ŃÇÇ1 ňëŹŔĘÇ
ŃÇÇ2 ÚśůŔ»╗ŠťČš»çšÜäňč║šíÇňçćňĄç
ŃÇÇŃÇÇ2.1 ŠŽéň┐ÁšÜäňč║šíÇ
ŃÇÇŃÇÇ2.2 šÄ»ňóâšÜäňč║šíÇ
ŃÇÇ3 ń╗Çń╣łŠś»ŠÁüšĘőň╝ĽŠôÄňćůŠáŞ´╝č
ŃÇÇ4 ň╝ĽŠôÄňćůŠáŞŠëÇňů│Š│ĘšÜäňŤŤńެńŞ╗ŔŽüÚŚ«Úóś
ŃÇÇŃÇÇ4.1 ŠĘíň×őńŞÄň«Üń╣ëň»╣Ŕ▒í
ŃÇÇŃÇÇ4.2 Ŕ░âň║ŽŠť║ňłÂńŞÄš«ŚŠ│Ľ
ŃÇÇŃÇÇ4.3 ŠëžŔí║ňłÂńŞÄšŐŠÇü
ŃÇÇŃÇÇ4.4 ň«×ńżőň»╣Ŕ▒íńŞÄŠëžŔíîšÄ»ňóâ
ŃÇÇ5 jbpm´╝îÔÇťš▓żš«ÇÔÇŁšÜäň╝ÇŠ║ÉŠÁüšĘőň╝ĽŠôÄ
ŃÇÇ6 jBpmŠÁüšĘőŠĘíň×őńŞÄň«Üń╣ëň»╣Ŕ▒í
ŃÇÇŃÇÇ6.1 ÚŽľňůłŔžúňć│ňŽéńŻĽňŻóň╝ĆňĆĆŔ┐░ńŞÇńެŠÁüšĘőšÜäÚŚ«Úóś
ŃÇÇŃÇÇ6.2 ŠŐŻŔ▒íšÜäŔŐéšé╣´╝łNode´╝ëňĺîŔŻČšž╗´╝łTransition´╝ë
ŃÇÇŃÇÇ6.3 ŠÁüšĘő´╝ÜŔŐéšé╣ńŞÄŔŻČšž╗šÜäš╗äňÉł
ŃÇÇŃÇÇ6.4 ŔŐéšé╣šÜäš▒╗ň×őňĺîŠëęň▒Ľ
ŃÇÇ7 jBpmšÜäŔ┐çšĘőŔ░âň║ŽŠť║ňłÂ
ŃÇÇŃÇÇ7.1 ňÉŞš║│Ŕç¬Petri NetŠÇŁŠâ│
ŃÇÇŃÇÇ7.2 TokenšÜäŠÄĘŔ┐Ť
ŃÇÇŃÇÇ7.3 ÚŁ×ňŞŞš«ÇňŹĽšÜäŔ░âň║ŽŠť║ňłÂ
ŃÇÇ8 jBpmšÜäŔ┐çšĘőŠëžŔí║ňłÂ
ŃÇÇŃÇÇ8.1 ŠëžŔí║ňłÂ
ŃÇÇŃÇÇ8.2 ňłćŠö»ňĄäšÉć
ŃÇÇ9 jBpmňćůŠáŞš╗ôŠ×äńŞÄň«×ńżőň»╣Ŕ▒í
ŃÇÇ10 ňÉÄŔ«░
ŃÇÇ1 ňëŹŔĘÇ
ŠÁüšĘőň╝ĽŠôÄňćůŠáŞń╗ůŠś»ÔÇťŠ╗íŔÂ│Processňč║ŠťČŔ┐ÉŔíîÔÇŁšÜ䊝Çňż«ň░Ćš╗ôŠ×ä´╝îŔÇ┤ńެň╝ĽŠôÄňłÖŔŽüňĄŹŠŁéňżłňĄÜ´╝îňîůŠőČÔÇťšŐŠÇüňşśňéĘÔÇŁŃÇüÔÇťń║őń╗ÂňĄäšÉćÔÇŁŃÇüÔÇťš╗äš╗çÚÇéÚůŹÔÇŁŃÇüÔÇťŠŚÂÚŚ┤Ŕ░âň║ŽÔÇŁŃÇüÔÇťŠÂłŠü»ŠťŹňŐíÔÇŁšşëšşëňĄľňŤ┤šÜ䊝ŹňŐíŠÇžňŐčŔâŻŃÇéň╝ĽŠôÄňćůŠáŞ´╝îń╗ůňîůňÉźŠťÇňč║ŠťČšÜäň»╣Ŕ▒íňĺŹňŐí´╝îń╗ąňĆŐšöĘń║ÄŔžúňć│ŠÁüšĘőŔ┐ÉŔíîÚŚ«ÚóśšÜäŔ░âň║ŽŠť║ňłÂňĺîŠëžŔí║ňłÂŃÇé
ŃÇÇňŽéŠ×ť´╝îńŻáŠÄîŠĆíń║ćńŞÇńެŠÁüšĘőň╝ĽŠôÄšÜäšüÁÚşé´╝îńŻáŠëŹŠťëŔâŻňŐŤšÉćŔžúň«âšÜäňůĘÚâĘŃÇéňÉŽňłÖ´╝îńŞÇńެň╝ĽŠôÄň»╣ńŻáŠŁąŔ»┤´╝îňĆ»ŔâŻňƬŠś»ńŞÇńެňĄŹŠŁéšÜäš╗ôŠ×ä´╝îńŞ░ň»îňĄÜňŻęAPIŃÇüń╗Ąń║║šť╝ŔŐ▒š╝şń╣▒šÜäÔÇťňŐčŔâŻÔÇŁňĺîÔÇťŠťŹňŐíÔÇŁŔÇîňĚ▓ŃÇé
ŃÇÇŠťČŔ║źňĚąńŻťŠÁüŔ┐ÖńެÚóćňččň░▒Šś»ńŞÇńެňżłÔÇťšőşš¬äÔÇŁšÜäÚóćňčč´╝îňŤŻňćůšÜäňÄéňĽćń╣čńŞŹŠś»ňżłňĄÜ´╝îňůÂńŞşŠťëÚâĘňłćň«×šÄ░ŠŐÇŠť»ň╣ÂńŞŹň╝▒ŃÇéńŻćňĆ»Ŕ⯊Âëń║Äň«ëňůĘšşëňŤáš┤á´╝îň╣Š▓튝ëňĄÜň░ĹŠŐÇŠť»ń║║ňĹśŠÄóŔ«ĘÔÇťŠĚ▒ň║ŽšÜäňĚąńŻťŠÁüŠŐÇŠť»ň«×šÄ░ÚŚ«ÚóśÔÇŁŃÇéŔÇîň╣┐ňĄžšÜäň╝ÇňĆĹšł▒ňąŻŔÇůňŹ┤Ŕ┐śňťĘŔŐ▒Ŕ┤╣ňĄžÚçĆšÜ䊌ÂÚŚ┤ňťĘŠĹŞš┤óÔÇťňŽéńŻĽšÉćŔžúňĚąńŻťŠÁüŃÇüňŽéńŻĽň║öšöĘňĚąńŻťŠÁüÔÇŁŃÇé ŠëÇń╗ąňťĘŠşĄń╣őň돴╝îňŤŻňćůň░ÜŠť¬ŠťëńŞÇš»çŠŐÇŠť»ŠľçšźáŠÄóŔ«ĘňĚąńŻťŠÁüň╝ĽŠôÄňćůŠáŞšÜäň«×šÄ░´╝îňŻôšäÂń╣čŠ▓튝ëŠÄóŔ«ĘjBpmň╝ĽŠôÄňćůŠáŞšÜ䊾皟áń║ćŃÇéňťĘwww.iteye.com ŠŐÇŠť»šźÖšé╣ňĺŚÜäblog´╝łhttp://blog.csdn.net/james999´╝ëńŞŐŠťëňçáš»çńŞôÚŚĘŠÄóŔ«Ęjbpmň║öšöĘšÜ䊾皟á´╝îň»╣ń║ÄňłŁŠşąŠâ│ń║ćŔžúňŽéńŻĽńŻ┐šöĘjbpmšÜäŔ»╗ŔÇůŠŁąŔ»┤´╝îňÇ╝ňżŚšťőšťőŃÇé
ŃÇÇň»╣ń║ÄŔ┐ÖŠľ╣ÚŁóšÜäŠŐÇŠť»ňłćń║ź´╝îň╝ÇŠ║ÉŠś»ńެńŞŹÚöÖšÜ䚬üšá┤ňĆúŃÇé
ŃÇÇŠťČš»çň░▒Šś»ń╗ąjBpmńŞ║ň«×ńżő´╝ąŔ»áÚçŐňĚąńŻťŠÁüň╝ĽŠôÄšÜäňćůŠáŞŔ«żŔ«íŠÇŁŔĚ»ňĺîš╗ôŠ×äŃÇéńŻćŠś»Ŕ┐Öń╗ůń╗ůŠś»ń╗ÄjBpmšÜäň«×šÄ░Ŕžĺň║ŽŠŁąŔżůňŐęňĄžň«ÂšÉćŔžú´╝îňŤáńŞ║ňĚąńŻťŠÁüň╝ĽŠôÄňćůŠáŞšÜäŔ«żŔ«íŃÇüň«×šÄ░Šś»ŠťëňżłňĄÜŠľ╣ň╝Ć´╝ÜŔ┐Öń╝ÜňŤáŠëÇÚÇëšÜäŠĘíň×őŃÇüŔ░âň║Žš«ŚŠ│ĽŃÇüŠÄĘŔ┐ŤŠť║ňłÂŃÇüšŐŠÇüňĆśŔ┐üŠť║ňłÂŃÇüŠëžŔí║ňłÂšşëňĄÜŠľ╣ÚŁóšÜäńŞŹńŞÇŠáĚ´╝îŔÇîń╝ÜňĚ«ňłźňżłňĄžŃÇ銻öňŽéňč║ń║ÄActivity DiagramŠĘíň×őšÜäjBpmňĺîňč║ń║ÄFSMŠĘíň×őšÜäOSWorkflowň╝ĽŠôÄňćůŠáŞń╣őÚŚ┤ň░▒ŠťëňżłňĄžšÜäňĚ«ňłźŃÇé
šŤŞŠ»öŔżâŔÇîŔĘÇ´╝îjBpmšÜäŠĘíň×őŠ»öŔżâňĄŹŠŁé´╝îŔÇîň╝ĽŠôÄňćůŠáŞň«×šÄ░šÜ䊻öŔżâÔÇťš▓żš«ÇÔÇŁ´╝îÚŁ×ňŞŞńż┐ń║ÄňĄžň«ÂÔÇťšö▒ŠÁůňůąŠĚ▒šÜäšÉćŔžúÔÇŁŃÇé
2 ÚśůŔ»╗ŠťČš»çšÜäňč║šíÇňçćňĄç
ŃÇÇ2.1 ŠŽéň┐ÁšÜäňč║šíÇ
ŃÇÇŠťČŠľçšÜäŔ»╗ŔÇůšżĄńŞ╗ŔŽüŠś»ÚŁóňÉĹŠťëńŞÇň«ÜňĚąńŻťŠÁüňč║ŠťČŠŽéň┐ÁšÜäň╝ÇňĆĹń║║ňĹśŃÇéŠëÇń╗ąŠťČŠľçŔ«ĄńŞ║ńŻáňĚ▓š╗ĆňůĚňĄçń║ćňŽéńŞőňč║ŠťČňĚąńŻťŠÁüščąŔ»ć´╝Ü
ŃÇÇ´╝ł1´╝ë ňłŁŠşąń║ćŔžúňĚąńŻťŠÁüš│╗š╗čš╗ôŠ×äŃÇ銻öňŽéšÉćŔžúňĚąńŻťŠÁüň╝ĽŠôÄňťĘňĚąńŻťŠÁüš│╗š╗čńŞşŠëÇňĄäšÜäńŻŹšŻ«ňĺîńŻťšöĘ
ŃÇÇ´╝ł2´╝ë ň»╣ŠÁüšĘőň«Üń╣ë´╝łProcess Definition´╝ëňĺîŠÁüšĘőň«×ńżő´╝łProcess Instance´╝뚍Şňů│ň»╣Ŕ▒튝ëŠëÇń║ćŔžúŃÇ銻öňŽéšÉćŔžúProcess Instanceń╗úŔíĘń╗Çń╣ł´╝îňĚąńŻťÚí╣´╝łWorkItem´╝ëń╗úŔíĘń╗Çń╣łŃÇé
2.2 šÄ»ňóâšÜäňč║šíÇ
ŃÇÇňťĘÚśůŔ»╗ŠťČš»çšÜ䊌ÂňÇÖ´╝îňŽéŠ×ťńŻáňĚ▓š╗ĆŠÉşň╗║ń║ćńŞÇňąŚjbpmšÜäň╝ÇňĆŚĻňóâ´╝îÚéúń╣łň░抝ëňŐęń║ÄńŻáŠŤ┤ň«╣ŠśôšÉćŔžúŠťČš»çšÜäňżłňĄÜňćůň«╣´╝îń╣čńż┐ń║Äň«×ÚÖůńŻôÚ¬îń╗úšáüŃÇéń╗Äwww.jbpm.orgň«śŠľ╣šŻĹšźÖńŞőŔŻŻjbpm-starters-kitň╝ÇňĆĹňîů´╝îŠîëšůžňůÂňĆéŔÇâŠëőňćî´╝îňĆ»ń╗ąňżłň«╣ŠśôňťĘeclipseň╝ÇňĆŚĻňóâńŞşň╗║šźőÚí╣šŤ«´╝łŠ×ťňŤżš▒╗ń╝╝ňŽéńŞő´╝Ü
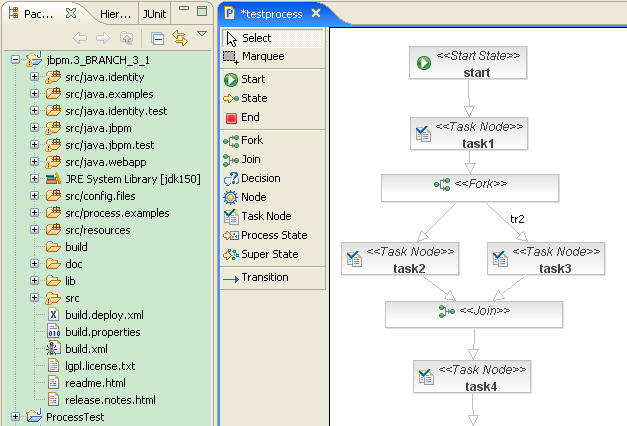  
 
ŃÇÇ3 ń╗Çń╣łŠś»ŠÁüšĘőň╝ĽŠôÄňćůŠáŞ´╝č
ŃÇÇŠłĹŠ»öŔżâŠÄĘň┤çÔÇťňż«ňćůŠáŞšÜäŠÁüšĘőň╝ĽŠôÄŠ×äŠ×ÂÔÇŁ´╝îň╣ÂňťĘŠťÇŔ┐ĹńŞĄńŞëň╣┤ňćůňćÖń║ćńŞĄš»çŠÄóŔ«ĘŠşĄŠľ╣ÚŁóšÜ䊾皟á´╝ÜšČČńŞÇš»çŠś»ňćÖń║Ä05ň╣┤7Šťłń╗ŻšÜäŃÇŐňż«ňćůŠáŞŠÁüšĘőň╝ĽŠôĊ׊×äńŻôš│╗ŃÇő´╝îšČČń║犜»07ň╣┤7Šťłń╗ŻšÜäŃÇŐňż«ňćůŠáŞŔ┐çšĘőň╝ĽŠôÄšÜäŔ«żŔ«íŠÇŁŔĚ»ňĺîŠ×äŠ×ÂŃÇő´╝łňĆŚŠÖ«ňůâŃÇŐÚôÂň╝╣ŃÇőŠŁéň┐Śš║ŽšĘ┐ŠëÇňćÖ´╝îň░ÜŠť¬ň»╣ňĄľňůČň╝Ç´╝ëŃÇé
ŃÇÇńŻćŔç│ń╗Őň»╣ňĄľÚśÉŔ┐░ň╝ĽŠôÄňćůŠáŞňł░ň║ĽŠś»ń╗Çń╣łŃÇé
 
ŃÇÇŠşúňŽéńŞŐÚŁóšÜäńŞĄň╝áňŤżŠëÇšĄ║´╝Ĺń╗ČňĆ»ń╗ąÚÇÜŔ┐çÔÇťňż«ňćůŠáŞÔÇŁšÜäŠ×äŠ×ŠŁąńŻ┐ňżŚŠÁüšĘőň╝ĽŠôÄšÜäš╗ôŠ×䊍┤ňŐáÔÇťŠŞůŠÖ░ÔÇŁŃÇéŔÇîŔâŻňÉŽň«×šÄ░ÔÇťňż«ňćůŠáŞÔÇŁšÜäŠá╣ŠťČ´╝îňłÖŠś»šťőńŻáŠś»ňÉŽŔâŻňĄčŔ«żŔ«íň╣ŠկŔ▒íňç║ÔÇťŔë»ňąŻšÜäň╝ĽŠôÄňćůŠáŞš╗ôŠ×äÔÇŁŃÇé
ŃÇÇňżłŠśżšä´╝îŔŽüŠâ│Ŕ«żŔ«íňç║ńŞÇňąŚš╗ôŠ×äń╝śŔ뻚Üäň╝ĽŠôÄňćůŠáŞ´╝îÚŽľŔŽüŠŁíń╗Âň░▒Šś»´╝ÜŠśÄšÖŻń╗Çń╣łŠś»ň╝ĽŠôÄňćůŠáŞŃÇé
ŃÇÇÚŽľňůłŠłĹń╗ČÚťÇŔŽüŠśÄšÖŻň╝ĽŠôÄŠś»ń╗Çń╣ł´╝îň╝ĽŠôÄňĆ»ń╗ąňüÜń╗Çń╣łŃÇéŔ┐ÖňťĘWfMCšÜäŃÇŐňĚąńŻťŠÁüňĆéŔÇâŠĘíň×őŃÇőńŞşňĚ▓š╗ĆŠťëňżłŔ»Žš╗ćšÜäŔžúšşö´╝ȊľçńŞŹňćŹÚçŹňĄŹŃÇéščąÚüôŔ┐Öńެń╗ůń╗ůŠś»ńŞŹňĄčšÜä´╝îńŻáŔ┐śÚťÇŔŽüňżłŠŞůŠÖ░šÜ䊜Ě֯ňŽéńŻĽňÄ╗ÔÇťńŞ║ŠÁüšĘőň╗║ŠĘíÔÇŁ´╝îŔÇîŔ┐ÖňłÖňťĘAalstňĄžňŞłŠëÇŔĹŚšÜäŃÇŐňĚąńŻťŠÁüš«íšÉćÔÇöÔÇöŠĘíň×őŃÇüŠľ╣Š│ĽŃÇüš│╗š╗čŃÇőńŞÇń╣ŽŠťëš╗ćŔç┤ÚśÉŔ┐░´╝Ȋľçń╣čńŞŹňćŹÚçŹňĄŹŃÇé
ŃÇÇńŻćňżłňĆ»Šâť´╝îŔç│ń╗Őň░ÜŠť¬ŠťëńŞÇŠťČńŞôÚŚĘšÜäń╣Žš▒ŹŠŁąŔ«║Ŕ┐░ÔÇťŔ┐çšĘőň╗║ŠĘ튾╣Š│ĽÔÇŁšÜä´╝ľŔÇůŔ»┤ňŽéńŻĽňłęšöĘŔ┐Öń║ŤŠŚóŠťëšÜäÔÇťŔ┐çšĘőň╗║ŠĘ튾╣Š│Ľ´╝łŔ»ŞňŽéFSMŃÇüPetriNetŃÇüEPCŃÇüActivity Diagramšşëšşë´╝ëÔÇŁŠŁąŔžúňć│ŠÁüšĘőÚŚ«ÚóśŃÇéŔ┐ÖńެňƬŔâŻňłćňłźŠčąÚśůšŤŞňů│ŔÁ䊾ִ╝ĄňĄäń╣čńŞŹňĆÖŔ┐░ŃÇéňŤáńŞ║ŠľçŠťČňƬŔ«▓ÔÇťň╝ĽŠôÄňćůŠáŞÔÇŁŃÇé
ŃÇÇňŽéŠ×ťŠłĹń╗ČŠÜéńŞöŠŐŐÚéúňĄŹŠŁéšÜäŠÁüšĘőńŞÜňŐíŠÇžÚŚ«Úóś´╝îŔ»ŞňŽéÔÇťš╗äš╗çŠĘíň×őňłćÚůŹÔÇŁŃÇüÔÇťňłćŠö»ŠŁíń╗ÂŔ«íš«ŚÔÇŁŃÇüÔÇťń║őń╗ÂňĄäšÉćÔÇŁŃÇüÔÇťŠÂłŠü»Ŕ░âň║ŽÔÇŁŃÇüÔÇťňĚąńŻťÚí╣ňĄäšÉćÔÇŁŃÇüÔÇťňşśňéĘÔÇŁŃÇüÔÇťň║öšöĘňĄäšÉćÔÇŁŃÇüń╗ąňĆŐÚéúń║ŤÔÇťňĆśŠÇüšÜäŔ»ŞňŽéń╝ÜšşżŃÇüňŤ×ÚÇÇń╣őš▒╗šÜäŠĘíň×őÔÇŁÚ⯚╗čš╗čšÜäŠŐŤň╝â´╝îňƬšĽÖńŞőÔÇťŠťÇňŹĽš║»šÜäŔ┐çšĘőŠÇžÚŚ«ÚóśÔÇŁ´╝îń╣čň░▒Šś»ÔÇťŔžúňć│ńŞÇńެŔ┐çšĘőŔ┐ÉŔíîÚŚ«Úóś´╝îŠîëšžęň║ĆšÜäń╗ÄńŞÇńެŔŐéšé╣ňł░ňĆŽńŞÇńެŔŐéšé╣šÜäŠëžŔíîÔÇŁŃÇéÔÇöÔÇöŔ┐Öň░▒Šś»ň╝ĽŠôÄňćůŠáŞŠëÇňů│Š│ĘšÜäŠá╣ŠťČÚŚ«ÚóśŃÇé
ńŞŐÚŁóŔ┐ÖňĆąŔ»Ł´╝îń╝░Ŕ«íń╝Üň╝ĽŔÁĚňżłňĄÜń║║ÔÇťŠőŹšáľÔÇŁŃÇéňťĘňżłňĄÜń║║šťőŠŁą´╝îňĚąńŻťŠÁüń╣őŠëÇń╗ąšťőŔÁĚŠŁąňżłÔÇťÚÜżÔÇŁ´╝îň░▒Šś»ňŤáńŞ║Ŕ┐Öń║ŤňĄŹŠŁéňĄÜňĆśšÜäÔÇťńŞÜňŐíŠÇžÚŚ«ÚóśÔÇŁÚ⯚╗čš╗čš╗ĹňťĘńŞÇńެÔÇťň╝ĽŠôÄÔÇŁńŞŐÚÇኳɚÜäŃÇé
ŃÇÇňůÂň«×´╝îŔ┐ÖŠś»ńŞĄńެÔÇťš╗┤ň║ŽÔÇŁšÜäÚŚ«Úóś´╝îń╣čň░▒Šś»ÔÇťň╝ĽŠôÄšÜäŠŐŻŔ▒íÔÇŁňĺîÔÇťň╝ĽŠôÄšÜäň║öšöĘÔÇŁŔ┐ÖńŞĄńެńŞŹňÉîš╗┤ň║Ž´╝îńŞŹňÉîň▒éÚŁóšÜäÚŚ«ÚóśŃÇéńŻćŔ┐Öš╗ŁńŞŹŠś»ńŞĄńެšőČšźőšÜäÚŚ«Úóś´╝îÔÇťň╝ĽŠôÄšÜäŠŐŻŔ▒íÔÇŁšÜäňąŻńŞÄňŁĆ´╝┤ŠÄąňŻ▒ňôŹňł░ÔÇťň╝ĽŠôÄšÜäň║öšöĘÔÇŁšÜäňĆ»ňĄŹŠŁéň║ŽňĺîňĆ»Šö»Šîüň║Ž´╝îňŻôšäŠłĹń╗Čń╣čńŞŹŔâŻňÉŽŔ«Ą´╝îÔÇťň╝ĽŠôÄšÜäň║öšöĘÔÇŁÚŚ«Úóśń╣芜»ńŞÇńެňżłňĄŹŠŁéšÜäÚŚ«ÚóśŃÇéńŻćŠťČŠľçŠś»šźÖňťĘÔÇťň╝ĽŠôÄšÜäŠŐŻŔ▒íÔÇŁŔ┐Öńެš╗┤ň║ŽŠŁąÚśÉŔ┐░ÚŚ«ÚóśšÜäŃÇéň»╣ń║ÄÔÇťň╝ĽŠôÄšÜäň║öšöĘÔÇŁÚŚ«Úóś´╝îňĆ»ňĆéŔÇ⊳ŚÜäňëŹńŻť´╝Ü2003ň╣┤11Šťłń╗ŻšÜäŃÇŐňĚąńŻťŠÁüŠĘíň×őňłćŠ×ÉŃÇőŃÇü2003ň╣┤12Šťłń╗ŻšÜäŃÇŐňĚąńŻťŠÁüŠÄłŠŁâŠÄžňłÂŠĘíň×őŃÇőŃÇü2004ň╣┤7Šťłń╗ŻšÜäŃÇŐňĚąńŻťŠÁüš│╗š╗čńŞşš╗äš╗çŠĘíň×őň║öšöĘŔžúňć│Šľ╣ŠíłŃÇőŃÇé
ŃÇÇń╣čň░▒Šś»Ŕ»┤´╝ȊľçńŞŹŠś»Šîçň»╝ňĄžň«ÂňŽéńŻĽňÄ╗ÔÇťńŻ┐šöĘjbpmÔÇŁ´╝îŔÇ»ÚśÉŔ┐░ÔÇťjbpmšÜäň╝ĽŠôÄšÜäňćůŠáŞÚâĘňłćŠś»ňŽéńŻĽŠ×äň╗║šÜäÔÇŁŃÇéńŻćŠťČŠľçšÜäńŞ╗ŠŚĘńŞŹŠś»ňĹŐŔ»ëňĄžň«ÂÔÇťjBpmŠś»ňŽéńŻĽŔ«żŔ«íň╝ĽŠôÄňćůŠáŞšÜäÔÇŁ´╝îŔÇ»ń╗ąjBpmńŞ║ńżő´╝ąń╗őš╗ŹÔÇťň╝ĽŠôÄňćůŠáŞÔÇŁŃÇé
4 ň╝ĽŠôÄňćůŠáŞŠëÇňů│Š│ĘšÜäňŤŤńެńŞ╗ŔŽüÚŚ«Úóś
ŃÇÇň╝ĽŠôÄňćůŠáŞŠëÇňů│Š│ĘšÜ䊜»ńŞÇńŞ¬ÚŁ×ňŞŞÔÇťŠŐŻŔ▒íÔÇŁň▒éÚŁóšÜäÚŚ«Úóś´╝îŔÇîńŞŹňÉîň╝ĽŠôÄňů│Š│ĘšÜäÔÇťńŞÇňąŚň«îŠĽ┤šÜäŠëžŔíîšÄ»ňóâÔÇŁŃÇ銳ľŔÇůŠłĹń╗ČňĆ»ń╗ąŔ┐Öń╣łŠŁąŔ»┤´╝îň╝ĽŠôÄňćůŠáŞšÜäŔüîŔ┤úŠś»ÚŁ×ňŞŞÔÇťš▓żš«ÇÔÇŁšÜä´╝Üší«ń┐ŁŠÁüšĘőŠîëšůžŠŚóŠťëšÜäň«Üń╣ë´╝îń╗ÄńŞÇńެŔŐéšé╣Ŕ┐ÉŔíîňł░ňĆŽńŞÇńެŔŐéšé╣´╝îň╣Šşúší«ŠëžŔíîňŻôňëŹŔŐéšé╣ŃÇé
ŠÇ╗šÜ䊣ąŔ»┤´╝îň╝ĽŠôÄňćůŠáŞńŞ╗ŔŽüňů│Š│ĘňŤŤńެŠľ╣ÚŁóšÜäÚŚ«Úóś´╝Ü
ŃÇÇ´╝ł1´╝ë ŠÁüšĘőň«Üń╣ëÚŚ«Úóś´╝ÜńŞŹŠś»Ŕ»┤ňŽéńŻĽňŤżňŻóňîľšÜäň«Üń╣ëŠÁüšĘő´╝îŔÇ»ňŽéńŻĽšöĘńŞÇňąŚň«Üń╣ëň»╣Ŕ▒í´╝ąŔ»áÚçŐŠëÇň«Üń╣ëšÜäŠÁüšĘőŃÇé
ŃÇÇ´╝ł2´╝ë ŠÁüšĘőŔ░âň║ŽÚŚ«Úóś´╝ÜŠĆÉńżŤń╗Çń╣łšÜ䊝║ňłÂ´╝îňĆ»ń╗ąší«ń┐ŁŠÁüšĘőŔâŻňĄčňĄäšÉćňĄŹŠŁéšÜäÔÇťŠÁüšĘőňŤżš╗ôŠ×äÔÇŁ´╝îŔ»ŞňŽéńŞ▓ŔíîŃÇüň╣ÂŔíîŃÇüňłćŠö»ŃÇüŔüÜňÉłšşëšşë´╝îň╣ÂňťĘŔ┐ÖňĄŹŠŁéš╗ôŠ×äńŞşší«ń┐ŁŠÁüšĘőń╗ÄńŞÇńެŔŐéšé╣Ŕ┐ÉŔíîňł░ňĆŽńŞÇńެŔŐéšé╣ŃÇé
ŃÇÇ´╝ł3´╝ë ŠÁüšĘőŠëžŔíîÚŚ«Úóś´╝ÜňŻôŠÁüšĘőŔ┐ÉŔíîňł░ŠčÉńެŔŐéšé╣šÜ䊌ÂňÇÖ´╝îÚťÇŔŽüńŞÇňąŚŠť║ňłÂŠŁąŔžúňć│´╝ÜŠś»ňÉŽŠëžŔíĄŔŐéšé╣´╝îň╣ÂňŽéńŻĽŠëžŔíĄŔŐéšé╣šÜäÚŚ«Úóś´╝îň╣š╗┤ŠîüŔŐéšé╣šŐŠÇüšöčňĹŻňĹĘŠťčŃÇé
ŃÇÇ´╝ł4´╝ë ŠÁüšĘőň«×ńżőň»╣Ŕ▒í´╝ÜÚťÇŔŽüńŞÇŠĽ┤ňąŚŠÁüšĘőň«×ńżőň»╣Ŕ▒튣ąŠĆĆŔ┐░ŠÁüšĘőň«×ńżőŔ┐ÉŔíîšÜäšŐŠÇüňĺîš╗ôŠ×ťŃÇé
4.1 ŠĘíň×őńŞÄň«Üń╣ëň»╣Ŕ▒í
ŃÇÇňĚąńŻťŠÁüň╝ĽŠôÄŠťČŔ║źň░▒Šś»ńŞÇšžŹÔÇťbase on modelÔÇŁšÜäš╗äń╗´╝îŠÁüšĘőň«×ńżőšÜäŠëžŔíîÚ⯊ś»ńżŁŔÁľń║ÄŠëÇň«Üń╣ëšÜäÔÇťŠÁüšĘőň«Üń╣ëÔÇŁ´╝îŔÇîňĚąńŻťŠÁüň╝ĽŠôÄňłÖŠś»ŠĆÉńżŤń║ćŔ┐ÖŠáĚńŞÇšžŹšÄ»ňóâ´╝ąš╗┤ŠîüŠÁüšĘőň«×ńżőšÜäŔ┐ÉŔíîŃÇé
ŃÇÇŠëÇń╗ąň╝ĽŠôÄňćůŠáŞ´╝îň┐ůÚí╗ŠĆÉńżŤńŞÇňąŚň«Üń╣ëň»╣Ŕ▒튣ąŠĆĆŔ┐░ÔÇťŠÁüšĘőň«Üń╣ëÔÇŁ´╝îň╣ÂńŞöŔ┐Öń║Ťň«Üń╣ëň»╣Ŕ▒íň┐ůÚí╗ňĆŹŠśáňç║ńŞÇšžŹÔÇťŠĘíň×őÔÇŁŃÇ銻öňŽéjBpmšÜäň«Üń╣ëň»╣Ŕ▒í´╝»ńŞÄňůŠëÇňč║ń║ÄšÜäActivity DiagramŠĘíň×őšŤŞň»╣ň║öšÜäŃÇé
4.2 Ŕ░âň║ŽŠť║ňłÂńŞÄš«ŚŠ│Ľ
ŃÇÇň╝ĽŠôÄňćůŠáŞšÜäňĆŽńŞÇńެÚçŹŔŽüňŐčŔ⯴╝îň░▒Šś»ń┐ŁŔ»üŠÁüšĘőň«×ńżőňçćší«šÜäń╗ÄńŞÇńެŔŐéšé╣Ŕ┐ÉŔíîňł░ňĆŽńŞÇńެŔŐéšé╣´╝îŔÇîŔ┐ÖňłÖÚťÇŔŽüńżŁŔÁľń║ÄńŞÇňąŚŔ░âň║ŽŠť║ňłÂŃÇé
ŃÇÇň╝ĽŠôÄšÜäŔ░âň║ŽŠť║ňłÂŠťëňżłňĄÜšžŹň«×šÄ░Šľ╣Š│Ľ´╝ëšÜäšöÜŔç│Šś»ńŞÄÔÇťŠëÇńżŁŔÁľšÜäŠĘíň×őŠťëňů│ÔÇŁŃÇéńŻćŠÖ«ÚüŹŠŁąŔ«▓´╝îňżłňĄÜň╝ĽŠôÄÚâŻňĆŚňł░Petri NetšÜäňŻ▒ňôŹ´╝îŔÇîÚççšöĘtokenŠŁąŔ░âň║ŽŃÇé
ŃÇÇjBpmŠťČŔ║źň░▒ňÉŞš║│šÜätokenŔ┐ÖňąŚŠť║ňłÂ´╝îňŻôšä´╝îńŞÄPetri NetšÜäŔ░âň║ŽŠť║ňłÂŔ┐śŠś»ŠťëŠëÇňî║ňłźŃÇ銳Ĺń╗Čň░ćňťĘńŞőÚŁóšÜäšźáŔŐéŔ»Žš╗ćń╗őš╗ŹŃÇé
4.3 ŠëžŔí║ňłÂńŞÄšŐŠÇü
ŃÇÇš╗ĆŔ┐çň╝ĽŠôÄšÜäŔ░âň║Ž´╝îň«×ńżőŔ┐ÉŔíîňł░ŠčÉńެŔŐéšé╣ń║ć´╝ĄŠŚÂň┐ůÚí╗ň┐ůÚí╗ŠĆÉńżŤńŞÇňąŚŠť║ňłÂ´╝ąňłĄŠľşňŻôňëŹŔŐéšé╣Šś»ňÉŽňĆ»ŠëžŔíî´╝îňŽéŠ×ťňĆ»ŠëžŔíî´╝îÚéúń╣łÚťÇŔŽüŠĆÉńżŤńŞÇňąŚruntime envriomentŠŁąŠëžŔíîŔŐéšé╣ÔÇöÔÇöŔ┐Öň░▒Šś»ň╝ĽŠôÄšÜäŠëžŔí║ňłÂŃÇé
ŃÇÇňĄŹŠŁéšÜäŠÁüšĘőň╝ĽŠôÄń╝ÜńżŁŔÁľń║ÄÔÇťŠÁüšĘőň«×ńżőšŐŠÇüÔÇŁŠłľÔÇťŠ┤╗ňŐĘň«×ńżőšŐŠÇüÔÇŁšÜäš║ŽŠŁčňĺîňĆśŔ┐üŠŁąŔ┐ŤŔíîňĄäšÉćŃÇéń╣őŠëÇŠťëŠťëŠŚÂňÇÖŠłĹń╗Čń╝ÜŠŐŐńŞÇńެŠÁüšĘőň╝ĽŠôÄń╣čňĆźňüÜÔÇťšŐŠÇüŠť║ÔÇŁ´╝îňżłňĄžšĘőň║ŽńŞŐń╣芜»Ŕ┐ÖńެňÄčňŤáŃÇé
4.4 ň«×ńżőň»╣Ŕ▒íńŞÄŠëžŔíîšÄ»ňóâ
ŃÇÇŠ»ĆńެńŞÇńެŠÁüšĘőň«×ńżő´╝îň┐ůÚí╗š╗┤ŠŐĄńŞÇňąŚň▒×ń║ÄŔç¬ňĚ▒šÜäÔÇťŔ┐ÉŔíîšÄ»ňóâňĺ░ŠŹ«ÔÇŁ´╝îŔÇîŔ┐ÖňłÖŠś»ň«×ńżőň»╣Ŕ▒íšÜäŔ┤úń╗╗ń║ćŃÇéňč║ŠťČńŞŐň«×ńżőň»╣Ŕ▒íń╝ÜňîůňÉźňŽéńŞőń┐íŠü»´╝Ü
ŃÇÇ´╝ł1´╝ë ńŞÄŠÁüšĘőň«×ńżőšÜäšŐŠÇüŠłľŠÄžňłÂń┐íŠü»
ŃÇÇ´╝ł2´╝ë ńŞÄŠ┤╗ňŐĘň«×ńżőšÜäšŐŠÇüŠłľŠÄžňłÂń┐íŠü»ŃÇéňŽéŠ×ťŠčÉń║Ťň╝ĽŠôÄńŞŹŠö»ŠîüŠ┤╗ňŐĘň«×ńżő´╝îÚéúń╣łň┐ůšäÂń╝ÜŠťëŠčÉń║ŤňůÂń╗ľň«×ńżőń┐íŠü»´╝îňĆ»ń╗ąňŻôňëŹŔŐéšé╣šÜäšŐŠłľŠÄžňłÂń┐íŠü»ŃÇé
ŃÇÇ´╝ł3´╝ë ńŞÇń║ŤńŞ┤ŠŚÂšÜäÔÇťŠëžŔíîÔÇŁń┐íŠü»´╝îńż┐ń║Äň╝ĽŠôÄÚĺłň»╣ŠčÉšžŹŠâůňćÁŔ┐ŤŔíîňĄäšÉć
ŃÇÇ5 jbpm´╝îÔÇťš▓żš«ÇÔÇŁšÜäň╝ÇŠ║ÉŠÁüšĘőň╝ĽŠôÄ
ŃÇÇňąŻšÜäň╝ÇŠ║ÉňĚąńŻťŠÁüň╝ĽŠôÄńŞŹňĄÜ´╝îjbpmňĺîosworkflowš«ŚŠś»ňůÂńŞşńŞĄńެŠťëšë╣Ŕë▓ŔÇîńŞöŠ»öŔżâň«╣Šśôň«×ÚÖůň║öšöĘšÜäŃÇ隍«ňëŹńŞÇń║ŤňŤŻňćůšÜäńŞşň░Ćň×őŠÁüšĘőň║öšöĘÚí╣šŤ«´╝îň░▒Šś»ňťĘjbpmŠłľosworkflowšÜäňč║šíÇńŞŐŠëęň▒Ľň«×šÄ░ŃÇéjBpmÚççšöĘń║ćActivity DiagramšÜäŠĘíň×ő´╝îŔÇîosworkflowňłÖŠś»FSMšÜäŠĘíň×őŃÇé
ŃÇÇňŻôšä´╝îŔ┐Öń╗ůń╗ůŠś»jbpm3ń╣őňÉÄšÜäń║őŠâůŃÇéŔç¬ń╗ÄŔóźJbossŠöÂŔ┤şń╣őňÉÄ´╝îjbpmň»╣ŠŚęňůłšÜä2.0Š×äŠ×ÂŔ┐ŤŔíîń║ćÚ珚╗ä´╝┤ńެš╗ôŠ×äň«îňůĘŠťČšŁÇÔÇťňż«ňćůŠáŞÔÇŁšÜäŠÇŁŠâ│Ŕ┐ŤŔíîŔ«żŔ«íŃÇé
ŃÇÇšÄ░ňťĘŔ┐ÖÚçîń╗ÄŠŐÇŠť»Ŕžĺň║ŽŠŁąňłćŠ×Éjbpm3šÜäń╝śšé╣´╝îš«ÇňŹĽšŻŚňłŚňçáńެňĄžň«ÂÚâŻň«╣ŠśôšťőŔžüšÜä´╝Ü
ŃÇÇ´╝ł1´╝ë jbpmšÜäŠĘíň×őŠś»ÚççšöĘUML Activity DiagramšÜäŔ»şń╣ë´╝îŠëÇń╗ąńż┐ń║Äň╝ÇňĆĹń║║ňĹśšÉćŔžúŠÁüšĘőŃÇé
ŃÇÇ´╝ł2´╝ë jbpmŠĆÉńżŤń║ćňĆ»Šëęň▒ĽšÜäEvent-ActionŠť║ňłÂ´╝ąŔżůňŐęŠ┤╗ňŐĘšÜäŠëęň▒ĽňĄäšÉćŃÇé
ŃÇÇ´╝ł3´╝ë jbpmŠĆÉńżŤń║ćšüÁŠ┤╗šÜ䊣íń╗ÂŔíĘŔżżň╝ĆŠť║ňłÂ´╝ąŔżůňŐꊣíń╗ÂŔžúŠ×ÉŃÇüŔäÜŠťČŔ«íš«ŚšÜäňĄäšÉćŃÇé
ŃÇÇ´╝ł4´╝ë jbpmŠĆÉńżŤń║ćňĆ»Šëęň▒ĽšÜäTaskňĆŐňłćÚůŹŠť║ňłÂ´╝ąŠ╗íŔÂ│ňĄŹŠŁéń║║ňĚąŠ┤╗ňŐĘšÜäňĄäšÉćŃÇé
ŃÇÇ´╝ł5´╝ë ňÇčňŐęhibernatešÜäORMšÜäń╝śňŐ┐´╝îjbpmŔâŻňĄčňżłň«╣ŠśôŠö»ŠîüňĄÜšžŹŠĽ░ŠŹ«ň║ôŃÇé
ŃÇÇňŻôšä´╝îŔ┐śŠťëńŞÇń║Ťń╝śšé╣´╝»ňżłňĄÜň╝ÇňĆĹń║║ňĹśň╣ÂńŞŹňĄ¬Š│ĘŠäĆšÜä´╝öňŽé´╝Ü
ŃÇÇ´╝ł1´╝ë jbpmšÜäNodeŠť║ňłÂÚŁ×ňŞŞšüÁŠ┤╗´╝îň╝ÇňĆĹń║║ňĹśňĆ»ń╗ąňżłň«╣Šśôň«ÜňłÂÔÇťńŞÜňŐíňîľŔ»şń╣ëšÜäŔŐéšé╣ÔÇŁ´╝îň╣Š╗íŔÂ│Ŕ┐ÉŔíÂňÇÖňĄäšÉćšÜäÚťÇŔŽüŃÇé
ŃÇÇŠťëňżłňĄÜšüÁŠ┤╗šÜäń╝śšé╣´╝îňŻôšäÂń╣čň░ĹńŞŹń║ćňşśňťĘńŞÇń║ŤÔÇťň▒ÇÚÖÉÔÇŁŃÇé
ŃÇÇ´╝ł1´╝ë ňżłŠśżšä´╝îňƬŔ⯊ťëńŞÇńެstart-stateŃÇé
ŃÇÇ´╝ł2´╝ë jbpmńżŁÚŁáTokenŠŁąŔ░âň║ŽňĺîŔ«íš«Ś´╝îňťĘňÉîńŞÇńެŠŚÂňł╗ńŞş´╝îńŞÇńެProcessInstanceňƬňůüŔ«ŞńŞÇńެTokenň»╣Ŕ▒íňƬňşśňťĘńŞÇńެNodeńŞş´╝łňłćŠö»ňŻôšäšöĘChild Tokenň»╣Ŕ▒íňĄäšÉć´╝ëŃÇéŠëÇń╗ąŠťČŔ┤ĘńŞŐň░▒ńŞŹŠö»ŠîüÔÇťmulti-instanceÔÇŁŠĘíň╝ĆŃÇé
ŃÇÇ´╝ł3´╝ë jbpmńŻťńŞ║ńŞÇŠČżň╝ÇŠ║ÉšÜäňĚąńŻťŠÁüň╝ĽŠôÄ´╝îňůŠŤ┤ňĄÜšÜ䊜»ňů│Š│ĘÔÇťňŽéńŻĽŔżůňŐęńŻáŠŤ┤ň«╣ŠśôšÜäŔ«ęŠÁüšĘőŔ┐ÉŔíîň«îŠłÉÔÇŁ´╝îńŻćŠś»ň╣ÂńŞŹŔ«░ňŻĽÔÇťŠÁüšĘőŔ┐ÉŔíîšÜäňÄćňĆ▓ňĺîŔŻĘŔ┐╣ÔÇŁŃÇéŔ┐ÖńŞÇšé╣ňĆ»Ŕ⯊ś»ńŞťŔą┐Šľ╣ŠľçňîľšÜäňĚ«ň╝éŠÇžŠëÇňťĘ´╝îňŤáńŞ║ňŤŻňćůšÜäŠÁüšĘőň║öšöĘ´╝öŔżâňů│Š│ĘÔÇťŔ┐ÉŔíîŔŻĘŔ┐╣ÔÇŁŃÇé
ŃÇÇŔç│ń║ÄňůÂń╗ľšÜäńŞÇń║Ťň▒ÇÚÖÉ´╝öňŽéńŞŹŠö»ŠîüÔÇťňŤ×ÚÇÇÔÇŁŃÇüÔÇťŔĚ│ŔŻČÔÇŁšşëŠôŹńŻť´╝îŔ┐Öń╣芜»ňŤáńŞ║ńŞťŔą┐Šľ╣ŠľçňîľšÜäňĚ«ň╝éŠëÇňťĘŃÇéŔą┐Šľ╣ń║║Ŕ«ĄńŞ║ÔÇťňżÇňŤ×ŠÁüŔŻČšÜäŠâůňćÁŔé»ň«Üń╣芜»ńŞÇšžŹńŞÜňŐíŔžäňłÖŠëÇň«Üń╣ë´╝îÚéúń╣łŔé»ň«ÜňĆ»ń╗ąÚÇÜŔ┐çňłćŠö»ŠłľŠŁíń╗ŠŁąŔžúňć│ÔÇŁ´╝îŔÇîńŞťŠľ╣ňłÖŠŐŐÔÇťňŤ×ÚÇÇńŻťńŞ║ńŞÇńެń║║ŠÇžňîľš«íšÉćňĺîňĄäšÉćšÜ䊯ťňťĘšë╣šé╣ÔÇŁŃÇéŠëÇń╗ąŔ»ŞňŽéŠşĄš▒╗šÜäńŞÇń║ŤÔÇťšë╣ň«ÜڝNJ▒éÔÇŁ´╝îń╝░Ŕ«íňƬŔâŻÚÇÜŔ┐çŠëęň▒ĽjbpmŠŁąň«×šÄ░ń║ć´╝îšöÜŔç│ŠťëŠŚÂňÇÖ´╝îš«ÇňŹĽšÜäŠëęň▒ĽŠś»ŠŚáŠ│ĽŔžúňć│ÚŚ«ÚóśšÜäÔÇöÔÇöŠşúňŽéńŞŐńŞÇŔŐéŠëÇŔ»┤šÜäÚéúŠáĚ´╝îÔÇťň╝ĽŠôÄšÜäŠŐŻŔ▒íÔÇŁń╝ÜňŻ▒ňôŹÔÇťň╝ĽŠôÄšÜäň║öšöĘÔÇŁšÜäňĄŹŠŁéň║ŽŠö»ŠîüŃÇé
ŃÇÇńŻćŠś»´╝îňŻôńŻáŔ»ĽňŤżń┐«Šö╣jbpmń╗úšáüšÜ䊌ÂňÇÖ´╝îńŻáń╝ÜÚíżŔÖĹjbpmšÜäLGPLňŹĆŔ««ňÉŚ´╝č´╝łňżłňĄÜňŤŻňćůń╝üńŞÜń╗ÄŠŁąńŞŹŔÇâŔÖĹŔ┐ÖńެňŹĆŔ««ÚŚ«Úóś´╝îň»ĺ´╝ëŃÇé
6 jBpmŠÁüšĘőŠĘíň×őńŞÄň«Üń╣ëň»╣Ŕ▒í
ŃÇÇ6.1 ÚŽľňůłŔžúňć│ňŽéńŻĽňŻóň╝ĆňĆĆŔ┐░ńŞÇńެŠÁüšĘőšÜäÚŚ«Úóś
ŃÇÇŔ┐ÖÚçîŔ»┤šÜäÔÇťň«Üń╣ëŠÁüšĘőÔÇŁň╣ÂńŞŹŠś»Ŕ»┤jbpm3ńŞşÚéúńެňč║ń║Äeclipse pluginšÜäňŤżňŻóňîľň╗║ŠĘíňĚąňůĚŃÇéŔÇ»ňŽéńŻĽňÄ╗Ŕžúňć│ÔÇťňŻóň╝ĆňîľšÜäŠĆĆŔ┐░ńŞÇńެŠÁüšĘőÔÇŁšÜäÚŚ«ÚóśŃÇé
ŃÇÇňŻóň╝ĆňîľšÜäŠĆĆŔ┐░ŠÁüšĘőň╣ÂńŞŹŠś»ńŞÇńެš«ÇňŹĽšÜäÚŚ«Úóś´╝îń╗ÄńŞŐńŞľš║¬ńŞâňŹüň╝Çňžő´╝îń║║ń╗Čň░▒ňťĘŠÄóš┤óšöĘňÉäšžŹňÉäŠáĚňĄÜšÜäŠĘíň×őŠŁąŠĆĆš╗śŠÁüšĘő´╝ÜPetri Net, FSM, EPC, Activity Diagram, ń╗ąňĆŐŔ┐ĹŠŁąšÜäXPDL MetaModelšşëšşë´╝îň╗Âń╝Şňł░ňŽéń╗ŐšÜäBPEL,BPMN,BPMDšşëšşëŃÇé
ŃÇÇjBpmÚççšöĘń║ćActivity DiagramšÜäŠĘíň×őŔ»şń╣ë´╝ÜňůÂň░ćšöĘStart StateŃÇüStateŃÇüAction State´╝łTask Node´╝ëŃÇüEnd StateŃÇüForkŃÇüJoinŃÇüDecisionŃÇüMergeŃÇüProcess StateŔ┐ÖňçáńެÔÇťňůâš┤áÔÇŁšÜäš╗äňÉłŠŁąŠĆĆŔ┐░ń╗╗ńŻĽńŞÇńެŠÁüšĘőŃÇéňůÂńŞşAction StateŠś»Activity DiagramńŞşšÜäŠáçňçćŔ»şń╣ë´╝îňťĘjBpmńŞ║ń║ćńż┐ń║ÄňĄžň«ÂšÉćŔžúňĺîńŻ┐šöĘ´╝îjBpmÚççšöĘń║ćTaskNodeŔ┐ÖńެŔ»şń╣ëŃÇé
ŃÇÇňťĘWfMCšÜäWorkflow Reference ModelńŞş´╝îň»╣ŠÁüšĘőň╝ĽŠôÄšÜäňŐčŔ⯊ĆĆŔ┐░´╝îňůÂńŞşň░▒ňîůňÉźńŞÇÚí╣´╝ÜŔžúŠ×ÉŠÁüšĘőň«Üń╣ëŃÇéňŽéŠ×ťŠâ│Š╗íŔÂ│Ŕ┐ÖŔ┐ÖňŐčŔ⯴╝îň돊ĆÉŠŁíń╗Âň░▒ň┐ůÚí╗ŠťëŠťÇňč║ŠťČšÜäńŞĄńެ´╝Ü
ŃÇÇ´╝ł1´╝ë ŠťëńŞÇňąŚňŻóň╝ĆňîľšÜäŠĆĆŔ┐░Ŕ»şŔĘÇ´╝łÚÇÜňŞŞńŞ║xmlŠá╝ň╝Ć´╝ëŃÇéňłęšöĘŔ┐ÖńެŠĆĆŔ┐░Ŕ»şŔĘÇňĆ»ń╗ąŠĆĆŔ┐░ńŞÇńެŠÁüšĘőšÜäň«Üń╣ëŃÇ銻öňŽéWfMCŠëÇŠĆÉňç║šÜäXPDLŔ┐ÖńެŠĆĆŔ┐░Ŕ»şŔĘÇŃÇéňŻôšä´╝îjBpmń╣芝ëŔç¬ňĚ▒šÜäńŞÇňąŚ´╝îňÉŹńŞ║jPDL´╝îń╣芜»ńŞÇńެxmlŠá╝ň╝ĆšÜäŃÇé
ŃÇÇ´╝ł2´╝ë ŠťëńŞÇňąŚň»╣Ŕ▒íÚŤćňĆ»ń╗ąňĆŹŠśáŠÁüšĘőšÜäň«Üń╣ëŠĘíň×őňĺîš╗ôŠ×ť´╝îńŞÇŔłČňĆźňüÜň«Üń╣ëň»╣Ŕ▒íŃÇéŠÁüšĘőň╝ĽŠôÄň░▒ÚťÇŔŽüŠŐŐÔÇťxmlŠá╝ň╝ĆšÜäŠÁüšĘőň«Üń╣ëÔÇŁŔžúŠ×ÉńŞ║ńŞÇňąŚň»╣Ŕ▒í´╝îŔÇîŔ┐ÖňąŚň»╣Ŕ▒íšÜäš╗ôŠ×äňłÖňĆŹŠśáń║ćŠÁüšĘőšÜäš╗ôŠ×äŃÇé
ŃÇÇŠłĹń╗ČŠÜéńŞöńŞŹňÄ╗ŠÄóŔ«ĘjPDLÚéúńެňŻóň╝ĆňîľšÜäxmlŔ»şŔĘÇ´╝îŔÇîŠŐŐÚçŹň┐âŠöżňťĘjBpmÚéúňąŚň«Üń╣ëň»╣Ŕ▒íńŞşŃÇéňŤáńŞ║Ŕ┐Öńެň«Üń╣ëň»╣Ŕ▒튜»ň▒×ń║ÄEngine KernelšÜäńŞÇÚâĘňłćŃÇé
6.2 ŠŐŻŔ▒íšÜäŔŐéšé╣´╝łNode´╝ëňĺîŔŻČšž╗´╝łTransition´╝ë
ŃÇÇÚŁóňÉĹň»╣Ŕ▒íšÜäš╗žŠë┐ŠÇžŃÇüňĄÜŠÇüŠÇžňĆ»ń╗ąŔ«ęŠłĹń╗Čń╗ÄŠťÇŠŐŻŔ▒íšÜäÚâĘňłćŠŁąŠĆĆŔ┐░ň»╣Ŕ▒íŃÇéÚéúń╣łŔ┐ÖňąŚň«Üń╣ëň»╣Ŕ▒íń╣čÚťÇŔŽüń╗ÄŠťÇňč║šíÇšÜäÔÇťŠŐŻŔ▒íÔÇŁŔ»┤ŔÁĚŃÇé
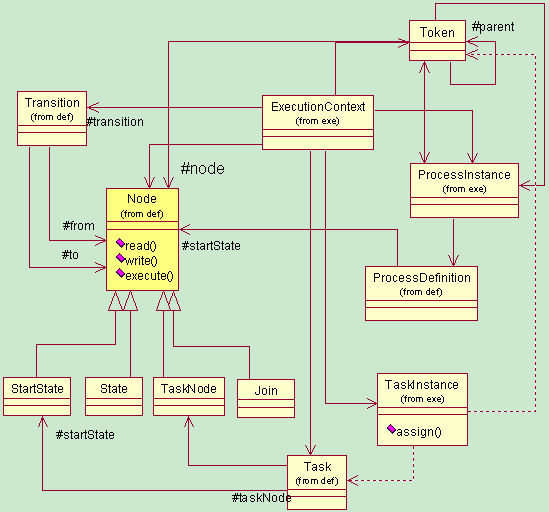
processšÜ䊝ČŔ┤Ęň░▒Šś»ÔÇťŔŐéšé╣ÔÇŁňĺîÔÇťŠťëňÉĹň╝žÔÇŁ´╝îňŻôšäÂńŻáń╣čňĆ»ń╗ąŔ»┤Šś»NodeňĺîLink´╝ľŔÇůNodeňĺîTransition´╝ľŔÇůActivityňĺîTransitionšşëšşëń╣őš▒╗šÜäŃÇéjBpmÚççšöĘšÜ䊜»NodeňĺîTransitionŠŁąŔíĘšĄ║ÔÇťŔŐéšé╣ÔÇŁňĺîÔÇťŠťëňÉĹň╝žÔÇŁŃÇéń║ÄŠś»ń╣Ä´╝îňťĘjbpmńŞşńŻáňĆ»ń╗ąšťőňł░Ŕ┐ÖŠáĚšÜäš╗ôŠ×äňů│š│╗´╝Ü
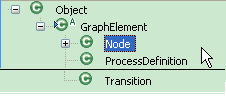  
 
ŃÇÇň»╣ń║ÄńŞÇńެŔŐéšé╣ŠŁąŔ»┤´╝îń╗Äň«Üń╣ëŔžĺň║Ž´╝îňůÂňƬňů│ň┐âňçáńެń║őŠâů´╝Ü
ŃÇÇ´╝ł1´╝ë Ŕ┐ÖŠś»ńެń╗Çń╣łš▒╗ň×őšÜäŔŐéšé╣ŃÇéŔ┐ÖńެŔŐéšé╣ňĆ»Ŕ⯊ś»start state´╝îń╣čňĆ»Ŕ⯊ś»ńŞÇńެtask node´╝ľŔÇůŠś»ńŞÇńެforkŃÇé
ŃÇÇ´╝ł2´╝ë Ŕ┐ÖńެŔŐéšé╣šÜäŔŻČňůąTransitionňĺîŔŻČňç║TransitionŃÇé
ŃÇÇňĆ»Ŕ⯊ťëšÜäń║║ń╝ÜŔ»┤´╝îŔ┐śÚťÇŔŽüňů│ň┐âŔŐéšé╣šÜäŔŻČňůąŔŻČňç║šÜäš▒╗ň×ő´╝öňŽéAnd SpliteŠłľŔÇůXor Joinń╣őš▒╗ŃÇéŔ┐Öńެň╣Š▓튝ëÚöÖ´╝îňŤáńŞ║ňżłňĄÜŠÁüšĘőŠĘíň×őšÜäŔŐéšé╣ňůâš┤áÚťÇŔŽüŔÇâŔÖĹŔ┐Öńެ´╝öňŽéWfMCšÜäXPDLŠĘíň×őŃÇéńŻćŠś»jBpmšÜäŔŐéšé╣Šś»Š▓튝ëŔ┐ÖŠáĚšÜäň▒׊ǞšÜä´╝ľŔÇůŔ»┤šÜ䊍┤ňçćší«ń║Ť´╝»Activity DiagramŠĘíň×őšÜäŔŐéšé╣Š▓튝ëŔ┐ÖŠáĚšÜäšë╣ŠÇžŃÇéŠ┤╗ňŐĘňŤżŠś»ÚççšöĘÔÇťForkÔÇŁŃÇüÔÇťJoinÔÇŁŔ┐ÖŠáĚšÜäŔŐéšé╣ŠŁąŔžúňć│ÔÇťňłćŠö»ÔÇŁÚŚ«ÚóśŃÇé
6.3 ŠÁüšĘő´╝ÜŔŐéšé╣ńŞÄŔŻČšž╗šÜäš╗äňÉł
ŃÇÇń╗ůňłęšöĘŔŐéšé╣ňĺîŔŻČšž╗šÜäš╗äňÉł´╝îň░▒ňĆ»ń╗ąŔíĘŔżżńŞÇńެÔÇťŔ┐çšĘő´╝łProcess´╝ëÔÇŁŃÇéňŻôšäÂŔ┐ÖńެŠÁüšĘőňƬŔâŻňĹŐŔ»ëń║║ń╗ČÔÇťňĄžŠŽéšÜäńŞÜňŐíŔ┐çšĘőÔÇŁ´╝îňŻôšäÂńŞŹňîůŠőČňżłňĄŹŠŁéšÜäń┐íŠü»ŃÇéňŽéńŞőňŤżŠëÇšĄ║´╝Ü
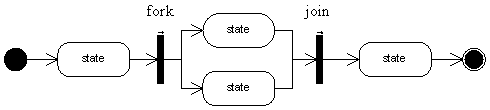  
 
ŃÇÇŔ┐ÖŠś»ńŞÇň╝áÚŁ×ňŞŞŠáçňçćšÜäÔÇťŠ┤╗ňŐĘňŤżÔÇŁ´╝îňŽéŠ×ťŠłĹń╗ČšöĘjbpmšÜäŔ«żŔ«íňÖĘ´╝îšťőšťőŔ┐ÖŠáĚńŞÇň╝áÔÇťŠÁüšĘőňŤżÔÇŁ´╝Ü
 
ŃÇÇńŞŹŔ«║ńŻáňŽéńŻĽš╗śšö╗´╝îŠö╣ňĆśńŞŹń║ćŔ┐Öň╝áňŤżšÜ䊝ČŔ┤Ę´╝Üň«âň░▒ňƬŠťëńŞĄńެňč║ŠťČňůâš┤á´╝ÜŔŐéšé╣ňĺîŔŻČšž╗ŃÇéňƬŠś»ŠťëšÜäŔŐéšé╣Šś»start-state´╝ëšÜ䊜»task-node´╝ëšÜ䊜»join´╝ëšÜ䊜»end stateŔÇîňĚ▓ŃÇé
6.4 ŔŐéšé╣šÜäš▒╗ň×őňĺîŠëęň▒Ľ
ŃÇÇŠłĹń╗ČňĆ»ń╗ąÚÇÜŔ┐çň«Üń╣ëŔç¬ňĚ▒šÜäNodeŔŐéšé╣ň»╣Ŕ▒í´╝ąŔíąňůůjbpmŔç¬ň«ÜšÜäŔŐéšé╣ň»╣Ŕ▒íŃÇéňƬڝÇŔŽüextends Node´╝îň╣ÂÚçŹňćÖŔ»╗ňćÖxmlšÜäreadňĺîwriteŠľ╣Š│Ľ´╝îÚçŹňćÖŔ┤čŔ┤úŠëžŔíîšÜäexecuteŠľ╣Š│Ľ´╝îňťĘorg/jbpm/graph/node/node.types.xmlńŞşÚůŹšŻ«ňŹ│ňĆ»´╝îňŻôšä´╝îńŻáňĆ»ń╗ąňćÖšÜ䊍┤ňŐáňĄŹŠŁé´╝┤ňŐáńŞÜňŐíňîľšÜäŔŐéšé╣ŃÇé
ŃÇÇ7 jBpmšÜäŔ┐çšĘőŔ░âň║ŽŠť║ňłÂ
ŃÇÇ7.1 ňÉŞš║│Ŕç¬Petri NetŠÇŁŠâ│
ŃÇÇjBpmšÜäŔ┐çšĘőŔ░âň║ŽŠť║ňłÂŠś»ňÉŞš║│ń║ćPetri NetšÜäńŞÇń║ŤŠÇŁŠâ│ŃÇé
ŃÇÇjBpmÚççšöĘTokenŠŁąŔíĘšĄ║ňŻôňëŹň«×ńżőŔ┐ÉŔíîšÜäńŻŹšŻ«´╝îń╣čňłęšöĘtokenňťĘŠÁüšĘőňÉäńެšé╣ń╣őÚŚ┤šÜäŔŻČšž╗ŠŁąŔíĘšĄ║ŠÁüšĘőšÜäŠÄĘŔ┐Ť´╝îňŽéńŞőňŤżŠëÇšĄ║´╝Ü
  
 
ŃÇÇňŻôjbpmŔ»ĽňŤżňÄ╗ňÉ»ňŐĘńŞÇńެŠÁüšĘőšÜ䊌ÂňÇÖ´╝îÚŽľňůłŠś»Š×äÚÇáńŞÇńެŠÁüšĘőň«×ńżő´╝îň╣ÂńŞ║ŠşĄŠÁüšĘőň«×ńżőňłŤň╗║ńŞÇńެRoot Token´╝îň╣ŠŐŐŔ┐ÖńެRoot TokenŠöżšŻ«ňťĘStart NodeńŞŐŃÇé
ŃÇÇń╗ąńŞőŠł¬ňĆľÚâĘňłćń╗úšáüň«×šÄ░´╝îń╗ůńżŤňĆéŔÇâŃÇéŠëőňĄ┤Šťëjbpm3šŤŞň║öň╝ÇňĆŚĻňóâšÜ䊝őňĆő´╝îňĆ»ń╗ąŠëôň╝ÇProcessInstanceňĺîTokenŔ┐ÖńŞĄńެš▒╗ŃÇé´╝łŠ│Ę´╝Üń╗ąńŞőŠëÇŠťëňĆéŔÇâń╗úšáü´╝îńŞ║ń║暬üňç║ńŞ╗Úóś´╝îÚâŻňĚ▓š╗Ćň░ćň«×ÚÖůń╗úšáüńŞşšÜäevent,logšşëňĄäšÉćňłáÚÖĄ´╝ë
|
public ProcessInstance( ProcessDefinition processDefinition ) {
this.processDefinition = processDefinition;
this.rootToken = new Token(this);
public Token(ProcessInstance processInstance) {
this.processInstance = processInstance;
this.node = processInstance.getProcessDefinition().getStartState();
|
jbpmŠś»ňůüŔ«ŞňťĘstart-stateŠëžŔíîTaskšÜä´╝îń╣čňůüŔ«ŞňťĘstart-stateňłŤň╗║ňĚąń║║ń╗╗ňŐíŃÇéńŞŹŔ┐犺ĄňĄäŠłĹń╗ČńŞŹń║łŔ«ĘŔ«║ŃÇé
7.2 TokenšÜäŠÄĘŔ┐Ť
ŃÇÇňŻôTokenňĚ▓š╗ĆňťĘStart-StateŔŐéšé╣ń║ć´╝Ĺń╗ČňĆ»ń╗ąň╝ÇňžőňżÇň돊ÄĘŔ┐Ť´╝ąń┐âńŻ┐ŠÁüšĘőň«×ńżőňżÇňëŹŔ┐ÉŔíîŃÇéň»╣ń║ÄňĄľÚâĘŠôŹńŻťŠŁąŔ»┤´╝îŔžŽňĆĹŠÁüšĘőň«×ńżőňżÇńŞőŔ┐ÉŔíîšÜäŠôŹńŻťŠťëńŞĄńެ´╝Ü
ŃÇÇ´╝ł1´╝ë ň╝║ňłÂŠëžŔíîProcessInstancešÜäsignalŠôŹńŻť
ŃÇÇ´╝ł2´╝ë ŠëžŔíîTaskInstancešÜäendŠôŹńŻťŃÇé
ŃÇÇńŻćŠś»´╝îŔ┐ÖńŞĄńެŠôŹńŻť´╝îÚ⯊ś»ÚÇÜŔ┐çÔÇťňŻôňëŹtokenšÜäsignalŠôŹńŻťÔÇŁŠŁąňćůÚâĘň«×šÄ░šÜä´╝îňŽéńŞőňŤżŠëÇšĄ║´╝Ü
ŃÇÇ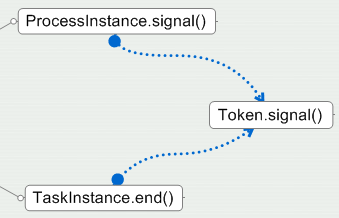 ┬á
 
ŃÇÇTokenšÜäSignalŠôŹńŻťŔíĘšĄ║´╝Üň«×ńżőÚťÇŔŽüšŽ╗ň╝ÇňŻôňëŹtokenŠëÇňťĘšÜäŔŐéšé╣´╝îŔŻČšž╗ňł░ńŞőńŞÇńެŔŐéšé╣ńŞŐŃÇéňŤáńŞ║NodeńŞÄNodeń╣őÚŚ┤Šś»ÔÇťTransitionÔÇŁŔ┐ÖńެŠíąŠóü´╝îŠëÇń╗ą´╝îňťĘŔŻČšž╗Ŕ┐çšĘőńŞş´╝îń╝ÜÚŽľňůłŠŐŐTokenŠöżňůąšŤŞňů│Ŕ┐ךÜäTranstionň»╣Ŕ▒íńŞş´╝îň揚ö▒Transitionň»╣Ŕ▒íŠŐŐTokenń║Ąš╗ÖńŞőńŞÇńެŔŐéšé╣ŃÇé
Ŕ«ęŠłĹń╗ČŠŁąšťőšťőTokenš▒╗ńŞşsignalŠľ╣Š│ĽšÜäÚâĘňłćń╗úšáüň«×šÄ░´╝îń╗ůńżŤňĆéŔÇâ´╝Ü
|
public void signal() {
//Š│ĘŠäĆExecutionContextň»╣Ŕ▒í
signal(node.getDefaultLeavingTransition(), new ExecutionContext(this));
}
void signal(Transition transition, ExecutionContext executionContext) {
// start calculating the next state
node.leave(executionContext, transition);
}
|
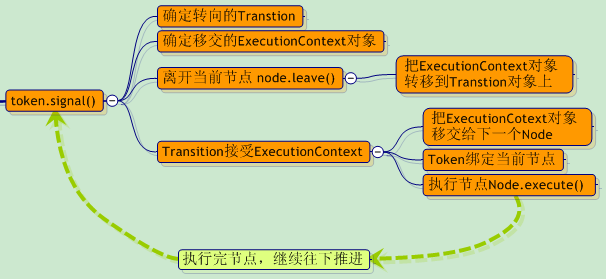
ŠÄąńŞőŠŁą´╝îŔ»ĚŠ│ĘŠäĆnode.leave()Ŕ┐ÖńެŠôŹńŻťŃÇéŔ┐ÖŠś»ńŞÇńެňżłŠťëŠäĆŠÇŁšÜäŔ»şń╣ëŔŻČŠŹó´╝ÜŠłĹń╗ČŠś»ÚççšöĘtokenšÜäsignalŠôŹńŻťŠŁąŔíĘšĄ║ňżÇńŞőńŞÇńެŔŐéšé╣ŠÄĘŔ┐Ť´╝îńŻćŠś»ň«×ÚÖůší«ň«×ŠëžŔíîšÜänode.leave ()ŠôŹńŻťŃÇé
ŃÇÇňŽéŠ×ťŔ┐Öňť░Šľ╣Ŕ«ęńŻáŔç¬ňĚ▒ŠŁąň«×šÄ░´╝îń╗úšáüń╝ÜńŞŹń╝Üň░▒Šś»Ŕ┐ÖŠáĚňşÉňĹó´╝čńŞŹňŽĘŠşĄňĄäŠâ│ńŞÇŠâ│ŃÇé
//ňüçŔ«żń╗úšáü´╝îń╗ůńżŤŠÇŁŔÇâ
void signal(Transition transition, ExecutionContext executionContext) {
transition.take(executionContext);
} |
ňëŹÚŁóŔ»┤Ŕ┐ç´╝îjbpmšÜäŔ░âň║ŽŠť║ňłÂňÉŞš║│šÜäPetri NetšÜäŠÇŁŠâ│ŃÇéňťĘPetri NetńŞş´╝îň╣Š▓튝ëtransitionńŞşÚę╗šĽÖtokenŔ┐ÖńެŔ»şń╣ë´╝îtokenňƬÚę╗šĽÖňťĘň║ôŠëÇ´╝łPlace´╝ëńŞşŃÇéŠëÇń╗ą´╝îjbpmŠşĄňĄäšÜäŔ«żŔ«íŠÇŁŔĚ»´╝»ń║ÄŠşĄŠťëńŞÇň«Üňů│š│╗šÜäŃÇéŠëÇń╗ąňƬŠś»ŠŐŐńŞÇńެExecutionContextň»╣Ŕ▒íŠöżňťĘń║ćtransitionńŞş´╝îŔÇîńŞŹŠś»ńŞÇńެtokenň»╣Ŕ▒íŃÇé
ŃÇÇŔ«ęŠłĹń╗ČŠŁąšťőšťőnodeň»╣Ŕ▒íšÜäleaveŠľ╣Š│Ľ´╝Ü
public void leave(ExecutionContext executionContext, Transition transition) {
Token token = executionContext.getToken();
token.setNode(this);
executionContext.setTransition(transition);
executionContext.setTransitionSource(this);
transition.take(executionContext);
} |
ŠłĹń╗ČšŤ┤ŠÄąŔĚčŔެŔ┐ŤTransitionšÜätakeŠôŹńŻť´╝Ü
public void take(ExecutionContext executionContext) {
executionContext.getToken().setNode(null);
// pass the token to the destinationNode node
to.enter(executionContext);
} |
š╗ĆŔ┐çŔ┐Öń╣łňĄÜšÜäńŞşÚŚ┤ŠşąÚ¬Ą´╝Ĺń╗Čš╗łń║ÄŠŐŐExecutionContextň»╣Ŕ▒íń╗ÄńŞÇńެnodeŔŻČšž╗ňł░ńŞőńŞÇńެnodeń║ćŃÇéŔ«ęŠłĹń╗ČŠŁąšťőšťőNodeň»╣Ŕ▒íšÜäenterŠôŹńŻť´╝Ü
public void enter(ExecutionContext executionContext) {
Token token = executionContext.getToken();
token.setNode(this);
// remove the transition references from the runtime context
executionContext.setTransition(null);
executionContext.setTransitionSource(null);
// execute the node
if (isAsync) {
} else {
execute(executionContext);
}
} |
Ŕç│ŠşĄ´╝îjBpmŠłÉňŐčšÜäń╗ÄńŞÇńެŔŐéšé╣ŔŻČšž╗ňł░ńŞőńŞÇńެŔŐéšé╣ń║ćŃÇéÔÇöÔÇö Ŕ┐Öň░▒Šś»jbpmšÜäŔ░âň║ŽŠť║ňłÂŃÇé
7.3 ÚŁ×ňŞŞš«ÇňŹĽšÜäŔ░âň║ŽŠť║ňłÂ
ŃÇÇŠÇÄń╣łŠáĚ´╝»ńŞŹŠś»ÚŁ×ňŞŞšÜäš«ÇňŹĽ´╝č
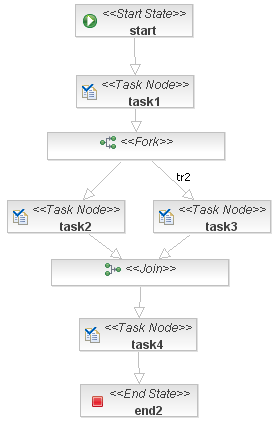
ŃÇÇŔ«ęŠłĹń╗ČŠŐŐŠĽ┤ńެŔ┐çšĘő´╝îšöĘńŞÇň╝ኍ┤ŠŞůŠÖ░šÜäÔÇťŠÇŁš╗┤ňŤżÔÇŁŠŁąň▒ĽšĄ║ńŞÇńŞő´╝Ü
 
ŃÇÇ8 jBpmšÜäŔ┐çšĘőŠëžŔí║ňłÂ
ŃÇÇ8.1 ŠëžŔí║ňłÂ
ŃÇÇňëŹÚŁóŠłĹń╗ČšÜäÔÇťŔ┐çšĘőŔ░âň║ŽŠť║ňłÂÔÇŁŠś»ńŞ║ń║ćŔ«ęŠÁüšĘőňĆ»ń╗ąŠşúší«šÜäń╗ÄÔÇťńŞÇńެŔŐéšé╣ŔŻČšž╗ňł░ńŞőńŞÇńެŔŐéšé╣ÔÇŁ´╝îŔÇČŔŐéŠëÇŔŽüŔ«▓ŔžúšÜäjbpmÔÇťŠëžŔí║ňłÂÔÇŁ´╝îňłÖŠś»ńŞ║ŠĆÉńżŤńŞÇńެŔ┐ÉŔí║ňłÂ´╝ąń┐ŁŔ»üÔÇťŔŐéšé╣šÜ䊺úší«ŠëžŔíîÔÇŁŃÇé
ŃÇÇÚŽľňůłŠłĹń╗ČÚťÇŔŽüŠśÄší«ňŽéńŞőšÜ䊎éň┐Á´╝Ü
ŃÇÇ´╝ł1´╝ë ŔŐéšé╣ŠťëňżłňĄÜńŞş´╝ƚžŹŔŐéšé╣šÜäŠëžŔí╣ň╝ĆŔé»ň«ÜŠś»ńŞŹńŞÇŠáĚšÜä
ŃÇÇ´╝ł2´╝ë ŔŐéšé╣ŠťëŔç¬ňĚ▒šÜäšöčňĹŻňĹĘŠťč´╝îńŞŹňÉîšÜäšöčňĹŻňĹĘŠťčڜŠ«Á´╝îŠëÇňĄäšÜäšŐŠÇüńŞŹňÉîŃÇé
ŃÇÇňťĘWfMCšÜäŃÇŐňĚąńŻťŠÁüňĆéŔÇâŠĘíň×őŃÇőŠľçŠíúńŞş´╝îńŞ║Š┤╗ňŐĘň«×ńżőňŻĺš║│ń║ćňçáńެňĆ»ňĆéŔÇâšÜäšöčňĹŻňĹĘŠťčŃÇé´╝łń╗ůńżŤňĆéŔÇâ´╝îň«×ÚÖůňżłňĄÜňĚąńŻťŠÁüň╝ĽŠôÄšÜäŔŐéšé╣šÜäšöčňĹŻňĹĘŠťčŔŽüŠ»öŔ┐ÖňĄŹŠŁé´╝ë
  
 
ŃÇÇńŻćŠś»´╝îjbpmň╣Š▓튝뚬üňç║ÔÇťŔŐéšé╣šöčňĹŻňĹĘŠťčÔÇŁŔ┐ÖńެšÉćň┐Á´╝îń╗ůń╗ůňƬŠś»ňťĘÔÇťEventÔÇŁńŞşńŻôšÄ░ňç║ňç║ŠŁąŃÇéňťĘŠłĹšťőŠŁą´╝îňĆ»Ŕ⯚ÜäňÄčňŤáŠťëńŞĄńެ´╝Ü
ŃÇÇ´╝ł1´╝ë jBpmŠ▓튝ëNodeInstanceŔ┐ÖńެŠŽéň┐ÁŃÇéňłęšöĘTokenňĺîTaskInstance´╝îjBpmŔÂ│ń╗ąŠîüń╣ůňîľŔÂ│ňĄčšÜäń┐íŠü»´╝îŔâŻňĄčŔ«ęŠÁüšĘőň«×ńżőŔ┐ůÚÇčň«ÜńŻŹňł░ňŻôňëŹŔ┐ÉŔíîšÜäšŐŠÇüŃÇé
ŃÇÇ´╝ł2´╝ë jBpmšÜäEventňĚ▓š╗ĆňżłńŞ░ň»î´╝îň╣ÂńŞöŔ┐ÖńެEventŠś»ňŤ┤š╗ĽÔÇťTokenšÜäŔŻČšž╗ÔÇŁŔÇîŔ«żšŻ«šÜä´╝îň╣ÂńŞŹŠś»ňŤ┤š╗ĽNodešÜäšöčňĹŻňĹĘŠťčŔ«żšŻ«šÜäŃÇé
ŃÇÇ´╝ł3´╝ë ÚÇÜňŞŞŠłĹń╗ČÚťÇŔŽüňťĘActiveňĺîCompletedšÜäšöčňĹŻňĹĘŠťčňćůŠëÇŔŽüŠôŹńŻťšÜäňłćŠö»ńŞÄŔüÜňÉł´╝îňťĘjBpmŠĘíň×őńŞşňłćňłźšö▒ForkŃÇüJoinń╣őš▒╗šÜäŔŐéšé╣ŠŤ┐ń╗úŃÇéŠëÇń╗ąjBpmŔ┐çňłćňů│Š│ĘNodešöčňĹŻňĹĘŠťčšÜäš«íšÉćŠäĆń╣ëńŞŹŠś»ÚŁ×ňŞŞňĄžŃÇé
ŃÇÇńŻťńŞ║ńެń║║´╝Ĺň╣ÂńŞŹŔíîŔÁĆjBpmŔ┐ÖŠáĚŠŐŤň╝âÔÇťŔŐéšé╣šöčňĹŻňĹĘŠťčš«íšÉćÔÇŁšÜäň«×šÄ░Šľ╣ň╝Ć´╝┤ŔíîŔÁĆOBE´╝łŠťÇŠŚęšÜäňč║ń║ÄXPDLŠĘíň×őšÜäjavaňĚąńŻťŠÁüň╝ĽŠôÄń╣őńŞÇ´╝ëšÜäšöčňĹŻňĹĘŠťčš║ŽŠŁčňĺîš«íšÉćŃÇéńŻćŠś»´╝îń╣čńŞŹňżŚńŞŹŠë┐Ŕ«Ą´╝îjBpmŔžäÚü┐ń║ćÔÇťš╣üšÉÉšÜäšŐŠÇüš╗┤ŠŐĄÔÇŁ´╝îňĆŹŔÇîŔ«ęňĄäšÉćňĆśňżŚÔÇťš«ÇŠśôÔÇŁ´╝îń╣芍┤ň«╣ŠśôŔóźňĄžň«ÂŠëÇšÉćŔžúňĺîŠÄąňĆŚ´╝îŔÇîŔ┐Öń╣芺úŠś»OBEÚÇÉŠŞÉŠÂłňĄ▒šÜäńŞÇńެňÄčňŤá´╝ÜŔ┐çń║ÄňĄŹŠŁéňĺîŔçâŔé┐ŃÇé
ŃÇÇŔ«ęŠłĹń╗ČňťĘňëŹÚŁóÚéúň╝ájBpmšÜäÔÇťŔ░âň║ŽŠť║ňłÂŠÇŁš╗┤ňŤżÔÇŁńŞŐ´╝îň揚ʏšĘŹŔíąňůůńŞÇšé╣´╝łńŞ║ń║暬üňç║ŠśżšĄ║´╝îńŞÄńŞŐňŤżŠťëŠëÇŠö╣ňŐĘ´╝ëŃÇé
Ŕ┐Öň╝áňŤżň║öŔ»ąňĆ»ń╗ąňżłňąŻšÜäŔ»áÚçŐňç║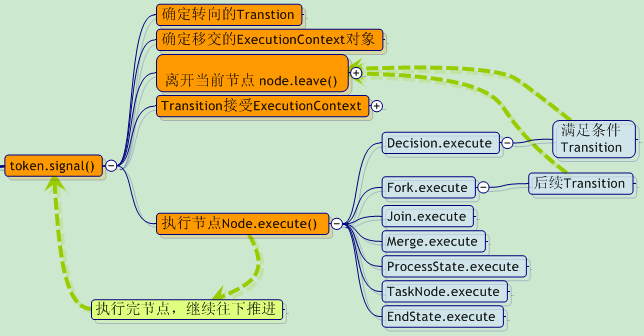 ´╝îŃÇÇjBpmŠś»ňŽéńŻĽŠëžŔíîňÉäšžŹŔŐéšé╣šÜä´╝îŔ┐Öń╣芜»ňżŚšŤŐń║ÄOOšÜäÔÇťňĄÜŠÇüńŞÄš╗žŠë┐ÔÇŁšë╣ŠÇžŃÇé
´╝îŃÇÇjBpmŠś»ňŽéńŻĽŠëžŔíîňÉäšžŹŔŐéšé╣šÜä´╝îŔ┐Öń╣芜»ňżŚšŤŐń║ÄOOšÜäÔÇťňĄÜŠÇüńŞÄš╗žŠë┐ÔÇŁšë╣ŠÇžŃÇé
ŃÇÇ8.2 ňłćŠö»ňĄäšÉć
ŃÇÇjBpmšÜäŠëžŔí║ňłÂÚŁ×ňŞŞš«ÇňŹĽ´╝îńŻćŔ┐śŠś»ÚťÇŔŽüšĘŹňż«ŔíąňůůńŞÇńŞőŠťëňů│ÔÇťňłćŠö»ÔÇŁŠľ╣ÚŁóšÜäňĄäšÉćŃÇé
ŃÇÇjBpmÚççšöĘsub tokenšÜ䊝║ňłÂŠŁąŔžúňć│ňłćŠö»Šľ╣ÚŁóšÜäňĄäšÉć´╝ÜňŻôÚüçňł░ŠťëňłćŠö»šÜ䊌ÂňÇÖ´╝îń╝ÜńŞ║Š»ĆńެňłćŠö»ŔŐéšé╣ňłŤň╗║ńŞÇńެchild tokenŃÇéňťĘŔüÜňÉłŔŐéšé╣´╝łJoinŠłľMerge´╝ë´╝îňłÖńżŁŔÁľňůÂňÉąŠłľň╝銺ąšÜäŔüÜňÉłŠľ╣ň╝Ć´╝ąňłćňłźňĄäšÉćŃÇé
ŃÇÇŠ»öňŽéŠłĹń╗ČňĆéšťőForkŔŐéšé╣šÜäŠëžŔíîń╗úšáü´╝łńŞ║ń║暬üňç║Ú珚é╣´╝îšťüšĽąÚâĘňłćń╗úšáü´╝ë´╝Ü
public void execute(ExecutionContext executionContext) {
Token token = executionContext.getToken();
Iterator iter = transitionNames.iterator();
while (iter.hasNext()) {
String transitionName = (String) iter.next();
forkedTokens.add(createForkedToken(token, transitionName));
}
iter = forkedTokens.iterator();
while( iter.hasNext() ) {
//šťüšĽąÚâĘňłćń╗úšáü
ExecutionContext childExecutionContext = new ExecutionContext(childToken);
leave(childExecutionContext, leavingTransitionName);
}
}
protected ForkedToken createForkedToken(Token parent, String transitionName) {
Token childToken = new Token(parent, getTokenName(parent, transitionName));
forkedToken = new ForkedToken(childToken, transitionName);
return forkedToken;
} |
Ŕç│ń║ÄMergeŔŐéšé╣´╝Ŋâ│ŠşĄňĄäńŞŹšöĘňťĘš┤»ŔÁśšÜäň▒ĽšĄ║´╝ëňů┤ŔÂúšÜä´╝îňĆ»ń╗ąňĆéšťőMergeš▒╗šÜäexecuteŠľ╣Š│Ľ´╝îňŹ│ňĆ»ŃÇé
9 jBpmňćůŠáŞš╗ôŠ×äńŞÄň«×ńżőň»╣Ŕ▒í
ŃÇÇJbpmň╝ĽŠôÄňćůŠáŞšÜäš╗ôŠ×äÚŁ×ňŞŞÔÇťš▓żš«ÇÔÇŁŃÇéÚÖĄń║抳Ĺń╗ČńŞŐÚŁóŠëÇŔ»┤šÜäÚéúń║Ťň«Üń╣ëň»╣Ŕ▒í´╝łňÉäšžŹNodeŔŐéšé╣ňĺîTranstion´╝ë´╝îŔ┐śŠťëňçáńެńŞÄÔÇťŔ┐ÉŔíîň«×ńżőÔÇŁšŤŞňů│šÜäň»╣Ŕ▒íŃÇéňŽéńŞőňŤżŠëÇšĄ║´╝îjbpmň╝ĽŠôÄňćůŠáŞň»╣Ŕ▒íńŞ╗ŔŽüŠś»ňťĘorg.jbpm.graph.defňĺîorg.jbpm.graph.exeňîůŃÇé
ŃÇÇ´╝ł1´╝ë ŠłĹń╗ČÚťÇŔŽüŠĆĆŔ┐░ńŞÇńެŠÁüšĘőň«×ńżő´╝îŠëÇń╗ąÚťÇŔŽüńŞÇńެProcessInstanceň»╣Ŕ▒íŃÇé
ŃÇÇ´╝ł2´╝ë Š»ĆńެŠÁüšĘőň«×ńżő´╝îÚâŻń╝Üš╗┤ŠŐĄńŞÇňąŚň▒×ń║ÄňůÂŔç¬ňĚ▒šÜäÔÇťŠëžŔíîšÄ»ňóâÔÇŁ´╝îń╣čň░▒Šś»ExecutionContextň»╣Ŕ▒íŃÇéŠ│ĘŠäĆ´╝îŔ┐ÖÚç»ńŞÇňąŚ´╝îŔÇîńŞŹŠś»ńŞÇńެŃÇé
 
ŃÇÇ10 ňÉÄŔ«░
ŃÇÇńŞŐňŹŐň╣┤ňćÖń║ćń║ŤbpmňĺîSOAšÜ䊾皟á´╝îń╣čŔóźcsdnšÜäňąŻňĆőŠő뚣Çň┐ŻŠéáń║ćńŞŹň░ĹŔ┐ÖŠľ╣ÚŁóšÜ䊎éň┐Á´╝îň╝äšÜäňąŻňâĆŠłĹň╝ÇňžőŠÉ×Ŕ┐ÖŠľ╣ÚŁóšÜäňĚąńŻťń╝╝šÜäŃÇéňůÂň«×ńŞŹšä´╝ČŔ┤ĘňĚąńŻťńŞÄŔ┐ÖŠťëÔÇťňĄęňúĄń╣őňłźÔÇŁ´╝îň«îňůĘŠś»ÚŁ×ňŞŞň║Ľň▒éšÜäjavaŠŐÇŠť»ň║öšöĘŃÇéŔÇîworkflow´╝îń╣芝ëńŞĄńŞëň╣┤Š▓튝ëń╗Äń║őŔ┐ÖŠľ╣ÚŁóšÜäň╝ÇňĆĹń║ć´╝îŠëÇń╗ąňćÖŠşĄš»çŠľçšźá´╝Çň«×Ŕ┤╣ń║ćšé╣ňŐčňĄźŃÇé
ŃÇÇŠâ│šŚŤšŚŤň┐źň┐źňćÖš»çŠťëňů│ÔÇťň╝ĽŠôÄňćůŠáŞÔÇŁšÜ䊾皟á´╝îŔ┐ÖńެŠâ│Š│Ľšö▒ŠŁąń╗ąňĆŐń║ć´╝îňŹ┤Šőůň┐âŔç¬ňĚ▒ńŞŹŔÂ│ń╗ąŔ»áÚçŐŠŞůŠąÜ´╝îňĆŹŔÇîň«╣ŠśôŔ»»ň»╝ń╗ľń║║´╝îÚüéńŞşÚÇöňĄÜŠČíŠöżň╝âŃÇé
ŃÇÇŠşúňŽéňëŹÚŁóŠëÇŔ»┤šÜäÚéúŠáĚ´╝îň╝ĽŠôÄňćůŠáŞšÜäň«×šÄ░´╝îň╣Š▓튝ëńŞÇňąŚÔÇťňŤ║ň«ÜšÜäŠĘíň╝ĆÔÇŁŠłľŔÇůÔÇťňŤ║ň«ÜšÜäň«×šÄ░ńŻôš│╗ÔÇŁ´╝îń╝ÜňŤáńŞ║ňżłňĄÜňŤáš┤áŔÇîÚÇኳÉň«×šÄ░ńŞŹňÉîŃÇéňŽéŠ×ťŠâ│ŠŐŐÔÇťň╝ĽŠôÄňćůŠáŞÔÇŁšÜäň«×šÄ░šťčŠşúŔ»áÚçŐŠŞůŠąÜ´╝îň┐ůÚí╗ŠŐŐŔ┐Öń║ŤšŤŞňů│ňŤáš┤áÚâŻŔ»áÚçŐŠśÄŠťŚÔÇöÔÇöńŻćŔ┐ÖńżŁšäŠś»ńŞÇńެŠÁęňĄžšÜäňĚąšĘőŃÇé
ňëŹń║ŤŠŚąňşÉ´╝îňĆŚŠťőňĆőŠëÇŠëś´╝îńŞ║ń╗ľń╗ČšÜäňůČňĆŞňşŽňĹśŔ«▓ń║ćňçáŔŐéňĚąńŻťŠÁüšÜäŔ»żšĘő´╝čÚŚ┤ň░ŁŔ»ĽjBpmŠŁąŔ»áÚçŐń║ćńŞÇńŞőň╝ĽŠôÄšÜäň«×šÄ░ŠÇŁŔĚ»´╝îňĆĹšÄ░ŠĽłŠ×ťńŞŹÚöÖŃÇéÔÇöÔÇöňĆŚŠşĄň╝ĽňĆĹ´╝îÚüéŔÉîňĆĹń║ćń╗ąjBpmńŞ║ň«×ńżő´╝ąš«ÇňŹĽŔ»áÚçŐÔÇťŠÁüšĘőň╝ĽŠôÄňćůŠáŞÔÇŁŠâ│Š│ĽŃÇé
ŃÇÇŔÇŚŠŚÂńŞÇňĹĘšÜäńŞÜńŻÖŠŚÂÚŚ┤´╝îŔÖŻšäÂŔ┐śňżłÚÜżŔ»áÚçŐŔç¬ňĚ▒šÜäňůĘÚâĘŠâ│Š│Ľ´╝îńŻćÔÇťšé╣ňç║ňçáńެŔŽüšé╣ÔÇŁ´╝îŔ┐śŠś»ň║öŔ»ąŠťëń║ćŃÇé





šŤŞňů│ŠÄĘŔŹÉ
"ŠĆşšžśjbpmŠÁüšĘőň╝ĽŠôÄňćůŠáŞŔ«żŔ«íŠÇŁŠâ│ňĆŐŠ×äŠ×Â" jbpmŠÁüšĘőň╝ĽŠôÄňćůŠáŞŠś»ŠîçŠÁüšĘőň╝ĽŠôÄńŞşŠťÇňč║ŠťČšÜäň»╣Ŕ▒íňĺŹňŐí´╝îń╗ąňĆŐšöĘń║ÄŔžúňć│ŠÁüšĘőŔ┐ÉŔíîÚŚ«ÚóśšÜäŔ░âň║ŽŠť║ňłÂňĺîŠëžŔí║ňłÂŃÇéň«âŠś»ŠÁüšĘőň╝ĽŠôÄšÜäšüÁÚşé´╝îŠÄîŠĆíń║ćŠÁüšĘőň╝ĽŠôÄňćůŠáŞšÜäŔ«żŔ«íŠÇŁŠâ│ňĺîš╗ôŠ×ä´╝îŠëŹŔ⯚ťčŠşú...
"ŠĆşšžśjbpmŠÁüšĘőň╝ĽŠôÄňćůŠáŞŔ«żŔ«íŠÇŁŠâ│ňĆŐŠ×äŠ×Â" jbpmŠÁüšĘőň╝ĽŠôÄňćůŠáŞŠś»ŠîçŠÁüšĘőň╝ĽŠôÄšÜ䊝Çňż«ň░Ćš╗ôŠ×ä´╝îń╗ůňîůňÉźŠťÇňč║ŠťČšÜäň»╣Ŕ▒íňĺŹňŐí´╝îń╗ąňĆŐšöĘń║ÄŔžúňć│ŠÁüšĘőŔ┐ÉŔíîÚŚ«ÚóśšÜäŔ░âň║ŽŠť║ňłÂňĺîŠëžŔí║ňłÂŃÇéjbpmŠÁüšĘőň╝ĽŠôÄňćůŠáŞšÜäŔ«żŔ«íŠÇŁŠâ│Šś»ňč║ń║Äňż«ňćůŠáŞšÜäŠÁüšĘőň╝ĽŠôÄ...
ŃÇŐŠĆşšžśJBPMň╝ĽŠôÄňćůŠáŞŔ«żŔ«íŠÇŁŠâ│ňĆŐŠ×äŠ×ÂŃÇőńŞÇŠľçŠĚ▒ňůąň뾊×Éń║ćJBPMŠÁüšĘőň╝ĽŠôÄšÜäŠáŞň┐âŔ«żŔ«íňÄčšÉćňĺîŠ×Š×ä´╝îńŞ║šÉćŔžúňĚąńŻťŠÁüň╝ĽŠôÄšÜ䊝ČŔ┤ĘŠĆÉńżŤń║ćň«ŁŔ┤ÁšÜäŔžćŔžĺŃÇ銝ȊľçńŞŹń╗ůŠĆşšĄ║ń║ćJBPMň╝ĽŠôÄňćůŠáŞšÜäňů│Úö«ŔŽüš┤á´╝îŔ┐śň»╣Š»öń║ćńŞŹňÉîňĚąńŻťŠÁüŠĘíň×őšÜäňĚ«ň╝é´╝îńŞ║ň╝ÇňĆĹŔÇů...
JBPM 4.4šöĘŠłĚŠëőňćî.chm jbpm-4.4 apiňŞ«ňŐꊾçŠíú.CHM jBPM-jPDLňşŽń╣ášČöŔ«░ÔÇöÔÇöŠÁüšĘőŔ«żŔ«íńŞÄŠÄžňłÂ.doc JBPM4.4ń╣őHelloWorldšĄ║ńżő.doc jbpm4.4ń╝Üšşżň«×ńżő.doc jbpm4.4ň«ëŔúůÚůŹšŻ«step by ...ŠĆşšžśjbpmŠÁüšĘőň╝ĽŠôÄňćůŠáŞŔ«żŔ«íŠÇŁŠâ│ňĆŐŠ×äŠ×Â.doc
Ŕç│ń║ÄŔâíÚĽ┐ňčÄ´╝łÚôšőÉ999´╝ëňťĘCSDN BlogńŞşŠĆşšžśšÜäjbpmŠÁüšĘőň╝ĽŠôÄňćůŠáŞŔ«żŔ«íŠÇŁŠâ│ňĆŐŠ×äŠ×´╝îňĆ»ŔâŻŔ»Žš╗ćŔ«ĘŔ«║ń║ćjbpmňŽéńŻĽň«×šÄ░Ŕ┐Öń║ŤŔ«żŔ«íšÉćň┐Á´╝îňîůŠőČŠÁüšĘőň«×ńżőšÜäňćůňşśŔíĘšĄ║ŃÇüń╗╗ňŐíŔ░âň║Žš«ŚŠ│ĽŃÇüŠîüń╣ůňîľšşľšĽąń╗ąňĆŐńŞÄňůÂń╗ľš│╗š╗č´╝łňŽéESBŃÇüEJBŃÇüSpringšşë´╝ëšÜä...
3. **ňĚąńŻťŠÁüň╝ĽŠôÄ**´╝ÜŃÇŐŠĆşšžśjBPMň╝ĽŠôÄňćůŠáŞŔ«żŔ«íŠÇŁŠâ│ňĆŐŠ×äŠ×ÂŃÇőŔ»Žš╗ćŔžúŠ×Éń║ćjBPMŔ┐ÖńŞÇŠÁüŔíîšÜäňĚąńŻťŠÁüň╝ĽŠôÄ´╝îňîůŠőČňůŠÁüšĘőň«Üń╣ëŔ»şŔĘÇŃÇüń╗╗ňŐíš«íšÉćŃÇüń║őń╗ÂňĄäšÉćňĺîŠîüń╣ůňť║ňłÂŃÇéňÉ´╝îňĚąńŻťŠÁüň╝ĽŠôÄšÜäŠáŞň┐âŔ░âň║Žš«ŚŠ│ĽňťĘŃÇŐňĚąńŻťŠÁüň╝ĽŠôÄŠáŞň┐âŔ░âň║Žš«ŚŠ│ĽńŞÄ...
9. **ŠĆşšžśjBPMň╝ĽŠôÄňćůŠáŞŔ«żŔ«íŠÇŁŠâ│ňĆŐŠ×äŠ×Â**´╝ÜjBPMŠś»ńŞÇńެň╝ÇŠ║ÉšÜäňĚąńŻťŠÁüňĺîńŞÜňŐíŔžäňłÖš«íšÉćš│╗š╗č´╝îŔ┐ÖńެŠľçŠíúňĆ»Ŕ⯊Ě▒ňůąň뾊×Éń║ćň«âšÜäŔ«żŔ«íňÄčňłÖŃÇüňćůÚâĘňĚąńŻťŠť║ňłÂňĺîŠ×Š×ä´╝îň»╣ň╝ÇňĆĹŔÇůšÉćŔžúňĺîńŻ┐šöĘjBPMňůĚŠťëŠîçň»╝ń╗ĚňÇ╝ŃÇé 10. **ňĚąńŻťŠÁüňĆéŔÇâŠĘíň×őšťčŔ░Ť*...