和debug task一样,profiling一个运行在分布式hadoop环境下的mapredeuce
job是比较困难的。但在hadoop中,是可以让用户针对某些tasks进行profiling采集的,当这些task执行完后,将这些
profiling日志保存的文件发送到作业的提交client机器上,然后用户就可以用自己熟悉的工具来分析这些profiling日志,进行
tasks执行瓶颈的分析。
使用方法:
在JobConf中,有几个配置选项是可以用来控制task profiling行为的。比如对一个job,想要开启对其tasks的profiling功能,并设置profiling相应的HPROF参数,可以按如下方式:
conf.setProfileEnabled(true);
conf.setProfileParams("-agentlib:hprof=cpu=samples,heap=sites,depth=6," +
"force=n,thread=y,verbose=n,file=%s");
conf.setProfileTaskRange(true, "0-2");
第一行表示打开profiling task的功能,该功能默认情况下是关闭的。调用该接口相当于设置配置选项 mapred.task.profile=true
,可以利用这种方式在hadoop job提交命令行上动态指定。
第二行是通过conf接口来设置对tasks进行HPROF 的profiling的采集参数,采用profiling
enable的方式运行的tasks,会采用每个task一个独立的JVM的运行方式运行(即使enable了job的jvm
reuse功能)。HPROF相关的采集参数设置,可以见其他资料。该选项也可以通过设置 mapred.task.profile.params
选项来指定。
第三行表示对job的哪些tasks需要进行profiling采集,第一true参数表示采集的是map
tasks的性能数据,false的话表示采集reduce的性能数据,第二个参数表示只采集编号为0,1,2的tasks的数据,(默认为0-2)。如
果想要采集除2,3,5编号的tasks,可以设置该参数为: 0-1,4,6-
只需在jobtracker上设置。
Example
还是拿wordcount来举例,提交job命令如下:
bin/hadoop jar hadoop-examples-0.20.2-luoli.jar wordcount \
-D mapred.reduce.tasks=10 \
-D keep.failed.task.files=fales \
-D mapred.task.profile=true \
-D mapred.task.profile.params="-agentlib:hprof=cpu=samples,heap=sites,depth=6,force=n,thread=y,verbose=n,file=%s" \
$input \
$output
这样,当job运行时,就会对前三个task进行profiling的采集,采集信息包括cpu的采样信息,内存分配的信息数据,stack
trace
6层的堆栈信息。这里需要注意的是,由于前三个tasks被进行了HPROF的性能采样,所以这几个tasks的执行效率会受到一定的影
响,profiling的信息越详细,性能影响就越大。如下图,前三个map就明显比其他的map运行的要慢很多。
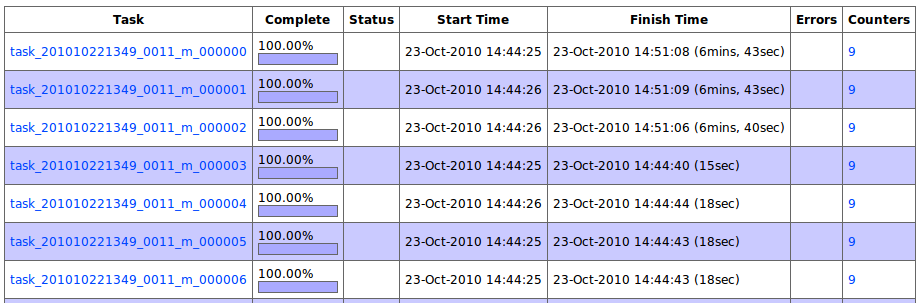
不过这种运行方式通常都不是线上运行方式,而是用来进行优化调试,所以关系不大。
而当job运行完成后,这三个tasks对应的profiling日志也会会传到提交机器上,供用户分析判断。如下图:

与此同时,tasks在tasktracker上也将这些profiling日志信息记录到了一个profile.out的日志文件中,该文件通常
位于tasktracker机器上的上${HADOOP_HOME}/logs/userlogs/${attempt_id}下,和该task的
stderr,stdout,syslog保存在同一个目录下,如下图:

该文件中的内容,还可以通过taskdetails.jsp的页面查看到。如下图:

有了这些信息,相信对于任何一位hadoop应用程序的开发者来说,就拥有了足够的定位job瓶颈的信息了。MR的应用程序开发同学,请优化您的job吧~~
分享到:





相关推荐
4. Profiling:性能分析是调优不可或缺的一步,Profiling可以帮助开发者了解程序在运行中的各种性能指标,从而定位性能瓶颈。 在配置参数调优的具体实践中,控制Map个数是一个关键步骤。Map任务的数量依赖于输入...
Profiling 是 Map/Reduce 框架中的一个概念,负责对作业的执行进行 profiling,以便了解作业的执行效率和瓶颈。 JobControl 是 Map/Reduce 框架中的一个概念,负责对作业的执行进行控制和监控,以便提高作业的执行...
3. **利用x86 PMU的Profiling工具**:利用Oprofile或Intel Vtune等工具对NameNode进行性能剖析,找出CPU热点。 4. **修改的perf工具**:使用自定义版本的perf工具进一步分析NameNode的性能瓶颈。 #### 三、RPC框架...
- **Profiling**:Profiling 功能可以帮助开发者了解作业性能瓶颈所在。 - **调试**:Hadoop 提供了一些调试工具,如日志记录和 JMX 监控,帮助开发者诊断问题。 - **JobControl**:JobControl 提供了一组用于管理多...
Profiling Tasks 177 MapReduce Workflows 180 Decomposing a Problem into MapReduce Jobs 180 JobControl 182 Apache Oozie 182 6. How MapReduce Works . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
它能够关联前后端调用链,进行性能分析和Profiling。 8. API 设计: 日志系统提供了多种API接口,包括: - Logging API:提供了类似logback/log4j/log4net的接口,并通过tags扩展来便于搜索查询。 - Trace API:...
Tplatform是文中提到的自实现MapReduce运行系统,它集成了Profiling功能,用于监控和分析系统性能。通过实验,可以在Tplatform上识别出如任务调度和“落后者”(Stragglers)问题等性能问题。“落后者”指的是在执行...
它还具有Hadoop(大数据)支持,可将文件移入Hadoop Grid或从Hadoop Grid移出,创建,加载和配置Hive表。 此项目也称为“ Aggregate Profiler”。此项目的Resful API的构建方式为(测试版)...
9. **Pandas Profiling**:这是一个用于数据探索的工具,可以自动生成详细的报告,包括数据类型、缺失值、统计摘要、相关性分析等,非常适合进行初步的数据清洗和理解。 10. **Apache Hive和HBase**:这两个是...
5. **Pandas-Profiling**:此库用于快速生成数据报告,它能自动分析数据集的统计特性,包括缺失值、异常值、相关性等,为数据探索提供便捷。 6. **Apache Spark与PySpark**:Spark是处理大规模数据的分布式计算框架...
Uber JVM Profiler provides a Java Agent to collect various metrics and stacktraces for Hadoop/Spark JVM processes in a distributed way, for example, CPU/Memory/IO metrics. Uber JVM Profiler also ...
此外,监控和调优工具,如Web UI、EventLog、Stage Profiling,帮助运维人员更好地理解应用程序的性能瓶颈并进行优化。 总结,Spark 2.3作为一个强大且易用的大数据处理框架,其在CDH环境中的应用进一步巩固了其在...
5. **Pandas-Profiling**:此库用于快速生成数据概览报告,帮助理解数据集的基本统计特性,如缺失值、异常值、数据分布等,为后续的数据清洗和分析提供指导。 6. **Matplotlib与Seaborn**:这两个库是Python数据...
对数据中心进行范围内的profiling和tracing,以及对Linux操作系统和大型系统开发的理解,都是确保高性能计算能力不可或缺的知识点。 总的来说,这些研究展示了高性能计算机体系结构在不断进化的技术环境中,如何...
流式计算系统的发展可以追溯到2008年Hadoop批量计算系统和2010年Bigpipe消息传输系统。2011年,DStream1.0纯流式计算系统诞生,2011年TM1.0小批量流式计算系统也相继问世。2017年,百度DStream3流式计算系统问世,...
数据流通常涉及Kafka作为消息中间件,以及Hadoop集群进行数据存储和处理。对于任务调度,可以使用Azkaban等工具来确保作业按计划执行,并关注负载均衡和防止死锁。 在线服务平台处理实时或近实时的数据,例如用户的...
* 数据存储:使用分布式存储系统,例如Hadoop、Spark等,来存储和处理大量的数据。 * 数据处理:使用大数据处理技术,例如MapReduce、Spark等,来处理和分析数据。 * 数据分析:使用数据挖掘和机器学习技术,来分析...
这通常通过JMX(Java Management Extensions)接口、Java Profiling工具或者自定义探针实现。 2. **实时监控**:通过收集的数据,系统实时显示各项性能指标,提供可视化界面,帮助管理员及时发现潜在的问题。例如,...
6. **Pandas-Profiling**:这个库用于生成详细的报告,对数据集进行快速探索性数据分析(EDA),包括描述性统计、缺失值检查、相关性分析等。 7. **Big Data处理框架集成**:Python可以与Hadoop、Spark等大数据处理...
此外,还有用于机器学习的Scikit-Learn、深度学习的TensorFlow和Keras,以及数据预处理的Pandas-Profiling。 2. **R语言**: R是专为统计分析设计的编程语言,拥有大量内置的统计函数和包,如ggplot2(用于美观的...