- жµПиІИ: 30033 жђ°
- жАІеИЂ:

- жЭ•иЗ™: еєњеЈЮ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 45)
- жИСзЪДйЧЃз≠Ф ( 1)
е≠Шж°£еИЖз±ї
- 2011-01 ( 1)
- 2010-12 ( 2)
- 2010-11 ( 17)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(дЇФ)---Page CacheдєЛеєґеПСжОІеИґ
- еНЪеЃҐеИЖз±їпЉЪ
- жФґиЧПиљђеПС
еЖЩеЬ®еЙНйЭҐ:жЬђиКВдЄїи¶Би∞Ии∞ИSQLiteзЪДйФБжЬЇеИґпЉМSQLiteжШѓеЯЇдЇОйФБжЭ•еЃЮзО∞еєґеПСжОІеИґзЪДпЉМжЙАдї•жЬђиКВзЪДеЖЕеЃєеЃЮйЩЕдЄКжШѓе±ЮдЇОдЇЛеК°е§Д
зРЖзЪДпЉМдљЖжШѓSQLiteзЪДйФБжЬЇеИґеЃЮзО∞йЭЮеЄЄзЪДзЃАеНХиАМеЈІе¶ЩпЉМжЙАдї•еЬ®ињЩйЗМеНХзЛђиЃ®иЃЇдЄАдЄЛгАВе¶ВжЮЬзЬЯж≠£зРЖиІ£дЇЖеЃГпЉМеѓєжХідЄ™дЇЛеК°зЪДеЃЮзО∞дєЯе∞±зРЖиІ£дЇЖгАВиАМи¶БзЬЯж≠£зРЖиІ£
SQLiteзЪДйФБжЬЇеИґпЉМжЬАе•љжЦєж≥Хе∞±жШѓйШЕиѓїSQLiteзЪДжЇРз†БпЉМжЙАдї•еЬ®йШЕиѓїжЬђжЦЗжЧґпЉМжЬАе•љиГљзїУеРИжЇРз†БгАВSQLiteзЪДйФБжЬЇеИґеЊИеЈІе¶ЩпЉМе∞љзЃ°еЬ®жЬђиКВдЄ≠зЪДжЇРз†БдЄ≠пЉМжИС
еЖЩдЇЖеЊИе§Ъж≥®йЗКпЉМдєЯжШѓжИСдЄ™дЇЇеЬ®з†Фз©ґжЧґзЪДдЄАзВєењГеЊЧпЉМдљЖжШѓжИСеПСзО∞дїЕдїЕзФ®и®Аиѓ≠пЉМдЉЉдєОдЄНиГљжККйЧЃйҐШиѓіжЄЕж•ЪпЉМеП™жЬЙйАЪињЗдљУдЉЪпЉМжЙНиГљзЬЯж≠£зРЖиІ£SQLiteзЪДйФБжЬЇеИґгАВе•љдЇЖпЉМдЄЛ
йЭҐињЫеЕ•ж≠£йҐШгАВ
 
SQLiteзЪДеєґеПСжОІеИґжЬЇеИґжШѓйЗЗзФ®еК†йФБзЪДжЦєеЉПпЉМеЃЮзО∞йЭЮеЄЄзЃАеНХпЉМдљЖдєЯйЭЮеЄЄзЪДеЈІе¶ЩпЉМжЬђиКВе∞ЖеѓєеЕґињЫи°МдЄАдЄ™иѓ¶зїЖ
зЪДиІ£еЙЦгАВиѓЈдїФзїЖйШЕиѓїдЄЛеЫЊпЉМеЃГеПѓдї•еЄЃеК©жЫіе•љзЪДзРЖиІ£дЄЛйЭҐзЪД
еЖЕеЃєгАВ
¬† 1гАБ
RESERVED LOCK SQLiteеЬ®pagerе±ВиОЈеПЦйФБзЪДеЗљжХ∞е¶ВдЄЛпЉЪ
¬† ¬† еЬ®еЗ†дЄ™еЕ≥йФЃзЪДйГ®дљНж†ЗиЃ∞жХ∞е≠ЧгАВ
(I)еѓєдЇОдЄАдЄ™иѓїдЇЛеК°дЉЪзЪДеЃМжХізїПињЗпЉЪ ж≥®пЉЪ
еЬ®дЄКйЭҐзЪДињЗз®ЛдЄ≠пЉМзФ±дЇОпЉИ1пЉЙзЪДжЙІи°МпЉМдљњеЊЧжЯРдЇЫжЧґеИїSQLiteе§ДдЇОдЄ§зІНзКґжАБпЉМдљЖеЃГжМБзї≠зЪДжЧґйЧіеЊИзЯ≠пЉМдїОжЯРзІНз®ЛеЇ¶дЄКжЭ•иѓіеПѓдї•ењљзХ•пЉМдљЖжШѓдЄЇдЇЖжККйЧЃйҐШиѓіжЄЕж•ЪпЉМеЬ®ињЩ
йЗМжППињ∞дЇЖињЩдЄАеЊЃе¶ЩиАМеЈІе¶ЩзЪДињЗз®ЛгАВ
 
4гАБ
SQLiteзЪДж≠їйФБйЧЃйҐШ
5гАБ
дЇЛеК°з±їеЮЛ(Transaction Types)
¬† жЙАдї•еЇФзФ®з®ЛеЇПеЇФиѓ•е∞љйЗПйБњеЕНдЇІзФЯж≠їйФБпЉМйВ£дєИеЇФзФ®з®ЛеЇПе¶ВдљХеБЪеПѓдї•йБњеЕНж≠їйФБзЪДдЇІзФЯеСҐпЉЯ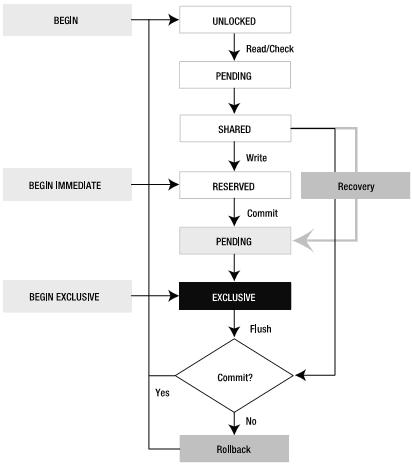
RESERVEDйФБжДПеС≥зЭАињЫз®Ле∞Жи¶БеѓєжХ∞жНЃеЇУињЫи°МеЖЩжУНдљЬгАВжЯРдЄАжЧґеИїеП™иГљжЬЙдЄАдЄ™
RESERVED LockпЉМдљЖжШѓRESERVEDйФБеТМSHAREDйФБеПѓдї•еЕ±е≠ШпЉМиАМдЄФеПѓдї•еѓєжХ∞жНЃеЇУеК†жЦ∞зЪДSHAREDйФБгАВ
дЄЇдїАдєИи¶БзФ®RESERVEDйФБпЉЯ
дЄї
и¶БжШѓеЗЇдЇОеєґеПСжАІзЪДиАГиЩСгАВ
зФ±дЇОSQLiteеП™жЬЙеЇУзЇІжОТжЦ•йФБпЉИEXCLUSIVE
LOCKпЉЙпЉМе¶ВжЮЬеЖЩдЇЛеК°дЄАеЉАеІЛе∞±дЄКEXCLUSIVEйФБпЉМзДґеРОеЖНињЫи°МеЃЮйЩЕзЪДжХ∞жНЃжЫіжЦ∞пЉМеЖЩз£БзЫШжУНдљЬпЉМињЩдЉЪдљњеЊЧеєґеПСжАІе§Іе§ІйЩНдљОгАВиАМSQLiteдЄАжЧ¶еЊЧеИ∞жХ∞жНЃеЇУ
зЪДRESERVEDйФБпЉМе∞±еПѓдї•еѓєзЉУе≠ШдЄ≠зЪДжХ∞жНЃињЫи°МдњЃжФєпЉМиАМдЄОж≠§еРМжЧґпЉМеЕґеЃГињЫз®ЛеПѓдї•зїІзї≠ињЫи°МиѓїжУНдљЬгАВзЫіеИ∞зЬЯж≠£йЬАи¶БеЖЩз£БзЫШжЧґжЙНеѓєжХ∞жНЃеЇУеК†EXCLUSIVE
йФБгАВ
2гАБPENDING LOCK
PENDING
LOCKжДПеС≥зЭАињЫз®ЛеЈ≤зїПеЃМжИРзЉУе≠ШдЄ≠зЪДжХ∞жНЃдњЃжФєпЉМеєґжГ≥зЂЛеН≥е∞ЖжЫіжЦ∞еЖЩеЕ•з£БзЫШгАВеЃГе∞Жз≠ЙеЊЕж≠§жЧґеЈ≤зїПе≠ШеЬ®зЪДиѓїйФБдЇЛеК°еЃМжИРпЉМдљЖжШѓдЄНеЕБиЃЄеѓєжХ∞жНЃеЇУеК†жЦ∞зЪДSHARED
LOCK(ињЩдЄОRESERVED LOCKзЫЄеМЇеИЂ)гАВ
дЄЇдїАдєИи¶БжЬЙPENDING
LOCK?
дЄїи¶БжШѓдЄЇдЇЖйШ≤ж≠ҐеЗЇзО∞еЖЩй•њж≠їзЪДжГЕеЖµ
гАВзФ±дЇОеЖЩдЇЛеК°еЕИи¶БиОЈеПЦRESERVED LOCKпЉМжЙАдї•еПѓиГљдЄАзЫідЇІзФЯжЦ∞зЪДSHARED
LOCKпЉМдљњеЊЧеЖЩдЇЛеК°еПСзФЯй•њж≠їзЪДжГЕеЖµгАВ
3гАБ
еК†йФБжЬЇеИґзЪДеЕЈдљУеЃЮзО∞
![]()
//иОЈеПЦдЄАдЄ™жЦЗдїґзЪДйФБ,е¶ВжЮЬењЩеИЩйЗНе§Ниѓ•жУНдљЬ,
//зЫіеИ∞busy еЫЮи∞ГзФ®еЗљжХ∞ињФеЫЮflase,жИЦиАЕжИРеКЯиОЈеЊЧйФБ
static int pager_wait_on_lock(Pager *pPager, int locktype){
int rc;
assert( PAGER_SHARED==SHARED_LOCK );
assert( PAGER_RESERVED==RESERVED_LOCK );
assert( PAGER_EXCLUSIVE==EXCLUSIVE_LOCK );
if( pPager->state>=locktype ){
rc = SQLITE_OK;
}else{
//йЗНе§НзЫіеИ∞иОЈеЊЧйФБ
do {
rc = sqlite3OsLock(pPager->fd, locktype);
}while( rc==SQLITE_BUSY && sqlite3InvokeBusyHandler(pPager->pBusyHandler) );
if( rc==SQLITE_OK ){
//иЃЊзљЃpagerзЪДзКґжАБ
pPager->state = locktype;
}
}
return rc;
}
WindowsдЄЛеЕЈдљУзЪДеЃЮзО∞е¶ВдЄЛпЉЪ
Code
static int winLock(OsFile *id, int locktype){
int rc = SQLITE_OK; /* Return code from subroutines */
int res = 1; /* Result of a windows lock call */
int newLocktype; /* Set id->locktype to this value before exiting */
int gotPendingLock = 0;/* True if we acquired a PENDING lock this time */
winFile *pFile = (winFile*)id;
assert( pFile!=0 );
TRACE5("LOCK %d %d was %d(%d)\n",
pFile->h, locktype, pFile->locktype, pFile->sharedLockByte);
/* If there is already a lock of this type or more restrictive on the
** OsFile, do nothing. Don't use the end_lock: exit path, as
** sqlite3OsEnterMutex() hasn't been called yet.
*/
//ељУеЙНзЪДйФБ>=locktype,еИЩињФеЫЮ
if( pFile->locktype>=locktype ){
return SQLITE_OK;
}
/* Make sure the locking sequence is correct
*/
assert( pFile->locktype!=NO_LOCK || locktype==SHARED_LOCK );
assert( locktype!=PENDING_LOCK );
assert( locktype!=RESERVED_LOCK || pFile->locktype==SHARED_LOCK );
/* Lock the PENDING_LOCK byte if we need to acquire a PENDING lock or
** a SHARED lock. If we are acquiring a SHARED lock, the acquisition of
** the PENDING_LOCK byte is temporary.
*/
newLocktype = pFile->locktype;
/*дЄ§зІНжГЕеЖµ: (1)е¶ВжЮЬељУеЙНжЦЗдїґе§ДдЇОжЧ†йФБзКґжАБ(иОЈеПЦиѓїйФБ---иѓїдЇЛеК°
**еТМеЖЩдЇЛеК°еЬ®жЬАеИЭйШґжЃµйГљи¶БзїПеОЖзЪДйШґжЃµ),
** (2)е§ДдЇОRESERVED_LOCKпЉМдЄФиѓЈж±ВзЪДйФБдЄЇEXCLUSIVE_LOCK(еЖЩдЇЛеК°)
**еИЩеѓєжЙІи°МеК†PENDING_LOCK
*/
/////////////////////(1)///////////////////
if( pFile->locktype==NO_LOCK
|| (locktype==EXCLUSIVE_LOCK && pFile->locktype==RESERVED_LOCK)
){
int cnt = 3;
//еК†pendingйФБ
while( cnt-->0 && (res = LockFile(pFile->h, PENDING_BYTE, 0, 1, 0))==0 ){
/* Try 3 times to get the pending lock. The pending lock might be
** held by another reader process who will release it momentarily.
*/
TRACE2("could not get a PENDING lock. cnt=%d\n", cnt);
Sleep(1);
}
//иЃЊзљЃдЄЇgotPendingLockдЄЇ1,дљњеТМеЬ®еРОйЭҐи¶БйЗКжФЊPENDINGйФБ
gotPendingLock = res;
}
/* Acquire a shared lock
*/
/*иОЈеПЦshared lock
**ж≠§жЧґ,дЇЛеК°еЇФиѓ•жМБжЬЙPENDINGйФБ,иАМPENDINGйФБдљЬдЄЇдЇЛеК°дїОUNLOCKEDеИ∞
**SHARED_LOCKED зЪДдЄАдЄ™ињЗжЄ°,жЙАдї•дЇЛеК°зФ±PENDING->SHARED
**ж≠§жЧґ,еЃЮйЩЕдЄКйФБе§ДдЇОдЄ§дЄ™зКґжАБ:PENDINGеТМSHARED,
** зЫіеИ∞еРОйЭҐйЗКжФЊPENDINGйФБеРО,жЙНзЬЯж≠£е§ДдЇОSHAREDзКґжАБ
*/
////////////////(2)/////////////////////////////////////
if( locktype==SHARED_LOCK && res ){
assert( pFile->locktype==NO_LOCK );
res = getReadLock(pFile);
if( res ){
newLocktype = SHARED_LOCK;
}
}
/* Acquire a RESERVED lock
*/
/*иОЈеПЦRESERVED
**ж≠§жЧґдЇЛеК°жМБжЬЙSHARED_LOCK,еПШеМЦињЗз®ЛдЄЇSHARED->RESERVEDгАВ
**RESERVED йФБзЪДдљЬзФ®е∞±жШѓдЄЇдЇЖжПРйЂШз≥їзїЯзЪДеєґеПСжАІиГљ
*/
////////////////////////(3)/////////////////////////////////
if( locktype==RESERVED_LOCK && res ){
assert( pFile->locktype==SHARED_LOCK );
//еК†RESERVEDйФБ
res = LockFile(pFile->h, RESERVED_BYTE, 0, 1, 0);
if( res ){
newLocktype = RESERVED_LOCK;
}
}
/* Acquire a PENDING lock
*/
/*иОЈеПЦPENDINGйФБ
**ж≠§жЧґдЇЛеК°жМБжЬЙRESERVED_LOCK,дЄФдЇЛеК°зФ≥иѓЈEXCLUSIVE_LOCK
**еПШеМЦињЗз®ЛдЄЇ:RESERVED->PENDINGгАВ
**PENDINGзКґжАБеП™жШѓеФѓдЄАзЪДдљЬзФ®е∞±жШѓйШ≤ж≠ҐеЖЩй•њж≠ї.
**иѓїдЇЛеК°дЄНдЉЪжЙІи°Миѓ•дї£з†Б,дљЖжШѓеЖЩдЇЛеК°дЉЪжЙІи°Миѓ•дї£з†Б,
**жЙІи°Миѓ•дї£з†БеРОgotPendingLockиЃЊдЄЇ0пЉМеРОйЭҐе∞±дЄНдЉЪйЗКжФЊPENDINGйФБгАВ
*/
//////////////////////////////(4)////////////////////////////////
if( locktype==EXCLUSIVE_LOCK && res ){
//ињЩйЗМж≤°жЬЙеЃЮйЩЕзЪДеК†йФБжУНдљЬпЉМеП™жШѓжККйФБзЪДзКґжАБжФєдЄЇPENDINGзКґжАБ
newLocktype = PENDING_LOCK;
//иЃЊзљЃдЇЖgotPendingLock,еРОйЭҐе∞±дЄНдЉЪйЗКжФЊPENDINGйФБдЇЖ,
//зЫЄељУдЇОеК†дЇЖPENDINGйФБ,еЃЮйЩЕдЄКжШѓеЬ®еЉАеІЛе§ДеК†зЪДPENDINGйФБ
gotPendingLock = 0;
}
/* Acquire an EXCLUSIVE lock
*/
/*иОЈеПЦEXCLUSIVEйФБ
**ељУдЄАдЄ™дЇЛеК°жЙІи°Миѓ•дї£з†БжЧґ,еЃГеЇФиѓ•жї°иґ≥дї•дЄЛжЭ°дїґ:
**(1)йФБзЪДзКґжАБдЄЇ:PENDING (2)жШѓдЄАдЄ™еЖЩдЇЛеК°
**еПШеМЦињЗз®Л:PENDING->EXCLUSIVE
*/
/////////////////////////(5)///////////////////////////////////////////
if( locktype==EXCLUSIVE_LOCK && res ){
assert( pFile->locktype>=SHARED_LOCK );
res = unlockReadLock(pFile);
TRACE2("unreadlock = %d\n", res);
res = LockFile(pFile->h, SHARED_FIRST, 0, SHARED_SIZE, 0);
if( res ){
newLocktype = EXCLUSIVE_LOCK;
}else{
TRACE2("error-code = %d\n", GetLastError());
}
}
/* If we are holding a PENDING lock that ought to be released, then
** release it now.
*/
/*ж≠§жЧґдЇЛеК°еЬ®зђђ2ж≠•дЄ≠иОЈеЊЧPENDINGйФБ,еЃГе∞ЖзФ≥иѓЈSHARED_LOCK(зђђ3ж≠•,еТМеی嚥зЫЄеѓєзЕІ),
**иАМеЬ®дєЛеЙНеЃГеЈ≤зїПиОЈеПЦдЇЖPENDINGйФБ,
**жЙАдї•еЬ®ињЩйЗМеЃГйЬАи¶БйЗКжФЊPENDINGйФБ,ж≠§жЧґйФБзЪДеПШеМЦдЄЇ:PENDING->SHARED
*/
//////////////////////////(6)/////////////////////////////////////
if( gotPendingLock && locktype==SHARED_LOCK ){
UnlockFile(pFile->h, PENDING_BYTE, 0, 1, 0);
}
/* Update the state of the lock has held in the file descriptor then
** return the appropriate result code.
*/
if( res ){
rc = SQLITE_OK;
}else{
TRACE4("LOCK FAILED %d trying for %d but got %d\n", pFile->h,
locktype, newLocktype);
rc = SQLITE_BUSY;
}
//еЬ®ињЩйЗМиЃЊзљЃжЦЗдїґйФБзЪДзКґжАБ
pFile->locktype = newLocktype;
return rc;
}
 
иѓ≠еП•еЇПеИЧпЉЪпЉИ1пЉЙвАФвАФ>пЉИ2пЉЙвАФвАФ>пЉИ6пЉЙ
зЫЄ
еЇФзЪДзКґжАБзЬЯж≠£зЪДеПШеМЦињЗз®ЛдЄЇпЉЪUNLOCKEDвЖТPENDING(1)вЖТPENDINGгАБ
SHARED(2)вЖТ
SHAREDпЉИ6пЉЙвЖТUNLOCKED
(II)еѓєдЇОдЄАдЄ™еЖЩдЇЛеК°еЃМжХізїПињЗпЉЪ
зђђдЄАйШґжЃµпЉЪ
иѓ≠еП•еЇПеИЧпЉЪпЉИ1пЉЙвАФвАФ>пЉИ2пЉЙвАФвАФ>пЉИ6пЉЙ
зКґжАБеПШ
еМЦпЉЪUNLOCKEDвЖТPENDING(1)вЖТPEN
DINGгАБSHARED(2)
вЖТSHARED(6)гАВж≠§жЧґдЇЛеК°иОЈеЊЧSHARED LOCKгАВ
зђђдЇМдЄ™йШґжЃµ
пЉЪ
иѓ≠еП•еЇПеИЧпЉЪпЉИ3пЉЙ
ж≠§жЧґдЇЛеК°иОЈеЊЧRESERVED LOCKгАВ
зђђдЄЙдЄ™йШґжЃµпЉЪ
дЇЛеК°жЙІи°МдњЃжФєжУНдљЬгАВ
зђђеЫЫдЄ™йШґжЃµпЉЪ
иѓ≠еП•еЇПеИЧпЉЪпЉИ1пЉЙвАФвАФ>пЉИ4пЉЙвАФвАФ>пЉИ5пЉЙ
зКґжАБеПШеМЦдЄЇпЉЪ
RESERVEDвЖТ
RESERVED гАБPENDING(1)
вЖТPENDINGпЉИ4пЉЙвЖТEXCLUSIVEпЉИ5пЉЙгАВ
ж≠§жЧґдЇЛеК°иОЈеЊЧжОТжЦ•йФБпЉМе∞±еПѓдї•ињЫи°МеЖЩз£БзЫШжУНдљЬдЇЖгАВ
SQLiteзЪДеК†йФБжЬЇеИґдЉЪдЄНдЉЪеЗЇзО∞ж≠їйФБ?
ињЩжШѓдЄАдЄ™еЊИжЬЙжДПжАЭзЪДйЧЃйҐШпЉМеѓєдЇОдїїдљХйЗЗеПЦеК†йФБ
дљЬдЄЇеєґеПСжОІеИґжЬЇеИґзЪДDBMSйГљеЊЧиАГиЩСињЩдЄ™йЧЃйҐШгАВжЬЙдЄ§зІНжЦєеЉПе§ДзРЖж≠їйФБйЧЃйҐШпЉЪпЉИ1пЉЙж≠їйФБйҐДйШ≤(deadlock
prevention)пЉИ2пЉЙж≠їйФБж£АжµЛ(deadlock detection)дЄОж≠їйФБжБҐе§Н(deadlock
recovery)гАВSQLiteйЗЗеПЦдЇЖзђђдЄАзІНжЦєеЉПпЉМе¶ВжЮЬдЄАдЄ™дЇЛеК°дЄНиГљиОЈеПЦйФБпЉМеЃГдЉЪйЗНиѓХжЬЙйЩРжђ°пЉИињЩдЄ™йЗНиѓХжђ°жХ∞еПѓдї•зФ±еЇФзФ®з®ЛеЇПињРи°МйҐДеЕИиЃЊзљЃпЉМйїШиЃ§дЄЇ1жђ°пЉЙ
вАФвАФињЩеЃЮйЩЕдЄКжШѓеЯЇжЬђйФБиґЕжЧґзЪДжЬЇеИґгАВе¶ВжЮЬињШжШѓдЄНиГљиОЈеПЦйФБпЉМSQLiteињФеЫЮSQLITE_BUSYйФЩиѓѓзїЩеЇФзФ®з®ЛеЇПпЉМеЇФзФ®з®ЛеЇПж≠§жЧґеЇФиѓ•дЄ≠жЦ≠пЉМдєЛеРОеЖНйЗНиѓХпЉЫжИЦиАЕ
дЄ≠ж≠ҐељУеЙНдЇЛеК°гАВиЩљзДґеЯЇдЇОйФБиґЕжЧґзЪДжЬЇеИґзЃАеНХпЉМеЃєжШУеЃЮзО∞пЉМдљЖжШѓеЃГзЪДзЉЇзВєдєЯжШѓжШОжШЊзЪДвАФвАФиµДжЇРжµ™иієгАВ
жЧҐзДґSQLiteйЗЗеПЦдЇЖињЩзІНжЬЇеИґпЉМжЙАдї•еЇФзФ®з®ЛеЇПеЊЧе§ДзРЖ
SQLITE_BUSY йФЩиѓѓпЉМеЕИжЭ•зЬЛдЄАдЄ™дЉЪдЇІзФЯSQLITE_BUSYйФЩиѓѓзЪДдЊЛе≠РпЉЪ

з≠Фж°Ие∞±жШѓдЄЇдљ†зЪД
з®ЛеЇПйАЙжЛ©ж≠£з°ЃеРИйАВзЪДдЇЛеК°з±їеЮЛгАВ
SQLiteжЬЙдЄЙзІНдЄНеРМзЪДдЇЛеК°з±їеЮЛпЉМињЩдЄНеРМдЇОйФБзЪДзКґжАБгАВдЇЛеК°еПѓдї•дїОDEFERREDпЉМIMMEDIATEжИЦиАЕ
EXCLUSIVEпЉМдЄАдЄ™дЇЛеК°зЪДз±їеЮЛеЬ®BEGINеСљдї§дЄ≠жМЗеЃЪпЉЪ
BEGIN [ DEFERRED | IMMEDIATE |
EXCLUSIVE ] TRANSACTIONпЉЫ
дЄАдЄ™deferredдЇЛеК°дЄНиОЈеПЦдїїдљХйФБпЉМзЫіеИ∞еЃГйЬАи¶БйФБзЪДжЧґеАЩпЉМиАМдЄФBEGINиѓ≠еП•жЬђиЇЂдєЯдЄНдЉЪеБЪ
дїАдєИдЇЛжГЕвАФвАФеЃГеЉАеІЛдЇОUNLOCKзКґжАБпЉЫйїШиЃ§жГЕеЖµдЄЛжШѓињЩж†ЈзЪДгАВе¶ВжЮЬдїЕдїЕзФ®BEGINеЉАеІЛдЄАдЄ™дЇЛеК°пЉМйВ£дєИдЇЛеК°е∞±жШѓDEFERREDзЪДпЉМеРМжЧґеЃГдЄНдЉЪиОЈеПЦдїїдљХ
йФБпЉМељУеѓєжХ∞жНЃеЇУињЫи°МзђђдЄАжђ°иѓїжУНдљЬжЧґпЉМеЃГдЉЪиОЈеПЦSHARED LOCKпЉЫеРМж†ЈпЉМељУињЫи°МзђђдЄАжђ°еЖЩжУНдљЬжЧґпЉМеЃГдЉЪиОЈеПЦRESERVED LOCKгАВ
зФ±
BEGINеЉАеІЛзЪДImmediateдЇЛеК°дЉЪиѓХзЭАиОЈеПЦRESERVED LOCKгАВе¶ВжЮЬжИРеКЯпЉМBEGIN
IMMEDIATEдњЭиѓБж≤°жЬЙеИЂзЪДињЮжО•еПѓдї•еЖЩжХ∞жНЃеЇУгАВдљЖжШѓпЉМеИЂзЪДињЮжО•еПѓдї•еѓєжХ∞жНЃеЇУињЫи°МиѓїжУНдљЬпЉМдљЖжШѓRESERVED LOCKдЉЪйШїж≠ҐеЕґеЃГзЪДињЮжО•BEGIN
IMMEDIATEжИЦиАЕBEGIN
EXCLUSIVEеСљдї§пЉМSQLiteдЉЪињФеЫЮSQLITE_BUSYйФЩиѓѓгАВињЩжЧґдљ†е∞±еПѓдї•еѓєжХ∞жНЃеЇУињЫи°МдњЃжФєжУНдљЬпЉМдљЖжШѓдљ†дЄНиГљжПРдЇ§пЉМељУдљ†COMMITжЧґпЉМдЉЪињФ
еЫЮSQLITE_BUSYйФЩиѓѓпЉМињЩжДПеС≥зЭАињШжЬЙеЕґеЃГзЪДиѓїдЇЛеК°ж≤°жЬЙеЃМжИРпЉМеЊЧз≠ЙеЃГдїђжЙІи°МеЃМеРОжЙНиГљжПРдЇ§дЇЛеК°гАВ
ExclusiveдЇЛеК°дЉЪиѓХзЭАиОЈеПЦеѓєжХ∞жНЃеЇУзЪД
EXCLUSIVEйФБгАВињЩдЄОIMMEDIATEз±їдЉЉпЉМдљЖжШѓдЄАжЧ¶жИРеКЯпЉМEXCLUSIVEдЇЛеК°дњЭиѓБж≤°жЬЙеЕґеЃГзЪДињЮжО•пЉМжЙАдї•е∞±еПѓеѓєжХ∞жНЃеЇУињЫи°МиѓїеЖЩжУНдљЬдЇЖгАВ
дЄК
йЭҐйВ£дЄ™дЊЛе≠РзЪДйЧЃйҐШеЬ®дЇОдЄ§дЄ™ињЮжО•жЬАзїИйГљжГ≥еЖЩжХ∞жНЃеЇУпЉМдљЖжШѓдїЦдїђйГљж≤°жЬЙжФЊеЉГеРДиЗ™еОЯжЭ•зЪДйФБпЉМжЬАзїИпЉМshared йФБеѓЉиЗідЇЖйЧЃйҐШзЪДеЗЇзО∞гАВе¶ВжЮЬдЄ§дЄ™ињЮжО•йГљдї•BEGIN
IMMEDIATEеЉАеІЛдЇЛеК°пЉМйВ£дєИж≠їйФБе∞±дЄНдЉЪеПСзФЯгАВеЬ®ињЩзІНжГЕеЖµдЄЛпЉМеЬ®еРМдЄАжЧґеИїеП™иГљжЬЙдЄАдЄ™ињЮжО•ињЫеЕ•BEGIN
IMMEDIATEпЉМеЕґеЃГзЪДињЮжО•е∞±еЊЧз≠ЙеЊЕгАВBEGIN IMMEDIATEеТМBEGIN
EXCLUSIVEйАЪ媪襀еЖЩдЇЛеК°дљњзФ®гАВе∞±еГПеРМж≠•жЬЇеИґдЄАж†ЈпЉМеЃГйШ≤ж≠ҐдЇЖж≠їйФБзЪДдЇІзФЯгАВ
еЯЇжЬђзЪДеЗЖеИЩ
жШѓпЉЪе¶ВжЮЬдљ†еЬ®дљњзФ®зЪДжХ∞жНЃеЇУж≤°жЬЙеЕґеЃГзЪДињЮжО•пЉМзФ®BEGINе∞±иґ≥е§ЯдЇЖгАВдљЖжШѓпЉМе¶ВжЮЬдљ†дљњзФ®зЪДжХ∞жНЃеЇУеЬ®еЕґеЃГзЪДињЮжО•дєЯи¶БеѓєжХ∞жНЃеЇУињЫи°МеЖЩжУНдљЬпЉМе∞±еЊЧдљњзФ®BEGIN
IMMEDIATEжИЦBEGIN EXCLUSIVEеЉАеІЛдљ†зЪДдЇЛеК°гАВ


- 2010-11-19 00:05
- жµПиІИ 1064
- иѓДиЃЇ(0)
- еИЖз±ї:жХ∞жНЃеЇУ
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
пЉИиљђпЉЙAndriodжШѓдїАдєИ
2010-12-02 11:24 1619еѓЉиѓїпЉЪSans SerifжШѓGoogleзЪД ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(еЕ≠)---еЖНи∞ИSQLiteзЪДйФБ
2010-11-19 00:09 948еЖЩеЬ®еЙН йЭҐпЉЪSQLiteе∞БйФБжЬЇеИґзЪДеЃЮзО∞йЬАи¶БеЇХе±ВжЦЗдїґз≥їзїЯзЪД ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(еЫЫ)---Page CacheдєЛдЇЛеК°е§ДзРЖ(3)
2010-11-19 00:01 975Code еЖЩеЬ®еЙНйЭҐпЉЪзФ±дЇО еЖЕеЃєиЊГе§ЪпЉМжЙАдї•жЦ≠зї≠ж≤°жЬЙеЖЩеЃМзЪД ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(еЫЫ)---Page CacheдєЛдЇЛеК°е§ДзРЖ(2)
2010-11-18 23:57 1171еЖЩеЬ®еЙНйЭҐпЉЪдЄ™дЇЇиЃ§дЄЇpagerе±ВжШѓSQLiteеЃЮзО∞жЬАдЄЇж†ЄењГзЪД ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(еЫЫ)---Page CacheдєЛдЇЛеК°е§ДзРЖ(1)
2010-11-18 23:53 957еЖЩеЬ®еЙНйЭҐпЉЪдїОжЬђзЂ†еЉАеІЛпЉМе∞ЖеѓєSQLiteзЪДжѓПдЄ™ж®°еЭЧињЫи°МиЃ®иЃЇгАВ ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(дЄЙ)---еЖЕж†Єж¶Вињ∞(2)
2010-11-18 23:48 1324еЖЩеЬ®еЙНйЭҐ:жЬђиКВ жШѓеЙНдЄ ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(дЄЙ)---еЖЕж†Єж¶Вињ∞(1)
2010-11-18 23:41 805еЖЩеЬ®еЙНйЭҐ:дїОжЬђ зЂ†еЉАеІЛ, ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(дЇМ)---иЃЊиЃ°дЄОж¶Вењµ(зї≠)
2010-11-18 23:38 1049еЖЩеЬ®еЙНйЭҐ:жЬђиКВ иЃ®иЃЇдЇЛеК°,дЇЛеК°жШѓDBMSжЬАж†ЄењГзЪДжКАжЬѓдєЛдЄА ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(дЇМ)---иЃЊиЃ°дЄОж¶Вењµ
2010-11-18 23:35 808еЖЩеЬ®еЙНйЭҐ:и∞Ґи∞ҐеРДдљНзЪД е ... -
пЉИиљђпЉЙSQLiteеЕ•йЧ®дЄОеИЖжЮР(дЄА)
2010-11-18 23:31 929еЖЩеЬ®еЙНйЭҐпЉЪеЗЇдЇОй°єзЫЃзЪД йЬАи¶Б,жЬАињСжЙУзЃЧеѓєSQLiteзЪДеЖЕж†Є ... -
пЉИиљђпЉЙжЈ±еЕ•з†Фз©ґBж†С糥еЉХпЉИдЇФпЉЙзї≠
2010-11-18 15:10 9355.3 йЗНеїЇ B ж†С糥еЉХ ... -
пЉИиљђпЉЙжЈ±еЕ•з†Фз©ґBж†С糥еЉХпЉИдЇФпЉЙ
2010-11-18 15:07 12045.¬†¬†¬†¬† йЗНеїЇ B ... -
пЉИиљђпЉЙжЈ±еЕ•з†Фз©ґBж†С糥еЉХпЉИеЫЫпЉЙзї≠
2010-11-18 14:58 9354.2¬† B ж†С糥еЉХзЪДеѓєдЇОеИ†йЩ§пЉИ DEL ... -
пЉИиљђпЉЙжЈ±еЕ•з†Фз©ґBж†С糥еЉХпЉИдЄЙгАБеЫЫпЉЙ
2010-11-18 14:44 7393.¬†¬†¬†¬† B ж†С糥 ... -
пЉИиљђпЉЙжЈ±еЕ•з†Фз©ґBж†С糥еЉХпЉИдЇМпЉЙ
2010-11-18 14:20 7692.¬†¬†¬†¬† B ж†С糥еЉХзЪДеЖЕйГ®зїУжЮД ... -
пЉИиљђпЉЙжЈ±еЕ•з†Фз©ґBж†С糥еЉХпЉИдЄАпЉЙ
2010-11-18 14:12 1019жСШи¶БпЉЪ жЬђжЦЗеѓєB ж†С糥еЉХзЪДзїУжЮДгАБеЖЕйГ®зЃ°зРЖз≠ЙжЦєйЭҐеБЪдЇЖдЄАдЄ™еЕ®йЭҐ ... -
пЉИиљђпЉЙBж†СгАБB-ж†СгАБB+ж†СгАБB*ж†СйГљжШѓдїАдєИ
2010-11-17 23:46 679B ж†С ¬†¬†¬†¬†¬†¬† еН≥дЇМеПЙжРЬ ... -
зФїUMLеЫЊжЧґж≥®жДПзЪДеЗ†дЄ™еОЯеИЩпЉИиљђпЉЙ
2010-08-03 12:34 1646иљѓдїґеЉАеПСдЄ≠пЉМеИЖжЮРеТМиЃЊиЃ°жЧґпЉМжЦЗж°£зЪДзЉЦеЖЩеТМжАЭжГ≥зЪДдЇ§жµБпЉМзїПеЄЄи¶БзїШеИґеРД ... -
дљ†жШѓдЄ™иљѓдїґжЮґжЮДеЄИеРЧпЉЯпЉИиљђпЉЙ
2010-07-14 11:11 675еЉАеПСеТМжЮґжЮДзЪДзХМйЩРйЪЊдї•ж ... -
(иљђ)еРМжЫ≤еЉВе•ПвАФвАФйЂШжХИиГљй°єзЫЃеЫҐйШЯзЪДдЇФе§ІзЙєзВє
2010-03-29 00:24 871еРМжЫ≤еЉВе•ПвАФвАФйЂШжХИиГљй°єз ...
зЫЄеЕ≥жО®иНР
SQLiteеЕ•йЧ®дЄОеИЖжЮР(еЫЫ)---Page CacheдєЛдЇЛеК°е§ДзРЖ.doc SQLiteеЕ•йЧ®дЄОеИЖжЮР(дЇФ)---Page CacheдєЛеєґеПСжОІеИґ.doc SQLiteеЕ•йЧ®дЄОеИЖжЮР(еЕ≠)---еЖНи∞ИSQLiteзЪДйФБ.doc
дЇМгАБAndroidдЄЛзЪДSQLiteзЉЦиѓСдЄОеЯЇз°АеЕ•йЧ® еЬ®AndroidеЉАеПСдЄ≠пЉМSQLiteйАЪињЗAndroid SDKзЪДSQLiteOpenHelperз±їињЫи°МжУНдљЬгАВ1пЉМй¶ЦеЕИпЉМжИСдїђйЬАи¶БеИЫеїЇдЄАдЄ™зїІжЙњиЗ™SQLiteOpenHelperзЪДе≠Рз±їпЉМеЃЪдєЙжХ∞жНЃеЇУзЙИжЬђеПЈеТМеНЗзЇІжЦєж≥ХгАВ2пЉМзДґеРОпЉМжИСдїђ...
2. **й°µпЉИPageпЉЙеТМзЉУе≠ШпЉИCacheпЉЙ**пЉЪSQLiteе∞ЖжХ∞жНЃе≠ШеВ®еЬ®й°µдЄКпЉМжѓПдЄ™й°µжЬЙеЫЇеЃЪзЪДе§Іе∞ПгАВзЉУе≠ШжЬЇеИґзФ®дЇОжПРйЂШжХ∞жНЃиЃњйЧЃйАЯеЇ¶гАВ 3. **иІ¶еПСеЩ®пЉИTriggerпЉЙ**пЉЪеЕБиЃЄеЬ®зЙєеЃЪдЇЛдїґпЉИе¶ВINSERTгАБUPDATEжИЦDELETEпЉЙеПСзФЯжЧґиЗ™еК®жЙІи°МжМЗеЃЪзЪДSQL...
1. еҐЮе§ІPage CacheпЉЪSQLiteдљњзФ®еЖЕе≠ШдЄ≠зЪДPage Cacheе≠ШеВ®жХ∞жНЃй°µпЉМеҐЮе§ІзЉУе≠ШеПѓдї•еЗПе∞Сз£БзЫШI/OгАВйАЪињЗPRAGMA cache_sizeеПѓдї•иЃЊзљЃзЉУе≠ШзЪДй°µйЭҐжХ∞йЗПпЉМдЊЛе¶В`PRAGMA cache_size = 2000;`и°®з§ЇиЃЊзљЃдЄЇ2000дЄ™й°µйЭҐпЉМжѓПдЄ™й°µйЭҐйАЪеЄЄжШѓ4KB...
йАЪињЗжЈ±еЕ•з†Фз©ґSQLiteжЇРз†БпЉМеЉАеПСиАЕеПѓдї•е≠¶дє†еИ∞жХ∞жНЃеЇУиЃЊиЃ°гАБSQLиІ£жЮРгАБе≠ШеВ®еЉХжУОгАБеєґеПСжОІеИґз≠Йж†ЄењГж¶ВењµпЉМињЩе∞ЖеѓєжПРеНЗжХ∞жНЃеЇУеЉАеПСеТМдЉШеМЦиГљеКЫе§ІжЬЙи£®зЫКгАВеРМжЧґпЉМжЇРз†БйШЕиѓїдєЯжШѓе≠¶дє†иљѓдїґеЈ•з®ЛеЃЮиЈµпЉМе¶ВйФЩиѓѓе§ДзРЖгАБжµЛиѓХеТМи∞ГиѓХзЪДе•љйАФеЊДгАВ
жАїзїУжЭ•иѓіпЉМSQLite3жЇРз†БжґµзЫЦдЇЖжХ∞жНЃеЇУз≥їзїЯиЃЊиЃ°зЪДе§ЪдЄ™ж†ЄењГйҐЖеЯЯпЉМеМЕжЛђSQLиІ£жЮРдЄОзЉЦиѓСгАБиЩЪжЛЯжЬЇжЙІи°МгАБжХ∞жНЃе≠ШеВ®дЄОзЉУе≠ШгАБдЇЛеК°зЃ°зРЖгАБеєґеПСжОІеИґдї•еПКйФЩиѓѓе§ДзРЖгАВеѓєSQLite3жЇРз†БзЪДжЈ±еЕ•е≠¶дє†дЄНдїЕеПѓдї•еЄЃеК©еЉАеПСиАЕзРЖиІ£жХ∞жНЃеЇУзЪДеЈ•дљЬеОЯзРЖпЉМ...
еҐЮе§І cache_size жИЦиАЕ page_size иЃЊзљЃпЉМеПѓдї•еҐЮеК†SQLiteеЬ®еЖЕе≠ШдЄ≠е≠ШеВ®зЪДжХ∞жНЃйЗПпЉМеЗПе∞Сз£БзЫШI/OгАВ 9. **з°ђдїґдЉШеМЦ**пЉЪеНЗзЇІз°ђдїґпЉМжѓФе¶ВдљњзФ®жЫіењЂзЪДSSDз°ђзЫШпЉМжИЦиАЕеҐЮеК†еЖЕе≠ШпЉМйГљиГљжШЊиСЧжПРеНЗSQLiteзЪДжАІиГљгАВ 10. **еНЗзЇІSQLiteзЙИжЬђ...
5. **й°µйЭҐзЉУе≠ШпЉИPage CacheпЉЙ**пЉЪдЄЇдЇЖжПРйЂШжАІиГљпЉМSQLiteзїіжК§дЇЖдЄАдЄ™еЖЕе≠ШдЄ≠зЪДжХ∞жНЃеЇУй°µйЭҐзЉУе≠ШгАВељУжХ∞жНЃйЬАи¶БиѓїеПЦжИЦеЖЩеЕ•жЧґпЉМдЉЪеЕИжУНдљЬзЉУе≠ШпЉМеЗПе∞Сеѓєз£БзЫШзЪДиЃњйЧЃгАВ 6. **糥еЉХпЉИIndexingпЉЙ**пЉЪSQLiteжФѓжМБе§ЪзІНз±їеЮЛзЪД糥еЉХпЉМе¶ВеФѓдЄА...
SQLite PRAGMA жШѓ SQLite жХ∞жНЃеЇУз≥їзїЯдЄ≠зЪДдЄАзІНзЙєжЃКеСљдї§пЉМеЃГзФ®дЇОжߕ胥еТМиЃЊзљЃ SQLite зОѓеҐГдЄ≠зЪДеРДзІНйЕНзљЃйАЙй°єеТМзКґжАБж†ЗењЧгАВPRAGMA еСљдї§жЧҐиГље§ЯиѓїеПЦељУеЙНзЪДйЕНзљЃеАЉпЉМдєЯиГљж†єжНЃйЬАи¶БиЃЊзљЃжЦ∞зЪДеАЉгАВињЩдљњеЊЧеЉАеПСдЇЇеСШеПѓдї•ж†єжНЃеЕЈдљУзЪДйЬАж±В...
SQLiteеЕЈе§ЗдЇЛеК°е§ДзРЖеКЯиГљпЉМеЕґзФЯеСљеС®жЬЯдїОеЉАеІЛеИ∞зїУжЭЯпЉМеМЕжЛђдЇЛеК°еѓєеЕґдїЦињЮжО•зЪДељ±еУНпЉМеѓєеєґеПСжАІзЪДжОІеИґиЗ≥еЕ≥йЗНи¶БгАВдЇЛеК°жШѓжХ∞жНЃеЇУзЃ°зРЖдЄ≠дЄАдЄ™йЭЮеЄЄйЗНи¶БзЪДж¶ВењµпЉМеЃГиГље§ЯдњЭиѓБжХ∞жНЃзЪДдЄАиЗіжАІеТМеЃМжХіжАІгАВ SQLiteзЪДйЫґйЕНзљЃињРи°Мж®°еЉПжДПеС≥зЭАеЃГ...
еЉАеПСйШґжЃµйАЪеЄЄдљњзФ®SQLiteжХ∞жНЃеЇУпЉМдљЖеЬ®зФЯдЇІзОѓеҐГдЄ≠пЉМдЄЇдЇЖжФѓжМБжЫіе§ІзЪДеєґеПСеТМжХ∞жНЃйЗПпЉМй°єзЫЃеИЗжНҐеИ∞дЇЖMySQLгАВDjangoзЪДжХ∞жНЃеЇУйЕНзљЃеЕБиЃЄзБµжіїеЬ∞еИЗжНҐдЄНеРМжХ∞жНЃеЇУгАВдЊЛе¶ВпЉМйАЪињЗеЃЪдєЙдЄАдЄ™е≠ЧеЕЄзїУжЮДпЉМеМЕеРЂдЄНеРМжХ∞жНЃеЇУзЪДйЕНзљЃпЉМзДґеРОж†єжНЃзОѓеҐГ...