通过上2篇博文,我们了解了分区表的理论,这一节就开始实战。本篇博文的内容如下:
1,建立分区表
2,查询分区
3,归档数据
4,添加分区
5,删除分区
6,查看元数据
PS下:最近收到很多朋友的消息和邮件,大多是关于数据库的问题,没有一一答复,由于平时工作比较忙,博客更新的比较慢,在这里说声抱歉。
OK,我们以一个销售数据库场景开始分区表实战。
第一步:建立我们要使用的数据库,最重要的是建立多个文件组。
CREATE DATABASE Sales ON PRIMARY
(
NAME = N'Sales',
FILENAME = N'C:\Sales.mdf',
SIZE = 3MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG1
(
NAME = N'File1',
FILENAME = N'C:\File1.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG2
(
NAME = N'File2',
FILENAME = N'C:\File2.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG3
(
NAME = N'File3',
FILENAME = N'C:\File3.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
)
LOG ON
(
NAME = N'Sales_Log',
FILENAME = N'C:\Sales_Log.ldf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
)
GO
第二步:建立分区函数,这里我们建立三个分区。 how(如何对数据进行分区)
USE Sales
GO
CREATE PARTITION FUNCTION pf_OrderDate (datetime)
AS RANGE RIGHT
FOR VALUES ('2003/01/01', '2004/01/01') --n不能超过 999,创建的分区数等于 n + 1
GO
第三步:创建分区方案,关联到分区函数 。 where(在哪里对数据进行分区)
USE Sales
GO
CREATE PARTITION SCHEME ps_OrderDate
AS PARTITION pf_OrderDate
TO (FG1, FG2, FG3)
GO
第四步:创建分区表。创建表并将其绑定到分区方案。这里我们建立2个表,表的结构一样。其中OrdersHistory表用于保存归档数据。
USE Sales
GO
CREATE TABLE dbo.Orders
(
OrderID int identity(10000,1),
OrderDate datetime NOT NULL,
CustomerID int NOT NULL,
CONSTRAINT PK_Orders PRIMARY KEY (OrderID, OrderDate)
)
ON ps_OrderDate (OrderDate)
GO
CREATE TABLE dbo.OrdersHistory
(
OrderID int identity(10000,1),
OrderDate datetime NOT NULL,
CustomerID int NOT NULL,
CONSTRAINT PK_OrdersHistory PRIMARY KEY (OrderID, OrderDate)
)
ON ps_OrderDate (OrderDate)
GO
通过以上四步,我们建立了分区表。接着我们要插入一些数据,来进行数据归档,分区查询等。
向数据表中写入2002年的范例数据
USE Sales
GO
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/6/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/8/13', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/8/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/9/23', 1000)
GO
向数据表中写入2003年的范例数据
USE Sales
GO
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/6/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/8/13', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/8/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/9/23', 1000)
GO
我们可以用下面的代码查询这2表:
SELECT * FROM dbo.Orders
SELECT * FROM dbo.OrdersHistory
查询的结果是Orders里面有8行数据,而OrdersHistory还没有数据。因为我们还没归档数据,所以OrdersHistory表还没有数据。
插入完数据后,我们来做如下实验:
1,查询某个分区
这里我们要用到$PARTITION 函数,这个函数可以帮助我们查询某个分区的数据,还可以检索某个值所隶属的分区号。$PARTITION 函数的进一步细节可以查看MSDN
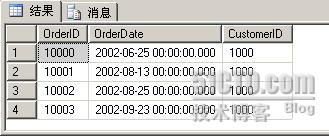
查询已分区表Order的第一个分区,代码如下:
SELECT *
FROM dbo.Orders
WHERE $PARTITION.pf_OrderDate(OrderDate) = 1
查询结果只包含2002年的数据,如下图:
如果想获得2003年的数据,需要如下的代码:
SELECT *
FROM dbo.Orders
WHERE $PARTITION.pf_OrderDate(OrderDate) = 2
我们还可以查询某个分区有多少行数据,代码如下:
SELECT $PARTITION.pf_OrderDate(OrderDate) AS Partition,
COUNT(*) AS [COUNT]
FROM dbo.Orders
GROUP BY $PARTITION.pf_OrderDate(OrderDate)
ORDER BY Partition ;
我们还可以通过$PARTITION 函数获得一组分区标示列值的分区号,例如获得2002属于哪个分区,代码如下:
SELECT Sales.$PARTITION.pf_OrderDate('2002')
很明显,2002年隶属于第1个分区,因为我们建立分区函数时用了RANGE RIGHT,所以返回1。你也可以把2002年换成2003,2004,2005,2009等等测试。你会发现,2003年属于第2个分区,2004年以后的都属于第3个分区。
2,归档数据
假如现在是2003年年初,那么我们就可以把2002年所有的交易记录归档到历史订单表HistoryOrder中。代码如下:
USE Sales
GO
ALTER TABLE dbo.Orders SWITCH PARTITION 1 TO dbo.OrdersHistory PARTITION 1
GO
此时如果我们再执行如下代码:
SELECT * FROM dbo.Orders
SELECT * FROM dbo.OrdersHistory
便会发现,Orders 表只剩2003年的数据,而OrdersHistory表中包含了2002年的数据。
当然如果到了2004年年初,我们也可以归档2003年的所有交易数据。代码如下:
USE Sales
GO
ALTER TABLE dbo.Orders SWITCH PARTITION 2 TO dbo.OrdersHistory PARTITION 2
GO
3,添加分区
由于目前我们只有三分分区,而这三个分区的区间如下:
|
文件组
|
分区
|
取值范围
|
|
FG1
|
1
|
(过去某年, 2003/01/01)
|
|
Fg2
|
2
|
[2003/01/01, 2004/01/01)
|
|
Fg3
|
3
|
[2004/01/01,未来某年)
|
所以假如到了2005年年初,我们需要为2005年的交易记录准备分区,代码如下:
USE Sales
GO
ALTER PARTITION SCHEME ps_OrderDate NEXT USED FG2
ALTER PARTITION FUNCTION pf_OrderDate() SPLIT RANGE ('2005/01/01')
GO
ALTER PARTITION SCHEME ps_OrderDate NEXT USED FG2 用来指定新分区的数据存储在那个文件。这里NEXT USED FG2 代表我们将新分区的数据保存在FG2文件组中,当然我们也可以在原有数据库上新建一个文件组,把新分区的数据保存在新文件组当中,这里我们直接用FG2文件组。
ALTER PARTITION FUNCTION pf_OrderDate() SPLIT RANGE ('2005/01/01') 代表我们创建一个新分区,而这里SPLIT RANGE ('2005/01/01')正是创建新分区的关键语法。
执行完上面的代码之后,我们就有了4个分区,此时的区间如下:
|
文件组
|
分区
|
取值范围
|
|
FG1
|
1
|
(过去某年, 2003/01/01)
|
|
Fg2
|
2
|
[2003/01/01, 2004/01/01)
|
|
Fg3
|
3
|
[2004/01/01, 2005/01/01)
|
|
Fg2
|
4
|
[2005/01/01, 未来某年)
|
4,删除分区
删除分区又称为合并分区,假如我们想合并2002年的分区和2003年的分区到一个分区,我们可以用如下的代码:
USE Sales
GO
ALTER PARTITION FUNCTION pf_OrderDate() MERGE RANGE ('2003/01/01')
GO
执行完上面的代码,此时分区区间如下:
|
文件组
|
分区
|
取值范围
|
|
Fg2
|
1
|
[过去某年, 2004/01/01)
|
|
Fg3
|
2
|
[2004/01/01, 2005/01/01)
|
|
Fg2
|
3
|
[2005/01/01, 未来某年)
|
合并2002和2003年的数据到2003年之后,我们执行如下代码:
SELECT Sales.$PARTITION.pf_OrderDate('2003')
你会发现返回的结果是1。而原来返回的是2,原因是2002年以前数据所在的那个分区合并到了2003年这个分区中了。
假如此时我们执行如下代码:
SELECT *
FROM dbo.OrdersHistory
WHERE $PARTITION.pf_OrderDate(OrderDate) = 2
结果一行数据都没返回,事实就这样,因为OrdersHistory 表中只存储了2002和2003年的历史数据,在没有合并分区之前,执行上面的代码肯定会查询出2003年的数据,但是合并了分区之后,上面代码实际查询的是第二个分区中2004年的数据。
不过当我们改成如下的代码:
SELECT *
FROM dbo.OrdersHistory
WHERE $PARTITION.pf_OrderDate(OrderDate) = 1
便会查询出8行数据,包括2002年和2003年的数据,因为合并分区后2002年和2003年的数据都成了第1个分区的数据了。
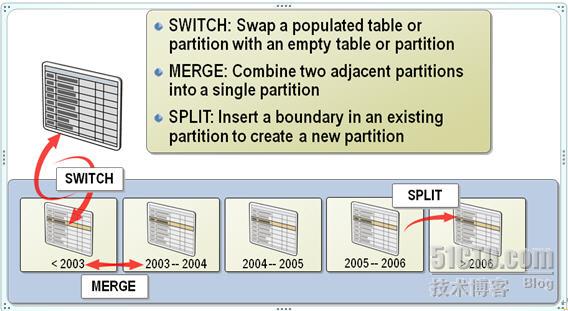
通过图形我们来回忆下归档数据、添加分区、合并分区。
5,查看元数据
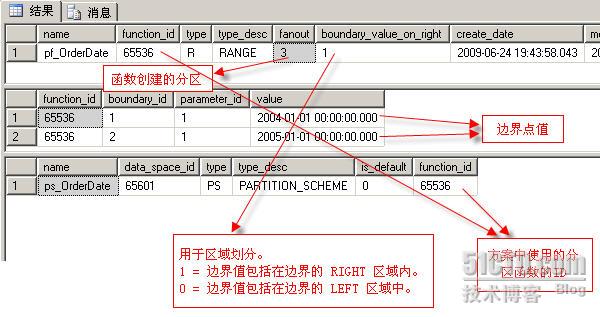
我们可以通过以下三个视图来观察我们创建的分区函数,分区方案,边界点值等。
select * from sys.partition_functions
select * from sys.partition_range_values
select * from sys.partition_schemes
查询的结果如下图:
本文出自 “李涛的技术专栏” 博客,请务必保留此出处http://terryli.blog.51cto.com/704315/169601
Great thanks 李涛





相关推荐
SQL 2000是微软公司推出的一款关系型数据库管理系统,全称为Microsoft SQL Server 2000。作为一款历史悠久的数据库系统,它在IT领域中占有重要地位,尤其是在企业级应用中。本文将深入探讨SQL 2000的核心特性和主要...
标题“SQL2022-SSEI-Dev.rar”表明这是一个与Microsoft SQL Server 2022相关的资源,特别是针对“SSEI”(可能是Server-Side Encryption Infrastructure)和“Dev”(开发版本)。这个压缩包包含了一个名为“SQL2022...
5. **(5)2k+1-1** - **知识点**: 二叉树性质 - **解析**: 该公式用于计算满二叉树或完全二叉树的节点数量。 6. **(6)就绪** - **知识点**: 进程状态 - **解析**: 进程状态之一,表示进程已准备好运行但未...
注意数据文件大小限制,比如AIX系统不超过1GB,NT/2K的FAT32分区不能超过4GB。 **四、数据库维护** 数据库维护包括但不限于: - 数据库备份与恢复。 - 性能监控与调优。 - 安全性管理,如权限设置和审计。 - 逻辑...
- **Sybase Open Client/Open Server**:提供接口,使应用程序能访问SQL Server或其他类型的数据库管理系统。 3. **Sybase安装** - **服务器端安装**:在服务器上安装Sybase数据库管理系统。 - **客户端安装**:...
#### 三、锁和表分区 **锁机制:** - **共享锁**:允许多个事务读取同一数据,但不允许写入。 - **排他锁**:允许一个事务写入数据,其他事务不能读取或写入该数据。 **表分区:** - 表分区可以提高查询性能,减少...
根据提供的信息,我们可以推断出这是一系列关于Oracle数据库学习的教学视频链接,由韩顺平教授。虽然直接的视频内容无法获取,但从标题和其他部分可以提取出与Oracle相关的知识点。 ### Oracle基础知识 #### 1. **...
#### 5. logoff —— 注销当前用户 - **功能**: 使当前用户注销系统。 - **应用场景**: 用户切换、安全维护时使用。 #### 6. tsshutdn —— 远程关机 - **功能**: 提供远程关闭或重启计算机的功能。 - **应用场景**...
7. **性能优化**:包括SQL优化、索引优化、分区技术、物化视图、数据库调优工具(如DBMS_XPLAN、AWR报告等)的应用,以提升数据库性能。 8. **数据库设计**:介绍关系数据库设计的基本原则,如范式理论,以及如何...
5239 网吧维护\资料\FW\ASP实现对SQL SERVER 数据库的操作.TXT 2945 网吧维护\资料\FW\MYSQL.TXT 11239 网吧维护\资料\FW\WIN2000SERVER安全设置的一些小技巧.TXT 0 网吧维护\资料\FW\WWW.TXT 6103 网吧维护\资料\FW...