[转载于] http://blog.21ic.com/user1/5585/archives/2009/56686.html
作者 xgywinner 日期 2009-3-18 11:57:00
来源:北京邮电大学学报
1 MPEG声音编码原理
MPEG声音编码是一种基于人耳听觉特性的子带声音编码算法,它属于一种感觉声音编码方法.感觉声音编码算法的基本结构如图1所示.根据编码器着重于频率分辨率还是时间分辨率,可分为子带编码器和变换编码器.MPEG声音第2层编码算法在频域上把声音信号划分为32个子带,属于一种子带编码器.在图1 中,时频映射也称滤波器组,用于把输入的声音信号映射成亚抽样的频率分量.根据使用的滤波器组的性质,即滤波器组在频域的分辨率的大小,这些频率分量又可叫做子带样值或频率线.
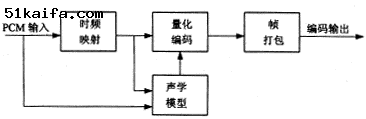
(a)

(b)
图1 感觉声音解码器结构框图
滤波器的输出或者与滤波器组并行的时频变换的输出,提供给心理声学模型以估计时间相关的声音掩蔽门限.心理声学模型使用了人们所知的同时掩蔽效应,包括有调音的掩蔽特性和无调音的掩蔽特性.如果使用声音的前后掩蔽效应,还可进一步提高掩蔽门限估计的准确性.子带样值或频率线按照尽量保证量化噪声的频谱处于掩蔽门限以下的准则进行量化和编码,这样能保证被人耳感知的量化引入的噪声最小.根据对复杂度的要求,可以使用块压扩或熵编码的分析合成方法.
帧打包把量化编码的输出和相关边信息按照规定的格式组合起来,以便供解码器使用.
2 编码质量和DSP速度
单片ADSP-2181实现MPEG声音编码关键需要解决两个问题:一是如何保证声音编码质量;其次是如何充分利用DSP的运算速度.而这两个问题往往又是一对矛盾,需要找到其最佳结合点.
一般而言,决定MPEG声音编码器的优劣主要是声学模型的好坏.但是,对于使用单片16bit定点DSP的应用而言,这个结论就不再适用了.分析表明,此时有限字长效应对编码质量的影响成了主要矛盾.特别是分析滤波器组,截尾效应竟带来了33倍于16bitAD转换量化误差的噪声,而窗系数的有限长度表示则使本来高达96dB旁瓣衰减的滤波器响应降低到不到70dB.因此,要保证声音编码质量,分析滤波器组算法必须进行精度扩展.
关于速度问题,首先想到的是使用快速算法,我们也尝试了在子带滤波中使用快速算法[4]. 但是,实践证明,这些快速算法使用在DSP上效果并不理想,其原因有以下3条:(1)只考虑了加法和乘法的次数,而对附值、寻址等操作毫不关心,但对所有指令都是单周期的DSP而言,乘法和加法的次数相对其他操作并不显得特别重要;(2)没有考虑DSP的硬件特点,其算法不能充分发挥DSP的乘累加器(MAC)并行处理的能力;(3)ADSP-2181是为16位算法操作优化的,在需要精度扩展的情况下,运算量将以数量级的速度急剧增加.
基于以上质量和速度要求的分析,我们选用了适合DSP乘累加指令的多相结构滤波器组实现方式,且采用基于MAC结构的精度扩展方法,较好地解决了编码质量和DSP速度之间的矛盾.另外,对抽样数据的输入方式、心理声学模型、比例因子编码都进行了适于ADSP-2181的改进,减少了运算量,保证了实时性.
3 算法的软件设计
软件设计是MPEG声音编码的单片DSP实现的核心,编码质量和速度的要求都需要通过精心设计DSP软件才能实现.
(1)基于MAC结构的精度扩展 MPEG声音编码的分析滤波器组可以有许多种实现方式,多相结构是MPEG标准推荐的一种,其数学表示为
(1)
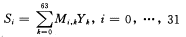
(2)
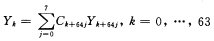
分析表明,对Yk进行双字扩展可将截尾效应带来的噪声降低33倍.但是,考虑到ADSP-2181只支持16bit的乘累加运算,需要对式(1)进行转化,即
(3) Yk=HYk+2-16LYk
(4)
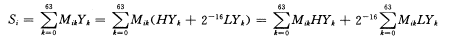
这样,就可利用DSP的乘累加器结构,运算量只增加约1倍,存储量只增加64个字.
(2)输入数据的组织 输入数据的组织不但要考虑方便地从数模转换器取得声音原始数据,还要考虑输入数据在片内数据RAM的存储适合作为多相滤波器组和声学模型的FFT运算的输入.多相滤波器组每次移入32个新的声音数据,移出32个旧的样值,操作如下:
Xi=Xi-32,i=511,510,…,32
Xi=next-input-audio-sample,i=31,30,…,0
然而ADSP-2181并不适于实现数据的移动,每个赋值运算需要两个指令才能完成,每次分析滤波操作需要1024个指令周期.如果利用ADSP- 2181的多通道自动缓冲串口及间接寻址能力,适当地组织输入声音数据,就可利用滑动窗的方法实现数据的移入和移出,如图2所示.
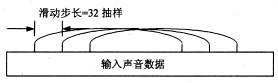
图2 多相滤波的滑动窗技术
为了保证帧边界处理的连续性,输入数据缓存应该设计成圆缓冲的形式,其长度应能存储两帧声音输入数据.当DSP在处理一帧数据时,输入数据可以缓冲到另一帧.这样,数据移动的开销就节约了.同时,输入数据的组织还要利于声学模型的FFT运算,FFT需要利用ADSP-2181的地址反转寻址模式.由于 FFT计算和输入数据的缓存是同时进行的,所以FFT计算的指针需要地址反转,而输入缓冲的指针却不能地址反转,否则会导致输入声音数据排列混乱. ADSP-2181提供这种能力,它的第一地址指针组I0,I1,I2,I3有地址反转能力,而第二地址指针组I4,I5,I6,I7却不受地址反转模式的影响.所以从第二地址指针组中选择指针进行输入缓冲,从第一地址指针组中选择指针进行FFT计算.
(3)声学模型的改进 用DSP实现心理声学模型的一个难题是其中有大量的对数运算,虽然可以用多项式逼近求得其近似值,但是其巨大的运算量说明这不是一个明智的选择.在改进的心理声学模型中,FFT运算后并不立即换算到对数域,而是用分段折线逼近线性域的掩蔽效应曲线.为简单起见,使用与标准一致的分段方法.逼近采用取指数的多项式展开的一次项的方法,这种方法虽然比较粗糙,但正如前面分析的那样,声学模型在16bit定点实现时不是主要矛盾,因而还是可以接受的.
得到掩蔽门限以后,为计算信掩比供比特分配使用,还是需要从线性域转换到对数域.这时,我们采用一种利用ADSP-2181移位器的近似计算方法.通过EXP指令,可以提取2进制补码小数的指数,对能量而言又有1bit约3dB.因而指数值乘3就近似得到该补码小数的dB值,尾数部分的影响忽略不计.
(4)比例因子的编码 MPEG声音编码标准中一共给出了63个比例因子,但是并不是所有这些比例因子都可以用16bit的2进制数表示.如果用双字进行精度扩展,在量化时又将面临双字除法的巨大开销,因此,只使用其中可以用16bit的2进制补码小数精确表示的子集,即序号为3的倍数且小于等于45 的比例因子.
采用比例因子子集后,比例因子编码就可以不再通过比较的方法得到,而可以直接通过计算子带最大幅度的指数获得,简化了比例因子的编码.
(5)软件仿真结果 结合上述各项算法改进,根据ADSP-2181的特点和MPEG标准,用AD公司的开发软件进行了软件仿真.表1列出了仿真得到的各个模块对运算量和存储量要求进行的估算结果.仿真在抽样率为48kHz,编码模式为立体声,输入信号为频率为1kHz的正弦波,输出码率为 192kbit/s的情况下进行.
由表1可知,ADSP-2181的性能得到了较充分的利用.仿真结果表明,在以上的条件下,解码输出的信噪比可达80dB左右.可见,所作的算法改进是比较有效的.
表1 各模块的运算量和存储量要求
| |
运算量/(106指令/s) |
程序存储量/103字 |
数据存储量/103字 |
| 子带滤波 |
18 |
3.0 |
6.5 |
| 声学模型 |
10 |
3.5 |
1.5 |
| 比特分配和量化 |
2 |
2.0 |
— |
| 格式化比特流 |
1 |
0.5 |
1.0 |
4 硬件设计
硬件结构框图如图3所示.各模块的基本功能如下:
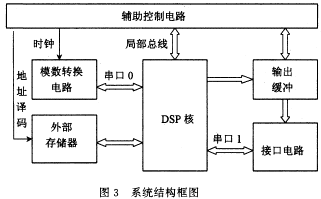
DSP核:除完成所有编码算法以外,还要完成对模数转换电路的初始化配置;通过辅助控制电路选择抽样时钟,通过接口电路接受主机的编码参数.
辅助控制电路:由FPGA及附属电路实现,完成时钟的产生、FIFO状态的监测、地址译码等功能.
输出缓冲:编码码流的暂时存储区,同时提供完全异步的输出接口方式.在需要实现图象声音唇形同步的应用中特别有用.
外部存储器:包括BDMA空间、I/O空间.
模数转换电路:完成声音的数字化,直接与DSP的串口0连接.抽样频率由外部提供的256倍抽样时钟的频率决定,正常工作前需要进行初始化.
接口电路:接口电路分为两部分,一部分是编码输出接口,另一部分是与主机连接的接口.主机接口使用RS232接口芯片完成DSP串口1与主机串口的连接,DSP使用中断和内部计时器实现异步串型通信.
上述方案已经在“九五”科技攻关项目中实现,实时编解码的声音通过了主观测试.
*国家“九五”重点科技攻关资助项目
作者单位:林胜 门爱东 北京邮电大学电信工程学院,北京100876;第一作者25岁,男,博士生
分享到:





相关推荐
《MPEG声音编码系统的单片DSP实现》这篇文章探讨了如何在单片数字信号处理器(DSP)上实现MPEG声音编码系统。MPEG声音编码是一种基于人耳听觉特性的子带编码算法,它利用人耳对不同频率和时间的敏感度进行高效编码,...
《MPEG声音编码的单片DSP实现》这篇文章探讨了如何在单片机上实现MPEG声音编码技术。MPEG声音编码是一种基于人耳听觉特性的高效编码算法,旨在利用人类听觉系统的感知特性来压缩音频数据。它采用子带编码策略,将...
在单片DSP实现MPEG声音编码方面,国外只有DEC、Philips和Xingit等少数公司有所成就,但这些解决方案不仅成本高昂,而且不提供源代码。相比之下,国内曾使用两片TI公司的TMS320C30来实现MPEG声音编码的第二层,这种...
总结来说,本文提出的多DSP方案解决了单片DSP在处理复杂视频编解码任务时的局限性,通过优化系统架构和资源分配,实现了高效、可扩展的MPEG-4编解码系统。这种设计不仅提高了系统的性能,还确保了良好的用户体验,...
在我国,数字电视节目在许多省市已经开始试播,由于用户端使用的基本都是模拟电视机,无法接收数字信号,因此需要一种接收装置来担当二者之间的桥梁,这就是机顶盒(SetTopBox,简称STB)。它是一种扩展电视机功能的...
尽管它在相同的比特率下能提供最佳音质,但由于其编码计算复杂度和运算量极大,通常难以用普通的DSP单片实现。 MPEG音频层III的压缩编码流程具有以下特点: 1. 利用耳蜗扩散函数(Cochlea spreading function)计算...
编码过程相对解码更为复杂,尤其是在单片定点数字信号处理器(DSP)上实现高质量的编码更是技术挑战。定点DSP,如Texas Instruments的TMS320C549,因其处理能力和效率适合于这种实时处理任务。然而,直接将复杂的MP3...
本文提出了一种以多DSP为核心,应用于MPEG-4编解码技术的系统设计,解决了单片DSP难以高效处理视频图像数据量巨大的问题,并设计出了相应的硬件平台方案。 设计中的核心挑战是如何实现MPEG-4视频编解码算法。视频...
总结来说,这种基于DSP和FPGA的视频编码器设计充分利用了两者的优点,实现了高效、实时的视频压缩,满足了现代视频应用对高清晰度和快速传输的需求。通过算法优化和硬件架构的创新,降低了系统的计算复杂度,提高了...
VS1053b音频编解码器是一款高度集成的单片音频处理芯片,由UnitedLink Technologies设计,专为各种音频格式的解码与编码需求而优化。这款芯片支持多种主流音频格式,包括Ogg Vorbis、MP3、AAC、WMA、MIDI以及IMA ...
该芯片内置了一个高性能且低功耗的DSP处理器核VS_DSP,具备5K指令RAM和0.5K数据RAM。此外,它还支持串行控制和数据输入接口、4个通用IO口、一个UART口,以及一个可变采样率的ADC、立体声DAC和音频耳机放大器等。VS...
TMS320DSC2x系列是TI推出的一种单片影像处理系统-on-chip(SoC),它结合了DSP和ARM7通用处理器,为数字相机提供了强大的处理能力。 TMS320DSC2x系列的创新之处在于将影像压缩和前端处理功能整合在一个专用芯片上,...
VS1003是一款集成度高的单片音频解码器,内置DSP处理器,支持MP3、WMA和MIDI等多种音频格式的解码,同时具备ADPCM编码功能。通过SPI总线,VS1003与MSP430F149单片机进行通信,MSP430F149是TI公司的16位超低功耗微...