жқҘе®һзҺ°еҲҶеә“еҲҶиЎЁзҡ„ж•°жҚ®и®ҝй—®пјҢиҝҷдёӘеңЁebayзҡ„жһ¶жһ„дёӯеҜ№еә”зҡ„е°ұжҳҜDALпјҢиҝҷдёӘжј”еҸҳзҡ„иҝҮзЁӢзӣёеҜ№иҖҢиЁҖйңҖиҰҒиҠұиҙ№иҫғй•ҝзҡ„ж—¶й—ҙпјҢеҪ“然пјҢд№ҹжңүеҸҜиғҪиҝҷдёӘйҖҡз”Ёзҡ„жЎҶжһ¶дјҡзӯүеҲ°еҲҶиЎЁеҒҡе®ҢеҗҺжүҚејҖе§ӢеҒҡпјҢеҗҢж—¶пјҢеңЁиҝҷдёӘйҳ¶ж®өеҸҜ иғҪдјҡеҸ‘зҺ°д№ӢеүҚзҡ„зј“еӯҳеҗҢжӯҘж–№жЎҲеҮәзҺ°й—®йўҳпјҢеӣ дёәж•°жҚ®йҮҸеӨӘеӨ§пјҢеҜјиҮҙзҺ°еңЁдёҚеӨӘеҸҜиғҪе°Ҷзј“еӯҳеӯҳеңЁжң¬ең°пјҢ然еҗҺеҗҢжӯҘзҡ„ж–№ејҸпјҢйңҖиҰҒйҮҮз”ЁеҲҶеёғејҸзј“еӯҳж–№жЎҲдәҶпјҢдәҺжҳҜпјҢеҸҲжҳҜдёҖйҖҡиҖғеҜҹе’ҢжҠҳзЈЁпјҢз»ҲдәҺжҳҜе°ҶеӨ§йҮҸзҡ„ж•°жҚ®зј“еӯҳиҪ¬з§»еҲ°еҲҶеёғејҸзј“еӯҳдёҠдәҶгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ

иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
еҲҶиЎЁжӣҙеӨҡзҡ„еҗҢж ·жҳҜдёҡеҠЎдёҠзҡ„еҲ’еҲҶпјҢжҠҖжңҜдёҠж¶үеҸҠеҲ°зҡ„дјҡжңүеҠЁжҖҒhashз®—жі•гҖҒconsistent hashз®—жі•зӯүпјӣ
DALж¶үеҸҠеҲ°жҜ”иҫғеӨҡзҡ„еӨҚжқӮжҠҖжңҜпјҢдҫӢеҰӮж•°жҚ®еә“иҝһжҺҘзҡ„з®ЎзҗҶпјҲи¶…ж—¶гҖҒејӮеёёпјүгҖҒж•°жҚ®еә“ж“ҚдҪңзҡ„жҺ§еҲ¶пјҲи¶…ж—¶гҖҒејӮеёёпјүгҖҒеҲҶеә“еҲҶ表规еҲҷзҡ„е°ҒиЈ…зӯүпјӣ
жһ¶жһ„жј”еҸҳ第八жӯҘпјҡеўһеҠ жӣҙеӨҡзҡ„webserver
еңЁеҒҡе®ҢеҲҶеә“еҲҶиЎЁиҝҷдәӣе·ҘдҪңеҗҺпјҢж•°жҚ®еә“дёҠзҡ„еҺӢеҠӣе·Із»ҸйҷҚеҲ°жҜ”иҫғдҪҺдәҶпјҢеҸҲејҖе§ӢиҝҮзқҖжҜҸеӨ©зңӢзқҖи®ҝй—®йҮҸжҡҙеўһзҡ„е№ёзҰҸз”ҹжҙ»дәҶпјҢзӘҒ然жңүдёҖеӨ©пјҢеҸ‘зҺ°зі»з»ҹзҡ„и®ҝй—®еҸҲејҖе§ӢжңүеҸҳж…ўзҡ„и¶ӢеҠҝ дәҶпјҢиҝҷдёӘж—¶еҖҷйҰ–е…ҲжҹҘзңӢж•°жҚ®еә“пјҢеҺӢеҠӣдёҖеҲҮжӯЈеёёпјҢд№ӢеҗҺжҹҘзңӢwebserverпјҢеҸ‘зҺ°apacheйҳ»еЎһдәҶеҫҲеӨҡзҡ„иҜ·жұӮпјҢиҖҢеә”з”ЁжңҚеҠЎеҷЁеҜ№жҜҸдёӘиҜ·жұӮд№ҹжҳҜжҜ”иҫғеҝ«зҡ„пјҢзңӢжқҘ жҳҜиҜ·жұӮж•°еӨӘй«ҳеҜјиҮҙйңҖиҰҒжҺ’йҳҹзӯүеҫ…пјҢе“Қеә”йҖҹеәҰеҸҳж…ўпјҢиҝҷиҝҳеҘҪеҠһпјҢдёҖиҲ¬жқҘиҜҙпјҢиҝҷдёӘж—¶еҖҷд№ҹдјҡжңүдәӣй’ұдәҶпјҢдәҺжҳҜж·»еҠ дёҖдәӣwebserverжңҚеҠЎеҷЁпјҢеңЁиҝҷдёӘж·»еҠ webserverжңҚеҠЎеҷЁзҡ„иҝҮзЁӢпјҢжңүеҸҜиғҪдјҡеҮәзҺ°еҮ з§ҚжҢ‘жҲҳпјҡ
1гҖҒApacheзҡ„иҪҜиҙҹиҪҪжҲ–LVSиҪҜиҙҹиҪҪзӯүж— жі•жүҝжӢ…е·ЁеӨ§зҡ„webи®ҝй—®йҮҸпјҲиҜ·жұӮиҝһжҺҘж•°гҖҒзҪ‘з»ңжөҒйҮҸзӯүпјүзҡ„и°ғеәҰдәҶпјҢиҝҷдёӘж—¶еҖҷеҰӮжһңз»Ҹиҙ№е…Ғи®ёзҡ„иҜқпјҢдјҡйҮҮеҸ–зҡ„ж–№жЎҲжҳҜиҙӯ 买硬件иҙҹиҪҪпјҢдҫӢеҰӮF5гҖҒNetsclarгҖҒAthelonд№Ӣзұ»зҡ„пјҢеҰӮз»Ҹиҙ№дёҚе…Ғи®ёзҡ„иҜқпјҢдјҡйҮҮеҸ–зҡ„ж–№жЎҲжҳҜе°Ҷеә”з”Ёд»ҺйҖ»иҫ‘дёҠеҒҡдёҖе®ҡзҡ„еҲҶзұ»пјҢ然еҗҺеҲҶж•ЈеҲ°дёҚеҗҢзҡ„иҪҜиҙҹиҪҪйӣҶзҫӨдёӯпјӣ
2гҖҒеҺҹжңүзҡ„дёҖдәӣзҠ¶жҖҒдҝЎжҒҜеҗҢжӯҘгҖҒж–Ү件е…ұдә«зӯүж–№жЎҲеҸҜиғҪдјҡеҮәзҺ°з“¶йўҲпјҢйңҖиҰҒиҝӣиЎҢж”№иҝӣпјҢд№ҹи®ёиҝҷдёӘж—¶еҖҷдјҡж №жҚ®жғ…еҶөзј–еҶҷз¬ҰеҗҲзҪ‘з«ҷдёҡеҠЎйңҖжұӮзҡ„еҲҶеёғејҸж–Ү件系з»ҹзӯүпјӣ
еңЁеҒҡе®Ңиҝҷдәӣе·ҘдҪңеҗҺпјҢејҖе§Ӣиҝӣе…ҘдёҖдёӘзңӢдјје®ҢзҫҺзҡ„ж— йҷҗдјёзј©зҡ„ж—¶д»ЈпјҢеҪ“зҪ‘з«ҷжөҒйҮҸеўһеҠ ж—¶пјҢеә”еҜ№зҡ„и§ЈеҶіж–№жЎҲе°ұжҳҜдёҚж–ӯзҡ„ж·»еҠ webserverгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ
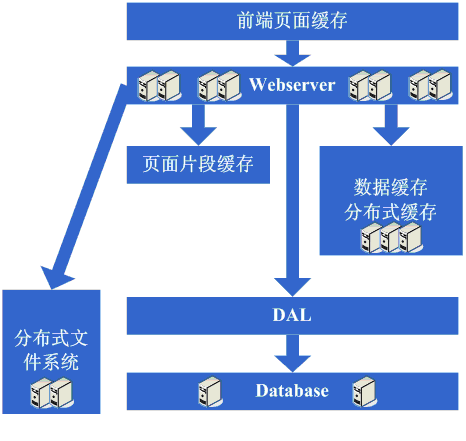
иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
еҲ°дәҶиҝҷдёҖжӯҘпјҢйҡҸзқҖжңәеҷЁж•°зҡ„дёҚж–ӯеўһй•ҝгҖҒж•°жҚ®йҮҸзҡ„дёҚж–ӯеўһй•ҝе’ҢеҜ№зі»з»ҹеҸҜз”ЁжҖ§зҡ„иҰҒжұӮи¶ҠжқҘи¶Ҡй«ҳпјҢиҝҷдёӘж—¶еҖҷиҰҒжұӮеҜ№жүҖйҮҮз”Ёзҡ„жҠҖжңҜйғҪиҰҒжңүжӣҙдёәж·ұе…Ҙзҡ„зҗҶи§ЈпјҢ并йңҖиҰҒж №жҚ®зҪ‘з«ҷзҡ„йңҖжұӮжқҘеҒҡжӣҙеҠ е®ҡеҲ¶жҖ§иҙЁзҡ„дә§е“ҒгҖӮ
жһ¶жһ„жј”еҸҳ第д№қжӯҘпјҡж•°жҚ®иҜ»еҶҷеҲҶзҰ»е’Ңе»үд»·еӯҳеӮЁж–№жЎҲ
зӘҒ然жңүдёҖеӨ©пјҢеҸ‘зҺ°иҝҷдёӘе®ҢзҫҺзҡ„ж—¶д»Јд№ҹиҰҒз»“жқҹдәҶпјҢж•°жҚ®еә“зҡ„еҷ©жўҰеҸҲдёҖж¬ЎеҮәзҺ°еңЁзңјеүҚдәҶпјҢз”ұдәҺж·»еҠ зҡ„webserverеӨӘеӨҡдәҶпјҢеҜјиҮҙж•°жҚ®еә“иҝһжҺҘзҡ„иө„жәҗиҝҳжҳҜдёҚеӨҹз”ЁпјҢиҖҢиҝҷдёӘж—¶еҖҷеҸҲе·Із»ҸеҲҶеә“еҲҶиЎЁдәҶпјҢејҖе§ӢеҲҶжһҗж•°жҚ®еә“зҡ„еҺӢеҠӣзҠ¶еҶөпјҢеҸҜиғҪдјҡеҸ‘зҺ°ж•°жҚ®еә“зҡ„иҜ»еҶҷжҜ”еҫҲй«ҳпјҢиҝҷдёӘж—¶еҖҷйҖҡеёёдјҡжғіеҲ°ж•°жҚ®иҜ»еҶҷеҲҶзҰ»зҡ„ж–№жЎҲпјҢеҪ“然пјҢиҝҷдёӘж–№жЎҲиҰҒе®һзҺ°е№¶дёҚ е®№жҳ“пјҢеҸҰеӨ–пјҢеҸҜиғҪдјҡеҸ‘зҺ°дёҖдәӣж•°жҚ®еӯҳеӮЁеңЁж•°жҚ®еә“дёҠжңүдәӣжөӘиҙ№пјҢжҲ–иҖ…иҜҙиҝҮдәҺеҚ з”Ёж•°жҚ®еә“иө„жәҗпјҢеӣ жӯӨеңЁиҝҷдёӘйҳ¶ж®өеҸҜиғҪдјҡеҪўжҲҗзҡ„жһ¶жһ„жј”еҸҳжҳҜе®һзҺ°ж•°жҚ®иҜ»еҶҷеҲҶзҰ»пјҢеҗҢж—¶зј–еҶҷдёҖдәӣжӣҙдёәе»үд»·зҡ„еӯҳеӮЁж–№жЎҲпјҢдҫӢеҰӮBigTableиҝҷз§ҚгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ
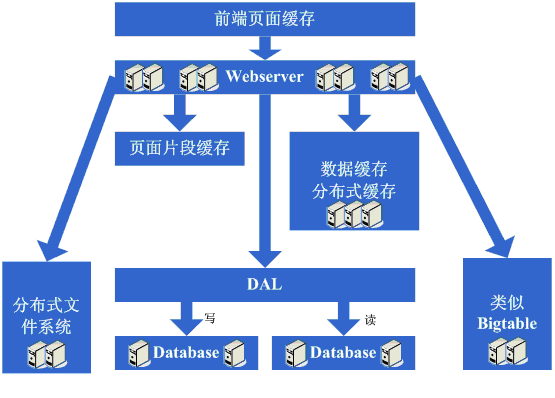
иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
ж•°жҚ®иҜ»еҶҷеҲҶзҰ»иҰҒжұӮеҜ№ж•°жҚ®еә“зҡ„еӨҚеҲ¶гҖҒstandbyзӯүзӯ–з•Ҙжңүж·ұе…Ҙзҡ„жҺҢжҸЎе’ҢзҗҶи§ЈпјҢеҗҢж—¶дјҡиҰҒжұӮе…·еӨҮиҮӘиЎҢе®һзҺ°зҡ„жҠҖжңҜпјӣ
е»үд»·еӯҳеӮЁж–№жЎҲиҰҒжұӮеҜ№OSзҡ„ж–Ү件еӯҳеӮЁжңүж·ұе…Ҙзҡ„жҺҢжҸЎе’ҢзҗҶи§ЈпјҢеҗҢж—¶иҰҒжұӮеҜ№йҮҮз”Ёзҡ„иҜӯиЁҖеңЁж–Ү件иҝҷеқ—зҡ„е®һзҺ°жңүж·ұе…Ҙзҡ„жҺҢжҸЎгҖӮ
жһ¶жһ„жј”еҸҳ第еҚҒжӯҘпјҡиҝӣе…ҘеӨ§еһӢеҲҶеёғејҸеә”з”Ёж—¶д»Је’Ңе»үд»·жңҚеҠЎеҷЁзҫӨжўҰжғіж—¶д»Ј
з»ҸиҝҮдёҠйқўиҝҷдёӘжј«й•ҝиҖҢз—ӣиӢҰзҡ„иҝҮзЁӢпјҢз»ҲдәҺжҳҜеҶҚеәҰиҝҺжқҘдәҶе®ҢзҫҺзҡ„ж—¶д»ЈпјҢдёҚж–ӯзҡ„еўһеҠ webserverе°ұеҸҜд»Ҙж”Ҝж’‘и¶ҠжқҘи¶Ҡй«ҳзҡ„и®ҝй—®йҮҸдәҶпјҢеҜ№дәҺеӨ§еһӢзҪ‘з«ҷиҖҢиЁҖпјҢдәәж°”зҡ„йҮҚиҰҒжҜӢ еәёзҪ®з–‘пјҢйҡҸзқҖдәәж°”зҡ„и¶ҠжқҘи¶Ҡй«ҳпјҢеҗ„з§Қеҗ„ж ·зҡ„еҠҹиғҪйңҖжұӮд№ҹејҖе§ӢзҲҶеҸ‘жҖ§зҡ„еўһй•ҝпјҢиҝҷдёӘж—¶еҖҷзӘҒ然еҸ‘зҺ°пјҢеҺҹжқҘйғЁзҪІеңЁwebserverдёҠзҡ„йӮЈдёӘwebеә”з”Ёе·Із»ҸйқһеёёеәһеӨ§ дәҶпјҢеҪ“еӨҡдёӘеӣўйҳҹйғҪејҖе§ӢеҜ№е…¶иҝӣиЎҢж”№еҠЁж—¶пјҢеҸҜзңҹжҳҜзӣёеҪ“зҡ„дёҚж–№дҫҝпјҢеӨҚз”ЁжҖ§д№ҹзӣёеҪ“зіҹзі•пјҢеҹәжң¬жҳҜжҜҸдёӘеӣўйҳҹйғҪеҒҡдәҶжҲ–еӨҡжҲ–е°‘йҮҚеӨҚзҡ„дәӢжғ…пјҢиҖҢдё”йғЁзҪІе’Ңз»ҙжҠӨд№ҹжҳҜзӣёеҪ“зҡ„йә»зғҰпјҢ еӣ дёәеәһеӨ§зҡ„еә”з”ЁеҢ…еңЁNеҸ°жңәеҷЁдёҠеӨҚеҲ¶гҖҒеҗҜеҠЁйғҪйңҖиҰҒиҖ—иҙ№дёҚе°‘зҡ„ж—¶й—ҙпјҢеҮәй—®йўҳзҡ„ж—¶еҖҷд№ҹдёҚжҳҜеҫҲеҘҪжҹҘпјҢеҸҰеӨ–дёҖдёӘжӣҙзіҹзі•зҡ„зҠ¶еҶөжҳҜеҫҲжңүеҸҜиғҪдјҡеҮәзҺ°жҹҗдёӘеә”з”ЁдёҠзҡ„bugе°ұеҜј иҮҙдәҶе…Ёз«ҷйғҪдёҚеҸҜз”ЁпјҢиҝҳжңүе…¶д»–зҡ„еғҸи°ғдјҳдёҚеҘҪж“ҚдҪңпјҲеӣ дёәжңәеҷЁдёҠйғЁзҪІзҡ„еә”з”Ёд»Җд№ҲйғҪиҰҒеҒҡпјҢж №жң¬е°ұж— жі•иҝӣиЎҢй’ҲеҜ№жҖ§зҡ„и°ғдјҳпјүзӯүеӣ зҙ пјҢж №жҚ®иҝҷж ·зҡ„еҲҶжһҗпјҢејҖе§Ӣз—ӣдёӢеҶіеҝғпјҢе°Ҷ зі»з»ҹж №жҚ®иҒҢиҙЈиҝӣиЎҢжӢҶеҲҶпјҢдәҺжҳҜдёҖдёӘеӨ§еһӢзҡ„еҲҶеёғејҸеә”з”Ёе°ұиҜһз”ҹдәҶпјҢйҖҡеёёпјҢиҝҷдёӘжӯҘйӘӨйңҖиҰҒиҖ—иҙ№зӣёеҪ“й•ҝзҡ„ж—¶й—ҙпјҢеӣ дёәдјҡзў°еҲ°еҫҲеӨҡзҡ„жҢ‘жҲҳпјҡ
1гҖҒжӢҶжҲҗеҲҶеёғејҸеҗҺйңҖиҰҒжҸҗдҫӣдёҖдёӘй«ҳжҖ§иғҪгҖҒзЁіе®ҡзҡ„йҖҡдҝЎжЎҶжһ¶пјҢ并且йңҖиҰҒж”ҜжҢҒеӨҡз§ҚдёҚеҗҢзҡ„йҖҡдҝЎе’ҢиҝңзЁӢи°ғз”Ёж–№ејҸпјӣ
2гҖҒе°ҶдёҖдёӘеәһеӨ§зҡ„еә”з”ЁжӢҶеҲҶйңҖиҰҒиҖ—иҙ№еҫҲй•ҝзҡ„ж—¶й—ҙпјҢйңҖиҰҒиҝӣиЎҢдёҡеҠЎзҡ„ж•ҙзҗҶе’Ңзі»з»ҹдҫқиө–е…ізі»зҡ„жҺ§еҲ¶зӯүпјӣ
3гҖҒеҰӮдҪ•иҝҗз»ҙпјҲдҫқиө–з®ЎзҗҶгҖҒиҝҗиЎҢзҠ¶еҶөз®ЎзҗҶгҖҒй”ҷиҜҜиҝҪиёӘгҖҒи°ғдјҳгҖҒзӣ‘жҺ§е’ҢжҠҘиӯҰзӯүпјүеҘҪиҝҷдёӘеәһеӨ§зҡ„еҲҶеёғејҸеә”з”ЁгҖӮ
з»ҸиҝҮиҝҷдёҖжӯҘпјҢе·®дёҚеӨҡзі»з»ҹзҡ„жһ¶жһ„иҝӣе…ҘзӣёеҜ№зЁіе®ҡзҡ„йҳ¶ж®өпјҢеҗҢж—¶д№ҹиғҪејҖе§ӢйҮҮз”ЁеӨ§йҮҸзҡ„е»үд»·жңәеҷЁжқҘж”Ҝж’‘зқҖе·ЁеӨ§зҡ„и®ҝй—®йҮҸе’Ңж•°жҚ®йҮҸпјҢз»“еҗҲиҝҷеҘ—жһ¶жһ„д»ҘеҸҠиҝҷд№ҲеӨҡж¬Ўжј”еҸҳиҝҮзЁӢеҗёеҸ–зҡ„з»ҸйӘҢжқҘйҮҮз”Ёе…¶д»–еҗ„з§Қеҗ„ж ·зҡ„ж–№жі•жқҘж”Ҝж’‘зқҖи¶ҠжқҘи¶Ҡй«ҳзҡ„и®ҝй—®йҮҸгҖӮ
зңӢзңӢиҝҷдёҖжӯҘе®ҢжҲҗеҗҺзі»з»ҹзҡ„еӣҫзӨәпјҡ
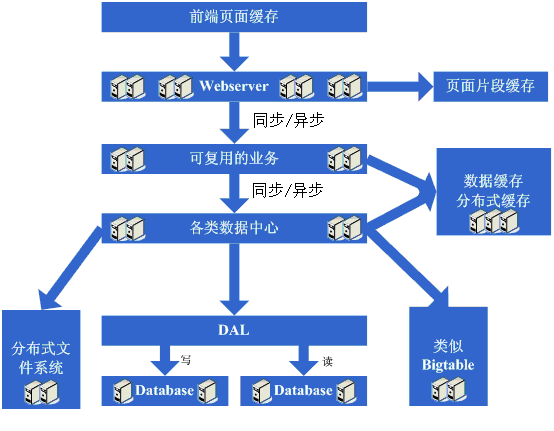
иҝҷдёҖжӯҘж¶үеҸҠеҲ°дәҶиҝҷдәӣзҹҘиҜҶдҪ“зі»пјҡ
иҝҷдёҖжӯҘж¶үеҸҠзҡ„зҹҘиҜҶдҪ“зі»йқһеёёзҡ„еӨҡпјҢиҰҒжұӮеҜ№йҖҡдҝЎгҖҒиҝңзЁӢи°ғз”ЁгҖҒж¶ҲжҒҜжңәеҲ¶зӯүжңүж·ұе…Ҙзҡ„зҗҶи§Је’ҢжҺҢжҸЎпјҢиҰҒжұӮзҡ„йғҪжҳҜд»ҺзҗҶи®әгҖҒ硬件зә§гҖҒж“ҚдҪңзі»з»ҹзә§д»ҘеҸҠжүҖйҮҮз”Ёзҡ„иҜӯиЁҖзҡ„е®һзҺ°йғҪжңүжё…жҘҡзҡ„зҗҶи§ЈгҖӮ
иҝҗз»ҙиҝҷеқ—ж¶үеҸҠзҡ„зҹҘиҜҶдҪ“зі»д№ҹйқһеёёзҡ„еӨҡпјҢеӨҡж•°жғ…еҶөдёӢйңҖиҰҒжҺҢжҸЎеҲҶеёғејҸ并иЎҢи®Ўз®—гҖҒжҠҘиЎЁгҖҒзӣ‘жҺ§жҠҖжңҜд»ҘеҸҠ规еҲҷзӯ–з•ҘзӯүзӯүгҖӮ
иҜҙиө·жқҘзЎ®е®һдёҚжҖҺд№Ҳиҙ№еҠӣпјҢж•ҙдёӘзҪ‘з«ҷжһ¶жһ„зҡ„з»Ҹе…ёжј”еҸҳиҝҮзЁӢйғҪе’ҢдёҠйқўжҜ”иҫғзҡ„зұ»дјјпјҢеҪ“然пјҢжҜҸжӯҘйҮҮеҸ–зҡ„ж–№жЎҲпјҢжј”еҸҳзҡ„жӯҘйӘӨжңүеҸҜиғҪжңүдёҚеҗҢпјҢеҸҰеӨ–пјҢз”ұдәҺзҪ‘з«ҷзҡ„дёҡеҠЎдёҚеҗҢпјҢдјҡжңүдёҚеҗҢзҡ„дё“дёҡжҠҖжңҜзҡ„йңҖжұӮпјҢиҝҷзҜҮblogжӣҙеӨҡзҡ„жҳҜд»Һжһ¶жһ„зҡ„и§’еәҰжқҘи®Іи§Јжј”еҸҳзҡ„иҝҮзЁӢпјҢеҪ“然пјҢе…¶дёӯиҝҳжңүеҫҲеӨҡзҡ„жҠҖжңҜд№ҹжңӘеңЁжӯӨжҸҗеҸҠпјҢеғҸж•°жҚ®еә“йӣҶзҫӨгҖҒж•°жҚ®жҢ–жҺҳгҖҒжҗңзҙўзӯүпјҢдҪҶеңЁзңҹе®һзҡ„жј”еҸҳиҝҮзЁӢдёӯиҝҳдјҡеҖҹеҠ©еғҸжҸҗеҚҮ硬件й…ҚзҪ®гҖҒзҪ‘з»ңзҺҜеўғгҖҒж”№йҖ ж“ҚдҪңзі»з»ҹгҖҒCDNй•ңеғҸзӯүжқҘж”Ҝж’‘жӣҙеӨ§зҡ„жөҒйҮҸпјҢеӣ жӯӨеңЁзңҹе®һзҡ„еҸ‘еұ•иҝҮзЁӢдёӯиҝҳдјҡжңүеҫҲеӨҡзҡ„дёҚеҗҢпјҢеҸҰеӨ–дёҖдёӘеӨ§еһӢзҪ‘з«ҷиҰҒеҒҡеҲ°зҡ„иҝңиҝңдёҚд»…д»…дёҠйқўиҝҷдәӣпјҢиҝҳжңүеғҸе®үе…ЁгҖҒиҝҗз»ҙгҖҒиҝҗиҗҘгҖҒжңҚеҠЎгҖҒеӯҳеӮЁзӯүпјҢиҰҒеҒҡеҘҪдёҖдёӘеӨ§еһӢзҡ„зҪ‘з«ҷзңҹзҡ„еҫҲдёҚе®№жҳ“пјҢеҶҷиҝҷзҜҮж–Үз« жӣҙеӨҡзҡ„жҳҜеёҢжңӣиғҪеӨҹеј•еҮәжӣҙеӨҡеӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳзҡ„д»Ӣз»ҚпјҢ:-)гҖӮ
ps:жңҖеҗҺйҷ„дёҠеҮ зҜҮLiveJournalжһ¶жһ„жј”еҸҳзҡ„ж–Үз« пјҡ
д»ҺLiveJournalеҗҺеҸ°еҸ‘еұ•зңӢеӨ§и§„жЁЎзҪ‘з«ҷжҖ§иғҪдјҳеҢ–ж–№жі•
http://blog.zhangjianfeng.com/article/743
еҸҰеӨ–д»ҺиҝҷйҮҢпјҡhttp://www.danga.com/words/еӨ§е®¶еҸҜд»ҘжүҫеҲ°жӣҙеӨҡе…ідәҺзҺ°еңЁLiveJournalзҪ‘з«ҷжһ¶жһ„зҡ„д»Ӣз»ҚгҖӮ
жң¬ж–ҮжқҘжәҗпјҡhttp://www.blogjava.net/BlueDavy/archive/2008/09/03/226749.html
еҲҶдә«еҲ°пјҡ





зӣёе…іжҺЁиҚҗ
еӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳе’ҢзҹҘиҜҶдҪ“зі»еӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳе’ҢзҹҘиҜҶдҪ“зі»
### еӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳдёҺзҹҘиҜҶдҪ“зі»и§Јжһҗ #### жһ¶жһ„жј”еҸҳзҡ„第дёҖжӯҘпјҡзү©зҗҶеҲҶзҰ»WebжңҚеҠЎеҷЁдёҺж•°жҚ®еә“ еңЁзҪ‘з«ҷеҸ‘еұ•зҡ„еҲқжңҹйҳ¶ж®өпјҢеҫҖеҫҖз”ұдәҺиө„жәҗйҷҗеҲ¶пјҢWebеә”з”ЁдёҺж•°жҚ®еә“йғЁзҪІеңЁеҗҢдёҖеҸ°жңҚеҠЎеҷЁдёҠгҖӮйҡҸзқҖз”ЁжҲ·и®ҝй—®йҮҸзҡ„еўһй•ҝпјҢеҚ•дёҖжңҚеҠЎеҷЁдёҠзҡ„...
жҖ»зҡ„жқҘиҜҙпјҢеӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳзҡ„зҹҘиҜҶдҪ“зі»еҢ…жӢ¬пјҡеҚ•дҪ“жһ¶жһ„гҖҒеһӮзӣҙжӢҶеҲҶгҖҒж°ҙе№іжү©еұ•гҖҒеҫ®жңҚеҠЎжһ¶жһ„гҖҒе®№еҷЁеҢ–гҖҒж•°жҚ®дёҖиҮҙжҖ§зҗҶи®әгҖҒзј“еӯҳжҠҖжңҜгҖҒCDNгҖҒNoSQLгҖҒж¶ҲжҒҜйҳҹеҲ—гҖҒзӣ‘жҺ§е’Ңж—Ҙеҝ—еҲҶжһҗзӯүеӨҡдёӘж–№йқўгҖӮзҗҶ解并жҺҢжҸЎиҝҷдәӣзҹҘиҜҶпјҢжңүеҠ©дәҺжһ„е»әй«ҳж•Ҳ...
еӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳе’ҢзҹҘиҜҶдҪ“зі» д№ӢеүҚд№ҹжңүдёҖдәӣд»Ӣз»ҚеӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳзҡ„ж–Үз« пјҢдҫӢеҰӮLiveJournalзҡ„гҖҒebayзҡ„пјҢйғҪжҳҜйқһеёёеҖјеҫ—еҸӮиҖғзҡ„пјҢдёҚиҝҮж„ҹи§ү他们讲зҡ„жӣҙеӨҡзҡ„жҳҜжҜҸж¬Ўжј”еҸҳзҡ„з»“жһңпјҢиҖҢжІЎжңүеҫҲиҜҰз»Ҷзҡ„и®Ідёәд»Җд№ҲйңҖиҰҒеҒҡиҝҷж ·зҡ„жј”еҸҳпјҢеҶҚ...
еӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳе’ҢзҹҘиҜҶдҪ“зі» д№ӢеүҚд№ҹжңүдёҖдәӣд»Ӣз»ҚеӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳзҡ„ж–Үз« пјҢдҫӢеҰӮLiveJournalзҡ„гҖҒebayзҡ„пјҢйғҪжҳҜйқһеёёеҖјеҫ—еҸӮиҖғзҡ„пјҢдёҚиҝҮж„ҹи§ү他们讲зҡ„жӣҙеӨҡзҡ„жҳҜжҜҸж¬Ўжј”еҸҳзҡ„з»“жһңпјҢиҖҢжІЎжңүеҫҲиҜҰз»Ҷзҡ„и®Ідёәд»Җд№ҲйңҖиҰҒеҒҡиҝҷж ·зҡ„жј”еҸҳпјҢеҶҚеҠ дёҠ...
### еӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳдёҺзҹҘиҜҶдҪ“зі»иҜҰи§Ј #### жһ¶жһ„жј”еҸҳзҡ„第дёҖжӯҘпјҡзү©зҗҶеҲҶзҰ»WebжңҚеҠЎеҷЁдёҺж•°жҚ®еә“ еңЁзҪ‘з«ҷеҲқеҲӣйҳ¶ж®өпјҢйҖҡеёёжҳҜйҖҡиҝҮдёҖеҸ°дё»жңәжқҘжүҝиҪҪжүҖжңүзҡ„еҠҹиғҪпјҢеҢ…жӢ¬WebжңҚеҠЎе’Ңж•°жҚ®еә“жңҚеҠЎгҖӮйҡҸзқҖз”ЁжҲ·и®ҝй—®йҮҸзҡ„еўһй•ҝпјҢеҚ•дёҖдё»жңәзҡ„жҖ§иғҪ...
гҖҠеӨ§еһӢзҪ‘з«ҷжһ¶жһ„жј”еҸҳе’ҢзҹҘиҜҶдҪ“зі»гҖӢжҳҜдёҖжң¬ж·ұе…ҘжҺўи®Ёжһ„е»әдёҺдјҳеҢ–еӨ§и§„жЁЎдә’иҒ”зҪ‘еә”з”Ёзҡ„жқғеЁҒж–ҮжЎЈгҖӮеңЁдә’иҒ”зҪ‘иЎҢдёҡеҝ«йҖҹеҸ‘еұ•зҡ„д»ҠеӨ©пјҢеӨ§еһӢзҪ‘з«ҷзҡ„жһ¶жһ„и®ҫи®Ўе·Із»ҸжҲҗдёәжҠҖжңҜеӣўйҳҹйқўдёҙзҡ„йҮҚеӨ§жҢ‘жҲҳд№ӢдёҖгҖӮжң¬д№Ұе…ЁйқўиҰҶзӣ–дәҶд»ҺеҲқжңҹзҡ„е°ҸеһӢзҪ‘з«ҷеҲ°еә”еҜ№...